
Abstract
In this paper, an efficient orthogonal neural network (ONN) approach is introduced to solve the higher-order neutral delay differential equations (NDDEs) with variable coefficients and multiple delays. The method is implemented by replacing the hidden layer of the feed-forward neural network with the orthogonal polynomial-based functional expansion block, and the corresponding weights of the network are obtained using an extreme learning machine(ELM) approach. Starting with simple delay differential equations (DDEs), an interest has been shown in solving NDDEs and system of NDDEs. Interest is given to consistency and convergence analysis, and it is seen that the method can produce a uniform closed-form solution with an error of order \(2^{-n}\), where n is the number of neurons. The developed neural network method is validated over various types of example problems(DDEs, NDDEs, and system of NDDEs) with four different types of special orthogonal polynomials.
Similar content being viewed by others

Introduction
Delay differential equation (DDE) plays a crucial role in epidemiology, population growth, and many mathematical modeling problems. In DDEs, the dependent variable depends not only on its current state but also on a specific past state. One type of DDE in which time delays are included in the state derivative is called the neutral delay differential equation (NDDE). Delay terms are classified into three types: discrete, continuous, and proportional delay. In this paper, we are focusing on proportional DDEs and NDDEs. One famous example of proportional delay differential equations is the pantograph differential equation which was first introduced in1.
Generally, the exact solution of delay differential equations is complicated to find, and due to the model’s complexity, many DDEs do not have an exact solution. Various numerical schemes have been developed over the years to find the approximate solution of delay differential equations. There are several articles2,3,4,5,6,7,8,9 that illustrate some exact and numerical methods for approximate solutions of DDEs and NDDEs.
Artificial neural networks(ANNs) have been utilised to produce an approximate solution of differential equations for the past 22 years. A neural network approach for several ordinary and partial differential equations was first proposed by Lagaris et al. in10. The approximate solution delivered by the artificial neural networks has a variety of advantages: (i) The derived approximation of the solution is in closed analytic form. (ii) The generalization ability of an approximation is excellent. (iii) Discretization of derivatives is not required. Many articles on approximation artificial neural network solutions to different differential equations are available in the literature11,12,13,14,15,16,17,18,19,20. As far as we know, the studies for obtaining an approximate solution to delay differential equations using artificial neural networks are limited. There is very little literature available for solving delay differential equations using ANNs. J. Fang et al. solved first-order delay differential equations with single delay using ANN21. In22, Chih-Chun Houe et al. obtained approximate solutions of proportional delay differential equation using ANN. All these artificial neural network approaches suffer from common problems: (1) All the algorithms are time-consuming and therefore they are computationally expansive numerical optimization algorithms, (2) They completely depend on the trial solution, which is difficult to construct for higher dimensional problems. Recently in23, Manoj and Shagun obtained an approximate solution of differential equations using an optimization-free neural network approach in which they trained the network weights using ELM algorithm24. In25, authors solved the first-order pantograph equation using the optimization-free ANN approach. Linear first-order delay differential-algebraic equations have been solved using Legendre neural network in26.
This work presents an orthogonal neural network with an extreme learning machine algorithm(ONN-ELM) to obtain an approximate solution for higher-order delay differential equations, neutral delay differential equations, and a system with multiple delays and variable coefficients. The ONN model is a particular functional link neural network(FLNN)12,27,28,29 case. It has the advantage of fast and very accurate learning. The entire procedure becomes much quicker than a traditional neural network because it removes the high-cost iteration procedure and trains the network weights using the Moore-Penrose generalized inverse. The following are the benefits of the proposed approach:
-
It is a single hidden layer neural network, we only need to train the output layer weights by randomly selecting the input layer weights.
-
We use an unsupervised extreme learning machine algorithm to train the output weights; no optimization technique is used in this procedure.
-
It is simple to implement, accurate compared to other numerical schemes mentioned in the literature, and runs quickly.
This work considers four different orthogonal polynomials-based neural networks: (i) Legendre neural network, (ii) Hermite neural network, (iii) Laguerre neural network, and (iv) Chebyshev neural network with ELM for solving DDEs, NDDEs, and systems of NDDEs with multiple delays and variable coefficients. The interest is to find the orthogonal neural network among these four that can produce more accurate solution.
The layout of this paper is as follows. In “Preliminaries” section, we present some definitions and properties of orthogonal polynomials and a description of the considered problems. In “Orthogonal neural network” section, we describe the architecture of the orthogonal neural network(ONN) with an extreme learning algorithm(ELM). “Error analysis” section discusses the convergence analysis and error analysis. The methodology of the proposed method is presented in “Methodology” section. Various numerical illustrations are presented in “Numerical illustrations” section and a comparative study is given in “Comparative analysis” section.
Preliminaries
In this section, first, we introduce basic definitions and some properties of the orthogonal polynomials. Throughout the paper, we will use \(P_n(x)\) to represent the orthogonal polynomial of order n.
Orthogonal polynomial
Definition 1
The orthogonal polynomials are special class of polynomials \({P_n(x)}\) defined on [a, b] that follow an orthogonality relation as,
where \(n,m \in N\), \(\delta _{m,n}\) is Kronecker delta, g(x) is a weight function and \(k_{n} = \int _{a}^b g(x)[P_n(x)]^{2} dx\).
Remark
-
1.
If a weight function \(g(x)=1\), then the orthogonal polynomial \(P_{n}(x)\) is called Legendre polynomial.
-
2.
If a weight function \(g(x)=(1-x^{2})^{-\frac{1}{2}}\), then the orthogonal polynomial \(P_{n}(x)\) is called Chebyshev polynomial of first kind.
-
3.
If a weight function \(g(x)=e^{-x^{2}}\), then the orthogonal polynomial \(P_{n}(x)\) is called Hermite polynomial.
-
4.
If a weight function \(g(x)=e^{-x}\), then the orthogonal polynomial \(P_{n}(x)\) is called Laguerre polynomial.
Properties of orthogonal polynomials
The following are some of the remarkable properties of a set of orthogonal polynomials:
-
Each polynomial \(P_n(t)\) is orthogonal to any other polynomial of degree \(<n\) in a set of orthogonal polynomials \(\{P_0(t),\ldots ,P_n(t),\ldots ,\}\).
-
Any set of orthogonal polynomials has a recurrence formula that connects any three consecutive polynomials in the sequence, i.e., the relation \(P_{n+1}(t)=(a_nt+b_n)P_{n}(t)-c_nP_{n-1}(t)\) exists, with constants \(a_n, b_n, c_n\) depending on n.
-
The zeroes of orthogonal polynomials are real numbers.
-
There is always a zero of orthogonal polynomial \(P_{n+1}(t)\) between two zeroes of \(P_{n}(t)\).
Moore-Penrose generalized inverse
In this section, the Moore-Penrose generalized inverse is introduced.
There can be problems in obtaining the solution of a general linear system \(Ax = y\), where A may be a singular matrix or may even not be square. The Moore-Penrose generalized inverse can be used to solve such difficulties. The term generalized inverse is sometimes referred to as a synonym of pseudoinverse. More precisely, we define the Moore-Penrose generalized inverse as follows:
Definition 2
30 A matrix B of order \(n\times m\) is the Moore-Penrose generalized inverse of matrix A of order \(m\times n\), if the following hold
where \(A^T\) denotes the transpose of matrix A. The Moore-Penrose generalized inverse of matrix A is denoted by \(A^\dagger\).
Definition 3
\(x_0 \in \mathbb {R}^n\) is said to be a minimum norm least-squares solution of a general linear system \(Ax = y\) if for any \(y \in \mathbb {R}^m\)
where \(\Vert . \Vert\) is the Euclidean norm.
In other words, if a solution \(x_0\) has the smallest norm among all the least-squares solutions, it is considered to be a minimum norm least-squares solution of the general linear system \(Ax = y\).
Theorem 1
30 Let B be a matrix with a minimum norm least-squares solution to the linear equation \(Ax = y\). Then \(B = A^\dagger\), the Moore-Penrose generalized inverse of matrix A, is both required and sufficient.
Problem definition
In this subsection, we present the general form of the pantograph equation, higher order delay differential equation, higher order neutral delay differential equation, and the system of higher order delay differential equation with variable coefficients and multiple delays.
The generalized Pantograph equation
Pantograph type equation arises as a mathematical model in the study of the wave motion of the overhead supply line to an electric locomotive. The following equation gives the generalized form of a pantograph type equation with multiple delays:
with initial conditions
where g(t), a(t), \(b_{i}(t)\) and \(c_{i}(t)\) is continuous function, \(0<q_i,q_{j}<1\) for some \(k,l \in \mathbb {N}\) and \(t\in [t_0,t_1]\) for some, \(t_0,t_1\in \mathbb {R}\).
Higher order DDEs and NDDEs
-
Consider the general form of Higher-order DDEs with multiple delay
$$\begin{aligned} z^{k}(t)=f\left( t,z(t),...z^{k-1}(t),z(q_{1}t),...z(q_{n}t)\right) , \end{aligned}$$(3)with initial conditions
$$\begin{aligned} z(t_{0})=z_{0},z'(t_{0})=z_{1},\ldots ,z^{k-1}(t_{0})=z_{k-1}, \end{aligned}$$(4)where \(q_{i}'s \in (0,1)\) for \(i=\)1,...,n and \(z^{k}\) denotes the kth derivative of z(t).
-
Consider the general form of Higher-order NDDEs with multiple delay
$$\begin{aligned} \begin{aligned} z^{k}(t)=f( t,&z(t),...z^{k-1}(t),z(q^{1}_{1}t),\ldots ,\\&z(q^{1}_{n_{1}}t),z'(q^{2}_{1}t),\ldots ,z'(q^{2}_{n_{2}}t),\ldots ,z^{k}(q^{k+1}_{1}t),\ldots ,z^{k}(q^{k+1}_{n_{k+1}}t)), \end{aligned} \end{aligned}$$(5)with initial condition
$$\begin{aligned} z(t_{0})=z_{0},z'(t_{0})=z_{1},\ldots ,z^{k-1}(t_{0})=z_{k-1}, \end{aligned}$$(6)where all \(q_{i}^{j}\in (0,1)\) for \(j=1,..,k+1\), \(i=1,\ldots ,n_j\), \(n_j, k\in \mathbb {N}\) and \(z^{k}\) denotes the kth derivative of z(t).
Higher order system of DDE
Consider the general form of higher order coupled neutral delay differential equation with multiple delays as:
where \(n_j,m_j,l_j,h_j \in \mathbb {N}\) and all \(q_{i_{1}}^{j},p_{i_{2}}^{j},r_{i_{3}}^{j},s_{i_{4}}^{j} \in (0,1)\) for \(j=1,..,k+1\), \(i_1=1,\ldots ,n_j\), \(i_2=1,\ldots ,m_j\), \(i_3=1,\ldots ,l_j\), \(i_4=1,\ldots ,h_j\).
Orthogonal neural network
In this section, we introduce the structure of a single-layered orthogonal neural network(ONN) model with an extreme learning machine(ELM) algorithm for training the network weights.
Structure of orthogonal neural network (ONN)
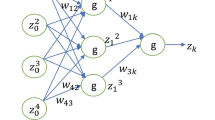
Orthogonal neural network(ONN) is a single-layered feed-forward neural network, which consists of one input neuron t, one output neuron \(N(t,{\textbf {a}},{\textbf {w}})\) and a hidden layer is eliminated by the orthogonal functional expansion block. The architecture of an orthogonal neural network is depicted in Fig. 1.

The structure of orthogonal neural network.
Consider a 1-dimensional input neuron t. The enhanced pattern is obtained by orthogonal functional expansion block as follows:
Here \(N(t,{\textbf {a}},{\textbf {w}})= \sum _{i=0}^{n} w_{i} P_{i}(a_{i}t)\) is the output of the orthogonal neural network, where \(a_i's\) are randomly selected fixed weights and \(w_{i}'s\) are the weights to be trained.
Extreme learning machine (ELM) algorithm
For a given sample points \((t_j,y_j)\), \(t_j \in \mathbb {R}^n\) and \(y_j \in \mathbb {R}\), for \(j=0,1,\ldots ,m\), a single-layer feed-forward neural network with \((n+1)\) neurons has the following output:
where \(g_i\) is the activation function of i-th neuron in a hidden layer, \(a_{i}'s\) are the randomly selected fixed weights between the input layer and hidden layer, and \(w_{i}'s\) are the weights between the hidden layer and output, which need to be trained.
When the neural network completely approximates the given data, i.e., the output of the neural network and actual data are equal, the following relation hold:
Equation (9) can be written in matrix form as:
where the hidden layer output matrix A is defined as follows:
and \({\textbf {w}}=[w_0,w_1,\ldots ,w_n]^T\), \({\textbf {b}}=[y_0,y_1,\ldots ,y_m]^T\).
For the given training points \(t_{j}'s\in \mathbb {R}^n\) and the weights \(a_{i}'s\), the matrix A can be calculated and the weights \(w_{i}'s\) can be calculated by solving the linear system \(A{\textbf {w}}={\textbf {b}}\).
Theorem 2
The system \(\textbf{A}\textbf{w}=\textbf{b}\) is solvable in the following several cases:
-
1.
If \(\textbf{A}\) is a square matrix, then \(\textbf{w}=\mathbf {A^{-1}}\textbf{b}\)
-
2.
If \(\textbf{A}\) is a rectangular matrix, then \(\textbf{w}=\mathbf {A^{+}}\textbf{b}\), and \(\textbf{w}\) is the minimal least square solution of \(\textbf{A}\textbf{w}=\textbf{b}\). Here \(\mathbf {A^{+}}\) is a pseudo inverse of \(\textbf{A}\).
-
3.
If \(\textbf{A}\) is a singular matrix, then \(\textbf{w}=\mathbf {A^{+}}\textbf{b}\) and \(\mathbf {A^{+}}\) = \(\mathbf {A^{T}}(\lambda \textbf{I}+\textbf{A}\mathbf {A^{T}})^{-1}\), where \(\lambda\) is the regularization coefficient. We can set a value of \(\lambda\) according to the specific instance.
Error analysis
This section will discuss the convergence result and error analysis of the ONN-ELM method for solving the delay and neutral delay differential equations.
Theorem 3
24 Let single layer feed-forward orthogonal neural network \(N(t,{\textbf {a}},{\textbf {w}})\) be an approximate solution of one-dimensional neutral delay differential equation, for \(m+1\) arbitrary distinct sample points \((t_j,y_j)\) for \(j=0,1,...m\), where \(t_i,y_i \in \mathbb {R}\), then the orthogonal expansion layer output matrix A is invertible, and \(\Vert A{\textbf {w}}-b \Vert =0\).
Theorem 4
Let \(z \in C^{\infty }(t_0,t_m)\), \(\widehat{z}_{n}=N(t,{\textbf {a}},{\textbf {w}})\) be the orthogonal neural network with n neurons in the hidden layer and \(e_{n}\) be the absolute error with n hidden neurons, then \(\Vert e_{n}\Vert \rightarrow 0\) as \(n\rightarrow \infty\).
Proof
The Taylor expansion formula gives us the following expression for z(t) on \((t_0, t_m)\):
Let us define \(z_n(t)=\sum _{i=0}^{n-1}\frac{z^i(t_0^+)}{i!}(t-t_0)^i\), then we get
Let \(L=span\{P_0(t),P_1(t),\ldots ,P_n(t)\}\) and let \(\widehat{z}_n(t)\) be the best approximation of z(t) in L given as, \(\widehat{z}_n(t)=\sum _{i=0}^{n-1}w_iP_i(a_it)\), where \(w_i\)’s are the weights obtained by ELM algorithm. we get
In particular, taking \(\bar{z}(t)=z_n(t)\) we have
Thus,
where, \(M=max\Vert z^{n}(c)(t-t_0)^n\Vert\), for \(t\in (t_0,t_m)\).
Moreover, from Eq. (16) we deduce that \(\Vert e_n(t)\Vert \rightarrow 0\) for large value of n. This shows that ONN has high representational abilities and it can approximate the exact solution with almost no error. \(\square\)
Methodology
This section explains the method to obtain an approximate solution of second-order NDDE using the ONN-ELM algorithm. It can be easily extended to the higher-order NDDE and the higher-order DDE is a special case of the higher-order NDDE.
Consider the general form of linear second-order NDDE
with initial condition \(z(a)=z_0\) and \(z'(a)=z_1\) or boundary condition \(z(a)=z_2\) and \(z(b)=z_3\), where \(z_0,z_1,z_2,z_3 \in \mathbb {R}\), \(a(t),b(t),c_{j}(t),d_{k}(t),e_{l}(t),f(t)\) are continuously differentiable function for \(t \in (a,b)\) and \(m_1,m_2,m_3 \in \mathbb {N}\).
Using ONN-ELM with n neurons, an approximate solution of Eq. (17) is obtained in the form:
where \(w_i\)’s are the output weights that need to be trained and \(P_i(t)\) is the i-th orthogonal polynomial.
Since the approximate solution obtained by the ONN-ELM algorithm is the linear combination of the orthogonal polynomials, it is infinitely differentiable and we have,
Substituting Eqs. (18)–(23) into the second order neutral delay differential equation (17), we have
We can write Eq. (24) as:
where,
Using the discretization of interval [a, b] as \(a=t_0<t_1<,\cdots ,<t_m=b\) for \(m\in \mathbb {N}\), define \(f_m=f(t_m)\). At these discretized points, Eq. (25) is to be satisfied, that is:
Equation (26) can be written as a system of equations as:
where \({\textbf {w}}=[w_0,w_1,\ldots ,w_n]^{T}\),
and \(b_1\) = \([f(t_0),f(t_1),\ldots ,f(t_m)]^{T}\).
Case:1 Consider Eq. (17) with the initial conditions. Then the following linear system is obtained:
Case:2 Consider Eq. (17) with the boundary conditions. Then the following linear system for NDDE is obtained:
To calculate the weight vector \({\textbf {w}}\) of the network, we use the extreme learning algorithm, that is:
where \(A^{\dagger}=(A^{T}A)^{-1}A^{T}\) is the least square solution of Eq. (27).
Note: Similar methodology can be used for the higher order neutral delay differential equation and the system of higher order neutral delay differential equations.

-
Steps of solving NDDEs using an ONN-ELM algorithm:
-
1.
Discretize the domain as \(a=t_0<t_1<t_2<...<t_m=b\).
-
2.
Construct the approximate solution by using the orthogonal polynomial as an activation function that is,
$$\begin{aligned} N(t,\textbf{w})= \sum _{i=0}^{n} w_{i} P_{i}(a_{i}t), \end{aligned}$$where \(a_i's\) are the randomly generated fixed weights.
-
3.
At the discrete points, substitute the approximate solution and its derivatives into the differential equation and its boundary conditions and obtain the system of equations \(\textbf{A}\textbf{w}=\textbf{b}\).
-
4.
Solve the system of equations \(\textbf{A}\textbf{w}=\textbf{b}\) by ELM algorithm and obtain the network weights \(w_i's\).
-
5.
Substitute the value of \(w_i's\) and get an approximate solution of DDE.
Numerical illustrations
This section considers the higher order delay and neutral delay differential equations with multiple delays and variable coefficients. We also consider the system of delay and neutral delay differential equations. In all the test examples, we use the special orthogonal polynomials based neural network like Legendre neural network, Laguerre neural network, Chebyshev neural network, and Hermite neural network. Further, to show the reliability and powerfulness of the presented method; we compare the approximate solutions with the exact solution. All computations are carried out using Python 3.9.7 on Intel(R) Core(TM) i5-8250U CPU @ 1.60GHz 1.80 GHz and the Window 10 operating system. We calculate the relative error which is defined as follows.
Example 6.1
22 Consider the second-order boundary valued proportional delay differential equation with variable coefficients
The exact solution of the given equation is \(te^{-t}\).
We employ four ONNs to obtain the approximate solution of the given second-order DDE with variable coefficients. We choose ten uniformly distributed points in [0, 1]. The relative errors for all ONNs are shown in Fig. 3. Obtained relative errors for different orthogonal neural networks are reported in Table 1, and we compare the approximate solutions with the exact solution in Fig. 2.
Table 1 and Fig. 3 clearly show that the Chebyshev polynomial-based ONN performs best with the maximum relative error \(5.61\times 10^{-8}\). Table 2 shows the comparison of the maximum relative error for Example 6.1 using the Legendre, Laguerre, Hermite, and Chebyshev neural networks with various numbers of neurons (n = 5, 8, and 11) and their respective computational time. Additionally, Table 2 shows that all four neural networks satisfy Theorem 4, and for \(n=5\), all four orthogonal neural networks show similar accuracy. However, Chebyshev neural network performs better with \(n=8,11\).

Comparison of the exact solution with the obtained approximate solutions of Example 6.1.

Error graph for different orthogonal neural networks with different numbers of neurons for Example 6.1.
Example 6.2
2 Consider the second-order neutral delay differential equation with multiple delays
where \(f(t)=-t^{2}-t+1\), \(t\in (0,1)\).
The exact solution of the given equation is \(z(t)=t^{2}\).
This equation is solved using four ONNs architecture with ten uniformly distributed training points and with 6,8, and 9 neurons in the hidden layer. Relative errors for the different ONNs with 6,8, and 9 neurons as activation functions are reported in Table 3. Figure 4 shows an error graph of different orthogonal neural networks, and a comparison of approximate solutions with the exact solution is shown in Fig. 5.
From Table 4 and Fig. 4 we conclude that for the given second-order neutral delay differential equation, Chebyshev polynomial-based ONN performs best with the maximum relative error \(7.19\times 10^{-14}\). Additionally, Table 3 shows that all four neural networks satisfy Theorem 4.

Error graph for different orthogonal neural networks with different numbers of neurons for Example 6.2.

Comparison of the exact solution with the obtained approximate solutions of Example 6.2.
Example 6.3
2 Consider the second-order neutral delay differential equation with variable coefficients
The exact solution of the given equation is \(z(t)=t^2+1\).
To obtain the approximate solution of the given equation, we use four ONNs with ten uniformly distributed training points in [0,1] and with 8,9, and 11 neurons as activation functions in the hidden layer. Relative errors for the different ONNs and with different numbers of neurons are reported in Table 6. The exact and approximate solutions are compared in Fig. 7. Figures 6, 7 shows the absolute relative error of four special ONNs.
From Table 5 and Fig. 6, we conclude that for the given second-order neutral delay differential equation, Chebyshev polynomial-based ONN provides the best accurate solution with the maximum relative error \(2.29\times 10^{-15}\). Additionally, Table 6 shows that all four neural networks satisfy Theorem 4.

Error graph for different orthogonal neural networks with different numbers of neurons for Example 6.3.

Comparison of the exact solution with the obtained approximate solutions of Example 6.3.
Example 6.4
31 Consider the third-order pantograph equation
The exact solution of the given equation is \(z(t)=cos(t)\).
To obtain the approximate solution of the given equation, we use four ONNs with ten uniformly distributed training points in [0,1] and with 8,11,13 neurons as activation functions in the hidden layer. Relative errors for the different ONNs with different numbers of neurons as activation functions are reported in Table 7. The exact and approximate solutions are compared in Fig. 8. Figure 9 shows the maximum relative error of four special ONNs with different numbers of neurons.
From Table 8 and Fig. 9, we conclude that for the given third-order neutral delay differential equation, Chebyshev polynomial-based ONN provides the best accurate solution with the maximum relative error \(3.77\times 10^{-10}\). Additionally, Table 7 shows that all four orthogonal neural networks satisfy Theorem 4.

Comparison of the exact solution with the obtained approximate solutions of Example 6.4.

Error graph for different orthogonal neural networks with different numbers of neurons for Example 6.4.
Comparative analysis
This section describes a comparative study of the proposed approach to the 1st-order pantograph equation and system of pantograph equations with other neural network approaches.
Example 7.1
25 Consider the pantograph equation with variable coefficients and multiple delays
where, \(g(t)=\frac{1}{8}e^{-t}(12sin(t)+4e^{t}sin(\frac{t}{2})-8cos(t)+3te^{\frac{2t}{3}}sin(\frac{t}{3}))\).
The exact solution of the given equation is \(z(t)=sin(t)e^{-t}\).
We employ four ONNs to obtain the approximate solution of a given pantograph equation with multiple delays. We choose eight uniformly distributed points in [0, 1] with 5,8 and 11 neurons in the hidden layer. The relative errors with all four ONNs with different numbers of neurons are shown in Fig. 11. Obtained relative errors for the different orthogonal neural networks are reported in Table 9, and we compare the approximate solutions with the exact solution in Fig. 10.
Table 9 and Fig. 11 clearly show that the Chebyshev polynomial-based ONN performs best with the maximum relative error \(3.40\times 10^{-11}\).
The maximum relative error of a simple feed-forward neural network(FNN) method in25 is \(4.05\times 10^{-10}\) and the maximum relative error of the proposed FLNN-based ONN method is \(3.40\times 10^{-11}\). This comparison shows that the ONN method can obtain a better accuracy solution than simple FNN. Additionally, Table 9 shows that all four orthogonal neural networks satisfy Theorem 4.

Comparison of the exact solution with the obtained approximate solutions of Example 7.1.

Error graph for different orthogonal neural networks with different numbers of neurons for Example 7.1.
Example 7.2
25 Consider the system of pantograph equation
The exact solutions of the given system of pantograph equation is \(z_1(t)=e^{t}\) and \(z_2(t)=e^{-t}\).
To obtain the approximate solutions of the given system of DDEs, we use four ONNs with twelve uniformly distributed training points in [0,1] and with 5,7, and 10 neurons in an orthogonal functional expansion block as activation functions. Relative errors for the different ONNs with 5,7, and 10 neurons as activation functions are reported in Tables 10 and 11. Comparison between the exact solution and approximate solutions are presented in Figs. 14 and 15. Figures 12, 13, 14 and 15 show the absolute relative error between four special ONNs and exact solutions.
From Tables 10 and 11, we conclude that for the given system of delay differential equation, Chebyshev polynomial-based ONN provides the best accurate solution for \(z_1(t)\) and \(z_2(t)\) with the maximum relative errors \(1.60\times 10^{-9}\) and \(5.11\times 10^{-11}\), respectively.
The maximum relative error of a simple feed-forward neural network(FNN) method in25 for \(z_1(t)\) and \(z_2(t)\) with twelve training points are \(1.93\times 10^{-9}\) and \(2.42\times 10^{-9}\) respectively and the maximum relative error of the proposed FLNN-based ONN method for \(z_1(t)\) and \(z_2(t)\) with twelve training points are \(1.60\times 10^{-9}\) and \(5.11\times 10^{-10}\) respectively. This comparison shows that the ONN method can obtain a better accuracy solution than simple FNN. Additionally, Tables 10 and 11 show that all four orthogonal neural networks satisfy Theorem 4.

Comparison of the exact solution \(z_1(t)\) with the obtained approximate solutions of Example 7.2.

Comparison of the exact solution \(z_2(t)\) with the obtained approximate solutions of Example 7.2.

Error graph of \(z_1(t)\) for different orthogonal neural networks with different numbers of neurons for Example 7.2.

Error graph of \(z_2(t)\) for different orthogonal neural networks with different numbers of neurons for Example 7.2.
Example 7.3
25 Consider the system of pantograph equation
where, \(f_{1}(t)=cos(0.3t)-sin(0.2t)-sin(t)+e^{0.3t}-e^{0.5t}\),
\(f_{2}(t)=-cos(0.3t)+cos(0.5t)-3sin(0.5t)+cos(t)-e^{0.7t}+e^{t}\),
\(f_{3}(t)=-cos(0.8t)+sin(0.2t)-3cos(t)-2sin(t)+e^{0.8t}-2e^{t}\).
The exact solutions of the given system of pantograph equation are \(z_1(t)=sin(t)\), \(z_2(t)=cos(t)\), and \(z_3(t)=e^{t}\).
To obtain the approximate solution of the given system of DDEs, we use four ONNs with ten uniformly distributed training points in [0,1] and with 7,10, and 13 neurons in an orthogonal functional expansion block as activation functions. Relative errors for the different ONNs with 7,10, and 13 neurons as activation functions are reported in Tables 12, 13, and 14. Comparison between the exact solution and approximate solutions are presented in Figs. 16, 17, 18, and 19. Figures 16, 20, and 21 show the absolute relative error between four special ONNs and exact solutions.
From Tables 12, 13 and 14, we conclude that for the given system of delay differential equation, Chebyshev polynomial-based ONN provides the best accurate solutions of \(z_1(t)\),\(z_2(t)\) and \(z_3(t)\) with the maximum relative errors \(1.98\times 10^{-10}\), \(3.11\times 10^{-10}\) and \(5.74\times 10^{-9}\) respectively.
The maximum relative error of a simple feed-forward neural network(FNN) method in25 for \(z_1(t)\), \(z_2(t)\) and \(z_3(t)\) with ten training points are \(8.78\times 10^{-8}\), \(1.42\times 10^{-8}\) and \(1.93\times 10^{-7}\) respectively and the maximum relative error of the proposed FLNN-based ONN method for \(z_1(t)\), \(z_2(t)\) and \(z_3(t)\) with ten training points are \(1.98\times 10^{-10}\), \(3.11\times 10^{-10}\) and \(5.74\times 10^{-9}\) respectively. This comparison shows that the ONN method can obtain a better accuracy solution than simple FNN. Additionally, Tables 12, 13 and 14 show that all four orthogonal neural networks satisfy Theorem 4.

Error graph of \(z_1(t)\) for different orthogonal neural networks with different numbers of neurons for Example 7.3.

Comparison of the exact solution \(z_1(t)\) with the obtained approximate solutions of Example 7.3.

Comparison of the exact solution \(z_2(t)\) with the obtained approximate solutions of Example 7.3.

Comparison of the exact solution \(z_3(t)\) with the obtained approximate solutions of Example 7.3.

Error graph of \(z_2(t)\) for different orthogonal neural networks with different numbers of neurons for Example 7.3.

Error graph of \(z_3(t)\) for different orthogonal neural networks with different numbers of neurons for Example 7.3.
Conclusion
In this paper, we obtained approximate solutions of higher order NDDEs, as well as a system of DDEs with multiple delays and variable coefficients, using four single-layer orthogonal polynomial-based neural networks: (i) Legendre neural network, (ii) Chebyshev neural network, (iii) Hermite neural network, and (iv) Laguerre neural network. For training the network weights, the ELM algorithm is used. It is proved that the relative error between the exact solution and approximate solutions obtained by ONNs is of order \(2^{-n}\), where \(n\) is the number of neurons. Further, it is shown that each orthogonal polynomial-based neural networks provide an approximate solution, that are in good agreement with the exact solution. However, it is observed that, among these four ONNs, the Chebyshev neural network provides the most accurate result.
The results in the section (6), (7) demonstrate that the proposed method is simple to implement and a powerful mathematical technique for obtaining the approximate solution of the higher order NDDEs as well as the system of DDEs.
Data availability
The data that support the findings of this investigation are accessible from the authors upon reasonable request. If necessary, you can contact by email sdubey@iitm.ac.in.
References
Ockendon, J. R. & Tayler, A. B. The dynamics of a current collection system for an electronic locomotive. Numer. Math. 72(2), 447–468 (1971).
Biazar, J. & Ghanbari, B. The homotopy perturbation method for solving neutral functional-differential equations with proportional delays. J. King Saud Univ.-Sci. 24(1), 33–37 (2012).
Bahşi, M.M. & Çevik, M. Numerical solution of pantograph-type delay differential equations using perturbation-iteration algorithms. J. Appl. Math. 2015 (2015).
Bahuguna, D. & Agarwal, S. Approximations of solutions to neutral functional differential equations with nonlocal history conditions. J. Math. Anal. Appl. 317(2), 583–602 (2006).
Dubey, S. A. The method of lines applied to nonlinear nonlocal functional differential equations. J. Math. Anal. Appl. 376(1), 275–281 (2011).
Aibinu, M., Thakur, S. & Moyo, S. Exact solutions of nonlinear delay reaction-diffusion equations with variable coefficients. Partial Differ. Equ. Appl. Math. 4, 100170 (2021).
Mahata, A., Paul, S., Mukherjee, S. & Roy, B. Stability analysis and Hopf bifurcation in fractional order SEIRV epidemic model with a time delay in infected individuals. Partial Differ. Equ. Appl. Math. 5, 100282 (2022).
Cakmak, M. & Alkan, S. A numerical method for solving a class of systems of nonlinear pantograph differential equations. Alex. Eng. J. 61(4), 2651–2661 (2022).
Muslim, M. Approximation of solutions to history-valued neutral functional differential equations. Comput. Math. Appl. 51(3–4), 537–550 (2006).
Lagaris, I. E., Likas, A. & Fotiadis, D. I. Artificial neural networks for solving ordinary and partial differential equations. IEEE Trans. Neural Netw. 9(5), 987–1000 (1998).
Aarts, L. P. & Van Der Veer, P. Neural network method for solving partial differential equations. Neural Process. Lett. 14(3), 261–271 (2001).
Mall, S. & Chakraverty, S. Application of Legendre neural network for solving ordinary differential equations. Appl. Soft Comput. 43, 347–356 (2016).
Raissi, M., Perdikaris, P. & Karniadakis, G. E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 378, 686–707 (2019).
Panghal, S. & Kumar, M. Multilayer perceptron and Chebyshev polynomials based neural network for solving Emden–Fowler type initial value problems. Int. J. Appl. Comput. Math. 6(6), 1–12 (2020).
Ezadi S. & Parandin N. An application of neural networks to solve ordinary differential equations (2013)
Liu, Z., Yang, Y. & Cai, Q. Neural network as a function approximator and its application in solving differential equations. Appl. Math. Mech. 40(2), 237–248 (2019).
Pakdaman, M., Ahmadian, A., Effati, S., Salahshour, S. & Baleanu, D. Solving differential equations of fractional order using an optimization technique based on training artificial neural network. Appl. Math. Comput. 293, 81–95 (2017).
Nguyen, L., Raissi, M. & Seshaiyer, P. Efficient Physics Informed Neural Networks Coupled with Domain Decomposition Methods for Solving Coupled Multi-physics Problems 41–53 (Springer, 2022).
Mall, S. & Chakraverty, S. Numerical solution of nonlinear singular initial value problems of Emden–Fowler type using Chebyshev neural network method. Neurocomputing 149, 975–982 (2015).
Dufera, T. T. Deep neural network for system of ordinary differential equations: Vectorized algorithm and simulation. Mach. Learn. Appl. 5, 100058 (2021).
Fang, J., Liu, C., Simos, T. & Famelis, I. T. Neural network solution of single-delay differential equations. Mediterr. J. Math. 17(1), 1–15 (2020).
Hou, C.-C., Simos, T. E. & Famelis, I. T. Neural network solution of pantograph type differential equations. Math. Methods Appl. Sci. 43(6), 3369–3374 (2020).
Panghal, S. & Kumar, M. Optimization free neural network approach for solving ordinary and partial differential equations. Eng. Comput. 37(4), 2989–3002 (2021).
Huang, G.-B., Zhu, Q.-Y. & Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 70(1–3), 489–501 (2006).
Panghal, S. & Kumar M. Neural network method: delay and system of delay differential equations. Eng. Comput. 1–10 (2021)
Liu, H., Song, J., Liu, H., Xu, J. & Li, L. Legendre neural network for solving linear variable coefficients delay differential-algebraic equations with weak discontinuities. Adv. Appl. Math. Mech. 13(1), 101–118 (2021).
Mall, S. & Chakraverty, S. Artificial Neural Networks for Engineers and Scientists: Solving Ordinary Differential Equations, 1st ed., 168 (2017)
Verma, A. & Kumar, M. Numerical solution of third-order Emden–Fowler type equations using artificial neural network technique. Eur. Phys. J. Plus 135(9), 1–14 (2020).
Verma, A. & Kumar, M. Numerical solution of Bagley–Torvik equations using Legendre artificial neural network method. Evol. Intell. 14(4), 2027–2037 (2021).
Serre, D. Matrices: Theory and Applications (Springer Inc, 2002).
Sezer, M. & Akyüz-Daşcıogˇlu, A. A Taylor method for numerical solution of generalized pantograph equations with linear functional argument. J. Comput. Appl. Math. 200(1), 217–225 (2007).
Acknowledgements
Chavda Divyesh Vinodbhai acknowledges the financial support provided by the MoE (Ministry of Education), Government of India, to carry out the work. The second author is thankful for the financial support received from the Indian Institute of Technology Madras.
Author information
Authors and Affiliations
Contributions
The contributions of each authors are equal.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Vinodbhai, C.D., Dubey, S. Numerical solution of neutral delay differential equations using orthogonal neural network. Sci Rep 13, 3164 (2023). https://doi.org/10.1038/s41598-023-30127-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-30127-8
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
