
Abstract
Demonstrating the practical advantage of quantum computation remains a long-standing challenge whereas quantum machine learning becomes a promising application that can be resorted to. In this work, we investigate the practical advantage of quantum machine learning in ghost imaging by overcoming the limitations of classical methods in blind object identification and imaging. We propose two hybrid quantum-classical machine learning algorithms and a physical-inspired patch strategy to allow distributed quantum learning with parallel variational circuits. In light of the algorithm, we conduct experiments for imaging-free object identification and blind ghost imaging under different physical sampling rates. We further quantitatively analyze the advantage through the lens of information geometry and generalization capability. The numerical results showcase that quantum machine learning can restore high-quality images but classical machine learning fails. The advantage of identification rate are up to 10% via fair comparison with the classical machine learning methods. Our work explores a physics-related application capable of practical quantum advantage, which highlights the prospect of quantum computation in the machine learning field.
Similar content being viewed by others


Introduction
Quantum computation is widely believed to have the potential to speed up classical computation1,2. This technology has possible applications in various fields, including machine learning3,4,5, materials discovery and synthesis6, and drug research and development7. Demonstrating quantum advantage in unknown applications or scientific problems is a crucial step toward illustrating the practical usage of quantum computation.
One of the challenges in quantum computation is to identify practical applications or problems where quantum algorithms can outperform classical ones8,9. Although various experiments have demonstrated quantum advantage, such as random circuit sampling10, Boson sampling11,12,13, and quantum walks14, they have limited practical applications in the near term. In the noisy intermediate-scale quantum (NISQ) era15, quantum noise cannot be fully eliminated, and the number of qubits is limited. Therefore, the focus is on demonstrating the advantage of quantum hardware-based computation in terms of sample or time complexity compared to classical counterparts16. Several research studies aim to clarify the advantage of quantum machine learning (QML), such as the rigorous speedup for discrete logarithm problems using the quantum kernel method17 and the theoretical advantage for identifying quantum states/processes using QML18. These works demonstrate the possibility of achieving theoretical quantum advantage in NISQ devices using QML to solve specific problems. Furthermore, hybrid QML has been experimentally demonstrated to generate high-quality images using ion-trap quantum computers19. QML has also been used to generate handwritten digits without the use of classical neural networks in superconducting quantum computers20. In these works, QML directly processes classical data using specific quantum encoding techniques. Although these works demonstrate the feasibility of QML, the practical quantum advantage has yet to be highlighted as pure classical datasets were used. QML has recently been applied in high-energy physics21,22 and quantum many-body physics23. These studies suggest that QML is more suitable for dealing with data generated from actual physical systems24,25. Recently, there has been a trend in QML applications, where in reduced resource scenarios, it is better to constrain the available resources rather than scale up the device26. Ghost imaging (GI) is a promising bridge connecting classical data and QML and is likely to be the first physics-related application in the classical regime to demonstrate quantum advantage.
GI retrieves an image by using two correlated beams, the reference beam, and the object beam27,28,29,30. The reference beam is typically captured by a spatial resolution detector and does not interact with the object. In contrast, the object beam records the object information by a bucket detector that lacks spatial resolution. Figure 1a shows the experimental setup. Early GI experiments were based on entangled light sources27, and the basis of correlated imaging was considered to be quantum entanglement properties31. Subsequently, it was demonstrated that ghost imaging can also be implemented using a classical light source28,32,33. Further, the reference beam can be replaced by a programmable spatial light modulator (SLM) or a digital micro-mirror device (DMD), which simplifies GI to a single-beam configuration34. Compared to a traditional array camera, GI is a time-for-space imaging method. Due to its inevitable time-consuming sampling, obtaining high-quality images at a low sampling rate is significant, under which the dimension of the bucket signals can be greatly reduced. The signals contain information about the physical process, leading to potential advantages when using QML. The bucket signals can be directly used for downstream tasks, such as imaging-free recognition35, tracking36, and segmentation37.

a The typical experimental setup for ghost imaging in which the patterns can be randomly sampled or optimized according to the poster processing and a single-pixel detector is used to measure the object-interacted light field modulated by the prescribed illumination patterns. The patterns and bucket signals are correlated to recover the image. b Hybrid quantum machine learning algorithm by combining the artificial neural network or convolution neural network enhances object identification and the quality of object imaging. Quantum feature encoding and learning operations are hardware-efficient such that they can be implemented in the noisy intermediate-scale quantum (NISQ) devices.
In this work, we propose a hybrid QML algorithm for GI systems to demonstrate their practical advantages in physically-inspired imaging systems. We investigate two challenging applications: object identification and imaging, which can be regarded as classification and regression problems in the machine learning field. We collect experimentally detected signals from the GI system to train QML models using a physical-inspired patch strategy to divide high-dimensional measured signals into low-dimensional pieces for accessible data encoding by current NISQ devices. We also build classical neural networks with an approximate number of trainable parameters to benchmark the performance fairly. In the identification and imaging applications, our hybrid QML methods are shown to be superior to their corresponding classical machine learning methods. We investigate the generalization capability of QML when reducing the training samples and quantify the quantum advantage using a capacity measure of QML from the perspective of information geometry. Furthermore, we study the impact of quantum noise in the QML method on the imaging application. Our results demonstrate the substantial advantage of QML algorithms in the GI system through rigorous quantitative analysis, highlighting their potential advantages in physically-related systems.
Results
Practical advantage of QML in GI
The hybrid quantum-classical machine learning algorithm presented in this work consists of a classical artificial neural network and a parameterized quantum circuit (PQC), as shown in Fig. 1b. The performance of the PQC can vary depending on its topology, but we utilize a typical circuit structure with interleaved single-qubit rotation layers and entangling layers, given the current availability of hardware. The QML model first maps the bucket signals B into the quantum Hilbert feature space using a predefined encoding strategy, such as angle encoding, amplitude encoding, or other quantum many-body inspired encoding38 (see Supplementary Note 2). While there have been numerical studies evaluating the performance of QML models in toy tasks, their practical application and advantage in classical tasks is still rare. We investigate the GI system and find that the measured bucket signals from the GI system are highly suitable for current QML models. We experimentally collect the bucket signals to constitute the dataset. Our hybrid quantum learning model is more practically relevant compared to previous works and has the potential to enhance the performance of the GI system, including object identification and imaging.
In our algorithm, we do not utilize the pattern information, and hence the identification and imaging process is blind. In GI, the target information is reconstructed based on the correlation between the illumination patterns and the acquired bucket intensities. However, environmental turbulence can prevent the detection or evaluation of illumination patterns in practical scenarios, such as remote sensing, biomedical imaging, and underwater perception. Therefore, reconstructing without illumination patterns is a natural way to address this problem39,40.
As shown in Fig. 1a, the single-beam ghost imaging technique retrieves an image by utilizing the correlation between the modulated patterns displayed on the digital DMD and the bucket signals collected by the detector. In this technique, a laser beam initially illuminates the DMD, which is loaded with various modulated patterns. The modulated light field then propagates toward the object, and after interacting with the scene, the transmitted or reflected light is collected by a bucket detector (i.e., a single-pixel detector). This physical process essentially encodes the scene information optically via the illumination light field. Consequently, the collected bucket signal B can be mathematically represented as follows
where \(I({\overrightarrow{r}}_{0})\) is the intensity distribution imprinted on the object plane, and \(S({\overrightarrow{r}}_{0})\) is the intensity transmission or reflection function of the object. According to GI theory33,41,42, a ghost image can be restored via intensity correlation as
where \(\Delta I({\overrightarrow{r}}_{o})\) and ΔB is the intensity fluctuations of illuminations and the bucket signals, respectively. The notation \(\left\langle \cdot \right\rangle\) presents the ensemble average. Eq. (2) indicates that one needs to detect a large number of intensities under corresponding illuminating patterns to retrieve an Np-pixel image. According to the Nyquist sampling criterion, the measurement number M needs to be at least equal to Np. In the case of M = Np, the illuminations need to be guaranteed orthogonal or simply set to point scanning. However, considering the noise disturbance and the cost of programmable modulators, random patterns are widely used in GI applications30,43,44,45, where the sampling needs to meet M ≫ Np.
In practical computational GI scenes, to reduce imaging time, the sampling is always limited and the illumination \(I({\overrightarrow{r}}_{o})\) is always approximated by the loaded patterns \(I(\overrightarrow{r})\). Thus, the solution of Eq. (2) can be presented as
In Eq. (3), M needs to be at least equal to the imaging pixel number Np, which is time-consuming. To accelerate the progress, GI is always performed under M ≪ Np. In this case, the image reconstruction of GI is an underdetermined optimization problem
where I is the measurement matrix consisting of the modulated illumination patterns \(I(\overrightarrow{r})\), and \({\left\Vert \cdot \right\Vert }_{2}\) denotes the L2 norm. The conventional method to directly solve the optimization problem is still hard, especially in cases where the sample rate is insufficient. To solve this underdetermined problem, a common practice is to introduce a regularization term into Eq. (4). The regularization term is also known as the sparsity constraint. For example, the compressed sensing (CS)46 construction algorithms are based on the sparsity of natural images and are widely used in GI42,47. However, CS-based methods usually need much time to iterate and have no generalization ability.
Machine learning has shown to be effective in improving optimization results under noisy measurements and ill-posed or uncertain measurement operators48,49,50. However, the need for large datasets and neural networks still limits its application. QML, specifically its hybrid version (see Methods), shows promise in enhancing learning capabilities and reducing neural network size. It is worth noting that the basis for patch processing of bucket signals (see Eq. (8)) is rooted in the independence of each bucket signal from the others. As per signals and systems theory51, the physical model presented in Eq. (1) is a basic linear time-invariant system, and the system’s response to independent illumination patterns (I1, I2, . . . , IM) will remain independent.
Object identification
Real-time identification of objects has significant applications in various fields, from remote sensing to biomedicine. Traditional image-based recognition suffers from high data dimensionality and long acquisition time. This has inspired researchers to use GI bucket signals directly for real-time target identification. This can be achieved by formulating the identification problem as a multi-class classification problem using machine learning, as shown in the imaging-free recognition branch of Fig. 1b. The proposed QML model maps the bucket signals into a classical neural network to reduce dimensionality. The pre-processed features are further mapped into a quantum encoder that maps classical features into a Hilbert space. The quantum learning operations transform the quantum feature vector, clustering the features with the same class label while separating those with different labels. Finally, a linear classifier classifies the bucket signals into their respective categories. The specific design of PQC can be found in Supplementary Note 2.
We collect the experimental data of handwritten digits to evaluate the proposed model on the recognition task. Detailed data acquisition is demonstrated in the Methods section. To illustrate the advantages of the QML algorithm, the number of training parameters for QML and classical machine learning (CML) are restricted to be approximately equal for a fair comparison and the prediction performances of QML and CML is displayed as Fig. 2 shows. We collect two types of bucket signals with optimized and random illumination patterns, with measurement times set at M = 16, 32, 64, 128. The illumination pattern can be optimized according to the identification accuracy by adopting a machine learning strategy and the details can refer to Supplementary Note 1. We propose the patch strategy to divide large M into small ones by executing multi-PQCs in parallel. For example, when M = 32, we have two PQCs each with 16 qubits to learn the feature information. One can also regard PQC with 8 qubits as an unit and simultaneously run 4 PQCs to extract the feature. As we have clarified previously, since we can regard each detection as one independent sampling process from the light field, the bucket signals can mathematically be viewed as independently identically distributed. Therefore, the patch strategy in QML is well-founded and interpretable, which is also very suitable for current NISQ devices. The training curves of QML with different M are shown in Fig. 2a–d, and the validation accuracy of CML and QML for the optimized and random patterns are demonstrated in Fig. 2b–e, respectively.

a The loss (left) and validation accuracy curve (right) of hybrid QML varied with the training epochs, where the bucket signals are measured based on the optimized patterns. b The ultimate identification precision of classical and hybrid (noisy, 10−3 or 3 × 10−3) QML with approximately equal size of parameter space varied with different numbers of optimized illumination patterns. c The t-distributed stochastic neighbor embedding (TSNE) visualization of raw bucket signals with random patterns (M = 16). d The loss (left) and validation accuracy (right) curve of hybrid QML varied with the training epochs based on random patterns. e The final accuracy of classical and hybrid (noisy, 10−3 or 3 × 10−3) QML for different number of random patterns. f The TSNE visualization of hybrid QML optimized bucket signals with random patterns (M = 16).
In both cases, QML showed a tangible advantage over CML when limiting the classical and quantum model to have approximately the same number of training parameters. Even when the quantum decoherence rate for each neighboring qubits is 10−3, a typical decoherence rate achievable for current NISQ devices, the quantum advantage still holds. However, when the decoherence rate is increased to 3 × 10−3, the accuracy enhancement weakens. The experimental results showed that large quantum error rates may counteract the quantum advantage for current NISQ devices in imaging identification tasks. Therefore, noise mitigating techniques to reduce the error rate are necessary to maintain the quantum advantage. Additionally, we visualize the original bucket signals and QML-learned features using the t-distributed stochastic neighbor embedding (TSNE) method (see Fig. 2f). QML mapped features are distributed separately in two-dimensional embedding, allowing for better identification error rates. Further details of TSNE can be found in Supplementary Note 3. Finally, we note that QML is less prone to overfitting compared to CML, with the QML model capturing more generalized representations due to the large feature Hilbert space.
To assess the generalization performance of QML in GI, we conducted experiments with smaller training datasets consisting of random patterns. The training samples are set to be 1 × 103, 2.5 × 103, 5 × 103, 104, 2 × 104, respectively. The results obtained through QML and CML methods are presented in Fig. 3. As expected, decreasing the training dataset size results in a decrease in the validation accuracy for both methods. However, for each measurement times M, QML outperforms CML in terms of prediction accuracy. Moreover, the difference in prediction accuracy between QML and CML remains consistent across all training dataset sizes. With a comparable number of training parameters, QML has demonstrated an empirical advantage of 3–10% in terms of identification accuracy compared to CML. Additionally, our experiments reveal that QML has strong generalization capabilities when the number of training samples is limited. This feature is particularly useful in scenarios with a low sampling rate and a small number of training samples. We also evaluate the prediction performance of QML and CML in two actual objects in the GI system. The results show that the QML-enhanced GI system has fewer prediction errors than the CML method. Further details can be found in Supplementary Note 4.

The generalization performance of classical machine learning (CML) and hybrid quantum machine learning (QML) is evaluated by the validation accuracy with different capacities of training samples. The classical neural network has the approximate number of training parameters with the hybrid QML.
Object imaging
As mentioned before in GI, imaging time and quality are mutually restricted. Therefore, we attempt to break this predicament by using hybrid QML. Object imaging requires reconstructing an image that is as identical as possible to the original object according to its single-pixel detected bucket signals. We study the performance of the hybrid QML, which combines the classical convolution networks as shown in the imaging branch of Fig. 1b. The convolution network is composed of the upsampling layer with bilinear interpolation to enlarge the image size and the multi-filter convolution layer to extract the local features. The upsampling and convolution layer are repeated for certain numbers until the reconstructed image size equals the original image size. We note that the upsampling layer has no trainable parameters and the convolution layer has a relatively smaller number of parameters compared to the fully-connected neural network. The hybrid QML first divides the bucket signals into several parts and maps them into parallel quantum encoders, respectively. Subsequently, each quantum encoder is followed by variational quantum layers to process the quantum features in Hilbert space. Then, each qubit is measured locally to estimate the predefined observable \(O={\otimes }_{i = 1}^{n}{Z}_{i}\) as the quantum output. The quantum output from different PQCs should be concatenated into a single vector that is then processed by classical convolution networks. For a fair comparison, we replace the PQC with the classical NN and both of them have the approximate number of trainable parameters. CML and QML have the same post-processing architecture i.e., they have identical convolution networks. In reality, our PQC architecture always has a smaller number of training parameters than classical NN. The details of the hyperparameters can be found in Supplementary Note 6.
To study the potential advantage of QML ghosting imaging, we conduct the optical experiments in Fig. 1a to collect the bucket signals. The dataset used to generate the buckets signals can be found in Method. We adopt the remote sensing images as our dataset. The images have a low signal-to-noise ratio and the contrast ratio of the images is also low. Reconstructing remote-sensing images is a challenging task in the field of imaging processing. By using a GI system, we collect the bucket signals as the input of the QML/CML and then output the reconstructed images. By using the MSE loss function, we can calculate the gradients of loss over each training parameter. The details can be found in Method. As we can see, the intuitive comparison from reconstructed images between QML and CML in Fig. 4a demonstrates that QML outperforms CML in terms of the resolution and outline of the images. Here, we do not concentrate on the resolution of reconstructed images. From Fig. 4b, we present the validation mean absolute error (MAE) of QML and CML. We can find that the MAE of the QML is much smaller than the CML. The ultimate MAE in the last epoch (500) of both CML and QML is presented in Fig. 4c. The final MAE of QML is 3.6, 4.2, 4.9, 5.9 fold smaller than the MAE of CML for M = 64, 128, 256, 512, respectively. Increasing the number of illumination patterns from M = 64 to 512, the MAE of the QML is decreased linearly. On the contrary, the MAE of the CML does not decrease, which indicates that the network did not converge well. In principle, increasing the number of patterns can increase the GI quality. This is illustrated by the differential ghost imaging (DGI)52 results (see Supplementary Note 4). DGI reconstruction requires the use of illumination speckles, which is not blind imaging. Even though we find that QML results are still better than DGI under the same sample rate.

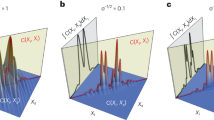
a QML-based GI and CML-based GI under different illumination patterns M = 64, 128, 256, 512. b The validation means absolute error (MAE) of QML (top panel) and CML (bottom panel) with a different number of patterns. c The final validation MAE of QML and CML under different M. d The validation curve for four types of illumination pattern where the parameterized quantum circuit (PQC) has decoherence quantum noise with the decoherence rate of three axes in Bloch sphere px = py = pz = 5 × 10−3. Inset is the validation MAE in the last epoch. e The validation MAE for four types of patterns where the PQC decoherence rate px = py = pz = 5 × 10−2.
We also investigate the performance of our QML model with practical quantum noise, such as decoherent noise. To simulate the noise, we insert Kraus operators after each two-qubit entangling gate, as entangling gates in NISQ devices are difficult to perfect and highly critical to the PQC. We simulat decoherent noise for each qubit operated by the entangling gate. Further details on the quantum circuit used can be found in Supplementary Note 2, while the results under the noise circuit can be found in Supplementary Note 4. From Fig. 4d, we observe that as the quantum noise rate increased to 5 × 10−3, the decreasing tendency of the mean absolute error (MAE) is different from Fig. 4b. The ultimate MAE shows a slight increase compared to the ideal case. Figure 4e also reveals that as the noise rate increased to 5 × 10−2, the final MAE increases even further compared to the case with a lower noise rate. In both noisy cases, however, increasing the illumination patterns decreases the MAE. These results demonstrate that noisy QML can still exploit additional information to increase learning capabilities. Furthermore, the results suggest that NISQ devices remain applicable, even when the fidelity of quantum gates is not perfect. Employing statistical information processing in QML can to some extent mitigate the effects of quantum noise.
To quantitatively illustrate the quality of the reconstructed images, we calculate two criteria: peak signal-to-noise rate (PSNR) and similar structure (SSIM). These two criteria are the common standards for evaluating the quality of the images. From Table 1, we find that the PSNR and SSIM of the test images reconstructed by the QML model are higher than CML. The maximum PSNR of QML is 8 dB higher than that of CML models. The CML model, in fact, cannot image in blind GI especially in large sampling rate. We can conclude that QML shows a practical advantage in blind GI over the image reconstruction capability compared to CML.
The QML model can make use of the measurement information to train the model. However, the CML model cannot correctly extract the additional measurement information to reduce the MAE. We suspect the reason is that the blind GI-based reconstruction tasks are too complex. Most of the existing conventional deep-learning-based works49,53,54 is to reconstruct images with known illumination patterns, and the input of such methods is generally the preliminary imaging result obtained using conventional methods, e.g., DGI52. The neural networks in these methods only need to learn how to improve the reconstruction quality. However, in our case, the network has to learn not only the illumination pattern matrix implicitly but also the image features, which will be increasingly difficult as the number of patterns increases. Alternatively, we can understand the problem from the other perspective. In learning-based ghost imaging, the neural network of CML/QML is trained to learn the inverse physical process of ghost imaging from data, specifically learning the mapping from one-dimensional bucket signals to two-dimensional images. By analogy, the learning process of CML/QML can be seen as approximating the inverse matrix of an M × Np matrix, where Np is the number of pixels. As the value of M increases, this learning process becomes more challenging.
Quantified advantage of QML models
To quantitatively characterize the learning capability of the QML and CML models, we make use of the measure of local effective dimension (LED) in information geometry to analyze the performance of ML models. Compared to other capacity measures such as the Vapnik-Chervonenkis dimension, Rademacher complexity, etc., LED is more practical and general in terms of the common criteria to evaluate the capability of ML models55. LED largely depends on the Fisher information, which is often approximated in practice and it is still closely related to generalization error. LED is defined based on a statistic model \({{{{{{{{\mathcal{M}}}}}}}}}_{\Theta }=\{p(\cdot ,\cdot ;\theta ):\theta \in \Theta \}\) and trained well parameter set θ⋆ ∈ Rd with d the total number of training parameters. It can be calculated by
where \(\kappa =\frac{\gamma {M}_{s}}{2\pi \log {M}_{s}}\) with γ denoting a constant \(\gamma \in \left(\frac{2\pi \log {M}_{s}}{{M}_{s}},1\right]\). \({{{{{{{{\mathcal{K}}}}}}}}}_{\epsilon }({\theta }^{\star })=\{\theta \in \Theta :| | \theta -{\theta }^{\star }| | \le \epsilon ,\epsilon \, > \,0\}\) denotes the ϵ-ball around trained well parameter set and the volume of the ball \({V}_{\epsilon }={\int}_{{{{{{{{{\mathcal{K}}}}}}}}}_{\epsilon }}{{{{{{{\rm{d}}}}}}}}\theta =\frac{{\pi }^{d/2}{\epsilon }^{d}}{\Gamma (d/2+1)}\in {R}_{+}\) where Γ denotes the Euler’s gamma function. The approximated normalized Fisher information matrix \(\hat{{{{{{{{\mathcal{F}}}}}}}}}(\theta )\) can be calculated by
where \({{{{{{{\mathcal{F}}}}}}}}(\theta )\in {R}^{d\times d}\) denotes the Fisher information matrix of p( ⋅ , ⋅ , ; θ). The probability function can be calculated by ML model with the probability rule, i.e., p(x, y; θ) = p(y∣x; θ)p(x) in which p(x) denotes the prior distribution of data samples and p(y∣x) denotes the conditional distribution of predicting the target given the samples as the input. The generalization error of ML models can be upper bounded by LED. More details about the LED can be found in Supplementary Note 5.
We calculate the LED of the trained models in identification task. We present the calculation results of normalized LEDs (LED averaged over the total number of parameters) by using Eq. (5) with test dataset under different number of extrapolation samples. The numerical results of normalized LEDs calculated by using training dataset can refer to Supplementary Note 5. It is assumed that the extrapolation data pairs obey the same probability distribution with the test data pairs. LED calculated by 10,000 test data pairs can be further extrapolated to larger number of data samples. In principle, smaller LED indicates a smaller generalization error and vice versa. In all experiments as Fig. 5 shows, QML models have smaller normalized LED value compared to CML models over all sampling rates and extrapolations. As the number of data samples becomes large, LED becomes larger implying that the generalization error is larger, which informs us that current ML models require increasing the training parameters to fit more data samples. The gap of normalized LED between the CML and QML models is also amplified since the QML models have stronger parameter efficiency over the CML models, i.e., the size of the QML models has a lower increment than the CML models when requiring fitting more complex data distributions. Besides increasing the sampling rate from 16 to 128, the normalized LED also increases slightly. Larger sampling rates leads to a more complex data distribution over the feature space since the noise and dimension increase. Therefore, it requires more powerful model such as ML models with deeper layers and more variational quantum parameters to learn the high-dimensional complex data. Overall, the normalized LED of the optimized patterns is smaller than the case of randomized patterns demonstrating that optimizing the patterns in GI system can increase the useful information of the bucket signals thus leading to a lower requirement of number of samples to train the ML models. These results quantitatively demonstrate the benefits of using optimized patterns from the perspective of information geometry. The normalized LED is a powerful capacity measure which directly connects the trainability, expressiveness and generalization error of ML models. Our numerical results demonstrate that QML models have stronger generalization capability over CML models when the number of parameters are assumed to be the same. We note that LED is concerned for the training process and specific dataset and the latter may also be the potential advantage source of QML56. Our work becomes the first one, to our knowledge that not only applies QML into practical and classical task but also quantitatively analyzes the quantum advantage in terms of the generalization error.

The top row is with random patterns: (a) M = 16, (b) M = 32, (c) M = 64, and (d) M = 128; The bottom row is with optimized patterns: (e) M = 16, (f) M = 32, (g) M = 64, and (h) M = 128. All results are obtained under the test dataset of MNIST and the numbers of extra data are from 105 to 108.
Discussion
In summary, we apply QML to practical GI systems to demonstrate its advantages experimentally and theoretically. We propose a hardware-efficient hybrid QML framework based on shallow variational quantum circuits and quantitatively demonstrate its practical advantages in classic GI task. We exploit a highly flexible physical-inspired patch strategy that is applicable for current NISQ devices when handling large-scale classical dataset. The strategy also makes the large-scale classical simulation of QML in the GI system possible.
Through collecting the experimental dataset with different sampling rates in imaging-free object identification and object imaging tasks in the GI system, we conduct plenty of machine learning experiments to demonstrate the advantage of the QML algorithm. The results show that the recognition rate of the QML algorithm is 3% ~ 10% higher than that of the CML algorithm in 10-category classification problem when they approximately have the same number of training parameters. We also testify the actual object based on the GI system and find the prediction errors of the QML method are much less than the CML algorithms. In the imaging task, QML-enhanced blind GI can fully make use of the information of a large sampling rate and reconstruct the object images with high PSNR. In contrast, CML cannot simultaneously learn the illumination patterns and the feature information of the object such that it cannot reconstruct a high-PSNR image. To quantitatively characterize the quantum advantage, we calculate the LED values of QML and CML models to evaluate the generalization error. We find that the generalization capability of QML models is stronger than CML models, which demonstrates that QML models are more expressive, thus certifying the quantum advantage. We attribute the superior performance of QML in part to the exponentially larger quantum-featured Hilbert space, which provides a more powerful learning capability in high-dimensional spaces.
Although other researches use QML in classical machine learning fields but achieve no obvious practical advantage, the application of real physical-related GI system amplifies the advantage of the QML algorithm. Our study presents a practical and crucial application for the QML field and also highlights the point that QML is likely to be suitable for processing physically system-generated datasets24. In future work, we will study the connections of QML and sparse encoding and other applications of QML in the GI system.
Methods
Hybrid quantum machine learning algorithm
The backbone of the hybrid quantum-classical machine learning algorithm consists of a classical artificial neural network and a parameterized quantum circuit (PQC) as Fig. 1b shows. The PQC with different topological structures has varied performance. However, considering the current hardware availability, we make use of the typical circuit structure with a hardware-efficient interleaved single-qubit rotation layer and entangling layer. The quantum learning model first maps the bucket signals B into the quantum Hilbert feature space with a predefined encoding strategy such as the angle encoding, amplitude encoding, and other quantum many-body inspired encoding38. In our scheme, the performance of different encoding schemes in identification and imaging branches is studied. We note that the amplitude encoding scheme saves the number of qubits exponentially compared to the angle encoding scheme, where a normalized M-dimensional data \(\overrightarrow{x},\overrightarrow{x}\in B\) only requires \(\log M\) qubits by using \(\left\vert {\psi }_{x}\right\rangle ={\sum }_{i}{x}_{i}\left\vert i\right\rangle\) to encode all classical information into a quantum state. In the NISQ devices, angle encoding is relatively easier to be implemented in practice. More concretely, the classical state \(\overrightarrow{x}\) can be encoded by
where L denotes the number of encoding layers, the parameters {θi} are the variational quantum parameters. When the required number of qubits is not supported by the device, we can patch the quantum learning model by dividing the classical state into independent parts. Thus, the encoded state can be written as the tensor product of local small-size embedding. Suppose n = M/N where N denotes the maximum number of qubits that a device allows, it turns out that
where (j − 1)N: jN denotes the jth part of the N-dimension classical state, \({\theta }_{i}^{j}\) are variational parameters of the jth patch of the ith layer, \({{{{{{{\mathcal{E}}}}}}}}\) is the encoding unitary operation. Therefore, we have \({\vert {\psi }_{x}\rangle }_{P}={\otimes }_{j = 1}^{n}\vert {\psi }_{{x}_{j}}\rangle\) and each local embedding can be processed by the following quantum learning operations. We remark that the patch strategy can reduce the demand for a large number of qubits and the theoretical performance can be guaranteed of the locality of different bucket signals. The quantum learning operations consist of multi-layers with a single-qubit rotation layer and an entangling layer. Formally, the final quantum state evolved by the learning operations is given by
where \({{{{{{{{\mathcal{U}}}}}}}}}_{i}^{j}\) denotes the variational learning operation, \({\vartheta }_{i}^{j}\) is the trainable parameter of jth patch in ith learning layer. To obtain the classical information of the final quantum state, we require measuring the observable \(O={\otimes }_{i = j}^{n}{O}_{j}\), that is
Unlike the quantum generative models where the discrete probability distribution is sampled from the quantum circuit by measuring the computational basis used as the feature representation, we regard the expectation values of the observable as the feature representation to make predictions. Arbitrary Hermitian operator can be decomposed into \({O}_{j}={\sum }_{i}{w}_{i}^{j}{h}_{i}^{j}\) where \({h}_{i}^{j}\) denotes the sub-Hamiltonian in the N-qubit Pauli group \({h}_{i}^{j}\in {{{{{{{{\mathcal{P}}}}}}}}}_{N}\), \({w}_{i}^{j}\) denotes the decomposed coefficients of jth local patch. Therefore, the observable average can be estimated via quantum expectation estimation method57 given by
More efficient estimation methods use importance sampling to adjust the number of shots allocated for each local Pauli observable58. The tensor product of independent quantum patches can be projected into a compact form by directly concatenating the different patches of observable expectation into a vector \(\langle \overrightarrow{O}\rangle\). In general, the observable can also be trained to adaptively adjust the measurement settings. The successive classical neural network takes the quantum output as inputs to make predictions. Especially for imaging problems, we require using convolution layers and upsampling layers to reconstruct the images based on the quantum feature representation.
We denote the classical neural network in objective identification as the functional mapping \({{{{{{{{\mathcal{F}}}}}}}}}_{C}\) and in imaging as \({{{{{{{{\mathcal{F}}}}}}}}}_{R}\). Hence, the post-classical processing of the quantum feature map in the identification task can be written as
where pind denotes the probability vector with each element corresponding to the identification probability of each category. In the imaging task, the reconstructed images can be written as
To train the identification branch with dataset size \(| {{{{{{{\mathcal{B}}}}}}}}|\), we make use of the cross-entropy (CE) loss function, that is
where K denotes the number of categories and y is the true label of the sample. To train the imaging branch, the MSE loss function is applied given by
where \({I}_{T}^{i}\) denotes the original image required to be reconstructed. Since \({{{{{{{{\mathcal{F}}}}}}}}}_{R},{{{{{{{{\mathcal{F}}}}}}}}}_{C}\) are differentiable over the trainable parameters, the parameters can be optimized by the stochastic gradient descent method. The gradient loss function over variational parameters can be estimated by parameter-shift rule57 by constructing an unbiased estimator of the observable. The parameter-shift rule is compatible with the classical stochastic gradient descent. We denote all the trainable parameters in quantum and classical neural networks as ν, then we can update the parameters in the different branches through
with the Adam optimizer59, where α is the learning rate and 〈 ⋅ 〉 denotes the mini-batch average. The training process terminates once the parameters converge toward a minimum of the loss function. Our proposed hybrid quantum-classical machine learning model is suited for the vast majority of the classical task such as pattern recognition and imaging task.
Machine learning and software specifications
Classical machine learning in object identification is composed of an artificial neural network (ANN), where the number of parameters (weights and bias in neurons) is approximately the same as the hybrid QML for a fair comparison. Hybrid QML has the potential advantage to surpass the pure classical neural network in terms of learning capability. Hybrid QML consists of classical ANN and PQC and they can cooperate to enhance the machine learning ability60. Current NISQ devices require that the algorithms should be resilient to quantum noise and the circuit should not be too deep since which can lead to the Barren Plateau61,62,63 and the fidelity of qubits in the real device also drops dramatically. Therefore, in our implementation, the number of layers is limited to 4 layers, i.e., our circuit is shallow. There are two types of hybrid QML methods in our work: (1) we stack multiple patches of PQC to separately map the divided bucket signal into quantum feature space, (2) we first map the bucket signal into the classical feature space through an ANN to reduce the dimension. Successively, we encode the reduced latent feature into the PQC with a fixed number of qubits. The training process is based on stochastic gradient descent to minimize the loss function until convergence.
The training process of the pure classical ANN has a mature mathematical toolbox i.e., automatic differentiation (AD) since all the operations in ANN are continuous and differentiable. However, in hybrid QML, the gradient calculation contains two parts: (1) the loss function over the classical parameters, and (2) the loss function over the quantum parameters. In a hybrid data pipeline, the most critical part is the quantum gradient estimation-based parameter shift rule, in which the observable of the jth patch over the quantum parameters is given by
where the vector ei is all zeros except that the position i is one. Then according to the chain rule, we have
The first part of the right-hand equation can be calculated based on classical AD, and the second part can be calculated with quantum expectation estimation. In the NISQ devices, suppose estimating the local observable of one patch PQC for each parameter requires L shots and the total shots are 2nL∣νQ∣ to obtain the gradient vector over all quantum parameters. Considering the practical sampling rate of the NISQ devices, estimating the quantum gradient based on the parameter shift rule is feasible.
In our hybrid QML, we use the classical simulation to build the PQC so that the gradient calculating is based on the AD even for the quantum part since all the quantum states and operations can be simulated by tensor operations for the mediate size of qubits. The latter is differentiable under current machine learning frameworks such as PyTorch64 and Tensorflow65. We use the tensorcircuit package66 as our software which supports vmap and jit and largely accelerates the simulation process. The classical ANN is constructed based on Tensorflow Keras. The details of quantum encoding, quantum learning operations, and measurements can be found in Supplementary Note 2.
Data acquisition
To train and evaluate the proposed model on the recognition task, we collect the experimental data based on the MNIST dataset67. Based on the imaging system shown in Fig. 1a, the handwritten digits multiplied with modulation patterns are loaded on DMD, and the corresponding bucket signals are collected by the sensor. The total MNIST data consists of the training set with 60,000 examples and a test set with 10,000 examples. The digit images are resized into 64 × 64 to match the size of the patterns. The number of samplings is set as 128, and we divide it into four different sampling ratios, i.e., 3.125% (128/4096), 1.5625% (64/4096), 0.78125% (32/4096), and 0.390625% (16/4096).
Similar to the classification task, we also build an aircraft imaging dataset based on an open-source remote sensing image database RarePlanes68. RarePlanes is a synthetic/real combination dataset, and we only use the real part of the data. Specifically, we first detect the position of planes in the remote sensing image based on the YOLO-v3 algorithm69. Second, these plane images are cropped into the same size as 64 × 64. Then, we divide the data into the training set with 3447 examples and the test set with 862 examples. Finally, in the same way, as MNIST’s bucket signals are collected, we collected the plane data at different sampling rates (12.5%, 6.25%, 3.125%, and 1.5625%) on the optical imaging system.
For the classification task, we use two illumination patterns to measure the target: random patterns and optimized patterns. As for the imaging task, only random patterns are used for measurements. The random patterns are generated by a computer with a wavelength of 680 nm, an aperture diameter of 0.08 m, and a propagation distance of 0.32 m. The generation of optimized patterns is demonstrated in Supplementary Note 1.
Experimental details
The optical imaging system we built for the experimental demonstration is shown in Fig. 1a. The light source from a pulsed laser is first filtered by a filter with a transmission wavelength of 680 nm. And then, the light illuminates the DMD (DLC9500P24, 1080 × 1920) after collimating. Each pattern has 64 × 64 pixels, and each pixel consists of 8 × 8 micro mirror units. We use a 4f system (Lens 1 and Lens 2) to project the illumination field \(I(\overrightarrow{r})\) at the DMD plane to the surface of the object. The focal length of Lens 1 and Lens 2 are both 100 mm. The transmitted or reflected light is collected by Lens 3 with a focal length of 150 mm. Finally, the information light is recorded by a detector. In our experiment, a CCD (iXon Ultra & Life 897, Andor) is used as the bucket detector, i.e., only the total intensity on the CCD is used for the correlation measurement.
To evaluate the generalization performance of the proposed method, a tiny license plate model is used as the object to be recognized. The size of the plate is 7 × 1.3 cm and the linewidth of numbers is 2 mm. To recognize the license plate, we sequentially move each digit into the field of view to collect the bucket signals for each digit on the license plate. Note that this imaging process is in a reflective way.
Data availability
All data needed to evaluate the conclusions are available from https://github.com/JayShaun/QMLGI. The data include the bucket signals of MNIST digits and the plane images. All the random and optimized patterns are also attached.
Code availability
The code used to generate data is available from https://github.com/JayShaun/QMLGI. The codes include the implementation of the QML and CML algorithms and other toolboxes to visualize the data.
References
Daley, A. J. et al. Practical quantum advantage in quantum simulation. Nature 607, 667–676 (2022).
Montanaro, A. Quantum algorithms: an overview. npj Quantum Inf. 2, 1–8 (2016).
Xiao, T., Fan, J. & Zeng, G. Parameter estimation in quantum sensing based on deep reinforcement learning. npj Quantum Inf. 8, 1–12 (2022).
Havlíček, V. et al. Supervised learning with quantum-enhanced feature spaces. Nature 567, 209–212 (2019).
Xiao, T., Huang, J., Li, H., Fan, J. & Zeng, G. Intelligent certification for quantum simulators via machine learning. npj Quantum Inf. 8, 138 (2022).
Sajjan, M. et al. Quantum machine learning for chemistry and physics. Chem. Soc. Rev. 51, 6475–6573 (2022).
Batra, K. et al. Quantum machine learning algorithms for drug discovery applications. J. Chem. Inf. Model. 61, 2641–2647 (2021).
Wossnig, L., Zhao, Z. & Prakash, A. Quantum linear system algorithm for dense matrices. Phys. Rev. Lett. 120, 050502 (2018).
Lund, A. P., Bremner, M. J. & Ralph, T. C. Quantum sampling problems, bosonsampling and quantum supremacy. npj Quantum. Inf. 3, 1–8 (2017).
Arute, F. et al. Quantum supremacy using a programmable superconducting processor. Nature 574, 505–510 (2019).
Arrazola, J. M. et al. Quantum circuits with many photons on a programmable nanophotonic chip. Nature 591, 54–60 (2021).
Spring, J. B. et al. Boson sampling on a photonic chip. Science 339, 798–801 (2013).
Tillmann, M. et al. Experimental boson sampling. Nat. Photonics 7, 540–544 (2013).
Zhu, Q. et al. Quantum computational advantage via 60-qubit 24-cycle random circuit sampling. Sci. Bull. 67, 240–245 (2022).
Lloyd, S. & Weedbrook, C. Quantum generative adversarial learning. Phys. Rev. Lett. 121, 040502 (2018).
Biamonte, J. et al. Quantum machine learning. Nature 549, 195–202 (2017).
Liu, Y., Arunachalam, S. & Temme, K. A rigorous and robust quantum speed-up in supervised machine learning. Nat. Phys. 17, 1013–1017 (2021).
Huang, H.-Y. et al. Quantum advantage in learning from experiments. Science 376, 1182–1186 (2022).
Rudolph, M. S. et al. Generation of high-resolution handwritten digits with an ion-trap quantum computer. Phys. Rev. X 12, 031010 (2022).
Huang, H.-L. et al. Experimental quantum generative adversarial networks for image generation. Phys. Rev. Appl. 16, 024051 (2021).
Wu, S. L. & Yoo, S. Challenges and opportunities in quantum machine learning for high-energy physics. Nat. Rev. Phys. 4, 143–144 (2022).
Wu, S. L. et al. Application of quantum machine learning using the quantum kernel algorithm on high energy physics analysis at the lhc. Phys. Rev. Res. 3, 033221 (2021).
Huang, H.-Y., Kueng, R., Torlai, G., Albert, V. V. & Preskill, J. Provably efficient machine learning for quantum many-body problems. Science 377, eabk3333 (2022).
Peters, E. et al. Machine learning of high dimensional data on a noisy quantum processor. npj Quantum Inf. 7, 1–5 (2021).
Huang, H.-Y., Kueng, R. & Preskill, J. Information-theoretic bounds on quantum advantage in machine learning. Phys. Rev. Lett. 126, 190505 (2021).
Lamata, L. Quantum machine learning implementations: proposals and experiments. Adv. Quantum Technol. 2300059 (2023).
Pittman, T. B., Shih, Y., Strekalov, D. & Sergienko, A. V. Optical imaging by means of two-photon quantum entanglement. Phys. Rev. A 52, R3429 (1995).
Bennink, R. S., Bentley, S. J. & Boyd, R. W. “two-photon” coincidence imaging with a classical source. Phys. Rev. Lett. 89, 113601 (2002).
Gatti, A., Brambilla, E., Bache, M. & Lugiato, L. A. Ghost imaging with thermal light: comparing entanglement and classicalcorrelation. Phys. Rev. Lett. 93, 093602 (2004).
Zhai, Y., Chen, X., Zhang, D. & Wu, L. Two-photon interference with true thermal light. Phys. Rev. A 72, 043805 (2005).
Scarcelli, G., Berardi, V. & Shih, Y. Can two-photon correlation of chaotic light be considered as correlation of intensity fluctuations? Phys. Rev. Lett. 96, 063602 (2006).
Gatti, A., Brambilla, E., Bache, M. & Lugiato, L. A. Correlated imaging, quantum and classical. Phys. Rev. A 70, 013802 (2004).
Valencia, A., Scarcelli, G., D’Angelo, M. & Shih, Y. Two-photon imaging with thermal light. Phys. Rev. Lett. 94, 063601 (2005).
Shapiro, J. H. Computational ghost imaging. Phys. Rev. A 78, 061802 (2008).
Ota, S. et al. Ghost cytometry. Science 360, 1246–1251 (2018).
Deng, Q., Zhang, Z. & Zhong, J. Image-free real-time 3-d tracking of a fast-moving object using dual-pixel detection. Opt. Lett. 45, 4734–4737 (2020).
Liu, H., Bian, L. & Zhang, J. Image-free single-pixel segmentation. Opt. Laser Technol. 157, 108600 (2023).
Schuld, M., Sweke, R. & Meyer, J. J. Effect of data encoding on the expressive power of variational quantum-machine-learning models. Phys. Rev. A 103, 032430 (2021).
Wang, F., Wang, H., Wang, H., Li, G. & Situ, G. Learning from simulation: an end-to-end deep-learning approach for computational ghost imaging. Opt. Express 27, 25560–25572 (2019).
Wu, H. et al. Deep-learning denoising computational ghost imaging. Opt. Lasers Eng. 134, 106183 (2020).
Cheng, J. & Han, S. Incoherent coincidence imaging and its applicability in x-ray diffraction. Phys. Rev. Lett. 92, 093903 (2004).
Katz, O., Bromberg, Y. & Silberberg, Y. Compressive ghost imaging. Appl. Phys. Lett. 95, 131110 (2009).
Zhang, D. et al. Wavelength-multiplexing ghost imaging. Phys. Rev. A 92, 013823 (2015).
Kingston, A. M. et al. Neutron ghost imaging. Phys. Rev. A 101, 053844 (2020).
Zhang, A., He, Y., Wu, L., Chen, L. & Wang, B. Tabletop x-ray ghost imaging with ultra-low radiation. Optica 5, 374–377 (2018).
Donoho, D. L. Compressed sensing. IEEE Trans. Inf. theory 52, 1289–1306 (2006).
Zhao, C. et al. Ghost imaging lidar via sparsity constraints. Appl. Phys. Lett. 101, 141123 (2012).
Lyu, M. et al. Deep-learning-based ghost imaging. Sci. Rep. 7, 1–6 (2017).
Rizvi, S., Cao, J., Zhang, K. & Hao, Q. Deepghost: real-time computational ghost imaging via deep learning. Sci. Rep. 10, 1–9 (2020).
Shang, R., Hoffer-Hawlik, K., Wang, F., Situ, G. & Luke, G. P. Two-step training deep learning framework for computational imaging without physics priors. Opt. Express 29, 15239–15254 (2021).
Oppenheim, A. V. et al. Signals & Systems (Pearson Educación, 1997).
Ferri, F., Magatti, D., Lugiato, L. & Gatti, A. Differential ghost imaging. Phys. Rev. Lett. 104, 253603 (2010).
He, Y. et al. Ghost imaging based on deep learning. Sci. Rep. 8, 1–7 (2018).
Shimobaba, T. et al. Computational ghost imaging using deep learning. Opt. Commun. 413, 147–151 (2018).
Abbas, A. et al. The power of quantum neural networks. Nat. Comput. Sci. 1, 403–409 (2021).
Huang, H.-Y. et al. Power of data in quantum machine learning. Nat. Commun. 12, 1–9 (2021).
Broughton, M. et al. Tensorflow quantum: A software framework for quantum machine learning. arXiv preprint arXiv:2003.02989 (2020).
Gu, A., Lowe, A., Dub, P. A., Coles, P. J. & Arrasmith, A. Adaptive shot allocation for fast convergence in variational quantum algorithms. arXiv preprint arXiv:2108.10434 (2021).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Blank, C., Park, D. K., Rhee, J.-K. K. & Petruccione, F. Quantum classifier with tailored quantum kernel. npj Quantum Inf. 6, 1–7 (2020).
Wang, S. et al. Can error mitigation improve trainability of noisy variational quantum algorithms?arXiv preprint arXiv:2109.01051 (2021).
Cerezo, M., Sone, A., Volkoff, T., Cincio, L. & Coles, P. J. Cost function dependent barren plateaus in shallow parametrized quantum circuits. Nat. Commun. 12, 1–12 (2021).
Uvarov, A. & Biamonte, J. D. On barren plateaus and cost function locality in variational quantum algorithms. J. Phys. A Math. Theor. 54, 245301 (2021).
Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 32 (2019).
Abadi, M. et al. {TensorFlow}: a system for {Large-Scale} machine learning. In 12th USENIX symposium on operating systems design and implementation (OSDI 16), 265–283 (2016).
Zhang, S.-X. et al. Tensorcircuit: a quantum software framework for the nisq era. Quantum 7, 912 (2023).
LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324 (1998).
Shermeyer, J. et al. Rareplanes: Synthetic data takes flight[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 207–217 (2021).
Redmon, J. & Farhadi, A. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767 (2018).
Acknowledgements
The authors thanks for the fruitful discussions with Peng Huang, Jingzheng Huang, Hongjing Li, Tao Wang and Jianhong Shi. This work is supported by National Natural Science Foundation of China (Grant No. 61701302, 61905140, and 61631014), and Science and Technology Commission of Shanghai Municipality (No. 22142201900).
Author information
Authors and Affiliations
Contributions
X.L.Z. conducted the ghost imaging experiments, and T.L.X. developed the simulation and implemented the algorithms, T.L.X. elaborated on the quantum machine learning architecture design, T.L.X., X.L.Z, X.Y.W., and J.P.F. operated the classical machine learning analysis, and G.Z. conceived the research. All the authors discussed and contributed to the writing of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Communications Physics thanks the anonymous reviewers for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xiao, T., Zhai, X., Wu, X. et al. Practical advantage of quantum machine learning in ghost imaging. Commun Phys 6, 171 (2023). https://doi.org/10.1038/s42005-023-01290-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s42005-023-01290-1
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
