
Abstract
An acceptance sampling plan has been designed in this study based on the Difference-in-Difference estimator. This plan is designed for the inspection of those product units whose life follows the normal distribution. The operating characteristic function is discussed for the two respective cases of the standard deviation known and unknown. The parameters of the proposed plan are determined by minimizing the sample size and followed by the satisfying optimization rule. The results are computed and tabulated for various parametric combinations of acceptable quality levels and limiting quality levels. The computations are performed by using R statistical programming software for all respective cases. The real-life application of the proposed sampling plan has been discussed and elaborated in detail.
Similar content being viewed by others
Introduction
An essential component of industrial production is the process of inspecting the finished goods through acceptance sampling plans after they are manufactured, as these plans are characterized by lot sentencing procedures. Dealing with these sampling plans is crucial since they will offer a better method for determining the minimum sample size in each scenario for lot sentencing and whether it is worthwhile to be accepted or rejected. To preserve or assert a certain level of reputation regarding the manufacturing lot, the industries are susceptible to passing through their ready or final production lots through suitable acceptance sampling plans1,2,3,4. The field of statistical process control (SPC) offers tools such as acceptance sampling plans that are better suited for a range of industrial settings5. In this situation, producers want to favor the minimum sample size acceptance sampling plans since they are eager to prevent needless inspection expenses and effort6. As a result, plans that align with production conditions are implemented. Producers are constantly interested in using effective, remarkable sample plans that need less inspection time and money to decrease losses and maintain high standards of quality7.
Similar to how effective sampling plans in production lines are crucial for quick lot sentencing, acceptance-sampling plans are among the most critical instruments for this purpose6. Plans come in two varieties: variable acceptance sampling plans and attribute plans. The literature on SPC is highly comprehensive and offers suitable acceptance sampling plans tailored to the requirements of the production settings. Earlier ones are thought to have easier industrial implementations among them. However, today's producers are more picky, using more data and being more sensitive to achieve the desired outcomes; for this reason, variable sampling plans are preferred over attribute sampling plans8. Since extraneous factors naturally disrupt manufacturing, there are two risks associated with lot sentencing that cannot be avoided: accepting the good lot and rejecting the bad one7. There are numerous real-world situations when having some extra, antecedent, or auxiliary knowledge can significantly enhance the decision-making process regarding lot sentencing methodology. Quality control literature favors the utilization of additional information in support of the study variable \(y\).
As8 utilized the single auxiliary variable in designing of acceptance sampling plan and successfully achieved improved results. The literature on statistical process monitoring control charts by using a single auxiliary variable is also quite enriched. A detailed discussion of this concept can be seen in9,10,11,12,13,14 and15. As16 presented auxiliary information-based arithmetic mean control chart17. Proposed auxiliary information EWMA control chart18. Developed the use of multivariate regression-based mean and variance control charts19. Constructed an individual monitoring control chart that is based on cluster-regression methods. Recently20, introduced the concept of auxiliary information to enhance the more proficient way of an acceptance sampling plan to accept the lot21, designed the economical way of an acceptance sampling plan despite having inspection errors22, utilized the regression estimator concept in developing the EWMA statistic based acceptance sampling plan23, employed the regression estimator in the presence of uncertainty to create a successful plan24, suggested repeated sample acceptance sampling strategy based on multiple dependent state sampling, both with and without the use of an auxiliary dataset to demonstrate the effectiveness of the suggested plan25, recommended product acceptance by taking into account the liner profiles of two suppliers using Wang's test statistic to determine the required minimum sample size to obtain an effective plan. Moreover26,27,28,29,30,31,32,33,34, and35 introduced more of this kind of concept procedure, which works well under certain production environments.
The new contribution of the presented research is the development of a new acceptance sampling plan when more than one auxiliary variable is demanded by both the producer and the consumer to estimate the study variable or the variable of interest in a much more precise manner to satisfy the risks respectively. The new index with three auxiliary variables used in this paper methodology is novel, and the use of the difference-in-difference estimator approach produces better results in terms of the smaller sample size needed to make a better decision of lot sentencing than the other existing acceptance sampling plans now in literature. To the best of the authors' knowledge, no attempt has been made to create an acceptance sampling plan in the literature. This leads to the creation of the suggested study. The difference estimator plays a significant role in the statistical literature, particularly in situations where the goal is to estimate the difference between two population parameters. Here are some contributions of the concept in statistical process control as acceptance sampling plans and examples as follows: Treatment Effects in Experimental Studies: Difference estimators are commonly used to assess treatment effects in experimental studies. They help quantify the impact of a treatment or intervention by comparing the outcomes. Example: In a clinical trial, a new drug's effectiveness is evaluated by measuring the difference in health outcomes between patients who received the drug and those who received a placebo to make a decision about the effectiveness of treatment. Before-and-After Studies: Difference estimators are valuable in assessing changes over time, as they quantify the difference in outcomes before and after an intervention or policy change. Example: A city implements a traffic management system, and the difference in traffic congestion levels before and after the system's implementation is used to estimate the system's impact. Paired Observations and Matched Samples: Difference estimators are commonly employed when dealing with paired observations or matched samples. They help account for individual variability by focusing on the differences within pairs or matched groups. Example: In a study comparing the effectiveness of two teaching methods, the difference in test scores for each student is calculated, and the average difference is used as the estimator. Economic Studies—Control Groups: Difference estimators are essential in economic studies, especially when dealing with observational data. They help control for unobserved factors by comparing differences in outcomes over time or between groups. Example: Evaluating the impact of a policy change on employment rates by comparing the differences in employment levels before and after the policy change. Quasi-Experimental Designs: In situations where true randomization is challenging, difference estimators are valuable in quasi-experimental designs, helping to control for confounding variables. Example: Assessing the impact of a new teaching method in a school where random assignment is not feasible, by comparing the difference in performance between classes that adopted the new method and those that did not. In summary, the difference estimator contributes to estimating and interpreting the impact of interventions, policy changes, or experimental conditions by quantifying the differences in outcomes, making it a versatile tool in various fields of study.
To develop an acceptance sample plan, we have incorporated in this study the use of two auxiliary variables in addition to the variable of interest. No acceptance sample strategy is created with two auxiliary variables, according to the authors' information. Thus, the suggested methodology, which was first put forth by36, uses the auxiliary data in the form of a Difference-in-difference (DID) estimator to examine the variable of interest. The minimum necessary lot inspection sample size is used to assess the proposed concept's competency. The remaining portions of the paper are divided as follows: The conceptual foundation of the DID estimator and the suggested plan's approach are covered in Sections "Methods" and "Results discussion". The real-world example and the determined findings from the simulation runs are described in Section "Results findings", and the concluding observations are contained in Section "Conclusions". Figure 1 displays the methodology's flowchart, while Table 1 lists the key symbols and notations before the Section "Introduction" introduction.

Flow Chart of the Proposed DID Sampling Plan Methodology.
Methods
In this section, the procedures opted to be discussed for the designs of the proposed sampling plan are mentioned here. The underlying problem statement and strength that need to be addressed are as follows:
At times, the producers seem it complicated to change the sampling schemes with a complex one than simply the simple random sampling scheme, and also the producers believe that various auxiliary information is readily available as part of the production system to use them in improving the precision of the study variable estimate than the usage of complex sampling schemes. This philosophy provides a better understanding of an acceptance sampling scheme as far as the utilization of various auxiliary variables in the estimation does not hamper the sampling cost and gives much-improved results to define defectives as defective items as well.
The proposed acceptance sampling plan is based on the DID estimator introduced by36, as follows:
The variable \(y\) is the study variable while \(x\) and \(z\) are the auxiliary variables. There are \(l\) random samples drawn for each variable \(\left\{\left({y}_{ij,}{x}_{ij,}{z}_{ij}\right): i=\mathrm{1,2},3,\dots ,l; j=\mathrm{1,2},3,\dots ,n\right\}\) with a sample of size \(n\) and taken as the tri-variate normal random variable which follows the normal distribution having mean \(\underset{\_}{\mu }\) as a vector of \(l\) values given as under:
and the variance–covariance matrix \(\sum_{\_}\) concerning the corresponding \(y,x,\) and \(z\) variables are as follows:
Here, \({\mu }_{y},{\mu }_{x}\) and \({\mu }_{z}\) are the population means of \(y, x,\) and \(z\) for the \(l\) terms and \({\sigma }_{y}^{2},{\sigma }_{x}^{2}\) and \({\sigma }_{z}^{2}\) are the population variances, while \({\rho }_{yx}\), \({\rho }_{yz}\) and \({\rho }_{xz}\) are the possible correlation coefficients between the respective three variables. The mean and variance of the \(DID\) estimator are given as:
and
The acceptance sampling plan that has been suggested is for the two cases of σ known and unknown, which are examined independently as follows:
Case 1 In σ known circumstances.
In terms of the single sampling-based acceptance sampling plan, the suggested sampling plan design implements the36 in statistical process control. It is suggested to use the following operating characteristic (OC) function with a smaller sample size (n) than the typical sampling schemes currently in use:
Here, \(E\) is the value of the acceptable, approved statistic provided as:
Here, \(k\) is the acceptance number that will be ascertained via simulation runs, and \(USL\) is the upper specification limit set by the manufacturer.
Design
The following are the steps involved in implementing the suggested sample design:
Step 1 Ascertain the critical risk values for producers and consumers, denoted as \(\alpha \) and \(\beta \), in addition to \(USL\). Compute the acceptance statistic \(E\) using a tri-variate simple random sample of size \(n\) from the lot.
Step 2 Take the following stance on the lot's disposition::
-
(1)
If \(E\ge k\), accept the inspected lot.
-
(2)
If \(E<k\), reject the inspected lot.
The OC function becomes
As per37, it is assumed that if the population under study follows the normal distribution then the distribution of the \({\overline{Y} }_{DID}\) will also follow the normal distribution.
Hence, it can be shown as
The probability of acceptance is:
The \({z}_{p}\) and \(\Phi (.)\) represents the \({p}^{th}\) percentile and the cumulative density function (CDF) following the standard normal distribution.
Rejecting a good lot and accepting a bad lot are the two risks associated with the lot sentencing procedure that are present in the acceptance sampling strategy. Let's designate \(\alpha \) as the producer's risk and \(\beta \) as the consumer's risk. We should also designate \({p}_{1}\) as the acceptable quality level (AQL) and \({p}_{2}\) as the limiting quality level (LQL). The suggested plan is based on certain plan parameters that were found in the simulation process' output so that the two connected points (\(\alpha ,{p}_{1}\)) and (\(\beta ,{p}_{2}\)) pass through the center of the curve end to end and satisfy the subsequent two-fold optimization procedures with the smallest possible sample size \((n)\).
As long as the following criteria are met:
and
Additionally, we set the correlation coefficient values to \({{{\rho }_{xz}=\rho }_{xy}=\rho }_{yz}=\rho \). The observed trend between the computed values is examined in the following manner based on Table 2:
-
1.
For the fixed values of \({p}_{1}\), sample size \(n\) decreases as \({p}_{2}\) increases. For instance, \({p}_{1}= 0.001\) at \(\rho =0.7\) for \({p}_{2} = 0.004,\) \(n=20; \mathrm{for }{p}_{2} = 0.006, n=11\); for \({p}_{2} = 0.008,\) \(n=8\). But \(n = 4\) for \({p}_{2}= 0.020\).
-
2.
For the fixed values of \({p}_{2}\), sample size \(n\) increases as \({p}_{1}\) decreases. For instance, \({p}_{2}= 0.020\) at \(\rho =0.7\) for \({p}_{1} = 0.001,\) \(n=4; \mathrm{for }{p}_{1} = 0.0025, n=7\); for \({p}_{1} = 0.005,\) \(n=14\). But \(n = 49\) for \({p}_{1}= 0.010\).
-
3.
As the value of the \(\rho \) decreases the value of sample size increases. For instance, at \({p}_{1}= 0.001\) and \({p}_{2} = 0.006\) at \(\rho =0.9\) the \(n=2; \mathrm{at }\rho =0.7\mathrm{ the } n=11\) and \(\rho =0.5\) the \(n=18.\)
The presented plan is turned into the existing plan when \({{{\rho }_{uv}=\rho }_{xy}=\rho }_{yx}=\rho =0\) then becomes a special case and in this case \({\overline{Y} }_{DID}=\overline{Y }\)
Case 2 In an unknown circumstance.
Similar to real-world scenarios, the majority of the time the \(\sigma \) is unknown and can be calculated using the sample standard deviation \((S)\). With the following steps, we suggest the sampling strategy for the \(\sigma \) unknown situation in adaptation:
Step 1 Take a random sample of size n from a lot and obtain the mean characteristic \(\overline{y }\). Then, calculate the following statistics:
and
Step 2 accept the lot if \({E}^{*}\ge k\), otherwise reject the lot.
The following is the derivation of the OC curve function for the acceptance probability/likelihood of the suggested plan:
Now, according to37:
We know that
where
So,
Equation (4) can be used to obtain the OC function, which is as follows:
Lastly, in the case where σ is unknown, the OC function can be expressed as follows:
As in case 1, the underlying optimization conditions will be followed to determine the plan parameters. The plan equations are subjected to the following constraints to minimize \(n\):
and
The values of \(n\) and \(k\) are found for various combinations of AQL and LQL and different values of \(\rho \), like the case when \(\sigma \) is known. We saw the corresponding tendency from Table 3, which is explained below:
-
1.
For the fixed values of \({p}_{1}\), sample size \(n\) decreases as \({p}_{2}\) increases. For instance, \({p}_{1}= 0.001\) at \(\rho =0.7\) for \({p}_{2} = 0.004,\) \(n=201; \mathrm{for }{p}_{2} = 0.006, n=110\); for \({p}_{2} = 0.008,\) \(n=77\). But \(n = 30\) for \({p}_{2}= 0.020\).
-
2.
For the fixed values of \({p}_{2}\), sample size \(n\) increases as \({p}_{1}\) decreases. For instance, \({p}_{2}= 0.020\) at \(\rho =0.7\) for \({p}_{1} = 0.001,\) \(n=30; \mathrm{for }{p}_{1} = 0.0025, n=51\); for \({p}_{1} = 0.005,\) \(n=97\).
-
3.
As the value of the \(\rho \) decreases the value of sample size increases. For instance, at \({p}_{1}= 0.001\) and \({p}_{2} = 0.006\) at \(\rho =0.9\) the \(n=103; \mathrm{at }\rho =0.7\mathrm{ the } n=110\) and at \(\rho =0.5\) the \(n=117.\)
Algorithm
The proposed plan design parameters are n and k under the single sampling scheme whose detail is described in section "Design". The algorithmic steps to elaborate the flow of computing the proposed plan parameters are as follows (Fig. 1 explains the algorithm via a flow-chart):
Step 1 Specify the values of \({p}_{1}\), \({p}_{2}\) and \(\rho \).
Step 2 Generate 100,000 values of n and k from the uniform distribution.
Step 3 Computation of values of OC functions against \({p}_{1}\), \({p}_{2}\) and \(\rho \).
Step 4 Find out the values of n and corresponding k that satisfy the plan equations.
Step 5 Find out the smallest values of n and corresponding k obtained in Step 4.
Step 6 The least possible value of n and k is obtained for 100,000 times simulation results.
Step 7 Choose the lowest value of n and corresponding k as the computed values from Step 6.
The concept needs to be addressed with theoretical significance and practical contributions which are provided as follows:
Theoretical significance
-
1.
Increased Precision Using three auxiliary variables in an estimator can enhance precision by incorporating more information, leading to more reliable and accurate estimates.
-
2.
Bias Reduction The inclusion of three auxiliary variables may reduce bias, making the estimator more robust and less susceptible to biases inherent in simpler models as discussed by … for developing the three auxiliary variables-based estimator to estimate the study variable.
-
3.
Model Flexibility Three auxiliary variables provide greater flexibility in modeling complex relationships, allowing for a more nuanced understanding of the underlying dynamics. That’s why researchers are making their focus to use auxiliary information-based estimators rather than utilizing complex sampling procedures which will compromise the lot sentencing cost as well.
Practical contribution
-
1.
Improved Predictive Power The use of three auxiliary variables can enhance predictive modeling, contributing to better predictions of the target variable.
-
2.
Variable Selection The three auxiliary variables can aid in identifying relevant factors, contributing to better-informed decision-making and understanding of the studied system.
-
3.
Generalization to Multivariate Cases Having three auxiliary variables is crucial for extending models to multivariate scenarios, capturing interactions between multiple variables.
In summary, employing an estimator with three auxiliary variables offers theoretical advantages such as increased precision and reduced bias, while practical contributions include improved predictive power, better variable selection, and the ability to handle more complex, multivariate situations.
Results discussion
In this paper, an attempt has been made to offer a comparison picture with the approximation approach as far as the acceptance sample plans are concerned, since, to the best of the authors' knowledge, no comparable method exists. In addition, the comparative study is provided with two auxiliary information-based acceptance sampling plans, as previously mentioned. This is because no such effort has been made in the literature for the three variables usage to estimate the study variable as provided in the proposed design.
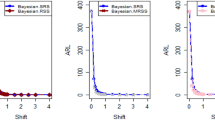
This section is divided into three sections: the specific case of the suggested plan, which explains its superiority over the existing sample plans in the literature, and a comparison study with the38 and39. Furthermore, it was discovered that the suggested sampling plan worked better than the current sampling plans, such as38,39, and the current sampling plans under the unique situation when ρ = 0. Figure 2 provides a graphic summary of the comparative analysis, demonstrating how the suggested plan outperformed the current plans in every way.

Efficiency Comparison of Existing Plans with Proposed DID Sampling Plan.
The proposed concept is much more suitable than the statistical process control acceptance sampling plans as far as economic studies and quasi-experimental designs, helpful to control confounding variable conditions. The suggested method requires a smaller sample size (ASNs) to be implemented for the lot sentencing procedure, according to the graphic display. This display is built using the known scenario \(\sigma =0.8\) and \(AQL=0.001\) fixed. The following is a thorough discussion of the comparative analysis between each current plan and the proposed plan:
A comparative study with 38
Firstly, a comparison has been made with the existing38 to prove the argument that the proposed concept outperformed the existing sampling plans. The comparative study results are shown in two respective tables for both \(\sigma \) known and unknown cases, such as Tables 4 and 5. In Table 4, the results are being considered for the \({p}_{1}=0.001\) and \({p}_{2}= 0.002, 0.003, 0.004 \& 0.006\) for \(\rho =0.8, 0.6 \& 0.4\). Similarly, in Table 5 the results are shown for the \({p}_{1}=0.0025\) and \({p}_{2}= 0.010, 0.015, 0.020 \& 0.025\) for \(\rho =0.8, 0.6 \& 0.4\) as there is a relationship between \(y\) and \(x\) where \(x\) is treated as a piece of auxiliary information. Hence, the findings can be explained as follows:
-
For the \({p}_{1}=0.001\) and \({p}_{2}= 0.002, 0.003 \& 0.006\) at \(\sigma \) known case from Table 4, the proposed plan gives \(n=\mathrm{57,22} \& 8\), for \(\rho =0.8\) while existing plan gives size \(n=153, 59 \& 21\), whereas for \(\rho =0.6\) the proposed plan gives \(n=106, 42 \& 15\) while existing plan gives \(n=172, 67 \& 24\). The same parametric behavior can be observed for the other parametric values as shown in Table 4.
-
For the \({p}_{1}=0.0025\) and \({p}_{2}= 0.010, 0.015 \& 0.020\) for the \(\sigma \) unknown case from Table 5, the proposed plan gives \(n=\mathrm{132,71} \& 49\), for \(\rho =0.8\) while existing gives size \(n=150, 82 \& 56\), whereas for \(\rho =0.6\) the proposed plan gives \(n=141, 76 \& 53\) while existing plan gives \(n=154, 84 \& 58\). The same can be seen for the other parametric values as shown in Table 5.
To demonstrate the concept's effectiveness, two auxiliary-information-based sampling plan is compared where successive occasions were targeted to estimate the study variable. To the best of the authors' knowledge, no attempt has been made to create an acceptance sampling plan in the literature with such utility. This leads to the creation of the suggested acceptance sampling plan design. So, the presented comparison is fine to the best of the author’s stance. The new index with three auxiliary variables used in this paper methodology is novel, and the use of the difference-in-difference estimator approach produces better results in terms of the smaller sample size needed to make a better decision of lot sentencing than the other existing acceptance sampling plans now in literature.
A comparative study with39
Secondly, to elaborate on the efficiency with an existing39 Table 6 is constructed to represent the comparison of the required sample size (n) for lot sentencing between the proposed acceptance sampling plan with the39. It is clear from the results that the proposed sampling plan requires a smaller sample size as compared to the existing sampling plan and the variables y, x, and z are correlated with each other. The following trend is demonstrated by the computed results:
-
For the \({p}_{1}=0.001\) and \({p}_{2}= 0.003, 0.020\) at \(\sigma \) known case from Table 5, the proposed plan gives sample size \(n=6 \& 2\), for \(\rho =0.9\) and size \(n=42 \& 5\), for \(\rho =0.6\), and size \(n=57 \& 7\), for \(\rho =0.4\) whereas the existing plan shows \(n=74 \& 8\).
-
For \({p}_{1}=0.0025\) and for \({p}_{2}= 0.010, 0.020\) gives sample size \(n=3 \& 2\), for \(\rho =0.9\) and size \(n=21 \& 9\), for \(\rho =0.6\), and size \(n=29 \& 12\), for \(\rho =0.4\) where as existing plan shows \(n=38 \& 16\).
A comparative study with the sampling plan by35
Thirdly, the computed results have also shown that the proposed design of the sampling plan is much better than a skip-lot sampling design presented by the35. It can be viewed by the tabular results that the proposed plan is providing a minimal sample size in both the \(\sigma \) known case (mention in Fig. 2 and Table 7). The following trend is observed:
-
For the \({p}_{1}=0.001\) and \({p}_{2}= 0.003, \mathrm{0.004,0.006}\) from Table 6, the existing plan35 gives sample size \(n=150, 90, \& 51\), for \(f=0.05\) and the proposed plan gives sample size \(n=22, 13, \& 8\), for \(\rho =0.8\), and size \(n=57, 35, \& 20\), for \(\rho =0.4\).
Hence, the proposed DID-Estimator-based sampling plan is much more efficient to use than the existing sampling plans.
A comparative study with sampling plan for \({\varvec{\rho}}=0.0\) (a special case)
Fourthly, as a special case of the proposed DID estimator when the \({\varvec{\rho}}\) between the variables \(x, y,\) and \(z\) becomes zero then it becomes the existing sampling plan and the determined results are mentioned in the last column of Tables 2, 3. The proposed plan results are compared with the results \(\rho =0.0\) then it can be seen that the proposed plan is more efficient than the existing one. The analysis is explained as follows:
-
For the \({p}_{1}=0.001\) and \({p}_{2}= 0.003, 0.020\) at \(\sigma \) known case from Table 2, the existing plan gives sample size \(n=6 \& 2\), for \(\rho =0.9\) and size \(n=42 \& 5\), for \(\rho =0.6\), and size \(n=57 \& 7\), for \(\rho =0.4\) whereas the existing plan shows \(n=74 \& 8\).
-
For \({p}_{1}=0.0025\) and for \({p}_{2}= 0.010, 0.020\) gives \(n=3 \& 2\), for \(\rho =0.9\) and size \(n=21 \& 9\), for \(\rho =0.6\), and size \(n=29 \& 12\), for \(\rho =0.4\) where as the existing plan shows \(n=39 \& 16\).
Results findings
To provide a real-life application of the proposed plan a real dataset was taken from the bakery products manufacturing industry which is furnished by Mason E. Wescott with \(k = 2\) predictor variables provided by40. The problem is to correlate the green strength (flexural strength before baking) of an electric circuit breaker chute to the hydraulic pressure used in forming them and the acid concentration. The data is given in Tables 8 and 9 (Appendices), with hydraulic pressure and green strength given in units of 10 lb/in2 and the acid concentration is given in percentage of the nominal rate for 20 observations. The data set normality is confirmed by Shapiro. test function using the Shapiro–Wilk test for conducting the goodness of fit test and the result gives \(p=0.0879.\)
The variable of interest is represented by \(Y\) (Green strength in units of 10 lb/in2) and Auxiliary variables are \(X\) (Hydraulic pressure in units of 10 ln/in2) and \(Z\) (Acid concentration as % of nominal rate) respectively. According to the steps of the proposed sampling plan (mentioned in section methods), we proceed as follows:
Step 1 A random sample of size \(n = 5\) is selected from Table 9 computed results (constructed for the obtained values of \(\rho \)) against \({p}_{1} = 0.05, {p}_{2} = 0.1\) and \(k = 1.4462\). Assuming the value of the upper specification limit as \(USL = 1200\).
\({\mu }_{y}=641.6, {\mu }_{x}=131.4, {\mu }_{z}=100.6, {\rho }_{yx}=0.521, {\rho }_{yz}=0.880,{\rho }_{xz}=0.152, \overline{y }=662.9\),
Step 2 From the above results we see that \(E<k\) i.e., 0.8796 < 1.4462, hence, the lot will be rejected.
Using multiple auxiliary variables was very helpful in obtaining an accurate estimate of the research variable. The sample demonstrated the strength of the suggested acceptance sampling approach, showing that even with a small sample size of five units, the plan may provide accurate results by assisting the researchers in determining the lot sentencing procedure.
Conclusions
Using the DID estimator developed by36, a single sample-based acceptance sampling strategy has been put forth in this paper. The assumption that the product inspection lifetime follows a normal distribution guides the study of the dependent variable together with two independent variables. This study creates an acceptance sampling strategy to implement the36 in a real-world industrial setting for quality assurance through SPC tools. The suggested plan OC function has been designed, and the simulation process's parametric outcomes are ascertained by utilizing an efficient grid search strategy to obtain the smallest possible sample size using R software. The findings are presented in detail in Tables 2, 3, where it is observed that the proposed sampling plan is more effective in providing the smaller sample size value needed for lot sentencing, while the flow chart and algorithm provide more information about the application and computations of the proposed plan. The results clearly show the significant superiority of the proposed plan over the current35,38,39, and the special case of the correlation zero. Furthermore, there is a good chance that the suggested strategy will be applied to other fields utilizing various sample schemes in the future. Other sectors can benefit more from implementing the DID estimator-based sample plan as it is evident that it is more efficient than the current sampling plans. Future research can examine the suggested study's use of ranked set sampling, multiple dependent state sampling, and repeating sampling.
Data availability
The data is given in the paper.
References
Ahmed, B., Ali, M. M. & Yousof, H. M. A novel G family for single acceptance sampling plan with application in quality and risk decisions. Ann. Data Sci. 1–19 (2022).
Algarni, A. Group acceptance sampling plan based on new compounded three-parameter Weibull model. Axioms 11, 438 (2022).
Kannan, G., Jeyadurga, P. & Balamurali, S. Economic design of repetitive group sampling plan based on truncated life test under Birnbaum-Saunders distribution. Commun. Stat. Simul. Comput. 51, 7334–7350 (2022).
Kenett, R. S., Zacks, S. & Gedeck, P. Modern Statistics: A Computer-Based Approach with Python (Springer Nature, 2022).
Tasias, K. A. Integrated quality, maintenance and production model for multivariate processes: A Bayesian approach. J. Manuf. Syst. 63, 35–51 (2022).
Julious, S. A. Sample Sizes for Clinical Trials (CRC Press, 2023).
Liu, S.-W., Wu, C.-W. & Wang, Z.-H. An integrated operating mechanism for lot sentencing based on process yield. Qual. Technol. Quant. Manag. 19, 139–152 (2022).
Wang, F. K. A single sampling plan based on exponentially weighted moving average model for linear profiles. Qual. Reliab. Eng. Int. 32, 1795–1805 (2016).
Naik, V. & Gupta, P. A general class of estimators for estimating population mean using auxiliary information. Metrika 38, 11–17 (1991).
Upadhyaya, L. N. & Singh, H. P. Use of transformed auxiliary variable in estimating the finite population mean. Biom. J. J. Math. Methods Biosci. 41, 627–636 (1999).
Magnus, J. R. Estimation of the mean of a univariate normal distribution with known variance. Econom. J. 5, 225–236 (2002).
Singh, H., Upadhyaya, L. & Chandra, P. A general family of estimators for estimating population mean using two auxiliary variables in two-phase sampling. Stat. Transit. 6, 1055–1077 (2004).
Shu, L., Tsung, F. & Tsui, K.-L. Effects of estimation errors on cause-selecting charts. IIE Trans. 37, 559–567 (2005).
Singh, R. & Mangat, N. S. Elements of Survey Sampling Vol. 15 (Springer Science & Business Media, 2013).
Naz, F., Abid, M., Nawaz, T. & Pang, T. Enhancing efficiency of ratio-type estimators of population variance by a combination of information on robust location measures. Sci. Iran. Trans. E Ind. Eng. 27, 2040–2056 (2020).
Ahmad, S., Abbasi, S. A., Riaz, M. & Abbas, N. On efficient use of auxiliary information for control charting in SPC. Comput. Ind. Eng. 67, 173–184 (2014).
Abbas, N., Riaz, M. & Does, R. J. An EWMA-type control chart for monitoring the process mean using auxiliary information. Commun. Stat. Theory Methods 43, 3485–3498 (2014).
Aksioma, D., Wibawati, & Jayanti, J. An implementation of regression adjustment control chart into production water. Int. J. Appl. Math. Stat. Transit. 53, 252–260 (2015).
Ong, H. C. & Alih, E. A control chart based on cluster-regression adjustment for retrospective monitoring of individual characteristics. PLoS One 10, e0125835. https://doi.org/10.1371/journal.pone.0125835 (2015).
Aslam, M., Satti, S. L., Moemen, M.A.-E. & Jun, C.-H. Design of sampling plan using auxiliary information. Commun. Stat. Theory Methods 46, 3772–3781 (2017).
Fallahnezhad, M., Qazvini, E. & Abessi, M. Designing an economical acceptance sampling plan in the presence of inspection errors based on maxima nomination sampling method. Sci. Iran. 25, 1701–1711 (2018).
Aslam, M., Azam, M. & Jun, C.-H. Sampling plan using EWMA statistic of regression estimator. Iran. J. Sci. Technol. Trans. A Sci. 42, 115–127 (2018).
Aslam, M. & Al-Marshadi, A. H. Design of sampling plan using regression estimator under indeterminacy. Symmetry 10, 754 (2018).
Khan, N., Aslam, M., Ahmad, L. & Jun, C.-H. Multiple dependent state repetitive sampling plans with or without auxiliary variable. Commun. Stat. Simul. Comput. Stat. 48, 1055–1069 (2019).
Aslam, M., Azam, M. & Jun, C.-H. Product acceptance determination by two suppliers with linear profiles. Sci. Iran. (2020).
Riaz, M. Monitoring process mean level using auxiliary information. Stat. Neerl. 62, 458–481 (2008).
Cheng, C.-S. & Chen, P.-W. An ARL-unbiased design of time-between-events control charts with runs rules. J. Stat. Comput. Simul. 81, 857–871 (2011).
Aslam, M., Balamurali, S. & Jun, C.-H. A new multiple dependent state sampling plan based on the process capability index. Commun. Stat. Simul. Comput. Stat. 1–17 (2019).
Bhattacharya, R. & Aslam, M. Generalized multiple dependent state sampling plans in presence of measurement data. IEEE Access 8, 162775–162784 (2020).
Aslam, M., Azam, M., Ahmad, L. & Smarandache, F. Optimization Theory Based on Neutrosophic and Plithogenic Sets 45–61 (Elsevier, 2020).
Banihashemi, A., Nezhad, M. S. F. & Amiri, A. A new approach in the economic design of acceptance sampling plans based on process yield index and Taguchi loss function. Comput. Ind. Eng. 159, 107155 (2021).
Wu, C.-W., Shu, M.-H., Wang, P.-A. & Hsu, B.-M. Variables skip-lot sampling plans on the basis of process capability index for products with a low fraction of defectives. Comput. Stat. 36, 1391–1413 (2021).
Fallah Nezhad, M. S. & Nesaee, M. Developing variables sampling plans based on EWMA yield index. Commun. Stat. Simul. Comput. 50, 1135–1153 (2021).
Naveed, M., Azam, M., Saeed, M., Khan, N. & Aslam, M. Sampling plans using extended EWMA statistic with and without auxiliary information. Kuwait J. Sci. 48 (2021).
Wu, C.-W., Lee, A. H. & Huang, Y.-S. A variable-type skip-lot sampling plan for products with a unilateral specification limit. Int. J. Prod. Res. 59, 4140–4156 (2021).
Awan, W. H. & Shabbir, J. On optimum regression estimator for population mean using two auxiliary variables in simple random sampling. Commun. Stat. Simul. Comput. Stat. 43, 1508–1522 (2014).
Duncan, A. Quality Control and Industrial Statistics 5th edn (Homewood, IL, Richard D. Irwin, 1986).
Azam, M., Nawaz, S., Arshad, A. & Aslam, M. Acceptance sampling plan using successive sampling over two successive occasions. J. Test. Eval. 44, 2024–2032 (2016).
Aslam, M., Azam, M. & Jun, C.-H. A new lot inspection procedure based on exponentially weighted moving average. Int. J. Syst. Sci. 46, 1392–1400 (2015).
Juran, J. & Godfrey, A. B. Quality handbook 173 (1999).
Acknowledgements
The authors are deeply thankful to the editor and reviewers for their valuable suggestions to improve the quality and presentation of the paper.
Author information
Authors and Affiliations
Contributions
M.A.Z., M.A.K., A.A., M.S. and M.A. wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Azam, M., Khan, M.A., Arshad, A. et al. Acceptance sampling plan based on difference in difference estimator with application. Sci Rep 13, 22305 (2023). https://doi.org/10.1038/s41598-023-49786-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-49786-8
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
