
Abstract
The stochastic addition of either vertices or connections in a network leads to the observation of the percolation transition, a structural change with the appearance of a connected component encompassing a finite fraction of the system. Percolation has always been regarded as a substrate-dependent but model-independent process, in the sense that the critical exponents of the transition are determined by the geometry of the system, but they are identical for the bond and site percolation models. Here, we report a violation of such assumption. We provide analytical and numerical evidence of a difference in the values of the critical exponents between the bond and site percolation models in networks with null percolation thresholds, such as scale-free graphs with diverging second moment of the degree distribution. We discuss possible implications of our results in real networks, and provide additional insights on the anomalous nature of the percolation transition with null threshold.
Similar content being viewed by others
Introduction
Percolation is among the simplest processes able to generate continuous phase transitions1,2. The model used to describe percolation assumes the presence of an underlying network structure where either nodes (site percolation) or edges (bond percolation) are randomly occupied with probability p. Nearest-neighbor occupied elements form connected clusters. In site percolation, for p=0, no elements are present in the system, so that all clusters have size zero. In bond percolation, for p=0, no nodes are connected in the system, so that all clusters have size equal to one. In both models, for p=1, only a single cluster, coinciding with the whole network, is present. The term percolation transition refers to the structural change, between these two extreme configurations, observed as a function of the occupation probability p. The change is usually monitored through the relative size of the largest cluster, or percolation strength, which is regarded as the order parameter of the percolation transition. In the limit of infinitely large networks, this observable is always equal to zero for any value of p≤pc, while it is finite for p>pc. Whereas the percolation threshold pc can be different in the two models, for a fixed underlying network, bond and site percolation processes have been always observed to behave identically around their respective threshold values. The exponent describing the power-law growth of the order parameter as a function of the distance from the critical point is the same in both processes1. This statement is true also for the critical exponents that describe the singular behavior of other observables, such as the distribution of the cluster size, and the average size of finite clusters. The specific values of the critical exponents play an important role in the characterization of the properties of the percolation transition, and they are used to group networks in different universality classes. In lattices for example, the values of the critical exponents depend only on the dimensionality of the euclidean space1. Such a dependence disappears above the upper-critical dimension, where the critical exponents stabilize to their mean-field values1. In random networks also, no differences have been reported between the critical exponents of the bond and site percolation models3,4,5,6. Theoretical approaches proposed so far indeed assume a perfect equivalence between the models6.
In this paper we are going to show that this assumption is incorrect. In graphs with null percolation threshold, as for example random networks with diverging second moment of the degree distribution, bond and site percolation strengths are characterized by different critical exponents. The breaking of the site-bond universality is accompanied with anomalies in the critical behavior of other macroscopic observables.
Results
Bond percolation model
We first derive the basic equations that support our statement, starting from the bond percolation model. We assume the presence of an underlying undirected and unweighted network composed of N nodes and E edges. The structure of the network is fully described by the adjacency matrix A. The generic element of this matrix equals one if the two corresponding nodes share an edge, whereas equals zero if no connection is present between the two vertices. The probability bi that node i is part of the largest cluster of the network is a function of A and the bond occupation probability p. Such a probability obeys the equation

Here,  is the set of neighbors of vertex i, while ci→j stands for the probability that node j is part of the largest cluster discounting the contribution of node i. Equation (1) is formulated according to the following straightforward argument. If node j is in the set
is the set of neighbors of vertex i, while ci→j stands for the probability that node j is part of the largest cluster discounting the contribution of node i. Equation (1) is formulated according to the following straightforward argument. If node j is in the set  of neighbors of vertex i, then pci→j is the probability that the connection between i and j is occupied, and node j is part of the spanning cluster thanks to a node different from i. Thus, the probability that node i does not belong to the largest cluster, i.e., 1−bi, is equal to the probability that none of its adjacent nodes, that are connected to vertex i by an occupied edge, are part of the largest cluster of the graph. Note that equation (1) is based on the hypothesis that the probabilities ci→j of all neighbors of node i are uncoupled, i.e., the so-called locally tree-like approximation6, hence their product appears on the r.h.s. of the equation. For consistency, the probability ci→j obeys
of neighbors of vertex i, then pci→j is the probability that the connection between i and j is occupied, and node j is part of the spanning cluster thanks to a node different from i. Thus, the probability that node i does not belong to the largest cluster, i.e., 1−bi, is equal to the probability that none of its adjacent nodes, that are connected to vertex i by an occupied edge, are part of the largest cluster of the graph. Note that equation (1) is based on the hypothesis that the probabilities ci→j of all neighbors of node i are uncoupled, i.e., the so-called locally tree-like approximation6, hence their product appears on the r.h.s. of the equation. For consistency, the probability ci→j obeys

where the product on the r.h.s. of the last equation runs over all neighbors of node j but vertex i. Given the adjacency matrix A of the underlying graph, and fixed a value of the occupation probability p, the solution of the bond percolation model can be obtained first by numerically solving the set of 2E equations (2), and then plugging these solutions into the set of N equations (1) to estimate the value of the variables bi. The order parameter of the transition can be finally computed as the average value of these variables over the entire network, i.e.,  . This quantity represents the percolation strength B over an infinite number of realizations of the bond percolation model on the graph. Using the Taylor expansion of equation (2) around ci→j=0, it can be shown that the percolation threshold equals the inverse of the largest eigenvalue of the non-backtracking matrix of the graph7, and that slightly on the right of the critical probability, every bi grows linearly with the sum of the components of the principal eigenvector of the non-backtracking matrix corresponding to edges pointing out from node i8.
. This quantity represents the percolation strength B over an infinite number of realizations of the bond percolation model on the graph. Using the Taylor expansion of equation (2) around ci→j=0, it can be shown that the percolation threshold equals the inverse of the largest eigenvalue of the non-backtracking matrix of the graph7, and that slightly on the right of the critical probability, every bi grows linearly with the sum of the components of the principal eigenvector of the non-backtracking matrix corresponding to edges pointing out from node i8.
Site percolation model
Under the locally tree-like approximation, the probability si that node i belongs to the largest cluster in the network is given by

where ti→j stands for the probability that node j is part of the largest cluster irrespective of vertex i. The probability si is written as the product of two contributions: the probability p that the node is occupied, and the probability that at least one of its neighbors is part of the largest cluster independently of node i. For consistency, the probability ti→j obeys

where we have excluded node i from the product on the r.h.s. As in the case of bond percolation, equations (4) form a set of 2E coupled equations whose solution can be obtained numerically for any value of p. The numerical solutions of equation (4) are then plugged into equation (3) to obtain the values of the variables s, and finally the order parameter of the transition is computed as  . Also in this case, the percolation threshold equals the inverse of the largest eigenvalue of the non-backtracking matrix of the graph9.
. Also in this case, the percolation threshold equals the inverse of the largest eigenvalue of the non-backtracking matrix of the graph9.
Relation between bond and site percolation
If we multiply both sides of equation (2) by p, we recover equation (4), with only the necessity of renaming pci→j→ti→j. The same is also true for equation (1) which reduces to equation (3) with a multiplication by p, and the additional change of variable pbi→si. As a consequence, the percolation strengths B and S are related by

which tells us that, in locally tree-like networks, the order parameters of the bond and site percolation models are linearly proportional10. Equation (5) holds with very high accuracy in many real networks, as long as their structure is sufficiently compatible with the locally tree-like approximation (see Fig. 1, Supplementary Figs 1-109, Supplementary Tables 1-3, and Supplementary Note 1 for results on 109 real networks11). To provide a quantitative test of this statement, we estimate the error associated to equation (5) as  , and use the average clustering coefficient C as a proxy for the validity of the tree-like ansatz. We find V<0.1 for all the real networks we analyzed (see Supplementary Tables 1-3), suggesting a good accuracy of equation (5) overall. For most networks with relatively low values of the clustering coefficient, equation (5) works exceptionally well (i.e., V<0.01). On the other hand, we find also a positive dependence of V on C, indicating that the accuracy of equation (5) decreases as the tree-like approximation becomes less reliable (see Supplementary Fig. 110).
, and use the average clustering coefficient C as a proxy for the validity of the tree-like ansatz. We find V<0.1 for all the real networks we analyzed (see Supplementary Tables 1-3), suggesting a good accuracy of equation (5) overall. For most networks with relatively low values of the clustering coefficient, equation (5) works exceptionally well (i.e., V<0.01). On the other hand, we find also a positive dependence of V on C, indicating that the accuracy of equation (5) decreases as the tree-like approximation becomes less reliable (see Supplementary Fig. 110).

(a) We consider the graph corresponding to the giant component of the peer-to-peer Gnutella network as of August 31, 2002 (refs 32, 33). The black thin line represents the site percolation order parameter S as a function of the site occupation probability p. We calculate also the order parameter B for bond percolation and multiply it by p to obtain the red dashed line. The average clustering coefficient of the network is C=0.0055. Such a low value indicates that the tree-like approximation holds with sufficient accuracy for this network. We further estimated the error V of the law S=pB, by considering the integral  . We find V=0.0002. (b) We consider the graph corresponding to the giant component of the Internet at the autonomous system level in the period January 2004 to November 2007 (ref. 34). The description of the various curves is identical to those appearing in panel a. The clustering coefficient for this network is C=0.2082. The error associated to equation (5) is V=0.0016.
. We find V=0.0002. (b) We consider the graph corresponding to the giant component of the Internet at the autonomous system level in the period January 2004 to November 2007 (ref. 34). The description of the various curves is identical to those appearing in panel a. The clustering coefficient for this network is C=0.2082. The error associated to equation (5) is V=0.0016.
Violation of the site-bond percolation universality
From equation (5) a difference in the critical behavior between the bond and site percolation models is straightforwardly deduced. In infinitely large networks, as the occupation probability tends to the critical threshold value from right, i.e.,  , the order parameter of the percolation transition decreases to zero as a power of the distance from the critical point, that is
, the order parameter of the percolation transition decreases to zero as a power of the distance from the critical point, that is  and
and  . Whereas in the former equations we stressed the possibility of a difference in the values of the critical exponents for the bond and site percolation models, we remark that there are not known examples of such observation. On the contrary, it is firmly believed that the value of critical exponents depends only on the geometry of the system but not on the specific ordinary percolation model considered1. By making use of the linear mapping of equation (5), we can write
. Whereas in the former equations we stressed the possibility of a difference in the values of the critical exponents for the bond and site percolation models, we remark that there are not known examples of such observation. On the contrary, it is firmly believed that the value of critical exponents depends only on the geometry of the system but not on the specific ordinary percolation model considered1. By making use of the linear mapping of equation (5), we can write  . If the percolation threshold is strictly larger than zero, as in the case of regular graphs, Erdös-Rényi models, or random scale-free graphs with finite second moment of the degree distribution, in the limit
. If the percolation threshold is strictly larger than zero, as in the case of regular graphs, Erdös-Rényi models, or random scale-free graphs with finite second moment of the degree distribution, in the limit  , the prefactor p on the l.h.s. of the previous equation acts as a multiplicative constant, and βb=βs. If instead pc=0, as in the case of random scale-free graphs with diverging second moment of the degree distribution3,12,13, the former equation becomes
, the prefactor p on the l.h.s. of the previous equation acts as a multiplicative constant, and βb=βs. If instead pc=0, as in the case of random scale-free graphs with diverging second moment of the degree distribution3,12,13, the former equation becomes  . The critical exponents of the percolation strengths of bond and site percolation are thus related by
. The critical exponents of the percolation strengths of bond and site percolation are thus related by

which tells us that, in locally tree-like graphs with null percolation thresholds, the site-bond universality is broken, and the critical exponents of the order parameters of the bond and site percolation models assume different values.
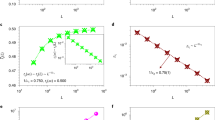
To validate our theoretical predictions, we numerically study the two percolation models in random graphs14,15 using the Monte Carlo algorithm introduced by Newman and Ziff16. We consider random network models that are sparse enough to satisfy the locally tree-like ansatz, and extrapolate critical exponent values of the transition for networks of infinite size by making use of finite-size scaling analysis1. First, we verify that for random graphs with nonvanishing percolation thresholds identical values for the critical exponents in bond and site percolation are indeed recovered (Supplementary Figs 111-118). In particular, for networks with power-law degree distribution but finite second moment, we obtain values of the critical exponents consistent with previous theoretical predictions5,17. These statements are valid not just for the critical exponent β, but also for the one that regulates the divergence of the average cluster size, as well as for the Fisher exponent of the distribution of cluster sizes at criticality1. Results for scale-free graphs with diverging second moment of the degree distribution, and thus null percolation thresholds, are reported in Fig. 2. For the bond percolation model, we recover the value of the exponent βb predicted by the theory of Cohen et al.5 For the site percolation model, we find instead results consistent with our equation (6) (see also refs 6, 18). These different values of the critical exponents are confirmed in Fig. 3 by the good scaling collapse among curves corresponding to different network sizes.

Results are obtained for random networks with degree distribution P(k)∼k−γ built according to the uncorrelated configuration model (see methods) and setting the degree exponent γ=2.5. Black squares refer to bond percolation, while red circles represent the results obtained for site percolation. (a) Best estimate of the pseudo-critical point pc(N) for different network sizes N. Simulation results (symbols) are compared with the expected power-law decay (full black and dashed red lines are guides to the eye) towards pc, with pc=0 and decay exponent 1/ν=(3−γ)/2. (b) Percolation strengths B (black squares) and S (red circles) at p=pc(N) as functions of the network size N. The full black line serves as a guide to the eye and decays with exponent βb/ν=1/2 as N grows (see methods). The dashed red line serves as a guide to the eye to indicate a power-law decay with an exponent βs/ν=(4−γ)/2 (see methods). (c) Maximal values of susceptibilities χB (black squares) and χS (red circles) as functions of N. The full black line increases as  , thus as N1/2. The dashed red line stands for guide to the eye for the power-law divergence
, thus as N1/2. The dashed red line stands for guide to the eye for the power-law divergence  , which means N(γ−2)/2.
, which means N(γ−2)/2.

We analyze the same networks as in Fig. 2, and test the validity of equation (13). (a) Collapse plot for the order parameter B of the bond percolation model in networks with different sizes. The collapse is obtained by setting βb/ν=1/2 and ν=2/(3−γ). The dashed line corresponds to a guide to the eye for a power-law with exponent equal to βb=1/(3−γ). The imperfect collapse for  is a consequence of the effective exponent βb/ν in Fig. 2b, which is slightly larger than the value 1/2 due to preasymptotic effects. (b) Same as in panel a, but for the site percolation model. In this case, we set βs/ν=(4−γ)/2 and ν=2/(3−γ). The dashed line is a guide to the eye for a power-law with exponent equal to βs=(4−γ)/(3−γ).
is a consequence of the effective exponent βb/ν in Fig. 2b, which is slightly larger than the value 1/2 due to preasymptotic effects. (b) Same as in panel a, but for the site percolation model. In this case, we set βs/ν=(4−γ)/2 and ν=2/(3−γ). The dashed line is a guide to the eye for a power-law with exponent equal to βs=(4−γ)/(3−γ).
Interpretation of universality breaking
What is the physical reason of the difference between the exponents β in the two percolation models? To get insights, consider a star-like graph, where a single node is connected to an infinitely large number of vertices. This structure represents the extreme limit of a network with diverging second moment of the degree distribution, and it is often used to understand basic mechanisms induced by the heterogeneity of the node degrees6. In the bond percolation model, every node at the end of an active edge is automatically part of the largest cluster. An increment in the occupation probability p generates a linear increment of the relative size of the largest cluster, that is B∼p. In the site percolation model instead, the largest cluster can grow only if the center of the star is active. This happens with probability p. If the center of the star is active, then the growth of the largest cluster is determined by the total number of other vertices that are active, that is the rate of growth of the largest cluster in the bond percolation model. Thus, the relative size of the largest cluster in the site percolation model behaves as S∼p2, in accordance with equation (6).
We expect the same physical principle to play a fundamental role in percolation processes on random graphs with degree distribution P(k). The giant connected component, near its point of creation, has degree distribution proportional to kP(k), hence it consists mostly of vertices with high degree or hubs6 (Supplementary Fig. 119). Bond and site percolation models differ, however, in the way nodes with different degree become part of connected clusters. In the bond percolation model, there is a preference for selecting edges attached to hubs, as kP(k) is the probability that a node at the end of a randomly selected edge has degree equal to k. In the site percolation model instead, a node with degree k is activated with probability P(k) so that there is a weaker preference to select hubs. However, when a high-degree vertex is activated, many edges are activated simultaneously, and many clusters can be merged together. Such a microscopic difference among the two models becomes apparent, with different values of the critical exponent β, only if the number of hubs is sufficiently large, as for example in scale-free graphs with P(k)∼k−γ and degree exponent 2<γ<3. For γ>3 instead, hubs are too rare to generate differences at the macroscopic level, and the site-bond percolation universality is restored.
Anomalies of percolation in scale-free graphs
The study of other macroscopic observables reveals that random networks with null percolation thresholds show anomalies not just at the level of the critical exponents of the order parameter, but in the nature of the transition itself. In ‘standard’ percolation transitions, the distribution of finite cluster sizes decreases at criticality as a power-law with an exponential cut-off diverging as the system becomes infinite1. In scale-free graphs with null percolation threshold the power-law decay is only a preasymptotic effect, visible only in finite-size systems. This is clearly seen in Fig. 4a,c, showing a power-law tail which tends to disappear in the limit of infinitely large networks. The vanishing of the power-law tail is confirmed in Fig. 4b,d, showing that all the distribution weight gets concentrated on clusters of size 1. This finding is in stark contrast with all theoretical predictions proposed so far5,6,19,20, which are inconsistent with each other, as they all provide different estimates for the Fisher critical exponent. We emphasize that their validity has been never systematically tested in numerical experiments. Our results can be interpreted by intuitive arguments. If the percolation threshold is zero, then the critical configuration is given by a disconnected network where all clusters have size one in bond percolation, and size zero in site percolation. Analogous considerations about the critical configuration have been deduced for self-similar graphs21, although no difference between site and bond percolation was studied. As a matter of fact, the Fisher critical exponent is not clearly defined, because the entire cluster size distribution does not decay as a power-law. The same argument implies also that the average size of finite clusters does not diverge at criticality and its associated critical exponent is equal to zero (Supplementary Figs 120 and 121).

We analyze the same networks as in Figs 2 and 3. (a) Probability distribution to observe a cluster of a given size in the bond percolation model for p=pc(N). Each curve corresponds to a different network size. The tail of the various distributions decays as a power-law for large values of the cluster sizes with exponent compatible with 5/2 (the dashed line is a guide to the eye) (b) Weight of clusters of size one, C(1), in the distribution of finite-cluster sizes. As the system size grows, C(1) tends to one in a power-law fashion (the red dashed line represents the best power-law fit of the empirical points and has decay exponent equal to 0.20). (c,d) Same as in panels (a,b) but for the site percolation model. In panel (c) the black dashed line serves as a guide to the eye for a power-law decay with exponent 5/2. In panel (d) the red dashed line represents the best power-law fit of the empirical points and has decay exponent equal to 0.18.
Discussion
The breakdown of site-bond percolation universality in locally tree-like networks with null thresholds is a surprising result. Although percolation processes have been extensively studied in the last decades, to the best of our knowledge, there are no previous findings of such discrepancy between the bond and site percolation models. A relation analogous to equation (6) has been found long ago in continuum percolation models for conductivity in d-dimensional porous rocks22. We stress however that the similarity is only formal, as here the relation is between standard bond and site percolation, while (ref. 22) connects the β exponents of an ordinary and a suitably modified continuum percolation process in d-dimensional spaces. Our results could therefore contribute to percolation theory by stimulating further research in a direction not yet explored. Also, we remark that scale-free graphs with diverging second moments of the degree distribution are regarded as prototypical models of a large variety of natural and man-made networks19,23. In this context, our results could have direct consequences in all situations where percolation plays a fundamental role, including spreading processes in networks24,25,26, as well as resilience properties of graphs to random breakdowns12,13,27. One may remark that many real networks are characterized by high values of the clustering coefficient28, and thus violate the tree-like approximation at the basis of our mathematical framework. We argue that a nonvanishing clustering coefficient is not a sufficient ingredient to restore the percolation universality class in networks with diverging second moment of the degree distribution. By repeating our numerical experiments on the generalization of the configuration model proposed by Newman29, that creates random scale-free networks with nonvanishing clustering coefficients, we find in fact that the anomalous phenomenology still persists (Supplementary Fig. 122). Other ingredients seem thus necessary to observe a nonvanishing percolation threshold and consequently to restore the percolation universality class in networks with diverging second moment of the degree distribution. For instance, we expect that scale-free network models characterized by spatial embedding30 or high density of cliques31 will not exhibit such an anomalous behavior.
Methods
Order parameters and critical exponents
The main order parameter used in the study of the percolation transition in networks is the so-called percolation strength, defined as the number of nodes belonging to the largest connected cluster of the network divided by the total number of vertices in the graph. In our paper, we indicated this quantity as B for bond percolation, and S for site percolation. In the limit of infinitely large systems, the order parameter B grows as a power-law function of the distance between the actual value of the occupation probability p and the critical threshold pc, that is

The same behavior is valid for S, and the critical exponent is denoted as βs. As already explained in the text, the value of the critical exponents βb and βs is the same if the percolation threshold pc is strictly larger than zero. Whereas B and S are based only on the size of the largest connected cluster in the network, there are other important macroscopic observables that account for the size of the other clusters, and critical exponents that are associated with them. In our paper, we considered the distribution of the cluster size at criticality which leads to the definition of the Fisher exponent τ, and the average size of finite clusters with associated critical exponent ω.
Numerical simulations
Given an undirected and unweighted network with N nodes and E edges composed of a single connected component, we study bond percolation using the Monte Carlo method proposed by Newman and Ziff16. In each realization of the method, we start from a configuration with no connections. We then sequentially add edges in random order and monitor the evolution of the size of the largest cluster in the network Z(p) as a function of the bond occupation probability p=e/E, where e indicates the number of edges added from the initial configuration, i.e., e=0. We repeat the entire process Q independent times and estimate the order parameter B as

where Zq(p) indicates the size of the largest cluster in the network observed, during the qth realization of the Monte Carlo algorithm, when the bond occupation probability equals p. The susceptibility χB is instead evaluated as

The numerical value of pc(N) is given by the value of p for which χB is maximum. In our simulations, we also keep track of the size z of all other clusters present in the network, and monitor the average size of finite clusters  , where the sum runs over all clusters excluding the largest one. Results shown in the paper are obtained by considering Q=10,000 in simulations of the percolation process in real networks (Fig. 1), and Q=1,000 (Figs 2 and 3) or Q=100 (Fig. 4) in artificial graphs.
, where the sum runs over all clusters excluding the largest one. Results shown in the paper are obtained by considering Q=10,000 in simulations of the percolation process in real networks (Fig. 1), and Q=1,000 (Figs 2 and 3) or Q=100 (Fig. 4) in artificial graphs.
Simulations for the site percolation model are performed in a similar way as described above for the bond percolation model. The initial configuration is given by a network with no nodes, i.e., n=0. Vertices are then sequentially introduced in the network in a random order. The occupation probability is defined as p=n/N, with n number of nodes added in the Monte Carlo algorithm. The definitions of the order parameter, the susceptibility and the average cluster size are identical to those of the bond percolation model. These quantities are respectively denoted as S, χS and  .
.
Random networks
The generation of a single instance of the Erdös-Rényi model with N nodes and average degree  is obtained by connecting each pair of nodes with probability
is obtained by connecting each pair of nodes with probability  .
.
To generate a random network with N nodes and power-law degree distribution

we make use of the so-called uncorrelated configuration model14,15. The support of the degree distribution is chosen in such a way that the resulting network has no degree-degree correlations, and is always composed of a single connected component. In the generation of a single instance of the network model, we first assign degrees to the nodes according to the prescribed P(k). Then, we attach pairs of nodes at random, preserving their pre-imposed degrees, but not allowing for multiple connections and self-loops.
To generate a random network with N nodes and nonvanishing clustering coefficient, we make use of the generalization of the uncorrelated configuration model proposed by Newman29. We first assign each node to a number of triangles randomly extracted from the power-law distribution

The support of the distribution is chosen in such a way that the resulting network has no degree-degree correlations, and is always composed of a single connected component. After each node has assigned a number t, we then attach triplets of nodes at random, preserving their pre-imposed number of triangles t, but not allowing for multiple connections and self-loops. The procedure generates a graph with power-law degree distribution with degree exponent γ, and average clustering coefficient  for all sizes N. The clustering coefficient C of the network is defined as the average value of the clustering coefficients of all the nodes in the graph. The clustering coefficient Ci for node i is defined as
for all sizes N. The clustering coefficient C of the network is defined as the average value of the clustering coefficients of all the nodes in the graph. The clustering coefficient Ci for node i is defined as

with Ai,j=1 if nodes i and j are connected, and Ai,j=0, otherwise.
Results appearing in the paper are obtained on single network instances.
Finite-size scaling analysis
On a finite network of size N, the order parameter B follows the scaling

where βb is the critical exponent that regulates the power-law behavior of B in the infinite-size limit, ν is the critical exponent associated with the correlation length of the system, and F is a scaling function. The exponent ν can be determined by monitoring how the pseudo-critical threshold pc(N) changes as a function of the network size. This quantity is determined by looking at the location of the peak of the susceptibility χB. The pseudo-critical threshold decays towards the percolation threshold pc as

If one measures the value of the order parameter B at p=pc(N), the argument of the universal function does not longer contain any dependence on either N and p, so that  , and the ratio of the critical exponents βb and ν can be determined from the decay of the order parameter B for different network sizes. By definition, the susceptibility χB diverges at pseudo-criticality as
, and the ratio of the critical exponents βb and ν can be determined from the decay of the order parameter B for different network sizes. By definition, the susceptibility χB diverges at pseudo-criticality as  . The same exact technique can be also used to determine the power-law scaling of the average cluster size
. The same exact technique can be also used to determine the power-law scaling of the average cluster size  . In the case of standard percolation transitions, the average cluster size is expected to diverge at (pseudo-) criticality as
. In the case of standard percolation transitions, the average cluster size is expected to diverge at (pseudo-) criticality as  . Critical exponents for the site percolation model are numerically determined in the same way as described above.
. Critical exponents for the site percolation model are numerically determined in the same way as described above.
Percolation thresholds and critical exponents
For a finite random network obeying the locally tree-like ansatz, and with degree distribution P(k), the pseudo-critical percolation threshold is determined as

with  and
and  respectively equal to the first and second moments of the degree distribution P(k)3,13. This expression is computed with the so-called heterogeneous mean-field theory. It allows us to determine the percolation threshold pc for networks with infinite sizes, and also the value of the critical exponent ν depending on how pc(N) approaches pc as N grows. If the degree distribution is given by equation (10), then we have
respectively equal to the first and second moments of the degree distribution P(k)3,13. This expression is computed with the so-called heterogeneous mean-field theory. It allows us to determine the percolation threshold pc for networks with infinite sizes, and also the value of the critical exponent ν depending on how pc(N) approaches pc as N grows. If the degree distribution is given by equation (10), then we have  and
and  , with c normalization constant. We have therefore different predictions based on the value of γ, i.e., depending on whether the second moment of the distribution is diverging or not as N increases. For the percolation threshold, we have
, with c normalization constant. We have therefore different predictions based on the value of γ, i.e., depending on whether the second moment of the distribution is diverging or not as N increases. For the percolation threshold, we have

For the critical exponent ν, we instead have

γ=3 is a pathological case where we do not expect a power-law decay of pc(N) to pc, but rather an exponential one. The prediction in the regime 2<γ<3 is obtained by accounting for the divergence of the second moment of the degree distribution with cutoff given by  . The prediction in the regime 3<γ≤4 has been obtained by Wu et al.17 For γ≥4 instead, the exponent ν equals its mean-field value.
. The prediction in the regime 3<γ≤4 has been obtained by Wu et al.17 For γ≥4 instead, the exponent ν equals its mean-field value.
The estimates of the critical exponent β for the percolation strength are instead given by

These predictions have been obtained by Cohen et al.5 In the regime γ≥4, β assumes its mean-field value. The results of our simulations show the prediction in the regime 2<γ<3 to be valid only for the bond percolation model, i.e., βb=1/(3−γ). For the site percolation model, we have instead βs=βb+1=(4−γ)/(3−γ).
According to our arguments, the exponents τ and ω, respectively used to characterize the distribution of cluster sizes and the average cluster size, are not defined in the regime 2<γ<3, where these quantities do not obey power-law scalings. They are instead well defined for γ>3, where Cohen et al.5 predicted

and

Again, the values of the critical exponents for γ>4 are given by their mean-field expectations. We stress also that the critical exponents are related by precise hyperscaling relationships. For example, we must have 2β/ν+ω/ν=1.
Additional information
How to cite this article: Radicchi, F. & Castellano, C. Breaking of the site-bond percolation universality in networks. Nat. Commun. 6:10196 doi: 10.1038/ncomms10196 (2015).
References
Stauffer, D. & Aharony, A. Introduction To Percolation Theory Taylor and Francis (1991).
Bollobas, B. & Riordan, O. Percolation Cambridge University Press (2006).
Callaway, D. S., Newman, M. E., Strogatz, S. H. & Watts, D. J. Network robustness and fragility: percolation on random graphs. Phys. Rev. Lett. 85, 5468 (2000).
Moore, C. & Newman, M. E. J. Exact solution of site and bond percolation on small-world networks. Phys. Rev. E 62, 7059–7064 (2000).
Cohen, R., Ben-Avraham, D. & Havlin, S. Percolation critical exponents in scale-free networks. Phys. Rev. E 66, 036113 (2002).
Dorogovtsev, S. N., Goltsev, A. V. & Mendes, J. F. Critical phenomena in complex networks. Rev. Mod. Phys. 80, 1275 (2008).
Karrer, B., Newman, M. E. J. & Zdeborová, L. Percolation on sparse networks. Phys. Rev. Lett. 113, 208702 (2014).
Radicchi, F. Percolation in real interdependent networks. Nature Phys. 11, 597–602 (2015).
Hamilton, K. E. & Pryadko, L. P. Tight lower bound for percolation threshold on an infinite graph. Phys. Rev. Lett. 113, 208701 (2014).
Faqeeh, A., Melnik, S. & Gleeson, J. P. Network cloning unfolds the effect of clustering on dynamical processes. Phys. Rev. E 91, 052807 (2015).
Radicchi, F. Predicting percolation thresholds in networks. Phys. Rev. E 91, 010801 (2015).
Albert, R., Jeong, H. & Barabási, A.-L. Error and attack tolerance of complex networks. Nature 406, 378–382 (2000).
Cohen, R., Erez, K., Ben-Avraham, D. & Havlin, S. Resilience of the internet to random breakdowns. Phys. Rev. Lett. 85, 4626 (2000).
Molloy, M. & Reed, B. A critical point for random graphs with a given degree sequence. Random Struct. Algor. 6, 161–180 (1995).
Catanzaro, M., Boguñá, M. & Pastor-Satorras, R. Generation of uncorrelated random scale-free networks. Phys. Rev. E 71, 027103 (2005).
Newman, M. E. J. & Ziff, R. Efficient monte carlo algorithm and high-precision results for percolation. Phys. Rev. Lett. 85, 4104 (2000).
Wu, Z. et al. Numerical evaluation of the upper critical dimension of percolation in scale-free networks. Phys. Rev. E 75, 066110 (2007).
Dorogovtsev, S. N. Lectures On Complex Networks, vol. 24, (Oxford University Press Oxford (2010).
Albert, R. & Barabási, A.-L. Statistical mechanics of complex networks. Rev. Mod. Phys. 74, 47 (2002).
Newman, M. E. J. Component sizes in networks with arbitrary degree distributions. Phys. Rev. E 76, 045101 (2007).
Serrano, M. A., Krioukov, D. & Boguñá, M. Percolation in self-similar networks. Phys. Rev. Lett. 106, 048701 (2011).
Trugman, S. A. & Weinrib, A. Percolation with a threshold at zero: a new universality class. Phys. Rev. B 31, 2974–2980 (1985).
Barabási, A.-L. & Albert, R. Emergence of scaling in random networks. Science 286, 509–512 (1999).
Pastor-Satorras, R. & Vespignani, A. Epidemic spreading in scale-free networks. Phys. Rev. Lett. 86, 3200 (2001).
Newman, M. E. Spread of epidemic disease on networks. Phys. Rev. E 66, 016128 (2002).
Pastor-Satorras, R., Castellano, C., Van Mieghem, P. & Vespignani, A. Epidemic processes in complex networks. Rev. Mod. Phys. 87, 925–979 (2015).
Kitano, H. Biological robustness. Nat. Rev. Genet. 5, 826–837 (2004).
Watts, D. J. & Strogatz, S. H. Collective dynamics of 'small-world' networks. Nature 393, 440–442 (1998).
Newman, M. E. Random graphs with clustering. Phys. Rev. Lett. 103, 058701 (2009).
Warren, C. P., Sander, L. M. & Sokolov, I. M. Geography in a scale-free network model. Phys. Rev. E 66, 056105 (2002).
Gleeson, J. P., Melnik, S. & Hackett, A. How clustering affects the bond percolation threshold in complex networks. Phys. Rev. E 81, 066114 (2010).
Ripeanu, M., Foster, I. & Iamnitchi, A. Mapping the gnutella network: properties of large-scale peer-to-peer systems and implications for system design. IEEE Internet Comput. 6, 2002 (2002).
Leskovec, J., Kleinberg, J. & Faloutsos, C. in ACM Transactions on Knowledge Discovery from Data (TKDD) vol. 1, 2 (ACM (2007).
Leskovec, J., Kleinberg, J. & Faloutsos, C. in KDD '05 Proceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining, 177–187ACM (2005).
Acknowledgements
We thank Marian Boguñá, Alessandro Flammini, and Romualdo Pastor-Satorras for a critical reading of the manuscript.
Author information
Authors and Affiliations
Contributions
All authors contributed to all aspects of this work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Supplementary information
Supplementary Information
Supplementary Figures 1-122, Supplementary Tables 1-3, Supplementary Note 1 and Supplementary References. (PDF 2161 kb)
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Radicchi, F., Castellano, C. Breaking of the site-bond percolation universality in networks. Nat Commun 6, 10196 (2015). https://doi.org/10.1038/ncomms10196
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/ncomms10196
This article is cited by
-
Percolation on feature-enriched interconnected systems
Nature Communications (2021)
-
Temporal profiles of avalanches on networks
Nature Communications (2017)
-
Non-criticality of interaction network over system’s crises: A percolation analysis
Scientific Reports (2017)
-
Social contagions on interdependent lattice networks
Scientific Reports (2017)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
