
Abstract
This study aimed to design an end-to-end deep learning model for estimating the value of fractional flow reserve (FFR) using angiography images to classify left anterior descending (LAD) branch angiography images with average stenosis between 50 and 70% into two categories: FFR > 80 and FFR ≤ 80. In this study 3625 images were extracted from 41 patients’ angiography films. Nine pre-trained convolutional neural networks (CNN), including DenseNet121, InceptionResNetV2, VGG16, VGG19, ResNet50V2, Xception, MobileNetV3Large, DenseNet201, and DenseNet169, were used to extract the features of images. DenseNet169 indicated higher performance compared to other networks. AUC, Accuracy, Sensitivity, Specificity, Precision, and F1-score of the proposed DenseNet169 network were 0.81, 0.81, 0.86, 0.75, 0.82, and 0.84, respectively. The deep learning-based method proposed in this study can non-invasively and consistently estimate FFR from angiographic images, offering significant clinical potential for diagnosing and treating coronary artery disease by combining anatomical and physiological parameters.
Similar content being viewed by others
Introduction
Cardiovascular diseases (CVD) are the leading cause of death worldwide1. These diseases have been a significant concern in recent decades2, with nearly 18.5 million people expected to die from cardiovascular disease in 2019 and deaths from these diseases predicted to reach 23.6 million by 20303.
Coronary artery disease is the most common CVD, affecting over twenty million adults in the United States and accounting for almost one-third of all cardiovascular-related deaths4. This disease leads to plaque accumulation in the coronary arteries, called stenosis5,6. Stenosis can occur as a partial or complete blockage of the coronary arteries, resulting in reduced blood supply to heart tissue7. Narrowing or blockage of the coronary arteries can lead to severe symptoms such as angina pectoris and even myocardial ischemia8.
Regarding the diagnosis of coronary artery disease, coronary angiography is considered the gold standard for evaluating the anatomical status of coronary arteries in patients9. Coronary angiography is an essential diagnostic tool for coronary artery disease, and the cardiologist's visual assessment of angiography images is used to identify narrowing and guide treatment10. However, visual evaluation of angiography images can lead to overestimating the severity of coronary artery stenosis11, and the variability in evaluation among evaluators makes it challenging12,13,14,15. On the other hand, visual evaluation is highly subjective and lacks accuracy, objectivity, and consistency16.
Although coronary angiography is a valuable method for describing the extent and severity of coronary artery disease, evidence shows that anatomical stenosis of the coronary arteries does not necessarily indicate the presence of myocardial ischemia, and the functional severity of coronary artery stenosis is the leading cause of myocardial ischemia17,18 The physiological assessment uses the fractional flow reserve (FFR) method, using a pressure wire to measure blood flow and pressure after passing through a stenosis following an agent such as adenosine injection. The results are displayed on a monitor along with the FFR value19. Based on extensive clinical evidence, using FFR to select patients and appropriate lesions for treatment helps avoid unnecessary procedures, reduces medical costs, and improves clinical outcomes20.
Various studies have shown that FFR is the gold standard for evaluating physiological coronary artery stenosis and making decisions regarding coronary revascularization. If this value is greater than or equal to 80, medical treatment is performed, and if it is less than 80, stenting is performed21,22,23,24,25. Using coronary angiography images alone in treatment decisions is challenging due to the variability in assessments among observers12,13,14. Additionally, performing revascularization without sufficient evidence of ischemia has significant health and economic consequences19,23. Therefore, evaluating coronary artery physiology is essential for providing appropriate treatment plans18.
However, despite the recommendations of treatment guidelines, the use of FFR for diagnosing coronary artery disease is limited worldwide26,27. It may be due to complexity, high cost, and the invasive nature of this method28. Treatment decisions still rely on visual estimation of stenosis severity from angiographic images, indicating a discrepancy between clinical guidelines and current practice29. On the other hand, visual assessment of angiographic images leads to an overestimation of coronary artery stenosis severity11. Since physiological assessment of stenosis severity during coronary angiography affects decision-making regarding revascularization in 43% of cases, all cardiac catheterization laboratories (Cath labs) should be capable of measuring the FFR17. Coronary angiography-based FFR eliminates the complications of the invasive nature of FFR and displays the values of coronary artery FFR30. Using FFR along with the coronary artery anatomy could significantly improve the clinical outcomes of patients. However, physiological assessment using anatomical data is challenging, and validation is required to confirm the accuracy of these models31. Therefore, physiological assessment using non-invasive methods with the help of angiographic images, obtaining the value of FFR, is of interest, and angiography image-based software provides the possibility of evaluating coronary artery physiology25.
In the past three decades, artificial intelligence (AI) has been widely used to improve the diagnostic accuracy of clinical tools and for data-driven decision-making in cardiovascular diseases. Additionally, AI-based systems can facilitate decision-making by improving interpretation processes, inference, and diagnostic accuracy28,32,33. As a subfield of artificial intelligence, machine learning has a subfield called deep learning, describing algorithms that analyze data with a logical structure similar to human reasoning. Deep learning is a subfield of machine learning that uses multiple layers of linear transformations to process data. Deep learning is a rapidly evolving field with many applications in medical imaging. Deep learning algorithms can extract and learn raw features from image data without limitations on feature extraction. Therefore, deep learning can be an ideal solution34. Deep learning is highly suitable for medical image segmentation35. Convolutional neural networks (CNN) are one of the most famous deep learning-based networks.
CNN is an artificial neural network consisting of convolutional, pooling, and fully connected layers. It has many applications for automatically extracting rules and features from various data types. CNNs are extensively used for image processing36 and classifying medical images37. They are used to segment coronary vessels9 and classify and identify stenosis in vessels36,38 using angiography images. Using pre-trained CNN models to increase accuracy and effectively reduce training time is a common approach in artificial neural networks. This method is referred to as transfer learning36.
This research endeavors to develop an advanced diagnostic and therapeutic system utilizing artificial intelligence (AI) techniques to surmount the constraints associated with traditional methods like coronary angiography and Fractional Flow Reserve (FFR) in the identification and treatment of moderate coronary artery stenosis. More specifically, our investigation aims to fill the existing gaps in this domain by introducing an innovative, comprehensive, and automated system, driven by artificial intelligence. This system is designed to process angiography images as input, providing a determination of FFR as either greater or less than 80. By doing so, it seeks to address the limitations inherent in conventional approaches, ushering in the integration of AI capabilities into the realm of cardiovascular diagnostics, allowing for the direct estimation of FFR values from angiography images.
Related works
Estimating FFR using AI methods has been an essential topic in recent years, as researchers have attempted to calculate FFR non-invasively. Various AI methods, including deep learning-based methods, machine learning-based methods, and a combination of them, have been used along with different imaging tools such as CCTV, OCT, XCA, and IVUS. Table 1 shows the studies conducted in this field39.
Methods
This section consists of two parts. The first part includes the population, data structure, and data preparation methods. The second part examines the structure of the proposed method, data pre-processing methods, and the architecture of the proposed model discussed in detail below.
Population
This retrospective cross-sectional study was conducted in 2023. The angiographic images of 41 patients who underwent angiography and FFR on the left anterior descending (LAD) coronary artery and were referred to a cardiac center between 2015 and 2022 were used in this study. Patients were referred for angiography based on symptoms such as chest pain or shortness of breath, as well as risk factors like family history, smoking, high cholesterol, etc., suggesting a preliminary diagnosis of coronary artery disease. Angiography was requested for further evaluation based on clinical presentation and noninvasive testing such as stress testing. The study participants ages ranged from 42 to 57 years and 19 participants were female. The participants had no stenosis, coronary flow impairment, acute myocardial infarction, or history of open-heart surgery. FFR was performed to physiologically evaluate the lesions with a visual estimation of 50% and 70% of stenosis. The data were collected by reviewing the medical records and the angiography department's archive. All patients underwent coronary angiography through the femoral artery using a Judkins catheter and conventional imaging. Multiple physicians performed angiography in all cases, and Ultravist-370 (Schering, Berlin, Germany) was used as the contrast agent. The injection was done manually (6–8 ml of contrast agent per injection). Coronary pressure was measured using a 0.014-inch pressure wire (St. Jude Medical, USA). The wire was guided and calibrated using a guiding catheter and placed approximately three centimeters past the stenosis. Maximum hyperemia was induced by intravenous administration of adenosine (average dose of 120 µg).
All experimental protocols were approved by the Institutional Review Board of Shahid Beheshti University of Medical Sciences, with the approval code IR.SBMU.RETECH.REC.1401.665, and were performed in accordance with relevant guidelines and regulations. Informed consent was obtained from all subjects and/or their legal guardians.
Data structure
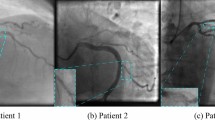
The training data used in this study consisted of 2390 images from 18 patients before and after revascularization (All of these patients underwent FFR procedure after revascularization surgery, and their FFR values were greater than 80). Given that the arterial structure of a patient before and after revascularization surgery is the same, and the only difference is the removal of stenosis and increase in flow at the site of the lesion, the angiography images of these patients before stenting were classified into the category of patients with FFR ≤ 80, and the images after revascularization surgery were classified into the category of patients with FFR > 80. Therefore, assuming that the proposed model is sensitive to these changes and learns the desired region of interest better, this category of images was selected as the training dataset. Additionally, for model evaluation, the test dataset consisted of 772 images from twenty-three patients, including 14 patients with FFR > 80 and nine patients with FFR ≤ 80, as described in Table 2. The before-and-after images of patients were not used in the test dataset, and the images in each category in this dataset only included unique images of unique patients to have a fair and unbiased evaluation of the model. Figure 1 shows a patient's FFR value before and after revascularization surgery and changes in the region of interest (ROI) indicated with a red circle in the image.

FFR Value before Revascularization is 0.8, and FFR Value after Revascularization is 0.9
Data preparation
An interventional cardiologist evaluated the angiography films of patients, and a total of 3625 black and white images related to the LAD artery from forty-one patients were included in the study, each measuring 512 × 512 pixels. This study classified patients into FFRH class for FFR > 80 and FFRL class for FFR ≤ 80.
Proposed method
Figure 2 illustrates the structure of the proposed method. First, pre-processing was performed on the input images, including decoding, resizing, normalization, augmentation, and histogram equalization. Then, the feature extractor inserted the obtained feature vector into the classifier block, and finally, the images were divided into two classes: FFR > 80 and FFR ≤ 80.

The overall structure of the proposed method.
Preprocessing
Pre-processing is an essential step in deep learning that involves transforming and preparing raw data for effective utilization by a neural network66. It involves various techniques such as decoding, resizing, normalization, augmentation, and histogram equalization.
Decoding
Image decoding is converting the encoded image back to an uncompressed bitmap. The attribute channels indicate the decoded image's desired number of color channels.
Resizing
The image size of 380 × 380 pixels was selected using Grid search.
Data normalization
Normalization was applied to all images before entering the network.
The data were normalized to reduce the effect of intensity variations between radiographs. Normalization involves scaling the pixel values of images to a standard range or mean and unit variance to reduce the impact of varying lighting conditions on the image. Scaling involves rescaling the data to have similar units so that no feature dominates another67.
For data normalization, first, the pixel‐level global mean and standard deviation (SD) were calculated for all the images; next, the data were normalized using Eq. 1 where μ is the global mean of the image set X, σ is the SD, ε = 1e − 10 is an insignificant value to prevent the denominator from turning zero, i = [1 − 2083] is the index of each training sample, and Zi is the normalized version of Xi (41).
Augmentation
Data augmentation is essential in deep learning models. It involves generalizing the training samples by transforming images without losing their semantic and intrinsic information. These transformations were randomly applied to the data68,69.
Data augmentation involves creating more training examples by transforming existing images through rotation, translation, contrast change, and zooming techniques.
Table 3 shows data augmentation techniques and the parameters used in this study.
Histogram equalization
The histogram information was used, and the most common intensity values were dispersed to produce a contrast-improved image70. Histogram equalization was performed using Eq. 2, where L is the maximum intensity level of the image; M: is the width of the image; N: is the height of the image; N: is the frequency corresponding to each intensity level; rj: the range of values from 0 to L-1; Pin: the total frequency that corresponds to a specific value of rj; Rk: the new frequencies; Sk: The new equalized histogram; where k = 0,1,2, ……, L − 113.
This study used this technique to adjust the contrast of the input image. Figure 3 shows an example of using this technique.

X-ray image before and after histogram equalization.
Model architecture
The proposed model consisted of feature extraction and classification blocks, explained in the following.
Feature extractor
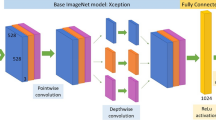
Nine famous pre-trained CNNs were used for image feature extraction, including DenseNet12171, InceptionResNetV272, VGG1673, VGG1973, ResNet50V274, Xception75, DenseNet20171, DenseNet16971, and MobileNetV3Large76. After running these networks on the dataset and evaluating them, DenseNet169 showed the best performance. This architecture consists of a convolutional layer, a pooling layer, four dense blocks, and three transition layers. the 4 dense blocks and 3 transition layers have been delineated separately using distinct boxes to showcase the individual components. For each dense block, the number of constituent layers is also indicated. For instance, Dense Block 1 is composed of 6 layers, with each layer utilizing batch normalization (BN), ReLU activation, followed by 1 × 1 and 3 × 3 convolutional filters of size 64. The subsequent Dense Blocks 2, 3 and 4 progressively increase the layers, while maintaining an identical structure of batch normalization, ReLU activation, and convolutional filtering. Finally, the transition layers in between the dense blocks employ batch normalization, ReLU activation, and 1 × 1 convolutions with 128, 256, and 512 filters respectively. We believe these model architecture clarifications provide improved understanding of the underlying DenseNet169 infrastructure per the reviewer’s suggestion. Please advise if further explanation or modification would be beneficial. Figure 4 illustrates the overall architecture of this network71.

DenseNet‐169 architecture‐based feature extraction block71.
Classifier
For classifying angiography images into two classes of FFR > 80 and FFR ≤ 80, a classifier block was designed, as shown in Fig. 5, in which two fully connected sequential blocks were used after the batch-normalization layer.

Classification block.
The first block consisted of dense, ReLU, Kernel Regularizer L1L2, batch‐normalization, and dropout layers. The second block comprised dense, ReLU, and batch‐normalization layers, respectively. Figure 6 displays these steps in detail.
The classifier was a dense layer with two neurons, and the Softmax function was applied to these representations. This function specified the probability of allocating each sample to one out of Two classes, and its value fell in the [0,1] range. Figure 5 displays these steps in detail.
Training and implementation
The feature extractor block was completely frozen using the transfer learning approach in the first training phase and included non-trainable parameters. This model was trained for several epochs with weights obtained after fitting the ImageNet dataset. However, all parameters of the classifier block were trainable.
The first training phase used the Adam optimizer with an initial learning rate of 1e-2 and a decay rate of 1e-5. The Adam optimizer with an initial learning rate of 1e-4 and a decay rate of 1e-6 was used in the second training phase. In both training phases, cosine Annealing was used. In the second phase of fine-tuning, all network layers except for the first eight layers, the feature extractor, and the first convolutional block were trainable and frozen.
The training process consisted of 120 epochs in the first phase and 600 in the second phase. Early stopping was considered at ten epochs in the first and 100 in the second phases. In the second phase of training, validation loss was also monitored. If it remained constant for ten epochs and did not improve, the learning rate would decline by 20%. Validation accuracy was also monitored, and only the model with the best weights obtained was saved. The optimal hyperparameter values were obtained using grid search. The value of the kernel regularizer parameters was l1 = 1e-5 and l2 = 1e-4. These architectures were implemented using Python language and the Keras library and executed on Google's TPU v3-8. Figure 7 shows the training and validation loss after 238 iterations during the training process.
Loss function
Cross-entropy was used as the loss function, which is a metric for measuring the performance of a classification model in machine learning and is defined by Eq. 3, Where P(x) is the probability of the event x in P, Q(x) is the probability of event x in Q, and the log is the base-2 logarithm77.
Learning rate schedule
The learning rate schedule is a pre-defined framework that adjusts the learning rate between epochs or iterations to avoid getting stuck in the local optimum as training progresses. This study used a warm restart cosine annealing for the learning rate scheduling program, considering the best weights as the restart points. It is demonstrated in the following equation (Eq. 4), where the best weights are considered as the restart points.
Within \(i\)-th run, the learning rate is decayed with a cosine annealing for each batch as follows:
\(\eta_{min}^{i}\) and \(\eta_{max}^{i}\) are ranges for the learning rate, and \(Tcur\) accounts for how many epochs have been performed since the last restart. Since Tcur is updated at each batch iteration t, it can take discredited values such as 0.1 and 0.2. Thus, \({ }\eta t = \eta_{max}^{i}\) when \(t = 0\) and \(Tcur = 0\). Once \(Tcur = { }Ti\), the \({\text{cos}}\) function will output − 1, so \(\eta t = \eta_{min}^{i}\)78.
Custom weighting
The unequal number of class samples, known as class imbalance, is an issue in machine learning classification problems. It affects the prediction model and leads to bias. Custom weighting was used to prevent this challenge, with a weight of 0.8 for the high-count class and 1.32 for the low-count class. These values represent the weighted average of the number of samples in each class.
Label smoothing
Label smoothing was used to improve the generalizability of the model.
Label smoothing is an effective regularization tool for deep neural networks (DNNs) and can implicitly calibrate the model's predictions. It significantly impacts the model interpretability and improves model calibration and beam search. It accounts for the possible mistakes in datasets, so maximizing the likelihood of \(\log p\left( {y{|}x} \right)\) can be directly harmful. For a small constant ε, the training set label \(y\) is correct with the probability of 1—ε and incorrect otherwise. Label Smoothing regularizes a model based on a Softmax with k output values by replacing the hard 0 and 1 classification targets with targets of \(\frac{{{\varvec{\upvarepsilon}}}}{k - 1}\), respectively76,79,80,81.
Techniques to prevent overfitting
Overfitting is a fundamental problem in supervised machine learning, preventing models from perfectly generalizing to observed training data and unseen test set data. Overfitting occurs due to noise, limited training set size, and classifier complexity82. In order to address concerns related to potential overfitting in our model, several regularization techniques were strategically incorporated during the model development phase. Batch Normalization was applied to normalize the activations of various layers, enhancing the stability of the learning process. Additionally, Dropout with a rate of 0.2 was implemented on specific layers to introduce a level of randomness, preventing the model from relying too heavily on specific features present in the training set. Furthermore, L1L2 Kernel Regularizer was employed on the Dense layer with carefully chosen coefficients to penalize large weights and reduce model complexity. These regularization techniques collectively contribute to the robustness of our model by striking a balance between fitting the training data and generalizing well to new, unseen data. The effectiveness of these measures is evident in the model's performance, as illustrated in Fig. 7 and discussed in the results section.
Mixed precision
Mixed precision decreased fitting/training time and reduced memory usage during training. Figure 6 illustrates the mechanism of this method.

Mixed precision training iteration for a layer83.

The loss of the proposed model during training. Model converged after 238 epochs.
Ethical approval
All experimental protocols were approved by the Institutional Review Board of Shahid Beheshti University of Medical Sciences, with the approval code IR.SBMU.RETECH.REC.1401.665, and informed consent was obtained from all subjects and/or their legal guardians.
Experiments
In this section, the performance evaluation parameters of the model are first explained, then the proposed method's performance is evaluated, and the model training results are reported. Furthermore, various well-known pre-trained networks were also used, and their training results were compared with the proposed method.
Evaluation metrics
Evaluation metrics are different types of measures to evaluate the performance of a deep learning model. They are mainly Accuracy (3), Precision (4), Recall (4), F-Measure (6), and Specificity. The number of true-positive (TP), false-positive (FP), true-negative (TN), and false-negative (FN) values are required to measure these parameters, as mentioned below.
Model evaluation
In this section, the evaluation results of the model on the test dataset were reported. For evaluating the proposed model, the cross-validation method was used. Cross-validation is a statistical method for evaluating and comparing learning algorithms by dividing the data into model training and validation84,85,86. The main form of cross-validation is k-fold cross-validation, where k equals the number of folds. This type of validation is performed as follows:
In each iteration, one or more learning algorithms use k = 1 folds of data to learn one or more models, and subsequently, the learned models are asked to make predictions about the data in the validation fold. The performance of each learning algorithm on each fold can be tracked using some predetermined performance metric like accuracy. Different methodologies, such as averaging, can be used to obtain an aggregate measure from these samples, or these samples can be used in a statistical hypothesis test to show that one algorithm is superior to another.
This study used five-fold cross-validation to validate the proposed model. The final results of evaluating the proposed model using this method are reported in Table 4 and Fig. 8.

Confusion matrix of model evaluation on the test data set.
The Receiver Operating Characteristic (ROC) curve in Fig. 9 illustrates the predictive model's performance for Fractional Flow Reserve (FFR) with an Area Under the Curve (AUC) of 0.81. This AUC value signifies a strong discriminatory capacity, effectively distinguishing between FFR > 80 and FFR < = 80 classes. Specifically, the model excels in discerning FFR > 80 and FFR < = 80 classes, as indicated by the AUC value. The 95% confidence interval for the AUC, [0.777, 0.833], ensures the precision of this discrimination. Moreover, the exceedingly low p-value (< 0.001) underscores the model's statistical significance, indicating a substantial and meaningful difference compared to the baseline value of 0.5.

Fig. 1—Receiver Operating Characteristic (ROC) curve on the test data set.
Review and comparison of pre-trained feature extractors
Nine pre-trained CNNs, including DenseNet121, InceptionResNetV2, VGG16, VGG19, ResNet50V2, Xception, MobileNetV3Large, DenseNet201, and DenseNet169 (Proposed), were used for image feature extraction and were evaluated with the test dataset. These models were compared based on the accuracy parameter. Table 5 shows the obtained results.
The performance outcomes from assessing the three highest-accuracy models using the evaluation the test data are presented in Table 6.
Discussion
In the present study, a fast, end-to-end, automated deep learning model was designed for estimating FFR values using angiography images. This model can classify angiography images into two classes, FFR > 80 and FFR < = 80, with no manual annotation and an overall accuracy of 81%. Multiple studies have shown a correlation between anatomical and physiological parameters87,88, and the current study's findings also provide further insights into how angiography features affect FFR values.
Although angiography is the gold standard for evaluating the severity of coronary lesions, physiological evaluation is the determining factor for treatment planning in patients with coronary artery disease89. FFR is considered the gold standard for the physiological assessment of coronary artery stenosis and is a strong indicator for diagnosis, treatment, and determining the approach for interventions. However, the invasive nature of FFR evaluation and its high cost has led to a lack of enthusiasm among healthcare professionals to use this method routinely in the Cath lab. The proposed method in this study has the potential to be used routinely in Cath labs due to its low cost, no need for additional data entry or extra workload for the cardiologist, online usability, and no need for changes in workflow in the Cath lab. However, this method requires external validation. External evaluation in deep learning checks a model's performance on new, distinct data, ensuring its generalization and minimizing overfitting for real-world applications90,91,92.
The present study shows that in recent years, significant efforts have been made to integrate anatomical and physiological parameters, indicating this method's clinical value for physicians and patients. However, integrating anatomical and physiological parameters is a significant challenge93. Various methods have been developed to calculate FFR without an invasive pressure wire or inducing hyperemia31. The present study's findings also demonstrate that image-based deep learning for determining FFR is a non-invasive and cost-effective method that can be used to match the visual and physiological features of coronary artery stenosis.
In recent years, an end-to-end framework has been introduced in deep learning, and its benefits in the health field have been investigated94,95. This study's proposed model demonstrates the advantages of using this approach for estimating FFR. Physicians can use this model to evaluate physiological conditions without entering additional data and manual annotation, only by inputting angiography images. Additionally, to facilitate the successful implementation of this method in Cath labs, systems based on this model can display FFR values online. On the other hand, the FAME study shows that only 35% of patients with stenosis between 50 and 70% are found to be significant stenosis in FFR evaluation. In other words, a model that can detect more insignificant stenosis will result in fewer unnecessary FFRs.
The existence of a non-invasive method for reducing unnecessary FFRs is also very important, and artificial intelligence, due to its non-invasiveness and the lack of need to change the workflow of the Cardiac catheterization laboratory, can be an excellent solution. This highlights the potential value of an accurate non-invasive AI-based FFR estimation approach. Such a method could help avoid unnecessary invasive FFR procedures and their associated costs and complications in cases where non-invasive assessment predicts non-significant stenosis. This is particularly relevant given that studies show only a subset of intermediate coronary lesions are found to be hemodynamically significant when measured invasively. More widespread adoption of validated non-invasive FFR estimation techniques may improve clinical workflows and benefit both patients and healthcare systems.
In the present study, the DenseNet169 model outperformed other models in detection of insignificant stenosis. Compared to other studies in this field, our proposed method requires only a single view from the angiography image with no need for annotation or additional parameters, without altering existing clinical workflows, yet still achieves state-of-the-art performance by utilizing a deep learning approach.
Study limitations and future considerations
While our study provides valuable insights into FFR estimation using angiography images, it is essential to acknowledge certain limitations. Firstly, the relatively small sample size of 41 patients might impact the generalizability of our findings. Future research endeavors should prioritize the inclusion of a larger and more diverse cohort to enhance the robustness and external validity of the proposed model.Additionally, this study focused solely on the parameters present in angiography images, omitting potential influential factors such as age and gender. The exclusion of these variables may limit the comprehensive understanding of FFR estimation. Future investigations could explore the incorporation of additional clinical parameters to refine and expand the predictive capabilities of the model. External evaluation of our method on independent datasets will also be important to further validate the generalizability of our findings. External evaluation is something that will be a focus of our future work.
Conclusion
This study designed an intelligent, fast, end-to-end, and automated method using the CNN architecture, the concept of transfer learning, and the pre-trained DenseNet169 network for estimating FFR values based on angiography images. This model can estimate FFR non-invasively with an overall accuracy of 81%. DL-based angiography image-derived FFR is a valuable tool for decision-making in diagnosing and treating stenosis in Cath labs. This model can assist cardiologists in decisions about diagnosis and treatment of moderate stenosis by combining physiological and anatomical parameters of coronary arteries.
Data availability
Due to the policies and guidelines of Shahid Beheshti University of Medical Science, data is not allowed for publication. The raw data supporting the conclusions of this article will be made available by the authors without undue reservation. The Python source codes used to develop the model are deposited on GitHub (https://github.com/MehradAria/FFR-Estimation).
Abbreviations
- A:
-
Automatically
- AI:
-
Artificial intelligence
- ANN:
-
Artificial neural network
- BRNN:
-
Bidirectional multilayer recursive neural network
- BRNN:
-
Bidirectional multilayer recursive neural network
- CAD:
-
Coronary artery disease
- CCTA:
-
Coronary computed tomography angiography
- cGAN:
-
Conditional generative adversarial network
- CVD:
-
Cardiovascular diseases
- DL:
-
Deep learning
- DNN:
-
Deep neural networks
- FFR:
-
Fractional flow reserve
- GB:
-
Gradient boosting
- GP:
-
LogitBoost
- GRU:
-
Gated recurrent units
- IVUS:
-
Intravascular ultrasound
- LAD:
-
Left anterior descending artery
- LCA:
-
Left coronary artery
- LCX:
-
Left circumflex artery
- LR:
-
Logistic regression
- LVM:
-
Left ventricular myocardial
- M:
-
Manually
- ML:
-
Machine learning
- MLNN:
-
Multilevel neural network
- MLP:
-
Multilayer perceptron
- OCT:
-
Optical coherence tomography
- RCA:
-
Right coronary artery
- RCNN:
-
Recurrent convolutional neural network
- RF:
-
Random forest
- SVM:
-
Support vector machine
- XCA:
-
X-ray coronary angiography
References
Roth, G. A. et al. Global, Regional, and National Burden of Cardiovascular Diseases for 10 Causes, 1990 to 2015. J Am Coll Cardiol. 70(1), 1–25 (2017).
Organization WH. Global status report on noncommunicable diseases 2014: World Health Organization; (2014).
Do, N. T., Bellingham, K., Newton, P. N. & Caillet, C. The quality of medical products for cardiovascular diseases: a gap in global cardiac care. BMJ Glob Health. 6(9), e006523 (2021).
Go, A. S. et al. Heart disease and stroke statistics–2013 update: a report from the American Heart Association. Circulation. 127(1), e6–e245 (2013).
Vlachopoulos C, O'Rourke M, Nichols WW. McDonald's blood flow in arteries: theoretical, experimental and clinical principles: CRC press; (2011).
Feigl EJPr. Coronary Physiology. (1983);63(1):1–205.
Rodrigues DL, Nobre Menezes M, Pinto FJ, Oliveira ALJae-p. Automated Detection of Coronary Artery Stenosis in X-ray Angiography using Deep Neural Networks2021 March 01, (2021):[arXiv:2103.02969 p.]. Available from: https://ui.adsabs.harvard.edu/abs/2021arXiv210302969R.
Wu, W. et al. Automatic detection of coronary artery stenosis by convolutional neural network with temporal constraint. Comput. Biol. Med. 118, 103657 (2020).
Iyer, K. et al. AngioNet: a convolutional neural network for vessel segmentation in X-ray angiography. Sci. Rep. 11(1), 18066 (2021).
Yang, M., Zhang, L., Tang, H., Zheng, D. & Wu, J. The guiding significance of fractional flow reserve (FFR) for coronary heart disease revascularization. Discov. Med. 31(162), 31–35 (2021).
Toth, G. G. et al. Revascularization decisions in patients with stable angina and intermediate lesions: Results of the international survey on interventional strategy. Circ. Cardiovasc. Interv. 7(6), 751–759 (2014).
Zir, L. M., Miller, S. W., Dinsmore, R. E., Gilbert, J. P. & Harthorne, J. W. Interobserver variability in coronary angiography. Circulation 53(4), 627–632 (1976).
DeRouen, T. A., Murray, J. A. & Owen, W. Variability in the analysis of coronary arteriograms. Circulation 55(2), 324–328 (1977).
Tonino, P. A. et al. Fractional flow reserve versus angiography for guiding percutaneous coronary intervention. New Eng. J. Med. 360(3), 213–224 (2009).
Pijls, N. H. et al. Fractional flow reserve versus angiography for guiding percutaneous coronary intervention in patients with multivessel coronary artery disease: 2-year follow-up of the FAME (Fractional flow reserve versus angiography for multivessel evaluation) study. J. Am. Coll. Cardiol. 56(3), 177–184 (2010).
Wang, L. et al. Coronary artery segmentation in angiographic videos utilizing spatial-temporal information. BMC Med. Imaging. 20(1), 110 (2020).
Gaede, L. et al. Coronary angiography with pressure wire and fractional flow reserve. Deutsch. Arztebl. Int. 116(12), 205–211 (2019).
Neumann, F. J. et al. 2018 ESC/EACTS Guidelines on myocardial revascularization. Eur. Heart J. 40(2), 87–165 (2019).
Stone, G. W. et al. Medical therapy with versus without revascularization in stable patients with moderate and severe ischemia: the case for community equipoise. J. Am. Coll. Cardiol. 67(1), 81–99 (2016).
Park, S. J. & Ahn, J. M. Should we be using fractional flow reserve more routinely to select stable coronary patients for percutaneous coronary intervention?. Curr. Opin. Cardiol. 27(6), 675–681 (2012).
Pijls, N. H. et al. Fractional flow reserve. A useful index to evaluate the influence of an epicardial coronary stenosis on myocardial blood flow. Circulation. 92(11), 3183–3193 (1995).
Kern, M. J. et al. Physiological assessment of coronary artery disease in the cardiac catheterization laboratory: A scientific statement from the American heart association committee on diagnostic and interventional cardiac catheterization. Council Clin. Cardiol. Circ. 114(12), 1321–1341 (2006).
Ciccarelli, G. et al. Angiography versus hemodynamics to predict the natural history of coronary stenoses. Circulation 137(14), 1475–1485 (2018).
Zimmermann, F. M. et al. Deferral vs. performance of percutaneous coronary intervention of functionally non-significant coronary stenosis: 15-year follow-up of the DEFER trial. Eur. Heart J. 36(45), 3182–3188 (2015).
Ono, M., Onuma, Y. & Serruys, P. W. The era of single angiographic view for physiological assessment has come. Is simplification the ultimate sophistication?. Catheter. Cardiovasc. Interventions. 1(97), 964–965 (2021).
Desai, N. R. et al. Appropriate use criteria for coronary revascularization and trends in utilization patient selection and appropriateness of percutaneous coronary intervention. Jama 314(19), 2045–2053 (2015).
Dicker, D. et al. Global, regional, and national age-sex-specific mortality and life expectancy, 1950–2017: A systematic analysis for the global burden of disease study 2017. The Lancet. 392(10159), 1684–1735 (2018).
Alizadehsani, R. et al. Coronary artery disease detection using artificial intelligence techniques: A survey of trends, geographical differences and diagnostic features 1991–2020. Comput. Biol. Med. 128, 104095 (2021).
Toth, G. G. et al. Response to letter regarding article, revascularization decisions in patients with stable angina and intermediate lesions: Results of the international survey on interventional strategy. Circ. Cardiovasc. Interv. 8(2), e002296 (2015).
Fearon, W. F. et al. Accuracy of fractional flow reserve derived from coronary angiography. Circulation 139(4), 477–484 (2019).
Morris, P. D., Curzen, N. & Gunn, J. P. Angiography-derived fractional flow reserve: more or less physiology?. J. Am. Heart Assoc. 9(6), e015586 (2020).
Ghaderzadeh, M., Aria, M. & Asadi, F. X-ray equipped with artificial intelligence: Changing the COVID-19 diagnostic paradigm during the pandemic. BioMed. Res. Int. 2021, 9942873 (2021).
Ghaderzadeh M, Aria M. Management of Covid-19 Detection Using Artificial Intelligence in 2020 Pandemic. Proceedings of the 5th International Conference on Medical and Health Informatics; Kyoto, Japan: Association for Computing Machinery; p. 32–8 (2021).
Monkam, P. et al. Detection and classification of pulmonary nodules using convolutional neural networks: A survey. IEEE Access. 7, 78075–78091 (2019).
Liu, X., Song, L., Liu, S. & Zhang, Y. A review of deep-learning-based medical image segmentation methods. Sustainability 13(3), 1224 (2021).
Gil-Rios, M.-A. et al. Automatic feature selection for stenosis detection in x-ray coronary angiograms. Mathematics. 9(19), 2471 (2021).
Yadav, S. S. & Jadhav, S. M. Deep convolutional neural network based medical image classification for disease diagnosis. J. Big Data. 6(1), 113 (2019).
Danilov, V. V. et al. Real-time coronary artery stenosis detection based on modern neural networks. Sci. Rep. 11(1), 7582 (2021).
Farhad, A. et al. Artificial intelligence in estimating fractional flow reserve: A systematic literature review of techniques. BMC Cardiovasc. Disorders. 23(1), 407 (2023).
Hatfaludi, C.-A. et al. Towards a deep-learning approach for prediction of fractional flow reserve from optical coherence tomography. Appl. Sci. 12(14), 6964 (2022).
Xue, J. et al. Functional evaluation of intermediate coronary lesions with integrated computed tomography angiography and invasive angiography in patients with stable coronary artery disease. J. Trans. Int. Med. 10(3), 255–263 (2022).
Lee, H. J. et al. Optimization of FFR prediction algorithm for gray zone by hemodynamic features with synthetic model and biometric data. Comput. Methods Program. Biomed. 220, 106827 (2022).
Roguin, A. et al. Early feasibility of automated artificial intelligence angiography based fractional flow reserve estimation. Am. J. Cardiol. 139, 8–14 (2021).
Fossan, F. E. et al. Machine learning augmented reduced-order models for FFR-prediction. Comput. Methods Appl. Mech. Eng. 1(384), 113892 (2021).
He XX, Guo BJ, Wang TH, Lei Y, Liu T, Zhang LJ, Yang XF, Editors. Classification of lesion specific myocardial ischemia using cardiac computed tomography radiomics. Conference on Medical Imaging—Computer-Aided Diagnosis; Houston, TX2020 (2020).
Cha, J. J. et al. Optical coherence tomography-based machine learning for predicting fractional flow reserve in intermediate coronary stenosis: A feasibility study. Sci. Rep. 10(1), 20421 (2020).
Kim, Y. et al. Coronary artery decision algorithm trained by two-step machine learning algorithm. RSC Advances. 10, 4014–4022 (2020).
Gao, Z. et al. Learning physical properties in complex visual scenes: An intelligent machine for perceiving blood flow dynamics from static CT angiography imaging. Neural Netw. Off. J. Int. Neural Netw. Soc. 123, 82–93 (2020).
Carson J, Chakshu NK, Sazonov I, Nithiarasu P. Artificial intelligence approaches to predict coronary stenosis severity using non-invasive fractional flow reserve. Proceedings of the Institution of Mechanical Engineers Part H Journal of Engineering in Medicine. 234 (2020).
Kawasaki, T. et al. Evaluation of significant coronary artery disease based on CT fractional flow reserve and plaque characteristics using random forest analysis in machine learning. Acad. Radiol. 27(12), 1700–1708 (2020).
Kumamaru, K. K. et al. Diagnostic accuracy of 3D deep-learning-based fully automated estimation of patient-level minimum fractional flow reserve from coronary computed tomography angiography. Eur. Heart J. Cardiovasc. Imaging. 21(4), 437–445 (2020).
Zreik M, Hampe N, Leiner T, Khalili N, Wolterink JM, Voskuil M, et al., editors. Combined analysis of coronary arteries and the left ventricular myocardium in cardiac CT angiography for detection of patients with functionally significant stenosis. Conference on Medical Imaging—Image Processing; Feb 15–19; Electr Network2021 (2021).
Yin, M., Yazdani, A. & Karniadakis, G. E. One-dimensional modeling of fractional flow reserve in coronary artery disease: Uncertainty quantification and Bayesian optimization. Comput. Methods Appl. Mech. Eng. 353, 66–85 (2019).
Dey, D. et al. Integrated prediction of lesion-specific ischaemia from quantitative coronary CT angiography using machine learning: a multicentre study. Eur. Radiol. 28(6), 2655–2664 (2018).
Zreik, M. et al. Deep learning analysis of coronary arteries in cardiac CT angiography for detection of patients requiring invasive coronary angiography. IEEE Trans. Med. Imaging. 39(5), 1545–1557 (2020).
Lee, J. G. et al. Intravascular ultrasound-based machine learning for predicting fractional flow reserve in intermediate coronary artery lesions. Atherosclerosis. 292, 171–177 (2020).
Wang, Z. et al. Diagnostic accuracy of a deep learning approach to calculate FFR from coronary CT angiography. J. Geriatric Cardiol. 16(1), 42–48 (2019).
Denzinger F, Wels M, Breininger K, Reidelshöfer A, Eckert J, Sühling M, et al., editors. Deep learning algorithms for coronary artery plaque characterisation from CCTA scans. Informatik aktuell; (2020).
Cho, H. et al. Angiography-based machine learning for predicting fractional flow reserve in intermediate coronary artery lesions. J. Am. Heart Assoc. 8(4), e011685 (2019).
van Hamersvelt, R. W. et al. Deep learning analysis of left ventricular myocardium in CT angiographic intermediate-degree coronary stenosis improves the diagnostic accuracy for identification of functionally significant stenosis. Eur. Radiol. 29(5), 2350–2359 (2019).
Hae, H. et al. Machine learning assessment of myocardial ischemia using angiography: Development and retrospective validation. PLoS Medicine. 15(11), e1002693 (2018).
Kim G, Lee JG, Kang SJ, Ngyuen P, Kang DY, Lee PH, et al., editors. Prediction of FFR from IVUS Images Using Machine Learning. 7th Joint International Workshop on Computing Visualization for Intravascular Imaging and Computer Assisted Stenting (CVII-STENT) / 3rd International Workshop on Large-scale Annotation of Biomedical data and Expert Label Synthesis (LABELS); Sep 16; Granada, SPAIN2018 (2018).
Zreik, M. et al. Deep learning analysis of the myocardium in coronary CT angiography for identification of patients with functionally significant coronary artery stenosis. Med. Image Anal. 44, 72–85 (2018).
Han, D. et al. Incremental role of resting myocardial computed tomography perfusion for predicting physiologically significant coronary artery disease: A machine learning approach. J. Nuclear Cardiol. 25(1), 223–233 (2018).
Itu, L. et al. A machine-learning approach for computation of fractional flow reserve from coronary computed tomography. J. Appl. Physiol. 121(1), 42–52 (2016).
Aria, M., Hashemzadeh, M. & Farajzadeh, N. QDL-CMFD: A Quality-independent and deep Learning-based Copy-Move image forgery detection method. Neurocomputing. 511, 213–236 (2022).
Aria, M., Nourani, E. & Golzari, O. A. ADA-COVID: Adversarial deep domain adaptation-based diagnosis of COVID-19 from Lung CT scans using triplet embeddings. Comput. Intell. Neurosci. 2022, 2564022 (2022).
Ghaderzadeh, M. et al. A fast and efficient CNN model for B-ALL diagnosis and its subtypes classification using peripheral blood smear images. Int. J. Intell. Syst. 37(8), 5113–5133 (2022).
Ghaderzadeh, M. et al. Deep convolutional neural network–based computer-aided detection system for covid-19 using multiple lung scans: Design and implementation study. J. Med. Int. Res. 23(4), e27468 (2021).
Khade PI, Rajput AS. Chapter 8—Efficient single image haze removal using CLAHE and Dark Channel Prior for Internet of Multimedia Things. In: Shukla S, Singh AK, Srivastava G, Xhafa F, editors. Internet of Multimedia Things (IoMT): Academic Press; p. 189–202 (2022).
Huang G, Liu Z, Van Der Maaten L, Weinberger KQ, editors. Densely connected convolutional networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; (2017).
Szegedy C, Ioffe S, Vanhoucke V, Alemi A, editors. Inception-v4, inception-resnet and the impact of residual connections on learning. Proceedings of the AAAI conference on artificial intelligence; (2017).
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:14091556. (2014).
He K, Zhang X, Ren S, Sun J, editors. Identity mappings in deep residual networks. Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14; (2016: Springer).
Chollet F, editor Xception: Deep learning with depthwise separable convolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; (2017).
Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z, editors. Rethinking the inception architecture for computer vision. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; (2016).
Kern-Isberner, G. Characterizing the principle of minimum cross-entropy within a conditional-logical framework. Artif. Intell. 98(1), 169–208 (1998).
Loshchilov I, Hutter F. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:160803983. (2016).
Müller R, Kornblith S, Hinton GE. When does label smoothing help? Advances in neural information processing systems. 32 (2019).
Müller R, Kornblith S, Hinton G. When Does Label Smoothing Help?2019 June 01, 2019:[arXiv:1906.02629 p.]. Available from: https://ui.adsabs.harvard.edu/abs/2019arXiv190602629M.
Zhang, C.-B. et al. Delving deep into label smoothing. IEEE Trans. Image Process. 30, 5984–5996 (2021).
Ying, X. An overview of overfitting and its solutions. J. Phys. Conf. Series. 1168(2), 022022 (2019).
Micikevicius P, Narang S, Alben J, Diamos G, Elsen E, Garcia D, et al. Mixed precision training. arXiv preprint arXiv:171003740. (2017).
Bayani, A. et al. Performance of machine learning techniques on prediction of esophageal varices grades among patients with cirrhosis. Clin. Chem. Lab. Med. CCLM. 60(12), 1955–1962 (2022).
Bayani, A. et al. Identifying predictors of varices grading in patients with cirrhosis using ensemble learning. Clin. Chem. Lab. Med. CCLM. 60(12), 1938–1945 (2022).
Zarean Shahraki, S. et al. Time-related survival prediction in molecular subtypes of breast cancer using time-to-event deep-learning-based models. Front. Oncol. 5(13), 1147604 (2023).
Wieneke, H. et al. Determinants of coronary blood flow in humans: Quantification by intracoronary Doppler and ultrasound. J. Appl. Physiol. 98(3), 1076–1082 (2005).
Chu, M., Dai, N., Yang, J., Westra, J. & Tu, S. A systematic review of imaging anatomy in predicting functional significance of coronary stenoses determined by fractional flow reserve. Int. J. Cardiovasc. Imaging. 33(7), 975–990 (2017).
Ciccarelli, G. et al. Angiography versus hemodynamics to predict the natural history of coronary stenoses: Fractional flow reserve versus angiography in multivessel evaluation 2 substudy. Circulation. 137(14), 1475–1485 (2018).
Yu, A. C., Mohajer, B. & Eng, J. External validation of deep learning algorithms for radiologic diagnosis: A systematic review. Radiol. Artif. Intell. 4(3), e210064 (2022).
Hutchinson B, Rostamzadeh N, Greer C, Heller K, Prabhakaran V, editors. Evaluation gaps in machine learning practice. Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency; (2022).
Liao TI, Taori R, Schmidt L. Why external validity matters for machine learning evaluation: Motivation and open problems.
Cho, H. et al. Angiography-based machine learning for predicting fractional flow reserve in intermediate coronary artery lesions. J. Am. Heart Assoc. 8(4), e011685 (2019).
Wang, F., Casalino, L. P. & Khullar, D. Deep learning in medicine—promise, progress, and challenges. JAMA Int. Med. 179(3), 293–294 (2019).
Yazhini K, Loganathan D, editors. A state of art approaches on deep learning models in healthcare: An application perspective. 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI); 2019 23–25 April (2019).
Funding
Throughout this study, no financial resources or funding were received.
Author information
Authors and Affiliations
Contributions
F.A., R.R., A.H. and M.A. were responsible for the conceptualization and design of the study. F.A. and M.A. undertook the design and implementation of the machine learning algorithms. F.A. handled data processing and cleansing, as well as the extraction of information from the E.H.R. systems. A.G. and A.R. contributed their clinical and technical expertise and guidance. The oversight of the entire project was conducted by R.R. and A.H. All Authors read and approved the final draft of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Arefinia, F., Aria, M., Rabiei, R. et al. Non-invasive fractional flow reserve estimation using deep learning on intermediate left anterior descending coronary artery lesion angiography images. Sci Rep 14, 1818 (2024). https://doi.org/10.1038/s41598-024-52360-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-52360-5
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
