
Abstract
The action observation network (AON) is a network of brain regions involved in the execution and observation of a given action. The AON has been investigated in humans using mostly electroencephalogram (EEG) and functional magnetic resonance imaging (fMRI), but shared neural correlates of action observation and action execution are still unclear due to lack of ecologically valid neuroimaging measures. In this study, we used concurrent EEG and functional Near Infrared Spectroscopy (fNIRS) to examine the AON during a live-action observation and execution paradigm. We developed structured sparse multiset canonical correlation analysis (ssmCCA) to perform EEG-fNIRS data fusion. MCCA is a generalization of CCA to more than two sets of variables and is commonly used in medical multimodal data fusion. However, mCCA suffers from multi-collinearity, high dimensionality, unimodal feature selection, and loss of spatial information in interpreting the results. A limited number of participants (small sample size) is another problem in mCCA, which leads to overfitted models. Here, we adopted graph-guided (structured) fused least absolute shrinkage and selection operator (LASSO) penalty to mCCA to conduct feature selection, incorporating structural information amongst the variables (i.e., brain regions). Benefitting from concurrent recordings of brain hemodynamic and electrophysiological responses, the proposed ssmCCA finds linear transforms of each modality such that the correlation between their projections is maximized. Our analysis of 21 right-handed participants indicated that the left inferior parietal region was active during both action execution and action observation. Our findings provide new insights into the neural correlates of AON which are more fine-tuned than the results from each individual EEG or fNIRS analysis and validate the use of ssmCCA to fuse EEG and fNIRS datasets.
Similar content being viewed by others


Introduction
Recent developments in non-invasive neuroimaging techniques have allowed for multi-modal measurement of brain activation, leading to more comprehensive understanding of the neural processes underlying cognition. One multi-modal approach is the combination of electrophysiological data derived from electroencephalography (EEG) with hemodynamic response data derived from functional near-infrared spectroscopy (fNIRS)1,2. EEG records electrical signal changes from neuronal firing through electrodes attached to the scalp. FNIRS is an optical neuroimaging technique that uses near-infrared light (670–820 nm wavelength) to measure the hemodynamic response in the cerebral cortex, providing an indirect measure (e.g., blood oxygenation) of neuronal activation. Although other methods can also measure the hemodynamic response, such as functional magnetic resonance imaging (fMRI), fNIRS is non-invasive, cost effective, easier to apply, and less susceptible to motion artifact, making it more amenable to studies related to motor activity3,4. EEG and fNIRS are a compelling combination of modalities due to their complementary features. EEG captures electrical activity with temporal resolution on the order of milliseconds, but lacks spatial resolution. Conversely, fNIRS has improved spatial resolution5,6,7 and greater tolerance to motion artifact than EEG, allowing the identification of specific regions of interest and greater flexibility in the behavioral paradigms employed. By combining these modalities, better understanding of neural activation can be achieved by leveraging the temporal resolution of EEG with the improved spatial resolution and methodological flexibility of fNIRS. Using this combined approach, studies of brain activation associated with live action or motor-based tasks may yield more specific, robust findings.
Concurrent recording of EEG and fNIRS could be particularly beneficial in understanding the human action-observation network (AON). The AON is a network of brain regions linking the actions of the self (action execution) to the actions of others (action observation)8. It has been proposed that the AON is associated with sophisticated social and learned behaviors that emerge in typically developing infants, such as complex imitation and shared emotion9. The AON has been widely studied in humans using EEG, namely through measurement of mu (μ) desynchronization10. It is suggested that μ desynchronization occurs both when someone performs an action and when they observe someone perform the same action, and thus has been the predominant measure of the AON in the human brain11. However, whether μ desynchronization truly reflects a mirroring system in the human brain remains controversial12,13. One reason for this controversy is the lack of spatial specificity in the measured neural response provided by EEG. fMRI studies have offered a more precise location of AON related brain activity14,15 and have identified a key set of regions, including the ventral premotor cortex (PMv), inferior frontal gyrus (IFG), and inferior parietal lobe (IPL)16,17. However, fMRI studies are limited due to their high sensitivity to motion artifact, which is problematic in AON experimental protocols that involve the execution of a motor behavior. Most fMRI studies do not include an execution condition15 or, if they do, the actions employed might not be ecologically valid (e.g., bite bars, ball squeezing)18,19. While the confines of fMRI are not ideal for adequate experimental designs of AON experiments, there is potential for fNIRS to fill this gap as it has increased spatial resolution compared to EEG and allows participants to move during data collection unlike fMRI3.
Combining data from multiple neuroimaging techniques could be useful in understanding brain mechanisms related to the AON20, but the analysis of multimodal information is inherently challenging. Canonical Correlation Analysis (CCA) is a classic way to evaluate the multivariate associations between two types of high dimensional data using canonical vectors or matrices (e.g., different neuroimaging modalities)21. However, CCA is designed for two datasets. Multiset CCA (mCCA) extends CCA to more than two datasets22. While CCA maximizes the correlation between two canonical variates, mCCA optimizes an objective function of the correlation matrix of canonical variates from multiple random vectors such that the correlation between canonical variates is maximized. This method has been applied to fMRI datasets on multiple participants23,24,25,26,27, multi-subject EEG datasets28,29, fMRI and EEG multi-subject datasets30, EEG and magnetoencephalography (MEG) multi-subject datasets31, and fMRI, structural MRI and EEG datasets32,33,34. There have also been previous studies using simultaneously recorded EEG and fNIRS. They have used a variety of data fusion approaches, including joint independent component analysis35, CCA5,6 or temporally encoded CCA36. However, despite the strengths and applicability of CCA in such studies, it performs poorly when the number of features (e.g., brain regions) exceeds the number of observations (e.g., participants), which is often true in neuroimaging data analysis. This makes overfitting and limited generalizability prominent obstacles to overcome when using this approach.
While CCA does not perform feature selection, sparse CCA (sCCA) contains a built-in procedure to address this concern. SCCA extends on CCA by using a regularization technique to identify a sparse set of canonical vectors (loading/projection vectors) for both sets of features. Although sCCA offers a simpler interpretation by creating sparse projection vectors with higher correlations, it does not consider the spatial correlation or structural relationship between input features (e.g., brain regions). This can limit usefulness of sCCA in high-dimensional data fusion looking to localize the neural response. Since neural activity in adjacent regions is likely more similar than neural activity in non-adjacent regions, correlating them so that their canonical coefficients have similar magnitudes can address this issue. Witten et al.37 introduced structured sCCA (ssCCA), which imposes a fused least absolute shrinkage and selection operator (LASSO) penalty38 that tends to group neighboring features to recover their spatial structure.
The present study uses a multiset version of sparse structured CCA (ssmCCA) to examine brain signals derived from concurrent EEG and fNIRS during an action execution-observation task. Specifically, ssmCCA is used to decode and fuse electrical and hemodynamic responses associated with neural activation to expand our understanding of brain activation during AON (execution and observation) conditions. Using a multimodal neuroimaging approach combining EEG and fNIRS to investigate the AON we aim to identify more specific regions of interest in the brain and further advance our understanding of social neuroscience. We propose that if EEG and fNIRS each contain greater temporal or spatial information respectively, then a multimodal imaging approach using fusion analysis will yield more specific brain activation patterns than either EEG or fNIRS when analyzed alone. This will be assessed by comparing the activation patterns yielded from the unimodal analyses of fNIRS and EEG to the multimodal approach using ssmCCA. This paper is organized as follows: first we introduce the mathematical approach behind ssmCCA, then the details of the experiment and data preprocessing for both fNIRS and EEG datasets are presented. The data fusion procedure is then applied and findings from this approach compared to unimodal EEG and fNIRS analyses are presented, followed by a discussion interpretting our results and relating them to the previous literature.
Method
Data fusion approach
Structured sparse CCA (ssCCA)
CCA is a standard method to explore the relationship between two sets of multi-dimensional variables. When the number of samples (i.e., participants) are smaller than the number of features (\(n \ll p\) and \(n \ll q\)), overfitting becomes an inevitable problem. Usually in this situation, only fractions of features in each set are necessary for characterizing the two-set correlation. To mitigate the overfitting and lack of generalization problem, a sparsity constraint has been added to the traditional CCA problem37,39. To make both canonical variates sparse, either an l1-norm (LASSO) term40,41 or a combination of l1-norm and l2-norm (fused LASSO)38,42 are added to the traditional CCA model. Recently, there have been a number of structured sparse CCA (ssCCA) approaches proposed using graph/network-guided fused LASSO penalties43,44,45,46. In this paper, we take advantage of the model suggested by He47 where a network is represented by undirected weighted graph, \({\mathcal{G}}\). GraphNet, a more general form of a traditional elastic net regularizer43,44,45,46, can be written as:
where \(M\) is a matrix, and (\(\lambda_{1} ,\gamma_{1}\)) are regularizing parameters. The vertices in \({\mathcal{G}}\) correspond to features (e.g., brain regions, optodes) and each edge, \(l_{ij}\), indicates if there is a link between optode \(i\) and \(j\) in \({\mathcal{G}}\); all the weights of \(l_{ij}\) in the network depend on their adjacency conditions (e.g., high or low correlation). We have an elastic net when \(M = I\) in a GraphNet. Generally, \(M = L\), where \(L\) is the Laplacian matrix of a graph. Let \(A\) be a sample correlation matrix, called the adjacency matrix, in which the higher pairwise correlation between two features corresponds to a larger weight. We identify \(p\) as features/brain regions in the dataset and a diagonal matrix, \(D\), with the following diagonal entries: (\(D = { }diag(d_{1} ,{ }d_{2} , \ldots ,d_{p}\)), where \(D\left( {i,i} \right) = { }\mathop \sum \limits_{j = 1}^{p} A\left( {i,j} \right)\). The Laplacian matrix, \(L\), is defined as \(L = D - W\). In the case of \(M = L\), it has been shown that:
where \(w_{ik}\) depends on pairwise correlation of \(X\) and \(Y\) respectively47. This cost function also indicates that the adjacent regions linked in initial structure are expected to have similar weights48,49. To this end, the ssCCA would be formulated as:
subject to:
where C = (\(c_{1} , c_{2} , c_{3} ,c_{4}\)) > 0 are regularization parameters. Here, \(c_{3}\) and \(c_{4}\) are used to regularize the cost function controlling for spatial structure, and \(L_{w1}\) and \(L_{w1}\) are Laplacian matrices of modality 1 and 2 associated with \(w_{1}\) and \(w_{2} ,\) respectively. Witten et al.37, Chen et al.43 reformulated the constraints on \(w_{1}\) and \(w_{2}\) in Lagrangian form:
where the regularization parameters \(\lambda_{1} , \lambda_{2} , \alpha_{1}\) and \(\alpha_{2}\) correspond to \(c_{1} , c_{2} , c_{3}\) and \(c_{4}\), in (3) respectively.
Structured sparse multiset CCA (ssmCCA)
Thus far, the ssCCA we have formulated does not consider more than two datasets. However, traditional CCA can be extended to more than two variables in different ways22. MCCA is the generalization of the CCA model where an objective (cost) function corresponding to the correlations between canonical vector pairs should be optimized such that the overall correlation between them is maximized: \(\left[ {w_{1}^{\left[ 1 \right]} ,w_{2}^{\left[ 1 \right]} \cdots w_{M}^{\left[ 1 \right]} } \right]\) = \(\mathop {{\text{max}}}\limits_{w}\)(\(|\rho_{k,l}^{\left[ n \right]} |)\). The subscript indicates the dataset, and the superscript indicates the observation in the dataset (e.g., \(\rho_{k,l}^{\left[ n \right]}\) is the correlation between the \(n\) th canonical variates from \(k\) th and \(l\) th datasets).
In order to solve mCCA Kettenring22 introduced five objective functions (e.g., \({\mathcal{F}}\left( { x} \right) = x\) indicates the sum of correlations (SUMCOR) cost function while \({\mathcal{F}}\left( { x} \right) = x^{2}\) corresponds to the sum of squares correlations (SSQCOR) cost function):
where function \({\mathcal{F}}\left( \cdot \right)\) is the cost function. Here, we chose the SUMCOR cost function to estimate canonical variates. The procedure can be summarized in the steps bellow.
Step 1
Step 2
subject to:
where \(d \le \min \left( {{\text{rank}}\left( {X_{m} } \right)} \right)\). The matrices \(L_{{w_{m}^{\left[ n \right]} }}^{\left[ n \right]}\) are the semi-positive definitive Laplacian matrices of \(M\) datasets, and \(c1_{m}^{\left[ n \right]}\) and \(c2_{m}^{\left[ n \right]}\) are the penalty terms for the \(n\) th observation throughout all the \(M\) datasets.
Step (1) can be solved using a partial derivative function of the SUMCOR objective function with respect to each \(w_{m}^{\left[ 1 \right]}\) and equating it to zero to find the optimizing point. Since the SUMCOR objective function is a linear function of each \(w_{m}^{\left[ 1 \right]}\), the partial derivative is a constant, and therefore the closed form solution exists. The iterative algorithm starts from randomly initializing canonical variates and each \(w_{k}^{\left[ 1 \right]}\) vector is updated subsequently to guarantee cost function optimization. All the \(w_{k}^{\left[ 1 \right]}\) vectors are updated after the one step procedure. The procedure continues until convergence criteria are met and the \(w_{k}^{\left[ 1 \right]}\) vectors are considered as the optimal solution.
At step (2), the SUMCOR problem in (8) can then be reformulated in Lagrangian form:
where 1 \(\le n \le N\), \(1 \le k,l \le M\), \(k \ne l.\) As a reminder, \(n\) represents the \(n\) th observation in \(k\) th and \(l\) th datasets, and the regularization parameters \(\lambda_{1k}^{\left[ n \right]} , \lambda_{2k}^{\left[ n \right]} , \alpha_{1k}^{\left[ n \right]}\) and \(\alpha_{2k}^{\left[ n \right]}\) correspond to \(c1_{k}^{\left[ n \right]}\), \(c2_{k}^{\left[ n \right]}\) , \(c1_{l}^{\left[ n \right]}\) and \(c2_{l}^{\left[ n \right]}\) in (8) respectively.
Parameter optimization
The parameters in (9) that should be optimized are (\(\lambda_{1k}^{\left[ n \right]} , \lambda_{2k}^{\left[ n \right]} , \alpha_{1k}^{\left[ n \right]}\), \(\alpha_{2k}^{\left[ n \right]}\)). We applied the leave-one-out cross validation technique in which we estimated the model parameters (canonical variates) for \(n\) − 1 samples (participants) and calculated the errors on our one-left-out sample. We adopted the two steps cross-validation technique50. First, we found optimal values of \(\alpha_{i}\) when \(\lambda_{i}\) was set to zero and, second, we used these optimal \(\alpha_{i}\) values to estimate optimal values of \(\lambda_{i}\). To address the overfitting problem and improve model generalization, Waaijenborg et al.51 suggested that the test sample correlation should be approximately equal to the training sample correlation. In other words, the absolute difference between the estimated canonical correlations of the training and test samples are minimized.
Participants
Data were collected at two sites: the National Institute of Health (NIH) and University of Maryland (UMD). At NIH, participants were recruited from the healthy volunteer database at the National Institutes of Health. At UMD, participants were recruited through the program for Research for Extra Credit supported by the Department of Psychology. All experiments and methods were performed in accordance with guidelines provided in the study protocol (number: 18-CH-0001), which was approved by the Office Of Research Support and Compliance (ORSC) at NIH. In addition, all participants signed an informed consent approved by each site’s Institutional Review Board (IRB) prior to the start of the experiment.
Forty healthy right-handed volunteers participated in the experiment at NIH the site; however, data from 27 participants had to be discarded as a result of technical malfunctions which caused either incomplete recording or poor signal quality in one or both modalities. The final sample consisted of seven females and six males. Twenty healthy volunteers participated at UMD. Data from eight participants was considered for further analysis (3 female and 5 male, mean age, 24.62 years). Between both sites, the final sample used for the data fusion algorithm consisted of 21 participants (22–29 years of age; mean age, 24.9 years).
Experimental design
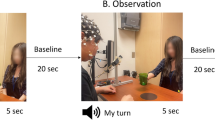
Our experiment was adapted from a paradigm used in the EEG mirror neuron literature with infant populations52. The paradigm consisted of 15 trials of action observation and 15 trials of action execution. Each trial was followed by a 20 s recovery period during which the participant passively viewed a moving pendulum. For further information on the paradigm we used please see Miguel et al.53.
Data acquisition
EEG and fNIRS data were recorded simultaneously. EEG data were collected using the Geodesic EEG System 400 (Magstim EGI, Eugene, OR) with 128 electrodes at a sampling rate of 256 Hz. Participants’ heads were fit with elastic EGI Geodesic Sensor Nets based on their head size. We measured head circumference, nasion-to-inion, and preauricular point distances to ensure proper placement of the EEG cap. The vertex (Cz) electrode was used as the reference. Data were exported to a MATLAB (Mathworks, Natick, MA) compatible format using Net Station software for offline processing with the EEGLab (v13.4.4b) toolbox54.
fNIRS data were collected using the Hitachi ETG-4100 system equipped with 10 infrared sources and 8 detectors placed over the somatosensory and parietal regions as in our previous fNIRS study investigating the AON53. A total of 24 channels (12 per hemisphere) measured changes in oxygenated hemoglobin (HbO) and deoxyhemoglobin (HbR) concentration.
After collecting experimental EEG/fNIRS data, we recorded the positions of sources and detectors on the head in reference to the nasion, inion, and preauricular landmarks using a 3D-magnetic space digitizer (Fastrak-Polhemus). This accounted for additional variations in cap placement and verified which channels covered each brain region. Figure 1 shows how fNIRS optodes were secured within the elastic of the EEG cap using custom-designed silicone fixtures, as well as the sensitivity profile of the fNIRS probe across the cortex.

source and detector pairs; yellow lines indicate fNIRS measurement channels. Six ROIs were derived from the 12 fNIRS channels located in each hemisphere: pre-central region, post-central region, superior parietal lobule, inferior parietal lobule, supra-marginal gyrus and angular gyrus.
fNIRS probe design. The picture on the top left shows how the fNIRS probe was embedded within an elastic, 128-electrode electroencephalogram (EEG) cap53. The top right, bottom left, and bottom right pictures depict the sensitivity profile for the fNIRS probe geometry generated in AtlasViewer software. The color scale indicates the relative sensitivity in log 10 units from − 1 (blue) to 1 (red). Dots represent
Preprocessing
EEG data preprocessing
EEG data were pre-processed using EEGLab software using the method proposed by Debnath and colleagues55. EEG channels on the boundary of the electrode net (24 channels) were excluded from analyses because they were contaminated by eye, face, and head movements (17, 38, 43, 44, 48, 49, 113, 114, 119, 120, 121, 125, 126, 127, 128, 56, 63, 68, 73, 81, 88, 94, 99, 107). Then, high-pass and low-pass filters with respective cut off frequencies of 0.3 and 49 Hz were applied to the continuous data. Using the EEGLAB plugin FASTER56, artifactual channels were identified and subsequently removed. In order to remove eye blinks, respiratory, and muscle movement noise in the data, we applied extended infomax independent component analysis (ICA). During preprocessing we used the interpolation option to estimate electrical activity of the noisy electrodes mentioned above that had been removed prior to the ICA. This is a popular and well-established technique that has been mentioned in the EEGLAB tutorial. Using the ADJUST plugin57 to EEGLAB, artifactual independent components (ICs) were removed and the remaining data were epoched into − 1.5 s to 1.5 s intervals relative to the “Start Action” (SA) marker for each trial. Therefore, we extracted a total of 30 segments encompassing the 15 trials of each condition (observation and execution). These preprocessed data were used to conduct unimodal EEG analyses to assess AON activity as detected by EEG alone and were also carried forward into the EEG-fNIRS fusion analysis.
fNIRS data preprocessing
The fNIRS signal was processed using HOMER2 (MGH—Martinos Center for Biomedical Imaging, Boston, MA, USA), a MATLAB software package (The MathWorks, Inc., Natick, MA, USA). Only valid trials as identified through behavioral coding were retained in HOMER2 for data processing. Using the optical density data, we used Principal Component Analysis (PCA) set at 0.9 for movement artifact removal58. Data were low-pass filtered at 0.5 Hz to remove physiological influence from the signal and were then used to calculate the change in concentration of the hemoglobin chromophores using to the modified Beer-Lambert Law59. Traces were then segmented into 25-s epochs around the trigger stimulus for each trial (start action; SA), with each epoch starting − 5 s prior to each stimulus (0 s). Baseline correction corresponded to the mean HbO/HbR values from − 5 to 0 s. The hemodynamic response function was then generated at each channel for each condition by participant by averaging all of a participant’s response curves from all trials within a condition into a single hemodynamic curve for each channel. Due to a greater signal to noise ratio we only used the HbO signal for remaining analyses, similar to previous work in fNIRS60.
Mapping fNIRS electrodes via Atlas Viewer
We determined the anatomical regions covered by each fNIRS channel within each participant using the optode coordinates taken from the Polhemus digitizer. These coordinates were then entered into AtlasViewer61 to scale the Colin29 brain atlas to each participant’s head. AtlasViewer generated the MNI coordinates of each channel and the corresponding region of interest (ROI) for each channel was identified. Due to differences in head size, channels were not consistently positioned over the same brain region for all participants. Hence, the analyses were conducted using an ROI approach. The ROIs indicated were: postcentral, precentral, supra-marginal, inferior parietal and angular, located in both left and right hemisphere. Using the preprocessed fNIRS data and the ROI data, unimodal fNIRS analyses were conducted to assess AON activity as detected by fNIRS alone and were also carried forward into the EEG-fNIRS fusion analysis.
EEG-fNIRS data fusion
First, we convolved the mean power in the \(\mu\) frequency band (8–13 Hz in adults) for each EEG channel with the hemodynamic response function (HRF) using a gamma distribution62. AON activation in EEG is characterized by decreased power in the \(\mu\) frequency band, whereas in fNIRS, AON activation is indexed by an increase in HbO over specific brain regions, specifically bilateral superior parietal lobule, bilateral inferior parietal lobule, right supra-marginal region and right angular gyrus53. To account for the power decrease in EEG, we used the inverse value of the power in the \(\mu\) frequency band for EEG prior to applying the HRF convolution. We also used a 1000 Hz sampling rate to resample the EEG data. Since SA markers were considered the set point (0) over a 3-s epoch from − 1.5 s to 1.5 s, a total of 3000 datapoints were extracted. This resulted in the EEG matrix \(E \in { }R^{{samples{ } \times { }channels}} { }\left( {R^{{3000 \times { }128}} } \right)\).
fNIRS data were averaged over all the 30-s trials, which consisted of − 5 s before the stimulus and 25 s after at each channel. The SA marker was considered as the zero point in time in both the fNIRS and EEG datasets. The fNIRS signal was sampled at a rate of 10 Hz, resulting in an fNIRS matrix for each participant of \(N \in { }R^{{samples{ } \times { }channels}} { }\left( {R^{{300 \times { }24}} } \right)\). After projecting the fNIRS dataset to MNI space for each subject, we used the 12 regions of interest identified in AtlasViewer (see preprocessing, Sect. 2.4.3). Hence, the final fNIRS data matrix was \(\in { }R^{{samples{ } \times { }ROIs}} { }\left( {R^{{300 \times { }12}} } \right)\). Since CCA requires the same number of data samples (though a different number of features is still possible), we downsampled the EEG datasets. The final EEG and fNIRS datasets had the following dimensions: \(E\) \(\in { }R^{{300 \times { }128}}\), \(N\) \(\in { }R^{{300 \times { }12}}\), respectively. Figure 2 illustrates our preprocessing pipeline.

Preprocessing workflow for EEG and fNIRS datasets. After preprocessing, 42 datasets in total entered the ssmCCA algorithm.
We randomly divided 21 datasets (overall 42 since each participant had two sets of data: one EEG and one fNIRS dataset) into two subsets: a training set and test set. The optimal parameters were obtained from the training dataset by threefold cross validation. Then, we used the estimated parameters on the test sets to predict the correlation between the datasets. The main reason we chose threefold cross validation over the leave-one-out technique is the lower variance provided by this method. In the case of leave-one-out, where 90% of data are used for training and 10% used for testing, the test set is very small, so there is high variation in the performance estimate across different samples of data and across the different partitions of the same data forming the training and test sets. threefold validation reduces this variance by averaging over 3 different partitions, so the performance estimate is less sensitive to the partitioning of the data. We also repeated threefold cross-validation, where the cross-validation is performed using different partitioning of the data to form 3 subsets, and then took its average as well.
Results
Unimodal fNIRS
FNIRS findings suggested that bilateral superior parietal lobule (SPL), bilateral inferior parietal lobule (IPL), right supra-marginal region (SMG) and right angular gyrus (AG) are candidate regions of the human AON, as previously reported in Miguel et al.53. Figure 3 represents a summary of our findings.

Unimodal fNIRS results. HbO reconstruction maps for Execution and Observation in the Left and Right Hemisphere from − 5 to 25 s. Overall, our results showed the parietal regions, including bilateral superior parietal lobule, bilateral inferior parietal lobule, right supra-marginal region and right angular gyrus are candidate regions of the human AON53.
Unimodal EEG
Results from EEG unimodal analysis indicated bilateral μ desynchronization in central and parietal regions for execution, whereas observation resulted in bilateral μ desynchronization in the parietal region (unimodal EEG findings are in the process of publication). Figure 4 provides a topographic view of the μ desynchronization from the EEG data.

source of μ desynchronization is unspecified across the cortex due to poor spatial resolution of EEG.
Unimodal EEG results. Our EEG results show strong μ desynchronization during execution and observation conditions. Here power synchronization is indicated by warmer colors on the colorbar, while desynchronization is shown using cooler colors. Thus, μ desynchronization can be seen in blue for both action execution and action observation. However, the
EEG-fNIRS fusion
We applied our proposed ssmCCA technique to analyze the correlation between EEG and fNIRS datasets of the 21 participants during the action execution and action observation conditions separately. Our ssmCCA aims to find canonical variates (components) that are the best representative of their own modalities and, at the same time, correlate robustly with the corresponding canonical variates of the other modality. Here, we extracted four canonical variates of which one was statistically significant. Table 1 shows these components, their corresponding correlation, and statistical significance for action execution and observation. Notably, the left parietal inferior region showed a significant correlation during action observation (r = 0.48, p = 0.041), and a marginally significant correlation during action execution (r = 0.39, p = 0.055). Figure 5 provides a schematic view of the brain regions associated with action execution and action observation.

Extraced brain regions associated with execution (axial view on the top left, sagittal view on the bottom left) and observation (axial view on the top right, sagittal view on the bottom right). The color bar refers to the significance of the region (component). Our analysis shows the left inferior parietal lobule is the region which shows the highest covariation in fNIRS and EEG recordings (the most significant component). Interestiingly, the covariation in fNIRS and EEG signals in the right hemisphere are not shown to relate in our AON paradigm. Image generated using BrainNet Viewer software63.
Moreover, we examined the performance of our ssmCCA approach to two other common CCA approaches, smCCCA and mCCA. In Fig. 6, the correlations of components 1 to 4 are plotted across all three fusion approaches, with ssmCCA showing the largest correlation magnitudes across all four components in both the action and observation conditions.

Correlations by their corresponding components resulting from EEG-fNIRS fusion applying mCCA, smCCA and ssmCCA.
Discussion
Recent studies have shown great potential in combining multimodal brain imaging data captured from multiple participants by leveraging the rich information each modality provides. In this study, we developed a ssmCCA algorithm to explore relationships between multi-modal datasets to take advantage of the relative strengths of both EEG and fNIRS. The focus of this work was to use multimodal, multi-participant data fusion to characterize the human AON while addressing common problems in medical data processing, such as smaller sample size and other CCA methodological challenges, and show greater specificity in findings using a multimodal approach than the unimodal approaches alone. It is worth noting that the significance of this work is two-fold: 1. It provides methodological advancement in the field of multimodel imaging, and 2. It addresses an important research question affording better understanding of the AON.
Our proposed ssmCCA is an unsupervised learning algorithm which finds canonical variates without any prior information. As the quality and interpretibilty of the CCA components depend on the usefulness and relevance of each set of extracted features that are active across sets, our proposed ssmCCA model combines mCCA with l1-norm type penalty to automatically remove irrelevant features (sparsity constraint). This feature selection enhancement also mitigates overfitting problems caused by high-dimensional data sets with few correlated components and a small sample size. Adding l2-norm penalty, we assure the correlation between canonical projections is maximized without neglecting the local structure of the data (i.e., the adjacency in brain regions). Figure 6 also shows the advantage of using ssmCCA over smCCA (without considering l2-norm penalty) and mCCA (with no consideration of l1-norm and l2-norm penalties). As shown, applying those regularizations has improved the correlation between the two datasets and provided us with more accurate representation. Not only has our study contributed to the advancement of a method to combine EEG and fNIRS datasets, but also added to the AON literature by identifying a candidate ROI of the AON system in humans.
Our results are consistent with the AON literature. The ssmCCA analysis indicates canonical components in the inferior parietal, postcentral, supra-marginal, and precentral regions of the left hemisphere when participants performed action execution. As is well-established, motor execution engages mostly the contralateral sensory-motor cortex64,65,66,67, indexed by the precentral and postcentral regions in our study. Since participants in this study were all right-handed, the major components were detected on the left side of the brain. In the observation condition, we see the extracted components in inferior parietal, supra-marginal, postcentral, and precentral regions in the left hemisphere. Although the same sensory-motor regions are activated, the more dominant regions seem to be more posterior during the observation condition, as found in previous studies11,68. More importantly, the left inferior parietal lobe is shown to undergo the highest covariation (equivalent to greater oxyhemoglobin/decreased μ power) of simultaneous EEG and fNIRS data across both action execution and action observation, indicating that this is the strongest AON candidate region. Several unimodal studies have indicated involvement of many of these regions during action execution and action observation15,69,70. Our fNIRS unimodal analysis also implicated these regions amongst a larger set of areas of the brain involved in the human AON Fig. 353. The unimodal fNIRS findings showed widespread activation across the parietal regions, including bilateral superior parietal lobule, bilateral inferior parietal lobule, right supra-marginal region and right angular gyrus, during action execution and action observation, whereas our multimodal analysis was able to identify regions with more specificity than the unimodal approach.
In addition, our results from the EEG unimodal analysis shows μ desynchronization in both execution and observation conditions across the cortex, with limited spatial specificity of μ desynchronization Fig. 4. However, we do see a “hemisphere effect” during execution such that there was greater activity in the left central compared to right central regions, which is consistent with the contralateral effect seen in our multimodal findings. However, there was no hemisphere effect in the observation condition when using the unimodal EEG analysis, thus characterization of the AON through EEG alone was not specific to one hemisphere. Therefore, the findings from our data fusion analysis appear to be consistent with both unimodal analyses while also more specific, pointing to the left inferior parietal lobe as the region that presents the highest covariation between EEG and fNIRS signals during an AON paradigm.
While the results from our study support the use of ssmCCA to fuse simultaneous EEG and fNIRS data in an attempt to better characterize the spatial profile of cortical activation during an AON paradigm, there were limitations that could be addressed in future research. For the sake of understanding the AON, especially given our findings of lateralized components, it will be important for future studies to include left-handed participants. Furthermore, we offered a comparison of the ssmCCA findings to the fNIRS alone and EEG alone findings; however, the EEG alone findings did not utilize source localization estimates. Given that sources for surface EEG are generally understood to originate from throughout the brain and show minimal spatial specificity, EEG source localization estimates would be a useful comparison to ssmCCA findings from the multimodal dataset, or even to use in the ssmCCA to further increase specificity of our findings. Lastly, the simultaneous collection of fNIRS and high density EEG data (128 + electrodes) was challenging. Not only was the initial integration of the two caps difficult, but data loss in one or both modalities led to a notably smaller sample size for the multimodal analyses. One potential solution is to determine whether high density EEG offers an advantage when using ssmCCA, or if a similar result could be obtained using a more sparse array of EEG electrodes. Determining this could minimize cap integration issues while offering the same quality of multimodal findings and will be further investigated. Similarly, in order to clarify the role of ssmCCA in multimodal analyses, it will also be useful to apply ssmCCA to multimodal datasets that are collected both simultaneously and sequentially. It is possible that sequential data collection can provide similar multimodal findings as simultaneous data collection when using ssmCCA, which again would minimize the integration issues mentioned above. Finally, we can also apply ssmCCA to investigate the temporal components of the AON by focusing on the timing aspects of EEG timeseries as opposed to the spatial aspects, as done in the present study. Since EEG captures cortical dynamics in milliseconds, and our paradigm recorded different action markers, such as starting the action and lifting the object, we could characterize how the AON is firing in relation to each of these actions, as well as the sequence AON activation over the course of the paradigm. This would help determine whether the sequence and timing of AON activation is the same during both action execution and action observation or if there is a time lag or difference in the activation sequence. However, this would require enough spatial resolution to delineate which cortical areas are firing at different times over the course of the paradigm, which is why the present study focused on improving spatial resolution with this approach. Nonetheless, ssmCCA could also potentially be used to calculate accurate timing of the AON response between conditions, which may afford additional insight into AON function.
Data availability
All raw nirs and mmf (EEG raw data) files that support the findings of this study along with the method implementation ssmCCA are available on Dash, a NIH Data and Specimen Hub https://dash.nichd.nih.gov/ Mirror Network in At-Risk Infants [Study ID: currently the data is being transferred. The ID will be generated upon a completion of data transfer].
References
Horwitz, B. & Poeppel, D. How can EEG/MEG and fMRI/PET data be combined?. Hum. Brain Mapp. 17(1), 1–3 (2002).
Nunez, P. L. & Silberstein, R. B. On the relationship of synaptic activity to macroscopic measurements: Does co-registration of EEG with fMRI make sense?. Brain Topogr. 13(2), 79–96 (2000).
Condy, E. E. et al. Characterizing the action-observation network through functional near-infrared spectroscopy: A review. Front. Hum. Neurosci. 15, 41 (2021).
Dashtestani, H. et al. The role of prefrontal cortex in a moral judgment task using functional near-infrared spectroscopy. Brain and behavior 8, e01116 (2018).
Al-Shargie, F. et al. Assessment of mental stress effects on prefrontal cortical activities using canonical correlation analysis: an fNIRS-EEG study. Biomed. Opt. Express 8(5), 2583–2598 (2017).
Al-Shargie, F. et al. Stress assessment based on decision fusion of EEG and fNIRS signals. IEEE Access 5, 19889–19896 (2017).
Bunge, S. A. & Kahn, I. Cognition: An overview of neuroimaging techniques (2009).
Pfurtscheller, G. & Da Silva, F. L. Event-related EEG/MEG synchronization and desynchronization: basic principles. Clin. Neurophysiol. 110(11), 1842–1857 (1999).
Meltzoff, A. N. ‘Like me’: A foundation for social cognition. Dev. Sci. 10(1), 126–134 (2007).
Kuhlman, W. N. Functional topography of the human mu rhythm. Electroencephalogr. Clin. Neurophysiol. 44(1), 83–93 (1978).
Fox, N. A. et al. Assessing human mirror activity with EEG mu rhythm: A meta-analysis. Psychol. Bull. 142(3), 291 (2016).
Hobson, H. M. & Bishop, D. V. Mu suppression—A good measure of the human mirror neuron system?. Cortex 82, 290–310 (2016).
Hobson, H. M. & Bishop, D. V. The interpretation of mu suppression as an index of mirror neuron activity: Past, present and future. R. Soc. Open Sci. 4(3), 160662 (2017).
Caspers, S. et al. ALE meta-analysis of action observation and imitation in the human brain. Neuroimage 50(3), 1148–1167 (2010).
Molenberghs, P. et al. Brain regions with mirror properties: A meta-analysis of 125 human fMRI studies. Neurosci. Biobehav. Rev. 36(1), 341–349 (2012).
Rizzolatti, G. The mirror neuron system and its function in humans. Anat. Embryol. 210(5–6), 419–421 (2005).
Van Overwalle, F. & Baetens, K. Understanding others’ actions and goals by mirror and mentalizing systems: A meta-analysis. Neuroimage 48(3), 564–584 (2009).
Filimon, F. et al. Human cortical representations for reaching: Mirror neurons for execution, observation, and imagery. Neuroimage 37(4), 1315–1328 (2007).
Jelsone-Swain, L. et al. Action processing and mirror neuron function in patients with amyotrophic lateral sclerosis: An fMRI study. PLoS ONE 10(4), e0119862 (2015).
Tulay, E. E. et al. Multimodal neuroimaging: basic concepts and classification of neuropsychiatric diseases. Clin. EEG Neurosci. 50(1), 20–33 (2019).
Hotelling, H. CCA: An r package to extend canonical correlation analysis. Biometrika (1936).
Kettenring. Canonical analysis of several sets of variables. Biometrika (1971).
Dashtestani, H. et al. Canonical correlation analysis of brain prefrontal activity measured by functional near infra-red spectroscopy (fNIRS) during a moral judgment task. Behav. Brain Res. 359, 73–80 (2019).
Deleus, F. & Van Hulle, M. M. Functional connectivity analysis of fMRI data based on regularized multiset canonical correlation analysis. J. Neurosci. Methods 197(1), 143–157 (2011).
Khalid, M. U. & Seghouane, A.-K. Multi-subject fMRI connectivity analysis using sparse dictionary learning and multiset canonical correlation analysis. 2015 IEEE 12th International Symposium on Biomedical Imaging (ISBI), IEEE (2015).
Li, Y.-O. et al. Joint blind source separation by multiset canonical correlation analysis. IEEE Trans. Signal Process. 57(10), 3918–3929 (2009).
Li, Y. O. et al. Group study of simulated driving fMRI data by multiset canonical correlation analysis. J. Signal Process. Syst. 68(1), 31–48 (2012).
Katthi, J. R. & Ganapathy, S. Deep Multiway Canonical Correlation Analysis for Multi-Subject EEG Normalization (2021). arXiv preprint arXiv:2103.06478.
Zhang, Y. et al. Sparse Bayesian multiway canonical correlation analysis for EEG pattern recognition. Neurocomputing 225, 103–110 (2017).
Correa, N. M. et al. Multi-set canonical correlation analysis for the fusion of concurrent single trial ERP and functional MRI. Neuroimage 50(4), 1438–1445 (2010).
de Cheveigné, A. et al. Multiway canonical correlation analysis of brain data. Neuroimage 186, 728–740 (2019).
Adalı, T. et al. Special section on multimodal biomedical imaging: Algorithms and applications (2013).
Correa, N. M. et al. Canonical correlation analysis for feature-based fusion of biomedical imaging modalities and its application to detection of associative networks in Schizophrenia. IEEE J. Sel. Top. Signal Process. 2(6), 998–1007 (2008).
Lahat, D. et al. Multimodal data fusion: An overview of methods, challenges, and prospects. Proc. IEEE 103(9), 1449–1477 (2015).
Al-Shargie, F. et al. Mental stress assessment using simultaneous measurement of EEG and fNIRS. Biomed. Opt. Express 7(10), 3882–3898 (2016).
Alyan, E. et al. Investigating frontal neurovascular coupling in response to workplace design-related stress. IEEE Access 8, 218911–218923 (2020).
Witten, D. M. et al. A penalized matrix decomposition, with applications to sparse principal components and canonical correlation analysis. Biostatistics 10(3), 515–534 (2009).
Tibshirani, R. et al. Sparsity and smoothness via the fused lasso. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 67(1), 91–108 (2005).
Witten, D. M. and R. J. Tibshirani (2009). "Extensions of sparse canonical correlation analysis with applications to genomic data." Stat Appl Genet Mol Biol 8: Article28.
Hastie, T. et al. Statistical Learning with Sparsity: The Lasso and Generalizations, Chapman and Hall/CRC (2019).
Rasmussen, M. A. & Bro, R. A tutorial on the Lasso approach to sparse modeling. Chemom. Intell. Lab. Syst. 119, 21–31 (2012).
Simon, N. et al. A sparse-group lasso. J. Comput. Graph. Stat. 22(2), 231–245 (2013).
Chen, J. et al. Structure-constrained sparse canonical correlation analysis with an application to microbiome data analysis. Biostatistics 14(2), 244–258 (2013).
Du, L. et al. GN-SCCA: GraphNet based sparse canonical correlation analysis for brain imaging genetics. Brain Inf. Health 2015(9250), 275–284 (2015).
Grosenick, L. et al. Interpretable whole-brain prediction analysis with GraphNet. Neuroimage 72, 304–321 (2013).
Yang, S., et al. Feature Grouping and Selection Over an Undirected Graph. KDD: 922–930.
He, X. Locality preserving projections. P. Niyogi. Neural Inf. Process. Syst 16, 585–591 (2004).
Mohammadi-Nejad, A.-R. Discovering true association between multimodal data sets using structured and sparse canonical correlation analysis: A simulation G.-A. Hossein-Zadeh, IEEE 13th International Symposium on Biomedical Imaging (ISBI) 820–823 (2016).
Mohammadi-Nejad, A. R. et al. Structured and sparse canonical correlation analysis as a brain-wide multi-modal data fusion approach. IEEE Trans. Med. Imaging 36(7), 1438–1448 (2017).
Lin, D. et al. Correspondence between fMRI and SNP data by group sparse canonical correlation analysis. Med. Image Anal. 18(6), 891–902 (2014).
Waaijenborg, S., et al. Quantifying the association between gene expressions and DNA-markers by penalized canonical correlation analysis. Stat. Appl. Genet Mol Biol. 7(1): Article3.
Cannon, E. N. et al. Relations between infants’ emerging reach-grasp competence and event-related desynchronization in EEG. Dev. Sci. 19(1), 50–62 (2016).
Miguel, H. O. et al. Cerebral hemodynamic response during a live action-observation and action-execution task: A fNIRS study. PLoS ONE 16(8), e0253788 (2021).
Delorme, A. & Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 134(1), 9–21 (2004).
Debnath, R. et al. The Maryland analysis of developmental EEG (MADE) pipeline. Psychophysiology 57(6), e13580 (2020).
Nolan, H. et al. FASTER: Fully automated statistical thresholding for EEG artifact rejection. J. Neurosci. Methods 192(1), 152–162 (2010).
Mognon, A. et al. ADJUST: An automatic EEG artifact detector based on the joint use of spatial and temporal features. Psychophysiology 48(2), 229–240 (2011).
Cooper, R. J. et al. A systematic comparison of motion artifact correction techniques for functional near-infrared spectroscopy. Front. Neurosci. 6, 147 (2012).
Delpy, D. T. et al. Estimation of optical pathlength through tissue from direct time of flight measurement. Phys. Med. Biol. 33(12), 1433 (1988).
Koizumi, H. et al. Optical topography: practical problems and new applications. Appl. Opt. 42(16), 3054–3062 (2003).
Aasted, C. M. et al. Anatomical guidance for functional near-infrared spectroscopy: AtlasViewer tutorial. Neurophotonics 2(2), 020801 (2015).
Lindquist, M. A. et al. Modeling the hemodynamic response function in fMRI: Efficiency, bias and mis-modeling. Neuroimage 45(1 Suppl), S187-198 (2009).
Xia, M. et al. BrainNet Viewer: A network visualization tool for human brain connectomics. PLoS ONE 8(7), e68910 (2013).
Balconi, M. et al. Transitive versus intransitive complex gesture representation: a comparison between execution, observation and imagination by fNIRS. Appl. Psychophysiol. Biofeedback 42(3), 179–191 (2017).
Balconi, M. et al. Transitive and intransitive gesture execution and observation compared to resting state: The hemodynamic measures (fNIRS). Cogn. Process. 16(1), 125–129 (2015).
Hardwick, R. M. et al. Neural correlates of action: Comparing meta-analyses of imagery, observation, and execution. Neurosci. Biobehav. Rev. 94, 31–44 (2018).
Hardwick, R. M. et al. A quantitative meta-analysis and review of motor learning in the human brain. Neuroimage 67, 283–297 (2013).
Debnath, R. et al. Mu rhythm desynchronization is specific to action execution and observation: Evidence from time-frequency and connectivity analysis. Neuroimage 184, 496–507 (2019).
Bhat, A. N. et al. Cortical activation during action observation, action execution, and interpersonal synchrony in adults: A functional near-infrared spectroscopy (fNIRS) study. Front. Hum. Neurosci. 11, 431 (2017).
Crivelli, D. et al. Linguistic and motor representations of everyday complex actions: an fNIRS investigation. Brain Struct. Funct. 223(6), 2989–2997 (2018).
Acknowledgements
The present study was supported by the Intramural Research Program (IRP) of the National Institute of Child Health and Human Development (Project Number: 1ZIAHD008882-10) and the National Institute of Health’s Bench-to-Bedside Program.
Funding
Open Access funding provided by the National Institutes of Health (NIH).
Author information
Authors and Affiliations
Contributions
H.D.: developed the algorithm and performed the computations, prepared the first draft of the manuscript. H.M.: managed protocols, designed and carried out the experiment at NIH site, contributed to the interpretation of the results, and critical revision of the article. E.C.: managed protocols, contributed to the interpretation of the results, and critical revision of the article. S.Z. designed and carried out the experiment at UMD site, contributed to the interpretation of the results, and critical revision of the article. J.M.: carried out the experiment at NIH site, performed the measurements, and critical revision of the article. R.D.: created a pipline and performed EEG data preprocessing, contributed to the interpretation of the results, and critical revision of the article E.S.: conceived the original idea, contributed to the interpretation of the results, and critical revision of the article. T.A.: supervised almost all of the technical details, and provided critical revision of the article and final approval. N.F.: was in charge of overall direction and planning, supervised the project and technical details, provided critical revision of the article and final approval. A.G.: was in charge of overall direction and planning, supervised the project and technical details, critical revision of the article and final approval. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dashtestani, H., Miguel, H.O., Condy, E.E. et al. Structured sparse multiset canonical correlation analysis of simultaneous fNIRS and EEG provides new insights into the human action-observation network. Sci Rep 12, 6878 (2022). https://doi.org/10.1038/s41598-022-10942-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-10942-1
This article is cited by
-
Simultaneous multimodal fNIRS-EEG recordings reveal new insights in neural activity during motor execution, observation, and imagery
Scientific Reports (2023)
-
Investigation of Neuromodulatory Effect of Anodal Cerebellar Transcranial Direct Current Stimulation on the Primary Motor Cortex Using Functional Near-Infrared Spectroscopy
The Cerebellum (2023)
-
Deep learning networks based decision fusion model of EEG and fNIRS for classification of cognitive tasks
Cognitive Neurodynamics (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
