
Abstract
The types and numbers of components in end-of-life (EOL) products are often uncertain during remanufacturing, leading to low disassembly efficiencies for traditional remanufacturing disassembly lines. To address this problem, a parallel mixed-flow workstation layout was designed, and a novel parallel mixed remanufacturing disassembly line balancing optimization method for multi-variety products was proposed. A mixed-flow product disassembly task hierarchical assignment matrix was constructed to perform disassembly task allocations for similar components. Furthermore, a parallel mixed-flow remanufacturing disassembly line balancing (PMRDLB) optimization model was developed with the optimization objectives of minimizing the number of workstations, the disassembly line balancing rate, and the remanufacturing value indexes of the components. Furthermore, the multi-objective non-dominated genetic optimization method (NSGA-III) was improved, in which a chromosome construction method, based on the parallel mixed-flow disassembly task allocation matrix, was proposed to conduct mapping between the chromosomes and the PMRDLB model. In addition, non-dominated solution sorting was performed based on a Pareto hierarchy, which increased the searching rate of the algorithm during optimization. Finally, a case study verified the effectiveness and feasibility of the proposed method.
Similar content being viewed by others

Introduction
Remanufacturing is a profitable means of recovering end-of-life (EOL) products. Disassembly is the key step in obtaining the remanufacturing cores. The remanufacturing disassembly line balancing problem (RDLBP) focuses on obtaining an optimal disassembly line configuration scheme with reasonable task allocations, balanced workstation operations, a high disassembly efficiency, and a low cost, thereby reducing the remanufacturing costs1,2.
Three classical disassembly line layouts exist: straight line, U-type, and parallel-type layouts. Therefore, the classical disassembly line balancing problem (DLBP) includes single-type linear bilateral disassembly line balancing3, incomplete single-type linear disassembly line balancing4, U-type disassembly line balancing5,6, and single-type parallel disassembly line balancing7,8,9,10.For example, to increase the disassembly efficiency for large products, a two-sided layout was introduced, and a mathematical model for a stochastic two-sided partial DLBP with multiple objectives, multiple constraints, and uncertainty was constructed and resolved based on the multi-objective discrete flower pollination algorithm3. Li et al.4 developed an incomplete single-type linear disassembly line balancing model and proposed the variable neighborhood particle swarm optimization algorithm. A profit-oriented U-shaped partial DLBP was proposed and solved using a discrete cuckoo search algorithm5. To improve the disassembly line production efficiency and reduce the production cost, the parallel disassembly line balancing problem was studied7,8. Zhu et al.10 developed a mathematical model for a multi-objective locally parallel disassembly line balancing problem and solved the problem using the hybrid group neighborhood search algorithm.
Unfortunately, the types and numbers of components are often uncertain for EOL products during remanufacturing disassembly, which causes significant challenges for batch disassembly. The same types of products must be identified and rearranged for the existing disassembly lines, which is a complicated and low-efficiency process. Thus, much attention has been paid to parallel mixed-flow disassembly lines since they can significantly improve disassembly efficiency2,8.Therefore, Agrawal and Tiwari11 introduced the mixed product disassembly line concept and constructed a random mixed U-shaped disassembly line model. Model resolution was difficult using traditional methods. Later, Xia et al.12 selected multiple products as the mixed products based on their structural similarities, developed a mixed disassembly line model under a random working environment, and solved the problem by adopting the adaptive simulated annealing genetic algorithm. Fang et al.13 constructed a multi-robot hybrid disassembly line model and applied the evolutionary simulated annealing algorithm to obtain the optimal solution. Zeng et al.14 constructed a multi-objective bucket-chain disassembly line model and proposed a multi-objective discrete flower pollination algorithm to solve the problem.
All of these researchers solved the mixed-flow disassembly line balancing problem by assuming multi-variety products as the mixed products. However, it becomes more difficult to construct a mixed product model as the products’ types and complexities increase. To address this problem, a hierarchical parallel workstation layout is designed for the first time in this paper, furthermore, a parallel mixed-flow remanufacturing disassembly line balancing (PMRDLB) optimization model was constructed for multi-variety products. The main features of the proposed model are outlined as follows:
-
1.
It not only made reasonable use of space but also improved the efficiency of parallel mixed-flow disassembly for multi-variety products with uncertain characteristics in remanufacturing disassembly lines.
-
2.
It overcame the difficulties of model construction and low computational efficiency caused by the traditional mixed disassembly line in which multiple products were regarded as a single imaginary mixed product.
The DLBP can be solved primarily by mathematical programming, heuristic optimization, or meta-heuristic optimization. Mathematical programming produces high solution precision, but it is only suitable for solving small-scale disassembly line balancing tasks15,16,17,18. Heuristic methods can solve large-scale disassembly line problems, but their solutions will be limited to local optima19,20. Meta-heuristic methods are the mainstream algorithms used to solve the DLBP; they include the multi-objective genetic algorithm (GA), the multi-objective genetic annealing algorithm, and the artificial fish swarm algorithm, among others21,22,23,24. These methods are often combined with multi-criteria decision technology when solving the problem25. Among them, the GA is robust and suitable for parallel computing and has been widely used for solving the DLBP26,27. Therefore, in this paper, which focuses on the layout characteristics of a multi-variety parallel mixed-flow remanufacturing disassembly line, an improved multi-objective non-dominated sorting genetic optimization method (Improved NSGA-III) is proposed to solve the PMRDLB problem.
Methods
Problem description
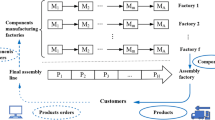
There are different types of EOL products for remanufacturing with uncertain quantities. To achieve a reasonable allocation of disassembly tasks for different types of products, this paper proposes a parallel mixed-flow disassembly line layout, as shown in Fig. 1.

Parallel mixed-flow remanufacturing disassembly line layout diagram.
If there were two kinds of EOL products to be disassembled and the number of components was uncertain, two disassembly lines were required. Parallel stations were arranged on each disassembly line, such as stations S1 and S3 in Fig. 1. The two adjacent disassembly lines had mixed-flow disassembly stations, such as stations S2 and Sm. All disassembly tasks were assigned to N workstations according to the determined beat time, CT.
The parallel mixed-flow remanufacturing disassembly line balancing problem focused on attaining a reasonable allocation of disassembly tasks in the layout shown in Fig. 1 to minimize the number of disassembly stations, prioritize the disassembly of components with high remanufacturing values and hazardous material properties, and rationally utilize the factory space of the enterprise.
To simplify the problem, three assumptions were made:
-
(1)
The disassembly time and remanufacturing value of each component were known, and all disassembly tasks were independent.
-
(2)
A disassembly task could not be interrupted.
-
(3)
The same disassembly task could not be assigned to multiple stations at the same time.
Judgment conditions for the mixed-flow disassembly of multi-variety products
Similarities and differences exist in the physical, material, and geometrical structures of various types of EOL products. Only products with certain similarities can be disassembled using a parallel mixed-flow disassembly line12. Therefore, it was necessary to determine the degree of product similarity.
It was assumed that the two disassembly task sets for the EOL products were
\({\mathbf{P}}_{1}=\left\{{a}_{1}^{1},{a}_{2}^{1},{a}_{3}^{1},\cdots ,{a}_{m1}^{1}\right\}\) and \({\mathbf{P}}_{2}=\left\{{a}_{1}^{2},{a}_{2}^{2},{a}_{3}^{2},\cdots ,{a}_{m2}^{2}\right\}\). The similar components set was
\(\mathbf{S}=\bigcap \left\{{a}_{1}^{1},{a}_{1}^{2},{a}_{2}^{1},{a}_{2}^{2},{a}_{3}^{1},{a}_{3}^{2}\cdots ,{a}_{m1}^{1},{a}_{m2}^{2}\right\}\), and the total components set was
\({\mathrm{P}}_{1}{\mathrm{P}}_{2}=\bigcup \left\{{a}_{1}^{1},{a}_{1}^{2},{a}_{2}^{1},{a}_{2}^{2},{a}_{3}^{1},{a}_{3}^{2}\cdots ,{a}_{m1}^{1},{a}_{m2}^{2}\right\}\). Thus, the similarity degree between the two products could be defined as follows:
where m1 and m2 are the numbers of components in the two EOL products to be disassembled. The larger the similarity degree was, the greater was the similarity between the components in geometrical, physical, and material aspects, among others. When \({\lambda }_{pro}=0\), there is no similarity between the components of the two EOL products. Empirically then, when \({\lambda }_{pro}\ge 0.7\), the mixed-flow disassembly can be performed12.
Mathematical model for the parallel mixed-flow remanufacturing disassembly line balancing (PMRDLB) problem
A mathematical model for the PMRDLB problem was developed based on the parallel mixed-flow remanufacturing disassembly line layout shown in Fig. 1. For clarification, the symbols utilized in the mathematical model are defined in Table 1, and the acronyms in this paper are listed in Table 2.
One clear difference between the PMRDLB problem and the traditional DLBP is the constraint conditions. All of the products in the parallel disassembly lines should not only meet the component disassembly priority relationship requirements but should also prioritize the disassembly of toxic and harmful components to reduce secondary pollution. This type of disassembly is more complex than single-product disassembly.
The disassembly priority relationship mapping matrix for the EOL product k is given by
In Eq. (2), if task i is performed before task j, then \({p}_{ij}\) = 1; otherwise, \({p}_{ij}\) = 0.
The component hazard mapping matrix for the EOL product k is defined as follows:
In Eq. (3), if disassembly task i is more hazardous than task j, then \({b}_{ij}\) = 1; otherwise, \({b}_{ij}\) = 0.
The disassembly priority relationship for the EOL product k was deduced from \({\mathbf{P}}_{mk}^{k}, {\mathbf{B}}_{mk}^{k}\), and the comprehensive matrix \({\mathbf{S}}_{mk}^{k}, \mathrm{as follows}\):
In Eq. (4), \({\mathbf{S}}_{ij}^{k}\) indicates that if disassembly task i has priority over task j, then \({\mathbf{S}}_{ij}=1\); otherwise, \({\mathbf{S}}_{ij}=0\).
According to Eq. (4), when the disassembly task j has the highest disassembly priority, it can be performed. Therefore, the feasibility conditions for disassembly task j were defined as follows:
The products’ disassembly tasks could be obtained from Eq. (5), and then, \({\mathbf{S}}_{mk}^{k}\) could be updated after disassembly. When \({\mathbf{S}}_{mk}^{k}={\left[0\right]}_{mk\times mk}\), all the disassembly tasks were finished, and the disassembly task hierarchical matrix, \({\mathbf{G}}^{k}\), for the EOL product k could be obtained.
The parallel mixed-flow disassembly task allocation matrix, \(\mathbf{G}=\left\{{\mathbf{G}}^{1},{\mathbf{G}}^{2},{\mathbf{G}}^{3},\cdots ,{\mathbf{G}}^{k}\right\}\), shown in Fig. 2, could then be obtained from Eqs. (2)–(5).

Parallel mixed-flow disassembly task allocation matrix.
Considering the uncertainty in the number of parts, during the construction of the disassembly sequence matrix for mixed-flow products, the largest number of parts among k products should be taken as the matrix column standard, and the elements of the matrix with insufficient parts among the other products should be filled with 0.
The mathematical model for the PMRDLB problem was formulated utilizing Eqs. (6)–(13).
Equations (6)–(9) represent the optimization objects. In these equations, f1 is the number of parallel mixed-flow disassembly line stations, f2 is the station equalization rate, and f3 is the remanufacturing value index, which ensures disassembly of the higher value remanufacturing components as early as possible to avoid secondary-operation damage to the remanufacturing cores. Equation (10) ensures that each disassembly line and disassembly task are assigned only to one station. Equation (11) guarantees that the maximum total disassembly time in each disassembly station does not exceed the beat time, CT. Equation (12) represents the workstation number range in the parallel disassembly line. Equation (13) ensures that the priority relationship constraint is met for all of the disassembly tasks during an EOL product’s disassembly.
PMRDLB problem solution based on the improved NSGA-III
Remanufacturing disassembly line balancing is a multi-objective optimization problem (MOP). The fast, non-dominated genetic algorithm NSGA-III with an elite strategy is characterized by fast operation and a high-precision solution. However, when it is used to solve the PMRDLB problem, its low sorting efficiency and unmatched hierarchical structure for disassembly tasks present significant challenges. Therefore, the NSGA-III algorithm was improved: the chromosome was coded based on the parallel mixed-flow disassembly task assignment matrix, and a non-dominant solution sorting method based on the Pareto rank was developed.
Chromosome construction method based on the parallel mixed-flow disassembly task assignment matrix
The multi-variety parallel mixed-flow remanufacturing disassembly line included many different kinds and quantities of EOL products. Therefore, a stratified two-segment chromosome coding method was proposed, as shown in Eq. (14).
In Eq. (14), the first segment, MixedS, represents the disassembly task sequences, and \(\mathrm{FV}\) denotes the multi-objective fitness function values. The number of workstations, f1, the equalization rate, f2, and the remanufacturing value index, f3, could be decoded according to Eqs. (7)–(9).
To improve the convergence speed and solution precision of the algorithm, a chromosome construction method, which was based on the parallel mixed-flow disassembly task allocation matrix, was proposed to ensure that all chromosomes were feasible solutions under the constraints of the parallel mixed-flow remanufacturing disassembly line. The method contained four primary steps:
Step 1: According to the disassembly process scheme for EOL products, k kinds of disassembly task priority matrices, \({\mathbf{P}}_{m}^{k}\), and hazard mapping matrices, \({\mathbf{B}}_{m}^{k}\), were constructed. The comprehensive priority matrix, \({\mathbf{S}}_{m}^{k}\), was deduced according to Eq. (4). The initial population matrix was defined as Q, and the layered matrix, \({\mathbf{G}}^{k}\), of disassemblable parts of EOL products was defined as a zero matrix.
Step 2: The disassemblable parts were put into the disassembly task hierarchy matrix, Gk, and the \({\mathbf{S}}_{m}^{k}\) matrix was simultaneously updated. It was determined whether \({\mathbf{S}}_{m}^{k}\) was a zero matrix. If so, i was set to 1 and the method moved to Step 3; otherwise, Step 2 was repeated.
Step 3: The ith line in Gk was removed, pop gene fragments were randomly generated and stored in Q, the ith line of Gk was set to 0, and i was incrementally increased.
Step 4: If \({\mathbf{G}}^{k}\) was determined to be a zero matrix, Q was output; if not, the method returned to Step 3.
A flowchart for the chromosome construction method is shown in Fig. 3.

Chromosome acquisition flowchart.
Chromosome evolutionary rules
The initial population could be determined according to the chromosome acquisition method presented in Fig. 3, and the offspring population would be generated by chromosome cross and mutation operations. Furthermore, the structural reference points were established based on the Pareto rank.
-
1.
Cross and mutation operations Two paternal chromosomes, 1 and 2, were randomly selected from the initial population, and two cross sites, 1 and 2, on the paternal chromosomes were randomly determined. The gene fragments between the two cross sites were called fragments 1 and 2, and the gene containing fragment 2 on paternal chromosome 1 was deleted. The gene containing fragment 1 on paternal chromosome 2 was also deleted, and fragment 2 was inserted into paternal chromosome 1 according to the cross positions 1 and 2 to form a new chromosome 1. Fragment 1 was inserted into paternal chromosome 2 according to the cross positions 1 and 2 to form a new chromosome 2. Two mutation sites, 1 and 2, were determined randomly, and genes were exchanged at these sites on the new chromosomes to form offspring chromosomes, 1 and 2. The schematic chromosome crossover and variation diagram is shown in Fig. 4a. The selected chromosome genes mutated to produce new chromosomes, as shown in Fig. 4b.
-
2.
Non-dominated ranking During the comparison process, if R1 and R2 fulfilled \({f}_{i}(R1)\le {f}_{i}(R2)(\forall i\in (\text{1,} \, \text{2,} \, {3}))\), then R1 dominated R2. If R1 was not dominated by other vectors, then R1 was the Pareto solution.The dominant relationship was determined by a Pareto comparison of the objective function values of R1 and R2. When R1 dominated R2, the Pareto level of R1 was 1 and was denoted as Pareto 1. Similarly, the chromosomes’ Pareto levels could also be obtained.The (s + 1)th generation was a combination of the parent population and the progeny population and was sorted according to the chromosomes’ Pareto ranks.

Schematic crossover and variation diagram.
Generation of the structured reference points
The NSGA-III ensures solution diversity by using a predefined set of reference points, which can be defined in a structured manner19. Reference points were uniformly distributed points in the PMRDLB model’s solution space, which was in an (M − 1) dimensional hyperplane, where M is the dimension of the target space, namely, the number of optimized targets. If each target was divided into H parts, there were four primary reference point generation steps:
Step 1: The number of reference points, H, was determined using the following equation:
where the pth coordinate axis was divided into several parts.
Step 2: The extremum point of the objective function was determined. The target value was very large, and the target value of the individual corresponded to the small points on other target values. The minimum value of the three objective functions in this study was \(\overline{Z }=\left({Z}_{1}^{\mathrm{min}},{Z}_{2}^{\mathrm{min}},{Z}_{3}^{\mathrm{min}}\right)\); so, the extreme point was solved according to Eq. (16).
Step 3: The distances between the target point and the reference points on extract chromosomes were calculated, and the selected chromosomes were added to the next generation population.
Step 4: Steps 2 and 3 were repeated until the population size was consistent.
PMRDLB model optimization process
Optimizing the PMRDLB model was performed to achieve a reasonable allocation of disassembly tasks at the stations. The optimization process included five primary steps: data preparation, initial population acquisition, non-dominated ranking based on the Pareto level, structured reference point generation, and optimal solution output.
Step 1: In the data preparation stage, the disassembly process plan for EOL products was analyzed to obtain the comprehensive priority relationship matrix and define and initialize the parameters, such as the population size (pop), the beat time (CT), and the number of iterations (Gen).
Step 2: The disassembly task allocation matrix was obtained, the objective function value was calculated, the chromosomes were generated, and the initial population was established.
Step 3: The offspring population was generated by cross and mutation operations. The parent and child populations were combined, and the chromosomes’ Pareto ranks were determined.
Step 4: Next-generation chromosomes were extracted based on the structured reference points.
Step 5: The optimal non-dominated solution set was obtained.
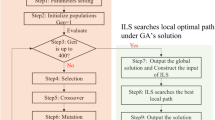
The solution process for the PMRDLB problem, which was based on the improved NSGA-III algorithm, is shown in Fig. 5.

Flowchart for the PMRDLB problem solution process.
Results and discussion
To verify the feasibility and effectiveness of the proposed method, a 34-component engine32 and a 37-component Passat B5 engine33 were selected for a case study. The remanufacturing values were generated by random numbers ranging from 0 to 100, and the component information is presented in Table 3.
Calculations of structural similarity between the two engines
The 34-component engine and the 37-component Passat B5 engine were two different kinds of engines with different uses. A similarity analysis was conducted on the two engines using expert judgment, and the results are presented in Table 4.
According to Eq. (1), the product similarity, \({\lambda }_{pro}=\frac{\bigcap \left\{{a}_{1}^{1},{a}_{1}^{2},{a}_{2}^{1},{a}_{2}^{2},{a}_{3}^{1},{a}_{3}^{2}\cdots ,{a}_{m1}^{1},{a}_{m2}^{2}\right\}}{\bigcup \left\{{a}_{1}^{1},{a}_{1}^{2},{a}_{2}^{1},{a}_{2}^{2},{a}_{3}^{1},{a}_{3}^{2}\cdots ,{a}_{m1}^{1},{a}_{m2}^{2}\right\}}=\frac{\mathbf{S}}{{\mathbf{P}}_{1}{\mathbf{P}}_{2}}=\frac{51}{{71}}\text{=} \, \text{0.71}\), was obtained, which satisfied \({\lambda }_{pro}\ge 0.7\). Therefore, the mixed-flow disassembly line operation could be conducted.
Problem-solving
The computer used in the case study was an Intel(R) Core I5-6200U CPU with 2.30 GHz and 12 GB RAM. The PMRDLB prototype system was developed using a professional edition of MATLAB R2016a in Windows 10.
After building the disassembly task allocation matrix according to Eqs. (2)–(6), the number of iterations and the population size were set to Gen = 200 and pop = 50, respectively. The disassembly task time, 730 s, was the total task time of the maximum disassembly workstation for the 34-component engine. Therefore, the beat time was CT ≥ 730 s, and five optimal disassembly line configuration schemes were obtained by 20 experiments, as shown in Table 5.
Taking plan 1 as an example, the disassembly task assignment results are shown in Fig. 6.

Parallel mixed-flow disassembly line layout for plan 1.
To verify the effectiveness of the model and method proposed in this paper, the objective function values f1, f2, and f3 of the mixed-flow disassembly line for task 1 under different layout forms were compared, and the results are shown in Table 6.
Table 6 shows that, compared with other layout forms, the parallel mixed-flow remanufacturing disassembly line improved the disassembly efficiency and had obvious advantages for solving the multi-variety EOL product disassembly problem. The disassembly line model for parallel mixed-flow remanufacturing proposed in this paper overcame the above shortcomings and solved the problem when there were many kinds of recovered waste products and the number of parts was uncertain. Experimental results showed that the method was feasible and effective.
Conclusions
There are many types of EOL products in remanufacturing disassembly lines, and the number of components is often uncertain. To solve this problem, a PMRDLB optimization model was proposed in this paper, and the NSGA-III algorithm was improved. Two engine cases were studied to verify the validity of the proposed model and method.
The method had three primary highlights:
-
(1)
In view of the uncertain characteristics of multi-variety products in remanufacturing disassembly lines, a parallel mixed-flow remanufacturing disassembly line layout was designed. It not only made reasonable use of space but also improved the efficiency of parallel mixed-flow disassembly for multi-variety products.
-
(2)
A construction method for the mixed-flow product disassembly task allocation matrix was proposed, which overcame the difficulties of model construction and low computational efficiency caused by the traditional mixed disassembly line in which multiple products were regarded as a single imaginary mixed product.
-
(3)
The NSGA-III algorithm was improved to solve the PMRDLB problem. A stratified two-segment chromosome coding method was adopted to ensure that all solutions were feasible. This method also improved the optimization efficiency.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Paprocka, I. & Skołud, B. A predictive approach for disassembly line balancing problems. Sensors. 22(10), 3920. https://doi.org/10.3390/s22103920 (2022).
Deniz, N. & Ozcelik, F. An extended review on disassembly line balancing with bibliometric and social network and future study realization analysis. J. Clean. Prod. 225, 697–715 (2019).
Wang, K., Li, X. & Gao, L. A multi-objective discrete flower pollination algorithm for stochastic two-sided partial disassembly line balancing problem. Comput. Ind. Eng. 130, 634–649 (2019).
Li, L. K. et al. Modeling and optimizing for multi-objective partial disassembly line balancing problem. J. Mech. Eng. 54(3), 1090–1097 (2018).
Li, Z. & Janardhanan, M. N. Modelling and solving profit-oriented U-shaped partial disassembly line balancing problem. Expert Syst. Appl. 183, 5431. https://doi.org/10.1016/j.eswa.2021.115431 (2021).
Li, Z., Kucukkoc, I. & Zhang, Z. Iterated local search method and mathematical model for sequence-dependent U-shaped disassembly line balancing problem. Comput. Ind. Eng. 137, 106056 (2019).
Aydemir, K. A. & Turkbey, O. Multi-objective optimization of stochastic disassembly line balancing with station paralleling. Comput. Ind. Eng. 65(3), 413–425 (2013).
Hezre, S. & Kara, Y. A network-based shortest route model for parallel disassembly line balancing problem. Int. J. Prod. Res. 53(6), 1849–1865 (2015).
Zhang, Z. Q. et al. Review of modeling theory and solution method for disassembly line balancing problems for remanufacturing. China Mech. Eng. 29(21), 2636–2645 (2018).
Zhu, L., Zhang, Z. & Guan, C. Multi-objective partial parallel disassembly line balancing problem using hybrid group neighborhood search algorithm. J. Manuf. Syst. 56, 252–269 (2020).
Agrawal, S. & Tiwari, M. K. A collaborative ant colony algorithm to stochastic mixed-model U-shaped disassembly line balancing and sequencing problem. Int. J. Prod. Res. 46(6), 1405–1429 (2008).
Xia, X. et al. A balancing method of mixed-model disassembly line in random working environment. Sustainability. 11(8), 2304 (2019).
Fang, Y. et al. Multi-objective evolutionary simulated annealing optimization for mixed-model multi-robotic disassembly line balancing with interval processing time. Int. J. Prod. Res. 1, 1–17 (2019).
Zeng, Y. et al. Pareto flower pollination algorithm for multi-objective bucket brigade mixed-model disassembly line balancing problem. Comput. Integr. Manuf. Syst. 26(03), 760–774 (2020).
Xiao, Q. X., Guo, X. P. & Gu, X. J. The stochastic mixed-model U-shaped disassembly line balancing and sequencing optimization problem with multiple constraints. Ind. Eng. Manag. 24(05), 87–96 (2019).
Paksoy, T. et al. Mixed model disassembly line balancing problem with fuzzy goals. Int. J. Prod. Res. 51(20), 6082–6096 (2013).
Kenger, Z. D., Koc, C. & Ozceylan, E. Integrated disassembly line balancing and routing problem. Int. J. Prod. Res. 58(23), 7250–7268 (2020).
Altekin, F. T., Kandiller, L. & Ozdemirel, N. E. Profit-oriented disassembly-line balancing. Int. J. Prod. Res. 46(10), 2675–2693 (2008).
Fang, Y. et al. Evolutionary many-objective optimization for mixed-model disassembly line balancing with multi-robotic workstations. Eur. J. Oper. Res. 276(1), 160–174 (2019).
Mete, S. et al. A solution approach based on beam search algorithm for disassembly line balancing problem. J. Manuf. Syst. 41, 188–200 (2016).
Mete, S. et al. Supply-driven re-balancing of disassembly lines: A novel mathematical model approach. J. Clean. Prod. 213, 1157–1164 (2019).
Jin, Y. D., Feng, J. B., Zhang, W. J. UAV task allocation for hierarchical multi-objective optimization in complex conditions using modified NSGA-III with segmented encoding. J. Shanghai Jiao tong Univ. (Science) (2021).
Ren, Y. et al. Disassembly line balancing problem using interdependent weights-based multi-criteria decision making and 2-Optimal algorithm. J. Clean. Prod. 174, 1475–1486 (2018).
Wang, K., Li, X., Gao, L., Li, P., et al. A genetic simulated annealing algorithm for parallel partial disassembly line balancing problem. Appl. Soft Comput. J. 107 (2021).
Wang, K., Li, X. & Gao, L. Modeling and optimization of multi-objective partial disassembly line balancing problem considering hazard and profit. J. Clean. Prod. 211, 115–133 (2019).
Zhu, L., Zhang, Z. & Wang, Y. A Pareto firefly algorithm for multi-objective disassembly line balancing problems with hazard evaluation. Int. J. Prod. Res. 56(24), 7354–7374 (2018).
Pistolesi, F. et al. EMOGA: A hybrid genetic algorithm with extremal optimization core for multi-objective disassembly line balancing. IEEE Trans. Industr. Inf. 14(3), 1089–1098 (2018).
Zhang, Z. et al. A Pareto improved artificial fish swarm algorithm for solving a multi-objective fuzzy disassembly line balancing problem. Expert Syst. Appl. 86, 165–176 (2017).
Wang, K. et al. Partial disassembly line balancing for energy consumption and profit under uncertainty. Robot. Comput. Integr. Manuf. 59, 235–251 (2019).
Mcgovern, S. M. & Gupta, S. M. A balancing method and genetic algorithm for disassembly line balancing. Eur. J. Oper. Res. 179, 692–708 (2007).
Zhang, Y., Hu, X. & Wu, C. A modified multi-objective genetic algorithm for two-sided assembly line re-balancing problem of a shovel loader. Int. J. Prod. Res. 56, 3043–3063 (2017).
Su, Y. J. Variable neighborhood search algorithm for disassembly line balancing problem. Southwest Jiao Tong University (in Chinese) (Chengdu,2015)
Tian, Y. T. Parallel disassembly sequence planning method for complex product remanufacturing. Inner Mongol University of Technology. (Hohhot ,2019) (in Chinese)
Xia, X. H. et al. Remanufacturing disassembly service line and balancing optimization method. Comput. Integr. Manuf. Syst. 24(10), 2492–2501 (2018) ((in Chinese)).
Acknowledgements
We thank LetPub (www.letpub.com) for its linguistic assistance during the preparation of this manuscript. This article is supported by the National Natural Science Foundation of China (No. 51965049) and Key Technology Research Plan of Inner Mongolia Autonomous Region (2021GG0261).
Funding
This article was funded by National Natural Science Foundation of China (51965049).
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yu, G., Zhang, X. & Meng, W. Modeling and solving the parallel mixed-flow remanufacturing disassembly line balancing problem for multi-variety products. Sci Rep 12, 15383 (2022). https://doi.org/10.1038/s41598-022-19783-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-19783-4
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
