
Abstract
Both intradialytic hypotension (IDH) and hypertension (IDHTN) are associated with poor outcomes in hemodialysis patients, but a model predicting dual outcomes in real-time has never been developed. Herein, we developed an explainable deep learning model with a sequence-to-sequence-based attention network to predict both of these events simultaneously. We retrieved 302,774 hemodialysis sessions from the electronic health records of 11,110 patients, and these sessions were split into training (70%), validation (10%), and test (20%) datasets through patient randomization. The outcomes were defined when nadir systolic blood pressure (BP) < 90 mmHg (termed IDH-1), a decrease in systolic BP ≥ 20 mmHg and/or a decrease in mean arterial pressure ≥ 10 mmHg (termed IDH-2), or an increase in systolic BP ≥ 10 mmHg (i.e., IDHTN) occurred within 1 h. We developed a temporal fusion transformer (TFT)-based model and compared its performance in the test dataset, including receiver operating characteristic curve (AUROC) and area under the precision-recall curves (AUPRC), with those of other machine learning models, such as recurrent neural network, light gradient boosting machine, random forest, and logistic regression. Among all models, the TFT-based model achieved the highest AUROCs of 0.953 (0.952–0.954), 0.892 (0.891–0.893), and 0.889 (0.888–0.890) in predicting IDH-1, IDH-2, and IDHTN, respectively. The AUPRCs in the TFT-based model for these outcomes were higher than the other models. The factors that contributed the most to the prediction were age and previous session, which were time-invariant variables, as well as systolic BP and elapsed time, which were time-varying variables. The present TFT-based model predicts both IDH and IDHTN in real time and offers explainable variable importance.
Similar content being viewed by others


Introduction
The number of patients on hemodialysis continues to increase, reaching more than 3.9 million worldwide1. Hemodialysis patients have death rates that are 10 to 15 times higher than those of nondialytic controls. Cardiovascular events, such as arrhythmia and cardiac arrest, account for half of all deaths2, and both intradialytic hypotension (IDH) and intradialytic hypertension (IDHTN) are significant risk factors for these events3,4,5,6. Early warning of IDH and IDHTN can assist clinicians in preparing management strategies, and an individualized approach may be necessary due to the heterogeneity of patients and their hemodialysis settings7,8. Accordingly, defining risk factors is an important step, and IDH and IDHTN share some characteristics in common, such as age and comorbidities9,10. Nevertheless, known risk factors alone cannot successfully predict IDH and IDHTN when varying blood pressures (BPs) on hemodialysis are not considered11,12,13. Due to the repeated occurrence of IDH and IDHTN, information on previous hemodialysis sessions may help predict outcomes in the next session12. However, most studies used this information as binary features only and not as a concrete structure to encode all information14,15.
The dataset on hemodialysis sessions is complex due to its multiple variables with time series data. While some variables may be regularly arranged, others may not, and there may be missing data in certain areas of the sessions. The deep learning method has brought revolutionary advances in controlling the hemodialysis dataset because it successfully addresses time-series variables9. Previously, our recurrent neural network (RNN)-based model had favorable performance in predicting IDH12, although IDHTN was not considered, and the information from previous sessions was used as a handcrafted and binary feature. A recent deep learning model, named the temporal fusion transformer (TFT)16, efficiently encodes both time-invariant and time-varying variables after shrinking unimportant features. It has shown high performance with time-series forecasting tasks, such as stock index prediction and traffic occupancy rate prediction, and provides insights into which time step feature information is considered important16. The TFT-based model with a multihorizon forecasting feature yields predicted values at many future time steps, and is designed to consider both time-varying inputs (i.e., the future variable cannot know in the current time step) and time-invariant variables (i.e., the past observed variable and the known future variable we can expect) at a single inference. Nevertheless, the hemodialysis dataset contains many missing values, which makes it difficult to directly apply the original version of TFT to handle it. Continuous quantile prediction, used to conservatively estimate and predict outputs for the purpose of risk management in the original TFT, did not fit our task. Therefore, we modified the internal structure of TFT to impute the missing values by encoding all timestamps from previous sessions. We also adjusted the output types to enable real-time prediction of binary outcomes, achieving high performance in predicting both IDH and IDHTN using a hemodialysis dataset. Accordingly, the model performance outperformed that of other machine learning models, such as RNN, light gradient boosting machine (LGBM), random forest (RF), and logistic regression (LR). The explainable attributions for each case may provide clinicians with insights on how to manage the next session to reduce the risk of IDH and IDHTN.
Methods
Data source and study approval
A retrospective analysis of electrical medical record (EMR) data was performed. The data from 342,361 sessions of 12,200 patients who underwent hemodialysis at Seoul National University Hospital between October 2004 and December 2020 were retrieved from the EMR system and our own vital sign registry (named CONTINUAL)17. The institutional review board of Seoul National University Hospital approved the study design (no. H-2008-142-1151), and the study was conducted in accordance with the principles of the Declaration of Helsinki. Our study was retrospective analysis, and thus, getting informed consent from subjects was waived from the institutional review board of Seoul National University Hospital.
Data collection and preparation
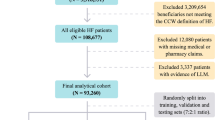
Sessions from patients who were < 18 years old (n = 20,014), had no initial BP records (n = 530), received < 2 h or > 6 h of hemodialysis (n = 9,647), and had > 1.5 h of time interval between BPs (n = 9396) were excluded. Accordingly, 302,774 sessions from 11,110 patients were ultimately used for model development. When there were no specific episodes or complications during hemodialysis, vital signs were monitored every hour. If vital signs became unstable, they were monitored more frequently.
The sessions were randomly split into training (70%), validation (10%), and test (20%) datasets based on patient information (Fig. 1A). The training and validation datasets were used for model development, while the test dataset was kept for evaluation. Each hemodialysis session was matched with up to 5 previous sessions within 1 month, and the set containing matched sessions was created for analysis (Fig. 1B). If dialysis information was not available for any of the previous 5 dialysis sessions within 1 month, the information on previous sessions was treated as missing values and ignored by attention masking.

Dataset development. (A), Flow chart of data collection and randomization. (B), An illustrative example of labeling and creating a set of matched sessions.
The dataset used to train the model contained a total of 66 variables, such as baseline characteristics, hemodialysis setting, vital signs, laboratory findings, and medications used. The time-varying variables included vital signs and hemodialysis setting, while others were time-invariant. The list and relevant missing ratio are available in Supplementary Table 1. For time-invariant variables, missing values were imputed by means for continuous variables with normal distribution, or medians for both continuous variables without normal distribution and categorical variables. A forward-filling method was used for time-varying variables. To enable the model to recognize missing values, we created an auxiliary column that indicates whether imputation was performed at each time step for every time-varying variable. The auxiliary column was encoded with 0 if imputation was conducted (i.e., the variable was filled with information from the previous session) or 1 if the original observed value was used. After imputation of the missing values, continuous variables were normalized using the mean and the standard deviation. Accordingly, 78 variables with 66 original variables and 10 auxiliary variables indicating imputation and 2 variables of elapsed times (e.g., hemodialysis time and interval with the previous session) were used in a training dataset.
Study outcomes
IDH was defined when systolic BP < 90 mmHg (termed IDH-1) and a decrease in systolic BP ≥ 20 mmHg and/or a decrease in mean arterial pressure ≥ 10 mmHg from the initial BP (termed IDH-2) occurred18,19. IDHTN was defined as an increase in systolic BP ≥ 10 mmHg from the initial systolic BP20,21. Because previous randomized controlled studies adopted the definition of IDHTN over multiple sessions22,23,24,25, we defined IDHTN-2 as cases with IDHTN occurring ≥ 4 of 6 consecutive sessions and applied it as a sensitivity analysis. Mean arterial pressure was calculated as ([2 × diastolic BP] + systolic BP) / 3. The occurrence of IDH and IDHTN within 1 h was labeled for model training (Fig. 1B).
Model development
To predict IDH and IDHTN, time-varying and time-invariant variables were considered simultaneously, all of which were dealt with in the TFT-based model. The TFT architecture was originally proposed to address multihorizon forecasting problems in various domains16, and we employed the architecture and modified several components of the original model to fit our task. The model has been designed to consider both short- and long-term temporal relationships to produce predictions with sequence-to-sequence and attention mechanisms, respectively.
To address the challenge of determining the precise relationship between unforeseen exogenous input variables and targets, we employed the gated residual network (GRN) as the primary computing layer in the TFT architecture. It comprised four dense layers and two activation layers (i.e., an exponential linear unit function and a sigmoid function) (Fig. 2A), and determined whether to skip the features. Note that GRN is used in the encoding module (detailed in Fig. 2B), the input layer of the single-headed attention module (the fourth layer of Fig. 2C), and the input layer of the classifier (the last layer of Fig. 2C).

Schematic diagram of the model structure. (A), The internal structure of gated residual units (GRNs). (B), Encoding module with GRN. Encoded feature shapes are presented as (B, F, H) or (B, H). (C), Feature processing pipeline. B, batch size; F, feature shape; H, hidden shape. RNN, recurrent neural network; SHA, single-headed attention.
The TFT architecture could yield importance scores among time-varying and time-invariant variables and timestamps from the variable selection module and single-headed attention module, respectively. The variable selection module chose pertinent input variables at each time step, and we extracted the attention weight that explained the feature importance from the module. The higher attention weight indicates a higher contribution to predicting the output (see the second layer of Fig. 2C). Figure 2B represents the encoding flow of generating variable selection weights. The processed inputs were multiplied by this module, and unnecessary inputs at each time step could be removed. The single-headed attention module captured the long-term relationships within inputs by preserving the causality information flow across multiple time steps. We extracted the attention weight that explained the temporal importance of the timestamps (see the fourth layer of Fig. 2C). This operation is identical to the structure of the paper that was first proposed, and a detailed process can be found in that paper26.
Finally, Fig. 2C summarizes the entire pipeline of data processing of the TFT architecture. Time-invariant and time-varying inputs were separately transformed by dense or embedding layers for continuous and categorical inputs, respectively. The features from the first layer were sequentially processed by encoding, RNN, single-headed attention, and classifier modules. In particular, the RNN module analyzed the short-term relationship of inputs by leveraging local context using a gated recurrent unit27, and the classifier module produced output by composing features from the previous layer with a single dense layer. Information on previous sessions was re-entered into the encoding module as time-invariant features of the current session after passing the pipeline. If there was no available information on previous sessions, the feature weight of the corresponding session in the encoding module was set to zero and did not affect the downstream calculation. The model finally calculated the probabilities of IDH-1, IDH-2, and IDHTN as outcomes. The detailed structure and source codes in Python are provided in https://github.com/dactylogram/HD_IDH_prediction/.
Other machine learning models, such as RNN, Light Gradient Boosting Machine, Random forest, and logistic regression were compared with the TFT-based model in predicting outcomes. The RNN model had the same structure as that in a previous study12, and it could handle time-varying features but did not use the information from the previous session. Other models could handle tabular datasets alone, and three timestamps, such as initiation, prediction, and the previous entry. The detailed methods and designs of canonical machine learning and deep learning models are presented in the Supplementary Methods.
Model evaluation
The area under the receiver operating characteristic curve (AUROC) and the area under the precision-recall curve (AUPRC) were used to evaluate the model performance. Comparisons between AUROCs was calculated by the DeLong test. Calibration ability was applied using a calibration plot. Evaluation metrics of precision, recall, and F1 score were also evaluated. All evaluation metrics were obtained from the test dataset. We set a threshold of 0.5 to determine the binary outcomes. The formulae with true positive (TP), false positive (FP), and false negative (FN) counts are represented as follows.
Results
Baseline characteristics
The baseline characteristics of clinical information and the hemodialysis sessions are presented in Table 1. Statistics for the variables in the dataset were described for each session. The mean age of the patients across the sessions was 62 ± 15 years, and 57.7% were female. The prevalence rates of diabetes mellitus and hypertension were 48.7% and 72.9%, respectively. The median values of initial systolic and diastolic BPs were 139 mmHg and 73 mmHg, respectively. The number of BP recordings per session was 7.1 ± 3.5.
IDH occurred in 54.1% (IDH-1 in 10.7%, and IDH-2 in 51.9%), and IDHTN occurred in 40.5%. IDHTN-2 definition was available in 95.5% of hemodialysis sessions, and the prevalence of IDHTN-2 was 23.1%. The occurrences of IDH-1, IDH-2 and IDHTN as the dialysis progressed were present in Supplementary Fig. 1. While the occurrence of IDH-1, IDH-2 and IDHTN did not largely change as the dialysis progressed, we observed an increase in IDH-1, IDH-2 and a decrease in IDHTN after nearly 4 h of dialysis. Detailed statistics from the training, validation, and test datasets are available in Supplementary Table 1.
Model performance
Table 2 represents AUROCs and AUPRCs as model performance. The TFT-based model achieved the highest AUROC value among the models evaluated (Ps < 0.001), and the AUROCs for IDH-1, IDH-2, and IDHTN were 0.953 (0.952–0.954), 0.892 (0.891–0.893), and 0.889 (0.888–0.890), respectively (Fig. 3A). The values of AUPRCs for IDH-1, IDH-2, and IDHTN in the TFT-based model were also higher than those obtained from other machine learning models (Fig. 3B). The TFT-based model achieved the highest F1 scores compared to the other machine learning models in predicting IDH-1 (0.630), IDH-2 (0.738), and IDHTN (0.668, Supplementary Table 2). The TFT-based model was well calibrated (Supplementary Fig. 2).

Plots of the model performance. (A), Area under the receiver operating curve (AUROC) in predicting outcomes. (B), Area under the precision-recall curve (AUPRC) in predicting outcomes. (C), AUROC of outcomes and timestamp count histogram according to the elapsed time. (D), AUPRC of outcomes and timestamp count histogram according to the elapsed time.
The values of AUROCs and AUPRCs remained consistent over the course of hemodialysis time (Fig. 3C,D), except for the AUPRC values at the beginning and end of the period. The AUPRCs of all three labels were relatively low at the start, and the predictive performance for IDH-1 and IDH-2 improved after approximately 3.5 h, while the predictive performance for IDHTN decreased. These changes in AUPRC appeared to correlate with the label prevalence over the duration of hemodialysis, as described in Supplementary Fig. 1.
When predicting IDHTN-2, the predictability of the model for IDH-1 and IDH-2 remained consistent, while there was an increase in AUROC (from 0.889 to 0.917) and a decrease in AUPRC (from 0.774 to 0.728). The changes in evaluation metrics might be associated with the change in prevalence.
Explainable feature importance
The TFT-based model provides attention weights of features that indicate which is the most important part of the data to which the model paid attention, and the sum of attention weights is equal to one. The information of previous sessions, age, dialyzer type, and predialytic weight showed higher attention weights among time-invariant variables (Fig. 4A). Among the time-varying variables, systolic BP was highly ranked, and elapsed time, diastolic BP, and ultrafiltration rate were the most important variables for the prediction of IDH and IDHTN (Fig. 4B).

Mean weights of time-invariant and time-varying features from the attention module in the model. (A), Weights of time-invariant features. (B), Weights of time-varying features. BP, blood pressure.
We provide an example of a session in which the presented TFT-based model can offer real-time probabilities for all outcomes (Fig. 5A). The occurrence of IDH and IDHTN could be explained by the attention weights of time-invariant and time-varying variables (Fig. 5B,C). Weights of time-varying variables from the encoding module and sequence positions from the single-headed attention module had slightly different values according to the timestamps (Fig. 5C,D), and systolic BP of the time-varying variable and the first timestamp (i.e., the initial recording of hemodialysis) of the single-headed attention sequence were highly related to the performance.

Explainability of one case with intradialytic hypotension (IDH) and hypertension (IDHTN). (A), Real-time prediction of outcomes using the model. Round circles on the lines of a probability represent true label positions. (B) Weights of time-invariant features by the model explainability. (C) Weights of time-varying features by the model explainability. (D) Weights of the sequence from single-headed attention according to the timestamps. The positions of the future sequences were masked, and their values were set to 0.
Slim version of the TFT model
According to the variable attention weights, we selected the top 10 (i.e., 2 time-varying and 8 time-invariant) or 30 (i.e., 6 time-varying and 24 time-invariant) variables to develop the slim TFT-based model. The slim TFT-based model achieved acceptable performance compared to the parent model; particularly, the slim model with 30 variables had noninferior AUROCs to the parent model (Table 3). The AUPRCs were also similar between the slim model and the parent models (Table 3). The results indicate that the single-headed attention module of the TFT-based model efficiently prioritized the most crucial parts of the input data while disregarding irrelevant parts, effectively ranking variables in a significant order.
Implication of the previous session in the model performance
To determine whether adding information about previous sessions to the model improves performance, AUROCs and AUPRCs were calculated depending on the number of previous sessions used in the model. Herein, the slim TFT-based model was used because of our limit in GPU memory. Both the AUROC and AUPRC achieved maximum values when 5 to 10 previous sessions were used in the model (Fig. 6). The model performance did not improve significantly even with > 10 previous sessions, implying that information on the most recent previous session was more valuable for prediction than data from the remote sessions.

Changes in AUROC (A) and AUPRC (B) according to the number of previous sessions used in the slim version model. *Maximum point of the performance metrics.
Discussion
The present TFT-based model could encode information from previous sessions as a time-invariant variable and achieve state-of-the-art performance in predicting both IDH and IDHTN in real-time. Another strength of the model was its ability to provide explainable variable importance and timestamps through attention weights. Model explainability could be utilized to reduce the number of required input variables without compromising performance. Information from previous sessions significantly contributed to predicting outcomes, with data from recent sessions proving more valuable than remote sessions in enhancing model performance.
Deep learning has been applied to predict the binary occurrence of intradialytic complications, such as IDH, IDHTN, and other clinical symptoms, using a tabular dataset of hemodialysis sessions14,15,28,29. We developed the RNN model to predict IDH in real-time using a time-series dataset, and its performance was acceptable12. In this study, to further enhance performance, we employed the TFT architecture with specific modifications, including handling missing values and implementing binary classification methods. As a result, our performance exceeded that of other machine learning or deep learning models. Although the number of input variables used has decreased, the slim TFT-based model still outperformed other machine learning or deep learning models in prediction outcomes. The results are attributable to the internal characteristics of the TFT architecture, such as effective feature extraction by removing unimportant features using GRN and encoding modules.
There have been several studies that utilized the hand-crafted (e.g., the lowest systolic BP) or selected (e.g., pre- or post-dialysis BP) information on the previous sessions to predict events in the subsequent session30,31. To the best of our knowledge, the present study represents the first attempt to incorporate entire sequences of previous hemodialysis sessions. The information on previous sessions could be encoded and integrated as time-invariant features in the model training. This process amplified the prediction performance, although a plateau in improvement was observed after the number of previous sessions exceeded 10. The results suggest that information on the recent previous session was more useful in prediction than that on the remote session, and a proper number of previous sessions was sufficient to achieve good performance, which would lead to less computational cost.
The present TFT-based model could provide information on feature attention weights, which we named explainability. There are indirect post-hoc methods to rank features, such as SHapley Additive exPlanations32 and class activation maps33, whereas the TFT-based model can directly correlate the rank of features with the internal single-headed attention module. The slim TFT-based model showed similar performance to the parent model only with subset variables because the importance ranking of features produced by the model was reliable.
Although the study results are informative, there are certain limitations to be discussed. Session information was mainly derived from patients with end-stage kidney disease; thus, our model performance may differ in the cases involving acute kidney injury requiring hemodialysis. The model primarily emphasized BP-related outcomes and did not address other intradialytic complications, such as arrhythmia, high pulse pressure, and sudden death. Certain time-invariant or time-varying variables (e.g., dialysis vintage and electrocardiogram) would be additionally helpful to predict IDH or IDHTN.
Conclusion
The present study introduces a novel model for real-time simultaneous prediction of IDH and IDHTN by incorporating information from previous sessions. Furthermore, the model provides feature attention weights to elucidate the significance of variables in the context of IDH or IDHTN. Accordingly, this explainable model assists clinicians in preparing for IDH and IDHTN in advance. The results of this study may also serve as an inspiration for other researchers to leverage information from previous sessions to improve the model performance in predicting intradialytic complications.
Data availability
Python code for model structure and describing dataset structures are provided in https://github.com/dactylogram/HD_IDH_prediction/. The other data including model training are available from the corresponding author upon request.
References
Jager, K. J. et al. Vol. 34 1803–1805 (Oxford University Press, 2019).
Johansen, K. L. et al. US renal data system 2020 annual data report: Epidemiology of kidney disease in the United States. Am. J. Kidney Dis. 77, A7–A8 (2021).
Flythe, J. E., Xue, H., Lynch, K. E., Curhan, G. C. & Brunelli, S. M. Association of mortality risk with various definitions of intradialytic hypotension. J. Am. Soc. Nephrol. 26, 724–734 (2015).
Inrig, J. K. Intradialytic hypertension: A less-recognized cardiovascular complication of hemodialysis. Am. J. Kidney Dis. 55, 580–589 (2010).
Singh, A. T., Waikar, S. S. & Mc Causland, F. R. Association of different definitions of intradialytic hypertension with long-term mortality in hemodialysis. Hypertension 79, 855–862 (2022).
Stefánsson, B. V. et al. Intradialytic hypotension and risk of cardiovascular disease. Clin. J. Am. Soc. Nephrol. 9, 2124–2132 (2014).
McIntyre, C. W. & Salerno, F. R. Diagnosis and treatment of intradialytic hypotension in maintenance hemodialysis patients. Clin. J. Am. Soc. Nephrol. 13, 486–489 (2018).
Van Buren, P. N. & Inrig, J. K. Mechanisms and treatment of intradialytic hypertension. Blood Purif. 41, 188–193 (2016).
Kanbay, M. et al. An update review of intradialytic hypotension: concept, risk factors, clinical implications and management. Clin. Kidney J. 13, 981–993 (2020).
Raikou, V. D. & Kyriaki, D. The association between intradialytic hypertension and metabolic disorders in end stage renal disease. Int. J. Hypertens. 2018 (2018).
Wang, F. et al. Intradialytic blood pressure pattern recognition based on density peak clustering. J. Biomed. Inf. 83, 33–39 (2018).
Lee, H. et al. Deep learning model for real-time prediction of intradialytic hypotension. Clin. J. Am. Soc. Nephrol. 16, 396–406. https://doi.org/10.2215/CJN.09280620 (2021).
Assimon, M. M. & Flythe, J. E. Intradialytic blood pressure abnormalities: The highs, the lows and all that lies between. Am. J. Nephrol. 42, 337–350 (2015).
Elbasha, A. M., Naga, Y. S., Othman, M., Moussa, N. D. & Elwakil, H. S. A step towards the application of an artificial intelligence model in the prediction of intradialytic complications. Alexandr. J. Med. 58, 18–30 (2022).
Chen, J.-B., Wu, K.-C., Moi, S.-H., Chuang, L.-Y. & Yang, C.-H. Deep learning for intradialytic hypotension prediction in hemodialysis patients. IEEE Access 8, 82382–82390 (2020).
Lim, B., Arık, S. Ö., Loeff, N. & Pfister, T. Temporal fusion transformers for interpretable multi-horizon time series forecasting. Int. J. Forecast. 37, 1748–1764 (2021).
Kim, S. et al. System of integrating biosignals during hemodialysis: the CONTINUAL (Continuous mOnitoriNg viTal sIgN dUring hemodiALysis) registry. Kidney Res. Clin. Pract. 41, 363–371 (2022).
Initiative, K. D. O. Q. Clinical practice guidelines for cardiovascular disease in dialysis patients. Am. J. Kidney Dis. 45, 1–153 (2005).
Kooman, J. et al. EBPG guideline on haemodynamic instability. Nephrol. Dial. Transplant. 22, ii22–ii44 (2007).
Inrig, J. et al. Association of intradialytic blood pressure changes with hospitalization and mortality rates in prevalent ESRD patients. Kidney Int. 71, 454–461 (2007).
Inrig, J. K., Patel, U. D., Toto, R. D. & Szczech, L. A. Association of blood pressure increases during hemodialysis with 2-year mortality in incident hemodialysis patients: A secondary analysis of the Dialysis Morbidity and Mortality Wave 2 Study. Am. J. Kidney Dis. 54, 881–890 (2009).
Nair, S. V. et al. Effect of low dialysate sodium in the management of intradialytic hypertension in maintenance hemodialysis patients: A single-center Indian experience. Hemodial. Int. 25, 399–406 (2021).
Inrig, J. K. et al. Probing the mechanisms of intradialytic hypertension: A pilot study targeting endothelial cell dysfunction. Clin. J. Am. Soc. Nephrol. CJASN 7, 1300 (2012).
Inrig, J. K. et al. Effect of low versus high dialysate sodium concentration on blood pressure and endothelial-derived vasoregulators during hemodialysis: a randomized crossover study. Am. J. Kidney Dis. 65, 464–473 (2015).
Bikos, A. et al. The effects of nebivolol and irbesartan on postdialysis and ambulatory blood pressure in patients with intradialytic hypertension: a randomized cross-over study. J. Hypertens. 37, 432–442 (2019).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30 (2017).
Cho, K. et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078 (2014).
Lin, C.-J. et al. Intelligent system to predict intradialytic hypotension in chronic hemodialysis. J. Formosan Med. Assoc. 117, 888–893 (2018).
Yang, X. et al. An optimized machine learning framework for predicting intradialytic hypotension using indexes of chronic kidney disease-mineral and bone disorders. Comput. Biol. Med. 145, 105510. https://doi.org/10.1016/j.compbiomed.2022.105510 (2022).
Zhang, H. et al. Real-time prediction of intradialytic hypotension using machine learning and cloud computing infrastructure. Nephrol. Dial. Transplant. gfad070 (2023).
Bi, Z. et al. A practical electronic health record-based dry weight supervision model for hemodialysis patients. IEEE J. Transl. Eng. Health Med. 7, 1–9 (2019).
Rodríguez-Pérez, R. & Bajorath, J. R. Interpretation of compound activity predictions from complex machine learning models using local approximations and shapley values. J. Med. Chem. 63, 8761–8777 (2019).
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A. & Torralba, A. in Proceedings of the IEEE conference on computer vision and pattern recognition. 2921–2929.
Author information
Authors and Affiliations
Contributions
D.Y. and S.S.H. contributed to the study concept and design. D.Y. and S.G.K. collected and verified the data. D.Y., H.L.Y., K.K., and S.S.H. analyzed the data and interpreted the results. D.Y. and S.S.H. wrote the manuscript. H.L.Y. critically revised the manuscript for intellectual content. K.K., D.K.K., K.H.O., K.W.J. and Y.S.K. supervised the conduct of the study. All authors contributed the interpretation of data, provided technical support, commented on drafts of the manuscript, and approved the final version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yun, D., Yang, HL., Kim, S.G. et al. Real-time dual prediction of intradialytic hypotension and hypertension using an explainable deep learning model. Sci Rep 13, 18054 (2023). https://doi.org/10.1038/s41598-023-45282-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-45282-1
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
