
Abstract
Domestication of horses fundamentally transformed long-range mobility and warfare1. However, modern domesticated breeds do not descend from the earliest domestic horse lineage associated with archaeological evidence of bridling, milking and corralling2,3,4 at Botai, Central Asia around 3500 bc3. Other longstanding candidate regions for horse domestication, such as Iberia5 and Anatolia6, have also recently been challenged. Thus, the genetic, geographic and temporal origins of modern domestic horses have remained unknown. Here we pinpoint the Western Eurasian steppes, especially the lower Volga-Don region, as the homeland of modern domestic horses. Furthermore, we map the population changes accompanying domestication from 273 ancient horse genomes. This reveals that modern domestic horses ultimately replaced almost all other local populations as they expanded rapidly across Eurasia from about 2000 bc, synchronously with equestrian material culture, including Sintashta spoke-wheeled chariots. We find that equestrianism involved strong selection for critical locomotor and behavioural adaptations at the GSDMC and ZFPM1 genes. Our results reject the commonly held association7 between horseback riding and the massive expansion of Yamnaya steppe pastoralists into Europe around 3000 bc8,9 driving the spread of Indo-European languages10. This contrasts with the scenario in Asia where Indo-Iranian languages, chariots and horses spread together, following the early second millennium bc Sintashta culture11,12.
Similar content being viewed by others


Main
We gathered horse remains encompassing all suspected domestication centres, including Iberia, Anatolia and the steppes of Western Eurasia and Central Asia (Fig 1a). The sampling targeted previously under-represented time periods, with 201 radiocarbon dates spanning 44426 to 202 bc, and five beyond 50250 to 47950 bc (Supplementary Table 1).

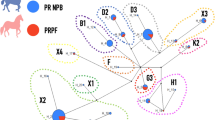
a, Temporal and geographic sampling. The red star indicates the location of the two TURG horses (late Yamnaya context) showing genetic continuity with DOM2. The dashed line indicates the inferred homeland of DOM2 horses in the lower Volga-Don region. Colours refer to regions and/or time periods delineating genetically close horses. The radius of each cylinder is proportional to the number of samples analysed (for <10 specimens; radius constant above this), and the height refers to the time range covered. b, Neighbour-joining phylogenomic tree (100 bootstrap pseudo-replicates). Samples are coloured according to a and the main phylogenetic clusters are numbered from 1 to 4. c, Fold difference between neighbour-joining-based and raw pairwise genetic distances. d, Pairwise distance matrix of Struct-f4 genetic affinities between samples. Increasing genetic affinities are indicated by a yellow-to-red gradient. e, Struct-f4 ancestry component profiles. f, Ancestry profiles of selected key horse groups and samples. PRZE, Przewalski; UP-SFR, Upper Palaeolithic Southern France.
The DNA quality enabled shotgun sequencing of 264 ancient genomes at 0.10× to 25.76× average coverage (239 genomes above 1× coverage), including 16 genomes for which further sequencing added to previously reported data. Enzymatic13 and computational removal of post mortem DNA damage produced high-quality data with derived mutations decreasing with sample age, as expected if mutations accumulate through time (Extended Data Fig. 1). We added ten published modern genomes, and nine ancient genomes characterized with consistent technology or covering relevant time periods and locations, to obtain the most extensive high-quality genome time series for horses.
Pre-domestication population structure
Neighbour-joining phylogenomic inference revealed four geographically defined monophyletic groups (Fig 1b). These closely mirrored clusters identified using an extension of the Struct-f4 method5 (Fig 1d–f, Extended Data Fig. 2, Supplementary Methods), except for the Neolithic Anatolia group (NEO-ANA), where the tree-to-data goodness of fit suggested phylogenetic misplacement (Fig 1c, Supplementary Methods).
The most basal cluster included Equus lenensis (ELEN), a lineage identified in northeastern Siberia from the Late Pleistocene to the late fourth millennium bc5,14,15. A second group covered Europe, including Late Pleistocene Romania, Belgium, France and Britain, and the region from Spain to Scandinavia and Hungary, Czechia and Poland during the sixth-to-third millennium bc. The third cluster comprised the earliest known domestic horses from Botai and Przewalski’s horses, as previously reported3, and extended to the Altai and Southern Urals during the fifth-to-third millennium bc. Finally, modern domestic horses clustered within a group that became geographically widespread and prominent following about 2200 bc and during the second millennium bc (DOM2). This cluster appears genetically close to horses that lived in the Western Eurasia steppes (WE) but not further west than the Romanian lower Danube, south of the Carpathians, before and during the third millennium bc. Significant correlation between genetic and geographic distances, and inference of limited long-distance connectivity with estimated effective migration surface16 (EEMS), confirmed the strong geographic differentiation of horse populations before about 3000 bc (Fig 2a, Extended Data Fig. 3a).

a–c, EEMS-predicted migration barriers16 and average ancestry components found in each archaeological site from before 3000 bc (a), during the third millennium bc (b) and after around 2000 bc (c). The size of the pie charts is proportional to the number of samples analysed in a given location (<10, constant above). Pie chart colours refer to K = 6 ancestry components, averaged per location. Regions inferred as geographic barriers are shown in shades of brown, and regions affected by migrations are shown in shades of blue. The base map was obtained from rworldmap46.
Horse ancestry profiles in Neolithic Anatolia and Eneolithic Central Asia, including at Botai, maximized a genetic component (coloured green in Fig. 1e, f) that was also substantial in Central and Eastern Europe during the Late Pleistocene (RONPC06_Rom_m34801) and the fourth or third millennium bc (Figs. 1e, 3a, Extended Data Fig. 4). It was, however, absent or moderately present in the Romanian lower Danube (ENEO-ROM), the Dnieper steppes (Ukr11_Ukr_m4185) and the western lower Volga-Don (C-PONT) populations during the sixth to third millennia bc. This indicates possible expansions of Anatolian horses into both Central and Eastern Europe and Central Asia regions, but not into the Western Eurasia steppes. The absence of typical NEO-ANA ancestry rules out expansion from Anatolia into Central Asia across the Caucasus mountains but supports connectivity south of the Caspian Sea prior to about 3500 bc.

a, Multi-dimensional scaling plot of f4-based genetic affinities. The age of the samples is indicated along the vertical axis. CA, Central Asia. b, Horse evolutionary history inferred by OrientAGraph19 with three migration edges and nine lineages representing key genomic ancestries (coloured as in Fig 1a). The model explains 99.99% of the total variance. The triangular pairwise matrix provides model residuals. The external branch leading to donkey was set to zero to improve visualization. c, LOCATOR20 predictions of the geographic region where the ancestors of DOM2, tarpan and modern Przewalski’s horses lived. The tarpan and modern Przewalski’s horses do not descend from the same ancestral population as modern domestic horses. The map was drawn using the maps R package47.
The origins of DOM2 horses
The C-PONT group not only possessed moderate NEO-ANA ancestry, but also was the first region where the typical DOM2 ancestry component (coloured orange in Fig. 1e, f) became dominant during the sixth millennium bc. Multi-dimensional scaling further identified three horses from the western lower Volga-Don region as genetically closest to DOM2, associated with Steppe Maykop (Aygurskii), Yamnaya (Repin) and Poltavka (Sosnovka) contexts, dated to about 3500 to 2600 bc (Figs. 2a, b, 3a). Additionally, genetic continuity with DOM2 was rejected for all horses predating about 2200 bc, especially those from the NEO-ANA group (Supplementary Table 2), except for two late Yamnaya specimens from approximately 2900 to 2600 bc (Turganik (TURG)), located further east than the western lower Volga-Don region (Figs. 2a, b, 3a). These may therefore have provided some of the direct ancestors of DOM2 horses.
Modelling of the DOM2 population with qpADM17, rotating18 all combinations of 2, 3 or 4 population donors, eliminated the possibility of a contribution from the NEO-ANA population, but indicated possible formation within the WE population, including a genetic contribution of approximately 95% from C-PONT and TURG horses (Supplementary Table 3). This was consistent with OrientAGraph19 modelling from nine lineages representing key ancestry combinations, which confirmed the absence of NEO-ANA genetic ancestry in DOM2 and confirmed DOM2 as a sister population to the C-PONT horses (Fig. 3b).
Identifying discrete populations and modelling admixture as single unidirectional pulses, however, was highly challenging given the extent of spatial genetic connectivity. Indeed, the typical DOM2 ancestry component was maximized in the C-PONT group, but declined sharply eastwards (TURG and Central Asia) in the third millennium bc as the proportion of NEO-ANA ancestry increased (Fig. 2a). This suggests a cline of genetic connectivity east of the Western Eurasia steppes and Central Asia, ruling out DOM2 ancestors further east than the western lower Volga-Don and Turganik. A similar genetic cline characterized the region located west of C-PONT, where the typical DOM2 ancestry component declined steadily in the Dnieper steppes, Poland, Turkish Thrace and Hungary in the fifth to third millennia bc. This eliminates the possibility of DOM2 ancestors further west than C-PONT and the Dnieper steppes. Furthermore, patterns of spatial autocorrelations in the genetic data20 indicated Western Eurasia steppes as the most likely geographic location of DOM2 ancestors (Fig. 3c). Combined, our results demonstrate that DOM2 ancestors lived in the Western Eurasia steppes, especially the lower Volga-Don, but not in Anatolia, during the late fourth and early third millennia bc.
Expansion of steppe-related pastoralism
Analyses of ancient human genomes have revealed a massive expansion from the Western Eurasia steppes into Central and Eastern Europe during the third millennium bc, associated with the Yamnaya culture8,9,11,12,21. This expansion contributed at least two thirds of steppe-related ancestry to populations of the Corded Ware complex (CWC) around 2900 to 2300 bc8. The role of horses in this expansion remained unclear, as oxen could have pulled Yamnaya heavy, solid-wheeled wagons7,22. The genetic profile of horses from CWC contexts, however, almost completely lacked the ancestry maximized in DOM2 and Yamnaya horses (TURG and Repin) (Figs. 1e, f, 2a, b) and showed no direct connection with the WE group, including both C-PONT and TURG, in OrientAGraph modelling (Fig. 3b, Extended Data Fig. 5).
The typical DOM2 ancestry was also limited in pre-CWC horses from Denmark, Poland and Czechia, associated with the Funnel Beaker and early Pitted Ware cultures (FB/PWC, FB/POL and ENEO-CZE, respectively). DOM2 ancestry reached a maximum 12.5% in one Hungarian horse dated to the mid-third millennium bc and associated with the Somogyvár-Vinkovci Culture (CAR05_Hun_m2458). qpAdm17 modelling indicated that its DOM2 ancestry was acquired following gene flow from southern Thrace (Kan22_Tur_m2386), but not from the Dnieper steppes (Ukr11_Ukr_m4185) (Supplementary Table 3). Combined with the lack of increased horse dispersal during the early third millennium bc (Fig. 2b, Extended Data Fig. 3b), these results suggest that DOM2 horses did not accompany the steppe pastoralist expansion north of the Carpathians.
By around 2200–2000 bc, the typical DOM2 ancestry profile appeared outside the Western Eurasia steppes in Bohemia (Holubice), the lower Danube (Gordinesti II) and central Anatolia (Acemhöyük), spreading across Eurasia shortly afterwards, eventually replacing all pre-existing lineages (Fig 2c, Extended Data Fig. 3c). Eurasia became characterized by high genetic connectivity, supporting massive horse dispersal by the late third millennium and early second millennium bc. This process involved stallions and mares, indicated by autosomal and X-chromosomal variation (Extended Data Fig. 3d), and was sustained by explosive demographics apparent in both mitochondrial and Y-chromosomal variation (Extended Data Fig. 3e, f). Altogether, our genomic data uncover a high turnover of the horse population in which past breeders produced large stocks of DOM2 horses to supply increasing demands for horse-based mobility from around 2200 bc.
Of note, the DOM2 genetic profile was ubiquitous among horses buried in Sintashta kurgans together with the earliest spoke-wheeled chariots around 2000–1800 bc7,9,23,24 (Extended Data Fig. 6). A typical DOM2 profile was also found in Central Anatolia (AC9016_Tur_m1900), concurrent with two-wheeled vehicle iconography from about 1900 bc25,26. However, the rise of such profiles in Holubice, Gordinesti II and Acemhöyük before the earliest evidence for chariots supports horseback riding fuelling the initial dispersal of DOM2 horses outside their core region, in line with Mesopotamian iconography during the late third and early second millennia bc27. Therefore, a combination of chariots and equestrianism is likely to have spread the DOM2 diaspora in a range of social contexts from urban states to dispersed decentralized societies28.
DOM2 biological adaptations
Human-induced DOM2 dispersal conceivably involved selection of phenotypic characteristics linked to horseback riding and chariotry. We therefore screened our data for genetic variants that are over-represented in DOM2 horses from the late third millennium bc (Extended Data Fig. 7). The first outstanding locus peaked immediately upstream of the GSDMC gene, where sequence coverage dropped at two L1 transposable elements in all lineages except DOM2. The presence of additional exons in other mammals suggests that independent L1 insertions remodelled the DOM2 gene structure. In humans, GSDMC is a strong marker for chronic back pain29 and lumbar spinal stenosis, a syndrome causing vertebral disk hardening and painful walking30.
The second most differentiated locus extended over approximately 16 Mb on chromosome 3, with the ZFPM1 gene being closest to the selection peak. ZFPM1 is essential for the development of dorsal raphe serotonergic neurons involved in mood regulation31 and aggressive behaviour32. ZFPM1 inactivation in mice causes anxiety disorders and contextual fear memory31. Combined, early selection at GSDMC and ZFPM1 suggests shifting use toward horses that were more docile, more resilient to stress and involved in new locomotor exercise, including endurance running, weight bearing and/or warfare.
Evolutionary history and origins of tarpan horses
Our analyses elucidate the geographic, temporal and biological origins of DOM2 horses. This study features a diverse ancient horse genome dataset, revealing the presence of deep mitochondrial and/or Y-chromosomal haplotypes in non-DOM2 horses (Supplementary Fig 1). This suggests that yet-unsampled divergent populations contributed to forming several lineages excluding DOM2. This was especially true in the Iberian group (IBE), where the expected genetic distance to the donkey was reduced (Extended Data Fig. 5f), but also in NEO-ANA according to OrientAGraph modelling (Fig 3b). Disentangling exact divergence and ancestry contributions of such unsampled lineages is difficult with the currently available data. It can, however, be stressed that Iberia and Anatolia represent two well-known refugia33, where populations could have survived and mixed during Ice Ages.
Finally, our analyses have solved the mysterious origins of the tarpan horse, which became extinct in the early 20th century. The tarpan horse came about following admixture between horses native to Europe (modelled as having 28.8–34.2% and 32.2–33.2% CWC ancestry in OrientAGraph19 and qpAdm17, respectively) and horses closely related to DOM2. This is consistent with LOCATOR20 predicting ancestors in western Ukraine (Fig 3c) and refutes previous hypotheses depicting tarpans as the wild ancestor or a feral version of DOM2, or a hybrid with Przewalski’s horses34.
Discussion
This work resolves longstanding debates about the origins and spread of domestic horses. Whereas horses living in the Western Eurasia steppes in the late fourth and early third millennia bc were the ancestors of DOM2 horses, there is no evidence that they facilitated the expansion of the human genetic steppe ancestry into Europe8,9 as previously hypothesized7. Instead of horse-mounted warfare, declining populations during the European late Neolithic35 may thus have opened up an opportunity for a westward expansion of steppe pastoralists. Yamnaya horses at Repin and Turganik carried more DOM2 genetic affinity than presumably wild horses from hunter-gatherer sites of the sixth millennium bc (NEO-NCAS, from approximately 5500–5200 bc), which may suggest early horse management and herding practices. Regardless, Yamnaya pastoralism did not spread horses far outside their native range, similar to the Botai horse domestication, which remained a localized practice within a sedentary settlement system2,36. The globalization stage started later, when DOM2 horses dispersed outside their core region, first reaching Anatolia, the lower Danube, Bohemia and Central Asia by approximately 2200 to 2000 bc, then Western Europe and Mongolia soon afterwards, ultimately replacing all local populations by around 1500 to 1000 bc. This process first involved horseback riding, as spoke-wheeled chariots represent later technological innovations, emerging around 2000 to 1800 bc in the Trans-Ural Sintashta culture7. The weaponry, warriors and fortified settlements associated with this culture may have arisen in response to increased aridity and competition for critical grazing lands, intensifying territoriality and hierarchy37. This may have provided the basis for the conquests over the subsequent centuries that resulted in an almost complete human and horse genetic turnover in Central Asian steppes11,21. The expansion to the Carpathian basin38, and possibly Anatolia and the Levant, involved a different scenario in which specialized horse trainers and chariot builders spread with the horse trade and riding. In both cases, horses with reduced back pathologies and enhanced docility would have facilitated Bronze Age elite long-distance trade demands and become a highly valued commodity and status symbol, resulting in rapid diaspora. We, however, acknowledge substantial spatiotemporal variability and evidential bias towards elite activities, so we do not discount additional, harder to evidence, factors in equine dispersal.
Our results also have important implications for mechanisms underpinning two major language dispersals. The expansion of the Indo-European language family from the Western Eurasia steppes has traditionally been associated with mounted pastoralism, with the CWC serving as a major stepping stone in Europe39,40,41. However, while there is overwhelming lexical evidence for horse domestication, horse-drawn chariots and derived mythologies in the Indo-Iranian branch of the Indo-European family, the linguistic indications of horse-keeping practices at the deeper Proto-Indo-European level are in fact ambiguous42 (Supplementary Discussion) . The limited presence of horses in CWC assemblages43 and the local genetic makeup of CWC specimens reject scenarios in which horses were the primary driving force behind the initial spread of Indo-European languages in Europe44. By contrast, DOM2 dispersal in Asia during the early-to-mid second millennium bc was concurrent with the spread of chariotry and Indo-Iranian languages, whose earliest speakers are linked to populations that directly preceded the Sintashta culture11,12,45. We thus conclude that the new package of chariotry and improved breed of horses, including chestnut coat colouration documented both linguistically (Supplementary Discussion) and genetically (Extended Data Fig. 8), transformed Eurasian Bronze Age societies globally within a few centuries after about 2000 bc. The adoption of this new institution, whether for warfare, prestige or both, probably varied between decentralized chiefdoms in Europe and urbanized states in Western Asia. The results thus open up new research avenues into the historical developments of these different societal trajectories.
Methods
Radiocarbon dating
A total of 170 new radiocarbon dates were obtained in this study. Dating was carried out at the Keck Carbon Cycle AMS Laboratory, UC Irvine following collagen extraction and ultra-filtration from approximately 1 g of osseous material. IntCal20 calibration48 was performed using OxCalOnline49.
Genome sequencing
All samples were collected with permission from the organizations holding the collections and documented through official authorization letters for partially destructive sampling from local authorities. Samples were processed for DNA extraction, library construction and shallow sequencing in the ancient DNA facilities of the Centre for Anthropobiology and Genomics of Toulouse (CAGT), France. The overall methodology followed the work from Seguin–Orlando and colleagues50. It involved: (1) powdering a total of 100–590 mg of osseous material using the Mixel Mill MM200 (Retsch) Micro-dismembrator; (2) extracting DNA following the procedure Y2 from Gamba and colleagues51, tailored to facilitate the recovery of even the shortest DNA fragments; (3) treating DNA extracts with the USER (NEB) enzymatic cocktail to eliminate a fraction of post mortem DNA damage13; (4) constructing from double-stranded DNA templates DNA libraries in which two internal indexes are added during adapter ligation and one external index is added during PCR amplification; and (5) amplification, purification and quantification of DNA libraries before pooling 20–50 DNA libraries for low-depth sequencing on the Illumina MiniSeq instrument (paired-end mode, 2 × 80). All three indexes of each library were unique in a given sequencing pool.
Raw fastQ files were demultiplexed, trimmed and collapsed when individual read pairs showed significant overlap using AdapterRemoval252 (version 2.3.0), disregarding reads shorter than 25 bp. Processed reads were then aligned against the nuclear and mitochondrial horse reference genomes53,54, and appended with the Y-chromosome contigs from55 using the Paleomix bam_pipeline (version 1.2.13.2) with the mapping parameters recommended by Poullet and Orlando56. Sequencing reads representing PCR duplicates or showing a mapping quality below 25 were disregarded. DNA fragmentation and nucleotide misincorporation patterns were assessed on the basis of 100,000 random mapped reads using mapDamage257 (version 2.0.8). Paleomix returned provisional estimates of endogenous DNA content and clonality, as defined by the fraction of retained reads mapping uniquely against the horse reference genomes and those mapping at the same genomic coordinates, respectively. These numbers guided further experimental decisions, including (1) the sequencing effort to be performed per individual library; (2) the preparation of additional libraries from left-over aliquots of USER-treated DNA extracts, or following treatment of DNA extract aliquots with the USER enzymatic cocktail; and (3) the preparation of additional DNA extracts. After initial screening for library content, sequencing was carried out on the Illumina HiSeq4000 instruments from Genoscope (paired-end mode, 2 × 76; France Génomique), except for four samples (BPTDG1_Fra_m11800, Closeau3_Fra_m10400, Novoil1_Kaz_m1832 and Novoil2_Kaz_m1832), for which sequencing was done at Novogene Europe on an Illumina NovaSeq 6000 instrument (S4 lanes, paired-end mode, 2 × 150). Overall, we obtained sequence data for a total of 264 novel ancient horse specimens and 1,029 DNA libraries (980 new), summing up to 31.86 billion sequencing read pairs and 100.82 billion collapsed read pairs, which was sufficient to characterize 226 novel ancient genomes showing a genomic depth-of-coverage of at least 1× (median 2.80-fold, maximum 25.76-fold) (Supplementary Table 1).
Allele sampling, sequencing error rates, genome rescaling and trimming
Following previous work5,58, error rates are defined as the excess of mutations that are private to the ancient genome, relative to a modern genome considered as error-free. Mutations were polarized using an outgroup genome representing a consensus built from seven male specimens of diverse equine species (Equus africanus somaliensis, Equus asinus, Equus burchelli, Equus grevyi, Equus hartmannae, Equus hemionus onager and Equus kiang59), according to a majority rule in which at maximum 2 of the 7 individuals showed an alternative allele. Minor and major alleles were identified using ANGSD60 (version 0.933-86-g3fefdc4, htslib: 1.10.2-106-g9c35744) and the following parameters: -baq 0 -doMajorMinor 2 -uniqueOnly 1 -minMapQ 25 -minQ 30 -minind 7 -doCounts 1 -doMaf 1.
Error rate estimates ranged between 0.000337 and 0.003966 errors per site and revealed that nucleotide C→T and G→A misincorporation rates were still inflated relative to their reciprocal substitution types (T→C and A→G), despite USER treatment. Therefore, individual BAM alignment files were processed to further reduce nucleotide misincorporation rates. To achieve this, we used PMDtools61 (version 0.60) to bin apart reads likely containing post mortem DNA damage (--threshold 1; DAM) from those that did not (--upperthreshold 1; NODAM). NODAM-aligned reads were then directly trimmed by 5 bp at their ends, where individual base qualities generally drop. The base quality of aligned DAM reads was first rescaled using mapDamage257 (version 2.0.8), penalizing all instances of potential derivatives of post mortem cytosine deamination, then further trimmed by 10 bp at both ends. The resulting NODAM and DAM aligned reads were merged again to obtain final BAM sequence alignments. Final error rate estimates ranged between 0.000080 and 0.000933 errors per site (Supplementary Table 1).
Uniparentally inherited markers and coat colouration
Mitochondrial genomes for the 264 newly sequenced samples were characterized from quality-filtered BAM alignment files (minMapQ=25, minQ=30), using a majority rule requiring at least five individual reads per position. Their resulting complete mitochondrial genome sequences were aligned together with a total of 193 sequences previously characterized3,5,14,15,58,62,63 using mafft64 (version 7.407). Sequence alignments were split into six partitions, following previous work5, including the control region, all tRNAs, both rRNAs and each codon position considered separately. Maximum-likelihood phylogenetic reconstruction was performed using RAxML65 (version 8.2.11) with default parameters, and assessing node support from a total of 100 bootstrap pseudo-replicates. The same partitions were provided as input for BEAST66 (version 2.5.1), together with calibrated radiocarbon years (Supplementary Table 1). Specimens lacking direct radiocarbon dates or identified as not belonging to the DOM2 cluster were disregarded (Supplementary Table 1). While the former ensured precise tip-calibration for molecular clock estimation (assuming uncorrelated log-normal relaxed model), the latter prevented misinterpreting spatial variation in the population structure as changes in the effective population size67. The best substitution model was selected from ModelGenerator68 (version 0.85) and Bayesian Skyline plots69 were retrieved following 1,000,000,000 generations, sampling 1 every 1,000 and disregarding the first 30% as burn-in. Convergence was visually checked in Tracer70 (version 1.7.2).
The Y-chromosome maximum-likelihood tree was constructed calling individual haplotypes from trimmed and rescaled BAM sequence alignments against the contigs described by Felkel and colleagues55, filtered for single copy MSY regions. The final multifasta sequence alignment included sites covered in at least 20% of the specimens, pseudo-haploidizing each position and filtering out transitions, as done with autosomal data. It was further restricted to specimens showing at least 20% of the final set of positions covered. This represented a total of 3,195 nucleotide transversions for 142 specimens. The final tree was computed using IQtree (version 1.6.12), following AICc selection of the best substitution model and 1,000 ultrafast bootstrap approximation for assessing node support71,72. The Y-chromosome Bayesian skyline plot was obtained following the same procedure as above. Maximum-likelihood trees and Bayesian skyline plots are shown in Supplementary Fig 1 and Extended Data Fig. 3e, f, respectively.
The presence of alleles associated with or causative for a diversity of coat colouration changes was investigated using individual BAM read alignments. For a total of 43 genomic locations representing biallelic SNPs, we simply counted the proportion of reads supporting the associated or causative allele. Results were summarized in the heat map shown in Extended Data Fig. 8, with respect to the sample ordering displayed in the neighbour-joining phylogenetic reconstruction, and limited to those 13 loci that were polymorphic in our horse panel for clarity.
Neighbour-joining phylogeny, genetic continuity and population modelling
Phylogenetic affinities were first estimated by performing a BioNJ tree reconstruction with FastME73 (version 2.1.4), based on the pairwise matrix of genetic distances inferred from the bed2diffs_v1 program16. Node supports were assessed using a total of 100 bootstrap pseudo-replicates. The ‘goodness-of-fit’ of the neighbour-joining tree to the data was evaluated by comparing the patristic distances and raw pairwise distances. Patristic distances were obtained from the ape74 R package (version 5.5) and their ratios to raw pairwise distances were averaged for each given individual (Fig 1c). Averaged ratios equal to one support perfect phylogenetic placement for the specimen considered.
Genetic continuity between each individual specimen predating about 2200 bc and DOM2 horses was tested following the methodology from Schraiber75, which implements a likelihood-ratio test to compare the statistical support for placing DOM2 and the ancient specimen in a direct line of ancestry or as two sister groups. This methodology relies on exact allele frequency estimates within DOM2 and read counts for putatively ancestral ancient samples. To exclude residual sequencing errors within DOM2 horses, we, thus, conditioned these analyses on variants segregating at least as doubletons in positions covered in at least 75% of the DOM2 samples. Linked variation was pruned using Plink76 (version v.1.9), with the following parameters, --indep-pairwise 50 10 0.2, which provided a panel of about 1.4 million transversions. Allele frequencies were polarized considering the outgroup genome used for measuring error rates. Results from direct ancestry tests are summarized in Supplementary Table 2.
The complex genetic makeup of some individuals (CAR05_Hun_m2458 and Kan22_Tur_m2386) and/or group of individuals (DOM2) was investigated using the f4-statistics-based ancestry decomposition approach implemented in qpAdm17 (version 7.0), in which one particular (group of) individual(s) is modelled as a linear, additive combination of candidate population sources (‘left’ populations). We followed the rotating strategy recommended by Harney and colleagues18 to assess all possible combinations of two, three and four donors (‘left’) selected from a total of 18 populations. The remaining 14, 15 and 16 populations were used as reference (‘right’) populations (Supplementary Table 3).
We selected a total of nine horse lineages representing the main phylogenetic clusters, and carrying genetic ancestry profiles representative of the complete dataset, to model the population evolutionary history using OrientAGraph19 (version 1.0). By implementing a network orientation subroutine that enables throughout exploration of the graph space, OrientAGraph constitutes a marked advancement in the automated inference of admixture graphs. We considered scenarios from zero to five migration pulses (M = 0 to 5; Extended Data Fig. 5a–e), and the population model assuming M = 3 is represented in Fig 3b. This analysis was conditioned on sites covered at least in one specimen of each population group. This filter yielded a set of 7,936,493 fully orthologous nucleotide transversions.
Struct-f4, ancestry components and multi-dimensional scaling
We extended the Struct-f4 package so as to assess individual genetic affinities within a panel of genomes, and to decompose them into K genetic ancestries. Struct-f4, thus, achieves similar objectives to other clustering methods, such as ADMIXTURE77 and Ohana78, but does not assume Hardy–Weinberg equilibrium. The latter assumption is known to cause misinterpretation of highly drifted samples as ancestral homogeneous groups instead of highly derived mixtures from multiple populations, as thoroughly described elsewhere79. To circumvent this, Struct-f4 relies on the calculation of the widely used f4 statistics, which were originally devised not only to test for admixture, but also to quantify the drift between the internal nodes of a population tree. The latter provides a direct representation of the true ancestral populations. Overall, Struct-f4 thus implements a more natural and robust (model-free) approach than other clustering alternatives.
Struct-f4 is based on a mixture model that parametrizes the drift that occurred between a given number of K pre-defined ancestral populations, and the mixing coefficient of each individual. Model parameters are estimated using an adaptive Metropolis–Hastings Markov chain Monte Carlo integration, identifying optimal numerical solutions for parameters by means of likelihood maximization. Struct-f4 was validated following extensive coalescent simulations with fastsimcoal280 (version 2.6.0.3). An example of such simulation designed to mimic the complex horse evolutionary history is provided in Extended Data Fig. 2, based on mutation and recombination rates of 2.3 × 10−8 and 10−8 events per generation and bp, respectively. Struct-f4 is implemented in Rcpp and only takes the full set of f4-statistics as input to automatically return individual ancestry coefficients, without requiring pre-defined, ad-hoc sets of reference and test populations.
Multi-dimensional scaling was carried out based on the co-ancestry semi-matrix summarizing the drift measured between each pair of individuals, as returned by Struct-f4, removing the domestic donkey outgroup prior to using the cmdscale R function.
Isolation by distance and spatial connectivity
Spatial barriers to gene flow prior to about 3000 bc, between about 3000 and 2000 bc and following about 2000 bc were run using EEMS16 (built with Eigen version 3.2.2 and Boost version 1.57, and using rEEMSplots version 0.0.0.9000) for 50 million iterations and considering a burn-in of 15 million iterations. Convergence was ensured from visual inspection of likelihood trajectories as well as by the strong correlation obtained between the observed and fitted genetic dissimilarities. Pie-charts depicting the ancestry proportions inferred by Struct-f4 were overlaid on the migration surfaces to facilitate tracking the geographic position of each excavation site, averaging ancestry proportions or using individual ancestry profiles if only one sample was characterized genetically at that location. Spatial pie-chart projection was carried out using the draw.pie R function from the mapplots package81 (version 1.5.1). The size of each individual pie-chart was commensurate with the number of samples excavated at a given geographic location, provided that the number of samples was lower than 10, while set to a constant maximum radius otherwise.
Partial Mantel tests measuring the correlation between geographic and genomic distances over time were carried out using the ncf R package82 (version 1.2.9). This test corrected for the time variation present within each window, similar to the approach described by Loog and colleagues83. Haversine geographic distances between pairs of ancient samples were computed using the geosphere package (version 1.5.10) in R84, from the corresponding longitude and latitude coordinates, while radiocarbon date ages were considered as point estimates (Supplementary Table 1). The matrix of pairwise genetic distances was obtained from the bed2diffs_v1 program provided together with the EEMS software16. The analysis was carried out for autosomes and the X chromosome separately, so as to investigate possible sex-bias in horse dispersal. Confidence intervals were calculated by sampling with replacement individuals within each time window.
Sliding time windows (step size = 250 years) were broadened forward in time until including at least ten specimens covering two-thirds of the total geographic area sampled in this study. The area delimited by a set or subset of GPS coordinates was calculated using the GeoRange R package85 (version 0.1.0) and the age of the window was set to the average age amongst the samples included. Additionally, pairwise distances involving samples located less than 500 km away and separated by less than 500 years were masked in the corresponding matrices to estimate the patterns of isolation by distance between demes, instead of within demes. This whole scheme was designed to prevent regional effects, caused by the over-representation of particular regions in specific time intervals.
The LOCATOR20 program (version 1.2) was run using a geolocated reference panel consisting of all non-DOM2 horses (n = 136), except the tarpan and the four Przewalski’s horses present in our dataset, and considering nucleotide transversions covered at least in 75% of the samples, for a total of 3,194,008 SNPs. The geographic origin of each DOM2 horse was then estimated from the geographic structure defined by the populations present in the reference panel. Default parameters were used, except that the width of each neural layer was 512 (instead of 256). The best run was selected as the one showing the lowest validation error from a total of 50 independent runs. The analysis was repeated for the tarpan as well as the four Przewalski’s horses present in our dataset.
Selection scans
To pinpoint genetic changes potentially underlying biological adaptation within DOM2 horses, we contrasted the frequency of each nucleotide transversion in our dataset (n = 10,205,277) in DOM2 (n = 141) and non-DOM2 horses (n = 142). The extensive number of samples represented provided unprecedented resolution into patterns of allele frequency differentiation, and encompassed the largest diversity of non-DOM2 horses characterized to date. Weir and Cockerham FST index values between both groups were calculated using Plink76 (version 1.9) and visualized using the GViz R package86 (version 1.36.2), together with external genomic tracks provided by the gene models annotated for EquCab3 (Ensembl v0.102) and the interrupted repeats precomputed for the same assembly and stored in the UCSC browser.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this paper.
Data availability
All collapsed and paired-end sequence data for samples sequenced in this study are available in compressed fastq format through the European Nucleotide Archive under accession number PRJEB44430, together with rescaled and trimmed bam sequence alignments against both the nuclear and mitochondrial horse reference genomes. Previously published ancient data used in this study are available under accession numbers PRJEB7537, PRJEB10098, PRJEB10854, PRJEB22390 and PRJEB31613, and detailed in Supplementary Table 1. The genomes of ten modern horses, publicly available, were also accessed as indicated in their corresponding original publications59,63,87,88,89.
Code availability
The Struct-f4 software is available without restriction on Bitbucket (https://bitbucket.org/plibradosanz/structf4/src/master/).
References
Kelekna, P. The Horse in Human History (Cambridge Univ. Press, 2009).
Outram, A. K. et al. The earliest horse harnessing and milking. Science 323, 1332–1335 (2009)
Gaunitz, C. et al. Ancient genomes revisit the ancestry of domestic and Przewalski’s horses. Science 360, 111–114 (2018).
Olsen, S. L. in Horses and Humans: The Evolution of Human Equine Relationships (eds Olsen S. L.et al.) 81–113 (Archaeopress, 2006).
Fages, A. et al. Tracking five millennia of horse management with extensive ancient genome time series. Cell 177, 1419-1435.e31 (2019).
Guimaraes, S. et al. Ancient DNA shows domestic horses were introduced in the southern Caucasus and Anatolia during the Bronze Age. Sci. Adv. 6, eabb0030 (2020).
Anthony, D. W. The Horse, the Wheel and Language (Princeton Univ. Press, 2007).
Haak, W. et al. Massive migration from the steppe was a source for Indo-European languages in Europe. Nature 522, 207–211 (2015).
Allentoft, M. E. et al. Population genomics of Bronze Age Eurasia. Nature 522, 167–172 (2015).
Demoule, J. P. Mais où sont passés les Indo-Européens ? Le mythe d'origine de l'Occident (Le Seuil, 2014).
de Barros Damgaard, P. et al. 137 ancient human genomes from across the Eurasian steppes. Nature 557, 369–374 (2018).
Narasimhan, V. M. et al. The formation of human populations in South and Central Asia. Science 365, eaat7487 (2019).
Rohland, N., Harney, E., Mallick, S., Nordenfelt, S. & Reich, D. Partial uracil-DNA-glycosylase treatment for screening of ancient DNA. Philos. Trans. R. Soc. Lond. B 370, 20130624 (2015).
Schubert, M. et al. Prehistoric genomes reveal the genetic foundation and cost of horse domestication. Proc. Natl Acad. Sci. USA 111, E5661-E5669 (2014).
Librado, P. et al. Tracking the origins of Yakutian horses and the genetic basis for their fast adaptation to subarctic environments. Proc. Natl Acad. Sci. USA 112, E6889-E6897 (2015).
Petkova, D., Novembre, J. & Stephens, M. Visualizing spatial population structure with estimated effective migration surfaces. Nat. Genet. 48, 94–100 (2016).
Patterson, N. et al. Ancient admixture in human history. Genetics 192, 1065–1093 (2012).
Harney, É., Patterson, N., Reich, D. & Wakeley, J. Assessing the performance of qpAdm: a statistical tool for studying population admixture. Genetics 217, iyaa045 (2021).
Molloy, E. K., Durvasula, A. & Sankararaman, S. Advancing admixture graph estimation via maximum likelihood network orientation. Bioinformatics 37, i142–i150 (2021).
Battey, C., Ralph, P. L. & Kern, A. D. Predicting geographic location from genetic variation with deep neural networks. eLife 9, e54507 (2020).
de Barros Damgaard, P. et al. The first horse herders and the impact of early Bronze Age steppe expansions into Asia. Science 360, eaar7711 (2018).
Reinhold, S. et al. in Appropriating Innovations: Entangled Knowledge in Eurasia, 5000–1500 bce (eds Stockhammer, P. W. & Maran, J.) 78–97 (Oxbow Books, 2017).
Kristiansen, K. in Trade and Civilization. Economic Networks and Cultural Ties, from Prehistory to the Early Modern Period (eds Kristiansen, K. et al.) (Cambridge Univ. Press, 2018).
Chechushkov I. V., & Epimakhov, A. V. in The Puzzle of Indo-European Origins and Dispersals: Archeology, Linguistics and Genetics (eds Kristiansen, K. et al.) (Cambridge Univ. Press, in the press).
Littauer, M. A., & Crouwel, J. H. The origin of the true chariot. Antiquity 70, 934–939 (1996).
Lindner, S. Chariots in the Eurasian Steppe: a Bayesian approach to the emergence of horse-drawn transport in the early second millennium BC. Antiquity 94, 361–380 (2020).
Moorey, P. R. S. Pictorial evidence for the history of horse-riding in Iraq before the Kassite period. Iraq 32, 36–50 (1970).
Kanne, K. Riding, ruling, and resistance equestrianism and political authority in the Hungarian Bronze Age. Curr. Anthropol. (in the press).
Suri, P. et al. Genome-wide meta-analysis of 158,000 individuals of European ancestry identifies three loci associated with chronic back pain. PLoS Genet. 14, e1007601 (2018).
Jiang, H. et al. Two GWAS-identified variants are associated with lumbar spinal stenosis and Gasdermin-C expression in Chinese population. Sci. Rep. 10, 21069 (2020).
Tikker, L. et al. Inactivation of the GATA cofactor ZFPM1 results in abnormal development of dorsal raphe serotonergic neuron subtypes and increased anxiety-like behavior. J. Neurosci. 40, 8669–8682 (2020).
Takahashi, A. & Miczek, K. A. Neurogenetics of aggressive behavior: studies in rodents. Curr. Top. Behav. Neurosci. 17, 3–44 (2014).
Schmitt, T. & Varga, Z. Extra-Mediterranean refugia: the rule and not the exception? Frontiers Zool. 9, 22 (2012).
Spasskaya, N. N., & Pavlinov, I. in Zoological Research (Arch. Zoological Museum, Moscow State Univ., 2016).
Colledge, S., Conolly, J., Crema, E., & Shennan, S. Neolithic population crash in northwest Europe associated with agricultural crisis. Quat. Res. 92, 686–707 (2019).
Outram, A. K. & Bogaard, A. Subsistence and Society in Prehistory: New Directions in Economic Archaeology (Cambridge Univ. Press, 2019).
Anthony, D. W. in Social Complexity in Prehistoric Eurasia: Monuments, Metals and Mobility (eds Hanks, B. K. & Lindruff, K. M.) Ch. 4 (2009).
Maran, J., Bajenaru, R., Ailincai, S.-C., Popescu, A.-D. & Hansen, S. I. Objects, ideas and travelers. Contacts between the Balkans, the Aegean and Western Anatolia during the Bronze and Early Iron Age. In: Proc. of the Conference in Tulcea 10-13 November, 2017 (Rudolf Habelt, 2020).
Glob, P. V. Denmark: An Archaeological History from the Stone Age to the Vikings (Cornell Univ. Press, 1971).
Gimbutas, M. The first wave of Eurasian Steppe pastoralists into Copper Age Europe. J. Indo. Eur. Stud. 5, 277–338 (1977).
Anthony, D. W. The “Kurgan Culture,” Indo-European origins, and the domestication of the horse: a reconsideration. Curr. Anthropol. 27, 291–313 (1986).
Renfrew, C. They ride horses, don’t they?: Mallory on the Indo-Europeans. Antiquity 63, 843–847 (1989).
Vandkilde, H. Culture and Change in Central European Prehistory (Aarhus Univ. Press, 2007).
Häusler, A. in Indogermanen und das Pferd (eds Hänsel, B. & Zimmer, S.) 217–257 (Archaeolingua Alapitvany, 1994).
Kroonen, G., Barjamovic, G. & Peyrot, M.Linguistic supplement to de Barros Damgaard et al. 2018: Early Indo-European languages, Anatolian, Tocharian and Indo-Iranian https://zenodo.org/record/1240524#.YFtLgGjTVMQ (2018).
South, A. rworldmap: a new R package for mapping global data. R J. 3, 35-43 (2011).
Brownrigg, R. maps: draw geographical maps. R package version 3.3.0 https://CRAN.R-project.org/package=maps (2018).
Reimer, P. et al. The IntCal20 Northern Hemisphere radiocarbon age calibration curve (0–55 cal kBP). Radiocarbon 62, 725 (2020).
Ramsey, C. B. Bayesian analysis of radiocarbon dates. Radiocarbon 51, 337–360 (2009).
Seguin-Orlando, A. et al. Heterogeneous hunter-gatherer and steppe-related ancestries in Late Neolithic and Bell Beaker genomes from present-day France. Curr. Biol. 31, 1072–1083.e10 (2021).
Gamba, C. et al. Comparing the performance of three ancient DNA extraction methods for high-throughput sequencing. Mol. Ecol. Resour. 16, 459–469 (2016).
Schubert, M., Lindgreen, S. & Orlando, L. AdapterRemoval v2: rapid adapter trimming, identification, and read merging. BMC Res. Notes 9, 88 (2016).
Kalbfleisch, T. S. et al. Improved reference genome for the domestic horse increases assembly contiguity and composition. Commun. Biol. 1, 197 (2018).
Xu, X. & Arnason, U. The complete mitochondrial DNA sequence of the horse, Equus caballus: extensive heteroplasmy of the control region. Gene 148, 357–362 (1994).
Felkel, S. et al. The horse Y chromosome as an informative marker for tracing sire lines. Sci. Rep. 9, 6095 (2019)
Poullet, M. & Orlando, L. Assessing DNA sequence alignment methods for characterizing ancient genomes and methylomes. Front. Ecol. Evol. 8, 105 (2020).
Jónsson, H., Ginolhac, A., Schubert, M., Johnson, P. L. F. & Orlando, L. mapDamage2.0: fast approximate Bayesian estimates of ancient DNA damage parameters. Bioinformatics 29, 1682–1684 (2013).
Orlando, L. et al. Recalibrating Equus evolution using the genome sequence of an early Middle Pleistocene horse. Nature 499, 74–78 (2013).
Jónsson, H. et al. Speciation with gene flow in equids despite extensive chromosomal plasticity. Proc. Natl Acad. Sci. USA 111, 18655–18660 (2014).
Korneliussen, T. S., Albrechtsen, A. & Nielsen, R. ANGSD: analysis of next generation sequencing data. BMC Bioinformatics 15, 356 (2014).
Skoglund, P. et al. Separating endogenous ancient DNA from modern day contamination in a Siberian Neandertal. Proc. Natl Acad. Sci. USA 111, 2229–2234 (2014).
Librado, P. et al. Ancient genomic changes associated with domestication of the horse. Science 356, 442–445 (2017).
Der Sarkissian, C. et al. Evolutionary genomics and conservation of the endangered Przewalski’s horse. Curr. Biol. 25, 2577–2583 (2015).
Katoh, K. & Standley, D. M. MAFFT multiple sequence alignment software version 7: improvements in performance and usability. Mol. Biol. Evol. 30, 772–780 (2013).
Stamatakis, A. RAxML version 8: a tool for phylogenetic analysis and post-analysis of large phylogenies. Bioinformatics 30, 1312–1313 (2014).
Bouckaert, R. et al. BEAST 2.5: An advanced software platform for Bayesian evolutionary analysis. PLoS Comput. Biol. 15, e1006650 (2019).
Heller, R., Chikhi, L. & Siegismund, H. R. The confounding effect of population structure on Bayesian skyline plot inferences of demographic history. PLoS ONE 8, e62992 (2013).
Keane, T. M., Creevey, C. J., Pentony, M. M., Naughton, T. J. & Mclnerney, J. O. Assessment of methods for amino acid matrix selection and their use on empirical data shows that ad hoc assumptions for choice of matrix are not justified. BMC Evol. Biol. 6, 29 (2006).
Drummond, A. J., Rambaut, A., Shapiro, B. & Pybus, O. G. Bayesian coalescent inference of past population dynamics from molecular sequences. Mol. Biol. Evol. 22, 1185–1192 (2005).
Rambaut, A., Drummond, A. J., Xie, D., Baele, G. & Suchard, M. A. Posterior summarization in Bayesian phylogenetics using Tracer 1.7. Syst Biol 67, 901–904 (2018).
Nguyen, L.-T., Schmidt, H. A., von Haeseler, A. & Minh, B. Q. IQ-TREE: a fast and effective stochastic algorithm for estimating maximum-likelihood phylogenies. Mol. Biol. Evol. 32, 268–274 (2015).
Hoang, D. T., Chernomor, O., von Haeseler, A., Minh, B. Q. & Vinh, L. S. UFBoot2: improving the ultrafast bootstrap approximation. Mol. Biol. Evol. 35, 518–522 (2018).
Lefort, V., Desper, R. & Gascuel, O. FastME 2.0: a comprehensive, accurate, and fast distance-based phylogeny inference program. Mol. Biol. Evol. 32, 2798–2800 (2015).
Paradis, E., & Schliep, K. ape 5.0: an environment for modern phylogenetics and evolutionary analyses in R. Bioinformatics 35, 526–528 (2019).
Schraiber, J. Assessing the relationship of ancient and modern populations. Genetics 208, 383–398 (2018).
Purcell, S. et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 81, 559–575 (2007).
Alexander, D. H., Novembre, J. & Lange, K. Fast model-based estimation of ancestry in unrelated individuals. Genome Res. 19, 1655–1664 (2009).
Cheng, J. Y., Mailund, T. & Nielsen, R. Fast admixture analysis and population tree estimation for SNP and NGS data. Bioinformatics 33, 2148–2155 (2017).
Lawson, D. J., van Dorp, L. & Falush, D. A tutorial on how not to over-interpret STRUCTURE and ADMIXTURE bar plots. Nat. Commun. 9, 3258 (2018).
Excoffier, L., Dupanloup, I., Huerta-Sánchez, E., Sousa, V. C. & Foll, M. Robust demographic inference from genomic and SNP data. PLoS Genet. 9, e1003905 (2013).
Gerritsen, H. mapplots: data visualisation on maps. R package version 1.5.1 https://CRAN.R-project.org/package=mapplots (2018).
Bjornstad, O. N. & Cai, J. ncf: spatial covariance functions. R package version 1.2-9 http://ento.psu.edu/directory/onb1 (2020).
Loog, L. et al. Estimating mobility using sparse data: application to human genetic variation. Proc. Natl Acad. Sci. USA 114, 12213–12218 (2017).
Hijmans, R. J., Williams, E. & Vennes, C. E.. geosphere: spherical trigonometry. R package version 1.5.1 (2019).
Boyle, J. GeoRange: calculating geographic range from occurrence data. R package version 0.1.0. (2017).
Hahne, F. & Ivanek, R. Visualizing genomic data using Gviz and Bioconductor. Methods Mol. Biol. 1418, 335–351 (2016).
Renaud, G. et al. Improved de novo genomic assembly for the domestic donkey. Sci. Adv. 4, eaaq0392 (2018).
Jagannathan, V. et al. Comprehensive characterization of horse genome variation by whole-genome sequencing of 88 horses. Anim. Genet. 50, 74–77 (2019).
Andersson, L. S. et al. Mutations in DMRT3 affect locomotion in horses and spinal circuit function in mice. Nature 488, 642–646 (2012).
Teufer, M. Ein Scheibenknebel aus Dzarkutan (Süduzbekistan). Archäologische Mitteilungen aus Iran und Turan. Band 31, 69–142 (1999).
Chechushkov, I. V. Wheel Complex of the Late Bronze Age Era of Steppe and Forest-Steppe Eurasia (from Dnieper to Irtysh). PhD thesis. Department of Archeology and Ethnography of the Federal State Budgetary Institution of Science, Institute of History and Archeology of the Ural Branch of the Russian Academy of Sciences (2013).
Acknowledgements
We thank all members of the AGES group at CAGT. We are grateful for the Museum of the Institute of Plant and Animal Ecology (UB RAS, Ekaterinburg) for providing specimens. The work by G. Boeskorov is done on state assignment of DPMGI SB RAS. This project was supported by the University Paul Sabatier IDEX Chaire d’Excellence (OURASI); Villum Funden miGENEPI research programme; the CNRS ‘Programme de Recherche Conjoint’ (PRC); the CNRS International Research Project (IRP AMADEUS); the France Génomique Appel à Grand Projet (ANR-10-INBS-09-08, BUCEPHALE project); IB10131 and IB18060, both funded by Junta de Extremadura (Spain) and European Regional Development Fund; Czech Academy of Sciences (RVO:67985912); the Zoological Institute ZIN RAS (АААА-А19-119032590102-7); and King Saud University Researchers Supporting Project (NSRSP–2020/2). The research was carried out with the financial support of the Russian Foundation for Basic Research (19-59-15001 and 20-04-00213), the Russian Science Foundation (16-18-10265, 20-78-10151, and 21-18-00457), the Government of the Russian Federation (FENU-2020-0021), the Estonian Research Council (PRG29), the Estonian Ministry of Education and Research (PRG1209), the Hungarian Scientific Research Fund (Project NF 104792), the Hungarian Academy of Sciences (Momentum Mobility Research Project of the Institute of Archaeology, Research Centre for the Humanities); and the Polish National Science Centre (2013/11/B/HS3/03822). This project has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie (grant agreement 797449). This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreements 681605, 716732 and 834616).
Author information
Authors and Affiliations
Contributions
Designed, conceived and coordinated the study: L.O. Provided samples, reagents and material: A. Perdereau, J.-M.A., B.S., A.A.T., A.A.K., S.A., A.H.A., K.A.S.A.-R., T. Seregély, L.K., R.I., O.B.-L., P.B., M.O., J.-C.C., M.B.-M., N.A., M.G., M.M.-d.H., J.W., S.P., A.L.-K., K. Tunia, M.N., E.R., U.S., G. Boeskorov, L.L., R.K., L.P., A. Bălășescu, V. Dumitrașcu, R.D., D.G., V.K., A.S.-N., B.G.M., Z.G., K.S., G.K., E.G., R.B., M.E.A., G.S., V. Dergachev, H.S., N.T., S.G., A. Kasparov, A.E.B., M.A.A., P.A.N., E.Y.P., V.P., G. Brem, B.W., C.S., M.K., K. Kitagawa, A.N.B., A. Bessudnov, W.T., J.M., J.-O.G., J.B., D.E., K. Tabaldiev, E.M., B.B., T.T., M.P., S.O., C.A.M., S.V.L., S.A.C., A.N.E., M.P.I., J.L.G., E.R.G., S.C., C.O., J.L.A., N. Kotova, A. Pryor, P.C., R.Z., A.T., N.L.M., T.K., D.L., M. Marzullo, O.P., G.B.G., U.T., B.C., S.L., H.D., M. Mashkour, N.Y.B., P.W.S., J.K., W.H., A.M.-M., N.B., M.H., A. Ludwig, A.S.G., J.P., K.Y.K., T.-O.I., N.A.B., S.K.V., N.N.S., K.V.C., N.A.P., G.F.B., E.P., M.S., E.A., A. Logvin, I.S., V. Logvin, S.K., V. Loman, I.K., I.M., V.M., S. Sakenov, V.V., E.U., V.Z., B.A., A.B.B., A. Kalmykov, S.R., S.H., A.I.Y., A.A.V., A.E., N.S.B., N.R., P.A.K., P.F.K., D. Anthony, G.J.K., K. Kristiansen, P.W., A.O. and L.O. Performed radiocarbon dating: J.S. Performed wet-lab work: N. Kahn, A. Fages, M.A.K., T. Suchan, L.T.-C., S. Schiavinato, A.F., A. Perdereau, C.G., L.C., A.S.-O and C.D.S., with input from L.O. Analysed genomic data: P.L. and L.O. Analysed uniparental markers: D. Alioglu, with input from P.L. and L.O. Prepared the linguistic index: G.J.K. Interpreted data: P.L. and L.O., with input from B.A., S.R., S.H., D. Anthony, G.J.K., K. Kristiansen and A.O. Wrote the article: L.O., with input from P.L., B.A., S.R., S.H., D. Anthony, G.J.K., K. Kristiansen, A.O. and all co-authors. Wrote the Supplementary Information: P.L., A. Fages, G.J.K. and L.O., with input from all co-authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature thanks Samantha Brooks, Fiona Marshall and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Proportion of missing derived mutations at sites representing nucleotide transversions.
Proportions are provided relative to the genome of a modern Icelandic89 (P5782) horse (Spearman correlation coefficient between total transversion errors and time, R=−0.77 p-value =0).
Extended Data Fig. 2 Struct-f4 validation.
a, Simulated demographic model. A single migration pulse is assumed to have occurred 150 generations ago from population E into B. The magnitude of the migration represents 5% to 25% of the effective size of population B. The model was also simulated in the absence of migration (i.e. m=0%). Five individuals are simulated per population considered, except for the outgroup where only one individual was considered. b, Correlation of the expected levels of gene-flow with the predicted E-ancestry component in individuals i belonging to population B, as well as with the average Z-scores of the f4(A, Bi; E, Outgroup) configurations, which reflects the stochasticity resulting from the simulations, prior to any inference. Each point represents a simulated individual. Colors indicate the 10 independent simulation replicates carried out. c, Predicted ancestry profiles in the absence (m=0%) and with gene flow (m=25% and K=7, as per the number of internal nodes immediately ancestral to the 10 extant populations).
Extended Data Fig. 3 Mobility and demographic shifts.
a–c, Correlation between observed pairwise genetic distances between demes as inferred by EEMS16 and Haversine geographic distances prior to ~3,000 BCE (a), during the third millennium BCE (b) and after ~2,000 BCE (c). d, Isolation-by-distance patterns through time inferred from autosomal (red) and X-chromosomal (blue) variation. e–f, Bayesian Skyline plots reconstructed from mtDNA (e) and Y-chromosomal variation (f). The third millennium BCE is highlighted in blue. The red line indicates the median of the 95% confidence range, shown in grey.
Extended Data Fig. 5 OrientAGraph19 population histories and genetic distances to the domestic donkey.
a–e, OrientAGraph19 models and residuals assuming M=0 to M=5 migration edges and considering nine lineages representing key genomic ancestries (colored as in Fig 1a). M=3 is shown in Fig 3b. f, Pairwise genetic distances between a given horse and the domestic donkey plotted as a function of the age of the horse specimen considered.
Extended Data Fig. 7 DOM2 selection signatures.
a, Manhattan plot of FST-differentiation index between DOM2 and non-DOM2 horses along the 31 EquCab3 autosomes. FST outliers are highlighted using an empirical P-value threshold of 10−5 (red dashed line). The two outlier regions on chromosomes 3 and 9 are highlighted within red frames. b, FST-differentiation index and genomic tracks around the ZFPM1 gene. Depth represents the accumulated number of reads per position within DOM2 (blue) and non-DOM2 (magenta) genomes. c, Same as Panel b at GSDMC.
Extended Data Fig. 8 Normalized read coverage supporting the presence of causative alleles for coat coloration variation.
Each column represents a particular genome position where genetic polymorphisms associated or causative for coat coloration patterns have been described. The exact EquCab3 genome coordinates are indicated in the locus label. Specimens (rows) are ordered according to their phylogenetic relationships, as shown in Fig 1b. The color gradient is proportional to the fraction of reads carrying the causative variant. Loci that are not covered following trimming and rescaling of individual BAM sequence alignment files are indicated with a white cross.
Supplementary information
41586_2021_4018_MOESM1_ESM.pdf
Supplementary Information Supplementary Methods; Supplementary Discussion; Supplementary Notes. This file provides full description of archaeological material and contexts, develops the methodology underlying genome analyses, and summarizes linguistic information on Indo-European equine and Indo-Iranian chariotry terminology. A full list of supplementary references is provided.
41586_2021_4018_MOESM4_ESM.jpg
Supplementary Fig. 1 Mitochondrial and Y-chromosome phylogenies This figure provides ML phylogenies mtDNA (a) and the Y-chromosome (b), with full sample labels. Node support is assessed using 100 bootstrap pseudo-replicates.
Supplementary Tables 1–3
Table1 provides details on archeological contexts and DNA data. Table 2 presents the results of genetic continuity tests, while Table 3 summarizes the best ancestry profiles identified with qpAdm.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Librado, P., Khan, N., Fages, A. et al. The origins and spread of domestic horses from the Western Eurasian steppes. Nature 598, 634–640 (2021). https://doi.org/10.1038/s41586-021-04018-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-021-04018-9
This article is cited by
-
Improving data archiving practices in ancient genomics
Scientific Data (2024)
-
Ancient equine genomes reveal dawn of horse domestication
Nature (2024)
-
Non-Synonymous Substitutions in Cadherin 13, Solute Carrier Family 6 Member 4, and Monoamine Oxidase A Genes are Associated with Personality Traits in Thoroughbred Horses
Behavior Genetics (2024)
-
Originals or local replicas? The techno-functional analysis of the disc-shaped antler cheekpieces from the Bronze Age settlement at Sărata Monteoru, south-eastern Romania
Archaeological and Anthropological Sciences (2024)
-
Unveiling the population genetic structure of Iranian horses breeds by whole-genome resequencing analysis
Mammalian Genome (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.

{kind=link}