
Abstract
Identifying research teams constitutes a fundamental step in team science research, and universities harbor diverse types of such teams. This study introduces a method and proposes algorithms for team identification, encompassing the project-based research team (Pbrt), the individual-based research team (Ibrt), the backbone-based research group (Bbrg), and the representative research group (Rrg), scrutinizing aspects such as project, contribution, collaboration, and similarity. Drawing on two top universities in Materials Science and Engineering as case studies, this research reveals that university research teams predominantly manifest as backbone-based research groups. The distribution of members within these groups adheres to Price’s Law, indicating a concentration of research funding among a minority of research groups. Furthermore, the representative research groups in universities exhibit interdisciplinary characteristics. Notably, significant differences exist in collaboration mode and member structures among high-level backbone-based research groups across diverse cultural backgrounds.
Similar content being viewed by others

Introduction
Team science has emerged as a burgeoning field of inquiry, attracting the attention of numerous scholars (e.g., Stokols et al., 2008; Bozeman & Youtie, 2018; Coles et al., 2022; Deng et al., 2022; Forscher et al., 2023), who endeavor to explore and try to summarize strategies for fostering effective research teams. Conducting team science research would help improve team efficacy. The National Institutes of Health in the USA pointed out that team science is a new interdisciplinary field that empirically examines the processes by which scientific teams, research centers, and institutes, both large and small, are structured (National Research Council, 2015). In accordance with this conceptualization, research teams can be delineated into various types based on their size and organizational form. Existing research also takes diverse teams as focal points when probing issues such as team construction and team performance. For example, Wu et al. (2019) and Abramo et al. (2017) regard the co-authors of a single paper as a team, discussing issues of research team innovation and benefits. Meanwhile, Zhao et al. (2014) and Lungeanu et al. (2014) consider the project members as a research team, exploring issues such as internal interest distribution and team performance. Boardman and Ponomariov (2014), Lee et al. (2008), and Okamoto and Centers for Population Health and Health Disparities Evaluation Working Group (2015) view the university’s research center as a research group, investigating themes about member collaboration, management, and knowledge management portals.
Regarding the definition of research teams, some researchers believe that a research team is a collection of people who work together to achieve a common goal and discover new phenomena through research by sharing information, resources, and professional expertise (Liu et al., 2020). Conversely, others argue that groups operating across distinct temporal and spatial contexts, such as virtual teams, do not meet the criteria for teams, as they engage solely in collaborative activities between teams. According to this perspective, Research teams should be individuals collaborating over an extended period (typically exceeding six months) (Barjak & Robinson, 2008). Contemporary discourse on team science tends to embrace a broad conceptualization wherein research teams include both small-scale teams comprising 2–10 individuals and larger groups consisting of more than 10 members (National Research Council, 2015). These research teams are typically formed to conduct a project or finish research papers, while research groups are formed to solve complex problems, drawing members from diverse departments or geographical locations.
Obviously, different research inquiries are linked to different types of research teams. Micro-level investigations, such as those probing the impact of international collaboration on citations, often regard co-authors of research papers as research teams. Conversely, meso-level inquiries, including those exploring factors impacting team organization and management, often view center-based researchers as research groups. Although various approaches can be adopted to identify research teams, such as retrieving names from research centers’ websites or obtaining lists of project-funded members, when the study involves a large sample size and requires more data to measure the performance of research teams, it becomes necessary to use bibliometric methods for team identification.
Existing literature on team identification uses social network analysis (Zhang et al., 2019), cohesive subgroup (Dino et al., 2020), faction algorithm (Imran et al., 2018), FP algorithm (Liao, 2018), etc. However, these identification methods often target a singular type of research team or fail to categorize the identified research teams. Moreover, existing studies mostly explore the evolution of specific disciplines (Wang et al., 2017), with limited attention devoted to identifying university research teams and the influencing factors of team effectiveness. Therefore, this study tries to develop algorithms to identify diverse university research teams, drawing insights from two universities characterized by different cultural backgrounds. It aims to address two research questions:
-
(1)
How can we identify different types of university research teams?
-
(2)
What are the characteristics of research groups within universities?
Literature review
Why is it necessary to identify research teams? The research focuses on scientific research teams, mostly first identifying the members of research teams through their names on the list of funding projects or institutions’ websites and then conducting research through questionnaires or interviews. However, this methodology may compromise research validity for several reasons. Firstly, the mere inclusion of individuals on funding project lists does not guarantee genuine research team membership or substantive collaboration among members. Secondly, the institutional website generally announces important research team members, potentially overlooking auxiliary personnel or important members from external institutions. Thirdly, reliance solely on lists of research team members fails to capture nuanced information about the team, such as their research ability or communication intensity, thus hindering the exploration of team science-related issues.
Consequently, researchers have turned to co-authorship and citation to identify research teams using established software tools and customized algorithms. For example, Li and Tan (2012) applied UCINET and social network analysis to identify university research teams, while Hu et al. (2019) used Citespace to analyze research communities of four disciplines in China, the UK, and the US. Similarly, some researchers also identify the members and leaders of research teams by using and optimizing existing algorithms. For example, Liao (2018) applied the Fast-Unfolding algorithm to identify research teams in the field of solar cells, while Yu et al. (2020) and Li et al. (2017) employed the Louvain community discovery algorithm to identify research teams in artificial intelligence. Lv et al. (2016) applied the FP-GROWTH algorithm to identify core R&D teams. Yu et al. (2018) used the faction algorithm to identify research teams in intelligence. Dino et al. (2020) developed the CL-leader algorithm to confirm research teams and their leaders. Boyack and Klavans (2014) regard researchers engaged in the same research topic as research teams based on citation information. Notably, these community detection algorithms complement each other, offering versatile tools for identifying research teams.
Despite the utility of these identification methods, they are not without limitations. For example, fixed software algorithms are constrained by predefined rules, posing challenges for researchers seeking to customize identification criteria. Moreover, for developed algorithms, although algorithms based on computer programming languages have high accuracy, they overemphasize the connection relationship between members and do not consider the definition of research teams. In addition, research based on co-authorship networks and community identification algorithms faces inherent problems: (1) Ensuring temporal consistency in co-authorship networks is challenging due to variations in publication timelines, potentially undermining the temporal alignment of team member collaborations; (2) The lack of stability in team identification result means that different identification standards would produce different outcomes; (3) Team members only belong to one research team, but in the actual process, researchers often participate in multiple research teams with different identities, or the same members conduct research in different team combinations.
In summary, research teams in a specific field can be identified using co-authorship information, designing or introducing identification algorithms. However, achieving more accurate identification necessitates consideration of the nuanced definition of research teams. Therefore, this study focuses on university research teams, addressing temporal and spatial collaboration issues among team members by incorporating project information and first-author information. Furthermore, it tackles the issue of classifying research team members by introducing Price’s Law and Everett’s Rule. Additionally, it tackles the issue of team members’ multiple affiliations through the Jaccard Similarity Coefficient and the Louvain Algorithm. Ultimately, this study aims to achieve the classification recognition of university research teams.
Team identification method
An effective team identification method requires both consideration of the definition of research teams and the ability to transform this definition into operable programming languages. University research teams, by definition, comprise researchers collaborating towards a shared objective. As a typical form of the output of a research team, the co-authorship of a scientific research paper implies information exchange and interaction among team members. Thus, this study uses co-authorship relationships within papers to reflect the collaborative relationships among research team members. In this section, novel algorithms for identifying research teams are proposed to address deficiencies observed in prior research.
Classification of research team members
A researcher might be part of multiple research teams, with varying roles within each. Members of the research team can be categorized according to how the research team is defined.
The original idea of team member classification
The prevailing notion of teams underscores the collaborative efforts between individual team members and their contributions toward achieving research objectives. This study similarly classifies team members based on these dual dimensions.
In terms of overall contributions, members who make substantial contributions are typically seen as pivotal figures within the research team, providing the primary impetus for the team’s productivity. Conversely, those with lesser input only contribute to specific facets of the team’s goals and engage in limited research activities, thus being regarded as standard team members.
In terms of collaboration, it is essential to recognize that high levels of contribution do not inherently denote a core position within a team. The collaboration among team members serves as an important indicator of their identity characteristics within the research team. Based on the collaboration between members, this study believes that researchers who have high contributions and collaborate with many high-contribution team members assume the core members of the research team. Conversely, members who have high contributions but only collaborate with a limited number of high-contribution team members are identified as backbone members. Similarly, members displaying low levels of contributions but collaborating widely with high contributors are categorized as ordinary members. Conversely, those with low contributions and limited collaboration with high-contributing team members are regarded as marginal members of the research team.
Establishment of team member classification criteria
This study introduces Price’s Law and Everett’s Rule to realize the idea of team member classification.
In terms of overall contribution, the well-known bibliometrics Price, drawing from Lotka’s Law, deduced that the number of papers published by prolific scientists is 0.749 times the square root of the number of papers published by the most prolific scientist in a group. Existing research also used this law when analyzing prolific authors of an organization. This study believes that prolific authors who conform to Price’s Law are important members who contribute more to the research team.
In terms of collaboration, existing research mostly employs the concept of factions. Factions refer to a relationship where members reciprocate and cannot readily join new groups without altering the reciprocal nature of their factional ties. However, in real-world settings, relationships with overtly reciprocal characteristics are uncommon. Therefore, to ensure the applicability and stability of the faction, Seidman and Foster (1978) proposed the concept of K-plex, pointing out that in a group of size n, when the number of direct connections of any point in the group is not less than n-k, this group is called k-plex. For k-plex, as the number k increases, the stability of the entire faction will decrease. Addressing this concern, renowned sociologist Martin Everett (2002), based on the empirical rule of research, proposed specific values for k and corresponding minimum group sizes, stipulating that the overall team size should not fall below 2k-1 (Scott, 2017). The expression is:
In other words, for a K-plex, the most acceptable definition to qualify as a faction is when each member of the team is directly connected to at least (n − 1)/2 members of the team. Applied to research teams, this empirical guideline necessitates that team members maintain collaborative ties with at least half or more of the team.
Based on Price’s Law and Everett’s Empirical Rule, this study gives the criteria for distinguishing prolific authors, core members, backbone members, ordinary members, and marginal members of research teams. The specifics are shown in the following Table 1.
Classification of research teams
Within universities, a diverse array of research teams exists, categorized by their scale, the characteristics of funded projects, and the platforms they rely upon. This study proposes the identification algorithms for project-based teams, individual-based teams, backbone-based groups, and representative groups.
Project-based research teams: identification based on research projects
Traditional methods for identifying research teams attribute co-authorship to collaboration among multiple authors without considering the time scope. However, in practice, collaborations vary in content and duration. Therefore, in the identification process, it is necessary to introduce appropriate standards to distinguish varying degrees of collaboration and content among scholars.
Research projects serve as evidence of researchers engaging in the same research topic, thereby indicating that the paper’s authors belong to the same research team. Upon formal acceptance of a research paper, authors typically append funding information to the paper. Therefore, papers sharing the same funding information can be aggregated into paper clusters to identify the research team members who completed the fund project. The specific steps proposed for identifying a single research project fund are as follows.
Firstly, extract the funding number and regard all papers attached with the same funding number as a paper cluster. Secondly, construct a co-authorship network based on the paper cluster. Thirdly, identify the research team using the team member classification criteria.
Individual-based research teams: team identification based on the first author
For research papers lacking project numbers, clustering can be performed based on the contribution and research experience of the authors. Each co-author of the research paper contributes differently to the paper’s content. In 2014, the Consortia Advancing Standards in Research Administration Information (CASRAI) proposed classification standards for paper contributions, including 14 types such as conceptualization, data processing, formal analysis, funding acquisition, investigation, methods, project management, resources, software, supervision, validation, visualization, paper writing, review, and editing.
In this study, the primary author of a paper lacking project funding is considered the initiator, while other authors are seen as contributors who advance and finalize the research. For papers not affiliated with any project, the first author and all their published papers form a paper group for team identification purposes. The procedure entails the following steps: Initially, gather the first author and all papers authored by them within the identification period to constitute a paper group. Subsequently, a co-authorship network will be constructed using the papers within the group. Lastly, the research team will be identified based on the criteria for classifying team members.
Backbone-based research group: merging based on project-based and individual-based research teams
Research teams can be identified either by a single project number or by individual researchers. Upon identification, it becomes evident that many research teams share similar members. This is because a research team may engage in multiple projects, and some members collaborate without funding support. While identification algorithms are suitable for evaluating the quality of a research article or funding, they may not suffice when assessing the research group, or they may not suffice when assessing the key factors affecting their performance. To address this, it is necessary to merge highly similar individual-based or project-based research teams according to specific criteria. The merged one should be termed a group, as it encompasses multiple project-based and individual-based research teams.
In the pursuit of building world-class universities, governments worldwide often emphasize the necessity of fostering research teams led by discipline backbones. In this vein, this study further develops a backbone-based research group identification algorithm, which considers project-based and individual-based research teams.
Identification of university discipline backbone members
Previous studies have summarized the characteristics of the university discipline backbones, revealing that these individuals often excel in indicators such as degree centrality, eigenvector centrality, and betweenness centrality. Each centrality indicator demonstrates a strong positive correlation with the author’s output volume, indicating that high-productive researchers with more collaborators are more inclined to be university discipline backbones. Based on these characteristics, Price’s law is applied, defining discipline backbone members as researchers whose publications count exceeds 0.749 times the square root of the highest publication count within the discipline.
Team identification with discipline backbone members as the Core
Following the identification of discipline backbones, this study consolidates paper groups wherein the discipline backbone serves as the core member of either individual-based or project-based research teams. Subsequently, backbone-based research groups are formed.
Merging based on similarity perspective
It should be noted that different discipline backbones may simultaneously participate as core members in the same individual-based or project-based research teams. Consequently, distinct backbone-based research groups may encompass duplicate project-based and individual-based research teams, necessitating the merging of backbone-based research groups.
To address this redundancy issue, this study introduces the concept of similarity in community identification. In the community identification process, existing algorithms often assess whether to incorporate members into the community based on their level of similarity. Among various algorithms for calculating similarity, the Jaccard coefficient is deemed to possess superior validity and robustness in merging nodes within network communities (Wang et al., 2020). Its calculation formula is as follows.
Ni denotes the nodes within subset i, while Nj represents the nodes within subset j; Ni ∩ Nj signifies the nodes present in both subsets, whereas Ni∪Nj encompasses all nodes in subsets i and j. Existing research shows that when the Jaccard coefficient equals or exceeds 0.5 (Guo et al., 2022), the community identification algorithm achieves optimal precision.
In the context of this study, Ni represents the core and backbone members of research group i, while Nj denotes the core and backbone members of research group j. If these two groups exhibit significant overlap in core and backbone members, the papers from both research groups are merged into a new set of papers to identify the research team.
Given the efficacy of the Jaccard similarity measure in identifying community networks and merging, this study employs this principle to merge backbone-based research groups. Specifically, groups are merged if the Jaccard similarity coefficient between their core and backbone members equals or exceeds 0.5. Subsequently, new research groups are formed based on the merged set of papers.
It’s important to note that during the merging process, certain research teams within a backbone-based group may be utilized multiple times. Initially, the merging occurs based on the core and backbone members of the backbone-based research group, adhering to the Jaccard coefficient criterion. However, since project or individual-based research teams within a backbone-based research group may be reused, resulting in the similarity of research papers across different groups, the study further tested the team duplication of the merged papers of various groups. During the research process, it was found that the research papers within groups often exhibit similarity due to their association with multiple funding projects. Therefore, a principle of “if connected, then merged” was adopted among groups with highly similar research papers to ensure the heterogeneity of papers within the final merged research groups.
The generation process of the backbone-based research groups is illustrated in Fig. 1 below. Initially, university discipline backbones α, β, γ, θ, δ, and ε are each designated as core members within project-based or individual-based research teams A, B, C, D, E, and F, among which αβγ, γθ, θδ, δε ‘s core and backbone members’ Jaccard coefficient meet the merging standard and generate lines. After the first merging, the Jaccard coefficient of the papers of the αβγ, γθ, θδ, δε are calculated, and the lines are generated because of a high duplicated papers between γθ, θδ, and θδ, δε. Finally, αβγ and γθδε are retained based on the rule.
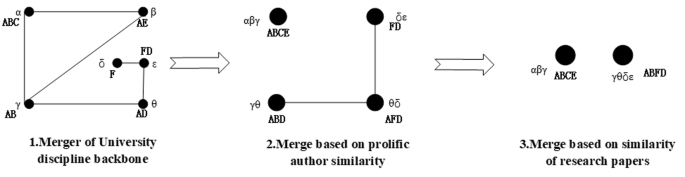
The α, β, γ, θ, δ, and ε are core members within project-based or individual-based research teams. The A, B, C, D, E, and F are project-based or individual-based research teams. From step 1 to step 2, research groups are merged according to the Jaccard coefficient between research team members. From step 2 to step 3, research groups are merged according to the Jaccard coefficient between research group papers.
In summary, the process of identifying a backbone-based research group involves the following steps: (1) Identify prolific authors within the university’s discipline by analyzing all papers published in the field, considering them as the discipline’s backbones members; (2) Merge the project-based and individual-based research teams wherein university discipline backbones are core member, thereby forming backbone-based research groups; (3) Merge the backbone-based research group identified in step (2) based on the Jaccard coefficient between their core and backbone members; (4) Calculate the Jaccard coefficient of the papers of the merged groups in step (3), merge the groups with significant paper overlap, and generate new backbone-based research groups.
The research groups identified through the above steps offer two advantages: Firstly, they integrate similar project-based and individual-based research teams, avoiding redundancy in team identification outcomes. Secondly, the same member may participate in different research teams, assuming distinct roles within each, thus better reflecting the complexity of scientific research practices.
Representative team: consolidation via backbone-based research group
When universities introduce their research groups to external parties, they typically highlight the most significant research members within the institution. Although the backbone-based research group has condensed the project-based and individual-based research teams, there may still be some overlap among members from different backbone-based research groups.
In order to create condensed and representative research groups that accurately reflect the development of the university’s discipline, this study extracts the core and backbone members identified in the backbone-based research group. It then identifies the representative group using the widely utilized Louvain algorithm (Blondel et al., 2008) commonly employed in research group identification. This algorithm facilitates the integration of important members from different backbone-based research groups while ensuring there is no redundancy among group members. The merging process is shown in Fig. 2.

Each pass is made of two phases: one where modularity is optimized by allowing only local changes of communities, and one where the communities found are aggregated in order to build a new network of communities. The passes are repeated iteratively until no increase in modularity is possible.
Research team identification process and its pros and cons
Overall, the method of identifying university research teams proposed in this research encompasses four stages: Initially, research teams are categorized into project-based research teams and individual-based research teams based on information provided with research papers, distinguishing between those supported by funding projects and those not. Subsequently, the prolific authors of universities are identified to combine individual-based and project-based research teams, and backbone-based research groups are generated. Finally, representative research groups are established utilizing the Louvain algorithm and the interrelations among members within the backbone-based research groups. The entire process is depicted in Fig. 3 below.
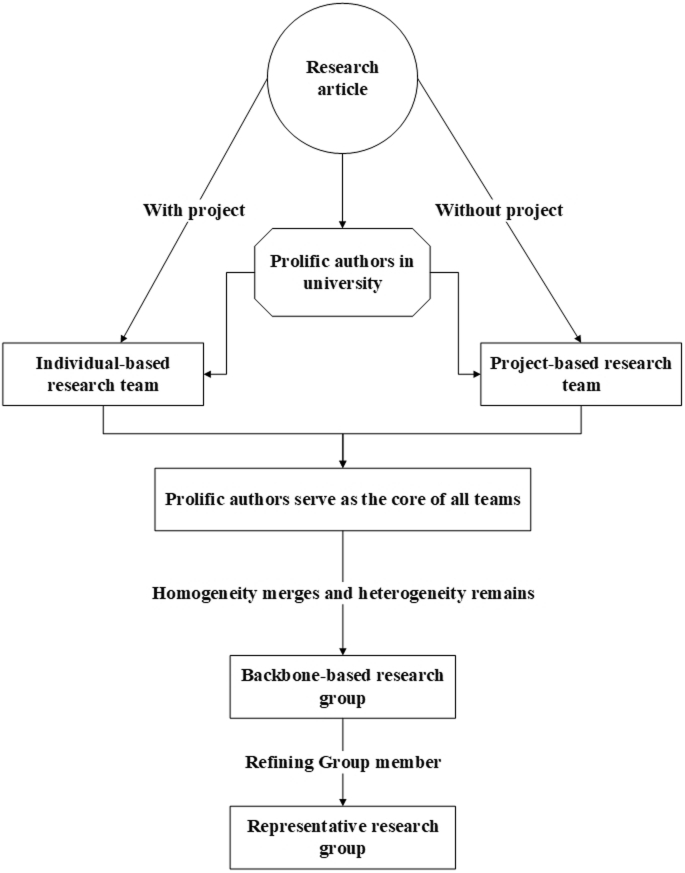
Different university research teams are identified at different stage.
Each type of research team or group has its advantages and disadvantages, as shown in Table 2 below.
Validation of identification results
In order to verify the accuracy of the identification results, the method proposed by Boyack and Klavans (2014), which relies on citation analysis, is utilized. This method calculates the level of consistency regarding the main research areas of the core and backbone members, thereby verifying the validity of the identification method.
In the SCIVAL database, all research papers are clustered into relevant topic groups, providing insights into the research area of individual authors. By examining the research topic clusters of team papers in the SCIVAL database, the predominant research areas of prolific authors can be determined. Authors sharing common research areas within a university are regarded as constituting a research team. Given that authors often conduct research in various research areas, this study focuses solely on the top three research areas for each author.
As demonstrated in Table 3 below, for the prolific authors A, B, C, D, and E of the research team, their top three research areas collectively span five distinct fields. By calculating the highest value of the consistency among these research areas, it can be judged whether these researchers can be classified as members of the same research group. As depicted in Table 3, the main research areas of all prolific authors include Research Area 3, indicating that this field is one of the three most important research areas for all prolific authors. This consistency validates that the main research areas of the five authors align, affirming their classification within the same research team.
Data collection and preprocessing
In order to present the distinct characteristics of various types of scientific research teams as intuitively as possible, this study focuses on the field of material science, with Tsinghua University and Nanyang Technological University selected for analysis. The selection of these two institutions is driven by several considerations: (1) both universities boast exceptional performance in the field of material science on a global scale, consistently ranking within the top 10 worldwide for numerous years; (2) The scientific research systems in the respective countries where these universities are situated differ significantly. China’s scientific research system operates under a government-led funding model, whereas Singapore’s system involves a multi-party funding approach with contributions from the government, enterprises, and societies. By examining universities from these distinct scientific research cultures, this study aims to validate the proposed methods and highlight disparities in the characteristics of their scientific research teams. (3) Material science is inherently interdisciplinary, with contributions from researchers across various domains. Although the selected papers focus on material science, they may also intersect with other disciplines. Therefore, investigating research teams in material science could somewhat represent the interdisciplinary research teams.
The data utilized in this study is sourced from the Clarivate Analytics database, which categorizes scientific research papers based on the subject classification catalogs. In order to ensure the consistency and reliability of scientific research paper identification, this study focuses on the papers published in the field of material science by the two selected universities between 2017 and 2021. Additionally, considering the duration of funded projects, papers associated with projects that have appeared in 2017–2021 within ten years (2011–2022) are also included for analysis to enhance the precision of identification. In order to ensure the affiliation of a research team with the respective universities, this study exclusively considers papers authored by the first author or the corresponding author affiliated with the university as the subject of analysis.
Throughout this process, it should be noted that the name problem in identifying scientific research. Abbreviations, orders, and other name-related information are cleaned and verified. Given that this study exports data utilizing the Author’s Full name and restricts it to specific universities and disciplines, the cleaning process targets the rectification of identification discrepancies arising from a minority of abbreviations and similar names. The specific cleaning procedures entail the following steps.
First, all occurrences of “-” are replaced with null values, and names are standardized by capitalization. Second, the Python dedupe module is employed to mitigate ambiguity in author names, facilitating the differentiation or unification of authors sharing the same surname, name, and initials. List and output all personnel names of each university in this discipline and observe in ascending order. Third, a comparison of names and abbreviations is conducted in reverse order, alongside their respective affiliations and replacements in the identification data. For example, names such as “LONG, W.H” “LONG, WEN, HUI” and “LONG, WENHUI” are uniformly replaced with “LONG, WENHUI.” Fourth, identify and compare similar names in both abbreviations and full forms and confirm whether they are consistent by scrutinizing their affiliations and collaborators. Names exhibiting consistency are replaced accordingly, while those lacking uniformity remain unchanged. For example, “LI, W.D” and “LI, WEIDE” lacking common affiliations and collaborators, are not considered the same person and thus remain distinct.
The publication of the two universities in the field of Materials Science and Engineering across two distinct time periods is shown in Table 4 below.
Based on the publication count of papers authored by the first author or corresponding author from both universities, Tsinghua University demonstrates a significantly higher publication output than Nanyang Technological University, indicating a substantial disparity between the two institutions.
Subsequent to data preprocessing, this study uses the Python tool to develop algorithms in accordance with the proposed principles, thereby facilitating the identification of research teams and groups.
Results
This study has identified several research teams through the sorting and analysis of original data. In order to provide a comprehensive overview of the identification results, this study begins by outlining the characteristics of the identification results and then analyzes the research teams affiliated with both universities, focusing on three aspects: scale, structure, and output.
Identification results of university research teams
The results reveal that both Tsinghua University and Nanyang Technological University boast a considerable number of Pbrts, indicating that most of the researchers from both universities have received funding support. Additionally, a small number of teams have not received funding support, although their overall proportion is relatively low. The Bbrgs predominantly encompass the majority of the Ibrts and Pbrts, underscoring the significant influence of the discipline backbone members within both universities. Notably, the total count of Rrg across the two universities stands at 39, reflecting that many research groups are supporting the construction of material disciplines in the two universities (Table 5).
In order to validate the accuracy of the developed method, this study verifies the effectiveness of the identification algorithm. Given that the method emphasizes the main research area of its members, it is appropriate to apply it to the verification of the Bbrgs, which encompass the majority of the individual-based and project-based teams.
The analysis reveals that the consistency level of the most concentrated research area within the identified Bbrgs is 0.93. This signifies that within a Bbrg comprising 10 core or backbone members, a minimum of 9.3 individuals share the same main research area. Moreover, across Bbrgs of varying sizes, the average consistency level of the most concentrated research area also reached 0.90, indicating that the algorithm proposed in this study is valid (Table 6).
Analysis of the characteristics of Bbrg in universities
The findings of the analysis show that the Bbrgs encompass the vast majority of Pbrts and Ibrts within universities. Consequently, this study further analyzes the scale, structure, and output of the Bbrgs to present the characteristics of university research teams.
Group scale
Upon scrutinizing the distribution of Bbrgs across the two universities, it is observed that the number of core members is similar. Bbrg with a core member scale of 6–10 individuals are the most prevalent, followed by those with a scale of 0–5 members. Additionally, there are Bbrgs comprising 11–15 members, with relatively fewer Bbrgs consisting of 15 members or more. On average, the number of core members in Bbrgs stands at 7.08. Tsinghua University has more Bbrgs than Nanyang Technological University, while the average number of core members is relatively less. Notably, the proportion of core and backbone members amounts to nearly 12%, ranging from 11.22% to 13.88% (Table 7).
Group structure
The structural attributes of the research groups could be assessed through network density among core members, core and backbone members, and all team members. Additionally, departmental distribution can be depicted based on the identification of core members and their organizational affiliations. The formula for network density calculation is as follows:
Note: R is the number of relationships, and N is the number of members.
Overall, the network density characteristics exhibit consistency across both universities. Specifically, the network density among research group members tends to decrease as the group size expands. The network density among core members is the highest, while that among all members records the lowest. Comparatively, the average amount of various types of network density at Tsinghua University is relatively lower than that at Nanyang Technological University, indicating a lesser degree of connectivity among members within Tsinghua University’s research group. However, the network density levels among core members and core and backbone members of research teams in both institutions remain relatively high. Notably, the network density of backbone-based research groups exceeds 0.5, indicating a close collaboration among the core and backbone members of these university research groups (Table 8).
The T-test analysis reveals no significant difference in the network density among core members between Tsinghua University and Nanyang Technological University. This suggests that core members of research groups from universities with high-level discipline often maintain close communication. However, concerning the network density among core and backbone members and all members, the average amount of Tsinghua University’s research groups is significantly lower than those of Nanyang Technological University. This implies less direct collaboration among prolific authors at Tsinghua University, with backbone members relying more on different core members of the group to carry out research.
To present the cooperative relationship among the core and backbone members of the Bbrgs, the prolific authors associated with the backbone-based research groups are extracted. Subsequently, the representative research groups affiliated with Nanyang Technological University and Tsinghua University are identified using the fast-unfolding algorithm. The resultant collaboration network diagram among prolific authors is depicted in Fig. 4, wherein each node color corresponds to different representative research groups of the respective universities.

Nodes (author) and links (relation between different authors) with the same color could be seen as the same representative research group.
The network connection diagram of Nanyang Technological University illustrates the presence of 39 Rrgs, including Rrgs from the School of Materials Science and Engineering and the Singapore Centre for 3D Printing. Owing to the inherently interdisciplinary characteristics of the materials discipline, its research groups are not only distributed in the School of Materials Science and Engineering; other academic units also have research groups engaged in materials science research.
Further insights into the distribution of research groups can be gleaned by examining the departments to which the primary members belong. Counting the departmental affiliations of the members with the highest centrality in each representative team reveals that, among the 39 Rrgs, the School of Materials Science and Engineering and the College of Engineering boast the highest number of affiliations, with nine core members of the research groups coming from these two departments, Following closely is the School of Physical and Mathematical Sciences. Notably, entities external to the university, such as the National Institute of Education and the Singapore Institute of Manufacturing Technology, also host important representative groups, underscoring the interdisciplinarity nature of material science. The distribution of Rrgs affiliations is delineated in Table 9.
Similar to Nanyang Technological University, Tsinghua University also exhibits tightly woven connections within its backbone-based research group in Materials Science and Engineering, comprising a total of 39 Rrgs. Compared with Nanyang Technological University, Tsinghua University boasts a larger cohort of core and backbone members. The collaboration network diagram of representative groups is shown below (Fig. 5).

Nodes (author) and links (relation between different authors) with the same color could be seen as the same representative research group.
Similar to Nanyang Technological University, representative research groups at Tsinghua University are distributed in different schools within the institution, with the School of Materials being the directly related department. In addition, the School of Medicine and the Center for Brain-like Computing also conduct research related to materials science (Table 10).
By summarizing the departmental affiliations of the research groups, it becomes evident that the Rrgs in Materials Science and Engineering at these universities span various academic departments, reflecting the interdisciplinary characteristics of the field. The network density of the research groups is also calculated, with Nanyang Technological University exhibiting a higher density (0.028) compared to Tsinghua University (0.022), indicating tighter connections within the representative research groups at Nanyang Technological University.
Group output
In order to control the impact of scale, this study compares several metrics, including publication, publication per capita of core and backbone members, capita of the most prolific author within the groups, field-weighted citation impact, and citations per publication of Bbrgs at these two top universities.
Regarding publications, the average number and the T-test results show that Tsinghua University significantly outperforms Nanyang Technological University, suggesting that the Bbrgs and prolific authors affiliated with Tsinghua University are more productive in terms of research output.
However, in terms of field-weighted citation impact and citations per publication of the Bbrgs, the average number and the T-test results show that Tsinghua University is significantly lower than that of Nanyang Technological University, which indicates the research papers originating from the Bbrgs at Nanyang Technological University have a greater academic influence (see Table 11).
Typical cases
To intuitively present the research groups identified, this study has selected the two Bbrgs with the highest number of published papers at Tsinghua University and Nanyang Technological University for analysis, aiming to offer insights for constructing research teams.
Basic Information of the Bbrgs
Examining the basic information of the Bbrgs reveals that although Kang Feiyu’s group at Tsinghua University comprises fewer researchers than Liu Zheng’s group at Nanyang Technological University, Kang Feiyu’s group has a higher total number of published papers. In order to measure the performance of the research results of these two Bbrgs, the field-weighted citation impact of their research papers was queried using SCIVAL. The results showed that the field-weighted citation impact of Kang Feiyu’s group at Tsinghua University was higher, indicating a greater influence in the field of Materials Science and Engineering. Furthermore, the identity information of the two group leaders was compared. It was found that Kang Feiyu, in addition to being a professor at Tsinghua University, holds administrative positions as the dean of the Shenzhen Graduate School of Tsinghua University. Meanwhile, LIU, Zheng, mainly serves as the chairman of the Singapore Materials Society alongside his role as a professor (see Table 12).
Characteristics of team member network structure
In order to reflect the collaboration characteristics of research groups, this study calculates the network density of the two groups and utilizes VOSviewer to present the collaboration network diagrams of their members.
In terms of network density, both groups exhibit a density of 1 among core members, indicating that the collaboration between core members is tight. However, regarding the network density of core and backbone members, as well as all members, Liu Zheng’s group at Nanyang Technological University demonstrates a higher density. This indicates a stronger interconnectedness between the backbone and other members within the group (refer to Table 13).
For the co-authorship network diagram of group members, distinctive characteristics are observed between the two Bbrgs. In Kang Feiyu’s team, the core members exhibit prominence, with sub-team structures under evident each team member (Fig. 6). Conversely, while Liu Zheng’s team also features different core members, the centrality within each member is not obvious (Fig. 7).

Nodes (author) and links (relation between different authors) with the same color could be seen as the same sub-team.

Nodes (author) and links (relation between different authors) with the same color could be seen as the same sub-team.
Discussion and conclusion
Distinguishing different research teams constitutes the foundational stage in conducting team science research. In this study, we employ Price’s Law, Everett’s Rule, Jaccard Similarity Coefficient, and Louvain Algorithm to identify different research teams and groups in two world-leading universities specializing in Materials Science and Engineering. Through this exploration, we aim to explore the characteristics of research teams. The main findings are discussed as follows.
First, based on the co-authorship and project data from scholarly articles, this study develops a methodology for identifying research teams that distinguishes between different types of research teams or groups. In contrast to the prior identification method, our algorithms could identify different types of research teams and realize the member classification within research teams. This affords greater clarity regarding collaboration time and content among team members. The validation of identification results, conducted using the methodology proposed by Boyack and Klavans (2014), demonstrates the consistency of the main research areas among identified research group members. This validation shows the accuracy and efficacy of the research team identification methodology proposed in this study.
Second, universities have different types of research teams or groups, encompassing both project-based research teams and individual-based research teams lacking project support. Among these, most research teams rely on projects to conduct research (Bloch & Sørensen, 2015). Concurrently, this research finds that university research groups predominantly coalesce around eminent scholars, with backbone-based research groups comprising the majority of both project-based and individual-based research teams. This phenomenon shows the concentration of research resources within a select few research groups and institutions, a concept previously highlighted by Mongeon et al. (2016), who pointed out that research funding tends to be concentrated among a minority of researchers. In this research, we not only corroborate this assertion but also observe that researchers with abundant funding collaborate to form research groups, thereby mutually supporting each other. In addition, based on the structures of research groups at Nanyang Technological University and Tsinghua University, one could posit that these institutions resemble what might be termed a “rich club” (Ma et al., 2015). However, despite the heightened productivity of relatively concentrated research groups at Tsinghua University in terms of research output, their academic influence pales compared to that of Nanyang Technological University. To enhance research influence, it seems that the funding agency should curtail funding allocations to these “rich” research groups and instead allocate resources to support more financially challenged research teams. This approach would serve to alleviate the trend of concentration in research project funding, as suggested by Aagaard et al. (2020).
Thirdly, research groups in Material Science and Engineering exhibit obvious interdisciplinary characteristics. Despite all research papers being classified under the Material Science and Engineering discipline, the distribution of research groups across various academic departments suggests a pervasive interdisciplinary nature. This phenomenon underscores the interconnectedness of Materials Science and Engineering with other disciplines and serves as evidence that members from diverse departments within high-caliber universities actively engage in collaborative efforts. Previous research conducted in the United Kingdom has revealed that interdisciplinary researchers from arts and humanities, biology, economics, engineering and physics, medicine, environmental sciences, and astronomy occupy a pivotal position in academic collaboration and can obtain more funding (Sun et al., 2021). In this research, similar conclusions are also found in Material Science and Engineering.
Fourth, the personnel structure distribution in university research groups adheres to Price’s Law, wherein prolific authors are a small part of the group members, with approximately 20% of individuals contributing to 80% of the work. Backbone-based research groups, comprising predominantly project-based and individual-based research teams in universities, typically exhibit a core and backbone members ratio of approximately 10%–15%, aligning with Price’s Law. Peterson (2018) also pointed out that Price’s Law is almost universally present in all creative work. Scientific research relies more on innovative thinking and collaboration among researchers, and the phenomenon was first confirmed within university research groups. Besides, systematic research activities require many researchers to participate, but few people make important intellectual support and contributions. In practical research endeavors, principal researchers, such as professors and associate professors, often exhibit higher levels of innovation and stability, while graduate students and external support staff tend to be more transient, engaging in foundational research tasks.
Fifth, regarding the research group with the highest publication count of the two universities, Tsinghua University has more core members, highlighting the research model centered around a single scholar, while Nanyang Technological University exhibits a more dispersed distribution of researchers. This discrepancy may be attributed to differences in the university’s system. In China, valuable scientific research often unfolds under the leadership of authoritative scholars, typically holding multiple administrative roles, thus exhibiting hierarchical centralization within the group. This hierarchical structure aligns with Merton’s Sociology of Science (1973), positing that the higher the position of scientists, the higher their status in the hierarchy, facilitating increased funding acquisition and research impact. Conversely, Singapore’s research system is more like that of developed countries such as the UK and the US, fostering a more democratic culture where communication among members is more open. This relatively flat team culture is conducive to generating high-level research outcomes (Xu et al., 2022). However, concerning the field-weighted citation impact of research group papers, the Chinese backbone-based research group outperforms in both publication volume and academic influence, suggesting that this organizational characteristic is more suitable for China and is more conducive to doing research with stronger academic influence.
The research teams and groups in these top two universities offer insights for constructing science teams: Firstly, the university should prioritize individual-based research teams to enhance the academic influence of their research. Secondly, intra-university research teams should foster collaboration across different departments to promote interdisciplinary research, contributing to the advancement of the discipline. Thirdly, emphasis should be placed on supporting core and backbone members who often generate innovative ideas and contribute more to the academic community. Fourth, the research team should cultivate a suitable research atmosphere according to their cultural background, whether centralized or democratic, to harness researchers’ strengths effectively.
This research proposes a method for identifying university research teams and analyzing the characteristics of such teams at the top two universities. In the future, further exploration into the role of different team members and the development of more effective research team construction strategies are warranted.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author upon reasonable request. The data about the information of research papers authored by the two universities and the identification results of the members of university research teams are shared.
References
Aagaard K, Kladakis A, Nielsen MW (2020) Concentration or dispersal of research funding? Quant Sci Stud 1(1):117–149. https://doi.org/10.1162/qss_a_00002
Abramo G, D’Angelo CA, Di Costa F (2017) Do interdisciplinary research teams deliver higher gains to science? Scientometrics 111:317–336. https://doi.org/10.1007/s11192-017-2253-x
Barjak F, Robinson S (2008) International collaboration, mobility and team diversity in the life sciences: impact on research performance. Soc Geogr 3(1):23–36. https://doi.org/10.5194/sg-3-23-2008
Boardman C, Ponomariov B (2014) Management knowledge and the organization of team science in university research centers. J Technol Transf 39:75–92. https://doi.org/10.1007/s10961-012-9271-x
Boyack KW, Klavans R (2014) 12 Identifying and Quantifying Research Strengths Using Market Segmentation. In: Beyond bibliometrics: Harnessing multidimensional indicators of scholarly impact, 225, MIT Press, Cambridge
Bozeman B, Youtie J (2018) The strength in numbers: The new science of team science. Princeton University Press. https://doi.org/10.1515/9781400888610
Bloch C, Sørensen MP (2015) The size of research funding: Trends and implications. Sci Public Policy 42(1):30–43. https://doi.org/10.1093/scipol/scu019
Blondel VD, Guillaume JL, Lambiotte R, Lefebvre E (2008) Fast unfolding of communities in large networks. J Stat Mech Theory Exp 2008(10):P10008. https://doi.org/10.1088/1742-5468/2008/10/P10008
Coles NA, Hamlin JK, Sullivan LL, Parker TH, Altschul D (2022) Build up big-team science. Nature 601(7894):505–507. https://doi.org/10.1038/d41586-022-00150-2
Dino H, Yu S, Wan L, Wang M, Zhang K, Guo H, Hussain I (2020) Detecting leaders and key members of scientific teams in co-authorship networks. Comput Electr Eng 85:106703. https://doi.org/10.1016/j.compeleceng.2020.106703
Deng H, Breunig H, Apte J, Qin Y (2022) An early career perspective on the opportunities and challenges of team science. Environ Sci Technol 56(3):1478–1481. https://doi.org/10.1021/acs.est.1c08322
Everett M (2002) Social network analysis. In: Textbook at Essex Summer School in SSDA, 102, Essex Summer School in Social Science Data Analysis, United Kingdom
Forscher PS, Wagenmakers EJ, Coles NA, Silan MA, Dutra N, Basnight-Brown D, IJzerman H (2023) The benefits, barriers, and risks of big-team science. Perspect Psychological Sci 18(3):607–623. https://doi.org/10.1177/17456916221082970
Guo K, Huang X, Wu L, Chen Y (2022) Local community detection algorithm based on local modularity density. Appl Intell 52(2):1238–1253. https://doi.org/10.1007/s10489-020-02052-0
Hu Z, Lin A, Willett P (2019) Identification of research communities in cited and uncited publications using a co-authorship network. Scientometrics 118:1–19. https://doi.org/10.1007/s11192-018-2954-9
Imran F, Abbasi RA, Sindhu MA, Khattak AS, Daud A, Amjad T (2018) Finding research areas of academicians using clique percolation. In 2018 14th International Conference on Emerging Technologies (ICET). IEEE, pp 1–6. https://doi.org/10.1109/ICET.2018.8603549
Lee HJ, Kim JW, Koh J, Lee Y (2008) Relative Importance of Knowledge Portal Functionalities: A Contingent Approach on Knowledge Portal Design for R&D Teams. In Proceedings of the 41st Annual Hawaii International Conference on System Sciences (HICSS 2008). IEEE, pp 331–331, https://doi.org/10.1109/HICSS.2008.373
Liao Q (2018) Research Team Identification and Influence Factors Analysis of Team Performance. M. A. Thesis. Beijing Institute of Technology, Beijing
Li Y, Tan S (2012) Research on identification and network analysis of university research team. Sci Technol Prog policy 29(11):147–150
Li G, Liu M, Wu Q, Mao J (2017) A Research of Characters and Identifications of Roles Among Research Groups Based on the Bow-Tie Model. Libr Inf Serv 61(5):87–94
Liu Y, Wu Y, Rousseau S, Rousseau R (2020) Reflections on and a short review of the science of team science. Scientometrics 125:937–950. https://doi.org/10.1007/s11192-020-03513-6
Lungeanu A, Huang Y, Contractor NS (2014) Understanding the assembly of interdisciplinary teams and its impact on performance. J Informetr 8(1):59–70. https://doi.org/10.1016/j.joi.2013.10.006
Lv L, Zhao Y, Wang X, Zhao P (2016) Core R&D Team Recognition Method Based on Association Rules Mining. Sci Technol Manag Res 36(17):148–152
Ma A, Mondragón RJ, Latora V (2015) Anatomy of funded research in science. Proc Natl Acad Sci 112(48):14760–14765. https://doi.org/10.1073/pnas.1513651112
Merton RK (1973) The sociology of science: Theoretical and empirical investigations. University of Chicago Press, Chicago
Mongeon P, Brodeur C, Beaudry C, Larivière V (2016) Concentration of research funding leads to decreasing marginal returns. Res Eval 25(4):396–404. https://doi.org/10.1093/reseval/rvw007
National Research Council (2015) Enhancing the effectiveness of team science. The National Academies Press, Washington, DC
Okamoto J, Centers for Population Health and Health Disparities Evaluation Working Group (2015) Scientific collaboration and team science: a social network analysis of the centers for population health and health disparities. Transl Behav Med 5(1):12–23. https://doi.org/10.1007/s13142-014-0280-1
Peterson JB (2018) 12 rules for life: An antidote to chaos. Random House, Canada
Scott J (2017) Social network analysis. Sage Publications Ltd, London
Seidman SB, Foster BL (1978) A graph‐theoretic generalization of the clique concept. J Math Sociol 6(1):139–154. https://doi.org/10.1080/0022250X.1978.9989883
Sun Y, Livan G, Ma A, Latora V (2021) Interdisciplinary researchers attain better long-term funding performance. Commun Phys 4(1):263. https://doi.org/10.1038/s42005-021-00769-z
Stokols D, Hall KL, Taylor BK, Moser RP (2008) The science of team science: overview of the field and introduction to the supplement. Am J Prev Med 35(2):S77–S89. https://doi.org/10.1016/j.amepre.2008.05.002
Wang C, Cheng Z, Huang Z (2017) Analysis on the co-authoring in the field of management in China: based on social network analysis. Int J Emerg Technol Learn 12(6):149. https://doi.org/10.3991/ijet.v12i06.7091
Wang T, Chen S, Wang X, Wang J (2020) Label propagation algorithm based on node importance. Phys A Stat Mech Appl. 551:124137. https://doi.org/10.1016/j.physa.2020.124137
Wu L, Wang D, Evans JA (2019) Large teams develop and small teams disrupt science and technology. Nature 566(7744):378–382. https://doi.org/10.1038/s41586-019-0941-9
Xu F, Wu L, Evans J (2022) Flat teams drive scientific innovation. Proc. Natl Acad. Sci 119(23):e2200927119. https://doi.org/10.1073/pnas.2200927119
Yu H, Bai K, Zou B, Wang Y (2020) Identification and Extraction of Research Team in the Artificial Intelligence Field. Libr Inf Serv 64(20):4–13
Yu Y, Dong C, Han H, Li Z (2018) The Method of Research Teams Identification Based on Social Network Analysis:Identifying Research Team Leaders Based on Iterative Betweenness Centrality Rank Method. Inf Stud Theory Appl 41(7):105–110
Zhao L, Zhang Q, Wang L (2014) Benefit distribution mechanism in the team members’ scientific research collaboration network. Scientometrics 100:363–389. https://doi.org/10.1007/s11192-014-1322-7
Zhang M, Jia Y, Wang N, Ge S (2019) Using Relative Tie Strength to Identify Core Teams of Scientific Research. Int J Emerg Technol Learn 14(23):33–54. https://www.learntechlib.org/p/217243/
Author information
Authors and Affiliations
Contributions
Zhe Cheng contributed to the study conception, research design, data collection, and data analysis. Zhe Cheng wrote the first draft of the manuscript. Yihuan Zou made the last revisions. Yihuan Zou and Yueyang Zheng supervised, proofread, and commented on previous versions of this manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
This article does not contain any studies with human participants performed by the authors.
Informed consent
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cheng, Z., Zou, Y. & Zheng, Y. A method for identifying different types of university research teams. Humanit Soc Sci Commun 11, 523 (2024). https://doi.org/10.1057/s41599-024-03014-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1057/s41599-024-03014-4
