
Abstract
This study focused on comparing distributed learning models with centralized and local models, assessing their efficacy in predicting specific delivery and patient-related outcomes in obstetrics using real-world data. The predictions focus on key moments in the obstetric care process, including discharge and various stages of hospitalization. Our analysis: using 6 different machine learning methods like Decision Trees, Bayesian methods, Stochastic Gradient Descent, K-nearest neighbors, AdaBoost, and Multi-layer Perceptron and 19 different variables with various distributions and types, revealed that distributed models were at least equal, and often superior, to centralized versions and local versions. We also describe thoroughly the preprocessing stage in order to help others implement this method in real-world scenarios. The preprocessing steps included cleaning and harmonizing missing values, handling missing data and encoding categorical variables with multisite logic. Even though the type of machine learning model and the distribution of the outcome variable can impact the result, we reached results of 66% being superior to the centralized and local counterpart and 77% being better than the centralized with AdaBoost. Our experiments also shed light in the preprocessing steps required to implement distributed models in a real-world scenario. Our results advocate for distributed learning as a promising tool for applying machine learning in clinical settings, particularly when privacy and data security are paramount, thus offering a robust solution for privacy-concerned clinical applications.
Similar content being viewed by others


Introduction
As the use of Artificial Intelligence (AI) is increasing in the healthcare space1, increased demand for ethical usage of personal patient data is occurring as well2. This has been happening both on the governmental side, with several regulations passed to protect citizens’ data and personal information (such as GDPR in the EU3 and HIPPA in the US4), and on the public side, with an increased concern with continuous data breaches across institutions5. So, we are now faced with a dilemma on a compromise between what is possible to do with the available data and what should be done regarding patient privacy6. This is the main reason why health institutions implement burdensome processes and methodologies for sharing patient data, often costing a great deal of time, money, and human resources, seldomly overtaking the ideal time frame for analysing such data. Due to these privacy concerns, the traditional method for using data in healthcare is, nowadays, by focusing on data from a single institution in order to predict or infer something regarding those patients; this could be understood as local learning. This approach has some drawbacks, namely data quantity, data quality and possible class imbalance7, never quite raising into its full potential for promoting best healthcare practices8,9,10 with data sharing between institutions. In order to overcome this issue, there are a few, more complex, systems that consolidate data from several institutions, so more robust algorithms could be trained. However, this globally centralised consolidation of data encompasses a very important data breach hazard.
This is the setting where distributed learning could create a greater impact. A halfway point between local and centralised learning is where we train several models, one in each institution (or silo), and where the sole information that leaves the premises is a trained model or its metadata. A distributed model is built as the aggregation of all the local models, consequently aiming to create a model similar to one globally trained with all the data in a centralised server. However, the distributed model never contacted with any data, only the local models did. This provides the opportunity to create better models, improve data protection, reduce training time and cost and provide better scaling capabilities11.
While numerous multi-institutional initiatives have successfully established integrated data repositories for healthcare research, there remains an incomplete understanding of the performance and scalability of distributed systems when directly compared to traditional, centralised models. Specifically, the nuanced behaviors of these distributed frameworks under real-world data conditions-contrasted against classical models that utilize consolidated data-have yet to be fully delineated. This paper aims to critically evaluate the efficacy and suitability of distributed mechanisms within the healthcare domain, assessing their potential as viable alternatives to conventional machine-learning pipelines. The objectives of this paper include:
-
Evaluate a distributed model against its local counterparts and against the centralized version;
-
Describe the preprocessing required to implement distributed learning with real world data;
Theoretical background and related work
Distributed learning12 can be understood as training several models in a different setting and then aggregating them as a whole. There are two main branches of these approaches, distinguishable by the existence of a central orchestrator server: federated learning where such an entity exists, and peer-to-peer (or swarm)6 learning where it does not. Distributed learning can be implemented in various ways, depending on the chosen base algorithm. One common method is averaging the weights of models, primarily utilized in federated averaging. Alternatively, distributed systems can aggregate individual models into an ensemble, enhancing performance by leveraging the strengths of different models12. Even though distributed learning has been receiving a lot of attention recently, only some of its concepts have been focused on, mainly distributed-deep learning with a federated learning approach13,14. These methods use the strength of neural networks and several algorithms such as federated averaging to create distributed models capable of handling complex data like text, sound, or image15. However, considering that there are great amounts of information, especially in healthcare, stored as tabular data16,17,18,19,20 and that neural networks are often not the best tool for such data structures and often outperformed by boosting algorithms and tree based models21,22, there is a lack of knowledge in the traditional machine learning techniques in a distributed manner. This is specially important since tabular data comes mainly from Electronic Health Records (EHRs) and this kind of data is often of lower quality, with missing values, and with a high number of categorical variables and unstructured/semi-structured variables which make the application of classical machine-learning algorithms harder than for example images, which are mainly computer and systematically generated23.
Nevertheless, there have been some health-related distributed machine-learning projects successfully implemented, such as euroCAT24 which implemented an infrastructure across five clinics in three countries. SVM models were used to learn from the data distributed across the five clinics. Each clinic has a connector to the outside where only the model’s parameters are passed to the central server which acts as a master deployer regarding the model training with the radiation oncology data. Also, ukCAT25 did similar work, with an added centralised database in the middle, but the training being done with a decentralized system. There are also reports of a study that introduces “confederated machine learning” for modeling health insurance data that is fragmented both horizontally (by individual) and vertically (by data type), without the need for central data consolidation. It showcases the method’s efficacy in predicting diseases like diabetes and heart conditions across data silos, achieving notable prediction accuracy, thereby advancing federated learning in healthcare by accommodating complex data separations and enhancing model training without compromising patient privacy or data security26. Distributed initiatives have also been covered in a review by Kirienko et al.27, where we can see very few papers have described a distributed learning approach without federation. However, from these, we can highlight the works of Wang et al.28 tried to use these approaches to detect re-hospitalization for heart failure and Tuladhar et al.12 where they used the distributed approach to detect several diseases like diabetes, heart disease, and mild cognitive impairment.
Several studies have examined model evaluation in distributed settings, such as comparing centralized and distributed machine learning using the MNIST dataset29. Others have evaluated federated learning on the MNIST, MIMIC-III, and PhysioNet ECG datasets, though these studies did not compare federated learning to other methodologies30. Tuladhar and colleagues have also investigated healthcare images and various public and curated datasets12. Morevoer, none of them address the challenges of using real-world data and how to implement these methodologies in live scenarios. Additionally, a scoping review emphasizes the importance of thoroughly evaluating distributed and federated models against local models31. To our knowledge, this study is the first to evaluate distributed machine learning on such a broad scale with real-world tabular clinical data from nine distinct sources, employing various algorithms and outcome variables, and comparing these methods to both centralized and local approaches. This evaluation encompasses both federated and peer-to-peer methodologies.
Materials
Clinical data was gathered from nine different Portuguese hospitals regarding obstetric information, pertaining to admissions from 2019 to 2020. This originated nine different files representing different sets of patients but with the same features associated to them. The software for collecting data was the same in every institution (although different versions existed across hospitals) - ObsCare32. The data columns are the same in every hospital’s database. Each hospital was considered a silo and summary statistics of the different silos are reported in the Tables 1 and 2. The data dictionary is in Appendix A. The datasets were anonymized and de-identified prior to analysis and each hospital was assigned a number to ensure confidentiality. Each dataset represents a different hospital, which we will use for this analysis as a isolated silo and the number of patients in each dataset is reported in the last row of the Tables 1 and 2. Dataset comprised of patient’s features like age and weight and characteristics as well, like if the patient smoked during pregnancy or had gestational diabetes. The dataset also comprises information about the pregnancy like number of weeks, type of birth, bishop score (pre-labor scoring system used to predict the success of induction of labor), or if the pregnancy was followed by a specific physician in a specific scenario.
This study received Institutional Review Board approval from all hospitals included in this study with the following references: Centro Hospitalar São João; 08/2021, Centro Hospitalar Baixo Vouga; 12-03-2021, Unidade Local de Saúde de Matosinho; 39/CES/JAS, Hospital da Senhora da Oliveira; 85/2020, Centro Hospitalar Tamega Sousa; 43/2020, Centro Hospitalar Vila Nova de Gaia/Espinho; 192/2020, Centro Hospitalar entre Douro e Vouga; CA-371/2020-0t_MP/CC, Unidade Local de saúde do Alto Minho; 11/2021. All methods were carried out in accordance with relevant guidelines and regulations.
Methods
The section will cover the steps we took for evaluating the models. We first addressed the preprocessing of the data, then the training of the models and finally the evaluation of the models. The evaluation was done by comparing the performance of the distributed model with the local and centralised models. The performance was measured by the AUROC, AUPRC, RMSE and MAE. The results were then compared using a 2-sample T-test.
Preprocessing
The initial dataset underwent preprocessing by eliminating attributes that were missing more than 90% of their data across all storage units (or silo). We standardized the representation of missing values, which varied widely, including representations such as “-1” “missing” or simply blank spaces. For imputation, we utilized the mean for continuous variables (calculated within site) and introduced a special category (NULLIMP) for categorical variables. We converted all categories into numerical values based on a predefined mapping that covered all potential categories across the datasets. Although this approach introduces an ordinal relationship and potential bias is created among features, we disregarded this concern because the methodology was uniformly applied across all datasets intended for training local, distributed and centralised. These preprocessing tasks were executed once for each dataset and silo.
However, in the context of training classification models, it is crucial that all classes of the target variable are known at the time of training and are represented in each split of the cross-validation process. To address this, we employed SMOTE33 to up-sampled low-frequency target classes. We established a threshold of n<25 for low-frequency variables to ensure that each cross-validation split contained at least two instances of the class-although a minimum of 10 instances (10 splits) might suffice, we opted for 25 to mitigate potential distribution issues and have at least two examples of the class in each split. Additionally, we created dummy rows for missing target classes by imputing the mean for continuous variables and the mode for categorical variables (calculated within site). The necessity for up-sampling and missing variable creation was evaluated and applied as needed for each training session and for each target, considering that each session’s split could result in a training set lacking instances of low-frequency classes.
All procedures were coded in python 3.9.7 with the usage of the scikit-learn library34 and mlxtend library35.
Model training
To avoid pitfalls of inductive bias from a certain learning strategy, we learned six different models (i) Decision Trees, (ii) Bayesian methods, (iii) a logistic regression model with Stochastic Gradient Descent, (iv) K-nearest neighbours, (v) AdaBoost and (vi) Multi-layer Perceptron. The decision was to create diversity in the models used, in order to assess if the training methodology could have an impact on distributed model creation. The distributed model was an ensemble of models from each silo on a weighted soft-voting basis. The weights were defined by weighted averages of the scores each model obtained in the training set. Then the final result is obtained by creating a weighted average of the class predictions for classification and a weighted average for regression. A model like this can be implemented with peer-to-peer or federated approaches. Nineteen features were used as target outcomes. These features were selected by filtering by the percentage of null values (below 50%). This choice was related to maintaining a equilibrium between having a wide range of variables to test how the target variables affects the outcome and having target variables that did go through an harsh imputation mechanism. For categorical outcomes, thirteen were selected (AA—Baby’s Position on Admission (like vertex, cephalic or transverse); ANP—Baby’s Position on Delivery (like vertex, cephalic or transverse); AGESTA—Number of Pregnancies; APARA—Number of born babies; GS—Blood Group; GR—Robson Group, which is a system used to categorize all women giving birth into ten groups based on characteristics that are clinically relevant to the outcome of delivery; TG—Pregnancy Type (like spontaneous or In vitro fertilisation); TP—Delivery Type (like vaginal or C-section); TPEE—if the delivery was spontaneous, meaning that no induction was needed; TPNP—Actual Type of Delivery, or the actual delivery method; V—if the mother was followed by physician; VCS—if the mother was followed by a physician in primary care; VNH—if the mother was followed by a physician in the same hospital of the delivery;). For continuous variables, six were selected (IA—Mother’s Age; IGA—Weeks on Admission; IMC—Body Mass Index ; NRCPN—Number of consultations; PI—Weight of the mother at the start of pregnancy; SGP—number of weeks on Delivery). Given the wide range of different variables, there is the potential of using the predictions of the models in the whole pregnancy process. More information about the variables can be seen in Tables 1 and 2. Local models were built with each silo’s data. The centralised model was trained with a training dataset from all the silos combined.
Model performance evaluation
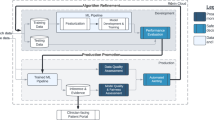
All models were built for a certain outcome variable with a repeated cross-validation (2 times and 10 splits each) and then compared, over ten stochastic runs, with evaluation being performed on a test set held out from each silo. By performing cross-validation twice, we aimed to generate a more robust estimation of the model’s performance metrics by averaging the results over two separate runs, each partitioning the data differently. This approach is particularly useful in scenarios where data is limited or highly variable, as it provides a clearer insight into the model’s expected performance in unseen data scenarios. The metrics used for classification models were Weighted Area Under the Receiver Operating Characteristic Curve (AUROC) computed as One-versus-Rest, Weighted Area Under the Precision-Recall Curve (AUPRC). The metrics for regression models were Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE). The algorithm is shown in the Algorithm 1. This rendered over 1000 different combinations. When a variable was used as outcome to predict, all others were used as predictors.

Creation and evaluation of the three different models. We first preprocessed data. Then for each target, we created a distributed and centralised model. Then, over ten repetitions per silo, we created a new train and test set and local model and tested the centralised, distributed and local on this test set.
After all the data was collected, we used the standard independent 2-sample T-test to check if the differences were significant with a \(\alpha\) of 0.05. First, we compared the overall performance of the distributed model vs their centralised and local counterpart. We also compared every distributed model per algorithm and sequentially the centralised and correspondent local model across all algorithms and repetitions and outcome variables with 2-sample T-test as well.
Results
Table 3 shows the aggregated metrics for AUROC, AUPRC, RMSE and MAE for distributed, centralised and local models predicting capabilities on each silo. The data refers to the mean of the metric values for all columns tested as targets for all methods and all silos. We also calculated the 95% confidence interval for each model (local and distributed per silo) in order to assess how well the distributed model would work as opposed to the local one per silo. We also calculated the p Value for the means of the distributed vs centralised and distributed vs local.
Table 4 shows all iterations of the tests and how the distributed model compared with the centralised and the local for each silo, target variable, repetition and machine learning model like described in Algorithm 1. The rows describe the relationship of the distributed and the centralized and the columns the relationship between the distributed model and the corresponding local model.
Figure 1 shows the AUROC of each algorithm and silo on the Y axis and target variable and type of model on the X. The color bar refers to the value of the AUROC. Blue being lower values and red bigger values. The same type of graph was created for regression, where the Fig. 2 shows the MAE for each silo and algorithm and target variable and type of model.

Heatmap of classification algorithm and silo vs target variable and model type. Value is the AUROC mean of all 10 experiments. Y axis is the algorithm and silo. X axis is target variable and method. AA position admission, ANP position on delivery, AGESTA nr of pregnancies, APARA nr of born babies, GS blood group, GR Robson group, TG pregnancy type, TP delivery type, TPEE spontaneous delivery, TPNP actual type of delivery, V followed physician, VCS followed physician primary care, VNH followed physician hospital delivery.

Heatmap of regression algorithm and silo vs target variable and model type. Value is the MAE mean of all 10 experiments. The y axis is the algorithm and silo. X axis is target variable and method. IA mother age, IGA weeks on admission, IMC BMI, NRCPN nr of consultations, PI weight start of pregnancy, SGP weeks on delivery.
Discussion
A significant finding is that nearly 59% of distributed models demonstrated comparable, if not superior, performance relative to their centralized counterparts (Table 4 last column, first two values for each algorithm). From these, 41.9% were also better or equal to the local model. Using the best-performing algorithm (SGD), we observe a 77.2% improvement in distributed settings compared to centralized, and a 66% improvement over both centralized and local models. This outcome underlines the potential of distributed models to offer reliable inference capabilities that match those of traditional centralized models, without sacrificing predictive accuracy. Furthermore, the adoption of distributed models enhances privacy for data owners, presenting a compelling case for their broader application in data-sensitive environments. Overall, our results suggest that it is possible to implement a distributed model without significantly losing information. Our analysis suggests that SGD, Adaboost and Naive Bayes approaches are suitable for such distributed approached with tabular data. In contrast, MLPerceptron, Decision Trees and KNN do not seem to be a good approach for such use cases.
However, there are still issues to be addressed. This methodology presents hurdles regarding categorical class handling. Firstly, all classes should be known first-hand and should be given to each model even if that silo in particular has no cases of that class. Secondly, low-frequency classes are also an issue to be addressed, since training the model with cross-validation will raise problems because each split should have all classes present. Our approach relied on sample creation for low and non-existent target classes. However, this approach is adding information to the model that is not originally there. The way we chose for minimising this issue was by creating dummy variables with median and mode imputations based only on the information in the dataset. Nevertheless, non-existent classes are impossible to address without prior information. These class problems could be partially tackled in production by implementing data management and governance procedures, namely data dictionaries. Still on data preprocessing, we applied ordinal encoding to the variables which will create a natural hierarchy between variables. One solution for this is to create binary columns for each class in each column. This will remove the hierarchy between classes but increase variable numbers and training time considerably.
Another issue to consider is the path adopted to build the distributed model. In this case, it was decided to develop an ensemble of models with voting. However, other methods could have been employed, like parameter averaging, that should be tested as well. In particular, the usage of more robust neural networks could be assessed as well. We chose not to test state-of-the-art neural networks since the data volume was low for that use case and several papers have already demonstrated that neural networks are not the most suitable tool for tabular data36,37. We chose to add MLPerceptron as a baseline for comparison with the remaining algorithms. The results show us that the performance was below the other algorithms, but in this concrete case, the problem may reside in the architecture chosen and hyperparameters used in the Cross-validation which may have lead to underfitting. Despite this, a precise and thorough demonstration of this use case would be important to consider such scenarios.
Furthermore, the algorithm underlying the distributed model is of importance as well for its performance versus the centralised model. Figs. 1 and 2 and Table 4 show us that Decision trees and K-nearest neighbours implemented in a centralised manner are consistently better than the distributed counterpart. This is specially notorious in the case of the decision trees. We believe this may be related to way the algorithm is implemented. A centralised version may be able to create optimal splits in the data, while the distributed version may not be able to do so. This is a topic that should be further explored.
Even though this improvement may have a relationship to the target variable (i.e. Fig. 2 for IA and IGA variables), it is still an important fact to take into account when implementing such architectures. The performance of the models is also interesting to catch differences in silos. See silo 6 for TPNP (Fig. 1) where silo 6 consistently behaves differently than the rest. Checking performance data regarding regression tasks, we can see a drop in performance for PI and IA. While the explanation for the performance of IA can be explained by the average value of it which is 66, which is the highest average in the dataset. This means that the model will have a harder time predicting these values, being also true for the distributed model. This is a topic that should be further explored.
As for implementation, specially preprocessing, we found that having the description of data across silos is vital since we might need to convert and encode data. This is a step that should be taken into account when implementing such a system. This might be easier to implement in a federated manner, where a central orchestrator could take care of this. If an implementation like peer-to-peer is implemented, the metadata should also be shared or defined a priori. Other important issue is related with absence of data and missing values and categories. Most machine learning models expect a specific size of input data. This is a problem when we have missing values or categories that are not present in the training set. Our approach was to handle it with synthetic data generation which may suffice for most scenarios. Regarding the prediction capability as a whole, we found that this data is suitable to apply machine-learning models in order to predict several clinical outcomes, with very good results for several target variables.
Conclusion
This study represents a comprehensive evaluation of distributed machine learning using real-world tabular obstetrics data from nine distinct sources on such a significant scale. It encompasses a variety of algorithms and outcome variables, comparing these to both centralized and local approaches. Our work demonstrated the performance of distributed models using real-world data by comparing their performance with that of local models, which are trained with data from individual silos, and centralized models, which utilize data from all silos. The findings reveal that an ensemble of models, essentially a distributed model as investigated in this study, can capture the nuances of the data, achieving performance comparable to a model constructed with comprehensive data. Although the performance of these models is shaped by factors such as the inherent characteristics of the target variables and the data distribution across different silos, we are now fairly confident that distributed learning represents a significant advancement. Particularly, if a distributed model can match or surpass the performance of a centralized model, this is notably beneficial. Such an outcome underscores the value of distributed models as they not only maintain, but potentially enhance, predictive accuracy while offering a higher degree of data privacy compared to centralized systems. This balance of privacy with efficiency is especially crucial in fields where data sensitivity is paramount, making distributed learning an appealing option when evaluated against both centralized and local models. Considering the robust performance metrics observed, with AUROC/AUPRC scores exceeding 80% and MAE maintained below 1, further investigation into distributed models is warranted. Specifically, we aim to develop distributed models for predicting clinical outcomes, such as delivery type or Robson Group classifications, which hold significant potential for real-world clinical application like reducing unnecessary Cesarean Sections or accelerating diagnosis. Our findings highlight that distributed learning not only advances data privacy while maintains high prediction accuracy, promising substantial benefits for clinical practices.
Data availability
The data that support the findings of this study are available from the source hospitals but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of the hospitals ethics committee and privacy officers. The code used to generate the results and graphics is available here: https://github.com/joofio/Evaluating-distributed-learning-algorithms-on-real-world-healthcare-data.
References
Ravì, D. et al. Deep learning for health informatics. IEEE J. Biomed. Health Inform. 21, 4–21. https://doi.org/10.1109/JBHI.2016.2636665 (2017).
Char, D. S., Shah, N. H. & Magnus, D. Implementing machine learning in health care—Addressing ethical challenges. N. Engl. J. Med. 378, 981–983 (2018).
Albrecht, J. P. How the GDPR will change the world. Eur. Data Protect. Law Rev. 2, 287–289. https://web.archive.org/web/20211014090922. https://edpl.lexxion.eu/article/EDPL/2016/3/4 (Lexxion Publisher, 2016).
Office for Civil Rights. Guidance Regarding Methods for De-identification of Protected Health Information in Accordance with the Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule. (U.S. Department of Health and Human Services, 2013).
Abdulrahman, S. et al. A survey on federated learning: The journey from centralized to distributed on-site learning and beyond. IEEE Internet Things J. (2021).
Warnat-Herresthal, S. et al. Swarm learning for decentralized and confidential clinical machine learning. Nature 594, 265–270 (2021).
Rajkomar, A., Dean, J. & Kohane, I. Machine learning in medicine. N. Engl. J. Med. (2019).
Xu, J. et al. Federated learning for healthcare informatics. J. Healthc. Inform. Res. . arXiv:3320.4939 (2020).
Yang, Y. C. et al. Influential usage of big data and artificial intelligence in healthcare. Comput. Math. Methods Med. 2021, 5812499 (2021).
Wang, F. & Preininger, A. AI in health: State of the art, challenges, and future directions. Yearb. Med. Inform. 28, 16–26 (2019).
Jatain, D., Singh, V. & Dahiya, N. A contemplative perspective on federated machine learning: Taxonomy, threats & vulnerability assessment and challenges. J. King Saud Univ. Comput. Inf. Sci. (2021).
Tuladhar, A., Gill, S., Ismail, Z. & Forkert, N. D. Building machine learning models without sharing patient data: A simulation-based analysis of distributed learning by ensembling. J. Biomed. Inform. 106, 103424. https://web.archive.org/web/20210625175422. https://www.sciencedirect.com/science/article/pii/S1532046420300526 (2020).
Xu, J. et al. Federated learning for healthcare informatics. J. Healthc. Inform. Res. 5, 1–19. https://doi.org/10.1007/s41666-020-00082-4 (2021) arXiv:3320.4939.
Lee, G. H. & Shin, S.-Y. Federated learning on clinical benchmark data: Performance assessment. J. Med. Internet Res. 22, 10 (2020).
Prayitno, et al. A systematic review of federated learning in the healthcare area: From the perspective of data properties and applications. Appl. Sci. 11, 11191. https://doi.org/10.3390/app112311191 (2021).
Álvarez Sánchez, R., Beristain Iraola, A., Epelde Unanue, G. & Carlin, P. TAQIH, a tool for tabular data quality assessment and improvement in the context of health data. Comput. Methods Prog. Biomed. 181, 104824. https://doi.org/10.1016/j.cmpb.2018.12.029 (2019).
Di Martino, F. & Delmastro, F. Explainable AI for clinical and remote health applications: A survey on tabular and time series data. Artif. Intell. Rev. 1–55. https://doi.org/10.1007/s10462-022-10304-3. arXiv:3632.0613 (2022).
Payrovnaziri, S. N. et al. Explainable artificial intelligence models using real-world electronic health record data: A systematic scoping review. J. Am. Med. Inform. Assoc. JAMIA 27, 1173–1185. https://doi.org/10.1093/jamia/ocaa053 (2020) arXiv:3241.7928.
McElfresh, D. et al. When Do Neural Nets Outperform Boosted Trees on Tabular Data? arXiv:2305.02997 (2023).
Klambauer, G., Unterthiner, T., Mayr, A. & Hochreiter, S. Self-Normalizing Neural Networks. arXiv:1706.02515 (2017).
Borisov, V. et al. Deep neural networks and tabular data: A survey. IEEE Trans. Neural Netw. Learn. Syst. 1–21 https://doi.org/10.1109/TNNLS.2022.3229161. arXiv:2110.01889 (2022).
Grinsztajn, L., Oyallon, E. & Varoquaux, G. Why do tree-based models still outperform deep learning on tabular data? https://doi.org/10.48550/arXiv.2207.08815. arXiv:2207.08815 (2022).
Peek, N. & Rodrigues, P. P. Three controversies in health data science. Int. J. Data Sci. Anal. 6, 261–269. https://doi.org/10.1007/s41060-018-0109-y (2018).
Deist, T. M. et al. Infrastructure and distributed learning methodology for privacy-preserving multi-centric rapid learning health care: euroCAT. Clin. Transl. Radiat. Oncol. 4, 24–31 (2017).
Price, G., van Herk, M. & Faivre-Finn, C. Data mining in oncology: The ukCAT project and the practicalities of working with routine patient data. Clinical Oncology (Royal College of Radiologists (Great Britain)) 29, 814–817, https://doi.org/10.1016/j.clon.2017.07.011 (2017).
Liu, D., Fox, K., Weber, G. & Miller, T. Confederated learning in healthcare: Training machine learning models using disconnected data separated by individual, data type and identity for Large-Scale health system Intelligence. J. Biomed. Inform. 134, 104151. https://doi.org/10.1016/j.jbi.2022.104151 (2022).
Kirienko, M. et al. Distributed learning: A reliable privacy-preserving strategy to change multicenter collaborations using AI. Eur. J. Nucl. Med. Mol. Imaging 48, 3791–3804. https://doi.org/10.1007/s00259-021-05339-7 (2021) arXiv:3384.7779.
Wang, Y. et al. A fast divide-and-conquer sparse Cox regression. Biostatistics (Oxford, England) 22, 381–401. https://doi.org/10.1093/biostatistics/kxz036 (2019) arXiv:3154.5341.
Chandiramani, K., Garg, D. & Maheswari, N. Performance analysis of distributed and federated learning models on private data. Proc. Comput. Sci. 165, 349–355 (2019).
Lee, G. H. & Shin, S.-Y. Federated learning on clinical benchmark data: Performance assessment. J. Med. Internet Res. 22, 9 (2020).
Li, S. et al. Federated and distributed learning applications for electronic health records and structured medical data: A scoping review. J. Am. Med. Inform. Assoc. 30, 2041–2049. https://doi.org/10.1093/jamia/ocad170 (2023).
VirtualCare. Obscare.https://virtualcare.pt/portfolio/vc-obscare-2-2/. Accessed 26 Feb 2024 (2024).
Chawla, N. V., Bowyer, K. W., Hall, L. O. & Kegelmeyer, W. P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 16, 321–357 (2002).
Pedregosa, F. et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Raschka, S. Mlxtend: Providing machine learning and data science utilities and extensions to Python’s scientific computing stack. J. Open Source Softw.https://doi.org/10.21105/joss.00638 (2018).
Grinsztajn, L., Oyallon, E. & Varoquaux, G. Why do tree-based models still outperform deep learning on tabular data? arXiv:2207.08815 (2022).
Borisov, V. et al. Deep Neural Networks and Tabular Data: A Surveyhttps://doi.org/10.48550/arXiv.2110.01889 (2022).
Acknowledgements
The authors would like to acknowledge—Project “NORTE-01-0247-FEDER-038393” (ObsCare WCR—Worldwide Maternal and Child Care and Research) is financed by the North Portugal Regional Operational Program (NORTE2020), under the PORTUGAL 2020 Partnership Agreement, and through the European Regional Development Fund (ERDF).
Author information
Authors and Affiliations
Contributions
J.A., P.R., and R.C. conceived the study. J.A. wrote the code, conducted the experiments, and analyzed the data. P.R and R.C. contributed to the experimental design and were in charge of overall direction and planning. All authors contributed to the interpretation of the results. J.A drafted the manuscript, which was reviewed, revised and approved by all authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
A: Data dictionary
A: Data dictionary
Initial | Description |
|---|---|
IA | Mother age |
GS | Blood group |
PI | Weight at the beginning of pregnancy |
PAI | Weight on admission |
IMC | BMI |
CIG | If smoker during pregnancy |
APARA | Number of previously born babies |
AGESTA | Number of pregnancies |
EA | Number of previous eutocic deliveries with no assistance |
VA | Number of previous eutocic deliveries with help of vacuum extraction |
FA | Number of previous eutocic deliveries with help of forceps |
CA | Number of previous C-sections |
TG | Pregnancy type (spontaneous, in vitro fertilisation...) |
V | If the pregnancy was accompanied by physician |
NRCPN | Number of prenatal consultations |
VH | If the pregnancy was accompanied by a physician in a hospital |
VP | If the pregnancy was accompanied by a physician in a private clinic |
VCS | If the pregnancy was accompanied by a physician in a primary care facility |
VNH | If the pregnancy was accompanied by a physician in the hospital the delivery was made |
B | Pelvis adequacy |
AA | Baby’s position on admission |
BS | Bishop score |
BC | Bishop score cervical consistency |
BDE | Bishop score fetal station |
BDI | Bishop score dilatation |
BE | Bishop score effacement |
BP | Bishop score cervical position |
IGA | Number of weeks on admission |
TPEE | If the delivery was spontaneous |
TPEI | If the delivery was induced |
RPM | If there was a rupture of the amniotic pocket before delivery began |
DG | Gestational diabetes |
TP | Delivery type |
ANP | Baby’s position on delivery |
TPNP | Actual type of delivery |
SGP | Pregnancy weeks on delivery |
GR | Robson group |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Coutinho-Almeida, J., Cruz-Correia, R.J. & Rodrigues, P.P. Evaluating distributed-learning on real-world obstetrics data: comparing distributed, centralized and local models. Sci Rep 14, 11128 (2024). https://doi.org/10.1038/s41598-024-61371-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-61371-1
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
