
Abstract
Estuaries are one of the most important coastal ecosystems. While microbiomes and viromes have been separately investigated in some estuaries, few studies holistically deciphered the genomes and connections of viruses and their microbial hosts along an estuarine salinity gradient. Here we applied deep metagenomic sequencing on microbial and viral communities in surface waters of the Pearl River estuary, one of China’s largest estuaries with strong anthropogenic impacts. Overall, 1,205 non-redundant prokaryotic genomes with ≥50% completeness and ≤10% contamination, and 78,502 non-redundant viral-like genomes were generated from samples of three size fractions and five salinity levels. Phylogenomic analysis and taxonomy classification show that majority of these estuarine prokaryotic and viral genomes are novel at species level according to public databases. Potential connections between the microbial and viral populations were further investigated by host-virus matching. These combined microbial and viral genomes provide an important complement of global marine genome datasets and should greatly facilitate our understanding of microbe-virus interactions, evolution and their implications in estuarine ecosystems.
Measurement(s) | bacteria • Archaea • viruses |
Technology Type(s) | Shotgun Sequencing |
Sample Characteristic - Organism | estuary metagenome |
Sample Characteristic - Environment | subtropical estuarine |
Sample Characteristic - Location | Pearl river estuary |
Machine-accessible metadata file describing the reported data: https://doi.org/10.6084/m9.figshare.17139998
Similar content being viewed by others
Background & Summary
Estuaries are transitional environments between ocean and river. Complex and dynamic estuarine ecosystems are distinguishable from oceanic environments by significant variety of physical, chemical and geomorphologic conditions1,2,3,4. These factors have structured a highly unique estuarine microbial and viral community5,6,7. In addition, most estuarine ecosystems are impacted by strong anthropogenic stresses1. Viruses play essential roles in marine ecosystems by mortality8,9 and reprogramming the metabolic processes of hosts10. There is a great interest to investigate the genomic characteristics, evolutionary mechanisms, community composition and interactions of microorganisms and viruses in coastal environments11,12. While the abundance, distribution and function of prokaryotes or viruses in estuaries have been reported by using meta-omics approaches13,14,15,16,17,18, few studies have investigated bacteria, archaea and viruses simultaneously and none has delineated the potential connections between the microbiome and the virome. Therefore, a holistic estuarine genome dataset recovering both microbiome and virome will allow the analysis of microbe-virus interactions in this unique ecosystem.
The Pearl River is the second largest river in China with an average annual discharge flux of about 3.5 × 1011 m3 fresh water and 8.87 × 107 tons suspended sediment19. Locating in the most densely industrialized and urbanized region in China, the Pearl River is heavily impacted by human activities including agricultural irrigation, industrial and domestic emissions and aquaculture20,21. While some ecological and genomic studies on the bacterial or viral communities at the Pearl River estuary (PRE) have been performed13,15,17, none of them has produced a combined dataset including both the microbial hosts and the viruses. Such a dataset is therefore urgently demanded to unveil the dynamic and diverse biological processes coupling with physiochemical factors at this estuary.
Here, we sequenced 15 deep-sequencing metagenomes of surface water with three size-fractions collected at five sampling sites along the salinity gradient of the PRE in August 2016 (Fig. 1a). Seawater was filtered through cellulose membranes subsequently. The 0.7–2.7 μm and 0.22–0.7 μm fractions were used to produce particle-attached and free-living prokaryotic metagenomes, respectively. To collect the viral fraction, surface water was prefiltered by using filters of 2.7 μm and 0.22 µm pore-size, subsequently, and then concentrated with 30 kilodalton (kDa) pore-size filters by using tangential-flow filtration. Further concentration and purification were done via polyethylene glycol (PEG) precipitation and cesium chloride (CsCl) step-gradient ultracentrifugation (Fig. 1b). DNA was extracted from the cellular (0.7–2.7 μm and 0.22–0.7 μm) and viral (<0.22 μm) fractions for metagenomic sequencing.

Sampling sites in the PRE and methods used for this study. (a) yellow dots represent the sampling sites. (b) the study workflow in processing PRE metagenome sequences.
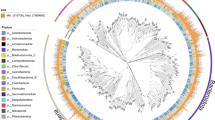
Overall, 13,305,017 contigs were generated by assembling quality checked sequencing reads (Table 1). A total of 1,205 non-redundant metagenome assembled genomes (MAGs) with the estimated completeness ≥50% and contamination ≤10% were reconstructed based on multi-strategy binning according to the MIMAG criteria22 (Supplementary Table 1). Phylogenomic analysis based on single-copy marker genes showed that these MAGs belonged to 32 bacterial and four archaeal phyla according to the Genome Taxonomy Database (GTDB) taxonomy23 (Fig. 2, 3). We found that 24.8% and 86.8% of total MAGs did not have close relatives at genus and species level based on 95% average nucleotide identity (ANI). A total of 78,502 non-redundant viral contigs were predicted from the cellular microbiomes (0.2–2.7 μm) and viromes (<0.2 μm). They were then clustered into 56,289 viral populations24,25,26. Taxonomic classification of viral populations was performed based on closest relative affiliation24 (Supplementary Table 2). Only 15.3% populations could be assigned according to the RefSeqVirus database leaving the rest majority unclassified. A total of 15 viral families were identified including ssDNA, dsDNA and ssRNA viruses and the primary group belongs to order Caudovirales (Table 2). Virus-host pair prediction was performed based on clustered regularly interspaced short palindromic repeats (CRISPR) -spacer matching and 11 virus-host pairs were identified (Fig. 4). Among them, an Acinetobacter junii and a Rickettsiales bacterium were found being infected by more than one type of virus.

Phylogenomic analysis of archaeal MAGs. The maximum likelihood tree was reconstructed based on the concatenation of 41 single copy marker genes spanning a set of 41 MAGs (in red) obtained in this study and a set of 163 reference genomes (in black). The number of MAGs discovered in this study in each phylum is indicated in the parenthesis after the phylum name. The bootstrap values >0.9 are shown as dots on nodes. The tree is unrooted. Source data are provided as a Source Data file.

Phylogenomic analysis of bacterial MAGs. The maximum likelihood tree was reconstructed based on the concatenation of 41 single copy markers. The number of MAGs discovered in this study in each phylum is indicated in the parenthesis after the phylum name. Number of MAGs from the PRE metagenomes in each phylum or class are indicated in between parenthesis in red. The bootstrap values >0.9 are shown as dots on nodes. The tree is unrooted. Source data are provided as a Source Data file.

Network analysis of virus-host pairs. The hollow circles represent the viruses. The solid circles represent the prokaryotic hosts. The colors indicate the phyla of the hosts.
All of the primary contigs, non-redundant MAGs and viral-like contigs have been deposited in the National Center for Biotechnology Information (NCBI) BioProject database and the figshare website. The microbial and viral genomes provided here suggest great biological diversity in the PRE ecosystems. This combined dataset allows for systematic study on microbial-virial interactions including the regulatory mechanisms of viruses in manipulating estuarine biogeochemistry under anthropogenic impacts.
Methods
Sampling, DNA extraction and sequencing
Bacterial, archaeal and viral sample collection and particle size-based fractionation was done by filtration27. To obtain the cellular fractions, about 500 L surface water (0.5–1.0 m in depth) was collected at each sampling site in PRE in August 2016 within three days (Fig. 1a, Table 3). The water samples were first filtered through 2.7 μm pore-size glass fiber filters (Shanghai Mosutech, Shanghai, China) to remove large particles and the filtrates were then successively filtered through 0.7 and 0.22 μm pore-size membrane filters (Pellicon cartridge, Millipore Corp., Billerica, MA, USA) to collect particulate associated and free-living microbial cells, respectively. The filters were stored in liquid nitrogen temporarily on board and then transferred to −80 °C freezers when back to laboratory for long-term storage until further processing. To collect viral particles, 200 L prefiltered seawater was further filtered through 2.7 μm and 0.2 μm pore-size membrane filters. A tangential-flow filtration 30 kDa cartridge was (0.5 m2 Pellicon cartridge, Millipore Corp., Billerica, MA, USA) applied to increase viral particle concentration till a final liquid volume of 2 L and the liquid was kept at 4 °C till further process28. Physiochemical measurements of water and the methods to generate these measurements have been published by He et al.23. The measurements are also available in Table 3.
DNA was extracted from the 0.2 and 0.7 μm pore-size membrane filters by using the FastDNA® SPIN kit for soil (MP Biomedicals, Solon, OH, USA) following the manufacturers’ instructions. For virome samples, a series of enrichment operations were applied to increase the concentration of the virial suspension28 (Fig. 1b). Firstly, PEG8000 (10% w/v) was dissolved in DNase I (Sigma-Aldrich) treated viral concentrate and incubated at 4 °C overnight to precipitate viral particles. The PEG pellet was resuspended after centrifugation (10, 000 × g for 1 h) and then purified by CsCl density gradient ultracentrifugation (1.7, 1.5, and 1.35 g/mL CsCl layers). After centrifugation, viral like particles was concentrated in 1.5–1.35 g/mL CsCl layers according to the physical properties of various virions. After collection and purification, a phenol-chloroform extraction following the ethanol precipitation method was applied to extract viral genomic DNA14,28.
The extracted prokaryotic and viral DNA were fragmented by sonication to a size of 350 bp. The DNA fragments were then end-polished, A-tailed, and ligated with the full-length adaptor to construct TruSeq metagenome libraries. Libraries were analyzed for size distribution using the Agilent2100 Bioanalyzer (Agilent, USA) and quantified using real-time PCR. They were then sequenced on an Illumina HiSeq 2500 platform at Novogene Bioinformatics Technology Co., Ltd. (Beijing, China) to generate 150 bp paired-end reads. The FASTQ files containing raw reads are available on NCBI. The overall study workflow is show in Fig. 1b.
Sequence quality check and assembly
The reads_qc module of MetaWRAP (v1.2.1)29 was applied for adaptor trimming and contamination removal for the raw sequencing reads to generate high-quality clean reads by calling Cutadapt30 and FastQC31 with the default parameters. Clean reads of the cellular fractions were assembled into contigs by using MetaWRAP employing megahit with k-mer values list of 21, 29, 39, 59, 79, 99, 119 and 14129. The IDBA-UD software (v1.1.3) was applied to assemble the viral metagenomes with default parameters32. Contigs of length longer than 1 kb were used for further analysis as suggested by the MIMAG and the MIUViG standards22,26 (Table 1).
MAG generation, refinement, quality check and taxonomic annotation
For each prokaryotic metagenome, MAGs were recovered by using the binning module and bin_refinement module of MetaWRAP29. First, the binning module of MetaWRAP employing METABAT33 and CONCOCT34 was applied to recover the original genome MAGs sets based on tetranucleotide frequencies and read coverage. These MAGs sets were pooled and dRep (v2.6.2) was performed to remove redundant MAGs35. The bin_refinement module of MetaWRAP was used to refine the MAGs to produce final MAGs. The completeness and contamination of archaeal and bacterial MAGs were estimated by running CheckM (v1.0.11)36 (Supplementary Table 1). Taxonomic classification of the final MAGs was conducted by using GTDB-tk (v1.3.0, Release 95)37 (Supplementary Table 1). MAGs are considered of the same species if they have ANI values larger than 95% by compared to a reference genome.
Phylogenomic analysis
We used 41 single-copy marker proteins to infer the maximum likelihood trees of archaeal and bacterial MAGs38,39, respectively. Specifically, putative coding DNA sequences for each draft genome were predicted by using Prodigal (v2.6.3; -m -p meta)40. Putative single copy genes of each MAGs were identified by using hmmsearch (HMMER v.3.1b2; -E 1E-5)41 based on Hidden Markov Models (HMMS) described by Sunagawa et al.39. Amino acid sequences of these genes were aligned, respectively, by using Clustal Omega (v1.2.4)42 and further automatically trimmed by using trimAL (v1.4.1; -automated1)43. The alignments of proteins were concatenated by using ScaFos (v1.2.5) and missing data were filled with gaps44. The phylogenomic tree of concatenated alignment was reconstructed by using IQ-TREE (v.2.0.3; -st AA -m LG + PMSF + G -B 1000 --bnni)45 and visualized in the Interactive Tree of Life (iTOL, v.5.1.1)46.
Viral contig identification, dereplication and taxonomic classification
Following assembly, putative viral contigs were identified from contigs of all the three size fractions with length greater than 1.5 kb by using VirSorter (v1.0.6)47 and VirFinder (v1.1)48 as described by Gregory et al.24. First, contigs identified as ‘lytic/prophage categories 1 and 2′ and ‘circular’ by VirSorter were assigned as viral contigs. The rest contigs of length >5 kb were kept for further classification. Among them, those identified as ‘lytic/prophage categories 1,2′ by VirSorter, or as viruses by VirFinder with score >0.9 (p < 0.05) were assigned as viral contigs. Those identified as ‘lytic/prophage category 3′ by VirSorter and as viruses by VirFinder with score 0.7–0.9 (p < 0.05) were also assigned as viral contigs. Those identified as ‘lytic/prophage category 3’ by VirSorter but not as viruses by VirFinder with score >0.7 (p < 0.05), and those identified as viruses by VirFinder with score 0.7–0.9 (p < 0.05) but not as ‘lytic/prophage categories 1–3’ by VirSorter were further analyzed through CAT49 and only those having 40% genes classified as viruses were kept. In total, 97,003 viral contigs were identified. Redundancy of these contig sequences was removed by using CD-HIT at 99% identity (v4.6.8, −c 0.99 −aS 0.99)50. The resulting 78,502 non-redundant viral contigs were further grouped into 56,289 viral populations by using nucmer based on the criterion that virial contigs in the same population share 80% of their genes and have 95% average nucleotide identify as previously described51,52 (Fig. 1b). CheckV (v0.8.1) was used to determine the completeness and quality of the identified viral populations53 (Supplementary Table 3). We used VirSorter to identify prophages by the de novo predictions of categories 4 and 547.
Taxonomic classification of viral populations was performed with a complementary approach by using vConTACT254 and blastp55. First, the ORFs of each population were derived by using prodigal40. Second, the protein sequences of population contigs >10 kb were analyzed by using vConTACT2 with Viral RefSeq release 201 based on genome gene-sharing profiles. Then, family level taxonomy of the remaining population including those that could not be assigned by vConTACT2 were further defined by closest relative affiliation using blastp against the Viral RefSeq database with the following principle: identity ≥30%, bit-score ≥50, and E value ≤0.001. Only the population with more than half of proteins assigned to the same viral family was considered as a viral family (Supplementary Table 2).
Host prediction of viral sequences
In order to link viral contigs to their putative microbial hosts, CRISPR spacers in MAGs were identified by using CRISPRDetect (v2.5)56. Spacer sequences were then matched to viral contigs by using fuzznuc57. Host and virus infection networks were reconstructed in Cytoscape (v3.8.0)58.
Data Records
Raw reads generated in this study have been deposited in the National Center for Biotechnology Information BioProject database with the project ID PRJNA76304359. Contigs, MAGs, viral genomes and source data files including the genome trees and associated amino acid alignments have been deposited in the figshare website60. A full copy of this dataset is also available in the National Omics Data Encyclopedia (https://www.biosino.org/node/) with the project ID OEP00166261.
Technical Validation
Additional technical validation should be applied by researchers to confirm the accuracy of draft MAGs and VAGs used for specific downstream purposes.
Code availability
All versions of third-party software and scripts used in this study are described and referenced accordingly in the Methods sub-sections for ease of access and reproducibility.
References
Best, J. Anthropogenic stresses on the world’s big rivers. Nat. Geosci. 12, 7–21 (2018).
Carvalho, T. M. & Fidelis, T. The relevance of governance models for estuary management plans. Land Use Policy 34, 134–145 (2013).
Zapata, C., Puente, A., Garcia, A., Garcia-Alba, J. & Espinoza, J. Assessment of ecosystem services of an urbanized tropical estuary with a focus on habitats and scenarios. PLoS One 13, e0203927 (2018).
Campbell, B. J. & Kirchman, D. L. Bacterial diversity, community structure and potential growth rates along an estuarine salinity gradient. ISME J. 7, 210–220 (2013).
Sun, M. et al. Uncultivated viral populations dominate estuarine viromes on the spatiotemporal scale. mSystems 6, e01020–20 (2021).
Liu, L., Cai, L. & Zhang, R. Co-existence of freshwater and marine T4-like myoviruses in a typical subtropical estuary. FEMS Microbiol. Ecol. 93 (2017).
Xie, W. et al. Localized high abundance of Marine Group II archaea in the subtropical Pearl River Estuary: implications for their niche adaptation. Environ. Microbiol. 20, 734–754 (2018).
Chen, X., Ma, R., Yang, Y., Jiao, N. & Zhang, R. Viral regulation on bacterial community impacted by lysis-lysogeny switch: a microcosm experiment in eutrophic coastal waters. Front. Microbiol. 10, 1763 (2019).
Manea, E. et al. Viral infections boost prokaryotic biomass production and organic C cycling in hadal trench sediments. Front. Microbiol. 10, 1952 (2019).
Warwick-Dugdale, J., Buchholz, H. H., Allen, M. J. & Temperton, B. Host-hijacking and planktonic piracy: how phages command the microbial high seas. Virol. J. 16, 15 (2019).
Tyson, G. W. et al. Community structure and metabolism through reconstruction of microbial genomes from the environment. Nature 428, 37–43 (2004).
Anantharaman, K. et al. Thousands of microbial genomes shed light on interconnected biogeochemical processes in an aquifer system. Nat. Commun. 7, 13219 (2016).
Ni, Z., Huang, X. & Zhang, X. Picoplankton and virioplankton abundance and community structure in Pearl River Estuary and Daya Bay, South China. J. Environ. Sci. (China) 32, 146–154 (2015).
Cai, L., Zhang, R., He, Y., Feng, X. & Jiao, N. Metagenomic analysis of virioplankton of the subtropical Jiulong River estuary, China. Viruses 8, 35 (2016).
Zhang, C. et al. The communities and functional profiles of virioplankton along a salinity gradient in a subtropical estuary. Sci. Total Environ. 759, 143499 (2021).
Liu, Y. et al. Differences in metabolic potential between particle-associated and free-living bacteria along Pearl River Estuary. Sci. Total Environ. 728, 138856 (2020).
Fortunato, C. S. & Crump, B. C. Microbial gene abundance and expression patterns across a river to ocean salinity gradient. PLoS One 10, e0140578 (2015).
Natascha, S. & Meinhard, S. Composition and dynamics of particle-associated and free-living bacterial communities in the Weser estuary, Germany. Aquat. Microb. Ecol. 30, 221–237 (2003).
Zhang, J. et al. The subtropical Zhujiang (Pearl River) Estuary: Nutrient, trace species and their relationship to photosynthesis. Estuarine Coastal and Shelf Science 49, 385–400 (1999).
Li, Y. et al. Distribution, seasonality, and fluxes of dissolved organic matter in the Pearl River (Zhujiang) estuary, China. Biogeosciences 16, 2751–2770 (2019).
Peng, X. et al. Persistence, temporal and spatial profiles of ultraviolet absorbents and phenolic personal care products in riverine and estuarine sediment of the Pearl River catchment, China. J. Hazard Mater. 323, 139–146 (2017).
Bowers, R. M. et al. Minimum information about a single amplified genome (MISAG) and a metagenome-assembled genome (MIMAG) of bacteria and archaea. Nat. Biotechnol. 35, 725–731 (2017).
He, C. et al. Molecular composition and spatial distribution of dissolved organic matter (DOM) in the Pearl River Estuary, China. Environ. Chem. 17, 240–251 (2020).
Gregory, A. C. et al. Marine DNA viral macro- and microdiversity from pole to pole. Cell 177, 1109–1123 e1114 (2019).
Roux, S., Emerson, J. B., Eloe-Fadrosh, E. A. & Sullivan, M. B. Benchmarking viromics: an in silico evaluation of metagenome-enabled estimates of viral community composition and diversity. PeerJ. 5, e3817 (2017).
Roux, S. et al. Minimum information about an uncultivated virus genome (MIUViG). Nat. Biotechnol. 37, 29–37 (2019).
Karsenti, E. et al. A holistic approach to marine eco-systems biology. PLoS Biol. 9, e1001177 (2011).
Thurber, R. V., Haynes, M., Breitbart, M., Wegley, L. & Rohwer, F. Laboratory procedures to generate viral metagenomes. Nat. Protoc. 4, 470–483 (2009).
Uritskiy, G. V., DiRuggiero, J. & Taylor, J. MetaWRAP-a flexible pipeline for genome-resolved metagenomic data analysis. Microbiome 6, 158 (2018).
Martin, M. Cutadapt removes adapter sequences from high-throughput sequencing reads. EMBnet. J. 17, 10–12 (2011).
Brown, J., Pirrung, M. & McCue, L. A. FQC Dashboard: integrates FastQC results into a web-based, interactive, and extensible FASTQ quality control tool. Bioinformatics 33, 3137–3139 (2017).
Peng, Y., Leung, H. C., Yiu, S. M. & Chin, F. Y. IDBA-UD: a de novo assembler for single-cell and metagenomic sequencing data with highly uneven depth. Bioinformatics 28, 1420–1428 (2012).
Kang, D. D. et al. MetaBAT 2: an adaptive binning algorithm for robust and efficient genome reconstruction from metagenome assemblies. PeerJ. 7, e7359 (2019).
Alneberg, J. et al. Binning metagenomic contigs by coverage and composition. Nat. Methods 11, 1144–1146 (2014).
Olm, M. R., Brown, C. T., Brooks, B. & Banfield, J. F. dRep: a tool for fast and accurate genomic comparisons that enables improved genome recovery from metagenomes through de-replication. ISME J. 11, 2864–2868 (2017).
Parks, D. H., Imelfort, M., Skennerton, C. T., Hugenholtz, P. & Tyson, G. W. CheckM: assessing the quality of microbial genomes recovered from isolates, single cells, and metagenomes. Genome Res. 25, 1043–1055 (2015).
Chaumeil, P. A., Mussig, A. J., Hugenholtz, P. & Parks, D. H. GTDB-Tk: a toolkit to classify genomes with the genome taxonomy database. Bioinformatics 36, 1925–1927 (2019).
Martinez-Gutierrez, C. A. & Aylward, F. O. Phylogenetic signal, congruence, and uncertainty across bacteria and archaea. Mol. Biol. Evol, msab254 (2021).
Sunagawa, S. et al. Metagenomic species profiling using universal phylogenetic marker genes. Nat. Methods 10, 1196–1199 (2013).
Hyatt, D. et al. Prodigal: prokaryotic gene recognition and translation initiation site identification. BMC Bioinform. 11, 119 (2010).
Finn, R. D., Clements, J. & Eddy, S. R. HMMER web server: interactive sequence similarity searching. Nucleic Acids Res. 39, W29–37 (2011).
Sievers, F. & Higgins, D. G. in Multiple Sequence Alignment Methods (ed. Russell, D. J.). Ch. 6, 105–116 (Humana Press, 2014).
Capella-Gutierrez, S., Silla-Martinez, J. M. & Gabaldon, T. trimAl: a tool for automated alignment trimming in large-scale phylogenetic analyses. Bioinformatics 25, 1972–1973 (2009).
Roure, B., Rodriguez-Ezpeleta, N. & Philippe, H. SCaFoS: a tool for selection, concatenation and fusion of sequences for phylogenomics. BMC Evol. Biol. 7(1), 1–12 (2007).
Minh, B. Q. et al. IQ-TREE 2: New models and efficient methods for phylogenetic inference in the genomic era. Mol. Biol. Evol. 37, 1530–1534 (2020).
Letunic, I. & Bork, P. Interactive Tree Of Life (iTOL) v5: an online tool for phylogenetic tree display and annotation. Nucleic Acids Res. 49, W293–W296 (2021).
Roux, S., Enault, F., Hurwitz, B. L. & Sullivan, M. B. VirSorter: mining viral signal from microbial genomic data. PeerJ. 3, e985 (2015).
Ren, J., Ahlgren, N. A., Lu, Y. Y., Fuhrman, J. A. & Sun, F. VirFinder: a novel k-mer based tool for identifying viral sequences from assembled metagenomic data. Microbiome 5, 69 (2017).
von Meijenfeldt, F. A. B., Arkhipova, K., Cambuy, D. D., Coutinho, F. H. & Dutilh, B. E. Robust taxonomic classification of uncharted microbial sequences and bins with CAT and BAT. Genome Biol. 20, 217 (2019).
Fu, L., Niu, B., Zhu, Z., Wu, S. & Li, W. CD-HIT: accelerated for clustering the next-generation sequencing data. Bioinformatics 28, 3150–3152 (2012).
Brum, J. R. et al. Ocean plankton. Patterns and ecological drivers of ocean viral communities. Science 348, 1261498 (2015).
Kurtz, S. et al. Versatile and open software for comparing large genomes. Genome Biol. 5, R12 (2004).
Nayfach, S. et al. CheckV assesses the quality and completeness of metagenome-assembled viral genomes. Nat. Biotechnol. 39, 578–585 (2021).
Bin Jang, H. et al. Taxonomic assignment of uncultivated prokaryotic virus genomes is enabled by gene-sharing networks. Nat. Biotechnol. 37, 632–639 (2019).
Altschul, S. F., Gish, W., Miller, W., Myers, E. W. & Lipman, D. J. Basic local alignment search tool. J. Mol. Biol. 215, 403–410 (1990).
Biswas, A., Staals, R. H., Morales, S. E., Fineran, P. C. & Brown, C. M. CRISPRDetect: A flexible algorithm to define CRISPR arrays. BMC Genomics. 17, 356 (2016).
Rice, P., Longden, I. & Bleasby, A. EMBOSS: the european molecular biology open software suite. Trends Genet. 16, 276–277 (2000).
Shannon, P. et al. Cytoscape: a software environment for integrated models of biomolecular interaction networks. Genome Res. 13, 2498–2504 (2003).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRP337539 (2021).
Xu, B. et al. Pearl river estuary microbiome and virome. figshare https://doi.org/10.6084/m9.figshare.16618255.v7 (2021).
National Omics Data Encyclopedia https://www.biosino.org/node/project/detail/OEP001662 (2021).
Acknowledgements
This study was supported by National Natural Science Foundation of China (Nos. 91951120, 91851210, 42141003), the State Key R&D Project of China Grant (No. 2018YFA0605800), the Shenzhen Key Laboratory of Marine Archaea Geo-Omics, Southern University of Science and Technology (ZDSYS201802081843490), the Southern Marine Science and Engineering Guangdong Laboratory (Guangzhou) (No. K19313901), and the Project of Educational Commission of Guangdong Province of China (No. 2020KTSCX123). Computation in this study was supported by the Centre for Computational Science and Engineering at the Southern University of Science and Technology.
Author information
Authors and Affiliations
Contributions
R.Z., L.F. and C.Z. conceived this study. B.X., F.L. and L.C. collected the samples and extracted DNA. B.X. analyzed the metagenome data, produced the genomes and conducted all other analyses. B.X., R.Z., L.F. and C.Z. interpreted the results and drafted the manuscript. All authors contributed to the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files associated with this article.
About this article

Cite this article
Xu, B., Li, F., Cai, L. et al. A holistic genome dataset of bacteria, archaea and viruses of the Pearl River estuary. Sci Data 9, 49 (2022). https://doi.org/10.1038/s41597-022-01153-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-022-01153-4
This article is cited by
-
Trait biases in microbial reference genomes
Scientific Data (2023)
-
Ecophysiology and genomics of the brackish water adapted SAR11 subclade IIIa
The ISME Journal (2023)
-
Mining of novel secondary metabolite biosynthetic gene clusters from acid mine drainage
Scientific Data (2022)
