
Abstract
Childhood malnutrition is associated with high morbidity and mortality globally1. Undernourished children are more likely to experience cognitive, physical, and metabolic developmental impairments that can lead to later cardiovascular disease, reduced intellectual ability and school attainment, and reduced economic productivity in adulthood2. Child growth failure (CGF), expressed as stunting, wasting, and underweight in children under five years of age (0–59 months), is a specific subset of undernutrition characterized by insufficient height or weight against age-specific growth reference standards3,4,5. The prevalence of stunting, wasting, or underweight in children under five is the proportion of children with a height-for-age, weight-for-height, or weight-for-age z-score, respectively, that is more than two standard deviations below the World Health Organization’s median growth reference standards for a healthy population6. Subnational estimates of CGF report substantial heterogeneity within countries, but are available primarily at the first administrative level (for example, states or provinces)7; the uneven geographical distribution of CGF has motivated further calls for assessments that can match the local scale of many public health programmes8. Building from our previous work mapping CGF in Africa9, here we provide the first, to our knowledge, mapped high-spatial-resolution estimates of CGF indicators from 2000 to 2017 across 105 low- and middle-income countries (LMICs), where 99% of affected children live1, aggregated to policy-relevant first and second (for example, districts or counties) administrative-level units and national levels. Despite remarkable declines over the study period, many LMICs remain far from the ambitious World Health Organization Global Nutrition Targets to reduce stunting by 40% and wasting to less than 5% by 2025. Large disparities in prevalence and progress exist across and within countries; our maps identify high-prevalence areas even within nations otherwise succeeding in reducing overall CGF prevalence. By highlighting where the highest-need populations reside, these geospatial estimates can support policy-makers in planning interventions that are adapted locally and in efficiently directing resources towards reducing CGF and its health implications.
Similar content being viewed by others

Main
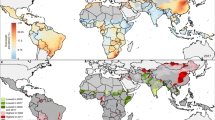
Despite improvements in nearly all LMICs, stunting remained the most widespread and prevalent indicator of CGF throughout the study period. Overall, estimated childhood stunting prevalence across LMICs decreased from 36.9% (95% uncertainty interval, 32.8–41.4%) in 2000 to 26.6% (21.5–32.4%) in 2017. Progress was particularly noticeable in Central America and the Caribbean, Andean South America, North Africa, and East Asia regions, and in some coastal central and western sub-Saharan African (SSA) countries, where most areas with estimated stunting prevalence of at least 50% in 2000 had reduced to 30% or less by 2017 (Fig. 1a, b). By 2017, zones with the highest prevalence of stunting primarily persisted throughout much of the SSA, Central and South Asia, and Oceania regions, where large areas had estimated levels of at least 40%, such as in the first administrative-level units of Nigeria’s Jigawa state (60.6% (51.5–69.7%)), Burundi’s Karuzi province (60.0% (51.4–67.5%)), India’s Uttar Pradesh state (49.0% (48.5–49.5%)), and Laos’s Houaphan province (58.3% (50.7–66.8%)) (Extended Data Fig. 1). In 2017, Guatemala (47.0% (40.2–54.6%)), Niger (47.5% (42.2–53.9%)), Burundi (54.2% (46.3–61.2%)), Madagascar (49.8% (43.2–57.2%)), Timor-Leste (49.8% (43.4–56.2%)), and Yemen (45.4% (38.8–51.5%)) had the highest national-level stunting prevalence.

a, b, Prevalence of stunting in children under five at the 5 × 5-km resolution in 2000 (a) and 2017 (b). c, Overlapping population-weighted tenth and ninetieth percentiles (lowest and highest) of 5 × 5-km grid cells and AROC in stunting, 2000–2017. d, Overlapping population-weighted quartiles of stunting prevalence and relative 95% uncertainty in 2017. e, f, Number of children under five who were stunted, at the 5 × 5-km (e) and first-administrative-unit (f) levels. g, 2000–2017 annualized decrease in stunting prevalence relative to rates needed during 2017–2025 to meet the WHO GNT. h, Grid-cell-level predicted stunting prevalence in 2025. Maps were produced using ArcGIS Desktop 10.6. Interactive visualization tools are available at https://vizhub.healthdata.org/lbd/cgf.
Even within the aforementioned regions where reductions were most evident, local-level estimates revealed communities in which levels still approached those seen in SSA and South Asia; areas in southern Mexico and central Ecuador had estimated stunting prevalence of at least 40%, and areas in western Mongolia reached at least 30%. Wide within-country disparities were apparent in several instances, indicating large areas left behind by the general pace of progress that require attention (Fig. 1a, b). Although most countries successfully reduced stunting prevalence, subnational inequalities (disparities between second administrative-level units (henceforth ‘units’)) remained widespread globally—especially evident in Vietnam, Honduras, Nigeria, and India (Extended Data Fig. 2). Among the top quintile of widest disparities, Indonesia experienced a twofold difference in stunting levels in 2017, ranging from 21.0% (16.2–27.0%) in Kota Yogyakarta regency (Yogyakarta province) to 51.5% (40.6–62.3%) in Sumba Barat regency (Nusa Tenggara Timur province). Stunting levels varied fourfold in Nigeria, ranging from 14.7% (9.1–21.0%) in Surulere Local Government Area (Lagos state) to 64.2% (54.2–74.6%) in Gagarawa Local Government Area (Jigawa state) in 2017.
Evaluated from estimates of population-weighted prevalence for areas with the highest and lowest estimated prevalence of stunting (ninetieth and tenth percentiles, respectively), locations in central Chad, Pakistan, and Afghanistan, in northeastern Angola, and throughout the Democratic Republic of the Congo and Madagascar had among the lowest annualized rates of change (AROC), indicating stagnation or increase over the study period (Fig. 1c); in 2017, these countries also had large geographical areas among the most highly prevalent for stunting. By contrast, areas scattered throughout Peru, northwestern Mexico, and eastern Nepal had among the highest stunting levels in 2000, but also the highest rates of decline; by 2017, many of these areas were subsequently no longer in the highest-prevalence decile.
The absolute number of children under five who were stunted was also unequally distributed (Fig. 1e, f), with a large proportion concentrated in a few nations in 2017; overall, 85.1% (84.4–85.7%) of all stunted children under five lived in Africa or Asia. Of the 176.1 million (151.6–203.3 million) children who were stunted in 2017, just over half (50.1% (48.5–52.0%)) lived in only four countries: India (51.5 million (47.7–55.3 million) children; 28.6% (27.1–30.4%) of global stunting), Pakistan (10.7 million (9.3–12.1 million); 6.8% (6.7–6.9%)), Nigeria (11.8 million (10.7–13.0 million); 6.6% (6.4–6.8%)), and China (16.2 million (14.0–18.5 million); 9.0% (9.1–8.9%)). Although China had a low prevalence of national stunting (10.8% (9.1–12.6%)) in 2017, the prevalence was high in India (39.3% (39.1–39.6%)), Pakistan (44.0% (38.4–49.9%)), and Nigeria (38.2% (34.5–42.0%)). Even with moderate levels of stunting (10 to <20%)10, these highly populous countries would substantially contribute to the global share owing to their population size, and reducing their levels would markedly decrease the number of stunted children.
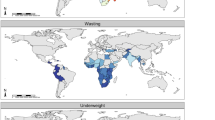
Childhood wasting was less widespread than stunting (Fig. 2a, b), affecting 8.4% (7.9–9.9%) of children under five in LMICs in 2000, and 6.4% (4.9–7.9%) by 2017. Wasting reached critical levels (at least 15%)11 nationally in 13 LMICs in 2000 and 7 LMICs in 2017, although only in Mauritania (20.7% (16.5–25.6%)) did all units exceed these levels (Extended Data Fig. 3). Critical wasting prevalence was concentrated in few areas across the globe in 2017, including the peri-Sahelian areas of countries stretching from Mauritania to Sudan, as well as areas in South Sudan, Ethiopia, Kenya, Somalia, Yemen, India, Pakistan, Bhutan, and Indonesia. Most LMICs reduced within-country disparities between their highest- and lowest-prevalence units between 2000 and 2017, most notably in Algeria, Uzbekistan, and Egypt (Extended Data Fig. 4). Even against a backdrop of national-level declines, however, broad within-country disparities in wasting remained in countries such as Indonesia, Ethiopia, Nigeria, and Kenya. An estimated ninefold difference in wasting prevalence occurred among Kenya’s units in 2017, ranging from 2.9% (1.6–4.9%) in Tetu constituency (Nyeri county) to 28.3% (20.2–37.3%) in Turkana East constituency (Turkana county); higher-resolution estimates reveal areas with a wasting prevalence of at least 25%. High-prevalence areas in 2000 typically remained within the highest population-weighted decile for wasting in 2017, including the units of Rabkona county (Unity state) in northern South Sudan (27.8% (19.8–37.6%) in 2000; 17.3% (8.8–21.9%) in 2017), the Tanout department (Zinder region) in southern Niger (21.6% (17.3–26.7%) in 2000; 16.5% (11.3–23.3%) in 2017), and Alor regency (Nusa Tenggara Timur province) in southeastern Indonesia (16.4% (9.6–25.8%) in 2000; 20.7% (12.8–30.3%) in 2017) (Fig. 2c).

a, b, Prevalence of child wasting in children under five at the 5 × 5-km resolution in 2000 (a) and 2017 (b). c, Overlapping population-weighted tenth and ninetieth percentiles (lowest and highest) of 5 × 5-km grid cells and AROC in wasting, 2000–2017. d, Overlapping population-weighted quartiles of wasting prevalence and relative 95% uncertainty in 2017. e, f, Number of children under five affected by wasting, at the 5 × 5-km (e) and first-administrative-unit (f) levels. g, 2000–2017 annualized decrease in wasting prevalence relative to rates needed during 2017–2025 to meet the WHO GNT. h, Grid-cell-level predicted wasting prevalence in 2025. Maps were produced using ArcGIS Desktop 10.6. Interactive visualization tools are available at https://vizhub.healthdata.org/lbd/cgf.
The absolute number of children affected by wasting was unequal both across and within countries (Fig. 2e, f). Of the 58.3 million (47.6–70.7 million) children affected by wasting in 2017, 57.1% (52.7–61.6%) occurred in four of the most populous countries: India (26.1 million (23.1–29.0 million); 44.7% (41.0–48.6%) of global wasting), Pakistan (3.5 million (2.8–4.3 million); 6.0% (5.8–6.1%)), Bangladesh (1.8 million (1.2–2.4 million); 3.0% (2.6–3.4%)), and Indonesia (2.0 million (1.7–2.3 million); 3.4% (3.3–3.5%)). On the basis of standard thresholds11, these countries had serious levels of national wasting prevalence (10 to <15%), ranging from 12.2% (9.7–14.9%) in Pakistan to 15.7% (15.5–15.9%) in India, and all but Bangladesh had areas with estimated wasting levels above 20%; increased efforts, especially in densely populated areas with high prevalence and absolute numbers, could immensely reduce global child wasting.
The prevalence of underweight—a composite indicator of stunting and wasting—followed the scattered pattern of high-stunting areas in SSA and spanning Central Asia to Oceania, and the high prevalence belt of wasting along the African Sahel (Extended Data Fig. 5a, b). Affecting 19.8% (17.3–22.7%) of children under five across LMICs in 2000 and 13.0% (10.4–16.0%) in 2017, reductions in underweight prevalence were most notable for countries in Central and South America, southern SSA, North Africa, and Southeast Asia. For example, by 2017, estimated underweight prevalence had decreased to less than or equal to 20% for nearly all areas in Namibia. By contrast, peri-Sahelian countries stretching from Mauritania to Somalia maintained an estimated underweight prevalence of at least 30% in many areas. Large geographical areas across Central and South Asia also maintained high prevalence of underweight during the study period; in particular, India, Pakistan, and Bangladesh sustained estimated prevalence of at least 30% in most locations. Although levels of child underweight had largely reduced since 2000, within-country disparities remained widespread; 71.4% (75 out of 105) of LMICs experienced at least a twofold difference across units in 2017 (Extended Data Fig. 6).
Prospects for reaching 2025 targets
We estimate that broad areas across Central America and the Caribbean, South America, North Africa, and East Asia had high probability (>95%) of having already achieved targets for both stunting and wasting in 2017 (Extended Data Fig. 7). Exceptions to these regional patterns exist; areas with stagnated progress and less than 50% probability of having achieved the World Health Organization’s Global Nutrition Targets for 2025 (WHO GNTs) in 2017 were found throughout much of Guatemala and Ecuador for stunting and in southern Venezuela for wasting (Figs. 1g, 2g, Extended Data Fig. 7). Even within countries that had achieved targets, there remain areas with slow progress; locations in central Peru for stunting and southwestern South Africa for wasting had not achieved targets in 2017 (less than 5% probability)—nuances otherwise hidden by aggregated estimates. Owing to stagnation or increases in prevalence, broad areas in SSA and substantial portions across Central Asia, South Asia, and Oceania (for example, in the Democratic Republic of the Congo and Pakistan for stunting; in Yemen and Indonesia for wasting) require reversal of trends or acceleration of declines in order to meet international targets (Figs. 1g, 2g).
Despite predicted improvements in AROC for 2017–2025, many highly affected countries are predicted to have areas that maintain estimated stunting levels of at least 40% or wasting levels of at least 15% in 2025 (Figs. 1h, 2h). Accounting for uncertainty in 2000–2017 AROC estimates, and with 2010 national-level estimates as a baseline for the 40% stunting reduction target, 44.8% (47 out of 105) of LMICs are estimated to nationally meet WHO GNT (>95% probability) for stunting by 2025 (Supplementary Table 13). At finer scales, 17.1% (n = 18) and 7.6% (n = 8) of LMICs will meet the stunting target in all first and second administrative-level units in 2025, respectively (Extended Data Fig. 8a, d, Supplementary Table 13). Similarly, 35.2% (n = 37) of LMICs are estimated to reduce to or maintain less than 5% wasting prevalence by 2025 (>95% probability) based on current trajectories (Supplementary Table 13). Fewer countries were estimated to meet wasting targets in all first administrative-level (16.2% (n = 17)) or second administrative-level (9.5% (n = 10)) units (Extended Data Fig. 8b, e, Supplementary Table 13). Only 26.7% (n = 28) of LMICs will meet national-level targets for both stunting and wasting by 2025, and only 4.8% (n = 5) will achieve both targets in all units (Supplementary Table 13).
Discussion
Although commendable declines in CGF have occurred globally, this progress measured at a coarse scale conceals subnational and local underachievement and variation in achieving the WHO GNTs. Supporting conclusions in the Global Nutrition Report12, our results show that most LMICs will not reach WHO GNTs nationally, and even fewer will meet targets across subnational units. Our mapped results show broad heterogeneity across areas, and reveal hotspots of persistent CGF even within well-performing regions and countries, where increased and targeted efforts are needed. In 2017, one in four children under five across LMICs still suffered at least one dimension of CGF, and the largest numbers of affected children were often in specific within-country locations. Although the national prevalence of CGF was generally lower in Central America and the Caribbean, South American, and East Asian countries, there are communities in these regions in which levels of CGF remain as high as those in SSA and South Asia. Regardless of overall declines, many subnational areas across LMICs maintained high levels of CGF and require substantial acceleration of progress or reversal of increasing trends to meet nutrition targets and leave no populations behind.
To our knowledge, this study is the first to estimate CGF comprehensively across LMICs at a fine geospatial scale, providing a precision public health tool to support efficient targeting of local-level interventions to vulnerable populations. Although densely populated areas may have relatively low prevalence of CGF, the absolute number of affected children may still be high; thus, both relative and absolute estimates are important to determine where additional attention is needed. To achieve international goals, more concerted efforts are needed in areas with decreasing or stagnating trends, without diminishing support in areas that demonstrate progress nor contributing to increases in obesity. In future work, we plan to determine how to stratify our estimates of CGF by sex and age, assess the double burden of child undernutrition and overweight, analyse important maternal indicators that affect child nutritional status outcomes (such as anaemia), and continue to monitor progress towards the 2025 WHO GNTs. These mapped estimates enable decision-makers to visualize and compare subnational CGF and nutritional inequalities, and identify populations most in need of interventions13.
Methods
Overview
Building from our previous study of CGF in Africa9, we used Bayesian model-based geostatistics14—which leveraged geo-referenced survey data and environmental and socioeconomic covariates, and the assumption that points with similar covariate patterns and that are closer to one another in space and time would be expected to have similar patterns of CGF—to produce high-spatial-resolution estimates of the prevalence of stunting, wasting, and underweight among children under five across LMICs. Stunting, wasting, and underweight were defined as z-scores that were two or more standard deviations below the WHO healthy population reference median for length/height-for-age, weight-for-length/height, and weight-for-age, respectively, for age- and sex-specific curves6. Using an ensemble modelling framework that feeds into a Bayesian generalized linear model with a correlated space–time error, and 1,000 draws from the fitted posterior distribution, we generated estimates of annual prevalence for each indicator of CGF on a 5 × 5-km grid over 105 LMICs for each year from 2000 to 2017 and mapped results at administrative levels to provide relevant subnational information for policy planning and public health action. For this analysis, we compiled an extensive geo-positioned dataset, using data from 460 household surveys and reports representing 4.6 million children. To ensure comparability with national estimates and to facilitate benchmarking, these local-level estimates were calibrated to those produced by the Global Burden of Disease (GBD) Study 20171, and were subsequently aggregated to the first administrative level (for example, states or provinces) and second administrative level (for example, districts or departments) in each LMIC. We also predict CGF prevalence for 2025 based on 2000–2017 trajectories and estimate the AROC required to meet the WHO GNTs by 2025. In addition, we estimate the 2017 absolute numbers of children under five affected by each CGF indicator in LMICs based on our prevalence estimates and the size of the populations of children under five15,16. Furthermore, we provide figures that demonstrate subnational disparities between each country’s second administrative-level units with the highest and lowest estimated prevalence for 2000 and 2017 (Extended Data Figs. 2, 4, 6). We re-estimate CGF prevalence for the 51 African countries included in our previous analysis9 using 28 additional surveys, and extend time trends to model each year from 2000 to 2017. Owing to these improvements in data availability and methodology, the estimates provided here supersede our previous modelling efforts.
Countries were selected for inclusion in this study using the socio-demographic index (SDI)—a summary measure of development that combines education, fertility, and poverty, published in the GBD study1. The analyses reported here include countries in the low, low-middle, and middle SDI quintiles, with several exceptions (Supplementary Table 3). China, Iran, Libya, and Malaysia were included despite high-middle SDI status in order to create better geographical continuity. Albania and Moldova were excluded owing to geographical discontinuity with other included countries and lack of available survey data. We did not estimate for the island nations of American Samoa, Federated States of Micronesia, Fiji, Kiribati, Marshall Islands, North Korea, Samoa, Solomon Islands, or Tonga, where no available survey data could be sourced. The flowchart of our modelling process is provided in Extended Data Fig. 9.
Surveys and child anthropometry data
We extracted individual-level height, weight, and age data for children under five from household survey series including the Demographic and Health Surveys (DHS), Multiple Indicator Cluster Surveys (MICS), Living Standards Measurement Study (LSMS), and Core Welfare Indicators Questionnaire (CWIQ), among other country-specific child health and nutrition surveys7,17,18,19 (Supplementary Tables 4, 5). Included in our models were 460 geo-referenced household surveys and reports from 105 countries representing approximately 4.6 million children under five. Each individual child record was associated with a cluster, a group of neighbouring households or a ‘village’ that acts as a primary sampling unit. Some surveys included geographical coordinates or precise place names for each cluster within that survey (138,938 clusters for stunting, 144,460 for wasting, and 147,624 for underweight). In the absence of geographical coordinates for each cluster, we assigned data to the smallest available administrative areal unit in the survey (termed a ‘polygon’) while correcting for the survey sample design (16,554 polygons for stunting, 18,833 for wasting, and 19,564 for underweight). Boundary information for these administrative units was obtained as shapefiles either directly from the surveys or by matching to shapefiles in the Global Administrative Unit Layers (GAUL)20 or the Database of Global Administrative Areas (GADM)21. In select cases, shapefiles provided by the survey administrator were used, or custom shapefiles were created based on survey documentation. These areal data were resampled to point locations using a population-weighted sampling approach over the relevant areal unit with the number of locations set proportionally to the number of grid cells in the area and the total weights of all the resampled points summing to one16.
Select data sources were excluded for the following reasons: missing survey weights for areal data, missing sex variable, insufficient age granularity (in months) for calculations of length/height-for-age z-scores and weight-for-age z-scores in children ages 0–2 years, incomplete sampling (for example, only children ages 0–3 years measured), or untrustworthy data (as determined by the survey administrator or by inspection). We excluded data for children for whom we could not compute age in both months and weeks. Children with height values ≤0 cm or ≥180 cm, and/or with weight values ≤0 kg or ≥45 kg were also excluded from the study. We also excluded data that were considered outliers according to the 2006 WHO Child Growth Standards recommended range values, which were values <−6 or >6 length/height-for-age z-score for stunting, <−5 or >5 weight-for-length/height z-score for wasting, and <−6 or >5 weight-for-age z-score for underweight3,4. Details on the survey data excluded for each country are provided in Supplementary Table 6. Data availability plots for all the CGF indicators by country, type, and year are included in Supplementary Figs. 2–16.
Child anthropometry
Using the height, weight, age, and sex data for each individual, height-for-age, weight-for-height, and weight-for-age z-scores were calculated using the age-, sex-, and indicator-specific LMS (lambda-mu-sigma) values from the 2006 WHO Child Growth Standards3,4. The LMS methodology allows for Gaussian z-score calculations and comparisons to be applied to skewed, non-Gaussian distributions22. We classified stunting, wasting, or underweight if the height/length-for-age, weight-for-height/length, or weight-for-age, respectively, was more than two standard deviations (z-scores) below the WHO growth reference population6. These individual-level data observations were then collapsed to cluster-level totals for the number of children sampled and total number of children under five affected by stunting, wasting, or underweight.
Temporal resolution
We estimated the prevalence of stunting, wasting, and underweight annually from 2000 to 2017 using a model that allows us to account for data points measured across survey years. As such, the model would also allow us to predict at monthly or finer temporal resolutions; however, we are limited both computationally and by the temporal resolution of the covariates.
Seasonality adjustment
Owing to the acute nature of wasting and its relative temporal transience, wasting data were pre-processed to account for seasonality within each year of observation. Across LMICs, large proportions of the population live in rural areas and have livelihoods that rely on agriculture and livestock. Seasonality affects the availability of and access to food, sometimes owing to natural disasters or climate events (for example, floods, monsoons, or droughts) that vary by season. Generalized additive models were fit to wasting data across time using the month of interview and a country-level fixed effect as the explanatory variables, and the wasting z-score as the response. A 12-month periodic spline for the interview month was used, as well as a spline that smoothed across the whole duration of the dataset. Once the models were fit, individual weight-for-height/length z-score observations were adjusted so that each measurement was consistent with a day that represented a mean day in the periodic spline. The seasonality adjustment had relatively little effect on the raw data9.
Spatial covariates
To leverage strength from locations with observations to the entire spatiotemporal domain, we compiled several 5 × 5-km raster layers of possible socioeconomic and environmental correlates of CGF in the 105 LMICs (Supplementary Table 7, Supplementary Fig. 17). Covariates were selected based on their potential to be predictive for the set of CGF indicators, after reviewing literature on evidence and plausible hypotheses as to their influence. Acquisition of temporally dynamic datasets, where possible, was prioritized to best match our observations and thus predict the changing dynamics of the CGF indicators. Of the twelve covariates included, eight were temporally dynamic and were reformatted as a synoptic mean over each estimation period or as a mid-period year estimate: these covariates included average daily mean rainfall (precipitation), average daily mean temperature, enhanced vegetation index, fertility, malaria incidence, educational attainment in women of reproductive age (15–49 years old), population, and urbanicity. The remaining four covariate layers were static throughout the study period and were applied uniformly across all modelling years; growing season length, irrigation, nutritional yield for vitamin A, and travel time to nearest settlement of >50,000 inhabitants.
To select covariates and capture possible nonlinear effects and complex interactions between them, an ensemble covariate modelling method was implemented23. For each region, three sub-models were fit to our dataset using all of our covariate data as explanatory predictors; these sub-models were: generalized additive models, boosted regression trees, and lasso regression. Each sub-model was fit using fivefold cross-validation to avoid overfitting, and the out-of-sample predictions from across the five holdouts were compiled into a single comprehensive set of predictions from that model. In addition, the same sub-models were run using 100% of the data, and a full set of in-sample predictions were created. The three sets of out-of-sample sub-model predictions were fed into the full geostatistical model14 as the explanatory covariates when performing the model fit. The in-sample predictions from the sub-models were used as the covariates when generating predictions using the fitted full geostatistical model. A recent study demonstrated that this ensemble approach can improve predictive validity by up to 25% over an individual model23.
Geostatistical model analysis
Binomial count data were modelled within a Bayesian hierarchical modelling framework using a logit link function and a spatially and temporally explicit hierarchical generalized linear regression model to fit prevalence of each of our indicators in 14 regions24 of LMICs (North Africa, western SSA, central SSA, eastern SSA, southern SSA, Middle East, Central Asia, East Asia, South Asia, Southeast Asia, Oceania, Central America and the Caribbean, Andean South America, and Tropical South America; see Extended Data Fig. 10). For each region, we explicitly wrote the hierarchy that defines our Bayesian model.
For each binomial CGF indicator, we modelled the average number of children with stunting, wasting, or who were underweight in each survey cluster, d. Survey clusters are precisely located by their GPS coordinates and year of observation, which we map to a spatial raster location, i, at time, t. We observed the number of children reported to be stunted, wasted, or underweight, respectively, as binomial count data, Cd, among an observed sample size, Nd. As we may have observed several data clusters within a given location, i, at time, t, we refer to the probability of stunting, wasting, or underweight, p, within a given cluster, d, by its indexed location, i, and time, t, as pi(d),t(d).
For indices d, i, and t, *(index) is the value of * at that index. The probabilities, pi,t, represent both the annual prevalence at the space–time location and the probability that an individual child was afflicted with the risk factor given that they lived at that particular location. The annual prevalence, pi,t, of each indicator was modelled as a linear combination of the three sub-models (generalized additive model, boosted regression trees, and lasso regression), rasterized covariate values, Xi,t, a correlated spatiotemporal error term, Zi,t, and country random effects, ϵctr(i), with one unstructured country random effect fit for each country in the modelling region and all ϵctr sharing a common variance parameter, γ2, and an independent nugget effect, ϵi,t, with variance parameter, σ2. Coefficients in βh in the three sub-models h = 1, 2, 3 represent their respective predictive weighting in the mean logit link, while the joint error term, Zi,t, accounts for residual spatiotemporal autocorrelation between individual data points that remains after accounting for the predictive effect of the sub-model covariates, the country-level random effect, ϵctr(i), and the nugget independent error term, ϵi,t. The residuals, Zi,t, are modelled as a three-dimensional Gaussian process (GP) in space–time centred at zero and with a covariance matrix constructed from a Kronecker product of spatial and temporal covariance kernels. The spatial covariance, Σspace, is modelled using an isotropic and stationary Matérn function25, and temporal covariance, Σtime, as an annual autoregressive (AR1) function over the 18 years represented in the model. In the stationary Matérn function, Γ is the gamma function, Κv is the modified Bessel function of order v > 0, κ > 0 is a scaling parameter, D denotes the Euclidean distance, and ω2 is the marginal variance. The scaling parameter, κ, is defined to be \(\kappa =\sqrt{8v}/\delta \) in which δ is a range parameter (which is about the distance where the covariance function approaches 0.1) and v is a scaling constant, which is set to 2 rather than fit from the data26,27. This parameter is difficult to reliably fit, as documented by many other analyses26,28,29 that set this to 2. The number of rows and the number of columns of the spatial Matérn covariance matrix are both equal to the number of spatial mesh points for a given modelling region. In the AR1 function, ρ is the autocorrelation function (ACF), and k and j are points in the time series where |k − j| defines the lag. The number of rows and the number of columns of the AR1 covariance matrix are both equal to the number of temporal mesh points (18). The number of rows and the number of columns of the space–time covariance matrix, Σspace ⊗ Σtime, for a given modelling region are both equal to: (the number of spatial mesh points × the number of temporal mesh points).
This approach leveraged the residual correlation structure of the data to more accurately predict prevalence estimates for locations with no data, while also propagating the dependence in the data through to uncertainty estimates14. The posterior distributions were fit using computationally efficient and accurate approximations in R-INLA30,31 (integrated nested Laplace approximation) with the stochastic partial differential equations (SPDE)27 approximation to the Gaussian process residuals using R project v.3.5.1. The SPDE approach using INLA has been demonstrated elsewhere, including the estimation of health indicators, particulate air matter, and population age structure9,32,33,34,35. Uncertainty intervals were generated from 1,000 draws (that is, statistically plausible candidate maps)36 created from the posterior-estimated distributions of modelled parameters. Further details on model and estimation processes are provided in the Supplementary Information.
Post estimation
To leverage national-level data included in the 2017 GBD study1 that were not within the scope of our current geospatial modelling framework, and to ensure alignment between these estimates and GBD national-level and subnational estimates, we performed a post hoc calibration to the mean of the 1,000 draws. We calculated population-weighted aggregations to the GBD estimate level, which was either at the national or first administrative level, and compared these estimates to our corresponding year estimates from 2000 to 2017. We defined the calibration factor to be the ratio between the GBD estimates and our current estimates for each year from 2000 to 2017. For some selected countries where GBD estimates were at the first administrative level, the calibration factors were also calculated at the lowest available subnational level. These countries included Brazil, China, Ethiopia, India, Indonesia, Iran, Mexico, and South Africa. Finally, we multiplied each of our estimates in a country-year (or first-administrative-year) by its associated factor. This ensures consistency between our geospatial estimates and those of the 2017 GBD1, while preserving our estimated within-country geospatial and temporal variation. To transform grid-cell-level estimates into a range of information useful to a wide constituency of potential users, these estimates were aggregated at first and second administrative-level units specific to each country and at national levels using conditional simulation37.
Although the models can predict all locations covered by available raster covariates, all final model outputs for which land cover was classified as ‘barren or sparsely vegetated’ on the basis of the most recently available Moderate Resolution Imaging Spectroradiometer (MODIS) satellite data (2013) were masked38. Areas where the total population density was less than ten individuals per 1 × 1-km grid cell were also masked in the final outputs.
Model validation
We assessed the predictive performance of the models using fivefold out-of-sample cross-validation strategies and found that our prevalence estimates closely matched the survey data. To offer a more stringent analysis by respecting some of the spatial correlation in the data, holdout sets were created by combining sets of data at different spatial resolutions (for example, first administrative level). Validation was performed by calculating bias (mean error), variance (root mean square error), 95% data coverage within prediction intervals, and correlation between observed data and predictions. All validation metrics were calculated on the out-of-sample predictions from the fivefold cross-validation. Furthermore, measures of spatial and temporal autocorrelation pre- and post-modelling were examined to verify correct recognition, fitting, and accounting for the complex spatiotemporal correlation structure in the data. All validation procedures and corresponding results are included in Supplementary Tables 14–22 and Supplementary Figs. 24–41.
Projections
To compare our estimated rates of improvement in CGF prevalence over the last 18 years with the improvements needed between 2017 and 2025 to meet WHO GNTs, we performed a simple projection using estimated annualized rates of change (AROC) applied to the final year of our estimates.
For each CGF indicator, u, we calculated AROC at each grid cell, m, by calculating the AROC between each pair of adjacent years, t:
We then calculated a weighted AROC for each indicator by taking a weighted average across the years, where more recent AROCs were given more weight in the average. We defined the weights to be:
in which γ may be chosen to give varying amounts of weight across the years. For any indicator, we then calculated the average AROC to be:
Finally, we calculated the projections, Proj, by applying the AROC in our 2017 mean prevalence estimates to produce estimates in 8 years from 2017 to 2025. For this set of projections, we selected γ = 1.7 for stunting, γ = 1.9 for wasting, and γ = 1.8 for underweight1.
This projection scheme is analogous to the methods used in the 2017 GBD measurement of progress and projected attainment of health-related Sustainable Development Goals1. Our projections are based on the assumption that areas will sustain the current AROC, and the precision is dependent on the level of uncertainty emanating from the estimation of annual prevalence.
Although the WHO GNT for wasting was to reduce prevalence to less than 5%, the WHO GNT for stunting was a 40% relative reduction in prevalence. For our analyses, we defined the WHO GNT for stunting and underweight (for which no WHO GNT was established) to be 40% reduction relative to 2010, the year the World Health Assembly requested the development of the WHO GNTs39.
Limitations
The accuracy of our models depends on the volume, representativeness, quality, and validity of surveys available for analysis (Supplementary Tables 4, 5, Supplementary Figs. 2–16). Persistent data gaps in national surveys include a lack of CGF data or household-level characteristics, such as hygiene and sanitation practices. The associated uncertainties of our estimates are higher in areas where data are either missing or less reliable (Figs. 1d, 2d, Extended Data Fig. 5d), and rely more heavily on covariates and borrowing from neighbouring areas for their modelling (Supplementary Table 7, Supplementary Fig. 17). Investments in improvements of health surveillance systems and including child anthropometrics as part of routine data collection for profiling population characteristics could improve the certainty of our estimates and better monitor progress towards international goals. In addition, measurement error in collecting anthropometric information, including the child’s age, height, and weight, could have introduced bias or error in the data across different survey types. The accuracy of age data may be affected by differences in sampling approaches and self-reporting bias, such as long recall period or selective recall. Weight and height measurements may be inaccurate owing to improper calibration of equipment, device inaccuracy, different measurement methods, or human error. We did not include a survey random effect to account for between-survey variability in data accuracy; given that most surveys represent a country-year, it would be difficult to distinguish these biases from temporal effects. Our calibration approach in the post-estimation process used only a ratio estimator and did not account for an additive effect, which may have introduced bias. Owing to the complexity of the boosted regression tree sub-model, we were unable to account for the uncertainty of our three sub-models in our final estimates (see Supplementary Information section 3.2.2 for more detail). It is worth noting that our analyses are descriptive and do not support causal inferences on their own. Future research is required to determine the causal pathways for each CGF indicator across and within LMICs.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this paper.
Data availability
CGF estimates can be further explored at various spatial scales (national, administrative, and local levels) through our customized online data visualization tools (https://vizhub.healthdata.org/lbd/cgf). The full output of the analyses and the underlying data used in the analyses are publicly available via the Global Health Data Exchange (GHDx; http://ghdx.healthdata.org/record/ihme-data/lmic-child-growth-failure-geospatial-estimates-2000-2017). Some data sources are under special licenses for the current study and are thus not publicly available. Supplementary Tables 4 and 5 show the incorporated data sources, and data with restrictions are marked with an obelisk symbol (†). All maps presented in this study are generated by the authors and no permissions are required to publish them.
The findings of this study are supported by data available in public online repositories, data publicly available upon request of the data provider, and data not publicly available owing to restrictions by the data provider. Non-publicly available data were used under license for the current study but may be available from the authors upon reasonable request and with permission of the data provider. Detailed tables and figures of data sources and availability can be found in Supplementary Tables 4, 5, and Supplementary Figs. 2–16.
Administrative boundaries were retrieved from the Global Administrative Unit Layers (GAUL)20 or the Database of Global Administrative Areas (GADM)21. Land cover was retrieved from the online Data Pool, courtesy of the NASA EOSDIS Land Processes Distributed Active Archive Center (LP DAAC), USGS/Earth Resources Observation and Science (EROS) Center, Sioux Falls, South Dakota40. Lakes were retrieved from the Global Lakes and Wetlands Database (GLWD), courtesy of the World Wildlife Fund and the Center for Environmental Systems Research, University of Kassel41,42. Populations were retrieved from WorldPop15,16. All maps in this study were produced using ArcGIS Desktop 10.6.
Code availability
Our study follows the Guidelines for Accurate and Transparent Health Estimate Reporting (GATHER; Supplementary Table 1). All code used for these analyses is publicly available online http://ghdx.healthdata.org/record/ihme-data/lmic-child-growth-failure-geospatial-estimates-2000-2017 and at http://github.com/ihmeuw/lbd/tree/cgf-lmic-2019.
References
Dicker, D. et al. Global, regional, and national age-sex-specific mortality and life expectancy, 1950–2017: a systematic analysis for the Global Burden of Disease Study 2017. Lancet 392, 1684–1735 (2018).
Victora, C. G. et al. Maternal and child undernutrition: consequences for adult health and human capital. Lancet 371, 340–357 (2008).
WHO & UNICEF. WHO Child Growth Standards and the Identification of Severe Acute Malnutrition in Infants and Children: A Joint Statement https://www.who.int/nutrition/publications/severemalnutrition/9789241598163/en/ (2009).
Wang, Y. & Chen, H.-J. In Handbook of Anthropometry (ed. Preedy, V. R.) 2, 29–48 (Springer New York, 2012).
Waterlow, J. C. et al. The presentation and use of height and weight data for comparing the nutritional status of groups of children under the age of 10 years. Bull. World Health Organ. 55, 489–498 (1977).
WHO Multicentre Growth Reference Study Group. WHO Child Growth Standards based on length/height, weight and age. Acta Paediatr. 450, 76–85 (2006).
ICF & USAID. The DHS Program: Demographic and Health Surveys https://dhsprogram.com/publications/Publication-Search.cfm?shareurl=yes&topic1=15&pubTypeSelected=pubtype_5 (accessed 13 September 2018).
Reich, B. J. & Haran, M. Precision maps for public health. Nature 555, 32–33 (2018).
Osgood-Zimmerman, A. et al. Mapping child growth failure in Africa between 2000 and 2015. Nature 555, 41–47 (2018).
de Onis, M. et al. Prevalence thresholds for wasting, overweight and stunting in children under 5 years. Public Health Nutr. 22, 1–5 (2018).
WHO. Nutrition Landscape Information System (NLIS) Country Profile Indicators Interpretation Guide https://www.who.int/nutrition/nlis_interpretationguide_isbn9789241599955/en/ (2010).
Development Initiatives. The 2018 Global Nutrition Report: Shining a Light to Spur Action on Nutrition https://globalnutritionreport.org/reports/global-nutrition-report-2018/ (2018).
Annan, K. Data can help to end malnutrition across Africa. Nature 555, 7 (2018).
Hotez, P. J. & Ribeiro, P. J. Model-Based Geostatistics (Springer New York, 2007).
WorldPop. WorldPop Dataset http://www.worldpop.org.uk/data/get_data/ (accessed 24 July 2017).
Tatem, A. J. WorldPop, open data for spatial demography. Sci. Data 4, 170004 (2017).
UNICEF. Multiple Indicator Cluster Surveys (MICS) http://mics.unicef.org (accessed 26 June 2019).
World Bank Group. Living Standards Measurement Survey (LSMS). http://surveys.worldbank.org/lsms (accessed 26 June 2019).
World Bank Group. Core Welfare Indicators Questionnaire Survey (CWIQ) http://ghdx.healthdata.org/series/core-welfare-indicators-questionnaire-survey-cwiq (accessed 21 April 2017).
GeoNetwork. The Global Administrative Unit Layers (GAUL) http://www.fao.org/geonetwork/srv/en/main.home (2015).
Global Administrative Areas (GADM). GADM Database of Global Administrative Areas http://www.gadm.org (2018).
Indrayan, A. Demystifying LMS and BCPE methods of centile estimation for growth and other health parameters. Indian Pediatr. 51, 37–43 (2014).
Bhatt, S. et al. Improved prediction accuracy for disease risk mapping using Gaussian process stacked generalization. J. R. Soc. Interface 14, 20170520 (2017).
Murray, C. J. L. et al. GBD 2010: design, definitions, and metrics. Lancet 380, 2063–2066 (2012).
Stein, M. L. Interpolation of Spatial Data (Springer New York, 1999).
Lindgren, F. & Rue, H. Bayesian spatial modelling with R-INLA. J. Stat. Softw. 63, jss.v063.i19 (2015).
Lindgren, F., Rue, H. & Lindström, J. An explicit link between Gaussian fields and Gaussian Markov random fields: the stochastic partial differential equation approach. J. R. Stat. Soc. Series B Stat. Methodol. 73, 423–498 (2011).
Rozanov, Y. A. Markov Random Fields (Springer-Verlag, 1982).
Whittle, P. On stationary processes in the plane. Biometrika 41, 434–449 (1954).
Rue, H., Martino, S. & Chopin, N. Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. J. R. Stat. Soc. Series B Stat. Methodol. 71, 319–392 (2009).
Martins, T. G., Simpson, D., Lindgren, F. & Rue, H. Bayesian computing with INLA: new features. Comput. Stat. Data Anal. 67, 68–83 (2013).
Golding, N. et al. Mapping under-5 and neonatal mortality in Africa, 2000-15: a baseline analysis for the Sustainable Development Goals. Lancet 390, 2171–2182 (2017).
Cameletti, M., Lindgren, F., Simpson, D. & Rue, H. Spatio-temporal modeling of particulate matter concentration through the SPDE approach. AStA Adv. Stat. Anal. 97, 109–131 (2013).
Alegana, V. A. et al. Fine resolution mapping of population age-structures for health and development applications. J. R. Soc. Interface 12, 20150073 (2015).
Kinyoki, D. K. et al. Assessing comorbidity and correlates of wasting and stunting among children in Somalia using cross-sectional household surveys: 2007 to 2010. BMJ Open 6, e009854 (2016).
Patil, A. P., Gething, P. W., Piel, F. B. & Hay, S. I. Bayesian geostatistics in health cartography: the perspective of malaria. Trends Parasitol. 27, 246–253 (2011).
Gething, P. W., Patil, A. P. & Hay, S. I. Quantifying aggregated uncertainty in Plasmodium falciparum malaria prevalence and populations at risk via efficient space-time geostatistical joint simulation. PLOS Comput. Biol. 6, e1000724 (2010).
Scharlemann, J. P. W. et al. Global data for ecology and epidemiology: a novel algorithm for temporal Fourier processing MODIS data. PLoS ONE 3, e1408 (2008).
de Onis, M. et al. The World Health Organization’s global target for reducing childhood stunting by 2025: rationale and proposed actions. Matern. Child Nutr. 9, 6–26 (2013).
Friedl, M. & Sulla-Menashe, D. MCD12Q1 v006. MODIS/Terra+Aqua Land Cover Type Yearly L3 Global 500m SIN Grid https://doi.org/10.5067/MODIS/MCD12Q1.006 (NASA EOSDIS Land Processes DAAC, 2019).
Lehner, B. & Döll, P. Development and validation of a global database of lakes, reservoirs and wetlands. J. Hydrol. (Amst.) 296, 1–22 (2004).
World Wildlife Fund. Global Lakes and Wetlands Database, Level 3 https://www.worldwildlife.org/pages/global-lakes-and-wetlands-database (2004).
Acknowledgements
This work was primarily supported by grant OPP1132415 from the Bill & Melinda Gates Foundation.
Author information
Authors and Affiliations
Consortia
Contributions
S.I.H. and N.J.K. conceived and planned the study. B.V.P., A.L.-A., and D.K.K. obtained, extracted, processed, and geo-positioned CGF data. L.E. constructed covariate data layers. D.K.K., A.E.O.-Z., and M.L.C. wrote the computer code and designed the statistical analyses. D.K.K. carried out the statistical analyses with input from A.E.O.-Z., M.L.C., N.J.H., and N.V.B. D.K.K. and L.E. prepared figures. D.K.K., L.E.S., and L.B.M. wrote the first draft of the manuscript with assistance from S.I.H. and M.F.S., and all authors contributed to subsequent revisions. All authors provided intellectual input into aspects of this study. Additional details on author contributions can be found in the Supplementary Information (section 8.0).
Corresponding author
Ethics declarations
Competing interests
This study was funded by the Bill & Melinda Gates Foundation. Co-authors employed by the Bill & Melinda Gates Foundation provided feedback on initial maps and drafts of this manuscript. Otherwise, the funders of the study had no role in study design, data collection, data analysis, data interpretation, writing of the final report, or the decision to publish. The corresponding author had full access to all the data in the study and had final responsibility for the decision to submit for publication.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Prevalence of stunting in children under five in LMICs at administrative levels 0, 1, 2, and at 5 × 5-km resolution in 2017.
Administrative level 0 are national-level estimates; administrative level 1 are first administrative-level (for example, states or provinces) estimates; administrative level 2 are second administrative-level (for example, districts or departments) estimates. Maps reflect administrative boundaries, land cover, lakes, and population; grey-coloured grid cells had fewer than ten people per 1 × 1-km grid cell and were classified as ‘barren or sparsely vegetated’15,16,20,21,40,41,42, or were not included in these analyses. Maps were produced using ArcGIS Desktop 10.6.
Extended Data Fig. 2 Geographical inequality in the prevalence of child stunting across 105 countries.
The bars represent the range of stunting prevalence in children under five in the second administrative-level units in each country. Bars indicating the range in 2017 are coloured according to the regions defined by the Global Burden of Disease (GBD)1. Grey bars indicate the range in 2000. The graph was produced using R project v.3.5.1.
Extended Data Fig. 3 Prevalence of wasting in children under five in LMICs at administrative levels 0, 1, 2, and at 5 × 5-km resolution in 2017.
Administrative levels are as described in Extended Data Fig. 1. Maps reflect administrative boundaries, land cover, lakes, and population; grey-coloured grid cells had fewer than ten people per 1 × 1-km grid cell and were classified as ‘barren or sparsely vegetated’15,16,20,21,40,41,42, or were not included in these analyses. Maps were produced using ArcGIS Desktop 10.6.
Extended Data Fig. 4 Geographical inequality in prevalence of child wasting across 105 countries.
The bars represent the range of wasting prevalence in children under five in the second administrative-level units in each country. Bars indicating the range in 2017 are coloured according to their GBD-defined1 regions. Grey bars indicate the range in 2000. The graph was produced using R project v.3.5.1.
Extended Data Fig. 5 Prevalence of underweight in children under five in LMICs (2000–2017) and progress towards 2025.
a, b, Prevalence of underweight in children under five at the 5 × 5-km resolution in 2000 (a) and 2017 (b). c, Overlapping population-weighted tenth and ninetieth percentiles (lowest and highest) of 5 × 5-km grid cells and AROC in underweight, 2000–2017. d, Overlapping population-weighted quartiles of underweight prevalence and relative 95% uncertainty in 2017. e, f, Number of underweight children under five, at the 5 × 5-km (e) and first-administrative-unit (f) levels. g, 2000–2017 annualized decrease in underweight prevalence relative to rates needed during 2017–2025 to meet WHO GNT. h, Grid-cell-level predicted underweight prevalence in 2025. Maps were produced using ArcGIS Desktop 10.6. Interactive visualization tools are available at https://vizhub.healthdata.org/lbd/cgf.
Extended Data Fig. 6 Geographical inequality in prevalence of child underweight across 105 countries.
The bars represent the range of underweight prevalence in the second administrative-level units in each country. Bars indicating the range in 2017 are coloured according to their GBD-defined1 regions. Grey bars indicate the range in 2000. The graph was produced using R project v.3.5.1.
Extended Data Fig. 7 Probability that WHO GNT had been achieved in 2017 at the first administrative and 5 × 5-km grid-cell levels for stunting, wasting, and underweight.
a–f, Probability of WHO GNT achievement in 2017 at the first administrative and 5 × 5-km levels for stunting (a, d), wasting (b, e), and underweight (c, f). Dark-blue and dark-red grid cells indicate >95% and <5% probability, respectively, of having met the WHO GNT in 2017. Given that there was no WHO GNT established for underweight, we based the underweight target on WHO GNT for stunting, as the conditions are similarly widespread and prevalent. Maps were produced using ArcGIS Desktop 10.6.
Extended Data Fig. 8 Probability of meeting WHO GNT in 2025 at the first administrative and 5 × 5-km grid-cell levels for stunting, wasting, and underweight.
a–f, Probability of WHO GNT achievement in 2025 at the first administrative and 5 × 5-km levels for stunting (a, d), wasting (b, e), and underweight (c, f). Dark-blue and dark-red grid cells indicate >95% and <5% probability, respectively, of meeting WHO GNT in 2025. Given that there was no WHO GNT established for underweight, we based the underweight target on WHO GNT for stunting as the conditions are similarly widespread and prevalent. Maps were produced using ArcGIS Desktop 10.6.
Extended Data Fig. 9 Flowchart of CGF prevalence modelling process.
The process used to produce CGF prevalence estimates in LMICs involved three main parts. In the data-processing steps (green), data were identified, extracted, and prepared for use in the models. In the modelling phase (red), we used these data and covariates in stacked generalization ensemble models and spatiotemporal Gaussian process models for each CGF indicator. In post-processing (blue), we calibrated the prevalence estimates to match 2017 GBD study1 estimates and aggregated the estimates to the first- and second-administrative-level units in each country.
Extended Data Fig. 10 Modelling regions.
Modelling regions24 were based on geographical and SDI regions from the GBD study1, defined as: Andean South America, Central America and the Caribbean, central SSA, East Asia, eastern SSA, Middle East, North Africa, Oceania, Southeast Asia, South Asia, southern SSA, Central Asia, Tropical South America, and western SSA. ‘High income country’ refers to regions not included in our models owing to high-middle or a high SDI. The map was produced using ArcGIS Desktop 10.6.
Supplementary information
Supplementary Information
Supplementary Discussion; Supplementary Tables; Supplementary Figures; Supplementary Methods. Additional discussion of associated causes of child growth failure, interventions, and future work. Supplementary Tables 1–22: data sources, fitted parameters, countries estimated to meet WHO GNTs in 2017 and 2025, predictive metrics. Supplementary Figures 1–41: data availability, covariates, seasonal adjustments, validation metrics. Additional methods details. Detailed author contributions.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Local Burden of Disease Child Growth Failure Collaborators. Mapping child growth failure across low- and middle-income countries. Nature 577, 231–234 (2020). https://doi.org/10.1038/s41586-019-1878-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-019-1878-8
This article is cited by
-
The impact of early-life exposure to high temperatures on child development: evidence from China
Population and Environment (2024)
-
Voice, access, and ownership: enabling environments for nutrition advocacy in India and Nigeria
Food Security (2024)
-
Can adoption of improved seed varieties spur long-term food security in Malawi?
Environment, Development and Sustainability (2024)
-
A systematic review with meta-analysis of the relation of aflatoxin B1 to growth impairment in infants/children
BMC Pediatrics (2023)
-
Mapping of nutrition policies and programs in South Asia towards achieving the Global Nutrition targets
Archives of Public Health (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
