
Abstract
The COVID-19 pandemic has been a great challenge to healthcare systems worldwide. It highlighted the need for robust predictive models which can be readily deployed to uncover heterogeneities in disease course, aid decision-making and prioritise treatment. We adapted an unsupervised data-driven model—SuStaIn, to be utilised for short-term infectious disease like COVID-19, based on 11 commonly recorded clinical measures. We used 1344 patients from the National COVID-19 Chest Imaging Database (NCCID), hospitalised for RT-PCR confirmed COVID-19 disease, splitting them equally into a training and an independent validation cohort. We discovered three COVID-19 subtypes (General Haemodynamic, Renal and Immunological) and introduced disease severity stages, both of which were predictive of distinct risks of in-hospital mortality or escalation of treatment, when analysed using Cox Proportional Hazards models. A low-risk Normal-appearing subtype was also discovered. The model and our full pipeline are available online and can be adapted for future outbreaks of COVID-19 or other infectious disease.
Similar content being viewed by others


Introduction
The COVID-19 pandemic, caused by the rapid spread of the original SARS-CoV-2 virus (and its follow-on variants) is one of the greatest health challenges faced in the modern age. As of May 2022 the global death toll exceeds 6.3 million people with more than 544 million confirmed infections1. Even though large-scale vaccination programs have mitigated the death toll and hospitalizations, seasonality of spread and new virus variants continue to cause new ‘waves’ of increased infection. As a result, COVID-19 still puts significant strain on healthcare systems worldwide. Even though the pandemic has been put into relative control in many countries, recent examples of virus resurfacing, e.g. the 2022 surge in Shanghai, China2 (due to mutations, lack of containment measures, and vaccine resistance) suggest the world is still in danger of further ‘waves’. Insights into factors which can predict mortality and morbidity of patients infected with SARS-CoV-2 can aid physicians, health facility managers and policy makers to make better informed decisions, both at present and in future epidemics. Moreover, the pandemic demonstrated the relative unpreparedness of healthcare systems to deal with many infected patients while providing adequate care to them. One aspect of this unpreparedness can be attributed to the lack of robust and appropriate disease models. Through the pandemic, there was a significant effort to develop algorithms and decision-support systems to aid triaging and patient management. While it is still difficult to say which models and AI tools have been useful, most studies relied on either established or newly-designed clinical scores (e.g. the NEWS-2 score3, ROX index4, ISARIC-4C5 score), classic machine learning classification (e.g. Support Vector Machines6), or neural networks/Deep Learning for either imaging7 or clinical data8 to predict patient outcomes. Of the methods utilised to date, clinical scores have shown most promise. Yet perhaps due to the rapid development and testing of methods, the majority of existing studies have shown significant limitations—e.g. lack of independent test dataset6,8, overfitting, miscalibration9 (especially for imaging-based deep learning models), non-availability of code implementation, lack of explainability, small sample size, or biased data selection7,9.
To overcome these limitations, we adapted an unsupervised algorithm, SuStaIn10, to be deployed to data from the first wave of the COVID-19 pandemic. SuStaIn has already shown great promise in in tackling several chronic diseases11,12,13, but it can now be used to gain insights and aid management of shorter-term, infectious disease. We used 11 routinely collected clinical measures on admission to hospital to disentangle distinct clusters of patients (called subtypes) and severity stages of the disease within subtypes, both of which were predictive of inpatient hospital outcomes. Predictions from SuStaIn provide insight into both disease subtypes and severity—a nuance which many models miss. It further balances model complexity, to capture biomarker dynamics, and explainability, which positions it as a useful clinical tool for triaging patients based on their SuStaIn subtype and stage. Unlike other predictive scales or deep-learning models, it is now readily deployable to future infectious disease epidemics and the model implementation is available online.
Methods
Population
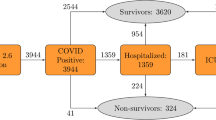
This study analysed data from the National COVID-19 Chest Imaging Database (NCCID), which comprised COVID-19 positive and negative patients14,15. All patients in the study were admitted with suspected COVID-19 infection. In patients with a confirmed positive Polymerase Chain Reaction (PCR) SARS-CoV-2 RNA test, NCCID also collected imaging: Computed Tomography (CT) and Chest X-ray (CXR), as well as clinical information, where the imaging was performed during the hospitalisation period and the salient clinical readings were acquired at admission. The study also included a group of patients who were hospitalized but were subsequently found to be negative for COVID-19. They had to have tested negative on repeated PCR for COVID-19 and not have been admitted to hospital in the subsequent month. All data used was collected from patients admitted to hospital in the UK from January 2020 to January 2021. The data was collected from 14 NHS Hospital Trust centres in the UK, comprising 52 hospitals, which submitted a variable number of cases each.
All data was previously gathered as part of the NCCID study and was stored and analysed in accordance with the established study guidelines as outlined in an earlier work describing the dataset14. Ethical approval was granted by the UK Health Research Authority and the Scottish Public Benefit Privacy Panel (PBPP), and was also reviewed by NHS Information Governance14. Processing of pseudonymised patient data for this study was allowed under a nationally issued Notice under Regulation 3(4) of the Health Service Control of Patient Information Regulations 2002 (COPI). This notice required all hospitals and NHS centres to share and process confidential patient information for COVID-19 purposes (protecting public health, providing healthcare services to the public and monitoring and managing the outbreak)15. Subject consent for publication was not required as all data was pseudonymised14. All data collection, processing and sharing in the NCCID study was done under the rules and conditions outlined in the Notice. Approval for the retrospective analysis of clinically data and imaging data in NCCID was obtained from the local research ethics committees and Leeds East Research Ethics Committee: 20/YH/0120.
Data preparation
Even though NCCID enrolled many centres in data collection, the significant load imposed by the ongoing COVID-19 pandemic led to many instances of missing data, especially in the clinical readings at admission. As a result, we used a portion of the NCCID dataset, primarily driven by data completeness. A total of 1344 subjects (referred to as case population) were used in the current study, in addition to 137 COVID-19 negative patients who were utilised as controls for the disease progression model (please see “Subtype and stage inference model”). Manual data quality assurance, curation and standardisation was performed on all clinical data.
We selected eleven clinical tests as biomarkers for disease progression modelling: creatinine, urea, C-reactive protein, lymphocyte count, platelet count, white cell count, respiratory rate, temperature, heart rate, systolic and diastolic blood pressure. Several of these measures have been suggested as being prognostically important in previous survival analyses3,5,16. The choice of clinical tests to include in our model was driven by previous use in research and by practicality. All clinical test results were recorded on admission of the patients to hospital.
The 1344 covid-positive cases were split randomly into a training and validation sample of 672 subjects after matching the two populations for age. All model training and tuning was performed solely on the training population and the patients in the validation population were used only at testing.
NCCID data was accessed through a UCL-owned XNAT instance. The Microsoft Azure platform and tools from Microsoft Project InnerEye Open Source Software were used for cloud-based modelling and analysis (https://aka.ms/InnerEyeOSS).
Subtype and stage inference model
Subtype and Stage Inference (SuStaIn) is an unsupervised learning algorithm that simultaneously identifies clusters (subtypes) and progression sequences (stages) of disease based on worsening biomarker readings. SuStaIn was first developed to model long-term chronic diseases such as Alzheimer’s10 and Chronic Obstructive Pulmonary Disease (COPD)11. Uniquely, it extracts a temporal (or pseudo-temporal) evolution of disease from single-timepoint, cross-sectional data to account for the inherent progression of diseases. The present study is the first to apply SuStaIn to an infectious disease in its acute phase.
Linear z-score SuStaIn was the chosen SuStaIn model, in which each of the eleven clinical biomarkers was transformed to a z-score with reference to a control population. The control population for this study consisted of 137 patients who were suffering from acute disease (initially suspected to be COVID-19) and were hospitalised but were later determined to not have COVID-19. This population was favourable for usage as controls to SuStaIn since all patients were unwell enough to be admitted to hospital but were not infected with COVID-19. By z-scoring the 11 biomarkers to this population, the effects of COVID-19 infection on the biomarkers were separated from the effects of other acute disease.
Several data preparation steps were carried out prior to initiating modelling with SuStaIn to isolate the COVID-19 signal from other potential covariates. First, the effects of age and sex on all 11 biomarkers were learned in the control population and regressed out from the entire population. Second, the distributions of biomarkers were checked for normality through the Shapiro–Wilk and D’Agostino’s K2 test. If a biomarker distribution failed any of the normality tests, a power transform (either the Box-Cox or Yeo-Johnson) was used to improve the normalisation of its distribution. The transformations were applied both on the control and case populations and were necessary since normal distributions are assumed by the linear z-score SuStaIn model.
Finally, each biomarker was transformed into a z-score with reference to the control population, as described earlier. Since some biomarkers were expected to increase or decrease with disease progression, those found to decrease in the case population with reference to the control population (implying negative z-scores), were inverted to ensure all biomarker progression was represented by monotonically increasing z-scores.
Several hyperparameters—model parameters which are not automatically learned, but are instead chosen and optimised by the researcher, were selected—namely the z-score thresholds which represent a stage of progression and the maximum number of subtypes (clusters) to search for. These were tuned and the best-fitting model selected. Table 1 outlines the z-score thresholds selected for each biomarker. When a biomarker reaches a certain z score value (e.g. z = 1 or z = 2), this represented a new disease severity stage.
After the model was trained (on the training population), each subject was assigned a SuStaIn subtype and stage. Subtype was assigned by selecting the most probable cluster. Instead of assigning a simple integer stage to each subject, a weighted stage was designated. For each subject, each stage was weighed by the probability of the subject belonging to that stage and the result was then summed, producing a continuous weighted stage. Subjects in the validation population were subtyped and staged using the model trained on the training population.
Frailty Cox proportional hazards models
To model the survival of patients admitted with COVID-19 infection, the Cox Proportional Hazards (PH) model was used. We used 5 predictor variables in the model: age, sex, subtype, weighted stage, and the subtype-weighted stage interaction. Two outcomes were predicted—time to in-hospital death and time to escalation of patient management. Escalation was defined as in-hospital deterioration which resulted in either ITU admission, intubation or death. The earliest of these 3 events was used as the measure of time to escalation for each patient. Observations were right censored to 6 months after hospital admission as this was the maximum hospital stay for some patients (before discharge or death). To account for the significant variability between centres, a frailty Cox PH model17 was adopted with NHS centre as the frailty variable, modelling the random effects in the population.
Results
Covid subtypes and severity progression
SuStaIn discovered 3 clinical subtypes of COVID-19 (based on the training population), characterised by distinct in-hospital disease progression. SuStaIn has previously been used to model long-term disease like Alzheimer’s or COPD, which span years, but we adapted it for the relatively short time span of an infectious disease (in-hospital monitoring for up to 6 months). Hence, the disease stages can be interpreted as sequences of progression in the severity of disease within each subtype. We named the three subtypes ‘General Haemodynamic’, ‘Renal’ and ‘Immunological’ (Fig. 1).

COVID-19 subtypes and disease severity progression. The warm colours represent disease stages progressing towards positive z-scores (z = 1, z = 2) and the cold colours—towards negative z-scores (z = − 1, z = − 2). Increased colour transparency signifies greater uncertainty. The f-value next to each subtype represents the fraction of the training population which was classified as belonging to this subtype.
Subtype 1: general haemodynamic
In this subtype, less severe disease was characterised by high diastolic blood pressure, temperature, respiratory and heart rate, which was then followed by further heart rate increases, elevated CRP and a decrease in lymphocyte levels.
Subtype 2: renal
The Renal subtype was characterised by early elevations in creatinine and urea levels, followed by a decrease of systolic blood pressure and an increase in CRP. Unlike the other 2 subtypes, which only exhibit abnormal creatinine and urea in late-stage disease (SuStaIn severity stages 12+), patients with the Renal subtype experienced these abnormalities early in their disease severity progression.
Subtype 3: immunological
In the Immunological subtype, COVID-19 began with abnormally low systolic blood pressure, followed by a cascade of decreases in lymphocyte and platelet count and then elevated temperature, heart rate and CRP levels at more advanced disease.
In all subtypes, abnormalities in the systolic and diastolic blood pressures seemed to be separated—being placed at the opposite ends of SuStaIn stage in all three subtypes.
Data exploration
SuStaIn modelling revealed a large proportion of patients were assigned to SuStaIn stage 0—a disease state, which was very similar to the control population. These patients were grouped into a separate, Normal-appearing Subtype 0—290 patients from the training population and 317 patients from the validation population were found to belong to this subtype. These subjects had a milder COVID-19 presentation and were later found to have a much higher probability of survival.
Furthermore, for the following biomarkers, progression represented a decrease rather than an increase in the real-value biomarker readings: systolic blood pressure, lymphocyte count and platelet count. This meant that for these 3 biomarkers, the average biomarker readings were lower in the case population as compared to the control population. Advancing of SuStaIn stages for these 3 biomarkers, therefore, represented decreases in their absolute values. For clinical context, Table 2 presents an overview of the absolute values of each biomarker for each subtype. General demographic data for the training and validation populations, in aggregate, and also split by subtype, can be found in Table 3.
Cox proportional hazards (PH) frailty model
SuStaIn subtype and weighted stage was found to be a significant predictor of both in-hospital escalation of patient management and in-hospital mortality for patients admitted with COVID-19. Cox PH models were fitted separately on the training and test populations and then set against one another to confirm consistency of the results. The Kaplan–Meier curves and model coefficients were examined as a form of validation, as suggested previously18.
Predicting escalation of patient management using SuStaIn
Table 4 is a summary of the multivariable Cox proportional hazards models fitted to both the training and validation population, with a frailty term accounting for bias between submitting NHS Hospital trusts. The results were consistent between populations, suggesting that SuStaIn subtype and stage generalise as predictors of escalation between 2 randomly selected populations (albeit in patients whose data was collected as part of the same study). The interaction of subtype and weighted stage, moreover, produced the greatest overlap in coefficients.
Model concordance was good and was nearly equal in the Cox models fitted to both the training (C index of 0.69, 95% CI 0.66–0.72) and validation (C index of 0.69, 95% CI 0.65–0.72) populations.
Early SuStaIn stages and Subtype 0 were found to predict much less frequent in-hospital escalation of treatment as compared to the other 3 subtypes (Fig. 2). Among the three subtypes, patients assigned to the Immunological subtype (subtype 3) were least likely to experience escalation of treatment, while the General Haemodynamic (subtype 1) and Renal (subtype 2) subtypes were more likely to require treatment escalation while hospitalised (Fig. 2). The Kaplan–Meier curves for SuStaIn subtypes were generally consistent in the training and validation populations. The only subtype showing poorer calibration between populations was the haemodynamic subtype where the KM curves differed between populations.

Kaplan–Meier plots for 6-month in-hospital escalation of treatment for the training (left) and validation (right) population. wstage—weighted SuStaIn stage.
SuStaIn stage on its own had significant discrimination for the need for escalation of treatment (Fig. 3) and was a better predictor of escalation than patient age or sex.

SuStaIn stage provides better discrimination of time to escalation than age or sex: left—training population, right—validation population. wstage—weighted SuStaIn stage. sex 0—female, sex 1—male.
Mortality prediction using SuStaIn
SuStaIn subtype and stage were also good predictors of in-hospital mortality. As shown in Table 5, the hazard ratio confidence intervals show good overlap between training and validation populations. For determining mortality, subtype and weighted stage on their own were better predictors than the subtype–stage interaction (which did not achieve significance at the 0.05 threshold in the training population). Model concordance for both the training and validation populations was equal: C index of 0.74, 95% CI 0.71–0.77 on the training population and C index of 0.74, 95% CI 0.71–0.77 on the validation population, showing a slightly better concordance than the models for escalation of patient management.
SuStaIn subtype 0 was, as with the models of treatment escalation, characterised by significantly lower in-hospital mortality. The Renal subtype demonstrated the highest risk of dying in hospital, showing consistent results of ~ 50% survival at 6 months in both the training and validation populations. Subtypes 1 and 3 had very similar prognoses in the training population (at ~ 70% 6-month survival), but subtype 3 showed slightly worse calibration in the validation population and a slightly worse survival.
SuStaIn stage was also, independently, associated with higher risk of in-hospital mortality (Fig. 4).

Kaplan–Meier plots for 6-month in-hospital mortality for the training (left) and validation (right) population. Wstage—weighted SuStaIn stage.
As expected, age was a strong predictor of in-hospital mortality, with older patients being at higher risk. Sex had a smaller effect on mortality, but calibration for sex was poor (Fig. 5), probably as a consequence of the random sampling used when creating the training and validation populations, which led to a slightly different proportion of men and women (Table 3).

SuStaIn stage provides better discrimination for 6-month in-hospital mortality than age or sex (left—training population, right—validation population. wstage—weighted SuStaIn stage. sex 0—female, sex 1—male.
Discussion
We demonstrated that an unsupervised machine learning model, traditionally used for long-term disease progression modelling—SuStaIn, is readily adaptable to a pandemic of viral disease. The three SuStaIn subtypes we discovered likely represent disease involvement in distinct organ systems while SuStaIn stages provide the required gradation to disease severity in patients with COVID-19, which is valuable for risk stratification and outcome prediction. The zeroth subtype also represents a valuable signal, characterizing patients who have been admitted to hospital but were in fact at low risk of death or escalation of treatment. The robustness of our results further highlights our model’s significance as a readily available clinical tool in future epidemics of influenza or further COVID-19 variants.
Several studies have previously investigated factors associated with differing severity of COVID-19 infection on a number of large-scale datasets, such as the NCCID, ISARIC, PHOSP-COVID19. As a result, various clinical measures and biomarkers have been derived for use as prognostic factors for patients diagnosed with COVID-19. Patients admitted for COVID-19 have been reported to have a ~ 5 times higher hazard ratio for death, ~ 4 higher hazard ratio for mechanical ventilation and 2.41 higher hazard ratio for being admitted to an intensive care unit (ITU)20 compared to influenza. In addition to the pulmonary manifestations of pneumonia and ARDS21, COVID-19 infection is further associated with injuries to other organs including: acute kidney injury, deep venous thrombosis, stroke, sepsis and sudden cardiac death20. To predict short-to-medium term outcomes (in-hospital death or ITU admission), the National Early Warning Score (NEWS2)—an existing risk stratification tool was initially used. However, studies have shown its low discrimination power when applied to COVID-19 patients3,4. A combination of NEWS2 with 8 further routinely collected blood and clinical measures (supplemental oxygen flow rate, urea, age, oxygen saturation, C-reactive protein, estimated glomerular filtration rate, neutrophil count, neutrophil/lymphocyte ratio) improved its discrimination power for severe COVID-19 outcomes, but model calibration remained poor3, necessitating the development of COVID-19 specific patient stratification and prognostication tools. One such tool was the ROX index, evaluated by Prower et al.4 The ROX index represents the ratio between the peripheral oxygen saturation (SpO2), and the concentration of oxygen in inhaled oxygen (21% in room air), divided by the patient’s respiratory rate and was developed to indicate the need for intubating patients suffering from hypoxia. The authors found that the ROX index predicted adverse events 5 h earlier than NEWS2 and provided a clinically useful warning signal. The study emphasized the prognostic importance associated with a deterioration in respiratory parameters in escalation management of COVID-19. Investigation into other prognostic factors for COVID-19 in hospitalized patients included the development of the ISARIC 4C Mortality Score5. The score ranges from 0 to 21 points and included eight routinely collected clinical readings: age, sex, number of comorbidities, respiratory rate, peripheral oxygen saturation, level of consciousness, urea level, and C reactive protein5. The ISARIC 4C Mortality score was developed on a large UK population (~ 58,000 patients), as part of the ISARIC study22 and the authors reported excellent discrimination of the score for in-hospital mortality and, more importantly, very good model calibration suggesting applicability of the score when used in new centres and populations. The performance of the score in predicting mortality was also superior and the authors compared their score to 15 other risk stratification scores5. The ISARIC 4C consortium further developed a Deterioration model (based on multiple logistic regression) to predict not only mortality, but clinical deterioration, defined as admission to ITU or need for mechanical ventilation16. The model displayed convincing discrimination and calibration by using 11 clinical biomarkers: age, sex, respiratory rate, oxygen saturation, room air or oxygen, level of consciousness (Glasgow Coma Scale), nosocomial infection, radiographic infiltrates, urea concentration, lymphocyte count and C reactive protein16.
While it is difficult to make direct model comparison due to an only partial overlap in the used clinical measures/biomarkers, we demonstrated that by using a purely cross-sectional clinical and biological data at admission for COVID-19 (11 routinely collected biomarkers) and modelling disease severity progression with SuStaIn, clinically meaningful subtypes and stages of COVID-19 can be derived. This departs from the idea of a one-size-fits-all index and allows us to model involvement in different organ systems through SuStaIn subtypes. In addition to being predictive of in-hospital outcomes, our results can be valuable for organ-specific studies of damage from COVID-19. Previous studies, using tools such as the ISARIC 4C22 or ROX index4 tried to use a single scale to predict patients outcomes and prioritise treatment. However, this view, while it has shown clinical utility, may miss the inherent nuance in the progression patterns of patients infected with Sars-CoV-2. In terms of triaging, our model can be used to assign patients admitted to hospital for COVID-19 to one of the 4 subtypes by simply taking the readings of the 11 biomarkers we used. Subtype 0 patients, while ill enough to be hospitalised, can be classified as ‘low-risk’ for either experiencing escalation of treatment or dying in hospital. Subtype 3 patients, similarly, are at a lower risk, but patients assigned to Subtypes 1 or 2, and especially at their more advanced SuStaIn stages, should be prioritised for treatment and monitored more closely.
The disease subtypes discovered by SuStaIn modelling broadly affect different systems within the body and consequences from COVID-19 in these systems have been previously described. The Renal subtype (Subtype 2) is consistent with several studies which identified some COVID-19 patients experiencing significant kidney problems or even acute kidney injury (AKI)23,24. In the consensus report, patients suffering AKI were at significantly increased risk of all-cause death in hospital23. Our model further provides stages within this subtype which can differentiate patients by considering all 11 readings. While patients admitted with just elevated urea and creatinine, for example, might belong to subtype 2, if they are relatively normal in the other 9 biomarkers, they may be assigned to an early SuStaIn stage. A clinician might then monitor development of further changes in biomarkers to diagnose severity progression within the Renal subtype, which can inform risk determination and treatment.
The General Haemodynamic subtype (Subtype 1) can be hypothesised to relate to the common blood-clotting and hyper-inflammatory effects, described in a number of studies25,26. An interesting finding which our model uncovered is that late-stage disease patients who are at the greatest risk of escalation and dying within this subtype (advanced SuStaIn stage) experience a drop in their lymphocytes, platelets, and systolic blood pressure. An early decrease in platelet count was found to predict mortality in a study in Wuhan27, which might represent a possible depletion of systemic platelets due to significant clotting in the lung. Another study also reported a trend of rather sharply dropping platelets in non-survivors over multiple timepoints during hospitalisation28. Indeed, late SuStaIn stages in both Subtypes 1 and 2 were characterised by a drop in platelet count—those were the patients at greatest risk of dying in hospital. Although our work reconstructs disease severity progression from just a single timepoint reading, patients assigned to the later SuStaIn stages of Subtypes 1 and 2 might have already had a reduced platelet count by the time of hospital admission (effectively more advanced disease). By examining the absolute values of platelet counts for these patients, the same ranges of values (between 100 and 150 × 109/L) were discovered in late-stage patients in our study and in Yang et al.28 The decreases in total lymphocyte count, characteristic of the late SuStaIn stages in subtype 1 and 2 patients is also consistent with a meta-analysis of 20 studies, which determined this decrease to be closely associated with advanced severity of disease29.
The Immunological subtype (subtype 3), on the other hand showed lower levels of lymphocytes and platelets in the lowest-risk, early disease stages. These findings highlight the importance of signals contained within the multitude of biomarkers routinely collected during medical care. Our model aggregated several of these biomarkers and benefited from the inferred clustering of disease and stages of disease severity rather than employing a one-size-fits-all approach for triaging and prognostication. While decreased lymphocytes and platelets might imply a high risk of death and escalation of treatment when occurring after a series of haemodynamic (Subtype 1) or renal (Subtype 2) symptoms, they might indicate lower risk if occurring without these symptoms as seen in Subtype 3. SuStaIn’s ability to disentangle sequences of progressing severity and subtype simultaneously provides a far more detailed picture than a single score for all patients.
Our approach also identified an interesting dissociation of systolic and diastolic blood pressure in all subtypes. Namely, the abnormally increased diastolic blood pressure and abnormally decreased systolic blood pressure were always placed at opposite ends of disease severity stages. This suggests that instead of one of the blood pressure phases indicating severe disease, it might be the effectively decreased pressure range between systole and diastole (pulse pressure) which hallmarked advanced COVID-19 and increased a patient’s chance of both escalation of treatment and death. This signal merits further investigation as two studies indicated that a high variability of blood pressure in COVID-19 patients is associated with poorer outcomes30 and, interestingly, that patients who have recovered from COVID-19 tend to have impaired aortic distensibility31.
The main strength of the present work is that it was able to demonstrate clinically significant differences in both escalation of treatment and mortality for patients hospitalised for COVID-19, based on 11 routine and easy to collect clinical measurements. We discovered 3 distinct subtypes of COVID-19, which might imply different underlying pathophysiology and disease course in different patients. Although the data we used was collected as part of a single study (the NHSX NCCID), it came from hospitals and NHS trusts throughout the UK and included patients from diverse socio-economic and racial backgrounds. We further employed one of the most challenging techniques for the validation of our Cox Proportional Hazards models—replication on a separate sample of patients. Our model can be readily applied, tested, and tuned on a larger sample of patients (e.g., from different studies) using the 11 biomarkers we studied. More broadly, our model can be further augmented should a more complete set of biomarkers, or other feasible biomarkers become available.
There were several limitations to this study. Methodologically, SuStaIn was developed for modelling long-term, chronic disease. This was the first time it was adapted to severe infectious disease. One of its assumptions is that biomarkers can only become more abnormal with time. This means that it cannot inherently derive the transient drops and increases in biomarkers, which might happen while a patient is hospitalised. Nevertheless, the model is still appropriate for stratification of patients and triaging since it focuses on the severe period of disease when patients are hospitalised and deteriorating. All clinical measurements in the NCCID were performed in this period. Hence, in this sense the learned model represents a progression of severity of disease and does not currently capture recovery. Furthermore, while the learned disease severity progression is currently unidirectional, the model poses no constraints on staging patients to an earlier (less severe) stage in case data was available for a follow-up visit. Hence, at the individual patient level, recovery can be modelled. Future work on making SuStaIn even more useful for shorter term infectious disease outbreaks could also relax the assumption of unidirectionality in disease progression, to capture potential population-wide increases and declines in health.
The data which was available for this study also had several limitations. First, the NCCID dataset did not track the presence of coronavirus variants (Alpha, Beta, Gamma, Delta, Omicron)15,32 and this information would have been useful for disease modelling since the population likely included different virus variants. However, the common nature of the biomarkers used in our models opens the way for relatively easy validation when new data becomes available. A follow-up timepoint to validate disease progression, as well as availability of additional variables such as patient blood type would also have benefitted our study. Furthermore, there was a risk of false negative PCR tests across the population, which might have caused presence of COVID-19 positive patients in the control population. Finally, the specific causes of death, for example cardiac arrest or pulmonary embolism due to COVID-19, were not recorded in the study—the availability of these would have brought further insight into the pathophysiology of COVID-19.
In conclusion, we found that by using 11 common clinical readings at admission to hospital for COVID-19, we could learn distinct COVID-19 subtypes and disease severity stages, which are predictive of patient outcomes. Importantly, we’ve adapted SuStaIn for use in further infectious disease flares and the model can be readily tune or retrained to capture a finer-grained picture of disease, which can aid patient triaging and resource prioritisation.
Data availability
The current study analysed data which was previously collected as part of the NCCID15. As described in the dataset overview study14, all data from the NCCID is available to any user by submitting an application through a rigorous Data Access Request (DAR) and then following the described procedure outlined in https://nhsx.github.io/covid-chest-imaging-database.
Change history
26 October 2023
A Correction to this paper has been published: https://doi.org/10.1038/s41598-023-45343-5
References
WHO Coronavirus (COVID-19) Dashboard|WHO Coronavirus (COVID-19) Dashboard With Vaccination Data. https://covid19.who.int/ (Accessed 6 Dec 2021).
Taylor, L. Covid-19: China installs fences and alarms in Shanghai in effort to curb cases. BMJ 377, o1076. https://doi.org/10.1136/BMJ.O1076 (2022).
Carr, E. et al. Evaluation and improvement of the National Early Warning Score (NEWS2) for COVID-19: A multi-hospital study. BMC Med. 19(1), 1–16. https://doi.org/10.1186/S12916-020-01893-3/FIGURES/3 (2021).
Prower, E. et al. The ROX index has greater predictive validity than NEWS2 for deterioration in Covid-19. EClinicalMedicine. https://doi.org/10.1016/J.ECLINM.2021.100828/ATTACHMENT/2EFE582C-B1B0-42A2-92A1-B674722AF52E/MMC1.DOCX (2021).
Knight, S. R. et al. Risk stratification of patients admitted to hospital with covid-19 using the ISARIC WHO Clinical Characterisation Protocol: Development and validation of the 4C Mortality Score. BMJ 370, 22. https://doi.org/10.1136/BMJ.M3339 (2020).
Booth, A. L., Abels, E. & McCaffrey, P. Development of a prognostic model for mortality in COVID-19 infection using machine learning. Mod. Pathol. 34(3), 522–531. https://doi.org/10.1038/s41379-020-00700-x (2020).
Meng, L. et al. A deep learning prognosis model help alert for COVID-19 patients at high-risk of death: A multi-center study. IEEE J. Biomed. Health Informatics. 24(12), 3576–3584. https://doi.org/10.1109/JBHI.2020.3034296 (2020).
Abdulaal, A. et al. Prognostic modeling of COVID-19 using artificial intelligence in the United Kingdom: Model development and validation. J. Med. Internet Res. 22(8), e20259. https://doi.org/10.2196/20259 (2020).
Wynants, L. et al. Prediction models for diagnosis and prognosis of covid-19: Systematic review and critical appraisal. BMJ 369, 26. https://doi.org/10.1136/BMJ.M1328 (2020).
Young, A. L. et al. Uncovering the heterogeneity and temporal complexity of neurodegenerative diseases with Subtype and Stage Inference. Nat. Commun. 9(1), 4273. https://doi.org/10.1101/236604 (2018).
Young, A. L. et al. Disease progression modelling in chronic obstructive pulmonary disease (COPD). Am. J. Respir. Crit. Care Med. https://doi.org/10.1164/rccm.201908-1600OC (2019).
Eshaghi, A. et al. Progression of regional grey matter atrophy in multiple sclerosis. Brain 141(6), 1665–1677. https://doi.org/10.1093/BRAIN/AWY088 (2018).
Vogel, J. W. et al. Four distinct trajectories of tau deposition identified in Alzheimer’s disease. Nat. Med. 27(5), 871–881. https://doi.org/10.1038/s41591-021-01309-6 (2021).
Cushnan, D. et al. An overview of the National COVID-19 Chest Imaging Database: Data quality and cohort analysis. Gigascience. https://doi.org/10.1093/GIGASCIENCE/GIAB076 (2021).
Jacob, J. et al. Using imaging to combat a pandemic: Rationale for developing the UK National COVID-19 Chest Imaging Database. Eur. Respir. J. https://doi.org/10.1183/13993003.01809-2020 (2020).
Gupta, R. K. et al. Development and validation of the ISARIC 4C deterioration model for adults hospitalised with COVID-19: A prospective cohort study. Lancet Respir. Med. 9(4), 349–359. https://doi.org/10.1016/S2213-2600(20)30559-2/ATTACHMENT/16F595E2-DD70-4112-979C-1F089794A49F/MMC1.PDF (2021).
Balan, T. A. & Putter, H. A tutorial on frailty models. Stat. Methods Med. Res. 29(11), 3424–3454. https://doi.org/10.1177/0962280220921889 (2020).
Royston, P. & Altman, D. G. External validation of a Cox prognostic model: Principles and methods. BMC Med. Res. Methodol. 13(1), 1–15. https://doi.org/10.1186/1471-2288-13-33 (2013).
Evans, R. A. et al. Physical, cognitive, and mental health impacts of COVID-19 after hospitalisation (PHOSP-COVID): A UK multicentre, prospective cohort study. Lancet Respir. Med. 9(11), 1275–1287. https://doi.org/10.1016/S2213-2600(21)00383-0 (2021).
Xie, Y., Bowe, B., Maddukuri, G. & Al-Aly, Z. Comparative evaluation of clinical manifestations and risk of death in patients admitted to hospital with covid-19 and seasonal influenza: Cohort study. BMJ 371, 4677. https://doi.org/10.1136/BMJ.M4677 (2020).
Yang, X. et al. Clinical course and outcomes of critically ill patients with SARS-CoV-2 pneumonia in Wuhan, China: A single-centered, retrospective, observational study. Lancet Respir Med. 8(5), 475–481. https://doi.org/10.1016/S2213-2600(20)30079-5 (2020).
Millar, J. et al. Robust, reproducible clinical patterns in hospitalised patients with COVID-19 (2020) (in Press) https://doi.org/10.1101/2020.08.14.20168088.
Nadim, M. K. et al. COVID-19-associated acute kidney injury: Consensus report of the 25th Acute Disease Quality Initiative (ADQI) Workgroup. Nat. Rev. Nephrol. 16(12), 747–764. https://doi.org/10.1038/s41581-020-00356-5 (2020).
Bruchfeld, A. The COVID-19 pandemic: Consequences for nephrology. Nat. Rev. Nephrol. 17(2), 81–82. https://doi.org/10.1038/s41581-020-00381-4 (2020).
Gustine, J. N. & Jones, D. Immunopathology of hyperinflammation in COVID-19. Am. J. Pathol. 191(1), 4–17. https://doi.org/10.1016/J.AJPATH.2020.08.009 (2021).
McFadyen, J. D., Stevens, H. & Peter, K. The emerging threat of (micro)thrombosis in COVID-19 and its therapeutic implications. Circ. Res. 127(4), 571–587. https://doi.org/10.1161/CIRCRESAHA.120.317447 (2020).
Zhao, X. et al. Early decrease in blood platelet count is associated with poor prognosis in COVID-19 patients—indications for predictive, preventive, and personalized medical approach. EPMA J. 11(2), 139. https://doi.org/10.1007/S13167-020-00208-Z (2020).
Yang, X. et al. Thrombocytopenia and its association with mortality in patients with COVID-19. J. Thromb. Haemost. 18(6), 1469–1472. https://doi.org/10.1111/JTH.14848 (2020).
Huang, W. et al. Lymphocyte subset counts in COVID-19 patients: A meta-analysis. Cytom. Part A. 97(8), 772–776. https://doi.org/10.1002/CYTO.A.24172 (2020).
Ran, J. et al. Blood pressure control and adverse outcomes of COVID-19 infection in patients with concomitant hypertension in Wuhan, China. Hypertens. Res. 43(11), 1267–1276. https://doi.org/10.1038/s41440-020-00541-w (2020).
Küçük, U., Gazi, E., Duygu, A. & Akşit, E. Evaluation of aortic elasticity parameters in survivors of COVID-19 using echocardiography imaging. Med. Princ. Pract. https://doi.org/10.1159/000522626 (2022).
Cushnan, D. et al. Towards nationally curated data archives for clinical radiology image analysis at scale: Learnings from national data collection in response to a pandemic. Digit. Health 7, 205520762110486. https://doi.org/10.1177/20552076211048654 (2021).
Acknowledgements
This project was supported by the Microsoft Studies in Pandemic Preparedness program and by by Azure sponsorship credits granted by Microsoft’s AI for Good Research Lab. This research was funded in whole or in part by the Wellcome Trust [209553/Z/17/Z]. For the purpose of open access, the author has applied a CC-BY public copyright licence to any author accepted manuscript version arising from this submission. JJ, was also supported by the NIHR UCLH Biomedical Research Centre, UK. The authors would like to extend their sincere thanks to Satsuma Lab alumnus Dr. Eyjolfur Gudmundsson for the advice on statistical analyses. The NCCID Collaborative also thanks Rumi Kidwai, Rowena Reyes and Marcelle de Sousa.
Author information
Authors and Affiliations
Consortia
Contributions
All authors contributed to the planning of the study and selecting an appropriate data cohort. A.Y., W.L., E.G., S.A., P.T., Y.H. and J.J. advised on forming the main objectives and the statistical modelling and analysis. Q.Y. contributed to data preparation, cleaning and pre-processing. B.R. conducted the main portion of data preparation and analysis. B.R. and A.Y. worked on the necessary modifications and tuning of the machine learning model. B.R. wrote the main manuscript text and all authors contributed to the editing and proofing of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: The original version of this Article contained an error in the spelling of the author Andrew Scarsbrook which was incorrectly given as Prof Andrew Scarsbrook. He is a member of NCCID NHS Trusts teams.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rangelov, B., Young, A., Lilaonitkul, W. et al. Delineating COVID-19 subgroups using routine clinical data identifies distinct in-hospital outcomes. Sci Rep 13, 9986 (2023). https://doi.org/10.1038/s41598-023-32469-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-32469-9
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
