
Abstract
The emergence of large language models has led to the development of powerful tools such as ChatGPT that can produce text indistinguishable from human-generated work. With the increasing accessibility of such technology, students across the globe may utilize it to help with their school work—a possibility that has sparked ample discussion on the integrity of student evaluation processes in the age of artificial intelligence (AI). To date, it is unclear how such tools perform compared to students on university-level courses across various disciplines. Further, students’ perspectives regarding the use of such tools in school work, and educators’ perspectives on treating their use as plagiarism, remain unknown. Here, we compare the performance of the state-of-the-art tool, ChatGPT, against that of students on 32 university-level courses. We also assess the degree to which its use can be detected by two classifiers designed specifically for this purpose. Additionally, we conduct a global survey across five countries, as well as a more in-depth survey at the authors’ institution, to discern students’ and educators’ perceptions of ChatGPT’s use in school work. We find that ChatGPT’s performance is comparable, if not superior, to that of students in a multitude of courses. Moreover, current AI-text classifiers cannot reliably detect ChatGPT’s use in school work, due to both their propensity to classify human-written answers as AI-generated, as well as the relative ease with which AI-generated text can be edited to evade detection. Finally, there seems to be an emerging consensus among students to use the tool, and among educators to treat its use as plagiarism. Our findings offer insights that could guide policy discussions addressing the integration of artificial intelligence into educational frameworks.
Similar content being viewed by others


Introduction
Generative artificial intelligence (AI) refers to the use of machine learning algorithms that build on existing material, such as text, audio, or images to create new content. Recent advancements in this field, coupled with its unprecedented accessibility, has led many to consider it a “game-changer that society and industry need to be ready for”1. In the realm of art, for example, Stable Diffusion and DALL-E have received significant attention for their ability to generate artwork in different styles2,3. Amper Music, another generative AI tool, is capable of generating music tracks of any given genre, and has already been used to create entire albums4,5. ChatGPT is the latest tool in this field, which can generate human-like textual responses to a wide range of prompts across many languages. More specifically, it does so in a conversational manner, giving users the ability to naturally build on previous prompts in the form of an ongoing dialogue. This tool has been described as an “extraordinary hit”6, and a “revolution in productivity”7, for its seemingly endless utility in numerous out-of-the-box applications, such as creative writing, marketing, customer service, and journalism, just to name a few. The capabilities of the tool have sparked widespread interest, with ChatGPT reaching one million users in only five days after its release8, and soaring to over 100 million monthly users in just two months.
In spite of its impressive ability, generative AI has been marred by ethical controversies. In particular, as generative AI models are trained on massive amounts of data available on the internet, there has been an ongoing debate regarding the ownership of this data9,10,11. Furthermore, as these tools continue to evolve, so does the challenge of identifying what is created by humans and what is created by an algorithm. In the context of education, ChatGPT’s ability to write essays and generate solutions to assignments has sparked intense discussion concerning academic integrity violations by school and university students. For instance, in the United States its use has been banned by school districts in New York City, Los Angeles, and Baltimore12. Similarly, Australian universities have announced their intention to return to “pen and paper” exams to combat students using the tool for writing essays13. Indeed, many educators have voiced concerns regarding plagiarism, with professors from George Washington University, Rutgers University, and Appalachian State University opting to phase out take-home, open-book assignments entirely14. In the realm of academic publishing, a number of conferences and journals have also banned the use of ChatGPT to produce academic writing15,16, which is unsurprising given that abstracts written by ChatGPT have been shown to be indistinguishable from human-generated work17. Yet, many have argued for the potential benefits of ChatGPT as a tool for improving writing output, with some even advocating for a push to reform the pedagogical underpinnings of the evaluative process in the education system18,19.
Previous work has examined the utility and performance of large language models in the context of education in a number of different disciplines, including medicine and healthcare20,21,22,23, computer and data science24,25,26, law27,28, business29, journalism and media30, and language learning31,32. While these studies demonstrated mixed results with regards to ChatGPT’s performance in standardized exams against that of students, studies which specifically compared the model’s performance against that of previous large language models all indicated a significant improvement in the task of question answering20,21,23. For instance, Kung et al. evaluated the performance of ChatGPT on the United States Medical Licensing Exam, where they show that ChatGPT performed at or near a passing level on all three stages of the test, without the need for additional specialized training or reinforcement21. Similarly, Pursnani et al. evaluated ChatGPT’s performance in the context of Engineering, testing the model on the US Fundamentals of Engineering exam33. In their study, they showed that the model’s performance varied across different sections of the exam, performing exceptionally in areas such as Ethics and Professional practice, while under-performing in others such as Hydrology. Despite these examples, the literature still lacks a systematic study comparing the performance of ChatGPT against that of students across various disciplines at the same institution. Moreover, the perspectives of students and educators around the globe regarding the usage of such technology remain unclear. Finally, the detectability of ChatGPT-generated solutions to homework remains unknown.
Here, we examine the potential of ChatGPT as a tool for plagiarism by comparing its performance to that of students across 32 university-level courses from eight disciplines. Further, we evaluate existing algorithms designed specifically to detect ChatGPT-generated text, and assess the effectiveness of an obfuscation attack that can be used to evade such algorithms. To better understand the perspectives of students and educators on both the utility of ChatGPT as well as the ethical and normative concerns that arise with its use, we survey participants (N=1601), recruited from five countries, namely Brazil, India, Japan, United Kingdom, and the United States. Additionally, we survey 151 undergraduate students and 60 professors more extensively at the authors’ institution to explore differences in perceptions of ChatGPT across disciplines. We find that ChatGPT’s performance is comparable, or even superior, to that of students on nine out of the 32 courses. Further, we find that current detection algorithms tend to misclassify human answers as AI-generated, and misclassify ChatGPT answers as human-generated. Worse still, an obfuscation attack renders these algorithms futile, failing to detect 95% of ChatGPT answers. Finally, there seems to be a consensus among students regarding their intention to use ChatGPT in their schoolwork, and among educators with regard to treating its use as plagiarism. The inherent conflict between these two poses pressing challenges for educational institutions to craft appropriate academic integrity policies related to generative AI broadly, and ChatGPT specifically. Our findings offer timely insights that could guide policy discussions surrounding educational reform in the age of generative AI.
Results
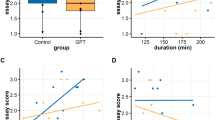
We start off by exploring the current capabilities of generative AI to solve university-level exams and homework. To this end, we reached out to faculty members at New York University Abu Dhabi (NYUAD), asking them to provide 10 questions from a course that they have taught at the university, along with three randomly-chosen student answers to each question. Additionally, for each course, ChatGPT was used to generate three distinct answers to each of the 10 questions. Both students’ and ChatGPT’s answers were then compiled into a single document in random order, labelled as “Submission 1” to “Submission 6”. Each of these submissions were then graded by three different graders, recruited by the faculty member who had taught that course; see Methods for more details, and Supplementary Table 1 for inter-rater reliability. While the inter-rater reliability for the majority of courses was greater than 0.6, six of the 32 courses did not meet this threshold. Four of these six courses were essay-based and inherently subjective which may explain this discrepancy. However, the remaining two courses (Human-Centered Data Science and Object Oriented Programming) were not. Nonetheless, if we exclude these two courses from our analysis, we see qualitatively similar results. The results of this evaluation can be found in Fig. 1a, and see Supplementary Table 2 for the numeric values. Apart from Mathematics and Economics, each discipline has at least one course on which ChatGPT’s performance is comparable to, or even surpasses, that of students. These courses are: (i) Data Structures; (ii) Introduction to Public Policy; (iii) Quantitative Synthetic Biology; (iv) Cyberwarfare; (v) Object Oriented Programming; (vi) Structure and Properties of Civil Engineering Materials; (vii) Biopsychology; (viii) Climate/Change; and (ix) Management and Organizations. As a robustness check, we standardized the grades given by each grader of each course to account for grader-specific effects, and again found ChatGPT’s performance is comparable, or superior, to student in the above nine courses (Supplementary Table 3).
Having analyzed ChatGPT’s performance on different courses, we now perform an exploratory analysis of how its performance varies along different levels of cognition and knowledge. To this end, we asked participating faculty to specify where each of their questions fell along the “knowledge” and “cognitive process” dimensions of Anderson and Krathwohl’s taxonomy34; see Table 1 for a description of the levels that constitute each dimension. The results of this analysis are summarized in Fig. 1b. Interestingly, the gap in performance between ChatGPT and students is substantially smaller on questions requiring high levels of knowledge and cognitive process, compared to those requiring intermediate levels. Also interesting is ChatGPT’s performance on questions that require creativity—the highest level along the cognitive process dimension—receiving an average grade of 7.5 compared to the students’ average grade of 7.9. Perhaps unsurprisingly, the only questions on which ChatGPT outperforms students are those requiring factual knowledge, attesting to the massive amounts of data on which it was trained. Finally, we compare ChatGPT’s performance against different types of questions. To this end, for each question, we asked the participating faculty to specify whether the question: (i) involves mathematics; (ii) involves code snippets; (iii) requires knowledge of a specific author, paper/book, or a particular technique/method; and (iv) is a trick question. The results are summarized in Fig. 1c. Again, we find that the largest performance gap between ChatGPT and students was for math-related questions, followed by trick questions. For the time being, humans seem to outperform ChatGPT in these areas.

Comparing ChatGPT to university-level students. Comparing ChatGPT’s average grade (green) to the students’ average grade (blue), with error bars representing 95% confidence intervals. (a) Comparison across university courses. (b) Comparison across the “cognitive process” and “knowledge” dimensions of Anderson and Krathwohl taxonomy’s of learning. (c) Comparison across question types. p-values are calculated using bootstrapped two-sided Welch’s T-test, and only shown for courses where GPT does not receive a significantly lower grade compared to students (** = \(p < 0.01\); *** = \(p < 0.001\); \(ns =\) not significant, i.e., \(p > 0.05\)).
To understand how the use of ChatGPT is perceived by educators and students, we fielded a global survey in five countries, namely Brazil, India, Japan, the UK, and the US, targeting a minimum of 100 educators and 200 students per country; see Methods for more details. A summary of our findings can be seen in Fig. 2. Before delving into this analysis, it should be noted that students and educators in our survey come from various levels of the education. As such, we performed a similar analysis focusing only on undergraduate and postgraduate students, as well as university-level educators, and found broadly similar results; see Supplementary Figure 1. We start off by comparing the responses of students vs. educators in different countries; see panels a-c in Fig. 2. Here, each plot corresponds to a different question in the survey, asking about the degree to which respondents agree or disagree with a particular statement about ChatGPT (\(-2 =\) strongly disagree; \(-1 =\) disagree; \(0 =\) neutral; \(1 =\) agree; \(2 =\) strongly agree). We present statements in three broad categories: (i) the ethics of using ChatGPT in the context of education in panel a; (ii) the impact of ChatGPT on future jobs in panel b; and (iii) the impact of ChatGPT on inequality in education in panel c; see Supplementary Figure 1 for the remaining statements on the survey. Starting with panel a (ethics), there seems to be a consensus that using ChatGPT in school work should be acknowledged. In contrast, opinions vary when it comes to determining whether the use of ChatGPT in homework is unethical and whether it should be prohibited in school work, e.g., students in India and the US believe it is unethical and should be prohibited, while those in Brazil believe otherwise. Moving on to panel b (jobs), students in all five countries believe they can outsource mundane tasks to ChatGPT, and the educators in Brazil and India seem to agree with this statement. India is the only country where educators believe ChatGPT is needed to increase their competitiveness in their job, and the students therein agree the most with this statement. Moreover, educators and students in India are the only ones who worry that ChatGPT will take their job in the future. In terms of panel c (inequality), there seems to be a consensus that ChatGPT will increase the competitiveness of non-native English students. When it comes to whether ChatGPT will reduce inequality in education, educators in Brazil and Japan (the two non-English speaking countries in our sample) agree with this statement, while those in the remaining three countries disagree.
Next, we compare the distribution of the educators’ and students’ responses to the following question: “What percentage of your students/peers do you think will use ChatGPT in their studies?”. The results are depicted in Fig. 2d, where the distributions of educators and students responses are illustrated in orange and blue, respectively, with vertical lines of the same colors representing the means. The black vertical line represents the percentage of students who answered “Yes” to the question: “Considering your next term of studies, would you use ChatGPT to assist with your studies?”. As can be seen in the fourth row, representing the average response across the five countries, 74% of students indicate that they would use ChatGPT (black line), while both educators and students underestimated this share. For the students who said they would use it (74%), their main reasons are to improve their skills and save time (Fig. 2f). As for those who said they would not use ChatGPT (26%), their main reasons are not knowing how to do so or not having a need for it, rather than a fear of being penalized or acting unethically (Fig. 2g).
Finally, we perform an OLS regression analysis to explore which factors that might be associated with the students’ decision to use ChatGPT during their next term of studies. Figure 2e summarizes the results for a few independent variables of interest; the remaining variables can be found in Supplementary Figure 2, 3. As can be seen, students from Brazil and India are significantly more likely, and students from Japan are significantly less likely, to use ChatGPT than those from the USA. As for prior experience with ChatGPT, those who have used it are significantly more likely to use it again. On the contrary, simply hearing about ChatGPT is not significantly associated with the students’ decision to use it to assist with their studies. Finally, students from poor and working class backgrounds are significantly more likely to indicate they would use ChatGPT for their studies compared to upper class students.

Global survey responses. (a–c) Educators’ average responses (x-axis) and students’ average responses (y-axis) to eight questions regarding ChatGPT; \(1 =\) agree; \(-1 =\) disagree; \(\star =\) average over the five countries. (d) Distributions of students’/educators’ estimation of the percentage of their peers/students who they believe will use ChatGPT in their studies. The dashed black line represents the percentage of students who indicated they would use ChatGPT in their studies. (e) OLS-estimated coefficients and 95% confidence intervals of selected independent variables predicting a student’s decision to use ChatGPT in their next term of studies; see Supplementary Materials for all independent variables considered. (f-g) A breakdown of why students indicated they would or would not use ChatGPT.
Having analyzed the global survey, we now shift our attention to the second survey, which was conducted at the authors’ institution—NYUAD. While this survey is narrower in scope than the previous one, it focuses on university students and professors, allowing us to examine variances in responses with respect to GPA in the case of students, and type of appointment in the case of professors. Figure 3a depicts the responses of 151 students (y-axis) and 60 professors (x-axis) with regards to the same eight statements discussed earlier, grouped into three broad categories: (i) the ethics of using ChatGPT in the context of education in red; (ii) the impact of ChatGPT on future jobs in green; and (iii) the impact of ChatGPT on inequality in education in blue; see Supplementary Figure 5 for the remaining statements. As can be seen, professors agreed more, or disagreed less, with all statements in category (i) compared to students (notice how all red data points fall below the diagonal) while students agreed more, or disagreed less, with all statements in categories (ii) and (iii). Despite these differences, professors and students seem to agree that ChatGPT’s use should be acknowledged, and neither believes that it will take their future job.
Figure 3b shows students’ empirical expectations (first and third rows) and normative expectations (second and fourth rows) of whether they plan to use ChatGPT to assist with their assignments (first two rows) and whether they think one should use ChatGPT to assist with one’s assignment (last two rows). The majority of students plan to use ChatGPT to assist with their assignments (57%), and expect their peers to use it for this purpose (64%). Moreover, the majority believe ChatGPT should be used (61%), and expect that their peers believe it should be used (55%), to assist with assignments. Similarly, Fig. 3c depicts professors’ empirical expectations (first and third rows) and normative expectations (second and fourth row) of whether they plan to treat ChatGPT’s use as plagiarism (first two rows) and whether they think one should treat ChatGPT’s use as plagiarism (last two rows). Most professors plan to treat the use of ChatGPT as plagiarism (69%), and expect others to do so (71%). Furthermore, the majority believe the use of ChatGPT should be treated as plagiarism (72%), and expect that their peers believe it should be treated as such (73%).
Figure 3d compares students’ intention to use ChatGPT for their studies across disciplines, GPA, and socioeconomic status. Starting with discipline, the majority of students from all four disciplines indicated that they plan on using ChatGPT. As for GPA, disregarding those who preferred not to disclose their GPA, the majority of students from all GPA brackets into which students fell indicated that they would use the tool. Similarly, with regards to socioeconomic status, the majority of students from all socioeconomic mentioned they would use ChatGPT. As for professors, Fig. 3e compares responses on whether they plan to treat the usage of ChatGPT as plagiarism across disciplines, length of teaching experience, and type of appointment at the institution. As shown in this figure, in each discipline apart from Engineering, the majority of faculty intend to treat it as plagiarism. In terms of teaching experience, again, the majority of faculty intend to do so, regardless of their experience. Similarly, for each type of appointment at the institution, the majority of faculty plan on treating the use of ChatGPT as plagiarism.

NYUAD survey responses. (a) Professors’ responses (x-axis) and Students’ responses (y-axis) to eight statements regarding ChatGPT; the statements about ethics, employment, and inequality are colored in red, green, and blue, respectively. (b - c) Descriptive norms and Injunctive norms of students and professors at NYUAD with regards to using ChatGPT, and treating it as plagiarism, respectively. (d) Comparing student responses across disciplines, GPA, and socioeconomic status. (e) Comparing professor responses across disciplines, length of teaching experience, and type of appointments.
We conclude our analysis by assessing the detectability of using ChatGPT. To this end, we use two classifiers, namely GPTZero35 and OpenAI’s own AI text classifier36, both of which are designed specifically to determine whether a body of text has been generated using AI. We use these classifiers to quantify the percentage of human submissions that are misclassified as ChatGPT, as well as the proportion of ChatGPT submissions that are misclassified as human. More formally, our goal is to construct a normalized confusion matrix for each classifier, and to quantify its false-positive and false-negative rates; see Methods for more details. Out of all 320 questions in our dataset, there were 40 questions whose answers consisted entirely of mathematical equations that are incompatible with the classifiers; those were excluded from our evaluation, leaving us with 280 questions. The results are depicted in Fig. 4a. As can be seen, OpenAI’s Text Classifier misclassifies 5% of student submissions as AI-generated, and 49% of ChatGPT’s submissions as human-generated. GPTZero has a higher false positive rate (18%), but a lower false-negative rate (32%).
Next, we analyze the degree to which these classifiers are susceptible to obfuscation attacks. We devised a simple attack that involves running the ChatGPT-generated text through Quillbot37—a popular paraphrasing/re-writing tools utilized by students worldwide. Our “Quillbot attack” was chosen since it can be readily implemented by students, without requiring any technical know-how; see Methods for a detailed description of the attack, and see Fig. 4b for a stylized example of how it works. Out of the 280 questions, 47 required answers that involved snippets of computer code. For those questions, about half of the ChatGPT submissions were already misclassified as human-generated, without any obfuscation attacks. Based on this, as well as the fact that Quillbot does not work on code snippets, we excluded those questions from the sample on which we run the Quillbot attack. The results of this evaluation are summarized in Fig. 4c. As shown in this figure, the attack is remarkably effective. In the case of OpenAI’s text classifier, the false-negative rate increased from 49% to 98%, and in the case of GTPZero, the false-negative rate increased from 32% to 95%. Figure 4d evaluates the two classifiers on various courses. In the left column, triangles represent the percentage of student submissions that are misclassified as AI-generated. In the right column, the solid and empty circles represent the percentage of ChatGPT submissions that are misclassified as human-generated before, and after, the Quillbot attack, respectively, with arrows highlighting the difference between the two circles. Note that there are a handful of courses for which there are no empty circles since they include code snippets. As the figure illustrates, in each discipline, there are courses for which students’ submissions are misclassified, as well as courses for which ChatGPT submissions are misclassified. Importantly, the Quillbot attack is successful on all courses, often increasing the false-negative rate to 100%. Supplementary Figure 6 analyzes the performance of both classifiers on different question types, and analyzes their performance along both dimensions of the Anderson and Krathwohl taxonomy38.

Evaluating AI-text detectors. Quantifying the degree to which GPTZero and AI text classifier can identify whether a body of text is AI-generated. (a) Normalized confusion matrices of GPTZero and AI text classifier. (b) An example of the Quillbot attack taken from our dataset, with changes highlighted in different colors. (c) Normalized confusion matrices after deploying the Quillbot attack. (d) Evaluating the two classifiers on different courses.
Discussion
This study aimed to provide both quantitative and qualitative insights in the perceptions and performance of current text-based generative generate AI in the context of education. We surveyed educators and students at the authors’ institution and in five countries, namely Brazil, India, Japan, UK, and USA, regarding their perspectives on ChatGPT. There is a general consensus between educators and students that the use of ChatGPT in school work should be acknowledged, and that it will increase the competitiveness of students who are non-native English speakers. Additionally, there is a consensus among students that, in their future job, they will be able to outsource mundane tasks to ChatGPT, allowing them to focus on substantive and creative work. Interestingly, the majority of surveyed students expressed their intention to use ChatGPT despite ethical considerations. For example, students in India think the use of ChatGPT in homework is unethical and should not be allowed, while those in Brazil think it is ethical and should be allowed, yet in both countries, the vast majority of surveyed students (94%) indicated that they would use it to assist with their homework and assignments in the coming semester. The negative implications of this finding go beyond the university, as studies have demonstrated that academic misconduct in school is highly correlated to dishonesty and with similar decision-making patterns in the workplace39,40.
The NYUAD survey allowed us to examine whether there exists a descriptive norm among students backed by injunctive norms regarding the use of ChatGPT, and among professors with regards to treating ChatGPT’s use as plagiarism. More specifically, we investigate whether individuals prefer to conform to these behaviours on the condition that they expect the majority of their peers would also conform to them41,42,43. Our results indicate that the majority of students plan to use ChatGPT to assist with their assignments, and believe their peers would approve of its use, implying that the use of ChatGPT is likely to emerge as a norm among students. Similarly, we find that the majority of professors plan to treat the use of ChatGPT as plagiarism tool, and believe their peers would approve of treating it as such, implying that the treatment of ChatGPT as plagiarism is likely to emerge as a norm among professors. The inherent conflict between these two could create an environment where students’ incentives suggest they should hide the use of ChatGPT while professors are eager to detect its use (and may expect their colleagues to do the same). This poses a major challenge for educational institutions to craft appropriate academic integrity policies related to generative AI broadly, and ChatGPT specifically.
When comparing ChatGPT’s performance to that of students across university-level courses, the results indicate a clear need to take “AI-plagiarism” seriously. Specifically, ChatGPT’s performance was comparable, if not superior, to students’ performance on 12 (38%) out of the 32 courses considered in our analysis. These findings, coupled with the clear ease with which students can avoid detection by current AI-text classifiers as demonstrated in our study, suggests that educational institutions are facing a serious threat with regards to current student evaluation frameworks. To date, it is unclear whether to integrate ChatGPT into academic and educational policies, and if so, how to enforce its usage. While several school districts, and even an entire country in the case of China, have already banned access to the tool44, the degree to which these measures can be effectively enforced remains unknown. Treating the use of ChatGPT as plagiarism is likely to be the most common approach to counter its usage. However, as we have shown, current measures to detect its usage are futile. Other universities have opted to change their evaluative processes to combat the tool’s usage, by returning to in-person hand-written and oral assessments13—a step that may undo decades of advancements aimed at deploying alternatives to high stakes examinations that disadvantage some categories of students and minorities45. Our findings suggest that ChatGPT could disrupt higher education’s ability to verify the knowledge and understanding of students, and could potentially decrease the effectiveness of teacher feedback to students. In education, it is crucial to confirm that what is being assessed has been completed by the person who will receive the associated grades. These grades go on to influence access to scholarships, employment opportunities, and even salary ranges in some countries and industries46. Teachers use assessment to give feedback to learners, and higher education institutions use the assessment process to credential learners. The value of the degree granted is in part linked to the validity of the assessment process. Countermeasures to academic misconduct such as plagiarism include applying detection software, such as Turnitin, and emphasising honor codes in policy and cultural norms. Higher education, in particular, is susceptible to disruption by ChatGPT because it makes it very difficult to verify if students actually have the skills and competencies their grades reflect. It disrupts how learning is assessed because demonstrated learning outcomes may be inaccurate and thus, prolific use could diminish the academic reputation of a given higher education institution. Our findings shed light on the perceptions, performance, and detectibility of ChatGPT, which could guide the ongoing discussion on whether and how educational policies could be reformed in the presence of not only ChatGPT, but also its inevitably more sophisticated successors.
Given the novelty of large language models such as ChatGPT, research on the impact of this technology on the education sector remains a potentially fruitful area of research. Future work may examine any temporal variation in sentiments towards such models as they become increasingly accessible across the globe. While our work has examined student and educator sentiments towards ChatGPT in the two months following its release, such sentiments may evolve over time, and hence, future work may evaluate any changes in these sentiments. Similarly, the utility and performance of large language models will also continue to improve over time. In the six months since the release of ChatGPT to the public, numerous other large language models have also been released47,48,49,50, including ChatGPT’s own successor, GPT 451. Hence, future work may examine the performance of newer and more complex models on courses from all levels of the educational ladder where such technology is likely to be utilized by students. Indeed, the vast majority of studies evaluating the performance of large language models have done so at a higher education level, with only a few doing so at a high-school level or lower52. Moreover, as such technology continues to evolve, so will the classifiers built to detect text, images, audio, and other forms of content created by generative artificial intelligence. Simultaneously, techniques used to evade such detection will also improve, thereby opening important research questions on the efficacy of such techniques, given their impact on regulating the use of large language models in educational contexts. While our study demonstrated potential issues that ChatGPT introduces in the process of student evaluation, it could also be potentially utilized as an assistive tool that can facilitate both teaching and learning53,54,55. For example, teachers could use large language models as a pedagogical tool to generate multiple examples and explanations when teaching55, and students could use them as a tutor that is available at their disposal to answer questions and provide explanations54. Hence, future work should examine both the issues such technology presents from the perspective of plagiarism as well as the opportunity this technology provides for students and educators in and outside of the classroom.
Methods
ChatGPT performance analysis
All faculty members at New York University Abu Dhabi (NYUAD) were invited to participate in this study and were asked to provide student assessments from their courses. In particular, they were asked to follow these steps: (i) select a course that they have taught at NYUAD; (ii) randomly select 10 text-based questions from labs, homework, assignments, quizzes, or exams in the course; (iii) randomly select three student submissions for each of the 10 questions from previous iterations of the course; (iv) convert any hand-written student submissions into digital form; (v) obtain students’ consent for the usage of their anonymized submissions in the study; and (vi) obtain students’ confirmation that they were 18 years of age or older.
When choosing their questions, participating faculty were given the following guidelines: (i) Questions should not exceed 2 paragraphs (but the answer could be of any length); (ii) No multiple-choice questions were allowed; (iii) No images, sketches, or diagrams were allowed in the question nor the answer; (iv) No attachments are allowed in the question nor the answer (i.e., a paper or a report to be critiqued, or summarized etc.); (v) The question could include a table, and the answer could have a table to be filled; (vi) The question and the answer could include programming code; (vii) The question and the answer could include mathematics (e.g., equations); and (viii) Fill-the-gap questions were allowed.
For each course, ChatGPT was used to generate three distinct answers to each of the 10 questions. More specifically, the question’s text was entered into ChatGPT verbatim, without any additional prompt or text. To generate unique responses, the “Regenerate response” button was clicked until a unique answer was generated. Any changes in the wording or phrasing in the answer was considered to be a unique response. This step was carried out between the 13th and 29th of January, 2023. Both students’ and ChatGPT’s answers were then compiled into a single document in random order, labelled as “Submission 1” to “Submission 6”. The faculty responsible for each course was asked to recruit three graders (either teaching assistants, postdoctoral fellows, research assistants, PhD students, or senior students who have taken the course before and obtained a grade of A or higher), and to provide the graders with rubrics and model solutions to each question. The participating faculty was instructed not to inform the graders that some of the submissions are AI-generated. Each grader was compensated for their time at a rate of $15 per hour. The participating faculty vetted the graders’ output and ensured that the grading is in line with the rubrics.
For each of their 10 questions, the faculty were asked to answer the following: (i) Where does the question fall along the “knowledge” dimension and the “cognitive process” dimension of the Anderson and Krathwohl taxonomy34; (ii) Does the question or the answer involve mathematics? (Yes/No); (iii) Does the question or the answer involve snippets of computer code? (Yes/No); (iv) Does the question or the answer require knowledge of a specific author, scientific paper/book, or a particular technique/method? (Yes/No); and (v) Is the question a trick question? (Yes/No). To explain what a trick question is, the following description was provided to participating faculty: “A trick question is a question that is designed to be difficult to answer or understand, often with the intention of confusing or misleading the person being asked. Trick questions are often used in games and puzzles, and can be used to test a person’s knowledge or problem-solving skills”.
Survey
Participants were recruited from Brazil, India, Japan, United Kingdom, and United States, with a minimum of 200 students and 100 educators per country; see Supplementary Table 4, 5 for descriptive statistics, and Supplementary Note 1.1, 1.2 for the complete survey instrument. The survey was piloted in the United States on Prolific with open-ended questions to investigate that respondents did not find anything odd or surprising about survey questions, and also to ensure no new topics emerged about ChatGPT that the opinion statements covered. Data collection was conducted using the SurveyMonkey platform. Studies have shown the validity of using this platform to conduct surveys used in academic research, in addition to the numerous studies which use such platforms for conducting surveys globally56,57,58,59,60. The platform utilizes email and location verification for fraud detection and ID exclusions, thereby guarding against duplicate and bot-submitted responses. SurveyMonkey enables the targeting of samples with pre-specified demographics. Specifically, in the US, we identified educators as those whose job is “educator (e.g., teacher, lecturer, professor),” and identified students as those who had a “student status.” As for the remaining four countries, the above filters were not available on SurveyMonkey. Therefore, we recruited 100 respondents whose primary role is “Faculty/Teaching Staff” and recruited 200 respondents whose occupation was “studies.” In addition, we ensured that the analytical sample only contains current students and educators who are either teachers or professors based on respondents’ self-reports. Respondents filled out the survey in the official language of their country. The global surveys were conducted on the 19th and 20th of January, 2023.
As for the NYUAD survey, it includes responses from 151 students (out of a total of 2103, 7.2%) and 60 professors (out of a total of 393, 15.2%) collected between January 23rd and February 3rd, 2023. This survey used the same questions as those used in the global survey, but with a few additions. Specifically, for students, we asked them to specify their current cumulative GPA, year of study, as well as empirical and normative expectations43,61 related to the use of ChatGPT among students. As for faculty, we asked them about the number of years they have been teaching, their academic division, their appointment type (e.g., tenure, tenure track, contract, or visiting), as well as their empirical and normative expectations surrounding the treatment of ChatGPT as plagiarism. We excluded student participants who indicated that they aware of our study, as well as faculty members who coauthored the paper. Descriptive statistics can be found in Supplementary Tables 6, 7, while the survey questions can be found in Supplementary Notes 1.3, 1.4.
Obfuscation attacks
Once all student and ChatGPT submissions were collected for all courses, they were used to test two classifiers designed specifically to determine whether a body of text has been generated using AI, namely, GPTZero35, and OpenAI’s own AI text classifier36. The former classifies text into five categories: (i) “likely to be written entirely by a human”, (ii) “most likely human written but there are some sentences with low perplexities”, (iii) “more information is needed”, (iv)“includes parts written by AI”, (v) “likely to be written entirely by AI”. As for the latter, it classifies text into five categories: (i) very unlikely, (ii) unlikely, (iii) unclear if it is, (iv) possibly, or (v) likely AI-generated. We start our analysis by examining the proportion of human submissions that are misclassified as ChatGPT, as well as the proportion of ChatGPT submissions that are misclassified as human. More formally, our goal is to construct a normalized confusion matrix for each classifier, to quantify its false-positive and false-negative rates. For both classifiers, ChatGPT submissions that are classified as categories (i) or (ii) are treated as false negatives, while human submissions that are classified as (iv) or (v) are treated as false positives. As for submissions classified as (iii), we consider them to be classified as human. This decision is motivated by our context, where the classifier is used to detect AI-plagiarism. Given that a student is arguably “innocent until proven otherwise”, having an inconclusive classification means that, as far as the teacher is concerned, there is no conclusive evidence incriminating the student of AI-plagiarism, implying that such a classification has practically the same consequences as being classified as human. Based on this, ChatGPT submissions that are classified as (iii) are treated as false negatives.
To evaluate the classifiers’ susceptibility to obfuscation attacks, we devised a simple attack that involves running the ChatGPT-generated text through Quillbot. Our attack starts by setting the “Synonym” slider in Quillbot to the highest level, which maximizes the number of modifications introduced to the text. Then, we run every ChatGPT-generated submission through each of the “Modes” available on Quillbot, each resulting in a different output. Each output is then re-analyzed on both classifiers, and if any of them manages to flip the text classification from category (iv) or (v) to any other category, the attack on this particular submission is considered successful.
Ethical approval
The research was approved by the Institutional Review Board of New York University Abu Dhabi (HRPP-2023-5). All research was performed in accordance with relevant guidelines and regulations. Informed consent was obtained from all participants in every segment of this study.
Data availability
All of the data used in our analysis can be found at the following repository: https://github.com/comnetsAD/ChatGPT.
Change history
10 October 2023
A Correction to this paper has been published: https://doi.org/10.1038/s41598-023-43998-8
References
Larsen, B. Generative AI: A game-changer society needs to be ready for. https://www.weforum.org/agenda/2023/01/davos23-generative-ai-a-game-changer-industries-and-society-code-developers/.
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C. & Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv preprintarXiv:2204.06125 (2022).
Mostaque, E. Stable Diffusion public release (2022). https://stability.ai/blog/stable-diffusion-public-release.
Music, A. AI music composition tools for content creators. https://www.ampermusic.com/.
Plaugic, L. Musician Taryn Southern on composing her new album entirely with AI (2017). https://www.theverge.com/2017/8/27/16197196/taryn-southern-album-artificial-intelligence-interview.
Sample, I. ChatGPT: What can the extraordinary artificial intelligence chatbot do? (2023). https://www.theguardian.com/technology/2023/jan/13/chatgpt-explainer-what-can-artificial-intelligence-chatbot-do-ai.
Watkins, M. D. ’A revolution in productivity’: What ChatGPT could mean for business (2022). https://www.imd.org/ibyimd/technology/a-revolution-in-productivity-what-chatgpt-could-mean-for-business/.
Mollman, S. ChatGPT gained 1 million users in under a week. Here’s why the AI chatbot is primed to disrupt search as we know it (2022). https://finance.yahoo.com/news/chatgpt-gained-1-million-followers-224523258.html.
Vincent, J. The scary truth about AI copyright is nobody knows what will happen next (2022). https://www.theverge.com/23444685/generative-ai-copyright-infringement-legal-fair-use-training-data.
Vincent, J. AI art tools Stable Diffusion and Midjourney targeted with copyright lawsuit (2023). https://www.theverge.com/2023/1/16/23557098/generative-ai-art-copyright-legal-lawsuit-stable-diffusion-midjourney-deviantart.
Korn, J. Getty Images suing the makers of popular AI art tool for allegedly stealing photos (2023). https://edition.cnn.com/2023/01/17/tech/getty-images-stability-ai-lawsuit/index.html.
Shen-Berro, J. New York City schools blocked ChatGPT. Here’s what other large districts are doing (2023). https://www.chalkbeat.org/2023/1/6/23543039/chatgpt-school-districts-ban-block-artificial-intelligence-open-ai.
Cassidy, C. Australian universities to return to ‘pen and paper’ exams after students caught using AI to write essays (2023). https://www.theguardian.com/australia-news/2023/jan/10/universities-to-return-to-pen-and-paper-exams-after-students-caught-using-ai-to-write-essays.
Huang, K. Alarmed by A.I. Chatbots, universities start revamping how they teach (2023). https://www.nytimes.com/2023/01/16/technology/chatgpt-artificial-intelligence-universities.html.
Vincent, J. Top AI conference bans use of ChatGPT and AI language tools to write academic papers (2023). https://www.theverge.com/2023/1/5/23540291/chatgpt-ai-writing-tool-banned-writing-academic-icml-paper.
Tools such as ChatGPT threaten transparent science; here are our ground rules for their use (2023). https://www.nature.com/articles/d41586-023-00191-1.
Else, H. Abstracts written by ChatGPT fool scientists. Nature 613, 423 (2023).
Lipman, J. & Distler, R. Schools shouldn’t ban access to ChatGPT (2023). https://time.com/6246574/schools-shouldnt-ban-access-to-chatgpt/.
Roose, K. Don’t ban ChatGPT in schools. Teach with it. (2023). https://www.nytimes.com/2023/01/12/technology/chatgpt-schools-teachers.html.
Gilson, A. et al. How well does ChatGPT do when taking the medical licensing exams? The implications of large language models for medical education and knowledge assessment. medRxiv 2022–12 (2022).
Kung, T. H. et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLoS Digital Health 2, e0000198 (2023).
Sallam, M. ChatGPT utility in healthcare education, research, and practice: systematic review on the promising perspectives and valid concerns. Healthcare 11, 887 (2023).
Fijačko, N., Gosak, L., Štiglic, G., Picard, C. T. & Douma, M. J. Can ChatGPT pass the life support exams without entering the American heart association course? Resuscitation185 (2023).
Ibrahim, H., Asim, R., Zaffar, F., Rahwan, T. & Zaki, Y. Rethinking homework in the age of artificial intelligence. IEEE Intell. Syst. 38, 24–27 (2023).
MacNeil, S. et al. Generating diverse code explanations using the GPT-3 large language model. In Proceedings of the 2022 ACM conference on international computing education research, 37–39 (2022).
Qureshi, B. Exploring the use of chatgpt as a tool for learning and assessment in undergraduate computer science curriculum: Opportunities and challenges. arXiv preprintarXiv:2304.11214 (2023).
Choi, J. H., Hickman, K. E., Monahan, A. & Schwarcz, D. ChatGPT goes to law school. Available at SSRN (2023).
Hargreaves, S. ‘Words Are Flowing Out Like Endless Rain Into a Paper Cup’: ChatGPT & Law School Assessments. The Chinese University of Hong Kong Faculty of Law Research Paper (2023).
Cribben, I. & Zeinali, Y. The benefits and limitations of ChatGPT in business education and research: A focus on management science, operations management and data analytics. Operations Management and Data Analytics (March 29, 2023) (2023).
Pavlik, J. V. Collaborating with ChatGPT: Considering the implications of generative artificial intelligence for journalism and media education. J. Mass Commun. Educat. 78, 84–93 (2023).
Ji, H., Han, I. & Ko, Y. A systematic review of conversational AI in language education: Focusing on the collaboration with human teachers. J. Res. Technol. Educ. 55, 48–63 (2023).
Hong, W. C. H. The impact of ChatGPT on foreign language teaching and learning: Opportunities in education and research. J. Educat. Technol. Innovat.5 (2023).
Pursnani, V., Sermet, Y. & Demir, I. Performance of ChatGPT on the US fundamentals of engineering exam: Comprehensive assessment of proficiency and potential implications for professional environmental engineering practice. arXiv preprintarXiv:2304.12198 (2023).
Krathwohl, D. R. A revision of Bloom’s taxonomy: An overview. Theory Pract. 41, 212–218 (2002).
GPTZero: Humans deserve the truth. https://gptzero.me/. Accessed: 2023-02-03.
QuillBot’s AI-powered paraphrasing tool will enhance your writing. https://quillbot.com/. Accessed: 2023-02-03.
Wilson, L. O. Anderson and Krathwohl Bloom’s taxonomy revised understanding the new version of Bloom’s taxonomy. The Second Principle 1–8 (2016).
Harding, T. S., Passow, H. J., Carpenter, D. D. & Finelli, C. J. An examination of the relationship between academic dishonesty and professional behavior. In 33rd Annual frontiers in education, 2003. FIE 2003., vol. 3, S2A–6 (IEEE, 2003).
Nonis, S. & Swift, C. O. An examination of the relationship between academic dishonesty and workplace dishonesty: A multicampus investigation. J. Educ. Bus. 77, 69–77 (2001).
Cialdini, R. B., Reno, R. R. & Kallgren, C. A. A focus theory of normative conduct: Recycling the concept of norms to reduce littering in public places. J. Pers. Soc. Psychol. 58, 1015 (1990).
Bicchieri, C. Norms, preferences, and conditional behavior. Polit. Philos. Econ. 9, 297–313 (2010).
Bicchieri, C. The grammar of society: The nature and dynamics of social norms (Cambridge University Press, Cambridge, 2005).
Schwartz, E. H. ChatGPT banned on Chinese social media app WeChat (2022). https://voicebot.ai/2022/12/28/chatgpt-banned-on-chinese-social-media-app-wechat/.
Johnson, D. D., Johnson, B., Farenga, S. J. & Ness, D. Stop High-Stakes Testing: An Appeal to America’s Conscience (Rowman & Littlefield, 2008).
Kittelsen Røberg, K. I. & Helland, H. Do grades in higher education matter for labour market rewards? A multilevel analysis of all Norwegian graduates in the period 1990–2006. J. Educ. Work 30, 383–402 (2017).
Google (2023). https://bard.google.com/.
HuggingFace (2023). https://huggingface.co/chat/.
DeepMind (2023). https://www.deepmind.com/blog/building-safer-dialogue-agents.
TII (2023). https://falconllm.tii.ae/.
OpenAI (2023). https://openai.com/research/gpt-4.
Lo, C. K. What is the impact of ChatGPT on education? A rapid review of the literature. Educat. Sci. 13, 410 (2023).
Mollick, E. R. & Mollick, L. New modes of learning enabled by ai chatbots: Three methods and assignments. Available at SSRN (2022).
Mollick, E. & Mollick, L. Assigning AI: Seven approaches for students, with prompts. arXiv preprintarXiv:2306.10052 (2023).
Mollick, E. R. & Mollick, L. Using AI to implement effective teaching strategies in classrooms: Five strategies, including prompts. Including Prompts (March 17, 2023) (2023).
Bentley, F. R., Daskalova, N. & White, B. Comparing the reliability of Amazon Mechanical Turk and Survey Monkey to traditional market research surveys. In Conf. Hum. Factors Comput. Syst. - Proc., 1092–1099 (2017).
Mielke, J., Vermaßen, H. & Ellenbeck, S. Ideals, practices, and future prospects of stakeholder involvement in sustainability science. Proc. Natl. Acad. Sci. U.S.A. 114, E10648–E10657 (2017).
Parsa, S. et al. Obstacles to integrated pest management adoption in developing countries. Proc. Natl. Acad. Sci. U.S.A. 111, 3889–3894 (2014).
Evans, R. R. et al. Developing valid and reliable online survey instruments using commercial software programs. J. Consum. Health Internet 13, 42–52 (2009).
Péloquin, K. & Lafontaine, M.-F. Measuring empathy in couples: Validity and reliability of the interpersonal reactivity index for couples. J. Pers. Assess. 92, 146–157 (2010).
Bicchieri, C. Norms in the Wild (Oxford University Press, Oxford, 2016).
Acknowledgements
K.M. acknowledges funding from the NYUAD Center for Interacting Urban Networks (CITIES), funded by Tamkeen under the NYUAD Research Institute Award CG001.
Author information
Authors and Affiliations
Contributions
T.R. and Y.Z. conceived the study and designed the research; H.I., B.B, N.G., T.R., and Y.Z. wrote the manuscript; H.I., BA.A., and B.B performed the literature review; H.I., T.R., and Y.Z. collected the data; K.M. designed the surveys and ran the NYUAD survey; H.I. and Y.Z. ran the global survey; H.I., F.L., R.A., S.B., T.R., and Y.Z. analyzed the data and ran the experiments; H.I., F.L., R.A., S.B., T.R., and Y.Z. designed the obfuscation attack; H.I., F.L., R.A., S.B., and Y.Z. ran the obfuscation attack; H.I., F.L., T.R., and Y.Z. produced the visualizations; W.A., T.A., BE.A., R.B., J.B., E.B., K.C., M.C., M.D., B.G.S., Z.E., D.F., AL.G., AN.G., N.H., A.H., A.K., L.K., K.K., K.L., S.S.L., S.M., M.M., D.M., A.M., M.P., A.R., D.Z., N.G., K.M., T.R., and Y.Z. provided course questions and answers, and recruited graders.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: In the original version of this Article Dania Zantout was incorrectly affiliated with ‘Division of Social Science, New York University Abu Dhabi, Abu Dhabi, UAE’. The correct affiliation is listed here: Division of Science, New York University Abu Dhabi, Abu Dhabi, UAE.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ibrahim, H., Liu, F., Asim, R. et al. Perception, performance, and detectability of conversational artificial intelligence across 32 university courses. Sci Rep 13, 12187 (2023). https://doi.org/10.1038/s41598-023-38964-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-38964-3
This article is cited by
-
Robots learning to imitate surgeons — challenges and possibilities
Nature Reviews Urology (2024)
-
The model student: GPT-4 performance on graduate biomedical science exams
Scientific Reports (2024)
-
A multinational study on the factors influencing university students’ attitudes and usage of ChatGPT
Scientific Reports (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
