
Abstract
Potato is an important crop in the genus Solanum section Petota. Potatoes are susceptible to multiple abiotic and biotic stresses and have undergone constant improvement through breeding programs worldwide. Introgression of wild relatives from section Petota with potato is used as a strategy to enhance the diversity of potato germplasm. The current dataset contributes a phased genome assembly for diploid S. okadae, and short read sequences and de novo assemblies for the genomes of 16 additional wild diploid species in section Petota that were noted for stress resistance and were of interest to potato breeders. Genome sequence data for three additional genomes representing polyploid hybrids with cultivated potato, and an additional genome from non-tuberizing S. etuberosum, which is outside of section Petota, were also included. High quality short reads assemblies were achieved with genome sizes ranging from 575 to 795 Mbp and annotations were performed utilizing transcriptome sequence data. Genomes were compared for presence/absence of genes and phylogenetic analyses were carried out using plastome and nuclear sequences.
Similar content being viewed by others


Background & Summary
Potato is currently the third most important crop for human consumption with increasing production in the developing world and it is an important sustainable global food security crop for climate-smart agriculture1,2. Breeding for improved nutritious potato varieties suitable for sustainable production and climate change resilience will be aided by introgression of diverse genes from native Andean cultivars and landraces along with wild Solanum relatives of potato3. The genebank at the International Potato Center (CIP) and other genebanks globally, carry diverse germplasm used by breeding programs for genetic improvement of the crop4,5. The CIP genebank has potato cultivars, landraces, and wild Solanum germplasm collected from a wide range of environments in North and South America with variation in abiotic and biotic stress. Native Andean cultivars and landraces also carry beneficial nutrients and bioactive compounds for human health6,7.
A reference genome sequence for a doubled monoploid potato clone DM1-3 516 R44 (DM) was released in 2011 and later improved8,9,10. Low depth sequencing of potato varieties and wild species aligned against the DM reference was used to assess genome diversity, copy number variation (CNVs), introgressions, and selective sweeps11,12,13. Since then, the genomes of additional potato clones, diploid as well as tetraploid, have been sequenced and de novo assembled14,15,16,17,18,19,20.
Potato and its wild relatives are in the genus Solanum section Petota, which consists of over 100 species that form tubers21. Increasing knowledge on the genetic potential of species in section Petota will increase capacity for their use in enhancing potato germplasm. Genomes of several wild species are also available22,23,24,25 and a Petota super pangenome representing 60 species was recently released26. The current data set includes a phased genome assembly of the wild species S. okadae, for which short reads and the mitogenome were previously published26,27. In addition, the study contributes Illumina short read sequences (50–100x sequencing depth) and de novo assemblies (3,328–59,223 N50) for genomes of 16 wild species in section Petota that were noted for stress resistance and of interest to potato breeders. An S. etuberosum genome from outside section Petota was also included in this data set, as were three polyploid hybrids. For most of the species in this project, these are the first genome sequences released of their species. Taxonomic groupings of the species of section Petota into Clade 1 + 2, Clade 3 and Clade 4 were represented in the genomes sequenced.
Transcriptome sequence data was generated and used for annotation. Both nuclear and organellar genome sequences are provided. Comparative analysis of the presence/absence variation against the Petota super pangenome provided insight into the diversity of the species in the phylogenetic analysis.
Methods
Solanum okadae (OKA15) genome sequencing
Botanical S. okadae seed sourced from US Genebank NRSP-6 (PI 458367) were sown on agar media. Individual clones were propagated in vitro. Seventeen lines were planted in the greenhouse and self-pollinated. While abundant flowering was noted, a single line, OKA15, was selected for further study26,27. The 10X Genomics short reads were previously published26,27. High molecular weight DNA for S. okadae OKA15 was prepared using a modified CTAB procedure28 and used for Hi-C (chromatin interactions), Pacific Biosciences (PacBio) and Nanopore sequencing. The Hi-C library preparation was done using Phase Genomics Proximo Plant Hi-C version 4.0, and sequenced at Génome Québec’s Sequencing centre, Montreal, Canada, on Illumina NovaSeq. 6000 platform in PE 100 bp mode with ~3B reads, while both the PacBio libraries (sequenced on Sequel II system using the SMRT technology (HiFi) at a depth of 100X,) and the Nanopore ONT libraries (sequenced on the PromethION at a depth of 100X) were prepared and sequenced by Novogene (Novogene Co., Ltd, Beijing, China).
Genome and transcriptome sequencing
A total of 23 additional accessions representing potato wild relatives or hybrids with agronomically important traits such as disease resistance, cold and drought tolerance, and other biotic and abiotic stresses were selected for this study (Table 1). The genomic DNA of these accessions was isolated from in vitro or greenhouse grown plantlets or leaves. The library construction, quality control, and sequencing were done by Novogene (Novogene Co., Ltd, Beijing, China). The genomic DNA was fragmented, ligated with adapters, and PCR amplified to construct single libraries with an insert size of 350 bps. The sequencing was performed on the Illumina NovaSeq. 6000 platform, in a paired-end mode (2 X 150 bp) at ~50x or ~100x depth (Table 2). Similarly, total RNA was extracted from these accessions, including from OKA15, from leaf, shoot, flower, and/or tuber tissues. The RNA-Seq library construction used standard protocol (Novogene) and sequencing was done on the Illumina NovaSeq. 6000 platform (PE150) (Table 2).
S. okadae OKA15 phased genome assembly and quality control
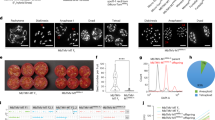
The Nanopore reads were adapter trimmed using porechop v0.2.4 (https://github.com/rrwick/Porechop) and default parameters. hifiasm v0.16.1-r37529 was used to generate a haplotype-resolved assembly using the PacBio HiFi and the Hi-C reads (Fig. 1). Organellar genomes were removed from both resulting haplotype assemblies. The HiFi and Nanopore reads were used to scaffold the haplotype assemblies. Hi-C reads were trimmed using fastp v0.23.130, and mapped to haplotype assemblies individually using the Arima mapping pipeline (https://github.com/ArimaGenomics/mapping_pipeline) and default parameters. The alignments were filtered to keep only the unique alignments (samtools view -q 40)31. The scaffolding was performed using YaHS32. Hi-C maps were generated using Juicer33 and manually reviewed using JBAT33. Any duplicated contigs from the assemblies were removed using mummer34. Gaps were closed using tgsgapcloser35 with PacBio and Nanopore reads. A custom repeat library was constructed using Repeatmodeler36 and repeats were masked using Repeatmasker37 and default parameters. RNA-Seq reads were filtered using Kraken238 and trimmed using fastp30, then aligned to the assembly using hisat239. Structural annotations were identified using Braker340, and curated using gfacs41, and functional annotations were generated using ahrd (https://github.com/groupschoof/AHRD) and interproscan42.

The haplotypes of the phased Solanum okadae (OKA15) genome.
Quality control and analysis of WGS and RNA-Seq for additional potato wild relatives
Quality control was performed on the raw sequencing data (WGS and RNA-Seq) using FastQC v0.11.943. An adaptor removal and read quality trimming was performed on the raw reads using Trimmomatic v0.3944. Genome heterozygosity and estimated size were determined using the trimmed WGS reads. First, k-mer frequencies were calculated for each genome (k = 21) and a k-mer histogram was generated using Jellyfish v2.3.045. The k-mer histogram was used to generate various genome characteristics with GenomeScope 2.046. The polyploid genomes of S. brevicaule (=oplocense) X S. tuberosum (B1595106), S. tarnii X S. tuberosum (SH7_18_3), and S. commersonii X S. andigena (cxa70P5) hybrids showed higher rates of heterozygosity (Fig. 2), as seen in previous potato polyploid genomes20, while the S. etuberosum (etb0161) genome showed very low levels of heterozygosity. The estimated haploid genome sizes ranged from 575 Mbp in S. pinnatisectum (S7) to 795 Mbp in S. tarnii X S. tuberosum (SH7_18_3).

The k-mer coverage plots of each of 23 genome sequences from potato wild relatives (Solanum sp).
De novo assembly and annotation
Each genome was assembled into contigs from the raw Illumina reads using the de novo assembler MaSuRca v4.0.547. Organelle sequences were removed from the resulting assemblies using publicly available potato plastome48,49 and mitogenome sequences27,50. The de novo assemblies were aligned against the organellar reference using nucmer from Mummer v4.0.0beta2 utilities34 and the alignments were filtered for 95% identity and 200 bp alignment length. Any contigs with >95% coverage against the organelles were removed, as well as organellar sequences at the start and ends of contigs. The resulting filtered contigs were queried against the non-redundant nucleotide database using blast+ v2.11.051 to remove contaminant sequences. Any contig with a reliable match (90% query converge with 90% sequence identity) to organisms outside of green plants were removed from the assembly. Finally, contigs that are less than 200 bp in length were removed and the remaining contig ids were modified to create a final clean assembly file using BBmap v38.8652 (Table 3). The plastomes of each genome were assembled and annotated from raw Illumina reads using the Plastaumatic53 pipeline. The quality of each de novo assembly was calculated using QUAST v5.0.254 to determine the assembly lengths, N50 values etc, and BUSCO v5.2.255 to check for the completeness of the assembly by looking for the presence of single copy orthologs from Viridiplantae (Fig. 3). An assembly was aligned against its reference genome22 when available using nucmer from mummer v4.0.0beta234 and the alignment statistics were generated using dnadiff.

BUSCO quality assessment results of short reads de novo genome assemblies for 24 potato wild relatives or hybrid clones (Solanum sp). The bar plot shows the percent of BUSCO genes (Viridiplantae dataset) present in each genome assembly. Species information and accession numbers are detailed in Table 1.
The genome assemblies were annotated using the RNA-Seq data as the evidence for gene prediction along with homology-based prediction. The two accessions (B1595106 and SH7_18_3) with no RNA-Seq data were annotated only with the protein sequences. A repeat masking was performed on each genome assembly using RepeatMasker v4.1.2-pl37 with a custom repeat library of potato reference sequences constructed by concatenating repeat libraries from the Petota super pangenome26 and DMv6.19. Table 4 details the number of bases masked in each genome and size of different types of transposable elements found in them. Then the structural annotation was performed using BRAKER v2.1.640,56,57 in two runs, one with the RNA-Seq data as evidence and another run with protein sequences as evidence. The trimmed RNA-Seq reads of each accession were aligned to its genome assembly using HiSAT2 v2.2.139 for BRAKER157. Most of the accessions have an optimal RNA-Seq alignment rate (>65%) against their short read de novo assemblies. The alignment files were sorted and indexed using SAMtools v1.16.131. Then the structural annotation was performed using the BRAKER pipeline58,59,60,61,62,63 on the masked genome assembly with the alignment file. The BRAKER pipeline performed gene prediction by AUGUSTUS v3.4.064 and GeneMark-ET65,66 to generate gene structural annotations. For the homology-based prediction (BRAKER2), Solanales protein sequences from OrthoDB along with the protein sequences from potato reference genomes9,18,67 were combined to create a protein database for BRAKER. The BRAKER1 and BRAKER2 results were combined to select transcripts based on support by extrinsic evidence using TSEBRA v1.0.368 to get a high-confidence gene set. The annotations for the accessions with no RNA-Seq data (B1595106 and SH7_18_3) were obtained from the BRAKER2 run with protein sequences as evidence. Since no RNA-Seq evidence was available for these two, all the predicted structural genes were added to the final gene set. Figure 4 shows the number of genes and transcripts predicted in these accessions by the BRAKER pipeline. A total of 31,247–47,705 high confidence genes (i.e. genes with RNA-Seq evidence) were found in these genomes, with S. etuberosum having the lowest number of genes and the S. commersonii X S. andigena hybrid having the greatest number of genes. A high confidence gene set was not generated for B1595106 and SH7_18_3 genomes due to lack of the RNA-Seq data. A functional annotation was performed using Interproscan v5.52-8642 against the PFAM database. Approximately 65–70% of the annotated genes in all the genomes were found to have PFAM domains, except for the SH7_18_3, and B1595106 genomes (for which RNA-Seq data was not available).

The number of high-confidence genes and transcripts found in 22 potato wild relatives accessions (Solanum sp). The two columns for each genome represent the total number of predicted genes and transcripts (larger number on top of bar) along with their proportions of functional annotations (smaller number inside bar). Species information and accession numbers are detailed in Table 1.
Presence/absence variation analysis
The trimmed reads of each genome were aligned to the Petota super pangenome26 using bwa v0.7.1769. The resulting alignments were filtered to keep only properly paired (-f 2) and remove secondary alignments (-F 2048), then sorted and indexed using SAMtools v1.1331. The gene presence/absence variations (PAVs) were identified in each genome using SGSGeneLoss v0.170 with minCov = 2 and lostCutoff = 0.2. These PAVs were used to generate a maximum-likelihood phylogenetic tree using IQ-TREE v2.1.371 with GTR2 + FO + R4 as a substitution model and 1000 bootstrap replicates and S. etuberosum set as an outgroup (Fig. 5). A multiple sequence alignment of the 23 plastomes was made using MAFFT v772, followed by a plastome based parsimonious phylogenetic tree constructed using paup v4.0a73 with 1000 bootstrap replicates and S. etuberosum as an outgroup (Fig. 6). The phylogenetic trees were visualized in FigTree v1.4.4 (http://tree.bio.ed.ac.uk/software/figtree/).

A whole genome presence-absence variation (PAV) based phylogenetic tree showing the relatedness of potato wild relatives (Solanum sp). The S. etuberosum genome sequence was used as an outgroup. The numbers at the nodes represent bootstrap support values. For clarity of the figure, only key values are given, and the ones omitted are all 100.

A plastome sequence based phylogenetic tree of 24 potato wild relatives (Solanum sp). The S. etuberosum was used as an outgroup. The numbers at the nodes represent bootstrap support values.
Data Records
S. okadae (OKA 15) genome sequence data is deposited at NCBI under BioProject PRJNA68456574 and BioSample SAMN1786056075: the Hi-C data under SRR2608197276; Nanopore SRR2087005177; PacBio SRR2087005278; Illumina reads SRR1448238479; and the phased haplotype genome assemblies are available under BioProject PRJNA101811580 (haplotype 1) JAWDCX00000000081 and PRJNA101811582 (haplotype 2) JAWDCY00000000083. The OKA 15 RNA-Seq data BioSamples are available under SAMN37429684- SAMN3742968684,85,86 and the RNA-Seq Illumina reads are available under SRR26082554-SRR2608255687,88,89.
All other data used in this study is deposited in NCBI and available under the BioProject PRJNA77936890. The sample descriptions of the 23 genomes used in the genome sequencing are available under the BioSample accession numbers (SAMN2344097791, SAMN23440980 – SAMN2344098392,93,94,95, SAMN23440986 – SAMN2344099096,97,98,99,100, SAMN23440993 – SAMN23440998101,102,103,104,105,106, SAMN23441000 – SAMN23441002107,108,109, SAMN23441004 – SAMN23441007110,111,112,113). The Illumina WGS reads of each genome were deposited with their respective Biosample IDs under the Sequence Read Archive (SRA) submission (SRR17078416 – SRR17078418114,115,116, SRR17078420117, SRR17078422 – SRR17078424118,119,120, SRR17078426 – SRR17078432121,122,123,124,125,126,127, SRR17078435 – SRR17078439128,129,130,131,132, SRR17078441 – SRR17078444133,134,135,136). The final genome assemblies were deposited under the WGS assembly projects with the accession numbers JAJONR000000000 – JAJONU000000000137,138,139, JAJONW000000000 – JAJOOD000000000140,141,142,143,144,145,146,147,148, JAJOOF000000000 – JAJOOJ000000000149,150,151,152,153, JAJOOM000000000 – JAJOOP000000000154,155,156,157, JAJOOS000000000158, JAKRZT000000000159 and the 23 plastome sequences were deposited in the GenBank database with the accession numbers OM638053-OM638057160,161,162,163,164, OM638059-OM638064165,166,167,168,169,170, OM638066-OM638068171,172,173, OM638071-OM638072174,175, OM638074-OM638077176,177,178,179, OM638081-OM638083180,181,182. A complete list of WGS raw data and assemblies are available in Table 5. The sample descriptions of the RNA-Seq samples are available under the BioSample accession numbers SAMN32886741 – SAMN32886746183,184,185,186,187,188, SAMN32886748 – SAMN32886751189,190,191,192, SAMN32886756 – SAMN32886763193,194,195,196,197,198,199,200, SAMN32886766 – SAMN32886771201,202,203,204,205,206, SAMN32886782 – SAMN32886784207,208,209, SAMN32886786210, SAMN32886787211, SAMN32886790 – SAMN32886796212,213,214,215,216,217,218, SAMN32886798219, SAMN32886799220 and their raw sequencing reads are available under the SRA accession numbers SRR23225904 - SRR23225909221,222,223,224,225,226, SRR23225913227, SRR23225914228, SRR23225916 – SRR23225918229,230,231, SRR23225929232, SRR23225930233, SRR23225933234, SRR23225938 – SRR23225940235,236,237, SRR23225942 – SRR23225944238,239,240, SRR23225947 – SRR23225951241,242,243,244,245, SRR23225953 – SRR23225955246,247,248, SRR23225960 – SRR23225962249,250,251, SRR23225964252, SRR23225966 – SRR23225971253,254,255,256,257,258 (Table 6). The gene annotations are available at the following link: https://potatogenomeportal.org/download
Technical Validation
Sequencing data quality control
The quality of the raw WGS and RNA-Seq reads were checked using FastQC43. Various metrics such as per base sequence quality, overall read quality score, GC content, N content, and overrepresented sequences were analyzed to detect low quality sequences or biases in the data. We have found no issues or bias in the WGS reads, whereas the RNA-Seq data is found to have overrepresented sequences in some of the datasets, which is not unusual for RNA-Seq data. We have also checked for viral genome sequences in the RNA-Seq data since potato plants are frequently found to have various types of potato viruses. The reads were classified using kraken2 v2.1.238 by searching against their own genome assemblies and potato virus sequences downloaded from NCBI. Most genomes have very few hits to the viral sequences, and we removed reads that have hits to viruses from each sample and used the clean reads in the following analyses.
Quality assessment of the genome assemblies
The de novo genome assembly quality was assessed by QUAST54 and BUSCO55 where contiguity and completeness of the assemblies were analyzed. The OKA15 genome assembly haplotype 1 and 2 have a complete BUSCO score of 98.3% and 98.5%, respectively, when compared to the (solanales_odb10). Merqury259 was used to estimate the completeness (QV). The complete OKA15 assembly was 99.4%, while haplotype 1 and haplotype 2 were 65 and 65% complete individually (meaning 15–30% of the reads map equally well to both haplotypes). Haplotype 1 (hap1) has 214 contigs with a total length of 729 Mb. The largest contig is 84.7 Mb and the N50 is 58.6 Mb. Haplotype 2 (hap2) has 131 contigs with a total length of 726 Mb, the largest contig is 83.2 Mb and the N50 58.4 Mb. The heterozygosity of the oka15 genome was calculated using jellyfish45 and found to be 0.87%.
The S. etuberosum genome, which has been self-pollinated for several generations, has the best assembly of all with an N50 value of 59,223, 34,061 contigs, and 610 Mbp genome size. The three tetraploids (B1595106, SH7_18_3, and cxa70P5), and a diploid S. chacoense (chc0917) have fragmented assemblies (Table 2). Nine genome assemblies from this study were also compared with long-read assemblies of the same species from a recent study22. Overall, the amount of sequences that mapped to their individual reference ranged from ~85–99% with ~79–98% of the assembly coverage (Table 7). The BUSCO assessment of the assemblies revealed the majority of them are complete with presence of >80% complete genes (Fig. 2). Overall, the S. etuberosum genome has the highest percent of core plant orthologous genes with 94.1% of genes present as complete copies, followed by the chq762573 and pur1868 genomes with 92% and 89.6% of complete BUSCO genes. The SH7_18_3, cxa70P5, and B1595106 genomes have a higher percentage of fragmented genes among the 23 genomes. High rates of heterozygosity and higher ploidy levels are the major contributing factors to highly fragmented assemblies38.
Phylogenetic inference
Previous studies classified section Petota (tuber-bearing) into major Clades and subgroups13,26,260,261. Here we have reconstructed phylogenetic trees from the PAV data (Fig. 5) as well as plastome sequences (Fig. 6) to understand the relationship between these genomes. The results have shown similar groupings as previous studies where S. pinnatisectum (Clade 1 + 2), S. paucissectum, S. piurae, and S. chiquidenum (Clade 3), and the remaining accessions (Clade 4) separated into different clades. Within Clade 4, the S. megistacrolobum accessions formed a sister clade to Clade 4 South, something which was also seen in the Petota pangenome26. S. okadae placed in the Clade 4 South as also seen in the Petota pangenome. The S. tarnii X S. tuberosum (SH7_18_3) genome, which is a somatic hybrid between S. tarnii (Clade 1 + 2 species) and S. tuberosum (Clade 4) obtained by in vitro fusions of protoplasts, placed differently in the PAV and plastome phylogenetic trees. In the plastome phylogenetic tree, it is grouped with the Clade 1 + 2 species, whereas, in the PAV tree it is grouped with another S. tuberosum hybrid (Clade 4) showing the phylogenetic difficulty with hybrids and the importance of including both nuclear and organellar data. Moreover, genomes that are known to be closely related are grouped together, and genomes representing the same species grouped together, which validates the use of PAVs in determining phylogenetic relationships26.
Usage Notes
The Solanum section Petota has over 100 cultivated and wild species. The potato crop wild relatives are an excellent source of genetic variation; however, not many sequencing efforts have been carried out to study these wild species. Here, we present the 24 phased chromosomes for S. okadae, and genome and transcriptome data for an additional 23 potato wild relative accessions. Though most of these are short-read assemblies, they are a useful tool for exploring genetic diversity that can provide insight in potato pre-breeding. The WGS reads can be used in various analyses such as determining SNPs, structural variations, and PAVs to understand the genetic diversity that exists within the section Petota. The RNA-Seq data of these wild species with important agronomic traits is especially crucial to understand their transcriptome profile. S. okadae foliage has been shown to contain the glycoalkaloid tomatine, and undetectable levels of solanine and chaconine, and carries Colorado potato beetle resistance, drought and cold tolerance (but not frost) and moderate late blight resistance262,263,264,265.
Code availability
All software with their specific version used for data processing are clearly described in the methods section. If no specific variable or parameters are mentioned for a software, the default parameters were used.
References
Devaux, A., Kromann, P. & Ortiz, O. Potatoes for sustainable global food security. Potato Res. 57, 185–199 (2014).
Hancock, R. D. et al. Physiological, biochemical and molecular responses of the potato (Solanum tuberosum L.) plant to moderately elevated temperature. Plant Cell Environ. 37, 439–450 (2014).
Fumia, N. et al. Wild relatives of potato may bolster its adaptation to new niches under future climate scenarios. Food Energy Secur, https://doi.org/10.1002/fes3.360 (2022).
Jansky, S. H. et al. A case for crop wild relative preservation and use in potato. Crop Sci. 53, 746–754 (2013).
Bradshaw, J. E., Bryan, G. J. & Ramsay, G. Genetic resources (including wild and cultivated Solanum species) and progress in their utilisation in potato breeding. Potato Research 49, 49–65 (2006).
Bellumori, M. et al. A study on the biodiversity of pigmented Andean potatoes: Nutritional profile and phenolic composition. Molecules 25, (2020).
Giusti, M. M., Polit, M. F., Ayvaz, H., Tay, D. & Manrique, I. Characterization and quantitation of anthocyanins and other phenolics in native Andean potatoes. J. Agric. Food Chem. 62, 4408–4416 (2014).
Potato Genome Sequencing Consortium et al. Genome sequence and analysis of the tuber crop potato. Nature 475, 189–195 (2011).
Pham, G. M. et al. Construction of a chromosome-scale long-read reference genome assembly for potato. Gigascience 9, (2020).
Yang, X. et al. The gap-free potato genome assembly reveals large tandem gene clusters of agronomical importance in highly repeated genomic regions. Mol. Plant 16, 314–317 (2023).
Hardigan, M. A. et al. Genome reduction uncovers a large dispensable genome and adaptive role for copy number variation in asexually propagated Solanum tuberosum. Plant Cell 28, 388–405 (2016).
Hardigan, M. A. et al. Genome diversity of tuber-bearing Solanum uncovers complex evolutionary history and targets of domestication in the cultivated potato. Proc. Natl. Acad. Sci. USA 114, E9999–E10008 (2017).
Li, Y. et al. Genomic analyses yield markers for identifying agronomically important genes in Potato. Mol. Plant 11, 473–484 (2018).
Achakkagari, S. R. et al. Genome sequencing of adapted diploid potato clones. Front. Plant Sci. 13, 954933 (2022).
Bao, Z. et al. Genome architecture and tetrasomic inheritance of autotetraploid potato. Mol. Plant 15, 1211–1226 (2022).
Sun, H. et al. Chromosome-scale and haplotype-resolved genome assembly of a tetraploid potato cultivar. Nat. Genet. 54, 342–348 (2022).
Hoopes, G. et al. Phased, chromosome-scale genome assemblies of tetraploid potato reveal a complex genome, transcriptome, and predicted proteome landscape underpinning genetic diversity. Mol. Plant 15, 520–536 (2022).
Zhou, Q. et al. Haplotype-resolved genome analyses of a heterozygous diploid potato. Nat. Genet. 52, 1018–1023 (2020).
van Lieshout, N. et al. Solyntus, the new highly contiguous reference genome for potato (Solanum tuberosum). G3 10, 3489–3495 (2020).
Kyriakidou, M. et al. Genome assembly of six polyploid potato genomes. Sci Data 7, 88 (2020).
Ovchinnikova, A. et al. Taxonomy of cultivated potatoes (Solanum section Petota: Solanaceae). Bot. J. Linn. Soc. 165, 107–155 (2011).
Tang, D. et al. Genome evolution and diversity of wild and cultivated potatoes. Nature 606, 535–541 (2022).
Kyriakidou, M. et al. Structural genome analysis in cultivated potato taxa. Theor. Appl. Genet. 133, 951–966 (2020).
Leisner, C. P. et al. Genome sequence of M6, a diploid inbred clone of the high‐glycoalkaloid‐producing tuber‐bearing potato species Solanum chacoense, reveals residual heterozygosity. Plant J. 94, 562–570 (2018).
Aversano, R. et al. The Solanum commersonii genome sequence provides insights into adaptation to stress conditions and genome evolution of wild potato relatives. Plant Cell 27, 954–968 (2015).
Bozan, I. et al. Pangenome analyses reveal impact of transposable elements and ploidy on the evolution of potato species. Proc. Natl. Acad. Sci. USA 120, e2211117120 (2023).
Achakkagari, S. R. et al. The complete mitogenome assemblies of 10 diploid potato clones reveal recombination and overlapping variants. DNA Res. 28, (2021).
Hamilton, J. P. et al. Chromosome-scale genome assembly of the ‘Munstead’ cultivar of Lavandula angustifolia. BMC Genomic Data 24, 75 (2023).
Cheng, H. et al. Haplotype-resolved de novo assembly using phased assembly graphs with hifiasm. Nat Methods 18, 170–175 (2021).
Chen, S. et al. fastp: an ultra-fast all-in-one FASTQ preprocessor. Bioinformatics 34, i884–i890 (2018).
Li, H. et al. The Sequence Alignment/Map format and SAMtools. Bioinformatics 25, 2078–2079 (2009).
Zhou, C. et al. YaHS: yet another Hi-C scaffolding tool. Bioinformatics 39, btac808 (2023).
Durand, N. et al. Juicer provides a one-click system for analyzing loop-resolution Hi-C experiments. Cell Systems 3, (2016).
Marçais, G. et al. MUMmer4: A fast and versatile genome alignment system. PLoS Comput. Biol. 14, e1005944 (2018).
Xu, M. et al. TGS-GapCloser: A fast and accurate gap closer for large genomes with low coverage of error-prone long reads. GigaScience 9, giaa094 (2020).
Flynn, J. M. et al. “RepeatModeler2 for Automated Genomic Discovery of Transposable Element Families.”. Proc. Natl. Acad. Sci. USA 117, 9451–57 (2020).
Smit, A. et al. RepeatMasker Open-4.0. http://www.repeatmasker.org (2015).
Wood, D. E. et al. Improved metagenomic analysis with Kraken 2. Genome Biol. 20, 257 (2019).
Kim, D. et al. Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype. Nat. Biotechnol. 37, 907–915 (2019).
Brůna, T. et al. BRAKER2: Automatic Eukaryotic Genome Annotation with GeneMark-EP+ and AUGUSTUS Supported by a Protein Database. NAR Genomics & Bioinformatics 3 (2021).
Caballero, M. & Wegrzyn, J. gFACs: Gene Filtering, Analysis, and Conversion to Unify Genome Annotations Across Alignment and Gene Prediction Frameworks. Genomics, Proteomics & Bioinformatics 17, 305–10 (2019).
Quevillon, E. et al. InterProScan: Protein Domains Identifier. Nucleic Acids Res. 33, W116–20 (2005).
Andrews, S. FastQC: a quality control tool for high throughput sequence data. Version 0.11.9. Babraham Bioinformatics, Babraham Institute, UK. https://www.bioinformatics.babraham.ac.uk/projects/fastqc/ (2019).
Bolger, A. M., Lohse, M. & Usadel, B. Trimmomatic: a flexible trimmer for Illumina sequence data. Bioinformatics 30, 2114–2120 (2014).
Marçais, G. & Kingsford, C. A fast, lock-free approach for efficient parallel counting of occurrences of k-mers. Bioinformatics 27, 764–770 (2011).
Ranallo-Benavidez, T. R., Jaron, K. S. & Schatz, M. C. GenomeScope 2.0 and Smudgeplot for reference-free profiling of polyploid genomes. Nat. Commun. 11, 1432 (2020).
Zimin, A. V. et al. The MaSuRCA genome assembler. Bioinformatics 29, 2669–2677 (2013).
Achakkagari, S. R. et al. Complete plastome assemblies from a panel of 13 diverse potato taxa. PLoS One 15, e0240124 (2020).
Achakkagari, S. R., Tai, H. H., Davidson, C., Jong, H. D. & Strömvik, M. V. The complete plastome sequences of nine diploid potato clones. Mitochondrial DNA B Resour 6, 811–813 (2021).
Achakkagari, S. R. et al. Complete mitogenome assemblies from a panel of 13 diverse potato taxa. Mitochondrial DNA B Resour 6, 894–897 (2021).
Camacho, C. et al. BLAST+: architecture and applications. BMC Bioinformatics 10, 421 (2009).
Bushnell, B. BBMap: A fast, accurate, splice-aware aligner. https://www.osti.gov/biblio/1241166 (2014).
Chen, W., Achakkagari, S. R. & Strömvik, M. Plastaumatic: Automating plastome assembly and annotation. Front. Plant Sci. 13, 1011948 (2022).
Gurevich, A., Saveliev, V., Vyahhi, N. & Tesler, G. QUAST: quality assessment tool for genome assemblies. Bioinformatics 29, 1072–1075 (2013).
Simão, F. A., Waterhouse, R. M., Ioannidis, P., Kriventseva, E. V. & Zdobnov, E. M. BUSCO: assessing genome assembly and annotation completeness with single-copy orthologs. Bioinformatics 31, 3210–3212 (2015).
Hoff, K. J., Lomsadze, A., Borodovsky, M. & Stanke, M. Whole-Genome Annotation with BRAKER. Methods Mol. Biol. 1962, 65–95 (2019).
Hoff, K. J., Lange, S., Lomsadze, A., Borodovsky, M. & Stanke, M. BRAKER1: Unsupervised RNA-Seq-Based Genome Annotation with GeneMark-ET and AUGUSTUS. Bioinformatics 32, 767–769 (2016).
Barnett, D. W., Garrison, E. K., Quinlan, A. R., Strömberg, M. P. & Marth, G. T. BamTools: a C++ API and toolkit for analyzing and managing BAM files. Bioinformatics 27, 1691–1692 (2011).
Lomsadze, A., Ter-Hovhannisyan, V., Chernoff, Y. O. & Borodovsky, M. Gene identification in novel eukaryotic genomes by self-training algorithm. Nucleic Acids Res. 33, 6494–6506 (2005).
Buchfink, B., Xie, C. & Huson, D. H. Fast and sensitive protein alignment using DIAMOND. Nat. Methods 12, 59–60 (2014).
Stanke, M., Diekhans, M., Baertsch, R. & Haussler, D. Using native and syntenically mapped cDNA alignments to improve de novo gene finding. Bioinformatics 24, 637–644 (2008).
Iwata, H. & Gotoh, O. Benchmarking spliced alignment programs including Spaln2, an extended version of Spaln that incorporates additional species-specific features. Nucleic Acids Res. 40, e161 (2012).
Gotoh, O. A space-efficient and accurate method for mapping and aligning cDNA sequences onto genomic sequence. Nucleic Acids Res. 36, 2630–2638 (2008).
Stanke, M., Schöffmann, O., Morgenstern, B. & Waack, S. Gene prediction in eukaryotes with a generalized hidden Markov model that uses hints from external sources. BMC Bioinformatics 7, 62 (2006).
Lomsadze, A., Burns, P. D. & Borodovsky, M. Integration of mapped RNA-Seq reads into automatic training of eukaryotic gene finding algorithm. Nucleic Acids Res. 42, e119 (2014).
Brůna, T., Lomsadze, A. & Borodovsky, M. GeneMark-EP+: eukaryotic gene prediction with self-training in the space of genes and proteins. NAR Genom Bioinform 2, (2020).
Petek, M. et al. Cultivar-specific transcriptome and pan-transcriptome reconstruction of tetraploid potato. Scientific Data 7, 1–15 (2020).
Gabriel, L., Hoff, K. J., Brůna, T., Borodovsky, M. & Stanke, M. TSEBRA: transcript selector for BRAKER. BMC Bioinformatics 22, 566 (2021).
Li, H. Aligning sequence reads, clone sequences and assembly contigs with BWA-MEM. arXiv [q-bio.GN] (2013).
Golicz, A. A. et al. Gene loss in the fungal canola pathogen Leptosphaeria maculans. Funct. Integr. Genomics 15, 189–196 (2015).
Minh, B. Q. et al. IQ-TREE 2: New models and efficient methods for phylogenetic inference in the genomic era. Mol. Biol. Evol. 37, 1530–1534 (2020).
Katoh, K., Rozewicki, J. & Yamada, K. D. MAFFT online service: multiple sequence alignment, interactive sequence choice and visualization. Brief. Bioinform. 20, 1160–1166 (2019).
Swofford, D. L. PAUP: phylogenetic analysis using parsimony (and other methods), 4.0 beta. http://paup.csit.fsu.edu/.
NCBI BioProject https://identifiers.org/bioproject:PRJNA684565 (2020).
NCBI BioSample https://identifiers.org/biosample:SAMN17860560 (2021).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR26081972 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR20870051 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR20870052 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR14482384 (2023).
NCBI BioProject https://identifiers.org/bioproject:PRJNA1018115 (2024).
NCBI Nucleotide https://identifiers.org/nucleotide:JAWDCX000000000 (2023).
NCBI BioProject https://identifiers.org/bioproject:PRJNA1018116 (2024).
NCBI Nucleotide https://identifiers.org/nucleotide:JAWDCY000000000 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN37429684 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN37429685 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN37429686 (2021).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR26082554 (2021).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR26082555 (2021).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR26082556 (2021).
NCBI BioProject https://identifiers.org/bioproject:PRJNA779368 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440977 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440980 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440981 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440982 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440983 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440986 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440987 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440988 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440989 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440990 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440993 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440994 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440995 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440996 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440997 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23440998 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23441000 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23441001 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23441002 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23441004 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23441005 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23441006 (2021).
NCBI BioSample https://identifiers.org/biosample:SAMN23441007 (2021).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078416 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078417 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078418 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078420 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078422 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078423 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078424 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078426 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078427 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078428 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078429 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078430 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078431 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078432 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078435 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078436 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078437 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078438 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078439 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078441 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078442 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078443 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR17078444 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJONR000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJONS000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJONT000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJONU000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJONW000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJONX000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJONY000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJONZ000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOOA000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOOB000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOOC000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOOD000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOOF000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOOG000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOOH000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOOI000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOOJ000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOOM000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOON000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOOO000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOOP000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAJOOS000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:JAKRZT000000000 (2023).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638053 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638054 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638055 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638056 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638057 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638059 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638060 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638061 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638062 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638063 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638064 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638066 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638067 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638068 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638071 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638072 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638074 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638075 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638076 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638077 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638081 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638082 (2022).
NCBI Nucleotide https://identifiers.org/nucleotide:OM638083 (2022).
NCBI BioSample https://identifiers.org/biosample:SAMN32886741 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886742 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886743 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886744 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886745 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886746 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886748 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886749 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886750 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886751 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886756 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886757 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886758 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886759 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886760 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886761 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886762 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886763 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886766 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886767 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886768 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886769 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886770 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886771 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886782 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886783 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886784 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886786 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886787 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886790 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886791 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886792 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886793 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886794 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886795 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886796 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886798 (2023).
NCBI BioSample https://identifiers.org/biosample:SAMN32886799 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225904 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225905 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225906 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225907 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225908 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225909 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225913 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225914 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225916 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225917 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225918 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225929 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225930 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225933 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225938 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225939 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225940 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225942 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225943 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225944 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225947 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225948 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225949 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225950 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225951 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225953 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225954 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225955 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225960 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225961 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225962 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225964 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225966 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225967 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225968 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225969 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225970 (2023).
NCBI Sequence Read Archive https://identifiers.org/insdc.sra:SRR23225971 (2023).
Rhie, A. et al. Merqury: reference-free quality, completeness, and phasing assessment for genome assemblies. Genome Biol. 21, 245 (2020).
Spooner, D. M., Ghislain, M., Simon, R., Jansky, S. H. & Gavrilenko, T. Systematics, diversity, genetics, and evolution of wild and cultivated potatoes. Bot. Rev. 80, 283–383 (2014).
Huang, B., Ruess, H., Liang, Q., Colleoni, C. & Spooner, D. M. Analyses of 202 plastid genomes elucidate the phylogeny of Solanum section Petota. Sci. Rep. 9, 4454 (2019).
Karki, H. S., Jansky, S. H. & Halterman, D. A. Screening of Wild Potatoes Identifies New Sources of Late Blight Resistance. Plant disease 105, 368–376 (2020).
Pelletier, Y., Clark, C. & Tai, G. C. Resistance of three wild tuber-bearing potatoes to the Colorado potato beetle. Entomologia Experimentalis et Applicata 100, 31–41 (2001).
Watanabe, K. N., Kikuchi, A., Shimazaki, T. & Asahina, M. Salt and drought stress tolerances in transgenic potatoes and wild species. Potato Res. 54, 319–324 (2011). (2011).
Vega, S. E. & Bamberg, J. B. Screening the US potato collection for frost hardiness. American Pot. J. 72, 13–21 (1995).
Acknowledgements
The authors would like to acknowledge the potato breeding and genebank teams at Agriculture and Agri-Food Canada (Sylvia Steeves, Emily McCoy, Martin Lagüe); USDA, Aberdeen, ID, USA; and at The International Potato Center (CIP), Lima, Peru for maintenance and propagation of clones used in the study; Thiago Mendes, Mariela Aponte and Edith Poma (CIP) for providing plant material; Daniel Philippe Matton (Université de Montreal, Canada) and Ramona Thieme (Julius Kühn-Institut, Germany) for germplasm transferred to the Canadian Potato Gene Resources Genebank. Funding for the study was provided by a grant from Agriculture and Agri-Food Canada (International Collaboration Program) “Genome sequencing of wild Solanum diploids“ to CIP; a grant from the Agriculture and Agri-Food Canada Genomics Research and Development Initiative to H.H.T.; an AAFC-Génome Québec joint call Management Driven Genomics award “Revolutionizing potato variety development for climate smart potato” to HHT and MVS (J-002367/GQ-AAC-2019-2); a Compute Canada RPP award (Research Portals and Platforms: “The Potato Genome Diversity Portal”) and a Compute Canada Resources for Research Groups award (“Structural variation analyses of complex plant genomes in search of climate smart adaptations”) to MVS; and a 10-year project to strengthen food and nutrition security worldwide by supporting the conservation and use of crop diversity supported by the Government of Norway (NORAD) (“Biodiversity for Opportunities, Livelihoods and Development (BOLD)” (Project CONT-0791 “CWR-derived potatoes integrated in breeding pipelines for climate change resilience of farming communities of Ecuador, Kenya and Peru” to CIP), managed by the Crop Trust and implemented in partnership with national and international genebanks and seed system actors and researchers around the world.
Author information
Authors and Affiliations
Contributions
H.H.T., N.L.A., N.M.C., H.L.K., B.B., M.V.S. - designed the overall project and supervised experiments. S.R.A., I.B., J.C.C.T., L.P., J.S., H.J.M., H.H.T., N.L.A., N.M.C., H.L.K., B.B., - performed experiments and/or provided germplasm and data. H.J.M. prepared the S. okadae materials and genome sequencing libraries. S.R.A., I.B., J.C.C.T., H.H.T. analyzed data. S.R.A., J.C.C.T., H.H.T., N.L.A., H.L.K., N.M.C., M.V.S. prepared the manuscript. All authors have read and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Achakkagari, S.R., Bozan, I., Camargo-Tavares, J.C. et al. The phased Solanum okadae genome and Petota pangenome analysis of 23 other potato wild relatives and hybrids. Sci Data 11, 454 (2024). https://doi.org/10.1038/s41597-024-03300-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03300-5
