
Abstract
In the face of energy crisis, manufacturers pay more and more attention to energy-saving scheduling. In the paper, we consider the distributed heterogeneous re-entrant hybrid flow shop scheduling problem (DHRHFSP) with sequence dependent setup times (DHRHFSP-SDST) considering factory eligibility constraints under time of use (TOU) price, which means that each job can only be assigned to its available set of factories and all factories have different number of machines and processing capacity, and so on. To deal with DHRHFSP-SDST, a multi-objective Artificial Bee Colony Algorithm (MOABC) is proposed to optimize both the makespan and total energy consumption. For the MOABC, firstly, a hybrid initialization method is presented to initialize the population; then, due to the electricity price shows significant differences vary from periods under TOU price, the energy saving operator based on right-shift strategy is proposed to avoid processing jobs with the high electricity price without affecting the productivity; thirdly, based on the full consideration of distributed heterogeneous and factory eligibility, crossover and mutation operators, three neighborhood search operators and new food sources generation strategy are designed; lastly, extensive experiments demonstrate the effectiveness of the proposed algorithm on solving the DHRHFSP-SDST.
Similar content being viewed by others

Introduction
Cooperative production among enterprises is becoming more common as globalization progresses. Therefore, enterprise managers decentralize production centers and transform them into distributed factories to reduce production costs, manage risks and improve enterprise competitiveness1,2,3. Hybrid flow shop scheduling problem (HFSP) widely exists in production practice, such as textile, semiconductor and paper industries4. It needs to solve two subproblems: machine selection and operation sequencing. Contrast to HFSP, the distributed hybrid flow shop problem (DHFSP) considers multiple factories, and it is an HFSP problem in each factory. As a result, DHFSP must address three subproblems: factory selection, machine selection and operation sequencing. DHFSP is currently being studied by researchers, and some preliminary findings have been produced. To solve the DHFSP, Shao et al.5 designed a hybrid algorithm based on DNEH and a multi-neighborhood iterated greedy algorithm to minimize makespan. Jiang et al.6 addressed the DHFSP using a novel evolutionary algorithm to minimize makespan and total energy consumption (TEC). Li et al.7,8 suggested two improved discrete artificial bee colony (DABC) algorithms for the DHFSP and DHFSP with sequence dependent setup times (SDST) to minimize makespan, separately. Meng et al.9 tackled the DHFSP with SDST using three mixed-integer linear programming (MILP) model. Cai et al.10 designed a VNS algorithm to minimize makespan and the total delay time for the DHFSP with SDST. Zheng et al.11 proposed an EDA algorithm based on iterated greedy search to solve the multi-objective fuzzy DHFSP.
However, most of the previous studies assume that the factory is identical in the distributed scheduling problem, and lack of consideration for the constraint of heterogeneous factory. In addition, most of the optimization objectives are time related indicators, while there are few environmental related indicators such as energy consumption. Lu et al.12 addressed the distributed heterogeneous flow shop scheduling problem (DHFSP) using a hybrid algorithm. Focus on the DHFSP, an evolutionary algorithm is designed to minimize the makespan and TEC13. Liu et al.14 proposed a DABC algorithm for the distributed heterogeneous scheduling problem (DHSP). Focus on the no-wait DHFSP, a DABC algorithm is designed to minimize makespan15. Zhao et al.16 designed a self-learning discrete yaya algorithm to solve the no-idle DHFSP to minimize the total tardiness (TD), TEC, and factory load balancing. In recent years, environmental issues have gotten a lot of attention. Reducing carbon emissions and developing green economy have become the consensus of all countries in the world. Green scheduling, as we all know, is a strategy for conserving energy and lowering emissions. For the energy-efficient scheduling problem, He et al.17 studied the energy-efficient job shop scheduling problem with SDST to minimize makespan, TD and TEC. Pan et al.18 provided a bi-population evolutionary algorithm to solve the energy-efficient fuzzy flexible job shop scheduling problem (FJSP). Wang et al.19 designed a whale swarm algorithm for the distributed welding flow shop scheduling problem aiming at minimizing the TEC and makespan. Focus on the energy-efficient distributed permutation flow-shop inverse scheduling problem, a hybrid collaborative algorithm is designed20. Lian et al.21 studied the energy-efficient HFSP in steelmaking plants. For convenience, these above publications are classified by shop floor category, objectives, solving approach (algorithms), (see Table 1).
In practice, some machines are new and some ones are old in the same factory, the processing capacity varies from machines, and some jobs cannot be processed on all factories. If there is a machine in a factory that is not suitable for one job, the job cannot be arranged to the factory, namely factory eligibility. In addition, statistics22 show that: in actual production, non-processing time accounts for more than 90% of the whole production time. Therefore, auxiliary time such as setup times can not be ignored. However, in classical job scheduling optimization problems, setup time is usually considered in processing time or ignored. At present, no published relevant research results have been found about the distributed heterogeneous re-entrant hybrid flow shop scheduling problem with sequence dependent setup times considering factory eligibility constraints (DHRHFSP-SDST) under TOU price. As a result, this article focused on the DHRHFSP-SDST, which introduces new economic and environmental dimensions to this problem and realizes green production. The following are the primary contributions of this paper:
-
(1)
Aiming at the DHRHFSP-SDST, the MOABC algorithm is proposed to solve it. Meanwhile, crossover and mutation operators, three neighborhood search operators and new food sources generation strategy are designed to improve the performance of the algorithm.
-
(2)
According to the characteristic that the electricity price varies from hour to hour in one day, the implementation of green scheduling under TOU price is studied.
-
(3)
Considering the factory eligibility and SDST constraints, the effective factory allocation method, encoding and decoding strategy are designed.
The rest of the article is structured as follows: In “Problem description” section, the DHRHFSP-SDST is described; In “Methods” section, a MOABC algorithm is presented. In “Simulation experiment” section, some simulation experiments and the discussions are carried out. Finally, some conclusion and future works are discussed.
Problem description
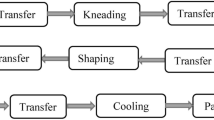
DHRHFSP-SDST can be described as follows. n jobs need to be processed in F heterogeneous factories and each factory has an only one HFSP that has the same amount of stages. At each stage, there is one or more unrelated parallel machines (UPM). All jobs have the similar process routes, but some jobs may visit the same stage many times and can skip certain stages until all operations are completed. Each job has at least one factory that can process it. Due to the different quality, quantity and condition of machines in factories, some jobs cannot be processed on all machines. If there is a machine in a factory that is not suitable for one job, the job cannot be arranged to the factory, namely factory eligibility23. The setup time of an operation cannot be ignored, and it is related to machine and the adjacent operations, namely SDST. The aim of this problem is to allocate all jobs to the available factories reasonably and determine the processing sequence in each factory, so as to minimize the makespan and total energy cost considering factory eligibility and sequence dependent setup times. Figure 1 is the production model of the DHRHFSP-SDST.

The production model of DHRHFSP-SDST.
The main assumptions for DHRHFSP-SDST are as follows:
-
(1)
Each job can be allocated to just one of the factories that are available and the processing time of the same operation varies from machines and factories.
-
(2)
The number of UPMs in each factory varies, but the number of stages remains the same.
-
(3)
The first operation's setup time on each machine is not considered.
-
(4)
Once a job has been assigned to a factory, all of its operations should be handled at that factory.
-
(5)
The processing time and setup time of all operations are known, the unit energy consumption in the processing state, idle state and setup state are known, and the TOU price scheme is known.
-
(6)
Regardless of the machine failure, the energy consumption of power on/off, the buffer between adjacent machines is infinite.
Notations
Notation | Description |
|---|---|
F | Number of factories |
f | Index for factories, f = 1, 2, …, F |
j,h,v | Index for job, j,h,v = 1, 2, …, n |
L | A large positive number |
\(s\) | Number of stages in each factory |
\(i\) | Index for stage,\(i\) = 1, 2, …, s |
r | Number of re-entrances |
\(k\) | Index of operations for job j, \(k \le r*s\) |
Ojk | The k-th operation of job j |
\(m_{if}\) | Number of UPMs at stage i in factory f |
u | Index for UPM at stage i in factory f, u = 1, 2, …,\(m_{if}\) |
\(M\) | The total number of machines in all factories, \(M = \sum\limits_{f = 1}^{F} {\sum\limits_{i = 1}^{s} {m_{if} } }\) |
\(q\) | Index of machines,\(q\) = 1, 2, …, M |
\(U_{if}\) | Operations set that are processed at stage i in factory f |
\(S_{jkf}\) | Starting time of \(O_{jk}\) in factory f |
\(E_{jkf}\) | Ending time of \(O_{jk}\) in factory f |
\(p_{jkuif}\) | Processing time of \(O_{jk}\) on machine u at stage i in factory f |
\(u_{jhuif}\) | Sequence dependent setup time of job h when job j and h are processed successively on machine u of station i in factory f |
Cj | Job j’s finished time |
Sq | Machine q’s startup time |
Tq | Machine q’s showdown time |
PIq | Energy consumption per unit time of machine q in the idle state |
PWq | Energy consumption per unit time of machine q in the processing state |
PSq | Energy consumption per unit time of machine q in the setup state |
\(f(t)\) | TOU price function |
Yjf | 1 if job j is assigned to factory f, and 0 otherwise |
Qif | 1 if job j can be processed in factory f; 0 otherwise |
Xjkuig | 1 if Ojk is assigned to machine u at stage i in the factory g, and 0 otherwise |
\(Z_{{jkj^{^{\prime}} k^{^{\prime}} uif}}\) | 1 if Ojk precedes \(O_{{j^{\prime } k^{\prime } }}\) are processed successively on machine u of station i in factory f, and 0 otherwise |
\(y_{q}^{t}\) | 1 if the machine q is in the processing state at time t, and 0 otherwise |
\(x_{q}^{t}\) | 1 if the machine q is in the idle state at time t, and 0 otherwise |
\(\lambda_{q}^{t}\) | 1 if the machine q is in the setup state at time t, and 0 otherwise |
Optimized objectives
Based on the existing literatures1,2, a mathematical model for bi-objective DHRHFSP-SDST is presented to minimize the makespan (Cmax) and total energy cost (TC). In real manufacturing, if the machines utilized for each operation varies, the processing time and energy usage differ. Similarly, different time periods are selected for processing, and the corresponding electricity price is different, so the processing energy consumption cost is also different. If the electricity price peak is avoided and the processing is selected in the trough period, the processing energy consumption cost will be reduced, but the standby energy consumption cost may increase and the maximum completion time may be extended due to the delay.
In which, PC, IC, and SC represent the energy cost of machines in processing, idle, and setup states, respectively.
s.t.
Formulas (1–2) are the objective functions. Formulas (3–5) are the three components of TC. Constraint (6) requires that each job be allocated to just one factory. Constraint (7) indicates that each job must be arranged to a factory that can process it. Constraint (8) indicates that in the processing cycle, each machine only has three states: processing, idle and setup. Constraint (9) assures that each operation will only be processed on one machine at one stage. Constraint (10) assures that the starting time is not earlier than the prior operation's finishing time. Constraints (11–13) ensure that each machine can only process one operation at a time. Constraints (14–15) indicate the \(S_{jkg}\) and \(E_{jkg}\). Constraints (16–17) indicate the \(C_{j}\).
Methods
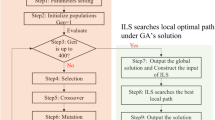
The DHRHFSP-SDST is an NP hard problem that is difficult to solve using exact approaches. Metaheuristic algorithms have a significant benefit in terms of balancing computation time and solution quality. The artificial bee colony algorithm (ABC) is a novel intelligent optimization algorithm based on the honeybee's honey harvesting process, which has three major components: food source, employed bees and unemployed bees24. The food sources are the feasible solution of the optimization problem to be solved and the quality of the food sources or the feasible solutions is evaluated by the amount of nectar of nectar sources, namely the fitness. The number of employed bees or onlooker bees is equal to the number of food sources. The task of the employed bees is mainly to find information about food sources and share it with the onlooker bees with a certain probability. Unemployed bees include onlooker bees and scout bees. After receiving the information transmitted by the employed bees, the onlooker bees chose the satisfactory nectar source greedily for tracking. If a food source has not been further updated after limit times cycle, the onlooker bee will become a scout bee, and the scout bee will find a new food source instead of the original one.
As shown in Fig. 2, the improved MOABC algorithm proposed. A hybrid initialization method is presented to initialize the population; then, due to the electricity price shows significant differences vary from periods under TOU price, the energy saving operator based on right-shift strategy is proposed to avoid processing jobs with the high electricity price without affecting the productivity; lastly, based on the full consideration of distributed heterogeneous, factory eligibility and SDST features, crossover and mutation operators, three neighborhood search operators and new food sources generation strategy are designed.

Flow chart of MOABC algorithm.
Individual expression
In the MOABC algorithm, each feasible solution represents a food source. According to the characteristics of DHRHFSP-SDST, we employ the representation as in Naderi and Ruiz25 for the classic distributed permutation flow shop scheduling problem. To be more descriptive, the individual is represented by f vectors, one for each factory. Each vector is a job list that represents the jobs sequence processed in the factory. An individual may be written as π = {π1, π2, … , πF} using the aforementioned encoding approach, in which πf denotes the permutation that is the order of jobs processed in factory f, as shown in Fig. 3.

Individual expression.
Decoding method
Assign the jobs to the appropriate factory according to the encode schema and, if possible, place it on a machine that can process it as soon as possible. The decoding process is shown in Figs. 4 and 5, and the detailed decoding steps are as follows.

The decoding diagram of operation \(O_{vk}\) when \(E_{vk} \le B_{{m ( r{ + }1 ) }} - st_{vjmf}\).

The decoding diagram of operation \(O_{vk}\) when \(E_{vk} > B_{{m ( r{ + }1 ) }} - st_{vjmf}\).
Step 1 Assign all jobs to corresponding factories according to individual π and initialize f = 1, index = 1.
Step 2 Traverse all of the jobs in factory f and set joblist = \(\pi^{f}\).
Step 3 Assuming \(v = joblist(index)\), if job v is the first job processed in the factory f, all operations of job v will be arranged on the earliest machine that can complete the operation, and the starting and ending times of each operation will be recorded, and then turn to step 8, otherwise turn to step 4.
Step 4 From the available machines set machineset, choose the appropriate machine for operation \(O_{vk}\).
Step 5 Assume that machine u is selected from machineset to process operation \(O_{vk}\). Then the starting time \(S_{vkf}\) and ending time \(E_{vkf}\) of operation \(O_{vk}\) can be obtained by the following formulas.
where \(E_{v(k - 1)f}\) represents the ending time of the previous operation of job v. If operation \(O_{vk}\) is the first operation of job v, then \(E_{v(k - 1)f} { = }0\). \(p_{u}\) refers to the ending time of an operation on machine \(u\). \(u_{hvuif}\) is the SDST of operation \(O_{vk}\). If \(O_{vk}\) is the first operation of machine u, then \(u_{hvuif} { = }0\).
Step 6 Select an appropriate insertion point for operation \(O_{vk}\) on machine \(u\) of factory f to minimize \(S_{vkf}\). The detailed steps are as follows:
-
(1)
Obtain all the operation sets ops in the current state of machine u, and arrange them in ascending order according to the ending time.
-
(2)
Get the ending time \(C_{mr}\) of the r-th operation in ops. \(p_{u} = C_{mr}\), where r = 0 means that operation \(O_{vk}\) is regarded as the first operation of the equipment, and \(p_{u} = C_{mr} = 0\).
-
(3)
According to the formulas (18) and (19), the starting time and ending time of operation \(O_{vk}\) are calculated. If the r-th operation is the last operation on machine u, return \(S_{vkf}\) and \(E_{vkf}\), and end the judgment. Otherwise, if \(E_{vkf} \le B_{{u(r{ + }1)f}} - u_{vjuif}\), where \(B_{{u(r{ + }1)f}}\) is the starting time of the (r + 1)-th operation on the machine u, return \(S_{vkf}\) and \(E_{vkf}\), and end the judgment. Otherwise, r = r + 1, go to (2).
Step 7 Repeat Step 6 until all the machines in machineset are traversed to get the smallest \(S_{vkf}\). If multiple insertion points have the same \(S_{vkf}\), select one with smaller idle time between the insertion point and the previous operation.
Step 8 index = index + 1, repeat Step 3—Step 7 until all jobs in \(joblist\) are processed.
Step 9 f. = f + 1, go to step 2 until all factories are traversed.
Step 10 Calculate the objective function values Cmax and TC.
Consider the following scenario: 2 factories, 8 jobs and 2 stages. The number of UPMs at each stage in factory1 is 2 and 2. The amount of UPMs at each stage in factory2 is 1 and 2. The factory eligibility constraints is F1 = {1,2}, F2 = {1}, F3 = {1,2}, F4 = {2}, F5 = {1,2}, F6 = {1}, F7 = {1,2}, F8 = {1,2}, which indicates that job 1, job3, job5, job7 and job 8 can be processed in all factories, job 2 and job6 can be processed in factory 1 only and job4 can be processed in factory2 only. To make things more understandable, assume that π = {[1–8]} with π1 = [1, 2, 6–8] and π2 = [3–5], which means that job1, job 2, job6, job7 and job8 are processed in factory1 in the order job1 → job 2 → job6 → job7 → job8, while job3, job4 and job5 are processed in factory2 in the order job3 → job4 → job5. For instance, in factory1, all of job 1's operations are scheduled on the machine that can complete them the earliest. Then, all operations of the rest jobs will be placed on the machines that can complete them the earliest by selecting the proper insertion points. The processing times of 8 jobs in each available factory is shown in Table 2. \(p_{vk}\) = 0 means that the job is not machined at this stage in this round. Meanwhile, Tables 3 and 4 show the sequence dependent setup times and the TOU price scheme, respectively.
The Gantt charts obtained according to the above decoding method are shown in Figs. 6 and 7. Among them, 1(1) denotes the first operation of job 1, and in addition, 1–3 on machine 2 denote the sequence dependent setup times between job 1 and job 3 on machine 2. The \(C_{max}\) and TC in each factory are 33 h, 524.896 CNY and 26 h, 261.656 CNY respectively. Therefore, the two objective values are \(C_{max} { = }\) max(33,26) = 33 h and \(TC{ = }\) 524.896 + 261.656 = 786.552 CNY.

Gantt chart of factory1.

Gantt chart of factory2.
Energy saving operator based on right-shift strategy
Because waiting states for machines and jobs are unavoidable in SRHFSP-SDST, we can make full use of these waiting periods by adjusting the processing times of the operations to reduce the TC. Based on the factory assignment, job sequencing and machine assignment, the energy saving operator based on right-shift strategy (ESRS) is added to select the appropriate starting processing time for each operation and try to avoid processing jobs in the periods with high electricity prices to achieve a lower TC without deteriorating Cmax. According to various constraints, all operations can only be shifted to the right. Furthermore, the adjustment of the latter operation will affect the previous operation and only machines with idle periods have the potential to shift to right, so the right shift procedure must be carried from back to front. The specific steps of ESRS is as follows:
Step 1 Input a solution. Generate a scheduling scheme according to the decoding method, and record the starting time and ending time of all operations, the starting time and ending time of all setup periods and initialize f = 1.
Step 2 Put the starting time and ending time of all idle time periods of machines in plant f into the set \(idle\), and record the information about the previous and the next operations of all the idle periods. If there is only one operation \(O_{vk}\) on the machine and its completion time is less than Cf , then the time period [\(E_{vk}\), \(C_{f}\)] is added to the idle.
Step 3 Sort the idle periods in idle in descending order by the ending time of each idle period.
Step 4 Traverse all idle periods in idle. Suppose that the idle time period is \(\left[ {start,end} \right]\) and the previous operation is \(O_{vk}\), then the ending time of \(O_{vk}\) after the right-shift is \(\overline{{E_{vk} }} = min(end,S_{vk + 1} )\). If \(O_{jk}\) is the last operation of job v, then \(\overline{{E_{vk} }} = C_{f}\). If \(E_{jk} < \overline{{E_{jk} }}\), it means that operation \(O_{vk}\) meets the condition of shift to right, and the step size is \(\overline{{E_{vk} }} - E_{vk}\). Meanwhile, adjust the operation's processing and setup times and move to step 2. If \(E_{jk} { = }\overline{{E_{jk} }}\), continue with the next idle period until the idle is traversed.
Step 5 f. = f + 1, repeat Step2–Step5 until all factories are traversed.
Step 6 Generate a new scheduling scheme.
After adding ESRS to the scheduling scheme shown in Figs. 6, 7, 8 and 9 illustrate the revised Gantt charts with the objective values \(C_{max} { = }\) 33 h and \(TEC{ = }\) 751.366 CNY. By comparison, TC was reduced by 35.186 CNY, up to 4.47%, without affecting \(C_{max}\). The reason is that the processing periods of operations 6(2), 6(4) and 4(4) are shifted from the period with high electricity price to low electricity price.

Factory1's Gantt chart with ESRS.

Factory2's Gantt chart with ESRS.
Figures 10 and 11 show the energy consumption curve (EC curve) of all machines in each factory. As seen in the figures, if there is a discrepancy between the dotted and solid lines, the electrical load has transferred. In particular, electricity is charged at a high (low) price in the vicinity of 18–21 (25–28) hours in factory1. After ESRS, the TC in the first phase drops, whereas the TC in the second period rises. Factory2 is similar to that in factory1. Evidently, total energy costs can be reduced by avoiding higher price periods.

The EC curve in factory1.

The EC curve in factory2.
Population initialization
The quality of the initial population has a direct impact on the performance of the MOABC algorithm. According to the characteristics of solving problem and various constraints, three kinds of population initialization methods are designed in this paper. To guarantee the population's variety, the Randomly_initialization method is used for 20% of the population. In addition, to ensure the quality of the solutions, 40% individuals are generated equitably based on two greedy methods: makespan_based_initialization and TC_based_initialization.



Employed bee phase
Crossover and mutation operators are used in the employed bee phase to enhance the population's diversity. Crossover is an indispensable part in the evolutionary process, which generates new individuals by exchanging genes between two different parental individuals. According to the characteristics of the encoding and the factory eligibility constraints, this paper adopts the crossover operator as shown in Fig. 12. First, select factory f randomly and swap the jobs in factory f between two parent individuals. Then, remove the jobs duplicated with factory f in Parent1 and Parent 2. Thirdly, copy the remaining jobs in Parent1 into offspring 1 and the remaining jobs in Parent 2 into offspring 2. Lastly, copy part of the jobs in Parent 2 into offspring 1 and part of the jobs in Parent 1 into offspring 2.

Crossover operator.
To avoid that the better food source obtained after the crossover operate is not destroyed, the following selection strategy is designed. If O1 and O2 are generated by the crossover operator performed on the parent food sources P1 and P2. Select a better one as Xbetter. If f(Xbetter)\(\prec\) f(P1), then P1 \(\leftarrow\) Xbetter and limit = 0 else if f(Xbetter)\(\prec\) f(P2), then P2 \(\leftarrow\) Xbetter and limit = 0; else perform the following mutation operator. To avoid the infeasible solution caused by mutation operator and reduce the extra repair work, three mutation operators are designed in the paper.
Swap_in_Critical_Factory
Select two jobs from \(\pi^{{F_{*} }}\) randomly and exchange the positions of two jobs.
Inverse_in_Critical_Factory
Select two jobs from \(\pi^{{F_{*} }}\) randomly and inverse the jobs between the selected two jobs.
Insert_among_Factories
Remove a job from \(\pi^{{F_{*} }}\) and reinsert it into the position selected from one of its available factories Fr randomly.
The above mutation operators can be executed for 15 cycles at most in the paper. If \(\pi^{^{\prime}}\) is generated by the one of the mutation operators performed on the parent food source π in a certain cycle. If f(π’)\(\prec\) f(π), then π \(\leftarrow\)\(\pi^{^{\prime}}\), limit = 0 and the cycle is terminated If the f(\(\pi^{^{\prime}}\)) and f(π) do not dominate each other, then f(\(\pi^{^{\prime}}\)) will be compared with other individuals in the populations (denotes as \(\pi^{^{\prime\prime}}\)) to see if there is a dominant relationship between them. If there is a dominant relationship, the dominant solution will be abandoned and continue with next cycle. If there is no solution that can dominate f(π) at the end of 15 cycles, then limit = limit + 1. The pseudocode of the mutation operators is as follows, and F* is the critical factory with the greatest makespan among all factories.

Onlooker bee phase
To reduce the makespan, it is necessary to readjust the factory assignment and job sequence between the non-critical factory and critical factory or within the critical factory. Based on the theory of the critical factory and the features of the problem, the neighborhood search method is used in the onlooker bee phase, which consists of three kinds of neighborhood structures.
Greedy_Insert_in_Critical_Factory
Remove a job from \(\pi^{{F_{*} }}\) randomly and reinsert it into all possible position of the original jobs sequence of factory F*. The original solution is replaced if the neighboring solution is better than it.
Greedy_Swap_in_Critical_Factory
Select a job from \(\pi^{{F_{*} }}\) randomly and swap it with the rest jobs of factory F* one by one. The original solution is replaced if the neighboring solution is better than it.
Greedy_Insert_among_Factories
Remove a job from \(\pi^{{F_{*} }}\) randomly and reinsert it into all possible position in the rest of its available factories. The original solution is replaced if the neighboring solution is better than it.

Scout bee phase
For the MOABC, if the fitness value of the employed bee in the same food source is not improved by more than limit times searches, the employed bee is converted to a scout bee. In such a situation, a new individual will replace the old food source. To be specific, the process of obtaining new food sources is as follows: firstly, select a food source from the external archives randomly; then, the mutation operator proposed in this paper is used to explore near the food source; lastly, get the new food source after the mutation operator.
Simulation experiment
Since there are few studies on the DHRHFSP-SDST, three representative algorithms NSGA-II26, MO-GVNS27 and SPEA-II are selected for comparative study. These three algorithms are widely used in solving mixed flow shop scheduling problems. In addition, MATLAB R2017a is used in this paper implements algorithm programming.
Test instances and parameter settings
The test instances in this paper are named using f*j*s*r*, where * is a positive integer. For example, the instance f2j15s3r1 represents that 15 jobs are processed in 2 factories with 3 stages and 1 re-entrance. According to the combination of the number of jobs, stages and re-entrance with different scales, 48 examples are generated. The value ranges of all variables are shown in Table 5. The TOU price function is shown in Table 4. It's easy to observe that the on-peak price is over four times higher than the off-peak price. With such a vast disparity, energy-intensive industrial companies may save a significant amount of energy consumption costs.
The key parameters in MOABC are population size Ps, crossover probability Pc and mutation probability Pm. Taguchi method28 is used to do the orthogonal experiment. The factor level of each parameter is shown in Table 6. According to the L16(43) orthogonal table, each combination parameters in the orthogonal table is run 20 times independently. In the paper, the limit is 5 and max iterations is 120 for each algorithm. The average value of the dominant indicator Ω of 10 randomly selected cases represents the response variable (RV), as shown in Table 7, where Ω refers to the probability that the non-dominated solution set of an algorithm is optimal pareto fronts (OPF) at the same time. The greater the RV value, the better the performance of the parameter combination.
The larger value of Ps can promote the exploration capability but results in huge computation time. An appropriate Pc can improve the global search ability of the algorithm, and an appropriate Pm can accelerate the convergence of the algorithm to the optimal solution, and will not cause the solutions close to the optimal solution to be destroyed due to mutation. According to Fig. 13, the parameter values are set as follows: Ps = 100, Pc = 0.7 and Pm = 0.15, the algorithm has the best performance.

Factor level trend.
Performance metrics
Two performance metrics IGD and C-metric in literature29 are used to measure the convergence and coverage of the algorithms. The smaller the IGD values, the better the algorithm's performance. On the contrary, the larger the C-metric value, the better the algorithm's performance. Furthermore, because the test instances' OPF are unknown, we substitute approximate Pareto-front (APF) for OPF. For each instance, APF may aggregate the non-dominant solutions acquired by all algorithms into a set and then eliminate the dominant solutions from the set.
Effectiveness of energy cost saving operator based on the right shift
MOABC is compared with MOABC1 (MOABC without energy-saving operator based on the right shift) to verify the effectiveness of the energy saving operator. 12 instances are selected randomly, and the average values of IGD as well as C-metric obtained from 20 runs of each instance are listed in Table 8. The optimal value for each metric is shown in bold. Meanwhile, the Wilcoxon signed rank sum test results are given in Table 8, and the significance level is 0.05, in which "†" represents that MOABC algorithm is significantly better than the comparison algorithm, "‡" represents that MOABC algorithm is significantly worse than the comparison algorithm, and " = " represents that MOABC algorithm has no significant difference with the comparison algorithm. As can be seen from Table 8, in terms of C-metric, the two algorithms have significant differences, and MOABC is better. The IGD metric of MOABC is smaller than that of MOABC1 in all instances. Therefore, the energy saving operator designed in this paper makes full use of the characteristics of the problem and the TOU price policy to improve the individual, which is very effective.
The relative change rate of the average value of Cmax and TC about each instance is shown in Fig. 14, where the expressions of the relative change rate are shown in (20) and (21). \(makespan_{{}}^{{{\text{MOABC1}}}}\) and \(TC^{{{\text{MOABC1}}}}\) represent the average value of the two objective function values obtained by MOABC1, \(makespan_{{}}^{{{\text{MOABC}}}}\) and \(TC^{{{\text{MOABC}}}}\) represent the average value of the two objective function values obtained by MOABC. Meanwhile, the negative sign represents the relative increase. As can be seen from Fig. 14, after adding the energy saving operator, TC changes greatly, while the influence on makespan is small and can be ignored. which further proves the effectiveness of the energy saving operator.

The relative change rate.
Effectiveness of population initialization
MOABC is compared with MOABC2, which generate the initial population completely randomly, to verify the effectiveness of hybrid population initialization strategy. 12 instances are selected randomly, and the average values of IGD as well as C-metric obtained from 20 runs of each instance are listed in Table 9. The best value for each metric is highlighted in bold. Table 9 shows that two algorithms have significant differences in terms of C-metric, and MOABC is better. The IGD metric of MOABC is smaller than that of MOABC2 in all instances except the f2j15s4r2. It demonstrates that the initialization strategy helps to improve the algorithm's performance.
Comparison with other algorithms
For the 48 instances with different scale, each algorithm is executed 20 times. Table 10 lists the average values of IGD, C-metric and the Wilcoxon signed rank test results after 20 runs of the four algorithms. It can be seen from Table 10 that except for a few instances, the IGD and C-metric indexes of MOABC are significantly better than those of NSGA-II, MO-GVNS and SPEA-II. The box plot of IGD and C-metric metrics is shown in Figs. 15 and 16. From Fig. 15, it is clear that MOABC not only has good convergence but also has uniform scalability. From Fig. 16, it can be seen that the C-metric of MOABC is much larger than other algorithms on all test instances.

Box plot of C-metric for MOABC vs. other three algorithms.

The box plot of IGD.
Taking f2j15s3r1instance as an example, in which 15 jobs are processed in 2 factories. In factory1, the number of UPMs at each stage are 2, 2 and 2. In factory2, the number of UPMs at each stage are 2, 2 and 1. The machine eligibility constraints is \(F_{1} = \left\{ 2 \right\}\), \(F_{2} = \left\{ 2 \right\}\), \(F_{3} = \left\{ 1 \right\}\), \(F_{4} = \left\{ 1 \right\}\), \(F_{5} = \left\{ 1 \right\}\), \(F_{6} = \left\{ {1,2} \right\}\), \(F_{7} = \left\{ 1 \right\}\), \(F_{8} = \left\{ 2 \right\}\), \(F_{9} = \left\{ {1,2} \right\}\), \(F_{10} = \left\{ {1,2} \right\}\), \(F_{11} = \left\{ 1 \right\}\), \(F_{12} = \left\{ 2 \right\}\), \(F_{13} = \left\{ 2 \right\}\), \(F_{14} = \left\{ 1 \right\}\) and \(F_{15} = \left\{ {1,2} \right\}\). The convergence curves of Cmax and TC for MOABC, NSGA-II, Mo-GVNS and SPEA-II algorithms are shown in Figs. 17 and 18. From the figures, we can see that two objectives of MOABC decline rapidly in the early stage of evolution, and gradually converge in the later stage, and the two goals converge to 53 h and 2050 yuan respectively, which are significantly smaller than the convergence values of other algorithms.

Convergence diagram of instance f2j15s3r1 about TC.

Convergence diagram of instance f2j15s3r1 about Cmax.
Taking the feasible solution \(\pi {{ = \{ [7,14,3,5,11,4,10,9,15]}},{{[2,1,8,13,12,6]\} }}\) as an example, without considering the characteristics of TOU price, the Gantt charts of the two factories are shown in Figs. 19 and 20 respectively, and \(C_{max} = max\left( {58,59} \right) = 59\) hours and TC = 1432.2 + 897.7 = 2329.9 yuan. Figures 21 and 22 are the Gantt charts of the solution with energy saving operator, and the two objective values are \(C_{max} = max\left( {58,59} \right) = 59\) hours and TC = 1349.7 + 845 = 2194.7 yuan. By comparison, under the premise of keeping the production efficiency unchanged, the processing periods of many operations, such as 7(5), 4(1), 11(4), 10(1), 11(6), 9(2), 3(2), 13(1), 12(4) and 8(4), have been shifted, and TC has been reduced by 135.2, up to 5.80%. To sum up, the MOABC algorithm proposed in this paper can effectively solve DHRHFSP-SDST under TOU price.

The Gantt chart of instance f2j15s3r1 in factory1 without considering TOU price.

The Gantt chart of instance f2j15s3r1 in factory2 without considering TOU price.

The Gantt chart of instance f2j15s3r1 in factory1 considering TOU price.

The Gantt chart of instance f2j15s3r1 in factory2 considering TOU price.
Conclusions and further works
The distributed re-entrant hybrid flow shop problem has attracted the attention of many scholars since it was proposed, but there are still many problems to be further studied and expanded. In the paper, we consider the distributed heterogeneous re-entrant hybrid flow shop scheduling problem with sequence dependent setup times (SDST) considering factory eligibility constraints (DHRHFSP-SDST) under time of use (TOU) price policy. According to the characteristics of this problem, a multi-objective artificial bee colony algorithm (MOABC) is proposed. The main improvements include encoding and decoding methods, energy saving operators, three neighborhood search operators and new food sources generation strategy. Finally, a large number of simulation experiments verify the effectiveness and superiority of the algorithm. Under the TOU price policy, although the total electricity consumption does not decrease, it can reasonably shift the electricity load and reduce the total cost of electricity consumption. In the future, we will further study green scheduling problems, such as designing better swarm intelligence algorithm, collaborative optimization of distributed scheduling and pre-maintenance, and so on.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable.
References
Ying, K., Lin, S. & Wan, S. Bi-objective reentrant hybrid flowshop scheduling: An iterated Pareto greedy algorithm. Int. J. Prod. Res. 52, 5735–5747 (2014).
Pan, J. & Chen, J. Mixed binary integer programming formulations for the reentrant job shop scheduling problem. Comput. Oper. Res. 32, 1197–1212 (2005).
Cai, J. & Lei, D. A cooperated shuffled frog-leaping algorithm for distributed energy-efficient hybrid flow shop scheduling with fuzzy processing time. Complex Intell. Syst. 7, 2235–2253 (2021).
Ruiz, R. & Maroto, C. A genetic algorithm for hybrid flowshops with sequence dependent setup times and machine eligibility. Eur. J. Oper. Res. 169, 781–800 (2006).
Shao, W., Shao, Z. & Pi, D. Modeling and multi-neighborhood iterated greedy algorithm for distributed hybrid flow shop scheduling problem. Knowl.-Based Syst. 194, 105527 (2020).
Jiang, E., Wang, L. & Wang, J. Decomposition-based multi-objective optimization for energy-aware distributed hybrid flow shop scheduling with multiprocessor tasks. Tsinghua Sci. Technol. 26, 646–663 (2021).
Li, Y., Li, F., Pan, Q.-K., Gao, L. & Tasgetiren, M. F. An artificial bee colony algorithm for the distributed hybrid flowshop scheduling problem. Procedia Manufact. 39, 1158–1166 (2019).
Li, Y. et al. A discrete artificial bee colony algorithm for distributed hybrid flowshop scheduling problem with sequence-dependent setup times. Int. J. Prod. Res. 59, 3880–3899 (2021).
Meng, L. et al. Novel MILP and CP models for distributed hybrid flowshop scheduling problem with sequence-dependent setup times. Swarm Evol. Comput. 71, 101058 (2022).
Cai, J., Zhou, R. & Lei, D. Fuzzy distributed two-stage hybrid flow shop scheduling problem with setup time: Collaborative variable search. J. Intell. Fuzzy Syst. 38, 3189–3199 (2020).
Zheng, J., Wang, L. & Wang, J. A cooperative coevolution algorithm for multi-objective fuzzy distributed hybrid flow shop. Knowl.-Based Syst. 194, 105536 (2020).
Lu, C., Gao, L., Yi, J. & Li, X. Energy-efficient scheduling of distributed flow shop with heterogeneous factories: A real-world case from automobile industry in China. IEEE Trans. Ind. Inf. 17, 6687–6696 (2021).
Wang, G., Li, X., Gao, L. & Li, P. Energy-efficient distributed heterogeneous welding flow shop scheduling problem using a modified MOEA/D. Swarm Evol. Comput. 62, 100858 (2021).
Liu, Q., Li, X., Gao, L. & Wang, G. Mathematical model and discrete artificial Bee Colony algorithm for distributed integrated process planning and scheduling. J. Manuf. Syst. 61, 300–310 (2021).
Haoran, L., Xinyu, L. & Liang, G. A discrete artificial bee colony algorithm for the distributed heterogeneous no-wait flowshop scheduling problem. Appl. Soft. Comput. 100, 106946 (2021).
Zhao, F., Ma, R. & Wang, L. A self-learning discrete jaya algorithm for multiobjective energy-efficient distributed no-idle flow-shop scheduling problem in heterogeneous factory system. IEEE T. Cybern. https://doi.org/10.1109/TCYB.2021.3086181 (2021).
He, L. et al. Multiobjective optimization of energy-efficient JOB-shop scheduling with dynamic reference point-based fuzzy relative entropy. IEEE Trans. Ind. Inf. 18, 600–610 (2022).
Pan, Z., Lei, D. & Wang, L. A bi-population evolutionary algorithm with feedback for energy-efficient fuzzy flexible job shop scheduling. IEEE Trans. Syst. Man Cybern. Syst. https://doi.org/10.1109/TSMC.2021.3120702 (2021).
Wang, G., Li, X., Gao, L. & Li, P. An effective multi-objective whale swarm algorithm for energy-efficient scheduling of distributed welding flow shop. Ann. Oper. Res. 310, 223–255 (2022).
Mou, J., Duan, P., Gao, L., Liu, X. & Li, J. An effective hybrid collaborative algorithm for energy-efficient distributed permutation flow-shop inverse scheduling. Fut. Gener. Comp. Syst. 128, 521–537 (2022).
Lian, X., Zheng, Z., Wang, C. & Gao, X. An energy-efficient hybrid flow shop scheduling problem in steelmaking plants. Comput. Ind. Eng. 162, 107683 (2021).
Wein, L. & Chevalier, P. A broader view of the job-shop scheduling problem. Manage. Sci. 38, 1018–1033 (1992).
Bektur, G. Distributed flow shop scheduling problem with learning effect, setups, non-identical factories, and eligibility constraints. Int. J. Ind. Eng. 29, 21–44 (2022).
Li, Y., Huang, W., Wu, R. & Guo, K. An improved artificial bee colony algorithm for solving multi-objective low-carbon flexible job shop scheduling problem. Appl. Soft Comput. 95, 106544 (2020).
Naderi, B. & Ruiz, R. The distributed permutation flowshop scheduling problem. Comput. Oper. Res. 37, 754–768 (2010).
Cai, S., Yang, K. & Liu, K. Multi-objective optimization of the distributed permutation flow shop scheduling problem with transportation and eligibility constraints. J. Oper. Res. Soc. China 6, 391–416 (2018).
Siqueira, E., Souza, M. & Souza, S. An MO-GVNS algorithm for solving a multiobjective hybrid flow shop scheduling problem. Int. Trans. Oper. Res. 27, 614–650 (2020).
Cao, L., Ye, C. M., Cheng, R. & Wang, Z. K. Memory-based variable neighborhood search for green vehicle routing problem with passing-by drivers: A comprehensive perspective. Compl. Intell. Syst. https://doi.org/10.1007/s40747-022-00661-5 (2022).
Wang, G., Gao, L., Li, X., Li, P. & Tasgetiren, M. Energy-efficient distributed permutation flow shop scheduling problem using a multi-objective whale swarm algorithm. Swarm Evol. Comput. 57, 100716 (2020).
Acknowledgements
This work was supported by Humanities and Social Science research project of Henan Province (2023-ZZJH-074) and Doctoral research startup fund project of Nanyang Institute of Technology (NGBJ-2022-50).
Author information
Authors and Affiliations
Contributions
K.F.G. conducted the research, prepared the manuscript, wrote codes, corrected and analyzed all data. L.L. initiated research, invented algorithm and wrote codes. Z.Y.W. supervised the research and prepared the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Geng, K., Liu, L. & Wu, Z. Energy-efficient distributed heterogeneous re-entrant hybrid flow shop scheduling problem with sequence dependent setup times considering factory eligibility constraints. Sci Rep 12, 18741 (2022). https://doi.org/10.1038/s41598-022-23144-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-23144-6
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
