
Abstract
Hand–foot–mouth disease (HFMD) is a viral disease that occurs primarily in children. Meteorological factors have a significant impact on its popularity annually in Korea. This study proposes a new HFMD prediction model using a dual-attention-based recurrent neural network (DA-RNN) and important weather factors for HFMD in Korea. First, suspected cases of HFMD in each state were predicted using meteorological factors from the DA-RNN. Second, the weather factors were divided into six categories: temperature, wind, rainfall, day length, humidity, and air pollution to conduct sensitivity analysis. Because of this prediction, the proposed model showed the best performance in predicting the number of suspected HFMD cases in a week compared with other RNN methods. Sensitivity analysis showed that air pollution and rainfall play an important role in HFMD in Korea. This model provides information for HFMD prevention and control and can be extended to predict other infectious diseases.
Similar content being viewed by others



Introduction
Hand–foot–mouth disease (HFMD) is a viral disease caused by the transmission of coxsackievirus A16 (CoxA16) and enterovirus 71 (EV 71) into the intestine1. It mostly affects preschoolers and is caused by respiratory secretions and excretions from gathering places for children. Most of these diseases have mild symptoms; however, death occurs in severe cases2,3. Asia shows a recurring trend annually4,5. Because no specific treatment or vaccine is available, only treatments to alleviate symptoms in cases of infection have been performed6. Various causative organisms can re-infect the disease. Models capable of predicting disease patterns are essential for disease prevention.
Asia has periodic fluctuations that show a repetitive epidemic pattern, with the peak of the epidemic occurring every summer before COVID-197. It is classified as a national infectious disease (Level 4) in Korea and is reported by the National Institute of Health through the sampling surveillance system. Suspected cases among 1000 patients are reported to the Korea Centers for Disease Control and Prevention on a weekly basis8. Previous research has demonstrated a significant correlation between HFMD and meteorological conditions such as average temperature, relative humidity, wind speed, and sunshine hours9,10,11. Among these meteorological conditions, it is important to determine the meteorological factors that should be prioritized.
Numerous studies have been conducted to generate HFMD predictive models11,12,13,14,15. A mathematical model was used to determine the seasonality of HFMD infectivity and to predict the number of patients, which showed that peaks occur annually in summer and autumn13. Long short-term memory (LSTM), autoregressive integrated moving average (ARIMA), and nonlinear autoregressive (NAR) neural networks have been used to determine the most appropriate model using machine learning and statistical methods. These methodologies accounted for the seasonal and trending characteristics of HFMD. However, these studies did not identify the factors that significantly influence seasonality14. Similarly, the time-series pattern was learned using the LSTM method to predict HFMD generation and determine the contribution of meteorological factors to spatiotemporal effects using a statistical method called geodetector12. In this study, we identified HFMD predictors and influential meteorological factors. However, the performance of the LSTM deteriorates as the length of the time series increases. Recently, models that predict epidemics in the form of extended LSTM using attention techniques have been developed16,17.
Numerous studies on forecasting models using meteorological factors have been conducted in China. In Korea, the epidemiological characteristics and spatiotemporal distribution of HFMD in children under six years of age were evaluated using national health insurance data, and the prevalence pattern was evaluated using the spatiotemporal clustering method15. However, meteorological factors that significantly affect the prevalence of HFMD in Korea have not yet been studied.
The limitations of previous studies were overcome by predicting HFMD using a dual attention-based recurrent neural network (DA-RNN) model18 with 20 meteorological factors. Through the training of this model, we identified important meteorological factors associated with HFMD in Korea that are unknown to our knowledge. This study provides the information necessary to establish national management and prevention strategies in the future. This model could be extended to predict other infectious diseases.
Results
Epidemiological and meteorological characteristics
In Korea, HFMD was reported to exhibit an annual repeating pattern from 2011 to 2020. The most prevalent weeks were typically those between weeks 25 and 30. The other two are represented by 2015, which had week 22 as the popular, and 2020, which had week 38 as the popular week. The size of the prevalence varied significantly from year to year, with 2019 showing the highest level (66.7 thousand parts, 27 weeks) and 2020 showing the lowest level (2.2 thousand parts, 38 weeks). The HFMD statistics for each year are shown in Fig. 1A.

Epidemiological and meteorological characteristics. (A) Number of suspected HFMD cases per thousand people per week. (B) Average, maximum, and minimum temperatures among the temperature group. (C) Maximum instantaneous wind speed and average wind speed among the wind group. (D) Maximum rainfall and 1 h maximum rainfall among the rainfall group. (E) Day length per year among the sunshine group. (F) Average and minimum humidity among the humidity group. (G) SO2, O3, and NO2 among the air pollution group.
Table 2 shows 20 meteorological factors from six groups used from 2011 to 2020. Figure 1B–G show some meteorological factors by group. Figure 1 shows the epidemiological and meteorological characteristics from 2011 to 2020, and similar patterns can be identified for each period. Supplementary Table S1 shows the Pearson’s correlation analysis between epidemiological and meteorological characteristics.
Estimation of suspected HFMD patients
Twenty meteorological factors were normalized and used. Meteorological factors and weekly HFMD data from 2011 to 2018 were used as training sets for the DA-RNN. Meteorological factors and HFMD data from 2019 to 2020 were used as a test set to check the forecasting model, which was saved after 1000 epochs. The mean absolute error (MAE), root mean square error (RMSE), mean absolute percentage error (MAPE), and R-squared score (R2) were used to evaluate the performance of the experiment. Table 1 compares the performances of each method. DA-RNN achieved the best performance for all evaluation indicators. Figure 2 shows the training and test prediction results for LSTM, GRU, seq2seq, encoder attention-based seq2seq, decoder attention-based seq2seq, and DA-RNN.

Estimation of suspected HFMD patients. In (A) LSTM; (B) GRU; (C) Seq2seq; (D) encoder attention-based seq2seq; (E) decoder attention-based seq2seq; (F) DA-RNN. The orange, blue, and green lines represent the actual data value, predicted value of the train, and predicted value of the test, respectively.
Sensitivity analysis
The sensitivity test results are shown in Fig. 3. The sensitivity analysis compared the evaluation scores (MAE, RMSE, MAPE, and R2) by eliminating them by group, as shown in Table S2.

Sensitivity analysis results. (A) Spider map of the sensitivity analysis important value results; (B) Important scores; (C) Encoder attention scores of the DA-RNN test results.
In order to determine important meteorological groups by objectifying the evaluation scores obtained from the sensitivity experiment, a spider map was obtained through the defined important values, which is shown in Fig. 3A. The importance score was calculated based on the area of this spider map, and the larger the value, the greater the importance, which is shown in Fig. 3B.
The predicted important score after removing the five elements from the temperature group was 0.0892. The predicted important score two elements of the wind group removed was 0.6455; the predicted important score with two elements of the rainfall group removed was 0.891; the predicted important score with two elements of the day length group deleted was 0; the important score with two elements of the humidity group omitted was 0.5624; and the important score with five elements of the air pollution group deleted was 0.6485. The important score results for each group are shown in Fig. 3B. Supplementary Fig. S2 shows the sensitivity analysis important score results.
Because of the characteristics of its structure, DA-RNN calculates the attention scores of features every time, which can confirm changes in the importance of meteorological factors. Figure 3C shows changes in the importance of meteorological factors during the test period. Although the score values vary depending on the period, rainfall and air pollution groups have high important scores over the overall time.
Method
Figure 4 summarizes the HFMD prediction using DA-RNN. After data collection and normalization, weekly HFMD data were regression-targeted using DA-RNN to predict weekly suspected HFMD cases per 1000 people and to discriminate between important meteorological factor groups.
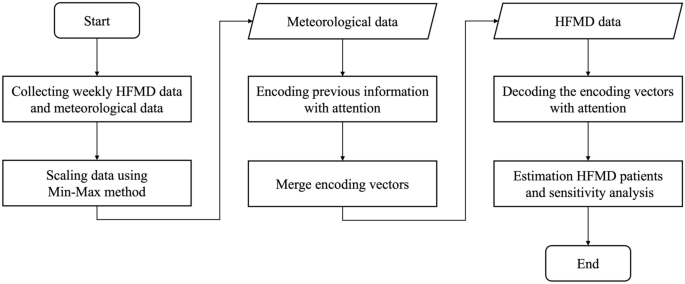
Framework diagram.
Data collection
HFMD data were obtained from 2011 to 2020 from the number of suspected cases per 1,000 people per state provided by the Korea Centers for Disease Control and Prevention19. For meteorological factors, 15 types of data on temperature, wind speed, precipitation, day length, and humidity from 2011 to 2020 were collected using the Korea Meteorological Data Open Portal20. Five types of air pollution data were collected from 2011 to 2020 through AirKorea21.
Table 2 shows 20 meteorological factors and descriptions used for predicting HFMD. These meteorological factors were classified into six categories: (1) Temperature: average temperature (°C), average maximum temperature (°C), maximum temperature (°C), average minimum temperature (°C), and minimum temperature (°C); (2) Wind: average wind speed (m/s), maximum wind speed(m/s), and maximum instantaneous wind speed(m/s); (3) Rainfall: average rainfall (mm), maximum rainfall (mm), 1 h maximum rainfall (mm); (4) Sunshine: day length (hr) and day length per year (MJ/m2); (5) Humidity: average humidity and minimum humidity; (6) Air pollution: SO2, CO, O3, NO2, and PM10. Statistics on meteorological factors are shown in Fig. 1B–G.
Data normalization
Normalization pre-processing is essential when there is a difference in the scale of features between the data. Min–max normalization converts all features between zero and one22. The min–max normalization equation is as follows:
where \(x\) denotes each feature value and \(x{^\prime}\) denotes the change in scaling. Min and max are the maximum and minimum values of each feature.
Estimation of suspected HFMD patients using DA-RNN
The traditional RNN successfully uses a time-series prediction algorithm, which has the problem of vanishing gradients. LSTM and GRU have been used to overcome this limitation. The LSTM and GRU are shown in Figure S323,24. However, the same problem occurs when the time series increases. The structure of the encoder-decoder network was used; a representative example is Seq2Seq25,26. This structure has been extended to an attention mechanism that provides a score for past information because the performance degradation problem occurs when the input sequence is lengthy. Qin et al. proposed a DA-RNN as a time-series prediction model18. This structure overcomes the shortcomings of the RNN model in existing time-series studies using two attention mechanisms with encoder and decoder structures. The structure of this study’s model is shown in Fig. 5. The attention mechanism does not use the input data of each forecasting point in the same ratio but rather evaluates the attention score related to the data of the corresponding forecasting point and uses it for prediction. Among various attention scores, the Bahdanau (concate) method was used26.

DA-RNN diagram. (A) Encoder (B) Decoder.
This study compares the prediction results obtained using LSTM, GRU, and seq2seq to confirm the prediction performance of DA-RNN. The importance of the weather factor in the encoder and the temporal importance in the decoder were calculated. To confirm the influence of the importance calculation of each structure, the prediction results obtained through a single attention mechanism in the encoder and decoder were compared.
DA-RNN is an encoder-decoder-based algorithm comprising an attention mechanism in each encoder and decoder. The input data tensor consists of n driving series and n-1 target series during the T time step, and the output data are the T time step, which is called the target series of T time steps. Each encoder passes through the input attention and encoder LSTM structure. The input attention shown in Fig. 5 can be expressed mathematically as follows:
where \({x}^{k}\) denotes the kth weather variable, \({h}_{t-1}\) denotes the hidden encoder state, and w denotes the encoder cell state. \({e}_{t}^{k}\) is calculated using the Bahdanau method as the kth attrition score of t time, and the attrition distribution \({\alpha }_{t}^{k}\) is calculated using softmax and calculated as the attention value \(\widetilde{{x}_{t}}\) of t time. The mathematical expression of the encoder LSTM is expressed as follows:
where \(b\) denotes the bias, and the encoder LSTM has the same structure as the general LSTM. \({f}_{t}\) is a forget gate, \({i}_{t}\) is an input gate, \({o}_{t}\) is an output gate, \({s}_{t}\) is a cell state, and \({h}_{t}\) is a hidden state. \(\sigma\) and \(\odot\) are sigmoid function and element wise multiplication, respectively.
The decoder has a temporal attention and an LSTM decoder structure. The temporal attention is expressed mathematically as follows:
The hidden state calculated using the encoder was used as the input for temporal attention. Similarly, the attention score \({l}_{t}^{k}\) was calculated using the Bahdanau method, and the attention distribution \({\beta }_{t}^{i}\) was calculated using the activation function softmax to obtain the temporal attention value \({\mathrm{c}}_{\mathrm{t}}\) at time t. In the LSTM decoder, the calculated attention value, and previous target value \({y}_{t-1}\) were concatenated and used.
The mathematical expression of the decoder LSTM is identical to that of the encoder LSTM, as expressed in the following equation.
The DA-RNN model was configured using Python 3.9.7, PyTorch 1.11, Numpy 1.21.4, and Pandas 1.3.4.
Accuracy analysis of prediction
Four evaluation scores—MAE, RMSE, MAPE, and R2—were computed to assess the effectiveness of the various methods for HFMD prediction. If \({y}_{T}\) is the actual value and \(\widehat{{y}_{T}}\) is the value predicted by the methods, each score is mathematically expressed as follows:
We set the accuracy scores metrics defined (MAE, RMSE, MAPE, R2).
Sensitivity analysis
A drop group important measure was performed to determine the importance of the six meteorological groups. Accuracy scores metrics are calculated by removing each group of the meteorological group one by one. The smaller the calculated MAE, RMSE, and MAPE are, the better the performance is, but the closer R2 is to 1, the better the performance is. Therefore, the value of 1- R2 was used to provide the same standard.
To determine the order of important meteorological groups, we went through three steps. First, we calculated the important value to measure the accuracy scores for each meteorological group. Total group accuracy scores are values using all meteorological groups, and drop group accuracy scores are defined as accuracy scores with one group removed. The formula for calculating important value is as follows;
(Important value) = (total group accuracy scores) − (drop group accuracy scores).
After calculation, this important value was normalized to a minimum value of 0 and a maximum value of 1. The closer it is to 1, the higher the importance, and the closer it is to 0, the lower the importance.
Second, normalized important values are expressed as spider maps. We know that the group with the largest width in this spider map is the group with the highest importance. Thirdly, to determine the order of importance, we calculated the width of each group in the spider map to determine the order.
Ethical considerations
This study analyzed publicly available HFMD and meteorological data19,20,21. Publicly available data with no personally identifiable information did not require ethical approval.
Discussion
This study explores the meteorological factors that predict and influence the prevalence of HFMD in Korea. This study aimed to predict the number of suspected HFMD cases per 1,000 people per week and analyze the sensitivity of meteorological factors. We conducted HFMD prediction and sensitivity analysis using the time-series forecasting method DA-RNN. First, we estimated the number of suspected cases per 1000 people with HFMD from 2019 to 2020 using 2011 to 2018 data and all meteorological factors. To evaluate the performance of DA-RNN, we experimented with LSTM, GRU, Seq2seq, encoder attention-based seq2seq, and decoder attention-based seq2seq under the same experimental conditions. Second, MAE, RMSE, MAPE, and R2 were compared to determine the most influential group when meteorological factors were divided into groups based on temperature, wind, rainfall, sunshine, and humidity under the same conditions and when each group was excluded.
The DA-RNN outperformed other methods in terms of MAE, RMSE, MAPE, and R2 metrics (0.8544, 2.7117, 0.3163, and 0.9333, respectively). This was confirmed using single attention, demonstrating the importance of calculating the weights of the wake-up factors in the encoder attention mechanism. Using the sensitivity test results, among the six meteorological groups, rainfall, air pollution, wind and humidity groups were identified as groups of overall importance (see Supplementary Information).
According to GeoDetector theory, the meteorological factors affecting HFMD in Guangxi, an inland region of China, are similar to temperature and rainfall. However, because our country is surrounded by sea on three sides, not only rainfall but also humidity has a significant impact. This is consistent with a study in Japan, which has a similar topography, where relative humidity was found to be an important factor in HFMD10. We have added the day-length group and air pollution to examine the meteorological factors in previous studies. The prevalence pattern of HFMD from 2011 to 2019 and that in 2020 differed significantly, which indirectly confirms the great influence of the air pollution group on the degree of social activity of people owing to the impact of COVID-19.
This study has several limitations. First, the pattern of HFMD in 2020 changed significantly because of COVID-19. We chose the air pollution group as an indirect factor; however, the pattern was not sufficiently learned because of the lack of directly related data. Therefore, factors related to social phenomena and population density should be considered in future research. Additionally, the terrestrial viewpoint was not considered in this study. Therefore, it is necessary to establish a system that can evaluate risk levels by region and provide alerts. In this study, only meteorological factors were considered, which may have led to inaccurate forecasts, considering that other factors might be important. Subsequently, social and terrestrial factors should be considered to improve the accuracy of the DA-RNN model for HFMD prediction. To the best of our knowledge. This study is the first to use a DA-RNN for HFMD in Korea and reveals important meteorological factors. This model can significantly influence government policy by differentiating between the meteorological factors to be observed when predicting HFMD in Korea. This study’s framework could be extended to other epidemiological studies and time-series problems.
Conclusion
This study proposes a new model to predict the number of suspected weekly HFMD cases using 20 meteorological factors. The meteorological factors were divided into six groups, and a sensitivity test was conducted to determine the most influential group. Our model uses the DA-RNN and shows good prediction results even in 2019 and 2020, which test period are difficult to predict compared with other models. The results showed that the factors that significantly affect HFMD are rainfall, air pollution, wind, humidity group. These results show the need for governments to consider meteorological factors in HFMD prevention guidelines.
Data availability
The meteorological dataset used in this study is available on the Korean Statistical Information Service website (https://kosis.kr/). The air pollution dataset used in this study is available on the Airkorea website (https://www.airkorea.or.kr/). The HFMD datasets used in this study are available on the Korea Centers for Disease Control and Prevention website (https://www.kdca.go.kr/npt/biz/npp/iss/hfmdStatisticsMain.do).
References
Ho, M. Enterovirus 71: The virus, its infections and outbreaks. J. Microbiol. Immunol. Infect. 33(4), 205–216 (2000).
Xiao-Fang, W. A. N. G., Jiao, L. U., Xiao-Xia, L. I. U. & Ting, D. A. I. Epidemiological features of hand, foot and mouth disease outbreaks among Chinese preschool children: A meta-analysis. Iran. J. Public Health 47(9), 1234 (2018).
Shekhar, K. et al. Deaths in children during an outbreak of hand, foot and mouth disease in Peninsular Malaysia–clinical and pathological characteristics. Med. J. Malaysia 60(3), 297–304 (2005).
Zhao, T. S. et al. A review and meta-analysis of the epidemiology and clinical presentation of coxsackievirus A6 causing hand-foot-mouth disease in China and global implications. Rev. Med. Virol. 30(2), e2087 (2020).
Kim, S. J. et al. Risk factors for neurologic complications of hand, foot and mouth disease in the Republic of Korea, 2009. J. Korean Med. Sci. 28(1), 120–127 (2013).
Li, X. W. et al. Chinese guidelines for the diagnosis and treatment of hand, foot and mouth disease (2018 edition). World J. Pediatr. 14(5), 437–447 (2018).
Ma, E., Lam, T., Chan, K. C. & Wong, C. Changing epidemiology of hand, foot, and mouth disease in Hong Kong, 2001–2009. Jpn. J. Infect. Dis. 63(6), 422–426 (2010).
Guideline for the prevention and control of enterovirus infection and hand, foot and mouth disease. Korea Centers for Disease Control and Prevention. 2017. http://www.cdc.go.kr/index.es?sid=a2.
Ma, E., Lam, T., Wong, C. & Chuang, S. K. Is hand, foot and mouth disease associated with meteorological parameters?. Epidemiol. Infect. 138(12), 1779–1788 (2010).
Onozuka, D. & Hashizume, M. The influence of temperature and humidity on the incidence of hand, foot, and mouth disease in Japan. Sci. Total Environ. 410, 119–125 (2011).
Wang, P., Zhao, H., You, F., Zhou, H. & Goggins, W. B. Seasonal modeling of hand, foot, and mouth disease as a function of meteorological variations in Chongqing, China. Int. J. Biometeorol. 61, 1411–1419 (2017).
Gu, J. et al. A method for hand-foot-mouth disease prediction using GeoDetector and LSTM model in Guangxi, China. Sci. Rep. 9(1), 17928 (2019).
Huang, Z. et al. Seasonality of the transmissibility of hand, foot and mouth disease: A modelling study in Xiamen City, China. Epidemiol. Infect. 147, e327 (2019).
Wang, Y. et al. Development and evaluation of a deep learning approach for modeling seasonality and trends in hand-foot-mouth disease incidence in mainland China. Sci. Rep. 9(1), 8046 (2019).
Baek, S., Park, S., Park, H. K. & Chun, B. C. The epidemiological characteristics and spatio-temporal analysis of childhood hand, foot and mouth disease in Korea, 2011–2017. PLoS ONE 15(1), e0227803 (2020).
Zhu, X. et al. Attention-based recurrent neural network for influenza epidemic prediction. BMC Bioinform. 20(18), 1–10 (2019).
Fu, B. et al. Attention-based recurrent multi-channel neural network for influenza epidemic prediction. In 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) (ed. Fu, B.) 1245–1248 (IEEE, 2018).
Qin, Y., Song, D., Chen, H., Cheng, W., Jiang, G., & Cottrell, G. A dual-stage attention-based recurrent neural network for time series prediction. Preprint at https://arXiv.org/quant-ph/1704.02971 (2017).
Public Health Weekly Report Disease Surveillance Statistics, 2018 PHWR. Korea Centers for Disease Control and Prevention. https://www.kdca.go.kr/npt/biz/npp/iss/hfmdStatisticsMain.do.
Korean Statiatical Information Service. [Cited 27 February 2022]. https://kosis.kr/.
Airkorea. https://www.airkorea.or.kr/.
Al Shalabi, L. & Shaaban, Z. Normalization as a preprocessing engine for data mining and the approach of preference matrix. In 2006 International conference on dependability of computer systems (eds Al Shalabi, L. & Shaaban, Z.) 207–214 (IEEE, 2006).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997).
CHUNG, Junyoung, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling. Preprint at https://arXiv.org/quant-ph/1412.3555 (2014).
Cho, K. et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. Preprint at https://arXiv.org/quant-ph/1406.1078 (2014).
Chorowski, J. K., Bahdanau, D., Serdyuk, D., Cho, K., & Bengio, Y. Attention-based models for speech recognition. Adv. Neural Inform. Process. Syst. 28 (2015).
Acknowledgements
This work was supported by the BK21 FOUR Program by a Pusan National University Research Grant, 2021, and the National Research Foundation of Korea(NRF) grant funded by the Korea government (MSIT) (No. 2022R1A5A1033624).
Author information
Authors and Affiliations
Contributions
S.L. and S.K. analyzed the data. S.L. and S.K. retrieved and managed data. S.L. were involved in conception and design of this study and wrote the whole manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lee, S., Kim, S. Dual-attention-based recurrent neural network for hand-foot-mouth disease prediction in Korea. Sci Rep 13, 16646 (2023). https://doi.org/10.1038/s41598-023-43881-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-43881-6
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
