
Abstract
Adipogenesis is a process in which fat-specific progenitor cells (preadipocytes) differentiate into adipocytes that carry out the key metabolic functions of the adipose tissue, including glucose uptake, energy storage, and adipokine secretion. Several cell lines are routinely used to study the molecular regulation of adipogenesis, in particular the immortalized mouse 3T3-L1 line and the primary human Simpson-Golabi-Behmel syndrome (SGBS) line. However, the cell-to-cell variability of transcriptional changes prior to and during adipogenesis in these models is not well understood. Here, we present a single-cell RNA-Sequencing (scRNA-Seq) dataset collected before and during adipogenic differentiation of 3T3-L1 and SGBS cells. To minimize the effects of experimental variation, we mixed 3T3-L1 and SGBS cells and used computational analysis to demultiplex transcriptomes of mouse and human cells. In both models, adipogenesis results in the appearance of three cell clusters, corresponding to preadipocytes, early and mature adipocytes. These data provide a groundwork for comparative studies on these widely used in vitro models of human and mouse adipogenesis, and on cell-to-cell variability during this process.
Similar content being viewed by others


Background & Summary
Adipose tissue carries out multiple roles that affect whole-body metabolism. In addition to storing energy in the form of lipids, it contributes to the homeostatic maintenance of blood glucose levels by taking up glucose in response to insulin and regulates the function of other metabolic organs by secreting hormones such as leptin and adiponectin1,2.
Adipogenesis is a differentiation process in which fat-specific progenitor cells (preadipocytes) convert into adipocytes, which carry out key metabolic functions of the adipose tissue. In vivo, preadipocytes are located in proximity of blood vessels within adipose tissue and contribute to adipose tissue maintenance and expansion in obesity3. Dysregulation of adipogenesis can result in metabolic disease, including insulin resistance and type 2 diabetes4.
Several preadipocyte in vitro models are routinely used to study the molecular regulation of adipogenesis. The most commonly used in vitro models include the immortalized mouse 3T3-L1 cell line5 and the primary, non-immortalized, non-transformed human Simpson-Golabi Behmel syndrome (SGBS) cell line6. These cellular models brought on major breakthroughs in our understanding of molecular mechanisms of adipogenic differentiation, both in development and in obesity7,8. However, adipogenic models show high levels of cell-to-cell heterogeneity in their differentiation responses to stimuli9. This heterogeneity can be due to multiple factors, including variations in preadipocyte commitment and stochasticity of responses to differentiation stimuli. Despite that, adipogenesis is often studied using bulk approaches, such as bulk RNA-Sequencing, which ignore the variability between individual cells, likely masking the presence of distinct cell subpopulations during adipogenesis.
Here, we present a single-cell RNA-Sequencing (scRNA-Seq) dataset collected before and during adipogenic differentiation of 3T3-L1 and SGBS cells to allow for analyses of heterogeneity of transcriptional states before and during adipogenesis, as well as comparisons between mouse and human models of adipogenesis. To minimize technical variation, at two time points (before and during adipogenic differentiation) mouse and human cells were mixed in equal ratios and subjected to scRNA-Seq, followed by computational demultiplexing and separation of data from mouse and human cells (Fig. 1a). The time points were selected based on previously established time course comparison of adipogenesis in SGBS and 3T3-L1 cells10 and validated using light microscopy (Fig. 1b). Analysis of cells at later timepoints was not feasible due to the fragility of large adipocytes, which would preclude single-cell analysis. Through technical validation, we demonstrate quality of this dataset. By unsupervised clustering we identify cell populations that correspond to preadipocytes, differentiating and mature adipocytes in both models.

scRNA-Seq of mouse and human adipogenesis. (a) Schematic of the workflow. Human SGBS and mouse 3T3-L1 cells were analyzed at two time points, corresponding to before (D0) and during (D5 for 3T3-L1, D8 for SGBS) adipogenesis. At each time point, live cells were purified using exclusion of propidium iodide-stained cells by FACS. Equal numbers of SGBS and 3T3-L1 cells were then mixed and subjected to microfluidic single-cell capture with GelBeads-in-emulsion (GEMs) using 10X Chromium Controller. Single-cell cDNA libraries were prepared using the Chromium Single Cell 3′ Library & Gel Bead Kit (10X Genomics), followed by sequencing on Illumina HiSeq 4000. Computational analysis involved barcode processing, UMI counting, demultiplexing, gene and cell filtering, normalization, and clustering. (b) Representative light microscopy images of differentiated cells, SGBS at day 8 (D8) and 3T3-L1 at day 5 (D5), show similar pattern of lipid deposition in adipocytes (arrows). Scale bar: 50 µm.
This dataset complements recent advances in characterizing the transcriptome of adipose tissue in human and mice at a single-cell11,12,13,14 and single-nucleus level15, which revealed significant level of transcriptional heterogeneity within both adipose progenitor cells and adipocytes. In addition, the progress in adipocyte cell culture led to establishment of new models with improved translational relevance over cell lines. For example, our dataset can be used as a point of reference for the investigation using other models of adipogenesis, including primary adipocyte precursor cells (APCs)16,17 and adipose mesenchymal stem cells (AMSCs)18,19. In addition, transcriptome data from differentiated SGBS and 3T3-L1 cells can be utilized to compare with in vitro adipocyte biology models, such as cultured primary adipocytes20.
Methods
Cell culture
The 3T3-L1 preadipocyte cell line was maintained in Dulbecco’s Modified Eagle’s Medium (DMEM, Thermo Fisher) with 10% Fetal Bovine Serum (GeminiBio, lot #A22G00J), 100 units/ml penicillin and 100 µg/ml streptomycin, in a humidified 5% CO2 incubator. Cells were used at passage 7. For adipogenic differentiation cells were grown to confluency. 48 h past confluency, some of the cells were collected for scRNA-Seq analysis before adipogenesis (day 0, D0), while other cells were differentiated by stimulation with 1 µM dexamethasone, 0.5 mM IBMX, 10 µg/ml insulin in growth medium. After 48 h the medium was changed to growth medium with 10 µg/ml insulin in growth medium until day 5 (D5), when the cells were collected for scRNA-Seq analysis during adipogenesis.
The SGBS cell line was cultured and differentiated as previously described6, and used at passage 34. Cells were maintained in a humidified chamber at 37 °C with 5% CO2, and the media was replaced every 2-3 days. The standard culture media used was composed of DMEM/Nutrient Mix F-12 (Invitrogen), supplemented with 33 uM biotin, 17 uM pantothenic acid, 10% FBS and antibiotics (100 IU/ml penicillin and 100 ug/ml streptomycin). Cells were cultured for three days post-confluence, and either subjected to scRNA-Seq (D0, before differentiation) or differentiated. Differentiation was induced by the change of culture media to DMEM/F-12, 33 uM biotin, 17 uM pantothenic acid, 0.01 mg/ml human transferrin, 100 nM cortisol, 200 pM triiodothyronine, 20 nM human insulin (Sigma-Aldrich), 25 nM dexamethasone, 250 uM IBMX, 2 uM rosiglitazone, and antibiotics. After four days of differentiation, the medium was replaced with DMEM/F-12, 33 uM biotin, 17 uM pantothenic acid, 0.01 mg/ml human transferrin, 100 nM cortisol, 200 pM triiodothyronine, 20 nM human insulin and antibiotics. SGBS cells were cultured for eight days after the induction of differentiation and subjected to scRNA-Seq analysis (time point during differentiation, D8).
Both cell types were cultured in 6-well polystyrene tissue culture plates (Falcon, #353046).
Microscopy
Cultured cells were imaged using EVOS XL Core (Thermo Fisher Scientific) at 20X magnification.
Single-cell sorting and cDNA library preparation
On the day of collection, cells were detached from culture plates using TrypLE Select Enzyme (Gibco), centrifuged at 300 × g for 5 min and resuspended in PBS with 0.04% Bovine Serum Albumin. Lack of staining with Trypan Blue Solution (Gibco) was used to sort live cells using Influx sorter (Beckman Dickinson), with >95% of single cells quantified as live in all experiments. Equal numbers of sorted live SGBS and 3T3-L1 cells were mixed and subjected to single-cell capture on the 10X Chromium Controller device at Stanford Genomics Service Center during which single cells were encapsulated with individual Gel Beads-in-emulsion (GEMs) using the Chromium Single Cell 3′ Library & Gel Bead Kit (10X Genomics). The number of cells targeted in each experiment was 10,000, following manufacturer’s guidelines. In-drop reverse transcription and cDNA amplification was conducted according to the manufacturer’s protocol to construct expression libraries. Library size was checked using Agilent Bioanalyzer 2100 at the Stanford Genomics facility. The libraries were sequenced using Illumina HiSeq 4000.
Raw data processing
Cell Ranger v2.10 was used for processing and analysing the raw single cell FASTQ files. The following genome builds were used: mm10 for the mouse genome, hg19 for the human genome. Quality control (QC) steps that were taken to assess the quality of the sequencing data and to identify potential included: sample demultiplexing, read alignment and filtering, gene expression quantification, cell filtering and QC metrics, and data normalization and batch correction. The batch correction was performed with the Seurat base function “MergeSeurat”. 10,198 cells passed the QC when D0 SGBS and D0 3T3-L1 cells were analysed, compared to 6,785 cells when D5 3T3-L1 and D8 SGBS cells were analysed. Only reads mapping to mm10 or hg19 were used for downstream processing. Genome mapping was used to assign each cell as either human or mouse.
Bioinformatic analysis of scRNA-Seq data
Seurat v4.321 was used to merge processed data for two single-cell sequencing runs, combining sequencing data from different stages of adipocyte differentiation. The data was first split between human and mouse data, pre-processed using Seurat, then log normalized. The major variable features within the processed data were identified using Variance Stabilizing Transformation. The gene matrix was then visualized and analysed using principal component analysis (PCA), with gene associations to each principal component displayed. Seurat’s FindNeighbors and FindClusters functions (resolution = 0.09) were used to identify groups within the samples. The data were further visualized via the PCA, Uniform Manifold Approximation and Projection (UMAP), and t-distributed Stochastic Neighbor Embedding (t-SNE) dimensional reduction techniques. Seurat’s FindAllMarkers function identified genes specific to each cluster, with previous annotations indicating that genes were clustered by stages in cell differentiation. Feature plots for specific differentiation features were visualized in a t-SNE plot and through heatmaps for each cluster using Seurat’s DoHeatMap and FeaturePlot functions. Pseudotime analysis was performed using the Slingshot package in R to visualize the cell differentiation process. To visualize the overlap in cell markers between human and mouse cells, the Euler package was used to generate a Venn diagram.
Data Records
Sequencing data have been submitted to the NCBI Gene Expression Omnibus (GSE226365)22. The dataset consists of raw sequencing data in FASTQ format, separated by the time point: D0 3T3-L1 and D0 SGBS (GSM7073976) and D5 3T3-L1 and D8 SGBS (GSM7073977). In addition, we provide processed data, separated by time point and cell line, including barcodes.tsv, genes.tsv and matrix.mtx files, listing raw UMI counts for each gene (feature) in each cell (barcode) in a sparse matrix format as supplementary files. R Data files for processed Seurat data objects, gene marker tables, and quality control summaries can be found in the GEO submission22 and on the github repository.
Technical Validation
To validate the quality of our data, we investigated the technical quality and the unsupervised clustering and its reproducibility between the two datasets.
Quality control of the scRNA-Seq dataset
Interpretation of single-cell transcriptomics data is highly sensitive to technical artifacts. Sequencing data alignment using Cell Ranger led to the identification of comparable numbers of human and mouse cells within each of the analysed time points, as expected (Fig. 2a,b, Table 1). We used further steps to filter cells, removing any multiplets and cells with fewer than 200 genes detected (Fig. 2c,d, Table 2).

Single-cell RNA-Seq dataset quality assessment following inferring the species from transcriptome. (a,b) Plots representing quantification of the alignment of individual cell’s transcriptomes to the human (hg19) and mouse (mm10) genomes at (a) D0 3T3-L1/D0 SGBS, and (b) D5 3T3-L1/D8 SGBS. (c,d) Violin plots of gene counts (nFeature_RNA) and UMI counts (nCount_RNA) after quality control filtering in (c) SGBS cells and (d) 3T3-L1 cells, separated by the day of differentiation.
Annotation of cell subpopulations
Adipogenesis is a highly heterogeneous process, and we expected the addition of differentiation stimuli to result in the appearance of additional cell states compared to D0 of differentiation, prior to the exposure to differentiation media. In fact, for both 3T3-L1 and SGBS cells we identified three cell clusters whose transcriptional profiles suggest they are preadipocytes, differentiating cells and adipocytes, which is supported by the pseudotime analysis (Figs. 3a–c, 4a–c). Furthermore, in both cell models there was a clear separation of cells isolated at D0, which corresponded to the preadipocyte clusters, and cells isolated after the induction of adipogenesis (D5 in 3T3-L1, D8 in SGBS), which corresponded to the other clusters (Figs. 3d,e, 4d,e). Our scRNA-Seq dataset includes cells collected at two separate timepoints and processed independently, therefore we cannot rule out the presence of a batch effect contributing to the separation of D0 cells from later time points, which is a limitation of this study. However, analysis of the genes enriched in the identified cell clusters supports the view that the treatment with differentiation media affects the transcriptome, regardless of whether the cells fully differentiate, resulting in the differences between the clusters at D0 and D5/D8. In particular, adipogenesis is associated with major changes in the composition of the extracellular matrix (ECM) components. In line with previously published work, the preadipocyte cluster in SGBS cells showed enrichment in the expression of claudin 11 (CLDN11)23, and the clusters containing differentiating cells both in SGBS and 3T3-L1 models showed an enrichment of the expression of collagen type III alpha 1 chain (COL3A1, Col3a1) which is associated with adipogenic differentiation24. Furter, adipocyte markers fatty acid binding protein 4 (FABP4)25,26, adiponectin (ADIPOQ)27, and perilipin 4 (PLIN4)28 were identified in the SGBS adipocyte cluster and Fabp425,26, lipoprotein lipase (Lpl)29, and resistin (Retn)30 were identified in the 3T3-L1 adipocyte cluster (Figs. 3f, 4f, 5–7, Table 3). Full list of marker genes is provided as a.csv file with the GEO submission (#GSE226365)22.

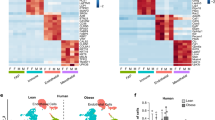
Clustering of scRNA-Seq data in human SGBS cells. (a) Primary component analysis (PCA) plot. (b) UMAP plot. (c) Pseudotime analysis. (d) t-SNE plot. (e) Assignment of cells by differentiation day (D0 vs. D8), superimposed on the t-SNE plot. (f) Heatmap showing the expression of top 10 enriched genes per cell cluster.

Clustering of scRNA-Seq data in murine 3T3-L1 cells. (a) Primary component analysis (PCA) plot. (b) UMAP plot. (c) Pseudotime analysis. (d) t-SNE plot. (e) Assignment of cells by differentiation day (D0 vs. D5), superimposed on the t-SNE plot. (f) Heatmap showing the expression of top 10 enriched genes per cell cluster.

Feature plots showing the expression of cluster marker genes for individual clusters in human SGBS cells. (a) Cluster 0 (preadipocytes); (b) Cluster 1 (differentiating); (c) Cluster 2 (adipocytes).

Feature plots showing the expression of cluster marker genes for individual clusters in mouse 3T3-L1 cells. (a) Cluster 0 (preadipocytes); (b) Cluster 1 (differentiating); (c) Cluster 2 (adipocytes).

Venn diagram representation of the number of unique and shared marker genes between SGBS and 3T3-L1 cell lines, separated by cell cluster.
Code availability
All analytical code used for processing and technical validation is available on the GitHub Repository (https://github.com/christopherjin/SGBS_3T3-L1_differentiation_scRNASeq). The provided R code was run and tested using R 4.2.2.
References
Scheja, L. & Heeren, J. The endocrine function of adipose tissues in health and cardiometabolic disease. Nat. Rev. Endocrinol. 15, 507–524 (2019).
Frayn, K., Karpe, F., Fielding, B., Macdonald, I. & Coppack, S. Integrative physiology of human adipose tissue. Int. J. Obes. Relat. Metab. Disord. 27, 875–888 (2003).
Tang, W. et al. White fat progenitor cells reside in the adipose vasculature. Science 322, 583–586 (2008).
Smith, U. & Kahn, B. B. Adipose tissue regulates insulin sensitivity: role of adipogenesis, de novo lipogenesis and novel lipids. J. Intern. Med. 280, 465–475 (2016).
Mackall, J., Student, A., Polakis, S. E. & Lane, M. Induction of lipogenesis during differentiation in a” preadipocyte” cell line. J. Biol. Chem. 251, 6462–6464 (1976).
Wabitsch, M. et al. Characterization of a human preadipocyte cell strain with high capacity for adipose differentiation. Int. J. Obes. Relat. Metab. Disord. 25, 8–15 (2001).
Tews, D. et al. 20 Years with SGBS cells-a versatile in vitro model of human adipocyte biology. Int. J. Obes. (Lond) 46, 1939–1947 (2022).
Kuri‐Harcuch, W., Velez‐delValle, C., Vazquez‐Sandoval, A., Hernández‐Mosqueira, C. & Fernandez‐Sanchez, V. A cellular perspective of adipogenesis transcriptional regulation. J. Cell Physiol. 234, 1111–1129 (2019).
Park, B. O., Ahrends, R. & Teruel, M. N. Consecutive positive feedback loops create a bistable switch that controls preadipocyte-to-adipocyte conversion. Cell Rep. 2, 976–990 (2012).
Allott, E. H. et al. The SGBS cell strain as a model for the in vitro study of obesity and cancer. Clin. Transl. Oncol. 14, 774–782 (2012).
Vijay, J. et al. Single-cell analysis of human adipose tissue identifies depot-and disease-specific cell types. Nat. Metab. 2, 97–109 (2020).
Hildreth, A. D. et al. Single-cell sequencing of human white adipose tissue identifies new cell states in health and obesity. Nat. Immunol. 22, 639–653 (2021).
Hepler, C. et al. Identification of functionally distinct fibro-inflammatory and adipogenic stromal subpopulations in visceral adipose tissue of adult mice. Elife 7, e39636 (2018).
Schwalie, P. C. et al. A stromal cell population that inhibits adipogenesis in mammalian fat depots. Nature 559, 103–108 (2018).
Emont, M. P. et al. A single-cell atlas of human and mouse white adipose tissue. Nature 603, 926–933 (2022).
van Harmelen, V., Skurk, T. & Hauner, H. Primary culture and differentiation of human adipocyte precursor cells. Human cell culture protocols, 125–135 (2005).
Church, C., Berry, R. & Rodeheffer, M. S. Isolation and study of adipocyte precursors. Methods in enzymology 537, 31–46 (2014).
Fink, T. & Zachar, V. Adipogenic differentiation of human mesenchymal stem cells. Methods Mol. Biol. 698, 243–251 (2011).
Bengestrate, L. et al. Genome-wide profiling of microRNAs in adipose mesenchymal stem cell differentiation and mouse models of obesity. PLoS One 6, e21305 (2011).
Godwin, L. A. et al. A microfluidic interface for the culture and sampling of adiponectin from primary adipocytes. Analyst 140, 1019–1025 (2015).
Hao, Y. et al. Integrated analysis of multimodal single-cell data. Cell 184, 3573–3587 (2021).
Li, J., Jin, L., Bielczyk-Maczynska, E. & Knowles, J. W. GEO. https://identifiers.org/geo/GSE226365 (2023).
Ullah, M., Sittinger, M. & Ringe, J. Extracellular matrix of adipogenically differentiated mesenchymal stem cells reveals a network of collagen filaments, mostly interwoven by hexagonal structural units. Matrix Biol. 32, 452–465 (2013).
Al Hasan, M., Martin, P. E., Shu, X., Patterson, S. & Bartholomew, C. Type III collagen is required for adipogenesis and actin stress fibre formation in 3T3-L1 preadipocytes. Biomolecules 11, 156 (2021).
Bernlohr, D. A., Angus, C. W., Lane, M. D., Bolanowski, M. A. & Kelly, T. Jr. Expression of specific mRNAs during adipose differentiation: identification of an mRNA encoding a homologue of myelin P2 protein. PNAS 81, 5468–5472 (1984).
Matarese, V. & Bernlohr, D. Purification of murine adipocyte lipid-binding protein. Characterization as a fatty acid-and retinoic acid-binding protein. J. Biol. Chem. 263, 14544–14551 (1988).
Hu, E., Liang, P. & Spiegelman, B. M. AdipoQ Is a Novel Adipose-specific Gene Dysregulated in Obesity. J. Biol. Chem. 271, 10697–10703 (1996).
Wolins, N. E. et al. Adipocyte protein S3-12 coats nascent lipid droplets. J. Biol. Chem. 278, 37713–37721 (2003).
Semenkovich, C., Wims, M., Noe, L., Etienne, J. & Chan, L. Insulin regulation of lipoprotein lipase activity in 3T3-L1 adipocytes is mediated at posttranscriptional and posttranslational levels. J. Biol. Chem. 264, 9030–9038 (1989).
Steppan, C. M. et al. The hormone resistin links obesity to diabetes. Nature 409, 307–312 (2001).
Chan, S. S., Schedlich, L. J., Twigg, S. M. & Baxter, R. C. Inhibition of adipocyte differentiation by insulin-like growth factor-binding protein-3. Am. J. Physiol. Endocrinol. Metab. 296, E654–E663 (2009).
Quinkler, M., Bujalska, I. J., Tomlinson, J. W., Smith, D. M. & Stewart, P. M. Depot-specific prostaglandin synthesis in human adipose tissue: a novel possible mechanism of adipogenesis. Gene 380, 137–143 (2006).
Ambele, M. A., Dessels, C., Durandt, C. & Pepper, M. S. Genome-wide analysis of gene expression during adipogenesis in human adipose-derived stromal cells reveals novel patterns of gene expression during adipocyte differentiation. Stem Cell Res. 16, 725–734 (2016).
Song, N.-J. et al. Small molecule-induced complement factor D (Adipsin) promotes lipid accumulation and adipocyte differentiation. PLoS One 11, e0162228 (2016).
Morales, L. D. et al. Further evidence supporting a potential role for ADH1B in obesity. Sci. Rep. 11, 1932 (2021).
Christy, R. et al. Differentiation-induced gene expression in 3T3-L1 preadipocytes: CCAAT/enhancer binding protein interacts with and activates the promoters of two adipocyte-specific genes. Genes Dev. 3, 1323–1335 (1989).
Yang, X. et al. The G0/G1 switch gene 2 regulates adipose lipolysis through association with adipose triglyceride lipase. Cell Metab. 11, 194–205 (2010).
Anand, A. & Chada, K. In vivo modulation of Hmgic reduces obesity. Nat. Genet. 24, 377–380 (2000).
Watanabe, T. et al. Annexin A3 as a negative regulator of adipocyte differentiation. J. Biochem. 152, 355–363 (2012).
Hung, S.-C., Chang, C.-F., Ma, H.-L., Chen, T.-H. & Ho, L. L.-T. Gene expression profiles of early adipogenesis in human mesenchymal stem cells. Gene 340, 141–150 (2004).
Li, C. et al. Matrix Gla protein regulates adipogenesis and is serum marker of visceral adiposity. Adipocyte 9, 68–76 (2020).
Kansara, M. S., Mehra, A. K., Von Hagen, J., Kabotyansky, E. & Smith, P. J. Physiological concentrations of insulin and T3 stimulate 3T3-L1 adipocyte acyl-CoA synthetase gene transcription. Am. J. Physiol. 270, E873–E881 (1996).
Acknowledgements
The authors would like to thank Dr. Erik Ingelsson for his support of this project. We acknowledge the technical assistance of the Stanford Genomics Service Center and the Stanford Shared FACS Facility. E.B.M. was supported by the American Heart Association (AHA) postdoctoral fellowship (18POST34030448). T.Q. was supported by R01HL134817, R01HL139478, R01HL156846, R01HL151535, R01HL145708, UM1 HG011972 from the NIH, as well as by a Human Cell Atlas grant from the Chan Zuckerberg Foundation. J.W.K. was funded by NIH R01 DK116750, R01 DK120565, R01 DK106236, R01 DK107437, P30DK116074, and ADA 1-19-JDF-108.
Author information
Authors and Affiliations
Contributions
J.L. conceived the project, conducted experiments and analysed the data; C.J. conducted bioinformatic analyses, created figures and wrote the manuscript; S.G. assisted with bioinformatic analysis; A.R. assisted with bioinformatic analysis; M.W. provided critical resources for the project; C.Y.P. conceived the project and assisted with the experiments; T.Q. guided the bioinformatic analysis and critically reviewed the manuscript; E.B.M. analysed data, created figures and wrote the manuscript with the input from all the authors; J.W.K. oversaw the project and critically reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, J., Jin, C., Gustafsson, S. et al. Single-cell transcriptome dataset of human and mouse in vitro adipogenesis models. Sci Data 10, 387 (2023). https://doi.org/10.1038/s41597-023-02293-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-02293-x
