
Abstract
Previous research investigating relations between general intelligence and graph-theoretical properties of the brain’s intrinsic functional network has yielded contradictory results. A promising approach to tackle such mixed findings is multi-center analysis. For this study, we analyzed data from four independent data sets (total N > 2000) to identify robust associations amongst samples between g factor scores and global as well as node-specific graph metrics. On the global level, g showed no significant associations with global efficiency or small-world propensity in any sample, but significant positive associations with global clustering coefficient in two samples. On the node-specific level, elastic-net regressions for nodal efficiency and local clustering yielded no brain areas that exhibited consistent associations amongst data sets. Using the areas identified via elastic-net regression in one sample to predict g in other samples was not successful for local clustering and only led to one significant, one-way prediction across data sets for nodal efficiency. Thus, using conventional graph theoretical measures based on resting-state imaging did not result in replicable associations between functional connectivity and general intelligence.
Similar content being viewed by others

Introduction
Any system composed of interrelated elements can be modeled as a network1. One of the most challenging and complex systems found in nature is the human brain2,3. It is not possible to study the whole brain's connectivity at a cellular level using current in-vivo neuroimaging methods4. Nevertheless, over the past four decades, structural and functional neuroimaging studies have generated an enormous amount of knowledge about the human brain at a macroscopic scale5. For example, it has been observed that human brain networks are organized in a ‘small-world’ manner. That is, a high level of local clustering, which enables segregated functionally coherent units of local information processing, co-exists with long-distance connections, ensuring integration of information across different regions1,6,7,8. As no two individual’s brains are completely alike3, many studies addressed the question whether interindividual differences in structural or functional brain properties are linked to interindividual differences in human behavior. Within the field of psychology, examining interindividual differences in the form of general cognitive performance (i.e. intelligence) exhibits the longest research tradition9.
Intelligence can be defined as the "[…] ability to understand complex ideas, to adapt effectively to the environment, to learn from experience, to engage in various forms of reasoning, to overcome obstacles by taking thought"10. Spearman11 observed that individuals who perform above average on one cognitive task also tend to do well on other cognitive tasks. Based on this observation, he identified the existence of a ‘general factor’ of intelligence that he termed ‘g’. Current hierarchically organized models still place g at the top of the hierarchy with more specific broadly organized cognitive abilities underneath that are then further subdivided at lower levels12. Interindividual differences in cognitive performance are not only relatively stable across tasks but also persist throughout the lifespan13. For example, the test–retest correlation of intelligence test scores at age 11 and age 77 was r = 0.63, which adjusted to r = 0.73 when corrected for attenuation of ability range within the re-tested sample13. Even with a repetition interval of 79 years, in which the subjects were tested for the second time at the age of 90, the correlation of the intelligence test scores was r = 0.54, which adjusted to r = 0.67 when corrected for attenuation of ability range within the re-tested sample14. Moreover, intelligence test scores predict many aspects of life and health such as job performance and longevity10,15,16,17,18. Given the considerable impact that g seems to have on life outcomes, the question "Where in the brain is intelligence?"19 has always been of special interest.
Many neuroscientific studies attempted to answer this question by employing various imaging techniques to analyze differences in the neural properties of brain regions and relate them to intelligence. Combined evidence from such studies led three independent meta-analyses19,20,21 to conclude that networks of brain areas widely distributed across the brain are associated with intelligence. Jung and Haier19 suggested that intelligence-related areas comprise an interconnected, widespread network (instead of working in isolation from each other) and proposed the Parieto-Frontal Integration Theory of intelligence (P-FIT). The conception of P-FIT represents an important milestone in the endeavor of identifying the neural basis of human intelligence. However, many years of neuroscientific intelligence research have passed since Jung and Haier first outlined their P-FIT network and new ideas were added to the original model such as the importance of subcortical structures20.
More recent studies have directed attention towards analysis of intelligence-related neural properties in terms of network organization2,22,23,24. One branch of network neuroscience23 is focused on functional connectivity within the human brain. This approach emerges from the idea that resting-state functional connectivity of anatomically separated brain regions, quantified via functional magnetic resonance imaging (fMRI), reflects the brain’s fundamental architecture of functional networks underlying task-related activities and behavior5,25,26,27. Functional connectivity among brain regions can be inferred from temporal correlations between spontaneous low-frequency fluctuations in the blood oxygenation level-dependent (BOLD) signals28,29. Given that functional connectivity appears to be unique to individuals, almost comparable to fingerprints in reliability and robustness30, studies began to focus on intelligence-related differences in the brain's intrinsic functional organization by applying graph theory.
Graph theory, a branch of mathematics concerned with representing and characterizing complex networks, provides a powerful possibility to specify the brain's topological organization3,31,32,33. One of the first studies employing it observed a negative association between intelligence quotient (IQ) scores and the characteristic path length of the resting-state brain network, indicating clear small-world organization22. As its characteristic path length is inversely related to a network's global efficiency31, their results suggested that intelligence depends on how efficiently information is globally integrated among different brain regions. Van den Heuvel et al.22 did not find a significant correlation between IQ scores and the global clustering coefficient, which measures the extent of local "cliquishness", an indicator of locally segregated information processing3,7,33. They also analyzed the topological properties of individual nodes (defined as single voxels) in relation to the rest of the brain. Voxels with significant correlations between their normalized path length and IQ scores were found in medial prefrontal gyrus, precuneus/posterior cingulate gyrus, bilateral inferior parietal regions, left superior temporal gyrus, and left inferior frontal gyrus. The observation that these voxels possessed more efficient (i.e. shorter) functional paths to other brain regions in more intelligent participants emphasized their relevance in the functional brain network. Later studies were able to provide further evidence of an association between intelligence and global efficiency by focusing their analyses on more specific aspects such as subnetworks, weak connections, or brain resilience34,35,36.
In contrast, Pamplona et al.37 did not observe a statistically significant relation between IQ scores and characteristic path length, global efficiency, or global clustering coefficient. On the level of individual network nodes, they reported significant correlations (uncorrected for multiple comparisons) between IQ scores and local efficiency values of bilateral pre-central regions as well as the left inferior occipital region. In line with the results of Pamplona et al.37, Hilger et al.38, who conceptualized their study similar to that of van den Heuvel et al.22, did not observe any relation between IQ scores and global efficiency, but reported significant associations between IQ scores and nodal efficiency. They observed associations between IQ scores and nodal efficiency in right anterior insula and dorsal anterior cingulate cortex as well as lower nodal efficiency in the left temporo-parietal junction area. As noted by Kruschwitz et al.39 among many others, the assumption that the brain's global functional network efficiency is associated with general intelligence has been widely accepted, but the empirical foundation of this claim is rather weak. While aforementioned studies had rather small samples of 1922, 2937, and 54 participants38, Kruschwitz et al.39 used a large sample (n = 1096) and high quality data from the Human Connectome Project40. They employed multiple network definitions and did not observe any significant associations between total cognition composite scores and characteristic path length, global efficiency, or global clustering coefficient39.
Taken together, these results question the proposed association of general intelligence and the brain’s global functional network efficiency. Not only are there contradicting results on a global level, but results on a nodal level also do not overlap locally. As discussed by Kruschwitz et al.39, methodological differences among studies limit their comparability and might contribute to differences in study observations. Our study utilized a multi-center approach, analyzing multiple, independent data sets to identify extents to which robust associations replicated across samples41. In a recent study, we were able to find such associations between general intelligence and white matter microstructure by following this approach42. Here, we examined associations between g and functional network properties in the same four independent data sets comprising more than 2000 healthy participants. All data sets were pre-processed and analyzed in the same manner to make them as comparable as possible. On the global level, we calculated associations between g and global efficiency, global clustering coefficient, and small-world propensity. On the nodal level, we used regularized elastic-net regressions to examine associations between g and nodal efficiency as well as local clustering coefficient of specific brain areas. To assess robustness of brain areas’ associations with general intelligence, we investigated whether the areas identified by the elastic-net analyses overlapped among data sets and tested the predictors identified in one sample in other samples. To test whether associations between graph metrics and g were affected by data reliability, we additionally investigated test–retest reliabilities of global and nodal metrics in two of the data sets.
Methods and materials
Given that the data sets included in our study employed different behavioral measures and imaging data were obtained on different scanners, pooling into one big sample was not possible.
Participants
RUB sample
The RUB sample consisted of 557 participants aged 18–75 (mean age: 27.3 years, SD = 9.4 years, 274 women, 503 right-handers). Participants were either financially compensated or received course credit for their participation. All participants reported freedom from neurological and mental illnesses. Individuals were excluded from participation if they had insufficient German skills or reported familiarity with any of the tests used. The study was approved by the local ethics committee of the Faculty of Psychology at the Ruhr-University Bochum (vote 165). All participants gave written informed consent and were treated according to the Declaration of Helsinki.
HCP sample
Data were provided by the Human Connectome Project, WU-Minn Consortium (Principal Investigators: David Van Essen and Kamil Ugurbil; 1U54MH091657), funded by the 16 United States National Institutes of Health (NIH) Institutes and Centers supporting the NIH Blueprint for Neuroscience Research and by the McDonnell Center for Systems Neuroscience at Washington University. We used the "1200 Subjects Data Release"40, which comprises behavioral and imaging data from 1206 young adults aged between 22 and 37. To calculate the g factor, all participants with missing data in any of the intelligence tests had to be excluded, which reduced the sample size to N = 1188 (mean age: 28.8 years, SD = 3.7 years, 641 females, 934 right-handers). HCP provides four resting-state functional magnetic resonance imaging (rsfMRI) scans from two different testing days (HCP_day_1 and HCP_day_2). However, not all rsfMRI data were available for all participants. Thus, the sample for HCP_day_1 was reduced to N = 1050 (mean age: 28.7 years, SD = 3.7 years, 564 females, 823 right-handers) and the sample for HCP_day_2 was reduced to N = 1011 (mean age: 28.7 years, SD = 3.7 years, 543 females, 794 right-handers). 1007 participants (mean age: 28.7 years, SD = 3.7 years, 539 females, 791 right-handers) completed all four rsfMRI scans (HCP_day_1_day_2). Participants reported no history of substance abuse or psychiatric, neurological, or cardiological diseases. All participants gave written informed consent43.
UMN sample
The UMN sample consisted of 335 participants aged between 20 and 40 (mean age: 26.3 years, SD = 5.0 years, 164 females, all right-handed) and all participants were included in calculating the g factor. As rsfMRI data were not available for all participants, our sample was reduced to N = 274 (mean age: 26.2 years, SD = 4.9 years, 135 females, all right-handed). Exclusion criteria were neurological or psychiatric disorders, current drug abuse, and current use of psychotropic medication. The study protocol was approved by the University of Minnesota Institutional Review Board and all participants gave written informed consent.
NKI sample
The "Enhanced Nathan Kline Institute—Rockland Sample" data set44 is part of the 1000 Functional Connectomes Project (https://fcon_1000.projects.nitrc.org/) and was downloaded from its official website (https://fcon_1000.projects.nitrc.org/indi/enhanced/). We only included healthy participants, who reported freedom from mental illness. The g factor was calculated based on 417 participants aged between 6 and 85 (mean age: 43.5 years, SD = 23.5 years, 273 females, 326 right-handers). The three available rsfMRI measurements from NKI differ in temporal resolution (NKI_TR645, NKI_TR1400, and NKI_TR2500). After excluding all participants without rsfMRI data we ended up with N = 385 for NKI_TR645 aged 6–85 (mean age: 44.4 years, SD = 22.8 years, 252 females, 303 right-handers), N = 348 for NKI_TR1400 aged 6–83 (mean age: 44.5 years, SD = 22.6 years, 228 females, 270 right-handers) and N = 383 for NKI_TR2500 aged 6–83 (mean age: 44.2 years, SD = 22.7 years, 251 females, 302 right-handers). The study was approved by the Institutional Review Boards at the Nathan Kline Institute and Montclair State University. Participants and – if underaged – their legal guardians gave written informed consent.
Intelligence measurement
Detailed descriptions of all intelligence measures used to calculate g factors can be found in Stammen et al.42. A short overview of all tests used is in the Supplementary Material (see “1. Intelligence measurement”).
Computation of the general intelligence factor (g)
As observed by Johnson et al.45 and Johnson et al.46, g factors derived from different test batteries are statistically equivalent, provided that included tests measure intelligence broadly enough. Since different test batteries were employed by our four samples, we decided to calculate g factors (one for each sample) to obtain intelligence measures comparable among data sets.
As described in Stammen et al.42, we computed g factor scores based on each sample’s intelligence test scores (see Supplementary Material). After regressing age, sex, age*sex, age2, and age2*sex from the test scores, we conducted exploratory factor analyses based on the standardized residuals to develop hierarchical factor models for each sample. Following this, we performed confirmatory factor analyses and assessed model fit by the chi-square (Χ2) statistic as well as the fit indices root mean square error of approximation (RMSEA), standardized root mean square residual (SRMR), comparative fit index (CFI), and Tucker-Lewis Index (TLI). From these models, we calculated regression-based g-factor scores for each participant, winsorizing outliers47. The postulated confirmatory factor models for the four samples, the z-standardized factor loadings, and the covariances between individual subtests are shown in Figs. 1–4 in Stammen et al.42. The evaluation of model fit yielded good (samples RUB and HCP) to excellent (samples UMN and NKI) fit (see Table 2 in Stammen et al.42).
Distribution of intelligence scores
The four samples included in our study employed different tests to assess intelligence. Hence, it is not possible to compare intelligence levels among samples directly. However, we utilized norming data of some tests to provide estimates for the intelligence levels of all samples as described in Stammen et al.42. For the RUB data set, the I-S-T 2000 R subtests generated a mean IQ of 115 (SD = 13.0), one standard deviation above average. For the HCP data set, Dubois et al.48 observed, based on norming data from the NIH toolbox subtests, that the sample’s mean scores for all tests were significantly higher than the general population means. Application of the standard Wechsler formulae revealed mean IQ scores of 114.1 (SD = 15.0) in the UMN sample and of 101.9 (SD = 13.1) in the NKI sample. The fact that three out of four samples had higher than average mean scores may have impacted the associations with functional brain metrics examined in our study.
Handedness measurement
Handedness was assessed using the Edinburgh handedness inventory49. Here, participants answer ten questions regarding their preferred hand for everyday tasks, e.g. writing. The lateralization quotient (LQ) is defined as LQ = [(R–L)/(R + L)] × 100, with R indicating the sum of right-hand responses and L indicating the sum of left-hand responses. Handedness was coded 1 for all participants whose LQ was greater than or equal to 60 (right-handed) and 0 for all other participants (mixed- or left-handed). We chose this cut-off value based on Dragovic50. Handedness was used as a control variable since the handedness ratios of our samples differed greatly.
Acquisition of anatomical data
RUB sample
Magnetic resonance imaging was conducted on a 3 T Philips Achieva scanner with a 32-channel head coil. The scanner was located at Bergmannsheil University Hospital in Bochum, Germany. T1-weighted data were obtained by means of a high-resolution anatomical imaging sequence with the following parameters: MP-RAGE; TR = 8.179 ms; TE = 3.7 ms; flip angle = 8°; 220 slices; matrix size = 240 × 240; resolution = 1 mm × 1 mm × 1 mm; acquisition time = 6 min.
HCP sample
Magnetic resonance imaging was conducted on a Siemens 3 T Connectome Skyra scanner with a 32-channel head coil and a "body" transmission coil designed by Siemens. The scanner was located at Washington University. T1-weighted data were obtained by means of a high-resolution anatomical imaging sequence with the following parameters: MP-RAGE; TR = 2400 ms; TE = 2.14 ms; flip angle = 8°; 256 slices; matrix size = 224 × 224; resolution = 0.7 mm × 0.7 mm × 0.7 mm; acquisition time = 7 min and 40 s.
UMN sample
All images were collected on a 3 T Siemens Trio scanner at the Center for Magnetic Resonance Research at the University of Minnesota in Minneapolis, using a 12-channel head coil. T1-weighted data were obtained by means of a high-resolution anatomical imaging sequence with the following parameters: MP-RAGE; TR = 1900 ms; TE = 0.29 ms; flip angle = 9°; 240 slices; matrix size = 256 × 256; resolution = 1 mm × 1 mm × 1 mm; acquisition time = 8 min.
NKI sample
All images were collected on a 3 T Siemens Trio scanner at the NKI in Orangeburg, New York, using a 32-channel head coil. T1-weighted data were obtained by means of a high-resolution anatomical imaging sequence with the following parameters: MP-RAGE; TR = 1900 ms; TE = 2.52 ms; flip angle = 9°; 176 slices; matrix size = 256 × 256; resolution = 1 mm × 1 mm × 1 mm; acquisition time = 4 min and 18 s.
Acquisition of resting-state fMRI data
RUB sample
Functional MRI resting-state images were acquired using echo planar imaging (TR = 2000 ms, TE = 30 ms, flip angle = 90°, 37 slices, matrix size = 80 × 80, resolution = 3 mm × 3 mm × 3 mm, acquisition time = 7 min). Participants were instructed to lay still with their eyes closed and to think of nothing in particular.
HCP sample
For the HCP sample, four rsfMRI measurements were available (HCP_day_1_ses_1, HCP_day_1_ses_2, HCP_day_2_ses_1, and HCP_day_2_ses_2). On each of two consecutive testing days, two rsfMRI scans were acquired with opposite encoding directions, namely left–right (session 1) and right-left (session 2). Participants had their eyes open and fixated on a cross-hair. Images were acquired using echo planar imaging (TR = 720 ms, TE = 33 ms, flip angle = 52°, 72 slices, matrix size = 104 × 90, resolution = 2 mm × 2 mm × 2 mm, acquisition time = 14 min and 33 s).
UMN sample
Functional MRI resting-state images were acquired using echo planar imaging (TR = 2000 ms, TE = 28 ms, flip angle = 80°, 35 slices, matrix size = 64 × 64, resolution = 3.5 mm × 3.5 mm × 3.5 mm, acquisition time = 5 min). Participants performed a basic fixation task. They fixated on a cross-hair and pressed a button when the cross-hair changed colors (this happened five times). This was done to minimize eye movement and to ensure that participants stayed awake.
NKI sample
The NKI sample provided three rsfMRI measurements, namely NKI_TR645, NKI_TR1400, and NKI_TR2500. All of them were acquired on the same day. Participants had their eyes open and fixated on a cross-hair. Images were obtained using echo planar imaging with the following parameters. NKI_TR645: TR = 645 ms, TE = 30 ms, flip angle = 60°, 40 slices, matrix size = 74 × 74, resolution = 3 mm × 3 mm × 3 mm, acquisition time = 9 min and 46 s. NKI_TR1400: TR = 1400 ms, TE = 30 ms, flip angle = 65°, 64 slices, matrix size = 112 × 112, resolution = 2 mm × 2 mm × 2 mm, acquisition time = 9 min and 35 s. NKI_TR2500: TR = 2500 ms, TE = 30 ms, flip angle = 80°, 38 slices, matrix size = 72 × 72, resolution = 3 mm × 3 mm × 3 mm, acquisition time = 5 min and 5 s.
Imaging processing
The RUB, NKI, and UMN datasets were pre-processed in the same manner (see Fig. 1). HCP data was obtained from the S1200 “Structural Preprocessed” and “Resting State fMRI 1 Preprocessed” packages40. All steps concerning construction of connectivity matrices, pruning, and calculation of graph theoretical metrics were identical for all data sets.

Pre-processing and analysis strategy of the four data sets. The HCP, NKI, RUB, and UMN samples were pre-processed in the same manner (light gray boxes). First, T1-weighted anatomical images were delineated into 180 cortical and 8 subcortical areas per hemisphere. Second, these areas were used as landmarks to extract mean time courses from resting-state images. Third, functional connectivity matrices were built by computing edge weights in the form of BOLD signal correlations. Fourth, pruning was applied to every data set to remove spurious connections from the network. Fifth, networks of all participants were pruned using OMST. Sixth, all functional connectivity matrices and graph theoretical metrics were computed. Seventh, partial correlation coefficients were calculated, and elastic-net regression was applied to investigate the association of graph theoretical metrics and g in all data sets. Eighth, the overlap between the results of the four different samples were compared and prediction models resulting from the elastic-net analysis in each sample were tested in the other independent samples. Finally, reliability of graph metrics was defined using the HCP and NKI samples.
Anatomical processing
Cortical surfaces of T1-weighted images were reconstructed using FreeSurfer (http://surfer.nmr.mgh.harvard.edu, version 6.0.0), along with the CBRAIN platform51, following established protocols52,53. During pre-processing, we employed skull stripping, gray and white matter segmentation, and reconstruction and inflation of the cortical surface. These steps were done individually for each participant. We conducted slice-by-slice quality control and manually edited inaccuracies of automatic pre-processing. For brain segmentation, we used the Human Connectome Project's multi-modal parcellation (HCPMMP), which comprises 180 areas per hemisphere and is based on structural, functional, topographical, and connectivity data from healthy participants54. The original data provided by the Human Connectome Project were converted to annotation files matching the standard cortical surface in FreeSurfer (fsaverage). The fsaverage segmentation was transformed to each participant's individual cortical surface and converted to volumetric masks. Additionally, we added eight subcortical gray matter structures per hemisphere to the parcellation (thalamus, caudate nucleus, putamen, pallidum, hippocampus, amygdala, accumbens area, ventral diencephalon)55. Finally, six regions representing the four ventricles of the brain were defined to serve as a control for later BOLD signal analyses. All masks were linearly transformed into the native space of the resting-state images and used as landmarks for graph-theoretical connectivity analyses. To serve as a control variable in statistical analyses, total brain volume was defined as the volume of all voxels that are neither brain stem, background, ventricles, cerebrospinal fluid, or choroid plexus (BrainSegNotVent). To control for head motion we chose the absolute value of head motion.
Resting-state fMRI processing
Pre-processing of rsfMRI data was conducted with the FSL toolbox MELODIC. The first two images of each resting-state scan were discarded to ensure signal equilibration, motion and slice timing correction, and high-pass temporal frequency filtering (0.005 Hz). We applied 6 mm spatial smoothing. We also applied ICA‐AROMA protocols as described by Pruim et al.56 to correct for micro movements. All 376 brain regions (360 cortical and 16 subcortical) were converted into the native space of the resting-state images for functional connectivity analysis. For each region, we computed a mean resting-state time course by averaging the time courses of relevant voxels. Partial correlations between the average time courses of all cortical and subcortical regions were calculated, while controlling average time courses extracted from white matter regions and ventricles57.
Statistical analysis
Computation of graph theoretical metrics
All analyses were carried out using MATLAB version R2021b (The MathWorks Inc., Natick, MA). For graph-theoretical connectivity analyses, we used the brain network with 376 nodes, consisting of the 360 cortical and 16 subcortical regions described above. Since each brain region can theoretically be connected to each other brain region, there was a total of 70,500 edges (one matrix triangle of a symmetrical 376-by-376 adjacency matrix without self-connections on the diagonal). Each edge was weighted based on the BOLD signal correlation between the two brain regions at the edge's endpoints. Negative correlation coefficients were replaced with zeros. The four rsfMRI scans of the HCP sample were treated as individual data sets (HCP_day_1_ses_1, HCP_day_1_ses_2, HCP_day_2_ses_1, and HCP_day_2_ses_2) but also conflated into bigger data sets. In more detail, we computed functional connectivity matrices for HCP_day_1, HCP_day_2, and HCP_day_1_day_2. Relevant BOLD signal correlations were calculated after concatenating time courses for the two scans on each day for HCP_day_1 and HCP_day_2 and after concatenating time courses for all four scans for HCP_day_1_day_2. For the sake of readability, we chose to only report results from HCP_day_1_ses_1 and HCP_day_1_ses_2, while omitting the remaining individual data sets, which produced highly similar results. To ensure that correlation coefficients were normally distributed, we Fisher z-transformed all values58. To prevent our analyses being affected by spurious connections57,59, while also avoiding arbitrary graph thresholds, we applied a data-driven topological filtering to the individual functional connectivity matrices using orthogonal minimum spanning trees (OMST)60,61. Graph metrics were computed using the Brain connectivity toolbox31. We chose global efficiency, nodal efficiency, global clustering, local clustering, and small-world propensity as measures to quantify network connectivity.
Orthogonal minimum spanning trees
For network pruning we used the Topological Filtering Toolbox as provided and described by Dimitriadis et al.60,61 (https://github.com/stdimitr/topological_filtering_networks). The OMST approach focuses on optimizing a function of the global efficiency (see below) and the wiring cost of the network (ratio of the total weight of the selected edges, aggregated over multiple iterations of OMST, of the filtered graph to that of the original fully weighted graph), while ensuring that the network is fully connected. It is a data-driven, iterative procedure creating multiple minimum spanning trees (MST) that are orthogonal to each other. MST creates a subgraph with the minimum set of edges (N-1) that connect all N nodes using Kruskal’s algorithm. After extracting the first MST, its N-1 edges are zeroed out in the original graph to maintain orthogonality and a second MST connecting all the N nodes with minimal total distance is extracted. These steps are repeated, and connections are aggregated across OMST until optimization of the function Global Cost Efficiency = global efficiency – wiring cost. The final filtered graph includes all MST that have been removed from the original graph. OMST is applied to every participant and the trade-off is optimized for each network individually, leaving all participants with their unique, but fully connected network. Dimitriadis et al.61 have shown that the OMST algorithm generated sparse graphs that outperformed many other thresholding schemes based on recognition accuracy and reliability of network metrics. OMST has been successfully applied in resting-state functional connectivity research62.
Global and nodal efficiency
Efficiency is a measure of functional integration capturing the brain’s ability to exchange specialized information within a network of distributed brain regions31. Shorter path lengths, indicating that two nodes are connected by a path with few edges, generally allow more efficient communication since signal transmission in fewer steps affords less opportunity for noise, interference or attenuation3. The shortest paths lengths \({d}_{ij}^{w}\) between all pairs of nodes can be obtained by calculating the inverse of the weighted adjacency matrix and running a search algorithm such as Dijkstra’s63 implemented in the Brain Connectivity Toolbox31. The global efficiency (E) of a network is calculated as the average inverse shortest path length between each pair of nodes i and j within the network G1. On the level of single nodes, nodal efficiency (Ei) can be determined as a metric quantifying the importance of each specific node i for information transfer within the network33. It is calculated as the average inverse shortest path length between a particular node and all other nodes within the network, where n is the number of nodes1,31.
Global and local clustering
Clustering is a measure quantifying the extent of local "cliquishness” and serves as an indicator of local connection segregation3,7,33. The local clustering coefficient Ci represents the probability that two randomly selected neighbors of a particular node i are also neighbors of each other (i.e. connections among these three nodes form a triangle). Ci is computed by dividing the existing connections among the node's neighbors by all possible connections7,33. The global clustering coefficient C is calculated as the average of all clustering coefficients of all nodes and reflects the occurrence of clustered connectivity around single nodes31. In the context of neurobiology, clustered connectivity indicates the existence of brain regions that constitute functionally coherent units with a high degree of within-unit information exchange3.
Here, n is the number of nodes, ki is the number of edges connected to a node i, and ti is the number of triangles attached to a node i7,31,64. As required by the Brain Connectivity Toolbox, coefficients were normalized to be between 0 and 1 before calculation31.
Small-world propensity
Small-world networks are characterized by high local clustering (segregated functionally coherent units) and short path lengths among clusters. The latter is typically realized by robust numbers of integrating, intermodular, long-range links6,7,31. To quantify the small-world structure of participants' functional connectivity matrices, we used the small-world propensity function as proposed by Muldoon et al.65. This function reflects the discrepancy of a network's clustering coefficient, Cobs, and characteristic path length, Lobs, from comparable lattice (Clatl, Llatt) and random (Crand, Lrand) networks65.
Partial correlations
The following statistical analyses were conducted in R Studio (1.3.1093) with R version 4.1.0. (2021-05-18). For each sample, outlier control was conducted, and outliers were winsorized47. Data points were treated as outliers if they deviated more than three interquartile ranges from the relevant variable’s group mean (g, global efficiency, global clustering, small-world propensity) and replaced by the respective threshold.
We calculated partial correlations between g and the following network properties: global efficiency, global clustering, and small-world propensity. We used the partial.cor function as implemented in the RcmdrMisc package to obtain two-sided p-values corrected for multiple comparisons using Holm's method66. Control variables were age, sex, age*sex, age2, age2*sex, handedness, total brain volume, and head motion. Some studies reported a negative association between head motion and cognitive performance67, so we added head motion as a control variable. The correlation between general intelligence and head motion reached statistical significance in HCP day 1 recordings and NKI recordings (HCP_day_1_ses_1: r = − 0.09, p = 0.002; HCP_day_1_ses_2: r = − 0.11, p = < 0.001; NKI_TR645: r = − 0.29, p < 0.001; NKI_TR1400: r = − 0.23; p < 0.001, NKI_TR2500: r = − 0.19, p < 0.001). However, this did not replicate in RUB, UMN, and HCP day 2 recordings (RUB: r = − 0.04, p = 0.292; UMN: r = − 0.07, p = 0.270; HCP_day_2_ses_1: r = − 0.01, p = 0.768; HCP_day_2_ses_2: r = − 0.02, p = 0.544), and adding head motion as a control variable did not lead to substantial changes of the results. Due to this, we suggest that future studies check for possible associations between head motion and general intelligence in their samples and control for head motion if an association is identified.
Brain area specific analysis via elastic-net regression
To examine the associations between general intelligence and network properties of single brain areas, we employed regularized elastic-net regression. This approach does not use p-values to determine the statistical significance of a predictor. Hence, it does not require a standard correction procedure for multiple comparisons (e.g. false discovery rate or Bonferroni). Instead, it utilizes regularization and cross-validation permitting models with many independent variables in a small sample. Regularization puts a penalty on all effect sizes. The penalty is calculated using k-fold cross-validation, a mechanism to avoid overfitting. This leads to small effect sizes being regularized to zero. Every non-zero effect size contributes uniquely to the association. In previous studies, elastic-net regression has already been successfully applied to research questions concerned with the association between brain properties and intelligence68,69,70.
For this step, we used the cv.glmnet function from the glmnet package. Alpha was set to 0.5, k was set to 10. All variables were standardized and residualized for age, sex, age*sex, age2, age2*sex, handedness, total brain volume, and head motion. We computed two elastic-net regression models for every rsfMRI measurement from all samples (RUB, HCP_day_1, HCP_day_1_ses_1, HCP_day_1_ses_2, HCP_day_2, HCP_day_1_day_2, UMN, NKI_TR645, NKI_TR1400, NKI_TR2500). The dependent variable was always g, the independent variables were either nodal efficiency of all 376 network nodes or local clustering of all 376 network nodes.
Overlap among samples and result validity
To assess result validity for the elastic-net regression analysis, we identified brain areas whose properties emerged as relevant associates of g among multiple regression models from all data sets. To this end, we included the elastic-net results from the RUB, HCP_day_1_day_2, UMN, and NKI_TR645 samples. HCP_day_1_day_2 was chosen to ensure comparability with previous studies48,71. NKI_TR645 was chosen over NKI_TR1400 and NKI_TR2500 since its TR is closer to that of the HCP sample. Furthermore, we investigated the overlap with results obtained from HCP data, once for the two measurement days (HCP_day_1 and HCP_day_2) and once for the two measurement sessions of the first day (HCP_day_1_ses_1 and HCP_day_1_ses_2). We also analyzed the intrasession overlap of results obtained from NKI data. Finally, we compared the two TR = 2000 ms data sets RUB and UMN as well as the two TR ≤ 720 ms data sets HCP and NKI.
As elastic-net regression is a data-driven procedure, relatively small fluctuations can influence which effects will remain non-zero after regularization. Thus, the comparison of elastic-net results alone is not sufficient to judge the validity of the models. To judge validity, we tested the models defined by elastic-net in each sample in all other samples. In more detail, we calculated multiple linear regression analyses in the testing samples with the predictors identified in one data set serving as independent variables and g serving as dependent variable. For example, predictors identified in the HCP_day_1_day_2 sample would be used to predict g in RUB, UMN, and NKI_TR645. Control variables were age, sex, age*sex, age2, age2*sex, handedness, total brain volume, and head motion. We used the coefficient of determination along with its significance value to conclude whether the set of predictors identified in one sample predicted intelligence successfully in the other samples. We used the elastic-net results of each sample in all other samples once. However, due to space limitations we will only show the results of four samples (RUB, HCP_day_1_day_2, UMN, and NKI_TR645) in the results section. For these analyses, the p-value was corrected for multiple comparisons using Bonferroni72.
Test–retest reliability of graph metrics
The HCP and NKI samples afforded examination of the graph theoretical measures’ test–retest reliability. In the HCP data set, we assessed reliability once between measurement days (HCP_day_1 and HCP_day_2) as well as within the first measurement day (HCP_day_1_ses_1 and HCP_day_1_ses_2). In the NKI data set, we examined the reliability of all three measurement sessions (NKI_TR645, NKI_TR1400, and NKI_TR2500). First, we investigated the reliability of global metrics (global efficiency, global clustering, and small-world propensity). We computed an intra-class correlation (ICC) (3, 1) two-way mixed effect model73, which is a robust measure of reliability in fMRI research74. Second, we investigated the reliability of nodal metrics (nodal efficiency and local clustering) for every brain area independently.
Split-half reliability of graph metrics
To investigate the internal consistency of graph metrics we additionally calculated split-half reliability. Internal consistency indicates a measure’s ability to be reliably correlated to other traits, as a measure cannot be more highly correlated with another trait than with itself75. While test–retest reliability can be influenced by external variables (e.g. participant’s mood, time of day), this risk is reduced for internal consistency. We split time courses into odd and even trials and repeated calculation of connectivity matrices (see “Computation of graph theoretical metrics”), OMST (see “Orthogonal minimum spanning trees”) as well as calculation of graph metrics (see “Global and nodal efficiency”–“Small-world propensity”). After repeating these steps, we calculated Pearson correlations between graph metrics from the odd half and the even half. Since splitting the data reduced the number of data points, the Pearson coefficients were corrected by employing the Spearman-Brown prediction formula, SB = 2r/(1 + r)75. Results are shown in Supplementary Tables S9, S10 and S11. In the HCP data set, we assessed split-half reliability only once within the first session of the first measurement day (HCP_day1_ses_1).
Results
Association between global brain metrics and g
Table 1 shows partial correlations between general intelligence and three global brain metrics (global efficiency, global clustering, and small-world propensity) controlling for age, sex, age*sex, age2, age2*sex, handedness, total brain volume, and head motion. Overall, we did not find consistent significant associations between any global brain metric and general intelligence. Nevertheless, there were significant positive associations between general intelligence and global clustering in the HCP sample (day 1 session 1) as well as in the NKI sample (NKI_TR645 and NKI_TR1400). All significant effect sizes were small with mean r = 0.10 (SD = 0.02)76.
Association validity for nodal efficiency and g
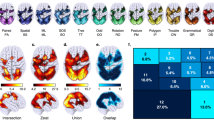
Figure 2 depicts the associations between general intelligence and nodal efficiency in all data sets (left and middle columns) as well as the overlaps between data-set pairs (right column). A complete list of all cortical and subcortical areas exhibiting unique associations with general intelligence is in Supplementary Table S1. Figure 2 does not show overlap among all data sets (RUB, HCP_day_1_day_2, UMN, and NKI_TR645) since there were no brain areas that had non-zero effect sizes in all data sets. Even when comparing different measurement sessions from the same data set (HCP_day_1 and HCP_day_2, HCP_day_1_ses_1 and HCP_day_1_ses_2, and NKI_TR645, NKI_TR1400, and NKI_TR2500), no more than 7% of brain regions overlapped (see Supplementary Table S2 for a complete list of overlapping areas).

Association between nodal efficiency and general intelligence. The left and middle columns show the results of brain area specific analyses relating nodal efficiency and general intelligence in all data sets. Brain areas exhibiting relevant associations are color-coded based on effect size. The overlaps between framed data-set pairs (left and middle columns) are depicted next to them (right column). Effect sizes of overlapping areas are averaged. Rows with gray backgrounds show within-sample overlaps, rows with white backgrounds between-sample overlaps. Subcortical areas and hemispheric specific illustrations are not shown but listed in Supplementary Table S2.
Table 2 shows how well the models defined via elastic-net regression in four samples (HCP_day_1_day_2, NKI_TR645, RUB, and UMN) tested in the other samples via multiple regression analyses performed. After correction for multiple comparisons using Bonferroni72, only the predictor set of the HCP_day_1_day_2 sample significantly predicted general intelligence in the UMN sample, explaining 9% of variance in g. In general, the explained variance in general intelligence varied between 1 and 11% in the different samples, while it was up to 18% when the predictors were tested with multiple regression analysis in the same sample. The complete results including all identified predictor sets tested in all samples via multiple linear regression analyses (uncorrected for multiple comparisons) for nodal efficiency can be found in Supplementary Tables S5 and S6. Supplementary Table S5 shows the coefficients of determination and the uncorrected p-values, while Supplementary Table S6 depicts the number of significant predictors when tested in other samples. The extent of explained variance in general intelligence predicted using a set of nodal efficiency variables identified in a different sample varied between 0 and 27% (see Table S5). 0 to 63% of the predictors identified via elastic-net were significantly associated with general intelligence in the new sample (uncorrected for multiple comparisons, see Supplementary Table S6).
Association validity among local clustering and g
Figure 3 depicts the associations between general intelligence and local clustering in all data sets (left and middle columns) as well as result overlaps between data-set pairs (right column). See Supplementary Table S3 for a complete list of all cortical and subcortical areas exhibiting unique associations with general intelligence. There was no area that had a non-zero effect size in all four data sets. Local clustering did not yield overlapping results even when comparing results from the same data set but different measurement sessions (HCP_day_1 and HCP_day_2, HCP_day_1_ses_1 and HCP_day_1_ses_2, and NKI_TR645, NKI_TR1400, and NKI_2500).

Association between local clustering and general intelligence. The left and middle columns show the results of brain area specific analyses relating local clustering and general intelligence in all data sets. Brain areas exhibiting relevant associations are color-coded based on effect size. The overlap between framed data set pairs (left and middle columns) are depicted next to them (right column). Effect sizes of overlapping areas are averaged. Rows with gray backgrounds show within-sample overlaps, rows with white backgrounds between-sample overlaps. Subcortical areas and hemispheric specific illustrations are not shown but listed in Supplementary Table S3.
Table 3 shows the performance of the models defined via elastic-net regression in four samples (HCP_day_1_day_2, NKI_TR645, RUB, and UMN) in the other samples tested with multiple regression analyses. As the elastic-net regression only identified predictors in the NKI_TR645 sample (out of these four samples), we could only test this model in the other samples. The predictor set of the NKI_TR645 did not predict significantly general intelligence in other samples, but explained 1% to 9% of variance in general intelligence. Using the predictor set for multiple linear regression analysis in the same sample resulted in an explained variance of 23%. The complete results including all identified predictor sets tested in all samples via multiple linear regression analyses (uncorrected for multiple comparisons) for local clustering can be found in Supplementary Tables S7 and S8. Supplementary Table S7 shows the coefficients of determination and the uncorrected p-values, while Supplementary Table S8 depicts the number of significant predictors when tested in other samples. The extent of explained variance in general intelligence predicted using a set of local clustering variables identified in a different sample varied between 0 and 18% (see Supplementary Table S7). 0 to 16% of the predictors identified via elastic-net were significantly associated with general intelligence in the new sample (uncorrected for multiple comparisons, see Supplementary Table S8).
Global brain metric reliability
Global graph metric reliability was quantified using ICC. Relevant coefficients are listed in Table 4. Global efficiency reliability across days can be considered moderate to fair73,77. Same-day reliability can be considered moderate to fair in the NKI sample and moderate to good in the HCP sample. In contrast, global clustering reliability can be considered only poor to fair across days. Same-day reliability can be considered poor for the HCP sample and poor to fair in the NKI sample. Same-day reliability of small-world propensity can be considered poor.
Reliability of nodal efficiency and local clustering
Figure 4 depicts reliability of nodal efficiency and local clustering as quantified by ICC. Reliability varied greatly among areas, with e.g. orbitofrontal and anterior cingulate areas showing relatively poor reliability. ICC for nodal efficiency in the HCP sample across days was between 0.55 and 0.17, with 2% of values being higher than 0.50 (moderate to fair reliability). ICC for nodal efficiency in the HCP sample on the same day was between 0.63 and 0.14 (ICC in 35% of areas > 0.50). ICC for nodal efficiency in the NKI sample was between 0.51 and 0.18 (ICC in 0.5% of areas > 0.50). ICC for local clustering in the HCP sample across days was between 0.42 and 0.01. ICC for local clustering in the HCP sample on the same day was between 0.41 and − 0.02. ICC for local clustering in the NKI sample was between 0.37 and − 0.01. A full list of ICC can be found in Supplementary Table S4.

Reliability of nodal efficiency and local clustering. Intra-class correlation coefficients (ICC) of areas where the calculation was possible are color-coded with red indicating low ICC and yellow indicating high ICC.
Split-half reliability for global brain metrics can be found in Supplementary Table S9, split-half reliability for nodal brain metrics can be found in Supplementary Tables S10 and S11. Split-half reliability of global efficiency ranged from SB = 0.95 to SB = 0.99, split-half reliability of global clustering ranged from SB = 0.90 to SB = 0.99 and split-half reliability of small-world propensity ranged from SB = 0.93 to SB = 0.98. Thus, internal consistency of global metrics can be considered good75. Split-half reliability of region-specific measures was more variable, with internal consistency ranging from SB = 0.80 to SB = 0.99 for nodal efficiency and from SB = 0.50 to SB = 0.98 for local clustering. On average, 100% of areas showed good internal consistency (SB > 0.80) concerning nodal efficiency, while only 59% of areas showed good internal consistency concerning local clustering.
Discussion
While van den Heuvel et al.22 found evidence for an association between general intelligence and global brain functional network efficiency, newer observations questioned the proposed relation37,38,39. The primary goal of our study was to investigate whether replicable associations between general intelligence and functional network properties exist using a multi-center approach. We computed partial correlations to examine the associations between g and global brain efficiency, global clustering, and small-world propensity and we employed regularized elastic-net regression analysis to examine the associations between general intelligence and the two region-specific metrics nodal efficiency and local clustering. On the global level, general intelligence showed no significant associations with global efficiency or small-world propensity in any data set, but significant positive associations with global clustering coefficient in two data sets. On the level of single brain regions, there were no brain areas that consistently showed positive or negative non-zero effect sizes across all data sets for nodal efficiency or local clustering. We found the overlap of elastic-net results to be poor when comparing different data sets. For local clustering, we did not identify any brain area being associated with general intelligence in three out of four data sets (RUB, HCP, UMN). Using the areas identified via elastic-net regression in the NKI data set to predict general intelligence via multiple linear regression in the other samples was not successful regarding local clustering. Regarding nodal efficiency, areas associated with general intelligence in the HCP sample were able to predict general intelligence in the UMN sample, but not the other way around. While internal consistency for global metrics was good, test–retest reliability estimates for global efficiency were poor to fair between days and moderate to good between sessions. All test–retest reliability estimates were poor for global clustering and small-world propensity. Additionally, region-specific test–retest reliability estimates, however, were poor for both nodal efficiency and local clustering. Internal consistency was good for nodal efficiency and acceptable for local clustering.
Our observation that general intelligence exhibited no significant association with global efficiency in any data set is consistent with results reported by previous studies37,38,39. It strengthens Kruschwitz et al.’s39 position that there is no robust relation between general intelligence and the efficiency of the brain’s intrinsic functional architecture. Although they employed multiple network definition schemes, ranging from 21,637 nodes to 100 nodes, they did not find any significant association between global efficiency and a composite score of cognitive performance in the HCP data set. There were several differences between our study and theirs. We used different approaches for data pre-processing and brain network definition, we employed pruning via OMST instead of thresholding the networks based on connection strength, and we estimated g instead of using a composite score based on subtests from the NIH Toolbox. Despite the differences between the study designs, we also found no association, neither in the HCP data set nor in the other data sets. As reliability of global efficiency was only poor to fair between days, it is likely that a lack of reliability is one cause of lacking robustness. Overall, our study has provided further evidence that there is no robust association between global efficiency and general intelligence.
We observed significant positive associations between general intelligence and global clustering coefficient in two NKI recordings, namely NKI_TR645, NKI_TR1400, and HCP_day_1_ses_1. Intelligence seemed, in those data sets, to involve functional brain architecture characterized by clustered connectivity around single nodes. A possible explanation for this might be that connected brain regions exhibit high information exchange and constitute functionally coherent units3, enabling faster and/or more direct information processing. However, this result could not be considered robust given that it could not be detected in the other data sets. Van den Heuvel et al.22, Pamplona et al.37, and Kruschwitz et al.39 also all reported non-significant results. Additionally, while the global clustering coefficients of the recording HCP_day_1_ses_1 was associated with general intelligence, this effect did not appear in the second session or the combined HCP_day_1 sample. This could be due to random fluctuations, but another possible reason could be the poor test–retest reliability of the global clustering coefficient (see Table 4). It is noteworthy that we constructed highly individualized functional connectomes via OMST which have been shown to have a greater test–retest reliability compared to conventional thresholds78. Improvements in test–retest reliability could be achieved by using whole-brain parcellations based on models integrating local gradient and global similarity approaches (e.g. Schaefer atlas79) or focusing on higher frequencies in the slow band for time series filtering to derive the connectivity78.
It is considered well established that the human brain exhibits a small-world organization1,6,7,8. We observed no significant association between general intelligence and small-world propensity. Again, this finding is not surprising considering the rather poor reliability of small-world propensity.
Results from the elastic-net analysis of specific brain regions showed poor overlap among different samples. When comparing the regularized elastic-net regression results from the RUB, HCP, UMN, and NKI data sets, we did not find a single brain area that exhibited consistent non-zero associations with nodal efficiency or local clustering. Surprisingly, overlaps across days and even on the same day from the same data set were also rather poor. Elastic-net regression is a data-driven procedure, meaning that relatively small fluctuations can influence which effects will remain non-zero after regularization. Therefore, we tested the models defined by elastic-net in the four samples (HCP_day_1_day_2, NKI_TR645, RUB, and UMN) in all other samples via multiple linear regression analysis. There was no successful prediction of general intelligence based on local clustering (see Table 2). Although the predictor set of nodal efficiency areas of the HCP_day_1_day_2 data set significantly predicted general intelligence in the UMN data set, there was no successful prediction in the NKI_TR645 or RUB data set (see Table 2). Thus, there was no predictor set that successfully predicted general intelligence in all other data sets, neither for nodal efficiency nor for local clustering. One possible reason for the lack of robustness could be that the graph theoretical measures used in our study are not reliable. Limited reliability results in attenuated effect sizes and therefore reduces statistical power80,81. Limited statistical power increases the probability of Type II errors, failures to detect true effects. Thus, even though the predictors associated with general intelligence in HCP_day_1_day_2 also predicted general intelligence in UMN, these results should be interpreted with caution. Overall, our results indicate that resting-state functional connectivity nodal efficiency and local clustering do not reliably predict general intelligence.
In addition the lack of reliability, there are other possible reasons for the lack of replicable associations between graph metrics and g among data sets. First, the samples used for our study vary in multiple demographic details, most importantly age span. While the RUB and NKI samples cover wide age ranges, the HCP and UMN samples comprise young to middle aged adults. Previous studies indicated that resting-state connectivity changes with age and that age is associated with decreasing segregation of brain systems82,83. We regressed age, along with sex and its age-interactions, from our data for analysis, but, when associations are reciprocal, this can remove relevant as well as irrelevant variance. In addition, the samples vary in other demographic factors such as sex ratio, handedness proportion, ethnic composition, and likely most importantly, average IQ scores. The latter in particular may have reduced measurable associations due to range restriction, though range restriction can also enhance them84. As three of our four samples show above average intelligence, our results might not be applicable to groups with average or low intelligence. However, many other studies in this area are also characterized by samples with similarly above average mean IQ scores22,37,38.
Second, the data sets vary in size. The relations between resting-state connectivity and g might be small and some or even all our samples underpowered to detect replicable results. Considerably larger data sets or different approaches might be necessary to reveal such subtle relations even though their impact on intelligence might be limited.
Third, while efficiency and clustering are prominent graph metrics in the literature, other graph metrics that model the modularity of brain networks may be robustly associated with intelligence. Modularity represents how strongly networks can be segmented into different modules that are tightly interconnected. To integrate information from different modules, so called connector-hubs are needed, which are nodes that are connected to multiple different modules. Interesting metrics to investigate in relation to intelligence are, for example the participation coefficient and the within-module degree. The participation coefficient represents the degree to which a node is connected to nodes from other modules, so connector-hubs are defined by having a high participation coefficient85. Within-module degree represents the degree to which a node is connected to nodes belonging to the same module. Studies reported that participation coefficient and within-module degree of frontal and parietal nodes in the resting-state network were positively associated with intelligence86. It was also found that a high participation coefficient in connector-hubs facilitated a more modular behavior of neighboring nodes85. Importantly, an increased participation coefficient in connector-hubs and subsequent increased modularity were positively associated with performance in working memory and language tasks. Thus, focusing on graph metrics concerning the modularity of brain networks may present promising candidates for future multi-center studies.
Fourth, the data sets vary in temporal resolution of functional imaging. Even though related images were pre-processed and analyzed in the same manner, this could make for crucial differences. Network neuroscience theory87 suggests that intelligent thinking relies on the flexibility of functional networks and ability to switch among various network states quickly. To capture this flexibility, measurements with high temporal resolution are recommended (TR < 700 ms, see Hilger et al.88). Our study cannot make inferences about flexibility, as we analyzed the complete resting-state sequence instead of conducting time-based analyses. Currently, few studies have investigated intelligence’s association with dynamic functional graph theory metrics. Hilger et al.88 found that the brain’s modularity during resting-state varied less in highly intelligent subjects than in average subjects. In contrast to this, static modularity was not related to intelligence. This indicates that intelligence may be related to the stability of the functional connectome. Stability of parietal and frontal nodes was reported to be especially crucial for intelligent thinking. Another study indicated that highly intelligent subjects may switch less often to network states defined by low global efficiency89. Considering these results, the average efficiency of the brain or a brain area over several minutes – as investigated in our manuscript – might be too shallow of a phenotype. To understand the neural underpinnings of intelligence, future studies should focus more on how network states of the brain change over time and how this may influence intelligence.
In addition to focusing on the flexible nature of brain networks, future studies should also investigate task-based functional connectivity networks, as their associations with behavior are usually stronger than those of resting-state networks90,91. Moreover, task-based approaches may provide more insight into the mechanisms behind network states and reveal which specific tasks or cognitive domains are dependent on functional flexibility. Another approach to refine analyses is to employ individualized localization methods, which are based on subject-specific resting-state measurements92. In more detail, these methods utilize individual resting-state patterns to individualize brain atlases, which are typically averaged in their discovery cohorts. Examples of this kind of parcellation are multi-session hierarchical Bayesian modeling (MS_HBM)93 and group prior individual parcellation (GPIP)94. When applied, MS_HBM tends to increase associations between resting-state functional connectivity and cognitive performance. Similar results can be obtained via techniques such as hyper-alignment, which identifies voxels with a similar pattern of neural activity and defines them as neural units95. While these methods have been applied to the HCPMMP atlas used in this study, we refrained from using resting state-based individual parcellation for several reasons. First, our aim was to identify causes of inconsistent results in previous studies. Thus, we wanted to maximize comparability among our samples. Second, HCPMMP is a multi-modal brain atlas and its construction did not rely on resting state data alone. Thus, HCPMMP would require a multi-modal individual parcellation. Furthermore, while individualized localization increases effect sizes, it is not clear whether it also increases replicability. Nevertheless, we highly encourage future studies to apply individualized localization to resting state-based brain atlases such as e.g. Schaefer et al.79.
In conclusion, the results of our multi-center study indicated that graph-theoretical measures of resting-state functional connectivity did not reliably associate with g, at least not in specific brain regions. While partial correlations between general intelligence and global efficiency showed no significant associations in any data set, significant positive associations were found between general intelligence and global clustering in two data sets. In contrast, on the level of single brain regions, neither for nodal efficiency nor for local clustering was there a single brain area that consistently showed positive or negative non-zero effect sizes across all data sets in our elastic-net approach. However, recent research proposes that functional connectivity is indeed relevant for intelligent thinking when its modularity is investigated in a dynamic manner. Additionally, we recommend future studies to investigate task-based functional connectivity rather than of resting-state functional connectivity.
Data availability
The data from Ruhr University Bochum (RUB) and University of Minnesota (UMN) underlying this study are available from the corresponding author upon reasonable request. The Human Connectome Project (HCP) sample is part of the S1200 release provided by the HCP and can be accessed via its ConnectomeDB platform (https://db.humanconnectome.org). The Nathan Kline Institute (NKI) sample is part of the NKI Rockland Sample release and can be accessed via (https://fcon_1000.projects.nitrc.org/indi/enhanced/).
References
Latora, V. & Marchiori, M. Efficient behavior of small-world networks. Phys. Rev. Lett. 87, 198701 (2001).
Li, Y. et al. Brain anatomical network and intelligence. PLoS Comput. Biol. 5, e1000395 (2009).
Sporns, O. Networks of the Brain (The MIT Press, 2011).
van Essen, D. C. & Ugurbil, K. The future of the human connectome. Neuroimage 62, 1299–1310 (2012).
van den Heuvel, M. P. & Hulshoff Pol, H. E. Exploring the brain network: A review on resting-state fMRI functional connectivity. Eur. Neuropsychopharmacol. 20, 519–534 (2010).
Bassett, D. S. & Bullmore, E. Small-world brain networks. Neuroscientist 12, 512–523 (2006).
Watts, D. J. & Strogatz, S. H. Collective dynamics of `small-world´ networks. Nature 393, 440–442 (1998).
Liao, X., Vasilakos, A. V. & He, Y. Small-world human brain networks: Perspectives and challenges. Neurosci. Biobehav. Rev. 77, 286–300 (2017).
Neubauer, A. C. & Fink, A. Intelligence and neural efficiency. Neurosci. Biobehav. Rev. 33, 1004–1023 (2009).
Neisser, U. et al. Intelligence: Knowns and unknowns. Am. Psychol. 51, 77–101 (1996).
Spearman, C. “General intelligence,” objectively determined and measured. Am. J. Psychol. 15, 201–292 (1904).
Flanagan, D. P. & Dixon, S. G. The Cattell-Horn-Carroll theory of cognitive abilities. In Encyclopedia of Special Education (eds Reynolds, C. R. et al.) (Wiley, 2013).
Deary, I. J. et al. The stability of individual differences in mental ability from childhood to old age: Follow-up of the 1932 Scottish mental survey. Intelligence 28, 49–55 (2000).
Deary, I. J., Pattie, A. & Starr, J. M. The stability of intelligence from age 11 to age 90 years: The Lothian birth cohort of 1921. Psychol. Sci. 24, 2361–2368 (2013).
Calvin, C. M. et al. Childhood intelligence in relation to major causes of death in 68 year follow-up: Prospective population study. BMJ 357, j2708 (2017).
Batty, G. D., Deary, I. J. & Gottfredson, L. S. Premorbid (early life) IQ and later mortality risk: Systematic review. Ann. Epidemiol. 17, 278–288 (2007).
Strenze, T. Intelligence and socioeconomic success: A meta-analytic review of longitudinal research. Intelligence 35, 401–426 (2007).
Schmidt, F. L. & Hunter, J. General mental ability in the world of work: Occupational attainment and job performance. J. Pers. Soc. Psychol. 86, 162–173 (2004).
Jung, R. E. & Haier, R. J. The Parieto-frontal integration theory (P-FIT) of intelligence: Converging neuroimaging evidence. Behav. Brain Sci. 30, 135–154 (2007).
Basten, U., Hilger, K. & Fiebach, C. J. Where smart brains are different: A quantitative meta-analysis of functional and structural brain imaging studies on intelligence. Intelligence 51, 10–27 (2015).
Santarnecchi, E., Emmendorfer, A. & Pascual-Leone, A. Dissecting the parieto-frontal correlates of fluid intelligence: A comprehensive ALE meta-analysis study. Intelligence 63, 9–28 (2017).
van den Heuvel, M. P., Stam, C. J., Kahn, R. S. & Hulshoff Pol, H. E. Efficiency of functional brain networks and intellectual performance. J. Neurosci. 29, 7619–7624 (2009).
Bassett, D. S. & Sporns, O. Network neuroscience. Nat. Neurosci. 20, 353–364 (2017).
Mišić, B. & Sporns, O. From regions to connections and networks: New bridges between brain and behavior. Curr. Opin. Neurobiol. 40, 1–7 (2016).
Biswal, B., Yetkin, F. Z., Haughton, V. M. & Hyde, J. S. Functional connectivity in the motor cortex of resting human brain using echo-planar MRI. Magn. Reson. Med. 34, 537–541 (1995).
Rosazza, C. & Minati, L. Resting-state brain networks: Literature review and clinical applications. Neurol. Sci. 32, 773–785 (2011).
Machner, B. et al. Resting-state functional connectivity in the dorsal attention network relates to behavioral performance in spatial attention tasks and may show task-related adaptation. Front. Hum. Neurosci. 15, 757128 (2022).
Friston, K. J., Frith, C. D., Liddle, P. F. & Frackowiak, R. S. Functional connectivity: The principal-component analysis of large (PET) data sets. J. Cereb. Blood Flow Metab. 13, 5–14 (1993).
Aertsen, A. M., Gerstein, G. L., Habib, M. K. & Palm, G. Dynamics of neuronal firing correlation: Modulation of “effective connectivity”. J. Neurophysiol. 61, 900–917 (1989).
Finn, E. S. et al. Functional connectome fingerprinting: Identifying individuals using patterns of brain connectivity. Nat. Neurosci. 18, 1664–1671 (2015).
Rubinov, M. & Sporns, O. Complex network measures of brain connectivity: Uses and interpretations. Neuroimage 52, 1059–1069 (2010).
Fornito, A., Zalesky, A. & Breakspear, M. Graph analysis of the human connectome: Promise, progress, and pitfalls. Neuroimage 80, 426–444 (2013).
Gong, G., He, Y. & Evans, A. C. Brain connectivity: Gender makes a difference. Neuroscientist 17, 575–591 (2011).
Santarnecchi, E. et al. Efficiency of weak brain connections support general cognitive functioning. Hum. Brain Mapp. 35, 4566–4582 (2014).
Santarnecchi, E., Rossi, S. & Rossi, A. The smarter, the stronger: Intelligence level correlates with brain resilience to systematic insults. Cortex 64, 293–309 (2015).
Song, M. et al. Default network and intelligence difference. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 1, 2212–2215 (2009).
Pamplona, G. S. et al. Analyzing the association between functional connectivity of the brain and intellectual performance. Front. Hum. Neurosci. 9, 61 (2015).
Hilger, K., Ekman, M., Fiebach, C. J. & Basten, U. Efficient hubs in the intelligent brain: Nodal efficiency of hub regions in the salience network is associated with general intelligence. Intelligence 60, 10–25 (2017).
Kruschwitz, J. D. et al. General, crystallized and fluid intelligence are not associated with functional global network efficiency: A replication study with the human connectome project 1200 data set. Neuroimage 171, 323–331 (2018).
van Essen, D. C. et al. The WU-Minn human connectome project: An overview. NeuroImage 80, 62–79 (2013).
Genç, E. & Fraenz, C. Diffusion-weighted imaging of intelligence. In The Cambridge Handbook of Intelligence and Cognitive Neuroscience (eds Barbey, A. K. et al.) 191–209 (Cambridge University Press, 2021).
Stammen, C. et al. Robust associations between white matter microstructure and general intelligence. Cereb. Cortex 33, 6723–6741 (2023).
van Essen, D. C. et al. The human connectome project: A data acquisition perspective. NeuroImage 62, 2222–2231 (2012).
Nooner, K. B. et al. The NKI-Rockland sample: A model for accelerating the pace of discovery science in psychiatry. Front. Neurosci. 6, 152 (2012).
Johnson, W. et al. Just one g: Consistent results from three test batteries. Intelligence 32, 95–107 (2004).
Johnson, W., Nijenhuis, J. T. & Bouchard, T. J. Still just 1 g: Consistent results from five test batteries. Intelligence 36, 81–95 (2008).
Wilcox, R. R. Introduction to Robust Estimation and Hypothesis Testing (Academic Press, 1997).
Dubois, J., Galdi, P., Paul, L. K. & Adolphs, R. A distributed brain network predicts general intelligence from resting-state human neuroimaging data. Philos. Trans. R. Soc. Lond. B Biol. Sci. 373, 20170284 (2018).
Oldfield, R. C. The assessment and analysis of handedness: The Edinburgh Inventory. Neuropsychologia 9, 97–113 (1971).
Dragovic, M. Categorization and validation of handedness using latent class analysis. Acta Neuropsychiatr. 16, 212–218 (2004).
Sherif, T. et al. CBRAIN: A web-based, distributed computing platform for collaborative neuroimaging research. Front. Neuroinform. 8, 54 (2014).
Dale, A. M., Fischl, B. & Sereno, M. I. Cortical surface-based analysis. I. Segmentation and surface reconstruction. Neuroimage 1999, 179–194 (1999).
Fischl, B., Sereno, M. I. & Dale, A. M. Cortical surface-based analysis. II. Inflation, flattening, and a surface-based coordinate system. Neuroimage 9, 195–207 (1999).
Glasser, M. F. et al. A multi-modal parcellation of human cerebral cortex. Nature 536, 171–178 (2016).
Fischl, B. et al. Automatically parcellating the human cerebral cortex. Cereb. Cortex 14, 11–22 (2004).
Pruim, R. H. R. et al. ICA-AROMA: A robust ICA-based strategy for removing motion artifacts from fMRI data. Neuroimage 112, 267–277 (2015).
Fraenz, C. et al. Interindividual differences in matrix reasoning are linked to functional connectivity between brain regions nominated by Parieto-Frontal integration theory. Intelligence 87, 101545 (2021).
Fisher, R. A. On the “probable error” of a coefficient of correlation deduced from a small sample. Metron 1, 3–32 (1921).
Song, M. et al. Brain spontaneous functional connectivity and intelligence. Neuroimage 41, 1168–1176 (2008).
Dimitriadis, S. I. et al. Data-driven topological filtering based on orthogonal minimal spanning trees: Application to multigroup magnetoencephalography resting-state connectivity. Brain Connect. 7, 661–670 (2017).
Dimitriadis, S. I., Salis, C., Tarnanas, I. & Linden, D. E. Topological filtering of dynamic functional brain networks unfolds informative chronnectomics: A novel data-driven thresholding scheme based on orthogonal minimal spanning trees (OMSTs). Front. Neuroinform. 11, 28 (2017).
Sassenberg, T. A. et al. Conscientiousness associated with efficiency of the salience/ventral attention network: Replication in three samples using individualized parcellation. Neuroimage 272, 120081 (2023).
Dijkstra, E. W. A note on two problems in connexion with graphs. Numer. Math. 1, 269–271 (1959).
Onnela, J. P., Saramaki, J., Kertesz, J. & Kaski, K. Intensity and coherence of motifs in weighted complex networks. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 71, 065103 (2005).
Muldoon, S. F., Bridgeford, E. W. & Bassett, D. S. Small-world propensity and weighted brain networks. Sci. Rep. 6, 22057 (2016).
Holm, S. A simple sequentially rejective multiple test procedure. Scand. J. Stat. 6, 65–70 (1979).
Geerligs, L., Tsvetanov, K. A., Cam, C. & Henson, R. N. Challenges in measuring individual differences in functional connectivity using fMRI: The case of healthy aging. Hum. Brain Mapp. 38, 4125–4156 (2017).
Zou, H. & Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 67, 301–320 (2005).
Góngora, D. et al. Crystallized and fluid intelligence are predicted by microstructure of specific white-matter tracts. Hum. Brain Mapp. 41, 906–916 (2020).
Genç, E. et al. Structural architecture and brain network efficiency link polygenic scores to intelligence. Hum. Brain Mapp. 357, 1–18 (2023).
Dubois, J. et al. Resting-state functional brain connectivity best predicts the personality dimension of openness to experience. Personal. Neurosci. https://doi.org/10.1017/pen.2018.8 (2018).
Bonferroni, C. E. Teoria statistica delle classi e calcolo delle probabilità. Pubbl. Ist. Super. Sci. Econ. Commer. Firenze 8, 1–62 (1936).
Koo, T. K. & Li, M. Y. A guideline of selecting and reporting intraclass correlation coefficients for reliability research. J. Chiropr. Med. 15, 155–163 (2016).
Caceres, A. et al. Measuring fMRI reliability with the intra-class correlation coefficient. Neuroimage 45, 758–768 (2009).
Luking, K. R. et al. Internal consistency of functional magnetic resonance imaging and electroencephalography measures of reward in late childhood and early adolescence. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 2, 289–297 (2017).
Cohen, J. A power primer. Psychol. Bull. 112, 155–159 (1992).
Cicchetti, D. V. Guidelines, criteria, and rules of thumb for evaluating normed and standardized assessment instruments in psychology. Psychol. Assess. 6, 284–290 (1994).
Jiang, C. et al. Optimizing network neuroscience computation of individual differences in human spontaneous brain activity for test-retest reliability. Netw. Neurosci. https://doi.org/10.1162/netn_a_00315 (2023).
Schaefer, A. et al. Local-global parcellation of the human cerebral cortex from intrinsic functional connectivity MRI. Cereb. Cortex 28, 3095–3114 (2018).
Kanyongo, G. Y., Brook, G. P., Kyei-Blankson, L. & Gocmen, G. Reliability and statistical power: How measurement fallibility affects power and required sample sizes for several parametric and nonparametric statistics. J. Mod. Appl. Stat. Methods 6, 81–90 (2007).
Zimmerman, D. W. & Zumbo, B. D. Resolving the issue of how reliability is related to statistical power: Adhering to mathematical definitions. J. Mod. Appl. Stat. Methods 14, 9–26 (2015).
Chan, M. Y. et al. Socioeconomic status moderates age-related differences in the brain’s functional network organization and anatomy across the adult lifespan. Proc. Natl. Acad. Sci. U.S.A. 115, E5144–E5153 (2018).
Chan, M. Y. et al. Decreased segregation of brain systems across the healthy adult lifespan. Proc. Natl. Acad. Sci. U.S.A. 111, E4997-5006 (2014).
Johnson, W., Deary, I. J. & Bouchard, T. J. Have standard formulas correcting correlations for range restriction been adequately tested?: Minor sampling distribution quirks distort them. Educ. Psychol. Meas. 78, 1021–1055 (2018).
Bertolero, M. A., Yeo, B. T. T., Bassett, D. S. & D’Esposito, M. A mechanistic model of connector hubs, modularity and cognition. Nat. Hum. Behav. 2, 765–777 (2018).
Hilger, K., Ekman, M., Fiebach, C. J. & Basten, U. Intelligence is associated with the modular structure of intrinsic brain networks. Sci. Rep. 7, 16088 (2017).
Barbey, A. K. Network neuroscience theory of human intelligence. Trends Cogn. Sci. 22, 8–20 (2018).
Hilger, K., Fukushima, M., Sporns, O. & Fiebach, C. J. Temporal stability of functional brain modules associated with human intelligence. Hum. Brain Mapp. 41, 362–372 (2020).
Xia, Y. et al. Tracking the dynamic functional connectivity structure of the human brain across the adult lifespan. Hum. Brain Mapp. 40, 717–728 (2019).
Greene, A. S., Gao, S., Scheinost, D. & Constable, R. T. Task-induced brain state manipulation improves prediction of individual traits. Nat. Commun. 9, 2807 (2018).
Sripada, C. et al. Toward a “treadmill test” for cognition: Improved prediction of general cognitive ability from the task activated brain. Hum. Brain Mapp. 41, 3186–3197 (2020).
DeYoung, C. G. et al. Reproducible between-person brain-behavior associations do not always require thousands of individuals. PsyArXiv (2022).
Kong, R. et al. Individual-specific areal-level parcellations improve functional connectivity prediction of behavior. Cereb. Cortex 31, 4477–4500 (2021).
Chong, M. et al. Individual parcellation of resting fMRI with a group functional connectivity prior. Neuroimage 156, 87–100 (2017).
Feilong, M., Guntupalli, J. S. & Haxby, J. V. The neural basis of intelligence in fine-grained cortical topographies. Elife https://doi.org/10.7554/eLife.64058 (2021).
Acknowledgements
The authors thank all research assistants for their support during the behavioral measurements. Further, the authors thank PHILIPS Germany (Burkhard Mädler) for the scientific support with the MRI measurements as well as Tobias Otto for technical assistance.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
E.G. conceived the project and supervised the experiments. E.G., O.G., C.F., C.Sc., D.M., C.St., W.J., and C.G.D. designed the project. D.M. and C.St. analyzed the data and wrote the manuscript text. C.F., C.Sc. and C.G.D. collected the data. W.J. calculated the g factor scores. All authors edited the manuscript.
Corresponding author
Ethics declarations
Competing interests
This work was supported by the Deutsche Forschungsgemeinschaft (GU 227/16-1). The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Metzen, D., Stammen, C., Fraenz, C. et al. Investigating robust associations between functional connectivity based on graph theory and general intelligence. Sci Rep 14, 1368 (2024). https://doi.org/10.1038/s41598-024-51333-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-51333-y
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
