
Abstract
We introduce a training protocol for developing machine learning force fields (MLFFs), capable of accurately determining energy barriers in catalytic reaction pathways. The protocol is validated on the extensively explored hydrogenation of carbon dioxide to methanol over indium oxide. With the help of active learning, the final force field obtains energy barriers within 0.05 eV of Density Functional Theory. Thanks to the computational speedup, not only do we reduce the cost of routine in-silico catalytic tasks, but also find an alternative path for the previously established rate-limiting step, with a 40% reduction in activation energy. Furthermore, we illustrate the importance of finite temperature effects and compute free energy barriers. The transferability of the protocol is demonstrated on the experimentally relevant, yet unexplored, top-layer reduced indium oxide surface. The ability of MLFFs to enhance our understanding of extensively studied catalysts underscores the need for fast and accurate alternatives to direct ab-initio simulations.
Similar content being viewed by others
Introduction
Computational modeling plays a central role in understanding heterogeneous catalysis at an atomic scale. By complementing experimental observations, simulations are used to discover detailed reaction mechanisms, rationalize catalytic trends, and guide the design of catalytic materials1,2. Limited by the computational cost of ab-initio methods, however, catalytic systems are often represented by small idealized surfaces with individual molecules adsorbed at a specific active site. Under these approximations, Density Functional Theory (DFT) is extensively used to draw connections between adsorption properties and catalytic activity3,4,5. However, neglecting more complex effects, such as interactions between different adsorbates, poisoning, finite temperature, and complex surface morphology, can severely limit the relevance of computational studies to experimental observations4,6,7,8,9,10. Furthermore, selecting viable reaction paths and specific intermediate configurations requires expert knowledge or extensive trial and error. Finding all relevant reaction mechanisms and accurately predicting reaction rates would require extensive screening11. For large reaction networks and complex surfaces, this goes beyond DFT capabilities.
An alternative is to use empirically parameterized force fields, which are orders of magnitude faster. However, while there exist reactive force fields12, their parameters need to be adjusted for every novel system and often deviate significantly from the true PES due to their limited expressivity13.
Machine learning force fields (MLFFs) offer a way to bridge this gap. Rather than starting a new electronic structure calculation for each step in a simulation, the MLFF predicts energy and forces for novel configurations using a model trained on a set of reference configurations. Apart from being orders of magnitude faster for small systems, local MLFFs scale linearly with system size, are reactive, and systematically improvable by augmenting the training set. Recent innovations in describing atomic environments and training frameworks have allowed MLFF to describe more and more complex interactions in both molecules and materials14,15,16,17,18,19,20. In the context of heterogeneous catalysis, MLFFs have evolved from capturing low dimensional cuts of the PES to the direct simulation at the micron-scale13,17,21. The pioneering neural network potential by Lorenz et al. described the six degrees of freedom of the hydrogen molecule on a fixed catalyst surface21. This early-stage MLFF was able to describe hydrogen dissociation in this simplified system. More recently Vandermause et al. ran direct reactive molecular dynamics (MD) of 80 H2 molecules over an interacting platinum surface, replicating experimental dissociation, recombination, and diffusion rates13. In addition to MLFFs trained for specific catalytic reactions, large training sets with up to 55 different elements have emerged22,23,24,25. Accurate potentials trained on such datasets can be used for screening of desired catalytic properties. Nevertheless, the accuracy in adsorption energy and energy barriers currently remains significantly lower than can be obtained for system-tailored MLFFs13,24.
In this paper, we focus on training an MLFF for a specific system. We go beyond describing a single reaction step and focus on exploring the entire reaction pathway of CO2 hydrogenation to methanol with a single potential. We develop a hands-off training protocol for rapidly generating MLFFs, that can predict adsorption energies and energy barriers using nudged elastic bands (NEBs), starting only from a set of suggested intermediates along the desired reaction path. The intermediate geometries could be obtained from a force field geometry optimization or manual placement. We show the efficacy of active learning26,27,28 in converging the modeled potential energy surface to that of DFT in the relevant domains. Ultimately, the final force field’s minimum energy paths (MEP) correspond to MEPs on the true DFT potential energy surface. The corresponding energy barriers are converged within one kT (45 meV) at reaction conditions (500K), where the entire reaction path spans 50 kT.
We validate our training protocol using a well-studied reaction mechanism, namely the carbon dioxide hydrogenation to methanol on an indium oxide surface2,29,30,31,32,33,34. In the context of reducing carbon dioxide emissions and carbon recycling, methanol synthesis from waste carbon oxide (CO and CO2) streams is of significant industrial importance. Indium oxide has emerged as a promising catalyst, particularly for operation under CO2-rich conditions, offering improved selectivity compared to copper-based catalysts that currently dominate industrial practice35,36. This reaction pathway, comprising ten intermediates and five distinct reactions, presents significant challenges for training a single MLFF due to the diversity of the adsorbate species, and the complexity of the surface structure. As a benchmark, we investigate the oxygen vacancy on cubic-In2O3(110) with the lowest formation energy, as reported by Dang et al.2. Additionally, we showcase the transferability of the protocol on a previously unexplored surface. Recent experimental and computational investigations have revealed that, under experimental conditions, the top surface of indium oxide undergoes complete reduction34,37. By applying our protocol to this reduced surface, we demonstrate its capability to describe a more realistic and experimentally relevant surface.
We illustrate the utility of a fast, yet accurate MLFF, by exploring multiple minimum energy paths for each reaction and calculating free energy barriers. This systematic investigation uncovers notable alterations in the reaction pathway. Specifically, we identify a preferred minimum energy path for the rate-limiting step, characterized by a substantially lower barrier. Additionally, investigations at finite temperatures, reveal that the true rate-limiting step corresponds to the production of formaldehyde.
Results
Active learning
It is common for ML force fields to be trained in an iterative manner, where novel configurations are sampled from MLFF simulations and added back into the training set. The relevant geometries can be selected manually or based on explicit criteria, such as changes in density or bonding topology26,38,39,40,41,42,43,44. While successful, this approach relies on human expert knowledge, which is inherently limited to a low-dimensional understanding of force field failures. More recently, active learning has been used to automate this process using a model’s uncertainty metric13,45,46,47,48,49,50,51.
We employ a sampling strategy based on the local energy uncertainty of individual atoms13,28,52. When the uncertainty of any atom exceeds a predefined threshold, new configurations are sampled from the ongoing simulation. These new geometries are subsequently evaluated with Density Functional Theory (DFT) and incorporated into the training set. In cases where the threshold is not reached during the simulation, we sample either the configuration with the highest uncertainty (for molecular dynamics simulations) or the final configuration (for optimization tasks). The machine learning force field (MLFF) is then retrained using the expanded dataset, and the aforementioned steps are repeated. This active learning loop continues until a desired level of accuracy is achieved.
Our specific active learning approach, as depicted in Fig. 2b, incorporates two distinct stopping criteria to guide the automatic iterative training of the MLFF. The first criterion, referred to as the uncertainty threshold (σthr), determines when to interrupt a simulation and sample a configuration. Throughout the training protocol, the uncertainty threshold is set to 50 meV, a choice that is justified in Fig. 1. The second criterion, referred to as the termination criterion, determines when to conclude the active learning loop and considers the MLFF to be sufficiently accurate for the intended task. The termination criteria are tailored to the specific simulation type (see “Training protocol”) and can be determined based on the observed DFT-MLFF error in the sampled configurations. The exact termination criteria depend on the user’s desired level of accuracy.

This figure demonstrates the initial iteration of active learning with molecules, highlighting the occurrence of a nonphysical bond break when the energy uncertainty surpasses a threshold of 50 meV. The top panel displays MD snapshots of formate (HCOO) on In2O3, where molecular atoms are color-coded by the local energy uncertainty, while the surface atoms are depicted in gray.
In this manner, the model’s accuracy at the desired task converges to the specified accuracy, without prior knowledge of the reaction path energetics. Active learning reduces the accumulation of uninformative training data, while systematically improving the model’s accuracy in relevant parts of the potential energy surface. The method section contains more detail on how the underlying sparse Gaussian process provides a cheap metric for the model’s predicted error.
The effectiveness of using local energy uncertainty to determine when to interrupt simulations is demonstrated through the initial iteration of running molecular dynamics (MD) with adsorbates. Figure 1 depicts the evolution of energy uncertainty for each atom during the MD. Notably, the four molecular atoms exhibit significantly higher uncertainty compared to the 79 bulk atoms. Throughout the MD trajectory, the local uncertainties remain relatively low, until the energy uncertainty of the hydrogen atom exceeds the predetermined threshold of 50 meV at 78 fs.
The substantial increase in uncertainty for the hydrogen atom suggests that the simulation has encountered an atomic environment that greatly differs from any seen in the training set. This indicates the need to sample a new configuration for the next iteration of the potential. It is noteworthy that only a few atoms exhibit a pronounced increase in uncertainty, highlighting the importance of monitoring individual atom energy errors rather than total errors. The specific threshold value becomes less critical due to the sharp rise in uncertainty observed. In this particular system, a threshold of 50 meV ensures that the sampled configurations remain chemically relevant and informative for further training iterations.
Training protocol
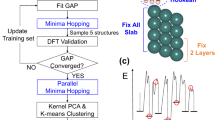
The training protocol consists of six active learning blocks which sample configurations from MD, geometry optimization, or nudge elastic band calculations. The flow chart in Fig. 2a shows how these blocks link in series to obtain the final training set. The only inputs to the protocol are the bulk configuration of indium oxide and the set of approximate geometries corresponding to the intermediates along the reaction path. These intermediate geometries can come from force field minimization, manual placement, or adsorption prediction tools like CatKit.

A flow chart (a) of the six active learning (AL) blocks that make up the protocol. Each active learning block (b) iteratively samples new training configurations, when the model uncertainty surpasses a threshold (σthr) until a sampled configuration satisfies the termination criterion (Δthr). Simulations include running MD, geometry optimization, and nudged elastic bands. The protocol is validated, by replicating the Dang et al.2 path (green) and used to optimize the path (purple), finding a 40% reduction in the rate-limiting energy barrier (c). The location of the oxygen vacancy is marked with a cross and the opacity of the surface atoms is reduced.
Throughout the protocol, we only ever perform single-point calculations with DFT, while all dynamical simulations are performed with the MLFF. Below we outline the protocol’s six active learning blocks and their termination criteria. Once a sampled configuration satisfies the termination criterion, the training protocol moves on to the next block. While we use very strict termination criteria, these will depend on the user’s desired accuracy.
The first two blocks model the surface itself, while the remaining four are used to capture inter-molecular and molecule-surface interactions. The first four blocks consist of running active learning with MD to gain a stable potential and the last two correspond to geometry optimization and nudge elastic band calculations to obtain accurate adsorption energies and barriers. We find that running active learning with MD before geometry optimization helps sample repulsive behavior effectively. The number of configurations in the training set, at each stage of the protocol, is tabulated in Supplementary Note 1.
Initial training set
The initial training set consists of the bulk, conventional unit cell of cubic In2O3, taken from the Materials Project53. Additionally, we included ten configurations obtained by rattling all atom positions with random displacements drawn from a Gaussian with standard deviation 0.02 Å and applying random deformation to the unit cell, with a standard deviation of 0.01. This ensures that we sample repulsive behavior immediately. Additionally, we obtain a set of initial geometries for the intermediates, referred to as approximate intermediates, which enter the protocol in blocks 3–5.
Bulk and surface dynamics
In the first two active learning blocks, we iteratively increase our training set until the potential can run stable dynamics. The potential is deemed stable if, during a 10 ps molecular dynamics (MD) run at 300K, the uncertainty threshold is never breached for all intermediates. We repeat the same procedure for the slab and oxygen vacancy of interest, requiring one additional iteration, using the same termination criterion.
Adsorbate dynamics
We now extend our model to capture molecule-surface interaction, creating a four-element force field (H, C, O, In). To reduce the number of iterations needed to obtain stable MD we enhance the training set before active learning with:
-
Dimers: configurations consisting of two atoms spaced such that their repulsive forces never exceed 20 eVÅ-1. We include four such dimer configurations for each possible combination between carbon, oxygen, and hydrogen, totaling 24 configurations. We set the energy and force weights of all dimer configurations at a factor of five lower than the rest of the training set.
-
CatKit configurations: obtained by placing the molecules of the intermediates around the active site using CatKit’s adsorbate placement tool54. Rather than placing molecules directly on the relaxed surface, we use the potential from the second block, to run MD on the active site first. This avoids sampling unnecessarily similar atomic environments from the surface. After placing the intermediates within 3 Å of the oxygen vacancy with CatKit, we select three adsorbate structures per intermediate using farthest point sampling of all atomic environments. Here we use the distances between SOAP vectors of the local environments to measure dissimilarity, following the same procedure as De et al.55.
We now run MD with the MLFF on all approximate intermediates for 1 ps. As previously we terminate active learning if, during MD, the predicted uncertainty stays below the threshold for all intermediates. As mentioned in “Active learning,” using the uncertainty estimate is crucial for sampling new configurations in this block.
Adsorbate geometry optimization
Using geometry optimization, we now try to find the DFT adsorbate structure starting from the approximate intermediates. During active learning, we monitor the performance of the potential by evaluating the GAP minima configurations with single-point DFT. If the DFT forces are sufficiently small for all intermediates, the MLFF’s minima correspond to true minima in the DFT potential energy surface and we terminate the active learning loop. However, if the DFT forces are above 0.2 eVÅ-1 for any intermediate, we add the configurations to the training set and continue the active learning loop. Note that the adsorbate structures further improve during the last active learning block.
Minimum energy path search
Before starting active learning, we add a set of linearly interpolated images between the reaction intermediates to the training set. Running active learning, we then perform NEB calculations, sample the resulting minimum energy paths, and add them to the training set. The active learning loop is terminated when the total energy error (DFT vs. MLFF) on all sampled configurations is less than 50 meV. Note that for each reaction, we run NEBs for all possible permutations of like atoms of the molecule (see “Lower rate-limiting step” for more detail). During sampling we only DFT evaluate the NEB path with the lowest energy.
Validation on known pathway
We validate the protocol, on an extensively explored reaction pathway: CO2 hydrogenation to methanol on indium oxide with a a single oxygen vacancy2,30,32,34. Figure 2c, shows the close alignment between DFT (black) and the final MLFF (green) throughout the entire reaction path. The final training set consists of 622 configurations. Supplementary Note 1 outlines the number of training configurations needed at each stage of the protocol.
Adsorption energies
The adsorption energies converge throughout the training protocol. Adsorbate-surface interactions are first sampled in active learning (AL) blocks three and four, after which the mean adsorption energy error is 82 meV. We improve upon this with AL and geometry optimization in block five. To allow for a direct comparison, relaxations are initialized from configurations similar to Reference2 (see Supplementary Note 2 for further details on starting configurations). After eleven iterations we reach the final termination criterion outlined in “Training protocol,” at which point the mean adsorption energy error is 23 meV across intermediates. These errors further reduce to 12 meV throughout NEB active learning. See Supplementary Figs. 1 and 2 for more details on the adsorption energy convergence across iterations.
Minimum energy path
Throughout the protocol, the energy barriers converge to those obtained with DFT. To validate the final force field, we initialize DFT-NEB calculations with the MLFF’s minimum energy paths (MEPs). We find that the DFT-NEBs are converged without a single optimization step and have a projected force below 0.05 eVÅ-1 for all five reactions. The MLFF has hence found true MEPs on the DFT potential energy surface. Note that as we aim to validate the protocol against Reference2 in this section, we don’t permute all atoms with similar species, as detailed in the protocol, but choose a permutation that is similar to the previously published literature.
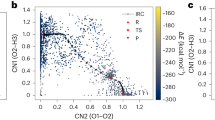
Figure 3, shows the convergence of the MEP throughout active learning iterations. We find that without any NEB active learning, it is possible to draw qualitative conclusions, with a mean barrier error of 50 meV. At this stage of the protocol, the training set only contains 325 configurations. After six iterations of NEB active learning, the GAP MEPs converge to those of DFT, providing an energy barrier estimate within 45 meV for all five reactions. As highlighted in “Computational cost comparison,” training an MLFF following this automated protocol requires approximately eight times fewer DFT single-point calculations, than running DFT-NEBs directly.

Barrier height comparison between DFT and GAP models at different AL iterations for all energy barriers (top panel). The bottom panel gives a detailed view of the different minimum energy paths throughout active learning for the third reaction (H2COO → H2CO + O).
Lower rate-limiting step
We initiate the training protocol afresh, assuming the adsorbate configurations are unknown for this reaction. To generate initial guesses for the reaction intermediates, we employ CatKit and select the adsorbate configuration closest to the position of the oxygen vacancy. After the successful termination of the protocol, the acquired training set contains 696 configurations. Figure 2c compares the reaction pathway of the resulting MLFF (purple) to the pathway explored by Dange et al.2 (green). The paths align closely except for a significant reduction in the rate-limiting barrier and the last reaction path. The difference in the last reaction step originates from a subtle rearrangement of the H3CO + H intermediate for the path found in the literature. As we start from CatKit configurations, in the training protocol these two intermediates are identical. Below we discuss in greater detail how the automatic protocol finds an optimized reaction path for the rate-limiting step.
When performing NEB calculations in an automatic fashion, a crucial consideration arises regarding the ordering of like atoms. Since the atoms in the initial image are connected to atoms in the final image along a smooth path, any alteration in the index of atoms in the initial image leads to a distinct reaction path. Traditionally, the selection of the most plausible arrangement has relied on chemical intuition. However, given the computational efficiency of NEB calculations with the Machine Learning Force Field (MLFF), we adopt a comprehensive approach by performing all possible permutations of like atoms of the molecule. Subsequently, we identify the path that exhibits the lowest energy as the preferred path.
This comprehensive approach unveils a preferential reaction path for the rate-limiting step (HCOO + H → H2COO). This optimized path, depicted in purple in Fig. 4, has a significantly reduced barrier of 1.0 eV. The insets reveal a key difference between the two paths: throughout the optimized path, one of the intermediate’s oxygen atoms occupies the oxygen vacancy. By screening permutations, we achieve a systematic approach to investigate barriers, avoiding the potential pitfalls of possibly misleading chemical intuition. We note that for larger intermediates, screening all possible permutations may become unfeasible. Here we suggest pre-selecting the most relevant permutations by comparing the geometric distance between the initial and final NEB configurations.

Comparison of two NEBs for the rate-limiting step, with different permutations of like atoms. The protocol investigates all possible permutations, finding a significantly lower barrier (green) than Reference2 (blue). Visualizations of the transition states (insets), show the the hydrogen atom’s trajectory and the location of the oxygen vacancy (white cross).
Finite temperature effects
Until now we have assumed that the zero kelvin potential energy surface can be used to infer properties of the catalyst. This approximation is often made due to the computational cost of DFT. We now illustrate the importance of incorporating finite temperature effects by investigating the free energy barrier of dioxymethylene to formaldehyde conversion (H2COO → H2CO + O). In doing so, we find that the energy barrier is larger than previously assumed and that formaldehyde production is the rate-limiting step.
We perform umbrella sampling at ambient and operating (500K) temperatures, using the distance between the oxygen atom and the carbon atom as a collective variable. Within the first picosecond of molecular dynamics, the starting configuration, taken as the local minima found in literature, moves to a lower energy state with different geometry. The insets in Fig. 5 illustrate that the H2COO intermediate preferentially binds to the indium atom, with lower oxygen coordination. Consequently, the minimum energy path (depicted by the bold line) differs from the path investigated in Reference2 (represented by the dotted path). With a barrier height of 1.1 eV, the production of formaldehyde (H2CO) rather than H2COO is rate-limiting. For a more detailed visual comparison of the paths, please refer to Supplementary Figs. 3–7. This exploration of the potential energy surface, facilitated by the computational speed of MLFF, reveals that although there may exist some high-energy local minima, their relevance to the overall reaction progression is limited. Finite temperature simulations promptly reveal the thermodynamically relevant intermediate geometries.

Comparison of the Reference2 path (dotted) and the minimum energy path (MEP, bold). The black lines represent NEB energies, while the green lines depict the free energy barriers along the MEP, calculated by umbrella integration. The insets display the transition states of Ref. 2 and the MEP, highlighting the distinct oxygen coordination of the two indium atoms (atom A is four-fold coordinated, atom B is three-fold coordinated).
By running umbrella sampling, we circumvent the approximation that reaction rates are solely determined by a single transition state and local energy minima on the potential energy surface. The temperature dependence of the free energy barrier can have a substantial impact on the predicted selectivity and activity of catalysts, as well as the behavior of micro-kinetic models employed to analyze the progression of reactions56,57,58,59.
Transferability to unexplored surfaces
To demonstrate the transferability of the automatic training protocol, we apply it to a previously unexplored surface. Additionally, we illustrate that the obtained training set can be effectively utilized by different machine learning methods, indicating its versatility beyond the specific GAP framework.
Reduced surface
Recent computational investigations have revealed the thermodynamic preference for the reduced surface under experimental conditions34. To evaluate the transferability of our protocol, we apply it to the top-layer reduced surface, yielding the reaction pathway depicted in Fig. 6. The construction of the training set for this force field required less than one thousand single-point DFT calculations, with 70% of the calculations dedicated to the final active learning phase to accurately determine energy barriers. Notably, the pathway reveals a large barrier for the hydrogenation of carbon dioxide.

Comparing the reaction pathway for the single oxygen vacancy and the top-layer reduced surface.
Doped surfaces
We examine the transferability of our training dataset to other machine learning force field frameworks. Specifically, we use MACE18, a higher-order equivariant message-passing neural network, to train an MLFF on the dataset acquired in “Validation on known pathway” for the single oxygen vacancy surface. Without any additional training data, it achieves a mean adsorption energy error of 38 meV.
Furthermore, we investigate the behavior of doped surfaces. Dopants play a crucial role in modifying the adsorbate structure and activation of intermediates, leading to significant changes in catalytic activity and selectivity60. In the case of indium oxide, platinum, and palladium dopants have been demonstrated to enhance catalytic performance by promoting H2 splitting61,62. These dopants not only increase the abundance of adsorbed hydrogen, needed for CO2 hydrogenation and vacancy formation but also influence the entire reaction pathway.
To avoid repeating the entire training protocol, which would be data-inefficient, we explore the possibility of enhancing the training set without additional active learning steps. We find that with sixty additional configurations, the MACE framework captures general trends in the adsorption energies, as visible in Fig. 7. The additional training configurations originate from the oxygen vacancy training set, where the Indium atom closest to the active site is replaced by a platinum atom and randomly rattled with a standard deviation of 1 Å. It is worth noting that improving the adsorption energies through active learning with the MACE model could be pursued, but is beyond the scope of this paper. Application to a different MLFF framework demonstrates the transferability of the acquired training data.

A comparison between the MACE18 model and DFT for both undoped and doped surfaces (a). The intermediates on the Pt-doped surface differ significantly, such as formate splitting into CO2 + H (b–e).
Exploration of adsorbate structures
We showed in “Finite temperature effects” that thermodynamically relevant adsorption configurations can elude DFT investigations, as adsorbates may get stuck in local energy minima. To investigate whether this is a more general property of these complex surfaces, we use the MLFF to sample adsorption configurations of the very first intermediate: CO2. A thorough sampling of the surface reveals a plethora of local minima as illustrated in Fig. 8b. Each such minimum is a potential starting structure for studying the subsequent reaction step. This suggests that running a small number of geometry optimization with expensive ab-initio methods is unsuited for conclusively finding adsorbate configurations.

Displaying 236 unique MLFF adsorption geometries (b) of carbon dioxide found with minima hopping and their adsorption energy distribution (a). Figure b-d contain only the molecular atoms of the adsorbate states, color-coded by adsorption energies, and the relaxed oxide surface in dark gray as a backdrop. All carbonate configurations are excluded, and their energies are shaded in gray in the histogram (a). A subset of MLFF minima (c) is relaxed with DFT (d) for validation.
We systematically screen local minima using minima hopping, which consists of alternating high-temperature MD with geometry optimization63,64. We use CatKit to sample ten starting configurations for each intermediate and then run ten iterations of active learning with minima hopping. The final potential finds 236 unique minima. All non-unique minima are removed, by comparing the local environment of the carbon atoms using SOAP vectors (see Supplementary Method 2 for details). To validate the new adsorbate geometries, we relax 25 MLFF-found minima with DFT to a maximum force of 0.01 eVÅ-1. We find that the MLFF (Fig. 8c) and DFT minima (Fig. 8d) are extremely similar. Note that the top two layers of the surface are not fixed and hence differ for all adsorbate configurations.
Figure 8 shows all 236 unique adsorption geometries placed on top of each other. For visualization purposes, only the CO2 molecules are included and color-coded by adsorption energy, while the geometry-optimized oxygen vacancy in dark gray acts as a backdrop. The lowest energy configurations are found when CO2 reacts with a surface oxygen atom to form carbonate. Previous studies, that also identified the thermodynamic stability of carbonate, found that it doesn’t partake in the conversion to methanol2. Carbonate configurations are hence excluded from the figure. As visible from the histogram, a significant number of local minima have negative adsorption energies.
Computational cost comparison
The findings summarized above rely heavily on the computational speedup gained by the MLFF. To compare the computational cost, we calculate the first energy barrier, starting from a simple interpolation of images with DFT. After 38 steps with BFGS, requiring 1092 single-point DFT evaluations, the NEB converges to 0.08 eVÅ-1. As a comparison, the final GAP model requires only 622 DFT training configurations and finds NEBs for all five reaction steps that converged to below 0.05 eVÅ-1, when evaluated with single point DFT. Running all DFT-NEBs would hence require approximately five thousand single-point evaluations, eight times more than the size of the training set.
Beyond its computational efficiency for routine catalytic tasks, the MLFF offers extensive exploration capabilities of the potential energy surface. Considering all feasible atom permutations within the same chemical species helps us obtain a 40% reduction in the activation energy of the rate-limiting step. Furthermore, determining the free energy barriers required 6.4 million samples of the potential energy surface. For an 84-atom configuration, the GAP model runs 9.2 steps per second on the dual AMD EPYC™ 7742 64-core processors at 2.25GHz. In contrast, a single DFT calculation requires an average of 33 minutes on the same hardware.
Discussion
We present an automatic training protocol for machine learning force fields (MLFF) capable of accurately capturing the energetics of a given heterogeneous reaction path. We validate our approach on the extensively explored conversion of CO2 to methanol on indium oxide with a single oxygen vacancy. The minimum energy paths (MEPs) for all five reactions found using the final MLFF correspond to true MEPs on the DFT potential energy surface. A single model is hence able to accurately describe a reaction with ten intermediaries on a complex oxide surface. Additionally, we showcase the transferability of the protocol by investigating the same mechanism on a new and previously unexplored surface: top-layer reduced indium oxide.
We show that MLFFs offer more than just computational cost reduction for routine computational catalysis tasks; they emerge as an essential tool for in-depth mechanistic catalytic investigations. By running multiple nudged elastic band calculations for each reaction, we find a preferred MEP for the rate-limiting step, with a 40% lower energy barrier. Moreover, through finite temperature sampling, we unveil lower minima for the intermediates of the subsequent largest barrier, identifying it as the true rate-limiting step. Finally, we illustrate the power of MLFFs by computing free energy barriers at ambient and operating temperatures, requiring over six million samples of the potential energy surface.
Accurately describing the true minimum energy path of individual reactions significantly influences the relevance of computational studies to experiment. Predictions from micro-kinetic or energetic span models can depend strongly on specific barriers, resulting in notable differences in observables, such as the turnover frequency or selectivity59,65. We anticipate that active learning protocols will facilitate the adoption of MLFFs in the wider catalysis community, enabling more comprehensive mechanistic explorations of catalytic cycles.
Methods
Machine learning framework
We use the Gaussian Approximation Potential (GAP) framework15 to fit DFT energies and forces obtained using QuantumEspresso66. GAP is chosen due to its maturity, past success in describing a wide variety of systems, and because it provides an analytical uncertainty estimate38,67,68. As a many-body descriptor, we use the smooth overlap of atomic positions (SOAP). To assess the transferability of the training set, we employ MACE18, a higher-order equivariant message-passing neural network that leverages recent advancements in graph neural networks for atomic simulations17,18,69.
Uncertainty estimation
Various approaches exist to predict a model’s error for active learning13,51,70,71. The Gaussian Approximation Potential framework allows for a rigorous estimate of the local energy uncertainty from the underlying Gaussian Process Regression (GPR). In the GAP framework, the total energy of a configuration with N atoms is given by the sum of atomic energies,
where \({{{{\boldsymbol{\rho }}}}}_{i}\) is a descriptor of an atom’s local atomic environment, that only depends on the positions and elements of its neighbors within a specified distance cutoff rcut. Thanks to this locality approximation the computational cost of the force field scales linearly with the number of atoms.
To describe the many-body atomic environment \({{{{\boldsymbol{\rho }}}}}\) we use the smooth overlap of atomic positions (SOAP) descriptor, which is invariant with respect to rotations, permutations, translations, and reflections72.
The local energy function ϵ is modeled using sparse GPR. To quantify the similarity between the two environments, we use a polynomial kernel,
where ζ is the polynomial degree and \({{\boldsymbol{\rho}}}\) are SOAP vectors. For a set of N and M local environments, we can define the kernel matrix \({[{{{\bf{{K}}}_{NM}}}]}_{nm}\equiv k({{{{\boldsymbol{\rho }}}}}_{n},{{{{\boldsymbol{\rho }}}}}_{m})\)19. If one were to perform GPR conditioned on a training set of N local environments \({{{{\boldsymbol{\rho }}}}}_{n}\) with ground truth energies y, the predicted energy distribution for unseen atomic environments \({{{{\boldsymbol{\rho }}}}}\) would be Gaussian
with mean and covariance,
where k and kN are the kernels between the environment \({{{{\boldsymbol{\rho }}}}}\), itself and the training set \({{{{\boldsymbol{\rho }}}}}_{n}\) respectively. While the time complexity of obtaining the true mean μ and covariance Σ functions would scale cubically with training set size, they can be approximated with a sparse method. Rather than quantifying the similarity of novel environments with all N training data points, we use a sparse set of M environments, where M ≪ N. Modifications to Equation (4) can be found, by minimizing the Kullback-Leibler divergence between the sparse method and the full posterior in Equation (3)73. The approximate mean and covariance functions are,
where
as found using variational inference73. The training cost of the resulting GAP model scales as \({{{\mathcal{O}}}}(N{M}^{2})\). During simulation, we use the mean of the sparse posterior distribution, while the variance Σ2 provides the local energy error estimate for active learning. As is commonly done within the GAP framework, we select a subset of M representative environments from the training set using CUR matrix decomposition19.
Computational details
DFT
All density functional theory calculations, including single-point evaluations, geometry optimizations as well as NEB74 calculations were done with QuantumEspresso66. We use the Perdew-Becke-Ernzerhof (PBE) functional75, core electrons are described by projector augmented-waves (PAW)76,77, the valence monoelectronic states are expanded as plain waves with a maximum kinetic energy of 884 eV (65 Ry). Core electrons are represented by pseudopotentials78 while the valence shell is represented with 4, 6, 13, and 16 electrons for C, O, In, and Pt. We use a dense reciprocal-space mesh, with a maximum spacing of 0.25 Å−1 and Gaussian smearing of 0.1 eV with an SCF convergence criterion of 10−7 eV, to ensure sufficient convergence of gradients, which is essential for training MLFFs. Reference2 used the Vienna Ab initio Simulation Package (VASP). A calculation on the reduced energy barrier for the rate-limiting step shows that QuantumEspresso calculations correlate well with those obtained from VASP (see Supplementary Method 1).
GAP
We used the Gaussian Approximation Potential (GAP)15,19 in combination with a double turbo SOAPs79 as our many-body descriptor, with 4 Å and 6 Å cut-offs. To evaluate the potential we use the quippy python interface80,81. A complete list of hyperparameters is included in Supplementary Method 2.
MACE
For the dopant section we use MACE18, a higher-order equivariant message-passing neural network. We use two message-passing layers, 256 channels, and equivariant messages of order L = 1. All further settings are tabulated in Supplementary Method 3.
Geometry optimization and NEB calculations
All slabs are centered between 8 Å of vacuum with the lowest two layers (40 atoms) fixed. Relaxations were converged to 0.001 eVÅ-1 and 0.01 eVÅ-1 when using the MLFF and DFT respectively unless explicitly stated otherwise. For NEBs calculations, the convergence criteria were set to 0.01 eVÅ-1 and 0.05 eVÅ-1 respectively. The criteria were set lower for the MLFF due to its smooth potential energy surface and minimal computational cost. All NEBs were calculated using the atomic simulation environment82 using splines and exponential preconditioning83. The initial image guesses were made using the IDPP method84. We use ten and twenty images per NEBs for the oxygen vacancy and reduced surface respectively.
Umbrella sampling
The free energy barriers are obtained using the Colvar85 package in combination with LAMMPS86. We run 110 ps of molecular dynamics for 32 bins along the collective variable, with a 1 fs time step and a spring constant of 75 eVÅ-2 for all temperatures. Starting configurations are taken from the relevant NEB path and allowed to equilibrate for 10 ps. Using umbrella integration87, the samples are mapped to the free energy barrier.
CatKit
CatKit54 was used to create initial adsorbate structures to start active learning and to initialize the minima-hopping configurations. Here all surface oxygen atoms were explicitly defined.
Active site
We investigate the same active site as Reference2. Specifically the oxygen vacancy on the 110 surfaces of cubic indium oxide, with the lowest formation energy. The vacancy configuration itself has 79 atoms per unit cell.
Data availability
The datasets generated throughout the active learning protocol and used to train the MLFFs are available in the Zenodo repository, https://doi.org/10.5281/zenodo.8268726.
Code availability
Both MLFF frameworks used during this investigation, GAP and MACE, are publicly available.
References
Pinheiro Araújo, T. et al. Flame spray pyrolysis as a synthesis platform to assess metal promotion in In2O3-catalyzed CO2 hydrogenation. Adv. Energy Mater. 12, 2103707 (2022).
Dang, S. et al. Rationally designed indium oxide catalysts for CO2 hydrogenation to methanol with high activity and selectivity. Sci. Adv. 6, eaaz2060 (2020).
Hammer, B., Hansen, L. B. & Nørskov, J. K. Improved adsorption energetics within density-functional theory using revised Perdew-Burke-Ernzerhof functionals. Phys. Rev. B 59, 7413–7421 (1999).
Chen, B. W. J., Xu, L. & Mavrikakis, M. Computational methods in heterogeneous catalysis. Chem. Rev. 121, 1007–1048 (2021).
Nørskov, J. K. et al. Origin of the overpotential for oxygen reduction at a fuel-cell cathode. J. Phys. Chem. B 108, 17886–17892 (2004).
Zhuo, M., Borgna, A. & Saeys, M. Effect of the CO coverage on the Fischer–Tropsch synthesis mechanism on cobalt catalysts. J. Catal. 297, 217–226 (2013).
Bonati, L. et al. Non-linear temperature dependence of nitrogen adsorption and decomposition on Fe(111) surface. Preprint, Chemistry (2023).
Reuter, K. & Scheffler, M. Composition, structure, and stability of RuO2 (110) as a function of oxygen pressure. Phys. Rev. B 65, 035406 (2001).
Timmermann, J. et al. IrO2 surface complexions identified through machine learning and surface investigations. Phys. Rev. Lett. 125, 206101 (2020).
Stocker, S. et al. Estimating free energy barriers for heterogeneous catalytic reactions with machine learning potentials and umbrella integration. Preprint at 10.26434/chemrxiv-2023-br1h5 (2023).
Johnson, M. S. et al. Pynta-an automated workflow for calculation of surface and gas-surface kinetics. J. Chem. Inf. Model. 63, 5153–5168 (2023).
Senftle, T. P. et al. The ReaxFF reactive force-field: development, applications and future directions. npj Comput. Mater. 2, 1–14 (2016).
Vandermause, J., Xie, Y., Lim, J. S., Owen, C. J. & Kozinsky, B. Active learning of reactive Bayesian force fields applied to heterogeneous catalysis dynamics of H/Pt. Nat. Commun. 13, 5183 (2022).
Behler, J. & Parrinello, M. Generalized neural-network representation of high-dimensional potential-energy surfaces. Phys. Rev. Lett. 98, 146401 (2007).
Bartók, A. P., Payne, M. C., Kondor, R. & Csányi, G. Gaussian approximation potentials: the accuracy of quantum mechanics, without the electrons. Phys. Rev. Lett. 104, 136403 (2010).
Drautz, R. Atomic cluster expansion for accurate and transferable interatomic potentials. Phys. Rev. B 99, 014104 (2019).
Batzner, S. et al. E(3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials. Nat. Commun. 13, 2453 (2022).
Batatia, I., Kovacs, D. P., Simm, G., Ortner, C. & Csanyi, G. MACE: higher order equivariant message passing neural networks for fast and accurate force fields. Adv. Neural Inf. Process. Syst. 35, 11423–11436 (2022).
Deringer, V. L. et al. Gaussian process regression for materials and molecules. Chem. Rev. 121, 10073–10141 (2021).
Gelžinytė, E., Öeren, M., Segall, M. D. & Csányi, G. Transferable machine learning interatomic potential for bond dissociation energy prediction of drug-like molecule. Preprint, Chemistry (2023).
Lorenz, S., Groß, A. & Scheffler, M. Representing high-dimensional potential-energy surfaces for reactions at surfaces by neural networks. Chem. Phys. Lett. 395, 210–215 (2004).
Tran, K. et al. Methods for comparing uncertainty quantifications for material property predictions. Mach. Learn. Sci. Technol. 1, 025006 (2020).
Mamun, O., Winther, K. T., Boes, J. R. & Bligaard, T. High-throughput calculations of catalytic properties of bimetallic alloy surfaces. Sci. Data 6, 76 (2019).
Chanussot, L. et al. Open Catalyst 2020 (OC20) dataset and community challenges. ACS Catal. 11, 6059–6072 (2021).
Tran, R. et al. The Open Catalyst 2022 (OC22) dataset and challenges for oxide electrocatalysis. ACS Catal. 13, 3066–3084 (2023).
Bernstein, N., Csányi, G. & Deringer, V. L. De novo exploration and self-guided learning of potential-energy surfaces. npj Comput. Mater. 5, 99 (2019).
Zhang, L., Lin, D.-Y., Wang, H., Car, R. & E, W. Active learning of uniformly accurate interatomic potentials for materials simulation. Phys. Rev. Mater. 3, 023804 (2019).
Smith, J. S., Nebgen, B., Lubbers, N., Isayev, O. & Roitberg, A. E. Less is more: sampling chemical space with active learning. J. Chem. Phys. 148, 241733 (2018).
Ye, J., Liu, C. & Ge, Q. DFT study of CO2 adsorption and hydrogenation on the In2O3 surface. J. Phys. Chem. C 116, 7817–7825 (2012).
Ye, J., Liu, C., Mei, D. & Ge, Q. Active oxygen vacancy site for methanol synthesis from CO2 hydrogenation on In2O3(110): a DFT study. ACS Catal. 3, 1296–1306 (2013).
Zhang, M., Wang, W. & Chen, Y. Insight of DFT and ab initio atomistic thermodynamics on the surface stability and morphology of In2O3. Appl. Surf. Sci. 434, 1344–1352 (2018).
Frei, M. S. et al. Mechanism and microkinetics of methanol synthesis via CO2 hydrogenation on indium oxide. J. Catal. 361, 313–321 (2018).
Dou, M., Zhang, M., Chen, Y. & Yu, Y. DFT study of In2O3 -catalyzed methanol synthesis from CO2 and CO hydrogenation on the defective site. New J. Chem. 42, 3293–3300 (2018).
Cao, A., Wang, Z., Li, H. & Nørskov, J. K. Relations between surface oxygen vacancies and activity of methanol formation from CO2 hydrogenation over In2O3 surfaces. ACS Catal. 11, 1780–1786 (2021).
Nakamura, J., Choi, Y. & Fujitani, T. On the issue of the active site and the role of ZnO in Cu/ZnO methanol synthesis catalysts. Top. Catal. 22, 277–285 (2003).
Studt, F. et al. The mechanism of CO and CO2 hydrogenation to methanol over Cu-based catalysts. ChemCatChem 7, 1105–1111 (2015).
Bielz, T. et al. Hydrogen on In2O3: reducibility, bonding, defect formation, and reactivity. J. Phys. Chem. C 114, 9022–9029 (2010).
Bartók, A. P., Kermode, J., Bernstein, N. & Csányi, G. Machine learning a general-purpose interatomic potential for silicon. Phys. Rev. X 8, 041048 (2018).
Deringer, V. L. & Csányi, G. Machine learning based interatomic potential for amorphous carbon. Phys. Rev. B 95, 094203 (2017).
Deringer, V. L., Caro, M. A. & Csányi, G. A general-purpose machine-learning force field for bulk and nanostructured phosphorus. Nat. Commun. 11, 5461 (2020).
Deringer, V. L. et al. Origins of structural and electronic transitions in disordered silicon. Nature 589, 59–64 (2021).
Behler, J. First principles neural network potentials for reactive simulations of large molecular and condensed systems. Angew. Chem. Int. Ed. 56, 12828–12840 (2017).
Schütt, K. T., Sauceda, H. E., Kindermans, P.-J., Tkatchenko, A. & Müller, K.-R. SchNet – a deep learning architecture for molecules and materials. J. Chem. Phys. 148, 241722 (2018).
Chmiela, S., Sauceda, H. E., Poltavsky, I., Müller, K.-R. & Tkatchenko, A. sGDML: constructing accurate and data efficient molecular force fields using machine learning. Comput. Phys. Commun. 240, 38–45 (2019).
Botu, V., Batra, R., Chapman, J. & Ramprasad, R. Machine learning force fields: construction, validation, and outlook. J. Phys. Chem. C 121, 511–522 (2017).
Podryabinkin, E. V., Tikhonov, E. V., Shapeev, A. V. & Oganov, A. R. Accelerating crystal structure prediction by machine-learning interatomic potentials with active learning. Phys. Rev. B 99, 064114 (2019).
Jørgensen, M. S., Larsen, U. F., Jacobsen, K. W. & Hammer, B. Exploration versus exploitation in global atomistic structure optimization. J. Phys. Chem. A 122, 1504–1509 (2018).
Vandermause, J. et al. On-the-fly active learning of interpretable Bayesian force fields for atomistic rare events. npj Comput. Mater. 6, 20 (2020).
Sivaraman, G. et al. Machine-learned interatomic potentials by active learning: amorphous and liquid hafnium dioxide. npj Comput. Mater. 6, 1–8 (2020).
Young, T. A., Johnston-Wood, T., Deringer, V. L. & Duarte, F. A transferable active-learning strategy for reactive molecular force fields. Chem. Sci. 12, 10944–10955 (2021).
van der Oord, C. et al. Hyperactive learning for data-driven interatomic potentials. npj Comput Mater 9, 168 (2023).
Jinnouchi, R., Karsai, F. & Kresse, G. On-the-fly machine learning force field generation: application to melting points. Phys. Rev. B 100, 014105 (2019).
Jain, A. et al. Commentary: the materials project: a materials genome approach to accelerating materials innovation. APL Mater. 1, 011002 (2013).
Boes, J. R., Mamun, O., Winther, K. & Bligaard, T. Graph theory approach to high-throughput surface adsorption structure generation. J. Phys. Chem. A 123, 2281–2285 (2019).
De, S., Bartók, A. P., Csányi, G. & Ceriotti, M. Comparing molecules and solids across structural and alchemical space. Phys. Chem. Chem. Phys. 18, 13754–13769 (2016).
Li, X. & Rupprechter, G. Sum frequency generation spectroscopy in heterogeneous model catalysis: a minireview of CO-related processes. Catal. Sci. Technol. 11, 12–26 (2021).
Khatamirad, M. et al. A data-driven high-throughput workflow applied to promoted In-oxide catalysts for CO2 hydrogenation to methanol. Catal. Sci. Technol. 13, 2656–2661 (2023).
Xie, W., Xu, J., Chen, J., Wang, H. & Hu, P. Achieving theory–experiment parity for activity and selectivity in heterogeneous catalysis using microkinetic modeling. Acc. Chem. Res. 55, 1237–1248 (2022).
Kozuch, S. & Shaik, S. How to conceptualize catalytic cycles? The energetic span model. Acc. Chem. Res. 44, 101–110 (2011).
Hannagan, R. T. et al. First-principles design of a single-atom–alloy propane dehydrogenation catalyst. Science 372, 1444–1447 (2021).
Frei, M. S. et al. Nanostructure of nickel-promoted indium oxide catalysts drives selectivity in CO2 hydrogenation. Nat. Commun. 12, 1960 (2021).
Frei, M. S. et al. Atomic-scale engineering of indium oxide promotion by palladium for methanol production via CO2 hydrogenation. Nat. Commun. 10, 3377 (2019).
Goedecker, S. Minima hopping: an efficient search method for the global minimum of the potential energy surface of complex molecular systems. J. Chem. Phys. 120, 9911–9917 (2004).
Jung, H., Sauerland, L., Stocker, S., Reuter, K. & Margraf, J. T. Machine-learning driven global optimization of surface adsorbate geometries. npj Comput. Mater. 9, 1–8 (2023).
Reuter, K. Ab initio thermodynamics and first-principles microkinetics for surface catalysis. Catal. Lett. 146, 541–563 (2016).
Giannozzi, P. et al. Advanced capabilities for materials modeling with quantum ESPRESSO. J. Phys. Condens. Matter Inst. Phys. J. 29, 465901 (2017).
Deringer, V. L. et al. Towards an atomistic understanding of disordered carbon electrode materials. Chem. Commun. 54, 5988–5991 (2018).
Monserrat, B., Brandenburg, J. G., Engel, E. A. & Cheng, B. Liquid water contains the building blocks of diverse ice phases. Nat. Commun. 11, 5757 (2020).
Schütt, K. et al. SchNet: a continuous-filter convolutional neural network for modeling quantum interactions. In Advances in Neural Information Processing Systems, Vol. 30 (Curran Associates, Inc., 2017).
Schran, C., Brezina, K. & Marsalek, O. Committee neural network potentials control generalization errors and enable active learning. J. Chem. Phys. 153, 104105 (2020).
Novikov, I. S., Gubaev, K., Podryabinkin, E. V. & Shapeev, A. V. The MLIP package: moment tensor potentials with MPI and active learning. Mach. Learn. Sci. Technol. 2, 025002 (2021).
Bartók, A. P., Kondor, R. & Csányi, G. On representing chemical environments. Phys. Rev. B 87, 184115 (2013).
Titsias, M. Variational learning of inducing variables in sparse Gaussian processes. In Proc. 12th International Conference on Artificial Intelligence and Statistics 567–574 (PMLR, 2009).
Berne, B. J., Ciccotti, G. & Coker, D. F. Classical and Quantum Dynamics in Condensed Phase Simulations: Proc. International School of Physics (World Scientific, 1998).
Perdew, J. P., Burke, K. & Ernzerhof, M. Generalized gradient approximation made simple. Phys. Rev. Lett. 77, 3865–3868 (1996).
Blöchl, P. E. Projector augmented-wave method. Phys. Rev. B 50, 17953–17979 (1994).
Kresse, G. & Joubert, D. From ultrasoft pseudopotentials to the projector augmented-wave method. Phys. Rev. B 59, 1758–1775 (1999).
Dal Corso, A. Pseudopotentials periodic table: from H to Pu. Comput. Mater. Sci. 95, 337–350 (2014).
Caro, M. A. Optimizing many-body atomic descriptors for enhanced computational performance of machine learning based interatomic potentials. Phys. Rev. B 100, 024112 (2019).
Kermode, J. R. F90wrap: an automated tool for constructing deep Python interfaces to modern Fortran codes. J. Phys. Condens. Matter 32, 305901 (2020).
Csanyi, G. et al. Expressive programming for computational physics in Fortran 950+. Newsl. Comput. Phys. Group 1–24 (2007). https://www.southampton.ac.uk/~fangohr/randomnotes/iop_cpg_newsletter/2007_1.pdf.
Larsen, A. H. et al. The atomic simulation environment—a Python library for working with atoms. J. Phys. Condens. Matter 29, 273002 (2017).
Makri, S., Ortner, C. & Kermode, J. R. A preconditioning scheme for minimum energy path finding methods. J. Chem. Phys. 150, 094109 (2019).
Smidstrup, S., Pedersen, A., Stokbro, K. & Jónsson, H. Improved initial guess for minimum energy path calculations. J. Chem. Phys. 140, 214106 (2014).
Fiorin, G., Klein, M. L. & Hénin, J. Using collective variables to drive molecular dynamics simulations. Mol. Phys. 111, 3345–3362 (2013).
Thompson, A. P. et al. LAMMPS - a flexible simulation tool for particle-based materials modeling at the atomic, meso, and continuum scales. Comput. Phys. Commun. 271, 108171 (2022).
Stecher, T., Bernstein, N. & Csányi, G. Free energy surface reconstruction from umbrella samples using Gaussian process regression. J. Chem. Theory Comput. 10, 4079–4097 (2014).
Acknowledgements
We thank the authors from Reference2 for sharing their NEB and geometry-optimized configurations to help validate the machine learning force field. We are grateful for computational support from the UK national high-performance computing service, ARCHER2, for which access was obtained via the UKCP consortium and funded by EPSRC grant reference EP/P022065/1 and EP/X035891/1. Additionally, LS acknowledges support from the EPSRC Centre for Doctoral Training in Chemical Synthesis with grant reference EP/S024220/1 and corporate funding from BASF SE.
Author information
Authors and Affiliations
Contributions
Authors G.C., A.S. and S.D. jointly conceived the research. Authors L.S., S.D. and E.F. did the calculations. Author L.S. drafted the paper. All authors edited the paper.
Corresponding authors
Ethics declarations
Competing interests
Authors L.S., E.F., A.S. and S.D. declare no financial or non-financial competing interests. Author G.C. is listed as an inventor on a patent filed by Cambridge Enterprise Ltd. related to SOAP and GAP (PCT/GB2009/001414, filed on 5 June 2009 and published on 23 September 2014).
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Schaaf, L.L., Fako, E., De, S. et al. Accurate energy barriers for catalytic reaction pathways: an automatic training protocol for machine learning force fields. npj Comput Mater 9, 180 (2023). https://doi.org/10.1038/s41524-023-01124-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41524-023-01124-2
