
Abstract
Polygenic risk scores (PRS) for prostate cancer incidence have been proposed to optimize prostate cancer screening. Prediction of lethal prostate cancer is key to any stratified screening program to avoid excessive overdiagnosis. Herein, PRS for incident prostate cancer was evaluated in two population-based cohorts of unscreened middle-aged men linked to cancer and death registries: the Västerbotten Intervention Project (VIP) and the Malmö Diet and Cancer study (MDC). SNP genotypes were measured by genome-wide SNP genotyping by array followed by imputation or genotyping of selected SNPs using mass spectrometry. The ability of PRS to predict lethal prostate cancer was compared to PSA and a commercialized pre-specified model based on four kallikrein markers. The PRS was associated with incident prostate cancer, replicating previously reported relative risks, and was also associated with prostate cancer death. However, unlike PSA, the PRS did not show stronger association with lethal disease: the hazard ratio for prostate cancer incidence vs. prostate cancer metastasis and death was 1.69 vs. 1.65 in VIP and 1.25 vs. 1.25 in MDC. PSA was a much stronger predictor of prostate cancer metastasis or death with an area-under-the-curve of 0.78 versus 0.63 for the PRS. Importantly, addition of PRS to PSA did not contribute additional risk stratification for lethal prostate cancer. We have shown that a PRS that predicts prostate cancer incidence does not have utility above and beyond that of PSA measured at baseline when applied to the clinically relevant endpoint of prostate cancer death. These findings have implications for public health policies for delivery of prostate cancer screening. Focusing polygenic risk scores on clinically significant endpoints such as prostate cancer metastasis or death would likely improve clinical utility.
Similar content being viewed by others

Introduction
Various studies have identified hundreds of common genetic polymorphisms associated with the risk of developing prostate cancer. While each risk variant individually only confers a modest increase in a man’s risk of being diagnosed with prostate cancer, the combined effect can be substantial. By weighting and summing these polymorphisms in a polygenic risk score (PRS), it is possible to identify a subset of men at higher risk of developing prostate cancer. For instance, one study showed that men at the top 1% of the PRS had a 5.7-fold increased risk compared to the population average1. Similar results have been found using other prostate cancer PRS2,3,4,5.
Prostate cancer is generally a very slow-growing disease. The high prevalence of cancer in the autopsy prostate6—over 50% in older men—demonstrates that the vast majority of men who develop prostate cancer never experience symptoms before dying of another cause. The introduction of screening using prostate-specific antigen (PSA) led to widespread overdiagnosis, defined here as detection of cancer that would never have caused morbidity or mortality during the course of a patient’s natural life. It has been estimated that there were 1.3 million more US prostate cancer diagnoses than expected in the first 20 years of clinical use7, with about 1 million men overtreated, that is, undergoing curative therapy of an overdiagnosed cancer.
The use of incident prostate cancer as an endpoint for PRS studies will include overdiagnosed cancers. It therefore remains an open question whether PRS based on such endpoints will reduce overdiagnosis. To aid decisions about early detection of clinically significant disease, we need to focus screening efforts on men at high risk of lethal disease using endpoints of distant metastasis or death from prostate cancer. We have studied molecular predictors of prostate cancer mortality in blood collected at baseline in two large, well-annotated, and carefully ascertained population-based epidemiologic cohort studies of 55,300 Swedish men who were not subject to prostate cancer screening and were followed for 20 years8,9. Combined, there were 4001 incident cases of prostate cancer resulting in 679 prostate cancer deaths or distant metastasis in these cohorts. Here, we apply a PRS1 to these cohorts to determine whether it is predictive of prostate cancer death either alone or above and beyond blood markers collected many years before prostate cancer was diagnosed8,9: PSA or the 4Kscore, a commercially available pre-specified model based on four kallikrein markers used to inform biopsy decision-making in men with elevated PSA10.
Results
Assay design for PRS
We took two distinct strategies to measure the SNPs from the PRS. In the Malmö Diet and Cancer study (MDC), we matched the SNPs reported in the PRS1 to GWAS data previously imputed to SNPs in the 1000 Genomes reference panel11 and were able to match 145 out of 146 SNPs. In the Västerbotten Intervention Project (VIP) cohort, we aimed to genotype all 145 SNPs using a mass spectrometry-based approach. For SNPs for which we could not design a well-performing assay, we attempted to genotype proxy SNPs in strong linkage disequilibrium (r2 > 0.8). After two rounds of design and testing, followed by genotyping on the full nested case-control VIP cohort, we obtained high-quality measurements for 125 of the 146 SNPs (or their proxies). For consistency, our primary analyses focus on the risk score using this set of 125 SNPs in both the VIP and MDC cohorts (“Modified” score).
Association of risk score with prostate cancer incidence and outcome
Details on the selection of men from these cohorts and their characteristics are presented (Tables 1 and 2; Supplementary Figs. 1 and 2). Men in the MDC ranged from age 48–73 although approximately half were in their 60 s at the time of blood draw. For the VIP cohort, 5%, 17%, and 78% in the cohort age within one year of 40, 50, and 60, respectively. Median follow-up among controls was 20 years (quartiles 17, 22) in the MDC cohort and 20 years (quartiles 17, 23) in the VIP cohort.
When we tested the modified risk score in our cohorts, we found a significant association with incident diagnosis of any grade prostate cancer with similar hazard ratios to those previously reported1 (p < 0.001; Tables 3 and 4). Similar results were found when we computed the risk score using all 145/146 variants for which we had 1000 Genomes imputation data in the MDC (Tables 3 and 4). We also found that the PRS was significantly associated with the endpoint of distant metastasis or death from prostate cancer (p < 0.001; Table 5). Importantly, however, the PRS could not differentially distinguish higher risk disease (Table 5) with similar estimates irrespective of endpoint; most notably, the hazard ratio for prostate cancer incidence (1.69 in VIP and 1.25 in MDC) was nearly identical to that for prostate cancer metastasis and death (1.65 in VIP and 1.25 in MDC).
Comparison with PSA and 4Kscore
We then went on to investigate the incremental value of this PRS compared to midlife levels of PSA or the 4Kscore8,9. The risk score remained significantly associated with prostate cancer distant metastasis or death after adjusting for either midlife PSA or the 4Kscore (Table 6). However, it did not improve discrimination over total PSA in all men (change in AUC −0.009) or in men with elevated PSA who might consider biopsy (change in AUC 0.006). The risk score did not improve the discrimination of the 4Kscore in men with higher PSA (Table 7). Importantly, the single PSA measurement predicts risk of future distant metastasis or death from prostate cancer far better than the PRS, with an AUC of 0.78 compared to 0.63.
Sensitivity analyses
We assessed the possibility that excluding the modifications we made to the PRACTICAL score due to the genotyping constraints in the VIP cohort affected the performance of the score. We calculated the PRACTICAL risk score, using the 145 out of 146 SNPs that were available in the MDC cohort, and repeated our analyses. Results were consistent with the modified PRACTICAL risk score analysis using both cohorts, with evidence of an improvement in discrimination above and beyond that of total PSA only for the men with PSA ≤ 1 ng/ml at baseline, but no improvement in discrimination for other PSA subgroups above and beyond that of total PSA or the 4Kscore measured at baseline (Supplementary Table 1). As a second sensitivity analysis, we repeated all analyses including the 50 men with PSA > 25 ng/ml at baseline; results were consistent with our main analysis (data not shown).
As numerous other PRSs for incident prostate cancer have recently been proposed3,4,12,13, as a sensitivity analysis we asked if any of these scores would improve the AUC when added to either midlife PSA or the 4KScore. As with the primary PRS we tested, no improvement in was observed by adding in a PRS (Supplementary Table 2).
Evaluation of PRS measured before blood-based biomarker measure
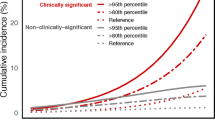
As genomic analyses become more common in the clinic, it is not unlikely that a man already had a baseline profile of common genetic variants measured prior to any screening. We therefore asked whether the PRS could allow pre-screening men to identify those who would not benefit from additional PSA testing. We asked what fraction of the cases who either had distant metastasis or death within 15 years (VIP cohort) or death from prostate cancer within 15 years (MDC cohort) would be found in various upper quantiles of the PRS. While we found that there was an excess of cases identified in the various quantiles of higher risk, it was not enough to be clinically meaningful (Fig. 1). For instance, in the MDC cohort, focusing on individuals in the top half of the PRS distribution would identify only 72% of the lethal prostate cancer cases. In contrast, the top half of the PSA distribution (PSA > 1 ng/ml) accounts for 92% of the lethal prostate cancer cases.

a PRS in MDC. b PSA in MDC. c PRS in VIP age 50. d PSA in VIP age 50. e PRS in VIP age 60. f PSA in VIP age 60.
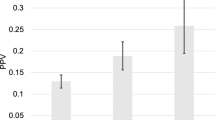
We found a potentially promising increase in AUC of the PRS for men with PSA ≤ 1 ng/ml (change in AUC 0.025), a threshold that has been proposed to determine the frequency of screening or whether to cease screening14,15. However, in a reclassification analysis, among 16,236 men with a PSA ≤ 1 ng/ml, 977 were reclassified to a risk greater than that associated with PSA of ≤1 ng/ml, with a small absolute change in risk. Similarly, among the 34,534 men with a PSA > 1 ng/ml, 1465 were reclassified (Fig. 2), with the change in absolute risk being small. The overall reclassification rate was 5%.

Reclassification shown in a the MDC cohort, b men sampled at age 50 in the VIP cohort, and c men sampled at age 60 in the VIP cohort. The x-axis is total PSA, and the y-axis is the equivalent total PSA based on predicted probability after incorporating the PRACTICAL risk score, for the outcome of prostate cancer metastasis or death (VIP) or prostate cancer death (MDC) within 20 years.
Discussion
We have shown that a PRS1 can not only predict the risk of incident diagnosis of any prostate cancer in independent cohorts but also predict which men may die from prostate cancer. Critically important however, the predictive value of this PRS is similar across increasingly aggressive phenotypes. There was no evidence that it provided additional clinical value to currently used biomarkers in aiding decision about biopsy or screening frequency.
Other PRS have been proposed for prostate cancer2,3,4,5 that were developed using similar statistical approaches and with the same endpoint of incident prostate cancer. The one PRS study that did consider mortality as an endpoint found that the PRS designed for incidence predicts mortality no better than incident cancer4. Unsurprisingly, in our sensitivity analysis, we found that none of these PRS compared favorably with using PSA testing alone. Thus, we consider it unlikely that improved PRS for incident prostate cancer will be sufficient to allow PRS to outperform PSA either singly or in combination.
We note recent proposals that prostate cancer screening strategies could be guided by germline genetic testing for prostate cancer risk. For instance, one group proposing a PRS explicitly recommend in the title of their paper that their marker should “guide screening for aggressive prostate cancer”2. Other groups have proposed16, based on mathematical models, that a “tailored screening program” based on polygenic risk, could “reduce overdiagnosis and improve the benefit-harm tradeoff”. Our data suggest that work to bring such proposals to fruition should focus on predictors of prostate cancer metastasis and death in the population, to avoid overdiagnosis of prostate cancer that is unlikely to reduce quality or length of life. Our findings might also help explain the disappointing results of the BARCODE1 study17, which investigated a strategy where men with a high PRS were sent straight to prostate biopsy. In a pilot study of 1434 men, this resulted in the detection of seven low-grade but no high-grade prostate cancers. We propose that PRSs that show stronger association with aggressive disease than indolent disease will have greater clinical utility.
While current prostate cancer risk SNPs are independent of disease aggressiveness, other yet to be identified SNPs may influence development of aggressive disease. It is interesting to note that these polygenic scores only consider common genetic variants in light of recent work showing that rare coding variants in DNA repair genes predispose to especially aggressive prostate cancer18. Polygenic models that are expanded to include such rare variants, as well as genetic factors influencing outcome independent of risk11 may better predict risk of lethal prostate cancer.
Our analyses are limited to individuals of European ancestry. As the scores tested were developed in this population, this does not detract from our primary findings. Nonetheless, research should examine whether variants associated with risk of overall prostate cancer in men of African ancestry are those also associated with the lethal phenotype. Despite needing to substitute or eliminate some SNPs for technical reasons in the analysis of the VIP cohort, we found in the MDC cohort that this modified 125-SNP score gave results that were strikingly similar to the full 145-SNP score, suggesting that this PRS is robust to slight changes in the SNPs used. As PRSs incorporate larger numbers of common variants with small effect sizes19, it is likely that genome-wide genotyping followed by imputation will be necessary to replicate the scores efficiently in external cohorts.
Our findings should not be generalized to impugn genetic risk scores in general. First, it is likely that a risk score designed for the endpoint of lethal prostate cancer would perform better. Second, our results are only pertinent to clinical utility of this score: the genetic loci, and target genes, implicated by GWAS retain their value for understanding prostate cancer etiology and providing potential targets in terms of chemoprevention or treatment.
The natural history of prostate cancer is that most men will die with rather than of disease. Screening for prostate cancer has led to widespread overtreatment and overdiagnosis. We have demonstrated that a PRS that predicts prostate cancer incidence does not have utility above and beyond that of PSA measured at baseline when applied to the clinically relevant endpoint of prostate cancer death. Therefore, using the PRS to determine which men should be subject to prostate cancer screening will not change the proportion subject to overdiagnosis and overtreatment. Subsequent research should focus on the clinically relevant endpoints of prostate cancer morbidity and mortality.
Methods
Data collection
Data from two large population-based studies were used for these analyses: the MDC and the VIP. These studies were approved by local institutional review boards (Research Ethics Board at Umeå University, number 2009-1436-31, for VIP and the Research Ethics Board at Lund University, numbers 617/2005 and LU 425-02, for MDC) and written informed consent was obtained from each participant in accordance with the principles of the Declaration of Helsinki. In the MDC study, blood samples were taken between 1991 and 1996 from 11,506 men born between 1923 and 1945 and living in Malmö, Sweden. Data on follow-up for prostate cancer diagnosis and death from prostate cancer were collected until December 31, 2014. A nested matched case-control set was selected from the full cohort, with men diagnosed with prostate cancer selected as cases, and controls matched based on age and time of blood draw. Men selected as cases or controls had kallikrein markers measured using their stored blood samples. Kallikrein marker measurements were imputed for those men not selected as cases or controls. Additional details on cohort selection and data collection have previously been published8.
The VIP is an ongoing population-based cohort study initiated in 1985 in which all residents of Västerbotten County, Sweden, are invited to receive a health examination at ages 40, 50, and 60 with blood drawn for cryopreservation. By February 2017, the study included data on 58,398 samples from 43,692 unique men. A nested matched case-control sample was also selected from the VIP cohort based on age and time of blood draw, with cases being defined as those diagnosed with prostate cancer. Kallikrein markers were measured from blood samples for those men selected as cases and controls. Kallikrein marker measurements were imputed for those men not selected as cases or controls. Details on cohort selection, case-control matching and data collection in this cohort have also been previously published9,20.
The original case-control sets were based on cases diagnosed with prostate cancer. As our endpoint of interest was prostate cancer metastasis or death, we re-selected a nested, matched case-control set from both the VIP and MDC cohorts separately. In these two case-control sets, cases were those men who had SNP information and kallikrein measurements available and had distant prostate cancer metastasis or died from prostate cancer. Three controls were identified for each case, with each control being event-free at the time of the matched case metastasis or death and within one year of the case’s age at blood draw.
Laboratory methods
All laboratory analyses were conducted blind to outcome and case-control status. We measured total and free PSA with the dual-label DELFIA ProStatus assay (PerkinElmer, Turku, Finland), calibrated against the World Health Organization (WHO) 96/670 (PSA-WHO) and WHO 68/668 (free PSA-WHO) standards, in previously unthawed cryopreserved heparin anticoagulated blood plasma. Intact PSA and hK2 were measured using F(ab’)2 fragments of the monoclonal capture antibodies to reduce the frequency of nonspecific assay interference and carried out as previously reported21,22.
Genetic methods
For the MDC, all prostate cancer cases were genotyped on a variant of the Illumina Omni2.5 platform, along with a subset of controls who were included in genotyping for other, non-cancer, studies on the MDC. After quality control, individual SNP profiles were phased with ShapeIT and imputed to the 1000 Genomes reference panel using IMPUTE2. SNPs of interest were then selected from the imputed data. For the MDC, SNP genotypes were considered on a continuous scale of 0–2 representing the expected allele dosage for the risk allele. We consider this subset of SNPs, with the same weights, to be representative of the original polygenic score. We used an automated process to match the SNPs in scores from the polygenic score catalog23 for our sensitivity analysis.
For VIP, we selected a proxy SNP on the basis of LD in the “EUR” (European ancestry) population in 1000 Genomes when an assay could not be designed or tested for the original SNP in the PRACTICAL PRS, or removed the SNP from the risk score if that proxy could not be designed or successfully tested and kept the same weights for proxies as those used in the PRS, recognizing that the actual estimate of the weight could be different for the proxy SNP in the original PRACTICAL dataset. The MassArray assays were then performed on all 6920 DNA samples from the nested case-control set of the VIP cohort. After accounting for SNPs for which assays could not be designed, replacing some of them with tags in strong linkage disequilibrium, and quality control of the resulting genotypes, we were able to obtain good quality genotypes for 125 of 138 SNPs attempted. VIP SNPs were coded as 0, 1, or 2 based on the observed count of risk alleles. We then used these SNPs to create a “Modified PRACTICAL” score, which we computed in both the MDC and VIP for consistency.
For VIP, when a genotype was missing we estimated the genotype value as the mean of the genotypes across the other individuals. The PRS was then computed as Σβixi where βi is the log of the per-allele odds ratio for SNP i and xi represents the expected number of risk alleles(0–2) for the SNP present in the individual.
Statistical methods
We began by attempting to replicate the PRACTICAL risk1 scores as reported in the original papers. To replicate the results of the PRACTICAL paper, a case-control dataset matched on any grade prostate cancer was used, and patients in the 99th centile or higher and patients in the 90–99th centiles were compared to those patients in the 25–75th centiles. Centiles of risk were calculated among patients without cancer in the full population data. Our primary analysis contains 125/146 SNPs that were available in both the VIP and MDC. We also conducted sensitivity analysis with a second modified PRACTICAL risk score that contains all SNPs available in the MDC (145/146), including those not available in the VIP; this analysis was conducted in the MDC only.
We then aimed to determine whether any of the PRSs predicted incident diagnosis of any grade prostate cancer, intermediate risk prostate cancer (clinical stage T2 or Gleason grade 7 or PSA ≥ 10 ng/ml and ≤20 ng/ml), high risk prostate cancer (clinical stage ≥ T3 or clinical stage N1 or clinical stage M1 or Gleason grade ≥ 8 or PSA > 20 ng/ml), or prostate cancer metastasis or death. In the VIP cohort, patients may have had multiple samples taken, so we selected the first observation for each patient. The risk scores were imputed separately in the VIP and MDC cohorts for those patients who were missing each score. The scores were standardized within each cohort by dividing by standard deviation. Cox proportional hazards models were created for time to each of the four outcomes, with the hazard ratio representing a 1 standard deviation increase in PRS.
We also assessed whether any of the PRSs added predictiveness above and beyond that based on total PSA or the 4Kscore measured at baseline. The four kallikrein markers were combined as previously described into a pre-defined statistical risk prediction model that gives the risk of ISUP Grade Group ≥ 2 prostate cancer (Gleason score ≥ 7) at prostate biopsy. This model is the same as the commercially available 4Kscore™, a comprehensively evaluated statistical model that is widely used in clinical practice10,24 and was completed and locked-down before application to these cohorts. We assessed the association between the risk score and case status using univariate logistic regression in two case-control cohorts (VIP and MDC) with controls matched on prostate cancer metastasis or death. Two multivariable logistic regression models were then used to test this association adjusting for either total PSA or 4Kscore at baseline. These associations were tested in all men, and in subgroups defined by PSA-level at baseline. Discrimination was calculated as the AUC. Patients with a PSA ≥ 25 ng/ml at baseline (N = 28 in MDC and N = 22 in VIP) were included only in a sensitivity analysis.
To evaluate if the PRS would be useful to pre-screen individuals before PSA testing, we used Lorenz curve analysis. We focused on a binary outcome: distant metastasis or prostate cancer death within 15 years (VIP cohort) or death from prostate cancer within 15 years (MDC cohort). For men in the control group who did not have total PSA and/or PRACTICAL Risk Score measured, these values were imputed using multiple imputation. For the VIP cohort, graphs were created separately for age 50 and age 60 cohorts. There are two versions of the PRACTICAL Risk score available. One version includes 145/146 SNPs in the original PRS1, but includes SNPs that are not available in the VIP cohort, and is therefore only available in the MDC cohort. The second modified version includes 125/146 SNPs, and only includes SNPs available in both MDC and VIP cohorts. For comparison, the Lorenz curves for total PSA in each cohort are also provided. Lorenz curve estimates were calculated in each of the ten imputed datasets. The mean across the ten imputations was used as the central estimate and the standard errors were calculated using Rubin’s rules. All analyses were performed using R 3.6.0.
Reclassification analysis
To assess the clinical utility of the PRS, a reclassification analysis was performed. The full MDC and VIP cohorts were used, including men with imputed marker measurements and risk scores. We used predictive mean matching to impute marker levels and PRSs for men who were included in the VIP and MDC cohorts but were not selected for marker measurement or genotyping. Imputation was performed separately for men aged 40, 50, and 60 in the VIP cohort. Marker values (total PSA, free PSA, intact PSA and hk2), modified PRACTICAL risk and modified Seibert hazard were imputed based on case status for the outcomes of incident any grade prostate cancer diagnosis (n = 213 with both markers and risk scores imputed, n = 60 with only markers imputed and n = 101 with only risk scores imputed in MDC; n = 942 with both markers and risk scores imputed, n = 49 with only markers imputed, n = 482 with only risk scores imputed in VIP), distant metastasis (n = 6 with both risk scores and markers imputed and 38 with only risk scores imputed in VIP) and prostate cancer death (n = 65 with both markers and risk scores imputed, n = 15 with only marker imputed and n = 27 with only risk scores imputed in MDC; n = 13 with both markers and risk scores imputed, n = 24 with risk scores only imputed in VIP). Statistical analyses were performed on the population level utilizing the measured and imputed values combined across ten imputations using Rubin’s rules.
These analyses were performed separately in each cohort, and separately by age in the VIP cohort. Two Cox proportional hazards models for the outcome of time to prostate cancer metastasis or death were created, one containing total PSA or the 4kscore, and the other containing total PSA or the 4kscore and the risk score. Restricted cubic splines were included for total PSA to account for non-linearity. The predicted probability of prostate cancer metastasis or death within 20 years was calculated from each model. We then calculated the number of men for whom a clinical decision to continue or not continue screening would change based on the addition of the risk score—that is, whether adding the risk score to total PSA would raise the risk in a patient with a PSA ≤ 1 ng/ml to a risk equivalent with a PSA > 1 ng/ml, or vice versa.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The datasets generated during and/or analyzed during the current study are not publicly available to maintain compliance with European data protection laws. Anonymized data are available after application to the MDCS Steering Committee (https://www.malmo-kohorter.lu.se/malmo-cohorts).
Code availability
The custom code used to generate these specific anlyses are available from the authors upon request.
References
Schumacher, F. R. et al. Association analyses of more than 140,000 men identify 63 new prostate cancer susceptibility loci. Nat. Genet. 50, 928–936 (2018).
Seibert, T. M. et al. Polygenic hazard score to guide screening for aggressive prostate cancer: development and validation in large scale cohorts. BMJ 360, j5757 (2018).
Mars, N. et al. Polygenic and clinical risk scores and their impact on age at onset and prediction of cardiometabolic diseases and common cancers. Nat. Med. 26, 549–557 (2020).
Shi, Z. et al. Performance of three inherited risk measures for predicting prostate cancer incidence and mortality: a population-based prospective analysis. Eur. Urol. 79, 419–426 (2020).
Kachuri, L. et al. Pan-cancer analysis demonstrates that integrating polygenic risk scores with modifiable risk factors improves risk prediction. Nat. Commun. 11, 6084 (2020).
Bell, K. J. L., Del Mar, C., Wright, G., Dickinson, J. & Glasziou, P. Prevalence of incidental prostate cancer: a systematic review of autopsy studies. Int. J. Cancer 137, 1749–1757 (2015).
Welch, H. G. & Albertsen, P. C. Prostate cancer diagnosis and treatment after the introduction of prostate-specific antigen screening: 1986-2005. J. Natl Cancer Inst. 101, 1325–1329 (2009).
Sjoberg, D. D. et al. Twenty-year risk of prostate cancer death by midlife prostate-specific antigen and a panel of four kallikrein markers in a large population-based cohort of healthy men. Eur. Urol. 73, 941–948 (2018).
Vertosick, E. A. et al. Prespecified 4 kallikrein marker model (4Kscore) at age 50 or 60 for early detection of lethal prostate cancer in a large population based cohort of asymptomatic men followed for 20 years. J. Urol. 204, 281–288 (2020).
Parekh, D. J. et al. A multi-institutional prospective trial in the USA confirms that the 4Kscore accurately identifies men with high-grade prostate cancer. Eur. Urol. 68, 464–470 (2015).
Li, W. et al. Genome-wide scan identifies role for AOX1 in prostate cancer survival. Eur. Urol. 74, 710–719 (2018).
Fritsche, L. G. et al. Cancer PRSweb: an online repository with polygenic risk scores for major cancer traits and their evaluation in two independent biobanks. Am. J. Hum. Genet. 107, 815–836 (2020).
Graff, R. E. et al. Cross-cancer evaluation of polygenic risk scores for 16 cancer types in two large cohorts. Nat. Commun. 12, 970 (2021).
Vickers, A. J. et al. Strategy for detection of prostate cancer based on relation between prostate specific antigen at age 40-55 and long term risk of metastasis: case-control study. BMJ. 346, https://www.bmj.com/content/346/bmj.f2023 (2013).
Vickers, A. J., Eastham, J. A., Scardino, P. T. & Lilja, H. The Memorial Sloan Kettering Cancer Center recommendations for prostate cancer screening. Urology 91, 12–18 (2016).
Callender, T. et al. Polygenic risk-tailored screening for prostate cancer: a benefit-harm and cost-effectiveness modelling study. PLoS Med. 16, e1002998 (2019).
Benafif, S. et al. The BARCODE1 pilot: a feasibility study of using germline SNPs to target prostate cancer screening. BJU Int. 129, 325–336 (2022).
Pritchard, C. C. et al. Inherited DNA-repair gene mutations in men with metastatic prostate cancer. N. Engl. J. Med. 375, 443–453 (2016).
Khera, A. V. et al. Genome-wide polygenic scores for common diseases identify individuals with risk equivalent to monogenic mutations. Nat. Genet. 50, 1219–1224 (2018).
Stattin, P. et al. Improving the specificity of screening for lethal prostate cancer using prostate-specific antigen and a panel of kallikrein markers: a nested case-control study. Eur. Urol. 68, 207–213 (2015).
Haiman, C. A. et al. Levels of beta-microseminoprotein in blood and risk of prostate cancer in multiple populations. J. Natl Cancer Inst. 105, 237–243 (2013).
Väisänen, V., Peltola, M. T., Lilja, H., Nurmi, M. & Pettersson, K. Intact free prostate-specific antigen and free and total human glandular kallikrein 2. Elimination of assay interference by enzymatic digestion of antibodies to F(ab’)2 fragments. Anal. Chem. 78, 7809–7815 (2006).
Lambert, S. A. et al. The Polygenic Score Catalog as an open database for reproducibility and systematic evaluation. Nat. Genet. 53, 420–425 (2021).
Bryant, R. J. et al. Predicting high-grade cancer at ten-core prostate biopsy using four kallikrein markers measured in blood in the ProtecT study. J. Natl Cancer Inst. 107, djv095 (2015).
Acknowledgements
This work was supported in part through the computational resources and staff expertise provided by Scientific Computing at the Icahn School of Medicine at Mount Sinai. We are grateful to Ros Eeles and Chris Haiman for many helpful discussions about earlier iterations of this manuscript. This work was supported by the National Institutes of Health/National Cancer Institute [R01 CA175491, R01 CA244948] and with a Cancer Center Support Grant to Memorial Sloan Kettering Cancer Center [P30 CA008748], a SPORE grant in Prostate Cancer to Dr. H. Scher [P50-CA92629], the Sidney Kimmel Center for Prostate and Urologic Cancers and David H. Koch through the Prostate Cancer Foundation. This work was also supported in part by the Swedish Cancer Society (CAN 2017/559), the Swedish Research Council (VR-MH project no. 2016-02974), and General Hospital in Malmö Foundation for Combating Cancer. Research reported in this paper was supported by the Office of Research Infrastructure of the National Institutes of Health under award number S10OD018522 and S10OD026880. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Author information
Authors and Affiliations
Contributions
All authors contributed to the conception and design (R.J.K., A.V., H.L.), acquisition of data (D.U., A.C.R., C.H., E.T., G.H., A.D., P.S., O.M.), or the analysis and interpretation of data (R.J.K., E.V., D.S., A.V., H.L.); drafting or revision of the manuscript; and final approval of the completed version. R.J.K. and E.V. contributed equally to this work.
Corresponding author
Ethics declarations
Competing interests
H.L. is named on a patent for intact PSA assays. A.V. and H.L. are named on a patent for a statistical method to detect prostate cancer that has been licensed to and commercialized by OPKO Health. They both receive royalties from sales of the test. A.V. has stock options and H.L. has stock in OPKO Health. No other authors have any competing interests to declare.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Klein, R.J., Vertosick, E., Sjoberg, D. et al. Prostate cancer polygenic risk score and prediction of lethal prostate cancer. npj Precis. Onc. 6, 25 (2022). https://doi.org/10.1038/s41698-022-00266-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41698-022-00266-8
