
Abstract
This N = 173,426 social science dataset was collected through the collaborative COVIDiSTRESS Global Survey – an open science effort to improve understanding of the human experiences of the 2020 COVID-19 pandemic between 30th March and 30th May, 2020. The dataset allows a cross-cultural study of psychological and behavioural responses to the Coronavirus pandemic and associated government measures like cancellation of public functions and stay at home orders implemented in many countries. The dataset contains demographic background variables as well as measures of Asian Disease Problem, perceived stress (PSS-10), availability of social provisions (SPS-10), trust in various authorities, trust in governmental measures to contain the virus (OECD trust), personality traits (BFF-15), information behaviours, agreement with the level of government intervention, and compliance with preventive measures, along with a rich pool of exploratory variables and written experiences. A global consortium from 39 countries and regions worked together to build and translate a survey with variables of shared interests, and recruited participants in 47 languages and dialects. Raw plus cleaned data and dynamic visualizations are available.
Measurement(s) | psychological measurement • anxiety-related behavior trait • Stress • response to • Isolation • loneliness measurement • Emotional Distress |
Technology Type(s) | Survey |
Factor Type(s) | geographic location • language • age of participant • responses to the Coronavirus pandemic |
Sample Characteristic - Organism | Homo sapiens |
Sample Characteristic - Location | global |
Machine-accessible metadata file describing the reported data: https://doi.org/10.6084/m9.figshare.13251776
Similar content being viewed by others
Background & Summary
In 2020, a new coronavirus pandemic spread across countries worldwide. This resulted not only in a global health crisis, but also in severe economic and socio-psychological consequences. To control the spread of the coronavirus, governments imposed a range of measures, including the closure of schools, workplaces, shopping areas and public amenities, forced isolation, virus-testing, and limits to civil liberties. Inevitably, these changes generated a variety of psychological responses in individuals, which in turn shaped the level of compliance with preventive measures. In fact, extant research on the factors that shape willingness to comply with public health efforts aimed at preventing or slowing the spread of epidemics has highlighted the importance of psychological and social factors1,2—for instance shared trust in state or health authorities3,4—in driving compliance with guidelines and restrictions. The implications of these complex factors to compliance with preventive measures imposed by different governments must be analysed in detail after the crisis. Indeed, the psychological and societal effects are likely to be more pronounced, more widespread, and longer-lasting than the purely somatic effects of the infection5.
To contribute to the understanding of the intersection between pandemic-related physical and behavioural issues, the present document describes a large-scale dataset collected through the collaborative COVIDiSTRESS global survey. The COVIDiSTRESS data collection efforts ran from 30th March to 30th May, 2020 by collaborators from 39 countries and regions with survey forms available in 47 languages and dialects. In total, 173,426 participants were recruited from 179 countries on six continents.
Pandemic outbreaks breed misinformation, and foster fear of contagion as well as uncertainty during the course of their spread5,6. Factors such as concerns regarding the severity of a disease, the perceived reliability of government information, and beliefs in the efficacy of preventive measures can influence individuals’ intentions to comply and engage in preventive behaviours7. Thus, the extent of compliance is influenced by the level of trust in one’s sources of information about a pandemic, as well as the perceived gravity of the disease. Concerns over one’s risk of contracting the disease during a pandemic can be a source of ongoing worry and anxiety as well as stress (e.g. H1N17 and MERS8). These concerns, as well as the confusion generated by the lack of established worldwide or national quarantine protocols, timely information and resources from public health systems9 may contribute to lower levels of compliance. Research indicates that the perception of openness and reliability of governments and health organisations10, levels of trust in media and medical authorities11,12 as well as perceptions of disease’s severity and the efficacy of one’s actions10,13,14 contribute to compliance with recommendations for preventive behaviour.
Both the medical situation and the psychological effects of isolation, confinement and information behavior15,16 need to be considered when prolonged periods of quarantine are implemented. A subset of negative effects on ‘cabin fever’ includes responses varying from anxiety and depression17 to impaired cognitive ability and hostility16,18. Efforts such as closing down schools and workplaces, and calls for people to self-isolate in their homes, are likely to constitute a source of both existential and practical stress unrelated to the fear of contracting the disease. Compliance with medical guidelines has been shown to decrease not just as a result of higher stress levels19, but also of minor everyday stressors such as workplace conflict or household responsibilities20. Prolonged states of emergency and the chronic psychological, social, and economic stressors related to them21,22 may decrease compliance with set behavioural objectives during pandemics. Conversely, social support from groups such as one’s family, friends, and colleagues moderate the effect of concern for the disease or other sources of stress on one’s psychological well-being23,24.
Hence, as an effort to help health authorities and decision makers organize informed responses, we initiated the COVIDiSTRESS open science collaboration. The dataset can help researchers and stakeholders identify nuances in psychological and behavioural risk factors in the context of the COVID-19 pandemic, and assist governments and other organizations in adopting constructive policies appropriate to each country.
Methods
Participants
173,426 people accessed an online survey link to provide their experiences over a period of 62 days (30th March to 30th May. The stored dataset represents 125,306 people who met inclusion criteria (18 years of age and older and gave informed consent). Demographic characteristics for countries with over 200 responses appear in Table 1. Given the urgent call for COVID-19 research, the survey received a waiver to commence data collection from the IRB office at Aarhus University, Denmark. Participants volunteered based on online and media appeals without monetary compensation; excepting some of the Japanese participants received 7 T-points (equivalent to about 0.065 USD) from the crowdsourcing service as a reward.
Materials
The full survey form in English can be accessed at https://doi.org/10.17605/OSF.IO/Z39US. The survey consisted of two parts. The first section comprised general demographic data, self-reports about the proximate effects of the COVID-19 pandemic (e.g. isolation status, first-hand experience, attenuated risk), modified version of the Asian Disease problem to examine participants’ risk taking intention under COVID-19 situation25, personality assessment (BFI-S26), Short self-report scale of loneliness27 (SLON-3) based on the UCLA loneliness scale, Perceived Stress Scale (PSS-1028), self-reports about the interpersonal and institutional trust (based on OECD guidelines 2017), and items measuring daily behaviours including compliance with general and social preventive measures. The second part contained sets of more specific items related to people’s experiences of distress and worry during the ongoing outbreak of coronavirus (e.g. access to amenities, loss of work, adapting work, education and social interactions to digital platforms, the social stresses of confinement with adults and children), as well as items which detected copying mechanisms of people during the COVID-19 crisis (e.g. social contact, staying informed, dedicating oneself to preparation, hobbies, religion) and the Social Provisions Scale (SPS-1029). Finally, participants were asked to report information behaviours in times of the coronavirus pandemic, and were invited to add a few lines of text, to illuminate their experience of the COVID-19 crisis beyond the closed-end items. Participants typically supplied their answers on a 6-point Likert scale ranging from ‘Strongly disagree’ to ‘Strongly agree’, with some variation based on established standards, as well as in text boxes to add other relevant factors. Validated short versions of established measures were used if available in local languages. The full list of variables included in the COVIDiSTRESS global survey as well as the response options participants used to answer the survey are available at https://osf.io/v68t9/. To protect participants’ data and avoid sensitive information, participants were not asked about COVID-19 symptoms or other aspects of their medical status. Additionally, no data that would allow identification of participants was collected.
Translation
The survey was translated into 47 languages and adapted to the dialects and vernacular of different regions (Afrikaans, Albanian, Arabic, Bangla, Indonesian, Bosnian, Bulgarian, Chinese [Simplified and Traditional], Croatian, Czech, Danish, Dutch [Belgium, Netherlands], English, Spanish [Argentina, Colombia, Cuba, Mexico, Spain], Filipino, Finnish, French, German, Greek, Hebrew, Hindi, Hungarian, isiXhosa, isiZulu, Italian, Japanese, Korean, Lithuanian, Nepali, Persian, Polish, Portuguese [Brazil, Portugal], Romanian, Russian, Slovakian, Serbian, Swedish, Turkish, Urdu, Vietnamese). The translations were completed by a forward translator from the original English version, and then validated through both panel and back-translation processes by separate translators when possible.
Data cleaning
Along with the original data file (COVIDiSTRESS global survey May 30 2020 (choice text).csv), we provide a cleaned data file (COVIDiSTRESS_May_30_cleaned_final.csv) where some cases were removed, and the issues regarding the coding of certain answers were corrected. R code used to clean the data is available online at the Open Science Framework (COVIDiSTRESS global survey30) and in supplementary information. The corrections made were:
-
Filtered out cases without consent and younger than 18 years old.
-
User Language – Bulgarian (BG): For responses between 2020-03-28 13:30:02 UTC and 2020-04-08 01:53:18 UTC, the order of the variable Country was mixed up for people who took the survey in Bulgarian language. Thus, the data was recoded.
-
User Language – Afrikaans (AFR): For responses before 2020-04-07 06:48:00, the order of the variable Country was mixed up for people who took the survey in Afrikaans language. Thus, the data was recoded.
-
User Language – Hebrew (HE): The variable Country was translated and arranged according to the Hebrew alphabetical order. Thus, the data was recoded.
-
User Language – Bengali (BAN): Variables Scale_PSS10_UCLA_6 and Scale_PSS10_UCLA_7 were swapped during translation, so they were swapped back in the data cleaning procedure.
-
Country: Removed dashes in front of the ‘- other’ responses in Country.
-
Start Date: Cases before the official launch date 2020-03-30 were excluded as they were test answers. Soft launch answers from Denmark and Kosovo before the start date were retained.
-
Marital Status: Except for the original English version of the survey, the order of the Dem_maritalstatus variable was mixed up in translations. The variable was recoded to correct this problem. There were some participants who had ‘5’ in Dem_maritalstatus. These responses were recoded as ‘Uninformative response’.
-
Education level and mother’s education level: Removed dashes in front of the response options. There were some participants who had ‘1’ in Dem_edu. These responses were recoded as ‘Uninformative response’.
-
Gender: The variable Dem_gender was inverted for languages SSP (Spanish - Spain) and SME (Spanish - Mexico) in the raw data file. Thus, in these responses, Male was recorded to Female and vice versa.
-
AD_Check, AD_gain and AD_loss: Shorten the response; PSS-10, Corona_concerns, Compliance, BFF, SPS-10, Coping, Expl_media, Distress scale, Trust in the country’s measures: Responses were converted from choice text to numeric.
-
Perceived Loneliness: The scale was initially coded as an extension of the PSS-10 battery. For clarity, the columns were renamed into Scale_PSS10_UCLA_11 through Scale_PSS10_UCLA_13 to Scale_Lon_1 through Scale_Lon_3.
-
Created composite scores: PSS-10, SPS-10, SLON-3, BFF-15.
-
Removed all new lines and “;” from participants’ additional text responses.
-
From 15th May onwards, additional items (Q50-Q62) were included for a location-specific sub-study on war trauma in Bosnia/Herzegovina. These were not part of our pre-registration. These columns were cleaned (see below), but not included in the current report:
-
Renamed new columns for clarity (Q50-Q62): born_92, experience_war, experience_war_TXT, war_injury, loss_during_war, time_spent_in_war, time_spent_in_war_TXT, Scale_UCLA_TRI_1:4 (4 items), PS_PTSD_1:5 (5 items)
-
War-related questions: Removed numbers, periods, and extra spaces in the responses for the experience_war, war_injury, loss_during_war, time_spent_in_war (i.e. “2. Yes” got simplified to “Yes”)
-
TRI_4: Responses were converted from choice text to numeric and composite score for the scale was calculated
-
PS-PTSD: Responses were converted from choice text to numeric
Note that correcting the error-coded variables (Gender, User Language Bulgarian, Afrikaans and Hebrew, Marital Status) is necessary for correct interpretation of the data. None of the other actions described above (e.g., recoding text into numerical values) affect the data interpretation in any way. Apart from filtering out test data (data before the official launch on 2020-03-30) and participants who declared that they are younger than 18, all data was retained. When recoding, all groups present in the raw data file were also preserved. For more details, please see the data cleaning R markdown file. Thereafter, the text description is based on the cleaned data.
Data Records
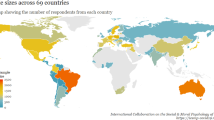
Raw data and code for cleaning is available at https://doi.org/10.17605/OSF.IO/Z39US30. Figure 1 shows a heat map of the countries from which the data were collected, coloured according to the sample size (n ≥ 200). The main characteristics of the survey are presented in Tables 1 to 6. Information on the basics (Table 1), gender (Table 2), education (Table 3), marital status (Table 4), current risk of infection (Table 5), and current isolation status (Table 6) for countries with their sample size of more than 200 are presented, respectively.

A world map visualizing the participants in each country. Only countries with n ≥ 200 are coloured.
Data visualization interface
In addition to the raw data, a dedicated Web application was developed to provide a general overview of the COVIDiSTRESS dataset (https://covidistress.france-bioinformatique.fr/). The Web application allows easy and dynamic generation of illustrations like age pyramids, zoomable world maps, and bar plots summarizing the main variables of the survey for each selected country. Two tabs of visualizations are provided: the first contains basic demographic variables like age, gender, and educational level by country; the second tab displays world maps of levels of stress, trust in institutions and concerns for self, friends, family, country, and other countries. The application is based on an R shiny server (https://rstudio.com/products/shiny/shiny-server/), together with the plot.ly31 and ggplot232 graphical libraries to generate dynamic plots. All the generated figures can be exported as PNG files.
Technical Validation
As of 30th May, the participants in our data represented 176 different countries. However, there were instances in which we only had one participant per country (i.e. The Bahamas, Uganda, etc.). For computational purposes, we decided to examine the data quality for 42 countries that had over 200 participants.
Overall, 25 of these 42 countries had more than 1,000 participants. Among these, Finland, France, and Denmark are the three countries with the highest numbers of respondents (over 10,000). At least 62% of the participants provided answers to half of the questions in the survey, and at least 47% responded to 90% of the questions. We added one variable, “answered_all,” that indicates whether a participant answered all questions for users’ information. Of all 125,360 participants included in the cleaned dataset, 42.48% answered all questions. Figure 2 demonstrates the proportion of valid data across 10 countries with the highest number of participants (top 10 countries). The mean age of participants (M = 39.22, SD = 14.09) falls between young- to mid-adulthood, and in most countries, the number of female participants is disproportionately higher. Figure 3 illustrates the distribution of gender in the top 10 countries. Similarly, our sample seems to disproportionately represent people with some levels of higher education (i.e. some college or higher). Figure 4 shows participants’ levels of education in the top 10 countries. Additional details on the sample characteristics (including age, gender, education level, and marital status) can be found in Table 1 through Table 4. The dataset also includes answers to questions related to the respondent’s current likelihood of infection (e.g. risk of infection with COVID-19 in the family and the degree of isolation), as shown in Tables 5 and 6. Given our narrow timeline and the convenience sampling method, we acknowledge that our samples may not be representative of the populations of interest. However, we believe that the data can still be meaningfully used to understand the experiences of certain groups of people during this pandemic.

The number of participants and proportions of valid data across ten countries with the largest samples.

The distribution of gender across ten countries with the largest samples (missing data were excluded from this depiction due to very low proportions).

The distribution of education across ten countries with the largest samples (missing data were excluded from this depiction due to very low proportions).
Aside from some specific questions on COVID-19 (i.e. self-protective behaviours, trust in the government’s agencies, etc.), our data includes several scales that were previously validated within certain populations, including the Asian Disease Problem, PSS-10, SPS-10, BFF-15 (BFI-S), and the SLON-3. Figure 5 illustrates Cronbach’s alphas for these scales in the top 10 countries. In Table 7, we presented several descriptive statistics of each of the aforementioned continuous scales. Below, we described the preliminary statistics of the scales for all 42 countries.

The Cronbach’s alpha reliability for each scale across ten countries with the largest samples.
Asian disease problem
The basic descriptive statistics of the Asian Disease Problem are summarized in Table 8. Specifically, among the 42 countries, at least 91% of the participants responded to this problem. They were randomly assigned to either of the gain or loss condition. Among those who responded, 50.27% were assigned to the gain condition, while 49.73% to the loss condition. Participants in the gain condition selected one of two options, Program A vs. B. Program A was selected by 66.20% of the participants in the gain condition, while 33.80% selected Program B. Those in the loss condition selected one of two options, Program C vs. D. Program C was selected by 36.54% of the participants in the loss condition, while 63.46% selected Program D.
PSS-10
The basic descriptive statistics of the PSS-10 are summarized in Table 9. Specifically, among the 42 countries, at least 75% of the participants rated this scale. The composite scale score ranges from 1 to 5, with a mean value falling between 2.30 and 3.13. The internal consistency of the scale, as measured by Cronbach’s alpha, ranges from 0.66 to 0.90.
SPS-10
The basic descriptive statistics of the SPS-10 are summarized in Table 10. Specifically, among the 42 countries, at least half of the participants rated this scale. The composite scale score ranges from 1 to 6, with a mean value falling between 3.55 and 5.20. The internal consistency of the scale, as measured by Cronbach’s alpha, ranges from 0.88 to 0.94.
SLON-3
The basic descriptive statistics of the SLON-3 are summarized in Table 11. Specifically, among the 42 countries, at least 77% of the participants rated this scale. The composite scale score ranges from 1 to 5, with a mean value falling between 1.89 and 3.05. The internal consistency of the scale, as measured by Cronbach’s alpha, ranges from 0.54 to 0.84.
BFF-15
This term was used for this project. This is more commonly known as the Big Five Inventory-SOEP (BFI-S).
Extraversion
The basic descriptive statistics of this subscale are summarized in Table 12. Specifically, among the 42 countries, at least 71% of participants rated this scale. The composite subscale score ranges from 1 to 6, with a mean value falling between 3.12 to 4.50. The internal consistency of the scale, as measured by Cronbach’s alpha, ranges from 0.51 to 0.86.
Neuroticism
The basic descriptive statistics of this subscale are summarized in Table 13. Specifically, among the 42 countries, at least 70% of the participants rated this scale. The composite subscale score ranges from 1 to 6, with a mean value falling between 2.91 and 3.80. The internal consistency of the scale, as measured by Cronbach’s alpha, ranges from 0.44 to 0.77.
Openness
The basic descriptive statistics of this subscale are summarized in Table 14. Specifically, among the 42 countries, at least 71% of the participants rated this scale. The composite subscale score ranges from 1 to 6, with a mean value falling between 3.36 and 4.97. The internal consistency of the scale, as measured by Cronbach’s alpha, ranges from 0.46 to 0.74.
Agreeableness
The basic descriptive statistics of this subscale are summarized in Table 15. Specifically, among the 42 countries, at least 71% of participants rated this scale. The composite subscale score ranges from 1 to 6, with a mean value falling between 3.62 and 4.85. The internal consistency of the scale, as measured by Cronbach’s alpha, ranges from 0.30 to 0.67.
Conscientiousness
The basic descriptive statistics of this subscale are summarized in Table 16. Specifically, among the 42 countries, at least 70% of participants rated this scale. The composite subscale score ranges from 1 to 6, with a mean value falling between 3.54 and 5.01. The internal consistency of the scale, as measured by Cronbach’s alpha, ranges 0.34 to 0.67.
Usage Notes
We recommend that any interested researchers use the raw or the cleaned version of the latest extracted data (available at https://doi.org/10.17605/OSF.IO/Z39US). The data was imported and cleaned using the R software for statistical analysis33 and packages tidyverse34, multicon35, qualtRics36, pacman37, and psych38. Before using the dataset, the steps in the Data cleaning section should be followed to ensure that the dataset is ready for analysis. The data cleaning procedure should involve excluding irrelevant cases, correcting some errors in value-coding, and renaming improperly named variables. In addition, the cleaning procedure should encompass recoding choice values to number, creating composite scores, and the estimation of the Cronbach alpha reliabilities for the measured scales (PSS-10, BFF-15, SPS-10, and SLON-3). However, for analysis in individual countries, we recommend checking for tau-equivalence before using Cronbach’s alpha for reliability estimation. If tau-equivalence is not achieved, Omega coefficient is more appropriate as a reliability indicator39,40. Before analysing the data, it should be noted that the answers in variables measuring distress (‘Expl_Distress_no’) are recoded to numeric values 1, 2, 3, 4, 5, and 6, measuring the degree of agreement, and 99, which means that the item does not apply to one’s current situation. Additionally, answers in the variable ‘Trust_countrymeasure’ are recoded on a scale from 0 to 10, where 0 and 10 suggest inappropriate measures (too little or too much) and values around 5 suggest appropriate measures.
To merge the present dataset with a pre-existing cross-cultural dataset by country and date, the variables ‘Country’ and ‘RecordedDate’ should be used.
Finally, the samples in the present dataset are not representative of the populations from which they are drawn (in each country). Thus, users who wish to address this issue may weigh the data by referring to demographic information for each country and apply the appropriate weights for the variables and countries of interest (e.g., age: http://data.un.org/Data.aspx?d=POP&f=tableCode%3A22; gender: https://ourworldindata.org/gender-ratio; education: https://ourworldindata.org/global-education; marital status: https://ourworldindata.org/marriages-and-divorces).
Code availability
Raw data and R-code for cleaning are available at https://doi.org/10.17605/OSF.IO/Z39US
Change history
03 February 2021
The OSF DOI, “https://doi.org/10.17605/OSF.IO/Z39US” has been updated in the Data Records section in both the HTML and PDF versions of this Data Descriptor.
References
Leung, C. M. et al. The impact of community psychological responses on outbreak control for severe acute respiratory syndrome in Hong Kong. J Epidemiol Commun H 57, 857–863 (2003).
Taylor, M. et al. Public health measures during an anticipated influenza pandemic: Factors influencing willingness to comply. Risk Manag Healthc Policy 2, 9–20 (2009).
Seligman, A. B. The Problem of Trust. Princeton (NJ: Princeton University Press, 1997)
Capelos, T. et al. Ingredients of institutional reputations and citizen engagement with regulators. Regul Gov 10(4), 350–376 (2016).
Taylor, S. The Psychology Of Pandemics: Preparing For The Next Global Outbreak Of Infectious Disease. (Cambridge Scholars Publishing, Newcastle upon Tyne, 2019).
Khan, S. & Huremović, D. Psychology of the pandemic. In Huremović, D. (Ed.) Psychiatry Of Pandemics: A Mental Health Response To Infection Outbreak. (pp. 37–44) (Springer Nature Switzerland, 2019)
Bults, M. et al. Perceived risk, anxiety, and behavioural responses of the general public during the early phase of the Influenza A (H1N1) pandemic in the Netherlands: Results of three consecutive online surveys. BMC Public Health 11(1), 2 (2011).
Ro, J.-S., Lee, J.-S., Kang, S.-C. & Jung, H.-M. Worry experienced during the 2015 Middle East Respiratory Syndrome (MERS) pandemic in Korea. PLoS ONE 12(3), e0173234 (2017).
Cava, M. A., Fay, K. E., Beanlands, H. J., McCay, E. A. & Wignall, R. The experience of quarantine for individuals affected by SARS in Toronto. Public Health Nurs 22(5), 398–406 (2005).
Bish, A. & Michie, S. Demographic and attitudinal determinants of protective behaviours during a pandemic: A review. Br J Health Psychol 15(4), 797–824 (2010).
Prati, G., Pietrantoni, L. & Zani, B. Compliance with recommendations for pandemic influenza H1N1 2009: The role of trust and personal beliefs. Health Educ Res 26(5), 761–769 (2011).
Gilles, I. et al. Trust in medical organizations predicts pandemic (H1N1) 2009 vaccination behavior and perceived efficacy of protection measures in the Swiss public. Eur J Epidemiol 26(3), 203–210 (2011).
Fung, I. C. H. & Cairncross, S. How often do you wash your hands? A review of studies of hand-washing practices in the community during and after the SARS outbreak in 2003. Int J Environ Health Res 17(3), 161–183 (2007).
Lau, J. T., Yang, X., Tsui, H., Pang, E. & Kim, J. H. SARS preventive and risk behaviours of Hong Kong air travellers. Epidemiol Infect 132(4), 727–736 (2004).
Oliver, D. C. Psychological effects of isolation and confinement of a winter-over group at McMurdo Station, Antarctica. In From Antarctica To Outer Space (pp. 217–227) (Springer, New York, NY, 1991).
Palinkas, L. A. & Suedfeld, P. Psychological effects of polar expeditions. Lancet 371(9607), 153–163 (2008).
Kehoe, J. P. & Abbott, A. P. Suicide and attempted suicide in the Yukon territory. Can J Psychiatry 20, 15–23 (1975).
Gunderson, E. E. Psychological studies in Antarctica. In Human Adaptability in Antarctic conditions (Antarctic Research Series, Vol. 22, pp.115–131) (Washington, DC: American Geophysical Union, 1974)
Karvinen, K. H., Murray, N. P., Arastu, H. & Allison, R. R. Stress reactivity, health behaviors, and compliance to medical care in breast cancer survivors. Oncol Nurs Forum 40(2), 149–156 (2013).
Hitchcock, P. B., Brantley, P. J., Jones, G. N. & McKnight, G. T. Stress and social support as predictors of dietary compliance in hemodialysis patients. Behav Med 18(1), 13–20 (1992).
Huremović, D. (Ed.). Psychiatry Of Pandemics: A Mental Health Response To Infection Outbreak. (Springer Nature Switzerland, 2019).
Brooks, S. K. et al. The psychological impact of quarantine and how to reduce it: Rapid review of the evidence. Lancet 395(10227), 912–920 (2020).
Mak, W. W., Law, R. W., Woo, J., Cheung, F. M. & Lee, D. Social support and psychological adjustment to SARS: The mediating role of self-care self-efficacy. Psychol Health 24(2), 161–174 (2009).
Wang, X., Cai, L., Qian, J. & Peng, J. Social support moderates stress effects on depression. Int J Ment Health Syst 8(1), 41 (2014).
Tversky, A. & Kahneman, D. The framing of decisions and the psychology of choice. Science 211, 453–458 (1984).
Lang, F., John, D., Lüdtke, O., Schupp, J. & Wagner, G. Short assessment of the Big Five: Robust across survey methods except telephone interviewing. Behav Res Methods 43(2), 548–567 (2011).
Hughes, M. E., Waite, L. J., Hawkley, L. C. & Cacioppo, J. T. A short scale for measuring loneliness in large surveys: Results from two population-based studies. Res Aging 26(6), 655–672 (2004).
Cohen, S., Kamarck, T. & Mermelstein, R. A global measure of perceived stress. J Health Soc Behav 24(4), 385–396 (1983).
Steigen, A. M. & Bergh, D. The Social Provisions Scale: Psychometric properties of the SPS-10 among participants in nature-based services. Disabil Rehabil 41(14), 1690–1698 (2019).
Lieberoth, A. et al. COVIDiSTRESS global survey. Open Science Framework https://doi.org/10.17605/osf.io/z39us (2020).
Sievert, C. Interactive Web-Based Data Visualization with R, plotly, and shiny. Chapman and Hall/CRC. ISBN 9781138331457, https://plotly-r.com (2020).
Wickham, H. ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York. ISBN 978-3-319-24277-4, https://ggplot2.tidyverse.org (2016).
R Core Team. R: A language and environment for statistical computing. R Foundation For Statistical Computing, Vienna, Austria. https://www.R-project.org/ (2019).
Wickham et al. Welcome to the tidyverse. J Open Source Softw 4(43), 1686 (2019).
Sherman, R. A. multicon: Multivariate constructs. R package version 1.6 https://CRAN.R-project.org/package=multicon (2015).
Ginn, J. & Silge, J. qualtRics: Download ‘Qualtrics’ Survey Data. R package version 3.1.2 https://CRAN.R-project.org/package=qualtRics (2020).
Rinker, T. W. & Kurkiewicz, D. pacman: Package management for R. version 0.5.0. Buffalo, New York http://github.com/trinker/pacman (2017).
Revelle, W. psych: Procedures for personality and psychological research. Northwestern University, Evanston, Illinois, USA, https://CRAN.R-project.org/package=psych Version = 1.9.12 (2019).
Dunn, T. J., Baguley, T. & Brunsden, V. From alpha to omega: A practical solution to the pervasive problem of internal consistency estimation. Br J Psychol 105(3), 399–412 (2014).
Revelle, W. & Condon, D. M. Reliability from α to ω: A tutorial. Psychol Assess 31(12), 1395–1411 (2019).
Acknowledgements
The COVIDiSTRESS consortium would like to acknowledge the additional contributions of numerous friends and collaborators in translating and sharing the COVIDiSTRESS survey, even if contributions were small or the person did not wish their name included as a member of the consortium. All funding information is listed in the supplementary material (Figure S1). We also want to address thanks to the IFB (Institut Français de Bioinformatique, https://www.france-bioinformatique.fr/) for hosting the server Shiny illustrating our results. This research was supported by JSPS KAKENHI Grants JP17H00875, JP18K12015, JP20H04581, JP20K14222, Czech Science Foundation GC19-09265J, Consejo Nacional de Ciencia y Tecnologia (Conacyt), Full National Scholarship - MSc degree (CVU: 613905), Research Foundation Flanders (FWO) postdoctoral fellowship, and The HSE University Basic Research Program. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Author information
Authors and Affiliations
Consortia
Contributions
Contributions from all the authors are listed in the supplementary material (Figure S1).
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files associated with this article.
About this article

Cite this article
Yamada, Y., Ćepulić, DB., Coll-Martín, T. et al. COVIDiSTRESS Global Survey dataset on psychological and behavioural consequences of the COVID-19 outbreak. Sci Data 8, 3 (2021). https://doi.org/10.1038/s41597-020-00784-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-020-00784-9
This article is cited by
-
War-related stress scale
BMC Psychology (2024)
-
A dataset on survey designs and quality of social and behavioral science surveys during the COVID-19 pandemic
Scientific Data (2024)
-
Exploring the role of country-level gender equality in the link between relationship status and perceived social support across 49 countries
Scientific Reports (2024)
-
Measuring various aspects of coronavirus anxiety: a psychometric evaluation of Pandemic anxiety and Coronophobia scales from the latent and network perspective
Current Psychology (2024)
-
Predictors of compliance with COVID-19 guidelines across countries: the role of social norms, moral values, trust, stress, and demographic factors
Current Psychology (2024)
