
Abstract
Diffractive optical networks unify wave optics and deep learning to all-optically compute a given machine learning or computational imaging task as the light propagates from the input to the output plane. Here, we report the design of diffractive optical networks for the classification and reconstruction of spatially overlapping, phase-encoded objects. When two different phase-only objects spatially overlap, the individual object functions are perturbed since their phase patterns are summed up. The retrieval of the underlying phase images from solely the overlapping phase distribution presents a challenging problem, the solution of which is generally not unique. We show that through a task-specific training process, passive diffractive optical networks composed of successive transmissive layers can all-optically and simultaneously classify two different randomly-selected, spatially overlapping phase images at the input. After trained with ~ 550 million unique combinations of phase-encoded handwritten digits from the MNIST dataset, our blind testing results reveal that the diffractive optical network achieves an accuracy of > 85.8% for all-optical classification of two overlapping phase images of new handwritten digits. In addition to all-optical classification of overlapping phase objects, we also demonstrate the reconstruction of these phase images based on a shallow electronic neural network that uses the highly compressed output of the diffractive optical network as its input (with e.g., ~ 20–65 times less number of pixels) to rapidly reconstruct both of the phase images, despite their spatial overlap and related phase ambiguity. The presented phase image classification and reconstruction framework might find applications in e.g., computational imaging, microscopy and quantitative phase imaging fields.
Similar content being viewed by others


Introduction
Diffractive Deep Neural Networks (D2NN)1 have emerged as an optical machine learning framework that parameterizes a given inference or computational task as a function of the physical traits of a series of engineered surfaces/layers that are connected by diffraction of light. Based on a given task and the associated loss function, deep learning-based optimization is used to configure the transmission or reflection coefficients of the individual pixels/neurons of the diffractive layers so that the desired function is approximated in the optical domain through the light propagation between the input and output planes of the diffractive optical network1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24. Upon the convergence of this deep learning-based training phase using a computer, the resulting diffractive surfaces are fabricated using, e.g. 3D printing or lithography, to physically form the diffractive optical network which computes the desired task or inference, without the need for a power source, except for the illumination light.
A diffractive optical network can be considered as a coherent optical processor, where the input information can be encoded in the phase and/or amplitude channels of the sample/object field-of-view. Some of the previous demonstrations of diffractive optical networks utilized 3D printed diffracted layers operating at terahertz (THz) wavelengths to reveal that they can generalize to unseen data achieving > 98% and > 90% blind testing accuracies for amplitude-encoded handwritten digits (MNIST) and phase-encoded fashion products (Fashion-MNIST), respectively, using passive diffractive layers that collectively compute the all-optical inference at the output plane of the diffractive optical network1,5,8. In a recent work6, diffractive optical networks have been utilized to all-optically infer the data classes of input objects that are illuminated by a broadband light source using only a single-pixel detector at the output plane. This work demonstrated that a broadband diffractive optical network can be trained to extract and encode the spatial features of input objects into the power spectrum of the diffracted light to all-optically reveal the object classes based on the spectrum of the incident light on a single-pixel detector. Deep learning-based training of diffractive optical networks have also been utilized in solving challenging inverse optical design problems e.g., ultra-short pulse shaping and spatially-controlled wavelength demultiplexing3,4.
In general, coherent optical processing and the statistical inference capabilities of diffractive optical networks can be exploited to solve various inverse imaging and object classification problems through low-latency, low-power systems composed of passive diffractive layers. One such inverse problem arises when different phase objects reside on top of each other within the sample field-of-view of a coherent imaging platform: the spatial overlap between phase-only thin samples inevitably causes loss of spatial information due to the summation of the overlapping phase distributions describing the individual objects, hence, creating spatial phase ambiguity at the input field-of-view.
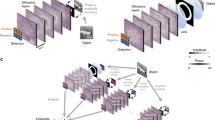
Here, we present phase image classification diffractive optical networks that can solve this phase ambiguity problem and simultaneously classify two spatially overlapping images through the same trained diffractive optical network (see Fig. 1). In order to address this challenging optical inference problem, we devised four alternative diffractive optical network designs (Fig. 1b–e) to all-optically infer the data classes of spatially overlapping phase objects. We numerically demonstrated the efficacy of these diffractive optical network designs in revealing the individual classes of overlapping phase objects using training and testing datasets that are generated based on phase-encoded MNIST digits25. Our diffractive optical networks were trained using ~ 550 million different input phase images containing spatially overlapping MNIST digits (from the same class as well as different classes); blind testing of one of the resulting diffractive optical networks using 10,000 test images of overlapping phase objects revealed a classification accuracy of > 85.8%, optically matching the correct labels of both phase objects that were spatially overlapping within the input field-of-view.

Schematic of a diffractive optical network that can all-optically classify overlapping phase objects despite phase ambiguity at the input; this diffractive optical network also compresses the input spatial information at its output plane for simultaneous reconstruction of the individual phase images of the overlapping input objects using a back-end electronic neural network. (a) Optical layout of the presented 5-layer diffractive optical networks that can all-optically classify overlapping phase objects, e.g., phase-encoded handwritten digits, despite the phase ambiguity at the input plane due to spatial overlap. The diffractive optical network processes the incoming object waves created by the spatially overlapping, phase-encoded digits e.g., ‘6’ and ‘7’, to correctly reveal the classes of both input objects (green). A separately trained shallow electronic neural network (with 2 hidden layers) rapidly reconstructs the individual phase images of both input objects using the optical signals detected at the output plane of the diffractive optical network. (b–d) Different detector configurations and class encoding schemes at the output plane of a diffractive optical network, devised to represent all the possible data class combinations at the input field-of-view created by overlapping phase objects.
In addition to all-optical classification of overlapping phase images using a diffractive optical network, we also combined our diffractive optical network models with separately trained, electronic image reconstruction networks to recover the individual phase images of the spatially overlapping input objects solely based on the optical class signals collected at the output of the corresponding diffractive optical network. We quantified the success of these digitally reconstructed phase images using the structural similarity index measure (SSIM) and the peak-signal-to-noise-ratio (PSNR) to reveal that a shallow electronic neural network with 2 hidden layers can simultaneously reconstruct both of the phase objects that are spatially overlapping at the input plane despite the fact that the number of detectors/pixels at the output plane of the diffractive optical network is e.g., ~ 20–65 times smaller compared to an ideal diffraction-limited imaging system. This means the diffractive optical network encoded the spatial features of the overlapping phase objects into a much smaller number of pixels at its output plane, which was successfully decoded by the shallow electronic network to simultaneously perform two tasks: (1) image reconstruction of overlapping spatial features at the input field-of-view, and (2) image decompression.
We believe that the presented diffractive optical network training and design techniques for computational imaging of phase objects will enable memory-efficient, low-power and high frame-rate alternatives to existing phase imaging platforms that often rely on high-pixel count sensor arrays, and therefore might find applications in e.g. microscopy and quantitative phase imaging fields.
Results
Spatial overlap between phase objects within the input field-of-view of an optical imaging system obscures the information of samples due to the superposition of the individual phase channels, leading to loss of structural information. For thin phase-only objects (such as e.g., cultured cells or thin tissue sections), when two samples \(e^{{j\theta_{1} \left( {x,y} \right)}}\) and \(e^{{j\theta_{2} \left( {x,y} \right)}}\) overlap with each other in space, the resulting object function can be expressed as \(e^{{j(\theta_{1} \left( {x,y} \right) + \theta_{2} \left( {x,y} \right))}}\), and therefore a coherent optical imaging system does not have direct access to \(\theta_{1} \left( {x,y} \right)\) or \(\theta_{2} \left( {x,y} \right)\), except their summation (see Fig. 1a). In the context of diffractive optical networks and all-optical image classification tasks, another challenging aspect of dealing with spatially overlapping phase objects is that the effective number of data classes represented by different input images significantly increases compared to a single-object classification task. Specifically, for a target dataset with \(M\) data classes represented through the phase channel of the input, the total number of data classes at the input (with two overlapping phase objects) becomes \(C\left( {\begin{array}{*{20}c} M \\ 2 \\ \end{array} } \right) + M = \frac{{M\left( {M - 1} \right)}}{2} + M\), where \(C\) refers to the combination operation . This means that if the diffractive optical network design assigns a single output detector to represent each one of these combinations, one would need \(\frac{{M\left( {M - 1} \right)}}{2} + M\) individual detectors. With the use of a differential detection scheme5 that replaces each class detector with a pair of detectors (virtually representing the positive and negative signals), then the number of detectors at the output plane further increases to \(2 \times \left( {\frac{{M\left( {M - 1} \right)}}{2} + M} \right)\).
To mitigate this challenge, in this work we introduced different class encoding schemes that better handle the all-optical classification of these large number of possible class combinations at the input. The output detector layout, D-1, shown in Fig. 1b illustrates one alternative design strategy where the problem of classification of overlapping phase objects is solved by using only \(2M\) individual detectors with a significant reduction in the number of output detectors when compared to \(\frac{{M\left( {M - 1} \right)}}{2} + M\). The use of \(2M\) single-pixel detectors at the output plane (see Fig. 1b), can handle all the combinations and classify the overlapping input phase objects even if they belong to the same data class or not. To achieve this, we have two different sets of detectors, \(\left\{ {D_{m}^{i} , m = 0,1,2, \ldots ,M - 1} \right\}\) and \(\left\{ {D_{m}^{ii} , m = 0,1,2, \ldots ,M - 1} \right\}\), which represent the classes of the individual overlapping phase images. The final class assignments in this scheme are given based on the largest two optical signals among all the \(2M\) detectors, where the assigned indices (m) of the corresponding two winner detectors indicate the all-optical classification results for the overlapping phase images. This is a simple class decision rule with a look up table of detector-class assignments (as shown Fig. 1b), where the strongest two detector signals indicate the inferred classes based on their \(m\). Stated mathematically, the all-optical estimation of the classes, \(\hat{\user2{c}} = \left[ {\widehat{{c_{1} }},\widehat{{c_{2} }}} \right]\), of the overlapping phase images is given by,
where \(I\) denotes the optical signals detected by \(2M\) individual detectors, i.e., \([D_{m}^{i}\), \(D_{m}^{ii}\)]. With the \(mod\left( * \right)\) operation in Eq. (1), it can be observed that when the ground truth object classes, \(c_{1}\) and \(c_{2}\), are identical, a correct optical inference would result in \(\widehat{{c_{1} }} = \widehat{{c_{2} }}\). On the other hand, when \(c_{1} \ne c_{2}\), there are four different detector combinations for the two largest optical signals that would result in the same (\(\widehat{{c_{1} }},\widehat{{c_{2} }}\)) pair according to our class decision rule. For example, in the case of the input transmittance shown in Fig. 1a, which is comprised of handwritten digits ‘6’ and ‘7’, the output object classes based on our decision rule would be the same if the two largest optical signals collected by the detectors correspond to: (1) \(D_{6}^{i}\) and \(D_{7}^{ii}\), (2) \(D_{7}^{i}\) and \(D_{6}^{ii}\), (3) \(D_{6}^{i}\) and \(D_{7}^{i}\) or (4) \(D_{6}^{ii}\) and \(D_{7}^{ii}\); all of these four combinations of winner detectors at the output plane would reveal the correct classes for the input phase objects in this example (digits ‘6’ and ‘7’).
Therefore, the training the diffractive optical networks according to this class decision rule requires subtle but vital changes in the ground truth labels representing the inputs and the loss function driving the evolution of the diffractive layers compared to a single-object classification system. If we denote the one-hot vector labels representing the classes of the input objects in a single-object classification system as, \(g^{1}\) and \(g^{2}\), with an entry of 1 at their \(c_{1}^{{{\text{th}}}}\) and \(c_{2}^{{{\text{th}}}}\) entries, respectively, for the case of spatially overlapping two phase objects at the input field-of-view we can define new ground truth label vectors of length \(2M\) using \(g^{1}\) and \(g^{2}\). For the simplest case of \(c_{1} = c_{2}\) (i.e., \(g^{1} = g^{2}\)), the \(2M\)-vector \(g^{e}\) is constructed as \({ {g^{e}}} = 0.5 \times \left[ { {g^{1}} ,g^{2} } \right]\). The constant multiplicative factor of 0.5 ensures that the resulting vector \(g^{e}\) defines a discrete probability density function satisfying \(\mathop \sum \limits_{1}^{2M} g^{e}_{m} = 1\). It is important to note that since \(c_{1} = c_{2}\), we have \(\left[ {g^{1} ,g^{2} } \right] = \left[ {g^{1} ,g^{2} } \right]\). On the other hand, when the overlapping input phase objects are from different data classes i.e., \(c_{1} \ne c_{2}\), we define four different label vectors \(\left\{ {g^{a} , g^{b} , g^{c} , g^{d} } \right\}\) representing all the four combinations. Among this set of label vectors, we set \({ g^{a}} = 0.5 \times \left[ {g^{1} ,g^{2} } \right]\) and \({ g^{b}} = 0.5 \times \left[ {g^{2} ,g^{1} } \right]\). The label vectors \(g^{c}\) and \(g^{d}\) depict the cases, where the output detectors corresponding to the input object classes lie within \(D_{m}^{i}\) and \(D_{m}^{ii}\), respectively. In other words, the \(c_{1}^{{{\text{th}}}}\) and \(c_{2}^{{{\text{th}}}}\) entries of \(g^{c}\) are equal to 0.5, and similarly the \(\left( {M + c_{1} } \right)^{{{\text{th}}}}\) and \(\left( {M + c_{2} } \right)^{{{\text{th}}}}\) entries of \(g^{d}\) are equal to 0.5, while all the rest of the entries are equal to zero.
Based on these definitions, the training loss function (\({\mathcal{L}}\)) of the associated forward model was selected to reflect all the possible input combinations at the sample field-of-view (input), therefore, it was defined as,
where \({\mathcal{L}}_{{\text{c}}}^{{\text{a}}} ,{\mathcal{L}}_{{\text{c}}}^{{\text{b}}} ,{\mathcal{L}}_{{\text{c}}}^{{\text{c}}}\), \({\mathcal{L}}_{{\text{c}}}^{{\text{d}}}\), and \({\mathcal{L}}_{{\text{c}}}^{{\text{e}}}\) denote the penalty terms computed with respect to the ground truth label vectors \(g^{a}\), \(g^{b}\), \(g^{c}\), \(g^{d}\), and \(g^{e}\), respectively, and \({\text{sgn}}\left( . \right)\) is the signum function. The classification errors, \({\mathcal{L}}_{{\text{c}}}^{{\text{x}}}\), are computed using the cross-entropy loss26
where x refers to one of a, b, c, d, or e, \(\overline{{I_{m} }}\) denotes the normalized intensity collected by a given detector at the output plane (see the Methods section for further details). The term \(g_{m}^{x}\) in Eq. (3) denotes the mth entry of the ground truth data class vector, \(g^{x}\).
Based on this diffractive optical network design scheme and the output detector layout D-1, we trained a 5-layer diffractive optical network (Fig. 1a,b) using the loss function depicted in Eq. (2) over ~ 550 million input training images containing various combinations of spatially overlapping, phase-encoded MNIST handwritten digits. Following the training phase, the resulting diffractive layers of this network, which we term as D2NN-D1, are illustrated in Fig. 2a. To quantify the generalization performance of D2NN-D1 for the classification of overlapping phase objects that were never seen by the network before, we created a test dataset, T2, with 10 K phase images, where each image contains two spatially-overlapping phase-encoded test digits randomly selected from the standard MNIST test set, T1. In this blind testing phase, D2NN-D1 achieved 82.70% accuracy on T2, meaning that in 8,270 cases out of 10,000 test inputs, the class estimates \(\left[ {\widehat{{c_{1} }},\widehat{{c_{2} }}} \right]\) at the diffractive optical network’s output plane were correct for both of the spatially overlapping handwritten digits. For the remaining 1730 test images, the classification decision of the diffractive optical network is incorrect for at least one of the phase objects within the field-of-view. Figure 2b–e depict some of the correctly classified phase image examples from the test dataset T2 with phase encoded handwritten digits, along with the resulting class scores at the output detectors of the diffractive optical network.

All-optical classification of spatially-overlapping phase objects using the diffractive optical network D2NN-D1, based on the detector layout scheme (D-1) shown in Fig. 1b. (a) The thickness profiles of the diffractive layers constituting the diffractive optical network D2NN-D1 at the end of its training. This network achieves 82.70% blind inference accuracy on the test image set T2. (b–e) Top: Individual phase objects (examples) and the resulting input phase distribution created by their spatial overlap at the input field-of-view. Bottom: The normalized optical signals, \(I\), synthesized by D2NN-D1 at its output detectors. The output detectors with the largest 2 signals correctly reveal the classes of the overlapping input phase objects (indicated with the green rectangular frames).
This blind inference accuracy of the diffractive optical network shown in Fig. 2a, i.e., D2NN-D1, can be further improved by combining the above outlined training strategy with a differential detection scheme, where each output detector in D1 (Fig. 1b) is replaced with a differential pair of detectors (i.e., a total of 2 × 2 M detectors are located at the output plane, see Fig. 1c). The differential signal between a pair of detectors shown in Fig. 1c encodes a total of 2xM differential optical signals and similar to the previous approach of D1, the final class assignments in this scheme are given based on the two largest signals among all the differential optical signals. With the incorporation of this differential detection scheme, the vector \(I\) in Eq. (1) is replaced with the differential signal5, \(\Delta I = I_{ + } - I_{ - } ,\) where \(I_{ + }\) and \(I_{ - }\) denote the optical signals collected by the \(2M\) detector pairs, virtually representing the positive and negative parts, respectively.
Using this differential diffractive optical network design, which we termed as D2NN-D1d (see Fig. 1c), we achieved a blind testing accuracy of 85.82% on the test dataset T2. The diffractive layers comprising the D2NN-D1d network are shown in Fig. 3a, which were trained using ~ \(550{ }\;{\text{million}}\) input phase images of spatially overlapping MNIST handwritten digits, similar to D2NN-D1. Compared to the classification accuracy attained by D2NN-D1, the inference accuracy of its differential counterpart, D2NN-D1d, is improved by > 3.1% at the expense of using \(2M\) additional detectors at the output plane of the optical network. Figure 3b–e illustrate some examples of the correctly classified phase images from the test dataset T2 with phase encoded handwritten digits, along with the resulting differential class scores at the output detectors of the diffractive optical network.

All-optical classification of spatially-overlapping phase objects using the diffractive optical network D2NN-D1d, based on the detector layout scheme D-1d shown in Fig. 1c. (a) The thickness profiles of the diffractive layers constituting the diffractive optical network D2NN-D1d at the end of its training. This network achieves 85.82% blind inference accuracy on the test image set T2. (b–e), Left: Individual phase objects (examples) and the resulting input phase distribution created by their spatial overlap at the input field-of-view. Middle: The normalized optical signals, \(I_{ + }\) and \(I_{ - }\), synthesized by D2NN-D1d at its output detectors. Right: The resulting differential signal, \({\Delta }I = I_{ + } - I_{ - }\). The largest two differential optical signals correctly reveal the classes of the overlapping input phase objects (indicated with the green rectangular frames).
The blind inference accuracies achieved by D2NN-D1 and D2NN-D1d (82.70% and 85.82%, respectively) on the test dataset T2, demonstrate the success of the underlying detector layout designs and the associated training strategy for solving the phase ambiguity problem to all-optically classify overlapping phase images using diffractive optical networks. When these two diffractive optical networks (D2NN-D1 and D2NN-D1d) are blindly tested over T1 that provides input images containing a single phase-encoded handwritten digit (without the second overlapping phase object), they attain better classification accuracies of 90.59% and 93.30%, respectively (see the Methods section). As a reference point, a 5-layer diffractive optical network design with an identical layout to the one shown in Fig. 1a, can achieve a blind classification accuracy of ~ 98%5,8 on test set T1, provided that it is trained to classify only one phase-encoded handwritten digit per input image (without any spatial overlap with other objects). This reduced classification accuracy of D2NN-D1 and D2NN-D1d on test set T1 (when compared to ~ 98%) indicates that their forward training model, driven by the loss functions depicted in Eqs. (2) and (3), guided the evolution of the corresponding diffractive layers to recognize the spatial features created by the overlapping handwritten digits, as opposed to focusing solely on the actual features describing the individual handwritten digits.
To further reduce the required number of optical detectors at the output plane of a diffractive optical network, we considered an alternative design (D-2) shown in Fig. 1d. In this alternative design scheme D-2, there are two extra detectors \(\left\{ {D_{Q}^{ + } ,D_{Q}^{ - } } \right\}\) (shown with blue in Fig. 1d), in addition to \(M\) class detectors \(\left\{ {D_{m} , m = 1,2, \ldots ,M} \right\}\) (shown with gray in Fig. 1d). The sole function of the additional pair of detectors \(\left\{ {D_{Q}^{ + } ,D_{Q}^{ - } } \right\}\) is to decide whether the spatially-overlapping input phase objects belong to the same or different data classes. If the difference signal of this differential detector pair (Fig. 1d) is non-negative (i.e., \(I_{{D_{Q}^{ + } }} \ge I_{{D_{Q}^{ - } }}\)), the diffractive optical network will infer that the overlapping input objects are from the same data class, hence there is only one class assignment to be made by simply determining the maximum signal at the output class detectors: \(\left\{ {D_{m} , m = 1,2, \ldots ,M} \right\}\). A negative signal difference between \(\left\{ {D_{Q}^{ + } ,D_{Q}^{ - } } \right\}\), on the other hand, indicates that the two overlapping phase objects are from different data classes/digits, and the final class assignments in this case of \(I_{{D_{Q}^{ + } }} < I_{{D_{Q}^{ - } }}\) are given based on the largest two optical signals among all the remaining \(M\) detectors at the network output, \(\left\{ {D_{m} , m = 1,2, \ldots ,M} \right\}\). Refer to the Methods section for further details on the training of diffractive optical networks that employ D-2 (Fig. 1d).
Similar to earlier diffractive optical network designs, we used ~ \(550\;{\text{million}}\) input phase images of spatially overlapping MNIST handwritten digits to train 5 diffractive layers constituting the D2NN-D2 network (see Fig. 4a). Figure 4b–d illustrate sample input phase images that contain objects from different data classes, along with the output detector signals that correctly predict the classes/digits of these overlapping phase objects; notice that in each one of these cases, we have at the output plane \(I_{{D_{Q}^{ + } }} < I_{{D_{Q}^{ - } }}\) indicating the success of the network’s inference. As another example of blind testing, Fig. 4e reports the diffractive optical network’s inference for two input phase objects that are from the same data class, i.e., digit ‘3’. At the network’s output, this time we have \(I_{{D_{Q}^{ + } }} > I_{{D_{Q}^{ - } }}\), correctly predicting that the two overlapping phase images are of the same class; the maximum output signal of the remaining output detectors \(\left\{ {D_{m} , m = 1,2, \ldots ,M} \right\}\) also correctly reveals that the handwritten phase images belong to digit ‘3’ with a maximum signal at \(D_{3}\). This D2NN-D2 design provides 82.61% inference accuracy on the test set T2 with 10 K test images, closely matching the inference performance of D2NN-D1 (82.70%) reported in Fig. 2. In fact, an advantage of this D2NN-D2 design lies in its inference performance and blind testing accuracy on test set T1, achieving 93.38% for classification of input phase images of single digits (without any spatial overlap at the input field-of-view).

All-optical classification of spatially-overlapping phase objects using the diffractive optical network D2NN-D2, based on the detector layout scheme D-2 shown in Fig. 1d. (a) The thickness profiles of the diffractive layers constituting the diffractive optical network D2NN-D2 at the end of its training. This network achieves 82.61% blind inference accuracy on the test image set T2. (b–e), Top: Individual phase objects (examples) and the resulting input phase distribution created by their spatial overlap at the input field-of-view. Bottom: The normalized optical signals, \(I\), synthesized by D2NN-D2 at its output detectors. For \(I_{{D_{Q}^{ + } }} < I_{{D_{Q}^{ - } }}\), the largest two optical signals correctly reveal the classes of the overlapping input phase objects (indicated with the green rectangular frames in (b–d). For \(I_{{D_{Q}^{ + } }} \ge I_{{D_{Q}^{ - } }}\), the largest optical signal correctly reveals the class of the overlapping input phase objects (indicated with the green rectangular frame in (e)).
We also implemented the differential counterpart of the detector layout D-2, which we term as D-2d (see Fig. 1e), where the \(M\) class detectors in D-2 are replaced with \(M\) differential pairs of output detectors. In this configuration D-2d, the total number of detectors at the output plane of the diffractive optical network becomes \(2M + 2\) and the all-optical inference rules remain the same as in D-2: for \(I_{{D_{Q}^{ + } }} \ge I_{{D_{Q}^{ - } }}\), the class inference is made by simply determining the maximum differential signal at the output class detectors, and for the case of \(I_{{D_{Q}^{ + } }} < I_{{D_{Q}^{ - } }}\) the inference of the classes of input phase images is determined based on the largest two differential optical signals at the network output. Figure 5a shows the diffractive layers of the resulting D2NN-D2d that is trained based on the detector layout, D-2d (Fig. 1e) using the same training dataset as before: ~ 550 million input phase images of spatially overlapping, phase-encoded MNIST handwritten digits. This new differential diffractive optical network design, D2NN-D2d, provides significantly higher blind inference accuracies compared to its non-differential counterpart D2NN-D2, achieving 85.22% and 94.20% on T2 and T1 datasets, respectively. Figure 5b–d demonstrate some examples of the input phase images from test set T2 that are correctly classified by D2NN-D2d along with the corresponding optical signals collected by the output detectors representing the positive and negative parts, \(I_{M + }\) and \(I_{M - }\), of the associated differential class signals, \(\Delta I_{M} = I_{M + } - I_{M - }\). As another example, the input phase image depicted in Fig. 5e has two overlapping phase-encoded digits from the same data class, handwritten digit ‘4’, and the diffractive optical network correctly outputs \(I_{{D_{Q}^{ + } }} > I_{{D_{Q}^{ - } }}\) with the maximum differential class score strongly revealing an optical inference of digit ‘4’.

All-optical classification of spatially-overlapping phase objects using the diffractive optical network D2NN-D2d, based on the detector layout scheme D-2d shown in Fig. 1e. (a) The thickness profiles of the diffractive layers constituting the diffractive optical network D2NN-D2d at the end of its training. This network achieves 85.22% blind inference accuracy on the test image set T2. (b–e) Left: Individual phase objects (examples) and the resulting input phase distribution created by their spatial overlap at the input field-of-view. Middle: The normalized optical signals, \(I_{ + }\) and \(I_{ - }\) , synthesized by D2NN-D2d at its output detectors. Right: The differential optical signal, \({\Delta }I = I_{ + } - I_{ - }\) (purple). For \(I_{{D_{Q}^{ + } }} < I_{{D_{Q}^{ - } }}\), the largest two differential optical signals correctly reveal the classes of the overlapping input phase objects (indicated with the green rectangular frames in (b–d). For \(I_{{D_{Q}^{ + } }} \ge I_{{D_{Q}^{ - } }}\), the largest differential optical signal correctly reveals the class of the overlapping input phase objects (indicated with the green rectangular frame in (e)).
Table 1 summarizes the optical blind classification accuracies achieved by different diffractive optical network designs, D2NN-D1, D2NN-D1d, D2NN-D2 and D2NN-D2d on test image sets T2 and T1. Even though D2NN-D1d achieves the highest inference accuracy for the classification of spatially overlapping phase objects, D2NN-D2d offers a balanced optical inference system achieving very good accuracy on both T1 and T2. These two differential diffractive optical network models outperform their non-differential counterparts with superior inference performance on both T2 and T1. The confusion matrices demonstrating the class-specific inference performances of the presented diffractive optical networks, D2NN-D1, D2NN-D1d, D2NN-D2 and D2NN-D2d, are also reported in Supplementary Figs. 1–4, respectively.
Next, we aimed to reconstruct the individual images of the overlapping phase objects (handwritten digits) using the detector signals at the output of a diffractive optical network; stated differently our goal here is to resolve the phase ambiguity at the input plane and reconstruct both of the input phase images, despite their spatial overlap and the loss of phase information. For this aim, we combined each one of our diffractive optical networks, D2NN-D1, D2NN-D1d, D2NN-D2 and D2NN-D2d, one by one, with a shallow, fully-connected (FC) electronic network with two hidden layers, forming a task-specific imaging system as shown in Fig. 6. In these hybrid machine vision systems, the optical signals synthesized by a given diffractive optical network (front-end encoder) are interpreted as encoded representations of the spatial information content at the input plane. Accordingly, the electronic back-end neural network is trained to process the encoded optical signals collected by the output detectors of the diffractive optical network to decode and reconstruct the individual phase images describing each object function at the input plane, resolving the phase ambiguity due to the spatial overlap of the two phase objects. Figure 6a–d illustrate 3 different input images taken from the test set T2 for each diffractive optical network design (D2NN-D1, D2NN-D1d, D2NN-D2 and D2NN-D2d) along with the corresponding image reconstructions at the output of each one of the electronic networks that are separately trained to work with the diffractive optical network (front-end). As depicted in Fig. 6, the electronic image reconstruction networks only have 2 hidden layers with 100 and 400 neurons, and the final output layers of these networks have 28 × 28 × 2 neurons, revealing the images of the individual phase objects, resolving the phase ambiguity due to the spatial overlap of the input phase images. The quality of these image reconstructions is quantified using (1) the structural similarity index measure (SSIM) and (2) the peak signal-to-noise ratio (PSNR). Table 2 shows the mean SSIM and PSNR values achieved by these hybrid machine vision systems along with the corresponding standard deviations computed over the entire 10 K test images (T2). For these presented image reconstructions, we should emphasize that the dimensionality reduction (i.e., the image data compression) between the input and output planes of the diffractive optical networks (D2NN-D1, D2NN-D1d, D2NN-D2 and D2NN-D2d) is 39.2 × , 19.6 × , 65.33 × and 35.63 × , respectively, meaning that the spatial information of the overlapping phase images at the input field-of-view is significantly compressed (in terms of the number of pixels) at the output plane of the diffractive optical network. This large compression sets another significant challenge for the image reconstruction task in addition to the phase ambiguity and spatial overlap of the target images. With these large compression ratios, the presented diffractive optical network-based machine vision systems managed to faithfully recover the phase images of each input object despite their spatial overlap and phase information loss, demonstrating the coherent processing power of diffractive optical networks as well as the unique design opportunities enabled by their collaboration with electronic neural networks that form task-specific back-end processors.

Reconstruction of spatially overlapping phase images using a diffractive optical front-end (encoder) and a separately trained, shallow electronic neural network (decoder) with 2 hidden layers. The front-end diffractive optical networks are (a) D2NN-D1, (b) D2NN-D1d, (c) D2NN-D2, and (d) D2NN-D2d, shown in Figs. 2a, 3a, 4a and 5a, respectively. The detector layouts at the output plane of these diffractive optical networks are (a) D-1, (b) D-1d, (c) D-2, and (d) D-2d with \(2M\), \(4M\), \(M + 2\) and \(2M + 2\) single pixel detectors as shown in Fig. 1b-d, respectively; for handwritten digits \(M = 10\). These four designs create a compression ratio of 39.2 × , 19.6 × , 65.33 × and 35.63 × between the input and output fields-of-view of the corresponding diffractive optical network, respectively. The mean SSIM and PSNR values achieved by these phase image reconstruction networks are depicted in Table 2 along with the corresponding standard deviation values computed over the 10 K test input images (T2).
Discussion
The optical classification of overlapping phase images using diffractive optical networks presents a challenging problem due to the spatial overlap of the input images and the associated loss of phase information at the input plane. Interestingly, different combinations of handwritten digits at the input present different amounts of spatial overlap, which is a function of the class of the selected input digits as well as the style of the handwriting of the person. To shed more light on this, we quantified the all-optical blind inference accuracies of the presented diffractive optical networks as a function of the spatial overlap percentage, \(\xi\), at the input field-of-view; see Fig. 7. In the first group of examples shown in Fig. 7a, the input fields-of-view contain digits from different data classes (\(c_{1} \ne c_{2}\)) and in the second group of examples shown in Fig. 7b, the spatially overlapping objects are from the same data class, \(c_{1} = c_{2}\). The input phase images in T2 exhibit spatial overlap percentages varying between ~ 20% and ~ 100%. Figure 7c,d illustrate the change in the optical blind inference accuracy of the diffractive optical network, D2NN-D1, as a function of the spatial overlap percentage, \(\xi\), for the first (\(c_{1} \ne c_{2}\)) and the second (\(c_{1} = c_{2}\)) group of test input images, respectively. When \(c_{1} \ne c_{2}\) as in Fig. 7c, the optical inference accuracy is hindered by the increasing amount of spatial overlap between the two input phase objects, as in this case, the spatial features of the effective input transmittance function significantly deviate from the features defining the individual data classes. In the other case shown in Fig. 7d, i.e., \(c_{1} = c_{2}\), the relationship between the spatial overlap ratio \(\xi\) and the blind inference accuracy is reversed, since, with \(c_{1} = c_{2}\), increasing \(\xi\) means that the effective phase distribution at the input plane resembles more closely to a single object/digit. The same behavior can also be observed for the other diffractive optical networks, D2NN-D1d, D2NN-D2 and D2NN-D2d, reported in Fig. 7e–j, respectively.

The variation in the optical blind inference accuracies of the presented diffractive optical networks as a function of the spatial overlap percentage \(\left( \xi \right)\) between the two input phase objects. (a) Sample input images from the test set T2 containing overlapping phase objects from different data classes along with the corresponding overlap percentages, \(\xi\). (b) Same as (a), except the overlapping objects are from the same data class. (c) The blind inference accuracy of the diffractive optical network, D2NN-D1, as a function of the overlap percentage, \(\xi\), and the histogram of \(\xi\), for test inputs in T2 that contain phase objects from two different data classes. (d), Same as (c), except that the test inputs contain phase objects from the same data class. (e,f), Same as (c,d), except, the diffractive optical network design is D2NN-D1d. (g,h), Same as (c,d), except, the diffractive optical network design is D2NN-D2. (i,j), Same as (c,d), except, the diffractive optical network design is D2NN-D2d.
Although our forward model during the training assumes that the input field-of-view contains two overlapping phase objects, we further tested the behavior of our diffractive models, D2NN-D1d and D2NN-D2d, for a hypothetical case, where more than two objects are present simultaneously at the input field-of-view as illustrated in Supplementary Fig. 5. Specifically, we conducted two different types of tests. In the first one, we created input objects with \(N = 3\), \(N = 4\) and \(N = 5\) spatially-overlapping phase-encoded handwritten digits from different classes and quantified the accuracy of the diffractive optical networks in determining the classes of the input objects correctly based on \(\arg \max_{n} ,\) where \(n = 2,3,..,N\). As shown in Supplementary Fig. 5, with \(N = 5\) phase objects spatially-overlapping within the same input field-of-view, D2NN-D1d can still correctly classify at least two of the overlapping objects, i.e., \(n = 2\), with an accuracy of 84.06% despite the severe contamination of the spatial information due to the presence of the additional input objects. On the other hand, the classification performance of the diffractive network decreases to 48.27%, 15.17% and 2.01% when it is asked to correctly classify \(n = 3\), \(n = 4\) and \(n = N = 5\) of the input objects that are simultaneously present at the input (see Supplementary Fig. 5a). This performance degradation is mainly because the diffractive optical network has never seen more than two objects overlapping at the input field-of-view during its training phase. To further explore the impact of the number of overlapping phase objects used during the training phase on the blind testing accuracy, we extended the detector configuration depicted in Fig. 1c, D-1d, to accommodate 2 × 5 M = 100 single-pixel detectors and trained from scratch a new diffractive optical network that was tasked to classify 5 overlapping handwritten digits. Compared to the classification performance of the D2NN-D1d shown in Fig. 3 with N = 5 spatially-overlapping phase objects, this new diffractive network achieved much higher classification accuracies, reaching 99.66%, 93.37%, 55.63% and 12.62% for \(n = 2\), \(n = 3\), \(n = 4\) and \(n = N = 5\), respectively (see Supplementary Fig. 6).
In the second testing scheme, we created input phase objects with N = 4, 6, 8, 10 and 12 spatially-overlapping digits from the same data class and quantified the performance of the diffractive networks in understanding that the objects inside the field-of-view represent only one data class/digit. The classification accuracies attained by D2NN-D1d and D2NN-D2d, in this case, stay above > 92% up to 4 overlapping samples from the same data class, with the former and the latter diffractive optical network achieving 92.81% and 92.88%, respectively. On the other hand, if more than 5 objects are overlapping within the input field-of-view, the classification accuracies of both of the diffractive models decrease below 80%, hinting at a significant spatial information loss caused by the superposition of a large number of input phase objects (see Supplementary Figs. 5b and 5d).
Next, to test the generalization of the presented diffractive optical framework over different datasets, we trained two new separate diffractive optical networks (each with 5 diffractive layers) that were tasked with the classification of spatially-overlapping, phase-encoded objects from a more challenging image dataset, i.e., Fashion-MNIST. In these two diffractive optical networks, the detector designs were identical to D1d and D2d shown in Fig. 1c,e, respectively. While the D2NN-D1d shown in Fig. 3 can achieve 85.82% accuracy for the classification of overlapping handwritten digits, its equivalent (see Supplementary Fig. 7) that is trained and tested on Fashion-MNIST dataset can attain 73.28% bling testing accuracy for the classification of overlapping, phase-encoded fashion products. The same comparison also reveals a similar classification accuracy for the D2NN-D2d model, which can classify the phase-encoded, spatially-overlapping fashion products within the input field-of-view with a classification accuracy of 72.21% (see Supplementary Fig. 8). In addition, we combined these two diffractive optical networks classifying overlapping fashion products with shallow, electronic image reconstruction networks, each having only 2 hidden layers. The structural quality of the images reconstructed by these subsequent shallow electronic networks using only the all-optical classification signals synthesized by the corresponding diffractive optical networks is still very good as shown in Supplementary Fig. 9. In summary, to the best of our knowledge, this manuscript reports the first all-optical multi-object classification designs based on diffractive optical networks demonstrating their potential in solving challenging classification and computational imaging tasks in a resource-efficient manner using only a handful detectors at the output plane. In the context of optical classification and reconstruction of overlapping phase objects, also resolving the phase ambiguity due to the spatial overlap of input images, this study exclusively focuses on a setting where the thin input objects are only modulating the phase of the incoming waves, and absorption is negligible. Without loss of generality, the presented diffractive design schemes with the associated loss functions and training methods can also be extended to applications, where the input objects partially absorb the incoming light.
Methods
Optical forward model of diffractive optical networks
D2NN framework formulates a given machine learning e.g., object classification or inverse design task as an optical function approximation problem and parameterizes that function over the physical features of the materials inside a diffractive black-box. As is the case in this study, this optical black-box is often modeled through a series of thin modulation layers connected by the diffraction of light waves. Here, we focused our efforts on 5-layer diffractive optical networks as shown in Fig. 1a, each occupying an area of \(106\;\lambda \times 106\;\lambda\) on the lateral space with \(\lambda\) denoting the wavelength of the illumination light. The modulation function of each diffractive layer was sampled and represented over a 2D regular grid with a period of 0.53 \(\lambda\) resulting in \(N = 200 \times 200\) different transmittance coefficients, i.e., the diffractive ‘neurons’. Based on the 0.53 \(\lambda\) diffractive feature size, we set the layer-to-layer axial distance to be 40 \(\lambda\) to ensure connectivity between all the neurons on two successive layers.
Following the same framework used in earlier demonstrations of diffractive optical networks with 3D printed layers4,6,8, we selected the diffractive layer thickness, \(h\), as a trainable physical parameter dictating the transmittance of each neuron together with the refractive index of the material. To limit the material thickness range during the deep learning-based training, \(h\) is defined as a function of an auxiliary, learnable variable, \(h_{a}\), and a constant base thickness, \(h_{b} ,\)
where the function, \(Q_{*} \left( . \right)\) represents the *-bit quantization operator and \(h_{m}\) is the maximum allowed material thickness. If the material thickness over the \(i^{{{\text{th}}}}\) diffractive neuron located at \(\left( {x_{i} ,y_{i} ,z_{i} } \right)\) is denoted by \(h\left( {x_{i} ,y_{i} ,z_{i} } \right)\), then the resulting transmittance coefficient of that neuron, \(t\left( {x_{i} ,y_{i} ,z_{i} } \right)\), is given by,
where \(n\left( \lambda \right)\) and \(\kappa \left( \lambda \right)\) are the real and imaginary parts of complex-valued refractive index of the diffractive material at wavelength, \(\lambda\). Following the earlier experimental demonstrations of diffractive optical networks, in this work we set the \(n\left( \lambda \right)\) and \(\kappa \left( \lambda \right)\) values to be 1.7227 and 0.031, respectively8. The parameter \(n_{s}\) in Eq. (5) refers to the refractive index of the medium, surrounding the diffractive layers; without loss of generality, we assumed \(n_{s} = 1\) (air). Based on the outlined material properties, the \(h_{m}\) and \(h_{b}\) in Eq. (4) were selected as 2λ and 0.66λ, respectively, ensuring that the phase modulation term in Eq. (5), \(\left( {n\left( \lambda \right) - n_{s} } \right)\frac{{2\pi h\left( {x_{i} ,y_{i} ,z_{i} } \right)}}{\lambda }\), can cover the entire [0-2π] phase modulation range per diffractive feature/neuron.
In this work, the light propagation between the diffractive layers was modeled using the Rayleigh-Sommerfeld diffraction integral, which assumes that the propagating light can be expressed as a scalar field. The exact modeling and computation of the light field diffracted by subwavelength features, in general, require the use of vector diffraction theory27,28. On the other hand, since we assume that (1) the diffractive layers are axially separated from each other by several tens of wavelengths, without carrying forward any evanescent fields, and (2) the smallest feature size on a diffractive layer is approximately half a wavelength, the use of scalar fields to represent the spatial information flow within a diffractive optical network is an acceptable approximation, just like employed in the simulation/modeling of diffraction-limited holographic imaging or display systems. In fact, various experimental demonstrations of 3D-fabricated diffractive optical networks designed using the same scalar field theory were reported in the literature1,4,6,8,12,29, confirming the validity of this assumption. According to the Rayleigh-Sommerfeld theory of diffraction, a neuron located at \(\left( {x_{i} ,y_{i} ,z_{i} } \right)\) can be viewed as the source of a secondary wave,
where \(r\) denotes the radial distance \(\sqrt {\left( {x - x_{i} } \right)^{2} + \left( {y - y_{i} } \right)^{2} + \left( {z - z_{i} } \right)^{2} }\). Based on this, the output wave emanating from the ith neuron on the kth layer, \(u_{i}^{k} \left( {x,y,z} \right)\) can be written as,
The term \(\mathop \sum \limits_{q = 1}^{N} u_{q}^{k - 1} \left( {x_{i} ,y_{i} ,z_{i} } \right)\) in Eq. (9) represents the wave incident on the \(i^{{{\text{th}}}}\) neuron on the \(k^{{{\text{th}}}}\) layer, generated by the neurons on the previous, \(\left( {k - 1} \right)^{{{\text{th}}}}\) diffractive layer.
In this study we also assumed that the transmittance function inside the input field-of-view, \(T_{in} \left( {x,y} \right)\), covers an area of 53 \(\lambda\) × 53 \(\lambda\) and without loss of generality, it is illuminated with a uniform plane wave. At the output plane, the width of each single-pixel detector was set to be 6.36 \(\lambda\) on both x and y directions for all four output detector configurations shown in Fig. 1b–d. Based on the outlined optical forward model, the diffractive optical networks process the incoming waves generated by the complex-valued transmittance function, \(T_{in} \left( {x,y} \right)\), formed by the overlapping thin phase objects and synthesize a 2D intensity distribution at the output plane for all-optical inference of the classes of the overlapping objects. The optical intensity distribution within the active area of each output detector is integrated to form elements of the vector, \(I\) in Eq. (1). The number of elements in this optical signal vector, \(I\), is equal to the number of output detectors, thus its length is \(2M\), \(4M,\) \(M + 2\) and \(2M + 2\) for D2NN-D1, D2NN-D1d, D2NN-D2 and D2NN-D2d, respectively. As part of our forward training model, \(I\) is normalized to form, \(\overline{I}\),
where the coefficient c in Eq. (8) serves as the temperature parameter of the softmax function depicted in Eq. (3), and it was empirically set to be 0.1 for training of all the diffractive optical networks. It is important to note that this normalization step in Eq. (8) is only used during the training stage, and once the training is finished, the forward inference directly uses the detected intensities to decide on the object classes based on the corresponding decision rules. While the vector \(\overline{I}\) is directly used in Eq. (3) for the D2NN-D1 network, in the case of D2NN-D1d, \(\overline{I}\) is split into two vectors of length \(2M\), i.e., \(I_{ + }\) and \(I_{ - }\), representing the signals collected by the positive and negative detectors, and the associated differential signal is computed as \({\Delta }I = I_{ + } - I_{ - }\). Accordingly, during the training of D2NN-D1d, the loss function depicted in Eq. (3), were computed using \({\Delta }I\) instead of \(\overline{I}\).
For the diffractive optical network D2NN-D2, the output of the normalization defined in Eq. (8) was split into two: \(I_{M}\) and \(I_{Q}\). The first part, \(I_{M}\), represents the optical signals coming from the \(M\) class specific detectors in the detector layout D-2 (the gray detectors Fig. 1d). The latter, \(I_{Q}\), contains two entries describing the positive and the negative parts of the indicator signals, \(I_{{D_{Q}^{ + } }}\) and \(I_{{D_{Q}^{ - } }}\) (see the blue detectors Fig. 1d). These two extra detectors, \(\left\{ {D_{Q}^{ + } ,D_{Q}^{ - } } \right\}\), form a differential pair that controls the functional form of the class decision rule based on the sign of the difference between the optical signals collected by these detectors. We accordingly determine the class assignments as follows,
To enable the training of diffractive optical networks according to the class assignment rule in Eq. (9), we defined a loss function, \({\mathcal{L}} = {\mathcal{L}}_{Q} + {\mathcal{L}}_{c}\), that corresponds to the superposition of two different penalty terms, \({\mathcal{L}}_{Q}\) and \({\mathcal{L}}_{c}\). Here, \({\mathcal{L}}_{Q}\) represents the error computed with respect to the binary ground truth indicator signal, \(g_{Q}\),
Accordingly, \({\mathcal{L}}_{Q}\) was defined as,
where \(\sigma \left( \cdot \right)\) denotes the sigmoid function. The classification loss, \({\mathcal{L}}_{c}\), on the other hand, is identical to the cross-entropy loss depicted in Eq. (3), except that the vector \(I\) is replaced with \(I_{M}\). Unlike the previous diffractive optical networks (D2NN-D1 and D2NN-D1d), the forward model of the diffractive optical networks trained based on the output detector layout D-2 do not require multiple ground truth vector labels. Simply the ground truth label vector of a given input field-of-view is defined as \(g = \frac{{g^{1} + g^{2} }}{2}\) satisfying the condition, \(\mathop \sum \limits_{1}^{M} g_{m} = 1\).
In the case of D2NN-D2d, the vector \(\overline{I}\) contains 3 main parts, \(I_{M + }\), \(I_{M - }\) and \(I_{Q}\) where \(I_{M + }\) and \(I_{M - }\) are length \(M\) vectors containing the normalized optical signals collected by the detectors representing the positive and negative parts of the final differential class scores \({\Delta }I_{M} = I_{M + } - I_{M - }\). Accordingly, in the associated forward training model, the intensity vector \(I_{M}\) in Eq. (9) is replaced with the differential signal, \({\Delta }I_{M} .\)
Testing of diffractive optical networks on the dataset T1
During the blind testing of the presented diffractive optical networks on the test set T1, the class estimation solely uses the \(\arg \max\) operation, searching for the highest class-score synthesized by the diffractive optical networks, based on the associated output plane detector layouts shown in Fig. 1. The purpose of this performance quantification using T1 is to reveal whether the diffractive optical networks trained based on overlapping input phase objects can learn and automatically recognize the characteristic spatial features of the individual handwritten digits (without any spatial overlap). For this goal, in the case of D2NN-D1 and D2NN-D1d, the class estimation rule in Eq. (1) was replaced with, \(\bmod \left( {\arg \max \left( I \right),M} \right)\) and \(\bmod \left( {\arg \max \left( {\Delta I} \right),M} \right)\), respectively. Since the input images in the test set T1 contain single, phase-encoded handwritten digits without the second overlapping phase object, the optical signals collected by the detectors, \(\left\{ {D_{Q}^{ + } ,D_{Q}^{ - } } \right\}\), at the output plane of the diffractive optical networks D2NN-D2 and D2NN-D2d become irrelevant for the classification of the images in T1. Therefore, the decision rule in Eq. (9) is simplified to \(\arg \max \left( {I_{M} } \right)\) and \(\arg \max \left( {\Delta I_{M} } \right)\) for the all-optical classification of the input test images in T1 based on the diffractive optical networks D2NN-D2 and D2NN-D2d, respectively.
Architecture and training of the phase image reconstruction network
The phase image reconstruction electronic neural networks (back-end) following each of the presented diffractive optical networks (front-end) include 4 neural layers. The number of neurons on their first layer is equal to the number of detectors at the output plane of the preceding diffractive optical network (D-1, D-1d, D-2 or D-2d, see Fig. 1a–d). The number of neurons, on the subsequent 3 layers are 100, 400, 1568, respectively. Note that the output layer of each image reconstruction electronic neural network has 2 × 28 × 28 neurons as it simultaneously reconstructs both of the overlapping phase objects, resolving the phase ambiguity due to the spatial overlap at the input plane. Each fully-connected (FC) layer constituting these image reconstruction networks applies the following operations:
where \(\rho_{l + 1}\) and \(\rho_{l}\) denote the output and input values of the \(l^{{{\text{th}}}}\) layer of the electronic network, respectively. The operator LReLU stands for the leaky rectified linear unit:
The batch normalization, BN, normalizes the activations at the output of LReLU to zero mean and a standard deviation of 1, and then shifts the mean to a new center, \(\beta^{\left( l \right)}\), and re-scales it with a multiplicative factor, \(\gamma^{\left( l \right)}\), where \(\beta^{\left( l \right)}\) and \(\gamma^{\left( l \right)}\) are learnable parameters, i.e.,
The hyperparameter \(\varepsilon\) is a small constant that avoids division by 0 and it was taken as \(10^{ - 3}\).
The training of the phase image reconstruction networks was driven by the reversed Huber (or “BerHu”) loss, which computes the error between two images, \(a\left( {x,y} \right)\) and \(b\left( {x,y} \right)\), as follows:
The hyperparameter \(\varphi\) in Eq. (15) is a threshold for the transition between mean-absolute-error and mean-squared-error, and it was set to be 20% of the standard deviation of the ground truth image.
If we let \(\phi_{p} \left( {x,y} \right)\) and \(\phi_{q} \left( {x,y} \right)\) denote the first and second output of each image reconstruction electronic network (i.e., 28 × 28 pixels per phase object), the image reconstruction loss, \({\mathcal{L}}_{r}\), was defined as the minimum of two error terms, \({\mathcal{L}}_{r}^{\prime }\) and \({\mathcal{L}}_{r}^{\prime \prime }\), i.e.,
where \(\phi_{1} \left( {x,y} \right)\) and \(\phi_{2} \left( {x,y} \right)\) denote the ground truth phase images of the first and second objects, respectively, which overlap at the input plane of the diffractive optical network. As there is no hierarchy or priority difference between the input objects \(\phi_{1} \left( {x,y} \right)\) and \(\phi_{2} \left( {x,y} \right)\), Eq. (16) lets the image reconstruction network to choose their order regarding its output activations.
Other details of diffractive optical network training
With the 0.53 \(\lambda\) lateral sampling rate in our forward optical model, the transmittance function inside the field-of-view, \(T_{in} \left( {x,y} \right)\), was represented as a \(100 \times 100\) discrete signal. In our diffractive optical network training, the 8-bit grayscale values of the MNIST digits were first converted to 32-bit double format, normalized to the range [0,1] and then resized to \(100 \times 100\) using bilinear interpolation. If we denote these normalized and resized grayscale values of the two input objects/digits that overlap at the input plane as \(\theta_{1} \left( {x,y} \right)\) and \(\theta_{2} \left( {x,y} \right)\) then the transmittance function within the input field-of-view, \(T_{in} \left( {x,y} \right)\), is defined as,
During the training of the presented diffractive optical networks, \(\theta_{1} \left( {x,y} \right)\) and \(\theta_{2} \left( {x,y} \right)\) are randomly selected from the standard 55 K training samples of MNIST dataset without replacement, meaning that, an already selected training digit was not selected again until all 55 K samples are depleted constituting an epoch of the training phase. In this manner, we trained the diffractive optical networks for 20,000 epochs, showing each optical network approximately 550 million different \(T_{in} \left( {x,y} \right)\) during the training phase. Supplementary Fig. 10 illustrates the convergence curves of our best performing diffractive optical networks models (D2NN-D1d and D2NN-D2d) over the course of these 20,000 epochs. Similarly, to generate the input fields in test dataset T2, we randomly selected \(\theta_{1} \left( {x,y} \right)\) and \(\theta_{2} \left( {x,y} \right)\) among the standard 10 K test samples of MNIST dataset, without replacement, and this was repeated two times providing us the 10 K unique phase input images of overlapping handwritten digits constituting T2. In our T2 test set, 8998 inputs contain overlapping digits from different data classes, while the remaining 1002 inputs have overlapping samples from the same data class/digit. The validation image set (Supplementary Fig. 10), on the other hand, contains 5 K unique phase input images created by randomly selecting \(\theta_{1} \left( {x,y} \right)\) and \(\theta_{2} \left( {x,y} \right)\) among the standard 10 K test samples of MNIST dataset without replacement. Note that the \(\theta_{1} \left( {x,y} \right)\) and \(\theta_{2} \left( {x,y} \right)\) combinations used in the validation set of Supplementary Fig. 10 are not included in T2 to achieve true blind testing without any data contamination.
The overlap percentage, \(\xi\), between any given pair of samples, \(\theta_{1} \left( {x,y} \right)\) and \(\theta_{2} \left( {x,y} \right)\) (see Fig. 7), is quantified by,
In Eqs. (18a) and ( 18b), \(\xi_{1}\) and \(\xi_{2}\) quantify the percentage of the input pixels that contain the spatial overlap with respect to \(\theta_{1} \left( {x,y} \right)\) and \(\theta_{2} \left( {x,y} \right)\), respectively, and the final \(\xi\) is taken as the max of these two values.
For the digital implementation of the diffractive optical network training outlined above, we developed a custom-written code in Python (v3.6.5) and TensorFlow (v1.15.0, Google Inc.). The backpropagation updates were calculated using the Adam30 optimizer with its parameters set to be the default values as defined by TensorFlow and kept identical in each model. The learning rate was set to be 0.001 for all the diffractive optical network models presented here. The training batch size was taken as 75 during the deep learning-based training of the presented diffractive optical networks. The training of a 5-layer diffractive optical network with 40 K diffractive neurons per layer for 20,000 epochs takes approximately 24 days using a computer with a GeForce GTX 1080 Ti Graphical Processing Unit (GPU, Nvidia Inc.) and Intel® Core ™ i7-8700 Central Processing Unit (CPU, Intel Inc.) with 64 GB of RAM, running Windows 10 operating system (Microsoft).
References
Lin, X. et al. All-optical machine learning using diffractive deep neural networks. Science 361, 1004–1008 (2018).
Mengu, D., Luo, Y., Rivenson, Y. & Ozcan, A. Analysis of diffractive optical neural networks and their integration with electronic neural networks. IEEE J. Select. Top. Quantum Electron. 26, 1–14 (2020).
Veli, M. et al. Terahertz pulse shaping using diffractive surfaces. Nat. Commun. 12, 37. https://doi.org/10.1038/s41467-020-20268-z (2021).
Luo, Y. et al. Design of task-specific optical systems using broadband diffractive neural networks. Light Sci. Appl. 8, 112 (2019).
Li, J., Mengu, D., Luo, Y., Rivenson, Y. & Ozcan, A. Class-specific differential detection in diffractive optical neural networks improves inference accuracy. Adv. Photonics 1, 046001. https://doi.org/10.1117/1.AP.1.4.046001 (2019).
Li, J. et al. Spectrally encoded single-pixel machine vision using diffractive networks. Sci. Adv. 7, eabd7690 (2021).
Mengu, D., Rivenson, Y. & Ozcan, A. Scale-, shift-, and rotation-invariant diffractive optical networks. ACS Photon. https://doi.org/10.1021/acsphotonics.0c01583 (2020).
Mengu, D. et al. Misalignment resilient diffractive optical networks. Nanophotonics 9, 4207–4219 (2020).
Kulce, O., Mengu, D., Rivenson, Y. & Ozcan, A. All-optical information-processing capacity of diffractive surfaces. Light Sci. Appl. 10, 25 (2021).
Rahman, M. S. S., Li, J., Mengu, D., Rivenson, Y. & Ozcan, A. Ensemble learning of diffractive optical networks. Light Sci. Appl. 10, 14 (2021).
Qian, C. et al. Performing optical logic operations by a diffractive neural network. Light Sci. Appl. 9, 59 (2020).
Goi, E. et al. Nanoprinted high-neuron-density optical linear perceptrons performing near-infrared inference on a CMOS chip. Light Sci. Appl. 10, 40 (2021).
Zhou, T. et al. Large-scale neuromorphic optoelectronic computing with a reconfigurable diffractive processing unit. Nat. Photon. 15, 367–373 (2021).
Chang, J., Sitzmann, V., Dun, X., Heidrich, W. & Wetzstein, G. Hybrid optical-electronic convolutional neural networks with optimized diffractive optics for image classification. Sci. Rep. 8, 12324 (2018).
Rahman, S. S. & Ozcan, A. Computer-free, all-optical reconstruction of holograms using diffractive networks. ACS Photonics 8(11), 3375–3384. https://doi.org/10.1021/acsphotonics.1c01365 (2021).
Luo, Y. et al. Computational imaging without a computer: Seeing through random diffusers at the speed of light. eLight 2, 4. https://doi.org/10.1186/s43593-022-00012-4 (2022).
Jiao, S. et al. Optical machine learning with incoherent light and a single-pixel detector. Opt. Lett. 44, 5186 (2019).
Huang, Z. et al. All-optical signal processing of vortex beams with diffractive deep neural networks. Phys. Rev. Appl. 15, 014037 (2021).
Shi, J. et al. Multiple-view D2NNs array: Realizing robust 3D object recognition. Opt. Lett. 46, 3388 (2021).
Ong, J. R., Ooi, C. C., Ang, T. Y. L., Lim, S. T. & Png, C. E. Photonic convolutional neural networks using integrated diffractive optics. IEEE J. Sel. Top. Quantum Electron. 26, 1–8 (2020).
Shi, J. et al. Anti-noise diffractive neural network for constructing an intelligent imaging detector array. Opt. Express 28, 37686 (2020).
Li, Y., Chen, R., Sensale-Rodriguez, B., Gao, W. & Yu, C. Real-time multi-task diffractive deep neural networks via hardware-software co-design. Sci. Rep. 11, 11013 (2021).
Yan, T. et al. Fourier-space diffractive deep neural network. Phys. Rev. Lett. 123, 023901 (2019).
Colburn, S., Chu, Y., Shilzerman, E. & Majumdar, A. Optical frontend for a convolutional neural network. Appl. Opt. 58, 3179 (2019).
LeCun, Y., Bottou, L., Bengio, Y. & Ha, P. Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2374 (1998).
Elfadel, I. M. & Wyatt, J. L., Jr. The ‘Softmax’ Nonlinearity: Derivation Using Statistical Mechanics and Useful Properties as a Multiterminal Analog Circuit Element. in Advances in Neural Information Processing Systems (eds. Cowan, J., Tesauro, G. & Alspector, J.) vol. 6 (Morgan-Kaufmann, 1994).
Kulce, O. & Onural, L. Power spectrum equalized scalar representation of wide-angle optical field propagation. J. Math. Imaging Vis. 60, 1246–1260 (2018).
Kulce, O., Onural, L. & Ozaktas, H. M. Evaluation of the validity of the scalar approximation in optical wave propagation using a systems approach and an accurate digital electromagnetic model. J. Mod. Opt. 63, 2382–2391 (2016).
Mengu D., Ozcan A. Diffractive all-optical computing for quantitative phase imaging, arXiv:2201.08964 (2022) https://doi.org/10.48550/arXiv.2201.08964
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv:1412.6980 (2014).
Acknowledgements
The Ozcan Research Lab at UCLA acknowledges the support of Office of Naval Research (ONR).
Author information
Authors and Affiliations
Contributions
D.M. developed the forward training models and conducted numerical experiments. M.V. provided assistance with the numerical testing. D.M., Y.R. and A.O. participated in the analysis and discussion of the results. D.M. and A.O. wrote the manuscript. A.O. initiated and supervised the project.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mengu, D., Veli, M., Rivenson, Y. et al. Classification and reconstruction of spatially overlapping phase images using diffractive optical networks. Sci Rep 12, 8446 (2022). https://doi.org/10.1038/s41598-022-12020-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-12020-y
This article is cited by
-
Diffractive optical computing in free space
Nature Communications (2024)
-
All-optical image classification through unknown random diffusers using a single-pixel diffractive network
Light: Science & Applications (2023)
-
Polarization multiplexed diffractive computing: all-optical implementation of a group of linear transformations through a polarization-encoded diffractive network
Light: Science & Applications (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
