
Abstract
Quantification of linkage disequilibrium (LD) patterns in the human genome is essential for genome-wide association studies, selection signature mapping and studies of recombination. Whole genome sequence (WGS) data provides optimal source data for this quantification as it is free from biases introduced by the design of array genotyping platforms. The Malécot-Morton model of LD allows the creation of a cumulative map for each choromosome, analogous to an LD form of a linkage map. Here we report LD maps generated from WGS data for a large population of European ancestry, as well as populations of Baganda, Ethiopian and Zulu ancestry. We achieve high average genetic marker densities of 2.3–4.6/kb. These maps show good agreement with prior, low resolution maps and are consistent between populations. Files are provided in BED format to allow researchers to readily utilise this resource.
Measurement(s) | Linkage Disequilibrium |
Technology Type(s) | whole genome sequencing |
Factor Type(s) | ethnic group |
Sample Characteristic - Organism | Homo sapiens |
Sample Characteristic - Location | Europe • Africa |
Machine-accessible metadata file describing the reported data: https://doi.org/10.6084/m9.figshare.9901838
Similar content being viewed by others

Background & Summary
Mapping of linkage disequilibrium (LD) is invaluable for many endeavours including identifying signatures of selection, refinement of signals in genome-wide association studies and studies into recombination1,2,3.
One approach to the quantification of LD is the generation of LD maps applying the Malécot-Morton model4,5. The product generated utilising the Malécot-Morton model are maps in cumulative linkage disequilibrium units (LDU), which are broadly analogous to an LD-based form of centimorgans. Previous studies have reported maps generated from array based genotyping data in multiple populations (e.g.6), allowing for cross-population comparisons.
The mathematical basis of LDMAP has been previously described4,5. In brief, LDMAP generates a cumulative map of LD distances between markers, based upon the Malécot-Morton model of association by distance:
where \(\widehat{\rho }\) is the association between two markers in a population, L is the component of \(\widehat{\rho }\) not due to LD, but due to confounding factors such as recent founder effects, M is the association at 0 distance (approximately 1 for monophyletic haplotypes), \(\epsilon \) is the rate of decline in the association between the markers and d is the physical distance between the markers5. The final LDU map is built by cumulative addition of \(\epsilon d\) for each inter-marker span.
The increasing availability of whole genome sequencing (WGS) data allows the investigation of LD patterns at the highest level, without the impact of issues such as ascertainment bias in the selection of single nucleotide polymorphism (SNP) markers. We have previously shown that WGS-based maps provide tangible benefits in their practical application. Arrays have been designed to give a reasonable coverage of LD information for a reduced set of SNPs, as such they have limited resolution and population-specific biases are introduced during SNP selection. Given that WGS variant identification is ‘hypothesis free’ (i.e. SNPs are not required to be pre-defined as in array genotyping), these data, and thus these maps, represent a maximally informative resource7.
The lack of ascertainment bias for SNP data collection is particularly important for African populations, as they have the greatest population diversity and are often under-represented in genomic studies. Though they are often underrepresented, these populations are particularly informative for many studies, given the extended time since a population bottleneck7,8. Higher resolution maps allow for analyses on a finer scale of the patterns of LD, such as structure within genes9.
Here, we report our generation of WGS based LD maps for four populations, one of European and three of African descent. These maps provide a valuable population genetic resource, providing a maximal resolution, selection bias free, dataset for studies which require the incorporation of LD statistics.
Methods
Autosomal WGS data from two cohort sequencing studies was utilised. African populations were sequenced within the African Genome Diversity Project8,10, utilising Illumina short read sequencing to an average depth of 4x. European ancestry individuals were sequenced by the Wellderly Study11, utilising Complete Genomics high depth sequencing. Multidimensional scaling as implemented in PLINK12 was applied to ensure genetic homogeneity within the sub-cohorts.
SNPs were subject to quality control prior to map generation. Specifically, they were required to have a minor allele frequency ≥1%, <5% genotype missingness and not to significantly deviate from Hardy-Weinberg equilibrium (at α = 10−3). All analyses were undertaken using the reference genome GRCh37 (hg19).
LD maps were made using LDMAP with default parameters. Owing to the computational intensity of LD map generation, this was performed for 12,000 marker overlapping segments, which were then concatenated into full chromosome maps, removing the 25 terminal markers of each segment to avoid end effects.
Data Records
LD maps reported here are freely available at https://doi.org/10.6084/m9.figshare.7850882 13. These data are in Browser Extensible Data (BED) format, including the cumulative LDU position of every SNP marker within the generated maps. Additionally, these data are also made available as the kb/LDU ratio for each inter-SNP span providing a view of the regional ‘intensity’ of LD.
For the African populations8, 95–100 individuals were utilised for each sub-population, yielding approximately 14 million SNP markers (Table 1). The European map utilised 454 individuals11, yielding approximately 7.5 million markers. The increased population diversity for the African compared to European population can be seen in the increase common SNP density, as well as the longer LDU length which corresponds to the longer total haplotypic diversity within a population.
Technical Validation
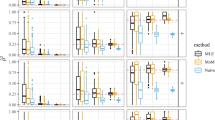
For these data, we can determine that they are robust as they are consistent with prior, lower resolution maps, and that they are consistent between populations assessed (Figs 1 and 2). As we know that patterns of recombination and thus LD are broadly consistent between populations, this meets our prior expectations; furthermore the total map lengths are proportional to time since an effective population bottleneck (being longer in African populations reflecting the additional diversity present)6,7,14.

Comparison of the four maps for chromosome 22. The raw cumulative maps are shown (left), as well as maps normalised to have the same total length (right). It can be seen that the contour profiles of the maps are highly similar, though there is variation in the total map length.

Comparison of the four maps for all autosomes. The raw cumulative maps are shown. It can be seen that the contour profiles of the maps are highly similar, with a consistend trend in LDU lengths for the populations, with European being consistently the shortest and Baganda/Zulu the longest.
Usage Notes
Maps can be readily incorporated into genomic analyses using tools such as BEDTools15, allowing annotation of regions with LD information for subsequent analysis such as determining whether a genomic feature has higher LD than background on average.
Genome wide association studies using a composite likelihood model can be undertaken with LD information as provided here, allowing for additional power for signal detection and refinement2,16.
Code Availability
The core LDMAP software is written in C, and made available at www.soton.ac.uk/genomicinformatics/research/ld.page.
References
Horscroft, C., Ennis, S., Pengelly, R. J., Sluckin, T. J. & Collins, A. Sequencing era methods for identifying signatures of selection in the genome. Briefings in Bioinformatics bby064 (2018).
Elding, H., Lau, W., Swallow, D. M. & Maniatis, N. Refinement in localization and identification of gene regions associated with crohn disease. American Journal of Human Genetics 92, 107–113 (2013).
Auton, A. & McVean, G. Recombination rate estimation in the presence of hotspots. Genome Research 17, 1219–1227 (2007).
Kuo, T.-Y., Lau, W. & Collins, A. R. LDMAP: the construction of high-resolution linkage disequilibrium maps of the human genome. In Collins, A. R. (ed.) Linkage Disequilibrium and Association Mapping, vol. 376 of Methods in Molecular Biology, 47–57 (Humana Press, 2007).
Tapper, W. et al. A map of the human genome in linkage disequilibrium units. Proc Natl Acad Sci USA 102, 11835–9 (2005).
Service, S. et al. Magnitude and distribution of linkage disequilibrium in population isolates and implications for genome-wide association studies. Nature Genetics 38, 556 (2006).
Pengelly, R. J. et al. Whole genome sequences are required to fully resolve the linkage disequilibrium structure of human populations. BMC Genomics 16, 666 (2015).
Gurdasani, D. et al. The african genome variation project shapes medical genetics in africa. Nature 517, 327 (2015).
Vergara-Lope, A., Ennis, S., Vorechovsky, I., Pengelly, R. J. & Collins, A. Heterogeneity in the extent of linkage disequilibrium among exonic, intronic, non-coding RNA and intergenic chromosome regions. European Journal of Human Genetics 27, 1436–1444 (2019).
European Genome-phenome Archive, https://identifiers.org/ega.dataset:EGAD00001001663 (2015).
Erikson, G. A. et al. Whole-genome sequencing of a healthy aging cohort. Cell 165, 1002–1011 (2016).
Purcell, S. et al. Plink: a tool set for whole-genome association and population-based linkage analyses. American Journal of Human Genetics 81, 559–75 (2007).
Jabalameli, M. R. et al. Whole-genome Linkage Disequilibrium Maps for European and African Populations. Figshare. https://doi.org/10.6084/m9.figshare.7850882.v1 (2019).
Bhérer, C., Campbell, C. L. & Auton, A. Refined genetic maps reveal sexual dimorphism in human meiotic recombination at multiple scales. Nature Communications 8, 14994 (2017).
Quinlan, A. R. & Hall, I. M. Bedtools: a flexible suite of utilities for comparing genomic features. Bioinformatics 26, 841–842 (2010).
Collins, A. & Lau, W. Chromscan: genome-wide association using a linkage disequilibrium map. Journal of Human Genetics 53, 121–126 (2008).
Acknowledgements
The authors acknowledge the use of the IRIDIS High Performance Computing Facility, and associated support services at the University of Southampton, in the completion of this work.
Author information
Authors and Affiliations
Contributions
A.V.-L. undertook data analysis. M.R.J. undertook data analysis. C.H. undertook data analysis. S.E. contributed to study design and supervision. A.C. contributed to study design and supervision. R.J.P. contributed to study design, data analysis, supervision and wrote the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
The Creative Commons Public Domain Dedication waiver http://creativecommons.org/publicdomain/zero/1.0/ applies to the metadata files associated with this article.
About this article

Cite this article
Vergara-Lope, A., Jabalameli, M.R., Horscroft, C. et al. Linkage disequilibrium maps for European and African populations constructed from whole genome sequence data. Sci Data 6, 208 (2019). https://doi.org/10.1038/s41597-019-0227-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-019-0227-y
This article is cited by
-
Polygenic prediction of human longevity on the supposition of pervasive pleiotropy
Scientific Reports (2024)
-
Diversity in human genetics studies accelerates discovery and improves health care
Nature Reviews Cardiology (2022)
-
Rare variant association testing in the non-coding genome
Human Genetics (2020)
