
Abstract
To overcome the disadvantages of premature convergence and easy trapping into local optimum solutions, this paper proposes an improved particle swarm optimization algorithm (named NDWPSO algorithm) based on multiple hybrid strategies. Firstly, the elite opposition-based learning method is utilized to initialize the particle position matrix. Secondly, the dynamic inertial weight parameters are given to improve the global search speed in the early iterative phase. Thirdly, a new local optimal jump-out strategy is proposed to overcome the "premature" problem. Finally, the algorithm applies the spiral shrinkage search strategy from the whale optimization algorithm (WOA) and the Differential Evolution (DE) mutation strategy in the later iteration to accelerate the convergence speed. The NDWPSO is further compared with other 8 well-known nature-inspired algorithms (3 PSO variants and 5 other intelligent algorithms) on 23 benchmark test functions and three practical engineering problems. Simulation results prove that the NDWPSO algorithm obtains better results for all 49 sets of data than the other 3 PSO variants. Compared with 5 other intelligent algorithms, the NDWPSO obtains 69.2%, 84.6%, and 84.6% of the best results for the benchmark function (\({f}_{1}-{f}_{13}\)) with 3 kinds of dimensional spaces (Dim = 30,50,100) and 80% of the best optimal solutions for 10 fixed-multimodal benchmark functions. Also, the best design solutions are obtained by NDWPSO for all 3 classical practical engineering problems.
Similar content being viewed by others

Introduction
In the ever-changing society, new optimization problems arise every moment, and they are distributed in various fields, such as automation control1, statistical physics2, security prevention and temperature prediction3, artificial intelligence4, and telecommunication technology5. Faced with a constant stream of practical engineering optimization problems, traditional solution methods gradually lose their efficiency and convenience, making it more and more expensive to solve the problems. Therefore, researchers have developed many metaheuristic algorithms and successfully applied them to the solution of optimization problems. Among them, Particle swarm optimization (PSO) algorithm6 is one of the most widely used swarm intelligence algorithms.
However, the basic PSO has a simple operating principle and solves problems with high efficiency and good computational performance, but it suffers from the disadvantages of easily trapping in local optima and premature convergence. To improve the overall performance of the particle swarm algorithm, an improved particle swarm optimization algorithm is proposed by the multiple hybrid strategy in this paper. The improved PSO incorporates the search ideas of other intelligent algorithms (DE, WOA), so the improved algorithm proposed in this paper is named NDWPSO. The main improvement schemes are divided into the following 4 points: Firstly, a strategy of elite opposition-based learning is introduced into the particle population position initialization. A high-quality initialization matrix of population position can improve the convergence speed of the algorithm. Secondly, a dynamic weight methodology is adopted for the acceleration coefficients by combining the iterative map and linearly transformed method. This method utilizes the chaotic nature of the mapping function, the fast convergence capability of the dynamic weighting scheme, and the time-varying property of the acceleration coefficients. Thus, the global search and local search of the algorithm are balanced and the global search speed of the population is improved. Thirdly, a determination mechanism is set up to detect whether the algorithm falls into a local optimum. When the algorithm is “premature”, the population resets 40% of the position information to overcome the local optimum. Finally, the spiral shrinking mechanism combined with the DE/best/2 position mutation is used in the later iteration, which further improves the solution accuracy.
The structure of the paper is given as follows: Sect. “Particle swarm optimization (PSO)” describes the principle of the particle swarm algorithm. Section “Improved particle swarm optimization algorithm” shows the detailed improvement strategy and a comparison experiment of inertia weight is set up for the proposed NDWPSO. Section “Experiment and discussion” includes the experimental and result discussion sections on the performance of the improved algorithm. Section “Conclusions and future works” summarizes the main findings of this study.
Literature review
This section reviews some metaheuristic algorithms and other improved PSO algorithms. A simple discussion about recently proposed research studies is given.
Metaheuristic algorithms
A series of metaheuristic algorithms have been proposed in recent years by using various innovative approaches. For instance, Lin et al.7 proposed a novel artificial bee colony algorithm (ABCLGII) in 2018 and compared ABCLGII with other outstanding ABC variants on 52 frequently used test functions. Abed-alguni et al.8 proposed an exploratory cuckoo search (ECS) algorithm in 2021 and carried out several experiments to investigate the performance of ECS by 14 benchmark functions. Brajević9 presented a novel shuffle-based artificial bee colony (SB-ABC) algorithm for solving integer programming and minimax problems in 2021. The experiments are tested on 7 integer programming problems and 10 minimax problems. In 2022, Khan et al.10 proposed a non-deterministic meta-heuristic algorithm called Non-linear Activated Beetle Antennae Search (NABAS) for a non-convex tax-aware portfolio selection problem. Brajević et al.11 proposed a hybridization of the sine cosine algorithm (HSCA) in 2022 to solve 15 complex structural and mechanical engineering design optimization problems. Abed-Alguni et al.12 proposed an improved Salp Swarm Algorithm (ISSA) in 2022 for single-objective continuous optimization problems. A set of 14 standard benchmark functions was used to evaluate the performance of ISSA. In 2023, Nadimi et al.13 proposed a binary starling murmuration optimization (BSMO) to select the effective features from different important diseases. In the same year, Nadimi et al.14 systematically reviewed the last 5 years' developments of WOA and made a critical analysis of those WOA variants. In 2024, Fatahi et al.15 proposed an Improved Binary Quantum-based Avian Navigation Optimizer Algorithm (IBQANA) for the Feature Subset Selection problem in the medical area. Experimental evaluation on 12 medical datasets demonstrates that IBQANA outperforms 7 established algorithms. Abed-alguni et al.16 proposed an Improved Binary DJaya Algorithm (IBJA) to solve the Feature Selection problem in 2024. The IBJA’s performance was compared against 4 ML classifiers and 10 efficient optimization algorithms.
Improved PSO algorithms
Many researchers have constantly proposed some improved PSO algorithms to solve engineering problems in different fields. For instance, Yeh17 proposed an improved particle swarm algorithm, which combines a new self-boundary search and a bivariate update mechanism, to solve the reliability redundancy allocation problem (RRAP) problem. Solomon et al.18 designed a collaborative multi-group particle swarm algorithm with high parallelism that was used to test the adaptability of Graphics Processing Units (GPUs) in distributed computing environments. Mukhopadhyay and Banerjee19 proposed a chaotic multi-group particle swarm optimization (CMS-PSO) to estimate the unknown parameters of an autonomous chaotic laser system. Duan et al.20 designed an improved particle swarm algorithm with nonlinear adjustment of inertia weights to improve the coupling accuracy between laser diodes and single-mode fibers. Sun et al.21 proposed a particle swarm optimization algorithm combined with non-Gaussian stochastic distribution for the optimal design of wind turbine blades. Based on a multiple swarm scheme, Liu et al.22 proposed an improved particle swarm optimization algorithm to predict the temperatures of steel billets for the reheating furnace. In 2022, Gad23 analyzed the existing 2140 papers on Swarm Intelligence between 2017 and 2019 and pointed out that the PSO algorithm still needs further research. In general, the improved methods can be classified into four categories:
-
(1)
Adjusting the distribution of algorithm parameters. Feng et al.24 used a nonlinear adaptive method on inertia weights to balance local and global search and introduced asynchronously varying acceleration coefficients.
-
(2)
Changing the updating formula of the particle swarm position. Both papers25 and26 used chaotic mapping functions to update the inertia weight parameters and combined them with a dynamic weighting strategy to update the particle swarm positions. This improved approach enables the particle swarm algorithm to be equipped with fast convergence of performance.
-
(3)
The initialization of the swarm. Alsaidy and Abbood proposed27 a hybrid task scheduling algorithm that replaced the random initialization of the meta-heuristic algorithm with the heuristic algorithms MCT-PSO and LJFP-PSO.
-
(4)
Combining with other intelligent algorithms: Liu et al.28 introduced the differential evolution (DE) algorithm into PSO to increase the particle swarm as diversity and reduce the probability of the population falling into local optimum.
Particle swarm optimization (PSO)
The particle swarm optimization algorithm is a population intelligence algorithm for solving continuous and discrete optimization problems. It originated from the social behavior of individuals in bird and fish flocks6. The core of the PSO algorithm is that an individual particle identifies potential solutions by flight in a defined constraint space adjusts its exploration direction to approach the global optimal solution based on the shared information among the group, and finally solves the optimization problem. Each particle \(i\) includes two attributes: velocity vector \({V}_{i}=\left[{v}_{i1},{v}_{i2},{v}_{i3},{...,v}_{ij},{...,v}_{iD},\right]\) and position vector \({X}_{i}=[{x}_{i1},{x}_{i2},{x}_{i3},...,{x}_{ij},...,{x}_{iD}]\). The velocity vector is used to modify the motion path of the swarm; the position vector represents a potential solution for the optimization problem. Here, \(j=\mathrm{1,2},\dots ,D\), \(D\) represents the dimension of the constraint space. The equations for updating the velocity and position of the particle swarm are shown in Eqs. (1) and (2).
Here \({Pbest}_{i}^{k}\) represents the previous optimal position of the particle \(i\), and \({Gbest}\) is the optimal position discovered by the whole population. \(i=\mathrm{1,2},\dots ,n\), \(n\) denotes the size of the particle swarm. \({c}_{1}\) and \({c}_{2}\) are the acceleration constants, which are used to adjust the search step of the particle29. \({r}_{1}\) and \({r}_{2}\) are two random uniform values distributed in the range \([\mathrm{0,1}]\), which are used to improve the randomness of the particle search. \(\omega\) inertia weight parameter, which is used to adjust the scale of the search range of the particle swarm30. The basic PSO sets the inertia weight parameter as a time-varying parameter to balance global exploration and local seeking. The updated equation of the inertia weight parameter is given as follows:
where \({\omega }_{max}\) and \({\omega }_{min}\) represent the upper and lower limits of the range of inertia weight parameter. \(k\) and \(Mk\) are the current iteration and maximum iteration.
Improved particle swarm optimization algorithm
According to the no free lunch theory31, it is known that no algorithm can solve every practical problem with high quality and efficiency for increasingly complex and diverse optimization problems. In this section, several improvement strategies are proposed to improve the search efficiency and overcome this shortcoming of the basic PSO algorithm.
Improvement strategies
The optimization strategies of the improved PSO algorithm are shown as follows:
-
(1)
The inertia weight parameter is updated by an improved chaotic variables method instead of a linear decreasing strategy. Chaotic mapping performs the whole search at a higher speed and is more resistant to falling into local optimal than the probability-dependent random search32. However, the population may result in that particles can easily fly out of the global optimum boundary. To ensure that the population can converge to the global optimum, an improved Iterative mapping is adopted and shown as follows:
$$\omega_{k + 1} = {\text{sin}}\left( {b \times \pi /\omega_{k} } \right) \times k/Mk$$(4)Here \({\omega }_{k}\) is the inertia weight parameter in the iteration \(k\), \(b\) is the control parameter in the range \([\mathrm{0,1}]\).
-
(2)
The acceleration coefficients are updated by the linear transformation.\({c}_{1}\) and \({c}_{2}\) represent the influential coefficients of the particles by their own and population information, respectively. To improve the search performance of the population, \({c}_{1}\) and \({c}_{2}\) are changed from fixed values to time-varying parameter parameters, that are updated by linear transformation with the number of iterations:
$$c_{1} = c_{max} - \left( {c_{max} - c_{min} } \right) \times k/Mk$$(5)$$c_{2} = c_{min} + \left( {c_{max} - c_{min} } \right) \times k/Mk$$(6)where \({c}_{max}\) and \({c}_{min}\) are the maximum and minimum values of acceleration coefficients, respectively.
-
(3)
The initialization scheme is determined by elite opposition-based learning. The high-quality initial population will accelerate the solution speed of the algorithm and improve the accuracy of the optimal solution. Thus, the elite backward learning strategy33 is introduced to generate the position matrix of the initial population. Suppose the elite individual of the population is \({X}=[{x}_{1},{x}_{2},{x}_{3},...,{x}_{j},...,{x}_{D}]\), and the elite opposition-based solution of \(X\) is \({X}_{o}=[{x}_{{\text{o}}1},{x}_{{\text{o}}2},{x}_{{\text{o}}3},...,{x}_{oj},...,{x}_{oD}]\). The formula for the elite opposition-based solution is as follows:
$$x_{oij} = k_{r} \times \left( {ux_{oij} + lx_{oij} } \right) - x_{ij}$$(7)$$ux_{oij} = {\text{max}}\left( {x_{ij} } \right) ,lx_{oij} = {\text{min}}\left( {x_{ij} } \right)$$(8)where \({k}_{r}\) is the random value in the range \((\mathrm{0,1})\). \({ux}_{oij}\) and \({lx}_{oij}\) are dynamic boundaries of the elite opposition-based solution in \(j\) dimensional variables. The advantage of dynamic boundary is to reduce the exploration space of particles, which is beneficial to the convergence of the algorithm. When the elite opposition-based solution is out of bounds, the out-of-bounds processing is performed. The equation is given as follows:
$$x_{oij} = rand\left( {lx_{oij} ,ux_{oij} } \right)$$(9)After calculating the fitness function values of the elite solution and the elite opposition-based solution, respectively, \(n\) high quality solutions were selected to form a new initial population position matrix.
-
(4)
The position updating Eq. (2) is modified based on the strategy of dynamic weight. To improve the speed of the global search of the population, the strategy of dynamic weight from the artificial bee colony algorithm34 is introduced to enhance the computational performance. The new position updating equation is shown as follows:
$$x_{ij} \left( {k + 1} \right) = \omega_{ } \times x_{ij} \left( k \right) + \omega^{\prime} \times v_{ij} \left( {k + 1} \right) + \rho \times \psi \times Gbest$$(10)Here \(\rho\) is the random value in the range \((\mathrm{0,1})\). \(\psi\) represents the acceleration coefficient and \({\omega }{\prime}\) is the dynamic weight coefficient. The updated equations of the above parameters are as follows:
$$\psi = \exp \left( {f\left( i \right)/u} \right)/\left( {1 + {\text{exp}}\left( { - f\left( i \right)/u} \right)} \right)^{iter}$$(11)$$\omega^{\prime} = 1 - \omega_{ }$$(12)where \(f(i)\) denotes the fitness function value of individual particle \(i\) and u is the average of the population fitness function values in the current iteration. The Eqs. (11,12) are introduced into the position updating equation. And they can attract the particle towards positions of the best-so-far solution in the search space.
-
(5)
New local optimal jump-out strategy is added for escaping from the local optimal. When the value of the fitness function for the population optimal particles does not change in M iterations, the algorithm determines that the population falls into a local optimal. The scheme in which the population jumps out of the local optimum is to reset the position information of the 40% of individuals within the population, in other words, to randomly generate the position vector in the search space. M is set to 5% of the maximum number of iterations.
-
(6)
New spiral update search strategy is added after the local optimal jump-out strategy. Since the whale optimization algorithm (WOA) was good at exploring the local search space35, the spiral update search strategy in the WOA36 is introduced to update the position of the particles after the swarm jumps out of local optimal. The equation for the spiral update is as follows:
$$x_{ij} \left( {k + 1} \right) = D \times e^{B \times l} \times \cos \left( {2 \times pi \times l} \right) + Gbest$$(13)Here \(D=\left|{x}_{i}\left(k\right)-Gbest\right|\) denotes the distance between the particle itself and the global optimal solution so far. \(B\) is the constant that defines the shape of the logarithmic spiral. \(l\) is the random value in \([-\mathrm{1,1}]\).\(l\) represents the distance between the newly generated particle and the global optimal position, \(l=-1\) means the closest distance, while \(l=1\) means the farthest distance, and the meaning of this parameter can be directly observed by Fig. 1.
Figure 1 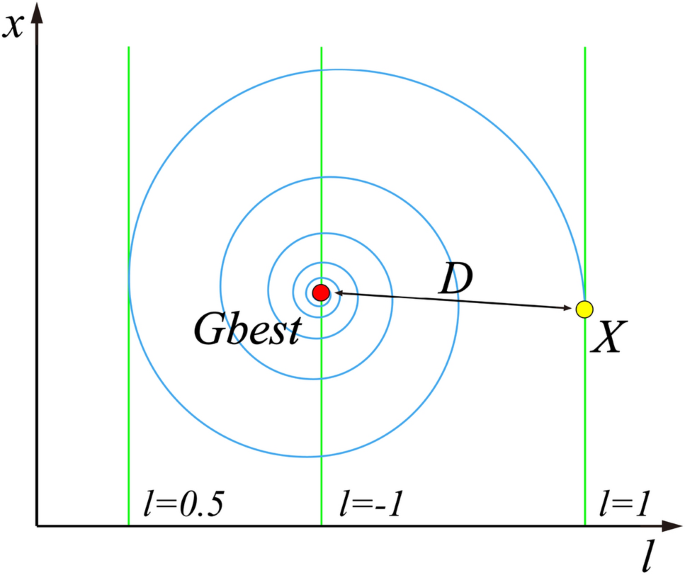
Spiral updating position.
-
(7)
The DE/best/2 mutation strategy is introduced to form the mutant particle. 4 individuals in the population are randomly selected that differ from the current particle, then the vector difference between them is rescaled, and the difference vector is combined with the global optimal position to form the mutant particle. The equation for mutation of particle position is shown as follows:
$$x^{*} = Gbest + F \times \left( {x_{r1} - x_{r2} } \right) + F \times \left( {x_{r3} - x_{r4} } \right)$$(14)where \({x}^{*}\) is the mutated particle, \(F\) is the scale factor of mutation, \({r}_{1}\), \({r}_{2}\), \({r}_{3}\), \({r}_{4}\) are random integer values in \((0,n]\) and not equal to \(i\), respectively. Specific particles are selected for mutation with the screening conditions as follows:
$$x\left( {k + 1} \right) = \left\{ { \begin{array}{*{20}l} {x^{*} ,} \hfill & {if\;\left( {rand\left( {0,1} \right) < Cr\, or\, i = = i_{rand} } \right)} \hfill \\ {x\left( {k + 1} \right),} \hfill & { otherwise} \hfill \\ \end{array} } \right.$$(15)where \(Cr\) represents the probability of mutation, \(rand\left(\mathrm{0,1}\right)\) is a random number in \(\left(\mathrm{0,1}\right)\), and \({i}_{rand}\) is a random integer value in \((0,n]\).
The improved PSO incorporates the search ideas of other intelligent algorithms (DE, WOA), so the improved algorithm proposed in this paper is named NDWPSO. The pseudo-code for the NDWPSO algorithm is given as follows:
Algorithm 1 

The main procedure of NDWPSO.



Comparing the distribution of inertia weight parameters
There are several improved PSO algorithms (such as CDWPSO25, and SDWPSO26) that adopt the dynamic weighted particle position update strategy as their improvement strategy. The updated equations of the CDWPSO and the SDWPSO algorithm for the inertia weight parameters are given as follows:
where \({\text{A}}\) is a value in \((\mathrm{0,1}]\). \({r}_{max}\) and \({r}_{min}\) are the upper and lower limits of the fluctuation range of the inertia weight parameters, \(k\) is the current number of algorithm iterations, and \(Mk\) denotes the maximum number of iterations.
Considering that the update method of inertia weight parameters by our proposed NDWPSO is comparable to the CDWPSO, and SDWPSO, a comparison experiment for the distribution of inertia weight parameters is set up in this section. The maximum number of iterations in the experiment is \(Mk=500\). The distributions of CDWPSO, SDWPSO, and NDWPSO inertia weights are shown sequentially in Fig. 2.

The inertial weight distribution of CDWPSO, SDWPSO, and NDWPSO.
In Fig. 2, the inertia weight value of CDWPSO is a random value in (0,1]. It may make individual particles fly out of the range in the late iteration of the algorithm. Similarly, the inertia weight value of SDWPSO is a value that tends to zero infinitely, so that the swarm no longer can fly in the search space, making the algorithm extremely easy to fall into the local optimal value. On the other hand, the distribution of the inertia weights of the NDWPSO forms a gentle slope by two curves. Thus, the swarm can faster lock the global optimum range in the early iterations and locate the global optimal more precisely in the late iterations. The reason is that the inertia weight values between two adjacent iterations are inversely proportional to each other. Besides, the time-varying part of the inertial weight within NDWPSO is designed to reduce the chaos characteristic of the parameters. The inertia weight value of NDWPSO avoids the disadvantages of the above two schemes, so its design is more reasonable.
Experiment and discussion
In this section, three experiments are set up to evaluate the performance of NDWPSO: (1) the experiment of 23 classical functions37 between NDWPSO and three particle swarm algorithms (PSO6, CDWPSO25, SDWPSO26); (2) the experiment of benchmark test functions between NDWPSO and other intelligent algorithms (Whale Optimization Algorithm (WOA)36, Harris Hawk Algorithm (HHO)38, Gray Wolf Optimization Algorithm (GWO)39, Archimedes Algorithm (AOA)40, Equilibrium Optimizer (EO)41 and Differential Evolution (DE)42); (3) the experiment for solving three real engineering problems (welded beam design43, pressure vessel design44, and three-bar truss design38). All experiments are run on a computer with Intel i5-11400F GPU, 2.60 GHz, 16 GB RAM, and the code is written with MATLAB R2017b.
The benchmark test functions are 23 classical functions, which consist of indefinite unimodal (F1–F7), indefinite dimensional multimodal functions (F8–F13), and fixed-dimensional multimodal functions (F14–F23). The unimodal benchmark function is used to evaluate the global search performance of different algorithms, while the multimodal benchmark function reflects the ability of the algorithm to escape from the local optimal. The mathematical equations of the benchmark functions are shown and found as Supplementary Tables S1–S3 online.
Experiments on benchmark functions between NDWPSO, and other PSO variants
The purpose of the experiment is to show the performance advantages of the NDWPSO algorithm. Here, the dimensions and corresponding population sizes of 13 benchmark functions (7 unimodal and 6 multimodal) are set to (30, 40), (50, 70), and (100, 130). The population size of 10 fixed multimodal functions is set to 40. Each algorithm is repeated 30 times independently, and the maximum number of iterations is 200. The performance of the algorithm is measured by the mean and the standard deviation (SD) of the results for different benchmark functions. The parameters of the NDWPSO are set as: \({[{\omega }_{min},\omega }_{max}]=[\mathrm{0.4,0.9}]\), \(\left[{c}_{max},{c}_{min}\right]=\left[\mathrm{2.5,1.5}\right],{V}_{max}=0.1,b={e}^{-50}, M=0.05\times Mk, B=1,F=0.7, Cr=0.9.\) And, \(A={\omega }_{max}\) for CDWPSO; \({[r}_{max},{r}_{min}]=[\mathrm{4,0}]\) for SDWPSO.
Besides, the experimental data are retained to two decimal places, but some experimental data will increase the number of retained data to pursue more accuracy in comparison. The best results in each group of experiments will be displayed in bold font. The experimental data is set to 0 if the value is below 10–323. The experimental parameter settings in this paper are different from the references (PSO6, CDWPSO25, SDWPSO26, so the final experimental data differ from the ones within the reference.
As shown in Tables 1 and 2, the NDWPSO algorithm obtains better results for all 49 sets of data than other PSO variants, which include not only 13 indefinite-dimensional benchmark functions and 10 fixed-multimodal benchmark functions. Remarkably, the SDWPSO algorithm obtains the same accuracy of calculation as NDWPSO for both unimodal functions f1–f4 and multimodal functions f9–f11. The solution accuracy of NDWPSO is higher than that of other PSO variants for fixed-multimodal benchmark functions f14-f23. The conclusion can be drawn that the NDWPSO has excellent global search capability, local search capability, and the capability for escaping the local optimal.
In addition, the convergence curves of the 23 benchmark functions are shown in Figs. 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18 and 19. The NDWPSO algorithm has a faster convergence speed in the early stage of the search for processing functions f1-f6, f8-f14, f16, f17, and finds the global optimal solution with a smaller number of iterations. In the remaining benchmark function experiments, the NDWPSO algorithm shows no outstanding performance for convergence speed in the early iterations. There are two reasons of no outstanding performance in the early iterations. On one hand, the fixed-multimodal benchmark function has many disturbances and local optimal solutions in the whole search space. on the other hand, the initialization scheme based on elite opposition-based learning is still stochastic, which leads to the initial position far from the global optimal solution. The inertia weight based on chaotic mapping and the strategy of spiral updating can significantly improve the convergence speed and computational accuracy of the algorithm in the late search stage. Finally, the NDWPSO algorithm can find better solutions than other algorithms in the middle and late stages of the search.

Evolution curve of NDWPSO and other PSO algorithms for f1 (Dim = 30,50,100).

Evolution curve of NDWPSO and other PSO algorithms for f2 (Dim = 30,50,100).

Evolution curve of NDWPSO and other PSO algorithms for f3 (Dim = 30,50,100).

Evolution curve of NDWPSO and other PSO algorithms for f4 (Dim = 30,50,100).

Evolution curve of NDWPSO and other PSO algorithms for f5 (Dim = 30,50,100).

Evolution curve of NDWPSO and other PSO algorithms for f6 (Dim = 30,50,100).

Evolution curve of NDWPSO and other PSO algorithms for f7 (Dim = 30,50,100).

Evolution curve of NDWPSO and other PSO algorithms for f8 (Dim = 30,50,100).

Evolution curve of NDWPSO and other PSO algorithms for f9 (Dim = 30,50,100).

Evolution curve of NDWPSO and other PSO algorithms for f10 (Dim = 30,50,100).

Evolution curve of NDWPSO and other PSO algorithms for f11(Dim = 30,50,100).

Evolution curve of NDWPSO and other PSO algorithms for f12 (Dim = 30,50,100).

Evolution curve of NDWPSO and other PSO algorithms for f13 (Dim = 30,50,100).

Evolution curve of NDWPSO and other PSO algorithms for f14, f15, f16.

Evolution curve of NDWPSO and other PSO algorithms for f17, f18, f19.

Evolution curve of NDWPSO and other PSO algorithms for f20, f21, f22.

Evolution curve of NDWPSO and other PSO algorithms for f23.
To evaluate the performance of different PSO algorithms, a statistical test is conducted. Due to the stochastic nature of the meta-heuristics, it is not enough to compare algorithms based on only the mean and standard deviation values. The optimization results cannot be assumed to obey the normal distribution; thus, it is necessary to judge whether the results of the algorithms differ from each other in a statistically significant way. Here, the Wilcoxon non-parametric statistical test45 is used to obtain a parameter called p-value to verify whether two sets of solutions are different to a statistically significant extent or not. Generally, it is considered that p ≤ 0.5 can be considered as a statistically significant superiority of the results. The p-values calculated in Wilcoxon’s rank-sum test comparing NDWPSO and other PSO algorithms are listed in Table 3 for all benchmark functions. The p-values in Table 3 additionally present the superiority of the NDWPSO because all of the p-values are much smaller than 0.5.
In general, the NDWPSO has the fastest convergence rate when finding the global optimum from Figs. 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18 and 19, and thus we can conclude that the NDWPSO is superior to the other PSO variants during the process of optimization.
Comparison experiments between NDWPSO and other intelligent algorithms
Experiments are conducted to compare NDWPSO with several other intelligent algorithms (WOA, HHO, GWO, AOA, EO and DE). The experimental object is 23 benchmark functions, and the experimental parameters of the NDWPSO algorithm are set the same as in Experiment 4.1. The maximum number of iterations of the experiment is increased to 2000 to fully demonstrate the performance of each algorithm. Each algorithm is repeated 30 times individually. The parameters of the relevant intelligent algorithms in the experiments are set as shown in Table 4. To ensure the fairness of the algorithm comparison, all parameters are concerning the original parameters in the relevant algorithm literature. The experimental results are shown in Tables 5, 6, 7 and 8 and Figs. 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 and 36.

Evolution curve of NDWPSO and other algorithms for f1 (Dim = 30,50,100).

Evolution curve of NDWPSO and other algorithms for f2 (Dim = 30,50,100).

Evolution curve of NDWPSO and other algorithms for f3(Dim = 30,50,100).

Evolution curve of NDWPSO and other algorithms for f4 (Dim = 30,50,100).

Evolution curve of NDWPSO and other algorithms for f5 (Dim = 30,50,100).

Evolution curve of NDWPSO and other algorithms for f6 (Dim = 30,50,100).

Evolution curve of NDWPSO and other algorithms for f7 (Dim = 30,50,100).

Evolution curve of NDWPSO and other algorithms for f8 (Dim = 30,50,100).

Evolution curve of NDWPSO and other algorithms for f9(Dim = 30,50,100).

Evolution curve of NDWPSO and other algorithms for f10 (Dim = 30,50,100).

Evolution curve of NDWPSO and other algorithms for f11 (Dim = 30,50,100).

Evolution curve of NDWPSO and other algorithms for f12 (Dim = 30,50,100).

Evolution curve of NDWPSO and other algorithms for f13 (Dim = 30,50,100).

Evolution curve of NDWPSO and other algorithms for f14, f15, f16.

Evolution curve of NDWPSO and other algorithms for f17, f18, f19.

Evolution curve of NDWPSO and other algorithms for f20, f21, f22.

Evolution curve of NDWPSO and other algorithms for f23.
The experimental data of NDWPSO and other intelligent algorithms for handling 30, 50, and 100-dimensional benchmark functions (\({f}_{1}-{f}_{13}\)) are recorded in Tables 8, 9 and 10, respectively. The comparison data of fixed-multimodal benchmark tests (\({f}_{14}-{f}_{23}\)) are recorded in Table 11. According to the data in Tables 5, 6 and 7, the NDWPSO algorithm obtains 69.2%, 84.6%, and 84.6% of the best results for the benchmark function (\({f}_{1}-{f}_{13}\)) in the search space of three dimensions (Dim = 30, 50, 100), respectively. In Table 8, the NDWPSO algorithm obtains 80% of the optimal solutions in 10 fixed-multimodal benchmark functions.
The convergence curves of each algorithm are shown in Figs. 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 and 36. The NDWPSO algorithm demonstrates two convergence behaviors when calculating the benchmark functions in 30, 50, and 100-dimensional search spaces. The first behavior is the fast convergence of NDWPSO with a small number of iterations at the beginning of the search. The reason is that the Iterative-mapping strategy and the position update scheme of dynamic weighting are used in the NDWPSO algorithm. This scheme can quickly target the region in the search space where the global optimum is located, and then precisely lock the optimal solution. When NDWPSO processes the functions \({f}_{1}-{f}_{4}\), and \({f}_{9}-{f}_{11}\), the behavior can be reflected in the convergence trend of their corresponding curves. The second behavior is that NDWPSO gradually improves the convergence accuracy and rapidly approaches the global optimal in the middle and late stages of the iteration. The NDWPSO algorithm fails to converge quickly in the early iterations, which is possible to prevent the swarm from falling into a local optimal. The behavior can be demonstrated by the convergence trend of the curves when NDWPSO handles the functions \({f}_{6}\), \({f}_{12}\), and \({f}_{13}\), and it also shows that the NDWPSO algorithm has an excellent ability of local search.
Combining the experimental data with the convergence curves, it is concluded that the NDWPSO algorithm has a faster convergence speed, so the effectiveness and global convergence of the NDWPSO algorithm are more outstanding than other intelligent algorithms.
Experiments on classical engineering problems
Three constrained classical engineering design problems (welded beam design, pressure vessel design43, and three-bar truss design38) are used to evaluate the NDWPSO algorithm. The experiments are the NDWPSO algorithm and 5 other intelligent algorithms (WOA36, HHO, GWO, AOA, EO41). Each algorithm is provided with the maximum number of iterations and population size (\({\text{Mk}}=500,\mathrm{ n}=40\)), and then repeats 30 times, independently. The parameters of the algorithms are set the same as in Table 4. The experimental results of three engineering design problems are recorded in Tables 9, 10 and 11 in turn. The result data is the average value of the solved data.
Welded beam design
The target of the welded beam design problem is to find the optimal manufacturing cost for the welded beam with the constraints, as shown in Fig. 37. The constraints are the thickness of the weld seam (\({\text{h}}\)), the length of the clamped bar (\({\text{l}}\)), the height of the bar (\({\text{t}}\)) and the thickness of the bar (\({\text{b}}\)). The mathematical formulation of the optimization problem is given as follows:

Welded beam design.
In Table 9, the NDWPSO, GWO, and EO algorithms obtain the best optimal cost. Besides, the standard deviation (SD) of t NDWPSO is the lowest, which means it has very good results in solving the welded beam design problem.
Pressure vessel design
Kannan and Kramer43 proposed the pressure vessel design problem as shown in Fig. 38 to minimize the total cost, including the cost of material, forming, and welding. There are four design optimized objects: the thickness of the shell \({T}_{s}\); the thickness of the head \({T}_{h}\); the inner radius \({\text{R}}\); the length of the cylindrical section without considering the head \({\text{L}}\). The problem includes the objective function and constraints as follows:

Pressure vessel design.
The results in Table 10 show that the NDWPSO algorithm obtains the lowest optimal cost with the same constraints and has the lowest standard deviation compared with other algorithms, which again proves the good performance of NDWPSO in terms of solution accuracy.
Three-bar truss design
This structural design problem44 is one of the most widely-used case studies as shown in Fig. 39. There are two main design parameters: the area of the bar1 and 3 (\({A}_{1}={A}_{3}\)) and area of bar 2 (\({A}_{2}\)). The objective is to minimize the weight of the truss. This problem is subject to several constraints as well: stress, deflection, and buckling constraints. The problem is formulated as follows:

Three-bar truss design.
From Table 11, NDWPSO obtains the best design solution in this engineering problem and has the smallest standard deviation of the result data. In summary, the NDWPSO can reveal very competitive results compared to other intelligent algorithms.
Conclusions and future works
An improved algorithm named NDWPSO is proposed to enhance the solving speed and improve the computational accuracy at the same time. The improved NDWPSO algorithm incorporates the search ideas of other intelligent algorithms (DE, WOA). Besides, we also proposed some new hybrid strategies to adjust the distribution of algorithm parameters (such as the inertia weight parameter, the acceleration coefficients, the initialization scheme, the position updating equation, and so on).
23 classical benchmark functions: indefinite unimodal (f1-f7), indefinite multimodal (f8-f13), and fixed-dimensional multimodal(f14-f23) are applied to evaluate the effective line and feasibility of the NDWPSO algorithm. Firstly, NDWPSO is compared with PSO, CDWPSO, and SDWPSO. The simulation results can prove the exploitative, exploratory, and local optima avoidance of NDWPSO. Secondly, the NDWPSO algorithm is compared with 5 other intelligent algorithms (WOA, HHO, GWO, AOA, EO). The NDWPSO algorithm also has better performance than other intelligent algorithms. Finally, 3 classical engineering problems are applied to prove that the NDWPSO algorithm shows superior results compared to other algorithms for the constrained engineering optimization problems.
Although the proposed NDWPSO is superior in many computation aspects, there are still some limitations and further improvements are needed. The NDWPSO performs a limit initialize on each particle by the strategy of “elite opposition-based learning”, it takes more computation time before speed update. Besides, the” local optimal jump-out” strategy also brings some random process. How to reduce the random process and how to improve the limit initialize efficiency are the issues that need to be further discussed. In addition, in future work, researchers will try to apply the NDWPSO algorithm to wider fields to solve more complex and diverse optimization problems.
Data availability
The datasets used and/or analyzed during the current study available from the corresponding author on reasonable request.
References
Sami, F. Optimize electric automation control using artificial intelligence (AI). Optik 271, 170085 (2022).
Li, X. et al. Prediction of electricity consumption during epidemic period based on improved particle swarm optimization algorithm. Energy Rep. 8, 437–446 (2022).
Sun, B. Adaptive modified ant colony optimization algorithm for global temperature perception of the underground tunnel fire. Case Stud. Therm. Eng. 40, 102500 (2022).
Bartsch, G. et al. Use of artificial intelligence and machine learning algorithms with gene expression profiling to predict recurrent nonmuscle invasive urothelial carcinoma of the bladder. J. Urol. 195(2), 493–498 (2016).
Bao, Z. Secure clustering strategy based on improved particle swarm optimization algorithm in internet of things. Comput. Intell. Neurosci. 2022, 1–9 (2022).
Kennedy, J. & Eberhart, R. Particle swarm optimization. In: Proceedings of ICNN'95-International Conference on Neural Networks. IEEE, 1942–1948 (1995).
Lin, Q. et al. A novel artificial bee colony algorithm with local and global information interaction. Appl. Soft Comput. 62, 702–735 (2018).
Abed-alguni, B. H. et al. Exploratory cuckoo search for solving single-objective optimization problems. Soft Comput. 25(15), 10167–10180 (2021).
Brajević, I. A shuffle-based artificial bee colony algorithm for solving integer programming and minimax problems. Mathematics 9(11), 1211 (2021).
Khan, A. T. et al. Non-linear activated beetle antennae search: A novel technique for non-convex tax-aware portfolio optimization problem. Expert Syst. Appl. 197, 116631 (2022).
Brajević, I. et al. Hybrid sine cosine algorithm for solving engineering optimization problems. Mathematics 10(23), 4555 (2022).
Abed-Alguni, B. H., Paul, D. & Hammad, R. Improved Salp swarm algorithm for solving single-objective continuous optimization problems. Appl. Intell. 52(15), 17217–17236 (2022).
Nadimi-Shahraki, M. H. et al. Binary starling murmuration optimizer algorithm to select effective features from medical data. Appl. Sci. 13(1), 564 (2022).
Nadimi-Shahraki, M. H. et al. A systematic review of the whale optimization algorithm: Theoretical foundation, improvements, and hybridizations. Archiv. Comput. Methods Eng. 30(7), 4113–4159 (2023).
Fatahi, A., Nadimi-Shahraki, M. H. & Zamani, H. An improved binary quantum-based avian navigation optimizer algorithm to select effective feature subset from medical data: A COVID-19 case study. J. Bionic Eng. 21(1), 426–446 (2024).
Abed-alguni, B. H. & AL-Jarah, S. H. IBJA: An improved binary DJaya algorithm for feature selection. J. Comput. Sci. 75, 102201 (2024).
Yeh, W.-C. A novel boundary swarm optimization method for reliability redundancy allocation problems. Reliab. Eng. Syst. Saf. 192, 106060 (2019).
Solomon, S., Thulasiraman, P. & Thulasiram, R. Collaborative multi-swarm PSO for task matching using graphics processing units. In: Proceedings of the 13th Annual Conference on Genetic and Evolutionary Computation 1563–1570 (2011).
Mukhopadhyay, S. & Banerjee, S. Global optimization of an optical chaotic system by chaotic multi swarm particle swarm optimization. Expert Syst. Appl. 39(1), 917–924 (2012).
Duan, L. et al. Improved particle swarm optimization algorithm for enhanced coupling of coaxial optical communication laser. Opt. Fiber Technol. 64, 102559 (2021).
Sun, F., Xu, Z. & Zhang, D. Optimization design of wind turbine blade based on an improved particle swarm optimization algorithm combined with non-gaussian distribution. Adv. Civ. Eng. 2021, 1–9 (2021).
Liu, M. et al. An improved particle-swarm-optimization algorithm for a prediction model of steel slab temperature. Appl. Sci. 12(22), 11550 (2022).
Gad, A. G. Particle swarm optimization algorithm and its applications: A systematic review. Archiv. Comput. Methods Eng. 29(5), 2531–2561 (2022).
Feng, H. et al. Trajectory control of electro-hydraulic position servo system using improved PSO-PID controller. Autom. Constr. 127, 103722 (2021).
Chen, Ke., Zhou, F. & Liu, A. Chaotic dynamic weight particle swarm optimization for numerical function optimization. Knowl. Based Syst. 139, 23–40 (2018).
Bai, B. et al. Reliability prediction-based improved dynamic weight particle swarm optimization and back propagation neural network in engineering systems. Expert Syst. Appl. 177, 114952 (2021).
Alsaidy, S. A., Abbood, A. D. & Sahib, M. A. Heuristic initialization of PSO task scheduling algorithm in cloud computing. J. King Saud Univ. –Comput. Inf. Sci. 34(6), 2370–2382 (2022).
Liu, H., Cai, Z. & Wang, Y. Hybridizing particle swarm optimization with differential evolution for constrained numerical and engineering optimization. Appl. Soft Comput. 10(2), 629–640 (2010).
Deng, W. et al. A novel intelligent diagnosis method using optimal LS-SVM with improved PSO algorithm. Soft Comput. 23, 2445–2462 (2019).
Huang, M. & Zhen, L. Research on mechanical fault prediction method based on multifeature fusion of vibration sensing data. Sensors 20(1), 6 (2019).
Wolpert, D. H. & Macready, W. G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1(1), 67–82 (1997).
Gandomi, A. H. et al. Firefly algorithm with chaos. Commun. Nonlinear Sci. Numer. Simul. 18(1), 89–98 (2013).
Zhou, Y., Wang, R. & Luo, Q. Elite opposition-based flower pollination algorithm. Neurocomputing 188, 294–310 (2016).
Li, G., Niu, P. & Xiao, X. Development and investigation of efficient artificial bee colony algorithm for numerical function optimization. Appl. Soft Comput. 12(1), 320–332 (2012).
Xiong, G. et al. Parameter extraction of solar photovoltaic models by means of a hybrid differential evolution with whale optimization algorithm. Solar Energy 176, 742–761 (2018).
Mirjalili, S. & Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67 (2016).
Yao, X., Liu, Y. & Lin, G. Evolutionary programming made faster. IEEE Trans. Evol. Comput. 3(2), 82–102 (1999).
Heidari, A. A. et al. Harris hawks optimization: Algorithm and applications. Fut. Gener. Comput. Syst. 97, 849–872 (2019).
Mirjalili, S., Mirjalili, S. M. & Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61 (2014).
Hashim, F. A. et al. Archimedes optimization algorithm: A new metaheuristic algorithm for solving optimization problems. Appl. Intell. 51, 1531–1551 (2021).
Faramarzi, A. et al. Equilibrium optimizer: A novel optimization algorithm. Knowl. -Based Syst. 191, 105190 (2020).
Pant, M. et al. Differential evolution: A review of more than two decades of research. Eng. Appl. Artif. Intell. 90, 103479 (2020).
Coello, C. A. C. Use of a self-adaptive penalty approach for engineering optimization problems. Comput. Ind. 41(2), 113–127 (2000).
Kannan, B. K. & Kramer, S. N. An augmented lagrange multiplier based method for mixed integer discrete continuous optimization and its applications to mechanical design. J. Mech. Des. 116, 405–411 (1994).
Derrac, J. et al. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 1(1), 3–18 (2011).
Acknowledgements
This work was supported by Key R&D plan of Shandong Province, China (2021CXGC010207, 2023CXGC01020); First batch of talent research projects of Qilu University of Technology in 2023 (2023RCKY116); Introduction of urgently needed talent projects in Key Supported Regions of Shandong Province; Key Projects of Natural Science Foundation of Shandong Province (ZR2020ME116); the Innovation Ability Improvement Project for Technology-based Small- and Medium-sized Enterprises of Shandong Province (2022TSGC2051, 2023TSGC0024, 2023TSGC0931); National Key R&D Program of China (2019YFB1705002), LiaoNing Revitalization Talents Program (XLYC2002041) and Young Innovative Talents Introduction & Cultivation Program for Colleges and Universities of Shandong Province (Granted by Department of Education of Shandong Province, Sub-Title: Innovative Research Team of High Performance Integrated Device).
Author information
Authors and Affiliations
Contributions
Z.Y., J.Q., and G.W. wrote the main manuscript text and prepared all figures and tables. J.C., P.L., K.L., and X.L. were responsible for the data curation and software. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Qiao, J., Wang, G., Yang, Z. et al. A hybrid particle swarm optimization algorithm for solving engineering problem. Sci Rep 14, 8357 (2024). https://doi.org/10.1038/s41598-024-59034-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-59034-2
Keywords
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
