
Abstract
In this study, an efficient method for estimating material parameters based on the experimental data of precipitate shape is proposed. First, a computational model that predicts the energetically favorable shape of precipitate when a d-dimensional material parameter (x) is given is developed. Second, the discrepancy (y) between the precipitate shape obtained through the experiment and that predicted using the computational model is calculated. Third, the Gaussian process (GP) is used to model the relation between x and y. Finally, for identifying the “low-error region (LER)” in the material parameter space where y is less than a threshold, we introduce an adaptive sampling strategy, wherein the estimated GP model suggests the subsequent candidate x to be sampled/calculated. To evaluate the effectiveness of the proposed method, we apply it to the estimation of interface energy and lattice mismatch between MgZn2 (\({{\rm{\beta }}}_{1}^{\text{'}}\)) and α-Mg phases in an Mg-based alloy. The result shows that the number of computational calculations of the precipitate shape required for the LER estimation is significantly decreased by using the proposed method.
Similar content being viewed by others
Introduction
Precipitate shape in materials intrinsically contains some information on material parameters. The interaction between the interface and strain energies determines the equilibrium shape of a coherent precipitate1,2,3,4,5,6. For example, the aspect ratio of a plate- or rod-shaped coherent precipitate, often observed in Mg-based alloys7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27, varies depending on the precipitate size, interface energy, and crystal lattice mismatch between the precipitate and matrix phases. In materials science, material parameters have often been estimated by using experimental data. For example, the interface energy can be estimated by fitting the Ostwald ripening model28 (theoretical formula) to time-series experimental measurement of precipitate radius. Most recently, there are some efforts to estimate material parameters by comparing data of microstructure evolution obtained by experiment and simulation29,30,31,32. However, the material parameter estimation by directly using experimental data of precipitate shape has not been reported yet. This is due to the fact that although there are some computational models to predict precipitate shape6,33,34,35, their computational cost is high and hence it is time-consuming to estimate material parameters by fitting the models to experimental data.
A precipitate prefers an energetically favorable shape that minimizes the total energy derived from the precipitation. When a spheroidal precipitate is assumed, the total energy (sum of the interface and strain energies) can be calculated as a function of the aspect ratio of the spheroid (precipitate shape) for the given values of material parameters and precipitate volume6. Hence, the material parameters involved in the total energy calculation can be estimated if the experimental data of the precipitate shape are obtained. However, considering that the computational cost of the total energy calculation is high and the number of candidate parameter conditions is large, an efficient method for material parameter estimation is necessary. Given that experimental data of precipitate shape are naturally uncertain, estimating the “low-error region (LER)” in the material parameter space seems to be crucial, where the discrepancy between the precipitate shape obtained through the experiment and that predicted using a computational model becomes small.
In this study, we propose an efficient method for estimating material parameters based on the experimental data of precipitate shape. First, a computational model that predicts the energetically favorable shape of the precipitate under a given material parameter condition is developed. When the d-dimensional material parameter (\({\boldsymbol{x}}\in {{\mathbb{R}}}^{d}\)) is given, we can calculate the discrepancy (y) between the precipitate shape obtained through the experiment and that predicted using the computational model. Then, we use the Gaussian process (GP) to model the x and y relation. GP has been widely used for a variety of problems in materials science such as materials discovery36, potential approximation37, and structure optimization38,39. Unlike classical deterministic regression models, GP represents an unknown target function value as a random variable of a Gaussian distribution, which enables us to simply quantify uncertainty of the current prediction. We utilized this uncertainty evaluation to define probabilistic estimation of LER for each uncalculated candidate x. Finally, we introduce an adaptive sampling strategy wherein the estimated GP model suggests the subsequent candidate x to be sampled/calculated so that the uncertainty of the LER estimation is efficiently reduced. Since our interest is only in LER, exhaustive sampling in the parameter space should be inefficient. Our strategy intensively selects samples which are effective for identifying LER efficiently, instead of trying to approximate the entire discrepancy surface precisely. The result showed that the proposed method can provide an efficient estimation of material parameters.
Results
To evaluate the effectiveness of the proposed method, we consider estimating the interface energy and lattice mismatch between the hexagonal MgZn2 (\({{\rm{\beta }}}_{1}^{\text{'}}\)) precipitate and hexagonal α-Mg matrix phases based on the experimental data on the shape of the \({{\rm{\beta }}}_{1}^{\text{'}}\) phase. The stress-free transformation strain (crystal lattice mismatch between the \({{\rm{\beta }}}_{1}^{\text{'}}\) and α phases) is expressed by
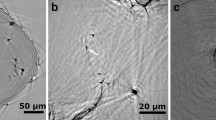
Here, \({\varepsilon }_{11}^{0}\), \({\varepsilon }_{22}^{0}\), and \({\varepsilon }_{33}^{0}\) are the lattice mismatch along \({[2\bar{1}\bar{1}0]}_{{\rm{\alpha }}}\), \({[01\bar{1}0]}_{{\rm{\alpha }}}\), and \({[0001]}_{{\rm{\alpha }}}\) of the α phase, respectively. Figure 1 shows the shape of the \({{\rm{\beta }}}_{1}^{\text{'}}\) phase observed in an aged Mg–Zn–Ca–Ag alloy24. The \({{\rm{\beta }}}_{1}^{\text{'}}\) phase has a rod shape along [0001]α. Hence, the values of \({\varepsilon }_{11}^{0}\) and \({\varepsilon }_{22}^{0}\) are assumed to be equal6. Based on the experimental data on the crystallographic orientation relationship between the \({{\rm{\beta }}}_{1}^{\text{'}}\) and α phases8 and lattice parameters of the two phases18,40, the lattice mismatch along [0001]α is \({\varepsilon }_{33}^{0}=0.00182\). Table 1 presents the change in the length and diameter of the rod-shaped \({{\rm{\beta }}}_{1}^{\text{'}}\) phase during aging at 160 °C measured via transmission electron microscopy (TEM)24. By using the experimental data listed in the table, we consider estimating the interface energy γ and the lattice mismatch \({\varepsilon }_{11}^{0}(\,=\,{\varepsilon }_{22}^{0})\).

Shape of the \({{\rm{\beta }}}_{1}^{\text{'}}\) phase investigated via transmission electron microscopy in Mg–Zn–Ca–Ag alloy, which is aged at 160 °C for 2 h. (Reprinted from Mater. Sci. Eng. A, Vol. 575, Bhattacharjee, T., Mendis, C.L., Oh-ishi, K., Ohkubo, T. & Hono, K., The effect of Ag and Ca additions on the age hardening response of Mg–Zn alloys, pp. 231–240, 2013, with permission from Elsevier).
We assume that the \({{\rm{\beta }}}_{1}^{\text{'}}\) phase has a spheroidal shape. Then, we prepare the computational model for predicting the energetically favorable shape of the precipitate (aspect ratio of the spheroid) with the given values of γ and \({\varepsilon }_{11}^{0}\) (refer to “Methods” section for details). To determine the candidate parameter \({\boldsymbol{x}}={(\gamma ,{\varepsilon }_{11}^{0})}^{{\rm{\top }}}\), we use 250 equally spaced grids in \({\varepsilon }_{11}^{0}\in [-\,0.250,-\,0.001]\) and 250 equally spaced grids in γ∈[0.001,0.250] (J m−2). Thus, we have a total of 62500 candidate parameter conditions xi(i = 1, …, 62500). In the given material parameter condition xi, the discrepancy in the aspect ratio between the precipitate obtained through the experiment (rexpt) and that predicted using the computational model (ri,comput) is defined as follows:
where t is time and \({\mathscr{T}}\) is a set of time when the shape of \({{\rm{\beta }}}_{1}^{\text{'}}\) is experimentally measured. We consider identifying the LER where the error yi is less than a given threshold h, i.e., yi ≤ h. Based on the standard deviation of rexpt listed in Table 1, h is assumed to have a value between 1 and 5. Figure 2 shows the heatmap of yi in the material parameter space, in which the LER for h = 1 and h = 5 are denoted by white and blue lines, respectively.

Heatmap of yi, which is the error in the aspect ratio between the precipitate obtained through the experiment and that predicted using the computational model. Low-error region (LER), where yi ≤ h, is shown for h = 1 and h = 5 as denoted by white and blue lines, respectively.
GP is used to model the relation between xi and yi. In this process, yi is modeled as yi = fi + e, where \(e \sim {\mathscr{N}}(0,\varepsilon )\) is an independent noise term with variance ε. We assume that the noise is negligible because it is associated with the numerical error of the computational model. Thus, we set a small value of ε, as will be described in “Methods” section. Then, the conditional distribution for fi after observing \({{\boldsymbol{y}}}_{{\mathscr{I}}}\) (a vector defined by yi for \(i\in {\mathcal I} \), where \( {\mathcal I} \subseteq \{1,\cdots ,N\}\) is a subset of indices for which yi is already calculated) is expressed as
where μ(xi) and σ(xi) are the conditional mean and covariance functions, respectively. In the proposed method, the estimated GP model suggests the subsequent candidate xi that has the maximum information gain (IG) among the uncalculated points (refer to “Methods” section for details). The intuition behind IG is to add a sample which has the highest uncertainty reduction among candidates. Our sampling strategy can be summarized as follows:
-
(a)
fit GP to the observed \({{\boldsymbol{y}}}_{{\mathscr{I}}}\), and obtain the probabilistic estimation of LER, and
-
(b)
select the candidate xi which has the highest IG evaluated through the fitted GP.
For the material parameter xi, we use the indicator variables as follows:
Figure 3 shows the sampling process of the proposed method. In the figure, the left, middle, and right columns are the heatmap of μ(xi), heatmap of IG, and predicted LER (blue regions are p(zi = 1) ≥ 0.5, where p represents the probability of zi), respectively. Note that it is known that μ(x) is equivalent to the well-known non-parametric regression model called kernel ridge regression (KRR)41. The non-parametric approach is suitable to our problem setting than the parametric approach such as classical linear regression. This is because, in the parametric approach, the discrepancy yi has to be modeled as an explicit function of material parameters, but the functional form of the discrepancy surface is not known beforehand. In the left columns in Fig. 3, the blue points are the sampled points, red point is the point to be sampled in the subsequent iteration, and black lines are the boundary of the LER for h = 5. Although the error surface in iteration 10 remains highly uncertain, a part of the LER is already identified. In iteration 50, the entire shape of the LER is barely identified, and the sampled points are mostly concentrated in the LER. In iteration 100, the points around the LER boundary are sampled to identify the region precisely.

Demonstration of the proposed sampling strategy with h = 5. The images on the left column are the heatmap of μ(xi). Blue points represent the calculated points, and the red point is the one to be calculated in the subsequent iteration. Black lines are the boundary of the LER for h = 5. The images at the middle column are the heatmap of IG. The images on the right column are the predicted LER. Blue regions are p(zi = 1) ≥ 0.5, and red regions are p(zi = 1) < 0.5. In each iteration, a candidate x which has the highest IG is sampled. Thus, the number of samples in each plot (a), (b), and (c) is equal to the number of iterations.
Figure 4 shows the performance evaluation. Our purpose is to identify LER. This problem setting can be seen as a variant of classification problem in which the binary label zi is needed to be predicted precisely. Thus, we evaluate accuracy of the LER prediction by zi by using standard evaluation measures of classification problem. We use three criteria, namely recall, precision, and F-score, that are extensively used in the field of information retrieval42. Each plot compares the performance of two GP models, that is, (1) GP with our sampling strategy and (2) GP with random sampling. For both sampling approaches, a candidate x is classified as LER if p(zi = 1) ≥ 0.5, which is equivalent to μ(xi) ≤ h. Since μ(xi) is equivalent to KRR, “GP + random sampling” can also be seen as a baseline defined by KRR with a naive sampling strategy. The left plot in Fig. 4 shows the recall, defined by

Performance evaluation with h = 5. The image on the left is the ratio of points i for which p(zi = 1) ≥ 0.5 among the points in LER (recall). The image at the middle is the ratio of points i for which yi ≤ h among the points in the predicted LER p(zi = 1) ≥ 0.5 (precision). The image on the right is the harmonic mean of recall and precision (F-score).
Thus, the recall is the ratio of the number of LER points that GP correctly identifies over the number of points in true LER. This can evaluate how many LER points are correctly identified. At the beginning of the iterations, the recall was approximately 0.1 for both sampling strategies owing to the absence of sampled points. However, we observe that the proposed method rapidly increased the recall substantially faster than the random sampling. The middle plot in Fig. 4 shows the precision, defined by
The precision has the same numerator as recall, but the denominator is the number of points predicted as LER by GP. This can evaluate specificity of the prediction, which cannot be considered by recall. Considering that most of the predicted LER was actually yi ≤ h (Fig. 3), the precision values are higher than the recall from the beginning of the iterations. Hence, the proposed sampling strategy is substantially better than the random sampling strategy. Given that recall and precision sometimes have a tradeoff relationship, their harmonic mean, referred to as F-score, is often used as the basis for a comprehensive evaluation. Figure 4 (right plot) shows the superior performance of the proposed method in F-score. The effectiveness of the proposed method was similarly evaluated when we set h = 1. The proposed method identified the LER accurately after 100 iterations despite the region was narrower than that of h = 5 (refer to Supplementary Information).
Discussion
Prior to material parameter estimation, determining the material parameter range of interest is crucial. In this study, the parameter ranges of \({\varepsilon }_{11}^{0}\) and γ were assumed to be \({\varepsilon }_{11}^{0}\in [\,-\,0.250,-\,0.001]\) and \(\gamma \in [0.001,0.250]\) (J m−2), respectively. When the \({{\rm{\beta }}}_{1}^{\text{'}}\) phase grows during aging heat treatment, the interface between \({{\rm{\beta }}}_{1}^{\text{'}}\) and α phases would shift from coherent to semi-coherent/incoherent. As TEM micrographs24 show, the α/\({{\rm{\beta }}}_{1}^{\text{'}}\) interface in the Mg–Zn–Ca–Ag alloy remains coherent during aging at 160 °C for 2–24 h because any dislocations do not occur at the interface. The coherent interface energy is generally less than 0.25 J m−2 (ref.5). Hence, the parameter range of \(\gamma \in [0.001,0.250]\) (J m−2) is reasonable. Furthermore, the absolute value of \({\varepsilon }_{11}^{0}\) larger than 0.25 was omitted from the parameter range of interest because this value was much larger than the reported values of the lattice mismatch between precipitate and matrix phases in several Mg-based alloys33,34,35.
The lattice mismatch between precipitate and matrix phases is often estimated from the lattice parameter information of the two phases and crystallographic lattice correspondence between the two phases4,33,34,35. However, regarding the nanometer-size precipitate, experimentally determining the lattice correspondence using TEM is challenging, specifically when the aspect ratio of the precipitate is high/low. Moreover, the aspect ratio of the nanometer-size \({{\rm{\beta }}}_{1}^{\text{'}}\) phase is higher than 10 (Table 1). Hence, the lattice correspondence between \({{\rm{\beta }}}_{1}^{\text{'}}\) and α phases along the crystallographic directions perpendicular to [0001]α is difficult to determine experimentally. In contrast, our method is based on the computational model for predicting the energetically favorable shape of precipitate with the given material parameters. The method can perform simultaneous estimation of the lattice mismatch and interface energy based on the experimental data of precipitate shape. Furthermore, it only requires at most 100 computational calculations of the precipitate shape to estimate the LER. Thus, we assume that the proposed method can be used for the effective utilization of the experimental data of precipitate shape for estimating material parameters.
The computational model used in predicting the energetically favorable shape of precipitate can be replaced by another computational model or simulation if necessary. The limitation of the computational model used in this study is that the precipitate shape is assumed to be spheroid and the interface energy anisotropy is ignored (refer to “Methods” section for details). In several Mg-based alloys43,44,45,46, the precipitate mostly has faced or lenticular shape, on which the anisotropy of the interface energy has significant effects34. Furthermore, although we assume that the precipitate takes on an energetically favorable shape, there would be some cases where the precipitate shape cannot be fully accommodated during aging. In the above-mentioned cases, the computational model used in this study should be replaced by a phase-field model33,34,35, which can simulate the microstructure evolution that takes place so as to reduce the total free energy of the microstructure47,48. The computational cost of the phase-field simulation in predicting precipitate shape change would be much higher than the computational model employed in this study. However, it is presumed that combining the phase-field and GP models with our sampling strategy would also provide an efficient estimation of material parameters based on the precipitate shape. Note that the material parameter estimation primarily from the precipitate shape is challenging in the case where the precipitate volume fraction is high and long-range interaction between the precipitates is strong because the precipitate shape is determined by not only the material parameters but also the precipitate spatial arrangement.
In summary, if a computational model for predicting the energetically favorable shape of precipitate with the given material parameters is available, it is possible to estimate material parameters based on the precipitate shape. The GP model combined with our sampling strategy can significantly reduce the computational cost required for the LER estimation and would be useful to accelerate the extraction of material parameters from experimental data of precipitate shape obtained at various temperatures in different alloys.
Methods
Prediction of the precipitate aspect ratio
When a spheroidal precipitate is assumed (x2/a2 + y2/b2 + z2/c2 = 1, a = b, r = c/a), the total energy (sum of the interface and strain energies) of the precipitate is formulated as a function of the aspect ratio of the spheroid r (ref.6).
where V0 is precipitate volume, Cijkl is elastic modulus tensor, \({\varepsilon }_{ij}^{0}\) is crystal lattice mismatch between the precipitate and matrix phases, Sijmn(r) is Eshelby’s tensor49, A(r) is interface area, and γ is interface energy (in J m−2). Note that anisotropy of the interface energy is ignored for simplicity. The computational cost for calculating Sijmn(r) is high because the surface integration must be numerically calculated6.
We consider predicting the aspect ratio of the \({{\rm{\beta }}}_{1}^{\text{'}}\) phase in the α phase with the given material parameters. \({\varepsilon }_{ij}^{0}\) is given by Eq. (1), where \({\varepsilon }_{11}^{0}={\varepsilon }_{22}^{0}\). As an example, Fig. 5 shows the total energy Etotal given by Eq. (5) as a function of the aspect ratio of the spheroid r. The calculation uses the following variables: interface energy γ = 0.1 J m−2; lattice mismatch \({\varepsilon }_{11}^{0}={\varepsilon }_{22}^{0}=0.01\) and \({\varepsilon }_{33}^{0}=0.002\); elastic modulus C11 = C22 = 0.597, C33 = 0.617, C12 = 0.262, C13 = C23 = 0.217, C44 = C55 = 0.164, and C66 = (C11−C12)/2 (1011 Pa)40; and \({{\rm{\beta }}}_{1}^{\text{'}}\) phase volume V0 = 5.2 × 105 nm3. The rotation axis of the spheroid is parallel to [0001]α and Etotal is normalized using Etotal of the spherical precipitate (r = 1) with the same volume of \({{\rm{\beta }}}_{1}^{\text{'}}\) phase. As shown in the figure, the total energy is minimized when 1/r = 0.67, indicating that with given material parameters, we can compute the aspect ratio of the precipitate (rcomput).

Total energy Etotal (sum of the strain and interface energies) of the spheroidal precipitate as a function of the aspect ratio of spheroid r.
GP model using selective sampling procedure
Suppose that \({{\boldsymbol{x}}}_{i}\in {{\mathbb{R}}}^{d}\) is a d-dimensional parameter of the computational model and \({y}_{i}\in {\mathbb{R}}\) is the discrepancy between the precipitate aspect ratio obtained through the experiment (rexpt) and that predicted using the computational model (ri,comput) (Eq. (2)). Considering that the aspect ratio of the precipitates in the TEM micrograph fluctuates (Fig. 1), the average of the aspect ratio is used to calculate yi. To incorporate this intrinsic uncertainty in the experimental measurement, we consider identifying the LER, where yi ≤ h. Compared with naturally searching a single optimal material parameter set, the LER provides the information as follows:
-
the region of possible good material parameter sets that can be estimated from the experimental data, and
-
the accuracy in identifying the material parameter sets from the current experimental measurement (large LER indicates that the error level h is substantially high for accurately identifying material parameter sets).
Considering that the computational cost of yi (or ri,comput) is high, we estimate the LER according to the limited number of calculations of yi based on a probabilistic model.
The relation between xi and yi is modeled by GP. For N different parameter sets xi(i = 1, …, N), the set of error values yi(i = 1, …, N) is approximated using the following multi-dimensional Gaussian distribution.
where \({\boldsymbol{f}}={({f}_{1},\cdots ,{f}_{N})}^{\top }\) and \({\mathscr{N}}({\boldsymbol{\mu }},\,{\boldsymbol{K}})\) is the Gaussian distribution with \({\boldsymbol{\mu }}\in {{\mathbb{R}}}^{N}\) as the mean vector and \({\boldsymbol{K}}\in {{\mathbb{R}}}^{N\times N}\) as the covariance matrix. The i,j element of the covariance matrix K is defined by the kernel function k(xi, xj) for which we use the standard Gaussian kernel as follows:
where θ1 and θ2 are the tuning parameters. Herein, the tuning parameters θ1 and θ2 in GP are optimized based on marginal likelihood maximization41 per iteration. By using the kernel function, the proximity of xi and xj is translated into the covariance of fi and fj. Let \( {\mathcal I} \subseteq \{1,\cdots ,N\}\) be the subset of indices for which yi is already calculated and \({{\boldsymbol{y}}}_{{\mathscr{I}}}\) be the vector defined by yi for \(i\in {\mathcal I} \). In this process, a calculated yi is defined as yi = fi + e, where \(e \sim {\mathscr{N}}(0,\varepsilon )\) is an independent noise term with variance ε. Herein, the variance ε is set to 10−8. The prior mean μ in Eq. (6) is set as the mean of observed yi for \(i\in {\mathcal I} \). Then, the conditional distribution for fi after calculating \({{\boldsymbol{y}}}_{{\mathscr{I}}}\) is expressed in Eq. (3). \({f}_{i}\,|\,{{\boldsymbol{y}}}_{{\mathscr{I}}}\) is called the predictive distribution, and μ(xi) and σ(xi) in this equation are analytically written as follows:
where I is identity matrix. Moreover, the vectors and matrices with subscripts represent subvectors and submatrices specified by the given indices (e.g., \({{\boldsymbol{K}}}_{i,{\mathscr{I}}}\) indicates the i-th row and the columns defined by \({\mathscr{I}}\)).
The indicator variable zi defined by Eq. (4) represents whether the parameter xi is expected to have lower error than the threshold h. Given that fi is the Gaussian random variable, the probability of zi is simply expressed as follows:
where Φ is the cumulative distribution function of the standard normal distribution. This probability provides a statistical estimation on the extent that the parameter xi has lower error than h based on the present calculations. Thus, a set of parameter that provides lower errors than h (i.e., LER) can be estimated as a set of xi satisfying the following equation.
Although GP provides the LER estimation, its reliability depends on the calculated points \( {\mathcal I} \) (i.e., training data). To obtain an accurate prediction efficiently, we introduce an adaptive sampling strategy, referred to as active learning50, in which the estimated GP model suggests the subsequent candidate xi to be sampled/calculated to gain the prediction reliability. The basic idea is to select a point xi that can primarily reduce the uncertainty of zi. The following entropy evaluates the current uncertainty of zi.
The uncertainty of zi after calculating yi is represented by the conditional entropy as follows:
Thus, by obtaining the difference between H(zi) and H(zi|yi), uncertainty reduction, referred to as IG, can be evaluated as follows:
The expectation in the second term H(zi|yi) is approximated by sampling from \(p({y}_{i}|{{\boldsymbol{y}}}_{{\mathscr{I}}})\), defined by the Gaussian \({\mathscr{N}}(\mu ({{\boldsymbol{x}}}_{i}),{\sigma }^{2}({{\boldsymbol{x}}}_{i})+\varepsilon )\). Given the sample\({\bar{y}}_{i}\) from \(p({y}_{i}|{{\boldsymbol{y}}}_{{\mathscr{I}}})\), fi is represented by \({\mathscr{N}}({\bar{y}}_{i},\varepsilon )\) because of our assumption that yi = fi + e (where \(e \sim {\mathscr{N}}(0,\varepsilon )\)). Then, we can easily calculate \(p({z}_{i}=1\,|\,{\bar{y}}_{i})=p({f}_{i}\le h\,|\,{\bar{y}}_{i})\), which is equal to the cumulative distribution function of \({f}_{i}|{\bar{y}}_{i} \sim {\mathscr{N}}({\bar{y}}_{i},\varepsilon )\). We iteratively select the point xi that has the maximum IGi among the uncalculated points.
Figure 6 presents the illustrative example of the proposed method. The three plots in each iteration are the estimated GP model, IG, and p(zi = 1). Our method iteratively selects a point that maximizes the IG per iteration, by which p(zi = 1) gradually takes a value close to 1 or 0. Therefore, by sampling the point that reduces the prediction uncertainty, the GP model immediately increases its confidence on the LER identification. The proposed method can be generally applied to types of problem where the surface of y is smooth in x space.

Illustrative example of the proposed method. The images on the left column are the prediction by GP. The predictive distribution is drawn at the point that has the maximum IG. The images at the middle are the IG, where the circle represents the maximum. The images on the right column are the probability of the LER: p(zi = 1).
Data availability
The Supplementary Information file provides the data supporting the results obtained in this study.
References
Thompson, M. E., Su, C. S. & Voorhees, P. W. Equilibrium shape of a misfitting precipitate. Acta Metall. Mater. 42, 2107–2122 (1994).
Schmidt, I. & Gross, D. The equilibrium shape of an elastically inhomogeneous inclusion. J. Mech. Phys. Solids 45, 1521–1549 (1997).
Schmidt, I., Mueller, R. & Gross, D. The effect of elastic inhomogeneity on equilibrium and stability of a two particle morphology. Mech. Mater. 30, 181–196 (1998).
Khachaturyan, A.G. Theory of Structural Transformations in Solids (Dover, 2008).
Porter, D. A., Easterling, K. E. & Sherif, M. Y. Phase Transformations in Metals and Alloys 3rd edition (CRC Press, 2009).
Tsukada, Y., Beniya, Y. & Koyama, T. Equilibrium shape of isolated precipitates in the α-Mg phase. J. Alloy. Compd. 603, 65–74 (2014).
Clark, J. B. Transmission electron microscopy study of age hardening in a Mg‒5 wt.% Zn alloy. Acta Metall. 13, 1281–1289 (1965).
Chun, J. S. & Byrne, J. G. Precipitate strengthening mechanisms in magnesium zinc alloy single crystals. J. Mater. Sci. 4, 861–872 (1969).
Nie, J. F. & Muddle, B. C. Precipitation hardening of Mg‒Ca(‒Zn) alloys. Scr. Mater. 37, 1475–1481 (1997).
Celotto, S. TEM study of continuous precipitation in Mg‒9 wt.% Al‒1 wt.% Zn alloy. Acta Mater. 48, 1775–1787 (2000).
Smola, B., Stulíková, I., Buch, F. & Mordike, B. L. Structural aspects of high performance Mg alloys design. Mater. Sci. Eng. A 324, 113–117 (2002).
Ping, D. H., Hono, K. & Nie, J. F. Atom probe characterization of plate-like precipitates in a Mg‒RE‒Zn‒Zr casting alloy. Scr. Mater. 48, 1017–1022 (2003).
Oh, J. C., Ohkubo, T., Mukai, T. & Hono, K. TEM and 3DAP characterization of an age-hardened Mg‒Ca‒Zn alloy. Scr. Mater. 53, 675–679 (2005).
Nie, J. F., Gao, X. & Zhu, S. M. Enhanced age hardening response and creep resistance of Mg‒Gd alloys containing Zn. Scr. Mater. 53, 1049–1053 (2005).
Sasaki, T. T., Oh-ishi, K., Ohkubo, T. & Hono, K. Enhanced age hardening response by the addition of Zn in Mg‒Sn alloys. Scr. Mater. 55, 251–254 (2006).
Mendis, C. L., Bettles, C. J., Gibson, M. A. & Hutchinson, C. R. An enhanced age hardening response in Mg‒Sn based alloys containing Zn. Mater. Sci. Eng. A 435–436, 163–171 (2006).
Mendis, C. L., Oh-ishi, K. & Hono, K. Enhanced age hardening in a Mg‒2.4 at.% Zn alloy by trace additions of Ag and Ca. Scr. Mater. 57, 485–488 (2007).
Sasaki, T. T., Ohkubo, T. & Hono, K. Precipitation hardenable Mg‒Bi‒Zn alloys with prismatic plate precipitates. Scr. Mater. 61, 72–75 (2009).
Oh-ishi, K., Watanabe, R., Mendis, C. L. & Hono, K. Age-hardening response of Mg−0.3 at.% Ca alloys with different Zn contents. Mater. Sci. Eng. A 526, 177–184 (2009).
Sasaki, T. T., Oh-ishi, K., Ohkubo, T. & Hono, K. Effect of double aging and microalloying on the age hardening behavior of a Mg‒Sn‒Zn alloy. Mater. Sci. Eng. A 530, 1–8 (2011).
Mendis, C. L., Oh-ishi, K., Ohkubo, T. & Hono, K. Precipitation of prismatic plates in Mg‒0.3Ca alloys with In additions. Scr. Mater. 64, 137–140 (2011).
Mendis, C. L., Oh-ishi, K. & Hono, K. Microalloying effect on the precipitation processes of Mg‒Ca alloys. Metall. Mater. Trans. A 43, 3978–3987 (2012).
Elsayed, F. R., Sasaki, T. T., Mendis, C. L., Ohkubo, T. & Hono, K. Compositional optimization of Mg‒Sn‒Al alloys for higher age hardening response. Mater. Sci. Eng. A 566, 22–29 (2013).
Bhattacharjee, T., Mendis, C. L., Oh-ishi, K., Ohkubo, T. & Hono, K. The effect of Ag and Ca additions on the age hardening response of Mg‒Zn alloys. Mater. Sci. Eng. A 575, 231–240 (2013).
Bhattacharjee, T., Nakata, T., Sasaki, T. T., Kamado, S. & Hono, K. Effect of microalloyed Zr on the extruded microstructure of Mg‒6.2Zn-based alloys. Scr. Mater. 90–91, 37–40 (2014).
Sasaki, T. T. et al. Strong and ductile heat-treatable Mg‒Sn‒Zn‒Al wrought alloys. Acta Mater. 99, 176–186 (2015).
Nakata, T. et al. Strong and ductile age-hardening Mg‒Al‒Ca‒Mn alloy that can be extruded as fast as aluminum alloys. Acta Mater. 130, 261–270 (2017).
Kahlweit, M. Ostwald ripening of precipitates. Adv. Colloid Interface Sci. 5, 1–35 (1975).
Ito, S. et al. Data assimilation for massive autonomous systems based on a second-order adjoint method. Phys. Rev. E 94, 043307 (2016).
Ito, S., Nagao, H., Kasuya, T. & Inoue, J. Grain growth prediction based on data assimilation by implementing 4DVar on multi-phase-field model. Sci. Technol. Adv. Mater. 18, 857–869 (2017).
Zhang, J. et al. Determining material parameters using phase-field simulations and experiments. Acta Mater. 129, 229–238 (2017).
Sasaki, K., Yamanaka, A., Ito, S. & Nagao, H. Data assimilation for phase-field models based on the ensemble Kalman filter. Comput. Mater. Sci. 141, 141–152 (2018).
Gao, Y. et al. Simulation study of precipitation in an Mg‒Y‒Nd alloy. Acta Mater. 60, 4819–4832 (2012).
Liu, H. et al. A simulation study of the shape of β′ precipitates in Mg‒Y and Mg‒Gd alloys. Acta Mater. 61, 453–466 (2013).
Ji, Y. Z. et al. Predicting β′ precipitate morphology and evolution in Mg‒RE alloys using a combination of first-principles calculations and phase-field modeling. Acta Mater. 76, 259–271 (2014).
Seko, A. et al. Prediction of low-thermal-conductivity compounds with first-principles anharmonic lattice-dynamics calculations and Bayesian optimization. Phys. Rev. Lett. 115, 205901 (2015).
Bartók, A. P., Payne, M. C., Kondor, R. & Csányi, G. Gaussian approximation potentials: the accuracy of quantum mechanics, without the electrons. Phys. Rev. Lett. 104, 136403 (2010).
Yamashita, T. et al. Crystal structure prediction accelerated by Bayesian optimization. Phys. Rev. Mater. 2, 013803 (2018).
Yonezu, T., Tamura, T., Takeuchi, I. & Karasuyama, M. Knowledge-transfer-based cost-effective search for interface structures: a case study on fcc-Al [110] tilt grain boundary. Phys. Rev. Mater. 2, 113802 (2018).
The Japan Institute of Metals and Materials (ed.) Kinzoku Data Book 4th rev. edition (Maruzen, 2004).
Rasmussen, C. E. & Williams, C. K. I. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning) (The MIT Press, 2005).
Manning, C.D., Raghavan, P. & Schütze, H. Introduction to Information Retrieval (Cambridge Univ. Press, 2008).
Vostrý, P., Smola, B., Stulíková, I., Buch, F. & Mordike, B. L. Microstructure evolution in isochronally heat treated Mg‒Gd alloys. Phys. Status Solidi A 175, 491–500 (1999).
Nishijima, M., Hiraga, K., Yamasaki, M. & Kawamura, Y. Characterization of β′ phase precipitates in an Mg‒5 at.% Gd alloy aged in a peak hardness condition, studied by high-angle annular detector dark-field scanning transmission electron microscopy. Mater. Trans. 47, 2109–2112 (2006).
Nishijima, M. & Hiraga, K. Structural changes of precipitates in an Mg‒5 at.% Gd alloy studied by transmission electron microscopy. Mater. Trans. 48, 10–15 (2007).
Nishijima, M., Yubuta, K. & Hiraga, K. Characterization of β′ precipitate phase in Mg‒2 at.% Y alloy aged to peak hardness condition by high-angle annualr detector dark-field scanning transmission electron microscopy (HAADF-STEM). Mater. Trans. 48, 84–87 (2007).
Chen, L. Q. Phase-field models for microstructure evolution. Annu. Rev. Mater. Res. 32, 113–140 (2002).
Steinbach, I. Phase-field models in materials science. Modelling Simul. Mater. Sci. Eng. 17, 073001 (2009).
Mura, T. Micromechanics of Defects in Solids 2nd rev. edition (Martinus Nijhoff, 1987).
Settles, B. Active Learning Literature Survey (Computer Science Technical Report 1648) (University of Wisconsin‒Madison, 2010).
Acknowledgements
This work was supported by JST PRESTO (JPMJPR15NB, JPMJPR15N2 and JPMJPR16N6), Advanced Low Carbon Technology Research and Development Program (ALCA), MEXT KAKENHI (16H06538, 17H04694), and MI2I project of JST Support Program for Starting Up Innovation Hub. The authors thank Dr. Sasaki, T.T. and Dr. Hono, K. (National Institute for Materials Science, Japan) for fruitful discussion on the orientation relationship between nanometer-size precipitate and matrix phases in Mg-based alloys.
Author information
Authors and Affiliations
Contributions
Y.T., M.K. and M.S. conceived and coordinated the project. H.F. developed a computational code for predicting precipitate shape with the help of Y.T. and T.K. S.T. developed a computational code of GP and selective sampling with the help of M.K. Y.T. and M.K. wrote the manuscript. All authors commented on the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tsukada, Y., Takeno, S., Karasuyama, M. et al. Estimation of material parameters based on precipitate shape: efficient identification of low-error region with Gaussian process modeling. Sci Rep 9, 15794 (2019). https://doi.org/10.1038/s41598-019-52138-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-52138-0
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
