
Abstract
We consider a basic quantum hybrid network model consisting of a number of nodes each holding a qubit, for which the aim is to drive the network to a consensus in the sense that all qubits reach a common state. Projective measurements are applied serving as control means, and the measurement results are exchanged among the nodes via classical communication channels. In this way the quantum-opeartion/classical-communication nature of hybrid quantum networks is captured, although coherent states and joint operations are not taken into consideration in order to facilitate a clear and explicit analysis. We show how to carry out centralized optimal path planning for this network with all-to-all classical communications, in which case the problem becomes a stochastic optimal control problem with a continuous action space. To overcome the computation and communication obstacles facing the centralized solutions, we also develop a distributed Pairwise Qubit Projection (PQP) algorithm, where pairs of nodes meet at a given time and respectively perform measurements at their geometric average. We show that the qubit states are driven to a consensus almost surely along the proposed PQP algorithm, and that the expected qubit density operators converge to the average of the network’s initial values.
Similar content being viewed by others


Introduction
Consensus seeking over complex networks has played a foundational role in the development of distributed computation and networked control systems1, 2. How a set of isolated processors communicating only by means of two-party messages reach a common state in the presence of faulty nodes was a prior concern for fault-tolerant distributed computation3. Distributed controller design that drives a network of autonomous agents to certain consensus state such as the network average or some leader’s state4 turned out to be a primary step towards control, estimation, and optimization of networked control systems1. In the past decades, tremendous research efforts have been devoted to efficient design and convergence analysis of consensus and synchronization algorithms motivated by various social, engineering, and physical systems5,6,7,8,9.
In particular, consensus over quantum networks where node states are in quantum space and algorithms must be implemented by feasible quantum means has drawn attention10, 11. Quantum particles (subsystems) can be interconnected by local environments which are by themselves also quantum systems, the resulting state evolution will lead to a symmetric state consensus over such a quantum network, a concept introduced in ref. 10. The reduced states of the nodes will in turn asymptotically tend to the average of the nodes’ initial reduced states, in the almost sure sense along the discrete algorithm10 and deterministically along a quantum consensus master equation11. Such methods are essentially coherent quantum control for open quantum systems12, where the involved local environments can only be engineered at a small scale. On the other hand, many types of quantum networks, especially quantum communication networks, are hybrid in the sense that both quantum and classical parts co-exist13, 14. Quantum operations (often being measurements) can be performed locally and then the outcomes of the measurements are exchanged via classical communications, leading to the so-called local-operation classical-communication (LOCC) networks which have served as protocols for quantum cryptography or potential tools for engineering complex quantum states15. Measurement-based quantum control has also been demonstrated as effective means of manipulating quantum states both theoretically and experimentally16,17,18,19.
In this paper, we consider a consensus seeking problem over a quantum hybrid network consisting of a number of nodes each holding a qubit, where projective measurements are applied and the measurement results are exchanged. This theoretical simplification has neglected the effects of coherent states and joint operations in realistic quantum information processing networks, but the quantum-operation/classical-communication nature of LOCC networks has been preserved and highlighted. The problem of centralized optimal path planning for the network with all-to-all classical communications is shown to be a stochastic optimal control problem, whose computation and communication complexities are analyzed. We also develop a distributed Pairwise Qubit Projection (PQP) algorithm, where pairs of nodes meet at a given time and respectively perform measurements at their geometric average. The qubit states are driven to a consensus almost surely along the proposed PQP algorithm. The expected qubit density operators actually converge to the average of the network’s initial values, consistent with the work10, 11 for open quantum networks. Some preliminary results of the current work were announced at Australian Control Conference in 201620.
Results
A Simplified Hybrid Quantum Network Model
Let a network of nodes be indexed in the set \({\rm{V}}=\{1,\ldots ,N\}\). Each node holds a qubit, i.e., a quantum system whose state space \( {\mathcal H} \) is a two-dimensional Hilbert space. Let |0〉 and |1〉 form an orthogonal basis of the qubit space \( {\mathcal H} \). Projective measurements can be performed at the individual qubits, respectively. An available projective measurement M α is described by its two eigenstates
and
We assume that the measurements are in the set
The outcomes of a measurement M α are indexed by \( \ltimes \), corresponding to eigenstate \(\cos \,\alpha |0\rangle +\,\sin \,\alpha |1\rangle \), and \(\rtimes \), corresponding to eigenstate \(\cos (\alpha +\pi \mathrm{/2)}|0\rangle +\,\sin (\alpha +\pi \mathrm{/2)}|1\rangle \). For the ease of presentation we will sometimes identify a measurement in the set \( {\mathcal M} \) with its angle \(\alpha \in [0,\pi \mathrm{/2)}\) since there is a natural one-to-one correspondence between the elements in \( {\mathcal M} \) and angles in the interval [0, π/2).
Time is slotted for \(t=0,1,\ldots \). The state space of the qubits \({\mathscr{S}}\subseteq {\mathcal H} \) contains all possible outcomes of the measurements:
The state of the qubit held by node i (or simply, qubit i) at time t is denoted by \({{\bf{x}}}_{i}(t)\in {\mathscr{S}}\). Similarly, noting that there is a one-to-one correspondence between a state in \({\mathscr{S}}\) and an angle in [0, π), we will identify x i (t) with its angle whenever convenient (This is to say, x i (t) can simply represent an angle \({{\bf{x}}}_{i}(t)\in [0,\pi )\), or represents a vector \(\cos ({{\bf{x}}}_{i}(t))|0\rangle +\,\sin ({{\bf{x}}}_{i}(t))|1\rangle \)). The network of nodes is interconnected by classical communications. At each time t, node i performs a measurement, denoted u i (t) and selected in the set \( {\mathcal M} \), whose outcomes can be exchanged via the classical communication links. The goal is to design efficient rules for the selection of the u i (t), so that the x i (t) will tend to a common state.
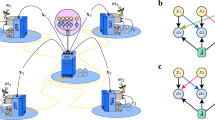
We give an example of the considered hybrid quantum network with 6 nodes in Fig. 1. Such a model is obviously a theoretical simplification since two important elements in real-world quantum communication or hybrid quantum information processing, coherent quantum states and joint measurements over multiple qubits, have been neglected15. However, despite of its simplicity, the model still captures the most fundamental aspect of local-operation classical-communication (LOCC) networks, where random outcomes of local quantum operations are shared with classical communications. More importantly, as will be seen from the results and the analysis, although coherent quantum states and joint measurements will change the state space, feasible actions, and state transition probabilities, the nature of the problem remains the same. Therefore, we would like to focus on this simple model in the current work where neat and analytical results become available with great clarity.

An illustration of a six-node quantum hybrid network: There is a qubit at each node, respectively; Projective measurements are performed at the individual qubits; Nodes are interconnected by classical communication links so that the outcomes of the measurements can be exchanged.
Centralized Solution
In this section, we investigate the scenario when the nodes are equipped with all-to-all classical communications and derive the optimal rules for measurement sequence selections at the qubits.
Finite Horizon Optimal Policy
We stack the states of the qubits into an N dimensional column vector by \({\bf{x}}(t)={({{\bf{x}}}_{1}(t)\ldots {{\bf{x}}}_{N}(t))}^{{\rm{{\rm T}}}}\). The vector \({\bf{u}}(t)={({{\bf{u}}}_{1}(t)\ldots {{\bf{u}}}_{N}(t))}^{{\rm{{\rm T}}}}\) denotes the selection of measurements performed. The outcome of the measurement u i (t) is \({{\bf{y}}}_{i}(t)\in \{ \ltimes ,\rtimes \}\). We also denote \({\bf{y}}(t)={({{\bf{y}}}_{1}(t)\ldots {{\bf{y}}}_{N}(t))}^{{\rm{{\rm T}}}}\). Suppose the process ends at t = T for some integer T ≥ 1. The measurement selection decision is denoted by
where the σ s assigning the value of u(s). The decision σ s can depend on all information available by the time slot \(s\in \{0,1,\ldots ,T-1\}\): x(t), y(t) for \(t=0,\ldots ,s\) and u(t) for \(t=0,\ldots ,s-1\). Formally we have
with σ s (·) can be an arbitrary function that takes values in \({ {\mathcal M} }^{N}\) for \(s=0,1,\ldots ,T-1\). All such decisions σ are put in a set \({\Upsilon }_{T}\).
For any fixed measurement decision σ, the agreement displacement at time T is characterized by the expected network fidelity:
where \({{\mathbb{E}}}_{\sigma }\) captures all randomness generated by the quantum measurements as well as possible random measurement decisions. The evolution of node states is governed by the quantum measurement principles and can be written as
where \({{\bf{u}}}_{i}^{{y}_{i}}(t)=\,\cos ({{\bf{u}}}_{i}(t))|0\rangle +\,\sin ({{\bf{u}}}_{i}(t))|1\rangle \) for \({y}_{i}= \ltimes \) and \({{\bf{u}}}_{i}^{{y}_{i}}(t)=\,\cos ({{\bf{u}}}_{i}(t)+\pi \mathrm{/2)}|0\rangle +\,\sin ({{\bf{u}}}_{i}(t)+\pi \mathrm{/2)}|1\rangle \) for \({y}_{i}=\rtimes \). By plain calculation we can further write
Here we have identified \({{\bf{u}}}_{i}^{{y}_{i}}(t)\) and x i (t) with their angles. Note that, the value and distribution of x(t + 1) is fully determined by y(t) and u(t). This is to say x(t) is Markovian. Finding the policy σ that miximizes f σ (T) is a stochastic optimal control problem21.
The optimal policy σ* that maximizes f σ (T) can be obtained as follows. Clearly σ* is Markovian in the sense that u(t) depends only on x(t) for all \(t=\mathrm{0,}\ldots ,T-1\) in the decision profile σ*. Introduce \(u={({u}_{1}\ldots {u}_{N})}^{{\rm{{\rm T}}}}\in {{\mathscr{S}}}^{N}\) and \(y={({y}_{1}\ldots {y}_{N})}^{{\rm{{\rm T}}}}\in {\{ \ltimes ,\rtimes \}}^{N}\). Define a function \({\bf{Q}}(u,y)={({q}_{1}\ldots {q}_{N})}^{{\rm{{\rm T}}}}\in {{\mathscr{S}}}^{N}\) by q i = u i if \({y}_{i}= \ltimes \) and q i = u i + π/2 if \({y}_{i}=\rtimes \). Introduce the cost-to-go function \(C(\cdot ,\cdot ):{S}^{N}\times \{0,1,\ldots ,T\}\to {\mathbb{R}}\) defined by
Then by a standard dynamic programming argument there holds
for \(x\in {{\mathscr{S}}}^{N}\) and \(t=\mathrm{0,1},\ldots ,T-1\). The boundary condition of (1) is
The optimal decision σ* is given by
for \(t=0,\ldots ,T-1\).
Infinite Horizon Optimal Policy
Next, we consider an infinite horizon scenario when the optimality criteria is given by the minimal steps in expectation required for reaching a perfect agreement in the network. Let
be a measurement selection policy for the entire time horizon, where for any \(s=0,1,\ldots ,{\sigma }_{s}\) maps to \({ {\mathcal M} }^{N}\) from all available information up to time s. All such decisions are put in the set \({\Upsilon }_{\infty }\). Consider the expected number of steps of reaching agreement at the qubits:
Clearly there exist simple policies in \({\Upsilon }_{\infty }\) under which g σ will be a finite number. We are interested in the optimal one that minimizes g σ .
Recall the definition of Q(u, y). Similarly, the optimal policy σ* that minimizes g σ is Markovian. In fact, it is also stationary in the sense that \({\sigma }_{t}^{\ast }({\bf{x}}(t)=x)={\sigma }_{s}^{\ast }({\bf{x}}(s)=x)\) for all s, t ≥ 0. Define cost-to-go function
In this case the function G(x) satisfies the following equation22
and the optimal decision σ* is given by
Computation/Communication Complexities
We would like to point out that the derived optimal network-level rules are conceptually equivalent to the single qubit framework17. Although the centralized optimal solutions are clear in theory for both finite and infinite time horizons, it is important to understand the amount of computation and communication resources required for implementing them in practice for a considerably large network.
The Bellman equations (1) and (3) involve a continuous action set \({ {\mathcal M} }^{N}\). Usually this is approximated by a proper discretization of \( {\mathcal M} \) into a finite set. For example, we can let the measurements be selected from ref. 18
Suppose \( {\mathcal M} \) has been discretized into a finite set with K elements. Note that this means that the state space \({\mathscr{S}}\) for each qubit is also discretized with 2K elements. We now discuss the finite horizon case in detail. From the computational side, solving the Bellman equation (1) relies on recursively along the equation (1) computing C(x, t) (and therefore obtain the optimal \({\sigma }_{t}^{\ast }(x)\)) from C(x, t + 1) for all \(t=T-1,\ldots ,0\) and all \(x\in {{\mathscr{S}}}^{N}\), starting with the boundary condition
The number of algebraic operations required in such process inevitably grows faster than K N. Therefore, practically it is almost impossible to numerically solve the Bellman equation (1) and obtain the optimal policy for a large network. In fact, even if the computation can be done off line, preserving the optimal policy relies on \(O\mathrm{((2}K{)}^{N}T\,\mathrm{log}\,K)\) bits of memory. Since each node relies on the states of all other nodes to carry out the optimal policy, the network requires all-to-all communications with O(N 2) bits of transmissions per step.
Distributed Solution
In this section, we discuss distributed solutions to the considered qubit consensus problem in the sense that nodes communicate with a few neighbours locally and then make measurement selection decisions individually.
The Algorithm
We assume that there is a connected underlying graph G = (V, E) with node set V and edge set E representing the classical communication links among the nodes, where a link \(\{i,j\}\in {\rm{E}}\) specifies that nodes i and j can exchange information their states. We denote \({{\rm{N}}}_{i}:=\{j:\{i,j\}\in {\rm{E}}\}\) as the neighbour set of node i. We also define
and
We propose the following algorithm.
Pairwise Qubit Projection (PQP). (i) At each t, a node i is drawn uniformly at random from the set V, and then node j is selected uniformly at random from the set N i ; (ii) The selected pair of nodes i and j exchanges their current states x i (t) and x j (t); (iii) Nodes i and j apply projective measurements
and all other nodes keep their current states.
We remark that the above algorithm is clearly inspired by the class of gossiping algorithms for classical communication networks and open quantum networks6, 10, 23. This proposed algorithm can be realized in fully distributed manner in the sense that nodes even need not to share a common clock and can simply follow independent Poisson processes to wake up6. Moreover, the pair section process can also be made deterministic and multiple disjoint pairs can be selected at a given time, which will not change the nature of the algorithm and actually can speed up the algorithm. The involved projective measurements introduce new type of randomness in the algorithm, which makes the PQP algorithm differ from the previous algorithms6, 10, 23 at a fundamental level.
Agreement Convergence
Let x(t) be driven by the proposed PQP algorithm. Suppose node pair \(\{i,j\}\) is selected at time t. Then from the quantum measurement postulate, independently among \(m\in \{i,j\}\) we have
with probability \({\cos }^{2}\,\frac{{{\bf{x}}}_{i}(t)-{{\bf{x}}}_{j}(t)}{2}\), and
with probability \({\sin }^{2}\,\frac{{{\bf{x}}}_{i}(t)-{{\bf{x}}}_{j}(t)}{2}\). The following result holds.
Theorem 1 Using the PQP algorithm, the hybrid quantum network reaches an agreement almost surely in the sense that
for all i, \(j\in {\rm{V}}\).
For the hybrid quantum network illustrated in Fig. 1, we plot a sample path at which consensus is reached and the trajectories of the expected states of the qubits, respectively, in Figs 2 and 3.

A sample path of x i (t), \(i=1,\ldots ,6\) along the PQP algorithm with initial value \({{\bf{x}}}_{i}\mathrm{(0)}=(i-1)\pi \mathrm{/6}\), \(i=1,\ldots \mathrm{,\; 6}\).

Trajectories of \({x}_{i}(t):={\mathbb{E}}({{\bf{x}}}_{i}(t))\), \(i=1,\ldots \mathrm{,\; 6}\) along the PQP algorithm with initial value \({{\bf{x}}}_{i}\mathrm{(0)}=(i-\mathrm{1)}\pi \mathrm{/6}\), \(i=1,\ldots \mathrm{,\; 6}\).
The Agreement Limit in Expectation
We introduce ρ i (t) as the density operator corresponding to \({{\bf{x}}}_{i}(t)\in {\mathscr{S}}\). Viewing also x i (t) as its angle in [0, π), we can formally write:
We also define \({\rho }_{i}(t)={\mathbb{E}}\{{{\boldsymbol{\rho }}}_{i}(t)\}\), where \({\mathbb{E}}\) is subject to the classical measure \({\mathbb{P}}\) capturing all randomness in the node pair selection process and in the quantum projective measurements. All the outcomes of the projective measurements have to be read out for carrying out the algorithm. Nonetheless ρ i (t) describes the distribution of ρ i (t) under the measure \({\mathbb{P}}\). We stack \({\boldsymbol{\rho }}(t)={({{\boldsymbol{\rho }}}_{1}(t)\ldots {{\boldsymbol{\rho }}}_{N}(t))}^{{\rm{{\rm T}}}}\) and \(\rho (t)={({\rho }_{1}(t)\ldots {\rho }_{N}(t))}^{{\rm{{\rm T}}}}\) as vectors of 2 × 2 density operators.
It turned out that it is more convenient to investigate the evolution of the x(t) from the corresponding density operators, whose original update is in fact rather complex. Let L G be the Laplacian of the graph G, defined by \({[{L}_{{\rm{G}}}]}_{ij}=-\mathrm{(1/}|{{\rm{N}}}_{i}|+\mathrm{1/}{|N}_{j}|)\) for \(\{i,j\}\in {\rm{E}}\), [L G] ij = 0 for \(i\ne j\) with \(\{i,j\}\notin {\rm{E}}\), and \({[{L}_{{\rm{G}}}]}_{ii}={\sum }_{j=1}^{N}\,{[{L}_{{\rm{G}}}]}_{ij}\). We have the following theorem.
Theorem 2 The density vector sequence \({(\rho (t))}_{t\ge 0}\) satisfies
Consequently, we have
with an exponential rate at 1 − λ 2(L G), where λ 2(L G) is the smallest positive eigenvalue of L G.
Theorem 2 shows that in the operator space, \({\mathbb{E}}\{{\boldsymbol{\rho }}(t)\}\) simply follows a linear time-invariant system and eventually leads to an average consensus. This result is related but also in contrast to the work of refs 10 and 11, which showed that a network of qubits interconnected by local environments can be driven to a consensus of their individual reduced states. The evolution of \({\mathbb{E}}\{{\bf{x}}(t)\}\) is on the other hand highly complex for which even a nonlinear recursive form is out of reach. An illustration of Theorem 2 is presented below for the hybrid quantum network in Fig. 4, where we plot
with ||·|| being the matrix 2-norm for \(i=1,\ldots ,6\), respectively.

Trajectories of \({D}_{i}(t),\,i=1,\ldots \mathrm{,\; 6}\) along the PQP algorithm with initial value \({{\bf{x}}}_{i}\mathrm{(0)}=(i-\mathrm{1)}\pi \mathrm{/6}\), \(i=1,\ldots \mathrm{,\; 6}\).
Discussions
We should emphasize that although both the centralized and distributed solutions are able to drive the quantum network to certain agreement states, the respective agreement limits have different indications. Due to the feedback nature of the centralized scheme, from the resulting agreement state limited information can be recovered on the network initial values. In this sense the quantum agreement under centralized decisions shares very little spirit in common with consensus seeking over classical networks3, 6. The usefulness of such a framework then lies in how we have resolved a global optimization problem over quantum networks with the help of classical communication and computing, shedding light on other optimal operation problems arising from quantum information processing, e.g., source allocation and packet routing. On the other hand, the presented distributed solution provides an alternative way of realizing quantum average consensus at least in the sense of expected network state, besides the open quantum network approach10, 11. On top of that more sophisticated protocols can be naturally expected, potentially leading to useful quantum algorithms as we have witnessed the parallel development for classical complex networks1, 2.
It is also worth noting that there are no fundamental obstacles in generalizing these results to more complex hybrid quantum networks. When coherent quantum states and joint measurements are involved, feasible network states and control actions will yield larger state spaces. However, the outcomes of the local quantum operations continue to depend only on the current state and control decisions at each individual node. Therefore, the resulting centralized schemes will define similar stochastic optimal control problems, which can be solved using the same methodologies. Decentralized schemes in that case have to rely on new algorithms that take into consideration features of the new state space and transition behaviors, but the critical insight remains to be using simple diffusive node interactions to create collective network state convergence.
Methods
Note that ρ i (t) is a random variable, whose realizations are always pure states. The expected value ρ i (t) of ρ i (t), is in general a mixed state.
Proof of Theorem 1
Define \({p}_{ij}=\mathrm{(1/}|{{\rm{N}}}_{i}|+\mathrm{1/}{|N}_{j}|)\) for \(\{i,j\}\in {\rm{E}}\) as the probability of link {i, j} being selected at a given time. Introduce \({\bf{h}}(t):={\sum }_{\{i,j\}:i < j}\,{\rm{Tr}}({{\boldsymbol{\rho }}}_{i}(t){{\boldsymbol{\rho }}}_{j}(t))\). Then we have
where in the first equality the \({{\mathbb{E}}}_{km}\) is subject to the randomness generated by quantum measurements at nodes k and m, and in the last equality we have used the fact that trace and expectation commute due to their linearity.
Proceeding with the first of the two trace terms in the right-hand side of (7), we have
where the first equality is due to independence of the outcome of the quantum measurements at nodes k and m, and the second equality utilizes (12). Meanwhile, considering the second trace term in the right-hand side of (7), it is easy to conclude from (12) that
As a result, from (7), (8) and (9) we have
Since \({\rm{Tr}}({{\boldsymbol{\rho }}}_{k}(t){{\boldsymbol{\rho }}}_{m}(t))\le 1\) always holds, (10) implies that {h(t)} is a submartingale. Moreover, \({\mathbb{E}}({\bf{h}}(t))\le N(N-\mathrm{1)/2}\) for all t by the definition of h(t). By the Martingale Convergence Theorem (Theorem 5.2.824), h(t) converges to a finite limit almost surely. We can further invoke the Dominated Convergence Theorem (e.g., Exercise 2.3.724) to yield that, \({\mathbb{E}}({\bf{h}}(t))\) converges to a finite limit. Hence, (10) implies
so \({\mathrm{lim}}_{t\to \infty }\,{\mathbb{E}}({\rm{Tr}}({{\boldsymbol{\rho }}}_{k}(t){{\boldsymbol{\rho }}}_{m}(t)))=1\) for all \(\{k,m\}\in {\rm{E}}\). However, as \({\rm{Tr}}({{\boldsymbol{\rho }}}_{k}(t){{\boldsymbol{\rho }}}_{m}(t))\le 1\) is a sure event, we conclude for any \(\varepsilon > 0\) that
i.e., \({\rm{Tr}}({{\boldsymbol{\rho }}}_{k}(t){{\boldsymbol{\rho }}}_{m}(t))\) converges to 1 in probability for all \(\{k,m\}\in {\rm{E}}\).
Finally, we notice that \({\rm{Tr}}({{\boldsymbol{\rho }}}_{k}(t){{\boldsymbol{\rho }}}_{m}(t))={\cos }^{2}\,({{\bf{x}}}_{k}(t)-{{\bf{x}}}_{m}(t))\). Therefore, \({\rm{Tr}}({{\boldsymbol{\rho }}}_{k}(t){{\boldsymbol{\rho }}}_{m}(t))\) converging to one in probability is equivalent to that x k (t) − x m (t) converging to zero in probability. While G is a connected graph, we further know that x i (t) − x j (t) converges to zero in probability for all i, \(j\in {\rm{V}}\). This immediately implies that h(t) will converge to N(N − 1)/2 in probability. However, we have known as a fact that h(t) converges in the almost sure sense. Therefore, h(t) must converge to N(N − 1)/2 almost surely, or equivalently, x i (t) − x j (t) converging to zero almost surely for all i, \(j\in {\rm{V}}\). The desired theorem holds and we have now completed the proof.
Proof of Theorem 2
Suppose node pair \(\{i,j\}\) is selected at time t. Then based on (6), we obtain
where the third equality holds from elementary sum-to-product trigonometric formulas. We further obtain
by collecting all events at the pairs of nodes. The convergence statement aligns with the same argument as used in ref. 6. This concludes the proof.
Conclusions
We have considered a consensus seeking problem over a quantum hybrid network. A number of nodes each holding a qubit apply projective measurements and the measurement results are exchanged via classical communications. Centralized optimal path planning for the network with all-to-all classical communications were derived by stochastic optimal control approach, whose overwhelming computation and communication complexities were shown for a large network. A distributed Pairwise Qubit Projection (PQP) algorithm was also proposed along which the qubit states can be driven to a consensus almost surely along the proposed PQP algorithm. Future work includes generalization of the optimal control and distributed control approaches to hybrid quantum networks in the presence of quantum links as entangled pairs for improving the efficiency and scalability of such networks in applications.
References
Egerstedt, M. & Mesbahi, M. Graph Theoretic Methods in Multiagent Networks (Princeton University Press, 2010).
Lynch, N. A. Distributed Algorithms (Morgan Kaufmann, San Mateo, CA, 1996).
Pease, M., Shostak, R. & Lamport, L. Reaching agreement in the presence of faults. J. ACM 27, 228 (1980).
Jadbabaie, A., Lin, J. & Morse, A. S. Coordination of groups of mobile autonomous agents using nearest neighbor rules. IEEE Trans. Autom. Cont. 48, 988 (2003).
Boyd, S., Diaconis, P. & Xiao, L. Fastest mixing Markov chain on a graph. SIAM Rev. 46, 667 (2004).
Boyd, S., Ghosh, A., Prabhakar, B. & Shah, D. Randomized gossip algorithms. IEEE Trans. Inf. Theory 14, 2508 (2006).
Golub, B. & Jackson, M. O. Amer Naive learning in social networks and the wisdom of crowds. Econ. J.: Microeconomics 2, 112 (2010).
Kar, S. & Moura, J. M. F. Distributed consensus algorithms in sensor networks: Quantized data and random link failures. IEEE Trans. Sig. Proc. 58, 1383 (2010).
Vicsek, T., Czirok, A., Jacob, E. B., Cohen, I. & Schochet, O. Novel type of phase transitions in a system of self-driven particles. Phys. Rev. Lett. 75, 1226 (1995).
Mazzarella, L., Sarlette, A. & Ticozzi, F. Consensus for quantum networks: from symmetry to gossip iterations. IEEE Trans. Autom. Cont. 60, 158 (2015).
Shi, G., Dong, D., Petersen, I. R. & Johansson, K. H. Reaching a quantum consensus: Master equations that generate symmetrization and synchronization. IEEE Trans. Autom. Cont. 61, 374 (2016).
Rivas, Á. & Huelga, S. F. Open Quantum Systems: An Introduction (Springer Briefs in Physics. Springer Berlin Heidelberg, 2011).
Acin, A., Cirac, J. I. & Lewenstein, M. Entanglement percolation in quantum networks. Nature 3, 539 (2007).
Cuquet, M. & Calsamiglia, J. Entanglement percolation in quantum complex networks. Phys. Rev. Lett. 103, 240503 (2009).
Perseguers, S., Lewenstein, M., Acin, A. & Cirac, J. I. Quantum random networks. Nature Physics 6, 539 (2010).
Blok, M. S., Bonato, C., Markham, M. L., Twitchen, D. J., Dobrovitski, V. V. & Hanson, R. Manipulating a qubit through the backaction of sequential partial measurements and real-time feedback. Nature Physics 10, 189 (2014).
Fu, S., Shi, G., Proutiere, A. & James, M. R. Feedback policies for measurement-based quantum state manipulation. Phys. Rev. A 90, 062328 (2014).
Pechen, A., Shuang, F., Il’in, N. & Rabitz, H. Quantum control by von Neumann measurements. Phys. Rev. A 74, 052102 (2006).
Wiseman, H. M. Quantum control: Squinting at quantum systems. Nature 470, 178 (2011).
Shi, G., Li, B., Miao, Z., Dower, P. M. & James, M. R. Agreement seeking in quantum hybrid networks: centralized and distributed solutions. Australian Control Conference, Newcastle (2016).
Bertsekas, D. P. & Shreve, S. E. Stochastic optimal control: The discrete time case (Academic Press New York, 1978).
Bertsekas, D. P. & Tsitsiklis, J. N. An analysis of stochastic shortest path problems. Math. Oper. Res. 16, 580 (1991).
Shi, G., Li, B., Johansson, M. & Johansson, K. H. Finite-time convergent gossiping. IEEE/ACM Trans. Networking 24, 2782 (2016).
Durrett, R. Probability Theory: Theory and Examples (Cambridge University Press: New York, 2010).
Acknowledgements
The work of B.L. is partially supported by National Natural Science Foundation of China (NSFC) under Grant 11301518 and the National Center for Mathematics and Interdisciplinary Sciences, Chinese Academy of Sciences.
Author information
Authors and Affiliations
Contributions
G.S. and M.R.J. conceived and designed initial idea of the study. G.S. and B.L. conducted the technical analysis of the research. Z.M. and P.D. contributed to useful ideas in completion of the work. G.S. and B.L. wrote the manuscript. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shi, G., Li, B., Miao, Z. et al. Reaching Agreement in Quantum Hybrid Networks. Sci Rep 7, 5989 (2017). https://doi.org/10.1038/s41598-017-05158-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-05158-7
This article is cited by
-
Quantum Clique Gossiping
Scientific Reports (2018)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
