
Abstract
Variational Quantum Eigensolver (VQE) methods aim to maximize the resources of existing noisy devices. However, they encounter difficulties in simulating molecules of industrially-relevant sizes, such as constructing the efficient ansatz. Adaptive variational algorithms (ADAPT-VQE) can solve this problem but with a significant increase in the number of measurements. Here, we reduce the measurement overhead of ADAPT-VQE via adding operator batches to the ansatz while keeping it compact. We reformulate the previously proposed qubit pool completeness criteria for the tapered qubit space and propose an automated pool construction procedure. Our numerical results indicate that reducing the qubit pool size from polynomial to linear conversely increases the number of measurements. We simulate a set of molecules, participating in the carbon monoxide oxidation processes using the statevector simulator and compare the results with VQE-UCCSD and classical methods. Our results pave the way towards usage of variational approaches for solving practically relevant chemical problems.
Similar content being viewed by others
Introduction
Simulating complex quantum systems is among the main potential applications of quantum computing devices1. The particular problem is calculating properties of molecules, which is hard to do with a reasonable accuracy (chemical accuracy, defined as 1 kcal/mole, which is required to predict chemical reaction rates) for large-scale systems using existing classical approaches2,3,4,5. Quantum chemistry algorithms based on the use of quantum computing consist of two large classes: methods for fault-tolerant quantum computers and noisy intermediate-scale quantum (NISQ) devices. Algorithms for NISQ devices take into account the limitations of the existing quantum processors, so they require low circuit depths that allow executing within the limited coherence time of the device. In this context, variational hybrid-classical algorithms6 are of the particular interest since they can be implemented even having limited resources of NISQ devices. Among existing methods, Variational Quantum Eigensolver (VQE) is a flagship hybrid quantum-classical algorithm for molecular simulations7. VQE can be seen as a general framework that consists of the following building blocks6: (i) preparation of parameterized state, (ii) cost function estimation, and (iii) parameter optimization. While the state preparation and cost function estimation are realized using a quantum device, optimization utilizes classical computers. The flexibility of VQE approach lies in the ability to implement both parts of the algorithm, quantum and classical, in diverse ways2,6,8.
As in classical methods of quantum chemistry, the choice of the ansatz for the molecular wavefunction is a crucial step in VQE implementations since it determines the accuracy of the obtained ground state energy. The main difficulty in the state preparation is the fact that the expressible and scalable ansatz becomes highly complex and has a long decomposition into quantum gates. Despite various hardware-efficient ansatzes have been used for simulations of small molecules7,9,10,11, their convergence for larger molecules remains uncertain due to the known problem of barren-plateaus12.
For scalable molecular simulations, VQE with chemistry-inspired ansatzes, such as unitary coupled cluster (UCC)10,13, is considered as the most reliable since it accounts for the special structure of the molecular wavefunction. In contrast to the classical projective coupled cluster approach (CCSD), its unitary variant is more preferable due to the lack of non-variational failure. The restriction of electronic excitations to single (S) and double (D) ones, known as VQE-UCCSD, remains the most popular approach with many reported numerical simulations14,15,16 and quantum simulations of small molecules17,18,19. In practice, implementations of the UCC ansatz require the use of the Suzuki-Trotter decomposition20. Since the circuit depth is one of the major limitations for NISQ processors, the first-order truncation, which neglects the error emerged by non-commuting terms in cluster operators, is a common choice. Despite the advantages provided by the UCCSD approach, accounting for single and double excitations is still not expressible enough in the presence of strong correlations14,20,21,22. As far as the correlation energy increases with the enhancement of the atomic basis set23,24, proper accounting for correlation effects is crucial for practically relevant molecular simulations.
A straightforward way to improve the accuracy of computations is to include triple excitations in the ansatz25. In classical computational chemistry, such extension leads to significant difficulties, so that is why CCSD(T) — coupled cluster method with perturbative inclusion of triplets — is considered as a gold standard providing a trade-off between the computational cost and precision26. For quantum processors, even a full implementation of the UCCSD circuits on a quantum computer is currently infeasible due to the sufficiently large gate count. Including triple excitations would lead to a huge overhead in the number of excitations scaling as \({{{{{{{\mathcal{O}}}}}}}}({N}^{3}{n}^{3})\), where N and n are numbers of spin-orbitals and electrons, respectively. This means that such an extension is not suitable for existing or near-future devices.
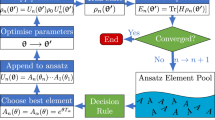
A possible solution is to use adaptive methods, such as ADAPT-VQE27, which iteratively construct the ansatz. At each step of the ansatz growing procedure, ADAPT-VQE adds a new operator from a fixed pool. The ansatz is built according to the gradient criterion, which approximates the idea of accounting for the maximal amount of the correlation energy by adding the operator with the largest gradient. In the reported numerical results, ADAPT-VQE is able to find a pathway to the desired state27,28,29,30,31. ADAPT-VQE simulations of the H6 molecule, a prototype of strongly correlated molecules, have been demonstrated by Grimsley et al.27. These results demonstrate that ADAPT-VQE outperforms VQE-UCCSD in terms of the accuracy for the considered example. The approach appears to be a useful tool for simulating molecules with strong correlation. We assume that calculations of larger molecules are needed to better understand the limitations of the algorithms.
In this work, we consider two strategies for selecting the operator pool: fermionic and qubit ADAPT-VQE approaches. Fermionic ADAPT-VQE uses UCCSD pool, whose size grows as \({{{{{{{\mathcal{O}}}}}}}}({N}^{2}{n}^{2})\). Qubit ADAPT-VQE instead consists of separate Pauli strings28 making it closer to the idea of hardware-efficient ansatzes and attractive from the circuit depth point of view. For both approaches, we use ADAPT-VQE procedure with qubit tapering32 to reduce the complexity of computations. This procedure greatly simplifies both the quantum and classical parts of the algorithm.
The major shortcoming of ADAPT-VQE is an overhead in the number of measurements on quantum devices compared to VQE-UCCSD. It consists of two parts: (i) computing derivatives in order to select an operator with the largest gradient from the pool and (ii) the parameter optimization procedure. The number of computed energy derivatives at each step equals the operator pool size. Here we propose to add multiple operators at each step of the ansatz growing procedure. We refer to this implementation as "batched ADAPT-VQE” and demonstrate its efficiency for both fermionic and qubit ADAPT-VQE implementations. Our numerical investigation demonstrates that such a procedure allows one to significantly reduce the number of computed derivatives in the gradient evaluation part of the algorithm and at the same time leads to insignificant losses in terms of circuit efficiency.
Additionally, we focus on the qubit ADAPT-VQE procedure. In the original paper27, the qubit pool is built by cutting fermionic excitations into individual Pauli strings, which leads to enlarging operator pool compared to the UCCSD one. However, the numerical results indicated the redundancy of such a pool: a partial removal of the pool operators does not affect the convergence. Recently, Shkolnikov et al.29 proposed a strategy of building complete pools for qubit ADAPT-VQE28, which grow linearly with the system size. In our work, we reformulate the completeness criteria for the molecules in the reduced qubit space after applying the qubit tapering procedure. Moreover, we propose an automated procedure for building linear and polynomial complete pools without manual analysis of molecular symmetries. We compare qubit ADAPT-VQE performance for linear and polynomial pools and discuss the difficulties encountered during the optimization procedure.
For numerical analysis, besides the common test molecules (H4, LiH, and H2O), we simulate a set of industrially-relevant molecules using the proposed method, such as O2, CO, and CO2, and compare the results obtained using VQE-UCCSD, ADAPT-VQE, and classical methods. These molecules are involved in carbon monoxide oxidation: CO + 1/2O2 → CO2. CO is a common product in partial oxidation of carbon-containing molecules33,34. As carbon monoxide is highly toxic for humans, the process of eliminating carbon monoxide emissions attracts much attention. Catalytic oxidation of CO into CO2 as a typical process for pollution reduction is of great industrial interest. In addition, our choice of the molecules is motivated by their following properties: (i) large correlation energy in the minimal basis set, (ii) set contains both singlet and triplet molecules, and (iii) computations of the considered molecules using simulators of quantum computing devices require less than 20 qubits making it possible to run experiments in a reasonable time. For better understanding the convergence of the considered methods, we estimate the electronic energy of CO oxidation reaction. Recently, carbon neutrality has become a global trend, and as part of this, the consideration of e-Fuel and other products is accelerating. In that sense, chemical reactions via CO2, CO, O2, H2O, etc. are of great importance for the future studies.
Summing up all the above, this work considers different approaches for building operator pool for ADAPT-VQE algorithm in tapered qubit space. We develop an automated procedure for constructing complete molecular qubit pools. In addition, we demonstrate numerically that reducing the pool size increases the number of measurements and offer an alternative strategy to reduce the measurement overhead by adding multiple operators to the ansatz simultaneously.
Results
Batched ADAPT-VQE
The ADAPT-VQE is a greedy iterative approach for building an efficient compact ansatz for approximating the molecular wavefunction27. In the original implementation of ADAPT-VQE27, a single operator with the largest gradient is added at each iteration. Such a construction of the ansatz is based on the gradient criterion, which approximates the idea of recovering most correlation energy. Indeed, the numerical investigation of ADAPT-VQE and randomly constructed ansatzes demonstrates significantly worse convergence of the latter with respect to parameter number in the quantum circuit. However, computations of the derivatives for the whole operator pool in order to add a single operator produce a notable overhead in the number of measurements. Due to the rather slow convergence of ADAPT-VQE for strongly correlated systems and the increasing size of the operator pool, the application of ADAPT-VQE for practically-relevant molecules is hindered.
In order to reduce the number of gradient computations, we introduce batched ADAPT-VQE that adds multiple operators with the largest gradients simultaneously (see Fig. 1). This approach allows reducing the number of gradient computations while building a compact ansatz.

Original ADAPT-VQE adds a single operator with the largest gradient value at each iteration. In our implementation of batched ADAPT-VQE, we add multiple operators with the largest gradients at each step of the ansatz growing procedure; k is the number of gradients that differ from the largest one by less than r time.
We apply batched ADAPT-VQE with both fermionic and qubit pools. The quantum circuit in fermionic ADAPT-VQE algorithm is obtained from the predefined operator pool, which consists of excitation operators. We note that here we define fermionic operators as in conventional UCCSD instead of originally used spin-adapted operators (see Methods, Section titled Fermionic Pool). As the pool size scales as \({{{{{{{\mathcal{O}}}}}}}}({N}^{2}{n}^{2})\), fermionic ADAPT-VQE introduces a polynomial overhead in the number of measurements compared to VQE with fixed circuits. Thus, adding multiple gradients to the pool has a practical advantage in both numerical simulations and experiments on a quantum computer.
In addition to fermionic ADAPT-VQE, we also investigate qubit ADAPT-VQE performance. Tang et al.28 proposed the qubit ADAPT-VQE approach, which builds a qubit pool from individual Pauli strings. Unlike qubit coupled cluster approach35,36, these Pauli strings are obtained by splitting each fermionic operator into subterms with all Z-Paulis being removed. This method of qubit pool construction leads to an increase in the pool size compared to the fermionic one. However, it was demonstrated that such qubit pool contains redundant operators and can be reduced to a pool of linear size. In the present work, we study qubit pools of both polynomial and linear sizes. Our numerical investigation demonstrates that even though reduction of the qubit pool size aims to reduce the measurement overhead, in practice polynomial pools require fewer derivative evaluations due to the slow convergence of ADAPT-VQE with a linear pool. Our numerical results illustrates that the use of the polynomial qubit pool with batched ADAPT-VQE is a more efficient strategy compared to implementations of qubit ADAPT-VQE with a linear pool.
Liu et al.30 added a fixed number of operators to improve fermionic ADAPT-VQE slow convergence caused by inaccurate identification of operators due to Valdemoro’s reconstruction of 3-RDM. The size of the batch in their implementation should be carefully tuned as inappropriate size leads to significant increases in the circuit depth. In our approach, we improve the original ADAPT-VQE approach by adding batches of operators of the varying sizes at each algorithm step. Note that we add the operators to the ansatz following the order of computed gradients. The adaptive size of the batch allows adding more operators at the beginning of the ansatz growing procedure when the energy difference is significant, and on the contrary, reduce the batch size when the ansatz is closer to the desired state (see Supplementary Information, Supplementary Fig. 1). The numerical results demonstrate that such an implementation makes it possible to build an ansatz close to the original one while reducing the computational cost.
At each ADAPT-VQE iteration, we pick all the gradients that differ from the largest by a ratio less than r, where r is incorporated as a hyperparameter (see Supplementary Information, Supplementary Fig. 2). We set r = 2 for all the considered molecules and our numerical results suggest that batched ADAPT-VQE produces circuits close to the ones obtained with original ADAPT-VQE. From the practical point of view, it is important that the hyperparameter value can be the same for different molecules.
Since batched ADAPT-VQE adds multiple operators at each step, it requires sizably fewer iterations to build an ansatz, which considerably reduces the cost of computing gradients with respect to operators in the pool. This is also important for classical simulations since computations for CO2 molecule (19 qubits) take a significant amount of time. We note that in the case of experiments on existing quantum devices, the restriction of the operator batch size at each iteration can be useful due to the controllability of the quantum circuit size. The performance of ADAPT-VQE under noisy conditions requires a separate study.
Complete pools
The initial formulation of qubit ADAPT-VQE considers pools of Pauli strings originated from UCCSD excitations. As such strings are obtained by cutting each fermionic excitation and removing Z Pauli operators, the pool grows polynomially with the system size as \({{{{{{{\mathcal{O}}}}}}}}({n}^{4})\). Theoretically, this produces an \({{{{{{{\mathcal{O}}}}}}}}({n}^{8})\) overhead in the number of measurements in the straightforward implementation29,30. That is why the idea of restricting the pool size seems to be attractive. We start our discussion with the papers on qubit ADAPT-VQE28,29 that propose the concept of minimal complete pools (MCPs) and prove their existence.
MCPs include a set of operators, individual Pauli strings, that can transform a reference state to any real state in the N-qubit Hilbert space. Tang et al.28 obtained a 3-qubit pool analytically and proved by induction that minimal complete pools exist for any N and have a size of 2N − 2. The authors derived a set of generators forming a theoretically complete pool, which performs successfully on random Hamiltonians. However, the derived pool is not appropriate for ADAPT-VQE molecular simulations as the Pauli strings used as generators do not account for specific symmetries presented in the molecular Hamiltonian.
Further study of MCPs by Shkolnikov et al.29 focused mainly on MCPs for molecular simulations. According to their results, the size of a minimal complete pool for molecular Hamiltonians is even less than for random Hamiltonians as it should preserve the molecular symmetries. The authors of Ref. 29 deeply analyzed these symmetries from the molecular group point of view and demonstrated how they force additional restrictions on the structure of Pauli string generators which form a complete pool. The following criteria have been formulated for minimal complete pools in molecular case29:
-
the number of electrons with a given spin changes by a multiple of 2;
-
each operator in the pool must conserve spatial parity;
-
the pool must contain enough "starters” for ADAPT-VQE to start;
-
the pool generates the biggest subgroup and subalgebra of those generated by a general non-symmetry-preserving MCP, that contain Pauli strings obeying conditions 1–2.
The most important challenge in practice is validating of the fourth criterion: the complexity of building Lie algebra scales exponentially with the number of qubits. This criterion can be replaced by checking the product group size and the inseparability condition: MCPs generators in a complete pool cannot be split into two mutually commuting sets. Additionally, a difficult part is the pool construction since in the original work authors performed manual analysis of molecular symmetries.
The practical implementation of qubit ADAPT-VQE with MCPs requires simple and automated ways of building the complete pools. Here we demonstrate how to apply the proposed pool completeness criteria to the MCPs built in the reduced qubit space, i.e., with qubit tapering procedure (see Methods, Section titled Qubit pool completeness). Thus, we not only build a pool of linear size for the molecule, but also remove qubits from the simulation, which significantly reduces the required computational resources. Additionally, we propose a greedy algorithm for building complete molecular pools from a predefined large pool. In this work, we use qubit pools originated from tapered fermionic UCCSD pools.
The proofs for the complete pool construction combined with qubit tapering are presented in the Methods section. Here, we only highlight the main steps of building a complete pool. We propose to select Pauli strings from the set of tapered UCCSD operators instead of manually constructing them. First, the Pauli strings from UCCSD satisfy the complete pool conditions for the considered molecules (see Methods, Section titled Qubit pool completeness). Second, most of Pauli strings from UCCSD correspond to double excitations that are starters for ADAPT-VQE, which allows satisfying criterion 3 without additional work. We propose the following scheme to build a complete pool in a reduced qubit space (a detailed scheme is illusrated in Fig. 2).
-
Taper off qubits based on Z2 symmetries for both molecular hamiltonian and UCCSD pool. This can be done using a built-in procedure in Qiskit or other frameworks for quantum computations. A more detailed explanation of the procedure can be found in Methods.
-
Cut the tapered UCCSD operators into individual Pauli strings. We additionally remove all Z-Paulis from the obtained strings. Although it is not a necessary step, it makes circuits significantly shallower according to our numerical investigation. At this step, we also check the completeness of the pool, which is inexpensive from the computational point of view (see Gauss method in Methods).
-
Select 2(N − Ns) strings from the pool constructed in the previous step to form a complete pool. Here Ns is a number of tapered qubits. We propose a greedy approach to select the strings that form a complete pool.

The scheme is applicable for constructing qubit linear minimal complete pool (Greedy MCP) and qubit polynomial complete pool with Pauli strings originated from each single and double fermionic excitation (Greedy sd).
The Pauli string selection from the UCCSD pool (step 3) can be implemented in various ways. As mentioned above, to create a complete pool, we need to check the size of the product group and pool inseparability. The detailed instructions on checking the above conditions are given in the Methods. We use a greedy algorithm to construct a complete pool by iteratively adding strings to the pool one by one. We follow several rules to construct the pool: (i) to satisfy the group size criterion, we choose only the strings that increase the group size (i.e., linearly independent with already added strings); (ii) to meet the inseparability criterion, we select a string that does not commute with the largest subset of added strings; (iii) to make the operators more diverse, we try to add the Pauli strings, which act by X/Y on different sets of qubits. Although the other ways of pool construction are possible, the numerical results confirm that the performance of the obtained greedy MCP pools is at least on par with the ones tested in the original work29 for H4 and LiH molecule. The advantage of the proposed algorithm for obtaining MCP lies in the combination of qubit reduction and the simplicity of the pool construction: by using operators from tapered fermionic excitations, we account for all the necessary symmetries, while the greedy algorithm builds a pool of the required rank.
We perform simulations for the H4 molecule in the minimal basis set (STO-3G) with the MCP pool given in ref. 29 (see MCP-11 in Fig. 3) on 8 qubits for the bond length R being equal to 1.0 and 2.0 Å. We apply the tapering procedure to the given pool MCP-11: we rotate the molecular hamiltonian and the MCP generators with a unitary transformation, such that the rotated generators act only by X or I on a subset of qubits and eliminate these qubits. The obtained pool contains Pauli strings acting on 5 qubits ("MCP-11; tapered”). Figure 3 shows that the tapered pool converges to the ground state with high precision (results for R = 1 Å are provided in Supplementary Information, Supplementary Fig. 3). The tapering procedure allows us to reduce the circuit depth significantly. We construct the "greedy MCP” pool consisting of 10 operators using the proposed computational scheme shown in Fig. 2. The greedy MCP pool demonstrates similar convergence with respect to the number of parameters compared to the tapered MCP-11, but reduces the required circuit depth due to the absence of Z Paulis.

The results are provided at molecular radius R equal 2.0 angstrom (Å). ΔE is the energy difference with the exact ground state energy in Hartree. MCP-11 is the minimal complete pool acting in the original qubit space of 8 qubits suggested in Ref. 29. `MCP-11, tapered' is built from MCP-11 by applying tapering procedure. Greedy-10 pool is a qubit linear complete pool constructed using the computational scheme proposed in this work and acts in a 5-qubit space.
For the LiH molecule, after freezing the inner orbital, there are 2 electrons, which leads to only 10 excitations in VQE-UCCSD after symmetry reduction (see Methods, Section titled Computational Details). The small size of the tapered fermionic pool leads to a special case, where the Pauli strings from UCCSD pool without Z Paulis do not form a complete pool. The rank of the pool is 10, while the required rank for a 6 qubit molecule should be 12. To overcome this difficulty, we first constructed the pool of 10 operators from the tapered UCCSD pool with removed Z paulis and then added two more operators with Z-paulis. The energy convergence with respect to the number of parameters and circuit depth for R = 3 Å is given in Fig. 4. As in the H4 case, tapering allows us to reduce the required circuit depth. The constructed pool "Greedy-12” demonstrates the excellent convergence compared to tapered MCP-14 and reduces the circuit depth.

The results are provided at molecular radius R equal 3.0 angstrom (Å). ΔE is the energy difference with the exact ground state energy in Hartree. MCP-14 is the minimal complete pool acting in the original qubit space of 10 qubits suggested in previous work29. `MCP-14, tapered' is built from MCP-14 by applying tapering procedure. Greedy-12 pool is a qubit linear complete pool constructed using the computational scheme proposed in this work and acts in a 6-qubit space.
The results for H4 and LiH are obtained at bond stretching when the correlation energy increases (the convergence of different pools for LiH molecule near the equilibrium is provided in Supplementary Information, Supplementary Fig. 4). Based on the provided numerical results, we expect that the proposed approach for pool construction is efficient for small molecules. Further, we use the pools constructed with the greedy algorithm to simulate larger molecules and compare the results to fermionic ADAPT-VQE approach and polynomial qubit pools.
Simulation of molecules
Here we present the simulation results for a set of larger molecules. We perform simulations on the Qiskit statevector simulator37 using various methods, including our improved version of the ADAPT-VQE approach – batched ADAPT-VQE. We start with benchmarking the methods on H2O at various bond lengths. Further, we present the simulation results for molecules involved in CO-oxidation: O2, CO, and CO2.
All the computations are performed in the minimal basis set using frozen core approximation and qubit tapering to reduce the required resources (see Methods, Section titled Computational Details). We compare numerical results obtained with trotterized (or disentangled) VQE-UCCSD with SD ordering20, ADAPT-VQE, and their various implementations (fermionic/qubit and original/batched).
To compare the computational cost, we calculate the total number of 1-parameter derivative computations Nd1 during the simulation: we consider both the ansatz growing phase in ADAPT-VQE case (i.e., derivatives with respect to each operator from the pool) and the VQE optimization procedure.
H2O molecule
For H2O, we simulate symmetrical stretching of two O-H bonds with a fixed angle of 104.51∘ (see Fig. 5). The UCCSD pool after symmetry reduction consists of 30 excitations acting on 8 qubits (see Methods, Table 1). Close to the equilibrium geometry (bond length R = 1.0 Å) and at R = 1.5 Å, fermionic VQE-UCCSD provides accurate results for the ground state energy (see f-UCCSD in Fig. 5b, c).

Fermionic ADAPT-VQE results are marked as "UCCSD-N'', where N indicates the size of the fermionic pool with single and double excitations. Qubit ADAPT-VQE results are referred to as Greedy-N (qubit linear complete pool) and Greedy sd-N (qubit polynomial complete pool with Pauli strings originated from each single and double fermionic excitation), where N is the qubit pool size. "f-UCCSD" refers to VQE-UCCSD result. With the green color we highlight the area, where the chemical accuracy threshold is satisfied. a Energy convergence with respect to the number of parameters for ADAPT-VQE and VQE-UCCSD. b Energy convergence with respect to the total number of derivative evaluations Nd1 for ADAPT-VQE and VQE-UCCSD. c Energy convergence with respect to the circuit depth for ADAPT-VQE and VQE-UCCSD.
With the bond stretching and increase in the correlation energy at R = 2.0 Å, VQE-UCCSD is not sufficient to reproduce the energy with the required accuracy. Fermionic ADAPT-VQE improves energy compared to VQE-UCCSD. At R = 1.0 Å and 1.5 Å fermionic ADAPT-VQE reaches the chemical accuracy threshold with 17 and 18 parameters, respectively, and increases Nd1 more than in 4 times (Fig. 5a). As the H-O distance increases, the number of required parameters grows to 29 parameters at R = 2.0 Å, which almost equals the size of the UCCSD pool. The total number of computed derivatives is higher in this case by order of magnitude.
Fermionic batched ADAPT-VQE reaches the threshold with a slight overhead in the number of parameters at these bond lengths — 22, 24, and 32 — which leads to an increase in the circuit depth by less than 20% compared to the original ADAPT-VQE (Fig. 5a). At the same time, fermionic batched ADAPT-VQE requires at least 3 times fewer derivative computations (Nd1, derivatives with respect to a single parameter) in total for each bond length. It is worth noting that at R = 2.0 Å batched ADAPT-VQE initially produces energies noticeably worse than the original implementation. Still, over a single iteration it improves the energy by 20 mHartree and at 22 parameters catches up with the original ADAPT-VQE values and further provides similar energies.
The observed results demonstrate that close to the VQE-UCCSD result, batched fermionic ADAPT-VQE is close to VQE-UCCSD in terms of computed derivatives Nd1, while the original ADAPT-VQE approache increases Nd1 significantly. Even though the convergence slows down near the threshold in the presence of strong correlation, batched fermionic ADAPT-VQE allows reducing the number of computed derivatives significantly.
To implement qubit ADAPT-VQE, we start by constructing a minimal complete pool with the proposed greedy approach. For H2O we obtain the pool of 16 operators (Greedy-16), which includes no more than a single Pauli string from each initial fermionic excitation after removing Z Paulis. At R = 1.0 Å, Greedy-16 demonstrates significantly slower convergence compared to fermionic ADAPT-VQE and reaches the energy threshold with 118 parameters. Batched ADAPT-VQE, in this case, reaches the threshold with 115 parameters and requires 1.8 times fewer derivatives. For R = 1.5 Å the situation changes: original ADAPT-VQE requires 108 parameters to reach the threshold, while batched implementation produces a large overhead and converges at 123 parameters. However, from the Fig. 5b, one can see that batched ADAPT-VQE still reduces the number of derivative computations by a half. Moreover, batched ADAPT-VQE does not lose in terms of the circuit depth here due to the usage of lightweight Pauli strings with no Z chains as well as Qiskit’s heavy transpilation of circuits. Finally, at R = 2.0 Å batched ADAPT-VQE performs worse than the original one and converges only with 101 parameters instead of 74 for original ADAPT-VQE and computing about 10% more derivatives.
One can see that in comparison to fermionic ADAPT-VQE, qubit ADAPT-VQE with greedy MCP produces a significant overhead in the number of derivative computations required to obtain accurate results. To verify that MCP in practice reduces the measurement overhead in qubit ADAPT-VQE, we compare the Greedy-16 performance with a qubit pool of size 30. This pool is obtained by the same greedy algorithm, but we pick 30 operators — at least a single operator from each UCCSD excitation after removing Z paulis — instead of 16. We refer to such pools as "Greedy sd-N”, where "sd” refers to picking operators from each UCCSD excitation. Thus, such pool is at least of the size of the UCCSD pool and satisfies the completeness criteria.
Our results demonstrate that such pool converges faster than MCP with respect to the number of parameters, total number of derivatives, and circuit depth. For R = 1.0 Å qubit ADAPT-VQE with Greedy sd-30 pool converges at a significantly smaller number of parameters (27 for both original and batched) compared to R = 2.0 Å (76 and 67 for original and batched, respectively), which matches the expectations as the correlation energy is small near the equilibrium. These results indicate that the completeness criterion is insufficient to construct an efficient pool for qubit ADAPT-VQE computations. Batched ADAPT-VQE with Greedy sd pool performs similar to the original ADAPT-VQE in terms of the parameter number and circuit depth (see Fig. 5), while reducing the total number of derivatives Nd1 significantly: from 2.2 fewer derivative evaluations at R = 1.5 up to 5 times at R = 2.0 Å. One can see that by using batched qubit ADAPT-VQE with Greedy sd pool we can reduce Nd1 by 1–2 orders of magnitude compared to the original qubit ADAPT-VQE with greedy MCP.
Considering our results, enlarging the qubit pool in the combination with batched ADAPT-VQE procedure appears to be an efficient implementation of qubit ADAPT-VQE. This observation contradicts the idea that the construction of a minimal linear pool reduces the measurement overhead. Numerically, it appears that limitation of the pool size leads to a significant increase in the number of iterations in the ansatz construction procedure.
O2 molecule
For the molecules involved in CO oxidation, we perform simulations at equilibrium geometries, precomputed classically with CCSD/STO-3G. The ground state of the molecular oxygen is triplet, with two electrons remaining unpaired on the π orbital. This is not a typical case for neutral molecules and thus a good testing case for ADAPT-VQE on open-shell systems. For O2, we use the unrestricted Hartree-Fock (UHF) state as a reference state in ADAPT-VQE and VQE-UCCSD computations.
With the use of the qubit tapering procedure, the Hamiltonian can be reduced from 16 to 11 qubits, while the operator pool size becomes relatively small for O2 molecule and consists of 24 excitations. VQE-UCCSD converges to the energy slightly above the chemical accuracy threshold (around 2 mHartree). Fermionic ADAPT-VQE (original and batched) converges to the fermionic VQE-UCCSD energy at 24 parameters, meaning no significant benefit in the parameter number observed in this case (Fig. 6a). Fermionic ADAPT-VQE reaches the chemical accuracy threshold with 27 parameters for both original and batched implementations. Batched ADAPT-VQE converges very similar to the original implementation producing similar quantum circuits and reducing the number of total derivative evaluations by 1.5 times at 27 parameters.

Fermionic ADAPT-VQE results are marked as "UCCSD-N'', where N indicates the size of the fermionic pool with single and double excitations. Qubit ADAPT-VQE results are referred to as Greedy-N (qubit linear complete pool) and Greedy sd-N (qubit polynomial complete pool with Pauli strings originated from each single and double fermionic excitation), where N is the qubit pool size. "f-UCCSD" refers to VQE-UCCSD result. By the green color we highlight the area, where the chemical accuracy threshold is satisfies. a Energy convergence for O2 molecule at the equilibrium geometry. As far as single qubit operator, which is obtained from each fermionic excitations do not form a complete pool, we add two extra operators to ensure pool completeness. Thus greedy sd pool contains 26 operators in this case. b Energy convergence for CO molecule at the equilibrium geometry. c Energy convergence for CO2 molecule at the equilibrium geometry.
Greedy MCP for O2 requires 22 operators (Greedy-22) and reaches the chemical accuracy threshold with 65 and 66 parameters for original and batched ADAPT-VQE, respectively, which reduces the circuit depth from about 2200 in fermionic ADAPT-VQE to 300. Batched ADAPT-VQE requires 2.7 times less derivative evaluations than the original one. Due to the small size of the tapered UCCSD pool we cannot pick a single operator from each excitation (after removing Z Paulis) and form a complete pool from such operators. For this reason, we add two extra operators to ensure the pool completeness. The obtained pool contains 26 operators (Greedy sd-26), which is very close to the MCP size. Qubit ADAPT-VQE converges slowly for both Greedy-22 and Greedy sd-26. Nevertheless, adding a few operators to the pool can improve the convergence in terms of both the circuit depth and the total number of derivatives. Batched qubit ADAPT-VQE with Greedy sd-26 pool performs better than other qubit ADAPT-VQE implementations in this case. Comparing these two extreme cases – batched ADAPT-VQE in combination with Greedy sd-26 pool and original ADAPT-VQE with MCP pool – we can reduce the number of total derivative evaluations by 5 times. It confirms our idea that decreasing the pool size is not sufficient to reduce the number of required measurements. On the contrary, O2 results follow the pattern observed for H2O for a larger operator pool: the convergence of qubit ADAPT-VQE improves while the computational cost reduces.
CO molecule
Carbon monoxide is a more complicated case compared to oxygen due to the larger number of electronic excitations. In computational chemistry, carbon monoxide is a known example when density functional theory (DFT) fails, which is appeared in the incorrect prediction of the CO adsorption on the transition metal surface38,39. The observed inconsistencies between classical simulations and experimental results make quantum simulations of reactions involving carbon monoxide an attractive problem with the proper development of quantum technologies. At this stage, we are only able to simulate an isolated CO molecule. However, even in the minimal basis set, it represents an interesting test case for quantum methods.
VQE-UCCSD simulations of CO molecule with STO-3G basis set have been reported previously15. This simulation uses 20 qubits since the symmetry reduction and the orbital freezing are not applied. The reported VQE-UCCSD energy (−111.363 Hartree) matches the classical CCSD result (−111.362 Hartree), which is about 10 mHartree higher than the exact one. This is a sizable deviation compared to small molecules, where VQE-UCCSD at equilibrium geometry accurately recovers correlation energy. Our simulations of CO require only 12 qubits, which greatly reduces the computational cost. VQE-UCCSD with 12 qubits for CO molecule fits previously reported results.
ADAPT-VQE convergence to the ground energy is presented in Fig. 6b. Fermionic ADAPT-VQE reaches VQE-UCCSD energy with 72 and 75 parameters (original and batched implementations), which is significantly less than the UCCSD pool size (85 operators). This allows reducing the circuit depth by about 30% compared to VQE-UCCSD. Fermionic batched ADAPT-VQE requires about 9 times fewer derivatives to reach VQE-UCCSD energy compared to the original one. When reaching the chemical accuracy threshold, batched ADAPT-VQE performs better as well: it converges with 128 parameters instead of 134 and with about 7 times fewer derivative computations.
Thus, fermionic batched ADAPT-VQE rapidly converges to VQE-UCCSD energy and has a reasonable overhead in the number of derivative evaluations (about 3500 Nd1 for batched fermionic ADAPT-VQE compared to 1275 Nd1 for fermionic VQE-UCCSD), while original ADAPT-VQE requires about 30,100. The observed results match the ones obtained for H2O: batched implementation of fermionic ADAPT-VQE can achieve VQE-UCCSD results more efficiently than VQE-UCCSD while significantly reducing the computational cost compared to original ADAPT-VQE. However, beyond this point the further energy improvement becomes slow from the optimization point of view, with the number of computed derivatives increasing to around 75,000 for batched ADAPT-VQE and 555,000 for original ADAPT-VQE. The original fermionic ADAPT-VQE produces a huge overhead in the number of derivative evaluations.
We perform qubit ADAPT-VQE computations for Greedy and Greedy sd pools for the CO molecule. Greedy MCP contains 24 operators (Greedy-24) for 12-qubit CO molecule, while the Greedy sd pool consists of 85 Pauli strings (Greedy sd-85). For Greedy-24 we perform original ADAPT-VQE computations up to 140 parameters to see if batched ADAPT-VQE matches its convergence curve.
With batched qubit ADAPT-VQE, we do not achieve chemical accuracy due to the high computational cost, but we achieve the level of the fermionic VQE-UCCSD energy. Both pools allow reducing the circuit depth significantly compared to UCCSD. Qubit ADAPT-VQE with Greedy sd-85 pool achieves VQE-UCCSD result with 164 and 156 parameters with original and batched implementations, respectively. Batched ADAPT-VQE reduces the number of computed derivatives by a factor of 5. Qubit ADAPT-VQE with Greedy sd pool turns out to be the most efficient in terms of circuit depth. However, the price we pay for the circuit reduction is the increase in the number of derivative evaluations by two orders of magnitude compared to VQE-UCCSD.
At the same time, batched ADAPT-VQE with Greedy-24 requires 413 parameters to reach VQE-UCCSD energy. The number of derivative evaluations is about 23 times higher for the MCP pool compared to Greedy sd-85 when computed with batched ADAPT-VQE.
The observed results demonstrate a vastly worse convergence of greedy pool than greedy sd, which again confirms that in practice, the linear pool does not reduce the measurement overhead, especially with the increase of the molecule complexity and size.
CO2 molecule
According to precise classical ab initio calculations, an accurate description of reaction energies involving carbon dioxide requires incorporating triple and even higher order of excitations in coupled cluster ansatz40. Such a slow convergence arises from the two degenerated π-molecular orbitals.
The full simulation of carbon dioxide in STO-3G basis set requires 30 qubits, which can be further reduced to 19 by freezing core orbitals and tapering 5 qubits considering the symmetry point group. To the best of our knowledge, it is the first such sizeable numerical computation of CO2 ground state energy using quantum computing devcies.
Due to the complex correlation effects, CCSD significantly deviates from the exact ground state energy at the equilibrium geometry. Energy recovered by fermionic VQE-UCCSD for carbon dioxide is close to the classical CCSD and is about 25 mHartree higher than the exact energy.
For fermionic ADAPT-VQE, we perform 55 iterations to check if batched ADAPT-VQE fits the original convergence curve (see Fig. 6c). Based on the previous results, we expect batched ADAPT-VQE to perform similarly to original ADAPT-VQE in circuit size. Fermionic batched ADAPT-VQE requires only 4 iterations and 176 parameters to achieve fermionic VQE-UCCSD energy. The number of parameters is thus significantly reduced compared to UCCSD, which has 204 excitations. The number of computed derivatives in batched fermionic ADAPT-VQE procedure is almost the same as in VQE-UCCSD (3900 and 4300 Nd1) in this case, due to the great parameter savings. As it is observed for other molecules, the convergence slows down significantly when we try to improve energy beyond VQE-UCCSD and approach the exact result. We perform simulations up to doubling the parameter number compared to the UCCSD pool size for fermionic and qubit batched ADAPT-VQE. For fermionic batched ADAPT-VQE, we achieved energy about 2.5 mHartree higher than the exact result, which is very close to the chemical accuracy threshold.
Since greedy MCP is not efficient for H2O and CO molecules, we run the simulation only for the Greedy sd pool due to the high computational cost of CO2 simulation. For original qubit ADAPT-VQE, we perform around 175 iterations to reach the gradient norm less than 10−1 (see Methods, Section titled Convergence Criteria). The energy difference between batched and original qubit ADAPT-VQE is less than 1 mHartree at a fixed number of parameters confirming batched ADAPT-VQE’s decent performance. Batched qubit ADAPT-VQE approaches VQE-UCCSD with 390 parameters (see Fig. 6c) and the circuit depth of 1560 in contrast to 24,800 for the fermionic VQE-UCCSD. However, such circuit reduction goes at the price of 40 times more derivative computations.
Electronic energy of reaction
Since relative energies but not their absolute values are crucial to determine the accuracy of ab initio methods, we can compare the electronic energy of CO-oxidation reaction computed by the studied methods:
Electronic energy of this reaction is given by the following formula:
Table 2 shows the electronic energy of reaction computed by different methods. Classical coupled cluster (CCSD) only slightly improves the uncorrelated Hartree Fock (HF) result. The inclusion of triplet excitations in coupled cluster is necessary for accurate estimation of the electronic reaction energy.
We compute the electronic energy of the reaction using only the batched implementation of ADAPT-VQE because CO2 molecule is too computationally expensive for the original ADAPT-VQE simulation. We compare energies obtained with different stopping criteria. By setting the maximum derivative value to 10−3 (or alternatively the gradient norm to 10−2) we could obtain accurate results for batched fermionic ADAPT-VQE. When stopping the simulation after reaching \(\max {g}_{i}\le 1{0}^{-2}\), batched ADAPT-VQE obtains energies close to VQE-UCCSD, but with shallower circuits. Therefore, the provided results for fermionic batched ADAPT-VQE can be regarded as a theoretical benchmark of the adaptive ansatz for reaching exact energy.
Qubit batched ADAPT-VQE converges significantly slower, which leads to a poor description of the reaction’s electronic energy. It is worth noting that energy underestimation also relates to the fact that qubit ADAPT-VQE quickly converges for O2 molecule compared to CO and CO2. It should be noted that both the maximum derivative value and gradient change non-monotonically, leading to a significant variance in the estimated reaction energy. As we do not achieve \(\max {g}_{i}\le 1{0}^{-3}\) for CO2, we estimate the "best” energy by taking the results for O2 and CO at the number of parameters two times larger than in the UCCSD pool. The best achieved energy for qubit ADAPT-VQE only slightly improves HF result. Improving VQE-procedure is necessary for qubit ADAPT-VQE to speed up the convergence and obtain an accurate result.
From the energies obtained with various stopping criteria, one can see sluggish convergence of qubit ADAPT-VQE on molecules with complicated electronic structures. Even stricter convergence criteria are required to further energy improvement, which would lead to a significant increase in the computational cost. Our simulation could reach fermionic VQE-UCCSD energy, which is already a promising result, as we tested it on complex and relatively large molecules.
Discussion
In this work, we have analyzed current implementations of the ADAPT-VQE approach for scalable quantum simulations. We have simulated molecules that are of interest for accurate quantum chemical calculations. We have carried out simulations of bond stretching of H2O molecule along with the molecules with multiple strong bonds (O2, CO, and CO2).
We have implemented fermionic and qubit ADAPT-VQE and proposed the algorithm implementation — batched ADAPT-VQE — which adds the varying number of operators from the pool at each iteration. Such implementation allows reducing the number of derivate evaluations and speed up the ansatz growing procedure. The convergence of batched ADAPT-VQE confirms its efficiency in constructing a relatively compact ansatz for fermionic and qubit polynomial pools while demonstrating up to an order reduction in the total number of 1-parameter derivative evaluations. The adaptive size of the batch eliminates the computationally expensive procedure of selecting the appropriate pool size for each molecule separately.
As expected, with fermionic ADAPT-VQE it is possible to achieve VQE-UCCSD results with the reduced number of parameters and shallower circuits. Still, the parameter reduction in our case is not as impressive as it was reported by Grimsley et al.27. Besides the complex electronic structure of the considered molecules, the operator pools are reduced significantly by accounting for molecular symmetry (see Table 1).
Our numerical results have demonstrated that batched fermionic ADAPT-VQE is a useful tool to improve the efficiency of VQE-UCCSD in terms of circuit depth while saving the number of computed derivatives significantly compared to the original fermionic ADAPT-VQE.
However, as the use of fermionic ADAPT-VQE is currently challenging for existing devices due to the deep quantum circuits, we pay particular attention to qubit ADAPT-VQE. Building on top of the work on minimal complete pools by Shkolnikov et al.29, we have combined MCP construction with qubit tapering procedure. Moreover, we have proposed a greedy algorithm for automated pool construction from UCCSD operators that do not require manual analysis of molecular hamiltonian symmetries. Our approach reduces the complexity of computations by reducing the number of qubits in the system. The constructed pools demonstrate excellent convergence for small molecules (H4 and LiH), however, with the increase of the size and complexity of the molecules, we observe that qubit ADAPT-VQE with MCP produces a vast overhead in the number of computed derivatives. Along with the MCPs, we studied polynomial-size qubit pools containing a single Pauli string from each UCCSD excitation after Z-pauli removal. Our numerical investigation leads to a suprising result: although theoretically, MCP is expected to reduce the measurement overhead in ADAPT-VQE, in practice, the qubit pool of the polynomial size requires significantly fewer derivative evaluations due to faster convergence. Moreover, the polynomial pool generates shallower circuits compared to MCP. Based on our numerical investigation, we suggest that using of batched ADAPT-VQE in combination with polynomial qubit pool is more efficient than reducing in the pool size in practice.
With qubit batched ADAPT-VQE using polynomial pools we could reach fermionic VQE-UCCSD results for all the considered molecules. Further improvement in the energy is possible, although it requires significant computational resources, namely, an increase in the number of computed derivatives due to the sluggish convergence. Similar behavior is also observed for the fermionic ADAPT-VQE in the case of a strong correlation when reaching the accurate energies. The bottleneck, in this case, lies in the VQE procedure, where we update all parameters simultaneously. Thus, we believe further study and improvements of the classical optimization routine are required to make progress and enable the practical application of ADAPT-VQE.
Despite the given shortcomings with the proper improvement of the optimization process, we expect both qubit and fermionic batched ADAPT-VQE are promising for molecular simulation due to the variable circuit size on near-term quantum devices. The investigation of ADAPT-VQE approaches in noisy conditions for moving towards experiments on real devices can be a subject of subsequent study.
Methods
Fermionic pool
We start with the spin-conserving fermionic operators from the conventional UCCSD:
where a†, a are fermionic creation and annihilation operators, respectively. The summation is carried over occupied and virtual spin-orbitals.
After mapping excitations to qubits, the fermionic excitations are rotated following symmetry transformation32 such that the operators in qubit representation act by X or I on the subset of qubits. These qubits are further removed from the simulation. Thus, after the qubit tapering procedure fermionic operators may includean odd total number of X and Y Pauli operators.
Qubit pool completeness
According to the theorems of completeness29, a minimal complete pool must contain 2N − 2 odd Pauli strings (i.e., strings having an odd number of Y Paulis), which generate the product group G with \(\frac{{2}^{N-1}({2}^{N-1}+1)}{2}\) odd Pauli strings. Let us leave out of the bracket the minimality of the pool and consider a pool with 2N generators that span all possible N-qubit Pauli strings, 4N in total. Adding back the two operators, we thus lose the information about the connection of two qubits, which was approved by Tang et al.28. Although we do not have an analytical proof for the general case, for the considered molecules, we observed that this connection forms between tapered qubits and thus could be skipped out. Moreover, the pool size increases only by a constant, which does not affect the complexity. bserved on the considered molecules.
Consider an N qubit molecule and a set of 2N odd Pauli strings, which generates a full product group with 4N possible Pauli strings (N positions with one of 4 matrices I, X, Y and Z at each). The number of odd Pauli strings in the full group is 2N(2N − 1)/2. The Lie algebra for the given set of operators consists of odd Pauli strings only, and its size is equal to 2N(2N − 1)/2 when the set forms a complete pool. Our goal is to find the size of the Lie algebra for the case of the symmetric molecular hamiltonian.
The unitary transformation U, which acts on the reference state \(U\left| {{\mbox{Ref}}}\right\rangle =\left|{{\Psi }}\right\rangle\) is a superposition of operators – Pauli strings – from the Lie algebra, and all the operators must obey the restrictions raised from the hamiltonian symmetries. This means that the operator pool does not need to generate the full Lie algebra, only its subalgebra with all “symmetric” odd Pauli strings. Based on Z2 symmetries, we can easily find the symmetry restrictions. For the qubit molecular hamiltonian, there exist Nsym Pauli strings S, which commute with the hamiltonian and are called symmetries. Based on these symmetries a unitary operator can be found that rotates a hamiltonian in such a way that it acts trivially or with at most one Pauli-gate (e.g. I/X) on a set of qubits Ns.
Now consider a subgroup of the full product G group, which spans all the symmetric odd Pauli strings Gos (we generate the full group and then select only the odd strings that commute with Z2 symmetries). If we rotate all strings from Gos by the unitary transformation UR, the rotated strings URGosUR have a specific structure and act by I or X on a subset of qubits.
The substring acting on Ns qubits is always even for the rotated strings at it contains no Y Paulis on these positions. T he number of odd Pauli strings then have the size of Lie algebra built on N − Ns qubits multiplied by the number of possible combinations on the Ns qubits:
If we taper off Ns from the computation, then the operator strings are reduced to the length N − Ns. The Lie algebra after tapering includes
elements, and the product group has \({2}^{N-{N}_{s}}\) pauli strings in total.
From the practical point of view, the considerations presented above allow us to formulate the completeness criterion for the molecule after the tapering procedure. Suppose the operator pool of odd Pauli strings generates a product group of the size \({2}^{N-{N}_{s}}\) and cannot be separated into two mutually commuting sets. In that case, the pool is complete for N − Ns qubit molecular hamiltonian.
To check the completeness criteria, we use the following procedure. To compute the product group size. we represent individual N-qubit Pauli strings as bitstrings of length 2N. This way, each Pauli matrix is represented by two bits – Z and X. I matrix corresponds to zeros in both bits, while Y corresponds to both ones. For example, the Pauli string IXZY transforms into the following bitstring:
This representation product of two Pauli strings is equivalent to the sum modulo two of their bitstrings up to a coefficient. For example:
To find the size of the product group for a certain pool, we need to know the size of the span for the corresponding bitstrings. We do so by running Gaussian elimination and finding the size K of the minimal generating set. The size of the product group is then equal to 2K.
To check the inseparability criterion, we build a graph with vertices representing Pauli strings from the pool. We connect vertices with an edge if the Pauli strings do not commute. The criterion is satisfied when the constructed graph has a single connected component. Both checks run in \({{{{{{{\mathcal{O}}}}}}}}({M}^{2}N)\) time, where M is the pool size, which is efficient enough.
Computational details
In this work, we perform noiseless (ideal) statevector simulations for the following set of molecules: H4, LiH, H2O, O2, CO, and CO2 in the minimal basis set (STO-3G). We use both frozen core approximation and molecular symmetry for all the molecules to optimize the required resources: both number of qubits and number of electronic excitations. To map the ansatz to a quantum circuit, we use Jordan-Wigner transformation41. Accounting for the molecular symmetry allows us to taper up to 5 qubits for the given molecules and reduce the operator pool significantly by excluding excitations =that commute with the qubit Hamiltonian (see Table 1). The symmetry reduction leads to a great decrease in the computational time on a classical simulator. Although circuit complexity in VQE-UCCSD can be reduced by excluding excitations based on the precomputed MP2 amplitudes13,14, we do not use any specific techniques suitable only for one of the methods. VQE results are provided for trotterized (or disentangled) UCCSD with SD ordering (singles applied first to the reference state)20.
We use Qiskit library37 for statevector simulations of quantum algorithms. All the circuit dimensions are given after applying built-in "heavy” transpilation in Qiskit. The circuit depth is given by the number of consecutive one-qubit gates and CNOTs. Even though more efficient circuits for implementing fermionic and qubit excitations have been proposed42,43, they can not be applied directly in our case due to the tapering procedure. We compare the results to the classical methods of quantum chemistry, such as CCSD, CCSD(T), and FCI (exact result in the given basis set). All the classical results are computed with PySCF package for quantum chemistry44.
Optimization strategy
The classical optimization routine in the VQE approach can be implemented in several ways. We initialize all parameters for VQE-UCCSD with zeros. For the ADAPT-VQE, we set initial parameters to optimal values obtained at the previous iteration, as was done in the original work27. Such initialization improves classical optimization, as parameters are already optimized to a quite sensitive level.
Gradient-based methods are considered to be efficient in statevector simulation for both VQE and ADAPT-VQE13,45. However, a separate study on the optimization strategy in the presence of noise is required. In this work, we use gradient-based Sequential Least SQuares Programming (SLSQP) optimizer46. We set a maximum number of iterations to 200 and stricted ftol to 10−10 in SLSQP optimizer for the considered molecules except for CO2 to avoid optimization difficulties.
In ADAPT-VQE, we calculate gradients in the VQE procedure and gradients with respect to the operators in the same way. Such implementation is appropriate for real devices and lassical simulators, making it a general approach. For the qubit operators, we calculate gradients directly using the parameter-shift rule47, which requires two circuit evaluations per one-parameter derivative. It is possible because qubit operators are represented by individual Pauli strings.
Fermionic operators do not allow direct application of the parameter-shift rule. Analytic gradients in the fermionic ADAPT-VQE and VQE-UCCSD can be computed with the recently proposed fermionic-shift gradients48 with 4 circuit evaluations per gradient or 2 evaluations introducing approximations. However, each circuit evaluation takes significant time because of the large gate count in fermionic methods and large molecules used for analysis (up to 19 qubits). Since we perform statevector simulations, we use numerical gradients for fermionic methods, as they are more efficient in terms of circuit evaluations: only k + 1 circuit evaluations are performed, where k is the number of parameters in a quantum circuit.
In the case of ideal (noiseless) simulations, numerical and analytic gradients exactly match each other, while numerical ones are less robust in the presence of noise. Analytic gradients, which we use for qubit methods, are important for future studies of qubit ADAPT-VQE performance in noisy conditions.
Convergence criteria
In our simulation, we run ADAPT-VQE procedure until the energy convergence. However, it is preferable to use some selected convergence criteria in practical simulation. In the original work27, the authors use a convergence threshold on the norm of the gradient vector:
Other options are also possible. Specifically, the threshold can be applied to the maximum gradient element instead of the gradient vector norm. According to our calculations, setting the threshold for the maximum derivative to 10−2 provides ADAPT-VQE energies close to the VQE-UCCSD results but with improved gate count.
Data availability
The data supporting the findings of this study are available from the corresponding authors upon reasonable request.
Code availability
The code that is deemed central to the conclusions is available from the corresponding author upon reasonable request.
References
Lloyd, S. Universal quantum simulators. Science 273, 1073–1078 (1996).
McArdle, S., Endo, S., Aspuru-Guzik, A., Benjamin, S. C. & Yuan, X. Quantum computational chemistry. Rev. Mod. Phys. 92, 015003 (2020).
Bauer, B., Bravyi, S., Motta, M. & Chan, G. K.-L. Quantum algorithms for quantum chemistry and quantum materials science. Chemical Rev. 120, 12685–12717 (2020).
Elfving, V. E. et al. How will quantum computers provide an industrially relevant computational advantage in quantum chemistry? Preprint at arXiv:2009.12472 (2020).
Fedorov, A. K. & Gelfand, M. S. Towards practical applications in quantum computational biology. Nat. Comput. Sci. 1, 114–119 (2021).
Cerezo, M. et al. Variational quantum algorithms. Nat. Rev. Phys. 38 (2021). https://doi.org/10.1038/s42254-021-00348-9.
Peruzzo, A. et al. A variational eigenvalue solver on a photonic quantum processor. Nat. Commun. 5, 4213 (2014).
Fedorov, D. A., Peng, B., Govind, N. & Alexeev, Y. VQE method: a short survey and recent developments. Mater Theory 6, 2 (2022)
Kandala, A. et al. Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets. Nature 549, 242–246 (2017).
Barkoutsos, P. K. et al. Quantum algorithms for electronic structure calculations: Particle-hole hamiltonian and optimized wave-function expansions. Phys. Rev. A 98, 022322 (2018).
Gard, B. et al. Efficient symmetry-preserving state preparation circuits for the variational quantum eigensolver algorithm. npj Quant. Inform. 6, 10 (2020).
Mcclean, J., Boixo, S., Smelyanskiy, V., Babbush, R. & Neven, H. Barren plateaus in quantum neural network training landscapes. Nat. Commun. 9, 4812 (2018).
Romero, J. et al. Strategies for quantum computing molecular energies using the unitary coupled cluster ansatz. Quantum Sci. Technol. 4, 014008 (2018).
Kühn, M., Zanker, S., Deglmann, P., Marthaler, M. & Weiss, H. Accuracy and resource estimations for quantum chemistry on a near-term quantum computer. J. Chem. Theory Comput. 15, 4764–4780 (2019).
Armaos, V., Badounas, D. A. & Deligiannis, P. Computational chemistry on quantum computers: Ground state estimation. Preprint at arXiv:1907.00362 (2019).
Rice, J. et al. Quantum computation of dominant products in lithium-sulfur batteries. J. Chem. Phys. 154, 134115 (2021).
O’Malley, P. J. J. et al. Scalable quantum simulation of molecular energies. Phys. Rev. X 6, 031007 (2016).
Hempel, C. et al. Quantum chemistry calculations on a trapped-ion quantum simulator. Phys. Rev. X 8, 031022 (2018).
McCaskey, A. et al. Quantum chemistry as a benchmark for near-term quantum computers. npj Quant. Inform. 5, 99 (2019).
Grimsley, H. R., Claudino, D., Economou, S. E., Barnes, E. & Mayhall, N. J. Is the trotterized uccsd ansatz chemically well-defined? J. Chem. Theory Comput. 16, 1–6 (2020).
Cooper, B. & Knowles, P. Benchmark studies of variational, unitary and extended coupled cluster methods. J. Chem. Phys. 133, 234102 (2010).
Lee, J., Huggins, W., Head-Gordon, M. & Whaley, K. Generalized unitary coupled cluster wavefunctions for quantum computation. J. Chem. Theory Comput. 15, 311–324 (2018).
Helgaker, T., Klopper, W. & Koch, H. Basis-set convergence of correlated calculations on water. J. Chem. Phys. 106, 9639–9646 (1997).
Varandas, A. Straightening the hierarchical staircase for basis set extrapolations: A low-cost approach to high-accuracy computational chemistry. Ann. Rev. Phys. Chem. 69, 177–203 (2018).
Musiał, M., Kucharski, S. & Bartlett, R. Coupled cluster study of the triple bond. J. Mol. Structure-theochem 547, 269–278 (2001).
Helgaker, T. et al. Highly Accurate Ab Initio Computation of Thermochemical Data, 1–30 (Springer Netherlands, Dordrecht, 2001).
Grimsley, H. R., Economou, S. E., Barnes, E. & Mayhall, N. J. An adaptive variational algorithm for exact molecular simulations on a quantum computer. Nat. Commun. 10, 3007 (2019).
Tang, H. et al. Qubit-adapt-vqe: An adaptive algorithm for constructing hardware-efficient ansätze on a quantum processor. PRX Quantum 2, 020310 (2021).
Shkolnikov, V. O., Mayhall, N. J., Economou, S. E. & Barnes, E. Avoiding symmetry roadblocks and minimizing the measurement overhead of adaptive variational quantum eigensolvers. Preprint at arXiv:2109.05340 (2021).
Liu, J., Li, Z. & Yang, J. An efficient adaptive variational quantum solver of the schrödinger equation based on reduced density matrices. J. Chem. Phys. 154 24, 244112 (2021).
Evangelista, F., Chan, G. & Scuseria, G. Exact parameterization of fermionic wave functions via unitary coupled cluster theory. J. Chem. Phys. 151, 244112 (2019).
Setia, K. et al. Reducing qubit requirements for quantum simulations using molecular point group symmetries. J. Chem. Theory Comput. 16, 6091–6097 (2020).
Al Soubaihi, R. M., Saoud, K. M. & Dutta, J. Critical review of low-temperature co oxidation and hysteresis phenomenon on heterogeneous catalysts. Catalysts 8 https://www.mdpi.com/2073-4344/8/12/660. (2018).
Dey, S. & Dhal, G. Catalytic conversion of carbon monoxide into carbon dioxide over spinel catalysts: An overview. Mater. Sci. Energy Technol. 2, 575–588 (2019).
Ryabinkin, I., Yen, T.-C., Genin, S. & Izmaylov, A. Qubit coupled cluster method: a systematic approach to quantum chemistry on a quantum computer. J. Chem. Theory Comput. 14, 6317–6326 (2018).
Ryabinkin, I. G., Lang, R. A., Genin, S. N. & Izmaylov, A. F. Iterative qubit coupled cluster approach with efficient screening of generators. J. Chem. Theory Comput. 16, 1055–1063 (2020).
Md Sajid Anis, H. A. et. al. Qiskit: an open-source framework for quantum computing. https://doi.org/10.5281/zenodo.4660156 (2021).
Soini, T., Genest, A. & Rösch, N. Assessment of hybrid density functionals for the adsorption of carbon monoxide on platinum model clusters. J. Phys. Chem. A 119, 4051–4056 (2015).
Feibelman, P. J. The co/pt(111) puzzle. J. Phys. Chem. B 105, 4018–4025 (2001).
Douglas-Gallardo, O. A., Saez, D. A., Vogt-Geisse, S. & Vöhringer-Martinez, E. Electronic structure benchmark calculations of inorganic and biochemical carboxylation reactions. J. Comput. Chem. 40, 1401–1413 (2019).
Jordan, P. & Wigner, E. Über das paulische äquivalenzverbot. Zeitschrift für Physik 47, 631–651.
Yordanov, Y. S., Arvidsson-Shukur, D. R. M. & Barnes, C. H. W. Efficient quantum circuits for quantum computational chemistry. Phys. Rev. A 102, 062612 (2020).
Yordanov, Y., Armaos, V., Barnes, C. & Shukur, D. Iterative qubit-excitation based variational quantum eigensolver. Preprint at arXiv:2011.10540v2 (2021).
Sun, Q. et al. Recent developments in the pyscf program package. J. Chem. Phys. 153, 024109 (2020).
Claudino, D., Wright, J., McCaskey, A. & Humble, T. Benchmarking adaptive variational quantum eigensolvers. Front. Chem. 8, 606863 (2020).
Kraft, D. A software package for sequential quadratic programming. Deutsche Forschungs- und Versuchsanstalt für Luft- und Raumfahrt Köln: Forschungsbericht https://books.google.ru/books?id=4rKaGwAACAAJ. (Wiss. Berichtswesen d. DFVLR, 1988).
Schuld, M., Bergholm, V., Gogolin, C., Izaac, J. & Killoran, N. Evaluating analytic gradients on quantum hardware. Phys. Rev. A 99, 032331 (2019).
Kottmann, J. S., Anand, A. & Aspuru-Guzik, A. A feasible approach for automatically differentiable unitary coupled-cluster on quantum computers. Chem. Sci. 12, 3497–3508 (2021).
Acknowledgements
The research is supported by the RSF (Grant No. 19-71-10092; part related to simulating LiH and H2O molecules using various VQE-based approaches) as well as by Nissan Research Division, Nissan Motor Co., Ltd. and Nissan Research Center-Russia. We are grateful to Dr. Atsushi Oma, Nissan Research Division, Nissan Motor Co., Ltd., for useful discussions. The development of the computational scheme for complete pools was supported by the Leading Research Center program (Agreement No. 014/20). The study of the qubit pool completeness was supported by the Priority 2030 program at the National University of Science and Technology “MISIS” under the project K1- 2022-027. We also acknowledge the use of Qiskit Library37 and QASM simulator.
Author information
Authors and Affiliations
Contributions
M.S. and A.F. jointly developed the problem statement and analyzed existing state-of-the-art techniques. M.S. implemented the considered methods and performed the simulation of molecules. M.S. and A.F. jointly analyzed the results and wrote the manuscript. A.F. supervised the project.
Corresponding author
Ethics declarations
Competing interests
Owing to the employments and consulting activities of authors, M.S. and A.F. have financial interests in the commercial applications of quantum computing. M.S. and A.F. do not have any non-financial competing interest.
Peer review
Peer review information
Communications Physics thanks Jinlong Yang and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sapova, M.D., Fedorov, A.K. Variational quantum eigensolver techniques for simulating carbon monoxide oxidation. Commun Phys 5, 199 (2022). https://doi.org/10.1038/s42005-022-00982-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s42005-022-00982-4
This article is cited by
-
Nuclear shell-model simulation in digital quantum computers
Scientific Reports (2023)
-
Overlap-ADAPT-VQE: practical quantum chemistry on quantum computers via overlap-guided compact Ansätze
Communications Physics (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
