
Abstract
Multi-terminal memristor and memtransistor (MT-MEMs) has successfully performed complex functions of heterosynaptic plasticity in synapse. However, theses MT-MEMs lack the ability to emulate membrane potential of neuron in multiple neuronal connections. Here, we demonstrate multi-neuron connection using a multi-terminal floating-gate memristor (MT-FGMEM). The variable Fermi level (EF) in graphene allows charging and discharging of MT-FGMEM using horizontally distant multiple electrodes. Our MT-FGMEM demonstrates high on/off ratio over 105 at 1000 s retention about ~10,000 times higher than other MT-MEMs. The linear behavior between current (ID) and floating gate potential (VFG) in triode region of MT-FGMEM allows for accurate spike integration at the neuron membrane. The MT-FGMEM fully mimics the temporal and spatial summation of multi-neuron connections based on leaky-integrate-and-fire (LIF) functionality. Our artificial neuron (150 pJ) significantly reduces the energy consumption by 100,000 times compared to conventional neurons based on silicon integrated circuits (11.7 μJ). By integrating neurons and synapses using MT-FGMEMs, a spiking neurosynaptic training and classification of directional lines functioned in visual area one (V1) is successfully emulated based on neuron’s LIF and synapse’s spike-timing-dependent plasticity (STDP) functions. Simulation of unsupervised learning based on our artificial neuron and synapse achieves a learning accuracy of 83.08% on the unlabeled MNIST handwritten dataset.
Similar content being viewed by others
Introduction
Artificial intelligence and neural network algorithms form the core of future technology and are increasingly important in perception and learning tasks. Recently, analog memory devices––i.e., “memristors (memory + resistor),” including resistive memory (ReM)1,2,3,4, phase change memory (PCM)5,6, and floating-gate memory (FGM)7,8,9,10,11,12,13 have been proposed to realize functionalities of neurons and synapses. Neuromorphic research using such memristors is mainly categorized into two fields, supervised learning and unsupervised learning. In supervised learning, the memristors are used for multi-level memories, and software processes sigmoid/hyperbolic-tangent at forward-propagation and differential weight at back-propagation computing11,12,13,14. Supervised learning exhibits high accuracy because its performance depends on the labeled data. In the unsupervised learning, the memristors fully mimic the learning rules of biological neurons and synapses in the brain, such as LIF of neurons and STDP of synapses14,15,16,17,18,19,20, allowing data to be learned without labels. This is a strong advantage that can learn unidentified data including most of the natural data. Ultimately, the system itself can learn and analyze things without human intervention.
Two-terminal memristors have demonstrated neuron functions for unsupervised learning. The PCM and Mott memristor implement partial LIF, such as the integrate function by PCM conductance change21 and fire function by interaction between two Mott memristors22. The full LIF function was demonstrated by a capacitive neural network23, where the capacitor and volatile (diffusive) memristor perform the functions of charge integration and leaky fire, respectively. However, insufficient nodes of memristors24 (two nodes: source and drain) and memtransistors24,25,26,27,28 (three nodes: source, drain and gate) failed the entire implementation of multi-connections between numerous neurons in the human brain. Recently, MT-MEMs are demonstrated using polycrystalline transition metal dichalcogenides (TMDs) by increasing the terminals from two to six29, and 2H–1 T′ phase transitions of MoS2 with five terminals30. The MT-MEMs successfully performed complex functions of heterosynaptic plasticity of synapse by controlling the multiple channel conductance using a single drain electrode. However, current MT-MEMs cannot be implemented to multi-connected artificial neurons because they have no capacitor that can charge or discharge electrical potential like the membrane of a neuron.
In this study, we demonstrate the multi-connected artificial neurons using a multi-terminal floating gate memristor (MT-FGMEM) by increasing the terminals from two7,8,9,10 and three11,12,13 to five (single cell) and nine (neurosynaptic network). The unique property of metallic graphene, which can shift the Fermi level (EF)31,32, provides additional band bending in the graphene/insulator/metal heterostructures; therefore, horizontally distant multiple electrodes can charge and discharge the shared graphene FG. Our MT-FGMEM shows an ideally linear conductance change to the voltage spikes (nonlinearity factor β = 0) because of the triode operation in the memristor, allowing linear weight change at the synapse and accurate spike integrate at the neuron membrane. The configuration of the multi-electrode MT-FGMEM and comparator emulates the temporal and spatial summation based on LIF functionality of multiple neuronal connections. The assembly of 9 × 3 neuron and synapse array successfully demonstrates spiking neurosynaptic network (SNN) for training and classification of directional lines functioned in visual area one (V1). At the simulation of unsupervised learning, our artificial neuron and synapse achieve an ideal learning accuracy of 83.08 % on no labeled input data.
Results and discussion
Electrical performance of multi-terminal floating gate memristor
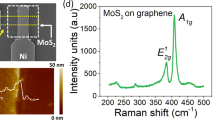
A schematic and an optical image of our MT-FGMEM are illustrated in Fig. 1a and b, respectively (other devices are shown in Supplementary Fig. S1). Fabrication details are shown in method and Supplementary Fig. S2. Our MT-FGMEM is formed of a van der Waals heterostructures (vdWHs) of 2D layers: monolayer MoS2 as a semiconductor channel, 5.5 nm h-BN as a tunneling insulator layer, and monolayer graphene as a FG (Fig. 1c and Supplementary Fig. S3). Five metal electrodes (V1, V2, V3, V4, and V5) are formed onto the MoS2. Typical memristive current–voltage (I–V) characteristics and FG potential profile of MT-FGMEM between the V1 and V2 electrodes are shown in Supplementary Fig. S4. It is noted that the memristive behavior is largely observed at the graphene MT-FGMEM, while the metal MT-FGMEM shows a small memristive memory window (Supplementary Fig. S5a). This is because the positive (negative) charges in graphene FG attracted by the negative (positive) drain bias shift the EF of graphene downward (upward), resulting in higher band bending at h-BN than fixed EF metal FG (Supplementary Fig. S5b, d). Although the on/off ratio of metal FGMEM can be increased from 5 to 100 by applying gate voltage (Vg = −10 V) to shift memory window into high transconductance region of the MoS2 channel32 (memtransistor behavior), it is still significantly lower than 108 on/off ratio of graphene-FG. Furthermore, graphene-FGMEM also operates as memtransistor, enhancing the on/off ratio to 109 by applying Vg = −40 V (Supplementary Fig. S5c).

a, b Schematic and optical images of the MT-FGMEM comprises monolayer MoS2/h-BN/graphene heterostructures as a semiconducting channel, a tunneling insulator, and a floating gate, respectively. Multiple electrodes V1, V2, V3, V4, and V5 are located on MoS2. VFG is connected to graphene to measure the FG potential. Scale bar is 10 µm. c Cross-sectional schematics, and operation principle of MT-FGMEM. d Electrical behaviors of V4-V5 channel before (dashed line) and after charging shared graphene floating gate by V1 (black line), V2 (red line) and V3 (blue line).
Our new structural concept, multiple electrodes, and multiple channels on a shared FG, allows controlling the conductance of channels by multi-electrode charging and discharging of a FG (Fig. 1c). By applying a positive (negative) voltage at the V1 ~ V5 electrode, hole (electron) charges tunnel from electrode to FG and then diffuse through the whole graphene layer. The hole (electron) charges at the graphene layer generate a positive (negative) gate field, indicating an increasing (decreasing) the conductance of all MoS2 channels on the shared graphene FG. Figure 1d shows the current changes in MoS2 channel (V4-V5) after applying +6 V at V1 (black line), V2 (red line) and V3 (blue line) electrodes. The current levels of MoS2 channel are changed from initial OFF-state (10−11 A) to ON-state (10−6–10−5 A). More explains are shown in Supplementary Fig. S6a, b (current change of V4–V5 channel by V1 = 4 V, V2 = 5 V and V3 = 6 V spikes) and Supplementary Fig. S7 (energy band diagrams of V1 ~ V3/h-BN/graphene FG/h-BN/V5(S) and V4/MoS2/V5(S)). This unique characteristic of our MT-FGMEM allows a multi-connection neuron, which will be discussed later.
Figure 2 shows the voltage-spike-based multi-level memory behavior in our MT-FGMEM. We initially apply continuous −6 V on the V1 electrode until the FG is fully charged by negative electrons; therefore, the negative FG voltage shifts the MoS2 conduction band upward (Fig. 2a-i). As a result, the electron carriers at the source are completely blocked by the MoS2 energy barrier at the reading bias (Vds = 10 mV). By applying a 6 V spike (0.01 s) on the V2 electrode, a certain number of positive holes are tunneled from V2 to FG (Fig. 2a-ii). The trapped holes generate a positive FG voltage, reducing the MoS2 channel barrier height by downshifting the MoS2 conduction band (Fig. 2a-ii, bottom image). At the reading bias (Vds = 10 mV), a few electrons can cross the slightly lowered MoS2 energy barrier. By applying additional sequential 6 V spikes to the V2 electrode (Fig. 2a-iii-iv), the number of positive holes in FG gradually increases, while the corresponding MoS2 energy barrier height gradually decreases. As a result, the number of electrons across the MoS2 barrier also increases stepwise with the number of spikes.

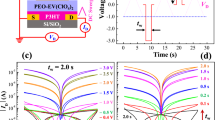
a Schematics of operation of spike-based multilevel memory in MT-FGMEM. (i) Full erasing by continuous negative bias on V1, (ii–iv) programming by positive-spike voltage on V2. Energy band diagram of the MoS2 channel between V2-S. b Typical electrical multilevel behavior of MT-FGMEM under the sequential spikes. Spikes (6 V, 0.1 s) are applied between V2-S electrodes (top panel-navy line), and FG potential (VFG, middle panel-olive line) and MoS2 channel current (Ids, bottom panel-orange line) are measured simultaneously. c Spike amplitude (Va) dependency on multilevel behavior. d Spike duration (tW) dependency on multilevel behavior. e Retention of multilevel in MT-FGMEM. f, g Multilevel potentiation, and depression of MT-FGMEM under 50 sequential spikes. h Representative current at each of the 50 levels in f and g. i Transfer characteristics of same device under gate voltage application on graphene. The dashed line indicates the theoretical simulation of the triode region in FET.
Figure 2b shows the experimental results of the multi-level memristive behavior of our MT-FGMEM under sequential voltage spikes. At each 6 V spike, the FG potential (VFG) and memristor current (Ids) are increased stepwise. The step size of each level can be controlled by modifying the spike amplitude (Va in Fig. 2c) and duration (tW in Fig. 2d). The step size shows an exponential relation with Va and tW (insets of Fig. 2c, d). It is noted that the capacitance (C) and charges (Q) of FG are calculated to C = 1.3 pF, Q = 66.5 fC by \(C=\frac{{\varepsilon }_{r}{\varepsilon }_{0}A}{d}=\frac{Q}{V}\), where \({\varepsilon }_{r}\) is relative permittivity of h-BN, \({\varepsilon }_{0}\) is absolute permittivity, A is area of MT-FGMEM, d is thickness of h-BN (7 nm) and V is voltage across the capacitor (ΔVFG = 0.05 V at each spike in Fig. 2b). The charging energy (E = QV) at each spike is 3.3 fJ. With effective charge trapping in the graphene FG, multi-current levels maintain stably over 1000 s with high on/off ratio over 105 (Fig. 2e), which is about ~10,000 times higher than other MT-MEMs29,30 at the same 1000 s retention. Our FGMEM also shows good stability in 10,000 s retention (Supplementary Fig. S8) and 10,000 cycles 2-level endurance and 2000 spikes multi-level endurance.
Figure 2f, g shows real-time measurement of 50 levels potentiation and depression, respectively. The reading voltage (Vds = 10 mV) is applied between the voltage spikes to measure the current through the MoS2 channel. The representative current at each level is plotted in Fig. 2h and fitted to synaptic conductance (G) equation:20
where the parameters α and β indicate the conductance change amount and nonlinearity, respectively. The potentiation of MT-FGMEM shows ideal linearity (β = 0 in Supplementary Fig. S9a). Ideal linearity of synapses promotes learning accuracy in neural network33. Our MT-FGMEM exhibits the best linearity among MT-MEMs (β = 429, 630 in Supplementary Table S1), implying that our MT-FGMEM is the most suitable device for multi-connected artificial neuron.
To investigate the high linearity of our MT-FGMEM, we measure the transfer characteristics of the MoS2/h-BN/graphene heterostructure by applying a gate voltage to the graphene electrode and measuring the current on the MoS2 channel (Fig. 2i). The current increases (decreases) linearly with the gate voltage (VG) at VG above the threshold voltage (VG > Vt = −0.3 V). There are two distinct current equations for a field-effect transistor (FET) depending on the drain voltage (VDS) and VG. In the triode region (VDS < VG − Vt), the FET current is expressed as \({I}_{D}=\mu {C}_{{{{{{\rm{ox}}}}}}}\frac{W}{L}\big[\left({V}_{G}-{V}_{t}\right){V}_{{{{{{\rm{DS}}}}}}}-\frac{1}{2}{{V}_{{{{{{\rm{DS}}}}}}}}^{2}\big]\), where \(\mu\), \({C}_{{{{{{\rm{ox}}}}}}}\), W, and L indicate the mobility, capacitance of the gate oxide, channel width, and channel length, respectively. In this region, the current (ID) linearly increases with VG at a fixed VDS (ID ∝ VG). In contrast, the FET current in the saturation region (VDS > VG − Vt) is expressed as \({I}_{D}=\mu {C}_{{{{{{\rm{ox}}}}}}}\frac{W}{2L}{\left({V}_{G}-{V}_{t}\right)}^{2}\). The current (ID) in this saturation region shows a parabolic increase with VG (ID ∝ VG2). In our device, VG, VDS, and Vt have values of −1 to 3 V, 0.01 V, and −0.3 V, respectively. Therefore, the triode (linear) and saturation (parabolic) regions are VG = −0.29 to 3 V (VG > VDS + Vt) and −1 to −0.29 V (VG < VDS + Vt), respectively. The measured current (blue and red circles) and theoretical current (black dashed line) clearly match in Fig. 2i. By using the triode region, where VG > VDS + Vt, the linear behavior between ID and VG can be obtained. The spike dependency of our MT-FGMEM also follows the trend of transfer behavior of the MoS2 transistor. A regular amount of charge constantly occurs at the FG through sequential spikes, resulting in a linear change in the FG potential. In the saturation region (0–7 spikes), a parabolic increase in current is observed along the number of spikes, while a linear increase is observed at 8–50 spikes in the triode region (Fig. 2h). The measured current (blue and red circles) clearly matches the theoretical transfer curve of the MoS2 transistor (black dashed line) shown in Fig. 2h. It is noted that the high linearity of MT-FGMEM is used for accurate spike integration in neuron’s membrane potential (Fig. 3) and linear synaptic weight changes between a pre- and post-neurons (Fig. 4). It also be noted that Fig. 2 shows multi-level behavior MT-FGMEM under series of single-spike application. The multi-level behavior of synapse between a pre- and post-spike is shown in Fig. 4.

a Illustration of five connections in biological neurons. Pre-spikes of pre-neurons (V1, V2, V3, and V4) are integrated at the membrane potential of post-neuron (VFG), and then generate post-spikes (Vp). b Membrane potential for typical neuronal spike process. c Schematics of ion movement through the membrane gates at (i) EPSP, (ii) IPSP, (iii) depolarization, and (iv) repolarization. d Schematics of five connections in artificial neurons formed of multi-terminal FG and comparator configuration. Pre-spikes (V1, V2, V3, and V4) are integrated at the FG potential (VFG), and then generate post-spike (Vp). e FG potential for neuronal spike process. f Schematics of FG charging and discharging at (i) EPSP, (ii) IPSP, (iii) depolarization, and (iv) repolarization. g Retention behavior of 7 nm h-BN (left panel) and 4 nm h-BN (right panel). h Schematics of temporal summation in biological neurons. i Temporal summation LIF process of MT-FGMEM and comparator configuration. j Schematics of spatial summation in biological neurons. k Spatial summation LIF process of MT-FGMEM and comparator configuration.

a Schematics of basic synapse-neuron assembly for unsupervised learning process by synaptic STDP and neuronal LIF functions. b, c STDP by correlation between pre-spike and post-spike. Only potentiation is used for our unsupervised learning simulation. d STDP based spike current change along the time difference between pre-spike and post-spike. e The unsupervised STDP weight change along the epoch (post-spike generation) in synapse (MT-FGMEM) and neuron (FG-com) unit cell. With (Δt ~ 0 s) or without feedback (Δt ~ \({{{{{\rm{\infty }}}}}}\)) of post-spike is controlled by connect and disconnect of feedback line, respectively.
Artificial neuron using MT-FGMEM and comparator configuration
Figure 3a shows a typical multi-connection of neurons where the central neuron (post-neuron) is connected to four pre-neurons. Figure 3b, c shows the neuron functions based on their membrane potential. The series of neuron processes are called LIF functions (details are shown in method)34. We demonstrated LIF function based on multi-connection neurons by using 5 terminals MT-FGMEM integrated with a comparator (Fig. 3d–f, and Supplementary Fig. S10). The FG-potential (VFG) emulates the temporal integration of pre-synaptic spikes by charge tunneling and trapping (Integration). As shown in Fig. 3e, f, VFG increases with positive spikes from V1, V2, and V4 ((i) in Fig. 3e, f) and decreases with negative spike from V3 ((ii) in Fig. 3e, f). The neuron threshold is emulated by applying a threshold voltage (Vth) to the reference electrode of the comparator. The FG is connected to the input electrode of the comparator to compare the VFG with Vth. The output voltage of the comparator (Vout) is 0.01 V (VCC in Supplementary Fig. S10) while the VFG is below Vth (Fig. 3e). Once the VFG exceeds Vth (>0 V) by signal integration ((iii) in Fig. 3e, f), the Vout of the comparator abruptly switches from VCC (0.01 V) to VEE (−7 V). The negative VEE is fed back to the V5 electrode on FG (Fig. 3d), releasing the FG potential to the initial state (−1.2 V). By reducing the VFG below Vth (<0 V), the Vout of the comparator returns to VCC ((iv) in Fig. 3e, f). These series of processes generate a post-spike (Fire). A highly reliable LIF profile is also observed in other FG-com neurons (Supplementary Fig. S11). The number of integrated spikes until the VFG exceeds Vth can be increased by adjusting the Va or tW of the spikes (Supplementary Fig. S11b). It is noted that the refractory period in our artificial neuron is about 1 μs, a propagation delay of comparator.
The leaky profile of the neuron membrane is an important process for naturally initializing the neuronal system without any external force. We emulate the neuronal leaky profile by decreasing the h-BN thickness. At a 7-nm-thick h-BN layer (left panel in Fig. 3g), once the charges are trapped at the FG, they cannot be released because the h-BN layer is thick enough to block the charge re-tunneling. Therefore, VFG shows a stepwise increase with the number of spikes. In contrast, the 4-nm-thick h-BN layer (right panel in Fig. 3g) is thin enough to tunnel out the trapped charges; therefore, the FG potential exponentially reduces over time by releasing the trapped charges. The leakage profile of charges in the FG is similar to the leakage of Na+ in the neuron membrane, allowing the imitation of the neuronal leaky process. The signal integration in this leaky FG can be performed by applying a series of spikes in a short period before the trap charges are fully released (Leaky-Integrate).
Figure 3h–k shows complete emulation of the neuron’s LIF process using our leaky-FG and comparator configuration: Fig. 3h, i for a temporal summation and Fig. 3j, k for a spatial summation. Temporal summation is the summing spikes generated by single pre-neuron at short intervals. Spatial summation is the summing spikes generated simultaneously by many different pre-neurons. At the temporal summation (Fig. 3h, i), a series of spikes with short intervals (0.1 s) are applied from single pre-neuron to neuron-FG for the integration process, which is initialized by separating each spike series with a long interval time (2.5 s). The maximum VFG gradually increases with the number of spikes in series, and finally, exceeds the Vth at five-series spikes (>0.7 V). Then, a post-spike (Vout) is generated using the same rule as that shown in Fig. 3e, f; these series of processes function as neuronal LIF. It is noted that the leaky profile of floating gate follows capacitor discharge (Supplementary Fig. S12). At the spatial summation (Fig. 3j, k), synchronized spikes from three different input neurons are applied to neuronal FG with a long interval time (0.5 s) between the spikes for leaky initialization. With increase the number of synchronized spikes, the maximum VFG gradually increases and exceeds the Vth at three synchronized spikes (>1 V). Then, a post-spike (Vout) is generated using the same rule as that shown in Fig. 3e, f. Spatial summation was performed using neurosynaptic network in Fig. 5. In nature, neuron performs LIF based on receiving unsynchronized spikes from multiple pre-neurons; described as stochastic spike arrival21,34. In real biological spiking neural network (SNN), temporal and spatial summation function simultaneously due to the unsynchronized spike timing. In our artificial SNN (Fig. 5), however, learning can function only with spatial summation due to the synchronized input spikes. Note that our MT-FGMEM based artificial neuron shows similar firing energy consumptions (250 pJ, Supplementary Fig. S13) with conventional neuron based on silicon integrated circuit (Si-IC, 286 pJ)19, while integration energy consumption dramatically reduces from 11.7 μJ (Si-IC) to 150 pJ (MT-FGMEM). The energy consumption of our artificial neuron is calculated by Δ(Vpre − Vpost) \(\times\) tW \(\times\) Ipost35. The energy consumption can be further lowered by reducing spike amplitude Δ(Vpre − Vpost) and duration (tW) with improved tunneling insulator properties, or reducing Ipost by increasing channel resistance.

a, b Optical images of neurosynaptic array with neuron-FG and synapse. c Monitoring the responses of orientation-selective neurons in visual cortex V1 to various directional stimuli. d 3 × 3 binary input images that represent the directions |, –, \ and circuit schematic of 3 output neurons, each with 9 synapses. e–g Real-time synaptic weight changes under 40 sequential input spikes (epoch). h–j Pattern classification by evolution of synapse conductance along the training epoch.
Spiking neurosynaptic single cell
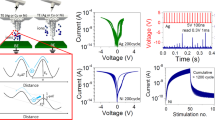
Figure 4 shows the learning in neurosynaptic single cell by synapse STDP and neuron LIF functions. In Fig. 4a–b, the functionality of the proposed neuron and synapse is measured in a neural unit circuit where the synapse is connected with the output post-neuron. It mimics a biological neural unit (Fig. 4a), where the synapse receives input spikes from the pre-neuron and propagates to the post-neuron according to their synaptic strength (Weighting). The post-neuron generates output spikes based on LIF. The synapse strength is then modulated according to the relative timing of the pre- and post-spikes, called STDP36. In our neural unit circuit, the input spike (Vpre) is applied between VS2 and VS3 of the synapse and converted into current (Imem = Vpre × G) according to the MoS2 conductance (G, Weighting, Supplementary Fig. S14). Imem flows to VN1 and charges the neuron-FG (n-FG) (Integration). We apply Vpre = 3.5 V, which is weak for tunneling electrons to 7 nm h-BN in synapse-FG (s-FG) but strong enough for tunneling electrons to 4 nm h-BN in n-FG. Once the integration potential in n-FG exceeds Vth, the output voltage of the comparator switches from VCC (0.01 V) to VEE (Vpost = −2 V). Then, the negative Vo (-Vpost) is not only applied to n-FG (VN2) to initialize the membrane potential (or for the winner-take-all (WTA) function) but also to s-FG (VS1) to update the synaptic weight according to the STDP rule.
Figure 4b and 4c shows the typical STDP behavior of our synapse. Vpre = 3.5 V and Vpost = −2 V spikes are applied at VS1 and VS2, respectively, for charging of s-FG. After the spiking, Vpre = 10 mV is applied between VS2 and VS3 to measure Imem. Vnet is the relative voltage between Vpre and Vpost at VS2. At a long timing difference (Fig. 4b), the separately applied Vpre and Vpost spikes generate a low Vnet (<3.5 V), causing no tunneling to s-FG and no change in Imem. In contrast, at a short timing difference (Fig. 4c), Vpre and Vpost spikes overlap and generate a high Vnet = 5.5 V, causing charge tunneling to s-FG. Positively charged s-FG increases the G of the MoS2 channel, increasing the Imem. The change in synaptic weight (G of MoS2) gradually increases with a decrease in the timing difference between Vpre and Vpost because an increase in Vnet width charges more carriers to s-FG (Fig. 4d and Supplementary Fig. S15).
The evolution of synapse’s weight in neurosynaptic single cell by synapse STDP and neuron LIF functions is shown in Fig. 4e. The synaptic weight (normalized Imem) is plotted along the number of Vpost spikes generated (epoch). At each Vpost spike generation (epoch), the synaptic weight is gradually increased by STDP of Vpre and Vpost feedback (Δt ~ 0 s, red dots in Fig. 4e). In contrast, with no Vpost feedback (disconnected feedback line), the synaptic weight shows no change because of no overlapping of Vpre and Vpost (Δt ~ \({{{{{\rm{\infty }}}}}}\), blue dots in Fig. 4e). The STDP learning in neuron-synaptic integration cell is the crucial element to demonstrate unsupervised learning.
Realization of spiking neurosynaptic network
The brain’s visual system is organized into a hierarchical structure of areas:37 visual area one (V1) initially perceives a line orientation in the small localized visual field (Fig. 5a)38, then inferotemporal visual cortex (V2 and V4) perceives increasingly larger and more complex object based on the V1 results obtained from several locals of visual field. Here, we experimentally emulate early-stage training and classification of V1 using our SNN. Figure 5 shows the experimental implementation of proposed SNN, consisting of 3 neurons with 9 synapses each, for training and classification of 3 × 3 binary image. Figure 5b-c shows optical image of our SNN. For large scale integration, monolayer MoS2 and monolayer graphene grown by chemical vapor deposition (CVD) are used as channel and floating gate, respectively, and Al2O3 grown by atomic layer deposition (ALD) is used as tunneling insulator (8 nm for synapse and 4 nm for neuron). Our artificial neurons show reliable spatial summation based on LIF function (Supplementary Figure S16). More details of fabrication are explained in method section. It is noted that the elongation RC delay (0.5 ps/μm2 in monolayer graphene39) of graphene FG by increasing the array size is negligible at our measurement rate (~ms).
Figure 5d shows circuit schematic of our SNN. It is noted that the training and recognition of line orientation is performed in collaboration between photoreceptors and visual area one (V1). At the beginning of training, the photoreceptors transform the light-signal to spike-signal. Based on spike-signals from photoreceptor array, the V1 trains and recognizes the line orientation by SNN training rule. In our experiment, we applied electrical spikes (3 V and 50 ms) instead of photoreceptor’s light to spike transform. In more precisely, the photoreceptor transforms edge-signal to spike-signal by using on-center-off-surround structure, but it is not considered in our SNN because our work focused on visual area one. At the training process, 40 sequential input spikes (3 V and 50 ms) of 3 × 3 binary image (vertical ‘|’, parallel ‘–’ and orthogonal ‘\’) are applied to input electrodes (V1 ~ V9). Three directional lines are selectively trained on three neurons (N1, N2 and N3) by controlling Vth of each neuron (Vth = 1 V for training neuron and Vth = 1.5 V for untraining neuron). The example of training vertical line ‘|’ on N1 neuron is shown in supplementary Figure S17. During training vertical line ‘|’ (Fig. 5e), the selected N1 neuron generates output spikes (Vo = −2 V), and then synapses W4-6 are weighted by large net voltage (Vnet = 5 V) with overlapping pre- (Vin) and post-spikes (Vo), while other synapses retain their weight due to small net voltage (Vnet = 2 V) only with post-spikes (Vo). It is noted that synaptic weight changes are observed when input and feedback spikes are applied together, while negligible weight changes are observed when input or feedback spikes are applied alone (Supplementary Figure S18). In the same way, the synapses of N2 (Fig. 5f) and N3 neurons (Fig. 5g) are weighted with parallel ‘–’ and orthogonal ‘\’ lines, respectively. At the classification process, feedback line is connected to an ammeter (Fig. 5d) to measure the conductance of 9 synapses of each neuron at the input voltages of the three binary images. The synapse conductance for the trained direction is clearly distinct from other untrained directions (Fig. 5h-j). Furthermore, the conductance difference between trained direction and other untrained directions increases as the number of epoch increases.
It is noted that learning algorithm of our current platform is supervised learning, where the selection of learning neuron is selected by controlling threshold voltage (Figure S17), Vth = 1 V for selected neuron and 1.5 V for unselected neuron. The fully unsupervised learning algorithm can be achieved by demonstrating the homeostatic plasticity of neuron - slight increase of Vth of firing neuron - as demonstrated in unsupervised learning SNN simulation (Fig. 6).

a Schematics of neuron (FG-com) and synapse (MT-FGMEM) array for unsupervised learning simulation of MNIST data sets without labels. b Accuracy variation along the nonlinearity factor (β) and the number of post-neurons. c Conductance potentiation of synapse along the number of spikes at different nonlinearity factors (β = 0 ~ 10). d Visualized synaptic conductance after 60,000 MNIST (no labels) training. The number of post-neurons is 10 (top panel) and 30 (bottom panel). e The number of neuronal fires in 10, 20, 30 and 100 post-neurons for the test label.
Spiking neurosynaptic network simulation based on MT-FGMEM
We estimated the unsupervised-learning-accuracy of our MT-FGMEM based SNN from the SNN simulation using MNIST date sets with no labels (Fig. 6). The learning mechanism in this SNN simulation is similar to experimental SNN in Fig. 5. In the schematics of the simulation (Fig. 6a), 784 pre-neurons (rows) and n-FGs of 10–100 post-neurons (columns) are connected by the MT-FGMEM synapse. The system self-learns MNIST handwritten datasets without labels by using functionalities of the synapse’s STDP and neuron’s LIF and WTA lateral inhibition. The details of the simulation are provided in the Method section. Figure 6b shows the final accuracy of the MNIST test datasets at the various potentiation nonlinearities of the synapse (β = 0–10, Fig. 6c). The accuracy is highest at ideal linearity (β = 0) and gradually decreases as the nonlinearity increases (β > 0). Supplementary Fig. S19 shows the visualized synaptic weights. At the ideal linearity (β = 0), the boundary of the visualized digit is very clear, allowing an accurate classification of the MNIST test digits. However, the increasing nonlinearity blurs the boundaries of the visualized digit, resulting in an inaccurate classification of the ambiguous MNIST test digits.
We investigate the accuracy over the number of post-neurons. The accuracy of 10 post-neurons is as low as 47.88% (Fig. 6b). Because our system uses unlabeled MNIST training sets, learning only depends on the bright pixel position of the digit images. Therefore, the same digits with very different pixel positions can be classified into different digits in unsupervised learning. The top panel of Fig. 6d shows trained synaptic Gs (weights) with 10 post-neurons. The synaptic Gs at the 2nd and 10th neurons, or the 3rd and 5th neurons, are classified into different digits in the system, even though they appear in human vision as similar numbers of 0 or 3, respectively. These same digits, but different pixel positions, occupy neurons at the beginning of unsupervised leaning; therefore, the remaining digits (such as 2 or 5) suffer the lack of neurons and fail to occupy it. The lack of neurons can be overcome by introducing additional post-neurons. The bottom panel of Fig. 6d shows trained synaptic Gs (or weights) with 30 post-neurons. All digits from 0 to 9 are completely occupied by a sufficient number of post-neurons. Figure 6e shows the number of selected labels of the 10,000 MNIST test set by post-neurons. For 20–100 neurons, we combine selections of multiple neurons representing the same digit (Supplementary Fig. S20). At 10 post-neurons, no post-neuron represents digit 5, while the 5th and 7th post-neurons represent digit 7. Furthermore, each post-neuron chooses many other digits besides their own. At 20 post-neurons, the post-neurons evenly represent all 10 digits (0–9), but the 4th and 8th post-neurons are closer to digit 9 rather than their own digit. At 30 neurons, the neurons clearly classify all digits from 0 to 9. As a result, the accuracy is significantly improved from 47.88% to 68.08% with an increase in the number of post-neurons from 10 to 30 (inset of Fig. 6b). The accuracy still shows a gentle improvement over 30 post-neurons because additional post-neurons cooperate with the recognition of various handwriting shapes. The maximum accuracy is 83.08% at 100 post-neurons (Fig. 6b).
In conclusion, we mimic the unsupervised learning capability of the human brain by using artificial neurons and synapses based on the MT-FGMEMs. The shiftable graphene EF allows the multi-terminal modulation of a memristor using horizontally distant electrodes. The linear FG potential change along the input spikes in our MT-FGMEM allows successful emulation of the synaptic STDP with ideal linearity and neuronal LIF with accurate spike integration. In the realization of the spiking neurosynaptic network by integration of synapse-neuron array, our device successfully performed classification of directional lines functioned in visual area one (V1). Our artificial neurons and synapses showed unsupervised learning capabilities with high learning accuracy on unlabeled input data. This sheds light on the foundation for global artificial intelligence technology roadmap via the multi-terminal memristor in van der Waals heterostructures.
Methods
Fabrication of MT-FGMEM devices based on graphene/h-BN/MoS2 heterostructures
The graphene/h-BN/MoS2 stacks were fabricated using a bottom-up assembly method including multiple wet and dry transfers. First, monolayer graphene was synthesized using chemical vapor deposition (CVD) on a copper substrate. The graphene was then transferred onto a Si substrate with a 300-nm-thick SiO2 coating by the wet bubble transfer method using NaOH (0.1 M) solution. Next, we prepared poly (methyl methacrylate) (PMMA)/poly (vinyl alcohol) (PVA)/300 nm SiO2/Si substrates and separately exfoliated h-BN and MoS2 flakes onto them through mechanical exfoliation with a scotch tape. The exfoliated h-BN flakes with thicknesses in the range of 4–8 nm was selected by optical contrast for deposition on top of graphene. The h-BN thicknesses were further confirmed by AFM after electrical measurements. After PVA dissolution in hot water, the h-BN/PMMA film was detached from the substrate and floated on the water surface. We used a holder with a hole to pull out the h-BN/PMMA film and load it onto a micromanipulator in a reverse manner. Then, the desired h-BN flake was aligned with the target graphene on a 300 nm SiO2/Si substrate and held in contact for 15 min at 100 °C to ensure that the PMMA film was entirely isolated from the holder. A similar process was employed to transfer the MoS2 monolayer flake on top of h-BN. The electrodes were fabricated using a combination of e-beam lithography followed by the deposition of Cr/Au (10/50 nm). In the last step, all samples were annealed at 300 °C for 3 h in a H2/Ar atmosphere (H2/Ar ratio of 50/200 sccm) to reduce the contaminants and air bubbles at the heterointerfaces. The complete sequence of the entire fabrication, along with the optical microscope images, is illustrated in Supplementary Fig. S2.
Fabrication of neurosynaptic network array
Parallel electrodes were patterned by photolithography and followed by the deposition of Cr/Au (10/50 nm) by e-beam evaporator. 10 nm of Al2O3 was grown by atomic layer deposition (ALD) as a spacer between parallel and vertical electrodes. Monolayer graphene layer was transferred and patterned by O2 plasma as a synapse floating gate. 1 nm Al layer was deposited by e-beam evaporator and naturally oxidized, which used as seeding layer for ALD of 3 nm Al2O3 on graphene surface. Another monolayer graphene layer was transferred and patterned by O2 plasma as a neuron floating gate, and then seeding layer of 1 nm Al and 3 nm Al2O3 layer were deposited. Total thicknesses of tunneling layers are 8 nm for synapse FG and 4 nm for neuron FG. The CVD grown MoS2 layer was transferred and patterned by O2 plasma as a channel in synapse and load-resistance between synapse and ground. For the interconnection between parallel electrodes and vertical electrodes, Al2O3 layer in interconnection area was etched by reactive ion etcher (RIE) with SF6 gas. Finally, vertical electrodes and MoS2 contact electrodes are patterned by photolithography and followed by the deposition of Cr/Au (10/30 nm) by e-beam evaporator.
Device characterization
The AFM images of the samples were recorded using an SPA400 atomic force microscope (SEIKO). Raman spectra were measured using the Witec system (532 nm wavelength). Electrical transport measurements were performed with a probe station and source/measure units (Keithley 4200, Agilent B1500, and Agilent B2902a) and a commercial voltage comparator (595-TLC393cP, Texas Instruments). The neuron FG of neurosynaptic network array is connected to comparator on bread board. The output line of comparator is connected to feedback line of neurosynaptic network array. Orientation line information is applied to the input lines of the neurosynaptic network array with Vpre spikes (3 V and 50 ms) using Agilent B1500. The conductance change of synapses STDP rule is measured by Agilent B1500.
LIF function of neuron
The multiple spikes from the four pre-neurons are propagated to the post-neuron by ion transport through the synapse. The excitatory postsynaptic potential (EPSP) signal enhances the membrane potential by transporting Na+ ((i) in Fig. 3b, c), while the inhibitory postsynaptic potential (IPSP) signal reduces the membrane potential by transporting Cl- ((ii) in Fig. 3c). The transported ions in the post-neuron gradually leak out over time, and then, the membrane potential finally returns to the resting potential (Leaky). If several pre-synaptic spikes propagate to the post-neuron in a short period, temporal signal integration is performed at the membrane potential (Integration). Once the membrane potential exceeds the threshold potential (Vth) by signal integration, leading to a fast inward flow of Na+, there is a substantial increase in the membrane potential ((iii) in Fig. 3c). At the maximum membrane potential (action potential), the neuron inactivates the Na+ channels and opens the K+ channels, releasing the membrane potential to the resting state ((iv) in Fig. 3b, c). As a result, a post-spike is generated (Fire). After firing, neuron takes recovery time for one millisecond (refractory period).
Simulation of spiking neurosynaptic network
The G of the synapses (normalized to 0–1) are initially set to small random values between 1 × 10−5 and 1 × 10−4. Once the pre-spikes (Vpre) of 784 MNIST pixel data (converted to 0 or 1) are fed to the pre-neurons, Imem (Vpre × G) flow and are added to post-neuron membrane (n-FG) according to its synaptic strength (G). Because of the randomly set initial synaptic Gs, each post-neuron has a different n-FG potential (sum of 784 input Imem). Due to this n-FG difference, only a single post-neuron with highest n-FG out of 10–100 post-neurons generates a post-spike (Vpost) when its n-FG (sum of 784 input Imem) overcome Vth. The Vpost is fed to the winner-take-all (WTA) line to initialize the n-FGs of all post-neurons (lateral inhibition); therefore, other post-neurons are not able to generate additional spike, which is a reminiscent of the WTA topology. The Vpost is also fed to its own feedback line to potentiate the synapse G according to the STDP rule, where Vpre and Vpost overlap each other. The potentiation of synapse G is modeled by equation20 \(\triangle G=\alpha {e}^{-\beta \frac{G-{G}_{{{\min }}}}{{G}_{{{\max }}}-{G}_{{{\min }}}}}\). The Vth of firing neuron is slightly increased for homeostatic plasticity. We used 60,000 MNIST training sets (without labels) for unsupervised learning. At each MNIST image, 1000 sequential Vpre (0 or 1) are emitted to input pre-neurons. When MNIST image is changed after 1000 sequential Vpre, n-FG of all post-neurons are initialized. The network is then tested on 10,000 MNIST test sets that are not presented during training. The labels of these test sets are used to quantitatively evaluate the recognition rate.
Data availability
The data that support the findings of this study are provided within the main text and Supplementary Information. Additional data related to this study are available from the corresponding authors upon reasonable request.
Code availability
Codes can be available from the corresponding authors upon reasonable request.
References
Strukov, D. B., Snider, G. S., Stewart, D. R. & Williams, R. S. The missing memristor found. Nature 453, 80–83 (2008).
Prezioso, M. et al. Training and operation of an integrated neuromorphic network based on metal–oxide memristors. Nature 521, 61–64 (2015).
Yang, J. J., Strukov, D. B. & Stewart, D. R. Memristive devices for computing. Nat. Nanotechnol. 8, 13–24 (2013).
Waser, R., Dittmann, R., Staikov, C. & Szot, K. Redox-based resistive switching memories nanoionic mechanisms, prospects, and challenges. Adv. Mater. 21, 2632–2663 (2009).
Wuttig, M. & Yamada, N. Phase-change materials for rewriteable data storage. Nat. Mater. 6, 824–832 (2007).
Wong, H. S. P. et al. Phase change memory. Proc. IEEE 98, 2201–2227 (2010).
Vu, Q. A. et al. Two-terminal floating-gate memory with van der Waals heterostructures for ultrahigh on/off ratio. Nat. Commun. 7, 12725 (2016).
Vu, Q. A. et al. A high-on/off-ratio floating-gate memristor array on a flexible substrate via CVD-grown large-area 2d layer stacking. Adv. Mater. 29, 1–7 (2017).
Ziegler, M., Oberländer, M., Schroeder, D., Krautschneider, W. H. & Kohlstedt, H. Memristive operation mode of floating gate transistors: a two-terminal MemFlash-cell. Appl. Phys. Lett. 101, 263504 (2012).
Danial, L. et al. Two-terminal floating-gate transistors with a low-power memristive operation mode for analogue neuromorphic computing. Nat. Electron. 2, 596–605 (2019).
Fuller, E. J. et al. Parallel programming of an ionic floating-gate memory array for scalable neuromorphic computing. Science 364, 570–574 (2019).
Park, E. et al. A 2D material-based floating gate device with linear synaptic weight update. Nanoscale 12, 24503 (2020).
Agarwal, S. et al. Using floating-gate memory to train ideal accuracy neural networks. IEEE J. Exp. Solid State Comp. Dev. 5, 52–57 (2019).
Feldmann, J., Youngblood, N., Wright, C. D., Bhaskaran, H. & Pernice, W. H. P. All-optical spiking neurosynaptic networks with self-learning capabilities. Nature 569, 208–214 (2019).
Seo, J. S. et al. A 45nm CMOS neuromorphic chip with a scalable architecture for learning in networks of spiking neurons. In IEEE Custom Integrated Circuits Conference (CICC) (IEEE, 2011).
Davies, M. et al. A neuromorphic manycore processor with on-chip learning. IEEE Micro. 38, 82–99 (2018).
Milo, V., Malavena, G., Compagnoni, C. M. & Ielmini, D. Memristive and CMOS devices for neuromorphic computing. Materials 13, 166 (2020).
Jeong, D. S. & Hwang, C. S. Nonvolatile memory materials for neuromorphic intelligent machines. Adv. Mater. 30, 1–27 (2018).
Wu, X., Saxena, V. & Zhu, K. Homogeneous spiking neuromorphic system for real-world pattern recognition. IEEE J. Emerg. Sel. Top. Circuits Syst. 5, 254–266 (2015).
Querlioz, D., Bichler, O., Dollfus, P. & Gamrat, C. Immunity to device variations in a spiking neural network with memristive nanodevices. IEEE Trans. Nanotechnol. 12, 288–295 (2013).
Tuma, T., Pantazi, A., Gallo, M. L., Sebastian, A. & Eleftheriou, E. Stochastic phase-change neurons. Nat. Nanotechnol. 11, 693–699 (2016).
Duan, Q. et al. Spiking neurons with spatiotemporal dynamics and gain modulation for monolithically integrated memristive neural networks. Nat. Commun. 11, 3399 (2020).
Wang, Z. et al. Capacitive neural network with neuro-transistors. Nat. Commun. 9, 3208 (2018).
Zhu, J., Zhang, T., Yanga, Y. & Huang, R. A comprehensive review on emerging artificial neuromorphic devices. Appl. Phys. Rev. 7, 011312 (2020).
Sagar, S., Mohanan, K. U., Cho, S., Majewski, L. A. & Das, B. C. Emulation of synaptic functions with low voltage organic memtransistor for hardware oriented neuromorphic computing. Sci. Rep. 12, 3808 (2022).
Mukherjee, A., Sagar, S., Parveen, S. & Das, B. C. Superionic rubidium silver iodide gated low voltage synaptic transistor. Appl. Phys. Lett. 119, 253502 (2021).
Das, B. C. et al. Redox-gated three-terminal organic memory devices: effect of composition and environment on performance. ACS Appl. Mater. Interfaces 5, 11052–11058 (2013).
Lee, H. et al. Dual-gated MoS2 memtransistor crossbar array. Adv. Func. Mater. 30, 2003683 (2020).
Sangwan, V. K. et al. Multi-terminal memtransistors from polycrystalline monolayer molybdenum disulfide. Nature 554, 500–504 (2018).
Zhu, X., Li, D., Liang, X. & Lu, W. D. Ionic modulation and ionic coupling effects in MoS2 devices for neuromorphic computing. Nat. Mater. 18, 141–148 (2019).
Yu, Y.-J. et al. Tuning the graphene work function by electric field effect. Nano Lett. 9, 3430–3434 (2009).
He, C. et al. Artificial synapse based on van der Waals heterostructures with tunable synaptic functions for neuromorphic computing. ACS Appl. Mater. Interfaces 12, 11945–11954 (2020).
Yu, S. Neuro-inspired computing using resistive synaptic devices (Springer-Verlag, 2017).
Gerstner, W., Kistler, W. M., Naud, R. Paninski, L. Neuronal dynamics (Cambridge University Press, 2014).
Van De Burgt, Y. et al. A non-volatile organic electrochemical device as a low-voltage artificial synapse for neuromorphic computing. Nat. Mater. 16, 414–418 (2017).
Yu, H. et al. Evolution of bio‐inspired artificial synapses: materials, structures, and mechanisms. Small 17, 2000041 (2021).
Bear, M.F., Connors, B.W., Paradiso, M.A. Neuroscience: exploring the brain (Wolters Kluwer, 2016).
Hubel, D. H. & Wiesel, T. N. Receptive fields, binocular interaction and functional architecture in the cat’s striate cortex. J. Physiol. 160, 106–154 (1962).
Contino, A. et al. Modeling of graphene for interconnect applications. In IEEE International Interconnect Technology Conference/Advanced Metallization Conference (IITC/AMC) (IEEE, 2016).
Acknowledgements
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIT) (NRF-2021R1A2C2004027, NRF-2020K1A3A1A05103462, NRF-2021R1A4A1033424), ICT Creative Consilience program (IITP-2020-0-01821), Advanced Facility Center for Quantum Technology, and Samsung Research Funding & Incubation Center of Samsung Electronics (SRFC‐MA1701‐01). Y.H.L. acknowledges the Institute for Basic Science (IBSR011-D1).
Author information
Authors and Affiliations
Contributions
W.J.Y. conceived the research. W.J.Y., Y.H.L., Q.A.V., and U.Y.W. designed the experiment and wrote the manuscript. U.Y.W. designed the neuron circuit and conducted electrical measurements. Q.A.V. performed most of the experiments, including device fabrication, characterization, and data analysis. S.B.P., M.H.P. and D.V.D. performed spiking neurosynaptic network. W.J.Y. and H.J.P. performed the spiking neural network simulation work. H.J.Y. and Y.H.L. participated in discussing the results. All authors have attended the revision of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Bikas Das, and the other, anonymous, reviewers for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Won, U.Y., An Vu, Q., Park, S.B. et al. Multi-neuron connection using multi-terminal floating–gate memristor for unsupervised learning. Nat Commun 14, 3070 (2023). https://doi.org/10.1038/s41467-023-38667-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-023-38667-3
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
