
Abstract
In real-world settings, learning is often characterised as intentional: learners are aware of the goal during the learning process, and the goal of learning is readily dissociable from the awareness of what is learned. Recent evidence has shown that reward and punishment (collectively referred to as valenced feedback) are important factors that influence performance during learning. Presently, however, studies investigating the impact of valenced feedback on skill learning have only considered unintentional learning, and therefore the interaction between intentionality and valenced feedback has not been systematically examined. The present study investigated how reward and punishment impact behavioural performance when participants are instructed to learn in a goal-directed fashion (i.e. intentionally) rather than unintentionally. In Experiment 1, participants performed the serial response time task with reward, punishment, or control feedback and were instructed to ignore the presence of the sequence, i.e., learn unintentionally. Experiment 2 followed the same design, but participants were instructed to intentionally learn the sequence. We found that punishment significantly benefitted performance during learning only when participants learned unintentionally, and we observed no effect of punishment when participants learned intentionally. Thus, the impact of feedback on performance may be influenced by goal of the learner.
Similar content being viewed by others

Introduction
Rewards and punishments play critical roles in shaping human behaviour during learning1,2,3. Yet despite the importance of valenced feedback for learning, the effects of reward and punishment on performance when learningsequencing skills have largely been unexplored4. In the context of sequence learning, two previous studies both demonstrated that punishment improves performance during learning5,6. However, punishment was not beneficial on a continuous sequencing task that required more fine motor control compared to the serial response time task (SRTT)6, suggesting that generalizing the effect of reward and punishment across tasks may be limited. In addition, our prior work has shown that the benefit of feedback to SRTT learning was more pronounced early in training (i.e. after initial exposure the sequence), suggesting that the benefit to learning may be stronger early in learning.
Even within the context of sequence learning, a number of factors affect how the task is learned. For example, when learning in naturalistic settings, humans often have a conceptual understanding of the behavior they intend to learn. Basketball players, for example, have an explicit goal: they should put the ball through the hoop. This intention (putting in the ball in the hoop) is used to guide their actions and shapes the learning process. Despite its importance, to our knowledge, little work has examined the influence of intention in the context of skill learning and feedback. Notably, the intention (i.e. putting the basketball in the hoop) is separable from the physical processes that accomplish this goal (i.e. the specific motor actions involved in shooting a basketball). Thus, it is possible to learn without intention, and it is also possible that what is learned is not known. When learning occurs in the absence of conscious awareness, it is often referred to as “implicit learning7.” Because these features of learning are separable, in this work we use the terms ‘unintentional’ and ‘intentional’ to refer to the goal of the participant during performance, and we use ‘implicit’ and ‘explicit’ to refer to the participant’s subjective awareness of what was learned.
The serial reaction time task (SRTT) is well-suited testing the influence of intentionality on learning. Using the SRTT, participants can be instructed to learn the sequence, and the explicit knowledge of the sequence can be assessed post-hoc through the use of awareness tests8,9,10. Only two previous studies have used the SRTT to study the influence of reward and punishment on sequence learning. In our previous study, participants were not told about the presence of a sequence and demonstrated implicit acquisition when tested at 30-days post-learning6. In the study by Wachter and colleagues, participants were excluded if they achieved explicit awareness of the presence of the sequence5.
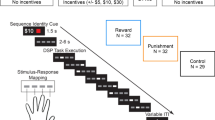
Given the central importance of both reward and punishment and intention to skill learning, we therefore investigated whether the intention to learn modulates the effect of valenced feedback on SRTT performance. The present study comprises two experiments in which participants performed the SRTT augmented with reward, punishment, or control feedback. In the first experiment (the unintentional learning condition), participants were told that a sequence would be present but to ignore the sequence during training, and to continue pressing buttons as fast and accurately as possible. In the second experiment (the intentional learning condition), participants were told to do their best to learn the sequence (Fig. 1). Sequence and random blocks were interleaved, so that we could continuously evaluate sequence knowledge expression. Based on prior work which showed that both reward and punishment enhanced early learning compared to control feedback, we were particularly interested in the difference between the intentional and unintentional learners during the early learning period.

Experimental design. (a) The study consisted of two experiments, which differed based on the instruction given to the participants. Participants performed the SRTT and were told either to learn the sequence intentionally (Experiment 2) or to try to ignore the sequence (Experiment 1). (b) The SRTT took place over 30 blocks. The first three blocks of the task (familiarization blocks [F]) contained no feedback and the stimulus appeared according to a random-sequence. The training period began at the fourth block (random-sequence [R]), at which point feedback was introduced. Beginning in the fifth block, fixed- and random- sequence blocks were presented in an alternating order. Participant’s RTs in each fixed-sequence [S] block relative to the subsequent random-sequence block indicated skill knowledge expression. After the 17th block (eighth fixed-/-random doublet), the immediate retention probe began. During the immediate retention probe, participants performed a random-sequence block without feedback. They then performed a fixed-sequence block followed by a random block, and comparison between these two blocks indicated retention. Participants then performed four consecutive fixed-sequence blocks, followed by a random block. Finally, participants performed a fixed- and random-block. (c) In both experiments, participants performed the SRTT with feedback, which was contingent on their speed and accuracy.
Results
The present study consisted of two experiments that examined intentional and unintentional learning, respectively. The results for each experiment are first presented separately and then the two experiments are formally compared in the final section.
Experiment 1 – Unintentional learning
Punishment improves sequence knowledge expression during unintentional learning
The reward, control, and punishment groups did not differ in their RT during the familiarization period (Blocks F1-F3; One-way ANOVA: F(2,33) = 1.372, p = 0.27). We first sought to determine whether training with reward or punishment influenced the acquisition and expression of sequence knowledge (indexed by comparing RTs during fixed- and random-sequence blocks) during the training period. To this end, we compared the baselined RT (i.e., improvement relative to the three familiarization blocks to control for individual differences in RT) during the training period (S1 through R8) using a repeated measures ANOVA with Feedback type (Reward/Punishment/Control), Sequence type (Fixed-/Random-sequence), and Block (1–8) as factors (Fig. 2).

Punishment improves unintentional sequence learning. (a) The participant’s performance during the training and probe blocks relative to their performance during the familiarization blocks. (b) Difference between fixed- and random-sequence RTs over the training period. The punishment group evidenced more sequence knowledge during the first block of training with feedback (S1 v R1), as well as during the final block of training (S8 v R8). Asterisks indicate significant difference (p < 0.05). Error bars show SEM. R = training random-sequence, S = training fixed-sequence, PR = probe random-sequence, PS = probe fixed-sequence.
This analysis revealed that the difference in RT between the fixed- and random-sequence blocks varied among the feedback groups over the course of learning (three-way interaction, Feedback type x Sequence type x Block: F(7,231) = 1.741, p = 0.049, η2 = 0.01). Follow-up analyses revealed that the punishment group evidenced greater sequence knowledge during the first block of training (S1 versus R1) compared to the reward and control groups (Punishment vs Reward: t(23) = 2.77, pcorr = 0.026; Punishment vs Control: t(23) = 2.79, pcorr = 0.026). The punishment group also evidenced greater sequence knowledge during the final block of training (S8 v R8) with feedback compared to the control group but not to the reward group (Punishment versus Control: t(23) = 2.81, pcorr = 0.022; Punishment versus Reward: t(23) = −1.013, pcorr = 0.19). There were no significant differences in performance between the feedback groups for any other block. There was no difference between the reward and control groups at the beginning (t(23) = 0.02, pcorr = 0.98) or end of training (t(23) = 1.0, pcorr = 0.57), suggesting that punishment, rather than reward, is beneficial to sequence knowledge expression during unintentional sequence learning.
In addition to the difference in sequence knowledge expression across the reward, control, and punishment groups, the overall RT differed across the feedback groups over time (Feedback type × Block interaction: F(11,183) = 2.47, p = 0.006, η2 = 0.018). Although we did not have any a priori expectation that RT would differ across the blocks, we conducted exploratory post-hoc analyses to better understand these effects. These post-hoc analysis revealed that the participants in the punishment group performed significantly faster than the control group during Block 3 (Punishment v Control; t(23) = 2.47, pcorr = 0.046) and Block 7 (Punishment v Control; t(23) = 2.67, pcorr = 0.033). The reward group was not significantly faster than the control group during any block (all ps > 0.05).
Across the training period, there was no effect of feedback type on accuracy during the training period with feedback (Main effect of feedback type: F(2,33) = 2.34, p = 0.112; Group x Block: F(14,231) = 0.97, p = 0.478; Group × Sequence type: F(2,231) = 0.58, p = 0.56; Group x Sequence type × Block: F(14,231) = 1.17, p = 0.30). These data are presented in Supplemental table 1.
Short-term retention is not impacted by valenced feedback during unintentional learning
We next sought to determine whether valenced feedback impacted short-term sequence-knowledge expression. First, to examine immediate skill performance, we compared RTs during the first fixed- and random-sequence blocks presented in the first probe block (PS1 v PR1) using a repeated measures ANOVA with Feedback type (Reward/Control/Punishment) and Sequence type (Fixed-/Random-sequence) as factors. All groups expressed skill knowledge during the immediate probe (Main effect of Sequence type, F(1,33) = 39.01, p < 0.001, η2 = 0.192; Fixed- vs Random-sequence: t(35) = 6.40, p < 0.001). There was no effect of feedback type on skill knowledge expression during the first probe block (Main effect of Feedback: F(2,33) = 1.10, p = 0.36; Feedback × Sequence interaction: F(2,33) = 0.616, p = 0.55).
Punishment has previously been shown to increase relearning rate in visuomotor adaptation tasks, and we sought to determine whether this phenomenon also occurred in sequence learning. To examine this question, we compared the RTs during the four consecutive fixed-sequence blocks in the probe period (PSt1-3 and PS2) using a repeated measures ANOVA with Feedback type (Reward/Punishment/Control) and Block (PSt1-PS2) as factors. There was no effect of Feedback type (F(2,33) = 1.02, p = 0.37), Block (F(3,99) = 2.098), p = 0.11), or Feedback type x Block interaction (F(6,99) = 0.95, p = 0.46). There was also no difference between the groups during the second probe block (after the retraining probe, PS2 v PR2; Feedback type × Sequence type: F(2,33) = 0.577, p = 0.57). While all groups demonstrated learning (retraining probe – Main effect of Sequence type: F(1,33) = 68.43, p < 0.001, η2 = 0.203), there was no difference in skill knowledge across the groups in the final skill knowledge probe (Feedback type x Sequence type: F(2,33) = 0.577, p = 0.57). In the final retention probe (PS3 v PR3), the punishment group was significantly faster than the control group (Main effect of Feedback type (F(2,33) = 3.942, p < 0.029, η2 = 0.193); Punishment versus Control: t(23) = 2.762, pcorr = 0.028, Punishment versus Reward: t(23) = 1.817, pcorr = 0.156, Reward versus Punishment: t(23) = 0.945, pcorr = 0.352). However, this was not specific to the trained sequence, as all groups showed learning (Main effect Sequence type F(1,33) = 57.512, p < 0.001, η2 = 0.240; fixed-sequence versus random-sequence: t(35) = 7.702, pcorr < 0.001), and there was no difference between the feedback groups in terms of sequence knowledge expression (Feedback type × Sequence type F(2,33) = 0.468, p = 0.63).
Feedback does not alter awareness during unintentional learning
Lastly, we sought to determine whether the addition of reward or punishment altered conscious awareness during unintentional skill learning. To assess the degree of implicit/explicit knowledge, we utilized two different measures. First, participants indicated knowledge via verbal report. For this test, we asked participants to verbally recall as much of the sequence as they were confident in producing. The number of sequential triplets included was compared across the groups using a one-way ANOVA. The feedback groups did not differ in the number of sequential items reported (F(2,33) = 1.62, p = 0.21).
Second, we used the process dissociation procedure10. To assess any purely implicit bias, before the presence of the sequence was reaffirmed, we asked participants to perform a series of button presses and try to be as random as possible (free generation). Then, participants were asked to include or exclude the sequence during a series of 100 button presses. One participant was removed from the analysis due to data collection failure. We calculated the area under the curve which describing the number of sequential items generated (doubles, triples, quads, etc) for each set of button presses and compared across the groups on this measure using a one-way ANOVA (Fig. 3).

Feedback did not impact awareness when learning unintentionally. There was no difference between the Feedback types with respect to explicit knowledge formed during the unintentional learning condition based on verbal report, as well as process dissociation procedure inclusion, exclusion, or free generation rates. Error bars show SEM. Colors: Black = control, red = reward, blue = punishment. Dashed lines indicate chance-level as determined by 1000 Monte-Carlo simulations.
Using this procedure, we found no difference in sequence inclusion on any set of presses between the control, reward, and punishment groups (Free generation: F(2,32) = 0.528, p = 0.95; Inclusion: F(2,32) = 0.400, p = 0.68; Exclusion: F(2,32) = 0.233, p = 0.79).
Unintentional learning summary
In summary, when learning unintentionally, we found that participants training with punishment demonstrated significantly more skill knowledge during the acquisition period than participants training with reward or control feedback. The feedback given during the training period did not influence participant’s ability to express sequence knowledge immediately after training once feedback was removed and did not systematically modulate the implicitness of the sequence acquisition.
Experiment 2 – Intentional learning
Punishment does not benefit intentional sequence learning
To determine whether punishment similarly benefitted intentional sequence learning, we performed the same experiment described above, but instructed participants to intentionally learn the sequence. Data from this experiment are shown in Fig. 4. There was no difference between the reward, punishment, and control groups during the Familiarization period (F1-F3; one-way ANOVA: F(2,33) = 1.094, p = 0.34). We next examined the impact of feedback on performance during the training period (S1-R8) using a repeated measures ANOVA with Feedback type (Reward/Punishment/Control), Sequence type (Fixed-/Random-sequence), and Block (1–8) as factors. When instructed to learn intentionally, all feedback types showed sequence knowledge improvement over time (Sequence type × Block interaction: F(7,231) = 4.81, p < 0.001, η2 = 0.02; fixed- versus random-sequence difference in Block 1 versus Block 8, t(35) = 3.781, p < 0.001). However, feedback type did not impact overall performance or sequence knowledge (Main effect of Feedback type: F(2,33) = 1.13, p = 0.34; Feedback type × Block: F(14,231) = 0.903, p = 0.56; Feedback type × Sequence type: F(2,33) = 0.244, p = 0.79; Group × Sequence type × Block: F(7,231) = 1.36, p = 0.18; Fig. 4). Thus, in contrast to the benefit of punishment to unintentional learning, when instructed to learn intentionally, the punishment group did not express sequence knowledge earlier than the reward and control groups.

Feedback does not impact performance during intentional sequence learning. (a) All feedback groups showed robust learning when instructed to learn the sequence (b) Difference in RTs during fixed- and random-sequence blocks across the learning period. All groups showed equivalent development of sequence knowledge. Error bars show SEM. R = random-sequence, S = fixed-sequence, PR = probe random-sequence, PS = probe fixed-sequence.
Feedback does not alter retention when learning intentionally
We next investigated whether feedback modulated retention or relearning after intentional sequence learning. All groups expressed skill knowledge during the first probe block (PS1 v PR1; Main effect of Sequence type, F(1,33) = 26.00, p < 0.001, η2 = 0.209; fixed- vs random-sequence: t(35) = 5.09, p < 0.001). However, there was no effect of feedback type on skill knowledge expression during the first probe block (Main effect of Feedback type: F(2,33) = 1.09, p = 0.35; Feedback type × Sequence type: F(2,33) = 0.26, p = 0.80).
When we examined relearning (PSt 1–3 and PS2), we found that the control, reward, and punishment groups all showed improvement during the relearning period (Main effect of Block: F(3,99) = 9.105, p < 0.001, η2 = 0.038). However, there was no effect of feedback on relearning (Main effect of Feedback type: F(2,33) = 0.68, p = 0.51; Feedback type × Block interaction: F(6,99)= 0.95, p = 0.46). Similar to unintentional learning, the control, reward, and punishment groups all showed sequence knowledge after relearning during probe block 2 (PS2 v PR2; Main effect of Sequence type: F(1,33)= 68.475, p < 0.001, η2 = 0.365), but there was no effect of Feedback type on the sequence knowledge expressed during probe block 2 (Feedback type × Sequence type: F(2,33)= 0.50, p = 0.61). In the final retention probe (PS3 v PR3), all groups showed learning (Main effect Sequence type F(1,33)= 30.97, p < 0.001, η2 = 0.312), but there was no effect of feedback on performance or evidenced knowledge (Main effect of Group: F(2,33)= 0.79, p = 0.47; Sequence type × Group F(2,33)= 1.05, p = 0.36).
Awareness was not modulated by feedback when learning intentionally
Finally, we sought to determine whether the degree of explicit awareness after intentional sequence learning was modulated by feedback (Fig. 5). The feedback groups did not differ in the number of sequential items verbally reported (F(2,33) = 0.36, p = 0.70). Using the process dissociation procedure described above, we found no difference in sequence inclusion on any set of presses (Random: F(2,32) = 0.35, p = 0.70; Inclusion: F(2,32) = 0.1.48, p = 0.24; Exclusion: F(2,32) = 0.7, p = 0.50).

There was no difference between the feedback groups with respect to explicit knowledge formed during intentional sequence learning. Error bars show SEM. Colors: Black = control, red = reward, blue = punishment. Dashed lines indicate chance-level based on 1000 Monte-Carlo simulations.
Intentional learning summary
In summary, the type of feedback given during training did not impact performance when participants learned intentionally. The type of feedback also did not impact retention or conscious knowledge expression.
Punishment specifically benefits unintentional learning
To formally test for a difference between the intentionality conditions, we directly compared participant’s performance during the training period from Experiments 1 and 2 (S1-R8) using a repeated measures ANOVA with Intentionality (Intentional/Unintentional), Feedback type (Reward/Punishment/Control), Sequence type (Fixed-/Random-sequence), and Block (1–8) as factors. The full ANOVA investigating whether intentionality influenced the effect of valenced feedback on sequence learning rate was not significant (4-way interaction, Intentionality × Feedback type × Sequence type x Block; F (28,462) = 1.483, p = 0.055, η2 = 0.028). However, based on our a priori hypothesis that intentionality would specifically impact early learning, we conducted a repeated measures ANOVA examining Block 1 (S1 v R1). For this ANOVA we considered Intentionality (Intentional/Unintentional), Feedback type (Reward/Punishment/Control), and Sequence type (Fixed-/Random-sequence) as factors. This analysis revealed that intentionality did impact the influence of feedback valence on early knowledge expression (three-way interaction, Intentionality x Feedback type x Sequence type; F (2,66) = 7.21, p = 0.001, η2 = 0.117). Follow-up tests revealed that intentionality specifically modulated the influence of punishment during Block 1 (S1 v R1; Fig. 6). The punishment group learning unintentionally evidenced more sequence knowledge during Block 1 compared to punishment group learning unintentionally (Unintentional Punishment vs Intentional Punishment: t(22) = 3.241, p = 0.0038). The unintentional punishment group did not perform significantly differently from the intentional reward or intentional control groups (Unintentional Punishment vs Intentional Reward: t(22) = 1.350, p = 0.19; Unintentional Punishment vs Intentional Control: t(22) = 1.733, p = 0.10). Intentionality did not influence sequence knowledge expression during Block 1 in either the reward or the control groups (Unintentional Control vs Intentional Control: t(22) = 0.658, p = 0.51; Unintentional Control vs Intentional Reward: t(22) = 0.583, p = 0.56; Unintentional Reward vs Intentional Reward: t(22) =1.531, p = 0.14; Unintentional Reward vs Intentional Control: t(22) = 0.58, p = 0.566). The feedback groups did not differ at any other blocks. Thus, these data support the conclusion that intentionality specifically modulates the impact of punishment on early learning.

Comparison of sequence knowledge expression (S1 v R1) across the feedback groups in unintentional versus intentional learning. The group of participants learning unintentionally with punishment performed significantly better than the group of participants learning intentionally with punishment, as well as the reward and control groups learning unintentionally. Asterisks indicate a significant difference (p < 0.05). Error bars show SEM.
With respect to awareness measures, intentional learning fostered significantly greater explicit awareness, as evidenced by a greater number of sequence items generated during the verbal report (F(1,66)= 6.452, p = 0.013, η2 = 0.086; Intentional v Unintentional: t(68)= 2.54, p = 0.013) and inclusion rate during the process dissociation procedure (F(1,66)= 6.39, p = 0.014, η2 = 0.084; Unintentional v Intentional: t(68)= 2.50, p = 0.014). There was no main effect or interaction with feedback group in the awareness tests for either experiment (all ps> 0.3).
Discussion
In this study we investigated whether the intention to learn interacts with the effects of valenced feedback on performance during sequence learning. We found that punishment enhanced early sequence knowledge expression when participants learned unintentionally (Experiment 1). However, when learning intentionally, all groups performed equally well (Experiment 2). Based on our prior work, we expected that punishment would specifically benefit sequence knowledge during early learning6. Direct comparison of the results of the two experiments revealed that punishment was, indeed, beneficial to sequence knowledge formation in the early phase of unintentional sequence learning. These results suggest that intentionality may influence the impact of valenced feedback given during performance.
The effect of reward and punishment on performance during learning has previously been characterized with a simple heuristic: punishment benefits performance, while reward benefits memory retention4,5,11. A previous study by our group demonstrated that this simple heuristic is not valid in all cases. Specifically, we showed that the impact of valenced feedback depends on the task being performed: while punishment benefited performance on the SRTT when learning unintentionally, punishment was detrimental to performance on a different motor learning task (the force tracking task). In the present study, we additionally show that even when participants are performing the same task, altering the intention of the participant may influence the effect of reward and punishment. This result further complicates the use of the simple heuristic outlined above even within the same task. Together, these two results suggest that valenced feedback interacts with skill learning in a complex manner.
Why might intentionality modulate the impact of feedback?
The central question raised by this study is why punishment benefits unintentional learning but not intentional learning. A critical component of intentional learning is the added cognitive load introduced by intentionally learning the sequence. The ‘cognitive load’ may be due to several factors, but two examples are i) the added ‘dual-task’ of learning to maximizing the amount earned, and ii) the added performance monitoring during negative feedback that may cause ‘choking under pressure’ in intentional learning tasks, or iii) fatigue caused by intensive training. Because the present task was self-paced and took place over a short duration, the third possibility is unlikely to cause the results observed here. In contrast, either, or both, of the former points might explain the different effects of punishment on intentional and unintentional sequence learning.
Introducing a competitive task
It is possible that the goal of learning the sequence acts as a distractor task that competes with the primary task of pressing buttons quickly and accurately. While participants in the intentional and unintentional learning conditions share the goal of maximizing the total money earned during the experiment, participants learning intentionally are also compelled to detect and learn a sequence, while participants learning unintentionally are not. The added cognitive load in the intentional condition, then, may be similar to dual-task learning. In dual-task learning, participants are forced to learn while simultaneously performing another task that competes for attention, for example counting tones12,13,14,15,16. Under dual-task conditions, sequence knowledge may take longer to be expressed12,13,14, and the detrimental effect of the added cognitive load may be more extreme when participants engage explicit strategies16.
Although it should be noted that visuomotor adaptation is generally considered to be a separate process from sequence learning, complementary evidence comes from the visuomotor adaptation literature (for an in-depth discussion regarding the SRTT and its relationship to other motor-learning tasks, see a recent review from Krakauer and colleagues17). Similar to prior work in sequence learning5,11, prior work using motor adaptation tasks have found that reward benefits retention, while punishment benefits performance during training18,19,20,21. For example, it has been found that the beneficial effect of reward-feedback to retention in visuomotor adaptation tasks appears to depend on explicit processes, and a distractor-task that disrupts explicit processes completely abolishes learning when participants must use reward-based feedback to adapt18,22,23. In addition, artificially increasing noise during adaptation learning is detrimental to learning through reinforcement, which is also consistent with the importance of explicit processes to adaptation learning24. While studies of visuomotor adaptation have not explored the role of explicit processes when learning with punishment, this could be an interesting avenue for future research.
Engaging alternative cognitive strategies
A second possible source of cognitive load that may account for the difference between intentional and unintentional learning is that the engagement of the intentional learning strategy in the context of negative feedback invokes meta-cognitive processes (e.g., performance monitoring) that interfere with learning25,26,27,28. One study has examined the role of performance monitoring in the context of the SRTT when learned unintentionally (implicitly). In this study, a control condition (no monitoring) was compared i) to an outcome-pressure condition, where participants were told that performance needed to improve to earn additional compensation, and ii) a monitoring-pressure condition, where participants were told that their performance was being videotaped and would be watched by researchers25. These researchers reported that while the outcome-pressure and control conditions did not differ in their performance during learning, the monitoring-pressure condition produced a significant detriment in performance. Thus, if participants engage in greater performance monitoring during the intentional learning condition, they might exhibit a similar deficit in performance.
In this study, we observed that the effect of feedback differed over the course of the learning period for participants in the unintentional learning condition. The punishment group showed greater sequence knowledge expression compared to the reward and control groups in the first and last learning blocks, but not during the middle blocks of the learning period. The time course of sequence knowledge expression may be due to the interleaving of fixed- and random-sequence blocks during the learning period. In the interleaved design, participants may undergo forgetting or unlearning of the sequence during the random-sequence blocks29,30,31. In this study, training with punishment might enhance early learning during the first sequence block, but also quicken adaptive forgetting during the subsequent random block, as instances of negative reinforcement may serve as an implicit signal to shift strategies or explore new behaviors (in this case, to “forget” any previously learned sequence knowledge). In contrast, participants training with reward may be less sensitive to slight changes in reinforcement frequency and be less likely to shift rules or undergo forgetting, leading to the development of sequence knowledge over a longer period of exposure. This pattern of behavior is consistent with a win-stay, lose shift strategy32,33. Notably, it has been shown that reward is not effective in shaping motor behaviours unless participants are aware of the manipulation being rewarded or if reward is too abundant34,35, probably due to participants not engaging in exploratory behaviors. Future work may also consider the psychological implications of reward and punishment given during learning, and how this interacts with behavioral variability and cognitive strategies.
The design implemented here precludes modelling the cognitive strategies, such as the win-stay lose-switch versus reinforcement learning strategies33. However, based on the role of dopamine in perseveration, i.e., the use of reinforcement-learning strategy, we are inclined to speculate that punishment may promote participants to update their sequence-item knowledge more rapidly (effectively facilitating a win-stay lose-switch strategy), while reward may facilitate greater use of a reinforcement-learning strategy and integrate their sequence-knowledge over a longer period of time36.
Recruiting different neural resources
Besides cognitive load, one potential explanation for the lack of benefit of punishment to performance is that learning with punishment and explicit sequence learning utilize shared neural substrates, and therefore compete for these resources. While our current data cannot speak directly to the neural basis of this effect, our prior work may provide insight into this question37. Explicit sequence learning is known to recruit the hippocampus38, and our previous fMRI experiment provides evidence that training with punishment also engages medial temporal lobe, while reward recruits the cortical motor network37. It is possible that these two processes interact competitively at the level of medial temporal lobe, thereby reducing the expression of early sequence knowledge. This possibility may be interesting to explore in the future using patients with medial temporal lobectomy39.
Reward and punishment did not impact immediate retention
Reward did not benefit performance on the immediate retention probes in the intentional or the unintentional learning conditions, which effectively replicates the similar null result found in prior work by our group6. One notable difference between the present study and our prior work as that we did not include a delayed retention test, and so it is possible that reward may have benefitted delayed retention or offline gains. However, in our previous work6 wherein we did measure performance after delay, we found no effect of feedback on retention. Given the widely observed benefit of reward to visuomotor adaptation memory retention, it will be important to understand whether any specific conditions reliably foster reward-related memory benefits in the context of sequence learning4,19,20,21.
Intention and awareness
One might ask whether it is possible to between distinguish intention and awareness. In the context of movement, fMRI evidence suggests that intention and awareness are separable at least at the neural level40,41. Additionally, our study demonstrates that intention and awareness are dissociable behaviorally. Based on the PDP several participants in the Unintentional learning condition demonstrated inclusion greater than chance-level, meaning that they had become aware of the sequence. On the other hand, multiple participants in the Intentional learning condition performed at or below chance level on the PDP, suggesting that they had no awareness of the sequence. This pattern of results demonstrates that awareness is dissociated from intention, although intention may bias implicit or explicit knowledge formation.
Historically, in a typical SRTT study of explicit and implicit knowledge, intention may be conflated with awareness8,9,42,43,44,45,46,47,48,49. Specifically, participants in an “explicit learning condition” will be made aware of the sequence and might be directed to learn the sequence, while participants in the “implicit learning condition” will not be made aware of the sequence and simply be told to press buttons. Despite the condition being assigned prior to learning (i.e. implicit or explicit conditions), awareness is assessed post-hoc: participants are classified as having acquired knowledge implicitly or explicitly on the basis of the awareness test5,8,9,10,43,44,45,46,49,50. At the end of learning, the participants in the explicit condition have intended to learn and may (or may not) end up being aware of the sequence they have been exposed to. On the other hand, the participants in the implicit condition learn unintentionally; however, it is possible that they will end up being aware of the sequence. Because participants are generally excluded from the experiment if they fail to show the expected type of sequence knowledge (explicit or implicit knowledge, e.g. Wachter et al. 20095), these studies end up preserving the intended grouping. However, we suggest that the difference in instruction also may lead to an unstated difference between the conditions: namely, that they had differing intentions during training.
Considerations
Our conclusion that intention impacts the influence of punishment on early sequence learning is drawn from the direct comparison of the performance during the first training block (i.e. S1 and R1) in the Intentional and Unintentional learning conditions. This comparison was motivated by our results6, which revealed that both punishment and reward led to better sequence knowledge expression early in learning. This comparison was therefore hypothesized a priori - we note that the omnibus ANOVA that included all training blocks (i.e. S1-S8 and R1-R8) did not show a significant interaction between Intention x Feedback x Block (p = 0.055). However, our study was appropriately powered to detect the difference between the groups observed in the initial block, where we hypothesized the difference between the feedback conditions would be observed. Because we detected the benefit of punishment as we expected, and effectively replicated our prior results, we are confident in our conclusion that punishment benefits early sequence knowledge expression when learning unintentionally.
Conclusions
One question that the current study does not address is the extent to which the intentional learning condition should be considered a separate task to unintentional learning. Implicit and explicit sequence learning are often considered together in the same studies and treated as equivalent conditions8,9,48,51, and so there is precedent in the literature to consider these types of manipulations as equitable variations of the same task. This assumption is primarily based on task demands; the two tasks are functionally equivalent, in the sense that the equivalent stimulus elicits the same response in both cases, and, importantly, the contingency to receive the reward or punishment is equivalent between the two tasks. Given these considerations although these variations of the task undoubtedly engage two different cognitive processes, the intentional and unintentional learning conditions may be comparable tasks.
In conclusion, in the present study we demonstrated that punishment may enhance early sequence knowledge expression (on the SRTT) specifically when participants learn unintentionally. As is the case with visuomotor adaptation, the effect of valenced feedback in sequence learning may also depend on explicit processes. Future work should consider other factors that might influence the impact of reward, including the participant’s psychological state prior to the experiment, their personality, and the time of day.
Methods
Participants
72 participants were recruited for this study. 36 participants were assigned to each experiment (Experiment 1: 18 female, age = 24.4 ± 3.1 [mean ± standard deviation]; Experiment 2: 17 female, age = 23.3 ± 2.4; Fig. 1a), such that 12 participants were assigned to each feedback group. We chose 12 participants in each group based on a power analysis of the difference in feedback conditions during early learning observed in our previous work6. There was no difference between the mean age of the participants in Experiments 1 and 2 (t(70) = 1.78, p = 0.0784). All participants were right-handed, free from neurological or psychiatric disorders, and had normal or corrected-to-normal vision. All participants gave informed consent and the study was performed with approval from the Oxford Central University Research Ethics Committee (R44415/RE001), and the study was run in accordance with the Declaration of Helsinki. Participants were compensated for their time in local currency (GBP, £).
Experimental outline
Participants trained on the serial reaction time task (SRTT) over 30 blocks. Each block contained 48 trials (Fig. 1b). During some blocks (“fixed-sequence blocks” [S]) the sequence of stimuli would appear according to a repeating pattern (described below for each task). During other periods, stimuli appeared in a pseudo-randomly determined order (“random-sequence blocks” [R]). During the training period, fixed- and random-sequence blocks were presented in an interleaved fashion52, to make gaining explicit knowledge more challenging, and to allow us to assess the development of sequence knowledge (compared to general skill) continuously across the learning period.
In both experiments, the task began with three random-sequence blocks without feedback (“familiarisation blocks”, F1, F2, F3) to familiarise participants to the task and to establish their baseline level of performance. The subsequent training period also began with a random block (R0), after which blocks alternated between random and sequence blocks (S1-R8, total number of blocks = 16). The training period concluded with a random block. The difference in performance between an S-block and the subsequent R-block (e.g., S1 – R1, S2 – R2, and so on) was used to index sequence knowledge during the training period8. Immediately following completion of the training period, participants were tested for sequence memory without feedback (the probe period). The probe period consisted of 9 blocks with either a fixed sequence (Probe fixed-sequence [PS]) or a random sequence (Probe random-sequence [PR]) without feedback in the following order: PR – PS – PR – PS – PS – PS – PS – PR – PS – PR. Sequence knowledge was indexed by comparing the initial probe sequence block (PS1) to the subsequent random block (PR2). The four fixed sequence blocks after the first sequence knowledge test (PSt 1–3 and PS2) were included to determine whether subjects trained with punishment relearn at a faster rate, as has been suggested by prior research using visuomotor adaptation tasks19. The probe period concluded with a second sequence knowledge test to determine whether the groups differed in sequence knowledge after the prolonged sequence period.
To test the impact of reward and punishment on skill learning, participants were randomized into one of three Feedback groups: reward, punishment, or uninformative (control). During the feedback period, reward, punishment, or control feedback was provided based on the participant’s ongoing performance.
Serial reaction time task
The version of the SRTT used here adds feedback to the traditional implementation. At the beginning of each block participants were presented with four “O”s, arranged along a horizontal line at the centre of the screen. These stimuli were presented in white on a grey background. A trial began when one of the “O”s changed to an “X”. Participants were instructed to respond as quickly and accurately as possible, using the corresponding button, on a four-button response device held in their right hand. The “X” disappeared once the subject made a response, followed by a 200 ms fixed inter-trial interval, during which time the four “O”s were displayed.
A block consisted of 48 trials. During fixed-sequence blocks, the stimuli appeared according to a fixed 12-item sequence repeated 4 times. The four sequences used in this study were taken from our previous study:6 1) 2,4,2,1,3,4,1,2,3,1,4,3; 2) 3,4,3,1,2,4,1,3,2,1,4,2; 3) 3,4,2,3,1,2,1,4,3,2,4,1; 4) 3,4,1,2,4,3,1,4,2,1,3,2. Participants were randomly assigned to one of the sequences. Each fixed block began at the same position in the sequence. In the random blocks, the stimuli appeared according to a pseudo-randomly generated sequence, without repeats on back-to-back trials, so, for example, participants would never see the triplet 1–1–2. Each block lasted roughly one minute, and the entire experimental session lasted approximately 35 minutes.
Between each block, participants were presented with the phrase “Nice job, take a breather.” After five seconds, a black fixation-cross appeared on the screen for 25 seconds. Five seconds before the next block began, the cross turned blue to cue the participants that the block was about to start.
The first button press made after stimulus presentation was considered the participant’s response. Only correct trials were considered for analysis of RTs. Trials with RTs less than 150 ms and greater than 800 ms were excluded from the analysis. The bounds of this exclusion criteria are consistent with prior work from our lab6,53.
Intentionality manipulation
In Experiment 1, after the familiarisation period, participants were given the following instructions, “During certain periods of time, you may have the feeling that the stimulus is following a fixed sequence. Please ignore the sequence and continue to perform as fast and accurately as possible.”
In Experiment 2, participants received the following instructions, “During certain periods of time, you may have the feeling that the stimulus is following a fixed sequence. Please do your best to learn the sequence, while also performing as fast and accurately as possible.”
Participants were not given any further instructions about the nature of the task. Thus, we refer to the participants in Experiment 1 as “unintentional learners” and those in Experiment 2 as “intentional learners.”
Valenced feedback
All participants were paid a base remuneration of £15 for participating in the study. At the conclusion of the familiarisation period, participants were told they could earn more money based on their performance. Participants were randomly assigned into the reward, punishment, or control feedback groups. The presence of reward or the absence of punishment was based on participant’s performance. In both versions of the SRTT, an initial criterion RT was defined based on the participant’s median performance during the final familiarization block. As participants progressed through training, this criterion was re-evaluated after each block, to encourage continuous improvement. In the reward group, the feedback indicated that the participant’s performance was improving. In the punishment group, the feedback indicated they were getting worse. The control group received feedback on 50% of trials that were randomly determined. Participants in the control group were told that the feedback was not meaningful. We considered the reward and punishment control groups together in the analyses, as is typical in these studies5,11.
Performance was defined as the accuracy (correct or incorrect) and RT of a given trial. Feedback was given on a trial-by-trial basis and was indicated to the participant by the white frame around the stimulus changing to either green (reward) or red (punishment). In the reward group, the participants were given feedback if their response was accurate and their RT was faster than their criterion RT, which indicated that they earned money (£0.02 from a starting point of £0) on that trial. In the punishment group, participants were given feedback if they were incorrect, or their RT was slower than their criterion, which indicated that they lost money (£0.02 deducted from a starting point of £20) on that trial. Participants in the control group saw red or green colour changes on 50% of trials that were randomly determined (and therefore unrelated to their performance).
The initial criterion RT was calculated as median performance in the final familiarization block (F1). After each block, the median + standard deviation of performance was calculated and compared with the criterion. If this test criterion was faster than the previous criterion, the criterion was updated. Only correct responses were considered when establishing the criterion RT.
To ensure they were adequately motivated, participants in the control group were told that they would be paid based on their speed and accuracy. Importantly, to control for the motivational differences between gain and loss, participants were not told the precise value of a given trial. This allowed us to assess the hedonic value of the feedback, rather than the level on a perceived-value function. For the reward and punishment groups, the current earning total was displayed (e.g., “You have earned £5.00”) between the blocks. For the control group the phrase, “You have earned money.” was presented.
Conscious recall
In both experiments to assess conscious recall, we used both verbal report and the process dissociation procedure10. For the verbal report, participants reported as much of the sequence as they knew. The total number of correct sequential items verbally reported was compared using a one-way ANOVA with Feedback type (Reward/Control/Punishment) as a factor for each experiment separately. We also confirmed that the Intentional instructions fostered more explicit knowledge than the Unintentional instructions using a two-way ANOVA with Feedback type (Reward/Control/Punishment) and Intentionality (Intentional/Unintentional) as factors.
For the process dissociation procedure, after completion of the probe blocks, participants performed 3 sets of 100 button presses. First, we asked participants to generate 100 button presses randomly with no repeats. At this point, the presence of the sequence was confirmed, and participants were then asked to input 100 button-presses while trying to repeat as much of the sequence as they could recall. Participants were specifically instructed that if they thought they knew any of the sequence, or several chunks of the sequence, that they should input those pieces as many times as they could. Participants were then asked to generate 100 button presses where they tried to exclude the sequence as much as possible. The ‘random generation’ test for the process dissociation procedure tested the hypothesis that reward may prime participants to perform the sequence more readily even during random button pressing. In addition, the exclusion condition was used to assess conscious ‘control’ over excluding the sequence, as has been implemented previously in the literature7,10,54. The area under the curve for each number of sequential items (triplets, quadruplets, quintuplets through dodecs) included in the 100 button presses generated by the subject was compared to chance, which was estimated via 10,000 Monte-Carlo simulations of 100 non-repeating items with the probability of occurrence uniformly distributed across the 4 buttons. The area under the curve for each group was compared using a one-way ANOVA with Feedback type (Reward/Control/Punishment) as a factor.
Statistical analysis
Data analysis was conducted using JASP (Version 0.8.4, for Mac). To ensure there were no initial differences between the groups, the mean RT during the familiarization blocks were compared using a one-way ANOVA with Feedback type (Reward/Punishment/Control) as a factor. To evaluate the impact of reward and punishment during the training period, RTs were compared across the groups using a repeated measures ANOVA with Feedback type (Reward/Punishment/Control), Sequence type (Fixed-/Random- sequence), and Block number (1–8) as factors. For the probe period, the first and second sequence knowledge tests were compared using a repeated measures ANOVA with Feedback type (Reward/Punishment/Control), Sequence type (Fixed-/Random- sequence), and Test (Test 1/Test 2) as factors. To test for differences in relearning, the four consecutive sequence blocks during the probe period were compared using a repeated measures ANOVA model with Feedback type (Reward/Punishment/Control) and block (PSt1-3 & PS2) as factors.
To formally test whether the learning rate differed between the unintentional and intentional experiments, RTs were compared across the groups using a repeated measures ANOVA with Experiment (Intentional/Unintentional), Feedback type (Reward/Punishment/Control), Sequence type (Fixed-/Random- sequence), and Block number (1–8) as factors. Because we were specifically interested in early learning, we also considered the effect of feedback specifically during early learning (Block 1) with a repeated measures ANOVA with Experiment (Intentional/Unintentional), Feedback type (Reward/Punishment/Control), Sequence type (Fixed-/Random- sequence) as factors.
Post-hoc tests were conducted using t-tests, with multiple comparisons corrected using the Bonferroni-Holm method where appropriate.
References
Freedberg, M., Glass, B., Filoteo, J. V., Hazeltine, E. & Maddox, W. T. Comparing the effects of positive and negative feedback in information-integration category learning. Mem. Cogn. 45, 12–25, https://doi.org/10.3758/s13421-016-0638-3 (2017).
Maddox, W. T. & Bohil, C. J. A theoretical framework for understanding the effects of simultaneous base-rate and payoff manipulations on decision criterion learning in perceptual categorization. J. Exp. Psychol. Learn. Mem. Cogn. 29, 307–320 (2003).
Frank, M. J. Dynamic Dopamine Modulation in the Basal Ganglia: A Neurocomputational Account of Cognitive Deficits in Medicated and Nonmedicated Parkinsonism. J. Cogn. Neurosci. 17, 51–72, https://doi.org/10.1162/0898929052880093 (2005).
Chen, X., Holland, P. & Galea, J. M. The effects of reward and punishment on motor skill learning. Curr. Opin. Behav. Sci. 20, 83–88, https://doi.org/10.1016/j.cobeha.2017.11.011 (2018).
Wachter, T., Lungu, O. V., Liu, T., Willingham, D. T. & Ashe, J. Differential effect of reward and punishment on procedural learning. J. Neurosci. 29, 436–443, https://doi.org/10.1523/JNEUROSCI.4132-08.2009 (2009).
Steel, A., Silson, E. H., Stagg, C. J. & Baker, C. I. The impact of reward and punishment on skill learning depends on task demands. Sci. Rep. 6, 36056, https://doi.org/10.1038/srep36056 (2016).
Destrebecqz, A. & Cleeremans, A. in Attention and implicit learning Vol. 48 Advances in consciousness research (ed Luis Jiménez) 181-213 (John Benjamins Publishing Company, 2003).
Robertson, E. M. The serial reaction time task: implicit motor skill learning? J. Neurosci. 27, 10073–10075, https://doi.org/10.1523/JNEUROSCI.2747-07.2007 (2007).
Robertson, E. M., Pascual-Leone, A. & Press, D. Z. Awareness modifies the skill-learning benefits of sleep. Curr. Biol. 14, 208–212, https://doi.org/10.1016/j.cub.2004.01.027 (2004).
Song, S. & Cohen, L. G. Conscious recall of different aspects of skill memory. Front. Behav. Neurosci. 8, 233, https://doi.org/10.3389/fnbeh.2014.00233 (2014).
Abe, M. et al. Reward improves long-term retention of a motor memory through induction of offline memory gains. Curr. Biol. 21, 557–562, https://doi.org/10.1016/j.cub.2011.02.030 (2011).
Cohen, A., Ivry, R. I. & Keele, S. W. Attention and structure in sequence learning. J. Exp. Psychology: Learning, Memory, Cognition 16, 17–30, https://doi.org/10.1037/0278-7393.16.1.17 (1990).
Heuer, H. & Schmidtke, V. Secondary-task effects on sequence learning. Psychol. Res. 59, 119–133, https://doi.org/10.1007/BF01792433 (1996).
Frensch, P. A., Wenke, D. & Rünger, D. A secondary tone-counting task suppresses expression of knowledge in the serial reaction task. J. Exp. Psychology: Learning, Memory, Cognition 25, 260–274, https://doi.org/10.1037/0278-7393.25.1.260 (1999).
Rah, S. K., Reber, A. S. & Hsiao, A. T. Another wrinkle on the dual-task SRT experiment: it’s probably not dual task. Psychon. Bull. Rev. 7, 309–313 (2000).
Jiménez, L. & Vázquez, G. A. Sequence learning under dual-task conditions: alternatives to a resource-based account. Psychol. Res. 69, 352–368, https://doi.org/10.1007/s00426-004-0210-9 (2005).
Krakauer, J. W., Hadjiosif, A. M., Xu, J., Wong, A. L. & Haith, A. M. Motor Learning. Compr. Physiol. 9, 613–663, https://doi.org/10.1002/cphy.c170043 (2019).
Song, Y. & Smiley-Oyen, A. L. Probability differently modulating the effects of reward and punishment on visuomotor adaptation. Exp Brain Res, 1-14, https://doi.org/10.1007/s00221-017-5082-5 (2017).
Galea, J. M., Mallia, E., Rothwell, J. & Diedrichsen, J. The dissociable effects of punishment and reward on motor learning. Nat. Neurosci. 18, 597–602, https://doi.org/10.1038/nn.3956 (2015).
Quattrocchi, G., Greenwood, R., Rothwell, J. C., Galea, J. M. & Bestmann, S. Reward and punishment enhance motor adaptation in stroke. J. Neurol. Neurosurg. Psychiatr. https://doi.org/10.1136/jnnp-2016-314728 (2017).
Therrien, A. S., Wolpert, D. M. & Bastian, A. J. Effective reinforcement learning following cerebellar damage requires a balance between exploration and motor noise. Brain: A J. Neurol. 139, 101–114, https://doi.org/10.1093/brain/awv329 (2016).
Codol, O., Holland, P. J. & Galea, J. M. The relationship between reinforcement and explicit control during visuomotor adaptation. Sci. Rep-Uk 8, 9121, https://doi.org/10.1038/s41598-018-27378-1 (2018).
Holland, P., Codol, O. & Galea, J. M. Contribution of explicit processes to reinforcement-based motor learning. J. Neurophysiol. 119, 2241–2255, https://doi.org/10.1152/jn.00901.2017 (2018).
Therrien, A. S., Wolpert, D. M. & Bastian, A. J. Increasing motor noise impairs reinforcement learning in healthy individuals. Eneuro 5, https://doi.org/10.1523/ENEURO.0050-18.2018 (2018).
DeCaro, M. S., Thomas, R. D., Albert, N. B. & Beilock, S. L. Choking under pressure: multiple routes to skill failure. J. Exp. Psychol. Gen. 140, 390–406, https://doi.org/10.1037/a0023466 (2011).
Beilock, S. L. & Carr, T. H. On the fragility of skilled performance: What governs choking under pressure? J. Exp. Psychology: Gen. 130, 701–725, https://doi.org/10.1037//0096-3445.130.4.701 (2001).
Sanders, S. & Walia, B. Shirking and “choking” under incentive-based pressure: A behavioral economic theory of performance production. Econ. Lett. 116, 363–366, https://doi.org/10.1016/j.econlet.2012.03.030 (2012).
Baumeister, R. F. & Showers, C. J. A review of paradoxical performance effects: Choking under pressure in sports and mental tests. Eur. J. Soc. Psychol. 16, 361–383, https://doi.org/10.1002/ejsp.2420160405 (1986).
Hall, K. G. & Magill, R. A. Variability of practice and contextual interference in motor skill learning. J. Mot. Behav. 27, 299–309, https://doi.org/10.1080/00222895.1995.9941719 (1995).
Cross, E. S., Schmitt, P. J. & Grafton, S. T. Neural substrates of contextual interference during motor learning support a model of active preparation. J. Cogn. Neurosci. 19, 1854–1871, https://doi.org/10.1162/jocn.2007.19.11.1854 (2007).
Wulf, G. & Schmidt, R. A. Variability in Practice. J. Mot. Behav. 20, 133–149, https://doi.org/10.1080/00222895.1988.10735438 (1988).
Estes, W. K. Toward a statistical theory of learning. Psychol. Rev. 57, 94–107, https://doi.org/10.1037/h0058559 (1950).
Worthy, D. A. & Maddox, W. T. A Comparison Model of Reinforcement-Learning and Win-Stay-Lose-Shift Decision-Making Processes: A Tribute to W.K. Estes. J. Math. Psychol. 59, 41–49, https://doi.org/10.1016/j.jmp.2013.10.001 (2014).
Manley, H., Dayan, P. & Diedrichsen, J. When money is not enough: awareness, success, and variability in motor learning. PLoS One 9, e86580, https://doi.org/10.1371/journal.pone.0086580 (2014).
van der Kooij, K., Oostwoud Wijdenes, L., Rigterink, T., Overvliet, K. E. & Smeets, J. B. J. Reward abundance interferes with error-based learning in a visuomotor adaptation task. PLoS One 13, e0193002, https://doi.org/10.1371/journal.pone.0193002 (2018).
den Ouden, H. E. M. et al. Dissociable effects of dopamine and serotonin on reversal learning. Neuron 80, 1090–1100, https://doi.org/10.1016/j.neuron.2013.08.030 (2013).
Steel, A., Silson, E. H., Stagg, C. J. & Baker, C. I. Differential impact of reward and punishment on functional connectivity after skill learning. Neuroimage, https://doi.org/10.1016/j.neuroimage.2019.01.009 (2019).
Schendan, H. E., Searl, M. M., Melrose, R. J. & Stern, C. E. An FMRI study of the role of the medial temporal lobe in implicit and explicit sequence learning. Neuron 37, 1013–1025, https://doi.org/10.1016/S0896-6273(03)00123-5 (2003).
Schapiro, A. C. et al. The hippocampus is necessary for the sleep-dependent consolidation of a task that does not require the hippocampus for initial learning. bioRxiv (2018).
Desmurget, M. & Sirigu, A. A parietal-premotor network for movement intention and motor awareness. Trends Cogn. Sci. 13, 411–419, https://doi.org/10.1016/j.tics.2009.08.001 (2009).
Lau, H. C., Rogers, R. D., Haggard, P. & Passingham, R. E. Attention to intention. Science 303, 1208–1210, https://doi.org/10.1126/science.1090973 (2004).
Butler, L. T. & Berry, D. C. Implicit memory: intention and awareness revisited. Trends Cogn. Sci. 5, 192–197, https://doi.org/10.1016/s1364-6613(00)01636-3 (2001).
Breton, J. & Robertson, E. M. Dual enhancement mechanisms for overnight motor memory consolidation. Nat Hum Behav 1, https://doi.org/10.1038/s41562-017-0111 (2017).
Brown, R. M. & Robertson, E. M. Off-line processing: reciprocal interactions between declarative and procedural memories. J. Neurosci. 27, 10468–10475, https://doi.org/10.1523/JNEUROSCI.2799-07.2007 (2007).
Robertson, E. M. New insights in human memory interference and consolidation. Curr. Biol. 22, R66–71, https://doi.org/10.1016/j.cub.2011.11.051 (2012).
Robertson, E. M., Pascual-Leone, A. & Miall, R. C. Current concepts in procedural consolidation. Nat. Rev. Neurosci. 5, 576–582, https://doi.org/10.1038/nrn1426 (2004).
Robertson, E. M., Press, D. Z. & Pascual-Leone, A. Off-line learning and the primary motor cortex. J. Neurosci. 25, 6372–6378, https://doi.org/10.1523/JNEUROSCI.1851-05.2005 (2005).
Sami, S., Robertson, E. M. & Miall, R. C. The time course of task-specific memory consolidation effects in resting state networks. J. Neurosci. 34, 3982–3992, https://doi.org/10.1523/JNEUROSCI.4341-13.2014 (2014).
Tunovic, S., Press, D. Z. & Robertson, E. M. A physiological signal that prevents motor skill improvements during consolidation. J. Neurosci. 34, 5302–5310, https://doi.org/10.1523/JNEUROSCI.3497-13.2014 (2014).
Song, S. & Cohen, L. G. Practice and sleep form different aspects of skill. Nat. Commun. 5, 3407, https://doi.org/10.1038/ncomms4407 (2014).
Robertson, E. M., Tormos, J. M., Maeda, F. & Pascual-Leone, A. The role of the dorsolateral prefrontal cortex during sequence learning is specific for spatial information. Cereb. Cortex 11, 628–635, https://doi.org/10.1093/cercor/11.7.628 (2001).
Song, S., Gotts, S. J., Dayan, E. & Cohen, L. G. Practice structure improves unconscious transitional memories by increasing synchrony in a premotor network. J. Cogn. Neurosci. 27, 1503–1512, https://doi.org/10.1162/jocn_a_00796 (2015).
Stagg, C. J., Bachtiar, V. & Johansen-Berg, H. The role of GABA in human motor learning. Curr. Biol. 21, 480–484, https://doi.org/10.1016/j.cub.2011.01.069 (2011).
Destrebecqz, A. et al. The neural correlates of implicit and explicit sequence learning: Interacting networks revealed by the process dissociation procedure. Learn. Mem. 12, 480–490, https://doi.org/10.1101/lm.95605 (2005).
Acknowledgements
A.S. and C.I.B. are funded by the NIMH internal research program (ZIA-MH002893). CJS holds a Sir Henry Dale Fellowship, funded by the Wellcome Trust and the Royal Society (102584/Z/13/Z). The Wellcome Centre for Integrative Neuroimaging is supported by core funding from the Wellcome Trust (203139/Z/16/Z). AS would like to thank the International Biomedical Research Alliance for their support.
Author information
Authors and Affiliations
Contributions
A.S., C.B., and C.J.S. designed the study. A.S. collected and analysed the data. A.S., C.B., and C.J.S. wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Steel, A., Baker, C.I. & Stagg, C.J. Intention to learn modulates the impact of reward and punishment on sequence learning. Sci Rep 10, 8906 (2020). https://doi.org/10.1038/s41598-020-65853-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-65853-w
This article is cited by
-
Repeated unilateral handgrip contractions alter functional connectivity and improve contralateral limb response times
Scientific Reports (2023)
-
Interactive effects of incentive value and valence on the performance of discrete action sequences
Scientific Reports (2021)
-
Cortical preparatory activity during motor learning reflects visuomotor retention deficits after punishment feedback
Experimental Brain Research (2021)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
