
Abstract
Simultaneous optimization of several competing objectives requires increasing the capability of optimization algorithms. This paper proposes the multi-objective moth swarm algorithm, for the first time, to solve various multi-objective problems. In the proposed algorithm, a new definition for pathfinder moths and moonlight was proposed to enhance the synchronization capability as well as to maintain a good spread of non-dominated solutions. In addition, the crowding-distance mechanism was employed to select the most efficient solutions within the population. This mechanism indicates the distribution of non-dominated solutions around a particular non-dominated solution. Accordingly, a set of non-dominated solutions obtained by the proposed multi-objective algorithm is kept in an archive to be used later for improving its exploratory capability. The capability of the proposed MOMSA was investigated by a set of multi-objective benchmark problems having 7 to 30 dimensions. The results were compared with three well-known meta-heuristics of multi-objective evolutionary algorithm based on decomposition (MOEA/D), Pareto envelope-based selection algorithm II (PESA-II), and multi-objective ant lion optimizer (MOALO). Four metrics of generational distance (GD), spacing (S), spread (Δ), and maximum spread (MS) were employed for comparison purposes. The qualitative and quantitative results indicated the superior performance and the higher capability of the proposed MOMSA algorithm over the other algorithms. The MOMSA algorithm with the average values of CPU time = 2771 s, GD = 0.138, S = 0.063, Δ = 1.053, and MS = 0.878 proved to be a robust and reliable model for multi-objective optimization.
Similar content being viewed by others

Introduction
Today, most of the engineering problems require dealing with multiple conflicting objectives instead of a single-objective. For such problems, the multi-objective optimization (MOO) is an efficient technique for finding a set of solutions that define the best tradeoff between competing objectives while satisfying several criteria. MOO was introduced by Vilfredo Pareto and today, it became an important tool for decision-making in many fields of engineering, where the optimal decisions should be taken between conflict objectives. Various methods have been proposed for the MOO. In 1984, Schaffer introduced the innovative idea of employing evolutionary optimization algorithms for multi-objective optimization1. Since then, several researchers have attempted to develop different types of multi-objective evolutionary algorithms2,3,4,5,6,7,8,9,10,11,12. The several advantages of the evolutionary optimization algorithms such as the gradient-free mechanism and the local optima avoidance have made them readily applicable to real problems in different fields of science.
The literature shows that the multi-objective evolutionary algorithms are able to efficiently approximate the true Pareto optimal solutions of multi-objective problems. However, in 1997, Wolpert and Macready, by proposing the No Free Lunch-NFL theorem, claimed that there is no optimization technique capable to solve all optimization problems13. According to this theorem, the superior performance of an optimization method in a category of problems cannot guarantee its’ superiority on another category of problems. This theorem encourages the researchers to propose new optimization evolutionary algorithms for new categories of problems in the study field.
Some of the most well-known multi-objective evolutionary algorithms which have had desirable performance in solving large scale engineering problems are Strength–Pareto Evolutionary Algorithm, SPEA14,15, Non-dominated Sorting Genetic Algorithm, NSGA16, Non-dominated Sorting Genetic Algorithm version 2, NSGA-II2, Multi-Objective Particle Swarm Optimization, MOPSO17, Multi-Objective Evolutionary Algorithm based on Decomposition, MOEA/D18, Pareto Archived Evolution Strategy, PAES19, and Pareto–frontier Differential Evolution, PDE20, Multi-Objective Water Cycle Algorithm, MOWCA21, and Multi-Objective Grey Wolf Optimizer, MOGWO22, Pareto envelope-based selection algorithm-II, PESA-II23 and Multi-Objective Ant Lion Optimizer, MOALO24.
All the aforementioned multi-objective algorithms are indeed the developed version of their single-objective algorithms. One of the strongest single-objective algorithms within the family of evolutionary algorithms is the moth swarm algorithm (MSA). The MSA has been proven to be superior to over 80 other evolutionary algorithms25,26,27,28,29,30,31,32,33. Due to the novelty of the MSA, there is still no study in the literature to design a multi-objective version of this algorithm. Accordingly, this paper proposes the multi-objective moth swarm algorithm (MOMSA), for the first time, in order to optimize the problems with multiple objectives. The proposed algorithm was tested on 7 multi-objective benchmark problems having 7 to 30 dimensions and the results were compared with three well-known meta-heuristics of MOEA/D, PESA-II and MOALO.
The rest of the paper is organized as follows. “Methodology” section presents a brief overview on the single-objective MSA, and next the modeling procedure of the multi-objective MSA followed by the utilized performance metrics. Next, the utilized benchmark functions (ZDT and DTLZ) are introduced and thereafter the comparative multi-objective algorithms are briefly introduced. The last part of “Methodology” section is devoted to the sensitivity analysis on the algorithms parameters. “Results and discussion” section provides the qualitative and qualitative results as well as relevant discussion. Eventually, “Conclusion” section concludes the work and outlines some recommendations for researchers.
Methodology
Single-objective MSA
Single-objective MSA, proposed by Mohamed et al.25, was inspired by the behavior of moths in the nature. Here, a brief overview on this algorithm is provided. More details and the mathematical explanations can be found in Mohamed et al.25.
In the MSA, three groups of moths (pathfinders, prospectors, and onlookers) and a light source are considered. Pathfinders are capable to find the best position over the optimization space with First-In, Last-Out principle to guide the movement of the main swarm. Prospectors tend to wander into a random spiral path nearby the light sources, which have been marked by the pathfinders. Onlookers drift directly toward the best global solution (moonlight), which has been achieved by prospectors’ moths. Therefore, the possible solution in MSA is represented by position of light source, and the quality of this solution is considered as luminescence intensity of the light source.
The MSA algorithm is performed through three phases of initialization, reconnaissance, and transverse orientation. At the beginning of the flight, the position of each moths (initial solution) is randomly determined by a randomization function (initialization phase). Then, the type of each moth in the population is selected based on the fitness value (objective function). The best moth is considered as pathfinder (light sources) and the best and worst groups of moths are considered as prospectors and onlookers, respectively. During the prospecting process, the moths may be concentrated in some parts of the response space, led to entrapment in the local optima and reducing the quality of some moth populations. To prevent premature convergence and improve the diversity in solutions, a part of the moth population is required to prospect the areas with less swarm. Pathfinders are responsible for this role. Thus, they update their position through interaction with each other and crossover operations and with the ability to fly long distances (known as lévy mutation) and prevent the stop in local optima (reconnaissance phase). The flight path of moths toward a light source can be described by cone-shaped logarithmic spirals. Accordingly, a set of paths located on the surface of the cone, with a fixed central angle, can describe the flight path of moths to the light source. A group of the moth with the highest luminescence intensities is selected as the prospectors. The number of prospectors should be reduced in each iteration (transverse orientation phase).
During the optimization process in the MSA, by reducing the number of prospectors, the number of onlookers increases. This leads to a faster convergence to the global solution. The increased convergence speed is in fact, due to the celestial navigation. An onlooker moth with the lowest luminescence can travel directly toward the best solution (moon). Hence, to control the recent movement, this step of the MSA algorithm is designed such a way that onlookers are forced to search more effectively through focusing on important points of prospector. To this purpose, the onlookers are divided into two parts with Gaussian walk and associative learning mechanism. In the MSA, the type of each moth is alternately varied. Thus, each prospector that provides a better solution (greater luminescence than the light source) is promoted to the pathfinder. At the end of each step, the new light and moonlight sources will be available as possible solutions.
The problem-solving steps of the single-objective MSA algorithm are shown by Algorithm 1 .

Mathematical model of multi-objective problems
Optimizing multi-objective problems (MOPs) involves more than one objective function that should be optimized simultaneously. Equation (12) expresses the mathematical form of the objective function of the MOP problem.
where \(X={x}_{1}, {x}_{2}, {x}_{3}, \dots , {x}_{d}\) is the vector of variables, and d and m refer to the number of variables and objectives, respectively.
The most common solution for MOPs is to keep a set of the best solutions in an archive and update it per iteration. In this method, the best solutions are defined as non-dominant solutions or Pareto optimal solutions. A solution can be considered as a non-dominant solution if and only if the following conditions are met34:
-
Pareto dominance: \(U=\left(u1, u2, u3,\dots , un\right)<V=(v1, v2, v3,\dots ,vn)\) if and only if U is slightly lower than V in the objective space, which means:
$$\left\{\begin{array}{c}{f}_{i}\left(U\right)\le {f}_{i}\left(V\right) \forall i\\ {f}_{i}\left(U\right)<{f}_{i}\left(V\right) \exists i\end{array}\right. \quad i=1, 2, 3,\dots , m.$$(13) -
Pareto optimal solution: U vector is an optimal solution if and only if none of the other solutions can dominate U. A set of Pareto optimal solutions is called Pareto optimal front (PFoptimal).
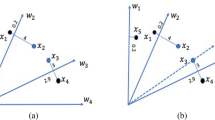
Figure 1 shows that of the three solutions A, B, and C, the solution C has the maximum values for f1 and f2; as a result, it is considered the dominant solution. On the contrary, both solutions A and B can be taken into account as non-dominant solutions.

Pareto optimal solutions (A and B) for 2D space.
Multi-objective MSA
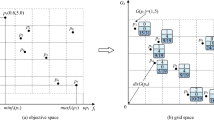
In order to develop the single-objective MSA to an efficient multi-objective optimization algorithm, the dominant features of the algorithm must be properly defined. Accordingly, the definition for selecting the type of moths and the best value (moonlight) should be changed to a multi-objective space. In this way, the crowding-distance mechanism was employed to select the most efficient (best) solutions in the population as the pathfinder moths and moonlight (global optimum). This mechanism shows the distribution of non-dominant solutions around a non-dominant solution. Figure 2 shows the calculation of crowding-distance for point i (moth) from the Pareto front.

Calculating crowding-distance for point i (moth).
The crowding-distance for a moth can also be calculated by the following equations:
where \({N}_{O}\) refers to the number of problem objective functions, \({\widehat{X}}_{f}^{l}\) refers to the Pareto front, \({f}_{j}^{max}\) and \({f}_{j}^{min}\) are the maximum and minimum values obtained for the jth objective function, and \({f}_{j}^{i+1}\) and \({f}_{j}^{i-1}\) are the values for the jth objective function for i + 1 and i − 1 moths.
A lower crowding-distance value shows a greater distribution of solutions in a specific region. In multi-objective problems (MOPs), this parameter is calculated in the objective spaces; hence, all the non-dominant solutions must be classified based on the values for one of the objective functions. These parameters should be calculated for each of the non-dominant solutions. An important step in the MOMSA is the selection of the moonlight and pathfinders from the population, as the best solution in each iteration. This affects the MOMSA synchronization capability and retains a good spread of non-dominant solutions.
The crowding-distance must be calculated for all non-dominant solutions and in all iterations of the algorithm. It is essential to determine the solutions having the highest crowding-distance values. Then, the non-dominant solutions are considered as the moonlight and the pathfinders. In addition, the prospectors and onlookers are determined based on the crowding-distance values. Some non-dominant solutions are made in proximity to the moonlight and pathfinders in the next iteration, and their distance values are reduced and declined.
It is essential to reserve the non-dominant solutions in an archive to achieve the Pareto front sets. This archive gets updated with each iteration and the dominated solutions are eliminated from the archive. Therefore, whenever the number of members in the Pareto archive becomes larger than the size of Pareto archive, the crowding-distance is used to eliminate the non-dominant solutions that have the lowest crowding-distance values among the Pareto archive members. MOMSA has a great potential for the exploitation in the design space, it focuses on the near-optimal solutions and exploits the long-distance solutions.
Furthermore, the Lévy mutation and the collaborative learning mechanisms were used to improve the exploitation and exploration capabilities of the developed algorithm, respectively. MOMSA usually starts with the exploitation phase, the prospectors move toward the pathfinders and the onlookers move toward the prospectors. However, in the early iteration, these motions act as a heuristic factor. This trend can be considered as the MOMSA capability to find a wide range of design space, while focusing on the optimal non-dominant solutions.
In MOMSA, a simple approach is defined to handle the limitations of MOPs. After obtaining a set of solutions in each iteration, all the limitations are investigated and some solutions in the possible space are selected. Then, the non-dominant solutions are selected from the possible solutions and are imported into the Pareto archive. Finally, the moonlight and pathfinders are selected from this archive for the next iteration. Different problem-solving steps of the MOMSA algorithm are shown in Algorithm 2.

Performance metrics
In order to evaluate the performance of multi-objective evolutionary algorithms in optimization of multi-objective problems, four performance metrics of generational distance (GD), metric of spacing (S), metric of spread (Δ), and maximum spread (MS) were used. Here, these metrics are briefly introduced.
GD, defined by Van Veldhuizen and Lamont35, refers to the distance between the generated Pareto front with the Pareto optimal front. This metric determines the ability of an algorithms to find a set of non-dominant solutions that has the lowest distance to the Pareto optimal front. In other words, the algorithms with the lowest GD have the best convergence with the Pareto optimal front. GD is calculated by Eq. (17)36:
where NPF is the number of members in the generated Pareto front (PF) and d is the Euclidean distance between ith member in PFg and the nearest member in PFoptimal. Figure 3 shows a schematic view of the GD metric in 2D space. The best metric derived for GD is zero, so that PFg is exactly on PFoptimal.

Schematic of the GD metric for MOPs35.
S refers to the metric of spacing which indicates the distribution of non-dominated solutions obtained by an algorithm. This metric shows how well the obtained solutions are distributed among each other37. This metric is calculated by Eq. (18)38:
where \({d}_{i}={min}_{j}(\left|{f}_{1}^{i}\left(x\right)-{f}_{1}^{j}\left(x\right)\right|+\left|{f}_{2}^{i}\left(x\right)-{f}_{2}^{j}\left(x\right)\right|\) , i,j = 1,2,…,NPF, and \(\overline{d }\) is the mean of all di. The lowest value of S leads to the best uniform distribution in PFg. If all the non-dominant solutions are evenly distributed in PFg, the values of di and d are the same; as a result, the value of S is equal to zero. Figure 4 shows a schematic view of S metric.

A schematic view of S metric for MOPs37.
Metric of spread (Δ) shows the extent of spread attained by the non-dominated solutions obtained from an algorithm38. It is calculated by Eq. (19)38:
where df and dl are the Euclidean distance between the extreme solutions (starting and ending points) in PFoptimal and PFg respectively, and di refers to the distance between each point in PFg and the closest point in PFoptimal. The value of Δ is always larger than zero and its lower value means the best distribution and extension of solutions. If Δ is equal to zero, the excellent conditions occur, indicating that extreme solutions of PFoptimal have been found and that \({d}_{i}=\overline{d }\) for all non-dominated points. Figure 5 shows a schematic view of Δ metric for a Pareto optimal front.

Maximum spread (MS) shows how much the starting and ending points of PF line overlap the similar points on the PFoptimal line; hence, the proximity of the two extreme points in PFoptimal and PFg is measured. In other words, this metric shows how much the lines of discovered non-dominant solutions overlap the Pareto line; therefore, the greater overlapping, the better. This metric is defined as Eq. (20)39:
where \({f}_{i}^{max}\) and \({f}_{i}^{min}\) are the maximum and minimum values of the ith objective in PFg, respectively, and \({F}_{i}^{max}\) and \({F}_{i}^{min}\) are the maximum and minimum values of the ith objective in PFoptimal, respectively. A larger value of MS refers to better expansion of solutions.
Benchmark problems
In order to evaluate the capability and performance of the developed MOMSA algorithm, which was coded in the programming section of MATLAB R2014a software (www.mathworks.com), several standard multi-objective benchmark functions were used. These problems were different types of multi-objective problems (MOPs) with various features that were selected from a set of valid studies. In all the benchmark functions, in order to achieve reliable results, 10 independent runs of each algorithm were compared. In all these cases, the mean of the best results was shown. Moreover, for appropriate and fair comparison with the other algorithms, the number of iteration and the size of the Pareto archive for all MOPs were considered as the same and determined by the sensitivity analysis.
ZDT benchmark problems
The ZDT test suite, created by Zitzler et al.39 consists of six test problems. It is the most widely employed suite of benchmark multi-objective problems in the EA literature. Table 1 shows the ZDT standard bi-objective benchmark functions with different dimensions.
DTLZ benchmark problems
The DTLZ test suite, created by Deb et al.40 is unlike the majority of multi-objective test problems in which the problems are scalable to any number of objectives. Table 2 shows DTLZ1 and DTLZ2 standard tri-objective benchmark functions with 7 and 12 dimensions.
Comparative algorithms
To investigate the efficiency of the proposed MOMSA, the results were compared with three well-known multi-objective algorithms of MOEA/D, SPEA-II and MOALO.
The MOEA/D algorithm, proposed by Zhang and Li18, needs to decompose the target MOP. Zhang and Li18 used the Tchebycheff decomposition approach to serve this purpose. In MOEA/D, the population is composed of the best solution found so far for each subproblem. Only the current solutions to its neighboring subproblems are exploited for optimizing a subproblem in MOEA/D. The PESA-II algorithm, proposed by Corne et al.23, utilizes a selection technique for MOO algorithms in which the unit of selection is a hyper box in the objective space. In this technique, instead of assigning a selective fitness to an individual, the selective fitness is assigned to the hyper boxes in objective space which are currently occupied by at least one individual in the current approximation to the Pareto frontier. A hyper box is thereby selected, and the resulting selected individual is randomly chosen from this hyper box. This method of selection is shown to be more sensitive to ensuring a good spread of development along the Pareto frontier than individual-based selection. The MOALO algorithm, proposed by Mirjalili et al.24, was inspired by the mimics the hunting mechanism of antlions and the interaction of their favorite prey, ants, with them in nature. In this algorithm, a repository is first employed to store non-dominated Pareto optimal solutions obtained so far. Solutions are then chosen from this repository using a roulette wheel mechanism based on the coverage of solutions as antlions to guide ants towards promising regions of multi-objective search spaces.
Sensitivity analysis
Sensitivity analysis is an essential ingredient of MOO algorithms building and quality assurance. In this study, a sensitivity analysis was carried out to obtain the best values of the algorithm’s parameters. Here the results of the sensitivity analysis on the number of iterations for all the utilized algorithms in solving the ZDT1 benchmark function are presented. As seen in Fig. 6, by increasing the number of iterations, the obtained Pareto front gets closer to the optimal Pareto front, so that, after 1000 iterations, the obtained Pareto front has been largely overlapped to the optimal Pareto front.

Sensitivity analysis on the number of iterations in the ZDT1 multi-objective test function.
The quantitative values of performance metrics at the Table 3 confirmed the above results. This table shows that after 1000 iterations, all the performance metrics of the utilized algorithms have reached their best values. Accordingly, the number of iterations was considered to be 1000 for all the algorithms.
Table 4 provides the best values of MOMSA, MOEA/D, MOALO, and PESA-II algorithms’ parameters based on the sensitivity analysis. In all the benchmark functions, in order to achieve reliable results, 10 independent runs of each algorithm were compared. Furthermore, to have a fair comparison, the size of Pareto archive was considered the same.
Results and discussion
As mentioned in the introduction, this study proposes the multi-objective moth swarm algorithm to solve various multi-objective problems. In order to evaluate the performance of the developed MOMSA algorithm, four evaluation metrics of GD, S, Δ, and MS were used. The results of MOMSA were compared with three well-known algorithms of MOEA/D, PESA-II and MOALO. Tables 5, 6, 7 and 8 indicate the values of the performance metrics (for 10 independent runs) of the utilized multi-objective algorithms in optimization of ZDT bi-objective and DTLZ tri-objective benchmark functions.
As can be seen, the developed MOMSA algorithm was superior in the majority of the standard bi-objective and tri-objective benchmark functions. In terms of CPU time, the proposed MOMSA algorithm had the lowest executing time for all the bi-objective and tri-objective benchmark functions. For example, for the ZDT6 bi-objective function, the CPU time for the MOMSA was 1579 s, while for the MOEAD, MOALO, and PESA-II, the CPU time was 1726s, 1953s, and 2393 s, respectively. Similar results were obtained for tri-objective functions. For example, for the DTLZ2 benchmark function, the CPU time for the MOMSA, MOEA/D, MOALO and PESA-II was 4184 s, 4215 s, 4581, and 4438 s, respectively. This indicates that the MOMSA was the fastest model in running the code, it can achieve impressive results in a much shorter time.
In terms of the GD metric, the MOMSA with the lowest GD outperformed in all the ZDT bi-objective benchmark functions. For example, the average value of GD for ZDT3 benchmark function obtained by the MOMSA algorithm was 0.017, while the corresponding values for MOEA/D, MOALO and PESA-II algorithms were 0.22, 0.028, and 0.087, respectively, indicating the higher performance of the MOMSA compared to the other algorithms. Therefore, it can be said that the MOMSA could find the non-dominant solutions with minimum distance from PFoptimal (GD metric) and had a better distribution than the three other algorithms. Also, for the tri-objective benchmark functions, the MOMSA though had the best results for DTLZ1, but for DTLZ2, it placed at the second rank after the MOEA/D algorithm.
For the S metric, while the MOMSA algorithm outperformed the other algorithms in optimizing the ZDT1, ZDT3 and ZDT6 benchmark functions, the MOALO and the MOEA/D algorithms demonstrated better results for the ZDT2 and ZDT6, respectively. In addition, for both the tri-objective standard functions (DTLZ1 and DTLZ2), the MOMSA was the superior model in terms of S.
The obtained results for Δ metric demonstrated that the MOMSA was superior for ZDT1 (Δ = 0.696) and ZDT3 (Δ = 0.910) functions, the MOEA/D was superior for ZDT6 (Δ = 1.137), DTLZ1 (Δ = 1.042) and DTLZ2 (Δ = 1.019) functions and the PESA-II produced the best results for ZDT2 (Δ = 0.721) and ZDT4 (Δ = 0.973) functions.
As seen in Table 8, the MOMSA outperforms the other algorithms for most of the benchmark functions in terms of MS metric, and the MOEA/D obtained the second rank. Overall, it is found from Tables 5, 6, 7 and 8 that the proposed MOMSA algorithm was superior to the three other studied algorithms, especially in GD and S metrics.
This superiority was also more evident in Figs. 7 and 8. These figures show a graphical comparison between the true (optimal) and the obtained Pareto fronts by the multi-objective algorithms in solving the ZDT and DTLZ standard multi-objective benchmark functions.



(a) Obtained Pareto optimal solutions by MOMSA, MOEA/D, MOALO, and PESA-II for ZDT1. (b) Obtained Pareto optimal solutions by MOMSA, MOEA/D, MOALO, and PESA-II for ZDT2. (c) Obtained Pareto optimal solutions by MOMSA, MOEA/D, MOALO, and PESA-II for ZDT3. (d) Obtained Pareto optimal solutions by MOMSA, MOEA/D, MOALO, and PESA-II for ZDT4. (e) Obtained Pareto optimal solutions by MOMSA, MOEA/D, MOALO, and PESA-II for ZDT6.

(a) Obtained Pareto optimal solutions by MOMSA, MOEA/D, MOALO, and PESA-II for DTLZ1. (b) Obtained Pareto optimal solutions by MOMSA, MOEA/D, MOALO, and PESA-II for DTLZ2.
For ZDT1 and ZDT2 benchmark function, two algorithms of MOMSA and MOEA/D yielded more accurate results, very close to the optimal Pareto front, but the MOALO could not cover the optimal Pareto front and the SPEA-II failed to produce satisfactory distribution and spread for the non-dominated solutions. For ZDT3 benchmark function, the proposed MOMSA was the only model. In addition, the proposed MOMSA was much more successful than the MOEA/D in optimizing the ZDT4 benchmark function, while the SPEA-II and MOALO algorithms were unable to produce reasonable results. For ZDT6 benchmark function, the distributions of the obtained fronts are similar for all the algorithms to some extent, slightly better for the MOMSA algorithm.
Similar results were obtained for the tri-objective benchmark functions of DTLZ1 and DTLZ2. As seen in Fig. 8, the proposed MOMSA was the only model that had impressive results. It could produce a better distribution and spread for the non-dominated solutions compared to the MOEA/D. In this case, the performance of MOALO and the SPEA-II was not acceptable. For the DTLZ2 benchmark function, the Pareto front obtained by MOEA/D algorithm was closer to the optimal Pareto front compared to the proposed MOMSA. Nevertheless, the MOMSA also gave quite good results. Both the MOEA/D and MOMSA algorithms were much more successful than the MOALO and SPEA-II algorithms. Comparing the graph of SPEA-II with that of MOALO indicates the superiority of the former algorithm in optimization of DTLZ2 benchmark function. All these results were quantitatively obtained in the previous section.
Figure 9 shows the boxplots of the metrics of spacing (S) derived from 10 independent runs of the MOMSA, MOEA/D, MOALO and SPEA-II algorithms in solving the ZDT multi-objective standard benchmark functions. As seen, the boxplots of the proposed MOMSA and the MOEA/D are narrower than the MOALO and SPEA-II for ZDT1, ZDT3 and ZDT6, indicating the superior performance of MOMSA and MOEA/D in solving those benchmark functions. These results prove that these two algorithms were able to provide remarkable convergence and coverage ability in solving multi-objective problems. For the ZDT2, the MOEA/D followed by PESA-II has narrower boxplots indicating the better efficiency of those algorithms compared to the MOMSA and MOALO. In ZDT4 benchmark problem, the MOMSA was the best model, it has the narrowest boxplot and located under the minima of MOALO, MOEA/D, and PESA-II algorithms. For ZDT6 benchmark function, the boxplot of all the algorithms are similar to some extent, slightly better for the MOEA/D algorithm. After that, the proposed MOMSA, and the MOALO placed in the next ranks. The results of PESA-II algorithm in solving the ZDT6 were poor. Similar results were observed for the three other performance metrics (GD, MS and Δ).

Boxplot of the statistical results for S evaluation metrics on ZDT bi-objective test function suite.
For the tri-objective benchmark functions of DTLZ1, as illustrated by Fig. 10, the boxplot of the MOMSA algorithm was super narrow and located under the minima of the other algorithms. After the MOMSA, the MOEA/D demonstrated better results followed by MOALO. The performance of PESA-II was poor. For the DTLZ2 benchmark function, the MOMSA had the lowest and the narrowest boxplot of S metric among all, indicating its highest efficiency in solving the DTLZ2 benchmark function. Similar results were obtained for the performance metrics of GD, MS and Δ.

Boxplot of the statistical results for S evaluation metrics on DTLZ1 and DTLZ2 tri-objective test function.
Conclusion
As the superiority of single-objective moth swarm algorithm (MSA) in solving various engineering problems was confirmed by previous studies, this study proposed the multi-objective version of MSA, called MOMSA, to solve various multi-objective problems. Accordingly, a series of improvements was applied in algorithms’ synchronization capability and selection method. The capability of the proposed MOMSA in comparison with three well-known multi-objective algorithms of MOEA/D, PESA-II, and MOALO were tested on 7 standard benchmark functions having 7 to 30 dimensions including five bi-objective ZDT functions and two tri-objective DTLZ functions. The results were evaluated by four performance metrics. It was found that the performance of the proposed MOMSA algorithm became more evident with increasing the dimensions and the complexity of the problem (ZDT1 to ZDT3). So that, in the ZDT1 problem with 30 decision variables, the MOMSA algorithm showed better performance (GD = 0.028, S = 0.050, Δ = 0.696, MS = 0.986) than the MOEA/D algorithm (GD = 0.159, S = 0.051, Δ = 1.044, MS = 1.518), and the MOALO algorithm (GD = 0.044, S = 0.071, Δ = 1.345, MS = 0.499), and the PESA-II algorithm (GD = 0.079, S = 0.068, Δ = 0.763, MS = 0.916). Also, the Pareto front derived by the MOMSA algorithm in most cases was more regular and at a more appropriate level than the MOAE/D, MOALO and SPEA-II algorithms. The results indicated the superior performance of the MOMSA and the MOEA/D algorithms over the other two algorithms in both the ZDT and DTLZ benchmark functions. The results also showed that, the dispersion of MOMSA and MOEA/D algorithm distances was smaller than the MOALO and the SPEA-II algorithms with theoretical solutions to the almost all of the ZDT and DTLZ benchmark functions. In addition to the strong convergence to the exact Pareto front, the proposed MOMSA had less dispersion in solutions and achieved the desirable solution in most of the benchmark problems. Regarding the impressive results of the MOMSA algorithm, this study recommends it as a robust and reliable multi-objective optimization model for various optimization problems.
References
Coello, C. C. Evolutionary multi-objective optimization: A historical view of the field. IEEE Comput. Intell. Mag. 1(1), 28–36 (2006).
Deb, K., Pratap, A., Agarwal, S. & Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 6(2), 182–197 (2002).
Abido, M. A. A novel multi-objective evolutionary algorithm for environmental/economic power dispatch. Electr. Power Syst. Res. 65, 71–81 (2003).
Agrawal, S., Panigrahi, B. K. & Tiwari, M. K. Multi-objective particle swarm algorithm with fuzzy clustering for electrical power dispatch. IEEE Trans. Evol. Comput. 12, 529–541 (2008).
Gong, D., Sun, J. & Ji, X. Evolutionary algorithms with preference polyhedron for interval multi-objective optimization problems. Inf. Sci. 233, 141–161 (2013).
Rao, R. V., Rai, D. P. & Balic, J. A multi-objective algorithm for optimization of modern machining processes. Eng. Appl. Artif. Intell. 61, 103–125 (2017).
Guo, Y. N., Cheng, J., Luo, S., Gong, D. & Xue, Y. Robust dynamic multi-objective vehicle routing optimization method. IEEE/ACM Trans. Comput. Biol. Bioinform. 15(6), 1891–1903 (2017).
Zhang, Y., Gong, D. W., Sun, J. Y. & Qu, B. Y. A decomposition-based archiving approach for multi-objective evolutionary optimization. Inf. Sci. 430, 397–413 (2018).
Guo, Y. N., Zhang, P., Cheng, J., Wang, C. & Gong, D. Interval multi-objective quantum-inspired cultural algorithms. Neural Comput. Appl. 30(3), 709–722 (2018).
Guo, Y. N., Zhang, X., Gong, D. W., Zhang, Z. & Yang, J. J. Novel interactive preference-based multiobjective evolutionary optimization for bolt supporting networks. IEEE Trans. Evol. Comput. 24(4), 750–764 (2019).
Guo, Y., Yang, H., Chen, M., Cheng, J. & Gong, D. Ensemble prediction-based dynamic robust multi-objective optimization methods. Swarm Evol. Comput. 48, 156–171 (2019).
Dhiman, G. et al. EMoSOA: A new evolutionary multi-objective seagull optimization algorithm for global optimization. Int. J. Mach. Learn. Cybern. 12(2), 571–596 (2021).
Wolpert, D. H. & Macready, W. G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1(1), 67–82 (1997).
Zitzler, E. Evolutionary Algorithms for Multiobjective Optimization: Methods and Applications Vol. 63 (Shaker, 1999).
Zitzler, E. & Thiele, L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 3(4), 257–271 (1999).
Srinivas, N. & Deb, K. Muiltiobjective optimization using nondominated sorting in genetic algorithms. Evol. Comput. 2(3), 221–248 (1994).
Coello, C. C. A., Pulido, G. T. & Lechuga, M. S. Handling multiple objectives with particle swarm optimization. IEEE Trans. Evol. Comput. 8(3), 256–279 (2004).
Zhang, Q. & Li, H. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 11(6), 712–731 (2007).
Knowles, J. & Corne, D. The Pareto archived evolution strategy: A new baseline algorithm for Pareto multiobjective optimisation. In Proc. 1999 Congress on Evolutionary Computation-CEC99 (Cat. No. 99TH8406), Vol. 1, 98–105. IEEE (1999).
Abbass, H. A., Sarker, R. & Newton, C. PDE: A Pareto-frontier differential evolution approach for multi-objective optimization problems. In Proc. 2001 Congress on Evolutionary Computation (IEEE Cat. No. 01TH8546), Vol. 2, 971–978. IEEE (2001).
Sadollah, A., Eskandar, H. & Kim, J. H. Water cycle algorithm for solving constrained multi-objective optimization problems. Appl. Soft Comput. 27, 279–298 (2015).
Mirjalili, S., Saremi, S., Mirjalili, S. M. & Coelho, L. D. S. Multi-objective grey wolf optimizer: A novel algorithm for multi-criterion optimization. Expert Syst. Appl. 47, 106–119 (2016).
Corne, D. W., Jerram, N. R., Knowles, J. D. & Oates, M. J. PESA-II: Region-based selection in evolutionary multiobjective optimization. In Proc. 3rd Annual Conference on Genetic and Evolutionary Computation, 283–290 (2001).
Mirjalili, S., Jangir, P. & Saremi, S. Multi-objective ant lion optimizer: A multi-objective optimization algorithm for solving engineering problems. Appl. Intell. 46(1), 79–95 (2017).
Mohamed, A. A. A., Mohamed, Y. S., El-Gaafary, A. A. & Hemeida, A. M. Optimal power flow using moth swarm algorithm. Electric Power Syst. Res. 142, 190–206 (2017).
Zhou, Y., Yang, X., Ling, Y. & Zhang, J. Meta-heuristic moth swarm algorithm for multilevel thresholding image segmentation. Multimedia Tools Appl. 77(18), 23699–23727 (2018).
Jevtic, M., Jovanovic, N., Radosavljevic, J. & Klimenta, D. Moth swarm algorithm for solving combined economic and emission dispatch problem. Elektron. ir Elektrotech. 23(5), 21–28 (2017).
Yang, X., Luo, Q., Zhang, J., Wu, X. & Zhou, Y. Moth swarm algorithm for clustering analysis. In International Conference on Intelligent Computing, 503–514. (Springer, 2017).
Akbarifard, S., Sharifi, M. R. & Qaderi, K. Data on optimization of the karun-4 hydropower reservoir operation using evolutionary algorithms. Data Brief 29, 105048 (2020).
Sharifi, M. R., Akbarifard, S., Qaderi, K. & Madadi, M. R. Developing MSA algorithm by new fitness-distance-balance selection method to optimize cascade hydropower reservoirs operation. Water Resour. Manage. 35(1), 385–406 (2021).
Madadi, M. R., Akbarifard, S. & Qaderi, K. Improved moth-swarm algorithm to predict transient storage model parameters in natural streams. Environ. Pollut. 262, 114258 (2020).
Akbarifard, S., Sharifi, M. R., Qaderi, K. & Madadi, M. R. Optimal operation of multi-reservoir systems: Comparative study of three robust metaheuristic algorithms. Water Supply 21(2), 941–958 (2021).
Sharifi, M. R., Akbarifard, S., Qaderi, K. & Madadi, M. R. Comparative analysis of some evolutionary-based models in optimization of dam reservoirs operation. Sci. Rep. 11(1), 1–17 (2021).
Coello, C. A. An updated survey of GA-based multiobjective optimization techniques. ACM Comput. Surv. (CSUR) 32(2), 109–143 (2000).
Van Veldhuizen, D. A. & Lamont, G. B. Multiobjective Evolutionary Algorithm Research: A History and Analysis. Technical Report TR-98-03 (Air Department of Electrical and Computer Engineering, Graduate School of Engineering, Air Force Institute of Technology, Wright-Patterson AFB, 1998).
Coello, C. C. & Pulido, G. T. Multiobjective structural optimization using a microgenetic algorithm. Struct. Multidiscipl. Optim. 30(5), 388–403 (2005).
Schott, J. R. Fault Tolerant Design Using Single and Multicriteria Genetic Algorithm Optimization (No. AFIT/CI/CIA-95–039) (Air Force Inst of Tech, Wright-Patterson AFB, 1995).
Deb, K. Multi-objective Optimization Using Evolutionary Algorithms Vol. 16 (Wiley, 2001).
Zitzler, E., Deb, K. & Thiele, L. Comparison of multiobjective evolutionary algorithms: Empirical results. Evol. Comput. 8(2), 173–195 (2000).
Deb, K., Thiele, L., Laumanns, M. & Zitzler, E. Scalable multi-objective optimization test problems. In Proc. 2002 Congress on Evolutionary Computation. CEC’02 (Cat. No. 02TH8600), Vol. 1, 825–830. IEEE (2002).
Acknowledgements
We are grateful to the Research Council of Shahid Chamran University of Ahvaz for financial support (GN: SCU.WH99.26878).
Author information
Authors and Affiliations
Contributions
S.A.: methodology, writing, original draft preparation, data analysis. M.R.S.: conceptualization, data collection, supervision. K.Q.: visualization, review, supervision. M.R.M.: review, English editing, supervision.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sharifi, M.R., Akbarifard, S., Qaderi, K. et al. A new optimization algorithm to solve multi-objective problems. Sci Rep 11, 20326 (2021). https://doi.org/10.1038/s41598-021-99617-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-99617-x
This article is cited by
-
Applying the new multi-objective algorithms for the operation of a multi-reservoir system in hydropower plants
Scientific Reports (2024)
-
Guided golden jackal optimization using elite-opposition strategy for efficient design of multi-objective engineering problems
Neural Computing and Applications (2023)
-
Optimization of hydropower energy generation by 14 robust evolutionary algorithms
Scientific Reports (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
