
Abstract
There have been numerous risk tools developed to enable triaging of SARS-CoV-2 positive patients with diverse levels of complexity. Here we presented a simplified risk-tool based on minimal parameters and chest X-ray (CXR) image data that predicts the survival of adult SARS-CoV-2 positive patients at hospital admission. We analysed the NCCID database of patient blood variables and CXR images from 19 hospitals across the UK using multivariable logistic regression. The initial dataset was non-randomly split between development and internal validation dataset with 1434 and 310 SARS-CoV-2 positive patients, respectively. External validation of the final model was conducted on 741 Accident and Emergency (A&E) admissions with suspected SARS-CoV-2 infection from a separate NHS Trust. The LUCAS mortality score included five strongest predictors (Lymphocyte count, Urea, C-reactive protein, Age, Sex), which are available at any point of care with rapid turnaround of results. Our simple multivariable logistic model showed high discrimination for fatal outcome with the area under the receiving operating characteristics curve (AUC-ROC) in development cohort 0.765 (95% confidence interval (CI): 0.738–0.790), in internal validation cohort 0.744 (CI: 0.673–0.808), and in external validation cohort 0.752 (CI: 0.713–0.787). The discriminatory power of LUCAS increased slightly when including the CXR image data. LUCAS can be used to obtain valid predictions of mortality in patients within 60 days of SARS-CoV-2 RT-PCR results into low, moderate, high, or very high risk of fatality.
Similar content being viewed by others


Introduction
The UK National Health Service (NHS) experienced unprecedented pressure due to the recurrent surges of coronavirus disease 2019 (COVID-19) cases caused by the SARS-CoV-2 virus. To date, more than two million confirmed cases in the UK have forced healthcare professionals to face complex decisions on how to effectively triage patients on admission who may need acute care. Admissions to hospital have increased from 6894 to 8431 in the seven days ending 8th March 2022 in the UK where routine lateral flow testing by the general public is no longer required and are ‘incidentally diagnosed’1. Conditions remain strained, and there is a need to develop risk tools to enable accurate and rapid triaging of SARS-CoV-2 positive patients. While prognostic tools are available, there is an ongoing need to develop tools that enable healthcare professionals to prevent unnecessary hospital admission and also work in combination with other predictive models commonly used in practice. Any new model must support the healthcare professional’s experiential knowledge and clinical reasoning2 in both patient care management and allocation of limited healthcare resources.
In hospitals, the main method used to detect COVID-19 is the reverse transcription-polymerase chain reaction (RT-PCR), and the severity of the infection determined by blood markers and chest radiological imaging such as X-ray and computed tomography (CT)3,4,5 scans. While CT is a sensitive tool, it is not used for periodic monitoring of patients. The use of x-ray is widespread and is used routinely to determine severity of lung injury. Its use has been included in numerous prognostic tools6, and in combination with other blood markers such as D-dimer, white blood count, and neutrophils7. However, some biomarkers such as D-dimer are not being routinely measured during hospital admission and triage.
Predictive models such as the National Early Warning Score 2 (NEWS2) is widely used in practice to observe and identify deteriorating patients8,9. Although favourable amongst healthcare professionals10, this predictive tool has caused increased false trigger rates for SARS-CoV-2 positive patients11,12. Another familiar tool in practice in the UK is the Acute Physiology and Chronic Health Evaluation II (APACHE II), which is a validated intensive care unit (ICU) scoring tool used to estimate ICU mortality. However, it has underestimated the mortality risk in SARS-CoV-2 positive patients13. Several published models have aimed to meet the clinician’s need to stratify high-risk SARS-CoV-2 positive patients; but they are yet to be widely clinically implemented or had poor clinician feedback14.
There are varying reports of changes in the full blood count, with it being reported that 80% of COVID-19 patients with severe symptoms and 20% of mild cases presented with lymphopenia15, which indicates that a low lymphocyte count is not an accurate marker taken alone16,17. Many studies have suggested the use of Interleukin 6 (IL6)16, Interleukin 10 (IL10)16, ferritin16, and D-Dimer7,17, since they are good discriminators of disease prognosis; but they are not routinely measured upon admission to hospital.
Here, we aim to avoid ‘clinical resistance’ by developing and validating a new simple and explainable prognostic tool that extends the widely used NEWS2 model18. This model combines clinical data, routine laboratory tests and chest x-ray (CXR) data to improve risk stratification and clinical intervention for SARS-CoV-2 infection. Studies have shown CXR results add value in the triage of patients who are SARS-CoV-2 positive19; however, the incremental prognostic value of CXR6 in addition to clinical data and routine laboratory tests remains to be consolidated in practice.
We used well-defined predictors and outcomes to limit model overfitting20. The model’s development and reporting adhered to the TRIPOD (transparent reporting of a multivariable prediction model for individual prediction or diagnosis) guidelines21,22 to publish a simple, user-friendly scoring system for adult patients admitted to hospital with SARS-CoV-2 infection. This resulted in improved integration of the best evidence into clinical care pathways that will assist clinicians in risk, patient, and resource management. The aim of this study was to develop a simple objective tool for risk stratification in SARS-CoV-2 infection by integrating results from rapid and routine clinical, laboratory and CXR image data that would easily support established triage practice in the hospital setting.
Methods
Sources of data
A prospective cohort study was conducted with the National COVID-19 Chest Imaging Database (NCCID)23 that collated clinical data from secondary and tertiary NHS Trusts across the UK with the aim to support SARS-CoV-2 care pathways (Supplementary Table 1). NHS staff submitted data for patients suspected of SARS-CoV-2 with a RT-PCR test that was positive or negative. The centralised data warehouse stored de-identified clinical data for those admitted to hospital between 23rd January 2020 and 7th December 2020, which was used for both the development and validation of the mortality risk tool.
To evaluate the tool’s generalised performance, a second dataset was used for external validation. The data extracted from the Laboratory Information Management System (LIMS) came from a large NHS Foundation Trust hospital in north-east England UK, which had not participated in the NCCID initiative. Patients who were admitted with suspected SARS-CoV-2 infection at the Accident and Emergency (A&E) Department between 1st March 2020 and 21st August 2020 were included. This population was representative of the adult general population and therefore patients aged 16 years and younger were excluded, as the laboratory data thresholds vary compared to adults. The datasets are retrospective and therefore consent is not possible.
Participants
The three datasets (‘development’, ‘internal’ and ‘external validation’) consisted of data for adult patients with positive RT-PCR results for the SARS-CoV-2 virus. To mitigate the issues with the lower RT-PCR sensitivity and accuracy during the initial stages of the pandemic, NCCID provided an overall SARS-CoV-2 status that was derived from cumulative RT-PCR tests. This approach was also applied to identify SARS-CoV-2 positive patients in the external validation dataset.
To evaluate the tool’s predictive performance, the NCCID dataset was non-randomly split with the admissions before 30th April 2020 making up the development cohort (n = 1434) and admissions on or after 1st May 2020 making up the internal validation cohort (n = 310) (Fig. 1). The external validation cohort (n = 741) was created by identifying fatal outcomes within 60 days of A&E admission of all patients who were confirmed positive for SARS-CoV-2 infection by RT-PCR. This approach was rationalised since patients were more comparable on latent variables such as co-morbid illnesses that were not explicitly captured during the LIMS data extraction of laboratory results. In addition, the filtering on admitted patients increased the density of laboratory results across all the candidate predictors, which made the model less reliant on imputation.

Patient flowchart with inclusion and exclusion criteria that established the development dataset as well as the internal and external validation datasets; n, number of patients in dataset.
Outcome
The primary outcome of interest was in-hospital mortality within 60-days of a positive SARS-CoV-2 RT-PCR test. To identify this outcome, the date of death was followed up and entered by hospital staff as part of the NCCID initiative.
Predictors
The NCCID dataset collected 38 clinical data points for each patient that served as candidate predictors. They were categorised into demographics, risk factors, past medical history (PMH), medications, clinical observations, chest imaging data, and laboratory parameters measured on admission. Chest X-ray (CXR) reports from the NCCID model development dataset and the external dataset were dichotomised as normal versus abnormal. All laboratory tests were measured before SARS-CoV-2 RT-PCR test and mortality date, which ensured these potential predictors were blinded to the outcome. The SARS-CoV-2 swab and RT-PCR results established the final COVID-19 status. In the event of deterioration, data points such as the NEWS2 score, Acute Physiology And Chronic Health Evaluation (APACHE) score, Intensive Therapy Unit (ITU) admission, intubation and mortality date were also recorded. Since the focus of the study was to identify predictors that were available at the point of admission, the ITU admission and intubation data were excluded in the final analysis.
From this extensive list, only the demographics, clinical observations, and laboratory parameters recorded at the time of admission for SARS-CoV-2 positive patients were included in the analysis as key predictors. Previous medical history, smoking status and current pharmaceutical interventions were not included in the analysis. This rationale was based on consultations with biomedical scientists and clinicians working in A&E departments to determine which rapid and routine laboratory tests would be clinically relevant candidate predictors, as well as previously published literature on prognostic factors associated with SARS-CoV-2 infection for the model development24.
To account for the risk of spurious selection or exclusion of important predictors in the model development, a minimum sample size of 380 was determined based on 10 outcome events per variable. Based on previous studies, a minimum sample size of 100 mortality events and 100 non-mortality events were required for external validation25.
Statistical analysis
Reliability of data was ensured by excluding patients from the development and internal validation datasets if information was missing on key characteristics, such as RT-PCR SARS-CoV-2 positive results at admission, and mortality dates outside the 60-day prediction interval (Fig. 2). Predictors with more than 40% missing values were also excluded from the modelling process (Supplementary Fig. 1). Missing data from the remaining predictors were handled using Multiple Imputation by Chained Equations (MICE), and ten different imputed datasets were combined using the Rubin rule26. Continuous predictors such as the laboratory tests and age were retained as continuous variables and not converted into categorical predictors using thresholds.

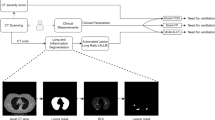
Model development, internal and external validation workflow. AUC-ROC, area under the receiver operating characteristic curve; GLMNET, Lasso and Elastic-Net Regularised Generalised Linear Models; MLR, multivariable logistic regression; LUCAS, model using Lymphocyte, Urea, CRP, Age, Sex; CXR, Chest X-ray; NEWS2, National Early Warning Score; n, the number of predictors.
An initial multivariable logistic regression (MLR) model started with 13 predictors with less than 40% missing values (Lymphocyte, Urea, CRP, Age, Sex, White Cell Count (WCC), Creatinine, Platelets, Diastolic BP (Blood Pressure), Systolic BP, Temperature, Heart rate, PaO2). Elastic Net (GLMNET)27, weighted combination of Least Absolute Shrinkage and Selection Operator (LASSO), and ridge regression were used to select predictors of importance. The optimal value of the shrinkage estimator for LASSO and the relative weights for LASSO and ridge regression were chosen using a ten-fold cross validation using the R-package caret28. Additionally, the performance of the MLR model was compared with the performance of the Random Forest Machine Learning approach29. The variable selection and construction of the Random Forest was performed using ten-fold cross validation. In each case, the imbalance in the positive and negative training samples was accommodated using the Synthetic Minority Oversampling Technique (SMOTE).
A second separate MLR model took a more pragmatic approach in predictor selection. From the 13 predictors of the first MLR model, we used only the blood panel measurements (Lymphocyte, Urea, CRP, WCC, Creatinine, Platelets) along with age and sex. In addition, it was assessed whether the inclusion of either NEWS2 or CXR or both improved this model’s performance.
Each model’s performance was assessed using Area Under the Receiving Operating Characteristics Curve (AUC-ROC) with a 95% confidence interval. The calibration performance of each model was measured as the slope of the calibration curve. The internal and external validation of each model were assessed with resampling. The predictor selection and entire modelling process were repeated in 1,000 bootstrap samples to estimate the realistic predictive measures for future patient cohorts. An AUC-ROC of 0.5 indicated a prediction based on random chance, 0.7–0.8 was considered acceptable, above 0.8 demonstrated excellent performance, and a value of 1.0 showed a perfect prediction30. We also evaluated the goodness of fit using the Brier score31, which is a measure to quantify the closeness of the probabilistic predictions to the binary ground-truth class labels. The score varies between 0 and 1, with the lower score indicating superior performance. Finally, the accuracy of the models was evaluated using the standard cut-off value of 0.5.
The internal validation included the NEWS2 score, which was not available for the external validation dataset. The statistical package R (3.5.3) was used to perform all statistical analyses and implement the methods employed in the model development, validation workflow, and primary model fitting, followed by both internal and external validation.
Data protection/Ethics
De-identified and pseudo-anonymised patient data were obtained from datasets, and the methods used were approved by the ethics committee as part of the existing Cardiac Magnetic Resonance Imaging (MRI) Database NHS Research Ethics Committee (REC) Integrated Research Application System (IRAS) Ref: 222349 and University of Brighton REC (8011). The need for informed consent was waived by the ethics committee due to retrospective nature of the study.
Results
Overall, the NCCID database comprised of 3,818 patients (from 23rd January 2020 to 31st December 2020). The number of patients that met the inclusion and missingness criteria were 1434 and 310, for the development and internal validation datasets, respectively (Fig. 1). All available data on positive patients were used in the external validation dataset, consisting of 242 fatal (mortality) and 499 non-fatal (no mortality) cases. The development dataset initially included 38 predictors (continuous and categorical), which was followed by the removal of variables with ≥ 40% missingness. Summary statistics of median with interquartile range (IQR) for continuous variables and proportions for categorical variables were presented and compared to those for the internal validation and external validation datasets (Table 1).
Model development
From the 38 predictors in the NCCID database, we selected 13 predictor variables that were judged to be clinically important and had no more than 40% missing values. These predictors relate to demographics, clinical observations and laboratory parameters recorded at the time of admission (Fig. 2). The variable importance plot indicates the relative importance of these predictors (Fig. 3); the most important predictor was sex, then lymphocyte count, urea, followed by age. The GLMNET model selection criteria optimally chose 8 predictors based on ten-fold cross validation that resulted in the MLR model having an AUC-ROC of 0.759 (Table 2). In contrast, the Random Forest model used all 13 predictors, which increased the complexity of the prediction and achieved a slightly higher AUC-ROC value of 0.806. Thus, the simplicity and ease of fitting our MLR model make it a robust score which can be easily adaptable to new datasets.

GLMNET (Lasso/Ridge) Variable importance plot with predictors having less than 40% missing values in the database. All patients are confirmed positive for SARS-CoV-2 by RT-PCR. The plot shows the importance of predictors in building the development predictive model. BP, blood pressure; PaO2, partial pressure of O2; WCC, white cell count; CRP, C-reactive protein.
The rapid blood test measurements, sex and age were recorded at the time of admission, and they parameterised our model. The relative difference of the laboratory parameters along with age, between patients with fatal and non-fatal outcomes, is presented as violin plots in Fig. 4.

Violin plots of individual blood variables parameters and age, categorised by patient outcome. The boxplots showing median and 1st and 3rd quartiles of the predictor variables are overlayed on the violin plots. All NCCID patients tested positive by the RT-PCR test for SARS-CoV-2. WCC, white blood count; CRP, C-reactive protein. The p-values are tests of equality of population using the Wilcoxon rank-sum test, where p < 0.05 implies statistically significant difference between the populations.
Starting with the MLR model with eight predictors, namely lymphocyte, urea, CRP, age, sex, WCC, creatinine, platelets, and using GLMNET for variable selection, a final model with 5 predictors was generated achieving AUC-ROC of 0.765 (Fig. 5). The predictors, namely Lymphocyte count, Urea, CRP, Age and Sex (LUCAS), were used in the final model with optimal accuracy results comparable to the MLR and Random Forest models with different numbers and sets of predictors included (Table 2). Sex had the greatest weight (0.22) in the model. The predicted probability of 60-day in-hospital mortality can be measured by the following expression:

Predictor plots; multivariate association between predictors (Sex, Age, Urea, CRP, Lymphocyte count, and their combination LUCAS) and probability of fatal outcome.
In the Sex category, values of 0 and 1 were used for Female and Male, respectively.
From our development cohort, the LUCAS model can accurately predict 93% of the true fatal outcomes and 33% of the true non-fatal outcomes. The confusion matrices for all three prediction models are presented in Supplementary Fig. 2 (with bootstrapping over 10 repetitions). Each entry in the confusion matrix represents the percentual average cell counts across resamples. Calibration measures are similar in all three models, with LUCAS model demonstrating the best calibration performance (Supplementary Fig. 3 and Table 2).
The first step taken to stratify the outcomes from each predictor involved effect plots along with the estimated linear predictor (linear combination of the predictors with the estimated coefficients of MLR) (Fig. 5). Each sub-plot in Fig. 5 indicates how the individual predictor is related to the probability of fatal outcome. The binary predictor of sex shows an increase in probability of fatal outcome for males. For the continuous predictors (age, urea, and CRP), we can see a clear increase in the probability of fatal outcome corresponding to the increase in value of these predictors. We can also observe that in the presence of other predictors, lymphocyte count is a weak predictor; there is a slight decrease in the probability of fatal outcome with the increase in lymphocyte count. We can also notice that the error band around the mean effects is quite wide on the higher values of CRP and lymphocyte count, which is most likely due to the small number of observations in the higher ranges of these two predictors. However, when taken together in the linear combination given by LUCAS, the MLR prediction curve has a steep slope with a very narrow error bar, which indicates a very robust and accurate mortality score.
Along with the exact values of the probability of fatal outcome based on the five predictors, we propose a risk stratification (Table 3) based on these probabilities, which allows a simplified interpretation of mortality to low, medium, high, and very high risk of a fatal outcome.
Though the percentage of missing predictors in our reduced models were negligible, sensitivity analysis was performed using complete case data and as expected the model performance did not change. We also note that the simple logistic regression was preferred over machine learning approaches such as Random Forest starting from same set of predictors, based on simplicity and their performance in the validation dataset.
Model validation
We have performed validation on an internal validation (NCCID Data between 1st May 2020 and 7th December 2020) cohort and external validation cohort consisting of data from a separate A&E site (n = 1012; between 1st March 2020 and 21st August 2020) with a small overlap with the available predictors from the derivation and internal validation cohort. However, all five predictors from the proposed model were present (LUCAS: Lymphocyte count, Urea, CRP, Age and Sex).
The median age of patients from the internal validation dataset was 74 years (IQR 62–84), which was not significantly different from the external validation dataset with a median of 76 years (IQR 61–84). The proportion of male patients was similar in both groups; 58% male in the internal validation set, and 55% male in external validation set (Table 1).
The performance of the LUCAS calculator on the internal validation cohort was very good; AUC-ROC 0.744 (CI: 0.673–0.808) with an accuracy 0.796 at the standard cut-off of 0.50 for the probability of a SARS-CoV-2 positive patient dying within 60 days of a positive test (Table 4). Use of the available NEWS2 data in combination with LUCAS had little effect on accuracy (AUC-ROC 0.747, CI: 0.668–0.821). In contrast, inclusion of CXR data in combination with LUCAS led to an increase in AUC-ROC to 0.770 (CI: 0.695–0.836). The choice to use the CXR outcome (normal vs abnormal) was therefore included in the simple LUCAS calculator as an optional extra predictor, as follows:
LUCAS showed an improved performance in the external validation cohort with an AUC-ROC value of 0.752 (CI: 0.713–0.790) compared to the internal dataset (AUC-ROC 0.744, CI: 0.673–0.808). By including CXR information, there is an improved prediction performance, with an AUC-ROC of 0.791 (CI: 0.746–0.833). Note that the NEWS2 score was not available for the external validation cohort, so this result could not be externally validated.
Discussion
We have developed and validated a simplified, fast-track mortality calculator based on three rapid and routine blood parameter measurements, age and sex, with the option to use CXR results. The LUCAS calculator is freely available, relies on objective measurements only, and has been both internally and externally validated. The primary intended use of the LUCAS calculator is to aid triage on patient admission to A&E following a positive SARS-CoV-2 RT-PCR test. The robustness and generalised results in the validation process classify the tool as an excellent candidate for risk management of the mortality level in a 60-day survival interval of adult SARS-CoV-2 positive patients. The LUCAS calculator delivered higher accuracy of the external validation compared with the internal validation set, which indicates a high level of generalisation. In addition, the incorporation of CXR results as normal versus abnormal improved the prediction performance.
The NCCID dataset collected 38 clinical data points for each patient which served as candidate predictors. These predictors were categorised into demographics, risk factors, past medical history (PMH), medications, clinical observations, chest-imaging data, and laboratory parameters measured on admission to hospital. All laboratory tests were measured before the SARS-CoV-2 RT-PCR test result and mortality date, which ensured these potential predictors were blinded to the outcome. The SARS-CoV-2 swab and RT-PCR results established the final COVID-19 status. Moreover, thorough study of other included measures, such as the NEWS2 score11, was also performed. As a result, a comprehensive study and evaluation of all the possible blood markers and clinical patient information were taken into consideration. This study shows that a simple and objective tool can risk stratify SARS-CoV-2 positive patients within one hour after hospital admission. The primary objective showed that rapid and routine laboratory blood tests and chest imaging data added predictive value beyond the RT-PCR test and clinical observations with high AUC-ROC.
The ability of the LUCAS calculator to predict future outcomes was evaluated by non-randomly splitting the NCCID dataset to train on admissions before 30th April 2020 and predicting the outcomes for patients admitted on or after 1st May 2020. The high prediction results of LUCAS in the internal validation dataset, as well as in the external validation dataset from a different NHS site (between 1st March 2020 and 21st August 2020), demonstrates the model’s robust and generalised performance.
Comparison with other studies
There have been many prognostic tools published, most notably the 4C Mortality Score32 and QCOVID33, which included large number of predictors in their algorithms. Our study is the first to combine a minimum number of blood results along with CXR data, to generate a simplified calculator based on as few objective predictors as possible.
The 4C Mortality Score includes 8 parameters including PMH, demographics and blood measurables, resulting in a higher AUC-ROC of 0.79032. However, gaining an accurate past medical history during triage is not always practical, and the 4C calculator was not externally validated. Our aim was to use the minimum number of predictors without losing accuracy, which was achieved using LUCAS that exhibits a similar level of prediction as the more complex and detailed 4C algorithm. The primary QCOVID score was developed as a risk prediction algorithm to estimate hospital admission and mortality outcomes, which also included large number of predictors including PMH33.
Numerous prediction models have been developed to aid triage and research into COVID-19 disease severity. While a great deal of useful insight into the disease has been gained from these studies and prognostic tools, there is a range of outcomes mostly due to some having a high risk of bias, lack of transparency or lack of internal34 or external validation32,35. Our study improves on these issues by conforming to the Prediction model Risk of Bias Assessment Tool (PROBAST)21 and being both internally validated from the same large NCCID dataset and externally validated in a smaller, separate hospital database. In addition, many studies require past medical history, or base the prediction on the underlying health conditions of the patient35,36. These data may be difficult to assess accurately on admission to hospital and may mislead should the patient have undiagnosed conditions. For this reason, we focused our model on measurables taken routinely on admission.
The NEWS2 score has been used routinely in hospitals to detect clinical deterioration, although it has mixed results in its success. In one multicentre retrospective study involving the inclusion of data from 1263 patients, the NEWS2 score was used to predict mortality, ICU admission and hospital mortality and resulted in an AUC-ROC of 0.65 for 30-day mortality9. This compares to our NEWS2 findings of an AUC-ROC 0.59 in development cohort and 0.66 in internal validation cohort. When we combined NEWS2 with LUCAS in predicting mortality within 60 days, this increased the AUC-ROC to 0.77 in development cohort and 0.75 in internal validation cohort, thus indicating an improvement of accuracy when in combination with the LUCAS algorithm. This large increase in predictive power also gives weight to the use of LUCAS over NEWS2 in prognosis modelling for COVID-19.
All the predictors used in the LUCAS calculator have been shown to be useful predictors in other published studies. Lymphocyte count17,20,37, urea32,38, and CRP39,40,41,42,43,44 are recognised as key measurable predictors of severity of SARS-CoV-2 infection, and age and sex are also well-known predictors of mortality32,33,38,43. While these factors have been used in other prediction models, our study is the first to use only these predictors in a prognostic score along with the option to use CXR data.
Inclusion of CXR data is optional for the online LUCAS calculator and based on simple outcome of normal/abnormal image results. The ability to include CXR results is not widely available in other prediction calculators and has been included in a study35 along with ten other parameters (symptoms, past medical history and measurables). More recently, some of the studies have included the CXR imaging in prognostic models45,46, with good accuracy; however, they have either utilised information such as electronic health records45 including comorbidities46,47, which are not always known at the point of care, additional blood biomarkers such as D-Dimer7,41 and lactate dehydrogenase42, which are not measured routinely during triage, or incorporated complex deep-learning methodologies46, affecting the explainability and simplicity of the model. Indeed, in a parallel study, we have developed a highly accurate deep-learning based model (DenResCov-19) to classify from CXR images patients positive for SARS-CoV-2, tuberculosis, and other forms of pneumonia6, which will be integrated into the LUCAS calculator in a future study. Our focus in this study, however, was to form a simplified model on rapid and routine blood test results, with the option to use CXR images, which we have achieved.
Throughout the study, we have carefully considered the risk of bias that is inherent in retrospective studies. By conducting both internal and external validation, the study here indicates a robust model with reduced bias, since only patients testing positive for SARS-CoV-2 were included in the development of the LUCAS algorithm. The size of the external validation set was smaller than the development set allowing us to check for discrimination of population size, and the results indicate that the LUCAS calculator can predict from small cohorts as well as it can from larger size populations.
The patient data was collected at an early stage of the pandemic when treatments differed compared to later in the year, which would affect the death rate in hospital. In addition, our results do not account for non-hospital deaths or deaths outside the 60-day window following diagnosis. Over time, any algorithm of mortality will change due to improvements in therapies as well as the use of vaccination which will change the profile of those at risk of COVID-19 related death48. While these changes in therapeutic interventions change over time49, multiple studies have reported the associated changes to inflammatory markers that are found in severe cases of COVID-1939. While improvements in medical care have significantly reduced mortality, the immunological responses that indicate severe cases of COVID-19 have not changed, making the use of prediction modelling important to aid in the triage of patients.
Conclusion
The major strengths of this study in mortality prediction of COVID-19 patients include the analytical approach taken, the comparison with the widely used NEWS2 score, the inclusion of CXR data, and the evaluation in both internal and external validation cohorts. The CXR data contributes to an improvement in the mortality prediction of the patient, although the CXR information used in the LUCAS calculator is binary (normal or abnormal). Further development of this work is currently ongoing, which will extract CXR image features using machine learning or deep learning methods6 and combine with LUCAS to deliver an automated, integrated biomarker-imaging analysis.
Data availability
The data that support the findings of this study are available from the NCCID23 and another NHS site; but restrictions apply to the availability of these datasets, which were used under license for the current study, and are not publicly available.
Code availability
The Simple Logistic Regression based calculator is freely available at https://mdscore.org/.
References
Iacobucci, G. Covid-19: Hospital admissions rise as cases increase in over 55s. BMJ 376, o654. https://doi.org/10.1136/bmj.o654 (2022).
Norman, G. Building on experience–the development of clinical reasoning. N. Engl. J. Med. 355, 2251–2252. https://doi.org/10.1056/NEJMe068134 (2006).
Gong, K. et al. A multi-center study of COVID-19 patient prognosis using deep learning-based CT image analysis and electronic health records. Eur. J. Radiol. 139, 109583–109583. https://doi.org/10.1016/j.ejrad.2021.109583 (2021).
Chieregato, M. et al. A hybrid machine learning/deep learning COVID-19 severity predictive model from CT images and clinical data. Sci. Rep. 12, 1. https://doi.org/10.1038/s41598-022-07890-1 (2022).
Shiri, I. et al. Machine learning-based prognostic modeling using clinical data and quantitative radiomic features from chest CT images in COVID-19 patients. Comput. Biol. Med. 132, 104304. https://doi.org/10.1016/j.compbiomed.2021.104304 (2021).
Mamalakis, M. et al. DenResCov-19: A deep transfer learning network for robust automatic classification of COVID-19, pneumonia, and tuberculosis from X-rays. Comput. Med. Imaging Graph. 94, 102008. https://doi.org/10.1016/j.compmedimag.2021.102008 (2021).
Alsagaby, S. A. et al. Haematological and radiological-based prognostic markers of COVID-19. J. Infect. Public Health 14, 1650–1657. https://doi.org/10.1016/j.jiph.2021.09.021 (2021).
RCP. National early warning score (NEWS) 2. Standardising the assessment of teh acute—illness severity in the NHS. In Royal College of Physicians working party (2017).
Scott, L. J. et al. Prognostic value of National Early Warning Scores (NEWS2) and component physiology in hospitalised patients with COVID-19: A multicentre study. Emerg. Med. J. https://doi.org/10.1136/emermed-2020-210624 (2022).
Fox, A. & Elliott, N. Early warning scores: A sign of deterioration in patients and systems. Nurs. Manag. (Harrow) 22, 26–31. https://doi.org/10.7748/nm.22.1.26.e1337 (2015).
Baker, K. F. et al. National Early Warning Score 2 (NEWS2) to identify inpatient COVID-19 deterioration: A retrospective analysis. Clin. Med. (Lond.) 21, 84–89. https://doi.org/10.7861/clinmed.2020-0688 (2021).
Baker, K. F. et al. COVID-19 management in a UK NHS foundation trust with a high consequence infectious diseases centre: A retrospective analysis. Med. Sci. (Basel) 9, 6. https://doi.org/10.3390/medsci9010006 (2021).
Stephens, J. R. et al. Analysis of critical care severity of illness scoring systems in patients with coronavirus disease 2019: A retrospective analysis of three UK ICUs. Crit. Care Med. 49, e105–e107. https://doi.org/10.1097/CCM.0000000000004674 (2021).
Wynants, L. et al. Prediction models for diagnosis and prognosis of covid-19: Systematic review and critical appraisal. BMJ 369, m1328. https://doi.org/10.1136/bmj.m1328 (2020).
Yang, X. et al. Clinical course and outcomes of critically ill patients with SARS-CoV-2 pneumonia in Wuhan, China: A single-centered, retrospective, observational study. Lancet Respir. Med. 8, 475–481. https://doi.org/10.1016/S2213-2600(20)30079-5 (2020).
Henry, B. M., de Oliveira, M. H. S., Benoit, S., Plebani, M. & Lippi, G. Hematologic, biochemical and immune biomarker abnormalities associated with severe illness and mortality in coronavirus disease 2019 (COVID-19): A meta-analysis. Clin. Chem. Lab. Med. 58, 1021–1028. https://doi.org/10.1515/cclm-2020-0369 (2020).
Kermali, M., Khalsa, R. K., Pillai, K., Ismail, Z. & Harky, A. The role of biomarkers in diagnosis of COVID-19—a systematic review. Life Sci. 254, 117788–117788. https://doi.org/10.1016/j.lfs.2020.117788 (2020).
Keegan, M. T. & Soares, M. What every intensivist should know about prognostic scoring systems and risk-adjusted mortality. Rev. Bras. Ter. Intensiva 28, 264–269. https://doi.org/10.5935/0103-507X.20160052 (2016).
Balbi, M. et al. Chest X-ray for predicting mortality and the need for ventilatory support in COVID-19 patients presenting to the emergency department. Eur. Radiol. 31, 1999–2012. https://doi.org/10.1007/s00330-020-07270-1 (2021).
Banerjee, A. et al. Use of machine learning and artificial intelligence to predict SARS-CoV-2 infection from full blood counts in a population. Int. Immunopharmacol. 86, 106705. https://doi.org/10.1016/j.intimp.2020.106705 (2020).
Wolff, R. F. et al. PROBAST: A tool to assess the risk of bias and applicability of prediction model studies. Ann. Intern Med. 170, 51–58. https://doi.org/10.7326/M18-1376 (2019).
Cabitza, F. & Campagner, A. The need to separate the wheat from the chaff in medical informatics Introducing a comprehensive checklist for the (self)-assessment of medical AI studies. Int. J. Med. Inform. 153, 7. https://doi.org/10.1016/j.ijmedinf.2021.104510 (2021).
Jacob, J. et al. Using imaging to combat a pandemic: Rationale for developing the UK National COVID-19 chest imaging database. Eur. Respir. J. 56, 2001809. https://doi.org/10.1183/13993003.01809-2020 (2020).
Maguire, D. et al. Prognostic factors in patients admitted to an urban teaching hospital with COVID-19 infection. J. Transl. Med. 18, 354. https://doi.org/10.1186/s12967-020-02524-4 (2020).
Vergouwe, Y., Steyerberg, E. W., Eijkemans, M. J. & Habbema, J. D. Substantial effective sample sizes were required for external validation studies of predictive logistic regression models. J. Clin. Epidemiol. 58, 475–483. https://doi.org/10.1016/j.jclinepi.2004.06.017 (2005).
Rubin, D. B. Multiple imputation for nonresponse in surveys. Wiley Ser. Prob. Stat. https://doi.org/10.1002/9780470316696 (1987).
Zou, H. H. Trevor regularization and variable selection via the elastic net. Stat. Methol. 67, 301–320. https://doi.org/10.1111/j.1467-9868.2005.00503.x (2005).
Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 28, 1–26. https://doi.org/10.18637/jss.v028.i05 (2008).
Breiman, L. Random forests. Mach. Learn. 45, 5–32. https://doi.org/10.1023/A:1010933404324 (2001).
Mandrekar, J. N. Receiver operating characteristic curve in diagnostic test assessment. J. Thorac. Oncol. 5, 1315–1316. https://doi.org/10.1097/JTO.0b013e3181ec173d (2010).
Steyerberg, E. W. et al. Assessing the performance of prediction models: A framework for traditional and novel measures. Epidemiology 21, 128–138. https://doi.org/10.1097/EDE.0b013e3181c30fb2 (2010).
Knight, S. R. et al. Risk stratification of patients admitted to hospital with covid-19 using the ISARIC WHO Clinical Characterisation Protocol: Development and validation of the 4C Mortality Score. BMJ 370, m3339. https://doi.org/10.1136/bmj.m3339 (2020).
Clift, A. K. et al. Living risk prediction algorithm (QCOVID) for risk of hospital admission and mortality from coronavirus 19 in adults: National derivation and validation cohort study. BMJ 371, m3731. https://doi.org/10.1136/bmj.m3731 (2020).
Duca, A., Piva, S., Foca, E., Latronico, N. & Rizzi, M. Calculated decisions: Brescia-COVID respiratory severity scale (BCRSS)/Algorithm. Emerg. Med. Pract. 22, CD1–CD2 (2020).
Liang, W. et al. Development and validation of a clinical risk score to predict the occurrence of critical illness in hospitalized patients with COVID-19. JAMA Intern. Med. 180, 1081–1089. https://doi.org/10.1001/jamainternmed.2020.2033 (2020).
Magro, B. et al. Predicting in-hospital mortality from Coronavirus Disease 2019: A simple validated app for clinical use. PLoS ONE 16, e0245281. https://doi.org/10.1371/journal.pone.0245281 (2021).
Rahman, T. et al. Mortality prediction utilizing blood biomarkers to predict the severity of COVID-19 using machine learning technique. Diagn. (Basel) 11, 1582. https://doi.org/10.3390/diagnostics11091582 (2021).
Bastug, A. et al. Clinical and laboratory features of COVID-19: Predictors of severe prognosis. Int. Immunopharmacol. 88, 106950. https://doi.org/10.1016/j.intimp.2020.106950 (2020).
Ji, P. et al. Association of elevated inflammatory markers and severe COVID-19: A meta-analysis. Med. (Baltim.) 99, e23315. https://doi.org/10.1097/MD.0000000000023315 (2020).
Tan, C. et al. C-reactive protein correlates with computed tomographic findings and predicts severe COVID-19 early. J. Med. Virol. 92, 856–862. https://doi.org/10.1002/jmv.25871 (2020).
Calvillo-Batllés, P. et al. Development of severity and mortality prediction models for covid-19 patients at emergency department including the chest x-ray⋆ Elaboración de modelos predictivos de la gravedad y la mortalidad en pacientes con COVID-19 que acuden al servicio de urgencias, incluida la radiografía torácica. Radiol. (Engl. Ed.) 64, 214–227 (2022).
Chatterjee, A., Wilmink, G., Woodruff, H. & Lambin, P. Improving and externally validating mortality prediction models for COVID-19 using publicly available data. BioMed 2, 13–26. https://doi.org/10.3390/biomed2010002 (2022).
Bhatia, S. et al. Severity and mortality prediction models to triage Indian COVID-19 patients. PLOS Digital Health 1, e0000020. https://doi.org/10.1371/journal.pdig.0000020 (2022).
Patel, D. et al. Machine learning based predictors for COVID-19 disease severity. Sci. Rep. 11, 4673. https://doi.org/10.1038/s41598-021-83967-7 (2021).
Wu, J.T.-Y. et al. Developing and validating multi-modal models for mortality prediction in COVID-19 patients: A multi-center retrospective study. CoRR https://doi.org/10.1007/s10278-022-00674-z (2021).
Cheng, J. et al. COVID-19 mortality prediction in the intensive care unit with deep learning based on longitudinal chest X-rays and clinical data. Eur. Radiol. 32, 4446–4456. https://doi.org/10.1007/s00330-022-08588-8 (2022).
Aljouie, A. F. et al. Early prediction of COVID-19 ventilation requirement and mortality from routinely collected baseline chest radiographs, laboratory, and clinical data with machine learning. J. Multidiscipl. Healthc. 14, 2017–2033. https://doi.org/10.2147/JMDH.S322431 (2021).
Lavine, J. S., Bjornstad, O. N. & Antia, R. Immunological characteristics govern the transition of COVID-19 to endemicity. Science 371, 741–745. https://doi.org/10.1126/science.abe6522 (2021).
Gavriatopoulou, M. et al. Emerging treatment strategies for COVID-19 infection. Clin. Exp. Med. 21, 167–179. https://doi.org/10.1007/s10238-020-00671-y (2021).
Acknowledgements
The researchers would like to thank Dr. Gautamananda Ray of NHS Greater Glasgow and Clyde hospitals and the biomedical scientists at Portsmouth Hospital NHS Trust for their advice.
Funding
EPSRC Impact Acceleration account fund EP/R511705/1; University of Brighton COVID-19 Research Urgency Fund. AS is funded by the Wellcome Trust fellowship 205188/Z/16/Z; AB is a Royal Society University Research Fellow and is supported by the Royal Society (Grant No. URF\R1\221314).
Author information
Authors and Affiliations
Contributions
Contributors: S.W., L.S.M. are joint last authors. L.S.M. is corresponding author for this article. Contributor Roles: sonceptualisation: S.R., A.S., A.B., M.M., S.W., L.S.M.; data curation: S.R., A.B., B.V.; formal analysis: S.R., A.B.; funding acquisition: S.R., A.S., L.S.M.; investigation: S.R., A.B.; methodology: S.R., A.S., A.B., M.M., B.V.; project administration: S.W., J.F.; resources: B.V., A.S.; software: S.R., A.B., B.V.; supervision: S.W.; validation: S.R., A.B., M.M., B.V.; visualisation: S.R., S.W., L.S.M.; writing original draft: S.W., L.S.M., S.R., A.B.; writing–review and editing: S.W., L.S.M., S.R., A.S., M.M., A.B., B.V., J.C., C.W.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ray, S., Banerjee, A., Swift, A. et al. A robust COVID-19 mortality prediction calculator based on Lymphocyte count, Urea, C-Reactive Protein, Age and Sex (LUCAS) with chest X-rays. Sci Rep 12, 18220 (2022). https://doi.org/10.1038/s41598-022-21803-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-21803-2
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
