
Abstract
In this paper, we study non-Bayesian and Bayesian estimation of parameters for the Kumaraswamy distribution based on progressive Type-II censoring. First, the maximum likelihood estimates and maximum product spacings are derived. In addition, we derive the asymptotic distribution of the parameters and the asymptotic confidence intervals. Second, Bayesian estimators under symmetric and asymmetric loss functions (Squared error, linear exponential, and general entropy loss functions) are also obtained. The Lindley approximation and the Markov chain Monte Carlo method are used to derive the Bayesian estimates. Furthermore, we derive the highest posterior density credible intervals of the parameters. We further present an optimal progressive censoring scheme among different competing censoring scheme using three optimality criteria. Simulation studies are conducted to evaluate the performance of the point and interval estimators. Finally, one application of real data sets is provided to illustrate the proposed procedures.
Similar content being viewed by others
Introduction
The Kumaraswamy (Kum.) distribution is similar to the Beta distribution, but it has a notable advantage of having an invertible cumulative distribution function that can be expressed in a closed-form. The Kum. distribution is a flexible distribution with two shape parameters that can be applied in finite probabilities ranging from 0 to 1, such as the COVID-19 data and the monthly water capacity of Shasta Reservoir from 1975 to 2016 (see Tu and Gui1. Kum.2,3 showed that commonly used probability distribution functions like the normal, log-normal, and beta distributions do not adequately model hydrological data such as daily rainfall and stream flow. As a result, Kum. introduced a new probability density function known as the sine power probability density function.
Kum.4 introduced the Kum. distribution as a versatile probability density function for double-bounded random processes. This distribution is suitable for modeling various natural phenomena with lower and upper bounds, such as individual heights, test scores, atmospheric temperatures, hydrological data, and more. Additionally, the Kum. distribution can be used when scientists need to model data with finite bounds, even if they are using probability distributions with infinite bounds in their analysis. The Kum. distribution's probability density function (pdf) is described by
where 0 < x < 1 and \(\alpha , \beta \) are two positive shape parameters. When \(\alpha \) = 1 and \(\beta \) = 1, then one can obtain a Uniform distribution \(U(0, 1)\) as special case of the Kum. distribution. The cumulative distribution function (cdf) of the Kum. distribution is given by
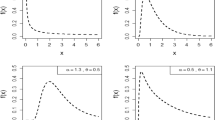
Figure 1 showed the behavior of pdf and cdf of the Kum. distribution at different values of the parameters \(\alpha \) and \(\beta \). In Fig. 1, we notice different patterns from the distribution according to the values of the parameters, where we notice the presence of a U-shaped shape \((\alpha =0.5, \beta =0.5)\), and the gamma distribution \((\alpha =2, \beta =5)\) and we find a form that approximates the exponential distribution at the rest of the values.

Behavior of Kum. Distribution.
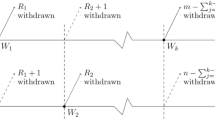
In industrial life testing and medical survival analysis, it is common for the object of interest to be lost or withdrawn before failure, or for the object's lifetime to be only known within an interval. This results in a sample that is incomplete, often referred to as a censored sample. There are various reasons for removal of experimental units, such as saving them for future use, reducing total test time, or lowering associated costs. Right censoring is a technique used in life-testing experiments to handle censored samples. The conventional Type-I and Type-II censoring schemes are the most common methods of right censoring, but they do not allow for removal of units at points other than the terminal point of the experiment, limiting their flexibility. To address this limitation, a more general censoring scheme called the progressive Type-II censoring scheme (PCS-II) has been proposed. as follows:
-
Suppose that \(n\) unite are placed on a test at time zero with \(m\) failures to be observed.
-
At the first failure, say \({x}_{(1)}, {R}_{1}\) of the remaining units are randomly selected and removed.
-
At the time of the second failure, \({x}_{(2)}, {R}_{2}\) of the remaining units are selected and removed.
-
Finally, at the time of the \({m}^{th}\) failure the rest of the units are all removed, \({R}_{m}=n-{R}_{1}-{R}_{2}-\dots -{R}_{m-1}-m\).
-
Thus, it is possible to witness the data \(\left\{\left({x}_{(1)}, {R}_{1}\right),\dots ,\left({x}_{(m)}, {R}_{m}\right)\right\}\) during a gradual censorship plan. Even though \({R}_{1},{R}_{2}, \dots ,{R}_{m}\) are encompassed as a section of the data, their values are previously known.
The joint probability density function of all \(m\) PCS-II order statistics is Balakrishnan and Aggarwala5
where
If \({R}_{1}={R}_{2}=\dots ={R}_{m-1}=0\), then \({R}_{i}=n-m\) which corresponds to the Type-II censoring. and If \({R}_{1}={R}_{2}=\dots ={R}_{m}=0\), then \(n=m\) which corresponds to the complete sample Wu6.
The theory of estimation consists of these methods by which are make inference or generalization about a population parameter. Today's trend is to distinguish between the non-Bayesian and Bayesian estimate methods. Any statistical or computational strategy that does not rely on Bayesian inference is referred to as a non-Bayesian method. Bayesian method utilizes prior subjective knowledge about the probability distribution of the unknown parameters in conjunction with information provided by the sample data. Non-Bayesian method and Bayesian method of estimation will be introduced in next sections.
Gholizadeh et al.7 examined the performance of Bayesian and non-Bayesian estimators in estimating the shape parameter, reliability, and failure rate functions of the Kumaraswamy distribution under progressively Type-II censored samples. They used various loss functions, such as squared error loss, Precautionary loss function, and linear exponential (LINEX) loss function, to obtain the maximum likelihood and Bayes estimates of the reliability and failure rate functions, both symmetric and asymmetric. Feroze and El-Batal8 focused on estimating two parameters of the Kumaraswamy distribution using progressive Type-II censoring with random removals. They derived the maximum likelihood estimate for the unknown parameters and also determined the asymptotic variance–covariance matrix. Eldin et al.9 studied parameter estimation for the Kumaraswamy distribution using progressive Type-II censoring. They obtained estimates through both maximum likelihood and Bayesian methods. In the Bayesian approach, the two parameters were considered as random variables and estimators for the parameters were obtained by employing the squared error loss function. Erick et al.10 focused on estimating parameters of test units from the Kumaraswamy distribution using a progressive Type-II censoring scheme. They employed the EM algorithm to derive maximum likelihood estimates for the parameters. Additionally, they calculated the expected Fisher information matrix based on the missing value principle. EL-Sagheer's11 study, various methods were used to estimate unknown parameters, lifetime parameters reliability and hazard functions of a two-parameter Kumaraswamy distribution based on progressively Type-II right-censored samples. These methods included maximum likelihood, Bayes, and parametric bootstrap. The classical Bayes estimates were obtained by utilizing the Markov chain Monte Carlo technique. Sultana et al.12 investigated the estimation problems of unknown parameters of the Kumaraswamy distribution under Type-I progressive hybrid censoring. They derived the maximum likelihood estimates of parameters using an EM algorithm. Bayes estimates were obtained under different loss functions using the Lindley method and importance sampling procedure. Tu and Gui1 discussed and considered the estimation of unknown parameters featured by the Kumaraswamy distribution on the condition of a generalized progressive hybrid censoring scheme. They derived the maximum likelihood estimators and Bayesian estimators under symmetric loss functions and asymmetric loss functions, like general entropy, squared error as well as Linex loss function. Since the Bayesian estimates fail to be of explicit computation, Lindley approximation, as well as the Tierney and Kadane method, is employed to obtain the Bayesian estimates. Ghafouri and Rastogi13 considered the estimation of the parameters and reliability characteristics of Kumaraswamy distribution using progressive first failure censored samples. They derived the maximum likelihood estimates using an EM algorithm and compute the observed information of the parameters that can be used for constructing asymptotic confidence intervals. Also, they computed the Bayes estimates of the parameters using Lindley approximation as well as the Metropolis–Hastings algorithm. Kohansal and Bakouch14 conducted a study on the estimation of unknown parameters in the Kumaraswamy distribution using adaptive Type-II hybrid progressive censored samples. Firstly, they obtained the maximum likelihood estimation of the parameters using different algorithms such as Newton–Raphson (NR) method, expectation maximization (EM), and stochastic EM (SEM). They also derived the asymptotic distribution of the parameters and calculated asymptotic confidence intervals to assess the uncertainty associated with the estimates. Moreover, two bootstrap confidence intervals they achieved. Second, the Bayesian estimation of the parameters was approximated by using the Markov Chain Monte Carlo algorithm and Lindley’s method. They derived the highest posterior density credible intervals of the parameters.
This paper is organized as follows: the maximum likelihood estimators and maximum product spacing estimators of the unknown parameters of the Kum. distribution is used to create non-Bayesian estimation methods in the next section. In this part, we will look at the existence and distinctiveness of MLEs. In addition, we introduce the asymptotic distribution for the unknown parameters and generate their asymptotic confidence intervals. “Bayesian estimation methods” section focuses on obtaining the Bayes estimates of the parameters. Lindley's approximation and the Markov Chain Monte Carlo method are utilized, assuming independent gamma priors for the parameters \(\alpha \) and \(\beta \). Additionally, the section includes the construction of the highest posterior density credible interval for the unknown parameters. The simulation results and data analysis are presented in “Simulation study and real data analysis” section, providing an examination of the performance of the estimation methods through various simulations and real data analysis. “Optimal progressive Type-II censoring scheme” section introduces an optimal progressive censoring scheme, comparing it to different competing censoring schemes. Finally, we conclude the paper in “Conclusions” section.
Non-Bayesian estimation methods
In this section, we examine the task of estimating Kum. parameters under PCS-II samples, employing two estimation techniques known as maximum likelihood estimators (MLEs) and maximum product spacing estimators (MPSEs).
Maximum likelihood estimation
Suppose that \(X=({x}_{\left(1\right)}, {x}_{\left(2\right)},\dots , {x}_{\left(m\right)})\) a PCS-II sample drawn from Kum. population whose pdf and cdf are given by (1) and (2), with the censoring scheme \(({R}_{1},{R}_{2}, \dots ,{R}_{m})\). From (1), (2) and (3) the likelihood function is then given by:
Taking log-likelihood function of (4), \(l\left(\alpha ,\beta \right)=\mathrm{log}L\left(\alpha ,\beta \right)\), one be obtaining:
Then, to estimate the parameter of the Kum. distribution, it can be obtained by finding the first partial derivative of (5) concerning parameters \(\alpha \) and \(\beta \) as follows:
Let the partial derivative to \(\alpha \) and \(\beta \) respectively be 0, we have
The maximum likelihood estimators (MLEs) \({\widehat{\alpha }}_{MLE}\) and \({\widehat{\beta }}_{MLE}\) are the solution of the two nonlinear equations that the system needs to be solved numerically to obtain parameters estimation values.
Maximum product spacings
Ng et al.15 introduced maximum product spacing (MPS) method based on PCS-II sample method, The MPS technique selects the parameter values that minimize the deviation of the observed data from a predetermined quantitative measure of uniformity.
from (2), one can get:
The natural logarithm of the product spacings function is
where \(S\left(\alpha ,\beta \right)=\mathrm{log}G\left(\alpha ,\beta \right)\). The MPS estimators of \(\alpha \) and \(\beta \), denoted by \({\widehat{\alpha }}_{MPS}\) and \({\widehat{\beta }}_{MPS}\), respectively, are obtained by solving the following normal equations simultaneously
and
To obtain estimates for the parameters, the system requires solving two nonlinear equations numerically, which leads to the solution of the MPS, \({\widehat{\alpha }}_{MPS}\) and \({\widehat{\beta }}_{MPS}\).
Asymptotic variance–covariance
The asymptotic variance–covariance matrix of the MLEs for the two parameters is the inverse of the observed Fisher information matrix as follows
and the variance–covariance matrix of parameters \(\alpha \) and \(\beta \) is given by
where
and
Using (6), an asymptotic \(100(1-\gamma )\mathrm{\%}\) confidence interval for the parameters \(\alpha \) and \(\beta \) can be easily obtained as
respectively. Here \(var(\widehat{\alpha })\) and \(var(\widehat{\beta })\) are the elements on the main diagonal of the variance–covariance. Where \({Z}_{\frac{\gamma }{2}}\) is the uppe \(\frac{\gamma }{2}\) percentile of the standard normal distribution, so MLE \(\sim N(0,{I}^{-1}\)).
Bayesian estimation methods
In this section, the Bayesian estimation (BE) of shape parameters \(\alpha \) and \(\beta \) denoted by \(\widetilde{\alpha }\) and \(\widetilde{\beta }\) respectively, are obtained under the assumption that \(\alpha \) and \(\beta \) are independent random variables with prior distributions Gamma(\({a}_{1},{b}_{1}\)) and Gamma(\({a}_{2},{b}_{2}\)) respectively with pdfs:
where the hyper parameters \({a}_{1},{b}_{1}\), \({a}_{2},\mathrm{and }{b}_{2}\) are chosen to reflect the prior knowledge about \(\alpha \) and \(\beta \). The joint prior for \(\alpha \) and \(\beta \) is given by
By applying Bayes' theorem and combining the likelihood function from (4) with the joint prior from (7), we can obtain the posterior distribution of the parameters \(\alpha \) and \(\beta \) denoted as \(\pi \left(\alpha ,\beta |x\right)\), which is proportional to the likelihood and prior. This can be expressed as:
when the likelihood function of \(\alpha \) and \(\beta \) as follows:
thus, the likelihood function in (4) can be rewritten as follows:
Hence, the taken \(\mathrm{exp}(\mathrm{log} )\) function will be
The join posterior density function of \(\alpha \) and \(\beta \) can be written as:
where:
Thus, the posterior density function can be rewritten as
The conditional posterior densities of \(\alpha \) and \(\beta \) are as follows:
where
Hence, the conditional posterior density of \(\alpha \) will be
and
where
Hence, the conditional posterior density of \(\beta \) will be
It is clear that \({\pi }_{2}\left(\beta |\alpha ,x\right)\) is the density function of a gamma \((m+{a}_{2}, {b}_{2}-\sum_{i=1}^{m}{(R}_{i}+1)\mathrm{log}\left(1-{{x}_{i}}^{\alpha }\right))\) random variable. BE are obtained based on three different types of loss functions, namely; the squared error (SE) loss function (as a symmetric loss function), linear exponential (LINEX) and general entropy (GE) loss functions (as asymmetric loss functions).
-
SE loss function
The SE loss function is a symmetric loss function and takes the form
where \(\widehat{\theta }\) is the estimate of the parameter \(\theta \). Under the SE loss function, the BE \({\widehat{\theta }}_{\mathrm{SE}}\) of \(\theta \) is given by
where \({E}_{\theta }\) stands for posterior expectation. The BE for the parameters \(\alpha \) and \(\beta \) of the Kum. distribution under SE loss function is the posterior mean, we have
and
-
LINEX loss function
Zellner16 represent the LINEX is an asymmetric loss function defined as
where \(\widehat{\theta }\) is the estimate of the parameter \(\theta \). Under the LINEX loss function, the BE \({\widehat{\theta }}_{\mathrm{LINEX}}\) of \(\theta \) is given by
where \({E}_{\theta }\) stands for posterior expectation. The parameter \(c\) represents the deviation direction, and the degree of deviation is reflected by its magnitude. When \(c < 0\), the underestimation is greater than the overestimation and the opposite is the case when \(c > 0\). As \(c\) approaches zero, the LINEX loss function can be transformed into the SE loss function. The BE for the parameters \(\alpha \) and \(\beta \) of the Kum. distribution under LINEX loss function may be defined as
where
and
where
-
GE loss function
This asymmetric loss function is another valuable tool for detecting overestimation or underestimation, and it's an extension of the entropy loss function. Calabria and Pulcini17 proposed the general entropy loss function with parameter \(q\) is given by
where \(\widehat{\theta }\) is the estimate of the parameter \(\theta \). Under the GE loss function, the BE \({\widehat{\theta }}_{\mathrm{GE}}\) of \(\theta \) is given by
where \({E}_{\theta }\) stands for posterior expectation. The proper choice for \(q\) is a challenging task for an analyst, because it reflects the asymmetry of the loss function. The BE for the parameters \(\alpha \) and \(\beta \) of the Kum. distribution under GE loss function may be defined as
where
and
where
After examining the BE equations presented above, it becomes apparent that they are all the ratios of two integrals and obtaining explicit expressions for these integrals is difficult. Consequently, it is necessary to use appropriate techniques to approximate these integrals. Thus, we provide the approximate BE of \(\alpha \) and \(\beta \) such as:
-
Lindley’s approximation
-
Markov chain Monte Carlo (MCMC)
Lindley’s approximation
Lindley suggested an estimate for calculating the ratio of integrals, as given in (8), using three distinct loss functions, which is based on the prior distributions of \(\alpha \) and \(\beta \). Consider the ratio of integral \(I(X)\), where
where \(g(\alpha ,\beta )\) is function of \(\alpha \) and \(\beta \) only and \(l\left(\alpha ,\beta \right)\) is the log-likelihood and \(\rho \left(\alpha ,\beta \right)=\mathrm{log}\pi \left(\alpha ,\beta \right)\). Using the approach developed in Lindley18, the ratio of integral \(I(X)\) can be written as
where
\(\widehat{\alpha }\) and \(\widehat{\beta }\) are the MLE of \(\alpha \) and \(\beta \) and then, partial derivatives of log-likelihood function of \({L}_{ijk}\) (5), one can be obtained as follows:
The partial derivatives of log-prior function as follows:
thus,
Lindley’s approximation SE loss function
When \(g\left(\alpha ,\beta \right)= \alpha \), we observe that
hence, the BE of \(\alpha \) can be obtained as
When \(g\left(\alpha ,\beta \right)= \beta \), we can derive that
hence, the BE of \(\beta \) can be obtained as
Lindley’s approximation LINEX loss function
When \(g\left(\alpha ,\beta \right)= {e}^{-c\alpha }\), we observe that
hence, the BE of \(\alpha \) can be obtained as
When \(g\left(\alpha ,\beta \right)= {e}^{-c\beta }\), we observe that
hence, the BE of \(\beta \) can be obtained as
Lindley’s approximation GE loss function
When \(g\left(\alpha ,\beta \right)= {\alpha }^{-q}\), we observe that
hence, the BE of \(\alpha \) can be obtained as
When \(g\left(\alpha ,\beta \right)= {\beta }^{-q}\), we observe that
hence, the BE of \(\beta \) can be obtained as
It is hard to obtain the third derivatives of the log-likelihood function, so the Metropolis–Hastings algorithm (MH) is used for computing the desired BE. There are two advantages of considering the MH algorithm over Lindley’s method. Firstly, there is no need to calculate up to the third derivatives of the log-likelihood function. Secondly, the samples obtained through the MH algorithm can be used to obtain highest posterior density (HPD) intervals for the distribution's unknown parameters, which is not possible with Lindley's method, for more details see Dey et al.19.
Markov chain Monte-Carlo
In this case, we apply the MCMC technique to produce samples from the posterior distributions. From these samples, we calculate the BE of the unknown parameters and construct the corresponding credible intervals. he conditional posterior densities of \(\beta \) in (10) are gamma densities with a shape parameter of \((m+{a}_{2})\) and a scale parameter of \(\left({b}_{2}-\sum_{i=1}^{m}{(R}_{i}+1)\mathrm{log}\left(1-{{x}_{(i)}}^{\alpha }\right)\right)\). Thus, samples of \(\beta \) can be easily generated using any gamma generating routine. The posterior of \(\alpha \) given in (9) does not present a standard form, but the plot of it shows that it is similar to a normal distribution with mean \(\alpha \) and standard deviation \({S}_{\alpha }\), here \({S}_{\alpha }\) represents the variance–covariance matrix. Therefore, to generate random numbers from this distribution, we use the Metropolis–Hastings algorithm with the normal proposal distribution to generate samples from it see Tierney20 and El-Sagheer11. Therefore, the MCMC is given as:
-
1.
Start initial value of \(\theta \) as \(\theta ={\theta }^{\left(0\right)}\), where \(\theta =(\alpha ,\beta )\).
-
2.
Set \(i=1\).
-
3.
Generate \({\beta }^{(i)}\) from Gamma \(\left(m+{a}_{2}, {b}_{2}-\sum_{i=1}^{m}{(R}_{i}+1)\mathrm{log}\left(1-{{x}_{(i)}}^{\alpha }\right)\right)\).
-
4.
Using the following Metropolis–Hastings, generate \({\alpha }^{(i)}\) from \({\pi }_{1}\left(\alpha |\beta ,x\right)\) with the normal proposal distribution \(N\left(\widehat{\alpha }, {S}_{\alpha }\right)\).
-
4.1
Generate a proposal \({\alpha }^{*}\) from \(N\left(\widehat{\alpha }, {S}_{\alpha }\right)\), where \({S}_{\alpha }\) is Standard deviation of \(\alpha \).
-
4.2
Calculate the acceptance probability \(\rho \) where \(\rho =\mathrm{min}\left(1, \frac{{\pi }_{1}\left({\alpha }^{*}|{\beta }^{(i)},x\right)}{{\pi }_{1}\left({\alpha }^{(i-1)}|{\beta }^{(i)},x\right)}\right)\).
-
4.3
Generate \(u\) from a uniform (0,1) distribution.
-
4.4
If \(u< \rho \), accept the proposal and set \({\theta }^{(i)}={\theta }^{*}\), else set \({\theta }^{(i)}={\theta }^{(i-1)}\).
-
4.1
-
5.
Set \(i=i+1\).
-
6.
Repeat steps 3–6 \(N\) times.
After drawing a random sample of size \(M\) from the posterior density, it's possible to discard some initial samples (burn-in) and then use the remaining samples to calculate BE of \(\theta =(\alpha , \beta )\). By doing this, it's possible to derive approximate Bayes point estimates of \(\alpha \) and \(\beta \) under the SE, LINEX, and GE loss functions as follows.
and
where \({l}_{B}\) represents the number of burn-in samples. For computation of the \(100(1-\gamma )\mathrm{\%}\) HPD interval of \(\theta \), order \({\theta }^{(1)}, {\theta }^{(2)}, \dots , {\theta }^{(M)}\) as \({\theta }^{(1)}< {\theta }^{(2)}< \dots <{\theta }^{(M)}\) . Then construct all the \(100(1-\gamma )\mathrm{\%}\) confidence intervals of \(\theta \), as:
Finally, the HPD confidence interval of \(\alpha \) and \(\beta \) is that interval which has the shortest length.
Elicitation of hyper-parameters
This section discusses the elicitation of hyper-parameter values when informative priors are considered. It is to be noted that the hyper-parameter values can be chosen depending on informative priors. Suppose that we have \(k\) samples available from the \(K\left(\alpha ,\beta \right)\) distribution, and that the associated maximum likelihood estimates of \(\left(\alpha ,\beta \right)\) be \(\left({\widehat{\alpha }}^{j}, {\widehat{\beta }}^{j}\right), j=\mathrm{1,2},\dots ,k\). The hyper-parameter values can now be obtained by equating the mean and variance of \(\left({\widehat{\alpha }}^{j}, {\widehat{\beta }}^{j}\right), j=\mathrm{1,2},\dots ,k\) with the mean and variance of examined priors. In the present work, we have considered the gamma prior of \(\alpha \) and \(\beta \) respectively are \({\pi }_{1}\left(\alpha \right)\propto {\alpha }^{{a}_{1}-1} {e}^{-{b}_{1}\alpha }\) and \({\pi }_{2}(\beta )\propto {\beta }^{{a}_{2}-1} {e}^{-{b}_{2}\beta }\) for which \(\mathrm{Mean}\left(\alpha \right)=\frac{{a}_{1}}{{b}_{1}}\) , \(\mathrm{Mean}\left(\beta \right)=\frac{{a}_{2}}{{b}_{2}}\) and \(\mathrm{Variance}\left(\alpha \right)=\frac{{a}_{1}}{{{b}_{1}}^{2}}\) , \(\mathrm{Variance}\left(\beta \right)=\frac{{a}_{2}}{{{b}_{2}}^{2}}\). Therefore, on equating mean and variance of \(\left({\widehat{\alpha }}^{j}, {\widehat{\beta }}^{j}\right), j=\mathrm{1,2},\dots ,k\) with the mean and variance of gamma priors, we get
We can find \({\widehat{a}}_{1}\) and \({\widehat{b}}_{1}\), estimators for \(a\) and \(b\), by solving Eqs. (11) as follows:
and
Solving the above equations yields the estimators for the hyper-parameters
for the prior distribution for \(\alpha \). Similarly, estimators for the hyper-parameters for the prior distribution for \(\beta \) can be found as
One may also refer to the work of Dey et al.19,21, and Singh and Tripathi22 in this regard.
Simulation study and real data analysis
The objective of this section is to evaluate the effectiveness of the different estimation methods that were discussed in the preceding sections. A real dataset is used to illustrative purposes, and a simulation study is conducted to observe how the proposed methods perform under a PCS-II.
Simulation study
In this subsection, we conduct a simulation study to compare the performance of different estimates and confidence intervals for the Non-BE and BE methods of unknown parameters of the Kum. distribution under a PCS-II. We will compute the Average, Mean Square Error (MSE), Confidence intervals (CI), average interval length (AIL), and the coverage probability (CP) to compare the performance of the different methods using a number of replications 1000. The performance of Non-BE and BE are compared based on the following assumptions:
1. values of \(\left(\alpha , \beta \right)=\left(0.5, 0.5\right), \left(0.5, 1\right), \left(1, 1\right), \;\mathrm{and}\;(1, 2)\).
2. Sample sizes of n = 40 and n = 80.
3. In this simulation, the algorithm proposed by Balakrishnan and Sandhu23 can be used to generate a progressively Type-II censored sample, removed items \({R}_{i}\) are assumed at different sample sizes \(n\) and the number of stages \(m\) as shown in Table 1.
Based on the generated data, we compute the MLEs, MPSs, and corresponding 95% asymptotic confidence intervals (Asy-CI). On deriving MLEs, be aware that the initial assume values are considered as true parameter values.
The gamma prior distribution is used to compute BE parameter using both symmetric and asymmetric loss functions. These estimates are obtained through Lindley's approximation and the MCMC method. To determine the values of the hyper-parameters, 500 complete samples of size 60 are constructed from the Kum. distribution with various values of \(\alpha \) and \(\beta \) using historical data. The obtained informative prior values are then used to evaluate the desired estimates. The MLEs are employed as initial values using the MH algorithm, along with the corresponding variance–covariance matrix \({S}_{\alpha }\) of \(\widehat{\alpha }\). In the end, the posterior density removed 2000 burn-in samples of the total of 10,000 generated samples and produced BE for three different loss functions: SE, LINEX at \(c = -0.5, 1.5\), and GE loss functions at \(q = 0.1, 2\). Additionally, HPD interval estimates were calculated using the approach developed by Chen and Shao24.
In Tables 2, 3, 4, 5, we display the Non-BE obtained by using MLE and MPS at different values of \(n\) and \(m\), respectively. Further, the first column represents the average estimates (Avg.) and the second column represents the mean square errors (MSEs). For confidence intervals, we have asymptotic confidence interval (Asy CI), average interval length (AIL), and coverage probability (CP) using the MLE.
Tables 6, 7, 8, 9, 10, 11, 12, 13 show BE obtained using Lindley's approximation and MCMC method with different loss functions, for various values of \(n\) and \(m\). The first column of the tables indicates the average estimates (Avg.), while the second column represents the mean square errors (MSEs). In Tables 14, 15, we present confidence intervals, which include the highest posterior density (HPD) intervals, average interval length (AIL), and coverage probability (CP) using the MCMC method.
Based on Tables 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, with an increase in the values of \((n, m)\), and specifically an increase in the value of \(m\) leads to a decrease in the MSEs, in addition to that the Avg. denotes the true value of the two parameters \(\alpha \) and \(\beta \), for all estimation methods. By comparing the performance of Non-BE methods, we note that estimates of MLE are more efficient than estimates of MPS. In comparison between the performance of the BE methods relative to the Lindley’s approximation, we find that the value of the MSEs decreases under the LINEX loss function when \(c = -0.5\), then followed by the SE loss function. As for the MCMC algorithm, we find that the MSEs value decreases under the SE loss function. In general, we note that estimates of MCMC are more efficient than estimates of Lindley’s approximation. From Tables 14, 15, it is observed that the HPD and Asy CI have the smallest and largest average lengths, respectively. As a general result, we see that when \(n\) increases, for all cases, the AIL decrease and the corresponding CP percentages increase.
The graphs of MCMC estimates for \(\alpha \) and \(\beta \) using MH algorithm are the plotting of estimates, histogram of estimates, and convergence of estimates, these graphs can be showed in Fig. 2. In Fig. 2 the plots display the random distribution of the values of \(\alpha \) and \(\beta \), which are observed to be scattered around the mean. Also, from the histograms of the MH sequences for \(\alpha \), we observe that choosing the normal distribution as a proposal distribution is quite appropriate.

Convergence of MCMC Estimates.
Real data application
In this subsection, we examine actual data that pertains to the Shasta reservoir's monthly water capacity in California, USA. The data covers the month of February between 1991 and 2010. see Sultana et al.25 and Sultana et al.12. The data points are listed below as follows.
To determine if the considered dataset can be appropriately analyzed using a Kum. distribution, a goodness of fit test is conducted. In addition to Kum. distribution, we also fit generalized exponential [Gen.Exp], Burr XII [Burr], and beta distributions to the data set. We judge the goodness of fit using various criteria, for example, negative log-likelihood criterion (NLC), Akaike information criterion (AIC) introduced by Akaike26, corrected AIC (AICc) introduced by Hurvich and Tsai27, and Bayesian information criterion (BIC) introduced by Schwarz28. The smaller the value of these criteria, the better the model fits the data. The results are shown in Table 16. For fitting the given data set graphically, the empirical cdf can be plotted with the corresponding fitted cdfs for Kum., Gen.Exp, Burr, and beta distributions. Also, the histogram can be plotted with the corresponding fitted pdf lines for the same distributions. Figure 3 showed the fitted lines for the cdfs and pdfs for the given data set and corresponding distributions. The figures also indicate that the Kum. distribution provide better fit than the other distributions at least for this data set.

Goodness of Fit Tests for Real Data.
Referring to the values reported in Table 16, we conclude that the Kum. distribution fits the data set good compared to the other models. Thus, the various point and interval estimates of \(\alpha \) and \(\beta \) for real data under PCS-II as following as in Tables 17, 18, 19.
In Table 17, we display the Non-BE obtained by using MLE and MPS at \(m=10\). We computed the average estimates (Avg.), standard deviation, and the asymptotic confidence interval (Asy CI) using the MLE.
In Tables 18, 19, we display the BE obtained by using Lindley’s approximation and MCMC method under different loss functions at \(m=10\) with different four schemes defined as: \({S}_{1}=\left(10, {0}^{*9}\right), {S}_{2}=\left(5,{0}^{*8}, 5\right),{S}_{3}=\left({0}^{*4}, \mathrm{5,5},{0}^{*4}\right), \;\mathrm{and}\;{S}_{4}=( {0}^{*9}, 10)\). We computed the average estimates (Avg.), standard deviation, and the highest posterior density (HPD) intervals using the MCMC. From Tables 17, 18, 19, we observed that the Avg. and MSEs of the different estimates are close together. MPS have the worst performance and Bayesian estimates have the best performance.
Figure 4 showed the profile-likelihood of the estimates of MLE and MPS under PCS-II: \({S}_{1}=\left(10, {0}^{*9}\right)\) with \(m =10\) for the parameters \(\alpha \) and \(\beta \). Form the Fig. 4, we can conclude the existences and uniqueness for the estimates of MLE and MPS where the maximum value of likelihood functions of MLE and MPS given estimates of \(\alpha \) and \(\beta \) has been achieved.

The Profile-likelihood of The Estimates of MLE and MPS Under PCS-II.
Optimal progressive Type-II censoring scheme
In the preceding sections, we have discussed both Non-BE and BE methods for estimating unknown parameters of the Kum. distribution when using PCS-II to obtain samples. To conduct a life-testing experiment using PCS-II, it is necessary to have advance knowledge of \(n, m,\) and \(({R}_{1},{R}_{2}, \dots ,{R}_{m})\). However, in many reliability and life testing studies, practical considerations require selecting the optimal PCS-II from a set of possible schemes. Balakrishnan and Aggarwala5 extensively discussed the problem of determining the best censoring plan using different setups. Comparing two different censoring schemes has been of great interest to several researchers. See, for example, Ng et al.29, Kundu30, Lee et al.31, Lee et al.32, and Ashour et al.33. To determine the optimum PCS-II, we consider an information measure as the following criteria.
Criterion 1: Minimizing the determinant of the variance–covariance matrix \(({I}^{-1})\) of the MLEs has been obtained in Eq. (6).
Criterion 2: Minimizing the trace of the variance–covariance matrix \(({I}^{-1})\) of the MLEs has been obtained in Eq. (6).
Criterion 3: depends on the choice of \(u\), and it is tends to minimize the variance of logarithmic of MLE of the \({u}^{-th}\) quantile \(\left(\mathrm{log}\left({\widehat{T}}_{u}\right)\right)\), where \(0<u<1\). Consider the \({u}^{-th}\) quantile of the Kum. distribution:
Hence, the logarithmic for \({T}_{u}\) of the Kum. distribution is given by
From Eq. (13), using the delta method, the variance of \(\mathrm{log}\left({\widehat{T}}_{u}\right)\) can be approximated by
where
is the gradient of \(\mathrm{log}\left({T}_{u}\right)\) with respect to the unknown parameters \(\alpha \) and \(\beta \).where
Thus, the variance of \(\mathrm{log}\left({\widehat{T}}_{u}\right)\) can be obtained as
The calculated values of determinant and trace of the variance–covariance matrix of the MLEs when \(\alpha =0.5\), \(\beta =1, n=\left(\mathrm{40,80}\right) \mathrm{and m}=(\mathrm{20,30,40},\mathrm{ and }60)\) are presented in Table 20. Based on three different quantiles namely: \(u=0.25, 0.5\mathrm{ and }0.75\), the Criterion 3 is computed. The calculated values of the three criteria are reported in Table 20.
Using the previous application in “Real data application” section, we considered a PCS-II sample of size \(m\) from the Kum. distribution. Using the variance–covariance matrix of the MLEs, we can easily compute the values of the trace and determinant of the variance–covariance matrix for all choices of \(n, m,\) and schemes \(({S}_{1},{S}_{2}, \dots ,{S}_{m})\) are presented in Table 21. Based on three different quantiles namely: \(u=0.25, 0.5\mathrm{ and }0.75\), the Criterion 3 is computed. These values indicate that the optimal censoring scheme is the one that yields the smallest determinant or trace of the variance–covariance matrix of the MLEs. From Table 21, therefore, the optimum scheme in Criterion 1, 2 is \((n, m, ({S}_{1},{S}_{2}, \dots ,{S}_{m}))= (20, 10, \left( {0}^{*9}, 10\right))\) but in Criterion 3 when the values of \((u=0.25, 0.5)\) the optimum scheme is \((n, m, ({S}_{1},{S}_{2}, \dots ,{S}_{m}))= (20, 10, \left({0}^{*4}, \mathrm{5,5},{0}^{*4}\right))\), and when the value of \(u\) was increased, it became the optimum scheme is \((n, m, ({S}_{1},{S}_{2}, \dots ,{S}_{m}))= (20, 10, \left( {0}^{*9}, 10\right))\).
Conclusion
This paper deals with the problem of estimating unknown parameters for a Kum. distribution under PCS-II from both BE and Non-BE perspectives. We obtained MLE, MPS, and asymptotic confidence interval estimates for the unknown parameters of a Kum. distribution. We also computed BE, including Lindley’s approximation and MCMC under both symmetric and asymmetric loss functions, along with their corresponding HPD interval estimates. We discussed how to choose hyper-parameter values based on past samples and compared the methods using MSE, AIL, and CP. Our results indicate that BE is superior to non-Bayesian estimates. We identified the optimal censoring scheme for life testing experiments based on three criteria measures, which is important information for reliability practitioners. The future work can be extended to studying neutrosophic statistics for the Kum. distribution. Another work could involve modeling COVID-19 data under different progressive censoring schemes.
Data availability
The data is available in this article.
References
Tu, J. & Gui, W. Bayesian inference for the Kumaraswamy distribution under generalized progressive hybrid censoring. Entropy 22(9), 1032 (2020).
Kumaraswamy, P. Sinepower probability density function. J. Hydrol. 31(1–2), 181–184 (1976).
Kumaraswamy, P. Extended sinepower probability density function. J. Hydrol. 37(1–2), 81–89 (1978).
Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 46(1–2), 79–88 (1980).
Balakrishnan, N. & Aggarwala, R. Progressive Censoring: Theory, Methods, and Applications (Springer, Berlin, 2000).
Wu, S. J. Estimation of parameters of Weibull distribution with progressively censored data. J. Jpn. Stat. Soc. 32(2), 155–163 (2002).
Gholizadeh, R., Khalilpor, M. & Hadian, M. Bayesian estimations in the Kumaraswamy distribution under progressively Type-II censoring data. Int. J. Eng. Sci. Technol. 3(9), 47–65 (2011).
Feroze, N. & El-Batal, I. Parameter estimations based on Kumaraswamy progressive type-II censored data with random removals. J. Mod. Appl. Stat. Methods 12(2), 19–35 (2013).
Eldin, M. M., Khalil, N. & Amein, M. Estimation of parameters of the Kumaraswamy distribution based on general progressive type-II censoring. Am. J. Theor. Appl. Stat. 3(6), 217–222 (2014).
Erick, W. M., Kimutai, K. A. & Njenga, E. G. Parameter estimation of Kumaraswamy distribution based on progressive type-II censoring scheme using expectation-maximization algorithm. Am. J. Theor. Appl. Stat. 5(3), 154–161 (2016).
El-Sagheer, R. M. Estimating the parameters of Kumaraswamy distribution using progressively censored data. J. Test. Eval. 47(2), 905–926 (2019).
Sultana, F., Tripathi, Y. M., Wu, S. J. & Sen, T. Inference for Kumaraswamy distribution based on Type-I progressive hybrid censoring. Ann. Data Sci. 1, 1–25 (2020).
Ghafouri, S. & Rastogi, M. K. Reliability analysis of Kumaraswamy distribution under progressive first-failure censoring. J. Stat. Model. Theory Appl. 1, 1–33 (2021).
Kohansal, A. & Bakouch, H. S. Estimation procedures for Kumaraswamy distribution parameters under adaptive type-II hybrid progressive censoring. Commun. Stat.-Simul. Comput. 50(12), 4059–4078 (2021).
Ng, H. K. T., Luo, L., Hu, Y. & Duan, F. Parameter estimation of three-parameter Weibull distribution based on progressively Type-II censored samples. J. Stat. Comput. Simul. 82(11), 1661–1678 (2012).
Zellner, A. Bayesian estimation and prediction using asymmetric loss functions. J. Am. Stat. Assoc. 81(394), 446–451 (1986).
Calabria, R. & Pulcini, G. An engineering approach to Bayes estimation for the Weibull distribution. Microelectron. Reliab. 34(5), 789–802 (1994).
Lindley, D. V. Approximate Bayesian method. Trab. Estad. Investig. Oper. 31, 223–237 (1980).
Dey, S., Dey, T. & Luckett, D. J. Statistical inference for the generalized inverted exponential distribution based on upper record values. Math. Comput. Simul. 120, 64–78 (2016).
Tierney, L. Markov chains for exploring posterior distributions. Ann. Stat. 1, 1701–1728 (1994).
Dey, S., Singh, S., Tripathi, Y. M. & Asgharzadeh, A. Estimation and prediction for a progressively censored generalized inverted exponential distribution. Stat. Methodol. 32, 185–202 (2016).
Singh, S. & Tripathi, Y. M. Estimating the parameters of an inverse Weibull distribution under progressive Type-I interval censoring. Stat. Pap. 59(1), 21–56 (2018).
Balakrishnan, N. & Sandhu, R. A. A simple simulational algorithm for generating progressive Type-II censored samples. Am. Stat. 49(2), 229–230 (1995).
Chen, M. H. & Shao, Q. M. Monte Carlo estimation of Bayesian credible and HPD intervals. J. Comput. Graph. Stat. 8(1), 69–92 (1999).
Sultana, F., Tripathi, Y. M., Rastogi, M. K. & Wu, S. J. Parameter estimation for kumaraswamy distribution based on hybrid censoring. Am. J. Math. Manag. Sci. 37(3), 243–261 (2018).
Akaike, H. Fitting autoregressive models for regression. Ann. Inst. Stat. Math. 21, 243–247 (1969).
Hurvich, C. M. & Tsai, C. L. Regression and time series model selection in small samples. Biometrika 76(2), 297–307 (1989).
Schwarz, G. Estimating the dimension of a model. Ann. Stat. 6(2), 461–464 (1978).
Ng, H. K. T., Chan, P. S. & Balakrishnan, N. Optimal progressive censoring plans for the Weibull distribution. Technometrics 46(4), 470–481 (2004).
Kundu, D. Bayesian inference and life testing plan for the Weibull distribution in presence of progressive censoring. Technometrics 50(2), 144–154 (2008).
Lee, K., Sun, H. & Cho, Y. Exact likelihood inference of the exponential parameter under generalized Type II progressive hybrid censoring. J. Kor. Stat. Soc. 45(1), 123–136 (2016).
Lee, K. & Cho, Y. Bayesian and maximum likelihood estimations of the inverted exponentiated half logistic distribution under progressive Type-II censoring. J. Appl. Stat. 44(5), 811–832 (2017).
Ashour, S. K., El-Sheikh, A. A. & Elshahhat, A. Inferences and optimal censoring schemes for progressively first-failure censored Nadarajah-Haghighi distribution. Sankhya A: Indian J. Stat. 84, 885–923 (2022).
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
Osama E. Abo-Kasem make the draft of the paper Ahmed R. El Saeed doing theoretical part Amira I. El Sayed doing simuatltion and real data analysis
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Abo-Kasem, O.E., El Saeed, A.R. & El Sayed, A.I. Optimal sampling and statistical inferences for Kumaraswamy distribution under progressive Type-II censoring schemes. Sci Rep 13, 12063 (2023). https://doi.org/10.1038/s41598-023-38594-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-38594-9
This article is cited by
-
Randomly Censored Kumaraswamy Distribution
Journal of Statistical Theory and Applications (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
