
Abstract
This article presents and investigates a modified version of the Weibull distribution that incorporates four parameters and can effectively represent a hazard rate function with a shape resembling a bathtub. Its significance in the fields of lifetime and reliability stems from its ability to model both increasing and decreasing failure rates. The proposed distribution encompasses several well-known models such as the Weibull, extreme value, exponentiated Weibull, generalized Rayleigh, and modified Weibull distributions. The paper derives key mathematical statistics of the proposed distribution, including the quantile function, moments, moment-generating function, and order statistics density. Various mathematical properties of the proposed model are established, and the unknown parameters of the distribution are estimated using different estimation techniques. Furthermore, the effectiveness of these estimators is assessed through numerical simulation studies. Finally, the paper applies the new model and compares it with various existing distributions by analyzing two real-life time data sets.
Similar content being viewed by others
Introduction
Statistical models are crucial in comprehending and predicting real-world phenomena. In numerous applications, it becomes necessary to utilize enhanced versions of well-established distributions. These new distributions offer greater flexibility when it comes to simulating real-world data with high skewness and kurtosis. Among the advantages of the new distribution is its suitability for various fields, including medical, financial, and engineering applications. Selecting the most appropriate statistical model for data analysis is both critical and challenging. For further exploration on the topic of distributions, I recommend referring to the following references: Almongy et al.1, Shafiq et al.2, and Meriem et al.3. These sources provide additional insights and information.
The Weibull distribution is extensively employed in the analysis of lifetime data and has demonstrated notable efficacy in capturing failure rates that display monotonic patterns. Its density shapes, which manifest as either right or left-skewed, render it well-suited for survival and reliability analysis. Nevertheless, the Weibull model is inadequate for accurately representing non-monotonic failure rates, such as those characterized by hazard functions exhibiting bathtub-shaped or upside-down bathtub-shaped patterns. To address this limitation, researchers have developed enhanced versions of the Weibull distribution that can accurately accommodate different hazard function shapes to represent complex failure models accurately. Xie and Lai4 introduced the additive Weibull distribution, incorporating a bathtub-shaped hazard function. Bebbington et al.5 proposed the flexible Weibull distribution, which modifies the hazard function to exhibit an increasing pattern followed by a bathtub shape. Lai et al.6 presented a new Weibull distribution model with three parameters and a bathtub-shaped hazard function.
Notwithstanding the progress made in the field, numerous prevailing models exhibit limited flexibility and may not yield optimal fits when applied to real-world data in engineering and related domains. To address this issue, researchers have employed diverse techniques to develop alternative distributions that enhance the flexibility of existing models. One approach involves generating a new distribution by combining two cumulative hazard rate (CHR) functions through a mixture model. It can be written as below:
with \(H\left( x\right)\) denoted the cumulative hazard rate function satisfies the following conditions
-
1.
\(\mathop {\lim }\limits _{x\rightarrow 0} H\left( x\right) =0\),
-
2.
\(\mathop {\lim }\limits _{x\rightarrow \infty } H\left( x\right) =\infty\),
-
3.
\(H\left( x\right)\) is a differentiable non-negative and non-decreasing.
By using Eq. (1), the generated cumulative density function (cdf) and probability density function (pdf) are, respectively, given by
Some generalized distributions generated according to (2) and (3) are listed in Table 1.
Bagdonavicius and Nikulin10 proposed an extension of the Weibull distribution, namely power generalized Weibull (PGW) distribution, and its cdf and pdf can be described as
and
and the relationship between cdf and pdf is given by
respectively, where \(\alpha\) and \(\theta\) are two shape parameters and \(\lambda\) is a scale parameter. PGW distribution contains constant, monotone (increasing or decreasing), bathtub-shaped, and unimodal hazard shapes. For more details about this extension, see, for example, Bagdonavicius and Nikulin11, Voinov et al.12, and Kumar and Dey13.
In this research article, we introduce a novel statistical model called the modified power generalized Weibull (MPGW) distribution. Four parameters characterize the MPGW distribution and exhibit several significant properties. This distribution’s probability density function (pdf) can assume different forms, including constant, monotonic (increasing or decreasing), and unimodal. Moreover, the hazard rate function (hrf) associated with the MPGW distribution can take on various shapes, such as constant, monotonic, bathtub, and upside-down bathtub.
We investigate several mathematical properties of the MPGW distribution and explore its applicability in different contexts. To estimate the model parameters, we employ various estimation techniques, including maximum likelihood estimation (MLE), the maximum product of spacing (MPS), least square estimators (LSE), and Cramer-von Mises estimators (CVE). These estimation methods enable us to determine the most suitable parameter values for the MPGW distribution based on the available data.
The proposed distribution was used in many fields of science such as engineering and bio-sciences as it can model many kinds of data because of the distribution’s great flexibility. For more details about similar papers see12,14 The rest of this paper is structured as follows. Section “The formulation of the MPGW distribution” described the new MPGW model and provided different distributional properties. Further, numerous statistical properties for the proposed distribution were introduced in Section “Statistical properties”. In Section “Estimation methods”, we established different estimation procedures for the unknown parameters of the suggested distribution. Monte Carlo simulation studies are performed in Section “Numerical simulation” to compare the proposed estimators. Finally, in Section “Real data analysis”, two real data sets defined by the survival field are analyzed for validation purposes, and we conclude the article in Section “Conclusion”.
Main contribution and novelty
This research paper presents a noteworthy advancement in the field of probability distributions by introducing a novel four-parameter generalization of the Weibull distribution. The proposed generalization offers the ability to model a hazard rate function that exhibits a bathtub-shaped pattern. The bathtub-shaped hazard rate function is of great interest in various domains, as it accurately captures the characteristics of failure rates observed in certain real-world scenarios. To evaluate the efficacy of the newly proposed model, we conducted an empirical investigation using two distinct real-life time data sets. These data sets were carefully selected to encompass diverse applications and ensure the generalizability of the findings. We could assess the model’s effectiveness in practical applications by employing the proposed four-parameter generalized Weibull distribution and comparing its performance with several existing distributions. Through a comprehensive analysis of the results, valuable insights were obtained regarding the capabilities and advantages of the novel four-parameter generalized Weibull distribution when applied to real-world data sets. The comparison of the proposed model with existing distributions provided a rigorous evaluation framework, enabling a thorough understanding of its performance in different scenarios. This study contributes to the existing body of knowledge by demonstrating the applicability and usefulness of the new distribution in capturing the complexities of time-to-failure data.
The formulation of the MPGW distribution
The MPGW distribution is generated by using \(H_{1} \left( x\right)\) of the PGW distribution and \(H_{2} \left( x\right)\) of the exponential distribution in Eqs. (2) and (3). Its cdf and pdf can be defined as the following
and the relationship between cdf and pdf can be written as
where \(\theta >0\), \(\lambda ,\alpha ,\beta \ge 0\) such that \(\lambda +\beta >0\) and \(\alpha +\beta >0\).
The hazard rate function (hrf) of the MPGW model can be expressed as
Table 2 summarized several well-known lifetime distributions from the newly suggested distribution, which is quite flexible.
Statistical properties
In this part of the study, we provided some mathematical properties of the MPGW distribution, especially moments, skewness, kurtosis, and asymmetry.
Behavior of the pdf of the MPGW distribution
The pdf limits of the MPGW distribution are
From the pdf of the MPGW distribution, the first derivative of the pdf is
where \(\psi \left( x\right) =\left( h\left( x\right) \right) ^{2} -h\mathrm{{'} }\left( x\right)\). It is clear that \(f\mathrm {{'} }\left( x\right)\) and \(\psi \left( x\right)\) have the same sign, and \(\psi \left( x\right)\) has not an explicit solution. Therefore, we can discuss the following special cases which depend on \(\theta\) and \(\alpha\):
-
Case 1: For \(\theta \le 1\) and \(\alpha \theta \le 1\), \(\psi \left( x\right)\) is negative which means \(f\left( x\right)\)is decreasing in x
-
Case 2: For \(\theta =1\), \(\psi \left( x\right)\) reduces to
$$\begin{aligned} \left( \alpha -1\right) \alpha \lambda ^{2} \left( 1+x\lambda \right) ^{\alpha -2} -\left( \beta +\alpha \lambda \left( 1+x\lambda \right) ^{\alpha -1} \right) ^{2}, \end{aligned}$$which has no solution for \(\alpha \le 1\) and the pdf becomes decreasing for all x.
-
Case 3: For \(\alpha =1\), \(\psi \left( x\right)\) reduces to
$$\begin{aligned} \theta \lambda \left( \theta -1\right) x^{\theta -2} -\left( \beta +\theta \lambda x^{\theta -1} \right) ^{2}, \end{aligned}$$which has no solution for \(\theta \le 1\) and the pdf becomes decreasing for all x.
-
Case 4: For\(\beta =0\) and \(\theta =1\), \(\psi \left( x\right)\) reduces to
$$\begin{aligned} \alpha \lambda ^{2} \left( 1+\lambda x\right) ^{-2+\alpha } \left( \alpha \left( 1-\left( 1+\lambda x\right) ^{\alpha } \right) -1\right) , \end{aligned}$$which has a solution for \(\alpha \mathrm {>}1\), therefore the mode (M) becomes
$$\begin{aligned} M=\frac{\left( 1-1/\alpha \right) ^{1/\alpha } -1}{\lambda }. \end{aligned}$$Case 5: For \(\alpha =1\)and \(\beta =0\), \(\psi \left( x\right)\) reduces to
$$\begin{aligned} \theta \lambda x^{\theta -2} \left( \theta \left( 1-x^{\theta } \lambda \right) -1\right) , \end{aligned}$$which has a solution for \(\theta \mathrm {>}1\), therefore the mode becomes
$$\begin{aligned} M=\left( \left( \theta -1\right) /\theta \lambda \right) ^{1/\theta }. \end{aligned}$$Case 6: For\(\alpha =1\), \(\beta =0\) and \(\theta =2\), \(\psi \left( x\right)\) reduces to
$$\begin{aligned} 2\lambda \left( 1-2x^{2} \lambda \right) , \end{aligned}$$in this case, the mode becomes
$$\begin{aligned} M=1/\sqrt{2\lambda }. \end{aligned}$$For different parameter values, Fig. 1 depicts the pdf plots of MPGW distribution. The graphs show that the pdf of MPGW is decreasing and uni-modal which gives our proposed model the superiority for analyzing lifetime data.
Figure 1 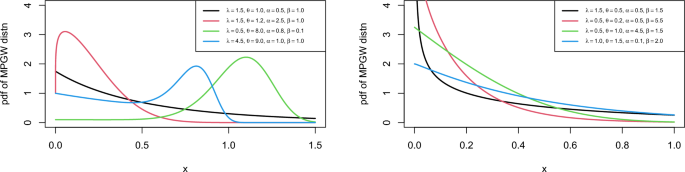
Plot for PDF of the MPGW model for different values of the parameters.

Behavior of the hazard rate function of the MPGW distribution
The hrf limits of the MPGW distribution are
and
The study of the shape of the hrf needs an analysis of the first derivative \(h\mathrm {{'} }\left( x\right)\) and it can be described as
where \(\eta \left( x\right) =\theta -1+\lambda \left( \alpha \theta -1\right) x^{\theta }\). Clearly, \(h\mathrm {{'} }\left( x\right)\) and \(\eta \left( x\right)\) have the same sign and \(\eta \left( x\right)\) has critical value at the point
From \(\eta \left( x\right)\), it can be noted that the hrf has different shapes written as:
-
Case1: \(\alpha \theta \mathrm {>}1\).
-
1.
If \(\theta \ge 1\), then \(h\mathrm {{'} }\left( x\right) >0\) and \(h\left( x\right)\) are monotonically increasing.
-
2.
If \(\theta \mathrm {<}1\), then the hrf is decreasing for \(x\mathrm {<}x^{*}\) and increasing for\(x\mathrm {>}x^{*}\). Hence, the hrf has a bathtub shape.
-
1.
-
Case2: \(\alpha \theta \mathrm {<}1\).
-
1.
If \(\theta \le 1\), then \(h\mathrm {{'} }\left( x\right) \mathrm {<}0\) and \(h\left( x\right)\) are monotonically decreasing.
-
2.
If \(\theta \mathrm {>}1\), this means \(\mathrm {0<}\alpha \mathrm {<}1\)and \(\mathrm {1<}\theta \mathrm {<}1/\alpha\), then the hrf is increasing for \(x\mathrm {<}x^{*}\)and the hrf is decreasing for \(x\mathrm {>}x^{*}\). Hence, the hrf has an upside-down bathtub shape.
-
1.
-
Case3: \(\alpha \theta =1\).
-
1.
\(h\mathrm {{'} }\left( x\right) \mathrm {=}0\) and \(h\left( x\right)\) are constant when \(\theta\).
-
2.
\(h\mathrm {{'} }\left( x\right) >0\) and \(h\left( x\right)\) are monotonically increasing where \(\theta \mathrm {>}1\).
-
3.
\(h\mathrm {{'} }\left( x\right) \mathrm {<}0\) and \(h\left( x\right)\) are monotonically decreasing where \(\theta \mathrm {<}1\).
Figure 2 displays the plot of hrf of MPGW model for multiple parameter values. The plots of hrf of MPGW are more efficient in modeling lifetime data.
Figure 2 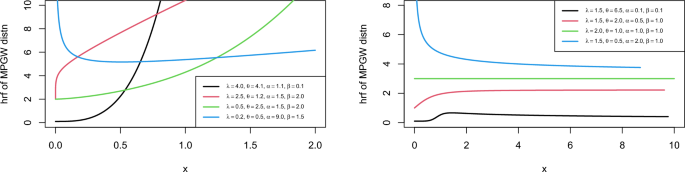
Plot for PDF of the MPGW distribution for different values of the parameters.
-
1.

Moments
Theorem 1
For any \(r\in N\), the rth raw moment of the MPGW model can be written as
Proof
By the pdf (8) and the definition of the rth raw moment, we have
In the general case, we suppose that \(\lambda\), \(\alpha\) and \(\beta \mathrm{>}0\). Using the following expansion of \(\textrm{e}^{-\beta x}\)given by
then Eq. (12) is rewritten as
Let \(I\left( r,i\right) =\int _{0}^{\infty }x^{r+i} \textrm{e}^{-\left( 1+\lambda x^{\theta } \right) ^{\alpha } } dx\) and \(u=\left( 1+\lambda x^{\theta } \right) ^{\alpha }\), we have
By using the expansion of \(\left( 1-u^{-1/\alpha } \right) ^{\left( r+i+1\right) /\theta -1}\) where \(\left| u^{-1/\alpha } \right| \mathrm{<}1\), above integral is described as
Hence, after some algebra, we get
let \(k\left( r,i\right) =\int _{0}^{\infty }x^{r+i+\theta -1} \left( 1+\lambda x^{\theta } \right) ^{\alpha -1} \textrm{e}^{-\left( 1+\lambda x^{\theta } \right) ^{\alpha } } dx\) and \(u=\left( 1+\lambda x^{\theta } \right) ^{\alpha }\), we have
Hence, after some algebra, we obtain
finally, substituting (14) and (15) into (13), we have
which completes the proof. \(\square\)
According to the results given in theorem 3, the mean and the variance of the proposed model, respectively, are \(\mu =\mu _{1}^{\mathrm{{'} }}\) and \(\sigma ^{2} =\mu _{2}^{\mathrm{{'} }} -\mu ^{2}\). As well as the measures of skewness, kurtosis, and asymmetry of the MPGW are given, respectively, by
and
Table 3 shows some necessary MPGW measures for various parameter combinations computed using the R program.
From the values of Table 3 it can be deduced that
-
1.
If \(\alpha\) increases and for fixed \(\beta\), \(\lambda\) and \(\theta\), the values of Mean and Variance of the suggested MPGW model tend to decrease, while the values of \(\beta _1\), \(\beta _2\) and \(\beta _3\) are increasing. The same result for \(\lambda\) with fixed \(\alpha\), \(\beta\) and \(\theta\).
-
2.
For fixed values of \(\alpha\), \(\lambda\) and \(\theta\) and for \(\beta\) augment, all values of Mean, Variance, \(\beta _1\), \(\beta _2\) and \(\beta _3\) of the MPGW model are decrease..
-
3.
The MPGW distribution is a flexible model for explaining more data sets.
Estimation methods
Here, we considered four estimation techniques for constructing the estimation of the unknown parameters for MPGW model. The determination of the estimate parameters using different procedures has been made available to various authors such as17,18,19.
Maximum likelihood estimation and its asymptotics
Let \(\{x_1, \ldots , x_n\}\) be a a random sample coming from MPGW\((\alpha , \beta , \lambda , \theta )\). Then, the corresponding log-likelihood function is described by
with \(\Theta =(\alpha , \beta , \lambda , \theta )\). Consequently, with respect to \(\alpha , \beta , \lambda\), and \(\theta\) and by taking the derivatives of (16), we can be determined the estimates \({\hat{\alpha }}_{MLE}\), \({\hat{\beta }}_{MLE}\), \({\hat{\lambda }}_{MLE}\) and \({\hat{\theta }}_{MLE}\) and these estimates are given respectively by
and
These estimates can be solved numerically using various approach methods, including Newton Raphson, bisection, or fixed point methods.
Least square estimation
Let \(x_1,\ldots ,x_n\) be a random sample from MPGW\((\alpha , \beta , \lambda , \theta )\) and \(x_{1:n}<\cdots <x_{n:n}\) represent the order statistics of the random sample from the MPGW model. The least-square estimator (LSE) which introduced by20) of \(\alpha , \beta , \lambda , \theta\), noted by \({\hat{\alpha }}_{LSE}\), \({\hat{\beta }}_{LSE}\), \({\hat{\lambda }}_{LSE}\) and \({\hat{\theta }}_{LSE}\)) can be described by minimizing
Maximum product of spacings
For \(x_1\le \cdots \le x_n\) representing the ordered statistics random sample from MPGW distribution, the maximum product of the spacings estimation (MPS) estimators of the proposed model resulted by maximizing the following equation
Cramer-von Mises minimum distance estimators
The Cramer-von Mises-type minimum distance estimators (CVEs) \({\hat{\alpha }}_{CVE}\), \({\hat{\beta }}_{CVE}\), \({\hat{\lambda }}_{CVE}\) and \({\hat{\theta }}_{CVE}\) of \(\alpha , \beta , \lambda , \theta\) are described respectively by minimizing
Numerical simulation
Here in this part of the work, we performed some results from simulation experiments so that you may assess how well the various estimating techniques provided in Section “Estimation methods” using different sample sizes, \(n = \{100, 300, 500, 700, 1000\}\) and different sets of initial parameters. After repeating the process \(K = 1000\), we generate different random samples from the suggested model. The following algorithm can be easily used to generate samples from the MPGW distribution
-
1.
Step 1: Generate u from U(0,1).
-
2.
Step 2: Generate x as x is the solution of equation \(1-\textrm{e}^{1-\left( 1+\lambda x^{\theta } \right) ^{\alpha } -\beta x}=u\).
Further, we compute the average values of biases (AB), mean square errors (MSEs), and mean relative errors (MREs) by the following equations
where \(\pmb \Theta\)=(\(\alpha , \beta , \lambda ,\theta\)). All calculations were performed by using the R software version 4.1.2.
Tables 4, 5 and 6 summarized the results of the simulation studies for the proposed model using the four estimation procedures. From the results, it can be concluded that as the sample size increases, all estimation methods of the proposed distribution approach to their initial guess of values. Furthermore, in all cases, the values of MSEs, and MREs tend to decrease. This ensures the consistency and asymptotically impartiality of all estimators. Additionally, by taking the MSE as an optimally criteria, we deduce that MLEs outperform alternative methods of estimate for the MPGWD.
Real data analysis
Through performing goodness-of-fit tests, we utilize two data sets to contrast the MPGW model with PGW distribution and the other four alternative existing models to see the effectiveness of the new model. The compared distributions:
-
1.
Additive modified Weibull (AMW) distribution4 with pdf defined as follows
$$\begin{aligned} g\left( x;\lambda ,\theta ,\alpha ,\beta \right) =\left( \alpha \theta x^{\theta -1} +\lambda \beta x^{\lambda -1} \right) \exp \left( -\alpha x^{\theta } -\beta x^{\lambda } \right) ;\, \, x\ge 0,\, \, \alpha ,\beta \ge 0,\theta \mathrm {>}0,0\mathrm {<}\lambda \mathrm {<}1. \end{aligned}$$ -
2.
Modified extension Weibull (MEW) distribution21 with pdf defined as follows
$$\begin{aligned} g\left( x;\lambda ,\theta ,\beta \right) =\lambda \beta \left( \theta x\right) ^{\beta -1} \exp \left[ \left( \theta x\right) ^{\beta } +\frac{\lambda }{\theta } \left( 1-e^{\left( \theta x\right) ^{\beta } } \right) \right] ,\, \, \, x\mathrm {>}0,\, \lambda ,\theta ,\beta \mathrm {>}0. \end{aligned}$$ -
3.
Extended Weibull (EW) distribution22 with pdf defined as follows
$$\begin{aligned} g\left( x;\lambda ,\alpha ,\beta \right) =\alpha \left( \lambda +\beta x\right) x^{\beta -2} \exp \left( -\lambda /x-\alpha x^{\beta } e^{-\lambda /x} \right) ,\, \, \, x\mathrm {>}0,\, \, \alpha ,\lambda ,\beta \mathrm {>}0. \end{aligned}$$ -
4.
Flexible Weibull (FW) distribution5 with pdf defined as follows
$$\begin{aligned} g\left( x;\alpha ,\beta \right) =\left( \alpha +\beta /x^{2} \right) \exp \left( \alpha x-\beta /x-e^{\alpha x-\beta /x} \right) ;x,\alpha ,\beta \mathrm {>}0. \end{aligned}$$ -
5.
Kumaraswamy Weibull (KW) distribution23 with pdf defined as follows
$$\begin{aligned} g\left( x;\lambda ,\theta ,\alpha ,\beta \right) =\alpha \beta \theta \lambda e^{-(\lambda x)^\theta } (\lambda x)^{\theta -1} \left( 1-e^{-(\lambda x)^\theta }\right) ^{\alpha -1} \left( 1-\left( 1-e^{-(\lambda x)^\theta }\right) ^\alpha \right) ^{\beta -1};x,\alpha ,\beta ,\theta ,\lambda >0. \end{aligned}$$ -
6.
Beta Weibull (BW) distribution24 with pdf defined as follows
$$\begin{aligned} g\left( x;\lambda ,\theta ,\alpha ,\beta \right) =\frac{\theta (x/\alpha )^{\theta -1}}{\alpha B(\alpha ,\beta )}(1-e^{-(x/\alpha )^{\theta }})^{\alpha -1} e^{-\beta (x/\alpha )^{\theta }};x,\alpha ,\beta ,\theta ,\alpha >0. \end{aligned}$$
The first data set represents the recorded remission times given in months from bladder cancer patients, reported by Lee and Wang25. The ordered array of the data is
0.08 | 1.35 | 2.46 | 3.25 | 3.88 | 4.98 | 5.62 | 7.26 | 8.26 | 10.34 | 12.63 | 17.12 | 25.82 |
0.2 | 1.4 | 2.54 | 3.31 | 4.18 | 5.06 | 5.71 | 7.28 | 8.37 | 10.66 | 13.11 | 17.14 | 26.31 |
0.4 | 1.46 | 2.62 | 3.36 | 4.23 | 5.09 | 5.85 | 7.32 | 8.53 | 10.75 | 13.29 | 17.36 | 32.15 |
0.5 | 1.76 | 2.64 | 3.36 | 4.26 | 5.17 | 6.25 | 7.39 | 8.65 | 11.25 | 13.8 | 18.1 | 34.26 |
0.51 | 2.02 | 2.69 | 3.48 | 4.33 | 5.32 | 6.54 | 7.59 | 8.66 | 11.64 | 14.24 | 19.13 | 36.66 |
0.81 | 2.02 | 2.69 | 3.52 | 4.34 | 5.32 | 6.76 | 7.62 | 9.02 | 11.79 | 14.76 | 20.28 | 43.01 |
0.9 | 2.07 | 2.75 | 3.57 | 4.4 | 5.34 | 6.93 | 7.63 | 9.22 | 11.98 | 14.77 | 21.73 | 46.12 |
1.05 | 2.09 | 2.83 | 3.64 | 4.5 | 5.41 | 6.94 | 7.66 | 9.47 | 12.02 | 14.83 | 22.69 | 79.05 |
1.19 | 2.23 | 2.87 | 3.7 | 4.51 | 5.41 | 6.97 | 7.87 | 9.74 | 12.03 | 15.96 | 23.63 | |
1.26 | 2.26 | 3.02 | 3.82 | 4.87 | 5.49 | 7.09 | 7.93 | 10.06 | 12.07 | 16.62 | 25.74 |
The second data set considered the values of the survival times given in days of guinea pigs infected with virulent tubercle bacilli, summarized by Bjerkedal14. The ordered array of the data is
0.1 | 0.74 | 1 | 1.08 | 1.16 | 1.3 | 1.53 | 1.71 | 1.97 | 2.3 | 2.54 | 3.47 |
0.33 | 0.77 | 1.02 | 1.08 | 1.2 | 1.34 | 1.59 | 1.72 | 2.02 | 2.31 | 2.54 | 3.61 |
0.44 | 0.92 | 1.05 | 1.09 | 1.21 | 1.36 | 1.6 | 1.76 | 2.13 | 2.4 | 2.78 | 4.02 |
0.56 | 0.93 | 1.07 | 1.12 | 1.22 | 1.39 | 1.63 | 1.83 | 2.15 | 2.45 | 2.93 | 4.32 |
0.59 | 0.96 | 1.07 | 1.13 | 1.22 | 1.44 | 1.63 | 1.95 | 2.16 | 2.51 | 3.27 | 4.58 |
0.72 | 1 | 1.08 | 1.15 | 1.24 | 1.46 | 1.68 | 1.96 | 2.22 | 2.53 | 3.42 | 5.55 |
Table 7 recorded different statistic measures for the two proposed data sets.
To assess the validity of the proposed model, we conducted several statistical tests and computed various criterion measures. Firstly, we computed the log-likelihood function (-L), then, we employed criterion measures such as the Akaike Information Criterion (\(\mathcal {A}_1\)) and the Bayesian Information Criterion (\(\mathcal {B}_1\)) to evaluate the performance of the model further. The model that yields the minimum values of these criteria is considered to be the most appropriate for the given data set. To complement the criterion measures, we also employed various test statistics, including the Cramér-von Mises (Cr), Anderson–Darling (An), and Kolmogorov–Smirnov (KS) tests. These tests assess the model’s overall fit by comparing the observed data with the model’s predicted values. The associated p-values obtained from these tests measure the statistical significance of the differences between the observed and predicted values. By considering these criterion measures and test statistics, we can comprehensively evaluate the validity of the proposed model. The model that exhibits the best fit, as indicated by the minimum values of the criterion measures and non-significant p-values from the test statistics, can be considered the most suitable for the given data set.
Tables 8 and 9, contain the values of criterion measure statistics for the fitted models by applying the two considered data sets. Based on these measures and along with the p-values of the proposed test statistics for each distribution, the MPGW model is the best candidate distribution for modeling the two data sets. The plots of the probability–probability (P–P) and quartile–quartile (Q–Q) of the suggested distributions using the two proposed data are shown in Figs. 3, 4, 5 and 6. This figure confirms this conclusion.

P-P plots of MPGW, GW, AMW, MEW, EW, FW, KW, and BW for the first data set.

QQ plots of MPGW, GW, AMW, MEW, EW, FW, KW, and BW for the first data set.

P-P plots of MPGW, GW, AMW, MEW, EW, FW, KW, and BW for the second data set.

QQ plots of MPGW, GW, AMW, MEW, EW, FW, KW, and BW for the second data set.

Curves of the pdfs for different fitting distributions using the first data set.

Curves of the pdfs for different fitting distributions using the second data set.
Figure 7 shows the curves of the pdfs for different fitting distributions using the first data set. Figure 8 shows the Curves of the pdfs for different fitting distributions using the second data set. Tables 10 and 11 contain The goodness of fit test for various fitting distributions by applying the first and second data sets, respectively.
Conclusion
This research paper introduces a novel distribution that involves compounding two cumulative hazard rate functions. We have derived a specific sub-model from the proposed distribution and established various mathematical properties related to it. We have applied four different estimation techniques to estimate the unknown parameters of our suggested model. Additionally, we have conducted simulation experiments to evaluate the effectiveness of these proposed estimation methods. Furthermore, we have analyzed two real engineering data sets to assess how well the MPGW model fits the data when compared to other well-known models. Our findings indicate that the MPGW model demonstrates a good fit to the data sets, highlighting its potential utility in practical applications.
Looking ahead, there are several potential avenues for future research. Firstly, we can extend our work to study the bivariate case and explore different properties of the proposed distribution within that context. Additionally, we can investigate the application of different censored methods, such as progressive type I, II, and hybrid censored methods, for estimating the unknown parameters of the proposed model. Moreover, we may explore the estimation of model parameters using Bayesian approaches and consider various loss functions, such as square error, Linex, and general entropy, to further enhance our understanding of the proposed model. The current study can be extended using neutrosophic statistics as future research; see26,27,28.
References
Almongy, H. M., Almetwally, E. M., Aljohani, H. M., Alghamdi, A. S. & Hafez, E. H. A new extended Rayleigh distribution with applications of covid-19 data. Results Phys. 23, 104012 (2021).
Shafiq, A. et al. A new modified kies fréchet distribution: Applications of mortality rate of covid-19. Results Phys. 28, 104638 (2021).
Meriem, B. et al. The power xlindley distribution: Statistical inference, fuzzy reliability, and covid-19 application. J. Funct. Spaces 2022, 1–21 (2022).
Xie, M. & Lai, C. D. Reliability analysis using an additive Weibull model with bathtub-shaped failure rate function. Reliab. Eng. Syst. Saf. 52(1), 87–93 (1996).
Bebbington, M., Lai, C. D. & Zitikis, R. A flexible Weibull extension. Reliab. Eng. Syst. Saf. 92(6), 719–726 (2007).
Lai, C. D., Xie, M. & Murthy, D. N. P. A modified Weibull distribution. IEEE Trans. Reliab. 52(1), 33–37 (2003).
Almalki, S. J. & Yuan, J. A new modified Weibull distribution. Reliab. Eng. Syst. Saf. 111, 164–170 (2013).
Sarhan, A. M. & Zaindin, M. Modified Weibull distribution. APPS Appl. Sci. 11, 123–136 (2009).
Kumar, C. S. & Nair, S. R. On some aspects of a flexible class of additive Weibull distribution. Commun. Stat.-Theory Methods 47(5), 1028–1049 (2018).
Bagdonavicius, V. & Nikulin, M. Accelerated Life Models: Modeling and Statistical Analysis (Chapman and Hall/CRC, 2001).
Bagdonavicius, V. & Nikulin, M. Chi-squared goodness-of-fit test for right censored data. Int. J. Appl. Math. Stat. 24(1), 1–11 (2011).
Voinov, V., Pya, N., Shapakov, N. & Voinov, Y. Goodness-of-fit tests for the power-generalized Weibull probability distribution. Commun. Stat.-Simul. Comput. 42(5), 1003–1012 (2013).
Kumar, D., Dey, S. & Nadarajah, S. Extended exponential distribution based on order statistics. Commun. Stat.-Theory Methods 46(18), 9166–9184 (2017).
Bjerkedal, T. Acquisition of resistance in guinea pies infected with different doses of virulent tubercle bacilli. Am. J. Hyg. 72(1), 130–48 (1960).
Nadarajah, S. & Haghighi, F. An extension of the exponential distribution. Statistics 45(6), 543–558 (2011).
Bain, L. J. Analysis for the linear failure-rate life-testing distribution. Technometrics 16(4), 551–559 (1974).
Meraou, M. A. & Raqab, M. Z. Statistical properties and different estimation procedures of Poisson–Lindley distribution. J. Stat. Theory Appl. 20(1), 33–45 (2021).
Benchiha, S. A. & Al-Omari, A. I. Generalized quasi lindley distribution: Theoretical properties, estimation methods and applications. Electron. J. Appl. Stat. Anal.14(1) (2021)
Almetwally, E. A. & Meraou, M. A. Application of environmental data with new extension of Nadarajah–Haghighi distribution. Comput. J. Math. Stat. Sci. 1(1), 26–41 (2022).
Swain, J. J., Venkatraman, S. & Wilson, J. R. Least-squares estimation of distribution functions in Johnson’s translation system. J. Stat. Comput. Simul. 29(4), 271–297 (1988).
Xie, M., Tang, Y. & Goh, T. N. A modified Weibull extension with bathtub-shaped failure rate function. Reliab. Eng. Syst. Saf. 76(3), 279–285 (2002).
Peng, X. & Yan, Z. Estimation and application for a new extended Weibull distribution. Reliab. Eng. Syst. Saf. 121, 34–42 (2014).
Cordeiro, G. M., Ortega, E. M. M. & Nadarajah, S. The Kumaraswamy Weibull distribution with application to failure data. J. Frankl. Inst. 347(8), 1399–1429 (2010).
Lee, C., Famoye, F. & Olumolade, O. Beta-Weibull distribution: Some properties and applications to censored data. J. Mod. Appl. Stat. Methods 6(1), 17 (2007).
Lee, E. T. & Wang, J. Statistical Methods for Survival Data Analysis Vol. 476 (Wiley, 2003).
Salem, S., Khan, Z., Ayed, H., Brahmia, A. & Amin, A. The neutrosophic lognormal model in lifetime data analysis: Properties and applications. J. Funct. Spaces 1–9, 2021 (2021).
Vishwakarma, G. K. & Singh, A. Generalized estimator for computation of population mean under neutrosophic ranked set technique: An application to solar energy data. Comput. Appl. Math. 41(4), 144 (2022).
Nayana, B. M., Anakha, K. K., Chacko, V. M., Aslam, M. & Albassam, M. A new neutrosophic model using dus-Weibull transformation with application. Complex Intell. Syst. 8(5), 4079–4088 (2022).
Acknowledgements
The researchers would like to acknowledge the Deanship of Scientific Research, Taif University for funding this work.
Author information
Authors and Affiliations
Contributions
All authors contributed equally to this work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shama, M.S., Alharthi, A.S., Almulhim, F.A. et al. Modified generalized Weibull distribution: theory and applications. Sci Rep 13, 12828 (2023). https://doi.org/10.1038/s41598-023-38942-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-38942-9
This article is cited by
-
The return period of heterogeneous climate data with a new invertible distribution
Stochastic Environmental Research and Risk Assessment (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
