
Abstract
Although the origin of the fat-tail characteristic of the degree distribution in complex networks has been extensively researched, the underlying cause of the degree distribution characteristic across the complete range of degrees remains obscure. Here, we propose an evolution model that incorporates only two factors: the node’s weight, reflecting its innate attractiveness (nature), and the node’s degree, reflecting the external influences (nurture). The proposed model provides a good fit for degree distributions and degree ratio distributions of numerous real-world networks and reproduces their evolution processes. Our results indicate that the nurture factor plays a dominant role in the evolution of social networks. In contrast, the nature factor plays a dominant role in the evolution of non-social networks, suggesting that whether nodes are people determines the dominant factor influencing the evolution of real-world networks.
Similar content being viewed by others

Introduction
Pioneered by Helen Jennings in the 1930’s1, the degree distribution is a key characteristic of empirical network studies. Previous studies on the degree distribution of complex networks have primarily focused on the tail of the distribution, in particular when it exhibits a power law, which has led to the theory that “scale-free networks” are ubiquitous in nature2,3,4,5,6,7. Numerous network evolution models have been proposed to explain the mechanism that causes the fat-tail of the degree distribution to follow a power law8,9,10,11,12, with the preferential attachment mechanism in the Barabási–Albert (BA) model being the most famous13. However, the debate about whether complex networks truly have scale-free properties has persisted12,14,15. Some scholars have proposed that we need to understand the scale-free properties and evolutionary origins of complex networks from a new perspective16,17,18. While the tail of the degree distribution may be approximated as a power law for many real-world networks19,20,21,22,23,24,25, the bulk (the small-degree end) tends to bend off in various networks such as Facebook (friendships network), Google (informational network), the patent network of USA (technological network), etc17,26. In this work, we will propose a model for network evolution with an emergent degree distribution that fits observations throughout the degree range, including both the tail and the bulk.
Our proposed network evolution model incorporates only two parameters: an intrinsic node weight (a.k.a. “fitness”27 or “quality”28) and the accumulated degree. These parameters effectively capture the dual influences of inherent characteristics (referred to as the “nature” factor) and environmental influences (referred to as the “nurture” factor) on the evolution of each node. We begin by demonstrating the core idea and formulation of our model. Following this, we proceed to solve the model analytically, focusing on deriving the analytical solutions for the distributions of degree k as well as the degree ratio η, more commonly referred to as the degree–degree distance17,29. We find that the statistically optimal fit to these analytical solutions accurately reproduces both the degree distribution and degree ratio distributions of 32 real-world networks. Additionally, we verify that our model can produce the actual growth process in several networks. We find that the nurture factor of nodes predominantly influences the evolution of social networks, implying that the node degree has a greater impact on node evolution than the node weight in social networks. Whereas the nature factor of nodes plays a leading role in the evolution of non-social networks, suggesting that the impact of node weight on node evolution is greater than that of node degree in non-social networks. This observation implies that whether nodes are people plays a crucial role in determining the dominant factor driving the evolution of real-world networks. It also indicates that collective human behaviors, within the context of social interactions, tend to favor the nurture factor over the nature factor.
Not only does the model provide statistically optimal fittings to the observed distributions, but it also reveals the evolutionary origin of complex networks in terms of the interplay between both nature and nurture factors. Compared with the classical complex network models8,13,28,30, the model still includes the preferential attachment mechanism, leading us to conclude that the scale-free property of complex networks should be understood as a mechanism, such as the preferential attachment mechanism, rather than a specific index, thus potentially resolving the long-standing debate about whether complex networks have scale-free properties.
Results
Nature–nurture model
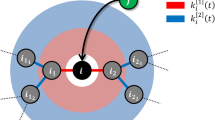
Our study posits that the evolution of complex networks is closely tied to the interplay between two key factors: the node’s weight reflecting its appeal within the network, which reflects the nature aspect of development, and the node’s degree, which signifies its nurture factor. This coupling of the nature and nurture factors of nodes plays a crucial role in shaping the network’s evolution, as shown in Fig. 1.

Suppose there are two nodes of different node weights and degrees in the network. The red node has a larger weight but a smaller degree (with three incident links). The blue node has a smaller weight but a larger degree (with six incident links). As new links are added to the network, if the network evolution is nature-dominant, then new links prefer connecting to the red node; else, if the network evolution is nurture-dominant, then new links prefer connecting to the blue node.
Before nodes join the network, we consider that their innate attractiveness are different in real world, similar to the Matthew effect31. For example, on Facebook, a user’s social prestige, status, and influence serve as their innate weight, with most users being ordinary and only a few having high social prestige, status, and influence. The more social prestige, status, and influence an individual has, the more attractive they are32. In general, we assume that the distribution of node weight ω in a complex network follows a power-law distribution ~ω−α, with α ≥ 0. This assumption also covers cases of a uniform distribution when α → 0, or a short-tail (e.g., exponential) distribution when α → ∞ (see Supplementary Discussion). The larger the nature weight ω of a node, the higher its probability Π(ω) of establishing new links with other nodes.
On the other hand, the node’s degree k reflects its nurtured attractiveness, which is akin to the snowball effect33 or recommendation systems28. Taking Twitter as an example, as a user’s number of followers grows, their attractiveness to other users increases, further boosting their follower count. The larger the nurture degree k of a node, the higher its probability Π(k) of establishing new links with other nodes.
Consequently, nodes with larger ω and k are more prone to establishing new links. This motivates us to choose the probability of a node being preferentially selected to form new links with other node as Π(ω, k) ~ ωk + a positive constant. This formulation is in line with the approach taken in the Bianconi–Barabási model30, where the probability is also a function of the product of ω and k.
Finally, we incorporate a cutoff parameter, \({\omega }_{\max }\), which restricts the value of ω to fall within the range of 1 to \({\omega }_{\max }\). This critical parameter serves to regulate the model’s inclination towards either “nature” or “nurture.” A smaller \({\omega }_{\max }\) results in less variability in the distribution of the “nature” influence, suggesting that the model leans towards “nurture.” Conversely, a larger \({\omega }_{\max }\) allows for greater variability, indicating that the model favors “nature.”
Taken together, our model is built on the following rules:
-
1.
Initially, there are N nodes but no link in the network. Each node i = 1, 2, ⋯ , N is assigned a weight ωi. Similar to other models with node weights generating the degree distribution8,30, the weight for each node is randomly sampled from a truncated power-law probability distribution, following the form ~ω−α, within a finite domain of \(\omega \in [1,\, \, {\omega }_{\max }]\).
-
2.
At each time step, two nodes are randomly and independently chosen, and a link is established between them. The probability of choosing a node depends on the nature weight ω and the nurture degree k of the node, given by
$${{\Pi }}(\omega,\, \, k)=\frac{\omega \left(k+b\right)}{\mathop{\sum }\nolimits_{i=1}^{N}{\omega }_{i}\left({k}_{i}+b\right)},\,$$(1)where b is a positive constant.
-
3.
After T time steps, a network of N nodes and T links is generated.
The degree distribution of the nature-nurture model can be written as follows:
where ni(T, k) is the probability that node i (of weight ωi) has degree k at time step T and \(c=\left(1-\alpha \right)/\left({\omega }_{\max }^{1-\alpha }-1\right)\) is the normalization coefficient. Further approximations allow us to derive an analytical form of P(k) (see “Methods”).
To demonstrate that the model can accurately replicate multiple topological features, not just degrees, in complex networks, we examine a link-based characteristic: the degree ratio η, defined as the ratio of the larger and smaller degree for each link (i, j), expressed as \(\eta=\max ({k}_{i}/{k}_{j},\, \, {k}_{j}/{k}_{i})\). Note that this can also be reformulated as \(\ln \eta=\left|\ln {k}_{i}-\ln {k}_{j}\right|\), which serves as a semi-metric on the set of edges34. Hence, η (or more precisely, \(\ln \eta\)) is often referred to as the degree–degree distance17. Notably, in many empirical networks, the degree ratio distribution exhibits a clearer power-law behavior than the degree distribution, signifying its usefulness in examining the scale-free properties of networks. The degree ratio distribution is given by
where nij(T, ki, kj, (i, j)) denotes the joint probability that nodes i and j have degrees ki and kj and they are also connected by a link (see “Methods”).
The reliability of the analytical solutions of our model is demonstrated through a comparison of the degree distributions and degree ratio distributions obtained from simulations and Eqs. (2) and (3)), respectively (Supplementary Fig. 1). The agreement between the simulation and analysis results confirms the reliability of the analytical solutions of the nature–nurture model.
We also present two supplementary models to serve as controls: a nature-only model and a nurture-only model (see “Methods”). In the former, we eliminate the effect of the degree k, so that Π(ω, k) → Π(ω) ∝ ω, only depending on ω. The resulting degree and degree-ratio distributions are as follows:
which can be further approximated to a classical power-law distribution P(k) ∝ k−α 17, and
where \({\mu }_{i}=2{\omega }_{i}T/N\bar{\omega }\) and \({\sigma }_{i}=\left(1-2{\omega }_{i}/N\bar{\omega }\right)2{\omega }_{i}T/N\bar{\omega }\), and \(\bar{\omega }={(2-\alpha )}^{-1}{\left({\omega }_{\max }^{1-\alpha }-1\right)}^{-1}(1-\alpha )\left({\omega }_{\max }^{2-\alpha }-1\right)\) is the average node weight of the network.
In the nurture-only model, we eliminate the effect of the weight ω, so that Π(ω, k) → Π(k) ∝ k + b, only depending on k. In the b → 0 limit, the resulting degree and degree-ratio distributions are29:
which is a power-law distribution with an exponential cutoff, and
where A = b and B = 2−1bNT−1, respectively.
Validation
We have gathered thirty-two real-world networks that span across social, informational, technological, biological and economic domains from the Colorado Index of Complex Networks (ICON). These networks vary in size, ranging from tens of thousands to hundreds of millions of nodes. Our data includes the most representative network platforms such as Facebook, Twitter, Wikipedia, Amazon, YouTube, Google, and Academia, among others. Descriptions for these networks can be found in Supplementary Table 1.
Figure 2 (and Supplementary Fig. 2) shows the optimal fitting results of the distributions of both degree k [Eq. (2)] and degree-ratio η [Eq. (3)] for thirty-two real-world networks. The parameters N and T in Eqs. (2) and (3) are fixed as the numbers of nodes and links of the fitted data, respectively. The optimal values of the fitting parameters \({\omega }_{\max }\), α, and b are provided in Supplementary Table 2. We find that the nature-nurture model simultaneously reproduces both the degree and the degree ratio distributions of real-world networks fairly well. These results suggest that the coupling of both nature and nurture factors of nodes plays an essential role in the evolution of complex networks.

A–P The observed degree distribution P(k) (blue) and degree-ratio distribution P(η) (red) in 32 real-world networks (other 16 in Supplementary Fig. 2) are fitted based on Eqs. (2) and (3) of the nature–nurture model. The parameters N and T match the number of nodes and links in the empirical data. The other fitting parameters, \({\omega }_{\max }\), α, and b are provided in Supplementary Table 2.
In particular, Fig. 3A shows the optimal values of \({\omega }_{\max }\) for the real-world networks, with blue and red circles representing eleven social and 21 non-social networks, respectively. We observe that the social and non-social networks are distributed in two distinct regions. In social networks, \({\omega }_{\max }\) tends to be smaller, while in non-social networks, \({\omega }_{\max }\) tends to be larger. This suggests that the nature factor of nodes plays a dominant role in the evolution of social networks, while the nurture factor of nodes plays a dominant role in the evolution of non-social networks. To corroborate this observation, we calculated the corrected Akaike Information Criterion (AICc)35—a statistical estimator that deals with the risks of both overfitting and underfitting—for the optimal fits of the distributions of k and η (Supplementary Table 3 and Fig. 3). This was conducted for the nature-nurture model as well as the control models, namely, the nature-only and nurture-only models. We find that the nature–nurture model is the most favored by AICc for 31 (96.9%) of the 32 real-world networks. By comparing only the control models [Fig. 3B, C], we find that the nurture-only model is favored by AICc for 81.8% of the social networks, yet the nature-only model is favored for 85.7% of the non-social networks. These results provide evidence that while the nature and nurture factors tend to dominate in the evolution of non-social and social networks, respectively, it is essential to consider the contributions from both aspects for an faithful representation of real-world network evolution.

A Optimal fitting parameter \({\omega }_{\max }\) of the nature-nurture model in various real-world networks. Social networks (blue) generally exhibit lower \({\omega }_{\max }\) values compared to non-social networks (red). B, C Preference for the nature-only (red) or nurture-only (blue) model in fitting social and non-social networks, respectively, based on the corrected Akaike information criterion for small sample sizes (AICc) provided in Supplementary Table 3.
Two networks, Academia (tracking citations between academic papers) and Zhihu (a Chinese Q&A forum), are accompanied by timestamps, allowing us to explore how their degree and degree-ratio distributions evolve over various time periods. Figure 4 shows the fitting results for the initial, middle, and final stages during the evolution of the two networks. Again, the parameters N and T in Eqs. (2) and (3) are fixed as the numbers of nodes and links of the fitted data. The other fitting parameters, \({\omega }_{\max }\), α, and b, at each stage are fixed to the optimal values of the Academia and Zhihu networks (obtained from Supplementary Table 2).

The observed degree distribution P(k) (blue) and degree-ratio distribution P(η) (red) in A–C Academia (a non-social network) and D–F Zhihu (a social network) are captured at different timestamped stages. Solid and dashed lines represent fits based on Eqs. (2) and (3) of the nature–nurture model, with AICc provided (Supplementary Table 5). The parameters N and T match the number of nodes and links in the empirical data at each evolutionary stage (Supplementary Table 4). The other fitting parameters, \({\omega }_{\max }\), α, and b are set according to the optimal values obtained in Supplementary Table 2.
The evolution fitting results (Supplementary Table 4) demonstrate that the nature-nurture model continues to simultaneously reproduce the distributions of k and η throughout the evolution process, from the initial to the final stage (Fig. 4). This confirms the model’s ability to capture the evolutionary dynamics of complex networks. Moreover, the nature–nurture model continues to be the most favored by AICc, compared to the control models (Supplementary Table 5) during the evolution. Between the nature-only and nurture-only models, the former is more favored by AICc for the non-social network Academia, while the latter is more favored for the social network Zhihu. The consistency of results across static and evolutionary networks highlights the universal applicability of the nature-nurture model.
The biggest difference between nodes in social networks and those in non-social networks is that nodes in social networks represent users, who are people with strong subjectivity and self-modification abilities in the postnatal evolution, albeit limited by innate factors. On the other hand, nodes in non-social networks represent non-people entities with innate attributes and functions, generally lacking the ability to self-modify in the postnatal evolution process. In human society, we may believe that a person’s efforts should carry more weight than their social background in determining social position. Therefore, in the evolution of social networks, it makes sense that the nurture factor plays a primary role. The result reveals a fresh aspect of the “nature vs. nurture” discussion from the perspective of network science: although both the nature and nurture factors impact individual human behaviors, the nurture factor assumes a more prominent role when determining collective behaviors within social networks, rather than focusing solely on individuals. Other systems have less pronounced structural feedback, and are thus determined by the innate attributes to a larger extent. As such, we propose that in the evolution of non-social networks, the nature factor of nodes should play a leading role. Therefore, whether nodes in complex networks are people or not determines the dominant factor influencing the evolution of complex networks.
Discussion
Since the publication of Galton’s renowned paper in 186536, the exploration of the relative effects of nature (genetics) and nurture (environment) on individuals has remained a central focus in the fields of biology and sociology, leading to a vast body of literature on this subject37,38,39,40,41,42,43. However, there have been relatively few studies that approach this discourse from the perspective of complex systems. Our research provides a refreshing insight into the ongoing “nature vs. nurture” discussion: while individual variations are significant (and may not be predictable), collective behaviors demonstrate predictability and can be categorized as either pro-nature or pro-nurture. This discovery underscores the potential of interdisciplinary studies that apply complex networks to diverse disciplines.
In conclusion, we propose a model of network evolution aiming to shed light on the evolutionary origin of complex networks. The optimal fitting results of the analytical solutions in the model reproduce the degree distributions and degree ratio distributions of both static and dynamic networks. These findings indicate that the coupling of both nature and nurture factors of nodes plays a crucial role in the evolution of complex networks, and our model can rather universally account for the evolution of complex networks. However, the strength of the nature and nurture components of the growth might vary, which furthermore gives a characterization of the network growth. In social networks, the nurture factor of nodes is dominant, implying that individuals can improve their social value through their acquired efforts instead of solely relying on their innate background. Conversely, in non-social networks, the nature factor of nodes plays a leading role, where the innate attributes and functions of agents provided by the system determine their acquired state and development in the system, suggesting that whether nodes are people determines the dominant factor influencing the evolution of complex networks.
In our work, we have not explicitly addressed the issue of network directionality. The primary goal of our study is to investigate the universal mechanisms that can be adaptable to the evolution of both undirected and directed networks. For directed networks, we treat the sum of node outdegrees and indegrees as the total degrees of a node, followed by calculating the degree distribution without explicitly delving into the directionality consideration. One way to modify our model to impose directionality is to specify edge directions between two nodes via some additional assumptions. For instance, in cases where two nodes are selected at each time step, the direction of the edge could be determined from the node with a lower weight or degree to the node with a higher weight or degree. In the future, it would be interesting to explore the effect of imposing network directionality on the network evolution (cf. ref. 28).
In spirit, our work conforms to the tradition of emphasizing the emergent scale-freeness of network evolution models. An interesting future direction would be to link this model to the other tradition of identifying scale-freeness by statistical tests14. One could potentially do this with a more direct statistical inference of the growth mechanisms (cf. ref. 44). Regardless, even in such a well-studied topic as general growth models for fat-tailed networks, there are open questions with unexplored solutions.
Methods
Degree and degree-ratio distributions of the nature–nurture model
Let node i have weight ωi and denote ni(T, k) as the probability that such a node has degree k at time step T. Following standard process3, we derive the Markovian rate equation for node i,
where Π(ω, k) is the preferential probability given in the main text [Eq. (1)]. The initial condition of Eq. (8) is
and the boundary condition is
We are also interested in \(P\left(({k}_{i},\, {k}_{j})| (i,\, j)\right)\), the conditional probability of randomly choosing a link that connects two nodes i and j of degrees ki and kj, respectively. To avoid potential overcounting, we always call the first selected node as i and the second selected node as j in our bidirectional selection process, so that (i, j) and (j, i) are counted as different pairs by us. As a conditional probability, however, \(P\left(({k}_{i},\, {k}_{j})| (i,\, j)\right)\) corresponds to the frequency of counting instances sampled from the pool of all links (~T), not nodes (≁N), and therefore one cannot directly establish a Markovian rate equation that is similar to Eq. (8). To circumvent this, for any pair of nodes i and j with weights ωi and ωj respectively, we introduce an auxiliary variable \({n}_{ij}(T,\, k,\, {k}^{{\prime} },\, (i,\, j))\) that denotes the joint probability of the spontaneous happening of three events at time step T: (1) node i has degree k, (2) node j has degree \({k}^{{\prime} }\), and (3) i and j are connected.
Now, the Markovian rate equation for \({n}_{ij}(T,\, k,\, {k}^{{\prime} },\, (i,\, j))\) is given by
The first three terms of Eq. (11) account for the probability that, when nodes i and j are already connected at time step T, whether they will acquire (or not) a new link to satisfy the conditions on their degrees being k and \({k}^{{\prime} }\) at time step T + 1. The last term accounts for the probability that, when nodes i and j are not connected at time step T (which approximately happens with probability \({n}_{i}(T,\, k-1){n}_{j}(T,\, {k}^{{\prime} }-1)\) when the network is sparse), whether i and j will be connected and match all three conditions at the next time step. The initial condition of Eq. (11) is
and the boundary conditions are
If we can solve ni(T, k) [Eq. (8)] and \({n}_{ij}(T,\, k,\, {k}^{{\prime} },\, (i,\, j))\) [Eq. (11)], which are functions of ωi (and ωj), then both degree distribution and degree ratio distribution can be calculated given the node weight distribution ρ(ω), which we have assumed to be a continuous power-law distribution ρ(ω) = cω−α within the range \(1\le \omega \le {\omega }_{\max }\), given the normalization coefficient \(c=\left(1-\alpha \right)/\left({\omega }_{\max }^{1-\alpha }-1\right)\). The DD is simply given by
To derive the degree ratio distribution, one has
which is the joint probability of randomly choosing a pair of nodes i and j that not only are connected but also have degrees ki and kj. Then, the degree ratio distribution is given by17
where in the second step we have used Bayes’ rule, given that P(i, j) = T/N2. Inserting Eq. (15) into Eq. (16) gives rise to P(η).
Unfortunately, Eqs. (8) and (11) are difficult to solve. This is since the implicit time dependence of the preferential probability Π(ω, k) is intractable. However, special solutions can be found under certain limits:
-
1.
In the nature-only limit, we can eliminate the nurture factor by letting b → ∞, while keeping the power-law exponent α of the weight distribution being finite. This reduces Eq. (1) to
$${{\Pi }}(\omega,\, k)\simeq \frac{\omega }{N\bar{\omega }},\, \,{{\mbox{when}}}\,b\to \infty,\,$$(17)which is independent of k. Hence, our introduced model reduces to a pure bidirectional-selection fitness model with a power-law weight (fitness) distribution, for which both the solutions of P(k) and P(η) are known17. The results are given in the main text [Eqs. (4) and (5)].
-
2.
In the nurture-only limit, we can eliminate the nurture factor by letting α → ∞, which also implies \({\omega }_{\max }\to 1\). This reduces Eq. (1) to
$${{\Pi }}(\omega,\, k)\simeq \frac{k+b}{2T+bN},\, \,{{\mbox{when}}}\,\alpha \to \infty,\,$$(18)given that \({\omega }_{i}\simeq \bar{\omega }\simeq 1\) and ρ(ω) ≃ δ(ω − 1). Hence, our introduced model reduces to a preferential attachment model but without the growth of N. For small b, analytical solutions of P(k) and P(η) can be found [Eqs. (6) and (7)].
-
3.
In the nature-nurture crossover, i.e., when both the bias b and the power-law exponent α are finite, it is possible to derive an approximate solution by the following ansatz,
$$\mathop{\sum }\limits_{i=1}^{N}{\omega }_{i}{k}_{i}\, \approx \, \chi \bar{\omega }T.$$(19)This is to explicate the time dependence of Π(ω, k) [Eq. (1)], by assuming that its denominator increases linearly with time T. Such a linear approximation is exact in the nurture-only limit (where χ = 2), but we observe that the linear approximation still holds even when taking the nature factor into account, as long as the variance of ω is not too great. Since higher ωi correlates with higher expectation of ki, we expect the following inequality,
$$\mathop{\sum }\limits_{i=1}^{N}{\omega }_{i}{k}_{i}\ge \mathop{\sum }\limits_{i=1}^{N}\bar{\omega }{k}_{i}\ge 2\bar{\omega }T,\,$$(20)which implies χ ≥ 2. The more variability there is in the distribution of ω, the larger χ is. To proceed, we employ numerical simulations to fix the parameter χ. Specifically, given a set of model parameters \({\omega }_{\max }\), α, and b, we run simulations of the nature-nurture model and fit \(\mathop{\sum }\nolimits_{i=1}^{N}{\omega }_{i}{k}_{i}\) as a function of T, deriving the corresponding χ. The parameter χ is further put in Eq. (1) to solve for P(k) and P(η), which, in turn, are used to fit the model parameters \({\omega }_{\max }\), α, and b. This leads to a set of self-consistent equations which converge to an optimal (or locally optimal) fit. For small b, the final solutions of P(k) and P(η) are similar to the nurture-only case, integrated over all possible ωi and ωj, given by
$$\begin{array}{r}P(k)\simeq \int\nolimits_{1}^{{\omega }_{\max }}d{\omega }_{i}c{\omega }_{i}^{-\alpha }{e}^{-{B}_{i}k}{k}^{A-1}{B}_{i}^{A}/{{\Gamma }}(A),\, \end{array}$$(21)and
$$P(\eta )\simeq \int\nolimits_{1}^{{\omega }_{\max }}d{\omega }_{i}\int\nolimits_{1}^{{\omega }_{\max }}d{\omega }_{j}c{\omega }_{i}^{-\alpha }c{\omega }_{j}^{-\alpha }\\ 2{B}_{i}^{A+1}{B}_{j}^{A+1}{\eta }^{A}{E}_{-2A-1}({B}_{j}+\eta {B}_{i})/{{\Gamma }}{(A+1)}^{2},\,$$(22)where A = b and \({B}_{i}={\left(b{\chi }^{-1}N{T}^{-1}\right)}^{2{\chi }^{-1}{\omega }_{i}{\bar{\omega }}^{-1}}\), respectively. The analytical results agree with simulation results (Supplementary Fig. 1).
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The processed data used in this study are available in the Colorado Index of Complex Networks (ICON) database [https://icon.colorado.edu].
Code availability
Custom code that supports the findings of this study is available at https://github.com/bnzu/nnne.
References
Jennings, H. Structure of leadership: development and sphere of influence. Sociometry 1, 99–147 (1937).
Price, D. J. S. A general theory of bibliometric and other cumulative advantage processes. J. Am. Soc. Inf. Sci. 27, 292–306 (1976).
Newman, M. E. J. Networks: An Introduction (Oxford University Press, 2010).
Dorogovtsev, S. N., Goltsev, A. V. & Mendes, J. F. F. Critical phenomena in complex networks. Rev. Mod. Phys. 80, 1275–1335 (2008).
Song, C., Havlin, S. & Makse, H. A. Self-similarity of complex networks. Nature 433, 392–395 (2005).
Radicchi, F., Ramasco, J. J., Barrat, A. & Fortunato, S. Complex networks renormalization: flows and fixed points. Phys. Rev. Lett. 101, 148701 (2008).
Zeng, A. et al. The science of science: from the perspective of complex systems. Phys. Rep. 714, 1–73 (2017).
Aiello, W., Chung, F. & Lu, L. A random graph model for power law graphs. Exp. Math. 10, 53–66 (2001).
Newman, M. E. J. Power laws, Pareto distributions and Zipf’s law. Contemp. Phys. 46, 323–351 (2005).
Krapivsky, P. L., Rodgers, G. J. & Redner, S. Degree distributions of growing networks. Phys. Rev. Lett. 86, 5401–5404 (2001).
Oikonomou, P. & Cluzel, P. Effects of topology on network evolution. Nat. Phys. 2, 532–536 (2006).
Voitalov, I., van der Hoorn, P., van der Hofstad, R. & Krioukov, D. Scale-free networks well done. Phys. Rev. Research 1, 033034 (2019).
Barabási, A.-L. & Albert, R. Emergence of scaling in random networks. Science 286, 509–512 (1999).
Broido, A. D. & Clauset, A. Scale-free networks are rare. Nat. Commun. 10, 1017 (2019).
Artico, I., Smolyarenko, I., Vinciotti, V. & Wit, E. How rare are power-law networks really? Proc. R. Soc. A 476, 20190742 (2020).
Holme, P. Rare and everywhere: perspectives on scale-free networks. Nat. Commun. 10, 1016 (2019).
Zhou, B., Meng, X. & Stanley, H. E. Power-law distribution of degree–degree distance: a better representation of the scale-free property of complex networks. Proc. Natl. Acad. Sci. USA 117, 14812–14818 (2020).
Serafino, M. et al. True scale-free networks hidden by finite size effects. Proc. Natl. Acad. Sci. USA 118, e2013825118 (2021).
Gjoka, M., Kurant, M., Butts, C. T. & Markopoulou, A. Walking in Facebook: a case study of unbiased sampling of OSNs. In 2010 Proc. IEEE Infocom 1–9 (IEEE, 2010).
Myers, S. A., Sharma, A., Gupta, P. & Lin, J. Information network or social network? the structure of the Twitter follow graph. In Proc. 23rd International Conference on World Wide Web 493–498 (Association for Computing Machinery, 2014).
Chen, Q., Chang, H., Govindan, R. & Jamin, S. The origin of power laws in Internet topologies revisited. In Proc. Twenty-first Annual Joint Conference of the IEEE Computer and Communications Societies, Vol. 2 608–617 (IEEE, 2002).
Dimitrov, D., Singer, P., Lemmerich, F. & Strohmaier, M. What makes a link successful on Wikipedia? In Proc. 26th International Conference on World Wide Web 917–926 (2017).
Eden, T., Jain, S., Pinar, A., Ron, D. & Seshadhri, C. Provable and practical approximations for the degree distribution using sublinear graph samples. In Proc. 2018 World Wide Web Conference 449–458 (Association for Computing Machinery, 2018).
Niu, J., Peng, J., Shu, L., Tong, C. & Liao, W. An empirical study of a Chinese online social network–Renren. Computer 46, 78–84 (2013).
Garcia, D., Mavrodiev, P. & Schweitzer, F. Social resilience in online communities: the autopsy of Friendster. In Proc. First ACM Conference on Online Social Networks 39–50 (Association for Computing Machinery, 2013).
Clauset, A., Tucker, E. & Sainz, M. The Colorado Index of Complex Networks. https://icon.colorado.edu (2016).
Caldarelli, G., Capocci, A., De Los Rios, P. & Muñoz, M. A. Scale-free networks from varying vertex intrinsic fitness. Phys. Rev. Lett. 89, 258702 (2002).
Pagan, N., Mei, W., Li, C. & Dörfler, F. A meritocratic network formation model for the rise of social media influencers. Nat. Commun. 12, 6865 (2021).
Meng, X. & Zhou, B. Scale-free networks beyond power-law degree distribution. Chaos Solitons Fractals 176, 114173 (2023).
Bianconi, G. & Barabási, A.-L. Bose-Einstein condensation in complex networks. Phys. Rev. Lett. 86, 5632 (2001).
Merton, R. K. The Matthew effect in science: the reward and communication systems of science are considered. Science 159, 56–63 (1968).
Lee, E. & Holme, P. Social contagion with degree-dependent thresholds. Phys. Rev. E 96, 012315 (2017).
Krackhardt, D. & Porter, L. W. The snowball effect: turnover embedded in communication networks. J. Appl. Psych. 71, 50 (1986).
Evans, T. S. & Chen, B. Linking the network centrality measures closeness and degree. Commun. Phys. 5, 1–11 (2022).
Burnham, K. P., Anderson, D. R., Burnham, K. P. & Anderson, D. R. Practical Use of the Information-Theoretic Approach (Springer, 1998).
Galton, F. Hereditary talent and character. Macmillan’s Mag. 12, 318–327 (1865).
McCall, R. B. Nature-nurture and the two realms of development: a proposed integration with respect to mental development. Child Dev. 52, 1–12 (1981).
Plomin, R. Nature, nurture, and social development. Soc. Dev. 3, 37–53 (1994).
Ridley, M. & Pierpoint, G. Nature via Nurture: Genes, Experience, and What Makes us Human, Vol. 19 (HarperCollins, 2003).
Robinson, G. E. Beyond nature and nurture. Science 304, 397–399 (2004).
Longino, H. E. Studying Human Behavior (University of Chicago Press, 2013).
Eagly, A. H. & Wood, W. The nature–nurture debates: 25 years of challenges in understanding the psychology of gender. Perspect. Psychol. Sci. 8, 340–357 (2013).
Plomin, R., Shakeshaft, N. G., McMillan, A. & Trzaskowski, M. Nature, nurture, and expertise. Intelligence 45, 46–59 (2014).
Overgoor, J., Benson, A. & Ugander, J. Choosing to grow a graph: modeling network formation as discrete choice. In The World Wide Web Conference 1409–1420 (Association for Computing Machinery, 2019).
Acknowledgements
B.Z. was supported by the Startup Foundation for Introducing Talent of NUIST and the Qinglan Project of Jiangsu Universities. P.H. was supported by JSPS KAKENHI Grant Number JP 21H04595. Z.G. is supported by the National Natural Science Foundation of China with Grant Number 72371137. X.L. was supported by the National Nature Science Foundation of China with Grant Numbers 72025405, 72088101 and 72001211, and the Hunan Science and Technology Plan Project with Grant Number 2020TP1013.
Author information
Authors and Affiliations
Contributions
All authors contributed to the research. B.Z. and X.M. conceived the research, performed the experiments, and analyzed the data. Z.G., C.Z., and Y.H. cleaned the data. B.Z. and X.M. wrote the first draft of the manuscript. P.H. and X.L. reviewed and edited the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Jan Nagler and Nicolo Pagan for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhou, B., Holme, P., Gong, Z. et al. The nature and nurture of network evolution. Nat Commun 14, 7031 (2023). https://doi.org/10.1038/s41467-023-42856-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-023-42856-5
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
