
Abstract
Deep learning (DL) has been widely investigated in breast ultrasound (US) for distinguishing between benign and malignant breast masses. This systematic review of test diagnosis aims to examine the accuracy of DL, compared to human readers, for the diagnosis of breast cancer in the US under clinical settings. Our literature search included records from databases including PubMed, Embase, Scopus, and Cochrane Library. Test accuracy outcomes were synthesized to compare the diagnostic performance of DL and human readers as well as to evaluate the assistive role of DL to human readers. A total of 16 studies involving 9238 female participants were included. There were no prospective studies comparing the test accuracy of DL versus human readers in clinical workflows. Diagnostic test results varied across the included studies. In 14 studies employing standalone DL systems, DL showed significantly lower sensitivities in 5 studies with comparable specificities and outperformed human readers at higher specificities in another 4 studies; in the remaining studies, DL models and human readers showed equivalent test outcomes. In 12 studies that assessed assistive DL systems, no studies proved the assistive role of DL in the overall diagnostic performance of human readers. Current evidence is insufficient to conclude that DL outperforms human readers or enhances the accuracy of diagnostic breast US in a clinical setting. Standardization of study methodologies is required to improve the reproducibility and generalizability of DL research, which will aid in clinical translation and application.
Similar content being viewed by others

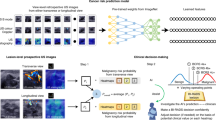
Introduction
Breast cancer is the world’s most prevalent cancer and remains the major cause of cancer-associated deaths globally. GLOBCAN estimated that in 2020, there were about 2.3 million women diagnosed with breast cancer and 685,000 breast cancer-associated deaths worldwide1. Early and accurate diagnosis results in better patient outcomes. Breast ultrasound (US) is low-cost, easy-to-operate, radiation-free, portable, and typically helpful for distinguishing between a cystic and a solid breast mass. The effectiveness of the US as a diagnostic tool for palpable breast abnormalities is widely recognized, especially in cases involving dense breast tissues or mammographically occult lesions2,3,4. Additionally, the US is considered the preferred imaging method for providing guidance during breast biopsy procedures5,6. However, the diagnostic efficacy and reproducibility of US examinations are relatively low due to their dependence on the knowledge and experience of the operators7,8.
Deep learning (DL), an innovative artificial intelligence (AI) technology, excels at image-related tasks, including abnormities detection, segmentation, and classification (Fig. 1). The integration of DL into the US imaging workflow offers numerous benefits, including improved efficiency, reduced errors, and automated quantitative assessments9. Consequently, significant efforts have been made to facilitate the clinical application of DL in medical imaging. For instance, the DL-based ultrasonography system known as S-Detect (Samsung Medison, Seoul, Korea) has gained increasing popularity for breast cancer diagnosis. This system enables automatic segmentation and interpretation of US morphological descriptions, providing a dichotomous classification (possibly benign or possibly malignant) that serves as a reference for radiologists during the final diagnostic process10.

a Clinical US workflow comprises image acquisition, image analysis (which may involve DL), report generation, and further procedures based on diagnostic reports. b A DL system comprises multiple layers where feature extraction, selection, and ultimate classification are performed simultaneously during training. US images as input are analyzed and the DL model gives binary classification (benign or malignant). Final assessment is made based on the decision of the DL system alone or in combination with human radiologists.
Several recent reports have suggested that DL-based interpretation of breast US is on par with or even superior to that of a human radiologist11,12,13,14,15. However, the application of DL in clinical practice remains controversial and results vary across different studies. Current reviews10,16 focused on evaluating the application potentials of commercial products, such as S-Detect. There is a paucity of evidence-based systematic reviews specific to the general diagnostic performance of employing DL models in clinical practice of breast US, in particular comprehensive comparison between DL and human readers. Our work aims to assess current evidence on the diagnostic performance of DL algorithms in the detection and classification of breast lesions in clinical US tests, including (1) whether standalone DL systems outperform radiologists in breast cancer diagnosis and (2) whether assistive DL systems can improve diagnostic performance when used in concert with human radiologists.
Results
Study selection and study characteristics
Database searches initially yielded 4017 unique results after removing 1898 duplicates, among which 96 potentially eligible studies were further reviewed through full texts. Overall, as shown in Fig. 2, 16 studies17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32 were ultimately included in this review, according to inclusion criteria. In addition, based on the PICO framework (population, intervention, comparison, outcome), exclusions and the corresponding reasons after full-text review were presented in Supplementary Tables 1 and 2.

Sixteen publications were included in the database (PubMed, Embase, Scopus, and Cochrane Library) after removing duplicates, irrelevant studies, and studies that did not meet the inclusion criteria.
The main characteristics of the included 16 publications, including 14 studies using standalone DL systems and 12 studies using assistive DL systems, were presented in Table 1, Supplementary Tables 3 and 4, and Supplementary Fig. 1. These studies comprised 9238 women in total, of which 3 studies30,31,32 recruited 901, 582, and 5012 female participants respectively, the remaining 13 studies17,18,19,20,21,22,23,24,25,26,27,28,29 included smaller numbers of women (from 40 to 472). Seven studies evaluated data from China19,21,23,27,29,30,32, 6 studies enrolled participants from Korea17,18,20,24,25,28, 2 from Italy22,26, and the remaining 1 study31 used public multisite data from which the countries were not reported. Of all studies, 15 were conducted in a diagnostic setting, while the remaining 1 was evaluated in a screening setting18. All included studies employed DL convolutional neural networks, of which 14 were commercial DL systems, including S-Detect17,18,19,20,21,22,23,24,25,26,28,29,30 and BU-CAD27, and 2 were investigator-derived DL systems31,32. In addition, there were 6 studies17,18,24,25,26,27,28 using retrospective US images to compare the diagnostic accuracy of DL systems and human readers. For prospective test accuracy studies, multiple reader multiple case studies were performed under laboratory conditions19,20,21,22,23,29,30,32, without any randomized controlled trials or cohort studies based on real-world settings. Nine publications17,18,19,20,22,27,29,30,31 followed the fifth edition of Breast Imaging Reporting and Data System (BI-RADS) to make the final assessment, another 7 articles did not specify which version was used. BIRAD-4a was clearly described as the cutoff value in 13 studies17,18,19,20,21,22,24,25,27,28,29,31,32, while 2 studies23,26 using BIRADS-4b as the cutoff value. Another study30 evaluated the diagnostic accuracy using BIRAD-4a and BIRADS-4b as cut-off values, respectively. All studies used pathology as the gold standard, among which 7 studies20,22,24,25,27,28,31 employed follow-up as a supplement to the reference standard.
Diagnostic performance comparison
DL can function either as a standalone system where the algorithms independently generate diagnostic decisions, or as an assistant to radiologists where the final diagnosis is made by radiologists considering the DL outcomes. Consequently, the development of a successful DL product necessitates not only the construction of robust DL algorithms but also the exploration of how the algorithm outputs can enhance radiologists’ diagnostic capabilities. It is crucial to investigate the usefulness of DL outputs for radiologists, quantify the benefits of DL in patient care, and determine strategies to optimize these advantages.
In test accuracy comparison between DL systems and human readers, 4 studies evaluated the diagnostic performance of DL systems as standalone19,22,26,31, 2 studies employed assistive DL systems17,21, and another 10 studies assessed the roles of DL systems as both standalone and assistive systems18,20,23,24,25,27,28,29,30,32. Those studies employed human readers at various levels of clinical experiences in breast US and investigated the performance of DL systems compared to experienced and less experienced human readers.
Standalone DL systems
In 14 studies using DL as a standalone system, the diagnostic accuracy of DL and human readers was compared (Table 2). In a study20 conducted by Cho et al. found DL had lower AUC than human readers. Two studies22,24 showed DL was equivalent to human readers in AUC. In contrast, another study32 reported a higher AUC of DL than human readers. More specifically, DL had superior AUC over less experienced human readers while comparable to experienced human readers in three studies19,24,29. As for accuracy, DL systems were more accurate than all human readers in two studies24,32. Wei et al.29 reported that DL was more accurate than less experienced human readers while comparable to experienced human readers. In contrast, another study showed DL was equivalent to less experienced human readers while more accurate than experienced human readers. In addition, standalone DL had lower sensitivity than overall human readers in five studies19,20,24,30,32. Another two studies26,28 found that DL was more sensitive than less experienced human readers but less sensitive than experienced human readers. In four studies19,20,24,32, DL exhibited higher specificity than overall human readers. In another study26, DL was more specific than less experienced human readers but less specific than experienced human readers. The remaining studies did not report comparable diagnostic measures between DL systems and human readers.
Assistive DL systems
In 12 studies that assessed assistive DL systems (Table 2), three studies18,27,32 reported improved AUC of human readers when combining with DL systems. Another study20 showed assistive DL had a comparable AUC to human readers alone. To investigate the assistive effects of DL on human readers with different experiences, two studies17,24 found that assistive DL systems had higher AUC than less experienced human readers but the positive impacts did not work for experienced human readers. In accuracy tests, assistive DL systems were more accurate than human readers in three studies20,24,32. However, no studies showed improved overall sensitivity of the combination of DL and human readers compared to human readers alone. One study28 reported improved sensitivity of an assistive DL system compared to less experienced human readers but this advantage was not maintained when used by experienced human readers. Improved specificity in overall human readers was reported in seven studies18,20,21,24,27,28,32 that used assistive DL systems. Interestingly, in a study17 reported by Park and coworkers, the assistive DL technology improved diagnostic specificity among experienced human readers but not among inexperienced readers. While in another study20, less experienced human readers were aided in terms of specificity by the assistive DL system.
In Fig. 3, we estimated the sensitivity and specificity of DL systems and average human readers. We tentatively infer both standalone and assistive DL systems are more specific than average human readers while whether they are more sensitive remains unclear. However, complete 2 × 2 contingency tables were not available in most studies so that we were unable to conduct a thorough diagnostic analysis for all included studies.

a Sensitivities of standalone DL systems and average human readers. b Specificities of standalone DL systems and average human readers. c Sensitivities of assistive DL systems and average human readers. d Specificities of assistive DL systems and average human readers. Error bar represents SD.
Quality assessment
Based on QUADAS-2 and QUADAS-C tools, we tailored the signal questions in four domains, including patient selection, index tests, reference standard, flow, and timing, to assess the quality and applicability of included studies (Supplementary Table 5). The studies with low, high, or unclear risk of bias and applicability concerns were summarized in Table 3, Figs. 4 and 5. Most studies showed a high risk of bias in the four domains. For example, the average cancer prevalence of included lesions was 39.5%, ranging from 6% to 64.7% (Supplementary Table 4 and Supplementary Fig. 1), which far exceeds the prevalence in screening and diagnostic settings33. This led to a high risk of bias in patient selection. Additionally, most study designs did not represent a complete US testing pathway applicable to clinical practice. For example, DL systems were used for image reading, but not integrated into clinical decisions, such as diagnosis, further tests, or follow-up. In contrast, the choice of patient management (e.g., biopsy, follow-up) to confirm disease status was based on the decision of the human readers rather than standalone or assistive DL systems. Meanwhile, for human readers, the testing pathway was also not applicable to clinical routines where they have access to patient’s clinical information as well as prior US images. The reference standards varied among the included 16 studies, of which 4 studies17,22,25,28 were at high risk of bias because the follow-up time of women with negative tests was <2 years, which is shorter than the recommended follow-up interval33 and therefore may underestimate the rate of missed cancers and overestimate diagnostic accuracy.

The proportion of studies with low, high, unclear risk of bias and concerns regarding applicability.

The proportion of studies with low, high, unclear risk of bias and concerns regarding applicability.
Discussion
This review presents a comprehensive overview of diagnostic performance in breast US of DL systems, which serve as standalone roles or aids to human readers. We identified 16 studies that compared the test accuracy measures of a commercial or in-house DL system to that of human readers. Diagnostic test outcomes varied substantially among the included studies. While we cautiously inferred DL systems were more specific than average human readers, which might help decrease the false positives, no consensus of AUC, accuracy, and sensitivity was found either in standalone or assistive DL systems. Importantly, one of the main concerns of DL studies is better imaging sensitivity might come at the cost of increased false positives and vice versa. Critical performance metrics such as AUC, accuracy, sensitivity, specificity, true positive, false positive, false negative, and true negative should be taken into consideration together. However, not all included studies reported these diagnostic measures. Although most of the included studies (14/16) use FDA-approved DL systems, the clinical effects of DL systems as standalone or assistive roles have not been fully revealed yet due to the lack of generalizable reporting or good study design. Therefore, our systematic review disagrees with findings from various publications, some of which have claimed that DL systems (e.g., S-Detect) outperform humans18,20,24 and have a significant role in assisting human readers in distinguishing between benign and malignant breast masses10,16. It does not necessarily mean that the DL algorithm in breast US itself is unreliable. It contrarily provides the directions for future improvement for this promising technology.
Our review found high heterogeneity stemming from study designs, methods, targeted populations, diagnostic measures, and human readers’ experiences, which hinders the comparability of evidence across included studies. There was a wide variation in the number and pathological type of selected lesions. Thirteen studies evaluated fewer than 500 women while the outcomes of another three studies were based on many more participants. Promising results from small populations may not be applicable to larger populations. In addition, the malignant proportions far exceed the cancer prevalence in the real world, which inevitably overestimates the sensitivity. Importantly, most of the included studies originated in Asia, and mostly at a single site, which may affect the external validity of reported results. Furthermore, compared with Caucasian women, Asian women generally have denser breasts and younger ages of onset of breast cancer. Discrepancies in race and ethnicity make it difficult to extrapolate the positive findings among Asian participants to multi-race and multi-ethnic populations. Hence, multicenter studies from different countries that recruit participants from multiple races and ethnicities are required to achieve higher applicability of these studies. Additionally, the test cutoff values varied among studies with some using BIRADS-4a while some using BIRADS-4b as the threshold for classifying malignancies. In this regard, test bias could have been introduced. These studies also set various definitions of experienced or less experienced human readers, which might lead to contrary conclusions among some studies. Furthermore, the included studies have some variation in reference standards, including pathological confirmation and follow-up time (7–35 months). The methods for obtaining pathological results were also inconsistent, including histopathologic results from US-guided biopsy, vacuum-assisted excision, or open surgery. These discrepancies suggest that accuracy evaluations are not comparable among studies. Overall, the current evidence base is not of sufficient quality to support a broad clinical practice recommendation of DL systems in breast US.
Furthermore, compared to other medical imaging modalities, such as MRI, DL-assisted US shows intrinsic limitations, which hinders its clinical applicability. For example, US imaging is dependent on its operators, resulting in high intra- and inter-observer variability in image acquisition and interpretation. Moreover, unlike MRI images viewing the whole lesion range, still US images are obtained from parts of targeted organs, which may cause under-representation or over-exaggeration. Additionally, US technology has been evolving fast over the recent decades. Older ultrasonograms are generally of lower resolution and higher noise, while up-to-date images are of higher resolution and lower noise. Thus, DL models that are trained with older images may not be externally valid for images acquired by advanced devices. Methodological considerations are highly demanded for generalized conclusions from DL studies in US technology.
In this systematic review, we followed an established methodology and stringent inclusion criteria and tailored the quality assessment tools for included studies. Our emphasis on comparisons with the diagnostic performance of humans in clinical practice may explain why our conclusions are more cautious than many of the papers we reviewed herein. Importantly, according to previous studies and the current guidelines, internal validation where training and validation were performed based on the same dataset, such as cross-validation, tends to overestimate accuracy and has limited generalizability because of overfitting33. Hence, at the initial stage of literature identification, only studies using external validation of test sets were included. Therefore, our work can provide a purposeful insight into the role of DL in the US diagnosis of breast cancer. However, this systematic review excluded non-English publications, which might introduce selection bias. In addition, we were unable to calculate comprehensive diagnostic measures due to insufficient data where accuracy, true positive, false positive, true negative, false negative, and statistical difference (or raw data to calculate) were not reported.
To ensure reproducibility and generalizability of the results of this promising technology, we recommend developing standardized DL research guidelines for further investigations. Aligned study designs, agreed-upon benchmarking data sets, complete performance metrics, standard imaging protocols and reporting formats, consistent cutoff values and reference standards will help decrease the heterogeneity and bias. Furthermore, multicenter studies are highly demanded to determine the diagnostic accuracy of DL products. Prospective, randomized controlled trials that are applicable to clinical testing pathways are significantly important to examine DL’s role in a clinical environment. Also, we need to identify the DL products with the best performance in terms of accuracy, efficiency, availability, cost-effectiveness, and safety to improve clinical workflows. DL-based breast US diagnosis is still in its infancy, and considerable efforts are needed to realize its positive impacts on radiologists and patients.
Methods
Protocol and registration
This systematic review was conducted following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses of Diagnostic Test Accuracy (PRISMA-DTA) statement34. Our review protocol was registered on the International Prospective Register of Systematic Reviews (PROSPERO: CRD42022349609).
Literature search
Literature searches were conducted by two librarians (H.B. and J.B.) to identify relevant studies published in English from four databases: PubMed, Embase, Scopus, and Cochrane Library. The publication time of studies was set from inception to 18 January 2023. The literature search was performed based on five themes: breast cancer, US, AI, accuracy, and diagnostic. The search keywords and strategies are shown in Supplementary Tables 6 and 7.
Study selection
Two reviewers (Q.D. and Z.X.) independently reviewed the titles and abstracts of all retrieved records for further identification according to the inclusion and exclusion criteria. Subsequently, the identified publications were screened by reviewing the full texts for final inclusion. Any discrepancies were resolved through discussion to reach a final consensus.
We applied rigorous inclusion and exclusion criteria to evaluate the integration of DL into clinical breast cancer diagnosis using the US. We included studies that focused on: (1) evaluating DL algorithms for breast cancer diagnosis using US; (2) assessing the test accuracy of DL algorithms for breast lesion diagnosis using US; and (3) utilizing histologically confirmed and/or follow-up reference standards. We excluded studies that: (1) did not compare the diagnostic performance of DL algorithms to that of human readers; (2) lacked external validation; (3) did not employ DL algorithms (e.g., utilizing traditional AI without binary classification or final decision); (4) solely focused on detecting specific cancer subtypes (e.g., ductal or lobular carcinoma) rather than overall diagnostic accuracy; (5) did not report diagnostic metrics beyond the receiver operating characteristic area under the curve (AUC); (6) involved participants under the age of 18; (7) included participants with implants, lactation, prior known breast cancer, or prior breast treatments such as surgery, radiation therapy, and chemotherapy; (8) enrolled male patients.
Data extraction
Study characteristics and test accuracy outcomes were independently extracted by two reviewers (Q.D. and Z.X.) from all included studies. Any disagreements were resolved by discussion. Extracted study characteristics included study design, population, US device vendors, dataset characteristics (training/validation/testing set), descriptions of the DL algorithms, descriptions of the human readers, reference standards, and any other pertinent information. Test performance characteristics included accuracy, AUC, sensitivity, and specificity.
Quality assessment
Two reviewers (Q.D. and Z.X.) independently assessed the quality of the selected studies using Quality for Assessment of Diagnostic Studies-2 (QUADAS-2) and QUADAS-C tools tailored to our review questions based on a breast US test pathway applicable to clinical settings (Supplementary Table 5). For risk of bias, patient selection, index tests, reference standards, flow, and timing were assessed, respectively. For applicability concerns, patient selection, index test, and reference standards were assessed. Any disagreements were resolved by discussion.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
All data generated and analyzed during this study are included in the article and its supplementary information files.
References
Sung, H. et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA 71, 209–249 (2021).
Harada-Shoji, N. et al. Evaluation of adjunctive ultrasonography for breast cancer detection among women aged 40–49 years with varying breast density undergoing screening mammography: a secondary analysis of a randomized clinical trial. JAMA Netw. Open 4, e2121505 (2021).
Ohuchi, N. et al. Sensitivity and specificity of mammography and adjunctive ultrasonography to screen for breast cancer in the Japan Strategic Anti-cancer Randomized Trial (J-START): a randomized controlled trial. Lancet 387, 341–348 (2016).
Dan, Q., Zheng, T., Liu, L., Sun, D. & Chen, Y. Ultrasound for breast cancer screening in resource-limited settings: current practice and future directions. Cancers 15, 2112 (2023).
Apesteguía, L. & Pina, L. J. Ultrasound-guided core-needle biopsy of breast lesions. Insights Imaging 2, 493–500 (2011).
Ghosh, K. et al. Breast biopsy utilization: a population-based study. Arch. Intern. Med. 165, 1593 (2005).
Catalano, O. et al. Recent advances in ultrasound breast imaging: from industry to clinical practice. Diagnostics 13, 980 (2023).
Berg, W. A., Blume, J. D., Cormack, J. B. & Mendelson, E. B. Operator dependence of physician-performed whole-breast US: lesion detection and characterization. Radiology 241, 355–365 (2006).
A, H., C, P., J, Q., Lh, S. & Hjwl, A. Artificial intelligence in radiology. Nat. Rev. Cancer 18, 500–510 (2018).
Li, J. et al. The value of S-Detect for the differential diagnosis of breast masses on ultrasound: a systematic review and pooled meta-analysis. Med. Ultrason. 22, 211 (2020).
Kim, J., Kim, H. J., Kim, C. & Kim, W. H. Artificial intelligence in breast ultrasonography. Ultrasonography 40, 183–190 (2021).
Shen, Y. et al. Artificial intelligence system reduces false-positive findings in the interpretation of breast ultrasound exams. Nat. Commun. 12, 5645 (2021).
Dembrower, K. et al. Effect of artificial intelligence-based triaging of breast cancer screening mammograms on cancer detection and radiologist workload: a retrospective simulation study. Lancet Digit. Health 2, e468–e474 (2020).
Pacilè, S. et al. Improving breast cancer detection accuracy of mammography with the concurrent use of an artificial intelligence tool. Radiol. Artif. Intell. 2, e190208 (2020).
Qian, X. et al. Prospective assessment of breast cancer risk from multimodal multiview ultrasound images via clinically applicable deep learning. Nat. Biomed. Eng. 5, 522–532 (2021).
Wang, X. & Meng, S. Diagnostic accuracy of S-Detect to breast cancer on ultrasonography: a meta-analysis (PRISMA). Medicine 101, e30359 (2022).
Park, H. J. et al. A computer-aided diagnosis system using artificial intelligence for the diagnosis and characterization of breast masses on ultrasound: added value for the inexperienced breast radiologist. Medicine (Baltimore) 98, e14146 (2019).
Kim, M. Y., Kim, S.-Y., Kim, Y. S., Kim, E. S. & Chang, J. M. Added value of deep learning-based computer-aided diagnosis and shear wave elastography to b-mode ultrasound for evaluation of breast masses detected by screening ultrasound. Medicine (Baltimore) 100, e26823 (2021).
Xiao, M. et al. An investigation of the classification accuracy of a deep learning framework-based computer-aided diagnosis system in different pathological types of breast lesions. J. Thorac. Dis. 11, 5023–5031 (2019).
Cho, E., Kim, E.-K., Song, M. K. & Yoon, J. H. Application of computer-aided diagnosis on breast ultrasonography: evaluation of diagnostic performances and agreement of radiologists according to different levels of experience. J. Ultrasound Med. 37, 209–216 (2018).
Wang, X.-Y., Cui, L.-G., Feng, J. & Chen, W. Artificial intelligence for breast ultrasound: an adjunct tool to reduce excessive lesion biopsy. Eur. J. Radiol. 138, 109624 (2021).
Di Segni, M. et al. Automated classification of focal breast lesions according to S-detect: validation and role as a clinical and teaching tool. J. Ultrasound 21, 105–118 (2018).
Xia, Q. et al. Differential diagnosis of breast cancer assisted by S-Detect artificial intelligence system. Math. Biosci. Eng. 18, 3680–3689 (2021).
Lee, S. E. et al. Differing benefits of artificial intelligence-based computer-aided diagnosis for breast US according to workflow and experience level. Ultrasonography 41, 718–727 (2022).
Choi, J. S. et al. Effect of a deep learning framework-based computer-aided diagnosis system on the diagnostic performance of radiologists in differentiating between malignant and benign masses on breast ultrasonography. Korean J. Radiol. 20, 749 (2019).
Nicosia, L. et al. Evaluation of computer-aided diagnosis in breast ultrasonography: improvement in diagnostic performance of inexperienced radiologists. Clin. Imaging 82, 150–155 (2022).
Lai, Y.-C. et al. Evaluation of physician performance using a concurrent-read artificial intelligence system to support breast ultrasound interpretation. Breast 65, 124–135 (2022).
Lee, J., Kim, S., Kang, B. J., Kim, S. H. & Park, G. E. Evaluation of the effect of computer aided diagnosis system on breast ultrasound for inexperienced radiologists in describing and determining breast lesions. Med. Ultrason. 21, 239 (2019).
Wei, Q. et al. The added value of a computer‐aided diagnosis system in differential diagnosis of breast lesions by radiologists with different experience. J. Ultrasound Med. 41, 1355–1363 (2022).
Wei, Q. et al. The diagnostic performance of ultrasound computer-aided diagnosis system for distinguishing breast masses: a prospective multicenter study. Eur. Radiol. 32, 4046–4055 (2022).
Ciritsis, A. et al. Automatic classification of ultrasound breast lesions using a deep convolutional neural network mimicking human decision-making. Eur. Radiol. 29, 5458–5468 (2019).
Gu, Y. et al. Deep learning based on ultrasound images assists breast lesion diagnosis in China: a multicenter diagnostic study. Insights Imaging 13, 124 (2022).
Freeman, K. et al. Use of artificial intelligence for image analysis in breast cancer screening programmes: systematic review of test accuracy. BMJ 374, n1872 (2021).
Salameh, J.-P. et al. Preferred reporting items for systematic review and meta-analysis of diagnostic test accuracy studies (PRISMA-DTA): explanation, elaboration, and checklist. BMJ 370, m2632 (2020).
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Nos. 82271998, 82071949, 81871371) and the Science and Technology Planning Project of Guangzhou City (No. 201804010106). The authors would like to thank the systematic review training offered by the Health Sciences Library of UNC-Chapel Hill.
Author information
Authors and Affiliations
Contributions
J.A.S.R. and Y.L. contributed to the study design, resources, funding, and manuscript revising. Q.D. and Z.X. contributed to publications identification and inclusion, data extraction, quality assessment, and manuscript drafting. H.B. and J.B. contributed to publications search, data proofing, and manuscript revising. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dan, Q., Xu, Z., Burrows, H. et al. Diagnostic performance of deep learning in ultrasound diagnosis of breast cancer: a systematic review. npj Precis. Onc. 8, 21 (2024). https://doi.org/10.1038/s41698-024-00514-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41698-024-00514-z
