
Abstract
Link weights are essential to network functionality, so weight prediction is important for understanding weighted networks given incomplete real-world data. In this work, we develop a novel method for weight prediction based on the local network structure, namely, the set of neighbors of each node. The performance of this method is validated in two cases. In the first case, some links are missing altogether along with their weights, while in the second case all links are known and weight information is missing for some links. Empirical experiments on real-world networks indicate that our method can provide accurate predictions of link weights in both cases.
Similar content being viewed by others

Introduction
Many real-world systems, such as social, biological and communication systems, can be described as networks, where nodes denote individuals and links represent interactions between them. Over the last few decades, the field of network science has been developed as a critical framework for understanding the organization of real networked systems1,2. Faithful representation of many real-world networks requires not only links to indicate the existence of interactions but also associated weights to express interaction strengths. Examples are ubiquitous. For example, in an airline network, the weight of a link may represent the number of flights3, the number of available seats4, or the number of passengers5 traveling between two airports. In food webs, link weights may represent energy or carbon flows between taxa6. In scientific collaboration networks, the weight of a link may quantify the number of papers co-authored by two researchers7.
Unfortunately, data collected from real-world networks are usually incomplete. This gives rise to two related data reconstruction problems. First, some links may be missing from the data, in which case we need to predict these missing links from the available data. This link prediction problem has received much attention in the past decade8,9,10,11,12, and many link prediction algorithms have been proposed for both unweighted9,13,14,15,16,17,18,19,20,21,22,23,24,25,26 and weighted27,28,29,30,31 networks. Second, the weights of some links may be unavailable. Of course, if the existence of a link is unknown, then its weight is obviously unavailable as well. However, even if the existence of a link is known, its weight may still be missing due to incomplete data, and in this case we need to estimate the missing weights. Unfortunately, only a few studies have focused on this second problem of weight prediction. Recently, Aicher et al. developed a weighted stochastic block model, that can be applied to infer both the existence and weights of links29. Zhao et al. proposed another method based on reliable routes to extend unweighted similarity indices to weighted ones30, which can be used to predict the weights of links by assuming that similarity scores are linearly correlated with link weights.
Although link prediction and weight prediction problems can be described by the same model, we believe it is better to separate these two tasks. First, they address different types of missing information, and therefore they CAN be separated. Second, according to the “no free lunch theorem”32, “if an algorithm performs well on a certain class of problems then it necessarily pays for that with degraded performance on the set of all remaining problems”. Based on this theory, separately designed link prediction and weight prediction algorithms should achieve better prediction performance than a single model for predicting both the existence and weights of links. Thus, we propose the following general process to predict the missing information. If links are missing from the data, we first perform link prediction and then predict the weights of the recovered links. If all of the links are available and the weights of only some links are missing, then we skip straight to weight prediction. The link prediction step of this process has been studied extensively, but the weight prediction step remains largely un-investigated. Therefore, in this paper we will focus on the essential problem of weight prediction.
In this study, we try to predict weights of links with the help of local structural information. We develop a novel method for predicting weights by examining the network structure surrounding a node, namely, its set of neighbors. The algorithm can be used in two cases, depending on whether there are missing links to be recovered or not. According to our assessments, the proposed method performs well in both cases. We hope this work may lead to a deeper insight into the design of weight prediction algorithms in weighted networks.
Results
Problem description
We are given an undirected weighted network G(V, E, W), where V, E and W denote the sets of nodes, links and link weights, respectively. Let Adj be the adjacency matrix of the network: if two nodes, say i and j, are connected, then we have aij = 1, where aij is the (i, j) entry of Adj; otherwise, aij = 0. Because the networks we considered here are undirected, the entries wij and wji of W are the same.
Usually, the incomplete information of networks, namely the missing links and their weights, is not available simultaneously. In this case, the prediction consists of two steps: link prediction and weight prediction. In the first step, our goal is to estimate the likelihoods of the existence of links in a given network. To do this, we assign a score, sxy, to each candidate node pair (x, y) ∈ U − E, where U stands for the universe of possible links to quantify the likelihood that the node pair (x, y) is connected, with a higher score indicating a more likely connection. Then, all candidate pairs are sorted by their scores in decreasing order, so that the most likely existed links are those with the highest ranks. More details about link prediction will be given in the Methods section. In the second step, we predict the weights for the highest-ranked links.
In the case where all the links are available and only the weights of some links are missing, we need to perform only the second step, i.e., weight prediction.
A weight prediction method based on neighbor set
Our method relies on the assumption that the formation of link weights is regulated by local clusterings in which homogenous links tend to have similar weights. The local structure we considered is the neighbor set of a node, defined as the set of nodes linked to it, which captures a great deal of information about the node. For instance, in online social networks, the neighbors of a node represent the friends of a person. The co-existence of two people in the same neighbor set enhances the probability of their relationship changing from non-friends to friends.
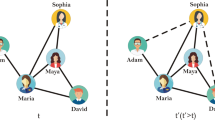
Our method of weight prediction can be well explained by considering a simple example, illustrated in Fig. 1. If a link is generated between nodes a and b, then one wish to have a guess of the weight, wab, of link (a, b). Since nodes a and b appear together in neighbor set A, according to our fundamental hypothesis, the weight of (a, b) is related to the weights of other similar links in A. Because only one other link (b, c) exists, here we focus on examining its relationship to the candidate link. From our perspective, the weight of (b, c) is correlated with the weights of links to common node α. For example, if Fig. 1 is an illustration of social networks and weights of the network indicate time commitments, then the amount of time b spends with c depends on the time α spends with b and c33. If the events “α is with b” and “α is with c” are independent of each other, then the event “b is with c” would have probability equal to the product of their probabilities. Based on this, one can simply estimate wab as  . If other similar links exist, an averaging strategy will be applied to combine the estimates. Similarly, one can use the weight of link (d, e) to infer the weight of link (a, f) across neighbor sets A and B by estimating the value of waf to be
. If other similar links exist, an averaging strategy will be applied to combine the estimates. Similarly, one can use the weight of link (d, e) to infer the weight of link (a, f) across neighbor sets A and B by estimating the value of waf to be  .
.

An illustration of neighbor set.
In this example, neighbor set A is defined as the set of neighbors of node α, which are a, b, c and d. Neighbor set B consists of three nodes, namely, d, e and f. Note that node α and node β have one common neighbor, which belongs to both neighbor sets A and B. Within neighbor set A, because there is only one link, the existence probability for the remaining possible links is  , while the remaining links in neighbor set B exist with probability
, while the remaining links in neighbor set B exist with probability  . Connections across neighbor sets A and B exist with probability
. Connections across neighbor sets A and B exist with probability  .
.
In practice, a node often belongs to more than one neighbor set. For example, in Fig. 1, node d belongs to both neighbor sets A and B. Indeed, any two candidate nodes may coexist in multiple neighbor sets. In this case, a natural approach is to calculate the individual contributions of different neighbor sets or pairs of neighbor sets to the candidate node pair and then combine them to obtain a more accurate weight. Viewed in terms of link formation, our hypothesis is that loosely connected clusterings are less likely than densely connected clusterings to form a link34 and thus contribute less to the link weight of the link once it is formed. Under this assumption, a more refined weight can be estimated based on the connection probabilities in or across different neighbor sets.
A detailed explanation is as follows. Suppose our goal is to estimate the weight of the link (x, y). Let Γ(x) be the set of neighbors of node x and  be the event that nodes x and y are connected. If nodes x and y both belong to the neighbor set of node α, i.e., x, y ∈ Γ(α), the weight of (x, y) can be written as
be the event that nodes x and y are connected. If nodes x and y both belong to the neighbor set of node α, i.e., x, y ∈ Γ(α), the weight of (x, y) can be written as

where

which is the average clustering weight over links similar to (x, y). Note that we apply add-one smoothing to preclude the possibility of an undefined fraction. Based on our hypothesis, in order to quantify the contribution of the neighbor set Γ(α) to the formation of wxy, we need to calculate the probability that the pair (x, y) is connected, given that both are in the neighborhood Γ(α). This probability can be estimated through

where |·| denotes the number of elements in the set. In fact, Eq. (3) is the clustering coefficient of node α, given by the link density within the neighbor set Γ(α).
On the other hand, if nodes x and y belong to different neighbor sets, say x ∈ Γ(α), y ∈ Γ(β), the weight of (x, y) can be described as

where

which is the average weight across clusterings. When nodes x and y appear in separate neighborhoods, we can use the connection probability across the two neighbor sets to measure their contribution to the formation of wxy. Then the probability that nodes x and y are connected can be written as

Clearly, this equation measures the connection density across neighbor sets Γ(α) and Γ(β).
Finally, by considering the contributions of different neighbor sets to the formation probability of the link (x, y), we can estimate wxy by

where  and
and  are normalized probabilities, defined as
are normalized probabilities, defined as

and

respectively.
Experimental results
First, we consider the case where information is missing regarding both existence and weights of links. To validate the prediction accuracy, the observed links are randomly divided into two parts: training set ET and validation set EV, where ET is regarded as the given information, and EV is only used for testing. Clearly, we have  and
and  . In this experiment, the training set contains 90% of the links, and the validation set contains the remaining 10%. With the help of link predictors, the candidate node pairs are sorted based on their scores. Then the top-L links are selected as the predicted link set EL. In this paper we set L as the size of validation set for the reason of weight prediction. After link prediction, the weight prediction algorithm is conducted. The corresponding predicted weight set and actual weight set are denoted as
. In this experiment, the training set contains 90% of the links, and the validation set contains the remaining 10%. With the help of link predictors, the candidate node pairs are sorted based on their scores. Then the top-L links are selected as the predicted link set EL. In this paper we set L as the size of validation set for the reason of weight prediction. After link prediction, the weight prediction algorithm is conducted. The corresponding predicted weight set and actual weight set are denoted as  and WL, respectively. The actual weights for non-observed links are set to zero. In most cases, this default value is reasonable. For example, in transportation networks, if there is no connection between two nodes, then the traffic flow directly between these two nodes is zero. For some special cases, this is not the appropriate default, such as for those networks whose weights denote distances between nodes. However, this default is appropriate for all networks we presented here. Then the accuracy of weight predictor can be estimated by calculating the Pearson correlation coefficient and root mean squared error (RMSE) between the vectors
and WL, respectively. The actual weights for non-observed links are set to zero. In most cases, this default value is reasonable. For example, in transportation networks, if there is no connection between two nodes, then the traffic flow directly between these two nodes is zero. For some special cases, this is not the appropriate default, such as for those networks whose weights denote distances between nodes. However, this default is appropriate for all networks we presented here. Then the accuracy of weight predictor can be estimated by calculating the Pearson correlation coefficient and root mean squared error (RMSE) between the vectors  and WL.
and WL.
Table 1 compares the accuracy of the linear-correlation method30 (refer to the Methods section for details) with that of our method, as measured by the Pearson correlation coefficient under different link prediction approaches. Each Pearson correlation coefficient is calculated between the vectors of predicted and actual weights for the top-L ranked links. A larger correlation coefficient indicates more accurate linear correlation between predicted and actual weights. As shown in the table, almost all of the correlation coefficients achieved by our method are larger than those from the linear-correlation method under every link prediction algorithm, indicating that the good performance is due to our method itself, regardless the detailed link prediction algorithms. The linear-correlation method assumes that weights of links measure similarities or affinities between nodes, so the correlation between similarities and weights is weak for those networks whose weights don’t exhibit similarities between nodes, such as the Everglades network. On such networks the linear-correlation method performs poorly. In contrast, our method can be applied to a wider range of networks, in which weights do not necessarily characterize similarities between nodes.
We also calculate the RMSE between the vectors of predicted and actual weights for the top-L ranked links. Detailed results are summarized in Table 2. As shown in the table, in most networks the weights predicted by our method have remarkably smaller errors than those predicted by the linear-correlation method under a variety of link prediction algorithms. In Everglades and USAir1, our method performs similarly to the linear-correlation method as measured by RMSE. However, combining with the metric of Pearson correlation coefficient, we can find that our method performs significantly better than the linear-correlation method on those networks. Furthermore, the linear-correlation method employs the information from the validation set to estimate the scaling coefficient in Eq. (19). As a result, predictive information from the validation set leaks into the optimization step and will lead to optimistically biased performance estimates35. This does not happen in our method because only the information from the training set is used.
Next, we consider the case where only the weight information is missing. In this case, we can directly set EL as EV. For our method, the link prediction is not needed, and we can directly perform weight prediction. However, since the linear-correlation method uses link prediction to calculate the similarity scores SV, it actually still needs to perform both link prediction and weight prediction.
The Pearson correlation coefficient and RMSE between the vectors of predicted weights and actual weights are presented in Tables 3 and 4, respectively. Compared with the linear-correlation method, our method generally gives better estimates of weights in most networks. On the other hand, the advantages of our method are not so apparent when using RMSE to measure accuracy.
Altogether, empirical experiments indicate that the weights of links can be recovered more correctly by our method, in contrast to the linear-correlation method.
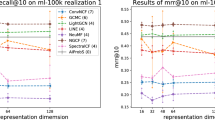
Furthermore, to assess the robustness of our method, we also present the accuracy results of weight predictions on different sizes of training set (ranging from 40% to 90%) in Figs 2 and 3. The results demonstrate that the advantages of our method is not sensitive to the density of the network. Because the CN-based (CN, WCN and rWCN) indices have similar precisions in link prediction, our weight prediction method yields roughly the same results using these indices, as observed from the nearly identical points in Fig. 2. The same phenomenon also occurs by employing AA-based (AA, WAA and rWAA) and RA-based (RA, WRA and rWRA) indices. These figures also show that our method outperforms the linear-correlation method in most cases.

Comparison of the Pearson correlation coefficient (r) for weight prediction accuracy under different link prediction algorithms with various training set sizes (f denotes the fraction of links from the original network which are used in the training set).
The first column of figures shows the results under the CN-based methods, the second shows the AA-based methods and the third shows the RA-based methods.

Comparison of the root mean squared error (e) for weight prediction accuracy under different link prediction algorithms with various training set sizes (f denotes the fraction of links from the original network which are used in the training set).
The first column of figures shows the results under the CN-based methods, the second shows the AA-based methods and the third shows the RA-based methods.
Discussion
In this paper, we explore the problem of weight prediction in weighted networks. A novel weight prediction algorithm which examines the local structure of neighbor set is proposed. To assess the prediction accuracy of our method, empirical experiments are conducted on six real-world networks. The simulation results demonstrate that our method can predict weights much more accurately than the linear-correlation method as measured by the Pearson correlation coefficient and root mean squared error. Furthermore, our method can be used no matter whether the existence of links is missing or not.
Methods
Link prediction algorithms
As described above, if the existence of some links is unknown, we need to determine which candidate links are most likely to exist before inferring their weights. Plenty of methods have been proposed to address this link prediction problem. Among them, Common Neighbors (CN) is the simplest framework to determine which non-connected node pair is more likely to become connected. Its basic assumption is that two nodes are more likely to form a link if they have more common neighbors. However, CN is limited in that it assumes all common neighbors contribute equally to the connection likelihood. Therefore, several variants of CN have been proposed to remedy this oversight, such as Adamic-Adar (AA)36 and Resource Allocation (RA)15, which amplify low-degree common neighbors by assigning more weight on them. The precise scores assigned by the different methods are



where kz is defined as the degree of node z.
In some real-world networks, links are naturally weighted. Murata and Moriyasu studied the way to extend similarity indices from unweighted networks to weighted networks27. Based on this method, the weighted versions of CN, AA and RA (denoted by WCN, WAA and WRA, respectively) are



where wxz is the weight of link (x, z).
Zhao et al. proposed another strategy to generalize similarity indices from unweighted networks to weighted ones based on reliable routes30. The weighted versions of CN, AA and RA (denoted as rWCN, rWAA, rWRA, respectively) based on this method are



Weight prediction algorithm for comparison
Now, with the aid of link prediction algorithms, we obtain a set of the candidate links most likely to exist. Because local information is applied for both our method and ref. 30, we compare our performance only with that method. In ref. 30, the authors assumed that the similarity index for link prediction between two unconnected nodes also reflects their interaction strength. Then, inspired by a linear correlation between similarity scores and link weights in many empirical networks, they set the weights of missing links proportional to their similarity scores. Formally, let the weighted adjacency matrix corresponding to the training set ET and validation set EV be denoted by WT and WV, respectively and let SV be the vector of similarity scores for links in EV. Given the linear correlation mentioned above, we want to find the prediction function F(WT) = λ · SV, which minimizes the difference between λ · SV and WV, where λ is a free parameter. This can be estimated by solving the following optimization problem:

where ||·||F is the Frobenius norm, defined as the square root of the sum of the squares of the matrix’s elements. For the sake of brevity, we will call this weight prediction method linear-correlation in this paper.
Data description
In this work, we consider six networks to evaluate our new weight prediction method. 1) Celegans1: a neural network of the nematode worm C. elegans, where nodes represent neurons, links join neurons if they have synaptic contacts, and the weight stands for the number of synapses between two neurons. 2) Everglades37: a food web network describing carbon exchanges in the Everglades during the wet season, where each node represents a taxon, and an edge denotes that one taxon uses another as food, with link weights representing trophic factors (feeding levels). 3) USAir137: a network of US air transportation, where the weights of links are the frequency of flights between airports. 4) USAir238: a network of flights between US airports in 2010. The weight of a link shows the number of flights between two airports. 5) Advogato38: a trust network of the Advogato online community, where nodes represent users of Advogato, links represent trust relationships and weights indicate the trust levels between users. 6) Geom37: a collaboration network of researchers in the area of computational geometry, where nodes represent authors, links join authors if they have coauthored a paper and weights are the numbers of joint works. To compare the results across different data sets, all link weights are normalized to fall with in the interval [0, 1] as in ref. 30.
Additional Information
How to cite this article: Zhu, B. et al. Weight prediction in complex networks based on neighbor set. Sci. Rep. 6, 38080; doi: 10.1038/srep38080 (2016).
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
Watts, D. J. & Strogatz, S. H. Collective dynamics of ‘small-world’ networks. Nature 393, 440–442 (1998).
Barabási, A. L. & Albert, R. Emergence of scaling in random networks. Science 286, 509–512 (1999).
Li, W. & Cai, X. Statistical analysis of airport network of china. Phys. Rev. E 69, 046106 (2004).
Barrat, A. et al. The architecture of complex weighted networks. Proc. Acad. Natl. Sci. USA 101, 3747–3752 (2004).
da Rocha, L. E. C. Structural evolution of the brazilian airport network. J. Stat. Mech-Theory E 2009, 04020 (2009).
Luczkovich, J. J. et al. Defining and measuring trophic role similarity in food webs using regular equivalence. J. Theor. Biol. 220, 303–321 (2003).
Newman, M. E. J. The structure of scientific collaboration networks. Proc. Acad. Natl. Sci. USA 98, 404–409 (2001).
Huang, Z., Li, X. & Chen, H. Link prediction approach to collaborative filtering. In Proceedings of the 5th ACM/IEEE-CS joint conference on Digital libraries, 141–142 (New York, USA, 2005).
Liben-Nowell, D. & Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Tec. 58, 1019–1031 (2007).
Lü, L. & Zhou, T. Link prediction in complex networks: A survey. Physica A 390, 1150–1170 (2011).
Wang, W. Q., Zhang, Q. M. & Zhou, T. Evaluating network models: A likelihood analysis. Europhys. Lett. 98, 28004 (2012).
Zhang, Q. M. et al. Measuring multiple evolution mechanisms of complex networks. Sci. Rep. 5, 10350 (2015).
Clauset, A., Moore, C. & Newman, M. E. Hierarchical structure and the prediction of missing links in networks. Nature 453, 98–101 (2008).
Guimerá, R. & Sales-Pardo, M. Missing and spurious interactions and the reconstruction of complex networks. P. Natl. Acad. Sci. USA 106, 22073–22078 (2009).
Zhou, T., Lü, L. & Zhang, Y. C. Predicting missing links via local information. Eur. Phys. J. B 71, 623–630 (2009).
Liu, Z., Zhang, Q. M., Lü, L. & Zhou, T. Link prediction in complex networks: A local naïve Bayes model. Europhys. Lett. 96, 48007 (2011).
Cannistraci, C. V., Alanis-Lobato, G. & Ravasi, T. From link-prediction in brain connectomes and protein interactomes to the local-community-paradigm in complex networks. Sci. Rep. 3, 1613 (2013).
Zhang, Q. M., Lü, L., Wang, W. Q. & Zhou, T. Potential theory for directed networks. Plos One 8, e55437 (2013).
Tan, F., Xia, Y. & Zhu, B. Link prediction in complex networks: A mutual information perspective. Plos One 9, e107056 (2014).
Liu, Z., Dong, W. & Fu, Y. Local degree blocking model for missing link prediction in complex networks. Chaos 25, 013115 (2015).
Zhu, B. & Xia, Y. An information-theoretic model for link prediction in complex networks. Sci. Rep. 5, 13703 (2015).
Lü, L. et al. Toward link predictability of complex networks. Proc. Natl. Acad. Sci. USA 112, 2325–2330 (2015).
Pan, L., Zhou, T. & Lü, L. Predicting missing links and identifying spurious links via likelihood analysis. Sci. Rep. 6, 22955 (2016).
Cui, W. et al. Bounded link prediction in very large networks. Physica A 457, 202–214 (2016).
Xu, Z., Pu, C. & Yang, J. Link prediction based on path entropy. Physica A 456, 294–301 (2016).
Ouyang, B., Jiang, L. & Teng, Z. A noise-filtering method for link prediction in complex networks. Plos One 11, e0146925 (2016).
Murata, T. & Moriyasu, S. Link prediction of social networks based on weighted proximity measures. In Proceedings of the IEEE/WIC/ACM international conference on Web Intelligence, 85–88 (New York, USA, 2007).
Lü, L. & Zhou, T. Link prediction in weighted networks: The role of weak ties. Europhys. Lett. 89, 18001 (2010).
Aicher, C., Jacobs, A. Z. & Clauset, A. Learning latent block structure in weighted networks. Journal of Complex Networks 3, 221–248 (2015).
Zhao, J. et al. Prediction of links and weights in networks by reliable routes. Sci. Rep. 5, 12261 (2015).
Zhu, B. & Xia, Y. Link prediction in weighted networks: A weighted mutual information model. Plos One 11, e0148265 (2016).
Wolper, D. H. & Macready, W. G. No free lunch theorems for optimization. IEEE T. Evolut. Comput. 1, 67–82 (1997).
Granovetter, M. S. The strength of weak ties. Am. J. Sociol. 78, 1360–1380 (1973).
Newman, M. E. J. Clustering and preferential attachment in growing networks. Phys. Rev. E 64, 025102 (2001).
Cawley, G. C. & Talbot, N. L. C. On over-fitting in model selection and subsequent selection bias in performance evaluation. J. Mach. Learn. Res. 11, 2079–2107 (2010).
Adamic, L. A. & Adar, E. Friends and neighbors on the web. Social networks 25, 211–230 (2003).
Batagelj, V. & Mrvar, A. Pajek datasets. Available: http://vlado.fmf.uni-lj.si/pub/networks/data/ (Data of access: 24/01/2016) (2006).
Kunegis, J. The koblenz network collection. Available: http://konect.uni-koblenz.de/ (Data of access: 24/01/2016) (2013).
Acknowledgements
This work is supported by the National Natural Science Foundation of China under Grant No. 61573310, and Zhejiang Provincial Natural Science Foundation of China under Grant Nos LY15F030006 and J20130411.
Author information
Authors and Affiliations
Contributions
B.Z. and Y.X. developed the weight prediction method. B.Z., Y.X. and X.Z. conceived and designed the experiments. B.Z. performed the experiments. B.Z., Y.X. and X.Z. analyzed the simulation results. B.Z., Y.X. and X.Z. wrote the manuscript text. B.Z. prepared figures and tables in the main manuscript. All authors reviewed the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Zhu, B., Xia, Y. & Zhang, XJ. Weight prediction in complex networks based on neighbor set. Sci Rep 6, 38080 (2016). https://doi.org/10.1038/srep38080
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep38080
This article is cited by
-
Link Prediction based on Quantum-Inspired Ant Colony Optimization
Scientific Reports (2018)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
