
Abstract
Deep learning-based object detection methods have achieved great performance improvement. However, since small kernel convolution has been widely used, the semantic feature is difficult to obtain due to the small receptive fields, and the key information cannot be highlighted, resulting in a series of problems such as wrong detection, missing detection, and repeated detection. To overcome these problems, we propose a large kernel convolution object detection network based on feature capture enhancement and vast receptive field attention, called LKC-Net. Firstly, a feature capture enhancement block based on large kernel convolution is proposed to improve the semantic feature capturing ability, and depth convolution is used to reduce the number of parameters. Then, the vast receptive filed attention mechanism is constructed to enhance channel direction information extraction ability, and it is more compatible with the proposed backbone than other existing attention mechanisms. Finally, the loss function is improved by introducing the SIoU, which can overcome the angle mismatch problem between the ground truth and prediction box. Experiments are conducted on Pascal VOC and MS COCO datasets for demonstrating the performance of LKC-Net.
Similar content being viewed by others

Introduction
Object detection is an important task in the field of computer vision, and it is also essential to be employed in other advanced visual tasks, such as behavior recognition1, attitude estimation2, and video segmentation3. The task of object detection is to use RGB images as input and realize location annotation, classification of interest targets, and display the confidence of their categories. Object detection has been widely used in many fields, including traffic detection4,5, medical detection6,7, industrial detection8,9, and many others.
The receptive field is an important design element for object detection. To expand the receptive field, researchers usually used a relatively large convolution kernel in the network model, so that the model could obtain more comprehensive features of the input image, such as LeNet(5*5)10 and AlexNet(5*5, 11*11)11. A large number of object detection networks based on large kernel convolution, including effective receptive field (ERF)12, RepLKNet13, and ViT14, have been proposed. Nevertheless, the incorporation of large kernel convolutions can bring some associated challenges. First, the inappropriate position of large kernel convolution may degrade the performance of the network. Second, it is difficult to determine the size of large kernel convolution that can achieve the best performance. Third, the introduction of large kernel convolution will result in a significant increase in the number of parameters and computation costs in the network. Therefore, this paper aims to determine the optimal position and size of large kernel convolution and reduce the number of parameters while maintaining the prediction performance.
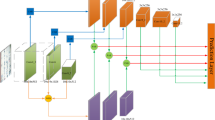
To address the above consideration, the ultimate goal of this paper is to propose an object detection network with a large kernel convolution block (LKC-Net). Firstly, a feature capture enhancement block based on large kernel convolution is proposed. The 1*1 convolution blocks in the neck’s bottom-up fusion feature convolution modules are replaced with 17*17 and 5*5 convolution blocks, respectively. The standard convolution is replaced with depthwise convolution to reduce network parameters and improve network efficiency. Then, the attention mechanism with a large receptive field is fused in the backbone to make the whole model more suitable for the large convolution kernel structure. Finally, the loss function is improved by introducing SIoU. The distance loss is modified, and angle loss is added to further improve the performance of network detection. The overview of the proposed network LKC-Net is shown in Fig. 1.

The overview of LKC-Net.
The contributions can be summarized as follows: (a) The feature capture enhancement block is designed to improve the feature capturing ability of the neck. The kernel size of the convolution blocks in the neck is enlarged to obtain a larger receptive field, and the depth convolution is used to reduce the number of parameters. Compared with the existing models, the proposed network has higher accuracy with the same number of parameters. (b) The vast receptive field attention is constructed to enhance the channel direction information extraction ability. The model integrates the attention mechanism with a large receptive field more compatible with the proposed backbone. Therefore, the detection accuracy can be further improved under the combined action of the large convolution neck and the large receptive field attention mechanism. (c) The loss function is improved by introducing the SIoU, which can overcome the angle mismatch problem between the ground truth and prediction box. This can effectively enhance the computational performance of the detection model. (d) The object detection model with a large kernel convolution block is proposed. The large kernel convolution neck structure integrates high-level and low-level features, which can improve the ability to extract semantic information features of image context. Therefore, the performance of network detection is enhanced. (e) Extensive experiments have been carried out on the Pascal VOC and MS COCO datasets, proving the advantages of LKC-Net over the existing methods by quantitative and qualitative evaluation.
The main structure of this paper is as follows: “Related works” introduces the related works to large kernel convolution and attention mechanism. In “Proposed method”, the objection detection model is proposed, and the main components are described in detail. A series of experiments and visualization is performed in “Experiment”. Conclusions are presented in “Conclusion”.
Related works
Overview of object detection
In recent years, object detection models have been mainly divided into two categories: two-stage detection model and one-stage detection model. The process of the two-stage object detection model is divided into two steps. In the first step, the candidate region is extracted from the input image. In the second step, the candidate region is send to the CNN network for detection. Classical two-stage object detection models include R-CNN15, Faster R-CNN16, etc. The two-stage model has been the leader in the field of object detection for a long period, but the fatal disadvantage of this kind model is that the detection speed is not efficient enough. Although some two-stage models have improved the detection speed, they still cannot meet the requirements of real-time detection. The one-stage model breaks the dominance of the two-stage model in terms of detection speed. With the advent of YOLO17 in 2015, the one-stage object detection model began to boom. Its basic idea is to divide the input image into \(S*S\) grids, and each grid predicts B bounding boxes. Then, the input image is send into the neural network to extract features. Finally, the network directly predicts and outputs the detection result. There are other one-stage object detection networks such as SSD18 and RetinaNet19. However, these models did not evolve as well as YOLO in subsequent versions, and YOLOV5 model is chosen as our baseline.
Large kernel convolution
The receptive field is an important element for object detection neural network models. The receptive field of a convolutional neural network unit corresponds to the fixed region in the image of the previous layer, and the image outside the corresponding region of the receptive field cannot affect the unit. The larger the receptive field the neural network unit owned, the more context information of the image received by the convolutional neural network unit. Therefore, enabling the network to extract features from images on a larger vision can be more sensitive to input images. There are many methods that use large kernel convolution to improve the receptive field of networks, such as LeNet(5*5)10, AlexNet(11*11)11, Inception(1*7, 7*1)20, GoogLeNet(7*7, 5*5)21. Chen. et al22also find that the large kernel convolution has excellent performance not only in 2D CNNs model but also in 3D CNNs.
Although large kernel convolution can better obtain contextual information on detection targets, some researchers have found that the size of the convolution kernel is not that the larger convolution kernel size leads to better model performance. Sheng et al.23 proposed that only local features can be observed if the receptive field is too small, and the relationship between features can be ignored. If the receptive field is too large, too much invalid information will be retrieved, decreasing the representation ability of the network. Han et al.24 tried the convolution kernel size of 7*7 and 9*9 in the segmentation task, and found that the 7*7 convolution kernel would improve the network. However, the 9*9 convolution kernel would cause performance degradation. Therefore, large kernel convolution of different sizes may affect downstream tasks differently.
This paper verifies the influence of convolution kernels with different sizes. On this basis, a context enhancement block is proposed, which can effectively enlarge the receptive field of the detection model, and it is combined with the YOLOV5 object detection model to improve the detection precision.
Attention mechanism
The attention mechanism originates from the study of the human visual system. When humans observe things with their eyes, they do not focus on everything in their visual field but selectively look at the part of their visual field that they want to get information from. Inspired by this observation, researchers have designed different attention mechanisms for various tasks to enhance the network’s attention to the target of interest. At present, the existing attention mechanisms include Squeeze-and-Excitation (SE)25, Convolutional Block Attention Module (CBAM)26, and Channel Attention (CA)26, etc. There are also some attention mechanism used for distill detection model to fusion different modality, such as modality attention-based fusion (MAF)27.
However, the experimental verification shows that the use of some attention mechanisms can not improve the network’s detection effect but reduces the network’s accuracy. This indicates that some existing attention mechanisms are not in harmony with large kernel convolution and even hinder the improvement of detection performance.
In this paper, the attention mechanism with a large receptive field is introduced to fit the detection network model of large kernel convolution. Under the combined action of the large convolution neck and the large receptive field attention mechanism, the network model can enhance the ability to extract context information from an image, thereby improving the detection accuracy of the network.
Loss function
The loss function of the YOLO series is composed of three kinds of losses, namely, box location loss, classification loss, and confidence loss. For box location loss, YOLO usually adopts IoU series losses, which have experienced from IoU loss to Generalized-IoU loss (GIoU)26, Distence-IoU loss (DIoU)28, Conplete-IoU loss (CIoU)28. In version 6.0 of YOLOV5, CIoU is used for IoU loss of positioning frame. Compared with DIoU, CIoU added the influence factor of the size of the detection frame and further considered the aspect ratio between the bounding box and the ground truth, making the prediction frame closer to the ground truth.
However, CIoU loss does not consider the angle problem between ground truth and the bounding box. The angle mismatch may cause the restriction for the prediction box in the training process and eventually lead to the training model with poor performance. Therefore, the SIoU is introduced into the proposed network to increase the angle matching between the bounding box and ground truth for improvement performance.
Proposed method
In this section, the object detection model with large kernel convolution based on feature capture enhancement and vast receptive field attention (LKC-Net) is proposed. Firstly, the feature context enhancement (FCE) block based on large kernel convolution is proposed. It is integrated into the neck network to enlarge the receptive field of the neck and enhance the neck’s ability to extract high-level feature context information in the bottom-up process. Then, the vast receptive field (VRF) attention mechanism is constructed to strengthen the network’s attention to extracting features in a larger receptive field. Finally, the loss function is improved by introducing the SIoU, which can overcome the angle mismatch problem between the ground truth and prediction box. The general structure of LKC-Net is illustrated in Fig. 2. The main components of the proposed model will be presented in what follows.

The Structure of LKC-Net.
Baseline
The baseline adopts the basic architecture of the YOLOV5s29 model. YOLOV5 is an end-to-end object detection model with different parameter sizes: S, M, and L, for different purposes. The network has been updated from version 1.0 to version 6.0. The whole network consists of three parts: the backbone, neck, and head. The backbone is used to extract the features of input images. The neck is used to integrate the high-level and low-level features extracted from the backbone network and thus strengthen the ability of the whole network to extract image features. The head is used to predict and output the result of the detection. The loss function used by YOLOV5 in version 6.0 is CIoU. Compared with DIoU28, CIoU considers the consistency of the aspect ratio of the three regression elements in the bounding box, which further improves the detection accuracy of the network. The CIoU loss function is defined as follows:
where IOU is the intersection ratio between the ground truth and the bounding box, \(\rho (\cdot )\) is the Euclidean distance, and c is the diagonal line containing the smallest box. \(\alpha\) is the weight function and is used to measure the consistency of the aspect ratio. It can be seen from the definition of \(\alpha\) that the CIoU loss tends to be optimized in the direction of increasing the overlap area.
Feature capture enhancement block
The high-level and low-level features extracted from the backbone network have different characteristics. The low-level feature contains less semantic information, but the information provided by the low-level feature is significant for predicting the object’s location. Compared with the low-level features, the high-level features contain richer semantic information. The prediction based on high-level semantic information can better identify the object’s content, but it is difficult to accurately predict the object’s location. In the neck network of the original YOLOV5 model, the strong semantic features extracted from the backbone are conveyed to the bottom-up structure, and the high-level semantics are integrated with the low-level semantics. Then, convolution is used to extract the fused features in the top-down path. Finally, the head outputs the result of the detection. In the neck of the original YOLOV5, the size of the bottom-up structure convolution kernel is 1*1. This part is mainly used to fuse the feature map extracted from the backbone network, and the 1*1 convolution is utilized to extract the spatial features in high latitudes.
However, the small kernel convolution results in the loss of contextual semantic information. To overcome this shortage, the convolution kernel size of bottom-up feature extraction is enlarged to improve the network’s ability to extract high-level features and strengthen the network’s common recognition of background and object information. Based on the above-mentioned consideration, the feature capture enhancement block (FCE) is proposed. FCE enlarges the size of the convolution kernel for extracting high-level semantic information in the neck network, i.e. the 1*1 convolutions are replaced by the 17*17 and 5*5 convolutions, respectively. FCE can enhance the feature capture ability of the original PANet bottom-up module. Furthermore, the original convolution mode is modified to the depth convolution. This not only increases the receptive field of the network but also reduces the parameters of the network. The feature capture enhancement block is shown in Fig. 3.

The feature capture enhancement block.
The number of parameters is reduced by utilized of the depth convolution. The analysis of the number of parameters in depthwise convolution and standard convolution is performed as follows. Let \(D_K\) be the size of the convolution kernel, M be the number of the feature map’s channels at the input end, N be the number of feature map channels at the output end, and \(D_F\) be the size of the feature map at the output end. The comparison of the parameter number of the two parts is as follows:
It can be seen that the number of parameters in FCE block decreases N times, where N is the number of channels in standard convolution. Thus, the FCE block effectively reduces the number of parameters and improves network efficiency.
Vast receptive field attention
In the process described above, the feature capture enhancement block can increase the receptive field and reduce the number of network parameters. This improvement may lead to the loss of the channel information, thus attention mechanism is added to obtain channel direction information. At present, some well-known attention mechanisms can enhance the ability of the network to obtain spatial information, such as SE25, CBAM26, and CA26. However, the experimental verification shows that the use of these attention mechanisms not only cannot improve the detection effect of the network but also reduces the accuracy of the network. The above attention mechanisms make the network backbone search for the target of interest in the limited receptive field, which leads to conflict with the neck network with large convolution features, resulting in an unsatisfactory result. Therefore, the vast receptive field (VRF) attention is constructed to increase the receptive field and promote the performance of the neck network with large convolution features. The structure of vast receptive field attention is shown in Fig. 4.

The vast receptive field attention.
Assuming the intermediate feature map \(F\in R^{C\times H\times W}\) as the input, the VRF attention mechanism first uses a convolution block to calculate the feature map \(M_C\in R^{C\times H\times W}\) that containing channel information. Then, the feature map is convolved twice to successively calculate the sum of two feature maps \(M_{VRa}\in R^{C\times H\times W}\) and \(M_{VRb}\in R^{C\times H\times W}\) with large receptive fields. Finally, the calculated attention feature map \(M_{VRb}\in R^{C\times H\times W}\) is multiplied by the input intermediate feature map to obtain the enhanced feature map \(F'\in R^{C\times H\times W}\). The overall process can be summarized as follows:
where \(F'\) is the final output feature map, and \(\otimes\) is the element-wize multiplication. \(M_C (F)\), \(M_{VRa}(F)\), and \(M_{VRb}(F)\) are the three convolution modes in VRF, which are defined as follows:
where \(f^{C\times 1\times 1}(F)\) represents the convolution whose convolution kernel is 1*1*C, \(f^{ 5\times 5}_{DW}(F)\) represents the convolution calculation whose convolution kernel is 1*5*5, and \(f^{7\times 7}_{DWd}(F)\) represents the deep cavity convolution whose convolution kernel is 1*7*7.
Loss function
The loss function in YOLOV5 comprises three parts: classification loss, location loss, and confidence loss. Among them, the classification loss refers to whether the prediction box and the corresponding classification are correct, the positioning loss refers to the error between the bounding box and GT, and the confidence loss refers to the confidence of the target detected by the network. The loss function is defined as follows:
where K, \(S^2\) and B are the index of the output feature map, the index of the cell on the feature map, and the index of the anchor on each cell, respectively. \(\alpha\) is the hyperparameter loss weight set for each loss. \(I^{obj}_{kij}\) represents the \(i_{th}\) cells and \(j_{th}\) anchor in feature map, whose value is 1 if it is positive, and 0 if not. \(\beta ^{balance}_{K}\) is the weight for balance three scales (80*80, 40*40, 20*20) feature map.
To overcome the angle mismatch problem between ground truth and bounding box, the loss function is improved by introducing the SIoU. The loss function is composed of four parts: angle, distance, shape, and IoU costs. The total box loss is as follows:
where \(\Delta\) is distance loss, \(\Omega\) is shape loss, and IoU is IoU loss. The loss function redefines distance loss and considers angle loss \(\Lambda\) into distance loss as follows:
where x is the hypotenuse for the connection \(\sigma\) which between the center points of the anchor box B and the ground true \(B^{GT}\), and the vertical distance \(C_h\) is the sine value of the opposite side, as shown in Fig. 5.

The angle loss of SIoU.
Experiment
In this section, the experiments are conducted to prove the effectiveness of the proposed model through quantitative and qualitative evaluation. The experiment is divided into four parts: (1) the experimental dataset and training environment configuration are introduced. (2) The quantitative evaluation is performed to verify the improvement of LKC-Net in accuracy on the Pascal VOC and MS COCO datasets. (3) The validity analysis and ablation experiment is performed to verify the effect of three innovative points in LKC-Net. (4) The qualitative evaluation is carried out to verify the improvement of LKC-Net in vision.
Introduction of datasets
Pascal VOC dataset
The PASCAL VOC Challenge30 consists of the following categories: Image Classification, Object Detection, Object Segmentation, Action Classification, etc. There are 20 main target categories in the Pascal VOC dataset. This paper mainly uses the object detection task data set of the VOC2007+2012 dataset for training, in which the train set contains 16,551 pictures, and the test set contains 4952 pictures. The representative pictures of the data set are shown in Fig. 6a.
MS COCO dataset
MS COCO31 is a very high industry status and large-scale dataset used for object detection, segmentation, image description, and other scenes. The dataset used in this paper is COCO2017, in which 80 categories of images are used for object detection. Dataset images are divided into train, verification, and test sets. There are 118,287 pictures in the train set, 5000 pictures in the verification set, and 40,670 pictures in the test set. The representative pictures of the data set are shown in Fig. 6b.

The representative pictures of Pascal VOC and MS COCO.
Experimental environment and hyperparameter settings
The experimental environment is PyTorch deep learning library, in which Pytorch version is 1.12.1+cu113, the version of torchaudio is 0.12.1+cu113, the version of torchextractor is 0.3.0. The version of torchvision is 0.13.1+cu113. The experiment is conducted on 12th Gen Intel(R) Core(TM) i7-12700@ 2.10GHz CPU, 32GB RAM, and NVIDIA RTX 3090 Ti GPU. The system is Windows 10 Pro version 19044.1826. The experimental hyperparameter settings are shown in Table 1.
Quantitative evaluation
Experiment on Pascal VOC datasset
In the training process of the Pascal VOC dataset, the weight of pre-training on the COCO dataset is chosen. The train and verification set of VOC2007 and VOC2012 is used for the model training. The final results is tested on the VOC 2007 test set. The proposed model LKC-Net is compared with Fast YOLO18, Faster R-CNN VGG-1618, ShuffleNetV2-SSDLite32, RefineDet512-VGG-1633, RFB Net512-VGG33, MobileNetV2-YOLOV434, EEEA-Net-c2- yolov434, SSD30018, YOLOV5s29, YOLOV6-N35, and YOLOV7-Tiny36. The detection result on the VOC dataset is shown in Table 2.
Table 2 shows that the mAP0.5 of LKC-Net is increased by 1.2% in comparison with the original YOLOV5s. Compared with the models with the large number of parameters, such as MobileNetV2-YOLOV4 and SSD300, the accuracy of LKC-Net is 2.5% higher than that of MobileNetV2-YOLOV4 and 2.4% higher than that of SSD300. In comparison with the models with similar parameters, such as YOLOV6-N and YOLOV7-Tiny, the detection accuracy of the LKC-Net is 4.7% higher than that of YOLOV6-N and 3.1% higher than that of YOLOV7-Tiny. In summary, LKC-Net achieves the best detection accuracy while maintaining a small number of parameters. Therefore, LKC-Net achieves optimal detection performance.
Experiment on MS COCO datasset
Furthermore, LKC-Net is compared with MNetV1-SSDLite37, MNetV2-SSDLite37, RefineDet512-VGG-1633, RFBNet512-VGG33, MnasNet-A1-SSDLite38, Retina Net640-ResNet-5039, YOLOV3-ASFF32040, PPYOLO-Tiny41641, YOLOV4-Tiny32042, YOLOX-Tiny43, YOLOV5s29,DAMO-YOLO-Ns44,DAMO-YOLO-NM44, PP-Picodet-M45, PP-PicoDet-MV3-large-1x45, PP-PicoDet-LCNet-1.5x45 EffificientDet-D046(512) and YOLOV7-Tiny64036. The accuracy of these algorithms on the MS COCO dataset is shown in Table 3.
Table 3 shows that the mAP0.5:0.95 of LKC-Net model increased by 1.2% compared with the YOLOV5s model. In comparison with the other lightweight YOLO model, it can be seen that the accuracy of LKC-Net is improved by 16.2% compared with MNetV1-SSDLite, 16.3% compared with MNetV2-SSDLite, and 15.4% compared with MnasNet-A1+SSDLite. It is 9.7% more accurate than YOLOV4-Tiny320 and 5.6% more accurate than YOLOX-Tiny. In comparison with other one-stage detection models, LKC-Net is 5.4% better than RefineDet512-VGG-16, 2.5% better than YOLOV6-N, 5.1% better than YOLOV7-Tiny, and 0.3% better than YOLOV3-ASFF320. In Comparsion with the selected SOTA methods, LKC-Net is 6.1% better than DAMO-YOLO-Ns,0.2% better than DAMO-YOLO-Nm, 4.1% better than PP-Picodet-M, 2.8% better than PP-PicoDet-MV3-large-1×, 3.8% better thanEffificientDet-D0. In summary, LKC-Net achieves the best detection accuracy while maintaining a small number of parameters. Therefore, LKC-Net has achieved the best detection performance.
Validity analysis and ablation experiment
Parameters and computation of different convolutions
To verify the improvement of feature capture enhancement block, the changes in the number of parameters and computation cost before and after adding the feature capture enhancement block are computed, as shown in Table 4.
Table 4 shows that when the size of the first convolutional block in the neck is increased to 17*17, the number of standard convolutional parameters increases from 7.23M to 29.25M, the number of parameters increases nearly four times, and the calculation amount increases from 16.6M to 34.2M, nearly two times. On this basis, when the size of the second convolution kernel block of the neck is increased to 5*5, the number of parameters is further increased from 29.25M to 30.82M, and the amount of computation is increased from 34.2 to 39.3%. However, when the feature capture enhancement block is replaced, it can be seen that the total parameters and computation cost of the network do not change significantly after increasing the size of the convolution kernel.
Different kernel sizes and attention mechanisms
The convolution kernel size of the standard convolution block in the original YOLOV5s is increased for the experiment. The original convolution kernel size is changed to 5*5. Then, the kernel size is gradually increased to obtain the best performance. It is found that the best convolution kernel size is the combination 17*17 of 5*5. The results are shown in Table 5.
Table 5 shows that when the kernel size is increased to 5*5, the detection effect is improved from 82.8 to 83.4% in comparison with the original YOLOV5s model. With the increase of the kernel size, the detection effect is also significantly enhanced, and the detection effect reaches the best (83.7%) when the kernel size is increased to 17*17. When the kernel size is increased to 19*19, the detection effect begins to deteriorate, and reduces the detection effect. The size of the second convolution kernel block also is increased to 5*5, and the model’s accuracy does not increase significantly at the beginning, remaining at 83.7%. When it increases again, the accuracy begins to plummet. Therefore, the optimal convolution kernel size is the combination 17*17 of 5*5.
To compare the influence of standard convolution and depthwise convolution, the comparison experiments for the method with standard convolution and depthwise convolution are conducted, as shown in Table 6.
Table 6 shows that when large kernel convolution is used in depthwise convolution, the number of parameters is almost a quarter of standard convolution, the number of parameters is a third of standard convolution, and the final effects of different convolutions are almost the same.
Furthermore, to verify the effect of different attention mechanisms on the model, a series of experiments with different attention mechanisms on the model is constructed, as shown in Table 7.
Table 7 shows that different attention mechanisms have different effects on the proposed model, among which the large receptive field attention mechanism has a better effect on detecting the convolution model with a large kernel. The other attention mechanisms, such as CBAM and SE, hinder the improvement of model accuracy. In the network with the addition of the FCE, the network detection accuracy with the addition of CBAM decreases from 83.7% to 83.2%. The accuracy of network detection with the addition of the SE attention mechanism also decreases from 83.7 to 83.2%, and the accuracy of network detection with the addition of the CA attention mechanism decreases from 83.7 to 83.6%. However, when the VRF attention mechanism is used, the accuracy of the model is improved from 83.7 to 83.8%.
Finally, we evaluate the influence of several different loss functions, including GIOU, DIOU and SIOU. The results are shown in Table 8. Table 8 shows that DIOU has a poor fit to the model, resulting in a loss of 0.2% in the proposed model, while GIOU and SIOU both have certain improvement effects on the model, increasing by 0.1% and 0.2% respectively. Therefore, SIOU is selected as the loss function for the model.
Ablation study
To demonstrate the respective roles of different components in the proposed model, including using large kernel convolution, the feature capture enhancement (FCE) block, the vast receptive field (VRF) attention mechanism, and the loss function, the ablation study on the Pascal VOC dataset is carried out. For a finer analysis, the three components are added successively in the ablation experiment, and the improvement on the model is shown in Table 9.
Table 9 shows that the enlargement of kernel size from 1*1 to 17*17 can improve the network detection performance. Although the accuracy of the model is improved by 1%, the number of parameters and calculation amount are significantly increased, as shown in Table 6. Then, FCE block is used to reduce the number of parameters and calculation amount. On this basis, VRF can enhance the attention of the network model to the channel direction of the feature map, which further improves the accuracy of the network model from 83.7 to 83.8%. Finally, the loss function introduced into the model further improves the detection accuracy of the proposed network from 83.8 to 84.0%.
Visualization comparison
Visualization comparison of receptive field
The Grad-CAM47 visualization method is used to conduct receptive field visualization experiments on the YOLOV5 network and LKC-Net network, as shown in Fig. 7.

Comparison of receptive field.
Figure 7 shows that the larger receptive field of LKC-Net is reflected in the third line of the heat map compared to the YOLOV5s, which means that the network pays more attention to the input image from a larger vision. As can be seen from Fig. 7, LKC-Net benefits from the large receptive field brought by the large convolution kernel, which makes LKC-Net not only interested in the target itself to be detected but also able to notice the contextual semantic information of the detected object.
Visualization experiments of improvement effect
To verify the improvement on the original YOLOV5s network, the visualization experiments of the improvement effect are performed, and the improvements of LKC-Net are shown in Fig. 8.

Performance improvements of LKC-Net.
Figure 8a show that the LKC-Net network can solve the problem of missing detection compared with the YOLOV5s network. The first group of pictures shows the missed chairs, the second group of pictures shows the missed dogs, the third group of pictures shows the missing boats, the fourth group of pictures shows the missing people, the fifth group of pictures shows the missed cats, the sixth group of pictures shows the missed cars, and the seventh group of pictures shows the missed chairs and potted plants. Figure 8b show that the LKC-Net network can solve the problem of YOLOV5s repeated detecting large objects in the image.The first and fifth sets of pictures show the repeated detection of ships, the second and fourth sets of pictures show the repeated detection of cat, the third set of pictures show the repeated detection of people, the sixth set of pictures show the repeated detection of planes, and the seventh set of pictures show the repeated detection of trains. Figure 8c show that LKC-Net can improve the YOLOV5s’s wrong detection problem. The first set of images corrected that the model detected tree trunk as bird, the second set of images corrected that the model detected potted plant as dog, the third set of images corrected that the model detected runway track as boat, the fourth set of images corrected that the model detected sofa as chair, the fifth set of images corrected that the model detected person as dog, the sixth set of images corrected that the model detected house as train, and the seventh set of images corrected that the model detected clock as person. Therefore, LKC-Net can effectively improve the problems of missing detection, wrong detection, and repeated detection by virtue of the large receptive field brought by the large kernel convolution.
Visualization of limitation
Although LKC-Net has significant performance improvements compared with the baseline model in different respects, there is still the limitation of the proposed method. In certain detection scenarios, when the distance between objects of the same class is small, it can cause the model to mistakenly recognize two objects as one object, as shown in Fig. 9. In the first image, the model identified two birds as one bird. The same problem occurs in the other three images.

Limitation of LKC-Net.
Conclusion
In this paper, an object detection network based on a large kernel convolutional neck network is proposed. Firstly, the feature capture enhancement block based on large kernel convolution is proposed to improve the semantic feature capturing ability, and the depth convolution is used to reduce the number of parameters. Then, the vast receptive field attention mechanism is constructed to enhance channel direction information extraction ability. The experimental results demonstrate the constructed attention mechanism is more compatible with the proposed backbone than other existing attention mechanisms. Third, the loss function is improved by introducing the SIoU to overcome the angle mismatch problem between the ground truth and prediction box. Pascal VOC and MS COCO datasets are used to compare the object detection performance of LKC-Net with other existing models. The quantitative evaluation results demonstrate that LKC-Net can achieve the best object detection performance in terms of accuracy while maintaining a small number of parameters. The qualitative evaluation results demonstrate that LKC-Net benefits from the large kernel convolution structure, which enhances contextual semantic information extraction ability and overcomes the wrong detection, missing detection, and repeated detection problems. In future work, we will focus on making the proposed network more lightweight and adjusting the convolution kernel size to further enhance object detection performance.In future work, we will focus on some promising directions worth pursuing including: make the proposed network more lightweight; adjuste the convolution kernel size to further enhance performance; combine the proposed method with different baselines.
Data availibility
The datasets used in this study are publicly available. Pascal VOC dataset is available on the official website: http://host.robots.ox.ac.uk/pascal/VOC/voc2012/. MS COCO dataset is available on the official website: https://cocodataset.org/#download. The images in this manuscript are all from publicly available Pascal VOC and MS COCO datasets.
References
Wang, J., Chen, Y., Hao, S., Peng, X. & Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recogn. Lett. 119, 3–11 (2019).
Sun, K., Xiao, B., Liu, D. & Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 5693–5703 (2019).
Lu, X. et al. See more, know more: Unsupervised video object segmentation with co-attention Siamese networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 3623–3632 (2019).
Shen, L., You, L., Peng, B. & Zhang, C. Group multi-scale attention pyramid network for traffic sign detection. Neurocomputing 452, 1–14 (2021).
Sharif, M. et al. Recognition of different types of leukocytes using yolov2 and optimized bag-of-features. IEEE Access 8, 167448–167459 (2020).
Zhuang, Z. et al. Cardiac VFM visualization and analysis based on yolo deep learning model and modified 2d continuity equation. Comput. Med. Imaging Graph. 82, 101732–101744 (2020).
Liu, P. et al. Detection of transmission line against external force damage based on improved yolov3. Int. J. Robot. Autom. 35, 460–468 (2020).
Xie, Y., Cai, J., Bhojwani, R., Shekhar, S. & Knight, J. A locally-constrained yolo framework for detecting small and densely-distributed building footprints. Int. J. Geogr. Inf. Sci. 34, 777–801 (2020).
Zhu, X., Lyu, S., Wang, X. & Zhao, Q. Tph-yolov5: Improved yolov5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2778–2788 (2021).
LeCun, Y. et al. Handwritten digit recognition with a back-propagation network. Adv. Neural. Inf. Process. Syst. 2, 396–404 (1989).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. Commun. ACM 60, 84–90 (2017).
Luo, W., Li, Y., Urtasun, R. & Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. Adv. Neural. Inf. Process. Syst. 29, 4898–4906 (2016).
Ding, X., Zhang, X., Han, J. & Ding, G. Scaling up your kernels to 31x31: Revisiting large kernel design in CNNs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 11963–11975 (2022).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv:2010.11929 (2020).
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 580–587 (2014).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 28, 91–99 (2015).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 779–788 (2016).
Liu, W. et al. Ssd: Single shot multibox detector. In Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14, 21–37 (Springer, 2016).
Lin, T.-Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision 2980–2988 (2017).
Szegedy, C., Ioffe, S., Vanhoucke, V. & Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31 4278–4284 (2017).
Szegedy, C. et al. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 1–9 (2015).
Chen, Y. et al. Scaling up kernels in 3d CNNs. arXiv:2206.10555 (2022).
Sheng, P., Shi, Y., Liu, X. & Jin, H. Lsnet: Real-time attention semantic segmentation network with linear complexity. Neurocomputing 509, 94–101 (2022).
Hu, H., Zhang, Z., Xie, Z. & Lin, S. Local relation networks for image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision 3464–3473 (2019).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 7132–7141 (2018).
Rezatofighi, H. et al. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 658–666 (2019).
Liu, T., Lam, K.-M., Zhao, R. & Qiu, G. Deep cross-modal representation learning and distillation for illumination-invariant pedestrian detection. IEEE Trans. Circuits Syst. Video Technol. 32, 315–329 (2021).
Zheng, Z. et al. Distance-iou loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34 12993–13000 (2020).
Jocher, G. Superviseultralytics/yolov5: V5.0-yolov5-p6 1280 models, aws, supervise.ly, and youtube integrations. Github.com (2021).
Everingham, M. et al. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 111, 98–136 (2015).
Lin, T.-Y. et al. Microsoft coco: Common objects in context. In Computer Vision-ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6–12, 2014, Proceedings, Part V 13 740–755 (Springer, 2014).
Ma, N., Zhang, X., Zheng, H.-T. & Sun, J. Shufflenet v2: Practical guidelines for efficient CNN architecture design. In Proceedings of the European Conference on Computer Vision (ECCV) 116–131 (2018).
Zhang, S., Wen, L., Bian, X., Lei, Z. & Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 4203–4212 (2018).
Termritthikun, C., Jamtsho, Y., Ieamsaard, J., Muneesawang, P. & Lee, I. Eeea-net: An early exit evolutionary neural architecture search. Eng. Appl. Artif. Intell. 104, 104397 (2021).
Li, C. et al. Yolov6: A single-stage object detection framework for industrial applications. arXiv:2209.02976 (2022).
Wang, C.-Y., Bochkovskiy, A. & Liao, H.-Y.M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv:2207.02696 (2022).
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. & Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 4510–4520 (2018).
Tan, M. et al. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2820–2828 (2019).
Liu, S., Huang, D. & Wang, Y. Learning spatial fusion for single-shot object detection. arXiv:1911.09516 (2019).
Bochkovskiy, A., Wang, C.-Y. & Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv:2004.10934 (2020).
Huang, X. et al. Pp-yolov2: A practical object detector. arXiv:2104.10419 (2021).
Wang, C.-Y., Bochkovskiy, A. & Liao, H.-Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 13029–13038 (2021).
Ge, Z., Liu, S., Wang, F., Li, Z. & Sun, J. Yolox: Exceeding yolo series in 2021. arXiv:2107.08430 (2021).
Xu, X. et al. Damo-yolo: A report on real-time object detection design. arXiv:2211.15444 (2022).
Yu, G. et al. Pp-picodet: A better real-time object detector on mobile devices. arXiv:2111.00902 (2021).
Tan, M., Pang, R. & Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 10781–10790 (2020).
Selvaraju, R.R. et al. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision 618–626 (2017).
Acknowledgements
This work was supported in part by the Natural Science Foundation of China under Grant 62266046, the Natural Science Foundation of Jilin Province, China, under Grant YDZJ202201ZYTS603, and the Natural Science Foundation of Jilin Provincial Department of Education, China, under Grant JJKH20230281KJ.
Author information
Authors and Affiliations
Contributions
All the authors contributed extensively to the manuscript. W.W. wrote the main manuscript, and helped with the formatting review and editing of the paper. L.S. designed the experiments and wrote the main manuscript. S.J. helped improve the experiments. J.H. reviewed and edited the original document. All authors have read and agreed to the publication of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, W., Li, S., Shao, J. et al. LKC-Net: large kernel convolution object detection network. Sci Rep 13, 9535 (2023). https://doi.org/10.1038/s41598-023-36724-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-36724-x
This article is cited by
-
Reparameterized dilated architecture: A wider field of view for pedestrian detection
Applied Intelligence (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
