
Abstract
This research paper presents the development of a nonlinear Muskingum model which achieves precise flood routing through river reaches while considering lateral inflow conditions. Fourteen pairs of flood hydrograph found at two specific United States Geological Survey (USGS) stations located along the Red River of the North, namely Grand Forks and Drayton, are used for the calibrations and validations of the Muskingum model. To enhance the accuracy of the procedure, a reach is divided into multiple sub-reaches, and the Muskingum model calculations are performed individually for each interval using the distributed Muskingum method. Notably, the model development process incorporates the use of the Salp Swarm algorithm. The obtained results demonstrate the effectiveness of the developed nonlinear Muskingum model in accurately routing floods through the very gentle river with a bed slope of (0.0002–0.0003). The events were categorized into three groups based on their dominant drivers: Group A (Snowmelt-driven floods), Group B (Rain-on-snow-induced floods), and Group C (Mixed floods influenced by both snowmelt and rainfall). For the sub-reaches in Group A, single sub-reach (NR = 1), the Performance Evaluation Criteria (PEC) yielded the highest value for SSE, amounting to 404.9 × 106. In Group B, when NR = 2, PEC results the highest value were SSE = 730.2 × 106. The number of sub-reaches in a model has a significant influence on parameter estimates and model performance, as demonstrated by the analysis of hydrologic parameters and performance evaluation criteria. Optimal performance varied across case studies, emphasizing the importance of selecting the appropriate number of sub-reaches for peak discharge predictions.
Similar content being viewed by others

Introduction
Flood routing is a process of simulating the movement of water in a river or stream system during a flood event using mathematical models. The goal of flood routing is to predict the behavior of the water as it moves through the system, including the peak flow, the timing of the peak flow, and the overall duration of the flood. There are two basic approaches to routing flood waves in natural channels: hydrologic (lumped) and hydraulic routing. Hydrologic (lumped) routing is a simplified approach that treats the entire river or stream system as a single unit. This approach relies on the storage continuity equation, which states that the change in storage in a system is equal to the difference between the inflow and outflow. Hydraulic routing is a more complex approach that considers the physical characteristics of the river or stream system, such as the channel geometry, the roughness of the bed, and the presence of any structures. Hydrologic routing is typically used for flood forecasting and planning, while hydraulic routing is more commonly used for the design and operation of flood control structures1, 2. The Muskingum model is a widely accepted hydrologic routing model due to its adequate levels of accuracy and the reliable relationships between its parameters and channel properties.
Muskingum model
The Muskingum method is founded on the fundamental principles of mass and momentum conservation, positing that the discharge at a given point in the river can be derived by subtracting the outflow from the inflow3. This model uses a linear reservoir approach to model the river channel characterized by two parameters, namely, the wave travel time (K) and the reach weighting factor (x).
The travel time (K) is the time required for the water to travel through the reach, which is dependent on the channel geometry, roughness, and other hydraulic characteristics. The reach weighting factor (x) is the proportion of the discharge that enters the reach from the upstream section, which is also known as the weighting coefficient. These parameters can be determined using various techniques, including trial and error, optimization algorithms, and regression analysis. The Muskingum model can be represented mathematically as follows4:
where O is the discharge at the downstream end of the reach (m3/s), and I is the discharge at the upstream end of the reach (m3/s). x is the weighting factor for the reach (ranges between 0 and 0.5 for reservoir storage and between 0 and 0.3 for stream channels5), K is the travel time for the reach(s), and S is the storage volumes of the reach (m3). By combining Eq. (1) with the continuity equation an explicit equation can be obtained to calculate the outflow at the next time step:
The subscripts 1 and 2 on I and O represent the values at time t1 and t2 respectively. C0, C1, and C2 are the coefficients.
The traditional linear Muskingum model seeks a method of parameter estimation to determine the values of K and x. However, the linear Muskingum model leads to considerable inaccuracy in the forecast of flood behavior throughout its propagation along a river because natural channel reaches often have a nonlinear storage-discharge connection. To address this limitation, models such as the Muskingum model have been modified to account for the nonlinearity of flow movement processes. Gill6 introduced a nonlinear storage equation using the exponent of the Muskingum storage equation as the third parameter, and later models such as the Nonlinear Muskingum model (NLMM) have been developed to include lateral inflows and better simulate the nonlinear processes of flood movements in rivers. As stated by Perumal et al.7 there exists no “truly physically based” flood routing model which does not require any calibration. Although the roughness factor is a property of the natural conditions, it is considered as a model tuning parameter in the routing process of Muskingum–Cunge models8, 9.
Furthermore, as pointed out by Koussis, nonlinear routing models like the nonlinear Muskingum model possess an advantage in their ability to accurately replicate the rapid surge of a flood wave, a task that linear models often struggle with10, 11. It should be noted that the Muskingum–Cunge is not a “linear model”. However, it is a “time-variant linear model”, which means that it is “locally linear” in time, but the overall behavior is nonlinear. Every flood routing model necessitates specific input parameters and data. In some river segments, all the required inputs are readily available, and the choice of a model can be based on personal expertise and computational capacity. When there are no constraints on these factors, the use of a dynamic wave model is the most suitable option. For the Muskingum–Cunge model, essential input parameters include initial conditions, upstream boundary conditions, Manning's roughness coefficient, length of the routing reach, river cross-sections, and the bed slope12, while nonlinear Muskingum model requires the initial condition, upstream boundary condition and the hydrologic parameters. One of the important motivations of the authors is to suggest alternative hydrological flood routing model for using in modeling software of hydrologic processes of watershed systems such as HEC-HMS (hydrologic modeling system) and SWAT (soil and water assessment tool). The proposed and rigorously validated distributed hydrological Muskingum model can serve as a valuable addition to hydrological software, effectively mitigating uncertainties in flood modeling. It's important to note that this study primarily emphasizes the nonlinear Muskingum routing models.
Nonlinear Muskingum model
Previous research has advocated a nonlinear Muskingum model for accounting nonlinearity, which allows for a better representation of the nonlinear relationship between the inflow at the upstream end and outflow at the downstream end of the river channel, which is presented in Eq. (3)5, 6, 13,14,15:
where m takes the nonlinearity without lateral inflow to the models. These models feature an extra parameter m (= exponent power), which may be calculated using various parameter estimation approaches. On the other hand, K with dimension of \({L}^{3(1-m)}{T}^{m}\) in nonlinear models unlike the linear model does not describe the travel time of the flood wave. In addition, x does not have to be the same as in the linear model. Equation (4) shows a modified storage equation that considers lateral inflow16:
where β is the parameter accounting for the lateral inflow. The storage at time t + 1 is shown in equation below.
By substituting Eq. (4) into Eq. (5), with consideration of lateral inflow in a nonlinear relationship between the inflow at the upstream end and outflow at the downstream end, the storage at time t + 1 is represented in Eq. (6):
The NLMM with the lateral inflow (NLMM-L) has been suggested as an accurate solution method for addressing the nonlinear Muskingum model17,18,19,20,21,22,23,24,25,26. The Muskingum model can be solved using various numerical methods, with the fourth-order Runge–Kutta method standing out as one of the most accurate approaches. Here, the fourth order Runge–Kutta method has been offered as an accurate and acceptable solution method among the different explicit solution methods for addressing the nonlinear Muskingum model since it is simpler than the Runge–Kutta–Fehlberg method27, 28.
It's important to note that Cunge12 established a vital connection between the flood routing parameters within the Muskingum approach and the channel properties, as well as flow characteristics. This connection was achieved by utilizing an approximation error derived from a Taylor series expansion of grid specifications and employing a diffusion analogy. Consequently, Cunge introduced a model known as the Muskingum–Cunge model, which has served as a cornerstone for further research and refinement7, 29,30,31,32,33,34,35.
This particular class of flood routing models necessitates a set of crucial input parameters, including the initial condition, upstream boundary condition, Manning's roughness coefficient, length of the routing reach, cross-sections along the river reach, and the bed slope. Within these inputs, the Manning's roughness coefficient stands out as a notable source of uncertainty for Muskingum–Cunge models. This coefficient is closely linked to surface roughness, vegetation, channel irregularities, channel alignment, silting, scouring, obstruction, channel size, and shape, as well as the magnitudes of stages and discharges36. Most of these factors exhibit variations from one flood event to another within a given river reach9. As a result, the roughness variations within a river reach are inherently three-dimensional, making them challenging to model. Therefore, there's a need to strategically select a single parameter as the roughness coefficient through a calibration process to align the flood routing results, particularly when only a single set of inflow and corresponding outflow hydrographs are available for the considered river reach7, 8.
In contrast, the traditional linear Muskingum model primarily relies on the initial condition, upstream boundary condition, and various hydrologic parameters10, 11. One of the principal motivations of the authors is to propose an alternative hydrological flood routing model suitable for integration into modeling software for hydrologic processes within watershed systems like HEC-HMS (hydrologic modeling system) and SWAT (soil and water assessment tool). Consequently, the primary focus of this study revolves around enhancing nonlinear Muskingum routing models.
To further improve its accuracy and convergence, optimization algorithms like the Salp Swarm algorithm have emerged as effective tools. Salp Swarm algorithm is a population-based optimization algorithm inspired by the swarming behavior of salps. The algorithm starts with a population of salps, each of which has a random position in the search space. In each iteration, the salps move towards the leader salp, which is the salp with the best fitness37. The salps that have the best fitness values are more likely to be selected for reproduction, and their offspring are added to the population. This process continues until the algorithm converges on an optimal solution38, 39. SSA has been shown to outperform other optimization algorithms in terms of both accuracy and convergence speed37 and has the potential to be used to solve a wide variety of problems40, 41.
Through the integration of the Salp Swarm algorithm and NLMM-L Muskingum method, the research seeks to address the challenges associated with snowmelt-induced flooding and provide more precise flood routing solutions for the study area. The objective of this research is to develop a nonlinear Muskingum model for the Red River between two USGS stream gauging stations, Grand Forks, and Drayton, in the US, using flood hydrographs caused by snowmelt in spring. This area was selected due to the recurrent flooding observed in the central part of the Red River and its adjacent floodplain regions, stretching between Grand Forks, ND, and Emerson, ND. These flood events are notably characterized by the substantial seasonal water area that consistently forms during wet spring periods42. The flat terrain and downstream ice jams in the Red River and Lake Winnipeg contribute to the frequent flooding during spring seasons in wet years, including 1997, 2009, 2011, and 2013. The repetitive nature of flood events in this section of the Red River underscores the importance of comprehending and effectively managing flood risks in the region.
The primary objective of this study is to develop a Muskingum model that can accurately estimate river discharge, considering lateral inflow conditions. The research methodology involves estimating the parameters (K, x, m, and β) of the nonlinear Muskingum models using a distributed flood routing model, utilizing the Salp Swarm algorithm. This approach divides the river reach into multiple intervals, allowing individual Muskingum model calculations for each interval, thereby improving the overall accuracy of the estimation process. The findings of this research are expected to contribute to the enhancement of flood forecasting and warning systems in the Red River basin, enabling better preparedness and response to flood events.
Study area
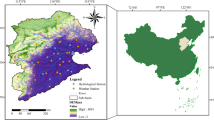
The Red River Basin, spanning both the United States and Canada, encompasses an area of 117,185 km2, with most of its expanse situated in North Dakota, South Dakota, and Minnesota43. Figure 1a shows the location of the basin. Characterized by a semi-arid climate, the region experiences cold winters and hot, dry summers, with the primary streamflow occurring during spring and early summer due to snowmelt or heavy rainfall44. The Red River itself is a prominent watercourse within the basin, flowing northward along the border between Minnesota and North Dakota, as well as the Canadian provinces of North Dakota and Manitoba. Notably, the river is prone to frequent flooding, owing to its gentle flow and flat topography, and its broad and shallow floodplain exacerbates the vulnerability to heavy rain or spring snowmelt, resulting in historically devastating floods45,46,47,48,49.

(a) Red River basin (b) USGS stations on Red River in Drayton and Grand Forks51. The map was created using ArcGIS Pro 2.8.0 (https://www.esri.com/en-us/arcgis/products/arcgis-pro/overview).
A recent study by Atashi et al.50 investigated various forecasting methods for water levels in flood warning systems. The study found that the Long Short-Term Memory (LSTM) method demonstrated superior accuracy and precision compared to classical statistical and machine learning approaches, making it a reliable choice for flood prediction, particularly for downstream stations lacking discharge information50.
Methodology
Grouping of dataset
For conducting flood routing analysis, it is essential to have observed flow hydrographs at specific upstream and downstream cross-section pairs.
For this study, we selected the existing USGS streamflow gauging stations at Drayton (Station No. 05092000) and Grand Forks (Station No. 05082500). These stations were chosen because they offer vital streamflow data necessary for hydrograph analysis in the region extending from Grand Forks to the US-Canada border. As mentioned, this area has experienced recurrent flooding, particularly in the central part of the Red River and the nearby floodplain regions, which extend from Grand Forks, ND, to Emerson, ND. The locations of the gauging stations are shown in Fig. 1b.
A total of fourteen flood events occurring between 1990 and 2022 were utilized to calibrate and validate the proposed model, with twelve events designated for calibration and two events for validation. These validation events specifically corresponded to the flood events in 2020 and 2022.
To form the groups, specific criteria were considered based on the distinct routing characteristics observed in different flood types. For instance, the 1997 flood primarily resulted from snowmelt with minimal rain-on-snow impact, while the 2022 flood predominantly comprised rain-on-snow conditions. The selection of these criteria was crucial to ensure accurate calibration results across all events. The summarized data for the fourteen flood occurrences between 1990 and 2022 is presented in Table 1, with the events categorized into Group A, Group B, and Group C. The criteria used for forming the groups include:
-
1.
Snowmelt dominant events: flood events where the primary driver was snowmelt with minimal rain-on-snow impact were categorized into Group A. These events typically exhibit specific routing characteristics associated with snowmelt-dominated hydrological processes.
-
2.
Rain-on-snow dominant events: flood events predominantly characterized by rain-on-snow conditions were categorized into Group B. These events show distinct routing behavior resulting from the combined effects of rain and snowmelt on the hydrological system.
-
3.
Mixed events: flood events that had a combination of snowmelt and rain-on-snow conditions were categorized into Group C. These events exhibit routing characteristics influenced by both snowmelt and rainfall contributions.
By categorizing the flood events into these distinct groups, it was possible to calibrate the model separately for each flood type, considering the specific routing behaviors associated with each category. Group A and Group B exhibit distinct variations in terms of precipitation amounts. Specifically, Group A demonstrates a lower range of monthly precipitation, ranging from 57. 2 to 141.0 mm during the selected years. In contrast, Group B showcases a higher range of monthly precipitation, ranging from 187.3 to 276.4 mm, observed specifically in the years 1999, 2004, 2013, and 2022.
Distributed nonlinear Muskingum model incorporating lateral inflows
Nonlinear Muskingum models consist of a series of nonlinear Muskingum reaches, which are further subdivided into equal nonlinear Muskingum sub-reaches. The distributed nonlinear Muskingum model, as depicted in Fig. 2, provides an illustrative representation of this arrangement. Only one set of hydrological model parameters (K, x, and m) needs to be calibrated and used in the nonlinear routing calculations. The flood hydrograph is routed from the main inflow hydrograph at the upstream section to the downstream section of the first sub-reach. The outcome is treated as the inflow for the second sub-reach and is routed subsequently to the downstream section of the second sub-reach52. To get the flood hydrograph at the downstream section of the final sub-reach, this process is repeated sequentially. The number of sub-reaches (NR) can be determined by trying different options and selecting the one that gives the best results. An objective function value and other performance evaluation criteria can be used to compare the different NR options. The continuity and storage equations used in the distributed nonlinear Muskingum model that includes lateral inflows are presented as follows:
where the lateral inflows varied linearly along the river reach and could be represented as a ratio of the inflow rate by considering the β parameter. β allows for the consideration of lateral inflow or outflow from the main channel during flood events. It represents the ratio of the inflow or outflow to the main channel flow within the reach. One of the assumptions used in the modeling process is that β is constant in time that means hydrograph shape of the lateral inflow wave is proportional to the upstream hydrograph inflow. t is the measure of time between zero and the flood's finish time. The spatial index between 2 and NR + 1 is called j. The following stages are used in the routing strategy for the distributed nonlinear Muskingum model utilizing the fourth order Runge–Kutta method:

Models for distributed nonlinear Muskingum model: (a) single reach with no sub-reaches, (b) two sub-reaches within a reach, (c) three sub-reaches within a reach, and (d) multi-interval sub-reach within a reach.
-
1.
Choose one, two, three, or more sub-reaches as NR and assume random values for the hydrological model parameters K, x, and m, as well as \(\beta\).
-
2.
Use Eq. (8) to estimate the starting storage. The starting flow rate at each sub-reach's downstream part is the same as the initial flow rate at the sub-reach's upstream section. Calculate the next storage.
-
3.
The next storage is computed by the present value plus the product of the size of the interval, Δt, and an estimated slope. The slope will be a weighted average of the following slopes using the Fourth order Runge–Kutta method:
$${{L}_{1}}_{t}^{j}=-\left(\frac{1}{1-X}\right){\left(\frac{{S}_{t}^{j}}{K}\right)}^{1/m}+\left(\frac{1+\beta }{1-X}\right){Q}_{t}^{j-1}$$(9)$${{L}_{2}}_{t}^{j}=-\left(\frac{1}{1-X}\right){\left(\frac{{S}_{t}^{j}+0.5{{L}_{1}}_{t}^{j}\Delta t}{K}\right)}^{1/m}+\left(\frac{1+\beta }{1-X}\right)\left(\frac{{Q}_{t}^{j-1}+{Q}_{t+1}^{j-1}}{2}\right)$$(10)$${{L}_{3}}_{t}^{j}=-\left(\frac{1}{1-X}\right){\left(\frac{{S}_{t}^{j}+0.5{{L}_{2}}_{t}^{j}\Delta t}{K}\right)}^{1/m}+\left(\frac{1+\beta }{1-X}\right)\left(\frac{{Q}_{t}^{j-1}+{Q}_{t+1}^{j-1}}{2}\right)$$(11)$${{L}_{4}}_{t}^{j}=-\left(\frac{1}{1-X}\right){\left(\frac{{S}_{t}^{j}+{{L}_{3}}_{t}^{j}\Delta t}{K}\right)}^{1/m}+\left(\frac{1+\beta }{1-X}\right){Q}_{t+1}^{j-1}$$(12)
By weight averaging these four slopes, one can calculate the next storage by using the following equation:
-
4.
Calculate the next outflow by using the following equation:
-
5.
Repeat Steps 3 and 4 for the following time intervals.
-
6.
Repeat Steps 2 and 5 for subsequent sub-reaches.
Salp swarm algorithm (SSA)
The Salp swarm algorithm (SSA) is a population-based swarm intelligence algorithm developed in 2017 by Mirjalili et al.37. The food source, which is the objective of the swarm, is represented by F. The leader of the swarm updates its position using a specific equation below:
where \({x}_{j}^{1}\) is the position of leader in jth dimension, \(U{b}_{j}\) are the upper and lower boundary at jth dimension, \({F}_{j}\) is the food source position. The coefficient \({c}_{1}\) plays an important role in SSA balancing exploration and exploitation. During the process of optimization, exploration refers to searching the search space thoroughly to find better solutions, while exploitation refers to utilizing the information present in the local region to improve the current solution. The parameter \({c}_{1}\) is gradually decreased over iterations and can be calculated using the following formula.
where l is the current iteration and L is the maximum number of iterations. The parameters \({c}_{2}\) and \({c}_{3}\) are random numbers generated within the interval [0,1]. \({c}_{3}\) is responsible for indicating whether the next position of current leader salp should be toward + ∞ or -− ∞. The other members of the salp swarm update their positions based on Newton's law of motion, which is expressed using the following equation:
where \(i\ge 2\), \({x}_{j}^{i}\) is the position of the ith follower in the jth dimension, t is the time, \({v}_{0}\) is the initial speed, and \(a= \frac{{v}_{final}}{{v}_{0}}\) where \(v=\left(x-{x}_{0}\right)/t\).
Since the time is considered as iterations and \({v}_{0}=0\), Eq. (15) can be reformulated as the equation below:
where \(i\ge 2\), \({x}_{j}^{i}\) is the position of the ith follower in the jth dimension.
The main steps of the SSA can be summarized as follows (see Fig. 3):
-
Parameter initialization: the algorithm starts by initializing the parameters such as the population size N, number of the iterations t and the maximum number of iterations \({max}_{itr}\).
-
Initial population: we generate the initial population \({x}_{i}\), \(i=\left\{1, ..., n\right\}\) randomly in the range [u,l], where u and l are the upper and lower boundaries, respectively.
-
Individual evaluations: every individual (solution) within the population is assessed by determining its value using the objective function, and the best overall solution is designated as F.
-
Exploration and exploitation: to balance between the exploration and the exploitation of the algorithm, the value of the parameter \({c}_{1}\) is updated as shown in Eq. (16).
-
Update the position of the solutions: the position of the leader solution and the other follower solutions are updated as shown in Eqs. (15) and (18), respectively.
-
Boundary violations: boundary violations occur when a solution goes beyond the allowable range of the search space while updating, and it is then adjusted to fall within the problem's range.
-
Termination criteria: the number of iterations t is increased gradually until it reaches to the maximum number of iterations \({max}_{itr}\). Then the algorithm terminates the search process and produces the overall best solution found.

Optimization algorithm flowchart for salp swarm algorithm (SSA).
Statistical performance evaluation criteria
Statistical performance evaluation criteria are metrics used to assess the accuracy and reliability of mathematical models, such as hydrological or hydraulic models. Some common statistical performance evaluation criteria used in the papers referenced5, 14, 53,54,55,56,57,58,59 are applied to assess the performance of the SSA-based routing results. These criteria are described below.
Sum of squared errors (SSE): the SSE measures the sum of the squared differences between predicted and observed values. It measures the model’s overall error and indicates how well the model fits the observed data.
where \({Q}_{i}\) and \({\widehat{Q}}_{\upiota }\) respectively are the observed and calculated outflow rates at the ith time, and N is the number of data.
The sum of absolute differences (SAD): the SAD measures the sum of the absolute differences between predicted and observed values. It is a measure of the overall deviation of the model from the observed data and is useful for evaluating the model's performance under conditions where large errors may have a significant impact.
Difference of peak observed (DPO): the DPO measures the difference between the predicted discharge values from the observed peak discharge values. It is a measure of the model's ability to accurately predict extreme events, such as floods or droughts, that may have a significant impact on the environment or society53.
The deviation of peak time of routed and actual outflows (DPOT).
\({T}_{pobs}\) and \({T}_{pest}\) denote the observed and estimated times to peak discharge, respectively. All the criteria presented are measurements of the accuracy of a routing model, with the optimum value at 0.
Results
Table 2 presents estimates of hydrologic parameters and performance evaluation criteria (PEC) values for Group A, considering different numbers of sub-reaches. The table encompasses sub-reach configurations ranging from 1 to 4, each characterized by Muskingum parameters (k, x, m, and β). The performance evaluation criteria include SSE, SAD, DPO, and DPOT.
The table clearly demonstrates that the number of sub-reaches employed has a substantial influence on both the estimates of hydrologic parameters and the corresponding PEC values. Analysis of the performance criteria indicates that the optimal performance is achieved when the Red River at Drayton station is considered as a single sub-reach. This is primarily due to the single sub-reach model exhibiting the lowest SSE values. Using the current study algorithm for Group A flood, the optimized parameters were determined to be K = 0.54, x = 0.24, m = 1.478, and β = 0.19 for NR = 1.
The hydrologic parameters estimates and performance evaluation criteria (PEC) values for Group B were investigated using various numbers of sub-reaches, ranging from 1 to 4. Each sub-reach was characterized by Muskingum parameters, namely K, x, m, and β. These findings are presented in Table 3, along with performance metrics including SSE, SAD, DPO, and DPOT. The analysis of performance criteria revealed that the optimal performance was achieved when employing two sub-reaches (NR = 2). This was primarily attributed to the fact that NR = 2 yielded the lowest SSE values. It is noteworthy that the Muskingum parameters for NR = 2 were determined as follows: K = 0.06, x = 0.06, m = 1.46, and β = 0.16.
The calculation of performance evaluation criteria (PEC) values necessitates the availability of at least one year of observed flood data for the corresponding validation period. Unfortunately, for Group C, no year of observed data was available, rendering the calculation of PEC values impossible. However, the hydrologic parameters estimate provided in Table 4 can still be employed to evaluate the performance of the model. These estimates allow for comparisons between the model's predictions and those of other models. The Muskingum parameters determined using the SSA technique are presented in Table 4.
For evaluation of the developed model in real field condition validation step has been considered. Tables 5 and 6 present examples of calibration simulation for Group A and B, respectively. Table 5 presents the measured inflow data from the Grand Forks USGS station, measured outflow data from the Drayton USGS station, and the corresponding routed outflow values for Group A, specifically when using a single sub-reach (NR = 1). The calibration years considered for Group A include 1997, 2001, 2005, 2006, 2009, 2010, and 2018. Similarly, Table 6 displays the measured inflow data from the Grand Forks USGS station, measured outflow data from the Drayton USGS station, and the associated routed outflow values for Group B. For Group B, the calibration years selected are 1999, 2004, and 2013, and these results correspond to the scenario where two sub-reaches are utilized (NR = 2).
These tables provide essential data for the calibration and validation of the respective models and facilitate the comparison between the simulated and observed flow values during the specified calibration years for each group.
Table 7 displays the validated inflow data from the Grand Forks USGS station, measured outflow data from the Drayton USGS station, and the corresponding routed outflow values for Group A in the year 2020 in Drayton, specifically when utilizing a single sub-reach (NR = 1).
Likewise, Table 8 presents the validated inflow data from the Grand Forks USGS station, measured outflow data from the Drayton USGS station, and the associated routed outflow values for Group B in the year 2022 in Drayton. For Group B, the model configuration involved two sub-reaches (NR = 2).
Furthermore, during the evaluation of the model's performance, it was observed that the model accurately predicted the maximum outflow discharge for both Group A in 2020 (NR = 1) and Group B in 2022 (NR = 2). Specifically, for Group A, the model's prediction of the maximum outflow discharge on April 14th exhibited only a 3.7% difference compared to the measured value. Similarly, for the 2022 flood classified as Group B with NR = 2, the difference was 2.84%. These minimal differences indicate a close agreement between the model's predictions and the actual measured values, suggesting a high level of accuracy in the model's ability to forecast future floods.
Figures 4 and 5 complement the information found in Tables 7 and 8 by presenting a visual depiction of the validation results for the flood data of Group A and B. The figures provide a graphical representation that enhances the understanding and analysis of the validation outcomes for the respective datasets.

Validation for Data of Group A, 2020 flood data.

Validation for Data of Group B, 2022 flood data.
Figures 4 and 5 serve as visual representations of the validation results for the flood data of Group A and B, respectively. These figures complement the information presented in Tables 7 and 8 by providing a graphical depiction of the validation outcomes. By utilizing visual representations, it becomes easier to comprehend and analyze the results of the validation process for each dataset. These figures display important information such as observed and simulated flood hydrographs, peak flow values, and timing of peak flows. They also show how well the simulated hydrographs match the observed data, indicating the accuracy of the routing model.
Upon careful examination of Tables 2, 3 and 4 it is evident that during the validation phase, the maximum deviation in peak time between the routed and actual outflows was only 2 units. This observation aligns with our previous experiences and findings, where we have encountered similar discrepancies when employing a dynamic wave model that considers all the necessary inputs for flood modeling1, 34. It is worth noting that when soft computing models are brought into the equation, such errors tend to be more pronounced.
It is essential to note that the absence of attenuation in the flood peak on the downstream side could be due to various factors. These include the absence of significant floodplain storage, a sufficiently large channel capacity, the lack of hydraulic controls such as dams or levees, and specific hydrological conditions such as continuous heavy rainfall or rapid snowmelt.
Discussion
In our recent paper, we conducted an existing case study to assess the performance of the proposed model using the inflow-outflow hydrograph data from Wilson60, which represents a smooth single-peak hydrograph. The distributed Muskingum method, implemented with the WOA algorithm, was employed for the routing process. Table 9 provides an overview of the Muskingum model routing parameters and performance evaluation criteria (PEC) obtained for the nonlinear Muskingum model parameters, as described in the material and methods section of the paper. The optimal parameter values for the Wilson flood data were determined using our research technique, yielding K = 0.865, x = 0.043, m = 1.478, and β = − 0.008 for NR = 3.
Furthermore, we analyzed the impact of varying the number of sub-reaches (NR) on the model's performance. The maximum outflow discharge, occurring at the 60th hour of the flood data, was examined for NR values ranging from 1 to 5. The results showed that the difference in peak discharge varied as follows: − 1.67%, 1.01%, 0.13%, 1.18%, and 0.96% for NR = 1 to NR = 5, respectively. Notably, NR = 3 exhibited the lowest difference in peak discharge compared to the Wilson flood data.
It is clear from comparing the findings of this case study with prior studies that the proposed model demonstrates consistent accuracy in predicting peak discharge across different datasets. Both the Group A and Group B case studies, along with the Wilson flood data, indicate close agreement between the model's predictions and the observed values. This reaffirms the model's reliability and its potential for effectively predicting future floods.
In comparison to the previous studies, our research offers distinctive findings. While Ayvaz and Gurarslan61 introduced a novel partitioning approach for flood routing models, our study focuses on analyzing the impact of varying the number of sub-reaches on the performance of the nonlinear Muskingum model. In contrast to the primary emphasis of Hirpurkar and Ghare62 on parameter estimation, our research evaluates the accuracy of peak discharge predictions using the proposed model. Furthermore, while Barbetta et al.63 addresses river discharge estimation and rating curve development, our study concentrates on peak discharge prediction and the model's reliability across diverse datasets. Importantly, our study distinguishes itself by utilizing a specific case study with real flood data, providing a unique and valuable contribution to the field. By analyzing actual data, our findings offer practical insights, showcasing the effectiveness of the proposed model in real-world scenarios. This emphasis on practicality enhances the applicability and relevance of our research.
Conclusion
This study aims to develop and evaluate a nonlinear Muskingum model for river modeling, with a specific focus on enhancing accuracy through the incorporation of lateral inflow. The Grand Forks and Drayton USGS stations serve as case studies for parameter estimation using the distributed Muskingum method. The results demonstrate that the developed nonlinear Muskingum model effectively routes floods through these stations. Our selection of this area is rooted in a prior spatial analysis we conducted, which highlighted a particular region's vulnerability. This area, situated between Grafton city, Grand Forks, and Emerson, demonstrated a high susceptibility to severe floods when we examined the permanent water area (PWA) and seasonal water area (SWA). Building upon these previous findings, our current research hones in on this specific locale, aiming to delve deeper into flood dynamics and comprehensively grasp the underlying factors that make it exceptionally vulnerable42.
Through an analysis of hydrologic parameters and model performance, the study underscores the significant impact of the number of sub-reaches on parameter estimation and modeling precision. Optimal model performance varies between case studies, underscoring the importance of selecting the appropriate number of sub-reaches for precise peak discharge predictions.
For Group A, where snowmelt is the primary driver with minimal rain-on-snow impact, the findings indicate that a single sub-reach provides the best performance in accurately predicting peak discharge. This suggests that a simplified representation of the river system adequately captures the routing characteristics of this flood type. In contrast, for Group B, representing flood events primarily characterized by rain-on-snow conditions, the study reveals that employing two sub-reaches optimizes model performance. This implies that considering additional sub-reaches is essential for accurately capturing the routing dynamics and behavior of this specific flood type.
The findings hold practical significance for flood prediction and management, offering valuable insights to decision-makers and stakeholders involved in flood mitigation. The proposed model holds potential for broader application beyond the specific case studies, contributing to enhanced river system modeling and flood management practices. For future studies, non-linear Muskingum model and Muskingum-Cunge approach should be compared in real field case studies to better understand their abilities compare to each other. Moreover, β parameter of the proposed model can be consider variable to examine effects of its variation on the model prediction performance.
Data availability
Some or all data, models, or code that support the findings of this study are available from the corresponding author upon reasonable request. These data include flood data for Drayton and Grand Forks.
References
Akbari, G. H., & Barati, R. Comprehensive analysis of flooding in unmanaged catchments. In Proceedings of the Institution of Civil Engineers-Water Management (Thomas Telford Ltd, 2012).
Akbari, G. H., Nezhad, A. H. & Barati, R. Developing a model for analysis of uncertainties in prediction of floods. J. Adv. Res. 3(1), 73–79 (2012).
McCarthy, G., The Unit Hydrograph and Flood Routing, Conference of North Atlantic Division (US Army Corps of Engineers, New London, CT. US Engineering, 1938).
Das, A. Parameter estimation for Muskingum models. J. Irrig. Drain. Eng. 130(2), 140–147 (2004).
Mohan, S. Parameter estimation of nonlinear Muskingum models using genetic algorithm. J. Hydraul. Eng. 123(2), 137–142 (1997).
Gill, M. A. Flood routing by the Muskingum method. J. Hydrol. 36(3–4), 353–363 (1978).
Perumal, M. et al. Evaluation of a physically based quasi-linear and a conceptually based nonlinear Muskingum methods. J. Hydrol. 546, 437–449 (2017).
Smith, M. W. Roughness in the earth sciences. Earth Sci. Rev. 136, 202–225 (2014).
Morvan, H. et al. The concept of roughness in fluvial hydraulics and its formulation in 1D, 2D and 3D numerical simulation models. J. Hydraul. Res. 46(2), 191–208 (2008).
Koussis, A. D. Assessment and review of the hydraulics of storage flood routing 70 years after the presentation of the Muskingum method. Hydrol. Sci. J. 54(1), 43–61 (2009).
Koussis, A. D. Reply to the Discussion of “Assessment and review of the hydraulics of storage flood routing 70 years after the presentation of the Muskingum method” by M Perumal. Hydrol. Sci. J. 55(8), 1431–1441 (2010).
Cunge, J. On the subject of a flood propagation computation method (Musklngum method). J. Hydraul. Res. 7(2), 205–230 (1969).
Singh, V. P. & Scarlatos, P. D. Analysis of nonlinear Muskingum flood routing. J. Hydraul. Eng. 113(1), 61–79 (1987).
Luo, J. & Xie, J. Parameter estimation for nonlinear Muskingum model based on immune clonal selection algorithm. J. Hydraul. Eng. 15(10), 844–851 (2010).
Easa, S. M., et al. Discussion: New and improved four-parameter non-linear Muskingum model. In Proceedings of the Institution of Civil Engineers-Water Management (Thomas Telford Ltd, 2014).
Karahan, H., Gurarslan, G. & Geem, Z. W. A new nonlinear Muskingum flood routing model incorporating lateral flow. Eng. Optim. 47(6), 737–749 (2015).
O’Donnell, T. A direct three-parameter Muskingum procedure incorporating lateral inflow. Hydrol. Sci. J. 30(4), 479–496 (1985).
Khan, M. H. Muskingum flood routing model for multiple tributaries. Water Resour. Res. 29(4), 1057–1062 (1993).
Kshirsagar, M., Rajagopalan, B. & Lal, U. Optimal parameter estimation for Muskingum routing with ungauged lateral inflow. J. Hydrol. 169(1–4), 25–35 (1995).
Choudhury, P. Multiple inflows Muskingum routing model. J. Hydrol. Eng. 12(5), 473–481 (2007).
Choudhury, P., Shrivastava, R. K. & Narulkar, S. M. Flood routing in river networks using equivalent Muskingum inflow. J. Hydrol. Eng. 7(6), 413–419 (2002).
Samani, H. M. & Shamsipour, G. Hydrologic flood routing in branched river systems via nonlinear optimization. J. Hydraul. Res. 42(1), 55–59 (2004).
Orouji, H., et al. Flood routing in branched river by genetic programming. In Proceedings of the Institution of Civil Engineers-Water Management (Thomas Telford Ltd, 2014).
Kumar, D. N., Baliarsingh, F. & Raju, K. S. Extended Muskingum method for flood routing. J. Hydro-environ. Res. 5(2), 127–135 (2011).
Atashi, V., Barati, R. & Lim, Y. H. Improved river flood routing with spatially variable exponent Muskingum model and sine cosine optimization algorithm. Environ. Processes 10(3), 42 (2023).
Atashi, V., Barati, R. & Lim, Y. H. Distributed Muskingum model with a Whale Optimization Algorithm for river flood routing. J. Hydroinform. 25, 4 (2023).
Vatankhah, A. R. Evaluation of explicit numerical solution methods of the Muskingum model. J. Hydrol. Eng. 19(8), 06014001 (2014).
Wang, J. et al. Discussion of “parameter estimation of the nonlinear Muskingum flood-routing model using a hybrid harmony search algorithm” by Halil Karahan, Gurhan Gurarslan, and Zong Woo Geem. J. Hydrol. Eng. 839, 842 (2014).
Todini, E. A mass conservative and water storage consistent variable parameter Muskingum-Cunge approach. Hydrol. Earth Syst. Sci. 11(5), 1645–1659 (2007).
Reggiani, P., Todini, E. & Meißner, D. A conservative flow routing formulation: Déjà vu and the variable-parameter Muskingum method revisited. J. Hydrol. 519, 1506–1515 (2014).
Reggiani, P., Todini, E. & Meißner, D. On mass and momentum conservation in the variable-parameter Muskingum method. J. Hydrol. 543, 562–576 (2016).
Tang, X.-N., Knight, D. W. & Samuels, P. G. Volume conservation in variable parameter Muskingum-Cunge method. J. Hydraul. Eng. 125(6), 610–620 (1999).
Perumal, M. & Sahoo, B. Volume conservation controversy of the variable parameter Muskingum-Cunge method. J. Hydraul. Eng. 134(4), 475–485 (2008).
Barati, R., Akbari, G. H. & Rahimi, S. Flood routing of an unmanaged river basin using Muskingum-Cunge model; field application and numerical experiments. Caspian J. Appl. Sci. Res. 2(6), 8–20 (2013).
Norouzi, H. & Bazargan, J. Flood routing using the Muskingum-Cunge method and application of different routing parameters. Sādhanā 47(4), 282 (2022).
Chow, V. T. Open-channel Hydraulics (McGram-Hill Book Company, 1959).
Mirjalili, S. et al. Salp swarm algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 114, 163–191 (2017).
Anderson, P. & Bone, Q. Communication between individuals in salp chains. II. Physiology. Proc. R. Soc. Lond. Ser. B Biol. Sci. 210(1181), 559–574 (1980).
Madin, L. P. Aspects of jet propulsion in salps. Can. J. Zool. 68(4), 765–777 (1990).
Andersen, V. & Nival, P. A model of the population dynamics of salps in coastal waters of the Ligurian Sea. J. Plankt. Res. 8(6), 1091–1110 (1986).
Henschke, N. et al. Population drivers of a Thalia democratica swarm: Insights from population modelling. J. Plankt. Res. 37(5), 1074–1087 (2015).
Atashi, V., Mahmood, T. H. & Rasouli, K. Impacts of climatic variability on surface water area observed by remotely sensed imageries in the Red River Basin. Geocarto Int. 25, 1–18 (2023).
Lim, Y. H. & Voeller, D. L. Regional flood estimations in Red River using L-moment-based index-flood and bulletin 17B procedures. J. Hydrol. Eng. 14(9), 1002–1016 (2009).
Board, R. R. B. Inventory Team Report: Hydrology (Red River Basin Board, 2000).
Burn, D. H. & Goel, N. Flood frequency analysis for the Red River at Winnipeg. Can. J. Civ. Eng. 28(3), 355–362 (2001).
Commission, I. J. Living with the Red: A report to the Governments of Canada and the United States on Reducing Flood Impacts in the Red River Basin (International Joint Commission, 2000).
Rannie, W. The 1997 flood event in the Red River basin: Causes, assessment and damages. Can. Water Resour. J. 41(1–2), 45–55 (2016).
Rogers, P., et al., A comparative hydrometeorological analysis of the 2009, 2010, and 2011 Red River of the North Basin Spring floods. National Weather Service, Central Region Technical Attachment 2013(13–03).
Ryberg, K.R., Macek-Rowland, K. M., Banse, T. A., & Wiche, G. J. A history of Flooding in the Red River Basin. 2007. https://pubs.er.usgs.gov/publication/gip55.
Atashi, V. et al. Water level forecasting using deep learning time-series analysis: A case study of Red River of the North. Water 14(12), 1971 (2022).
ArcGIS Pro (Version 3.0). Esri Inc. 2022; https://www.esri.com/en-us/arcgis/products/arcgis-pro/overview.
Farzin, S. et al. Flood routing in river reaches using a three-parameter Muskingum model coupled with an improved bat algorithm. Water 10(9), 1130 (2018).
Yoon, J. & Padmanabhan, G. Parameter estimation of linear and nonlinear Muskingum models. J. Water Resour. Plan. Manage. 119(5), 600–610 (1993).
Fuat Toprak, Z. & Savci, M. E. Longitudinal dispersion coefficient modeling in natural channels using fuzzy logic. CLEAN Soil Air Water 35(6), 626–637 (2007).
Toprak, Z. F. & Cigizoglu, H. K. Predicting longitudinal dispersion coefficient in natural streams by artificial intelligence methods. Hydrol. Processes Int. J. 22(20), 4106–4129 (2008).
McCuen, R. H., Knight, Z. & Cutter, A. G. Evaluation of the Nash-Sutcliffe efficiency index. J. Hydrol. Eng. 11(6), 597–602 (2006).
Kazemi, M. & Barati, R. Application of dimensional analysis and multi-gene genetic programming to predict the performance of tunnel boring machines. Appl. Soft Compu. 124, 108997 (2022).
Hosseini, K. et al. Optimal design of labyrinth spillways using meta-heuristic algorithms. KSCE J. Civ. Eng. 20, 468–477 (2016).
Alizadeh, M. J. et al. Prediction of longitudinal dispersion coefficient in natural rivers using a cluster-based Bayesian network. Environ. Earth Sci. 76, 1–11 (2017).
Wilson, E. M. Engineering hydrology. In Engineering Hydrology 1–49 (Springer, 1990).
Ayvaz, M. T. & Gurarslan, G. A new partitioning approach for nonlinear Muskingum flood routing models with lateral flow contribution. J. Hydrol. 553, 142–159 (2017).
Hirpurkar, P. & Ghare, A. D. Parameter estimation for the nonlinear forms of the Muskingum model. J. Hydrol. Eng. 20(8), 04014085 (2015).
Barbetta, S., Moramarco, T. & Perumal, M. A Muskingum-based methodology for river discharge estimation and rating curve development under significant lateral inflow conditions. J. Hydrol. 554, 216–232 (2017).
Acknowledgements
We express our sincere appreciation to the United States Geological Survey (USGS) for providing access to their invaluable data, which greatly contributed to the research and findings presented in this paper.
Author information
Authors and Affiliations
Contributions
VA conceived the study and drafted the manuscript; RB provided resources and data curation, validated the data, and reviewed and edited the manuscript; YHL supervised the work and reviewed and edited the manuscript. All authors have read and agreed to the published version of the manuscript. In addition, all authors have read, understood, and complied as applicable with the “Ethical responsibilities of Authors” statement as found in the “Instructions for Authors.”
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Atashi, V., Barati, R. & Lim, Y.H. Development of a distributed nonlinear Muskingum model by considering snowmelt effects for flood routing in the Red River. Sci Rep 13, 21356 (2023). https://doi.org/10.1038/s41598-023-48895-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-48895-8
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
