
Abstract
We report better-than-classical success probabilities for a complete Grover quantum search algorithm on the largest scale demonstrated to date, of up to five qubits, using two different IBM platforms. This is enabled by error suppression via robust dynamical decoupling. Further improvements arise after the use of measurement error mitigation, but the latter is insufficient by itself for achieving better-than-classical performance. For two qubits, we demonstrate a 99.5% success probability via the use of the [[4, 2, 2]] quantum error-detection (QED) code. This constitutes a demonstration of quantum algorithmic breakeven via QED. Along the way, we introduce algorithmic error tomography (AET), a method that provides a holistic view of the errors accumulated throughout an entire quantum algorithm, filtered via the errors detected by the QED code used to encode the circuit. We demonstrate that AET provides a stringent test of an error model based on a combination of amplitude damping, dephasing, and depolarization.
Similar content being viewed by others

Introduction
The best possible classical strategy for finding a particular ‘marked’ element in an unsorted list of length N requires querying half of the elements in the list on average; a quantum computer (QC) can do this in quadratically fewer queries using Grover’s search algorithm1. This algorithm is optimal and provably better than all classical strategies2. As one of the first algorithms with a provable quantum speedup, Grover search is often used as a subroutine for other quantum algorithms3,4. Over the last two decades, Grover search has been implemented on various quantum computing platforms5,6,7,8,9,10, albeit for relatively small N.
Encoding a list of length N requires \(n=\lceil {\log }_{2}(N)\rceil\) qubits. The list can be queried classically or using quantum queries; in both cases, one finds the marked element with some probability, which we refer to as the classical or quantum success probability. The largest implementation of Grover’s algorithm to date is for n = 8 qubits, but without demonstrating a better-than-classical quantum success probability5. Such better-than-classical performance has been achieved for n = 36,7 and n = 48 qubits. Ref. 9 reported better-than-classical success probabilities for n = 5 for a single marked state, leaving open the possibility that the success probability would be reduced by averaging over all marked states. Here, employing two seven-qubit IBM Quantum Platform (IQP) transmon qubit platforms ibm_nairobi (Nairobi) and ibmq_jakarta (Jakarta), we demonstrate higher average success probabilities than all previous implementations, for n ≤ 5.
Key to our demonstrations is the use of error suppression and mitigation strategies. In particular, we use the [[4, 2, 2]] quantum error-detecting code11,12, which encodes k = 2 logical qubits into n = 4 physical qubits and detects arbitrary single-qubit errors, to demonstrate a significant success probability enhancement relative to using two copies of n = 2 physical qubits. These success probabilities are further improved by combining error detection with measurement error mitigation13,14.
We use the quantum error detection results to perform what we call algorithmic error tomography: for each encoded algorithm execution, based on the possible measurement outcomes we compute the probability of an error detectable by the [[4, 2, 2]] code or of a logical error. This allows us to compute a detailed map of the errors that arise at the conclusion of the entire algorithm. In this sense, algorithmic error tomography provides a holistic and complementary perspective to techniques such as gate set tomography15,16, which instead focuses on individual gates applied during the algorithm.
We demonstrate better-than-classical performance for three or more physical qubits by employing error suppression via dynamical decoupling (DD)17,18,19,20. Toward this end, we consider three robust DD families: universally robust (UR)21, concatenated DD (CDD)22, and robust genetic algorithm (RGA)23 sequences. We find that robust sequences with few pulses are vital in achieving better-than-classical algorithmic performance.
We compare the experimentally obtained results for Grover’s algorithm with an error model based on the concatenation of amplitude damping, phase damping, and depolarization maps. Each map is parameterized by the calibration metrics provided by the IBM Quantum Platform (IQP) backend24. We test this model using the observed success probabilities and the algorithmic error tomography results; the latter provides a much more stringent test. We find good agreement with the model, but only after using DD. We interpret this in terms of the suppression of crosstalk by DD25,26, which is unaccounted for by the error model.
In summary, we demonstrate a better-than-classical Grover search on up to 5 qubits, enabled by quantum error detection and dynamical decoupling. That is, we demonstrate algorithmic performance that is enhanced beyond the break-even point—where protected operations outperform their unprotected counterparts—and the capabilities of the best possible classical algorithm executing the same task. Along the way, we introduce algorithmic error tomography—a characterization of errors afflicting an entire quantum algorithm based on the syndromes of a quantum error detecting code.
The structure of this paper is as follows. In the section “Grover’s Algorithm: background and implementation”, we summarize Grover’s algorithm’s salient aspects and discuss its implementation. In the section “Open system model”, we describe the open system model we use to compute the theoretically expected algorithmic performance. Details about our dynamical decoupling implementation are in the section “Dynamical decoupling”. The section “Two-qubit encoded Grover algorithm protected by quantum error detection” focuses on the performance of Grover’s algorithm on n = 2 qubits with and without error detection. Algorithmic error tomography is introduced in the section “Two-qubit encoded Grover algorithm protected by quantum error detection” as well. The results for 2 < n ≤ 5, where DD plays a crucial role in achieving better-than-classical performance, are given in the section “3-qubit to 5-qubit Grover’s algorithm protected by dynamical decoupling”. We conclude with observations and the implications of our results in the section “Discussion”. Additional details and calculations in support of the main text are provided in the section “Methods”.
Results
Grover’s Algorithm: background and implementation
Informally, the Grover problem is to search an unsorted list with N = 2n elements for a marked element. Formally, the goal is to find the marked n-bit bitstring m using the smallest number of queries of an oracle that implements a function fm: {0, 1}n ↦ {0, 1} defined as fm(x) = δx,m. Classically, after q queries, the probability of correctly identifying the marked element, which hereafter we refer to as the success probability, is \({p}_{{\rm{s}}}^{{{{\rm{C}}}}}(q,N)=(q+1)/N\) (see the section “Classical success probability”). Consequently, the classical algorithm requires O(N) queries.
Grover’s algorithm provides a quadratic quantum speedup, requiring only \(O(\sqrt{N})\) queries1. This scaling remains valid with more than one marked element27, or even for an arbitrary initial amplitude distribution over the list elements28. In the original setting of a single marked element, the state after q queries to the oracle is
where \(\left\vert {m}^{\perp }\right\rangle =\frac{1}{\sqrt{N-1}}{\sum }_{x\ne m}\left\vert x\right\rangle\) and \(\theta =\arcsin \left(\frac{1}{\sqrt{N}}\right)\). Thus, the quantum success probability is \({p}_{{\rm{s}}}^{{{{\rm{Q}}}}}(q,N)={\sin }^{2}\left[(2q+1)\theta \right]\), and the theoretically optimal number of queries is \({q}_{{{{\rm{opt}}}}}=\lfloor \frac{\pi }{4}\sqrt{N}\rfloor\). Note that \({p}_{{\rm{s}}}^{{{{\rm{C}}}}}(q,N) < {p}_{{\rm{s}}}^{{{{\rm{Q}}}}}(q,N)\) for all q < qopt. However, the theoretically optimal q is often not experimentally optimal. As circuit depth increases with the number of queries and the problem size, there is a trade-off between the added decoherence and the increase in the success probability. Most experimental implementations of Grover’s algorithm have focused on a single query5,6,7,8, but this strategy does not scale well, as both \({p}_{{\rm{s}}}^{{{{\rm{C}}}}}(1,N)\) and \({p}_{{\rm{s}}}^{{{{\rm{Q}}}}}(1,N)\) decrease exponentially with n. We adopt an empirical approach to identify the optimal number of queries such that ps is maximized. We set q = 2 for all problem sizes other than n = 2 where qopt = 1. We justify our choice of the number of queries in the section “Survey of dynamical decoupling sequences”.
A schematic illustrating the implementation of the n-qubit Grover algorithm is shown in Fig. 1a. The only multi-qubit operation is the n-qubit controlled-phase gate Cn−1Z, which needs to be implemented twice for each oracle query: once for the oracle and again for the amplitude amplification step. Different marked elements are represented by sandwiching the Cn−1Z gate with Xi or Ii depending on whether the corresponding bit bi in the marked bitstring m is 0 or 1. I.e., letting m = b1b2…bn, then Cn−1Z in the oracle layer is preceded and followed by \({X}^{1-{b}_{1}}\otimes {X}^{1-{b}_{2}}\cdots \otimes {X}^{1-{b}_{n}}\). Likewise, amplitude amplification is implemented as H⊗nX⊗n(Cn−1Z)X⊗nH⊗n.

a Circuit description for Grover’s algorithm. The relative amplitudes of all the states at each stage of the algorithm are shown. Starting with an equal superposition state, the oracle assigns a relative phase difference of π to the marked state. The amplitude amplification step then performs an inversion about the mean, allowing \(\left\vert m\right\rangle\) to have a larger probability amplitude than all other states. This round of querying and amplifying is repeated q times. The optimal number of rounds for the n-qubit Grover problem is \({q}_{{{{\rm{opt}}}}}=\lfloor \frac{\pi }{4}{2}^{n/2}\rfloor\). The only multi-qubit operation required to implement both the oracle and the amplitude amplification step is Cn−1Z (vertical line in the Oracle and Amplitude Amplification boxes). b Grover and DD. The timeline for one oracle query for 4-qubit Grover with the marked state \(\left\vert 1111\right\rangle\) is shown. Qubits q4 and q6 are spectators in this example. Recall that each oracle query for 4-qubit Grover requires two C3Z gates. C3Z requires 14 CNOTs, and the entire circuit uses 28 CNOTs; see the section “Circuit construction” for circuit compilation details. The pre-DD circuit elements are grayed out, and the colored lines represent the DD pulses. The DD sequence exemplified here uses four pulses for illustration purposes; in reality, we used longer sequences. The scheme demonstrated highlights four primary features of our implementation: (1) all idle intervals, including the ones on inactive qubits, are filled, (2) only one repetition of each sequence is performed, and the pulse interval is adjusted accordingly, (3) each pulse in the sequence can be unique, (4) a single qubit can experience multiple DD repetitions if there are multiple idle intervals.
For all problem sizes and oracles, we repeated each circuit for the maximum number of shots allowed on the QPU: 20,000 and 32,000 for Nairobi and Jakarta, respectively. The reported success probabilities were extracted by bootstrapping over these trials and all N possible marked states. All error bars reflect 95% confidence intervals obtained after bootstrapping unless specified otherwise.
Open system model
The QPUs used here are calibrated daily, and the following calibration metrics are recorded: the gate error eg and gate duration τg, the qubit damping timescale T1 and dephasing timescale T2, and the response matrix M for readout errors (see Supplementary Information). In this section, we describe how we estimate the theoretical performance of Grover’s algorithm using these metrics. The model described here is mathematically equivalent to the one used in Qiskit’s Aer API’s NoiseModel.from_backend() (see Supplementary information of Ref. 29).
In a closed system described by a state ρ, a unitary gate U acts as \({{{\mathcal{U}}}}(\rho )=U\rho {U}^{{\dagger} }\). In reality, the system is open, so we model gate U as a CPTP map \({{{\mathcal{E}}}}={{{\mathcal{D}}}}\circ {{\Phi }}\circ {{{\mathcal{A}}}}\circ {{{\mathcal{U}}}}\), where \({{{\mathcal{D}}}},{{{\mathcal{A}}}},{{\Phi }}\) are depolarizing, amplitude damping and phase damping maps respectively30. The amplitude damping and phase damping maps account for thermal relaxation, which we represent as \({{{\mathcal{R}}}}={{\Phi }}\circ {{{\mathcal{A}}}}\). The single-qubit Kraus operators for \({{{\mathcal{A}}}}=\{{A}_{0},{A}_{1}\}\) and Φ = {F0, F1} are
The n-qubit depolarizing map is
where d = 2n and \({{{\mathcal{D}}}}\) has d2 Kraus operators:
We parameterize these maps by their respective error probabilities pA, pΦ, and pD, which in turn depend on the calibration metrics eg, τg, T1, and T2. In particular,
where
and
is the average gate fidelity for a CPTP map \({{{\mathcal{E}}}}\). Here \({F}_{{{{\rm{pro}}}}}({{{\mathcal{E}}}})\) is the process fidelity of the map \({{{\mathcal{E}}}}\) with the target map \({{{\mathcal{U}}}}\), and d is the dimension of the map31,32.
For each gate, we know the total gate error eg, and so we compute pD by setting \(1-{e}_{{\rm {g}}}=F({{{\mathcal{D}}}}\circ {{{\mathcal{R}}}})\), which gives us Eq. (9) (see the section “Extracting the depolarizing parameter from gate errors” for more details). In other words, we assign any gate error not accounted for by relaxation to depolarization.
We require that pD ≥ 0 (i.e. \(F({{{\mathcal{R}}}} > 1-{e}_{{\rm {g}}})\) and if this condition is not met, then we assume that the error is entirely due to depolarization. In particular, when \(F({{{\mathcal{R}}}})\le 1-{e}_{\rm {{g}}}\), we set pD = egd/(d−1) and \({{{\mathcal{E}}}}={{{\mathcal{D}}}}\circ {{{\mathcal{U}}}}\). For idle intervals in the circuit, no gate error eg is reported by IQP24, and therefore we model idle intervals with duration τ as identity operations where only the relaxation \({{{\mathcal{R}}}}\) matters. This is equivalent to setting the gate error for idle intervals to \({e}_{{{{\rm{idle}}}}}=1-F({{{\mathcal{R}}}})\).
In summary, we model single-qubit gates U1Q with gate duration τg as
and two-qubit gates U2Q with duration τg acting on qubits j, k are modeled as
where \({{{\mathcal{D}}}}({p}_{{\rm {D}}})\) has 16 Kraus operators for n = 2 [see the section “Open system model”]. Idle intervals with duration τ are described by
Note that while we implement \({{{\mathcal{D}}}}\circ {{{\mathcal{R}}}}\), Qiskit’s API reverses this order. While these channels do not commute, we found no significant difference between these two orderings in our simulations. In order to account for systematic measurement errors, the response matrix M is applied to all reported probabilities.
The quantum circuit for each experiment is first compiled into the QPU’s native gate set and then scheduled using IQP’s API24. We use this circuit to determine the order of operations and then replace each unitary map \({{{\mathcal{U}}}}\) with the corresponding CPTP channel \({{{\mathcal{E}}}}\). In the end, we acquire a probability distribution corresponding to the theoretical estimate of the circuit’s output as measured in the computational basis.
Dynamical decoupling
DD is an open-loop quantum control technique wherein a sequence of pulses is strategically inserted between gates to suppress unwanted system-bath interactions17,18,19,20. While DD is fully compatible with quantum error correction33, its most economical form requires no encoding, measurements, or post-processing. It is, therefore, perhaps the least resource-intensive error suppression strategy. Error suppression via DD has a long history of experimental demonstrations on various quantum devices (see ref. 34 for a review). Here, we employ a ‘decouple then compute’ strategy35,36, whereby control pulses constituting short but complete DD sequences are interleaved with the quantum circuit, exploiting intervals when individual qubits in the corresponding quantum circuits are idle. A scheme demonstrating our strategy is shown in Fig. 1b. This interleaving strategy has been used to improve quantum volume37, variational quantum algorithms38, and most recently to demonstrate an algorithmic quantum speedup39.
In addition to the popular basic DD sequences—CPMG40 and XY418—we consider three robust sequence families: universally robust (UR) DD21, concatenated DD (CDD)22, and robust genetic algorithm (RGA) DD23 (see the section “Survey of dynamical decoupling sequences” for more details). Other than CPMG, these are all high-order, multi-axis sequences that are universal for single qubits, i.e., they suppress arbitrary single-qubit errors beyond first order in the Magnus or Dyson expansion41. Robustness refers to the mitigation of axis-angle and over/under-rotation errors. In addition, these sequences can cancel crosstalk errors25,26. Our sequence choice is informed by the results of ref. 42, which reported on a significantly more comprehensive survey of sequences using superconducting qubits and concluded that robust sequences are preferred default choices. Here we do not utilize the OpenPulse functionality of the IQP platforms, nor do we implement Uhrig-type43 non-uniform pulse interval DD sequences such as quadratic DD (QDD)44, which were also found to perform well in the survey42. Both have the potential to enhance our results and are attractive options for future studies.
Two-qubit encoded Grover algorithm protected by quantum error detection
The [[4, 2, 2]] code11 is the smallest possible qubit-based error-detecting code12 and has been invoked for proof-of-principle demonstrations of quantum error detection45. Notably, it has been used to improve Clifford gate set fidelities46 and the performance of variational algorithms47. However, measurement error mitigation (MEM) played a dominant role in Ref. 47, and it is unclear if error detection alone would have improved performance in that work. Here, we compare the performance of the two-qubit Grover algorithm with and without the [[4, 2, 2]] code and MEM. The unencoded version needs two qubits, while the encoded version requires four. To equalize resources, we simultaneously use two copies of the unencoded circuit and report the best fidelity of the two copies. We incorporate MEM using iterative Bayesian unfolding via the pyIBU package48 (see the Supplementary Information for details about MEM). Ultimately, we demonstrate a conclusive improvement in algorithmic performance due to quantum error detection.
Encoding into the [[4, 2, 2]] code
The stabilizers of the [[4, 2, 2]] code are XXXX and ZZZZ. The logical operators of this code can be chosen as \({\overline{X}}_{1}=XIXI,{\overline{X}}_{2}=XXII,{\overline{Z}}_{1}=ZZII\), and \({\overline{Z}}_{2}=ZIZI\). Two-qubit Grover also requires the encoded Hadamard \(\overline{H}\) and controlled-phase \(\overline{\,{{\mbox{C}}}\,Z}\). The deconstruction of the logical circuit into physical components is detailed in the section “Circuit construction”, and the resultant encoded two-qubit Grover circuit is shown in Fig. 2.

The two-qubit single-query (q = 1) Grover circuit encoded using the [[4, 2, 2]] code for the marked state \(\left\vert 01\right\rangle\) is shown. The encoding step (left dashed box) prepares the encoded initial state \(\left\vert \overline{00}\right\rangle =\frac{1}{\sqrt{2}}\left(\left\vert 0000\right\rangle +\left\vert 1111\right\rangle \right)\) (the 4-qubit GHZ state) from the physical initial state \(\left\vert 0000\right\rangle\). The encoded Grover circuit is implemented by converting each physical gate of the n = 2 case of Fig. 1a into its logical counterpart, which is then converted into a physical 4-qubit implementation (middle left and right dashed boxes). The amplitude amplification step is the 00-oracle sandwiched by Hadamard gates. See the section “Circuit construction” for further details. P = diag(1, i) is the phase gate. We post-select the measured results by decoding (right dashed box) and discarding any measurement outcome for which the code detects errors, i.e., does not result in one of the four decoded states \(\{\left\vert 0000\right\rangle ,\left\vert 0010\right\rangle ,\left\vert 0111\right\rangle ,\left\vert 0101\right\rangle \}\). Note that the circuit is not meant to be fault-tolerant, so decoding is acceptable.
The encoding and decoding circuits, Uenc and \({U}_{{{{\rm{enc}}}}}^{{\dagger} }\), are also depicted in Fig. 2. The logical basis states are:
These are also the four possible marked states in the two-qubit Grover problem. Consequently, after applying \({U}_{{{{\rm{enc}}}}}^{{\dagger} }\) to decode the results, only states from the set \({{{\mathcal{I}}}}=\{\left\vert 0000\right\rangle ,\left\vert 0010\right\rangle ,\left\vert 0111\right\rangle ,\left\vert 0101\right\rangle \}\) could have arisen from valid logical states. Therefore, we postselect by removing any of the 12 measurement outcomes that do not correspond to valid logical states, i.e., states in \({{{{\mathcal{I}}}}}^{\perp }={\{0,1\}}^{4}{\backslash}{{{\mathcal{I}}}}\). This does not guarantee that all measurement outcomes in \({{{\mathcal{I}}}}\) correspond to the correct marked state: logical errors that prepare the wrong marked state are undetected by the code and also appear as measurement outcomes in \({{{\mathcal{I}}}}\) (more on this below). However, since we know which marked state the circuit was supposed to prepare, we can still reliably check whether a given valid measurement outcome (in \({{{\mathcal{I}}}}\)) corresponds to the intended marked state.
Algorithmic error tomography
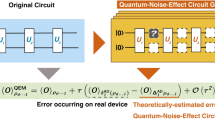
While the states in \({{{{\mathcal{I}}}}}^{\perp }\) do not correspond to valid (encoded) Grover algorithm outcomes, there is important information in such outcomes. They allow us to diagnose the frequency with which different sets of errors corresponding to the different syndromes of the [[4, 2, 2]] code appear at the end of the circuit (but before decoding) for a given encoded marked state. In this sense, these are the effective, or cumulative errors the code can detect at the conclusion of the algorithm, which is why we refer to the procedure we are about to describe as algorithmic error tomography (AET).
Let us first consider the different ways errors can occur before the measurement outcome is obtained. In principle, multiple errors of arbitrary weight can occur at multiple locations anywhere during the circuit, including between the decoding and measurement steps or even during the measurement. We will assume that the latter are perfectly implemented and show later that even decoding or measurement errors have a detectable signature. In other words, we assign a location to the cumulative errors as if they happened just before decoding, i.e., between the Amplitude Amplification and Measurement boxes in Fig. 2.
Then, given an [[n, k, 2]] stabilizer error-detecting code \({{{\mathcal{C}}}}\), in AET, we treat all these errors either as detectable or as logical errors. Formally, if \(\left\vert \overline{b}\right\rangle \in {{{\mathcal{C}}}}\) is a code basis state, where b ∈ {0, 1}k, E is an error, \({\overline{U}}_{{{{\rm{alg}}}}}\) is the unitary implementing the algorithm over the given encoding, \({U}_{{{{\rm{dec}}}}}={U}_{{{{\rm{enc}}}}}^{{\dagger} }\) is the decoding unitary for \({{{\mathcal{C}}}}\), and \({{{\mathcal{M}}}}\) denotes a projective measurement in the computational basis, then in AET we interpret each measurement outcome \({b}^{{\prime} }\in {\{0,1\}}^{n}\) as having arisen from \({{{\mathcal{M}}}}{U}_{{{{\rm{dec}}}}}E{\overline{U}}_{{{{\rm{alg}}}}}\left\vert {\overline{0}}^{k}\right\rangle\). More specifically, in the Grover case \({\overline{U}}_{{{{\rm{alg}}}}}\left\vert {\overline{0}}^{k}\right\rangle =\left\vert \overline{b}\right\rangle\), where \({\overline{U}}_{{{{\rm{alg}}}}}\) implements Grover’s algorithm for the marked state b (the first three boxes in Fig. 2).
\({{{\mathcal{M}}}}\) denotes a simultaneous measurement of the Pauli observables \({\{{Z}_{i}\}}_{i = 1}^{n}\), and each value of \({b}^{{\prime} }\) is one of the 2n possible measurement outcomes. These outcomes label the 2k logical outcomes of the logical Z operators \({\{{\overline{Z}}_{i}\}}_{i = 1}^{k}\) and the 2n−k error syndromes of the code \({{{\mathcal{C}}}}\). Each error syndrome corresponds to a particular set \({\{{(-1)}^{{s}_{i}}\in \{-1,1\}\}}_{i = 1}^{n-k}\) of eigenvalues of the n − k stabilizer generators \({\{{S}_{i}\}}_{i = 1}^{n-k}\), which we denote by si = 0 or si = 1 for the eigenvalue 1 or − 1, respectively. Thus, the no-error subspace is labeled by the bitstring s = 0n−k, while all other bitstrings \({{{s}}\in \{0,1\}}^{n-k}\setminus{0^{n-k}}\) label errors that are detectable by the code. The remaining k bits \({\{{z}_{i}\}}_{i = 1}^{k}\) label the measurement outcomes of the logical Z operators, i.e., the eigenvalues \({(-1)}^{{z}_{i}}\) of \({\overline{Z}}_{i}\), with 1 ≤ i ≤ k. Decoding the error syndromes and the logical outcomes can be done by backpropagating the individual Zi observables through the decoding circuit. This is best illustrated via the example of the [[4, 2, 2]] code, as we do next.
In the case of the [[4, 2, 2]] code, the four measured bits correspond to the eigenvalues of the stabilizer generators S1 = XXXX and S2 = ZZZZ and two logical operators \({\overline{Z}}_{1}\) and \({\overline{Z}}_{2}\). To see this, we backpropagate the Zi observables of each qubit through the Udecoding circuit in Fig. 2. Each time Zi passes a gate, we conjugate it by the gate’s inverse unitary (quantum evolution in the Heisenberg picture). For example, Z1 ↦ HZ1H = X1 ↦ CNOT X1 CNOT = X1X2 ↦ … ↦ X1X2X3X4, while Z2 ↦ CNOT Z2 CNOT = Z1Z2 ↦ … ↦ Z1Z2, etc. In this manner, we find that given a measured bitstring \({b}^{{\prime} }={b}_{1}^{{\prime} }{b}_{2}^{{\prime} }{b}_{3}^{{\prime} }{b}_{4}^{{\prime} }\):
-
1.
First (top) qubit: \({(-1)}^{{b}_{1}^{{\prime} }}=XXXX\)
-
2.
Second qubit: \({(-1)}^{{b}_{2}^{{\prime} }}=ZZII={\overline{Z}}_{1}\)
-
3.
Third qubit: \({(-1)}^{{b}_{3}^{{\prime} }}=IZZI={\overline{Z}}_{1}{\overline{Z}}_{2}\)
-
4.
Fourth qubit: \({(-1)}^{{b}_{4}^{{\prime} }}=IIZZ=ZZZZ\,{\overline{Z}}_{1}\),
where we have equated the operator with its eigenvalue in a slight abuse of notation. Consequently, \({S}_{1}=XXXX={(-1)}^{{b}_{1}^{{\prime} }}\) and \({S}_{2}=ZZZZ={(-1)}^{{b}_{2}^{{\prime} }+{b}_{4}^{{\prime} }}\), so that the error syndrome is given by
The logical outcomes are given by \({\overline{Z}}_{1}={(-1)}^{{b}_{2}^{{\prime} }}\) and \({\overline{Z}}_{2}={(-1)}^{{b}_{2}^{{\prime} }+{b}_{3}^{{\prime} }}\), i.e.,
It is simple to verify that the four states in the set \({{{\mathcal{I}}}}\) are then the unique set for which s1 = s2 = 0 (no error detected) while {z1, z2} ∈ {00, 01, 10, 11}. Each of the remaining 12 bitstrings corresponds to a non-trivial error syndrome; e.g., suppose that we measure the bitstring \({b}^{{\prime} }=1011\). Then s1 = 1, s2 = 0 + 1 = 1, so an error is detected. Note that this string also yields z1 = 0 and z2 = 0 + 1 = 1 as a logical measurement outcome, but this outcome must be ignored since it is accompanied by the detection of an error. The complete mapping from measured bitstrings \({b}^{{\prime} }\) to error syndromes s is given in Table 1.
As this analysis illustrates, the 4-qubit Hilbert space decomposes as \({{{\mathcal{H}}}}={{{\mathcal{C}}}}\oplus {{{{\mathcal{C}}}}}^{\perp }\), where the code space \({{{\mathcal{C}}}}={U}_{{{{\rm{enc}}}}}\,{{\mbox{span}}}\,({{{\mathcal{I}}}})\) corresponds to the four measurement outcomes s1 = s2 = 0 with z1, z2 ∈ {00, 01, 10, 11}, and the error subspace \({{{{\mathcal{C}}}}}^{\perp }={U}_{{{{\rm{enc}}}}}\,{{\mbox{span}}}\,({{{{\mathcal{I}}}}}^{\perp })\) corresponds to the remaining 12 measurement outcomes where s1 and s2 are not both zero. We can further decompose \({{{{\mathcal{C}}}}}^{\perp }\) into the three syndrome subspaces \({{{{\mathcal{C}}}}}_{01}^{\perp }\oplus {{{{\mathcal{C}}}}}_{10}^{\perp }\oplus {{{{\mathcal{C}}}}}_{11}^{\perp }\), where the subscripts denote s1 and s2 (z1 and z2 are arbitrary).
However, there is more we can extract from the measurement outcomes than just the syndromes, as shown in Table 2. Namely, each bitstring \({b}^{{\prime} }\) arises from a particular set of Pauli errors we can straightforwardly identify. Consider, e.g., the Grover circuit for the marked state \(\left\vert \overline{0}\overline{0}\right\rangle\). As mentioned above, in AET we treat the errors occurring during this circuit as an effective Heisenberg-picture Pauli error E between the conclusion of the circuit and the start of the decoding. Hence, \({U}_{{{{\rm{dec}}}}}E\left\vert \overline{0}\overline{0}\right\rangle\) represents the state arising prior to measurement, and when it is measured on a computational basis we obtain a bitstring \({b}^{{\prime} }\). We can now exhaustively identify the complete set of Pauli errors E giving rise to the same \({b}^{{\prime} }\), starting from \(\left\vert \overline{0}\overline{0}\right\rangle\), by solving \(\left\vert {b}^{{\prime} }\right\rangle ={U}_{{{{\rm{dec}}}}}E\left\vert \overline{0}\overline{0}\right\rangle\) for all compatible 4-qubit Pauli errors E (we are slightly abusing notation by writing \(\left\vert {b}^{{\prime} }\right\rangle\) in the binary representation instead of ±1). This set is given in the bottom half of the error outcome table (Table 2), where each column is labeled by the corresponding measurement outcome \({b}^{{\prime} }\), and the first four rows correspond to the marked states \(\left\vert \overline{0}\overline{0}\right\rangle ,\ldots ,\left\vert \overline{1}\overline{1}\right\rangle\). For example, the entry 0001 in column 5 of the row marked by \(\left\vert \overline{0}\overline{0}\right\rangle\) means that the measurement outcome was \({b}^{{\prime} }=0001\) for the oracle marking \(\left\vert \overline{0}\overline{0}\right\rangle\), and the complete set of errors that could have given rise to this measurement outcome is IIIX, IIZY, IZIY, … (see column 5). The [[4, 2, 2]] code does not distinguish between these errors but does detect them.
We re-emphasize that these errors are in the Heisenberg picture, i.e., they are the result of forward-propagating physical errors from the start of the circuit to the location corresponding to the point between the end of the Amplitude Amplification step and the start of the Measurement step in Fig. 2 (indeed, we derived them by back-propagating each Zi from the end of the Measurement step). Therefore they do not necessarily represent physical errors at this location, and an error operator such as ZIII listed in column 9 of Table 2 should not be confused with a physical Z error on the first qubit, since this ZIII error could have arisen from an actual physical XIII error if the latter took place between the P and H gates in the Amplitude Amplification step (see Fig. 2). Nevertheless since all of the gates in the encoded two-qubit Grover circuit after the CNOT gates of the Initialization step are single-qubit gates, any weight-1 physical error appearing after these CNOT gates will remain a weight-1 error in the Heisenberg picture. This means that if weight-1 physical errors dominate the higher-weight errors, then this will manifest as a predominance of a single column of the s = 10 syndrome, since by inspection of Table 2, column 9 corresponds to the largest number of weight-1 errors: four out of twelve. We will see the manifestation of this remark in the experimental results below.
The first four columns in Table 2 correspond to undetectable errors: the errors they list commute with the stabilizers of the [[4, 2, 2]] code (boxed in the first column) and correspond to logical errors. For example, \(IXYZ\left\vert \overline{0}\overline{0}\right\rangle =i\left\vert \overline{1}\overline{1}\right\rangle\). Thus, even if the measurement yields a bitstring in \({{{\mathcal{I}}}}\) (the first four columns), the state prepared by the circuit could have been the wrong marked state. Of course, this is only problematic when we do not know the correct answer in advance; in the present case, since we program the circuit, we can immediately check whether a given measurement outcome in \({{{\mathcal{I}}}}\) is the correct answer or one of the three other valid logical states.
We can now construct the algorithmic error tomography (AET) table: given a marked state b, each observed state \(\left\vert {b}^{{\prime} }\right\rangle\) will have an empirical probability \({p}_{{b}^{{\prime} }| b}={N}_{{b}^{{\prime} }}/{N}_{{{{\rm{tot}}}}}\), where \({N}_{{b}^{{\prime} }}\) is the number of times \(\left\vert {b}^{{\prime} }\right\rangle\) is observed out of a total of Ntot observations. The AET table thus gives us the empirical probabilities associated with the different errors classified in the error outcome table (Table 2).
Figures 3 and 4 show the AET tables after implementing or simulating the encoded two-qubit Grover algorithm on Jakarta and Nairobi, respectively. Each of the four panels corresponds to a different AET table, with the top row representing experiments and the bottom row representing simulations using the model of the section “Open system model”. The left and right panels of Fig. 3 exclude or include DD, respectively. We did not use DD in the Nairobi case (Fig. 4). Each row corresponds to a different encoded marked state z = z1z2 within each syndrome table. Other than the logical errors counted during postselection (first column), all other columns represent outcomes ignored during the postselection step. More precisely, the columns represent the empirical probabilities of observing the bitstrings starting from column 5 of Table 2. The column headers of the AET tables are the first row (i.e., marked state \(\left\vert \overline{00}\right\rangle\)) of Table 2.

The bitstring observed after Udec either corresponds to a marked entry or an error tabulated in Table 2. Column headers correspond to the bitstrings for the marked state \(\left\vert \overline{00}\right\rangle\), but the values inside the table are organized identically to Table 2 (starting from its first row, column 5). I.e., the c’th column of each of the four tables shown corresponds to the c + 4’th column of Table 2. For example, the percentages in the second row and fifth column of each of the four tables shown correspond to measuring the bitstring \({b}^{{\prime} }=1010\) when the marked state is \(\left\vert \overline{01}\right\rangle\) (since this is the bitstring found in column 9 of Table 2 in the row of \(\left\vert \overline{01}\right\rangle\)). The complete set of errors that could have given rise to this outcome is listed in column 9 of Table 2. Top: experimental results. The numbers in each box are the empirical percentage probabilities with 2σ standard deviation. Logical error percentage probabilities are shown in the first column of each table. Each row corresponds to a different marked state. The probabilities in each row do not sum to unity since we do not display the probability of obtaining the correct marked state. Left: without DD protection. Right: with DD protection. Bottom: the same for the simulated model.

It is visually clear from both Figs. 3 and 4 that the percentages in column 5 are higher than the rest. This result can be explained in terms of the above analysis of errors in the Heisenberg picture. Namely, column 5 corresponds to the errors in column 9 of Table 2, which contains the largest number of weight-1 errors. The data presented in Figs. 3 and 4 thus support the notion that the error processes underlying weight-1 errors are dominant. This analysis highlights the utility of AET as a diagnostic of the dominant errors in a given circuit and suggests that error-correcting codes can be correspondingly tailored and optimized.
We discuss these results in more detail in the following section, showing how AET in addition allows us to identify and mitigate qubit crosstalk.
DD protection and comparison with the open system model
Recall that we define the success probability ps as the probability of correctly identifying the marked element. We denote the empirical success probability obtained for a list of N elements after q oracle queries by \({p}_{{\rm {s}}}^{{{{\rm{e}}}}}(q,N)\). Our results are summarized in Fig. 5, which shows the failure probability (\(1-{p}_{\rm {{s}}}^{{{{\rm{e}}}}}(1,4)\)) for the unencoded and the encoded implementations on two different QPUs.

Two-qubit single-query Grover failure probability results without (Unenc) and with (Enc) postselection using the \(\left[\left[4,2,2\right]\right]\) code on Jakarta and Nairobi are shown. The transparent boxes represent the theoretically expected failure probabilities from the model described in the section “Open system model”, which does not include DD; their centers correspond to the average over marked states, and their boundaries correspond to 95% confidence intervals after bootstrapping. The colored bars represent the experimental results (see the legend), and the experimental error bars (black for Jakarta with DD and Nairobi, or pink for Jakarta without DD) correspond to 95% confidence intervals after bootstrapping. Dark green appears where the pink and light green colors (i.e., Jakarta with and without DD) overlap. In the Unenc case, we run two identical copies of the two-qubit Grover problem to equalize resources with the Enc case and choose the copy with the highest success probability. Also shown are the results with MEM using iterative Bayesian unfolding (see the Supplementary Information for details). Failure probabilities with and without DD protection are shown for Jakarta but not for Nairobi, where the simulated and observed error tomography and failure probabilities are in agreement (see the section “DD protection and comparison with the open system model”). The presence of DD does not affect the success probability in the encoded implementation, and as a result, the pink bars are mostly hidden behind the green bars. However, the nature of detected errors, even in the encoded case, is affected by DD (see Fig. 3). All data for different runs on the same QPU were collected on the same day; data from different QPUs were collected on different days.
Before comparing the results with and without encoding, we analyze whether the observed performance matches the model of the section “Open system model” in both cases. Let us focus first on Jakarta, where without DD, the empirical failure probabilities in the unencoded case are slightly higher than predicted; see the leftmost column of Fig. 5. Fortunately, in the encoded case, Jakarta’s failure probability overlaps with the prediction bands (Fig. 5, third column from the left). However, a closer look at the detected errors via AET reveals a different discrepancy. The simulated results for Jakarta (bottom-left panel in Fig. 3) do not quite match the empirical error profile (top-left panel of Fig. 3), in particular in the 1000 column for the marked state \(\left\vert \overline{00}\right\rangle\) (the yellow entry), which captures the errors listed in column 9 of Table 2. In other words, Jakarta does not quite match the simulations for unencoded or encoded circuits without DD: the empirical results show stronger syndrome s = 10-type errors and also a stronger marked state-dependent asymmetry in these errors than the simulations. In contrast, for Nairobi, Fig. 4 shows that the AET simulation results essentially agree with the empirically observed ones. This also holds for the simulated failure probabilities (Fig. 5).
To investigate Jakarta’s observed discrepancy, we first attempt to systematically amplify pD, T1, and T2 by multiplying each quantity by a phenomenologically determined variable λi (see Supplementary Information). This leads to a better overlap between predicted and observed success probabilities but does not reproduce the AET asymmetry seen in Fig. 3. This shows the limitations of the phenomenological model of the section “Open system model” and highlights the level of detail provided by AET.
However, the Jakarta discrepancy is effectively removed after the application of DD, as can be seen by comparing the top-right and bottom-right panels of Fig. 3. Our two-qubit Grover implementation uses four qubits, leaving three inactive qubits in the 7-qubit QPUs used in our experiments. As there are no idle intervals in the unencoded two-qubit Grover circuit, we applied the XY4 sequence on the inactive qubits—q2,q4, and q6 (see Supplementary Information). We applied the XY4 sequence to both the active and inactive qubits for the encoded case. Due to the relative sparsity of idle intervals in the two-qubit Grover circuits, we did not attempt to implement robust sequences, which require more pulses than XY4.
Figure 5 shows how the failure probability and the rates of various detected errors in Jakarta are affected by the presence of DD. For the unencoded case (the first two columns from the left of Fig. 5), DD improves the performance slightly, and the discrepancy between the predicted and observed failure probabilities is removed. The improvement by DD in the unencoded two-qubit Grover case is in concurrence with refs. 25,26, which showed the efficacy of the XY4 sequence in suppressing static ZZ crosstalk in superconducting qubits. In other words, these results confirm that ZZ crosstalk—which is well-documented for superconducting QCs49—likely contributes to the observed performance being slightly worse than expected from the model.
Adding the XY4 sequence removes most of the empirical-theoretical discrepancies in both the magnitude and the asymmetry of the errors exhibited by the AET profiles, as seen by comparing the top and bottom right of Fig. 3. With DD, the encoded circuits have a weaker state-wise asymmetry in s = 10-type errors than seen in the left column of Fig. 3. Moreover, the DD-protected circuits more closely reproduce the distribution of detected errors predicted by the model of the section “Open system model” than the same circuits without DD. This observation—that the agreement between our theoretical model and the experimental results improves under DD—is further validated below.
The close agreement we found for Nairobi between our (crosstalk-free) model and the experimental results without DD or MEM (Fig. 4 and the first and third from left columns of Fig. 5) suggests that crosstalk does not play a significant role in this QPU. Figure 5 does exhibit a significant discrepancy between the model and the experimental Nairobi results when MEM is included (second and last columns of Fig. 5). As we show in the Supplementary Information, this discrepancy arises from the choice to mitigate readout errors using iterative Bayesian unfolding (IBU)14.
Finally, Fig. 6 complements the first and last columns of Fig. 5, as well as the AET results, and shows the output distributions for Jakarta and Nairobi for the two-qubit Grover case, with and without encoding and MEM. The main observation is that for the unencoded case, the maximum success probability is obtained for the marked state \(\left\vert 00\right\rangle\), which is also the QPU’s ground state; this is unsurprising given the dominance of amplitude damping errors. With encoding plus error mitigation, the overall performance increases and becomes independent of the marked state.

The left and right panels show the output distribution for Jakarta (a) and Nairobi (b) with all possible oracles and two setups: unencoded and encoded with MEM. As in Fig. 5, Unenc corresponds to two copies of unencoded two-qubit Grover, of which the best result is reported. Enc corresponds to the results encoded using the [[4, 2, 2]] code. The Enc results are reported after postselection. Let ps(m, b, e) be the observed success probability for marked state m, detected state b, and experiment type e ∈ {Enc,Unenc + MEM,Enc + MEM}. The success probability changes from orange to green when \({p}_{s}(m,b,e) > \mathop{\max }\nolimits_{m,b}{p}_{s}(m,b,\,{{\mbox{Unenc}}}\,)\). Error bars correspond to 95% confidence intervals.
Success probability: beyond break-even improvement
We now focus on the effect of error detection on two-qubit Grover performance as seen in Fig. 5. Due to the shallow circuit depth, even without any error detection, \({p}_{{\rm {s}}}^{{{{\rm{e}}}}}(1,4) \sim 93.0 \%\)—already much higher than the classical success probability \({p}_{s}^{{{{\rm{C}}}}}(1,4)=\frac{1}{2}\). Adding error detection improves the success probability to ~96.0%. The effect of MEM is similar to that of error detection: the success probability increases to ~97.0%. Combining error detection with MEM results in additional improvement: we obtain success probabilities of ~98.5% on Nairobi and ~99.5% on Jakarta. Due to error detection and MEM, Jakarta’s success probabilities increase by an order of magnitude.
This improvement over the unencoded case is non-trivial, considering that the [[4, 2, 2]] code can only detect weight-1 errors, and the encoded circuit requires six two-qubit gates. In contrast, the unencoded version requires only two. The relatively high success probabilities we observe in the encoded case suggest that most errors, even those due to the two-qubit gates, manifest as weight-1 errors. This shows, albeit for a relatively small problem size, that error detection can more than offset the extra errors introduced due to increased circuit depth and complexity.
We have demonstrated an algorithmic beyond-break-even improvement using error detection in the sense that the protected algorithm clearly outperforms its unprotected counterpart. Previous break-even improvements were at the individual gate level50,51. Here we have demonstrated such an improvement at the level of the execution of an entire algorithm, albeit of a fixed size. The holy grail is to demonstrate the implementation of an algorithm for a family of problem sizes at the logical level with higher fidelity than the same algorithm executed at the physical level. Achieving this in our setting would require increasing the problem and code sizes. The family of [[2k + 2, k, 2]] subsystem quantum error detecting codes is an attractive option in this regard since all their logical operators can be chosen to be 2-local52, which simplifies the circuit design. An experimental implementation of such larger codes and problem sizes remains a coveted goal.
3-qubit to 5-qubit Grover’s algorithm protected by dynamical decoupling
Crossing the classical threshold in Grover’s search for an increasingly larger number of qubits is a meaningful goal, not only because the quadratic speedup offered by Grover’s algorithm leads to a more dramatic improvement as the problem size increases but also because it becomes more challenging to realize the speedup experimentally as the controlled phase gate Cn−1Z is an n-qubit entangling operation. In the implementation of ref. 5, 5-qubit Grover required nearly a thousand two-qubit gates, and for 8-qubit Grover, nearly 15,000 gates were used. Notably, this exponential increase in the number of two-qubit gates with problem size is because ref. 5 did not use ancilla qubits to make the circuits shallower. It is possible to implement Cn−1Z with circuits where two-qubit gates scale linearly with n (see the section “Circuit construction”). Ref. 8 employed shallower circuits for Cn−1Z and solved 5-qubit Grover with slightly better-than-random success probabilities but without better-than-classical performance. Ref. 9, which improved upon ref. 8, has reported the highest Grover’s algorithm success probabilities to date for n = 5, using a Honeywell ion-trap device; however, only a single marked state (\(\left\vert 01011\right\rangle\)) was tested. Whether the success probability averaged over all 25 marked states crosses the classical threshold remains to be tested. Ref. 8’s results on superconducting-qubit-based QCs for the same marked state had lower success probabilities than reported in our experiments. Using quantum multiprogramming, ref. 10 improved algorithmic success probabilities for quantum partial search (a variation of the canonical Grover search) even on superconducting-qubit-based devices. However, quantum multiprogramming could not increase algorithmic performance for the canonical Grover algorithm. While noteworthy, Ref. 10’s approach requires modifying Grover’s algorithm and substantially increasing the number of physical qubits used in the algorithm. Here our goal is to provide a comprehensive demonstration of better-than-classical performance for Grover’s algorithm, along with a theoretical model for the open-system effects that explain our results.
We use an efficient, ancilla-assisted implementation of generalized Toffoli-type gates8,53 to implement Cn−1Z (see the section “Circuit construction”). Our implementation, which builds upon the circuits from ref. 8, uses 8, 14, and 22 CNOTs for a single Cn−1Z gate for n = 3, 4, and 5, respectively. The deepest circuit we implement is two oracle queries for 5-qubit Grover, totaling 88 CNOTs. Despite being far shallower than ref. 5’s implementation, this is still a relatively deep circuit; e.g., the quantum supremacy demonstration of ref. 54 and the algorithmic quantum speedup demonstration of ref. 39 involved circuits of depth up to 40 and 44, respectively. As we detail next, owing to error suppression via DD, we crossed the classical probability threshold for all problem sizes, including for 5-qubit Grover.
Implementation with dynamical decoupling
DD sequences are inserted into idle intervals of a quantum circuit using the ‘decouple then compute strategy’ demonstrated in Fig. 1b, which shows the DD insertion scheme for a single query on a 4-qubit Grover circuit. In contrast to two-qubit Grover, where we restricted DD implementation to XY4, n ≥ 3 has ample idle intervals. Therefore we can implement robust sequences (RGA, CDD, UR) requiring more than four pulses. Each of these families has multiple members that are parameterized by the number of pulses in the sequence. We restrict our implementation to DD sequences with fewer than 32 pulses and, for each circuit, only consider sequences that we can fit in the idle intervals available in the quantum circuit.
At each problem size n, there are 2n possible oracles, each corresponding to one marked state \(\left\vert b\right\rangle\), where b ∈ {0, 1}n. We proceed as follows to avoid implementing this exponentially large set of oracles. Given 0 ≤ k ≤ n, there are \(\left(\begin{array}{c}n\\ k\end{array}\right)\) distinct bitstrings that are identical to 0k1n−k up to qubit permutation. Recall that marked states differ only by whether X or I gates surround the Cn−1Z gate. Thus, we only consider the n + 1 oracles with marked states \(\left\vert {0}^{k}{1}^{n-k}\right\rangle ,k\in \{0,\ldots ,n\}\). We then estimate the average success probability by computing
We use 〈p(n)〉 as the metric for selecting the optimal DD sequences among those we tested and to identify the experimentally optimal number of queries \({q}_{{{{\rm{opt}}}}}^{{\rm{e}}}\). Once the optimal DD sequence and \({q}_{{{{\rm{opt}}}}}^{{\rm{e}}}\) are identified for each n, we run the unprotected and the DD-protected Grover’s algorithm again at \({q}_{{{{\rm{opt}}}}}^{{\rm{e}}}\), but this time for all 2n oracles.
Optimal DD sequence and number of queries
Our first goal is to identify the best DD sequence and qopt. The determinations made in this step inform our choices for the next step. For conciseness, in this section, we focus on the results of the largest problem size we implemented, i.e., n = 5. The section “Survey of dynamical decoupling sequences” shows the results for 3 ≤ n ≤ 5 on both Nairobi and Jakarta. The performance of various DD sequences for Nairobi for 5-qubit Grover are compared in Fig. 7a by computing 〈p(5)〉. The unprotected evolution (Free) is marginally better than choosing an element randomly and does not cross the classical threshold. DD protection is necessary to cross this threshold, but the two-pulse sequences RGA2x and CPMG still result in worse-than-classical performance. The RGA and UR sequences perform well, particularly those with fewer than 12 pulses. RGA8a and RGA8c are tied as the best-performing sequences; we choose RGA8a for the next step, where we implement all of the 25 oracles. The performance improvement seen due to robust sequences is consistent across problem sizes and devices, as detailed in the section “Survey of dynamical decoupling sequences”.

a Average success probability for 5-qubit Grover with two oracle queries on Nairobi. The DD sequences are ranked in order of decreasing success probability. The two dotted lines represent success probabilities corresponding to a random and classical strategy, respectively. RGA8a and RGA8c are tied as the best-performing sequences. Free denotes the result of an unprotected implementation. Error bars correspond to 99% confidence intervals. b Success probabilities vs problem size. Nairobi (green) and Jakarta (orange) success probabilities for n ∈ {3, 4, 5} are shown for DD-protected and unprotected implementations. The translucent bands indicate the theoretically estimated success probabilities using the model described in the section “Open system model”. We performed q = 2 queries to the quantum oracle in all cases. The ideal success probabilities are 0.945, 0.908, and 0.602 for n = 3, 4, and 5, respectively. The white lines correspond to the success probabilities for the classical strategy and random sampling from the unsorted list (q = 0). Error bars correspond to 99% confidence intervals.
We also use 〈p(n)〉 to identify the experimentally optimal number of oracle queries \({q}_{{{{\rm{opt}}}}}^{{\rm {e}}}\). The theoretically optimal number of repetitions for n = 3, 4, 5 is qopt = 2, 3, 4, respectively. However, the section “Survey of dynamical decoupling sequences” shows that in reality, the theoretically expected qopt often leads to worse performance than \({q}_{{{{\rm{opt}}}}}^{{\rm {e}}}\). For the DD-protected implementation, q = 2 maximizes the success probability ps in all cases other than 5-qubit Grover on Jakarta, where the performance at q = 2 is comparable to q = 1. As DD protection is necessary to cross the classical threshold, for simplicity of analysis and to maximize ps we set q = 2 from here on.
Better-than-classical performance
Figure 8 shows our results for the 5-qubit Grover problem on Nairobi with and without DD. Even in our relatively shallow-depth implementation, before error suppression via DD (whether Free or Free + MEM), the final results are indistinguishable from randomly guessing the marked state. The results change significantly when we implement DD. With DD, the classical threshold is crossed by all marked states. Adding MEM improves the results slightly, but only when accompanied by DD.

Left: average success probability with and without DD or MEM for 5-qubit Grover implemented on Nairobi. The boxes correspond to the theoretically expected success probabilities. The quantum oracle is queried twice; in the ideal case, the success probability is 0.602. The unprotected (Free) evolution is on par with a random guess, significantly worse than the optimal classical strategy (dashed vertical line), and just adding MEM does not change the result. In contrast, the DD-assisted implementation crosses the classical threshold, and the results improve even more with MEM, up to a success probability of 0.15. Error bars correspond to 99% confidence intervals. Middle and right: the complete input-output maps for all 25 marked states, without and with DD + MEM, are shown. States are sorted by increasing Hamming weight; in the Free case, low Hamming weight states have a higher success probability (more green on the left). This is likely to be a consequence of amplitude damping (spontaneous emission), which favors the \(\left\vert 0\right\rangle\) state of each qubit. In the unprotected case (Free, middle), there is no discernible correlation between the input marked state and the output detected state. In the protected case (DD + MEM right), black-to-purple signifies better-than-classical success probability, and this threshold is crossed for all 32 marked states. The DD sequence used here is RGA8a23, which was the top-performing sequence in our DD survey [see Fig. 7a].
This dramatic improvement due to DD holds for other problem sizes as well. Figure 7b shows the success probabilities after two oracle queries on both devices for 3 ≤ n ≤ 5 (see Supplementary Information for the role of postselection in these results). At the two smaller problem sizes (n = 3, 4), the unprotected implementations are better than random sampling, but the success probability is relatively low. For n = 4, the unprotected quantum Grover circuit does not exceed the classical single-query threshold. It is effectively on par with random sampling for n = 5. In contrast, for all problem sizes, the DD-protected quantum strategy at q = 2 outperforms the classical strategy for q ≤ 3. DD-protected Grover performance at n = 3, 4, 5 is equivalent to classical q = 4, 5, 3 for Jakarta and q = 4, 5, 4 for Nairobi, respectively. Thus, DD is essential in attaining a better-than-classical performance.
The translucent bands in Fig. 7b and the boxes in Fig. 8 (left) show the theoretically expected results computed from the open system model with the IQP-supplied parameters. The success probability in this unprotected Grover case [dashed lines in Fig. 7b] is considerably lower than the theoretical expectation. This discrepancy is likely due to crosstalk and non-Markovianity, which are well-documented for IQP’s superconducting qubit-based QPUs. Once we use DD, the observed fidelities improve and are close to the theoretical predictions. This improvement is expected given DD’s ability to reduce the effect of crosstalk25,26 and non-Markovian effects.
With DD, the algorithmic performance approaches the expectations based on our error model. However, we emphasize that this model does not predict the QPU’s performance under DD; it simply tells us what the performance would be if the reported calibration metrics corresponded to observed dynamics. The overlap between the theoretically predicted (translucent) and the DD-protected (solid) performance implies that DD successfully mitigates the errors that our simple model does not account for. However, the model does not provide an upper bound on the possible performance improvement due to error suppression. For instance, better-optimized sequences could suppress idle-time errors further, and dynamically corrected gates can suppress errors during operations55,56.
We note that the restriction to n ≤ 5 arose not because of circuit width but depth. In particular, we used two oracle queries, though theoretically qopt = 4 at n = 5. The gap between the theoretically and experimentally optimal number of queries is expected to grow with problem size. As is true for any quantum algorithm, optimizing circuit compilation and increasing metrics such as T1, T2, and gate fidelities are all vital for scalability.
Discussion
We implemented Grover’s algorithm of various sizes on multiple superconducting qubit devices. To our knowledge, this is the largest successful demonstration of Grover’s algorithm for which the quantum strategy outperforms its classical counterpart. For two-qubit Grover, we focused on error detection via the [[4, 2, 2]] code and showed that it allowed us to achieve near-optimal performance. Along the way, we introduced the method of algorithmic error tomography. We showed that it provides a wealth of information complementary to previous protocols, such as gate set tomography or just measuring the success probability of an algorithm. We showed that error suppression via DD is essential in attaining better-than-classical performance for larger problem sizes.
Grover’s algorithm is a demanding algorithm5 as it requires multiple implementations of Cn−1Z – a fully entangling operation. The superconducting trimon device6, which prior to our results achieved the highest success probability for 3-qubit Grover, is an example of algorithm-tailored hardware where C2Z is a native gate. Constructing hardware that can natively perform such entangling operations may be one path to realizing the full potential of Grover’s algorithm. Still, it is desirable to achieve this goal with more general-purpose quantum hardware, as we have strived to do here.
Today’s quantum experimentalists have various error mitigation tools at their disposal. Measurement error mitigation14,57, dynamical decoupling, zero noise extrapolation13, and quantum error detection41 are complementary strategies that address different kinds of errors. Whether and which error mitigation method to employ must be decided based on the problem and available resources. In this work, we combined MEM with DD and quantum error detection. As expected, these strategies complement each other. However, we found that often, MEM only became useful after DD was employed. Dynamical decoupling, which arguably has the lowest resource overhead and requires no postprocessing, was the single most effective strategy in improving the performance of our implementation of Grover’s algorithm. Our work adds to the growing literature25,37,38,39,42,58 on the effectiveness of error suppression through DD.
While we demonstrated a crossing of the classical threshold at every problem size we tested, better-than-classical success probabilities are not enough to claim a provable quantum speedup59. Such a claim would require computing the scaling of the time-to-solution metric (including the overhead of post-selection and error mitigation, if applicable) as a function of problem size and extending it to the largest possible problem size that can be embedded on the device. Here we could not go to the largest possible problem size as even at n = 5, our circuit is quite deep—two queries required 88 two-qubit gates, and for a larger number of queries or qubits, we no longer observed a quantum advantage. Achieving quantum speedup for Grover search will require devices that can implement circuits much deeper than those used here without a catastrophic drop in fidelity. Recent results60,61 suggest that without significant improvements in the implementation of the surface code, the latter will not necessarily provide an advantage in the context of Grover’s algorithm (or other algorithms providing a quadratic speedup) over the type of error suppression and mitigation methods we have explored here. Thus, our results are likely to be necessary (but not sufficient) stepping stones toward a quantum speedup for Grover’s algorithm.
Methods
Classical success probability
Let \({p}_{{\rm {s}}}^{{{{\rm{C}}}}}(q,N)\) be the classical success probability after q oracle queries for an unsorted list with N elements. Suppose that we have made q calls to the oracle. The probability that the marked element is among the q queried elements is q/N. Since the oracle will confirm that the marked element is among these queries, the probability of correctly identifying the marked element is 1 in this case. Conversely, the probability that the marked element is among the remaining N−q elements is (N−q)/N, and in this case the probability of correctly guessing the identity of the marked element is 1/(N−q). By the law of total probability, we then have \({p}_{{\rm {s}}}^{{{{\rm{C}}}}}(q,N)=\frac{q}{N}\times 1+\frac{N-q}{N}\times \frac{1}{N-q}=\frac{q+1}{N}\).
Survey of dynamical decoupling sequences
In addition to the well-known XY4 and CPMG sequences, we consider three families of robust dynamical decoupling sequences. These sequences are expected to work well on a superconducting device with finite pulse width and flip-angle errors. The first sequence family is concatenated DD (CDD). CDD comprises recursively generated sequences by concatenating a base sequence such as the XY4 sequence. Formally,
Here we could only proceed as far as CDD2, as the idle intervals in the circuit were too short to incorporate higher-order CDD sequences.
The second family comprises the robust genetic algorithm (RGA) sequences23. These were found by assuming a generic single-qubit error term and a numerical optimization using genetic algorithms. A subset of the sequences was enforced to be robust against flip-angle errors. Therefore, these sequences are called robust genetic algorithm sequences. Due to duration constraints, we only attempted sequences up to 32 pulses, even though longer sequences were identified in ref. 23.
Here X means a π-rotation about the +x axis. In contrast, \(\bar{X}\) means a π-rotation about the—x-axis (see ref. 42 for a concise and detailed summary with more explicit definitions, including the effect of pulse width and the associated errors).
Finally, the third family is that of universally robust (UR) sequences21. UR sequences are defined such that
where (π)ϕ is rotation about the axis at an angle of ϕ from the +x-axis. We choose ϕ1 = 0, and ϕ2 = Φ(n) so that all URn sequences are palindromic. Once again, we constrained our survey to sequences with up to 32 pulses.
Our results from testing these three robust families of DD sequences are shown in Fig. 9. For n > 3, almost all DD sequences improved the success probability, but even among the sequences tried, there was considerable variation. Robust sequences with fewer than 12 pulses per DD cycle were the best performers. The eventual decrease in the performance of sequences with an increasing number of pulses is to be expected as they are implemented using noisy gates, and there is a trade-off between the protection provided by DD and the accumulation of gate errors. The RGA8c and RGA8a sequences performed consistently well and are the only sequences to cross the classical threshold on Jakarta for n = 5. RGA8c is also commonly known as the Eulerian DD (EDD) sequence, and RGA8a is a slightly modified version of EDD. These palindromic sequences are known to be robust against flip-angle and finite-width errors. The best sequence at each problem size is shown in Table 3.

a–f Performance of DD sequences, expanding on the results shown in Fig. 7a. Average success probability for n = 3, 4, 5 with two oracle queries on Jakarta (a–c) and Nairobi (d–f). The DD sequences are ranked in order of decreasing success probability. The two dotted lines represent success probabilities corresponding to a random and classical strategy, respectively. For n > 3, the unprotected evolution (Free) is marginally better than choosing an element randomly and does not cross the classical threshold. DD protection is necessary to cross the classical threshold, and the RGA and UR sequences with fewer than 12 pulses are the best performers. Error bars correspond to 99% confidence intervals. g and h Performance under different oracle query numbers. Success probabilities are shown as a function of the number of oracle queries for Jakarta (left) and Nairobi (right). All results included MEM and error bars represent 99% confidence intervals. Dashed red lines correspond to the optimal classical success probability. Except for n = 3, the classical threshold is crossed only with DD. In the main text, we set q = 2, which is the optimal number of repetitions for all instances other than n = 5 on Jakarta. Error bars correspond to 99% confidence intervals.
Figure 9g and h shows the experimental success probabilities for the unprotected and DD-protected Grover circuits for all queries q. Here, only the best DD sequence from the survey above (listed in Table 3) is used in each case. Theoretically, for n = 3, 4, 5, qopt = 2, 3, 4 respectively. Unfortunately, for 5-qubit Grover, software restrictions prevented us from going beyond q = 2 and 3 on Jakarta and Nairobi, respectively. However, it is already clear that the experimentally optimal value was reached in both cases. Recall that we restricted our results to q = 2 oracle queries in the main text. For n = 3, this is both experimentally and theoretically optimal. For Nairobi, two queries have the highest experimental success probability for all problem sizes. For Jakarta and n = 5, a single query has a slightly higher success probability, but the difference between q = 1 and q = 2 is not substantial. Overall, for simplicity of analysis, in the main text, we focused only on results for q = 2.
Finally, Fig. 10 shows the results for all oracles at two queries using the DD sequence found from the survey above. The results are qualitatively identical on both devices. We have already clarified that DD is necessary to cross the classical threshold. One might suspect that majority voting may suffice to declare a detected state as the marked state if it is the mode of its corresponding probability distribution. However, even under this criterion, for 5-qubit Grover, there is no way to detect the marked state without DD.

The panels show the output distribution for Jakarta (left) and Nairobi (right) after two oracle queries, complementing Fig. 8, which only shows Nairobi for n = 5. Each row represents a problem size in ascending order. In a row, the horizontal bar plot on the left shows the success probability under no error suppression and mitigation (Free), with measurement error mitigation (Free + MEM), with DD protection (DD), and with DD protection and measurement error mitigation (DD + MEM). The dashed horizontal line and the boxes represent the classical and the theoretically expected success probability, respectively. The second and third columns show the input-output map for Free and DD + MEM, highlighting the improvement offered by these strategies. The states are sorted by increasing Hamming’s weight. The transition from green to black occurs at the classical success probability threshold. With DD protection, the classical threshold is crossed in all cases.
Extracting the depolarizing parameter from gate errors
IQP devices are calibrated daily, and for each gate, the gate error eg and gate time τg are reported. The associated T1 and T2 times are also reported for each qubit. As eg is extracted in the presence of thermal relaxation errors, \({{{\mathcal{R}}}}={{\Phi }}\circ {{{\mathcal{A}}}},{p}_{{\rm {D}}}=f({e}_{{\rm {g}}},{\tau }_{{\rm {g}}},{T}_{1},{T}_{2})\). In order to extract pD from eg, we assume that
Using
where \({\mathbb{D}}\) is the completely depolarizing channel, we get
Consequently,
If we assume that there are no relaxation errors and only depolarizing noise affects the gate error eg, then pD = \(\frac{d}{d-1}\) eg.
Circuit construction
Recall that implementing the n-qubit Grover’s algorithm requires the Cn−1Z gate, the only multi-qubit gate necessary for both the oracle and the amplitude amplification step. We provide circuit diagrams for how each n-qubit controlled phase gate, Cn−1Z, was transpiled. We rely on previously known circuit designs for our circuit construction, particularly the circuits used by ref. 8.
Two-qubit Grover circuits
For two-qubit Grover, CZ does not require transpilation as CZ = H ⋅ CX ⋅ H. However, a few nuances must be considered when constructing the encoded two-qubit Grover circuits. There are three components to a Grover circuit with marked element m = b1b2: initialization into the state \(\left\vert \psi \right\rangle\), oracle query Om, and amplitude amplification A. More precisely,
To convert these circuits into their logical counterparts, we note that \({\overline{X}}_{1}=XIXI,{\overline{X}}_{2}=XXII,{\overline{Z}}_{1}=ZZII,{\overline{Z}}_{2}=ZIZI,{H}^{\otimes 4}={\overline{{{\mbox{SWAP}}}}}_{12}({\overline{H}}_{1}{\overline{H}}_{2})\) and \({P}^{\otimes 4}=({\overline{Z}}_{1}{\overline{Z}}_{2})\overline{\,{{\mbox{C}}}\,Z}\). It is also helpful to notice that [SWAP12, U ⊗ U] = 0 for any unitary U and [SWAP12, CZ] = 0. Moreover, \({{{\mbox{SWAP}}}}_{12}\left\vert {b}_{1}{b}_{1}\right\rangle =\left\vert {b}_{1}{b}_{1}\right\rangle\) and [SWAP12, O00] = 0 as O00 only has operators of the form U ⊗ U and CZ. Consequently,
Implementing the encoded Grover oracle is straightforward and does not involve any two-qubit operations:
Lastly,
The corresponding circuits for the marked state \(\left\vert 01\right\rangle\) are shown in Fig. 2.
3-qubit to 5-qubit Grover circuits
The problem of transpilation increases in complexity with problem size. Cn−1Z can be achieved by finding a circuit decomposition for the n-qubit Toffoli gate Cn−1X. It is known that the three-qubit Toffoli gate, C2X, can be implemented using six CNOTs62. However, this requires a fully connected architecture. As no fully connected group of three qubits can be found in the QPUs we used, we rely on the 8-CNOT decomposition8 of C2Z shown in Eq. (54).

Here T = Z1/4. For C3Z and C4Z we use relative-phase Toffoli gates53. Breaking down CkZ using CaZ and CbY such that a + b = k + c allows for CkZ to be implemented with fewer CNOTs as long as we use c ancillas. In our construction, we only use one ancilla for C3Z and C4Z. C2Y is shown in Eq. (55),

where G = Ry(π/4), and C3Y is shown in Eq. (56):

Finally, using the relative-phase Toffoli gates, C3Z can be written as in Eq. (57):

and likewise, C4Z can be constructed as in Eq. (58):

This scheme—where relative phase Toffoli gates53 are sewn together to generate a circuit for Cn−1Z (n > k + 2)—can be generalized. In particular, Cn−1Z can be implemented using C2Y, C2Y† and Cn−2Z, which in turn uses Cn−3Z. As a result of this recursion, the number of CNOTS for a Cn−1Z circuit is
Thus, the number of CNOTs required to implement a single query of n-qubit Grover scales as O(n). At the same time, the number of necessary ancillas is n−2, i.e., it also scales linearly with n. As we did by using Eq. (59), this linear scaling of ancillas could be avoided by considering CkY with k > 2 while increasing the number of CNOTs. Whether entangling fewer qubits by allowing for deeper circuits is worthwhile will depend on the QPU architecture under consideration. Note that the theoretically optimal number of queries qopt = O(2n/2) so at qopt, the number of CNOTs scales as O(2n/2n) where the exponential component will dominate. However, as we noted before, the experimentally allowed number of queries before decoherence takes over, might be less than qopt.
Data availability
The data supporting the findings of this paper is available here. https://www.dropbox.com/scl/fo/se3lsf5i20lf3j6gokt8n/h?rlkey=cfchyc0fuczs4c5hbf1pvyeq4&dl=0.
Code availability
The code supporting the findings of this paper is available here. https://www.dropbox.com/scl/fo/se3lsf5i20lf3j6gokt8n/h?rlkey=cfchyc0fuczs4c5hbf1pvyeq4&dl=0.
References
Grover, L. K. Quantum mechanics helps in searching for a needle in a haystack. Phys. Rev. Lett. 79, 325–328 (1997).
Bennett, C., Bernstein, E., Brassard, G. & Vazirani, U. Strengths and weaknesses of quantum computing. SIAM J. Comput. 26, 1510–1523 (1997).
Dürr, C., Heiligman, M., Hoyer, P. & Mhalla, M. Quantum query complexity of some graph problems. SIAM J. Comput. 35, 1310–1328 (2006).
Magniez, F., Santha, M. & Szegedy, M. Quantum algorithms for the triangle problem. SIAM J. Comput. 37, 412–424 (2007).
Lubinski, T. et al. Application-oriented performance benchmarks for quantum computing. IEEE Trans. Quantum Eng. (2023).
Roy, T. et al. Programmable superconducting processor with native three-qubit gates. Phys. Rev. Applied 14, 014072 (2020).
Figgatt, C. et al. Complete 3-Qubit Grover search on a programmable quantum computer. Nat. Commun. 8, 1–9 (2017).
Zhang, K., Rao, P., Yu, K., Lim, H. & Korepin, V. Implementation of efficient quantum search algorithms on NISQ computers. Quant. Inf. Proc. 20, 233 (2021).
Zhang, K., Yu, K. & Korepin, V. Quantum search on noisy intermediate-scale quantum devices. Europhys. Lett. 140, 18002 (2022).
Park, G., Zhang, K., Yu, K. & Korepin, V. Quantum multi-programming for Grover’s search. Quantum Inf. Proc. 22, 54 (2023).
Vaidman, L., Goldenberg, L. & Wiesner, S. Error prevention scheme with four particles. Phys. Rev. A 54, R1745–R1748 (1996).
Gottesman, D. Stabilizer codes and quantum error correction. Ph.D. thesis, California Institute of Technology (1997).
Kandala, A. et al. Error mitigation extends the computational reach of a noisy quantum processor. Nature 567, 491–495 (2019).
Nachman, B., Urbanek, M., de Jong, W. A. & Bauer, C. W. Unfolding quantum computer readout noise. npj Quantum Inf. 6, 84 (2020).
Blume-Kohout, R. et al. Robust, self-consistent, closed-form tomography of quantum logic gates on a trapped ion qubit. Preprint at http://arXiv.org/abs/1310.4492 (2013).
Merkel, S. T. et al. Self-consistent quantum process tomography. Phys. Rev. A 87, 062119– (2013).
Viola, L. & Lloyd, S. Dynamical suppression of decoherence in two-state quantum systems. Phys. Rev. A 58, 2733–2744 (1998).
Viola, L., Knill, E. & Lloyd, S. Dynamical decoupling of open quantum systems. Phys. Rev. Lett. 82, 2417–2421 (1999).
Zanardi, P. Symmetrizing evolutions. Phys. Lett. A 258, 77–82 (1999).
Vitali, D. & Tombesi, P. Using parity kicks for decoherence control. Phys. Rev. A 59, 4178–4186 (1999).
Genov, G. T., Schraft, D., Vitanov, N. V. & Halfmann, T. Arbitrarily accurate pulse sequences for robust dynamical decoupling. Phys. Rev. Lett. 118, 133202– (2017).
Khodjasteh, K. & Lidar, D. A. Fault-tolerant quantum dynamical decoupling. Phys. Rev. Lett. 95, 180501 (2005).
Quiroz, G. & Lidar, D. A. Optimized dynamical decoupling via genetic algorithms. Phys. Rev. A 88, 052306 (2013).
IBM Quantum. https://quantum-computing.ibm.com/ (2022).
Tripathi, V. et al. Suppression of crosstalk in superconducting qubits using dynamical decoupling. Phys. Rev. Appl. 18, 024068 (2022).
Zhou, Z., Sitler, R., Oda, Y., Schultz, K. & Quiroz, G. Quantum crosstalk robust quantum control. Phys. Rev. Lett. 131, 210802 (2023).
Boyer, M., Brassard, G., Hoyer, P. & Tapp, A. Tight bounds on quantum searching. Fortschr. Phys. 46, 493–505 (1998).
Biham, E., Biham, O., Biron, D., Grassl, M. & Lidar, D. A. Grover’s quantum search algorithm for an arbitrary initial amplitude distribution. Phys. Rev. A 60, 2742–2745 (1999).
Blank, C., Park, D. K., Rhee, J.-K. K. & Petruccione, F. Quantum classifier with tailored quantum kernel. npj Quantum Inf. 6, 1–7 (2020).
Rivas, A. & Huelga, S. F.Open Quantum Systems: An Introduction. Springer Briefs in Physics (Springer-Verlag, Berlin, Heidelberg, 2012).
Horodecki, M., Horodecki, P. & Horodecki, R. General teleportation channel, singlet fraction, and quasidistillation. Phys. Rev. A 60, 1888–1898 (1999).
Nielsen, M. A. A simple formula for the average gate fidelity of a quantum dynamical operation. Phys. Lett. A 303, 249–252 (2002).
Paz-Silva, G. A. & Lidar, D. A. Optimally combining dynamical decoupling and quantum error correction. Sci. Rep. 3, 1530 (2013).
Suter, D. & Álvarez, G. A. Colloquium: protecting quantum information against environmental noise. Rev. Mod. Phys. 88, 041001 (2016).
West, J. R., Lidar, D. A., Fong, B. H. & Gyure, M. F. High fidelity quantum gates via dynamical decoupling. Phys. Rev. Lett. 105, 230503 (2010).
Ng, H. K., Lidar, D. A. & Preskill, J. Combining dynamical decoupling with fault-tolerant quantum computation. Phys. Rev. A 84, 012305 (2011).
Jurcevic, P. et al. Demonstration of quantum volume 64 on a superconducting quantum computing system. Quantum Sci. Technol. 6, 025020 (2021).
Ravi, G. S. et al. Vaqem: a variational approach to quantum error mitigation. In 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA) 288–303 (IEEE, 2022).
Pokharel, B. & Lidar, D. A. Demonstration of algorithmic quantum speedup. Phys. Rev. Lett. 130, 210602 (2023).
Maudsley, A. A. Modified Carr–Purcell–Meiboom–Gill sequence for NMR Fourier imaging applications. J. Magn. Reson. (1969) 69, 488–491 (1986).
Lidar, D. & Brun, T. (eds) Quantum Error Correction (Cambridge University Press, Cambridge, UK, 2013).
Ezzell, N., Pokharel, B., Tewala, L., Quiroz, G. & Lidar, D. A. Dynamical decoupling for superconducting qubits: a performance survey. Phys. Rev. Appl. 20, 064027 (2023).
Uhrig, G. S. Keeping a quantum bit alive by optimized π-pulse sequences. Phys. Rev. Lett. 98, 100504 (2007).
West, J. R., Fong, B. H. & Lidar, D. A. Near-optimal dynamical decoupling of a qubit. Phys. Rev. Lett. 104, 130501 (2010).
Vuillot, C. Is error detection helpful on IBM 5Q chips?. Quantum Inf. Comput. 18, 0949–0974 (2018).
Harper, R. & Flammia, S. T. Fault-tolerant logical gates in the IBM quantum experience. Phys. Rev. Lett. 122, 080504 (2019).
Urbanek, M., Nachman, B. & de Jong, W. A. Error detection on quantum computers improving the accuracy of chemical calculations. Phys. Rev. A 102, 022427 (2020).
Srinivasan, S., Pokharel, B., Quiroz, G. & Boots, B. Scalable measurement error mitigation via iterative Bayesian unfolding. Preprint at http://arXiv.org/abs/2210.12284 (2022).
Krantz, P. et al. A quantum engineer’s guide to superconducting qubits. Appl. Phys. Rev. 6, 021318 (2019).
Ofek, N. et al. Extending the lifetime of a quantum bit with error correction in superconducting circuits. Nature 536, 441 EP (2016).
Ryan-Anderson, C. et al. Implementing fault-tolerant entangling gates on the five-qubit code and the color code. Preprint at http://arXiv.org/abs/2208.01863 (2022).
Marvian, M. & Lidar, D. A. Error suppression for Hamiltonian-based quantum computation using subsystem codes. Phys. Rev. Lett. 118, 030504 (2017).
Maslov, D. Advantages of using relative-phase Toffoli gates with an application to multiple control Toffoli optimization. Phys. Rev. A 93, 022311 (2016).
Arute, F. et al. Quantum supremacy using a programmable superconducting processor. Nature 574, 505–510 (2019).
Khodjasteh, K. & Viola, L. Dynamically error-corrected gates for universal quantum computation. Phys. Rev. Lett. 102, 080501 (2009).
Khodjasteh, K., Lidar, D. A. & Viola, L. Arbitrarily accurate dynamical control in open quantum systems. Phys. Rev. Lett. 104, 090501 (2010).
Maciejewski, F. B., Zimborás, Z. & Oszmaniec, M. Mitigation of readout noise in near-term quantum devices by classical post-processing based on detector tomography. Quantum 4, 257 (2020).
Pokharel, B., Anand, N., Fortman, B. & Lidar, D. A. Demonstration of fidelity improvement using dynamical decoupling with superconducting qubits. Phys. Rev. Lett. 121, 220502 (2018).
Ronnow, T. F. et al. Defining and detecting quantum speedup. Science 345, 420–424 (2014).
Campbell, E., Khurana, A. & Montanaro, A. Applying quantum algorithms to constraint satisfaction problems. Quantum 3, 167 (2019).
Sanders, Y. R. et al. Compilation of fault-tolerant quantum heuristics for combinatorial optimization. PRX Quantum 1, 020312 (2020).
Nielsen, M. A. & Chuang, I. L. Quantum Computation and Quantum Information (Cambridge University Press, 2010).
Acknowledgements
This research was supported by the ARO MURI grant W911NF-22-S-0007. This material is also based upon work supported by the National Science Foundation, the Quantum Leap Big Idea under Grant No. OMA-1936388. We acknowledge the use of IBM Quantum services for this work. The views expressed are those of the authors and do not reflect the official policy or position of IBM or the IBM Quantum team.
Author information
Authors and Affiliations
Contributions
Both authors contributed equally to conceiving and designing the experiment, and to writing the manuscript. B.P. was responsible for all the data collection and analysis. D.A.L. conceived the idea and formulation of algorithmic error tomography.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pokharel, B., Lidar, D.A. Better-than-classical Grover search via quantum error detection and suppression. npj Quantum Inf 10, 23 (2024). https://doi.org/10.1038/s41534-023-00794-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-023-00794-6
