
Abstract
Seismic waves can shake mountainous landscapes, triggering thousands of landslides. Regional-scale landslide models primarily rely on shaking intensity parameters obtained by simplifying ground motion time-series into peak scalar values. Such an approach neglects the contribution of ground motion phase and amplitude and their variations over space and time. Here, we address this problem by developing an explainable deep-learning model able to treat the entire wavefield and benchmark it against a model equipped with scalar intensity parameters. The experiments run on the area affected by the 2015 Mw7.8 Gorkha, Nepal earthquake reveal a 16% improvement in predictive capacity when incorporating full waveforms. This improvement is achieved mainly on gentle (~25°) hillslopes exposed to low ground shaking (~0.2 m/s). Moreover, we can largely attribute this improvement to the ground motion before and much after the peak velocity arrival. This underscores the limits of single-intensity measures and the untapped potential of full waveform information.
Similar content being viewed by others


Introduction
Earthquakes can cause hundreds of thousands of landslides, and in some cases, the losses may exceed those directly associated with the ground shaking1. This hazard chain takes place in just few minutes as the wavefield transits and interacts with the terrain, leading to widespread slope instabilities. Such short-term interactions can have repercussions lasting tens of years2. Therefore, understanding the failure mechanisms within those few minutes is vital to foresee the full chain of events2,3,4.
Physics-based and data-driven solutions2 encompass most of the available coseismic landslide models. Physics-based ones rely on geotechnical data, information hardly accessible for regional scale assessments5. Therefore, the main difference between these two approaches resides in the flexibility of data-driven models to be applied for regional or even global scale analyses. As for the physics-based category, Jibson5 mainly divides them into three alternatives: pseudo-static, stress-deformation, and permanent-deformation5. Permanent-deformation techniques such as the Newmark6 method and its simplifications7 are most commonly used for regional coseismic landslide modeling. This approach identifies critical acceleration thresholds in the ground motion signal, above which a given slope exhibits permanent deformation. This framework assumes that the main factors responsible for higher slope deformation are large amplitude and duration of shaking8. The main limitation in the applicability of the Newmark method is in the sparse density9 of seismic stations. Therefore, spatially continuous records of ground motion data cannot be retrieved even in tectonically active regions, where dense seismic networks are deployed9,10.
Data-driven approaches offer an alternative by using proxies rather than parameters required in physics-based methods11. Statistical methods such as binomial Generalized Linear12 and Additive13 Models reflect most of the literature until recently when they shared the stage with machine learning14 approaches. Overall, data-driven models perform analogous operations, where a set of explanatory variables is used to optimize the numerical distinction between slopes that have failed in response to ground shaking and those that did not. To date, data-driven approaches incorporate several ground motion intensity parameters such as peak ground velocity (PGV), acceleration (PGA), or Arias intensity2. Dahal et al.15 use synthetic waveforms to test 28 ground motion parameters and demonstrate that frequency content, total shaking, and duration can complement the information usually carried by peak proxies. However, even these parameters still convey a scalar representation of the full waveform, and they do not reflect the characteristics of seismic waves (e.g., frequency content and duration) that may play a role in the occurrence of landslides.
The problem of suitably exploiting time series exists across all scientific fields. For instance, a branch of machine learning known as natural language processing has been developed to recognize important characteristics in the continuous signal of written and spoken language. The two most common solutions correspond to long short-term memory16 (known as LSTM) and gated recurrent units17 (known as GRU). However, both have limits in capturing long-range dependencies in time-series data because of their sequential processing nature18,19,20. In other words, their structure sequentially processes the signal, and the influence estimated at each step is a priori constrained to decay over time. Thus, both models tend to forget the contribution coming from portions of the time sequence that are far away from each other. In geoscience, these models have been demonstrated to be convenient in the context of long-term precipitation analysis and associated landslides because they naturally reflect the different contributions coming from early preparatory21 and triggering22 precipitation. However, in the context of earthquake-induced landslides, the energy released by an earthquake propagates on very short timescales, making sequential models unsuited to treat an impulsive signal.
Conversely, a transformer architecture relies on an attention mechanism23 capable of looking at portions of the time series without prior assumptions on how certain information should be forgotten moving away from the start of the sequence24. Due to their flexibility, transformers have become a staple in computer vision25,26, natural language processing27 and constitute the fundamental backbone of the famous ChatGPT model series28.
Therefore, here, we aim to remove any scalar simplification requirement and implement a modeling architecture capable of interpreting the ground motion time series as a whole. For this reason, we designed an experiment where the prediction of coseismic landslides is tasked to a transformer architecture fed with full waveform. We also translated the model results to examine which segments of the synthetic waveforms carry relevant information for landslide hazard assessment. This model is benchmarked against a standard scalar counterpart to test whether the use of full waveforms is useful in the first place.
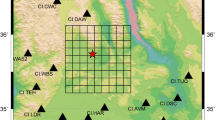
The study area where we run our experiment corresponds to the Nepalese landscape struck by the 7.8 Mw Gorkha Earthquake in 2015, for which ground motion simulations15, landslide inventory29, terrain30, and geological31 data are available. The earthquake occurred along the Main Himalayan Thrust (MHT) fault, and the hypocentre is located in the Northwestern sector (Fig. 1). The unilateral rupture propagated 110° east, lasting for ~50 s32, and the strike and dip of the fault was 293° and 7°, respectively33. Overall, more than 8,800 people were lost, with 23,000 injured34, followed by widespread infrastructural damage. An area of 28,344 km2 was scanned, and a polygonal inventory containing 24,990 coseismic landslides associated with this event was mapped (Fig. 1)29. We defined our experiment over the same region to ensure the validity of landslide presence/absence information and obtained ground motion data from the simulations made by Dahal et al.15. The authors simulated the Gorkha earthquake by using the finite fault model built by Wei et al.35, including the 3D topography through Salvus36,37. The 1D velocity structure is the same as proposed by Mahesh et al.38 with a mesh capable of simulating up to 3.0 Hz, although the waveforms were filtered down to 1.5 Hz due to the limitations in subsurface data and finite fault model.

a Dashed polygon shows the ground motion simulation domain defined by Dahal et al.15; the black solid polygon represents the study area where Roback et al.29 performed the landslide mapping. The epicenter is symbolized with a star, whereas locations where the landslide was initiated, are plotted with a red dot. The main Himalayan thrust fault system is shown in a yellow soild line. b Location of the study area with respect to administrative boundary of Nepal. Basemap source: Esri, USGS, and the GIS User Community.
Using the simulation by Dahal et al.15, full waveforms were extracted at the crown of each landslide reported by Roback et al.29. These locations constituted our landslide presence data. In binary classification, it is also necessary to extract the landslide absence information39. Therefore, we extracted a random and equal number of stable slopes at least steeper than 10° and located 500 m away from a failed slope. The combination of landslide presence and absence will constitute the modeling target of our analyses.
Results
Benchmarking
We recall that our transformer model is equipped with a full waveform time series (Mod1) and that we benchmarked its outputs against a standard model that simplifies the ground motion into its peak velocity (Mod2). The difference between the two is significant, as demonstrated by a 22% increase in performance. To enrich our experiment, we also added terrain and lithological information to the two models above (i.e., Mod3 and Mod4, respectively). As a result, the performance observed in Mod1 (AUC = 0.94) increased to 0.96 in Mod3. As for the jump from Mod2 to Mod4, this translated into a performance of 0.72 and 0.80, respectively. Therefore, even the more complex benchmark still showed an overall improvement of 16% between Mod3 and Mod4 (Fig. 2a).

a Receiver operating characteristic (ROC) curves and b full suite of examined metrics, including the area under the curve (AUC), accuracy score (ACC), intersection over union (IOU) and F1 score.
A similar modeling performance among the four models is also maintained when examining accuracy, intersection over union (IOU), and F1 scores (Fig. 2b). Mod2 and Mod4 appear significantly less capable of distinguishing failed slopes compared to Mod1 and Mod3, respectively. Also, the role of terrain and lithological characteristics led to a larger performance increase from Mod2 to Mod4 (i.e., 8%) rather than from Mod1 to Mod3 (i.e., 2%), likely because the latter can already rely on a large amount of information carried by the full waveforms.
Aside from the performance metrics, we also presented the spatial pattern of landslide probabilities for each model (Fig. 3). The output of Mod2 appears spatially smoothed (Fig. 3b). Even when including terrain and lithology, Mod4 still exhibits a smooth spatial pattern (Fig. 3d) represented by smeared values that are in the medium to small range without a clear distinction between landslide and non-landslide locations. Actually, what happens is that coseismic unstable slopes become associated mostly with high relief (Fig. 3e) and only marginally with high shaking (Fig. 3f). As a result, Mod4 largely overestimates slope instabilities in the north-east and north-west sectors, an effect that was not present in the simpler Mod2. Despite the spatial differences, another element of concern in both Mod2 and Mod4 is in their range of probabilities, which is biased toward small and medium values.

Mod1 to Mod4 output converted in map form (panels a–d). Panel e shows the relief map, whereas panel f reports the PGV overlayed by the landslide inventory. Basemap source: Esri, USGS, and the GIS User Community.
The use of full waveforms in Mod1 (Fig. 3a) largely addresses both issues mentioned above. The landslide predictive pattern appears less smooth, and the probability contrast between stable and unstable slopes becomes much more evident (the range now extends from 0 to 1). Another characteristic is that probabilistically unstable slopes cluster at the center of the study area. However, this sector unrealistically appears homogeneously unstable. Only in Mod3 (Fig. 3c), combining terrain and lithology to the full waveforms’ information, do the predictive patterns reach their best expression among all models.
Explainability
In the previous section, we acknowledged that the best performance metrics are obtained for Mod3. In this section, we will explore the reasons behind such a result, comparing Mod3 against its simpler version, Mod4. To do so, we identified failed slopes to which both models assigned landslide occurrence probability equal to or greater than 0.5, or (\(p\left\langle {{{{{\rm{Mod}}}}}}4\right\rangle \ge 0.5\wedge p\left\langle {{{{{\rm{Mod}}}}}}3\right\rangle \ge 0.5{|y}=1\)). These are unstable slopes correctly classified by both Mod3 and Mod4. Similarly, we checked failed slopes that only Mod3 was able to characterize with a probability equal to or greater than 0.5, or (\(p\left\langle {{{{{\rm{Mod}}}}}}4\right\rangle\, < \,0.5\wedge p\left\langle {{{{{\rm{Mod}}}}}}3\right\rangle \ge 0.5{|y}=1\)). These are unstable slopes correctly classified only by Mod3. In Fig. 4, we plot each of the two respective groups (panels a–c and d–f) according to the results obtained for the three main directions: East–West, North–South, and Up–Down. Along the y-axis, we present the 2-dimensional histogram of the explainability score generated by Mod3 for each time step of all waveforms, shown along the abscissa. The explainability score quantifies each time step’s contribution with respect to the final landslide occurrence probability. The x-axis is organized according to the PGV arrival (set at zero and symbolized with the solid purple line).

Explainability scores for all slopes in the study area were correctly classified by Mod3 and Mod4 (panels a–c), and failed slopes were recognized only by Mod3 (panels d–f). The purple line points at the arrival of the PGV. Panel g and h present the difference in probability between Mod3 and Mod4 (i.e., Mod3–Mod4) for the entire study area as well as a zoomed location, respectively. Basemap source: Esri, USGS, and the GIS User Community.
The first observation to be made is that in both cases, the direction where most of the explainability is scored corresponds to East-West, which is also the main direction of the rupture propagation during the Gorkha earthquake. The most important element to be stressed is the comparison between the E–W direction belonging to panels a and d. In the first case, where both Mod3 and Mod4 correctly perform, most of the yellow grids (the frequency of explainability scores) cluster around the PGV arrival. This is actually why the two models agree, as even a scalar representation of the full waveform would point at this approximate portion of the signal without relying on the information coming from the rest of the waveform. However, the situation is very different in panel d, where only Mod3 suitably recognizes landslides. There, the explainability scores shown in panel d do not only cluster around the PGV arrival as shown in panel a. Conversely, the explainability is shown to be densely distributed over most of the time series, even ~120 to ~160 s after the PGV.
This observation requires further investigation into what it potentially implies numerically, geographically, physically, and geomorphologically. Numerically, Mod4 is blind to the occurrence of 5260 landslides (or 21.26% with respect to the total). Conversely, Mod3 only misses 2059 landslides (or 8.32% with respect to the total) and captures 3201 landslides that Mod4 misses. As for what this translates in terms of landslide area, Mod4 captures landslides that failed up to 8.4 km2 as compared to the 11.1 km2 estimated by Mod3. Notably, the observed total failed surface is equal to 11.7 km2. Thus, Mod4 misses ~28% of the failed surface, whereas Mod3 only misses ~5%. Looking more into the extremes of the landslide area distribution, above the 95th percentile, Mod4 identifies landslides with an area of ~3700 m2, whereas the same estimated by Mod3 is ~4300 m2. The observed reference is 4315.99 m2. We also explore frequency area distributions40 in Supplementary Fig. 1, observing a higher capacity of Mod3 to predict the two tails of the distribution as compared to Mod4.
Extending the investigation towards geographic implications, we plot the landslide probability difference (Mod3–Mod4) in Fig. 4g. There, both models agree at locations highlighted in yellow (probability difference ~0) and disagree wherever the map presents blue (Mod4 > Mod3) and red colors (Mod3 > Mod4). Interestingly, the highest positive differences in probability (Mod3 > Mod4) cluster along topographic incisions (valleys) running roughly orthogonal to the Himalayan direction.
As for the physical meaning behind Mod3 and Mod4 differences, we revise the idea behind Fig. 4, leave behind probabilistic considerations, and focus on failed slopes. In Fig. 5, we select two representative slopes correctly classified by both Mod3 and Mod4, and two slopes only failed according to Mod3. In such a way, we graphically present the actual waveforms (gray lines) against their site-specific Mod3 scores, exploring potential physical considerations.

Panels a–d present the Mod3 scores against the synthetic waveforms. The x-axis is centered at zero, which corresponds to the PGV arrival time. Panels a and b correspond to slope examples correctly classified by Mod3 and Mod4; panels c and d only apply to correct classification examples from Mod3. Panel e presents the spatial distribution of the respective landslides. Panels f, g, and h show the difference in terms of slope, PGV, and landforms, respectively. Basemap source: Esri, USGS, and the GIS User Community.
Panels a and b show that landslides recognized by both Mod3 and Mod4 exhibit the largest explainability score (green line) close to the PGV (zero along the abscissa). The situation appears very different for landslides only predicted by Mod3. Panel c of Fig. 5 shows two large explainability scores in the early stages of the waveform. The first one is well aligned with the P wave arrival time, an observation that could indicate the ability of our transformer model to capture the influence of waveform phases. Panel d of Fig. 5 depicts another situation where the explainability scores in the early stages of the waveform are relatively low, and a peak score is visible around 150 seconds after the PGV. These results highlight the inadequate capacity of PGV to reflect influences across the full waveform and, in turn, the limited capacity to explain the whole coseismic landslide population. This also means that the Mod3 extracts valuable information from the full waveform, towards which Mod4 is blind.
To conclude the investigation, we explore the geomorphological differences between Mod3 and Mod4 (Fig. 5e). There, we plot landslide locations correctly predicted by both (in green) and those only recognized by Mod3 (in red). Landslides located by Mod3 occur on a gentler topography (Fig. 5f, maximum density at 30°) and with a lower shaking (Fig. 5g, maximum density at 0.2 m/s) compared to landslides predicted by both models (maxima at 40° and 0.4 m/s, respectively). Along the same reasoning, we also classified the Nepalese landforms41 and checked which type is associated with the most misclassifications in Mod4 (Fig. 5h). Open and upper slopes, midslope, and high ridges are also well represented in Mod4. However, Mod4 fails to predict failures at locations close to valleys, stream slopes, and midslope drainages. These are otherwise well recognized as unstable by Mod3.
Overall, these results imply that landslides on less susceptible hillslopes can be more successfully predicted by exploiting the full waveform information. Conversely, landslides triggered on high susceptible hillslopes (i.e., characterized by steep topography and high ground shaking) are already predictable using traditional peak intensity parameters. The realization of such distinction is particularly important because very steep and heavily shaken slopes are already intuitively susceptible. Thus, predicting that location should not require large modeling efforts, and the less susceptible slopes should rather be the target.
Discussion
Traditionally, data-driven coseismic landslide modeling approaches have always focused on ground motion intensity parameters2. These are essentially single scalar representations of the whole seismic sequence42. In turn, this has hindered considerations of the full characteristics of seismic signals. Even though intensity parameters carry important information about the seismic waveforms, they cannot accurately inform about the phase and amplitude and their temporal variations during the earthquake propagation43.
Our findings based on the coseismic landslides triggered by the 2015 Gorkha earthquake showed that the full waveform information translates into a minimum 16% increase across all the examined performance metrics. This occurs because earthquake properties such as amplitude, phase, frequency, and duration are embedded in the seismic waves. When exploring this theme further, what stood out is that Mod3 and Mod4 mostly agree in the northern sector of the earthquake-affected area. As for the slopes below the high mountain range, in particular, the use of PGV is not enough. Mod4 produces very smooth predictive patterns, underestimating the middle section of the Himalayan topographic profile and overestimating failures in safe locations. Notably, also the U.S. Geological Survey (USGS) near-real-time system44 seems to overpredict coseismic landslides45.
To benchmark our full waveform approach, below, we will present a series of additional experiments where our Mod3 is compared to alternatives equipped with scalar ground motion estimates. Looking into what is available at the USGS ShakeMap service46, some parameters constitute the standard for the coseismic landslide community44,47, and they are usually available in multiple versions, one empirically generated right after a major earthquake and few updates as more data becomes available with time48. Here, we opt to benchmark Mod3 against an equivalent that uses PGA and PGV, both in their first (2015) and last (2020) updated versions48. Moreover, we also include two more tests that look back at the original simulations from Dahal et al.15. The first one calculates Arias Intensity49,50, a common scalar proxy for amplitude and duration and widely used for coseismic landslide prediction51. The second one makes use of the full waveforms, like in Mod3, but filters out frequencies above 0.5 Hz. The rationale behind the latter is to include a sensitivity analysis. All the corresponding results are reported in Table 1. There, Mod3 outperforms all the alternatives across all metrics. The two pairs of USGS intensity parameters perform between ~8% and 13% worse than our Mod3. An even greater loss in performance is seen with Arias Intensity, likely because the synthetic waveforms do not contain high frequencies. For the very same reason, we interpret the minimal performance loss over the filtered waveforms. Furthermore, it is also interesting that Mod4 performs worse than the analogous equipped with ShakeMap intensity parameters. This demonstrates that the inclusion of high frequencies adds valuable information in the case of a scalar model. Nevertheless, this performance is still far from what full waveforms can achieve.
Moving away from performance-oriented considerations, Mod3 assigns its largest scores both close to the time of the peak velocity arrival and far from it. Determining which physical information corresponds to these portions of the ground motion sequence is not straightforward. Mod3 captures the E-W direction as responsible for most instabilities (see Fig. 4, panels a and d). This is reasonable as it aligns well with the Main Himalayan Thrust rupture, oriented at 110°.
Looking at single slopes such as in Fig. 5 (panels c and d), our transformer seems to highlight the importance of specific sections of the full waveform, these being potentially linked to the phase information, the interactions with topography, and surface wave arrival. We recall here that deep learning architectures are highly nonlinear and transform the available information into features from which a clear interpretation becomes challenging52. Therefore, the considerations we present below correspond to our understanding, something usually referred to as attribution in the literature53,54. For instance, Fig. 5 shows explainability scores that mark specific sections of the full waveform. Panel c highlights two explainability peaks very close to each other, one reasonably well aligned with the P phase arrival and one most likely with the S. This could be interpreted as the effect of two very different motion patterns affecting a given hillslope almost simultaneously. However, this could be the result of a number of interpretations. This is also the case for panel d. There, despite the similarity of the waveform with the one mentioned above, a relatively smaller explainability score can be seen in the early stages, followed by a much larger one in the late stages. This could be due to the different terrain and geological characteristics of the two sites, as well as the total shaking duration effect. A quick shaking, as intense as it may be, could still leave a slope unfailed. Conversely, a prolonged yet milder shaking could bring a slope to the brink of failure.
Focusing on the portion of the landscape these slopes occupy, Fig. 5 (panels f and g), a static PGV model identifies coseismic failures in slopes around 40° steep and with peak velocities of around 0.5 m/s (i.e., open and upper slopes, midslope and high ridges). Yet, slightly gentler slopes 30° with peak velocities centered around 0.25 m/s) are only predicted when using full waveforms, highlighting Mod3’s ability to predict failures occurring in the proximity of midslope drainages, valleys, and streams. These landforms, especially if far away from the source, only fail when considering the whole ground motion signal.
Although these are interesting observations, they still do not support near-real-time landslide hazard assessment tools. A number of reasons make this the case. Firstly, ground motion simulations require a relatively long time to generate, even when using high-performance computing facilities. Secondly, a good earthquake rupture model is usually not available right after an earthquake, thus limiting the quality of the synthetic waveforms. In relation to the quality, more could be said because coseismic landslides may also occur due to topographic amplification, a phenomenon that is dependent on the interaction between earthquake and landscape characteristics55. Therefore, to obtain a reliable description of the process, a 3D subsurface velocity structure, as well as the geotechnical characterization of the study area, may be required.
Therefore, in light of near-real-time requirements for disaster rescue operations, our Mod3 is still unsuitable at the current state of technology. This implies that we are and will still likely be largely dependent on peak-intensity models in the future to help mountainous communities that have suffered a large earthquake in a timely manner. However, further development to produce more reliable and fast ground motion simulations would definitely help make our approach operational.
Alternatively, scenarios could also be built prior to an earthquake occurrence. One could simulate several theoretical earthquakes and use the synthetic waveforms to obtain coseismic landslide scenarios that could be stored in an emergency response system56. Then, if and when an earthquake of similar characteristics would take place, the predicted scenario could be used to strategize disaster relief actions. The main limitations would boil down to the requirements for the numerical reproduction of shaking, especially in data-scare regions. In fact, the rupture geometry, energy release, and the subsurface structure are fundamental requirements for a reliable ground motion simulation. There are already challenges for data-rich situations, and they would become less and less reliable in regions with proportionally less information available.
Another fundamental element to be explored in the future lies in the size of coseismic landslides and the dependence on the full waveform characteristics. Frequency content and duration of ground shaking may alter the size of coseismic landslides57. For instance, higher frequencies exit hillslopes to the point of releasing small failures, and low frequencies exit much larger landslide bodies58,59. These arguments are not been tested yet in regional scale assessments exploiting the full waveforms. And yet, our results show that the use of full waveforms could enable a better prediction of landslide sizes and with it, the threat they pose to mountainous communities.
Aside from the long-term potential, the overarching theme related to the use of full waveforms to estimate coseismic landslides is where we believe research should mostly be dedicated to in the coming years. Future steps should involve testing a similar framework for different terrains, earthquake magnitudes, and rupture mechanisms. If analogous conclusions could be reached for different contexts, then the knowledge obtained could definitely be translated into better disaster responses in mountainous regions affected by large earthquakes.
Methods
The model in this study incorporates the entire ground-motion signal with morphometric parameters with a modified transformer neural network to include the terrain and lithological factors. In addition, we developed an explainable AI approach that enables us to understand how the model uses waveform information to predict landslides. This method allows both waveform and other predisposing conditions to be considered simultaneously. We then compared our model with three different models (benchmark models, see Table 2), which included intensity parameters and removed morphometry. The tested benchmark models included ground motion waveform only (Mod1), peak ground velocity only (Mod2), terrain, lithology, and ground motion waveform (Mod3), terrain, lithology, and peak ground velocity (Mod4). Furthermore, we developed an explainable artificial intelligence approach to understand the role of ground motion signals. The following section will further explain the details of each developed method.
Model definition and training
The existing transformer models25,60 only work with waveform data and do not include static variables, which are more common in geoscientific problems. In earth surface processes, many parameters are temporally varying (dynamic), whereas some stay the same over human timescale (static). In our case, ground motion is a dynamic variable, whereas the terrain properties are static. To resolve this problem, we modified the vanilla transformer neural network from Vaswani et al.60 to include static covariates.
Landslides (\(L\left(s,t\right)\)) are a spatiotemporal processes that are considered stochastic for modeling purposes61. In this case, let us assume that the landslide is a stochastic spatial process \(\left(L\left(s\right)\right)\) because we do not consider the multiple time frames to model a spatio-temporal process. Being a binary variable, a landslide can be represented by Bernoulli distribution as:
Where the probability of landslide \(p\left(s\right)\in \left({{{{\mathrm{0,1}}}}}\right)\) is what we try to estimate as a landslide susceptibility. For this, the landslide susceptibility is a function of different terrain and geologic as well as seismic variables. The main distinction between those two variables are that terrain and geologic factors are static and does not change during an earthquake event while the seismic energy is dynamic and changes over the time. Therefore, we can define them as static covariates \({X}_{S}\left(s\right)={x}_{S}\left(s\right)\) and dynamic covariates as \({X}_{D}\left(s,t\right)={x}_{D}\left(s,t\right)\). Now the landslide susceptibility, defined by the probability of occurrence of landslide is given by: \(p\left(s\right)=\Pr \in (0,1):\Pr \{{{{{{\rm{L}}}}}}\left({{{{{\rm{s}}}}}}\right)=1{{{{{\rm{|}}}}}}{{{{{{\rm{X}}}}}}}_{{{{{{\rm{s}}}}}}}\left({{{{{\rm{s}}}}}}\right)={{{{{{\rm{x}}}}}}}_{{{{{{\rm{s}}}}}}},{{{{{{\rm{X}}}}}}}_{{{{{{\rm{D}}}}}}}\left({{{{{\rm{s}}}}}},{{{{{\rm{t}}}}}}\right)={{{{{{\rm{x}}}}}}}_{{{{{{\rm{D}}}}}}}\left({{{{{\rm{s}}}}}},{{{{{\rm{t}}}}}}\right)\}\). To model this we use the deep learning model which will represent the potentially highly non-linear function which estimates \(p\left(s\right)\) given the input variables.
Now, to design the deep learning model, let the encoding part of the transformer model from Vaswani et al.60 be \({\tau }_{\left(s,t\right)}\). The function \({\tau }_{\left(s,t\right)}\) takes the input data \({X}_{D}\left(s,t\right)\) and generates feature space over the spatial domain s as \(f{1}_{\left(s\right)}={\tau }_{\left(s,t\right)\left({X}_{D}\left(s,t\right)\right)}\), where all the processing for dynamic data occurs, such as multi-head attention and positional encoding. Then, let us assume there is a deep neural network \({\delta }_{\left(s\right)}\), which is a function of static covariates \(X\left(s\right)={x}_{s}\) and produces the feature space \(f{2}_{\left(s\right)}={\delta }_{\left(s\right)}\left({X}_{s}\left(s\right)={x}_{s}\right)\). We concatenate both feature spaces into one tensor \(f{3}_{(s)}=f{1}_{(s)}\oplus f{2}_{(s)}\), which is then passed to a decoding block of deep neural networks \({\eta }_{\left(s\right)}\) providing a final output as the probability of landslide occurrence \(p\left(s\right)\). Therefore, the final model \({{{{{{\mathcal{M}}}}}}}_{\left(s\right)}\) looks like \(p(s)={{{{{{\mathcal{M}}}}}}}_{\left(s\right)}=\eta (\tau ({X}_{D}\left(s,t\right))\bigoplus \delta ({X}_{s}\left(s\right)={x}_{s}))|{X}_{s}\left(s\right)={x}_{s},{X}_{D}\left(s,t\right)={x}_{D}\left(s,t\right).\) The parameters in all functions \(\tau (s,t),\delta (s),\eta (s)\) (therefore, \({{{{{\mathcal{M}}}}}}(s)\)) is then estimated through backpropagation using a binary cross entropy loss function62 \(\iota =-\left(L\left(s\right)\log \left(p\left(s\right)\right)+\left(1-L\left(s\right)\right)\log \left(1-p\left(s\right)\right)\right)\). Where, L(s) is the observed landslide over space and \(p\left(s\right)\) is the predicted landslide probability over space.
The function \({\tau }_{\left(s,t\right)}\) consists of three input waveform parameters represented in east–west (E–W), north-south (N–S) and up–down (U–D) directions and has a depth of two transformer blocks. Each transformer block consists of a set of sequential layers where input \({X}_{D}\left(s,t\right)\) goes through layer normalization and multi-head attention followed by a dropout layer creating vector \(v{1}_{\left(s,t\right)}\). The vector \(v{1}_{\left(s,t\right)}\) is then added with \({X}_{D}\left(s,t\right)\) to include the attention mechanism and is normalized through a normalization layer creating the vector \(v{2}_{\left(s,t\right)}\). Subsequently, \(v{2}_{\left(s,t\right)}\) flows through a feed-forward block of convolution, rectified linear unit, dropout, convolution, and rectified linear unit. Finally adding the attention layer from the previous part (\(v{3}_{\left(s,t\right)}=v{1}_{\left(s,t\right)}+v{2}_{\left(s,t\right)}\)) to create an output of transformer encoder making a new input \({X}_{D}{\left(s,t\right)}_{n+1}\), for the next block. This is repeated many times as the number of transformer blocks, and after that, the output vector \(v{3}_{\left(s,t\right)}\) is passed through the global average pooling layer, creating feature space \(f{1}_{s}\). The global average pooling layer therefore squeezes the temporal information into spatial only information allowing us to combine the dynamic variables with static variables.
The part of \({\delta }_{\left(s\right)}\left({X}_{s}\left(s\right)={x}_{s}\right)\) processes the input static data \({X}_{s}\left(s\right)\) sequentially through dense blocks consisting of a series of fully connected, batch normalization, dropout, and rectified linear activation units. In this model, we have eight blocks to process the input \({X}_{s}\left(s\right)\) to obtain \(f{2}_{s}\). With both \({{{{{\rm{f}}}}}}{1}_{{{{{{\rm{s}}}}}}},f{2}_{s}\) available, we further process through a series of blocks consisting of a fully connected network, rectified linear units, and dropout layers. Finally passing it through the sigmoid activation function to generate pseudo-probabilities in terms of \(p(s)\).
We trained the model with Adam optimizer63 and the binary cross entropy loss function. The optimizer started with a learning rate of 1e−3 and exponentially decayed every 10,000 steps by a factor of 0.95 until the model converged (for further details, see parameters in the provided code). The training data was generated by randomly selecting 70% of the receiver locations, and the remaining 30% were kept as the test set. Moreover, the training data was further divided into the subset of 20% for the validation set during the model training process to evaluate the model and stop the training before overfitting. This data selection is kept constant for the entirety of the research, making it consistent over benchmarks.
Since our developed model consisted of a deep neural network and transformer components, we designed it in such a way that both \({\tau }_{\left(s,t\right)}\) and \({\delta }_{\left(s\right)}\) components can be turned off. Multiple benchmark models were created by turning each component off and on with different input variables, while keeping the output variables and ground truth (\(p(s)\) and \(L(s)\)) the same. Table 2 lists the models, their respective components, and used input variables.
Evaluation framework
We evaluated the classification capacity of the model by computing multiple evaluation metrics common to statistics and machine learning39,64. To evaluate the model performance, we used the area under the curve (AUC) of the receiver operating characteristics curve (ROC), which is a well-accepted method to evaluate the model performance and fit65. The ROC curve is generated by evaluating the fit between \(L(s)\) and \(p(s)\) by using a confusion matrix for different probability threshold values in the range of [0,1]. ROC represents the relation between false positive rate (FPR) and true positive rate (TPR), which are calculated as the ratio of false positive with negative instances and true positive with true instances, respectively. Once the ROC curve is identified, the AUC is calculated as \({{{{{\rm{AUC}}}}}}={\int }_{0}^{1}{{{{{\rm{TPR}}}}}}\cdot d\left({{{{{\rm{FPR}}}}}}\right)\).
To evaluate the model performance on the validation set, we used different scoring methods designed for the classification problem: Accuracy score (ACC), F1 score, and intersection over union (IOU) score. The accuracy score is a ratio between the total number of correct predictions and the total number of samples. The F1 score is more robust than the accuracy score and is sensitive to false positives as well as false negatives. It is calculated as twice the ratio of the product of precision and recall over the summation of precision and recall (\(F1=2\cdot \frac{{{{{{\rm{precision}}}}}}\cdot {{{{{\rm{recall}}}}}}}{{{{{{\rm{precision}}}}}}+{{{{{\rm{recall}}}}}}}\)). Precision and recall are the ratios of correctly predicted positive observations to the total predicted positives and the ratio of correctly predicted positive observations to the total actual positives, respectively. IOU score, on the other hand, represents the overlap between the observed and predicted landslides and A higher IOU indicates better alignment between the predicted and ground truth. It is calculated as a ratio of true positives over the union of all instances predicted as positive (both true and false positives) and all instances that are actually positive (both true positives and false negatives).
Explainability
To understand how the waveform component in our input data \({X}_{D}\left(s,t\right)\) influences the model output \({{{{{\rm{p}}}}}}\left({{{{{\rm{s}}}}}}\right)\), we implemented an explainable approach. The explainable artificial intelligence based evaluation in landslide hazard modeling is recent yet meaningful approach to understand the influence of input covariates on model output66. The method is based on the work of Cisneros et al.67 and Shrikumar et al.53, where we calculate the influence scores \(S\) based on the gradient of p(s) with respect to input vector \({X}_{D}\left(s,t\right)\) where it is set to zeros (\({X}_{D0}\left(s,t\right)\)) for baseline gradient \({\nabla }_{b}=\frac{\partial {{{{{{\mathscr{M}}}}}}}_{s}\left({X}_{D0}\left(s,t\right),{X}_{S}\left(s\right)\right)}{\partial {X}_{D0}\left(s,t\right)},\) and actual values for instance gradient \({\nabla }_{i}=\frac{\partial {{{{{{\mathscr{M}}}}}}}_{s}\left({X}_{{Di}}\left(s,t\right),{X}_{S}\left(s\right)\right)}{\partial {X}_{{Di}}\left(s,t\right)}\). This gradient can be assumed as the regression coefficient (\(m\)) in the case of linear regression problem \(y={mx}+c\). Since our model is highly non-linear, a direct comparison of \(m\) cannot be made; thus, we compare their relative change to understand how the variable \(t\) influences the model output. For that, we take a relative ratio of the gradients, also considering the actual change in values as below:
Notably, the score (\(S\)) here is calculated only for the waveform component and not for the constant variables because the influence of other covariates on landslide occurrence is well-known, and our focus is on understanding the role of ground motion waveform on landslide occurrences.
Data availability
All the pre-processed and raw datasets required to reproduce the results and the model output files are available via the open-access repository (stored in separate folders for relevant input and output files), which can be accessed via https://doi.org/10.5281/zenodo.10514311. The landslide inventory used in the study is available through Roback et al.29,68. The Geology data are available through Dahal et al.31. The ground motion simulation data is available via Dahal et al.15. The epicenter and shakemap-related ground motion parameters are available at United States Geological Survey (USGS) portal: https://earthquake.usgs.gov/earthquakes/eventpage/us20002926/shakemap/pga?source=us&code=us20002926. The Himalayan fault lines are available via International Center for Integrated Mountain Development (ICIMOD) data portal: https://rds.icimod.org/home/datadetail?metadataid=3437.
Code availability
All the models and their relevant parameters are openly available via the repository; https://github.com/ashokdahal/TransformerLandslide; a permanent release of the codes to reproduce the results and relevant plots in this paper are openly available via the archiving repository; https://doi.org/10.5281/zenodo.10514293. Python environment with Tensorflow library and GPU support is required to run the codes; a relevant package requirement file is available in the repository to prepare the necessary Python environment.
References
Bird, J. F. & Bommer, J. J. Earthquake losses due to ground failure. Eng. Geol. 75, 147–179 (2004).
Fan, X. et al. Earthquake-induced chains of geologic hazards: patterns, mechanisms, and impacts. Rev. Geophys. 57, 421–503 (2019).
Dunham, A. M. et al. Topographic control on ground motions and landslides from the 2015 Gorkha earthquake. Geophys. Res. Lett. 49, e2022GL098582 (2022).
Gischig, V. S. Rupture propagation behavior and the largest possible earthquake induced by fluid injection into deep reservoirs. Geophys. Res. Lett. 42, 7420–7428 (2015).
Jibson, R. W. Methods for assessing the stability of slopes during earthquakes—a retrospective. Eng. Geol. 122, 43–50 (2011).
Newmark, N. M. Effects of earthquakes on dams and embankments. Geotechnique 15, 139–160 (1965).
Jibson, R. W. Predicting earthquake-induced landslide displacements using Newmark’s sliding block analysis. Transp. Res. Rec. 1411, 9–17 (1993).
Bray, J. D. & Rathje, E. M. Earthquake-induced displacements of solid-waste landfills. J. Geotech. Geoenviron. Eng. 124, 242–253 (1998).
Li, Z. Recent advances in earthquake monitoring I: ongoing revolution of seismic instrumentation. Earthq. Sci. 34, 177–188 (2021).
Oth, A. et al. KivuSNet: the first dense broadband seismic network for the Kivu Rift Region (Western Branch of East African Rift). Seismol. Res. Lett. 88, 49–60 (2017).
Wasowski, J., Keefer, D. K. & Lee, C. T. Toward the next generation of research on earthquake-induced landslides: current issues and future challenges. Eng. Geol. 122, 1–8 (2011).
Atkinson, P., Jiskoot, H., Massari, R. & Murray, T. Generalized linear modelling in geomorphology. Earth Surface Process. Landforms 23, 1185–1195 (1998).
Hastie, T. J. Generalized additive models. in Statistical models in S. 249–307 (Routledge, 2017).
Goetz, J. N., Brenning, A., Petschko, H. & Leopold, P. Evaluating machine learning and statistical prediction techniques for landslide susceptibility modeling. Comput. Geosci. 81, 1–11 (2015).
Dahal, A. et al. From ground motion simulations to landslide occurrence prediction. Geomorphology 441, 108898 (2023).
Cho, K. et al. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. EMNLP 2014 − 2014 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference 1724–1734 https://doi.org/10.3115/v1/d14-1179 (2014).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735–1780 (1997).
Grigsby, J., Wang, Z., Nguyen, N. & Qi, Y. Long-Range Transformers for Dynamic Spatiotemporal Forecasting. (2021).
Reza, S., Ferreira, M. C., Machado, J. J. M. & Tavares, J. M. R. S. A multi-head attention-based transformer model for traffic flow forecasting with a comparative analysis to recurrent neural networks. Expert Syst. Appl. 202, 117275 (2022).
Tang, Z., Shi, Y., Wang, D., Feng, Y. & Zhang, S. Memory visualization for gated recurrent neural networks in speech recognition. ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings 2736–2740 https://doi.org/10.1109/ICASSP.2017.7952654 (2017).
Steger, S. et al. Deciphering seasonal effects of triggering and preparatory precipitation for improved shallow landslide prediction using generalized additive mixed models. Nat. Hazards Earth Syst. Sci. 23, 1483–1506 (2023).
Fang, Z. et al. Speech-recognition in landslide predictive modelling: a case for a next generation early warning system. Environ. Model. Softw. 170, 105833 (2023).
Graves, A. et al. Hybrid computing using a neural network with dynamic external memory. Nature 538, 471–476 (2016).
Mousavi, S. M., Ellsworth, W. L., Zhu, W., Chuang, L. Y. & Beroza, G. C. Earthquake transformer—an attentive deep-learning model for simultaneous earthquake detection and phase picking. Nat. Commun. 11, 1–12 (2020).
Parmar, N. et al. Image Transformer. 35th International Conference on Machine Learning, ICML 2018 9, 6453–6462 (2018).
Carion, N. et al. End-to-End Object Detection with Transformers. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 12346 LNCS, 213–229 (2020).
Chernyavskiy, A., Ilvovsky, D. & Nakov, P. Transformers: “The End of History” for Natural Language Processing? Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 12977 LNAI, 677–693 (2021).
Radford, A. et al. Language models are unsupervised multitask learners. OpenAI Blog 1, 9 (2019).
Roback, K. et al. The size, distribution, and mobility of landslides caused by the 2015 Mw7.8 Gorkha earthquake, Nepal. Geomorphology 301, 121–138 (2018).
Farr, T. G. & Kobrick, M. Shuttle Radar Topography Mission produces a wealth of data. Eos Trans. Am. Geophys. Union 81, 583–585 (2000).
Dahal, R. K. Rainfall-induced landslides in Nepal. Int. J. Eros. Control Eng. 5`, 1–8 (2012).
Grandin, R. et al. Rupture process of the Mw = 7.9 2015 Gorkha earthquake (Nepal): insights into Himalayan megathrust segmentation. Geophys Res. Lett. 42, 8373–8382 (2015).
Ekström, G., Nettles, M. & Dziewoński, A. M. The global CMT project 2004–2010: centroid-moment tensors for 13,017 earthquakes. Phys. Earth Planet. Inter. 200–201, 1–9 (2012).
Wu, Z. et al. Damage induced by the 25 April 2015 Nepal earthquake in the Tibetan border region of China and increased post-seismic hazards. Nat. Hazards Earth Syst. Sci. 19, 873–888 (2019).
Wei, S. et al. The 2015 Gorkha (Nepal) earthquake sequence: I. Source modeling and deterministic 3D ground shaking. Tectonophysics 722, 447–461 (2018).
Thrastarson, S. et al. Accelerating numerical wave propagation by wavefield adapted meshes. Part II: full-waveform inversion. Geophys. J. Int. 221, 1591–1604 (2020).
Van Herwaarden, D. P. et al. Accelerated full-waveform inversion using dynamic mini-batches. Geophys. J. Int. 221, 1427–1438 (2020).
Mahesh, P. et al. One-dimensional reference velocity model and precise locations of earthquake hypocenters in the Kumaon–Garhwal Himalaya. Bull. Seismol. Soc. Am. 103, 328–339 (2013).
Hosmer, D. W. & Lemeshow, S. Applied Logistic Regression. (Wiley, 2000).
Tanyaş, H., van Westen, C. J., Allstadt, K. E. & Jibson, R. W. Factors controlling landslide frequency–area distributions. Earth Surf. Process. Landf. 44, 900–917 (2019).
Jasiewicz, J. & Stepinski, T. F. Geomorphons — a pattern recognition approach to classification and mapping of landforms. Geomorphology 182, 147–156 (2013).
Housner, G. W. Strong ground motion. Earthq. Eng. 75, 91 (1970).
Rong, X. L. et al. Optimal ground motion intensity measure for seismic assessment of high-rise reinforced concrete structures. Case Stud. Constr. Mater. 18, e01678 (2023).
Nowicki Jessee, M. A. et al. A global empirical model for near-real-time assessment of seismically induced landslides. J. Geophys. Res. Earth Surf. 123, 1835–1859 (2018).
Allstadt, K. E. et al. Improving Near‐real‐time Coseismic Landslide Models: Lessons Learned From the 2016 Kaikōura, New Zealand, Earthquake. Bull. Seismol. Soc. Am. 108, 1649–1664 (2018).
Wald, D. J., Worden, C. B., Thompson, E. M. & Hearne, M. ShakeMap operations, policies, and procedures. Earthq. Spectra 38, 756–777 (2022).
Robinson, T. R. et al. Rapid post–earthquake modelling of coseismic landslide intensity and distribution for emergency response decision support. Nat. Hazards Earth Syst. Sci. 17, 1521–1540 (2017).
United States Geological Survey. Earthquake Hazards Program (2015). Available at: https://earthquake.usgs.gov/earthquakes/eventpage/us20002926/moment-tensor (Accessed: 6th Jan 2024).
Arias, A. A measure of earthquake intensity. Seismic design for nuclear plants 438–483 (1970).
Torgoev, A. & Havenith, H.-B. 2D dynamic studies combined with the surface curvature analysis to predict Arias Intensity amplification. J. Seismol. 20, 711–731 (2016).
Jibson, R. W. Regression models for estimating coseismic landslide displacement. Eng. Geol. 91, 209–218 (2007).
Razin, N. & Cohen, N. Implicit regularization in deep learning may not be explainable by norms. Adv. Neural Inf. Process. Syst. 33, 21174–21187 (2020).
Shrikumar, A., Greenside, P. & Kundaje, A. Learning important features through propagating activation differences. 34th International Conference on Machine Learning, ICML 2017 7, 4844–4866 (2017).
Achtibat, R. et al. From attribution maps to human-understandable explanations through concept relevance propagation. Nature Mach. Intell. 5, 1006–1019 (2023).
Von Specht, S., Ozturk, U., Veh, G., Cotton, F. & Korup, O. Effects of finite source rupture on landslide triggering: the 2016 Mw 7.1 Kumamoto earthquake. Solid Earth 10, 463–486 (2019).
Lombardo, L. & Tanyas, H. From scenario-based seismic hazard to scenario-based landslide hazard: fast-forwarding to the future via statistical simulations. Stoch. Environ. Res. Risk Assess. 36, 2229–2242 (2022).
Jibson, R. W. & Tanyaş, H. The influence of frequency and duration of seismic ground motion on the size of triggered landslides—a regional view. Eng. Geol. 273, 105671 (2020).
Bhandari, T., Hamad, F., Moormann, C., Sharma, K. G. & Westrich, B. Numerical modelling of seismic slope failure using MPM. Comput. Geotech. 75, 126–134 (2016).
Kramer, S. L. Geotechnical Earthquake Engineering. (Pearson Education India, 1996).
Vaswani, A. et al. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017-December, 5999–6009 (2017).
Campforts, B., Shobe, C. M., Overeem, I. & Tucker, G. E. The art of landslides: how stochastic mass wasting shapes topography and influences landscape dynamics. J. Geophys. Res. Earth Surf. 127, e2022JF006745 (2022).
Good, I. J. Maximum entropy for hypothesis formulation, especially for multidimensional contingency tables. Ann. Math. Stat. 34, 911–934 (1963).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. Preprint at arXiv https://doi.org/10.48550/arXiv.1412.6980 (2014).
Dwivedi, A. K. Performance evaluation of different machine learning techniques for prediction of heart disease. Neural Comput. Appl. 29, 685–693 (2018).
Lombardo, L. & Mai, P. M. Presenting logistic regression-based landslide susceptibility results. Eng. Geol. 244, 14–24 (2018).
Dahal, A. & Lombardo, L. Explainable artificial intelligence in geoscience: a glimpse into the future of landslide susceptibility modeling. Comput. Geosci. 176, 105364 (2023).
Cisneros, D., Richards, J., Dahal, A., Lombardo, L. & Huser, R. Deep graphical regression for jointly moderate and extreme Australian wildfires. Spatial Statistics. 59 100811 (2024).
Roback, K. et al. Map data of landslides triggered by the 25 April 2015 Mw 7.8 Gorkha, Nepal earthquake. US Geol. Surv. Data Release https://doi.org/10.5066/F7DZ06F9 (2017).
Acknowledgements
This work used the Dutch national e-infrastructure with the support of the SURF Cooperative using grant No. EINF-7984. This work was funded by the NATO Science for Peace and Security Program (SPS project G6190). We would also like to thank the KAUST competitive research grant (CRG) office for funding support for this research under grant URF/1/4338-01-01. We would like to thank Laura Gnesko from the University of Canterbury for proofreading the paper.
Author information
Authors and Affiliations
Contributions
Ashok Dahal proposed the research idea, which was further conceptualized by Hakan Tanyas and Luigi Lombardo. Ashok Dahal performed the analyses and developed the methods. The first version of the manuscript was written by all the co-authors and revised by Hakan Tanyas and Luigi Lombardo. Figures were edited and updated by Hakan Tanyas, whereas Luigi Lombardo supervised the overall process.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Communications Earth & Environment thanks the anonymous reviewers for their contribution to the peer review of this work. Primary Handling Editor Joe Aslin. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dahal, A., Tanyaş, H. & Lombardo, L. Full seismic waveform analysis combined with transformer neural networks improves coseismic landslide prediction. Commun Earth Environ 5, 75 (2024). https://doi.org/10.1038/s43247-024-01243-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s43247-024-01243-8
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
