
Abstract
In saliency-based compressive sampling (CS) for remote sensing image signals, the saliency information of images is used to allocate more sensing resources to salient regions than to non-salient regions. However, the pulsed cosine transform method can generate large errors in the calculation of saliency information because it uses only the signs of the coefficients of the discrete cosine transform for low-resolution images. In addition, the reconstructed images can exhibit blocking effects because blocks are used as the processing units in CS. In this work, we propose a post-transform frequency saliency CS method that utilizes transformed post-wavelet coefficients to calculate the frequency saliency information of images in the post-wavelet domain. Specifically, the wavelet coefficients are treated as the pixels of a block-wise megapixel sensor. Experiments indicate that the proposed method yields better-quality images and outperforms conventional saliency-based methods in three aspects: peak signal-to-noise ratio, mean structural similarity index, and visual information fidelity.
Similar content being viewed by others


Introduction
Remote sensing integrated camera (RSIC) technologies have become a new focus of research in small- and microsatellite photography1,2,3. Compressive sampling (CS) is considered the holy grail of RSIC technologies because it can improve the degree of integration of camera systems, compression systems, high-capacity storage systems, and high-speed image transmission systems. Efficiently performing CS is a key task in RSIC technology. Many CS imaging systems with various characteristics have recently been proposed4,5,6. CS is a novel sampling theory that functions at a much lower sampling rate than the Nyquist frequency7, 8. To reconstruct signals from significantly limited samples, CS relies on the fact that most natural signals are sparse and compressible, consistent with a proper basis function. A number of theoretical contributions to CS have been achieved in the past few years. For example, in 2010, Ying et al. proposed a saliency-based CS (S-CS) scheme based on the features of the human visual system (HVS) in which sensing resources are allocated to different blocks based on a saliency map9. This scheme allocates more sensing resources to salient regions than to non-salient regions to improve the reconstruction quality. S-CS is suitable for remote sensing imaging because remote sensing image interpretation mainly relies on the manual operations of interpreters. To some extent, the perceptual quality of remote sensing images can be influenced by visual attention, and the HVS pays more attention to salient regions of an image than to the rest of the image10.
S-CS can be modelled using a cross-correlation sampling system in which the optical signal is simultaneously sampled by a low-resolution (LR) sensor and a high-resolution (HR) sensor. In this paper, a block-wise megapixel sensor (BMPS) is used as the HR sensor. The BMPS is composed of multiple imaging units, each of which is a 16 × 16 pixel image block. Meanwhile, the LR sensor captures LR images. First, the saliency information is detected from the LR sensor images using the pulsed cosine transform (PCT) method. Next, the saliency information is calculated as follows:
where G represents a two-dimensional Gaussian low-pass filter, ⊗ denotes the convolution operation, abs(·) represents the absolute value function, C −1 is a two-dimensional inverse discrete cosine transform (DCT), sign(·) is the signum function, C(·) is a two-dimensional DCT, and X is the LR image. On the basis of the saliency information map, the number of sensing measurements can be calculated by applying the saliency monitoring algorithm to each corresponding image block, and then the BMPS processing is performed to complete the sensing sampling process. However, this remote sensing imaging process is subject to several inevitable drawbacks. First, the PCT method can generate significant errors in the calculation of the saliency information because it uses only the signs of the DCT coefficients. Second, the reconstructed images can exhibit blocking effects because image blocks are used as the processing units during the BMPS processing. Third, block-based S-CS in the image domain lacks robustness because it is incompatible with progressive coding, which is an important part of remote sensing applications. Finally, this method depends on an auxiliary LR sensor to perform compressive imaging, and the auxiliary LR sensor and its subsequent processing introduce a calculation process that can increase the load of the camera system.
Based on all of the above considerations, we thus propose a post-transform frequency saliency CS (PTFS-CS) method. In PTFS-CS, a post-wavelet transform to calculate the saliency information, using an approach that is proposed for the first time in this paper, and an optimized S-CS process is added to the calculation to obtain a better-quality image. The post-wavelet transform is defined as a secondary transform in the wavelet domain; i.e., the blocks of wavelet coefficients are further transformed using an orthonormal basis dictionary. The BMPS is composed of an image sensing layer (ISL), a wavelet transform layer (WTL), and a compressed sensing layer (CSL). The ISL acquires the original digital image through photoelectric conversion and analogue-to-digital conversion. The WTL applies a wavelet transform to the original image. The resulting images in the wavelet sub-bands are defined as the BMPS images. The CSL performs saliency-based CS in the post-wavelet domain. First, each pixel of a BMPS image is treated as a wavelet coefficient in PTFS-CS. Second, the spatial frequency in the post-wavelet domain is used to calculate the saliency information. Finally, S-CS is performed in the post-wavelet domain. The proposed PTFS-CS method has the advantages of high accuracy of the saliency information and high imaging quality without blocking effects. This method has potential applications in microsatellites, integrated cameras, and star trackers and also has potential to become a remote sensing CS imaging standard in the future.
Results
The overall architecture of the proposed PTFS-CS method is described diagrammatically in Fig. 1. The PTFS-CS procedure consists of two main parts, namely, CS and ground reconstruction. In CS, a complementary metal-oxide-semiconductor (CMOS) sensor is used to obtain the original image layer, as shown in Fig. 1. A three-level wavelet transform is performed in the original image layer to obtain the BMPS image. Next, a DCT is applied to the BMPS image to obtain the transformed post-wavelet coefficients. Afterwards, the saliency information calculation module obtains the saliency map by using (10). The constant matrices Q 4 × 4 and R 4 × 4, the latter of which is defined in (11), are saved in a parameter table for the saliency calculation. The sensing controller then directs the measurement sampling module to perform sensing sampling on the basis of the saliency map. The measurement data obtained through sensing sampling are transmitted to a ground reconstruction model (GRM) via multiple high-speed optical fibre transmission channels (OFTCs), in-orbit satellite downlink providers, ground receivers, and OFTCs. The GRM reconstructs the DCT coefficients, wavelet coefficients, and original images using a recovery algorithm based on orthogonal matching pursuit (OMP), an inverse DCT, and an inverse discrete wavelet transform (DWT), respectively. Considering the properties of the HVS, the PTFS-CS method exploits saliency information based on spatial frequency in the post-wavelet domain to allocate more sensing resources to salient regions than to non-salient regions. Based on the theory of CS, a recovery algorithm will obtain higher image quality for an image block with more sensing sources; thus, for a given number of sensing measurements for the entire image, the PTFS-CS method can reconstruct the salient regions much better than conventional compressive sampling. In addition, the proposed method is easy to implement. In particular, the saliency algorithm and the sensing measurement sampling process require only multiplication and addition operations, without iterative search algorithms. Such calculations are easy to implement on the hardware platforms of remote sensing cameras.

Overall architecture of the proposed PTFS-CS scheme.
In this paper, experimental tests of the proposed method based on remote sensing images are reported. A wavelet transform is applied to the remote sensing images to obtain BMPS images. Each image block in the BMPS images has dimensions of 16 × 16 pixels. Next, a DCT is applied to the BMPS images to obtain transformed post-wavelet coefficient blocks. After the DCT, an optimized saliency calculation method is applied to generate a saliency information map, as shown in Fig. 2(a).

A saliency information map (a) and the corresponding reconstructed image (b).
After the saliency information is calculated, a sensing measurement is performed on the transformed post-wavelet coefficient blocks to obtain sensing measurement images. Next, the sampled images are reconstructed using the orthogonal matching pursuit algorithm. The inverse DCT is computed to obtain the wavelet transform. Finally, the inverse DWT is computed to obtain the reconstructed image, as shown in Fig. 2(b). Figure 3 shows the reconstruction results of two saliency-based CS methods. As seen from the magnified regions of the three images, the reconstructed images obtained using the PCT-CS method exhibit blocking effects.

Reconstructed images obtained via PCT-CS and our method with M = 190 when the block size is 16 × 16 pixels: the original image (a); the reconstructed image obtained via PCT-CS, which exhibits blocking effects (b); and the reconstructed image obtained using our method, which does not exhibit blocking effects (c).
To test the performance of our method (a new post-wavelet saliency algorithm), we compare our method with two other CS algorithms, namely, PCT-CS9 and CS without a saliency map (CS-WSM). These three methods were applied to generate multiple reconstructed images for statistical analysis. As the first step, the reconstructed images were analysed in terms of the peak signal-to-noise ratio (PSNR). The compression ratio (CR) is the ratio between the number of sensing measurements (samples) and the number of BMPS imaging units. The PSNR can be calculated as \({\rm{PSNR}}=10\cdot {\mathrm{log}}_{10}({{\rm{MAX}}}^{2}/{\rm{MSE}})\), where MAX is 2B−1, with B being the bit depth of each pixel, and MSE is the squared error between the original and reconstructed images. Because the bit depth of the test images used in this study was 8 bits, the PSNR was set to \(10\times {\rm{1og}}({255}^{2}/{\rm{MSE}})\). A test image database of 150 remote sensing images depicting a variety of urban and natural scenes was used to measure the corresponding PSNRs. All images have dimensions of approximately 512 × 512 pixels. The average PSNR value was calculated as the final PSNR. The PSNRs calculated for the three different methods are shown in Table 1. Figure 4 Shows several images reconstructed using the different methods at different CRs.

Reconstructed images obtained using different methods at different CR values.
Two additional image quality assessment indexes were also analysed: the mean structural similarity index (MSSIM)13 and the visual information fidelity (VIF)14. The MSSIM and VIF are defined based on the structural information extracted by the HVS. The MSSIM values at different compression ratios are shown in Fig. 5, and the VIF results are shown in Fig. 6. Finally, we tested and analysed our approach on a self-developed CS testing platform to verify its performance and feasibility. The testing platform includes image simulation sources, an S-CS system, a CS server, a decoding unit, and a display system. The CS server produces simulated images, which are transmitted to the image simulation source unit. The image simulation source unit adjusts the output line frequency, image size, and output time to simulate the output of a CCD sensor. The CS system uses a Virtex-PRO Xilinx FPGA with a 32-bit MicroBlaze as its processor. The simulated images are 3072 × 1024 pixels in size. The depth of each pixel is 8 bits per pixel. The compressed bitstreams are decoded by the decoding unit. The CS server injected remote sensing images with different texture information into the image simulation source unit to test the performance of the proposed approach. The proposed method offers the complete integration of imaging and compression, which is useful for improving the degree of integration of a micro-camera system. We used two transform-based coding methods, JPEG200015 and CCSDS-IDC16, for a comparison of the compression performance. Table 2 shows the results obtained for the different algorithms.

MSSIM values at different compression ratios.

VIF values at different compression ratios.
To test the compression time of our method, the CCD line frequency was set to 7.2376 kHz. The size of each band was 3072 × 128 pixels. We compare the compression time of our algorithm with those of the other algorithms in Table 3. The processing time of our algorithm is 0.024 µs per sample, which is shorter than those of the other methods. Consequently, the compression of 3072 × 128 pixels requires only 8.25 milliseconds. In future applications, this algorithm could be optimized further on an FPGA on the basis of the CCD imaging principle.
Discussion
As seen from Table 1, the results of PCT-CS are more satisfactory than those of CS-WSM. The experimental results of our method are the best among the three tested methods. The average PSNR values for our method are higher than those for the other two because our method possesses several advantages compared with the others. First, the saliency calculation method is more efficient, meaning that more high-frequency information is retained in the reconstructed images. Second, the reconstructed images do not exhibit blocking effects because the DCT and CS processes are performed in the wavelet domain rather than in the original image domain. Third, any remaining redundancies between local neighbouring wavelet coefficients can be exploited because the wavelet coefficients are further transformed by the DCT and CS processes. Fourth, a sparser representation can be achieved in the CS process because it is performed in the post-wavelet domain. These advantages ensure that the proposed method can achieve a higher PSNR at a given CR. As seen from Figs 3~6, the method proposed in this paper uses the most optimal CS techniques, utilizing the post-wavelet method to perform CS and the transformed coefficient method for the saliency calculation; thus, compared with the traditional saliency-based approaches, our proposed method achieves better results. The results presented in Table 2 indicate that the proposed method performs slightly better than the JPEG2000 algorithm and yields improvements of between 0.66 dB and 2.48 dB compared with the CCSDS-IDC method. These results demonstrate that the edge and texture information is preserved in the reconstructed images.
According to the test results presented in Table 3, our method requires the shortest processing time because it utilizes only sensing measurements in the encoding process. For the decoding process, our method requires a relatively longer time because it uses an OMP-based algorithm to recover the original images. The complexity of the encoding part of our method is low, whereas the decoding part has a higher complexity. Conventional compression algorithms usually encode the transformed coefficients using bit-plane encoding17 or embedded block coding with optimization truncation18, and the complexities of the encoder and decoder are basically the same. In our method, some of the complexity of the encoder is transferred to the decoder, which is very suitable for in-orbit applications because the encoder usually operates on a satellite platform with limited resources (such as power, memory and processing capacity), whereas the decoding operations are performed on the ground, where processing resources are not limited and multiple cutting-edge technologies (such as graphical processing units (GPUs)) can be utilized to speed up the decoding process.
Conclusions
In this paper, we propose the PTFS-CS method, which treats wavelet coefficients as the pixels of a block-wise megapixel sensor and utilizes the spatial frequency in the post-wavelet domain to calculate the saliency information to guide the allocation of more sensing resources to salient regions than to non-salient regions. We prove that, as demonstrated by our experimental results, the use of frequency saliency for the allocation of sensing resources in the post-wavelet domain for remote sensing cameras can yield better images in terms of the PSNR, MSSIM, and VIF. The proposed post-wavelet saliency algorithm outperforms CS-WSM and PCT-CS and can satisfy the high quality requirements of a CS imaging camera. Thus, the proposed method offers significant benefits for future research based on remote sensing image analysis.
Method
S-CS based on a post-wavelet transform
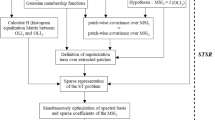
Figure 7 illustrates the principle of S-CS based on a post-wavelet transform. The BMPS consists of three layers, namely, an image sampling layer, a discrete wavelet transform (DWT) layer, and a CS layer. Photoelectric conversion and an analogue-to-digital (AD) converter are applied in the image sampling layer to digitize the image data; the digitized image data are regarded as the original images. In the DWT layer, a DWT is applied to the original images to extract wavelet sub-bands. In this paper, these wavelet sub-bands are defined as the BMPS images. Next, a DCT is applied to the BMPS images to obtain the DCT coefficients. The DCT is performed in the DWT domain. Therefore, we regard the DCT coefficients as the post-wavelet transformed coefficients. In our method, CS is performed in the post-wavelet transform domain based on the saliency information, as shown in Fig. 7.

Principle of S-CS based on post-wavelet processing.
In the post-wavelet S-CS process, each image block in the BMPS images contains 4 × 4 wavelet coefficients, and it is further transformed by using a basis function to perform S-CS. Theoretically, this basis function can be chosen to be a DCT, a bandelet basis function, principal component analysis, or a Hadamard transform. In this paper, we use the DCT as the basis function. For the implementation of post-wavelet S-CS, the different imaging units of the BMPS are denoted by LH i , HL i , and HH i , i = 1, 2, 3. In this paper, each imaging unit is divided into several blocks, denoted by I, with N I coefficients (specifically, N I = 256). To simplify the calculation, in each imaging unit of the BMPS, the N I coefficients are divided into 16 coefficient blocks, which are called “wavelet blocks”. As N I is set to 256 in this paper, each wavelet block is composed of 4 × 4 wavelet coefficients. When the distance (difference in coefficients) between adjacent wavelet blocks is greater than four pixels, the coefficient correlation between the adjacent wavelet blocks is relatively weak. Let f represent one wavelet-transformed block, which includes 16 wavelet coefficients that are expressed as N(N = 16) vector elements. Therefore, f can also be considered as a vector with N elements in RN. Let D be the post-wavelet transform dictionary, and let B denote the orthonormal basis function. The orthonormal basis consists of N basis vectors. Let the orthonormal basis be φ n , \(n\in [1,N]\). Then, \(={\{{\phi }_{n}\}}_{n=1}^{N}\). Let f b be a post-wavelet transformed coefficient block. Then, the post-wavelet transform can be expressed as
In each imaging unit of the BMPS, the post-wavelet transform is applied to all wavelet blocks. Let F be the set of transformed post-wavelet blocks from one imaging unit of the BMPS. Then, \(F=\{{f}_{1}^{b},{f}_{2}^{b},\cdots ,{f}_{{N}_{b}}^{b}\}\), where \({N}_{b}({N}_{b}=16)\) is the number of transformed post-wavelet blocks in F. Let Ω be the saliency map of the BMPS. Therefore, \(\Omega ={\{{F}_{q}\}}_{q=1}^{Q}\), where Q is the number of imaging units in the BMPS. Let \(\Gamma =\{{\tau }_{1},{\tau }_{2},\cdots ,{\tau }_{{M}_{q}}\}\) represent a sensing measurement matrix, where M q is the number of sensing measurements and satisfies M q ≪ N I . M q is determined by the saliency map, and \({M}_{q}\propto {F}_{q}\). Thus, the CS process can be expressed as \(Y=\Phi {f}^{b}=\Phi \Psi f=\Phi ^{\prime} f\), where Y is the new sample, Φ is the sensing basis function, Ψ is the representation basis function, and Φ′ is an incoherent sampling matrix. Because M q ≪ N I , image compression is achieved. After the CS process, the new sample Y is used to recover the original signal. Generally, the recovery of a signal \(\tilde{{f}^{b}}\) from Y may be an ill-posed problem because M q ≪ N I . However, such recovery is possible when the sensing basis function Φ and the representation basis function Ψ are incoherent, i.e., when any two vectors of Φ and Ψ are weakly correlated. With high probability, the incoherent sampling matrix Φ′ possesses the restricted isometry property (RIP) when \({M}_{q}\gg c\times K\times \,\mathrm{log}({N}_{I}/K)\), where c is a positive constant and K is the sparsity coefficient11, 12. If the RIP is satisfied, then an accurate reconstruction signal \(\tilde{{f}^{b}}\) can be reconstructed via \(\tilde{{f}^{b}}=\Psi \,\ast \,\tilde{x}\), where \(\tilde{x}\) is the solution to the l 1 norm minimization problem, \(\tilde{x}=\text{arg}{}_{x^{\prime} }{}^{{\rm{\min }}}\Vert x^{\prime} \Vert _{{l}_{1}}\), s.t. \(y=\Phi \text{'}x\text{'}\).
Fast saliency algorithm using spatial frequency
The saliency information is calculated in the post-wavelet transform domain via CS in the BMPS channel instead of the LR sensor channel. We use f′ to represent the two-dimensional BMPS image signal. The post-transformed coefficient matrix g can be obtained from \(\psi f^{\prime} \psi \) (\(g=\psi f^{\prime} {\psi }^{T}\)), where ψ is the basis matrix in D (the post-wavelet transform dictionary). Because the basis matrix in D is the DCT basis, ψ is an orthogonal transform matrix of the DCT that consists of the cosine coefficients, and ψ T consists of the transposed coefficients. As the basis matrix is orthogonal, the inverse matrix of ψ is equal to its transpose \(({\psi }^{-1}={\psi }^{{\rm{T}}})\). Consequently, the relationship between f′ and g can also be expressed as \(g={\psi }^{T}f^{\prime} \psi \). In the above-described transformation process, the total energy of the image f′ is constant before and after the transformation. An important energy constraint between f′ and g can thus be built as follows:
This energy constraint can also be expressed as \(\text{trace}(f^{\prime} f{^{\prime} }^{{\rm{T}}})=\text{trace}(g{g}^{{\rm{T}}})\), where trace(·) represents the trace operation for a matrix. The derivative or gradient is a natural basis for the spatial features of an image. The gradient of an image can be used to calculate its spatial frequency, which reflects the saliency of the image. In this paper, we use the frequency saliency information of each BMPS block, which can be expressed as
where E H and E V are the horizontal and vertical frequencies, respectively, of the image block; \(\partial {f}_{x}=f^{\prime} (x,y)-f^{\prime} (x-1,y)\); and \(\partial {f}_{y}=f^{\prime} (x,y)-f^{\prime} (x,y-1)\). In each block, we let \({\rm{\Delta }}{f}_{x}\) and \({\rm{\Delta }}{f}_{y}\) denote the difference matrices in the horizontal and vertical directions, which are composed of the \(\partial {f}_{x}\) and \(\partial {f}_{y}\) values, respectively. The cyclic matrix K is expressed as
On the basis of (5), the saliency components can be calculated as \({\rm{\Delta }}{f}_{x}=f^{\prime} K\) and \({\rm{\Delta }}{f}_{y}={K}^{T}f^{\prime} \). Thus, the following two saliency equations can be obtained:
where P is the transformed coefficient matrix of K. After the application of a \(4\times 4\) DCT, P is expressed as the following matrix: \({P}_{4\times 4}=[0\,0\,0\,0;-0.6533-0.2929\,0.2706\,0;0-0.9239-1\,0.3827;-\) \({0.27060-0.6533-1.7071]}_{4\times 4}\) P.As described in (6) and (7), gP and T g are the transformed coefficients of \({\rm{\Delta }}{f}_{x}\) and \({\rm{\Delta }}{f}_{y}\), respectively. Therefore, (4) can be expressed as
The frequency saliency information can also be expressed as \(\frac{1}{I\times J}[trace(gP{P}^{T}{g}^{T})+trace({g}^{T}P{P}^{T}g)]\). Let \(Q=P{P}^{{\rm{T}}}\), where the matrix Q is constant because P is the transformed coefficient matrix of K. Next, Kcan be transformed by using an 8 × 8 or 4 × 4 DCT to obtain the fixed matrix shown below: \({Q}_{4\times 4}={[0000;00.585800;0020;0003.4142]}_{4\times 4}\). In (9), the matrix Q is a diagonal matrix. Thus, (4) can be expressed as
with
According to (10), the saliency information in the frequency domain for each BMPS block can be expressed in terms of its transformed coefficients. Moreover, the relationship between the bit rate r and the number M of nonzero post-transformed coefficients quantized using a nearly uniform step quantization can be expressed as r ≈ γ 0 M, where γ 0 is a constant parameter. The post-transformed coefficients g(u, v) in (10) can be replaced with
According to (12), the elements of g(u, v) only take values of “1” and “0”; thus, the saliency information can be rapidly calculated, and the calculation can be easily implemented in hardware systems. After the saliency map is established based on Eqs (10) and (12), the sensing resources are allocated according to the established saliency map. Each imaging unit of the BMPS consists of a 16 × 16 pixel block. Considering that the post-transform saliency CS process is performed in the post-wavelet domain, the smallest number of BMPS sensing measurements (samples) is allocated to the lowest-resolution post-wavelet sub-band. For the post-wavelet sub-bands at other resolutions, the CS matrices have different sizes because the different imaging units contain different amounts of information. The sensing sampling process can be expressed as \({[{Y}_{1},{Y}_{2},\ldots ,{Y}_{{\rm{L}}}]}^{{\rm{T}}}={\rm{diag}}({\Phi }_{1},{\Phi }_{2},\ldots ,{\Phi }_{{\rm{L}}}){[{X}_{1},{X}_{2},\ldots ,{X}_{L}]}^{{\rm{T}}}\), where L is the number of imaging units of the BMPS, diag(·) denotes a diagonal matrix, and Φ P (p = 1, 2, …, L) is the CS sensing matrix of the pth imaging unit and is determined based on the saliency information map. Finally, the measured data sample Y is processed via quantization, entropy coding and packing to obtain the final encoded bitstream, which can be reconstructed by a recovery algorithm on the ground.
References
Li, J., Zhang, Y., Liu, S. & Wang, Z. Self-calibration method based on surface micromaching of light transceiver focal plane for optical camera. Remote Sensing 8, 893–913 (2016).
You, Z., Wang, C., Xing, F. & Sun, T. Key technologies of smart optical payload in space remote sensing. Spacecraft Recovery & Remote Sensing 34, 35–43 (2013).
Li, J., Xing, F., Chu, D. & Liu, Z. High-accuracy self-calibration for smart, optical orbiting payloads integrated with attitude and position determination. Sensors 16, 1176–1195 (2016).
He, K., Sharma, M. K. & Cossairt, O. High dynamic range coherent imaging using compressed sensing. Opt. Express 23, 30904–30916 (2015).
Bosworth, B. T. et al. High-speed flow microscopy using compressed sensing with ultrafast laser pulses. Opt. Express 23, 10521–10532 (2015).
Huang, J., Sun, M., Gumpper, K., Chi, Y. & Ma, J. 3D multifocus astigmatism and compressed sensing (3D MACS) based superresolution reconstruction. Biomed. Opt. Express 6, 902–917 (2015).
Donoho, D. L. Compressed sensing. IEEE Transactions on Information Theory 52, 1289–1306 (2006).
Candès, E. J., Romberg, J. & Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Transactions on information theory 52, 489–509 (2006).
Yu, Y., Wang, B. & Zhang, L. Saliency-based compressive sampling for image signals. IEEE signal processing letters 17, 973–977 (2010).
Cheng, M. M., Mitra, N. J., Huang, X., Torr, P. H. S. & Hu, S. M. Global contrast based salient region detection. IEEE Transactions on Pattern Analysis and Machine Intelligence 37, 569–582 (2015).
Candès, E. & Tao, T. Near optimal signal recovery from random projections: Universal encoding strategies. IEEE Trans. Inf. Theory 52, 5406–5425 (2006).
Dai, W. & Milenkovic, O. Subspace pursuit for compressive sensing signal reconstruction. IEEE Transactions on Information Theory 55, 2230–2249 (2009).
Wang, Z., Bovik, A., Sheikh, H. & Simoncelli, E. Image quality assessment: From error visibility structural similarity. IEEE Trans. Image Process. 13, 600–612 (2004).
Sheikh, H. & Bovik, A. Image information and visual quality. IEEE Trans. Image Process. 15, 430–444 (2006).
Taubman, D. High performance scalable image compression with EBCOT. IEEE Transactions on image processing 9, 1159–1170 (2000).
Garcia-Vilchez, F. & Serra-Sagrista, J. Extending the CCSDS recommendation for image data compression for remote sensing scenarios. IEEE Transactions on Geosciences and Remote Sensing 47, 3431–3445 (2009).
Seo, Y. H. & Kim, D. W. VLSI architecture of line-based lifting wavelet transform for motion JPEG2000. IEEE Journal of Solid-state Circuits 42, 431–441 (2007).
Mathiang, K. &Chitsobhuk, O. Efficient pass-pipelined VLSI architecture for context modeling of JPEG2000.Paper presented at Proceedings of IEEE 2007Asia-Pacific Confeirence on Communications, Bangkok, Thailand, 63–66 (18–20 Oct. 2007).
Acknowledgements
This work was supported by the National Science Foundation of China (no. 61505093, no. 61505090) and the National Key R&D Program of China (no. 2016YFC0103601).
Author information
Authors and Affiliations
Contributions
J.L. and Z.L. designed the initial experimental scheme and guided the experiments. F.L. developed the accuracy measurement method. J.L. performed the experiments, analysed the experimental data, and wrote the manuscript. Z.L. processed and analysed the experimental data and revised the manuscript. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, J., Liu, Z. & Liu, F. Compressive sampling based on frequency saliency for remote sensing imaging. Sci Rep 7, 6539 (2017). https://doi.org/10.1038/s41598-017-06834-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-06834-4
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
