
Abstract
Molecular targets and predictive biomarkers for prognosis in salivary duct carcinoma (SDC) have not been fully identified. We conducted comprehensive molecular profiling to discover novel biomarkers for SDC. A total of 67 SDC samples were examined with DNA sequencing of 464 genes and transcriptome analysis in combination with the clinicopathological characteristics of the individuals. Prognostic biomarkers associated with response to combined androgen blockade (CAB) treatment were explored using mRNA expression data from 27 cases. Oncogenic mutations in receptor tyrosine kinase (RTK) genes or genes in the MAPK pathway were identified in 55 cases (82.1%). Alterations in the phosphatidylinositol 3-kinase (PI3K)/AKT signaling pathway were identified in 38 cases (56.7%). Interestingly, patient prognosis could be predicted using mRNA expression profiles, but not genetic mutation profiles. The risk score generated from the expression data of a four-gene set that includes the ADAMTS1, DSC1, RNF39, and IGLL5 genes was a significant prognostic marker for overall survival in the cohort (HR = 5.99, 95% confidence interval (CI) = 2.73–13.1, p = 7.8 × 10−6). Another risk score constructed from the expression of CD3E and LDB3 was a strong prognostic marker for progression-free survival for CAB treatment (p = 0.03). Mutations in RTK genes, MAPK pathway genes, and PI3K/AKT pathway genes likely represent key mutations in SDC tumorigenesis. The gene expression profiles identified in this study may be useful for stratifying patients who are good candidates for CAB treatment and may benefit from additional systemic therapies.
Similar content being viewed by others

Introduction
Salivary duct carcinoma (SDC) is an aggressive malignancy that resembles high-grade mammary ductal carcinoma1,2,3. SDC was once regarded to account for 1–4% of all salivary gland carcinomas (SGCs)4,5,6, although recent studies have reported a higher incidence than previously recorded3,7. SDC usually occurs in major salivary glands such as the parotid gland and is often detected in males greater than 50 years old8,9. SDC can arise de novo or as the malignant component of carcinoma ex pleomorphic adenoma (PA)1,2,10.
The current treatments for SDC include complete surgical resection of the primary sites followed by adjuvant chemotherapy/radiotherapy2,3,8,9. However, recurrence and distant metastasis frequently occur, resulting in a poor prognosis. With conventional therapy, more than 50% of SDC patients die of their disease in 3–5 years, and they are at substantial risk of recurrence even after complete surgical resection. The 5-year overall survival (OS) ranges from 20 to 30%2,3,6,8,9,11. Efficacy data are limited for systemic therapy or radiation therapy for individuals with advanced SGC following resection1,2,8,9. Reliable prognostic biomarkers are desperately needed to select patients who are at high-risk for recurrence and who may benefit from additional systemic or radiation therapy1,2,3.
Similar to breast carcinoma, conventional immunohistochemistry has identified that SDC often exhibits overexpression of androgen receptor (AR), HER2 (coded by ERBB2 gene) and epidermal growth factor receptor (EGFR)8,12,13,14,15,16,17. However, SDC usually lacks estrogen receptor- or progesterone receptor-expression which is often observed in breast carcinoma12,18. Combined androgen blockade (CAB) with LHRH analog and bicalutamide, a common androgen deprivation therapy (ADT), has a relatively mild toxicity profile and is considered a promising treatment option for patients with unresectable AR–positive SGC. Several clinical trials have demonstrated a favorable response in patients treated with ADT8,19,20,21,22. In prostate cancer, generation of AR-V7 encoded by a splice variant of AR may confer resistance to androgen inhibitor treatment23, whereas few specific biomarkers predicting the efficacy of CAB treatment have been identified in SDC24,25,26,27,28. For HER2-targeted therapy, a combination of trastuzumab and chemotherapy resulted in impressive response rates in clinical trials29,30.
Due to the development of the next-generation sequencing, genetic, transcriptomic, and proteomic profiles have been investigated in SDC31,32,33,34,35,36. Tumor mutational burden is higher than other tumor types of SGC, and the phosphatidylinositol 3-kinase (PI3K)/AKT/mTOR pathway is the most frequently altered pathway37,38. Other mutations are frequently found in TP53, HRAS/NRAS, ERBB2, EGFR, BRAF and the CCND1/CDK pathway genes31,39,40,41,42,43. Reports have described prognostic factors of the clinical outcomes of SDC31,39. The degree of immune cell infiltration in tumor microenvironment is a predictive marker for immune checkpoint inhibitors34,36. However, studies have not presented abundant integrative analysis combining comprehensive molecular profiling data with detailed clinical data of SDC patients. Therefore, we performed an integrative analysis combining comprehensive cancer-gene panel along with RNA sequencing (RNA-seq) and analyzed these data in combination with detailed clinical features in a cohort of SDC patients.
Results
Patient characteristics
The study cohort comprised 76 SDC patients who underwent surgical resection between 2005 and 2017 at hospitals participating in the Japan SDC consortium. Nine cases were excluded because of poor DNA quality isolated from the specimens. The demographic and clinical data of the remaining 67 individuals, eight patients were female and 59 were male, are summarized in Table 1. The median age was 62.1 years old and was similar between female and male patients (mean, 59.4 vs. 62.6 years; p = 0.5). The most common location of the primary tumors was the parotid gland (76.1%) followed by the submandibular gland (20.9%). SDC occurred as a malignant component of carcinoma ex PA in twelve cases (17.9%). More than 50% of the patients had stage IV cancer (62.7 %), and had undergone surgery and chemotherapy/radiotherapy (56.7%). Cancer recurrence was observed in 73.1% of the patients after the initial treatment during the median follow-up time of 40 months. CAB treatment was administered to a total of 27 patients (40.3%).
Mutational profile of SDC by cancer gene panel sequencing
We used the TOP cancer gene panel44 to evaluate somatic single nucleotide variations (SNVs) and insertions/deletions (indels) for 464 genes in the panel, and to determine tumor mutation burden (TMB) and copy number variations. We identified frequent oncogenic mutations within the genes for the receptor tyrosine kinase (RTK)/MAPK signaling pathway including 24 cases with HRAS activating mutations, 7 cases with ERBB2 mutations, 5 cases with BRAF mutations, 4 cases with MAP2K4 mutations, and 13 cases with NF1 mutations (Fig. 1a). TP53 was altered in approximately half of the cases. Copy number analysis further identified six cases with ERBB2 amplification. In total, oncogenic mutations in RTK genes or genes in the MAPK pathway were present in 55 of the cases (82.1%). The list of all mutations found in our cohort is shown as Supplementary Data 1. We included the previous study results by Dalin et al.31 to indicate the mutation frequency of individual genes (Supplementary Fig. 1).

a Frequently mutated genes with color coding of their alteration status for each tumor. The gender, age, stage, primary site, tumor origin (de novo or ex pleomorphic adenoma), and tumor mutation burden (TMB) are shown at the top. b Schematic diagram depicting tyrosine kinase fusions. FGFR2, RET, and NTRK3 fusions identified by RNA-seq are shown with their functional domains. The FGFR2 gene (NM_000141) was disrupted downstream of exon 17 and was subsequently ligated upstream of either exon 2 of CCDC6 (NM_005436), exon 3 of KIAA1217 (NM_019590), or exon 10 of NOL4 (NM_003787). Exon 15 of NTRK3 gene (NM_002530) was ligated to exon 5 of ETV6 (NM_001987). The tyrosine kinase domain (TK) was maintained in all identified fusions. CC, coiled-coil domain; HLH, helix-loop-helix domain. c Driver mutations identified in tumors of the parotid and submandibular glands. d Comparison of the average age (left) and the highest variant allele frequency (right) of driver mutation-positive and -negative cases. The elements of boxplots are defined as follows: center line, median; lower bound of box, lower quartile; upper bound of box, upper quartile; lower whiskers, minimum value; upper whisker, maximum value.
In addition, the PI3K pathway was dysregulated in 38 tumors (56.7%) and mutations in PIK3CA (29 cases), PIK3R1 (5 cases), PTEN (7 cases) and AKT1 (1 case) were found in a mutually exclusive manner. HRAS mutations were significantly concurrent with PIK3CA mutations (83.3%). Other gene mutation identified in multiple cases were ZFHX3 (8 cases), FOXA1 (6 cases), ARID1A (6 cases), and KMT2A/C/D (5, 9, 3 cases, respectively). The average TMB was 2.3 mut/Mb and two cases (2.7%) exhibited hypermutation (>10 mut/Mb).
Detection of fusion genes in SDC by RNA-seq
RNA-seq identified four cases with tyrosine kinase fusion genes (FGFR2-CCDC6, FGFR2-KIAA1217, FGFR2-NOL4, and ETV6-NTRK3) and six cases with other fusions (CHCHD7-PLAG1, FGFR1-PLAG1, MAPK14-ZFAND3, NFIX-MAST1, SLC45A3-ELK4, TMCC1-PLXND1, and ERBB2-CTTN) (Fig. 1b and Supplementary Fig. 2).
In total, driver oncogenes, which we defined as oncogenic mutations in receptor tyrosine kinase (RTK) genes or genes in the MAPK pathway, were identified in 55 cases (82.1%).
mRNA expression analysis in SDC
The expression profile of ERBB2 established by RNA-seq was compared with the copy number data obtained from the TOP panels, protein expression by immunohistochemistry, and its copy number determined by FISH, and resulted in good concordance among the four assays (Supplementary Fig. 3). Thus, RNA-seq analysis is likely robust for the evaluation of ERBB2 aberrations. Similarly, the expression of AR (p = 7 × 10−4, low vs. high, Student’s t test) and EGFR (p = 0.02, 3+ vs. the others, Student’s t test) both correlated to the results obtained by immunohistochemical analysis. In contrast, CD274 encoding PD-L1 was more abundantly expressed in driver-negative compared with driver-positive tumors (p = 0.01, Student’s t test).
Association of genetic profiles with clinicopathological features
Approximately 40% of the tumors in the parotid gland harbored HRAS mutations and 40% of the submandibular tumors were positive for ERBB2 gene alterations (Fig. 1c). All HRAS-mutant tumors (23 cases) were de novo PDC, whereas 50% (6/12) of the tumors from ex PA had ERBB2 gene alterations.
To evaluate whether the driver mutations were the trunk ones, the variant allele frequency (VAF) of the driver genes was compared with the highest VAF among all mutated genes in each case. For the cases positive for driver mutations of SNVs and indels, the average ratio of driver VAF to the highest VAF was 75.5 (95% CI = 12.6–134), suggesting that the driver mutations are the founding ones in SDC (Supplementary Fig. 4).
There was no significant difference in the highest VAF between the driver-positive and -negative cases (an average of 36.4% vs. 44.8%, respectively, p = 0.05, Student’s t test) (Fig. 1d). The mean age of the driver-positive cases was slightly older compared with that of driver-negative cases (63.5 years old vs. 55.2 years old, respectively, p < 0.05, Student’s t test) (Fig. 1d). All clinicopathological features are shown as Supplementary Data 2.
Transcriptional profiles of SDC
We conducted a k-means cluster analysis of the tumors based on the gene expression profiles from RNA-seq data, and compared the clusters with clinicopathological features or gene mutational profiles (Fig. 2a). Clustering using the top 100 genes with the most variation of expression divided the cohort into three groups: cluster 1 (the left cluster in Fig. 2a), cluster 2 (middle) and cluster 3 (right) (Supplementary Data 3). Female patients were enriched in cluster 2 (p < 0.01, cluster 2 vs. the others, Fisher’s exact test), whereas male patients were enriched in cluster 3 (p < 0.05, cluster 3 vs. the others, Fisher’s exact test). There was no significant difference in progression-free survival (PFS) among the clusters (Fig. 2b). The median follow-up time was 40.3 months (range, 2.4–135 months) and the median PFS was 16.4, 11, 23.6 months for cluster 1–3, respectively (95% CI = 16–42.8 months, 6.6–41.1 months and 17.7–30.3 months). The median OS was 40.5, 36.5 and 46.5 months for cluster 1–3, respectively (95% CI = 38.7–64.2 months, 26.2–57.8 months and 37.5–55.6 months).

a K-means clustering analysis conducted with RNA-seq data. Clinical information (gender, age, primary site, lymph node involvement, and mutational status) is shown in the upper part. Fisher’s test identified factors associated with either group stratified by k-means clustering. b Kaplan–Meier curves of recurrence-free survival in the cohort stratified by k-means clustering as clusters 1–3. c GSEA results with the indicated gene sets differentially enriched among clusters defined by k-means clustering. Full GSEA results can be found in Supplementary Data 4.
Gene set enrichment analysis (GSEA) among the three clusters identified 2, 9 and 12 gene sets were upregulated in cluster 1–3, respectively (q < 0.01, one cluster vs. the others). Among these gene sets, “E2F_TARGETS” and “HALLMARK_INTERFERON_ RESPONSE” were enriched in cluster 2 while “HALLMARK_OXIDATIVE_PHOSPHORYLATION” was enriched in cluster 3 and “HALLMARK_EPITHELIAL_MESENCHYMAL_TRANSITION” was enriched in cluster 1. The data are bulk transcriptomes and the three clusters might well reflect the microenvironment composition (Fig. 2c and Supplementary Data 4). Expression of salivary gland marker genes including HTN1/3 and PRB1/2/3/4 encoding salivary glycoproteins was elevated specifically in cluster 1, suggesting salivary differentiation in the tumors of cluster 1 (Supplementary Data 3).
Risk assessment for survival after treatment of SDC
Risk assessment was conducted using RNA-seq data from 61 cases. The median follow-up time was 40.5 months (range: 10–135 months) and median OS was 40.5 months (95% confidence interval (CI) = 40.3–54.6 months). For the OS analysis, genes which satisfy the following conditions were selected: gene expression is >0 in more than 80% (49/61) of total samples and sd >1. Univariate Cox proportional hazards regression analysis showed a significant correlation between 9 genes and OS (p ≤ 2 × 10−3).
To generate an OS prognostic signature, these 9 genes were used for forward conditional stepwise regression with multivariable Cox analysis in the cohort. This procedure established a prognostic model with four genes including ADAMTS1, DSC1, RNF39, and IGLL5. We constructed a risk score with the regression coefficients from this model and performed manual selection with a suitable threshold at the 75th percentile, which was −0.6 (Fig. 3a). High-risk patients, as defined by the four-gene signature-based risk score, had significantly worse OS (p = 5 × 10−7, log-rank test) in the cohort (Fig. 3b).

a Four-gene expression and risk score distribution in the cohort by z-score. Red and light blue colors indicate higher and lower expression, respectively. Risk scores for all patients are plotted in ascending order and marked as low-risk (blue) or high-risk (red), as divided by the threshold (vertical black line). The risk score threshold was −0.6. b Kaplan–Meier curves of overall survival in the cohort stratified by the four-gene prognostic signature for high- and low-risk groups. The log-rank test was used to evaluate p values. c Heatmap of the top 200 differentially expressed genes between patients at high or low-risk, with red and blue indicating higher and lower expression, respectively. d Significantly different gene sets identified by GSEA as differentially overexpressed or underexpressed in high-risk tumors. Supplementary Data 4 presents the full GSEA results. NES normalized enrichment score, FDR false discovery rate.
To understand the biology underlying the high-risk tumors, we identified the top 100 significantly overexpressed genes and the top 100 underexpressed genes in the high-risk tumors (Fig. 3c and Supplementary Data 3). There were no differing clinical features between the low- and high-risk groups. However, TP53 mutations were significantly enriched in the high-risk group as determined by Fisher’s exact test (p < 0.01) (Supplementary Fig. 5). The gene sets related to cell proliferation, such as “G2M_CHECKPOINT” and “E2F_TARGETS,” were significantly enriched in the high-risk tumors, whereas gene sets including “MYOGENESIS” and “TNFA_SIGNALING_VIA_NFKB” were enriched in the low-risk group (Fig. 3d and Supplementary Data 4).
Using multivariable Cox analysis, the risk score for OS remained significant (HR = 5.62, p = 7.7 × 10−3) in the cohort independent of gender, age, primary site, response to first-line treatment, and gene mutations (Table 2). Additional risk factors for OS by univariate analysis included response to first-line treatment (SD; HR = 17.2, p = 6.5 × 10−4, PD; HR = 7.94, p = 2.1 × 10−4), PTEN mutations (HR = 2.51, p = 0.02), TP53 mutations (HR = 2.74, p = 3.0 × 10−3), the presence of fusion genes (HR = 2.6, p = 0.04), and the N2b/N2c of lymph node status (HR = 2.31, p = 0.01); however, none of these factors were significantly different in the multivariate analysis.
Risk assessment for CAB treatment
Biomarkers related to the response to CAB were derived from the mRNA expression data of 27 cases with CAB treatment. The median follow-up time was 22.2 months (range, 4.2–61.4 months) and the median PFS for CAB treatment was 9.9 months (95% CI = 6.7–13.0 months). Genes which satisfy the following conditions were selected for the analysis: the highest gene expression among the samples is >50. Univariate Cox proportional hazards regression analysis revealed 14 genes that were significantly correlated with PFS (p ≤ 2 × 10−3).
Fourteen genes were used to generate a prognostic signature using a forward conditional stepwise regression with multivariable Cox analysis for the cohort. This procedure established a prognostic model with two genes, CD3E and LDB3. We constructed a risk score with the regression coefficients from this model and conducted a manual selection of a suitable threshold at the 75th percentile (Fig. 4a). High-risk patients, as defined by the two-gene signature-based risk score, had a significantly worse PFS (p = 0.03, log-rank test) compared with the rest of the cohort (Fig. 4b). Neither the AR-V7 variant expression nor total AR expression correlated with patient response to CAB treatment (Fig. 4c and Supplementary Fig. 6).

a Two-gene expression and risk score distribution in the cohort by z-score. Red and light blue indicate higher and lower expression, respectively. Risk scores for all patients are plotted in ascending order and marked as low-risk (blue) or high-risk (red), as divided by the threshold (vertical black line). The risk score threshold was −4.0. b Kaplan–Meier curves of recurrence-free survival in the cohort stratified by the two-gene predictive signature in patients at high or low-risk. The log-rank test was used to evaluate p values. c Kaplan–Meier curves representing progression-free survival (PFS) in the cohort stratified by AR and AR-V7 expression. d Heatmap of the top 200 differentially expressed genes between patients at high or low-risk with red and blue indicating higher and lower expression, respectively. e Significantly different gene sets identified by GSEA as differentially overexpressed or underexpressed in high-risk tumors. Supplementary Data 4 presents the full GSEA results. NES normalized enrichment score, FDR false discovery rate.
We repeated the analysis of the differentially expressed genes using the set of patients defined by the two-gene signature to further understand the biology of high-risk tumors (Fig. 4d and Supplementary Data 3). Similar to the OS prognostic signature analyses, gene sets including “MYC_TARGETS_V1,” “FATTY_ACID_METABOLISM” and “ANDROGEN_RESPONSE” were significantly enriched in the high-risk tumors, whereas gene sets including “ALLOGRAFT_REJECTION,” “INTERFERON_GAMMA_RESPONSE” and “INFLAMMATORY_RESPONSE” were enriched in the low-risk group (Fig. 4e and Supplementary Data 4).
Immunohistochemistry of ADAMTS1, DSC1, RNF39, CD3 and LDB3 was performed to evaluate protein expression in tumor cells (Supplementary Fig. 7). The concordance between the FPKM and the protein expression intensity or the ratio of protein expression positive cells was not observed in respective genes (Supplementary Data 5).
Discussion
This is the first study to identify predictive biomarkers for CAB treatment and prognostic biomarkers of SDC using molecular profiling with next-generation sequencing combined with clinicopathological data. Our analysis identified driver mutations in the RTK/MAPK signaling pathway in 55 out of 67 tumors (82.1%). Given that the driver mutations were truncal, SDC likely depends on these driver genes for growth. There was no difference in the highest VAF of gene mutations between driver mutation-positive and -negative cases; therefore, the latter cases were the true negatives rather than the false negatives caused by low tumor content. Previous comprehensive genomic analysis of 31 SDC cases also revealed driver mutations in ~74% of the cases31. Our RNA-seq analysis identified RTK fusions and ERBB2 overexpression in multiple cases. Furthermore, we precisely depicted the involvement of genes that relate to histone modification, such as KMT2A/C/D, and to transcription factors, ZFHX3 and FOXA1, whose expression was identified as a favorable prognosis in our previous study45. The TMB of SDC was lower than those found in other solid tumors, which is consistent with a previous study31. Further analysis with whole-genome sequencing and long-read sequencing may be useful in deciphering the transformation mechanism of driver-negative SDC.
The utility of RNA-seq was demonstrated by the detection of fusion genes and through expression analyses. The presence of fusion genes was an independent marker for poor OS (HR = 2.6, p = 0.04) in this study. Especially, we identified targetable FGFR1/2 and NTRK3 fusions in multiple cases. It is promising that there has been recent developments and approval of targeted therapies for cholangiocarcinomas with FGFR2 fusions and for solid tumors with NTRK fusions46,47,48,49. Evaluation of mRNA expression with RNA-seq was well-correlated with the immunohistochemical staining for HER2, AR, and EGFR. The expression of CD274 was upregulated in the driver-negative group suggesting that PD-L1 inhibitors may represent a viable treatment option for these patients.
The two-gene signature and the expression of CD3E and LDB3, but not AR, successfully stratified patients by outcome to CAB treatment. CD3E encodes CD3-epsilon polypeptide which forms the T-cell receptor-CD3 complex and plays an important role in coupling antigen recognition to several intracellular signal transduction pathways50. The immunohistochemistry of CD3 confirmed that the CD3 expression was observed in lymphocytes but tumor cells suggesting CD3E RNA expression probably reflect the tumor immune contexture. The association of infiltrating CD8 + cytotoxic T cells, as well as that of CD3 + T cells, with favorable prognosis has been widely demonstrated in cancers with different histological features and anatomical location, in both primary and metastatic settings, including melanoma, most squamous cell carcinomas, large cell lung cancer and several types of adenocarcinoma51,52,53,54. The epsilon polypeptide is also involved in T-cell development. LDB3 encodes a PDZ domain-containing adapter protein in striated muscle to couple protein kinase C-mediated signaling through its LIM domains to the cytoskeleton55. What our analysis suggested was that the T-cell infiltration may be a predictive maker for CAB treatment and it was consistent with the previous studies which investigated the immune microenvironment and neoantigen landscape in SDC34,36.
Neither CD3E and LDB3 has been reported to be involved in the AR signaling pathway or the metabolism of dihydrotestosterone, a potent agonist of AR. Our GSEA analysis comparing high- and low-risk groups against CAB treatment revealed that the genes involved in androgen pathways are enriched in the low-risk group. This suggests that hormone signal dependency may be another predictive biomarker of the treatment.
We also defined a four-gene set (ADAMTS1, DSC1, RNF39, and IGLL5) for predicting aggressive SDC. This gene set may act as a valuable predictive biomarker to stratify patients who may benefit from additional systemic or radiation therapies. These four genes are related to multiple processes, such as inflammation and cell adhesion.
ADAMTS1 is a well-characterized matrix metalloproteinase-related enzyme. However, mammalian cell studies report conflicting roles of ADAMTS1 in cancer development56, and different mechanisms have been linked to its protumor/antitumor activities, including the regulation of angiogenesis, lymphangiogenesis, cell proliferation, adhesion, migration, and degradation or interactions with extracellular matrix components. For example, ADAMTS1 is downregulated in prostate and colorectal cancers by promoter hypermethylation57, but is overexpressed in pancreatic cancer58, fibrosarcoma59, and renal cell carcinoma60. Presently, the role of ADAMTS1 in SDC progression remains unclear.
DSC1 is a desmosomal cadherin that has an important role in cell–cell adhesion61. These cadherins include DSC1–3 and four desmogleins. DSC1 was reported to be involved in progression, metastatic potential, and cell adhesion processes in breast cancer62. Currently, little is known regarding the involvement of RNF39 and IGLL5 in tumorigenesis.
The GSEA analyses identified upregulated expression of genes involved in the G2/M checkpoint, cell cycle-related targets of E2F transcription factors, and epithelial–mesenchymal transition (EMT) in the high-risk group, whereas upregulated genes in the low-risk group were involved in myogenic differentiation. During EMT, epithelial cells lose their cell polarity and cell–cell adhesion, and gain migratory and invasive properties to become mesenchymal stem cells. The enriched gene set related to the cell cycle and EMT may indicate the capability of rapid cell growth, high invasion, and migration of aggressive SDC. Upregulated ADAMTS1 and DSC1 expression may have an important role in the survival and invasion of SDC cells, and may explain their association in patients with poor prognosis. Considering that mutations in TP53 or PTEN are also independent markers for poor prognosis, this combination of genetic and epigenetic changes may promote the progression and recurrence of SDC.
The discordance between protein expression and RNA-seq data is because the sensitivity of RNA-seq to quantify RNA expression might be higher compared with immunohistochemistry to quantify protein expression. In fact, the protein expression levels of DSC1, LDB3 and RNF39 in most samples were too low to be detected by immunohistochemistry while ADAMTS1 expression was moderately positive in all samples. The CD3 protein expression was observed in lymphocytes but tumor cells suggesting CD3E RNA expression probably reflect the tumor immune contexture. Although the concordance was not observed in these genes, we are confident that our RNA-seq is suitable for the evaluation of RNA expression as good correlations were observed in HER2, AR and EGFR expression (Supplementary Fig. 3). RNA-seq may be preferable method to evaluate expression of genes whose protein level are low or when the immunohistochemical analysis is not well optimized.
A major limitation of this study is that this a retrospective study without area under the curve assessment supporting the specificity of the biomarker signature. Therefore, prospective studies of independent cohorts should be conducted to validate the proof of concept. Another limitation is about TOP panel that it can’t detect all the mutations exiting in the cancer and doesn’t necessarily elucidate all tumor features. Therefore, comprehensive assays such as whole-genome sequencing and genome wide methylation analysis are needed to identify additional novel biomarkers.
In conclusion, our discoveries may have the potential for application in a clinical setting. Expression profiling may directly predict the efficacy of CAB treatment and the prognosis of SDC. Our genomic and transcriptomic analyses highlight the importance of precise tumor profiling to provide increased treatment options for SDC patients.
Methods
Study design and patient specimens
The study cohort consisted of 76 SDC patients who underwent surgical resection between October 2005 and September 2017 at hospitals in the Japan SDC consortium, including the International University of Health and Welfare, Mita Hospital, Tokyo Medical University Hospital, Tokyo Medical University Hachioji Medical Center, Hokkaido University, Niigata Cancer Center Hospital, Keio University, and Tokai University. Nine patients were excluded because of poor quality DNA and the analysis was conducted in the remaining 67 patients. Several cases were previously reported by Otsuka et al.9, Takase et al.16, Masubuchi et al.17, Shimura et al.41, Fushimi et al.20, Takahashi et al.29, and Okada et al.63. A board-certified pathologist (TN) specializing in salivary gland tumors reviewed the SDC histological features based on the criteria of the current World Health Organization classification. Fresh frozen specimens or formalin-fixed paraffin-embedded (FFPE) of surgically resected tumors were obtained from all patients. Approval for this study was obtained from the Ethics Committee of National Cancer Center (No. 2019-271), International University of Health and Welfare, Mita Hospital (No. 5-19-6), Tokyo Medical University (No. SH2563), Faculty of Medicine and Graduate School of Medicine, Hokkaido University (No. 017-0487), Keio University School of Medicine (No. 20120083), School of Medicine, Tokai University (No. 20R-204), Tokyo Medical University Hachioji Medical Center (No. SH2563) and Niigata Cancer Center Hospital (No. 2021-300). All subjects provided written informed consent, except for those who could not be reached because of loss of follow-up or death at registration. In these cases, the Institutional Review Board at each participating institution granted permission for the existing tissue samples to be used for research purposes. No samples from the patients who had opted out of participation were used in this study.
Immunohistochemistry and fluorescence in-situ hybridization (FISH)
Immunohistochemistry and FISH were conducted as previously described16,41. Briefly, FFPE tumor tissues were cut into 3 μm-thick sections, and a polymer-based detection system with heat-mediated antigen retrieval was used with primary antibodies against HER2 (Polyclonal, cat# A0485, Agilent Technologies, Santa Clara, CA) with 1:400 dilution, AR (clone AR441, cat# PM109AA, BIOCARE Medical LLC, CA), EGFR (clone 31G7, cat# 423701, NICHIREI BIOSCIENCES INC, Tokyo, Japan) in undiluted form, PD-L1 (clone 22C3, cat# M3653, Agilent Technologies) with 1:50 dilution, ADAMTS1 (cat# 12749-1-AP, Proteintech, Rosemont, IL) with 1:50 dilution, DSC1(clone A-4, cat# sc-398590, Santa Cruz Biotechnology, Dallas, TX) with 1:100 dilution, RNF39 (cat# HPA047115, Atlas Antibodies, Bromma, Sweden) with 1:200 dilution, CD3 (clone SP-7, cat# 413601, Nichirei Biosciences, Tokyo, Japan) with 1:100 dilution, and LDB3 (cat# 11004-1-AP, Proteintech) with 1:100 dilution. Diaminobenzidine was used to detect antigen-antibody reactions. Appropriate positive and negative controls were applied for all conditions. ERBB2 amplification was evaluated using PathVysion HER-2 DNA Probe Kit (cat# 02J01-031, Abbott Molecular, Des Plaines, IL). For the PD-L1 IHC 22C3 pharmDx assay, the slides were stained using a Dako Autostainer Link 48 platform with an automated staining protocol and the pathologists A. U. and T. H. used a light microscope to score the percentage of positive tumor cells in each sample.
Evaluation of HER2 status
HER2 positivity was defined as either immunohistochemically 3+ or ERBB2 amplification according to the American Society of Clinical Oncology/College of American Pathologists guidelines for breast cancer64. In Her2 Immunohistochemistry, 3+ stain was defined as a circumferential membrane staining that was complete and intense and exhibited >10% frequency of tumor cells. For ERBB2 copy number prediction with FISH analysis, 100 non-overlapping, intact interphase tumor nuclei stained with 4′,6-diamidino-2-phenylindole (DAPI) were evaluated. The ERBB2 gene (red signal) and CEP17 (green signal) copy numbers in each nucleus were assessed. ERBB2 amplification is annotated when the average ERBB2/CEP17 ratio was ≥2.0 in all nuclei or when the ERBB2 signals formed a tight gene cluster.
Assessment of immunohistochemistry of AR, EGFR, ADAMTS1, DSC1, RNF39, CD3 and LDB3
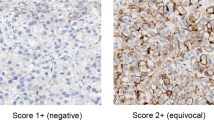
A case was considered positive for AR when ≥20% of tumor cell nuclei exhibited strong staining. The percentage of EGFR immunostaining cells was scored from 0 to 3+ as follows: 0, 0%; 1+, 1–10%; 2+, 11–30%; and 3+, >30%. Score 3+ was considered positive for EGFR. For ADAMTS1, DSC1, RNF39, CD3 and LDB3, staining intensity and ratio of positive cells were assessed. The staining intensity was scored from 0 to 3+ as follows: 0, negative; 1+, mildly positive; 2+, moderately positive; 3+, strongly positive.
DNA sequencing with the TOP cancer gene panel for mutation call and copy number analysis
Fresh frozen or FFPE SDC specimens were analyzed with TOP panel version 344. This evaluates nucleotide variants and insertions/deletions for 464 genes to calculate TMB and to infer copy number variation. Genomic DNA was extracted from FFPE samples using the GeneRead DNA FFPE Kit (Qiagen, Hilden, Germany) and 500 ng of each DNA sample was used for target fragment enrichment with an Agilent Kit (v6) (Agilent Technologies). Next-generation sequencing was conducted with a HiSeq2500 (Illumina) using a paired-end option and sequencing reads were independently aligned to the human reference genome (hg38) using BWA65, Bowtie2 (http://bowtie-bio.sourceforge.net/bowtie2/index.shtml), and NovoAlign (http://www.novocraft.com/products/novoalign/). Somatic mutations were called using MuTect (http://www.broadinstitute.org/cancer/cga/mutect), SomaticIndelDetector (http://www.broadinstitute.org/cancer/cga/node/87), and VarScan (http://varscan.sourceforge.net). The exclusion criteria for mutation analysis were (i) the read depth was <20 or the VAF was <0.1; (ii) mutations were supported by only one strand of the genome; or (iii) they were SNP in either the 1000 Genomes Project dataset (http://www.internationalgenome.org/) or our in-house database. Gene mutations were annotated by SnpEff (http://snpeff.sourceforge.net). Copy number was evaluated using our in-house pipeline to calculate the logR ratio (LRR) as follows: (i) used selected homozygous (VAF, ≤ 0.05 or ≥0.95) or a heterozygous (VAF, 0.4–0.6) SNP in the 1000 Genomes Project database; (ii) normal and tumor read depths at the selected SNP position were counted and adjusted based on GþC percentage around 100 bp from the position66; (iii) calculated the LRR = log2 (ti/ni), where ni and ti are the normal and tumor-adjusted depths at the SNP position; and (iv) each representative LRR was determined by the median of a moving window (1 Mb) around the SNP position. The values of the LRR of the copy number of the major allele and the minor allele were determined for every region of the entire genome. The p values for the gain or loss of respective genomic regions were determined from the LRRs with a permutation test (100,000 iterations) according to the algorithm used in GISTIC67, and q values were calculated using the R package q value (http://github.com/jdstorey/qvalue).
Transcriptome sequencing, expression analysis, and detection of fusion genes and exon skipping
Total RNA was extracted from fresh, frozen, or FFPE samples using RNA-Bee (Tel-Test Inc., Gainesville, FL) and treated with DNase I (Thermo Fisher Scientific, Waltham, MA). The RNA-seq library was prepared with a TruSeq RNA Access Library Prep Kit (Illumina, San Diego, CA). Sequencing was conducted from both ends of each cluster using a HiSeq 2500 (Illumina). RNA-seq was aligned to hg19 using TopHat (v2.0.9; https://ccb.jhu.edu/software/tophat/index.shtml). Gene expression was quantified using Cufflinks (v2.1.1; http://cole-trapnell-lab.github.io/cufflinks) and gene fusions were explored using the deFuse pipeline (https://bitbucket.org/dranew/defuse). The fusion genes which matched the following criteria were selected: fusion genes reported in COSMIC or fusions genes of kinase in the RTK/MAPK signaling pathway and the fusion split reads were >10. Exon skipping was analyzed using an in-house pipeline developed in the previous study68 according to the following steps: (i) aligned RNA-seq reads to hg38 and the NCBI reference sequence (RefSeq) using Burrows–Wheeler Aligner and Bowtie2; (ii) detected skipped exons in the mapped RefSeq data; (iii) created virtual transcriptome sequences dynamically; (iv) aligned RNA-seq reads to candidate transcriptome sequences; and (v) identified exon skipping candidates based on reads with a breakpoint.
Sanger sequencing
For capillary sequencing with a 3130xl Genetic Analyzer (Thermo Fisher Scientific), PCR products prepared from 10 ng of template cDNA were used to amplify FGFR2-CCDC6, FGFR2-KIAA1217, FGFR2-NOL4, ETV6-NTRK3, MAPK14-ZFAND3, NFIX-MAST1, SLC45A3-ELK4, TMCC1-PLXND1, and ERBB2-CTTN by GoTaq G2 Hot Start Master Mix Green (Promega, Madison, WI), in accordance with the manufacturer’s instructions with the following primers: 5′-GCAGTTGGTAGAAGACTTGGATCG-3′ and 5′-GCAAGGGTTTCTTTCTCCTTCTGC-3′ for FGFR2-CCDC6, 5′-GCAGTTGGTAGAAGACTTGGATCG-3′ and 5′-GACGTCTCTGATAAATGCTCGACC-3′ for FGFR2-KIAA1217, 5′-GCAGTTGGTAGAAGACTTGGATCG-3′ and 5′-ACAGCTGATGTTGAGTAAGTGGCC-3′ for FGFR2-NOL4, 5′-GAACCACATCATGGTCTCTGTCTC-3′ and 5′-CAGGAAGACCTTTCCAAAGGCTC-3′ for ETV6-NTRK3, 5′-GAACCTACAGAGAACTGCGGTTAC-3′ and 5′-TACTTGGAGCGGAATCATCGTCTG-3′ for MAPK14-ZFAND3, 5′-GCCACATCACATTGGAGTCACAATC-3′ and 5′-CAGCGCTCCAATATTCTTCAGCAG-3′ for NFIX-MAST1, 5′-TTCACCTTCTCAGCCCTGCAGATC-3′ and 5′-TTCTGCAGGAGCTGAAGAAGGAAC-3′ for SLC45A3-ELK4, 5′-TGTTCCATCCACAGAGTCTGTGTG-3′ and 5′-ACTCCTGTGTTTCCAACCAGTCTC-3′ for TMCC1-PLXND1, 5′-ATAACACCCACCTCTGCTTCGTG-3′ and 5′-CATACTTCCCGCCGAATCCTTTG-3′ for ERBB2-CTTN.
Signature generation and statistical analysis
The duration of OS for the risk assessment of survival was defined as the period between the beginning of treatment and the date of death from any cause or the last follow-up. For the OS analysis, genes which satisfy the following conditions were selected: gene expression is >0 in more than 80% (49/61) of total samples and sd >1. After this initial filtering, the p value was calculated and nine genes were p ≤ 0.002 and further analyzed for forward conditional stepwise regression with multivariable Cox analysis in the cohort. The duration of PFS for the risk assessment of CAB was defined as the period from the day of initiation of CAB treatment to the day of progressive disease or death. For the PFS analysis of CAB treatment, genes which satisfy the following conditions were selected: the highest gene expression among the samples is >50. After this initial filtering, the p value was calculated and 14 genes were p ≤ 0.002 and further used to construct a predictive model. Candidate genes were fitted in a stepwise multivariate Cox regression analysis to evaluate their relative contribution to survival prediction in the cohort. Genes that correlated with survival were included in the prognostic signature. According to the estimated regression coefficients in multivariate Cox regression analysis, a prognostic risk scores for predicting OS and PFS were calculated as similar to previous studies66. All statistical analyses were conducted using R software (version 3.5.1; https://www.r-project.org/) and relevant packages. Survival analysis and Cox regression analyses were conducted using the “survival” (v2.44.1.1) package. OS and PFS were analyzed using the Kaplan–Meier method and curve differences were evaluated using the log-rank test according to either the risk score or the driver mutation subtypes. GSEA was conducted using Java GSEA software (http://software.broadinstitute.org/gsea/index.jsp) (v2.2.4).
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
We have deposited the raw sequencing data of all new and unpublished DNA and RNA sequencing data presented in this paper under accession number hum0094 in the Japanese Genotype-Phenotype Archive which is hosted by the DNA Data Bank of Japan, under accession number JGAS000534.
Code availability
No unreported custom computer code or algorithm was used to generate the results of this paper. The references of all source codes are included within Materials and Methods.
References
Nagao, T., Licitra, L., Loening, T., Vielh, P. & Williams, M.D. Salivary duct carcinoma in WHO Classification of Head and Neck Tumours, 4th edition (eds l-Naggar, A.K., Chan, J.K.C., Grandis, J.R., Takata, T. & Slootweg, P.J.) 173–174 (IARC, 2017).
Nakaguro, M. et al. Salivary duct carcinoma: Updates in histology, cytology, molecular biology, and treatment. Cancer Cytopathol. 128, 693–703 (2020).
D’Heygere, E., Meulemans, J. & Vander Poorten, V. Salivary duct carcinoma. Curr. Opin. Otolaryngol. Head. Neck Surg. 26, 142–151 (2018).
Boukheris, H., Curtis, R. E., Land, C. E. & Dores, G. M. Incidence of carcinoma of the major salivary glands according to the WHO classification, 1992 to 2006: a population-based study in the United States. Cancer Epidemiol. Biomark. Prev. 18, 2899–2906 (2009).
Tamaki, T. et al. The burden of rare cancer in Japan: application of the RARECARE definition. Cancer Epidemiol. 38, 490–495 (2014).
Jayaprakash, V. et al. Survival rates and prognostic factors for infiltrating salivary duct carcinoma: Analysis of 228 cases from the Surveillance, Epidemiology, and End Results database. Head. Neck 36, 694–701 (2014).
El-Naggar AK, C.J., et al (eds). Salivary duct carcinoma, in WHO Classification of Head and Neck Tumours (ed 4). 173 (IARC, Lyon, France, 2017).
Boon, E. et al. Androgen deprivation therapy for androgen receptor-positive advanced salivary duct carcinoma: A nationwide case series of 35 patients in The Netherlands. Head. Neck 40, 605–613 (2018).
Otsuka, K. et al. Clinical Outcomes and Prognostic Factors for Salivary Duct Carcinoma: A Multi-Institutional Analysis of 141 Patients. Ann. Surg. Oncol. 23, 2038–2045 (2016).
Gilbert, M. R. et al. A 20-Year Review of 75 Cases of Salivary Duct Carcinoma. JAMA Otolaryngol. Head. Neck Surg. 142, 489–495 (2016).
Osborn, V. et al. Characterization, treatment and outcomes of salivary ductal carcinoma using the National Cancer Database. Oral. Oncol. 71, 41–46 (2017).
Williams, M. D. et al. Differential expression of hormonal and growth factor receptors in salivary duct carcinomas: biologic significance and potential role in therapeutic stratification of patients. Am. J. Surg. Pathol. 31, 1645–1652 (2007).
Hosal, A. S., Fan, C., Barnes, L. & Myers, E. N. Salivary duct carcinoma. Otolaryngol. Head. Neck Surg. 129, 720–725 (2003).
Nasser, S. M., Faquin, W. C. & Dayal, Y. Expression of androgen, estrogen, and progesterone receptors in salivary gland tumors. Frequent expression of androgen receptor in a subset of malignant salivary gland tumors. Am. J. Clin. Pathol. 119, 801–806 (2003).
Fan, C. Y., Melhem, M. F., Hosal, A. S., Grandis, J. R. & Barnes, E. L. Expression of androgen receptor, epidermal growth factor receptor, and transforming growth factor alpha in salivary duct carcinoma. Arch. Otolaryngol. Head. Neck Surg. 127, 1075–1079 (2001).
Takase, S. et al. Biomarker immunoprofile in salivary duct carcinomas: clinicopathological and prognostic implications with evaluation of the revised classification. Oncotarget 8, 59023–59035 (2017).
Masubuchi, T. et al. Clinicopathological significance of androgen receptor, HER2, Ki-67 and EGFR expressions in salivary duct carcinoma. Int J. Clin. Oncol. 20, 35–44 (2015).
Lewis, J. E., McKinney, B. C., Weiland, L. H., Ferreiro, J. A. & Olsen, K. D. Salivary duct carcinoma. Clinicopathologic and immunohistochemical review of 26 cases. Cancer 77, 223–230 (1996).
Viscuse, P. V., Price, K. A., Garcia, J. J., Schembri-Wismayer, D. J. & Chintakuntlawar, A. V. First Line Androgen Deprivation Therapy vs. Chemotherapy for Patients With Androgen Receptor Positive Recurrent or Metastatic Salivary Gland Carcinoma-A Retrospective Study. Front Oncol. 9, 701 (2019).
Fushimi, C. et al. A prospective phase II study of combined androgen blockade in patients with androgen receptor-positive metastatic or locally advanced unresectable salivary gland carcinoma. Ann. Oncol. 29, 979–984 (2018).
Locati, L. D. et al. Clinical activity of androgen deprivation therapy in patients with metastatic/relapsed androgen receptor-positive salivary gland cancers. Head. Neck 38, 724–731 (2016).
Uijen, M. J. M. et al. Systemic therapy in the management of recurrent or metastatic salivary duct carcinoma: A systematic review. Cancer Treat. Rev. 89, 102069 (2020).
Antonarakis, E. S. et al. AR-V7 and resistance to enzalutamide and abiraterone in prostate cancer. N. Engl. J. Med. 371, 1028–1038 (2014).
Cappelletti, V. et al. Tailoring treatment of salivary duct carcinoma (SDC) by liquid biopsy: ARv7 expression in circulating tumor cells. Ann. Oncol. 29, 1598–1600 (2018).
Dalin, M.G., Watson, P.A., Ho, A.L. & Morris, L.G. Androgen Receptor Signaling in Salivary Gland Cancer. Cancers (Basel) 9, https://doi.org/10.3390/cancers9020017 (2017).
van Boxtel, W. et al. Prediction of clinical benefit from androgen deprivation therapy in salivary duct carcinoma patients. Int J. Cancer 146, 3196–3206 (2020).
Lassche, G. et al. Predictive and Prognostic Biomarker Identification in a Large Cohort of Androgen Receptor-Positive Salivary Duct Carcinoma Patients Scheduled for Combined Androgen Blockade. Cancers (Basel) 13, https://doi.org/10.3390/cancers13143527 (2021).
Saigusa, N. et al. The Role of the EZH2 and H3K27me3 Expression as a Predictor of Clinical Outcomes in Salivary Duct Carcinoma Patients: A Large-Series Study With Emphasis on the Relevance to the Combined Androgen Blockade and HER2-Targeted Therapy. Front Oncol. 11, 779882 (2021).
Takahashi, H. et al. Phase II Trial of Trastuzumab and Docetaxel in Patients With Human Epidermal Growth Factor Receptor 2-Positive Salivary Duct Carcinoma. J. Clin. Oncol. 37, 125–134 (2019).
Limaye, S. A. et al. Trastuzumab for the treatment of salivary duct carcinoma. Oncologist 18, 294–300 (2013).
Dalin, M. G. et al. Comprehensive Molecular Characterization of Salivary Duct Carcinoma Reveals Actionable Targets and Similarity to Apocrine Breast Cancer. Clin. Cancer Res. 22, 4623–4633 (2016).
Ross, J. S. et al. Comprehensive genomic profiles of metastatic and relapsed salivary gland carcinomas are associated with tumor type and reveal new routes to targeted therapies. Ann. Oncol. 28, 2539–2546 (2017).
Mueller, S.A. et al. Molecular patterns in salivary duct carcinoma identify prognostic subgroups. Mod. Pathol. https://doi.org/10.1038/s41379-020-0576-2 (2020).
Linxweiler, M. et al. The Immune Microenvironment and Neoantigen Landscape of Aggressive Salivary Gland Carcinomas Differ by Subtype. Clin. Cancer Res. 26, 2859–2870 (2020).
Gargano, S. M. et al. Novel therapeutic targets in salivary duct carcinoma uncovered by comprehensive molecular profiling. Cancer Med. 8, 7322–7329 (2019).
Alame, M. et al. The molecular landscape and microenvironment of salivary duct carcinoma reveal new therapeutic opportunities. Theranostics 10, 4383–4394 (2020).
Wang, K. et al. Profiling of 149 Salivary Duct Carcinomas, Carcinoma Ex Pleomorphic Adenomas, and Adenocarcinomas, Not Otherwise Specified Reveals Actionable Genomic Alterations. Clin. Cancer Res. 22, 6061–6068 (2016).
Griffith, C. C., Seethala, R. R., Luvison, A., Miller, M. & Chiosea, S. I. PIK3CA mutations and PTEN loss in salivary duct carcinomas. Am. J. Surg. Pathol. 37, 1201–1207 (2013).
Grunewald, I. et al. Targeted next generation sequencing of parotid gland cancer uncovers genetic heterogeneity. Oncotarget 6, 18224–18237 (2015).
Chiosea, S. I. et al. Molecular characterization of apocrine salivary duct carcinoma. Am. J. Surg. Pathol. 39, 744–752 (2015).
Shimura, T. et al. Prognostic and histogenetic roles of gene alteration and the expression of key potentially actionable targets in salivary duct carcinomas. Oncotarget 9, 1852–1867 (2018).
Kim, Y. et al. Integrative genomic analysis of salivary duct carcinoma. Sci. Rep. 10, 14995 (2020).
Karpinets, T.V. et al. Whole-Genome Sequencing of Common Salivary Gland Carcinomas: Subtype-Restricted and Shared Genetic Alterations. Clin. Cancer Res. https://doi.org/10.1158/1078-0432.CCR-20-4071 (2021).
Kohsaka, S. et al. Comprehensive assay for the molecular profiling of cancer by target enrichment from formalin-fixed paraffin-embedded specimens. Cancer Sci. 110, 1464–1479 (2019).
Urano, M. et al. The high expression of FOXA1 is correlated with a favourable prognosis in salivary duct carcinomas: a study of 142 cases. Histopathology 73, 943–952 (2018).
Abou-Alfa, G. K. et al. Pemigatinib for previously treated, locally advanced or metastatic cholangiocarcinoma: a multicentre, open-label, phase 2 study. Lancet Oncol. 21, 671–684 (2020).
Drilon, A. et al. Efficacy of Larotrectinib in TRK Fusion-Positive Cancers in Adults and Children. N. Engl. J. Med. 378, 731–739 (2018).
Laetsch, T. W. et al. Larotrectinib for paediatric solid tumours harbouring NTRK gene fusions: phase 1 results from a multicentre, open-label, phase 1/2 study. Lancet Oncol. 19, 705–714 (2018).
Doebele, R. C. et al. Entrectinib in patients with advanced or metastatic NTRK fusion-positive solid tumours: integrated analysis of three phase 1-2 trials. Lancet Oncol. 21, 271–282 (2020).
Barber, E. K., Dasgupta, J. D., Schlossman, S. F., Trevillyan, J. M. & Rudd, C. E. The CD4 and CD8 antigens are coupled to a protein-tyrosine kinase (p56lck) that phosphorylates the CD3 complex. Proc. Natl Acad. Sci. USA 86, 3277–3281 (1989).
Galon, J. et al. Type, density, and location of immune cells within human colorectal tumors predict clinical outcome. Science 313, 1960–1964 (2006).
Fridman, W. H., Pages, F., Sautes-Fridman, C. & Galon, J. The immune contexture in human tumours: impact on clinical outcome. Nat. Rev. Cancer 12, 298–306 (2012).
Fridman, W. H., Zitvogel, L., Sautes-Fridman, C. & Kroemer, G. The immune contexture in cancer prognosis and treatment. Nat. Rev. Clin. Oncol. 14, 717–734 (2017).
Bruni, D., Angell, H. K. & Galon, J. The immune contexture and Immunoscore in cancer prognosis and therapeutic efficacy. Nat. Rev. Cancer 20, 662–680 (2020).
Pathak, P. et al. Myopathy associated LDB3 mutation causes Z-disc disassembly and protein aggregation through PKCalpha and TSC2-mTOR downregulation. Commun. Biol. 4, 355 (2021).
Cal, S. & Lopez-Otin, C. ADAMTS proteases and cancer. Matrix Biol. 44-46, 77–85 (2015).
Tan Ide, A., Ricciardelli, C. & Russell, D. L. The metalloproteinase ADAMTS1: a comprehensive review of its role in tumorigenic and metastatic pathways. Int J. Cancer 133, 2263–2276 (2013).
Masui, T. et al. Expression of METH-1 and METH-2 in pancreatic cancer. Clin. Cancer Res. 7, 3437–3443 (2001).
Casal, C. et al. ADAMTS1 contributes to the acquisition of an endothelial-like phenotype in plastic tumor cells. Cancer Res. 70, 4676–4686 (2010).
Wen, Y.C. et al. Melatonin-triggered post-transcriptional and post-translational modifications of ADAMTS1 coordinately retard tumorigenesis and metastasis of renal cell carcinoma. J. Pineal. Res. 69, e12668 (2020).
Faktor, J. et al. Proteomics Identification and Validation of Desmocollin-1 and Catechol-O-Methyltransferase as Proteins Associated with Breast Cancer Cell Migration and Metastasis. Proteomics 19, e1900073 (2019).
Kitajima, Y. New insights into desmosome regulation and pemphigus blistering as a desmosome-remodeling disease. Kaohsiung J. Med. Sci. 29, 1–13 (2013).
Okada, T. et al. Carboplatin and Docetaxel in Patients With Salivary Gland Carcinoma: A Retrospective Study. Vivo 33, 843–853 (2019).
Wolff, A. C. et al. Recommendations for human epidermal growth factor receptor 2 testing in breast cancer: American Society of Clinical Oncology/College of American Pathologists clinical practice guideline update. J. Clin. Oncol. 31, 3997–4013 (2013).
Li, H. & Durbin, R. Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics 25, 1754–1760 (2009).
Kohsaka, S. et al. Identification of Novel CD74-NRG2alpha Fusion From Comprehensive Profiling of Lung Adenocarcinoma in Japanese Never or Light Smokers. J. Thorac. Oncol. 15, 948–961 (2020).
Mermel, C. H. et al. GISTIC2.0 facilitates sensitive and confident localization of the targets of focal somatic copy-number alteration in human cancers. Genome Biol. 12, R41 (2011).
Kohsaka, S. et al. Comprehensive molecular and clinicopathological profiling of desmoid tumours. Eur. J. Cancer 145, 109–120 (2021).
Acknowledgements
The authors would like to thank Y. Yamamoto and A. Maruyama-Shiino for technical assistance. This study was supported by the grants from the Project for Cancer Research And Therapeutic Evolution (P-CREATE) under grant number JP20cm0106502, and the Practical Research for Innovative Cancer Control under grant number JP20ck0106536 from the Japan Agency for Medical Research and Development, AMED. This work was also supported by the JSPS Grants-in-Aid for Scientific Research (C) under grant number 18K09386 and 20K07417.
Author information
Authors and Affiliations
Contributions
S.K., Y.T., and H.M. conceived the project and designed the study. S.K., T.U., and H.M. developed the methodology. S.K. and Y.S. performed the experiments. S.K, T.U., and S.K. analyzed and interpreted the data. Y.T., M.A., M.N., H.H., N.S., S.K., K.T., T.T., H.O., T.K., K.O., H.T., D.K., C.F., T.S., A.S., I.O., T.O., Y.S., Y.I., Y.W., A.S., K.E., Y.S., M.U., Y.H., K.Y, Y.U., T.H., Y.S., T.S., and T.N. provided administrative, technical, or material support. S.K., Y.T., M.A., M.N., T.N., and H.M. wrote and edited the paper with feedback from all authors.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kohsaka, S., Tada, Y., Ando, M. et al. Identification of novel prognostic and predictive biomarkers in salivary duct carcinoma via comprehensive molecular profiling. npj Precis. Onc. 6, 82 (2022). https://doi.org/10.1038/s41698-022-00324-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41698-022-00324-1
