
Abstract
Nerve sheath tumors occur as a heterogeneous group of neoplasms in patients with neurofibromatosis type 1 (NF1). The malignant form represents the most common cause of death in people with NF1, and even when benign, these tumors can result in significant disfigurement, neurologic dysfunction, and a range of profound symptoms. Lack of human tissue across the peripheral nerve tumors common in NF1 has been a major limitation in the development of new therapies. To address this unmet need, we have created an annotated collection of patient tumor samples, patient-derived cell lines, and patient-derived xenografts, and carried out high-throughput genomic and transcriptomic characterization to serve as a resource for further biologic and preclinical therapeutic studies. In this work, we release genomic and transcriptomic datasets comprised of 55 tumor samples derived from 23 individuals, complete with clinical annotation. All data are publicly available through the NF Data Portal and at http://synapse.org/jhubiobank.
Measurement(s) | gene expression • gene_variant |
Technology Type(s) | RNA sequencing • exome sequencing • DNA sequencing |
Factor Type(s) | tumor type |
Sample Characteristic - Organism | Homo sapiens • Homo sapiens/Mus musculus xenograft |
Machine-accessible metadata file describing the reported data: https://doi.org/10.6084/m9.figshare.12037599
Similar content being viewed by others
Background & Summary
Neurofibromatosis type 1 (NF1) is a common neuro-genetic condition caused by mutations in the NF1 gene. It is characterized by a predisposition to the development of nerve sheath tumors, including cutaneous neurofibromas (cNF), plexiform neurofibromas (pNF), and malignant peripheral nerve sheath tumors (MPNST). Up to 50% of patients with NF1 develop pNF, and 55% of pNF in childhood are symptomatic, resulting in either pain, nerve or organ dysfunction or disfigurement1. Currently, surgery is the only treatment option for patients with NF1 who have symptomatic pNF. Progress in the development of nonsurgical therapy for pNF has been limited by a number of factors including: the lack of pNF specific cell culture-based2,3 and animal models4, and limited access to primary tissue from patients with NF1. Although progress is being made in the development and utilization of animal models and cell culture models5, the limited availability of primary patient tissue remains unaddressed.
To address this gap, we established a local biospecimen repository for the purpose of (1) banking blood fractions and tumor tissue from patients with NF1 undergoing surgical resection of cNF, pNF and/or MPNST at Johns Hopkins Hospital; (2) generating xenograft and cell line models to propagate primary human tissue and cells (3) creating the required infrastructure that supports the sharing of data and tissue resources with the scientific community. The biospecimen repository includes tissue, buffy coat, plasma and serum from patients with NF1 who are undergoing surgical removal of a lesion including, but not limited to, a cNF, diffuse superficial infiltrating neurofibromas, pNF, atypical neurofibromatous neoplasms of uncertain biologic potential (ANNUBP), and MPNST. Each tissue sample has an associated clinical data set and appropriate consent has been obtained to allow sharing of tissue for NF1 research within and outside of Johns Hopkins.
The Johns Hopkins Comprehensive Neurofibromatosis Center (JHCNC) serves a large volume of people with NF1. In concert with the JHCNC, our lab has successfully banked specimens from these patients when they are undergoing surgery, and created and maintained a fully annotated clinical database. All banking procedures are conducted as outlined by the NCI Best Practices6. Specimens are processed and implanted in mice quickly to minimize ischemia time, accurate identification of specimens is ensured by our practices, and all tumor specimens removed from different anatomical locations or different locations within the same tumor or patient are clearly identified and labeled (Fig. 1).

Overview of the Johns Hopkins University NF1 biospecimen repository.
We have leveraged our unique resources, including (1) one of the busiest NF clinics in the country, with specialized physicians and surgeons invested in the process of tissue collection and banking; (2) our expertise in tissue acquisition, handling, and xenograft production, and (3) the comprehensive data-sharing framework of the NF Data Portal7, to establish a key resource and enable sharing of the data generated with the NF1 research community. Currently, we are accruing samples from about twenty patients per year, and expect ongoing accrual at this rate for the foreseeable future.
Herein, we describe the data generated from the tissue bank and shared through the NF Data Portal. We sequenced DNA and/or RNA across 55 tumors from 23 unique patients, as well as any cell lines or xenografts derived from these patient samples. We also sequenced DNA of patient blood cells to include non-tumor (control) genomic data to facilitate downstream analysis. These data are a valuable resource for the NF research community that complements previous NF tumor characterization efforts8,9. All data are available to qualified researchers via the NF Data Portal to encourage biological exploration and identification of drug targets in NF1.
Methods
The generation of these data was a close collaboration between the physicians at Johns Hopkins Hospital, the staff of the JH NF1 biospecimen repository, and Sage Bionetworks.
Patient enrollment
All human subjects research was conducted according to widely accepted practice and under a Johns Hopkins Hospital (JHH) institutional review board (IRB)-approved protocol.
Patients with neurofibromatosis (NF1) having a clinically-indicated surgical resection or biopsy of a NF1-associated tumor (cNF, superficial diffuse infiltrating neurofibroma, pNF, ANNUBP, MPNST) were identified through the review of surgical schedules and communication from the clinical team to the research team at JHH. Patients were reviewed for study eligibility, and then written informed consent was obtained. The JHH IRB-approved consent form includes a description of the voluntary nature of the research and a description of clinical data that will be collected as well as the plan for genetic and genomic analyses and sharing of data. Blood was collected from the majority of patients on the day of surgery.
After successful collection of tumor tissue, the patient’s medical record was reviewed for pertinent demographic information and information related to their NF1 diagnosis (genomic findings, family history, age of diagnosis), characteristics (phenotypic findings, symptoms), and tumor burden (number and size of NF1-associated tumors). These clinical data were stored in a password protected and de-identified database.
Tumor preservation and quality control
Surgical specimens were couriered to surgical pathology immediately after resection either in saline or in a dry sterile collection cup. The study neuropathologist performed immediate inspection of the tumor to ensure that the sample contained adequate tumor tissue for clinical diagnostic needs. Upon approval, tumor pieces were sampled for banking and transported to the research laboratory in isotonic cell culture medium (RPMI with 20% FBS, supplemented with 1% penicillin-streptomycin and glutamine, PSG).
Specimens were sized into 5–10 mm aliquots under sterile conditions in a biosafety cabinet. Individual aliquots were placed into 10% neutral buffered formalin, cell freezing media (Sigma: C6295), and/or placed into an empty vial and snap frozen on dry ice.
All aliquots were stored with barcoded labels for tracking purposes. Specimens collected from pathologically heterogeneous tumors were embedded in O.C.T. compound (Optimal Cutting Temperature Compound, Fisher Sci 23–730–571) and sectioned into 5 μm sections. One slide from each individual aliquot was reviewed by the study pathologist to confirm histologic diagnosis not only of the tumor as a whole, but that tissue representation and quality was adequate per aliquot.
Cell culture
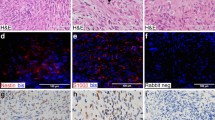
A tumor aliquot was mechanically dissociated into a cell suspension in a sterile petri dish filled with supplemented cell culture medium (RPMI, 20% FBS, 1% PSG) using a sterile scalpel. Dissociated cells in culture medium were placed into 75 cm2 flasks and maintained in an incubator (37 °C, 5% CO2). Cells were washed and medium changed twice weekly, and passaged until a stable culture was achieved (Fig. 2a,b). Cells were then viably frozen in Cell Freezing Medium (Sigma C6295) and placed in a Cool Cell temperature controlled freezing chamber at −80°C before transfer to liquid nitrogen for long-term storage.

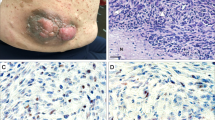
Characterization of patient-derived models. (a,b) Cells were cultured under standard conditions until the emergence of a consistently replicating population. (a) Measurement of cell growth rate and calculation of doubling time, shown as a percentage increase over day 0. (b) 10x photomicrograph of cultured cells at logarithmic growth phase. (c) Tumor fragments from freshly acquired specimens were implanted subcutaneously into mice; mice were monitored until the development of a palpable tumor. H&E images from three representative MPNST patient-derived xenografts (PDX).
Patient-Derived Xenograft (PDX) development
Tissue for PDX generation was maintained in supplemented media (RPMI 20% FBS 1% PSG) until implantation. Adult NOD scid gamma mice (Jackson laboratory: NOD.Cg-PrkdcscidIl2rgtm1Wjl/SzJ (005557)) were anesthetized using a mixture of ketamine and xylazine. Tumor pieces were cut into 2–3 mm fragments and dipped into ice-cold Matrigel (Corning: CB-40230) and immediately implanted into the mouse flank, pre-tibial space, or pre-sacral space.
Two to ten mice were implanted for each tumor where the diagnosis is known to be pNF or MPNST at the time of resection. The overall rate of successful generation of PDX from attempted tumors in this study was 50% for MPNST. Once the tumor reached approximately 15 mm in diameter, tumor was viably frozen in Cell Freezing Medium (Sigma C6295) and a small fragment was passaged into another mouse. Representative H&E images for novel PDX models are shown in Fig. 2c.
Exome sequencing
DNA was isolated from flash-frozen tumor sample using the QIAmp DNA Mini Kit (Qiagen 51304) and quantified and quality confirmed using the NanoDrop 2000 spectrophotometer. Germline DNA was isolated from patient blood, or in the rare case that sufficient blood could not be collected, normal tissue adjacent to tumor was used for germline. Specimens were sequenced by the Genetic Resources Core Facility at Johns Hopkins (https://grcf.jhmi.edu/) and processed similarly to previously published pNF resources9.
Quality control was carried out via 2% gels, OD260 readings, and volume checks upon sample receipt at CIDR (https://www.cidr.jhmi.edu) to confirm adequate quantity and quality of genomic DNA. Samples were then processed with an Illumina Infinium QCArray-24v1-0 array to confirm sex, identify unexpected duplicates and relatedness, confirm study duplicates and relatedness, provide sample performance information and sample identity confirmation against the sequencing data.
Exome capture was carried out using the Agilent SureSelectXT HumanAllExon V6 (Agilent S07604514) kit. 1 μg of genomic DNA was sheared using the Covaris E220 instrument (Covaris) with a shear time of 80 seconds in order to obtain larger insert sizes. A hybrid protocol for library preparation and whole exome enrichment was developed at CIDR (unpublished) based on methods and parameters from Fisher et al.10, applied to the reagents, volumes and parameters from the Agilent SureSelect XT kit and automated protocol (p/n G7550-90000 revision B). All processing was done in 96 well plate formats using robotics (Beckman FXp, Perkin Elmer Janus, Agilent Bravo, Beckman NX). ‘With Bead’ clean-ups were used following shearing, end repair, A-tailing and adapter ligation. The initial input of GE Healthcare Sera-Mag Magnetic SpeedBeads (Carboxylate-Modified) was based on volumes from the Agilent protocol. After the first clean up, the sample was eluted and the beads remained in the reactions through the final ligation clean-up. These reactions were carried out using the XT reagents, volumes and conditions described in the Agilent protocol. At pre-capture PCR the entire product was amplified, adjusting the water in the reaction to accommodate the increase in DNA sample volume. The PCR enzyme used in all steps was switched from Herculase to HiFi HotStart Ready Mix (Kapa Biosystems) to increase the coverage in GC rich regions. All other aspects follow the Agilent protocol except the number of PCR cycles was increased from 6–8 cycles. 750 ng of amplified library was used in an enrichment reaction following Agilent 24-hour hybridization protocol. Post- capture washing was done using the Agilent protocol except the ‘off-bead’ catch process from Fisher et al.10, with a slight change in which samples are not eluted off the DynaBeads (Invitrogen), instead post-capture PCR master mix and indexes are added directly to the beads. Post-capture PCR was done according to the Agilent protocol, with the adjustment of water volume and PCR cycles where needed.
Libraries were sequenced on the HiSeq2500 platform with template generation on the cBot. Conditions included 72 samples per flowcell, 125 base-pair paired-end runs and sequencing chemistry kits HiSeq PE Cluster Kit v4 and HiSeq SBS kit v4.
Exome-seq variant calling
Single nucleotide variant calling was carried out via a well-tested pipeline with the tools and parameters described in Table 1. Copy number alterations were analyzed using the GATK pipeline11 and additional single nucleotide variant analyses were done using the DeepVariant tool (release 0.8)12.
RNA-Sequencing
RNA was isolated from flash-frozen tumor specimens by grinding each with a mortar and pestle while frozen with liquid nitrogen. RNA was isolated using the RNeasy Mini Kit (Qiagen Cat No: 74104) and quantified and quality confirmed via a NanoDrop 2000 spectrophotometer. For each sample, paired-end RNA-Seq data run in eight lanes was concatenated into two fastq files. For each sample, paired-end RNA-Seq data were converted from bam files to two fastq files using BEDtools13. Quality control was performed using FastQC and combined into one file utilizing MultiQC14. The report was uploaded to Synapse. One sample (2-025 Neurofibroma) was found to have high a percentage of duplication (>90%) and was therefore removed from the study, which leaves 28 samples in total. Alignment was performed using Salmon (0.11.3)15 and aligned with gencode (version 29). The raw counts matrix was assembled by importing the output files of Salmon alignment via tximport. The alignment output files and the raw counts matrix were uploaded to Synapse16 and is also harmonized with previously-sequenced pNF cell culture data17. The analysis code is freely available at https://github.com/Sage-Bionetworks/JHU-biobank with a versioned repository available at Zenodo18.
Data Records
All de-identified data can be retrieved from the project site on the Synapse platform (http://synapse.org/jhubiobank)19. The project page describes the details of the project as well as how to gain access to the data. At the time of this publication, the site includes RNA and DNA data from 23 patients, as described in Table 2. Clinical metadata is available on the Synapse data site19. Samples characterized via exome-seq and RNA-seq are described in Table 3.
Technical Validation
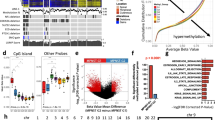
We evaluated the genetic fidelity of the PDX and cell line models by comparing mutational profiles of commonly mutated genes20,21,22,23,24,25 from the exome-seq data to showcase that the mutational profiles between the original tumor were maintained in the cell line and the PDX model, depicted in Fig. 3a. For the entire cohort sequenced using WES, NF1 alterations are shown, as well as genes commonly mutated in plexiform neurofibroma and MPNST, including CDKN2A, TP53, EED/ SUZ12, and ATRX, among others. Mutations in PRC2 complex genes are notably absent, other than in the single MPNST sample, consistent with current literature. Additional PDX and cell line models have been generated, and sequencing data from these will be released publicly once available.

Genomic profile of patient blood, tumor, and patient-derived cell line and xenograft samples. (a)Genomic alterations in commonly mutated genes across all samples for which there are sequencing data. Gene names are listed along the left, with the percent of samples in which that gene is mutated on the right. Sample metadata are located at the bottom of the figure. Common variants not included in the plot. (b) Legend for panel a. (c) Plots from copy ratio analysis of all chromosomes in the four samples derived from patient 2-031. (d) Top panel shows a diagrammatic representation of Chromosome 17 with NF1 locus highlighted by a yellow arrow (adapted from https://ghr.nlm.nih.gov/gene/NF1#location). The bottom four panels are high resolution visualizations of Chromosome 17 in 2-031 specimens showing a reduction in copy ratio at the NF1 locus (indicated by black arrows) in the MPNST tumor sample, the derived cell line, and the xenograft.
In addition to measuring single nucleotide variants (SNVs), we also measured copy ratio alterations to ensure that the cell line and xenograft models recapitulated the genomic profile of the original sample. Figure 3c shows plots of the copy ratios of all chromosomes in the various samples derived from patient 2-031. Figure 3d shows a higher resolution plot of the copy ratio specifically in Chromosome 17. There was a detectable reduction in copy ratio (CR) near the NF1 locus (CR of blood = 1, CR of tumor = 0.5). This reduction in copy ratio around the NF1 locus in the tumor tissue, indicated by the black arrow, was preserved across the cell line and xenograft models derived from the same patient.
For technical validation of RNA-seq data, the quality of RNA-seq data was re-evaluated in-silico after the initial quality control during sequencing. The z-scored total counts per gene were plotted (Fig. 4a) to show that the number of reads per gene were similarly distributed across all samples thus confirming that samples were of analytical quality.

Technical validation of RNA-seq data. (a) Boxplot of normalized counts (zScores) for each gene for each dataset. (b) Depicts the first two principal components of each sample, colored by tumor type. Shape represents whether the sample is a cell line (circle), xenograft (square), or tumor tissue (triangle).
Future directions
The JH NF1 biospecimen repository is an active and ongoing effort to collect and preserve tumor samples from patients with NF1, and to use these tumors for the generation of novel research tools including patient-derived cell lines and xenografts suitable for ongoing biological research and preclinical drug studies. This paper details the methods of our efforts, and with its publication, the release of data from the first cohort of specimens sequenced using RNA and whole exome sequencing. We continue to collect available samples and remain dedicated to this effort as a high research priority. A second cohort of samples is currently undergoing sequencing, and includes exome sequencing for 51 samples and RNA sequencing for 28 additional samples. These data will be made publicly available using the Synapse database, as will future data as our efforts continue. We are grateful to the NF1 research community for the recognition that the samples and their associated genomic data have received to date, and we are enthusiastic about future work in this arena.
Usage Notes
All data can be found on the Biobank Synapse project page at http://synapse.org/jhubiobank19. The data are freely available to qualified researchers upon request for access, following the instructions described on the project page.
Code availability
A Github repository (http://github.com/sage-bionetworks/JHU-biobank) con tains the codes required to generate the figures with a versioned repository available at Zenodo18. The tutorials are provided in R and Python languages, contained in the r_demos and py_demos directories respectively. All of the analytical code is provided in the directory marked “analysis”. Additionally, we have provided Docker containers and R scripts to facilitate reproducibility of the figures in the paper.
References
Korf, B. R. Plexiform neurofibromas. Am. J. Med. Genet. 89, 31–37 (1999).
Johnson, J. I. et al. Relationships between drug activity in NCI preclinical in vitro and in vivo models and early clinical trials. Br. J. Cancer 84, 1424–1431, https://doi.org/10.1054/bjoc.2001.1796 (2001).
Tentler, J. J. et al. Patient-derived tumour xenografts as models for oncology drug development. Nat. Rev. Clin. Oncol. 9, 338–350, https://doi.org/10.1038/nrclinonc.2012.61 (2012).
Cichowski, K. et al. Mouse models of tumor development in neurofibromatosis type 1. Science 286, 2172–2176 (1999).
Le, L. Q. & Parada, L. F. Tumor microenvironment and neurofibromatosis type I: connecting the GAPs. Oncogene 26, 4609–4616, https://doi.org/10.1038/sj.onc.1210261 (2007).
N.C.I. National Cancer Institute (NCI); Division of Cancer Treatment & Diagnosis. Cancer Diagnosis Program — BBRB Biorepositories & Biospecimen Research Branch: Best Practices, https://biospecimens.cancer.gov/bestpractices/ (2018).
Allaway, R. J. et al. Engaging a community to enable disease-centric data sharing with the NF Data Portal. Sci. Data 6, 319, https://doi.org/10.1038/s41597-019-0317-x (2019).
Gosline, S. J. et al. A high-throughput molecular data resource for cutaneous neurofibromas. Sci. Data 4, 170045, https://doi.org/10.1038/sdata.2017.45 (2017).
Ferrer, M. et al. Pharmacological and genomic profiling of neurofibromatosis type 1 plexiform neurofibroma-derived schwann cells. Sci. Data 5, 180106, https://doi.org/10.1038/sdata.2018.106 (2018).
Fisher, S. et al. A scalable, fully automated process for construction of sequence-ready human exome targeted capture libraries. Genome Biol. 12, R1, https://doi.org/10.1186/gb-2011-12-1-r1 (2011).
(How to part I) Sensitively detect copy ratio alterations and allelic segments, https://software.broadinstitute.org/gatk/documentation/article?id=11682 (2018).
Poplin, R. et al. A universal SNP and small-indel variant caller using deep neural networks. Nat. Biotechnol. 36, 983–987, https://doi.org/10.1038/nbt.4235 (2018).
Quinlan, A. R. BEDTools: The Swiss-Army Tool for Genome Feature Analysis. Curr Protoc Bioinformatics 47, 11 12 11-34, https://doi.org/10.1002/0471250953.bi1112s47 (2014).
Wingett, S. W. & Andrews, S. FastQ Screen: A tool for multi-genome mapping and quality control. F1000Res 7, 1338, https://doi.org/10.12688/f1000research.15931.2 (2018).
Patro, R., Duggal, G., Love, M. I., Irizarry, R. A. & Kingsford, C. Salmon provides fast and bias-aware quantification of transcript expression. Nat. Methods 14, 417–419, https://doi.org/10.1038/nmeth.4197 (2017).
Pollard, K. et al. JHU Biobank raw counts. Synapse https://doi.org/10.7303/syn19522967 (2020).
Pollard, K. et al. JHU Biobank harmonized RNAseq counts and metadata. Synapse https://doi.org/10.7303/syn20812185.1 (2020).
Gosline, S. B., J; Allaway, R; Guo, X; Doan, X. Sage-Bionetworks/JHU-biobank: JHU Biobank Code Repository. Zenodo https://doi.org/10.5281/zenodo.3726380 (2020).
Pratilas, C. A., Pollard, K. & Wang, J. A Nerve Sheath Tumor Bank from Patients with NF1. Synapse https://doi.org/10.7303/syn4939902 (2020).
Kourea, H. P., Orlow, I., Scheithauer, B. W., Cordon-Cardo, C. & Woodruff, J. M. Deletions of the INK4A gene occur in malignant peripheral nerve sheath tumors but not in neurofibromas. Am. J. Pathol. 155, 1855–1860, https://doi.org/10.1016/S0002-9440(10)65504-6 (1999).
Lee, W. et al. PRC2 is recurrently inactivated through EED or SUZ12 loss in malignant peripheral nerve sheath tumors. Nat. Genet. 46, 1227–1232, https://doi.org/10.1038/ng.3095 (2014).
Zhang, M. et al. Somatic mutations of SUZ12 in malignant peripheral nerve sheath tumors. Nat. Genet. 46, 1170–1172, https://doi.org/10.1038/ng.3116 (2014).
Hirbe, A. C. et al. BRAFV600E mutation in sporadic and neurofibromatosis type 1-related malignant peripheral nerve sheath tumors. Neuro Oncol. 16, 466–467, https://doi.org/10.1093/neuonc/not248 (2014).
Carroll, S. L. The Challenge of Cancer Genomics in Rare Nervous System Neoplasms: Malignant Peripheral Nerve Sheath Tumors as a Paradigm for Cross-Species Comparative Oncogenomics. Am. J. Pathol. 186, 464–477, https://doi.org/10.1016/j.ajpath.2015.10.023 (2016).
Hirbe, A. C. et al. Clinical genomic profiling identifies TYK2 mutation and overexpression in patients with neurofibromatosis type 1-associated malignant peripheral nerve sheath tumors. Cancer 123, 1194–1201, https://doi.org/10.1002/cncr.30455 (2017).
Li, H. Aligning sequence reads, clone sequences and assembly contigs with BWA-MEM. ArXiv, https://arxiv.org/abs/1303.3997 (2013).
Li, H. et al. The Sequence Alignment/Map format and SAMtools. Bioinformatics 25, 2078–2079, https://doi.org/10.1093/bioinformatics/btp352 (2009).
McKenna, A. et al. The Genome Analysis Toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res. 20, 1297–1303, https://doi.org/10.1101/gr.107524.110 (2010).
DePristo, M. A. et al. A framework for variation discovery and genotyping using next-generation DNA sequencing data. Nat. Genet. 43, 491–498, https://doi.org/10.1038/ng.806 (2011).
Wang, K., Li, M. & Hakonarson, H. ANNOVAR: functional annotation of genetic variants from high-throughput sequencing data. Nucleic Acids Res. 38, e164, https://doi.org/10.1093/nar/gkq603 (2010).
Acknowledgements
The JH NF1 biospecimen repository is supported by a grant from the Neurofibromatosis Therapeutic Acceleration Program (NTAP, http://www.n-tap.org/) to C.A.P. Analysis by Sage Bionetworks is supported through the Neurofibromatosis Therapeutic Acceleration Program (NTAP, http://www.n-tap.org/). Whole exome sequencing and RNA sequencing was conducted at the Genetic Resources Core Facility, Johns Hopkins Institute of Genetic Medicine, Baltimore, MD. All logos used in Fig. 1 were confirmed to be freely available for reuse. The DNA icon in Fig. 1 was licensed under CC BY-NC 4.0 and the test tube icon made freely available by www.flaticon.com. The authors acknowledge Dennis Zechman, Jr. for assistance with graphical design.
Author information
Authors and Affiliations
Contributions
K.P. specimen handling and clinical annotation, oversight of data integrity. D.M.L., J.O.B. and C.A.P. concept, design and scientific oversight. J.O.B., B.L.S., S.M.L. C.F.M., C.D.M. and A.J.B.: patient care and acquisition of specimens. J.O.B., B.L.S., S.M.L. and F.J.R. assignment of clinical diagnosis, verification of accuracy of specimen diagnosis. X.G, X.D, J.B, R.A. and S.G.: data curation and bioinformatic analysis. K.P., J.B., J.W., C.A.P. and S. G.: generation of figures. C.A.P. and S.G.: manuscript writing. All authors: final review of manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files associated with this article.
About this article

Cite this article
Pollard, K., Banerjee, J., Doan, X. et al. A clinically and genomically annotated nerve sheath tumor biospecimen repository. Sci Data 7, 184 (2020). https://doi.org/10.1038/s41597-020-0508-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-020-0508-5
This article is cited by
-
Malignant peripheral nerve sheath tumor: models, biology, and translation
Oncogene (2022)
-
Experimental models of undifferentiated pleomorphic sarcoma and malignant peripheral nerve sheath tumor
Laboratory Investigation (2022)
