
Abstract
Poly (ADP)-ribose polymerase 1 (PARP1) is an abundant nuclear protein well-known for its role in DNA repair yet also participates in DNA replication, transcription, and co-transcriptional splicing, where DNA is undamaged. Thus, binding to undamaged regions in DNA and RNA is likely a part of PARP1’s normal repertoire. Here we describe analyses of PARP1 binding to two short single-stranded DNAs, a single-stranded RNA, and a double stranded DNA. The investigations involved comparing the wild-type (WT) full-length enzyme with mutants lacking the catalytic domain (∆CAT) or zinc fingers 1 and 2 (∆Zn1∆Zn2). All three protein types exhibited monomeric characteristics in solution and formed saturated 2:1 complexes with single-stranded T20 and U20 oligonucleotides. These complexes formed without accumulation of 1:1 intermediates, a pattern suggestive of positive binding cooperativity. The retention of binding activities by ∆CAT and ∆Zn1∆Zn2 enzymes suggests that neither the catalytic domain nor zinc fingers 1 and 2 are indispensable for cooperative binding. In contrast, when a double stranded 19mer DNA was tested, WT PARP1 formed a 4:1 complex while the ∆Zn1Zn2 mutant binding saturated at 1:1 stoichiometry. These deviations from the 2:1 pattern observed with T20 and U20 oligonucleotides show that PARP’s binding mechanism can be influenced by the secondary structure of the nucleic acid. Our studies show that PARP1:nucleic acid interactions are strongly dependent on the nucleic acid type and properties, perhaps reflecting PARP1’s ability to respond differently to different nucleic acid ligands in cells. These findings lay a platform for understanding how the functionally versatile PARP1 recognizes diverse oligonucleotides within the realms of chromatin and RNA biology.
Similar content being viewed by others

Introduction
Poly (ADP) ribose polymerases (PARPs) are a diverse family of enzymes, with about 18 different protein members in humans. These enzymes are also known as ADP-ribosyl transferases (ARTs) for their ability to transfer ADP-ribose groups to protein substrates or to protein-ADP-ribose adducts (a process called PARylation). PARP1 is the most studied member of this family. PARylation of PARP1 contributes to its role in DNA repair, including repair of single-strand breaks (SSBs) and double-strand breaks (DSBs)1, in the stabilization of DNA replication forks2 and in the modification of chromatin structure3.
PARP1 as a multidomain protein (Fig. 1A and B), contains three main functional domains. The N-terminal part of the protein sequence folds to form three zinc fingers (Zn1, Zn2, Zn3), of which Zn1 and Zn2 are known DNA binding domains and Zn3 is hypothesized to bind RNA4,5. The central part of the protein encodes a BRCT(BRCA1 C-terminal)-fold‐containing automodification domain which may also bind DNA6,7 while the C-terminal sequences encode domains involved in protein interaction (WGR) and catalysis of ADP-ribose polymerization (CAT;6,8). Recently the WGR domain was also implicated in DNA binding9. Although Zn1, Zn2, Zn3 and WGR domains have been shown to collaborate in recognizing and binding to DNA strand breaks10, how these domains interact with a range of different DNA structures is still subject to debate. For instance, a mutant PARP1 protein containing only Zn1Zn2 domains, bound DNA as a dimer11,12 while other protein forms have been reported to bind DNA as a monomer10,13,14,15. Other studies showed that Zn3 homodimerization is not required for DNA-dependent activation of PARP111,14,16. A more recent study using single particle electron microscopy of human PARP1 provided structural evidence of the dimeric structure of PARP117. It is therefore possible that depending on the types of PARP1 structures or substrates PARP1 binds to, it could act as a monomer or a dimer.

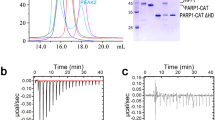
Characterization of PARP1 constructs: A. Top—schematic diagram showing the order and approximate location of the named structural domains. Bottom: schematic showing the different PARP1 constructs used in study. B. Alpha-fold prediction of PARP1 folded structure based on known structures of PARP1 domains bound to DNA93,94. C. Gels showing both Coomassie staining and Western blot analysis of the purified PARP1 proteins used in study (complete gel images are found in Supplemental Figure S2). D. Sedimentation velocity analysis of PARP1 proteins. Left: Time evolution of sedimentation for full-length PARP1 protein (4.6 µM) in buffer consisting of 10 mM Tris–HCl, pH 8.0, 100 mM NaCl, 0.1 mM EDTA, 0.1 mM TCEP. Samples were run at 35,000 rpm and 4 °C; absorbance data were acquired at 280 nm. Starting with the left-most curve, each succeeding scan represents a time increment of 5 min. Right: c(M) distributions calculated from numerical fits to the Lamm equation using the program SEDFIT48,49,50. Samples contained full-length PARP1 (4.6 µM; labeled WT), ∆Zn1∆Zn2 mutant PARP1 (6.1 µM; labeled ∆Zn), and ∆CAT PARP1 (7.1 µM, labeled ∆CAT) in the buffer and run conditions described above. Central values of these peaks are consistent with molecular weights predicted for monomers (see Table 2). The arrow indicates the presence of small concentrations of larger species.
The recruitment of PARP1 to DNA damage sites4,18 stimulates its catalytic activity, resulting in self-PARylation and PARylation of histones and non-histone proteins19,20,21. A consequence of PARP1 binding and activation is the relaxation of the chromatin structure to allow access by DNA-repair proteins. In transcription, PARP1 competes for binding with the repressive Histone H1, to stimulate gene expression3,22. Thus, in both DNA repair and transcription, PARP1 provokes a PAR-mediated recruitment and regulation of chromatin remodeling factors23,24,25, and/or PARylation of histones24,25,26,27, leading to an open chromatin structure, with subsequent gene expression.
In addition to binding chromatin and DNA, PARP1 also interacts with RNA during co-transcriptional splicing5,28,29,30,31 and while these studies show that PARP1 can bind a wide range of nucleic acid structures, important features of its binding mechanisms remain to be discovered. To date, the quaternary state of un-PARylated PARP1 is poorly defined, even though this is likely to be the starting state for PARP1 in its regulatory and catalytic interactions12,17,32. This is due in some part to the use of truncation mutants or chimeric proteins in studies that could answer this question. The removal of intrinsic domains or the addition of extrinsic ones can have significant effects on quaternary interactions (c.f.,33,34). A second question is one of binding mechanism(s). Several studies, including ours (below), give evidence that PARP1 can form multi-protein complexes with nucleic acids11,12, while others show single protein binding to isolated sites6,13,14,15,16,32. Again, in some cases this contrast might be attributed to use of protein truncation mutants that affect binding interactions, or to nucleic acid templates that limit interaction stoichiometry. Finally, while PARP1 has been shown to bind damaged DNA as a monomer13,14,35,36, whether it binds undamaged DNA independently as protein monomers or cooperatively has not received enough attention. Our aim in this report is to address these gaps in our knowledge. We have found that under native-like solution conditions, full-length WT-FL-PARP1 and its ∆CAT and ∆Zn1∆Zn2 mutants, sediment as monomers. We show that all three forms are active in binding single stranded and duplex DNAs as well as a single stranded RNA. We determine binding stoichiometries for complexes and find that all proteins tested can form multi-protein complexes and that binding is positively cooperative. In summary, there is a diversity of binding densities and binding site sizes. A full understanding of this diversity will be needed if we are to understand how PARP1 distributes between binding substrates in vivo.
Materials and methods
Materials
Reagents. [ \(\gamma\)32P]-ATP was from PerkinElmer; T4 polynucleotide kinase was purchased from New England Biolabs. Electrophoresis grade polyacrylamide was from VWR International. All other chemicals were reagent-grade or better.
Purification of PARP1 and its derivatives
His-tagged PARP1 expression vectors were a kind gift from the Pascal laboratory (University of Montreal) and purified as previously described (Supplemental Figure S1) and37. Briefly, the sequences corresponding to wild-type full-length (WT-FL-PARP1 hence called WT-PARP1, aa 1–1014), ∆CAT-PARP1 (aa 1–662), and ∆Zn1∆Zn2-PARP1 (aa 216–1014) were cloned into the pET28 expression vector. Proteins were expressed in One Shot BL21 (DE3) pLysS competent E. coli cells in the absence of benzamidine and purified by chromatographic fractionations in the following order: (1) Ni–NTA agarose (Qiagen); (2) HiTrap Heparin HP (GE Healthcare), and (3) a gel filtration with Superdex S200 (GE Healthcare). Fractions were monitored by SDS-PAGE and western blot using PARP1 N-terminal and C-terminal antibodies (Active Motif, Carlsbad, CA, USA). Pooled purified fractions (Fig. 1C and Supplemental Figure S2) were concentrated using an Amicon spin concentrator (10,000 Da cut-off, Millipore). The program SEDNTERP (http://www.jphilo.mailway.com/download. htm#SEDNTERP) was used to estimate protein extinction coefficients. This returned values of e280 = 1.19 × 105 M−1 cm−1 for WT-PARP1, e280 = 8.43 × 104 M−1 cm−1 for the ∆CAT protein, and e280 = 8.82 × 104 M−1 cm−1 for the ΔZn1ΔZn2 protein. Protein concentrations were determined by BCA Assay (Thermo Scientific) or by A280 using the molar extinction coefficients given above. PARP1 proteins prepared in this way have significant secondary structure as detected by circular dichroism (Supplemental Figure S3) and5. Results shown below indicate that these proteins have extended structures expected for native, multi-domain proteins, and that they have specific and distinctive DNA-binding activities.
Nucleic acids
The sequences of nucleic acids used in this study are given in Table 1. DNAs and RNAs were purchased from Integrated DNA Technologies Company (IDT). Oligonucleotides for use without 32P labels were purified by extensive dialysis at 4 °C against 10 mM Tris, 0.1 mM EDTA, pH 8.0. For assays using isotope detection, single-stranded nucleic acids were labeled at 5’ termini with 32P as described by Maxam and Gilbert38. Labeled oligonucleotides were purified by gel electrophoresis under denaturing conditions (25% polyacrylamide gel, 8 M Urea) and recovered by the crush–soak method38, concentrated by extraction with anhydrous n-Butanol and dialyzed at 4 °C against buffer containing 10 mM Tris, 0.1 mM EDTA, pH 8.0. Duplex DNAs were obtained by mixing the top strand (as shown in Table 1) with a 1.05-fold molar excess of unlabeled complement. Nucleic acid concentrations were measured by spectrophotometry at 260 nm, using extinction coefficients provided by the manufacturers. Complementary ssDNAs were heated, cooled to make dsDNAs and visualized on native PAGE (Supplemental Figure S4).
Sedimentation velocity analyses
Proteins were dialyzed against 10 mM Tris–HCl, pH 8.0, 150 mM NaCl, 0.1 mM EDTA, 0.1 mM TCEP at 4 °C, and the concentration was adjusted to a range of 0.2—1.0 mg/ml. Sedimentation velocity measurements were taken at 4 °C using an AN-60 Ti rotor in a Beckman XL-A analytical ultracentrifuge. Sedimentation coefficient distributions (c(s)), molecular weight distributions (c(M)), and translational friction coefficients (f) were obtained by direct boundary modeling using numerical solutions of the Lamm equation39, implemented in the program SEDFIT40, obtained from http://www.analytical-ultracentrifugation.com/default.htm. Buffer density and viscosity, and protein partial specific volumes were calculated using SEDNTERP41. SEDNTERP was also used to calculate the axial ratios of ellipsoids of revolution from measured translational friction coefficients. SEDNTERP was obtained from http://www.rasmb.bbri.org/.
Electrophoretic mobility shift assays
Binding reactions were carried out at 20 ± 1 °C in 25 mM Tris (pH 8.0), 150 mM NaCl, 50 mM arginine, 1 mM EDTA, 0.1 mM TCEP, and 1 mg/mL bovine serum albumin. Mixtures were equilibrated at 20 ± 1 °C for 30 min before electrophoresis. Duplicate samples incubated for longer periods gave identical results, indicating that equilibrium had been attained (result not shown). Electrophoresis was carried out in 8% polyacrylamide gels (75:1 acrylamide:bis-acrylamide), containing 90 mM Tris–borate, 2 mM EDTA buffer, pH 8.342. Following electrophoresis, autoradiographic images were captured on storage phosphor screens (GE Healthcare) detected with a Typhoon FLA 9500. Band-quantitation was performed using Image-Quant TL software (GE Healthcare), as described by the manufacturer.
Quantitative binding analysis
Association constants and cooperativity parameters were evaluated by direct titration of DNA with protein, with binding detected by EMSA. The total concentration of protein binding sites on DNA was always much less than that of the protein allowing the approximation [P]total = [P]free to be used. For the concerted binding of n protein molecules (P) to a single DNA (nP + D \(\rightleftarrows\) PnD), the apparent association constant is K’ = [PnD]/[P]n[D]. Here, K’ is the formation constant for the cooperative complex, containing contributions from both protein-DNA and protein–protein interactions. Separating variables and taking natural logarithms gives the following linear relationship.
Initial values of [P] were calculated for each titration step using the conservation relation [P] = [P]tot – n[PnD], in which [P]tot is the total protein concentration and n is an initial estimate of the stoichiometry. An updated estimate of n was then obtained from the linear dependence of ln[PnD]/[D] on ln[P]. The new value of n was fed back into the conservation relation and the cycle iterated until values of n and K’ ceased to change. Ultimately, the slope of the graph yields a value of the stoichiometry n, while at the mid-point of the titration (where ln [PnD]/[D] = 0), ln K’ = -n ln [P], allowing evaluation of the formation constant, K’. Values of K’ are difficult to compare when complexes differ in stoichiometry. However, assumption of equipartition of binding free energies allows evaluation of monomer-equivalent association constants, Kmono = (K’)1/n, which are easier to compare. This approach has been described previously43,44.
Cooperativity parameters were evaluated using the McGhee-von Hippel isotherm45 as modified by Record et al.46 to account for finite lattice size (Eq. 2).
Here ν is the binding density (protein molecules/nucleotide), calculated from stoichiometry values obtained with Eq. (1). The equilibrium association constant for binding a single site is given by K, the cooperativity parameter by ω, the length of the DNA in base pairs is N, and s is the occluded site size (the size of the site, in base pairs, that one protein molecule occupies to the exclusion of others).
Results
PARP1-protein and its derivatives sediment as monomers
Previously we showed that purified full-length PARP1 (WT-PARP1) and the deletion proteins (∆Zn1∆Zn2 and ∆CAT) (Fig. 1A and 1C) have closely similar CD spectra, consistent with the notion that these deletions do not cause large-scale loss of secondary structure5. However, these analyses did not reveal the oligomerization states of the proteins, a characterization that is essential for analysis of DNA binding. Sedimentation velocity analyses were performed to fill this gap in our knowledge. Shown in Fig. 1D is the time-evolution of the sedimenting boundary formed by the WT enzyme centrifuged at 4 °C and 35,000 rpm. Also shown are c(M) distributions obtained by sedimentation analysis for all three proteins. All preparations contained single dominant species with molecular weights (MW) in the range 70,000 ≤ MW ≤ 130,000, with no detectible low molecular weight material, and only traces of larger species (indicated by the arrow). The central values and 95% confidence limits of these MW distributions are shown in Table 2, together with monomer molecular weights calculated from amino acid compositions. A comparison of measured and calculated MW values shows that all enzymes sediment as monomers under these solution conditions.
Sedimentation velocity analysis also returns values of the translational frictional coefficient ratio f/f0, where f is the experimentally observed frictional coefficient and f0 is that of a sphere of equivalent volume, given by
where \(\eta\) is the solution viscosity, M the molecular weight, \(\overline{v}\) the partial specific volume, and NA the Avogadro’s number. For our proteins, values of f/f0 range from 2.31 to 3.01, indicating significant deviation from spherical symmetry (Table 2). Modeled as prolate ellipsoids of revolution, with typical values of protein hydration (0.3 g/g,47), these proteins are predicted to have axial ratios in the range 9.6–10.2. Such axial ratios are consistent with elongated structures in which compact domains are flexibly connected by short linkers10,14, unlike the AlphaFold prediction shown in Fig. 1B, which likely reflects the compact, DNA-bound PARP1 conformation. Similar values of f/f0 and corresponding axial ratios support the notion that the deletions that produce the ∆CAT and ∆Zn1∆Zn2 mutants do not cause large-scale changes in organization or folded state of the resultant proteins.
Rapidly equilibrating protein complexes are formed with a short, double-stranded DNA
Addition of a double-stranded 19-mer DNA (sequence shown in Table 1) to protein samples produced new solution components that could be detected by sedimentation velocity analysis. Shown in Fig. 2 are c(M) plots for free 19-mer DNA, free proteins, and protein-DNA mixtures containing full-length WT-PARP1, or ∆CAT-PARP1, or ∆Zn1-Zn2-PARP1 proteins. At the concentrations tested, DNA mixtures with WT protein contained no material that co-sedimented with free DNA, and two c(M) peaks with apparent molecular weights of 117,560 ± 25,870 and 276,590 ± 40,350. The first peak overlaps substantially with the c(M) distribution of free protein, and the second is larger than that expected for a complex containing 2 protein monomers. The width of the c(M) distributions prevents us from determining whether the smaller peak corresponds to free protein (MWpredicted = 113,907) or a 1:1 protein-DNA complex (MWpredicted = 125,524) however, the simplest interpretation is that it represents free protein. Our current interpretation of the larger peak is that it corresponds to a mixture of complexes containing at least 2 protein molecules. The large width of these peaks, and the fact that c(M) does not reach the baseline between them, suggests that binding precursors and products are equilibrating on a time scale like that of sedimentation48,49,50. DNA mixtures with the ∆CAT protein contained only a trace of material co-sedimenting with free DNA, and two c(M) peaks with apparent molecular weights of 75,190 ± 8,495 and 174,760 ± 18,680. These are comparable to values for free protein (MWpredicted = 74,522) and complexes with ≥ 2 protein molecules (MWpredicted, 2:1 = 160,661). Again, large peak-widths and the failure of the distribution to reach the baseline between them, suggest that components are equilibrating during sedimentation. DNA mixtures with the ∆Zn1∆Zn2 protein contained two c(M) peaks with apparent molecular weights of 27,050 ± 13,040 and 87,550 ± 15,230. The first value is larger than that of free DNA, although the c(M) envelopes overlap; the second is like that of free protein, but significantly less than that expected for a 1:1 complex (MWpredicted = 101,422). Our current interpretation of this pattern is that the first peak corresponds to DNA that migrates faster than unbound DNA, because it is equilibrating with protein, and the second peak depicts a sedimenting boundary with apparent molecular weight smaller than that of a 1:1 complex. Mobility like this would be observed if the DNA were equilibrating between complex and free states. A boundary that contains reaction components that equilibrate rapidly on the time scale of sedimentation does not correspond to a single species and is sometimes called a “reaction boundary”50. The formation of reaction boundaries during sedimentation complicates the estimation of binding stoichiometries and the estimation of affinities from the dependence of binding densities on protein concentration. We therefore turned to gel-electrophoretic mobility shift assays (EMSA), to take advantage of the kinetic stabilization of protein-nucleic acid complexes afforded by the gel environment51,52,53.

Sedimentation velocity analyses of mixtures containing duplex DNA and PARP1. Samples contained the duplex 19-mer DNA shown in Table 1 or the indicated protein, or a mixture of the two in buffer containing 10 mM Tris–HCl, pH 8.0, 100 mM NaCl, 0.1 mM EDTA, 0.1 mM TCEP. Samples for analysis of WT-PARP1 binding contained 1.6 µM DNA and/or 3.6 µM protein. Samples for analysis of ∆CAT PARP1 binding contained 2.1 µM DNA and/or 9.4 µM protein. Samples for analysis of ∆Zn1∆Zn2 PARP1 binding contained 1.8 µM DNA and/or 7.2 µM protein. All samples were centrifuged at 25,000 rpm and 4 °C; absorbance data were acquired at 260 nm. C(M) distributions40 are shown for DNA alone (D), or protein alone (P) or a mixture (P + D).
Full length- and ∆CAT-PARP-1 proteins form multi-protein complexes with duplex 19-mer DNA
Titration of the ds19-mer DNA with full-length WT-PARP1 produces a species that migrates slowly during native electrophoresis in 8% polyacrylamide gels (Fig. 3A, top left). Complexes with similar electrophoretic mobilities were formed with the ∆CAT- and ∆Zn1∆Zn2-proteins (middle and lower panels, respectively). Sharp band boundaries, and the small mole fractions of dissociated DNA migrating between free and bound bands (mole fractions < 0.05, result not shown) indicate that these complexes are quite stable under the conditions of gel electrophoresis. This contrasts with their behaviors during sedimentation in the ultracentrifuge. Constant mobility shifts over the full ranges of fractional saturation are consistent with homogeneous binding mechanisms.

(A) Titration of double-stranded and single stranded 19-mer DNAs with WT-PARP1, ∆CAT-PARP1 and ∆Zn1∆Zn2-PARP1 proteins, detected by EMSA (Supplemental Figure S5 contains the full image and experimental replicates are in supplemental Figure S6). Samples formed with dsDNA contained 0.06 µM DNA and 0 – 0.25 µM WT-PARP1, or 0 – 0.3 µM ∆CAT-PARP1, or 0 – 10.9 µM ∆Zn1∆Zn2-PARP1. Samples formed with ssDNA contained 0.06 µM DNA and 0 – 1.5 µM WT-PARP1, or 0 – 1.63 µM ∆CAT-PARP1, or 0 – 12.4 µM ∆Zn1∆Zn2-PARP1. Buffer, incubation and electrophoresis conditions are described in Methods. (B). Analyses of interactions of WT-, ∆CAT- and ∆Zn1∆Zn2-PARP1 proteins with duplex 19-mer DNA (left) or single-stranded 19-mer DNA (right). Graphs show data from 2 independent titrations, plotted as described for Eq. (1). Note that scales for these graphs are not identical. Solid grey lines are least squares fits to each data set and the x-axis, at y = 0, is indicated by a solid black line. For dsDNA binding, these analyses returned n = 4.1 ± 0.2 for WT-PARP1, 3.9 ± 0.2 for ∆CAT-PARP1, and 1.2 ± 0.1 for the ∆Zn1∆Zn2 enzyme. For binding ssDNA, these analyses returned n = 1.8 ± 0.1 for WT-PARP1, 1.0 ± 0.1 for ∆CAT-PARP1, and 1.0 ± 0.1 for the ∆Zn1∆Zn2 enzyme. Monomer-equivalent association constants derived from these analyses are given in Table 3.
Graphs of ln [PnD]/[D] as functions of ln [P] for dsDNA binding by WT-PARP1, ∆CAT- and ∆Zn1∆Zn2- enzymes are shown in Fig. 3B (left). As described for Eq. (1), the slopes of these graphs give estimates of binding stoichiometries (n), while titration-midpoints give estimates of formation constants. Constant slopes, over the full ranges of each titration, are consistent with homogeneous binding mechanisms. These analyses returned n = 4.1 ± 0.2 for the binding of WT-PARP1, 3.9 ± 0.2 for the ∆CAT enzyme, and 1.2 ± 0.1 for the ∆Zn1∆Zn2 enzyme (Table 3). The stoichiometries found by EMSA for WT- and ∆CAT-enzymes are roughly twice those estimated by c(M) sedimentation analysis, and that for the ∆Zn1∆Zn2 enzyme is roughly 15% larger than that found by c(M). These results support our interpretation that the sedimentation velocity patterns that we observed were reaction boundaries and not true species. The formation of high-stoichiometry complexes from free DNA, in a single step and without accumulation of stoichiometric intermediates, is a hallmark of positively cooperative binding. The striking difference in stoichiometries for WT and ∆Zn1∆Zn2 enzymes suggest that deletion of Zn1 and Zn2 domains imposes a change of binding mechanism, either through modification of DNA-binding surfaces, or protein–protein interaction surfaces, or both.
Equation 1 also provides a means of evaluating the formation constants (K’) of complexes (see above). Where n = 1, K’ is the association constant of the interaction. Were n > 1, K’ is the association constant for the overall assembly, taken as a single step. For complexes with n > 1, assumption of equipartition of binding free energies allows evaluation of monomer-equivalent association constants, Kmono = (K’)1/n. These are given in Table 3. Values from 3.1 × 105 M−1 (∆Zn1∆Zn2) to 1.3 × 107 M−1 (WT and ∆CAT enzymes), correspond to association free energies of -7.3 to -9.6 kcal/mol, in the mid-range of reported affinities for proteins binding to duplex DNAs54. The reduced affinity of the ∆Zn1∆Zn2 enzyme, compared to the WT and ∆CAT, reflects a role for zinc fingers 1 and 2 in DNA binding. This is in line with previous studies of Zn1 Zn2 binding to DNA55. However, the finding that the ∆Zn1∆Zn2 enzyme retains significant binding activity is consistent with other studies that other parts of the PARP1 structure also interact with DNA4,5,11,14,16,56,57.
Stoichiometries and affinities differ for single stranded and duplex DNAs
PARP1 binds damaged and undamaged DNAs58 as well as RNA molecules5,28,31,57,58,59, so it was of interest to discover whether PARP1 interactions with single-stranded DNAs resembled those with duplex. Shown in Fig. 3A (right) and Supplemental Figures S5 and S6, are titrations of a single-stranded 19mer DNA with FL, ∆CAT and ∆Zn1∆Zn2 enzymes. All enzymes gave single mobility-shifted species with mobility decrements like those seen with duplex DNA. While the ∆Zn1∆Zn2 enzyme did not reach binding saturation in the concentration range tested, the data quality in all sets was good enough for analysis (Fig. 3B). Graphed as described for Eq. (1), these data returned n = 1.8 ± 0.1 for the binding of FL enzyme, n = 1.0 ± 0.1 for the ∆CAT enzyme, and n = 1.0 ± 0.1 for the ∆Zn1∆Zn2 enzyme. These values are significantly smaller than those found with duplex DNA of the same length (Table 3), suggesting a dramatic change in DNA binding mechanism with substitution of single-stranded substrate for duplex. In addition, both the ∆CAT and ∆Zn1∆Zn2 enzymes retained binding activity, while forming complexes with smaller stoichiometry than that formed by the full-length enzyme. Functional implications of these results will be discussed below. Because the binding stoichiometries of the proteins differ, the simplest comparison of affinities uses monomer-equivalent association constants (Table 3). On this basis, substitution of single-stranded DNA for duplex reduces the affinities of FL- and ∆CAT-enzymes, while that of ∆Zn1∆Zn2 is not significantly changed. These differences may suggest a role for the Zn1 and Zn2 domains in the partition of PARP1 between single-stranded and double-stranded DNA sites.
PARP1 binds preferentially to sites of DNA damage60, sites of chromatin remodeling59,61, and some promoter sequences22,62,63. However, the roles of DNA sequence-specific and/or structure-specific interactions in its binding preferences remain to be determined. As a step in this process, we examined PARP1 binding to T20 (5’ labeled with cy3), a DNA of uniform base composition with a low propensity to form base-paired secondary structures. Shown in Fig. 4A (left), and Supplemental Figures S7-S8, all proteins formed strongly-mobility-shifted species with this DNA, with some material barely penetrating the gel. This is sometimes seen when complexes tend to aggregate, and here those species were quantitated as part of the bound fraction. Binding analysis carried out as described for Eq. (1) returned stoichiometries of 2.2 ± 0.1 for WT-PARP1, 1.9 ± 0.1 for ∆CAP-PARP1, and 1.7 ± 0.1 for ∆Zn1∆Zn2-PARP1. As before, the formation of these complexes without accumulation of 1:1 intermediates is evidence of positively-cooperative binding. The WT-PARP1 protein forms 2:1 complexes with ss19mer and T20 DNAs. However, the stoichiometries of complexes formed by ∆CAT-PARP1 are different (n = 1.0 ± 0.1 for the ss19mer but n = 1.9 ± 0.1 for T20). The ∆Zn1∆Zn2-PARP1 also gives different stoichiometries with ss19mer and T20 (n = 1.0 ± 0.1 for the ss19mer but n = 1.7 ± 0.1 for T20). While the small increase in DNA contour length (20nt as opposed to 19nt) might allow the binding of an additional protein monomer, another potential source of difference is sequence-specific interaction, since each ssDNA offers base-contacts that are not available in the other. However, we favor the first mechanism, because binding affinities on T20 DNA are, in fact, greater than those for the ss19mer. This suggests that feature(s) relevant to binding may be augmented in the longer polymer. Possibilities include better accommodation of proteins due to the increased length of T20, stronger interactions with oligo dT than with ss19mer sequences, and for the ∆CAT and ∆Zn1∆Zn2 enzymes (which form 2:1 complexes on T20), cooperative interactions that are not possible in the 1:1 complexes formed with the ss19mer.

(A) Titration T20 and U20 with WT-PARP1, ∆CAT-PARP1 and ∆Zn1∆Zn2-PARP1 proteins, detected by EMSA (Supplemental Figure S7 contains the full image and experimental replicates are in supplemental Figure S8). T20 samples contained 0.06 µM T20 DNA and 0 – 2.34 µM WT-PARP1, or 0 – 7.74 µM ∆CAT-PARP1, or 0 – 7.09 µM ∆Zn1∆Zn2-PARP1. U20 samples contained 0.06 µM U20 RNA and 0 – 0.68 µM WT-PARP1, or 0 – 4.91 µM ∆CAT-PARP1, or 0 – 3.08 µM ∆Zn1∆Zn2-PARP1. Buffer, incubation and electrophoresis conditions are described in Methods. (B) Analyses of interactions of WT-, ∆CAT- and ∆Zn1∆Zn2-PARP1 proteins with single-stranded T20 DNA (left) or single-stranded U20 RNA (right). Graphs are plotted as described for Eq. (1). Note that scales for these graphs are not identical. Solid grey lines are least squares fits to each data set and the x-axis, at y = 0, is indicated by a solid black line. For T20 DNA binding, these analyses returned n = 2.2 ± 0.1 for WT-PARP1, 1.9 ± 0.1 for ∆CAT-PARP1, and 1.7 ± 0.1 for the ∆Zn1∆Zn2 enzyme. For U20 RNA binding, analyses returned n = 1.9 ± 0.2 for WT-PARP1, 1.8 ± 0.1 for ∆CAT-PARP1, and 2.9 ± 0.2 for the ∆Zn1∆Zn2 enzyme. Monomer-equivalent association constants derived from these analyses are given in Table 4.
RNA binding
PARP1 binds RNA and important cellular functions have been attributed to its interactions with that polymer5,29,64. Since many secondary structures are available in natural RNAs, it is likely that PARP1-RNA complexes have a parallel variety in structure, stoichiometry, and stability. Here we examined binding to U20, which provides binding sites of uniform base composition and has a low propensity to form base-paired secondary structures. Shown in Fig. 4A (right) and Supplemental Figures S7-S8, all proteins formed single mobility-shifted species with this RNA. Binding quantitation and analysis as described for Eq. (1) returned stoichiometries of 1.9 ± 0.2 for WT-PARP1, 1.8 ± 0.1 for ∆CAT-PARP1, and 2.9 ± 0.2 for ∆Zn1∆Zn2-PARP1 (Fig. 4B). The first two values are like those found with T20, raising the possibility that WT- and ∆CAT-proteins bind similarly with U20 and its DNA analogue. The U20-binding of the ∆Zn1∆Zn2 protein contrasts with those of WT- and ∆CAT-molecules. The larger stoichiometry (2.9 ± 0.2) implies a smaller contour length per protein (~ 6.9nt/protein as opposed to ~ 10; Table 4) and suggests a different packing mechanism for this protein when it binds RNA. In this context, it is especially interesting that cooperative binding is preserved.
Evaluation of cooperativity
Shown in Fig. 5 are Scatchard plots of data for binding duplex and single-stranded 19mer DNAs (panel A) and for binding T20 DNA and U20 RNA molecules (panel B). The concave downward trends of these plots indicate positively cooperative binding45. Accordingly, we used the short-lattice version of the McGhee-von Hippel relation (Eq. 2) to estimate cooperativity values for interactions in complexes containing two or more proteins. Values returned by these analyses are given in Tables 3 and 4. The range of values over all complexes with n ≥ 2 is approximately 24 ≤ \(\omega\) ≤ 140. These are modest compared to some values reported for single-stranded binding proteins (\(\omega\) ≥ 103)65,66 but other molecular systems give values in the range that we report here (c.f.,67,68). Even these modest values are sufficient to give single-step binding transitions in which free nucleic acid substrates are converted into multi-protein complexes without significant accumulation of stoichiometric intermediates. This characteristic will be discussed more below.

(A) Scatchard plots for wild type PARP1 and ∆CAT PARP1 with single-stranded and duplex 19mer DNAs. The binding data is from the EMSA experiments shown in Fig. 4A. The smooth curves are fits of Eq. (2) to the data. The cooperativity parameters returned by these fits are shown in Table 3. Note that the scales for each graph differ from those of other graphs. (B) Scatchard plots for wild type, ∆CAT and ∆Zn1∆Zn2 PARP1 proteins with single-stranded T20 DNA and U20 RNA. The binding data is from the EMSA experiments shown in Fig. 5A. The smooth curves are fits of Eq. (2) to the data. The cooperativity parameters returned by these fits are shown in Table 4. Note that the scales for each graph differ from those of other graphs.
Discussion
PARP1 is a multi-functional enzyme that binds DNA57,58,69,70, RNA5,29,31,64 and many proteins20,21,71. PARP1 autoPARylates itself72,73 as well as modifying several substrates including DNA14,74,75,76, histones3,26,69,77, DNA repair proteins, and RNA splicing factors20,21,71. As a result, PARP1 is positioned at the intersection of important cellular pathways, including transcription, DNA repair and RNA maturation, where it has the potential to contribute to the coordination of these processes. This multiplicity of important functions justifies thorough characterization of its interactions with binding partners, substrates and products, and this effort is well underway5,31,57,58,59.
PARP1 is a modular enzyme, in which individual domains retain some of their functions in isolation or in the context of a subset of other PARP1 domains. This feature has been valuable for the assignment of functions to individual domains and an aid to crystallographic studies where flexible coupling between domains is sometimes problematic78,79. However, it can lead to an incomplete understanding of a function to which several domains contribute80. One such function is nucleic acid binding, where several PARP1 domains10,14,16 such as the Zn1 and Zn2 zinc-finger domains55, Zn311,14,16,56, WGR4 and the BRCT domain contribute to PARP1-DNA binding57. Another is protein multimerization, where two different domains may form the interaction interface. This idea is supported by recent studies of PARP1 multimerization with longer dsDNA to drive condensation in vivo81. Effects of changing the structural context of domains are evident in our comparison of the DNA binding stoichiometries of WT-PARP1 and the ∆Zn1∆Zn2 mutant with, for example, the double-stranded 19mer (Table 3). We believe that the functional effects of changing the structural context of domains account for most, if not all, of the binding differences that we have observed between WT, ∆CAT and ∆Zn1∆Zn2 proteins.
Our results show that WT, ∆CAT and ∆Zn1∆Zn2 proteins are monomers under our solution conditions, in the absence of nucleic acids. This is consistent with results of some previous studies13,14,81 although others report that free PARP is dimeric17,32,55,82. This difference in association state is probably due to differences in enzyme preparation or in the solution conditions under which measurements were made. Whatever the source, it emphasizes the importance of establishing the quaternary state of PARP1 as a part of studies of binding or enzymatic activity. Evidence that PARP1 is monomeric under our conditions argues against mechanisms in which it binds nucleic acids as a pre-formed dimer (or higher multimers in the reactions that form 3:1 and 4:1 complexes described in results). The model that we currently favor is one in which PARP1 binds first as a monomer, then cooperative interactions favor the formation of higher-stoichiometry complexes, if permitted by the structure of the nucleic acid substrate. At the start of a titration, all proteins bind isolated sites. After this initial phase, incoming proteins distribute between isolated sites and those adjacent to bound proteins. Positive cooperativity enhances the affinity of incoming proteins for sites adjacent to bound proteins. This difference in affinity ensures that adjacent sites fill up before isolated ones, saturating the first nucleic acids bound before significant binding to isolated sites occurs. Such a mechanism might lead to the formation of cooperative assemblies of PARP1 in vivo.
Here we have examined the binding of wild-type PARP1 and two truncation mutants to short nucleic acids (blunt ended with mixed nucleotides except for T20 and U20 – see Table 1), with results that shed light on their binding selectivities and protein–protein interactions. Cooperative binding is the most striking feature of these interactions. This is evidenced by the formation of complexes with stoichiometry ≥ 2 without prior accumulation of 1:1 complexes. All proteins tested were capable of cooperative binding. This was surprising, as the Zn-finger domains missing in the ∆Zn1∆Zn2 mutant are known DNA binding sites55, while the catalytic domain that is missing in ∆CAT is implicated in protein–protein interactions necessary for ADP-ribosylation of substrate proteins, including other molecules of PARP119,20,21. These results show that neither the Zn1Zn2 region nor the CAT domain alone are essential for nucleic acid binding or cooperativity. Since the effects of removing the Zn1Zn2 and CAT domains were tested separately, it remains possible that the presence of the CAT domain complements the loss of Zn1Zn2 functions, and vice-versa. However, these results are consistent with results suggesting that regions other than Zn1Zn2 contribute to PARP1-DNA binding14,57,83 and regions other than the CAT domain contribute to binding cooperativity. It has been shown that PARP1 adopts a collapsed conformation for substrate recognition9,84, potentially using various domains or combinations for multifunctionality. In DNA break recognition, domains such as Zn1, Zn2, Zn3, WGR, and catalytic domains converge at the damaged site as reflected in partial structures obtained with PARP1 fragments bound to a double-stranded DNA break14, and to nicked DNA6. This mechanism may occur in the recognition of dsDNA ends, recapitulating ds breaks and/or structure of the DNA, however further studies are needed to explore this idea. In addition, it has been argued that depending on the context, PARP1 may bind as a monomer or a dimer. Activating partners for PARP1 range from damaged/structured DNA85,86, nuclear proteins62,85,86,87 to post-translational modifications88, thus influencing its binding mode in non-active and activated states. In the absence of DNA damage, cooperativity with DNA, RNA, itself, and other proteins might help PARP1 in recognizing non-damaged DNAs serving as a hub in recruiting proteins, different nucleic acids for gene expression. A recent study showed PARP1 multimerization binding to dsDNA, highlighting the critical role of protein–protein interactions between two PARP1 molecules in bridging DNA molecules81.
The monomer-equivalent association constants that we have found lie in a range (105–108 M−1) that is typical of many protein-nucleic acid interactions. However, the differences in affinity that accompany substitution of one nucleic acid substrate for another are revealing. Thus, for the WT protein, substituting ss19mer for the duplex reduces affinity by ~ fourfold, but the same substitution for the ∆CAT protein reduces affinity by ~ 110-fold. Intriguingly, ∆CAT forms a 3.9:1 complex with ds19mer and only a 1:1 complex with ss19mer. This suggests that this double stranded DNA with mixed nucleotides might provide the surface needed for cooperativity by this mutant. In a similar vein, we found that the WT enzyme bound U20 RNA about 15-times more tightly than T20 DNA, while the ∆Zn1∆Zn2 mutant enzyme bound U20 RNA at most 40-times more tightly than T20 DNA, suggesting that domains other than Zn1Zn2 participate in RNA binding. A similar conclusion, based on different observations has been published5. The ∆CAT mutant protein showed a reduced difference in affinity for U20 and T20, with only two-fold greater affinity for U20 compared to T20 (Table 4). These results suggest that protein structures that play a role in distinguishing RNA from DNA, or possibly uridine from thymidine, have been modified by the mutations that excised the CAT domains.
All the proteins tested here were capable of binding cooperativity when the substrate was single-stranded T20 or U20. For the ∆CAT and ∆Zn1∆Zn2 enzymes, these results indicate that neither of these domains is a unique functional determinant of cooperative binding. Thus, it is striking that both ∆CAT and ∆Zn1∆Zn2 enzymes are limited to 1:1 complexes when the binding substrate is the slightly shorter ss19mer DNA. This might reflect sequence-specific differences in binding mechanism, or it might reflect a difference in the ability of these enzymes to bind 19 nt and 20 nt nucleic acids. We note that both WT and ∆CAT enzymes are capable of forming 4:1 complexes on ds19mer templates (corresponding to ~ 5 bp/protein), and ∆Zn1∆Zn2 forms a 3:1 complex on U20 (corresponding to ~ 6.6 nt/protein). Thus, all proteins are capable of tighter packing than that occurring in the 1:1 complexes. The roles of sequence and nucleic acid length in regulating the packing interactions of PARP1 are important questions for the future.
Cooperativity parameters, along with their standard deviations, were derived by fitting Eq. (2) to binding data. Experiment-specific values are detailed in Tables 3 and 4. Our cooperativity measurements exhibit overlapping error ranges, typically around ~ 30% of the central values. This prevents us from detecting small differences that may exist between different proteins or between different binding substrates. With that caveat, it is striking that similar cooperativity values are found in dense complexes (e.g., WT and ∆CAT proteins with double stranded 19mer; stoichiometry 4:1, average binding site sizes ~ 4.7 bp/protein) and more diffuse ones (e.g., proteins binding T20, stoichiometry ~ 2:1, average site sizes of ~ 10nt/protein). We do not know the geometry of these complexes, and so cannot account for this similarity. There are two non-mutually exclusive possibilities: 1. It is possible that PARP1 binds to the ends of the blunt-ended dsDNA reflecting dsDNA break recognition. Such a possibility was recently supported by Chappidi and colleagues81, showing that PARP1 binds to blunt-ended dsDNA and facilitates bridging between DNA fragments via PARP1-PARP1 interactions (positive cooperativity), crucial for condensing both PARP1 and DNA. 2. Another possibility is that cooperativity allows the sequential binding of PARP1 molecules along the DNA (binding site size as calculated in Tables 3 and 4). A better accounting for the contributions of cooperative binding to the stability of PARP1 complexes will have to wait for more detailed information about the distribution of these protein molecules on these DNA and RNA substrates.
Several studies have shown that PARP1 binds nicks, abasic sites and ends as a monomer6,35,89. While other studies using a Zn1-Zn2 domain fragment indicate that PARP1 binds to 3′ overhang DNA as a dimer12. These apparently conflicting results could reflect the use of different mutant proteins, or solution conditions or nucleic acid substrates. On the other hand, PARP1 may still bind as a monomer with subsequent cooperative binding between PARP1 molecules to ensure stable DNA binding. PARP1 was shown to bridge undamaged DNAs in loop stabilization58 and PARP1 can also move along undamaged DNA via the diffusion-limited ‘monkey-bar’ mechanism9. While these studies do not directly show that PARP1 binds as a monomer, they suggest cooperativity in PARP1 mode of binding. Additionally, PARP1's activity as a monomer14,90 or dimer11,91,92 can lead to PARylation in cis or trans. However, our studies do not assess PARP1's activity.
The ability to bind cooperatively in vitro may reflect an activity of the enzyme in vivo. The data presented here leads us to speculate that functional PARP1 complexes may contain ≥ 1 molecule of the enzyme. This idea is supported by the recent paper of Chappidi showing condensation of PARP1 molecules with dsDNA in the formation of condensates81. In addition, multimerization of PARP1 could enhance the occupancy of available DNA and RNA sites and contribute to self- and hetero-PARylation. Thus, the binding cooperativities of PARP1 may play roles in the delivery of poly ADP-ribosylation activity to genomic sites where this post-translational modification can play a regulatory role in gene expression.
Data availability
All data generated or analyzed during this study are included in this manuscript or supplementary information files.
References
Beck, C. et al. Poly(ADP-ribose) polymerases in double-strand break repair: focus on PARP1, PARP2 and PARP3. Exp. Cell. Res. 329(1), 18–25. https://doi.org/10.1016/j.yexcr.2014.07.003 (2014).
Ronson, G. E. et al. PARP1 and PARP2 stabilise replication forks at base excision repair intermediates through Fbh1-dependent Rad51 regulation. Nat. Commun. 9(1), 746. https://doi.org/10.1038/s41467-018-03159-2 (2018).
Krishnakumar, R. & Kraus, W. L. PARP-1 regulates chromatin structure and transcription through a KDM5B-dependent pathway. Mol. Cell 39(5), 736–749. https://doi.org/10.1016/j.molcel.2010.08.014 (2010).
Huambachano, O. et al. Double-stranded DNA binding domain of poly(ADP-ribose) polymerase-1 and molecular insight into the regulation of its activity. J. Biol. Chem. 286(9), 7149–7160. https://doi.org/10.1074/jbc.M110.175190 (2011).
Melikishvili, M. et al. Transcriptome-wide identification of the RNA-binding landscape of the chromatin-associated protein PARP1 reveals functions in RNA biogenesis. Cell Discov. 3, 17043. https://doi.org/10.1038/celldisc.2017.43 (2017).
Eustermann, S. et al. Structural basis of detection and signaling of DNA single-strand breaks by human PARP-1. Mol. Cell 60(5), 742–754. https://doi.org/10.1016/j.molcel.2015.10.032 (2015).
Rudolph, J. et al. HPF1 and nucleosomes mediate a dramatic switch in activity of PARP1 from polymerase to hydrolase. Elife https://doi.org/10.7554/eLife.65773 (2021).
Alemasova, E. E. & Lavrik, O. I. Poly(ADP-ribosyl)ation by PARP1: reaction mechanism and regulatory proteins. Nucleic Acids Res. 47(8), 3811–3827. https://doi.org/10.1093/nar/gkz120 (2019).
Rudolph, J. et al. Poly(ADP-ribose) polymerase 1 searches DNA via a “monkey bar” mechanism. Elife https://doi.org/10.7554/eLife.37818 (2018).
Langelier, M. F. et al. Crystal structures of poly(ADP-ribose) polymerase-1 (PARP-1) zinc fingers bound to DNA: structural and functional insights into DNA-dependent PARP-1 activity. J Biol. Chem. 286(12), 10690–10701. https://doi.org/10.1074/jbc.M110.202507 (2011).
Ali, A. A. E. et al. The zinc-finger domains of PARP1 cooperate to recognize DNA strand breaks. Nat. Struct. Mol. Biol. 19(7), 685–692. https://doi.org/10.1038/nsmb.2335 (2012).
Pion, E. et al. DNA-induced dimerization of poly(ADP-ribose) polymerase-1 triggers its activation. Biochemistry 44(44), 14670–14681. https://doi.org/10.1021/bi050755o (2005).
Eustermann, S. et al. The DNA-binding domain of human PARP-1 interacts with DNA single-strand breaks as a monomer through its second zinc finger. J. Mol. Biol. 407(1), 149–170. https://doi.org/10.1016/j.jmb.2011.01.034 (2011).
Langelier, M. F. et al. Structural basis for DNA damage-dependent poly(ADP-ribosyl)ation by human PARP-1. Science 336(6082), 728–732. https://doi.org/10.1126/science.1216338 (2012).
Spagnolo, L. et al. Visualization of a DNA-PK/PARP1 complex. Nucleic Acids Res. 40(9), 4168–4177. https://doi.org/10.1093/nar/gkr1231 (2012).
Langelier, M. F. & Pascal, J. M. PARP-1 mechanism for coupling DNA damage detection to poly(ADP-ribose) synthesis. Curr. Opin. Struct. Biol. 23(1), 134–143. https://doi.org/10.1016/j.sbi.2013.01.003 (2013).
Kouyama, K. et al. Single-particle analysis of full-length human poly(ADP-ribose) polymerase 1. Biophys. Physicobiol. 16, 59–67. https://doi.org/10.2142/biophysico.16.0_59 (2019).
D’Amours, D. et al. Poly(ADP-ribosyl)ation reactions in the regulation of nuclear functions. Biochem. J. 342(Pt 2), 249–268 (1999).
Gagné, J. P. et al. Proteome-wide identification of poly(ADP-ribose) binding proteins and poly(ADP-ribose)-associated protein complexes. Nucleic Acids Res. 36(22), 6959–6976. https://doi.org/10.1093/nar/gkn771 (2008).
Isabelle, M. et al. Investigation of PARP-1, PARP-2, and PARG interactomes by affinity-purification mass spectrometry. Proteome Sci. 8, 22. https://doi.org/10.1186/1477-5956-8-22 (2010).
Jungmichel, S. et al. Proteome-wide identification of poly(ADP-Ribosyl)ation targets in different genotoxic stress responses. Mol. Cell 52(2), 272–285. https://doi.org/10.1016/j.molcel.2013.08.026 (2013).
Krishnakumar, R. et al. Reciprocal binding of PARP-1 and histone H1 at promoters specifies transcriptional outcomes. Science 319(5864), 819–821. https://doi.org/10.1126/science.1149250 (2008).
Ahel, D. et al. Poly(ADP-ribose)-dependent regulation of DNA repair by the chromatin remodeling enzyme ALC1. Science 325(5945), 1240–1243. https://doi.org/10.1126/science.1177321 (2009).
Sellou, H. et al. The poly(ADP-ribose)-dependent chromatin remodeler Alc1 induces local chromatin relaxation upon DNA damage. Mol. Biol. Cell 27(24), 3791–3799. https://doi.org/10.1091/mbc.E16-05-0269 (2016).
Singh, H. R. et al. A poly-ADP-ribose trigger releases the auto-inhibition of a chromatin remodeling oncogene. Mol. Cell 68(5), 860-871.e867. https://doi.org/10.1016/j.molcel.2017.11.019 (2017).
Ciccarone, F., Zampieri, M. & Caiafa, P. PARP1 orchestrates epigenetic events setting up chromatin domains. Semin. Cell Dev. Biol. 63, 123–134. https://doi.org/10.1016/j.semcdb.2016.11.010 (2017).
Hananya, N. et al. Synthesis of ADP-ribosylated histones reveals site-specific impacts on chromatin structure and function. J. Am. Chem. Soc. 143(29), 10847–10852. https://doi.org/10.1021/jacs.1c05429 (2021).
Matveeva, E. et al. Involvement of PARP1 in the regulation of alternative splicing. Cell Discov. 2, 15046. https://doi.org/10.1038/celldisc.2015.46 (2016).
Ke, J. et al. PARP1-RNA interaction analysis: PARP1 regulates the expression of extracellular matrix-related genes in HK-2 renal proximal tubular epithelial cells. FEBS Lett. 595(9), 1375–1387. https://doi.org/10.1002/1873-3468.14065 (2021).
Kim, D. S. et al. Activation of PARP-1 by snoRNAs controls ribosome biogenesis and cell growth via the RNA helicase DDX21. Mol. Cell 75(6), 1270-1285.e1214. https://doi.org/10.1016/j.molcel.2019.06.020 (2019).
Nakamoto, M. Y. et al. Nonspecific binding of RNA to PARP1 and PARP2 does not lead to catalytic activation. Biochemistry 58(51), 5107–5111. https://doi.org/10.1021/acs.biochem.9b00986 (2019).
Vasil’eva, I. A. et al. (2019) Dynamic light scattering study of base excision DNA repair proteins and their complexes. Biochim. Biophys. Acta Proteins Proteom. 3, 297–305. https://doi.org/10.1016/j.bbapap.2018.10.009 (1867).
Carkaci-Salli, N. et al. Functional domains of human tryptophan hydroxylase 2 (hTPH2). J. Biol. Chem. 281(38), 28105–28112. https://doi.org/10.1074/jbc.M602817200 (2006).
Amblar, M. et al. The role of the S1 domain in exoribonucleolytic activity: Substrate specificity and multimerization. Rna 13(3), 317–327. https://doi.org/10.1261/rna.220407 (2007).
Liu, L. et al. PARP1 changes from three-dimensional DNA damage searching to one-dimensional diffusion after auto-PARylation or in the presence of APE1. Nucleic Acids Res. 45(22), 12834–12847. https://doi.org/10.1093/nar/gkx1047 (2017).
Mansoorabadi, S. O. et al. Conformational activation of Poly(ADP-ribose) polymerase-1 upon DNA binding revealed by small-angle X-ray scattering. Biochemistry 53(11), 1779–1788. https://doi.org/10.1021/bi401439n (2014).
Langelier, M. F. et al. Purification of human PARP-1 and PARP-1 domains from Escherichia coli for structural and biochemical analysis. Methods Mol. Biol. 780, 209–226. https://doi.org/10.1007/978-1-61779-270-0_13 (2011).
Maxam, A. M. & Gilbert, W. Sequencing end-labeled DNA with base-specific chemical cleavages. Methods Enzymol. 65(1), 499–560. https://doi.org/10.1016/s0076-6879(80)65059-9 (1980).
Adams, P. L. et al. Crystal structure of a group I intron splicing intermediate. RNA 10(12), 1867–1887. https://doi.org/10.1261/rna.7140504 (2004).
Schuck, P. Size-distribution analysis of macromolecules by sedimentation velocity ultracentrifugation and lamm equation modeling. Biophys. J. 78(3), 1606–1619. https://doi.org/10.1016/s0006-3495(00)76713-0 (2000).
Laue TM (1992) Short column sedimentation equilibrium analysis for rapid characterization of macromolecules in solution. Technical Information DS-835, Beckman Spinco Business Unit, Palo Alto, CA
Hellman, L. M. & Fried, M. G. Electrophoretic mobility shift assay (EMSA) for detecting protein-nucleic acid interactions. Nat. Protoc. 2(8), 1849–1861. https://doi.org/10.1038/nprot.2007.249 (2007).
Adams CA, Fried MG. Analysis of protein-DNA equilibria by native gel electrophoresis. Protein Interactions. 2007. p. 417–446.
Laue T, Shah B, Ridgeway T et al (1992) In Harding, SE, Rowe, AJ and Horton, JC. Analytical Ultracentrifugation in Biochemistry and Polymer Science:90–125
McGhee, J. D. & von Hippel, P. H. Theoretical aspects of DNA-protein interactions: Co-operative and non-co-operative binding of large ligands to a one-dimensional homogeneous lattice. J. Mol. Biol. 86(2), 469–489. https://doi.org/10.1016/0022-2836(74)90031-x (1974).
Tsodikov, O. V. et al. Analytic binding isotherms describing competitive interactions of a protein ligand with specific and nonspecific sites on the same DNA oligomer. Biophys. J. 81(4), 1960–1969. https://doi.org/10.1016/s0006-3495(01)75847-x (2001).
Perkins, S. J. X-ray and neutron scattering analyses of hydration shells: a molecular interpretation based on sequence predictions and modelling fits. Biophys. Chem. 93(2–3), 129–139. https://doi.org/10.1016/s0301-4622(01)00216-2 (2001).
Dam, J. & Schuck, P. Calculating sedimentation coefficient distributions by direct modeling of sedimentation velocity concentration profiles. Methods Enzymol. 384, 185–212. https://doi.org/10.1016/s0076-6879(04)84012-6 (2004).
Dam, J. et al. Sedimentation velocity analysis of heterogeneous protein-protein interactions: Lamm equation modeling and sedimentation coefficient distributions c(s). Biophys. J. 89(1), 619–634. https://doi.org/10.1529/biophysj.105.059568 (2005).
Schuck, P. On computational approaches for size-and-shape distributions from sedimentation velocity analytical ultracentrifugation. Eur. Biophys. J. 39(8), 1261–1275. https://doi.org/10.1007/s00249-009-0545-7 (2010).
Fried, M. & Crothers, D. M. Equilibria and kinetics of lac repressor-operator interactions by polyacrylamide gel electrophoresis. Nucleic Acids Res. 9(23), 6505–6525 (1981).
Fried, M. G. & Bromberg, J. L. Factors that affect the stability of protein-DNA complexes during gel electrophoresis. Electrophoresis 18(1), 6–11. https://doi.org/10.1002/elps.1150180103 (1997).
Vossen, K. M. & Fried, M. G. Sequestration stabilizes lac repressor-DNA complexes during gel electrophoresis. Anal. Biochem. 245(1), 85–92. https://doi.org/10.1006/abio.1996.9944 (1997).
Yang, W. & Deng, L. PreDBA: A heterogeneous ensemble approach for predicting protein-DNA binding affinity. Sci. Rep. 10(1), 1278. https://doi.org/10.1038/s41598-020-57778-1 (2020).
Zandarashvili, L. et al. Structural basis for allosteric PARP-1 retention on DNA breaks. Science 368, 6486. https://doi.org/10.1126/science.aax6367 (2020).
Langelier, M. F. et al. The Zn3 domain of human poly(ADP-ribose) polymerase-1 (PARP-1) functions in both DNA-dependent poly(ADP-ribose) synthesis activity and chromatin compaction. J. Biol. Chem. 285(24), 18877–18887. https://doi.org/10.1074/jbc.M110.105668 (2010).
Rudolph, J. et al. The BRCT domain of PARP1 binds intact DNA and mediates intrastrand transfer. Mol. Cell 81(24), 4994-5006.e4995. https://doi.org/10.1016/j.molcel.2021.11.014 (2021).
Bell, N. A. W. et al. Single-molecule measurements reveal that PARP1 condenses DNA by loop stabilization. Sci. Adv. https://doi.org/10.1126/sciadv.abf3641 (2021).
Hassa, P. O. & Hottiger, M. O. The diverse biological roles of mammalian PARPS, a small but powerful family of poly-ADP-ribose polymerases. Front. Biosci. 13, 3046–3082 (2008).
Pascal, J. M. The comings and goings of PARP-1 in response to DNA damage. DNA Repair. (Amst.) 71, 177–182. https://doi.org/10.1016/j.dnarep.2018.08.022 (2018).
Martinez-Zamudio, R. I. & Ha, H. C. PARP1 enhances inflammatory cytokine expression by alteration of promoter chromatin structure in microglia. Brain Behav. 4(4), 552–565. https://doi.org/10.1002/brb3.239 (2014).
Kraus, W. L. Transcriptional control by PARP-1: chromatin modulation, enhancer-binding, coregulation, and insulation. Curr. Opin. Cell Biol. 20(3), 294–302. https://doi.org/10.1016/j.ceb.2008.03.006 (2008).
Nalabothula, N. et al. Genome-wide profiling of PARP1 reveals an interplay with gene regulatory regions and DNA methylation. PLoS One 10(8), e0135410. https://doi.org/10.1371/journal.pone.0135410 (2015).
Eleazer, R. & Fondufe-Mittendorf, Y. N. The multifaceted role of PARP1 in RNA biogenesis. Wiley Interdiscip. Rev. RNA 12(2), e1617. https://doi.org/10.1002/wrna.1617 (2021).
Kreso, A. & Dick, J. E. Evolution of the cancer stem cell model. Cell Stem Cell 14(3), 275–291. https://doi.org/10.1016/j.stem.2014.02.006 (2014).
von Hippel, P. H. & Marcus, A. H. The many roles of binding cooperativity in the control of DNA replication. Biophys. J. 117(11), 2043–2046. https://doi.org/10.1016/j.bpj.2019.10.029 (2019).
Melikishvili, M. & Fried, M. G. Resolving the contributions of two cooperative mechanisms to the DNA binding of AGT. Biopolymers 103(9), 509–516. https://doi.org/10.1002/bip.22684 (2015).
Menetski, J. P. & Kowalczykowski, S. C. Interaction of recA protein with single-stranded DNA. Quantitative aspects of binding affinity modulation by nucleotide cofactors. J Mol Biol 181(2), 281–295. https://doi.org/10.1016/0022-2836(85)90092-0 (1985).
Maluchenko, N. V. et al. Mechanisms of nucleosome reorganization by PARP1. Int. J. Mol. Sci. https://doi.org/10.3390/ijms222212127 (2021).
Pandey, N. & Black, B. E. Rapid detection and signaling of DNA damage by PARP-1. Trends Biochem. Sci. 46(9), 744–757. https://doi.org/10.1016/j.tibs.2021.01.014 (2021).
Teloni, F. & Altmeyer, M. Readers of poly(ADP-ribose): Designed to be fit for purpose. Nucleic Acids Res. 44(3), 993–1006. https://doi.org/10.1093/nar/gkv1383 (2016).
Ogata, N. et al. Poly(ADP-ribose) synthetase, a main acceptor of poly(ADP-ribose) in isolated nuclei. J. Biol. Chem. 256(9), 4135–4137 (1981).
Talhaoui, I. et al. Poly(ADP-ribose) polymerases covalently modify strand break termini in DNA fragments in vitro. Nucleic Acids Res. 44(19), 9279–9295. https://doi.org/10.1093/nar/gkw675 (2016).
Muthurajan, U. M. et al. Automodification switches PARP-1 function from chromatin architectural protein to histone chaperone. Proc. Natl. Acad. Sci. USA 111(35), 12752–12757. https://doi.org/10.1073/pnas.1405005111 (2014).
Tao, Z., Gao, P. & Liu, H. W. Identification of the ADP-ribosylation sites in the PARP-1 automodification domain: analysis and implications. J. Am. Chem. Soc. 131(40), 14258–14260. https://doi.org/10.1021/ja906135d (2009).
Rouleau-Turcotte, E. et al. Captured snapshots of PARP1 in the active state reveal the mechanics of PARP1 allostery. Mol. Cell 82(16), 2939–2951. https://doi.org/10.1016/j.molcel.2022.06.011 (2022).
Huang, D. & Kraus, W. L. The expanding universe of PARP1-mediated molecular and therapeutic mechanisms. Mol. Cell https://doi.org/10.1016/j.molcel.2022.02.021 (2022).
Mooij, W. T., Mitsiki, E. & Perrakis, A. ProteinCCD: enabling the design of protein truncation constructs for expression and crystallization experiments. Nucleic Acids Res. https://doi.org/10.1093/nar/gkp256 (2009).
Edwards, A. M. et al. Protein production: Feeding the crystallographers and NMR spectroscopists. Nat. Struct. Biol. 7(Suppl), 970–972. https://doi.org/10.1038/80751 (2000).
Vishwanath, S., de Brevern, A. G. & Srinivasan, N. Same but not alike: Structure, flexibility and energetics of domains in multi-domain proteins are influenced by the presence of other domains. PLoS Comput. Biol. 14(2), e1006008. https://doi.org/10.1371/journal.pcbi.1006008 (2018).
Chappidi, N. et al. PARP1-DNA co-condensation drives DNA repair site assembly to prevent disjunction of broken DNA ends. Cell 187(4), 945–961. https://doi.org/10.1016/j.cell.2024.01.015 (2024).
Bauer, P. I. et al. Macromolecular association of ADP-ribosyltransferase and its correlation with enzymic activity. Biochem. J. 270(1), 17–26. https://doi.org/10.1042/bj2700017 (1990).
Ogden, T. E. H. et al. Dynamics of the HD regulatory subdomain of PARP-1; substrate access and allostery in PARP activation and inhibition. Nucleic Acids Res. 49(4), 2266–2288. https://doi.org/10.1093/nar/gkab020 (2021).
Langelier, M.-F. et al. NAD+ analog reveals PARP-1 substrate-blocking mechanism and allosteric communication from catalytic center to DNA-binding domains. Nat. Commun. 9(1), 844. https://doi.org/10.1038/s41467-018-03234-8 (2018).
Lonskaya, I. et al. Regulation of poly(ADP-ribose) polymerase-1 by DNA structure-specific binding. J. Biol. Chem. 280(17), 17076–17083. https://doi.org/10.1074/jbc.M413483200 (2005).
Potaman, V. N. et al. Specific binding of poly(ADP-ribose) polymerase-1 to cruciform hairpins. J. Mol. Biol. 348(3), 609–615. https://doi.org/10.1016/j.jmb.2005.03.010 (2005).
Kim, M. Y. et al. NAD+-dependent modulation of chromatin structure and transcription by nucleosome binding properties of PARP-1. Cell 119(6), 803–814. https://doi.org/10.1016/j.cell.2004.11.002 (2004).
Cohen-Armon, M. et al. DNA-independent PARP-1 activation by phosphorylated ERK2 increases Elk1 activity: a link to histone acetylation. Mol. Cell 25(2), 297–308. https://doi.org/10.1016/j.molcel.2006.12.012 (2007).
Steffen, J. D., McCauley, M. M. & Pascal, J. M. Fluorescent sensors of PARP-1 structural dynamics and allosteric regulation in response to DNA damage. Nucleic Acids Res. 44(20), 9771–9783. https://doi.org/10.1093/nar/gkw710 (2016).
Lilyestrom, W. et al. Structural and biophysical studies of human PARP-1 in complex with damaged DNA. J. Mol. Biol. 395(5), 983–994. https://doi.org/10.1016/j.jmb.2009.11.062 (2010).
Altmeyer, M. et al. Molecular mechanism of poly(ADP-ribosyl)ation by PARP1 and identification of lysine residues as ADP-ribose acceptor sites. Nucleic Acids Res. 37(11), 3723–3738. https://doi.org/10.1093/nar/gkp229 (2009).
Tao, Z. et al. Domain C of human poly(ADP-ribose) polymerase-1 is important for enzyme activity and contains a novel zinc-ribbon motif. Biochemistry 47(21), 5804–5813. https://doi.org/10.1021/bi800018a (2008).
Jumper, J. et al. Highly accurate protein structure prediction with AlphaFold. Nature 596(7873), 583–589. https://doi.org/10.1038/s41586-021-03819-2 (2021).
Varadi, M. et al. AlphaFold Protein Structure Database: massively expanding the structural coverage of protein-sequence space with high-accuracy models. Nucleic Acids Res. 50(D1), D439-d444. https://doi.org/10.1093/nar/gkab1061 (2022).
Acknowledgements
We would like to thank the members of the Fried and Fondufe-Mittendorf laboratories for critical reading of the manuscript.
Funding
Research reported in this publication was supported by the National Science Foundation grant, MCB 2016515 (Y.N.F.-M.) and the National Institutes of Environmental Health grants, R01 R01ES031846, R01ES034253 (Y.N.F.-M.).
Author information
Authors and Affiliations
Contributions
Conceptualization: M.M., M.G.F., and Y.F.-M.; methodology: M.M., M.G.F., and Y.N.F.-M.; software: M.M., M.G.F., and Y.N.F.-M.; validation: M.M., M.G.F., and Y.N.F.-M.; formal analysis: M.M., M.G.F., and Y.N.F.-M.; investigation: M.M., M.G.F., and Y.N.F.-M.; resources, M.M., M.G.F., and Y.N.F.-M.; data curation: M.M., M.G.F., and Y.N.F.-M.; writing—original draft preparation: M.M., M.G.F., and Y.N.F.-M.; supervision: M.G.F. and Y.N.F.-M.; project administration: M.G.F. and Y.N.F.-M.; funding acquisition: Y.N.F.-M. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Melikishvili, M., Fried, M.G. & Fondufe-Mittendorf, Y.N. Cooperative nucleic acid binding by Poly ADP-ribose polymerase 1. Sci Rep 14, 7530 (2024). https://doi.org/10.1038/s41598-024-58076-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-58076-w
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
