
Abstract
Although every life event is unique, there are considerable commonalities across events. However, little is known about whether or how the brain flexibly represents information about different event components at encoding and during remembering. Here, we show that different cortico-hippocampal networks systematically represent specific components of events depicted in videos, both during online experience and during episodic memory retrieval. Regions of an Anterior Temporal Network represented information about people, generalizing across contexts, whereas regions of a Posterior Medial Network represented context information, generalizing across people. Medial prefrontal cortex generalized across videos depicting the same event schema, whereas the hippocampus maintained event-specific representations. Similar effects were seen in real-time and recall, suggesting reuse of event components across overlapping episodic memories. These representational profiles together provide a computationally optimal strategy to scaffold memory for different high-level event components, allowing efficient reuse for event comprehension, recollection, and imagination.
Similar content being viewed by others

Introduction
There is a well-known saying that you cannot step into the same river twice. The events that make up our lives are extracted from complex and dynamic experiences, with pieces that never perfectly repeat. Traditional memory research, dating back to Ebbinghaus’s famous studies of forgetting1, has often focused on memory for specific details or instances. Yet many events have a predictable structure and overlapping components, such as a particular person, allowing us to generalize across experiences. It can be advantageous for the brain to establish and reuse high-level representations of different event components in order to efficiently form new memories and make inferences about the people, places, and situations that comprise them. This idea is well illustrated by Bartlett’s famous work, showing that people shape their memory for narratives according to their knowledge about the world2. However, little is known about whether or how the brain pulls apart and flexibly recombines elements across continuous events, like those in the real world, as they are experienced and recalled.
Recent evidence has indicated that the brain’s ‘default mode network’ (DMN) carries patterns of activity that distinguish one event from another in ongoing narratives, such as television episodes. Based on these studies, neural activity patterns in the DMN seem to reflect a broad understanding of an event, rather than specific elements of that event. For instance, DMN regions carry activity patterns over entire scenes of a movie, which are similar to those evoked when recalling that movie3,4,5. Moreover, activity patterns in DMN regions remain stable as an event unfolds, but these patterns shift abruptly at event transitions6,7. Other studies have suggested that certain components of the DMN—particularly, the medial prefrontal cortex (mPFC)—might represent abstract information about events that might generalize across instances of similar situations8. Related work suggests that DMN regions may carry information related to prior schematic knowledge about television shows and characters in those shows9. These findings show that the DMN maintains high-level representations, which may generalize across events. However, the nature of these representations, and the extent to which event content is represented in a unitary or modality-specific way, is not agreed upon.
Much of the DMN is comprised of parietal regions which have been proposed to support retrieval of event content, irrespective of information type or modality10,11,12. These regions have also been proposed to represent generalized semantic information about events13,14,15. Consistent with this view, recent work suggests that DMN regions may uniformly represent all aspects of an event in an integrated manner, with memory strength perhaps teasing apart the contributions of particular regions of the DMN16. This paints a unitary picture of the role of the DMN in event representation.
An alternative view is that the DMN can be divided into at least two subnetworks that interact with the hippocampus (HPC) to support event cognition and episodic memory17,18,19. According to this view, a posterior-medial (PM) network preferentially represents contextual and situational information at multiple levels of abstraction20, with parietal and parahippocampal cortex representing information about specific event contexts and mPFC representing schematic information that generalizes across similar situations21,22,23,24,25. Conversely, an anterior-temporal (AT) network is thought to represent information about entities, such as objects and people26,27,28. Information from the PM and AT Networks, in turn, may be integrated by the hippocampus, enabling information from events to be dissected, flexibly recombined in real-time, and reconstructed during episodic memory retrieval. Given the neural systems involved, this view has been called the PMAT Framework.
Although several recent studies have investigated DMN activity during naturalistic events such as films and narratives29,30, it is unknown whether the DMN represents individual events in a unitary way, or whether it carries different representations of people, contexts, and situations that can be flexibly constructed and recombined across multiple events. If event representations across the DMN are distributed and content-invariant, we would expect to see a uniform representation of event content across the entire DMN, with any nonoverlap across events reducing the similarity of those representations across regions. Conversely, different components of the DMN may act to scaffold different pieces of the experience. Specifically, the PM Network may preferentially represent some components of complex events (contextual information), whereas the AT Network may represent others (entities), and event representations across regions may depend on information content. Prior studies have shown dissociable representations of characters and spatial locations in a movie with divergent narratives31 and in imagined autobiographical events32. However, importantly, these prior studies did not focus on the stability of representations across multiple events with varying degrees of overlap. That is, we do not know whether some event information can be stably represented and reused in the face of interference from other kinds of information.
This leaves us with an important question: are events represented in the DMN on the basis of information type, and are these representations reused and flexibly recombined across experiences? To answer this, we used pattern similarity analysis of fMRI data during encoding and spoken recall of lifelike events. We designed a set of video clips depicting real-world situations, systematically combining information about entities (people) and contexts (four locations). We further manipulated contextual specificity (two classes of contexts with two exemplars of each), allowing us to examine whether any regions of the PM Network—for example, mPFC—would merge across contexts which share an abstract similarity.
Results
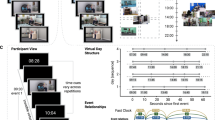
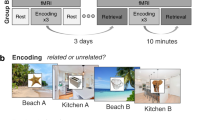
Participants viewed eight 35-s video clips combining a central person, each appearing in one of four contexts (Fig. 1A). To address context-specificity or generalization, we incorporated two different types of contexts (two distinct cafes and two distinct grocery stores). During encoding, participants viewed each event once per run, in randomized order, over three total encoding runs (i.e., each video was viewed a total of three times). Each clip consisted of a 5-s title screen, followed by the 35-s event, and a 10-s interval between events (Fig. 1B). During the single recall run, participants viewed the title screen for each event for 40 s (i.e., no video clip was played), during which they verbally recalled the event in as much detail as possible, followed by a 10-second interval between recall of events (Fig. 1C). Participants showed strong recall and recognition of all events, and showed no evidence of memory biases for or against event content (Table 1). See Methods for additional details, and Supplementary Information for statistical tests pertaining to behavioral performance.

A Eight videos were designed to systematically combine the information in events about local entities (i.e., central person) and contexts (i.e., specific location), with an additional layer of context type (i.e., café vs. grocery store). B Encoding trial structure (three runs, randomized event order). C Recall trial structure (one run, randomized event order). Permission has been acquired from Drs. Alex Barnett and Kamin Kim to depict them in this figure.
Regional differences in context, person, schema, and episode-specific patterns at encoding
Briefly, we separately modeled the unique activity pattern for each video clip. To characterize event representations during encoding, we correlated patterns of activity across events and across runs. To test a priori hypotheses about representational content across regions of interest (ROIs; Supplementary Fig. 1), event-by-event correlation matrices for each region were compared to hypothesized model matrices depicting Person, Context, Schema, and Episode-Specific (or Episodic) representations (Fig. 2). Per our experimental design, event schemas were operationalized as similarity across a general type of event (e.g., Cafe1 + Cafe2, or Store1 + Store2). As we expected similar response profiles across PM Network (PMC, ANG, and PHC) and AT Network regions (PRC and TP) (corroborated by analyses over individual ROIs; see Supplementary Information), we collapsed within-network across ROIs. Further details can be found in Methods, and full regional results (including PMC broken into constituent medial parietal subregions, Supplementary Fig. 3) as well as corroborating pattern similarity analyses broken down by event types can be found in Supplementary Information.

Event-by-event correlation matrices resulting from pattern similarity analyses were compared to hypothesized model matrices depicting Character, Context, Schema, and Episode-Specific representations via point-biserial correlations.
Event-by-event correlation matrices were compared to model matrices to test specific hypothesized representational profiles. In the PM Network (Fig. 3A), the average correlation matrix across participants was best described by the Context model matrix (r = 0.842, p = 2.88e−18) with significant correlations also found for the Schema (r = 0.629, p = 2.675e−08) and Episodic (r = 0.603, p = 1.326 e−07) matrices (Fig. 3B). The Person matrix fit was not significant (r = 0.095, p = 0.453). Model fits differed significantly (F(3,57) = 16.187, p = 9.95e−08), and the Context matrix fit was significantly stronger than each of the other three (pTukey < 0.05 corrected). Follow-up analyses confirmed that similar patterns of results were seen across the different PM Network ROIs (Supplementary Fig. 2).

A, B PM Network pattern similarity results most strongly fit the Context model matrix. C, D AT Network pattern similarity results most strongly fit the Person model matrix. E, F mPFC pattern similarity results most strongly fit the Schema model matrix. G, H HPC pattern similarity results most strongly fit the Episodic model matrix. (N = 20 participants, data presented as mean values ± SEM).
In the AT Network (Fig. 3C), the averaged correlation matrix was best described by the Person model matrix (r = 0.845, p = 1.722e−18), though fits for all other matrices were also significant: Context (r = 0.274, p = 0.028), Schema (r = 0.366, p = 0.003), Episodic (r = 0.575, p = 6.664e−07) (Fig. 3D). Model fits differed significantly (F(3,57) = 18.9, p = 1.24e−08), and the Person matrix was a significantly stronger fit than all other model matrices (pTukey < 0.05 corrected). Like PM Network analyses, AT Network regions (PRC, TP) showed highly similar response profiles (Supplementary Fig. 4).
The averaged correlation matrix in mPFC (Fig. 3E), was best described by the Schema model matrix (r = 0.914, p = 5.089e−26), with significant correlations also with the Context (r = 0.0.591, p = 2.759e−07) and Episodic (r = 0.385, p = 0.002) matrices (Fig. 3F). The fit with the Person matrix was not significant (r = 0.001, p = 0.995). Model fits differed significantly (F(3,57) = 42.916, p = 1.22e−14), with the Schema matrix being a stronger fit than the others (pTukey < 0.05 corrected).
Event correlations in HPC (Fig. 3G), were best described by the Episodic model matrix (r = 0.588, p = 1.305e−18) (Fig. 3H). Significant fits were also observed with the Context (r = 0.67, p = 1.38e−09), Schema (r = 0.535, p = 5.377e−06), and Person (r = 0.247, p = 0.049) matrices. Model fits differed significantly (F(3,57) = 29.6975, p = 1.08e−11). The Episodic model matrix was a stronger fit to the data than the Person or Schema matrices (pTukey < 0.05 corrected), though there was not a significant pairwise difference between the Episodic and Context matrices.
In contrast to model matrix comparisons, another method of analyzing the pattern similarity results reported in the main text is to collapse across events of a particular kind, and compare to other events of a different kind (e.g., [same character + same context] versus [same character + different context]). Per this analysis, we can factorially cross character (same vs. different) and context (same, similar, or different) and directly contrast z-scored pattern similarity scores across conditions. In the PM Network, we found a significant effect of Context (F(2,114) = 6.325, p = 0.002), with significant effects in each individual region (see Supplementary Information). This effect was driven by greater pattern similarity when participants viewed events that occurred within the same context compared to similar (pairwise contrasts: pTukey < 0.05 corrected) or different contexts (pairwise contrasts: pTukey < 0.05 corrected) (Fig. 4A). Pattern similarity did not differ between similar and different contexts. Conversely, we did not find an effect of Person (F(1,114) = 0.24, p = 0.625) nor an interaction (F(2,114) = 0.018, p = 0.982). In the AT Network, we found a significant effect of Person (F(1,114) = 20.139, p = 1.73e−05), but no effect of Context (F(2,114) = 1.617, p = 0.203) nor an interaction (F(2,114) = 0.194, p = 0.824). This was driven by significantly greater pattern similarity when participants viewed events depicting the same person compared to a different person (pairwise contrasts: pTukey < 0.05 corrected) (Fig. 4B). In mPFC, we found a significant effect of Context (F(2,114) = 13.569, p = 5.18e−06), but neither an effect of Person (F(1,114) = 0.108, p = 0.742) nor an interaction (F(2,114) = 0.09, p = 0.914). Here, we found higher pattern similarity for the same versus different contexts like the PM Network. However, unlike the PM Network, we also found higher pattern similarity for similar versus different contexts (pairwise contrasts: pTukey < 0.05 corrected), but not between same and similar contexts (Fig. 4C). Finally, in HPC, we found a significant effect of Context (F(2,114) = 5.018, p = 0.008) and a trending interaction (F(2,114) = 2.997, p = 0.054), but no effect of Person (F(1,114) = 1.96, p = 0.164). In line with model matrix analyses, post hoc contrasts revealed that pattern similarity was highest in HPC when viewing the same event (i.e., same person + same context; pairwise contrasts: pTukey < 0.05 corrected) (Fig. 4D).

A PM Network patterns show context-specificity. B AT Network patterns show person-specificity. C mPFC patterns generalize across similar contexts. D HPC patterns are episode-specific. (N = 20 participants, data presented as mean values ± SEM).
Content-selective neural reinstatement of event components during spoken recall
We next asked whether neural patterns associated with event content would be reinstated during spoken recall, and whether reinstated patterns would be modality-selective. Whole-event neural patterns were assessed in line with encoding-encoding analyses. For encoding-recall comparisons, we correlated patterns of activity from each event at encoding runs to event patterns for the single recall run, averaged across the three-run comparisons. In line with the above analyses, we collapsed across PM Network regions and AT Network regions (see Supplementary Information for full regional results), and event-by-event correlational patterns were compared to hypothesized model matrices, resulting in point-biserial correlations assessing model matrix fits (Fig. 2). Further details can be found in Methods.
During recall, the PM Network (Fig. 5A) was best described by the Context model matrix (r = 0.592, p = 2.604e−07), though a significant correlation was also observed with the Schema matrix (r = 0.426, p = 0.0004). The fit to the Episodic model was trending, but nonsignificant (r = 0.243, p = 0.053), and there was a significant negative fit to the Person model (r = −0.458, p = 0.0001). Model fits differed significantly (F(3,57) = 20.475, p = 3.97e−09), driven by a poorer fit to the Person matrix than other matrices (pTukey < 0.05 corrected) (Fig. 5B). Though the Context matrix was numerically the strongest fit to PMN reinstatement patterns at recall, this fit did not differ statistically from Schema and Episodic matrix fits at corrected thresholds.

A, B PM Network pattern reinstatement most strongly fits the Context model matrix. C, D AT Network pattern reinstatement most strongly fits the Person model matrix. E, F mPFC pattern reinstatement most strongly fits the Schema model matrix. G, H HPC pattern reinstatement most strongly fits the Episodic model matrix. (N = 20 participants, data presented as mean values ± SEM).
Encoding-retrieval pattern similarity in the AT Network (Fig. 5C), was best described by the Person matrix (r = 0.539, p = 2.904e−06), with a significant fit also to the Episodic matrix (r = 0.307, p = 0.014). The AT Network did not show significant correlations with the Context (r = 0.053, p = 0.677) or Schema (r = 0.144, p = 0.255) matrices. Model fits differed significantly (F(3,57) = 12.625, p = 1.95e−06), driven by a significantly better fit between the Person matrix and the Context and Schema matrices (pTukey < 0.05 corrected) (Fig. 5D).
In mPFC (Fig. 5E), encoding-recall pattern similarity data were best described by the Schema matrix (r = 0.774, p = 5.258e−14), with significant fits also for the Context (r = 0.424, p = 0.0001) and Episodic matrices (r = 0.369, p = 0.003). The Person matrix fit was not significant (r = 0.008, p = 0.944). Model fits differed significantly (F(3,57) = 7.276, p = 3.25e−04), driven by a significantly stronger fit between the data and the Schema matrix than other model matrices (pTukey < 0.05 corrected) (Fig. 5F).
HPC (Fig. 5G) encoding-retrieval pattern was best described by the Episodic matrix (r = 0.615, p = 6.548e−08), though fits all three other model matrices were also significant: Context (r = 0.521, p = 1.035e−05); Person (r = 0.299, p = 0.016); Schema (r = 0.321, p = 0.009). There was a significant difference among model fits (F(3,57) = 27.727, p = 3.459e−11). The Episodic matrix was a significantly stronger fit to the data than the Schema or Person matrices (pTukey < 0.05 corrected), though the Episodic and Context matrices did not differ significantly from one another (Fig. 5H).
Similar to our approach to encoding above, we analyzed recall-related pattern reinstatement as a function of the event type. In the PM Network, we found a significant effect of Context (F(2,114) = 3.887, p = 0.023), with significant effects in PMC and ANG, but not PHC (see Supplementary Fig. 5 and Fig. 6A). There was neither a significant effect of Person (F(1,114) = 0.382, p = 0.536), nor an interaction (F(2,114) = 0.005, p = 0.995). The AT Network showed a significant effect of Person (F(1,114) = 4.844, p = 0.029), which was found individually in PRC, but not TP (see Supplementary Fig. 6). We observed no effect of Context (F(2,114) = 0.016, p = 0.984) nor an interaction (F(2,114) = 0.029, p = 0.971) in the AT Network (Fig. 6B). In mPFC, we found a significant effect of Context (F(2,114) = 5.455, p = 0.005), but neither an effect of Person (F(1,114) = 0.441, p = 0.508) nor an interaction (F(2,114) = 0.007, p = 0.993) (Fig. 6C). Finally, HPC did not show a significant effect of either Person (F(1,114) = 2.273, p = 0.134) or Context (F(2,114) = 1.164, p = 0.316), but did show a significant interaction (F(2,114) = 3.597, p = 0.031) (Fig. 6D). Reinstated patterns were weaker and individual mean differences less pronounced than comparisons across encoding epochs, and no post hoc pairwise contrasts were significant at corrected thresholds.

A PM Network patterns show context-specificity. B AT Network patterns show person-specificity. C mPFC patterns generalize across similar contexts. D HPC patterns are episode-specific. (N = 20 participants, data presented as mean values ± SEM).
Event pattern reinstatement in the hippocampus correlates with details recalled
Finally, we asked whether neural pattern reinstatement was related to recall success. Prior studies have shown that encoding-retrieval similarity, particularly in or mediated by the HPC, correlates with memory performance33,34,35,36. In the present data, this analysis was conducted by correlating each subject’s HPC encoding-recall pattern similarity, averaged across all same-event comparisons, with the overall number of verifiable details they recalled across all events in the experiment. This was contrasted against the same analysis conducted over all mismatched events rather than the same events (i.e., the average pattern similarity value of each event at encoding compared to different events at recall). In other words, this analysis examines the relationship between general HPC pattern reinstatement during recall and overall recall success, comparing matched to mismatched events.
We found that the extent of pattern similarity between encoding and recall for the same events (i.e., encoding-recall match) was significantly correlated with the total number of verifiable details retrieved for all events across participants (r = 0.555, p = 0.011) (Fig. 7A). In contrast, events that were mismatched between encoding and recall showed no evidence of a relationship with HPC reinstatement (r = 0.015, p = 0.475) (Fig. 7B). A Fisher r-to-z transformation reveals a trending (but not statistically significant) difference between the correlations when directly compared via two-tailed test (z = 1.78, p = 0.0751). Though prior studies have found a relationship between reinstatement in PMC and subsequent memory measures3, this relationship was only trending and not significant in the current dataset (r = 0.385, p = 0.094). Moreover, no other ROIs in our data showed a significant relationship with recall. Taken together, these results indicate that neural patterns associated with complex events across multiple encoding episodes are, to some extent, brought back online during recall, and that this reinstatement of neural patterns follows information content dissociations present during encoding. Furthermore, the relationship between encoding and retrieval patterns for specific events in the HPC is correlated with overall recall success. We note that these findings were present when examining the total number of verifiable details across all events. When restricting analyses to reinstatement and recall of specific events, correlations trended similarly but were not statistically significant. Thus, these findings speak to overall relationships between HPC reinstatement and recall success, but cannot speak to this relationship at the level of single events.

Correlations are shown for A matched events and B mismatched events. (N = 20 participants, shaded region = 95% confidence interval. Data were evaluated using Pearson correlation coefficients, using two-sided tests).
Distinct timescales of pattern similarity across regions for specific events
In the above analyses, multi-voxel patterns were averaged across the duration of each event, similar to other recent approaches3,4,5. This was done to capture stable information content being represented across the duration of distinct events. However, we next conducted an exploratory analysis to test whether multi-voxel pattern information during events differed across regions as an event unfolded. Prior studies suggest distinct temporal receptive windows across the brain, with ‘slow’ timescale regions shifting their activity patterns on the order of tens of seconds to minutes during ongoing experiences29,37,38,39,40. In these studies, DMN regions have among the slowest representational timescales, which are sensitive to narrative understanding41 and have been shown to match human judgments of event transitions6. There is also growing evidence that hippocampal involvement in the coding of temporally extended events may be limited to times around event boundaries42,43. Our data provided an opportunity to examine regional differences in coding events at different timepoints.
We compared identical events across runs (i.e., same person and same context) given that all ROIs showed pattern similarity increases during these comparisons but not any other conditions. For these analyses, we modeled each TR in the run individually, in line with beta-series analysis44. Each TR from a given event in one encoding run was correlated with its corresponding TR in that same event in different runs. We binned these TRs into three different epochs, ignoring the first four TRs as these featured the event title. The remaining TRs were binned unevenly into event Onset (the first seven TRs), event Offset (the last seven TRs), and Mid-event (the intervening 15 TRs) epochs. We binned unevenly, opting for relatively shorter Onset and Offset epochs given prior evidence for the importance of HPC activity at event boundaries42,43. For each ROI, each epoch was contrasted against its mean pattern similarity value across all events, across all runs (i.e., the grand-mean).
In the PMN (Fig. 8A), pattern similarity for the same event across runs was significantly above the grand-mean at Mid event (t(19) = 2.723, p = 0.014) and event Offset (t(19) = 2.903, p = 0.009), but not at event Onset (t(19) = 1.518, p = 0.145). However, epochs did not differ significantly (F(2,38) = 0.877, p = 0.42). In the ATN (Fig. 8B), pattern similarity was significantly above the grand-mean at event Onset (t(19) = 2.115, p = 0.048) and Mid event (t(19) = 4.916, p = 9.594e−05), but not at event Offset (t(19) = 1.269, p = 0.219). Event epochs differed significantly (F(2,38) = 4.903, p = 0.013), and Mid-event pattern similarity was greater than event Offset (pTukey < 0.05 corrected). In mPFC (Fig. 8C), pattern similarity was significantly above the grand-mean at Mid event (t(19) = 3.672, p = 0.002) and event Offset (t(19) = 4.427, p = 0.0002), but not event Onset (t(19) = 1.611, p = 0.124). Event epochs did not differ significantly (F(2,18) = 1.753, p = 0.187). In HPC (Fig. 8D), pattern similarity was significantly different from the grand-mean at event Onset (t(19) = 7.983, p = 1.729e−07) and event Offset (t(19) = 5.079, p = 6.656e−05), but not at the Mid-event epoch (t(19) = 1.491, p = 0.153). Event epochs differed significantly (F(2,38) = 18.836, p = 2.07e−06), driven by greater pattern similarity at event Onset than Mid or Offset epochs (pTukey < 0.05 corrected). Thus, while all ROIs showed increases in pattern similarity for same-event comparisons, there were regional differences in when during the event correlated representations emerged.

A PM Network, B AT Network, C mPFC, D HPC. Red lines indicate the mean pattern similarity value across all events and across all runs for that ROI. (N = 20 participants, data presented as mean values ± SEM).
Discussion
Recent research has strongly implicated the DMN as being important for the ongoing perception of and memory of naturalistic events3,4,5. Here, we show that this network systematically deconstructs different aspects of events, such that they can be recombined and reused across different people, places, and situations. We found that areas in the PM Network carried information that generalized across different events that occurred in the same context, and to some extent across events depicting the same general situation. In mPFC, voxel pattern information is generalized to a remarkable extent across different events depicting the same situation, consistent with the processing of event schemas6. The AT Network, in contrast, carried information about individual people that was generalized across films in different contexts and situations. HPC patterns were highly event-specific, in contrast with what was observed in cortical regions, consistent with a role in detailed episodic memory. At recall, HPC pattern reinstatement correlated with retrieved verifiable details about events. Finally, we show evidence for distinct representational timescales for a given event, with HPC being unique in preferentially representing information about event onsets and offsets, but not mid-event epochs.
Previous studies have suggested that the DMN—in particular, the posterior-medial cortex and angular gyrus—plays an important role in memory, though there are a number of apparently conflicting accounts. One commonly held view is that parietal DMN areas represent retrieved event content in an integrated manner10,11,12,45. Others have argued that DMN areas represent semantic knowledge, again generalizing across domains and content13,14,15. Other views have emphasized multisensory integration, memory confidence46 or precision16, or the integration of information across a long timescale29,40. The present results are not entirely consistent with any of these views, and yet they might offer a step toward reconciling them. Many typical laboratory experiments use the information of a single type (e.g., objects or words, or simple associations between these), which may cause otherwise heterogeneous brain networks to act in a more unitary fashion. Conversely, even if participants recall precise item-level information in these experiments, this may be accompanied by strong reinstatement of contextual or situation associations, which can be difficult to characterize.
Our results—showing a preferential representation of contexts and situations by the PM Network and mPFC and preferential representation of people by the AT Network—better align with accounts suggesting that the DMN can be broken into smaller subnetworks. Based on anatomical and functional properties17,18, there is reason to believe that the PM Network preferentially represents information about the structure of an event, which is used to generate a mental model to guide comprehension and prediction as an event unfolds47. In contrast, the AT Network has been proposed to preferentially represent properties of people and things—the “content” that characterizes a specific event. In this perspective, the PM and AT Networks can be thought of as “episodic” in that they represent information that is used as a scaffold to understand and remember events19, and they can be thought of as “semantic” in that they carry information that generalizes across overlapping events. In general, our data are highly consistent with the PMAT framework17,18,19 in showing a stark distinction between the representation of contexts and situations versus the entities that occupy them. Further, our results extend this theoretical view to further validate its predictions in the face of complex, continuous events.
Our use of videos depicting real-world events may have permitted the construction and use of event models—mental representations of characters and situations that are strongly tied to the events depicted on the screen, but which also tap into more abstract processes required to understand events that occur in daily life. When recalling a complex event, reinstatement of information from the PM and AT Networks, transferred from other experiences, can serve as a scaffold to guide the recovery of precise information about an event. Interestingly, while event-by-event similarity patterns were still consistent with content-selectivity in PM and AT networks during recall, the specificity of this content selectivity (e.g., PM network for context) was reduced compared to encoding-encoding similarity. It is worth noting that this comparison is confounded by the temporal distance of the comparisons, such that the recall run is further in time from at least the earlier encoding runs. This could also in part be simply due to noisier comparisons when no visual stimulus is available, but an alternative possibility is that these cortico-hippocampal networks are more integrated during memory retrieval compared to encoding. In line with this, a recent study by Cooper and Ritchey48 suggest that greater inter-network connectivity may support the multidimensional nature of episodic memory retrieval.
Our findings showing flexible reuse of representations of event content are highly compatible with ideas proposed by Bartlett2. These ideas have since been elaborated on by Addis, Wong, and Schacter49, who have suggested that information in episodic memory can be recombined in the service of planning, simulation, and imagination. Although studies of episodic simulation have generally focused on the role of the anterior hippocampus, it is also well-established that the entire DMN contributes to the generation of imagined situations and events50. In our study, hippocampal representations were event-specific, whereas cortical areas carried information that was recombined across events. It is possible that, when imagining or simulating events, people might start by retrieving specific events (driven by hippocampal retrieval), and the PM and AT Networks might enable retrieved information about people, places, and situations to be recombined in novel ways to construct an elaborate event17,51.
Though the hippocampus is universally agreed to be critical for memory, its exact role is also a matter of ongoing study. One widely held view of the hippocampus is that it is important for creating and maintaining unique representations of specific events, in contrast to more generalized representations in the neocortex. This perspective, formalized into the Complementary Learning Systems framework, has been linked to a theoretical role in pattern separation52,53,54. Our results, showing hippocampal specificity in contrast to generalized representations across cortical networks, are broadly consistent with this view. Our findings also align with studies showing a relationship between the reinstatement of specific hippocampal patterns and retrieval success33,34,35,36. In contrast to representational specificity, other studies strongly suggest that the hippocampus has a role in genearalization55,56,57,58. Indeed, the hippocampus has the capacity to support specific pattern-separated representations as well as to support generalization via pattern completion59. Though our data more strongly support generalization in neocortical regions than the hippocampus, it is possible that the relative lack of specific instructions during event encoding resulted in a stronger bias to create and use specific hippocampal representations rather than to generalize across similar instances. That is, if individuals were incentivized to generalize across similar events (e.g., strategically collapse across events featuring the character Lisa), hippocampal representations may be driven away from specificity and more toward generalization. This possibility can be tested by future experiments.
Although our data support theories of content-based dissociations of the PM and AT Networks, we do not take this to suggest that all regions of each respective network are doing the same thing. For instance, context-specificity may differ across regions affiliated with the PM Network. In line with this, PM Network regions showed a significant fit with the Schema model matrix. This is consistent with other findings from Baldassano and colleagues8, who used typical progressions of events through airports and restaurants in movie and audio clips to test shared neural responses across different stories featuring schema-congruent event sequences. Baldassano and colleagues reported schema-level representations not only in mPFC, but also across other PM Network regions such as PMC and PHC. Their study differs markedly from our approach in that they sought to examine shared neural patterns across highly distinct events sharing a common schematic theme, whereas our approach was to systematically recombine characters and contexts to interrogate representations of specific event content. However, these findings are highly complementary. Additionally, recent work by Barnett et al. suggests that the DMN may feature up to 4 subnetworks rather than just 260. This study uses an atlas generated by Glasser and colleagues, which features a fairly large number of ROIs61. We chose to use a more typical approach to ROI delineation, in line with many prior studies3,4,5,6,7,8,9. Nonetheless, we did run a simple supplemental analysis based on the Barnett et al. networks, which can be found in the Supplementary Information (Supplementary Fig. 7). The general pattern of results is largely in line with the findings as presented here. Future studies can leverage these network-based analytical developments to parse the DMN at increasing levels of granularity.
Closely related to the topic of event memory is the way event representations evolve over time. Recent studies using naturalistic stimuli such as films have primarily focused on event boundaries rather than the content of events per se. A finding with increasing support is that the hippocampus and certain PM Network regions are transiently more active at event boundaries6,7,62, and may moreover strengthen functional interactions at event boundaries63. In contrast, these phenomena are generally not observed in AT Network regions63. The present study was not designed to examine event segmentation, but rather to examine the way specific components may be represented across events. However, some insight may be gained from our results. Event boundaries, which are often linked to story-related changes rather than individual actions, are reliably elicited by changes in spatiotemporal context64,65,66. The present data would lead to the accurate prediction that PM Network regions, supporting context representations, should be engaged at such moments.
Following this, exploratory analyses also suggest that event representations may come online at distinct epochs as events unfold. Notably, HPC patterns carried event-specific information at event onset and offset, corresponding to event boundaries. In general, cortical regions tended to carry information about event content most strongly in the middle of those events. This suggests that representational timescales may be another important factor which differs across regions, broadly consistent with prior work indicating multiple temporal receptive windows across the cortex in response to stimuli such as movies29,37,38,39,40. Our results also align with the idea of HPC being particularly important for encoding information at event boundaries, which has been supported by both empirical data and computational models42,43.
Having established what may be core components of event representations, future studies can more closely examine these factors with respect to the content of event representations. Events depicted in this study were only 40 s in duration, limiting analyses of the way different representations of event components may evolve over long timescales. Additionally, we did not systematically vary features of characters such as actions, intentions, and other similar factors which could influence event understanding by adding narrative context67,68,69. However, future work can build on this approach to test these questions. Another relevant topic is that of schema congruency, or the perceived appropriateness or fit of a situation and its component parts. Congruency has been found to affect recognition and recall of information, although there is conflicting evidence for whether congruent or incongruent events lead to stronger memory traces per se70,71,72,73. Notably, few studies manipulating and testing the effects of schema congruency per se have done so testing memory for dynamic, lifelike situations74. We suggest that our findings take a step beyond general ideas of schema and gist-based memory by systematically varying key event components, such as people, places, and situations. That is, our approach moves beyond dichotomous classifications such as gist versus detail or congruent versus incongruent. This allows for concrete, constructive formulations of what might make a memory representation more or less schematic, or generalized versus specific.
In sum, our results address a key gap in existing studies of event cognition and memory by revealing how the complementary functions of different cortico-hippocampal networks enable to brain to flexibly construct and reuse mental representations of event components across different episodic memories. These coding schemes together amount to an optimal and computationally efficient strategy for reducing complex events into key components, representing commonalities across events while also maintaining specific event representations. This provides a representational scaffold for processing, remembering, and even simulating events as we navigate through real-world experiences.
Methods
Participants
Participants were recruited from the University of California, Davis and the Davis, California community via flyer and email advertisement. Participants were paid $25 per hour, and gave written informed consent in accordance with the University of California, Davis Institutional Review Board under an approved protocol. Exclusion criteria included magnetic bodily implants, claustrophobia, a history of major psychiatric or neurological disorders, a concussion in the past 6 months, untreated diabetes or hypertension, current drug or alcohol abuse, left-handedness, age outside a range of 18-35 years, and 4 or fewer hours of sleep on the day of data collection.
We initially collected 24 participants and excluded one due to falling asleep during MRI scanning, two due to excessive motion in the MRI scanner, and one due to equipment malfunction during data collection. The final sample of 20 participants had a mean age of 23.4 years (SD = 3.1 years), consisting of 13 self-identified females and seven self-identified males.
Stimuli
Eight video clips were developed for use in the present experiment. These video clips were recorded at locations in Davis, California using a GoPro HERO + LCD camera, at 1080p 60fps resolution. Two members of the UC Davis Dynamic Memory Lab served as central characters. Several ‘takes’ were recorded for each video. Videos were then edited in the GoPro editing software to be 35 s in duration, and to include a 5 s title screen with white text against a black background for each event depicted (making each video 40 s in total).
Prior to video viewing, participants viewed a series of still images depicting the characters and locations subsequently viewed in the event videos. These data were not analyzed here. Videos were presented in the MRI scanner environment using PsychoPy version 3.1.5, and stimulus onset was synchronized with MRI pulse sequences via fiber optic trigger pulses sent to the stimulus computer. Videos were downsampled to from 1080p to 720p in the experiment to reduce the time taken to load and buffer the files in PsychoPy. After video viewing, participants were cued by on-screen text via PsychoPy to recall the events using an MRI-compatible microphone (see Procedure).
After in-scanner tasks, participants were given a True/False recognition test outside the scanner consisting of a series of single-sentence statements about video content. False statements were designed to probe for the accuracy of memory, but were not designed to test fine-grained mnemonic discrimination (i.e., they were not designed to be highly similar to factual events). Single sentences were presented in white text against a black background on a 2015 MacBook Pro 13” laptop.
Procedure
Participants arrived at the UC Davis Center for Neuroscience, and were escorted into the Dynamic Memory Lab testing space where they were briefed on the experiment, and gave written informed consent. Participants then completed an MRI screening form and demographics questionnaires. Upon successful screening for the experiment, participants were escorted to the Imaging Research Center, and were prepped to undergo scanning.
Scanning took place in a Siemens 3 T Skyra with a 32-channel head coil. Participants were fitted with MRI-compatible earbuds with replaceable foam inserts (MRIaudio), and were provided with additional foam padding inside the head coil for hearing protection and to mitigate head motion. Participants were additionally given bodily padding, blankets, and corrective lenses as needed. An MRI-compatible microphone (Optoacoustics FOMRI-III) with bidirectional noise-canceling was affixed to the head coil, and the receiver (covered by a disposable sanitary pop screen) was positioned over the participant’s mouth. Participants were given a description of strategies to remain still while speaking during functional image acquisition. During MRI data acquisition, an eye tracker was operational to monitor participants’ wakefulness and head motion during spoken recall, but no eye tracking data were recorded.
After testing the earbuds and microphone, high-resolution T1-weighted structural images were acquired using a magnetization-prepared rapid acquisition gradient echo (MPRAGE) pulse sequence (FOV = 256 mm, image matrix = 256 ×256, sagittal slices = 208, thickness = 1 mm). Participants then completed a functional imaging run in which they were shown still images of the central people and contexts subsequently shown in the videos (these data are not analyzed or discussed here). Participants then completed three runs in which all eight event videos were shown, in random order across runs and across participants. Video stimuli (title screen + event) were 40 s, with a 10 s inter-stimulus interval displaying a fixation cross. Instructions were to remain still and closely attend to the videos, as a memory for the videos would be tested later in the experiment. After the three encoding runs were completed, participants completed a spoken recall of each event. Event titles were displayed in random order, in white text against a black background for 40 s, with a 10 s inter-stimulus interval displaying a fixation cross. Participants were instructed to begin recalling the named event, in as much detail as possible and in order to the extent possible, and to stop recall either when finished or when the event title transitioned to the fixation cross. We reasoned participants would rarely exceed 40 s to recall the events based on pilot behavioral data, though we observed three instances across all subjects where recall for a given event was cut off due to a time-out. Functional images were acquired using a multi-band gradient echo planar imaging (EPI) sequence (TR = 1220 ms, TE = 24 ms, FOV = 192 mm, image matrix = 64 × 64, flip angle = 67, multi-band factor = 2, axial slices = 38, voxel size = 3 mm isotropic, P » A phase encoding, AC-PC alignment). A single four TR functional scan of reverse phase encoding polarity (A » P) was acquired for unwarping (see fMRI data preprocessing below).
Behavioral analyses
In-scanner recall was scored using an adapted version of the Autobiographical Memory Interview75,76 (see Cohn-Sheehy et al. for a highly similar adapted approach77). Three scorers transcribed the audio recording for each event into text, and segmented the document into meaningful detail units (Z.M.R. and two research assistants). Detail units refer to the smallest possible meaningful unit, and labels were assigned to those details on the basis of their content. These details were then classified as “verifiable” if they referred to a factually accurate piece of information pertaining to the events depicted in the videos, and were not preceded by statements of uncertainty (e.g., “maybe”). Redundant information was not counted. Once scoring was completed, interrater reliability was assessed, and was fairly high across the three raters overall (Pearson r = 0.86), and in terms of details scored as being verifiable (Pearson r = 0.84). Verifiable details were compared across characters and across contexts using one-way ANOVAs, and were correlated with pattern similarity and recall-driven reinstatement using Pearson correlations.
While we were interested in the extent to which participants might show intrusions and swaps of details across events that shared a focal person or context, we found that this was very rare in our sample. Specifically, only two participants swapped any details across such events, and in both cases, these were misattributions of single action details rather than multiple details, or confusion of two person-context pairings in their entirety. Thus, in the present data, there are too few instances of such intrusions or misattributions to be sufficiently powered to characterize such instances. Relatedly, a recall was scored purely in terms of verifiably-correct details, meaning they were compared to specific actions or moments depicted in a given episode. Thus, based on behavioral evidence as scored, a recall was assessed in terms of successful retrieval of a particular event. Follow-up analyses investigated the prevalence of what might be regarded as “schematic” details which broadly describe a situation but do not refer to specific actions or moments in a clip (e.g., “the barista runs the credit card”), but such instances were similarly too sparse across the data to conduct thorough analyses. In sum, the overall recall was clip-specific in the vast majority of instances.
Out-of-scanner recognition test results for each participant considered the distinction of true statements from false statements about the viewed events. To quantify this, we calculated a d’ score for each participant: z(Hit rate)—z(False Alarm rate). Similar to the in-scanner recall performance above, recognition memory scores were compared across characters and across contexts using one-way ANOVAs, and standard Pearson correlations were used to assess relationships with neural data across events. The ultimate goal of these analyses was to ensure that recognition and recall of event information were significantly nonzero, and unbiased across the events.
fMRI data preprocessing
Results included in this manuscript come from preprocessing performed using FMRIPREP version stable78,79 (RRID:SCR_016216), a Nipype80,81 (RRID:SCR_002502) based tool. Each T1w (T1-weighted) volume was corrected for INU (intensity non-uniformity) using N4BiasFieldCorrection v2.1.082 and skull-stripped using antsBrainExtraction.sh v2.1.0 (using the OASIS template). Brain surfaces were reconstructed using recon-all from FreeSurfer v6.0.183 (RRID:SCR_001847), and the brain mask estimated previously was refined with a custom variation of the method to reconcile ANTs-derived and FreeSurfer-derived segmentations of the cortical gray-matter of Mindboggle84 (RRID:SCR_002438). Spatial normalization to the ICBM 152 Nonlinear Asymmetrical template version 2009c85 (RRID:SCR_008796) was performed through nonlinear registration with the antsRegistration tool of ANTs v2.1.086 (RRID:SCR_004757), using brain-extracted versions of both T1w volume and template. Brain tissue segmentation of cerebrospinal fluid (CSF), white-matter (WM), and gray-matter (GM) was performed on the brain-extracted T1w using fast87 (FSL v5.0.9, RRID:SCR_002823).
Functional data were slice time corrected using 3dTshift from AFNI v16.2.0788 (RRID:SCR_005927) and motion corrected using mcflirt (FSL v5.0.989). Distortion correction was performed using an implementation of the TOPUP technique90 using 3dQwarp (AFNI v16.2.0788). This was followed by co-registration to the corresponding T1w using boundary-based registration91 with six degrees of freedom, using bbregister (FreeSurfer v6.0.1). Motion correcting transformations, field distortion correcting warp, BOLD-to-T1w transformation, and T1w-to-template (MNI) warp were concatenated and applied in a single step using antsApplyTransforms (ANTs v2.1.0) using Lanczos interpolation.
Physiological noise regressors were extracted by applying CompCor92. Principal components were estimated for the two CompCor variants: temporal (tCompCor) and anatomical (aCompCor). A mask to exclude signals with cortical origin was obtained by eroding the brain mask, ensuring it only contained subcortical structures. Six tCompCor components were then calculated including only the top 5% variable voxels within that subcortical mask. For aCompCor, six components were calculated within the intersection of the subcortical mask and the union of CSF and WM masks was calculated in T1w space, after their projection to the native space of each functional run. Frame-wise displacement93 was calculated for each functional run using the implementation of Nipype.
Many internal operations of FMRIPREP use Nilearn94 (RRID:SCR_001362), principally within the BOLD-processing workflow. For more details on the pipeline see https://fmriprep.readthedocs.io/en/stable/workflows.html.
fMRI data analysis—representational similarity analysis
All representational similarity analyses (RSA) were run on unsmoothed native-space functional images after the preprocessing steps described above. Each of the three encoding runs and the recall run of the raw data were entered into a general linear model (GLM) in AFNI using the 3dDeconvolve function. Nuisance regressors for linear scanner drift (first order polynomial), head motion (six directions plus their six derivatives), and the first two principal components of a combined white-matter and CSF mask (via aCompCor above). Given the relatively long 40 s duration of the “trials” being modeled and the 10 s gap between the videos, a least-squares all (LSA) approach was used, such that each run was modeled to produce beta estimate images for either encoding or recall of each of the 8 events. Though a number of prior studies examining naturalistic encoding and recall have not used GLMs to model data, and have instead used a time-shifted averaging approach, we chose to model the present data as this allowed us to more directly mitigate influences of signal drift, motion, and global nuisance signal in evaluating representational patterns. As events, including title screens, were 40 s in duration and the TR for our EPI sequence was 1.22 s, there were approximately 33 TRs covering each event. Encoding-encoding analyses simply computed event-by-event pattern similarity across runs, such that each event pattern similarity comparison was the average of three across-run comparisons (i.e., run1 to run2, run1 to run3, run2 to run3). For same-event comparisons, this resulted in 3 correlations across runs, which were averaged. For between-event comparisons, this resulted in 6 correlations across runs, which were averaged (twice the number of same-event comparisons). This is comparable to the split representational dissimilarity matrix approach taken by Henriksson and colleagues95. Correlation coefficients were then z-scored prior to model matrix comparisons or event-type analyses. Encoding-recall comparisons were followed the same principle as encoding-encoding comparisons, except the 33-TR events modeled at encoding were compared to variable TR events during recall. Specifically, the length of the recall epoch was defined as the duration of spoken recall for each participant (e.g., if a participant spoke for 18 TRs for a given event, the regressor for that event covered those 18 TRs). Recall betas were then compared to encoding betas across all three encoding runs.
Resultant beta images were masked using a region-of-interest (ROI) approach, based on theoretical interest in areas of the Posterior-Medial and Anterior-Temporal Networks. ROIs (Supplementary Fig. 1) of the PM Network—angular gyrus (ANG), posterior-medial cortex (PMC), and parahippocampal cortex (PHC)—were selected based on theoretical involvement in context representation, and involvement in recent studies of naturalistic events. Given accumulating evidence for schema representation in mPFC, we considered this region separately from the PM Network. ROIs in the AT Network—perirhinal cortex (PRC) and temporal poles (TP)—were selected due to demonstrated sensitivity to item-level information. Hippocampal, parahippocampal, and perirhinal ROIs were derived from in-house hand-traced template images in MNI space96, which were warped to each subject’s native space using ANTs. All other ROIs are derived from the FreeSurfer Desikan atlas. Multi-voxel patterns were extracted from each ROI mask and written to CSV files for subsequent analyses using the 3dmaskdump function in AFNI. Voxels with null values in any scanning run were excluded.
For model matrix comparisons (see below), each event pattern was correlated with the other event pattern. For conditional comparisons across RSA results, we collapsed events across 4 key conditions: (1) same event (i.e., person-in-context), (2) same person, different context, (3) same person, similar context, (4) same context, different person), and (5) different person, different context. Pairwise comparisons across each event were conducted within subjects, and the resulting correlation coefficients were z-scored. For each ROI, events satisfying each condition were averaged, and conditional averages were statistically compared against one another using two-way ANOVAs, with person and context information as factors. Significant effects were evaluated using Tukey’s HSD for post hoc comparisons.
fMRI data analysis—model matrix comparisons
To probe specific hypotheses about the representation of a person, context, schema, and episodic specificity in our ROIs, we compared event-by-event correlation matrices for pattern similarity data to model matrices. Beta images resulting from the preprocessing steps described above underwent pairwise comparisons across events for each participant and for each ROI, resulting in an event-by-event correlation matrix. This was compared to four model matrices: (1) an episode-specific matrix, in which events were hypothesized to correlate only with themselves, (2) a person matrix, in which events were hypothesized to correlate with those events which featured the same person, (3) a context matrix, in which events were hypothesized to correlate with those events which featured the same context, and (4) a schema matrix, in which events were hypothesized to correlate with those events which featured a similar context (e.g., two similar but not identical cafes). Model matrices were constructed simply to feature a value of 1 in hypothesized high-correlation cells, and a value of 0 in hypothesized low-correlation cells. In general, model fit was evaluated using a point-biserial correlation between the pattern similarity matrix and the model matrices for each ROI. Model fits were evaluated in two ways. First, for each ROI, we computed the biserial correlation between group average event-wise pattern similarity data and each of the 4 model matrices using the lower half of the matrix (i.e., excluding redundant comparisons), yielding overall model matrix correlations per region. Second, to incorporate sensitivity to variability across participants and to directly compare different model fits per region, we assessed the model fits for each participant per ROI. For this approach, each participant’s model fit correlations were z-scored, and correlations were aggregated across participants. Finally, one-way ANOVAs and post hoc Tukey’s HSD comparisons were used to relate the overall fits of the empirical data to the models, and to directly compare fits across models within each ROI. We note that, with this approach, some model matrices will share mutual information (e.g., the Episodic matrix is a component of all other matrices), but we can nonetheless assess the relative fit of each matrix for a given region.
fMRI data analysis—time-binned analyses
Additional exploratory analyses were conducted examining pattern similarity across events on the order of TRs. Preprocessed data were modeled distinctly from prior analyses: rather than a beta image being generated for each event, a beta image was generated for each time step comprising an event (similar to a beta-series correlation approach44. Confound regressors were unchanged from the other GLM which modeled whole events with single regressors. The analysis consisted of a TR-by-TR pattern similarity analysis within an event pair (rather than event-by-event pattern similarity analysis) across ROIs and collapsed across participants. Given that different ROIs responded to different conditions, we chose to compare only same-event neural patterns across runs for this analysis, as this is the only condition in which all ROIs reliably showed pattern similarity increases across participants. Furthermore, given evidence for distinct mechanisms of hippocampal encoding at event boundaries42,43, we binned the time series to attempt to isolate boundary-relevant activity from mid-event patterns. We ignored the first four TRs as these timepoints featured the event title. We binned the next TRs as follows: event Onset (the first seven TRs), event Offset (the final seven TRs), and Mid-event timepoints (the intermediate 15 TRs). This additionally simplified analyses of the data while nonetheless allowing for the evaluation of a temporally-evolving change in pattern similarity. We conducted two sets of analyses for these data. The first analysis was a series of one-sample t-tests against the mean pattern similarity value across all encoding runs, evaluating whether pattern similarity for same-event comparisons was significantly different from the baseline pattern similarity of that ROI across all events, at each of the three epochs we defined. The second analysis was a one-way ANOVA with post hoc Tukey’s HSD to test whether the three event epochs differed significantly from one another.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Processes generated in this study have been deposited in the repository found at the following link: https://github.com/zreagh/8vid. The full dataset, including raw data, is available by request to the corresponding author due to file size and potentially identifying information. Source data are provided with this paper.
Code availability
Code for main analyses can be found at the following link: https://github.com/zreagh/8vid.
References
Ebbinghaus, H. Memory: A Contribution to Experimental Psychology (Teachers College, Columbia Univ., 1913).
Bartlett, F. C. Remembering: A Study in Experimental and Social Psychology (Cambridge Univ. Press, 1932).
Bird, C. M., Keidel, J. L., Ing, L. P., Horner, A. J. & Burgess, N. Consolidation of complex events via reinstatement in posterior cingulate cortex. J. Neurosci. 35, 14426–14434 (2015).
Chen, J. et al. Shared memories reveal shared structure in neural activity across individuals. Nat. Neurosci. 20, 115–125 (2017).
Oedekoven, C. S. H., Keidel, J. L., Berens, S. C. & Bird, C. M. Reinstatement of memory representations for lifelike events over the course of a week. Sci. Rep. 7, 14305 (2017).
Baldassano, C. et al. Discovering event structure in continuous narrative perception and memory. Neuron 95, 709–721.e5 (2017).
Ben-Yakov, A. & Henson, R. N. The hippocampal film editor: sensitivity and specificity to event boundaries in continuous experience. J. Neurosci. 38, 10057–10068 (2018).
Baldassano, C., Hasson, U. & Norman, K. A. Representation of real-world event schemas during narrative perception. J. Neurosci. 38, 9689–9699 (2018).
Raykov, P. P., Keidel, J. L., Oakhill, J., & Bird, C. M. Activation of person knowledge in medial prefrontal cortex during the encoding of new lifelike events. Cerebral Cortex. 31, 3494–3505 (2021).
Kuhl, B. A. & Chun, M. M. Successful remembering elicits event-specific activity patterns in lateral parietal cortex. J. Neurosci. 34, 8051–8060 (2014).
Bonnici, H. M., Richter, F. R., Yazar, Y. & Simons, J. S. Multimodal feature integration in the angular gyrus during episodic and semantic retrieval. J. Neurosci. 36, 5462–5471 (2016).
Lee, H. & Kuhl, B. A. Reconstructing perceived and retrieved faces from activity patterns in lateral parietal cortex. J. Neurosci. 36, 6069–6082 (2016).
Binder, J. R. & Desai, R. H. The neurobiology of semantic memory. Trends Cogn. Sci. 15, 527–536 (2011).
Devereux, B. J., Clarke, A., Marouchos, A. & Tyler, L. K. Representational similarity analysis reveals commonalities and differences in the semantic processing of words and objects. J. Neurosci. 33, 18906–18916 (2013).
Rugg, M. D. & King, D. R. Ventral lateral parietal cortex and episodic memory retrieval. Cortex 107, 238–250 (2018).
Richter, F. R., Cooper, R. A., Bays, P. M. & Simons, J. S. Distinct neural mechanisms underlie the success, precision, and vividness of episodic memory. Elife 5, e18260 (2016).
Ranganath, C. & Ritchey, M. Two cortical systems for memory-guided behaviour. Nat. Rev. Neurosci. 13, 713–726 (2012).
Ritchey, M., Libby, L. A. & Ranganath, C. Cortico-hippocampal systems involved in memory and cognition. Prog. Brain Res. 219, 45–64 (2015).
Reagh, Z. M. & Ranganath, C. What does the functional organization of cortico-hippocampal networks tell us about the functional organization of memory? Neurosci. Lett. 680, 69–76 (2018).
Ritchey, M. & Cooper, R. A. Deconstructing the posterior medial episodic network. Trends Cogn. Sci. 24, 451–465 (2020).
van Kesteren, M. T. R. et al. Differential roles for medial prefrontal and medial temporal cortices in schema-dependent encoding: from congruent to incongruent. Neuropsychologia 51, 2352–2359 (2013).
Preston, A. R. & Eichenbaum, H. Interplay of hippocampus and prefrontal cortex in memory. Curr. Biol. 23, R764–R773 (2013).
Ghosh, V. E. & Gilboa, A. What is a memory schema? A historical perspective on current neuroscience literature. Neuropsychologia 53, 104–114 (2014).
Spalding, K. N., Jones, S. H., Duff, M. C., Tranel, D. & Warren, D. E. Investigating the neural correlates of schemas: ventromedial prefrontal cortex is necessary for normal schematic influence on memory. J. Neurosci. 35, 15746–15751 (2015).
Gilboa, A. & Marlatte, H. Neurobiology of schemas and schema-mediated memory. Trends Cogn. Sci. 21, 618–631 (2017).
Peelen, M. V. & Caramazza, A. Conceptual object representations in human anterior temporal cortex. J. Neurosci. 32, 15728–15736 (2012).
Nestor, A., Plaut, D. C. & Behrmann, M. Unraveling the distributed neural code of facial identity through spatiotemporal pattern analysis. Proc. Natl Acad. Sci. USA 108, 9998–10003 (2011).
Tsantani, M., Kriegeskorte, N., McGettigan, C. & Garrido, L. Faces and voices in the brain: a modality-general person-identity representation in superior temporal sulcus. NeuroImage 201, 116004 (2019).
Hasson, U., Chen, J. & Honey, C. J. Hierarchical process memory: memory as an integral component of information processing. Trends Cogn. Sci. 19, 304–313 (2015).
Bird, C. M. How do we remember events? Curr. Opin. Behav. Sci. 32, 120–125 (2020).
Milivojevic, B., Varadinov, M., Grabovetsky, A. V., Collin, S. H. & Doeller, C. F. Coding of event nodes and narrative context in the hippocampus. J. Neurosci. 36, 12412–12424 (2016).
Robin, J., Buchsbaum, B. R. & Moscovitch, M. The primacy of spatial context in the neural representation of events. J. Neurosci. 38, 2755–2765 (2018).
Ritchey, M., Wing, E. A., LaBar, K. S. & Cabeza, R. Neural similarity between encoding and retrieval is related to memory via hippocampal interactions. Cereb. Cortex 23, 2818–2828 (2013).
Gordon, A. M., Rissman, J., Kiani, R. & Wagner, A. D. Cortical reinstatement mediates the relationship between content-specific encoding activity and subsequent recollection decisions. Cereb. Cortex 24, 3350–3364 (2014).
Wing, E. A., Ritchey, M. & Cabeza, R. Reinstatement of individual past events revealed by the similarity of distributed activation patterns during encoding and retrieval. J. Cogn. Neurosci. 27, 679–691 (2015).
Tompary, A., Duncan, K. & Davachi, L. High-resolution investigation of memory-specific reinstatement in the hippocampus and perirhinal cortex. Hippocampus 26, 995–1007 (2016).
Hasson, U., Yang, E., Vallines, I., Heeger, D. J. & Rubin, N. A hierarchy of temporal receptive windows in human cortex. J. Neurosci. 28, 2539–2550 (2008).
Lerner, Y., Honey, C. J., Silbert, L. J. & Hasson, U. Topographic mapping of a hierarchy of temporal receptive windows using a narrated story. J. Neurosci. 31, 2906–2915 (2011).
Honey, C. J. et al. Slow cortical dynamics and the accumulation of information over long timescales. Neuron 76, 423–434 (2012).
Chen, J., Hasson, U. & Honey, C. J. Processing timescales as an organizing principle for primate cortex. Neuron 88, 244–246 (2015).
Simony, E. et al. Dynamic reconfiguration of the default mode network during narrative comprehension. Nat. Commun. 7, 12141 (2016).
Ben-Yakov, A., Eshel, N. & Dudai, Y. Hippocampal immediate poststimulus activity in the encoding of consecutive naturalistic episodes. J. Exp. Psychol. Gen. 142, 1255–1263 (2013).
Lu, Q., Hasson, U. & Norman, K. A. A neural network model of when to retrieve and encode episodic memories. eLife 11, e74445 (2022).
Rissman, J., Gazzaley, A. & D’Esposito, M. Measuring functional connectivity during distinct stages of a cognitive task. Neuroimage 23, 752–763 (2004).
Thakral, P. P., Madore, K. P. & Schacter, D. L. A role for the left angular gyrus in episodic simulation and memory. J. Neurosci. 37, 8142–8149 (2017).
Sestieri, C., Corbetta, M., Romani, G. L. & Shulman, G. L. Episodic memory retrieval, parietal cortex, and the default mode network: functional and topographic analyses. J. Neurosci. 31, 4407–4420 (2011).
O’Reilly, R. C., Ranganath, C. & Russin, J. L. The structure of systematicity in the brain. Curr. Dir. Psychol. Sci. 31, 124–130 (2022).
Cooper, R. A. & Ritchey, M. Cortico-hippocampal network connections support the multidimensional quality of episodic memory. Elife 8, e45591 (2019).
Addis, D. R., Wong, A. T. & Schacter, D. L. Remembering the past and imagining the future: common and distinct neural substrates during event construction and elaboration. Neuropsychologia 45, 1363–1377 (2007).
Bellana, B., Liu, Z.-X., Diamond, N. B., Grady, C. L. & Moscovitch, M. Similarities and differences in the default mode network across rest, retrieval, and future imagining. Hum. Brain Mapp. 38, 1155–1171 (2017).
Schacter, D. L., Benoit, R. G. & Szpunar, K. K. Episodic future thinking: mechanisms and functions. Curr. Opin. Behav. Sci. 17, 41–50 (2017).
Marr, D. Simple memory: a theory for archicortex. Philos. Trans. R. Soc. London. B, Biol. Sci. 262, 23–81 (1971).
O’Reilly, R. C. & McClelland, J. L. Hippocampal conjunctive encoding, storage, and recall: avoiding a trade-off. Hippocampus 4, 661–682 (1994).
Yassa, M. A. & Stark, C. E. L. Pattern separation in the hippocampus. Trends Neurosci. 34, 515–525 (2011).
Kumaran, D. & McClelland, J. L. Generalization through the recurrent interaction of episodic memories: a model of the hippocampal system. Psychol. Rev. 119, 573–616 (2012).
Schlichting, M. L., Mumford, J. A. & Preston, A. R. Learning-related representational changes reveal dissociable integration and separation signatures in the hippocampus and prefrontal cortex. Nat. Commun. 6, 8151 (2015).
Berens, S. C. & Bird, C. M. The role of the hippocampus in generalizing configural relationships. Hippocampus 27, 223–228 (2017).
Bowman, C. R. & Zeithamova, D. Abstract memory representations in the ventromedial prefrontal cortex and hippocampus support concept generalization. J. Neurosci. 38, 2605–2614 (2018).
Rolls, E. T. The mechanisms for pattern completion and pattern separation in the hippocampus. Front. Syst. Neurosci. 7, 74 (2013).
Barnett, A. J. et al. Inrinsic connectivity reveals functionally distinct cortico-hippocampal networks in the human brain. PLoS Biol. 19, e3001275 (2021).
Glasser, M. F. et al. A multi-modal parcellation of human cerebral cortex. Nature 536, 171–178 (2016).
Reagh, Z. M., Delarazan, A. I., Garber, A. & Ranganath, C. Aging alters neural activity at event boundaries in the hippocampus and Posterior Medial network. Nat. Commun. 11, 3980 (2020).
Cooper, R. A., Kurkela, K. A., Davis, S. W., & Ritchey, M. Mapping the organization and dynamics of the posterior medial network during movie watching. NeuroImage 236, 118075 (2021).
Zwaan, R. A., Langston, M. C. & Graesser, A. C. The construction of situation models in narrative comprehension: an event-indexing model. Psychol. Sci. 6, 292–297 (1995).
Zacks, J. M., Speer, N. K. & Reynolds, J. R. Segmentation in reading and film comprehension. J. Exp. Psychol. Gen. 138, 307–327 (2009).
Zacks, J. M. The brain’s cutting-room floor: segmentation of narrative cinema. Front. Hum. Neurosci. 4, 168 (2010).
Zacks, J. M., Speer, N. K., Swallow, K. M., Braver, T. S. & Reynolds, J. R. Event perception: a mind-brain perspective. Psychol. Bull. 133, 273–293 (2007).
Zacks, J. M., Kumar, S., Abrams, R. A. & Mehta, R. Using movement and intentions to understand human activity. Cognition 112, 201–216 (2009).
Richmond, L. L. & Zacks, J. M. Constructing experience: event models from perception to action. Trends Cogn. Sci. 21, 962–980 (2017).
van Kesteren, M. T. R., Ruiter, D. J., Fernández, G. & Henson, R. N. How schema and novelty augment memory formation. Trends Neurosci. 35, 211–219 (2012).
Brod, G., Lindenberger, U., Werkle-Bergner, M. & Shing, Y. L. Differences in the neural signature of remembering schema-congruent and schema-incongruent events. Neuroimage 117, 358–366 (2015).
Greve, A., Cooper, E., Tibon, R. & Henson, R. N. Knowledge is power: prior knowledge aids memory for both congruent and incongruent events, but in different ways. J. Exp. Psychol. Gen. 148, 325–341 (2019).
Richter, F. R., Bays, P. M., Jeyarathnarajah, P. & Simons, J. S. Flexible updating of dynamic knowledge structures. Sci. Rep. 9, 2272 (2019).
Bonasia, K. et al. Prior knowledge modulates the neural substrates of encoding and retrieving naturalistic events at short and long delays. Neurobiol. Learn. Mem. 153, 26–39 (2018).
Diamond, N. B., Armson, M. J. & Levine, B. The truth is out there: accuracy in recall of verifiable real-world events. Psychol. Sci. 31, 1544–1556 (2020).
Levine, B., Svoboda, E., Hay, J. F., Winocur, G. & Moscovitch, M. Aging and autobiographical memory: dissociating episodic from semantic retrieval. Psychol. Aging 17, 677–689 (2002).
Cohn-Sheehy, B. I. et al. Narratives bridge the divide between distant events in episodic memory. Mem. Cognit. 50, 478–494 (2021).
Esteban, O. et al. fMRIPrep: a robust preprocessing pipeline for functional MRI. Nat. Methods 16, 111–116 (2019).
Esteban, O. et al. fMRIPrep: a robust preprocessing pipeline for functional MRI. https://doi.org/10.5281/ZENODO.4252786 (2020).
Gorgolewski, K. et al. Nipype: a flexible, lightweight and extensible neuroimaging data processing framework in Python. Front. Neuroinform. 5, 13 (2011).
Gorgolewski, K. J. et al. Nipype: a flexible, lightweight and extensible neuroimaging data processing framework in Python. 0.13.1. https://doi.org/10.5281/ZENODO.581704 (2017).
Tustison, N. J. et al. N4ITK: improved N3 bias correction. IEEE Trans. Med. Imaging 29, 1310–1320 (2010).
Dale, A. M., Fischl, B. & Sereno, M. I. Cortical surface-based analysis. Neuroimage 9, 179–194 (1999).
Klein, A. et al. Mindboggling morphometry of human brains. PLoS Comput. Biol. 13, e1005350 (2017).
Fonov, V., Evans, A., McKinstry, R., Almli, C. & Collins, D. Unbiased nonlinear average ageappropriate brain templates from birth to adulthood. Neuroimage 47, S102 (2009).
Avants, B., Epstein, C., Grossman, M. & Gee, J. Symmetric diffeomorphic image registration with cross-correlation: evaluating automated labeling of elderly and neurodegenerative brain. Med. Image Anal. 12, 26–41 (2008).
Zhang, Y., Brady, M. & Smith, S. Segmentation of brain MR images through a hidden Markov random field model and the expectation-maximization algorithm. IEEE Trans. Med. Imaging 20, 45–57 (2001).
Cox, R. W. AFNI: software for analysis and visualization of functional magnetic resonance neuroimages. Comput. Biomed. Res. 29, 162–173 (1996).
Jenkinson, M., Bannister, P., Brady, M. & Smith, S. Improved optimization for the robust and accurate linear registration and motion correction of brain images. Neuroimage 17, 825–841 (2002).
Andersson, J. L. R., Skare, S. & Ashburner, J. How to correct susceptibility distortions in spinecho echo-planar images: application to diffusion tensor imaging. Neuroimage 20, 870–888 (2003).
Greve, D. N. & Fischl, B. Accurate and robust brain image alignment using boundary-based registration. Neuroimage 48, 63–72 (2009).
Behzadi, Y., Restom, K., Liau, J. & Liu, T. T. A component based noise correction method (CompCor) for BOLD and perfusion based fMRI. Neuroimage 37, 90–101 (2007).
Power, J. D. et al. Methods to detect, characterize, and remove motion artifact in resting state fMRI. Neuroimage 84, 320–341 (2014).
Abraham, A. et al. Machine learning for neuroimaging with scikit-learn. Front. Neuroinform. 8, 14 (2014).
Henriksson, L., Khaligh-Razavi, S. M., Kay, K. & Kriegeskorte, N. Visual representations are dominated by intrinsic fluctuations correlated between areas. NeuroImage 114, 275–286 (2015).
Ritchey, M., Montchal, M. E., Yonelinas, A. P. & Ranganath, C. Delay-dependent contributions of medial temporal lobe regions to episodic memory retrieval. Elife 4, e05025 (2015).
Acknowledgements
We thank Jessica Macaluso and Ryan Bugsch for assisting with the scoring of recall transcripts. We thank current and former members of the Dynamic Memory Lab for crucial feedback, with special thanks to Brendan Cohn-Sheehy, Jordan Crivelli-Decker, and Derek Huffman. We thank Alex Barnett and Kamin Kim for acting in the videos in addition to providing helpful input. We thank Sarah Morse for their helpful input on the manuscript. We thank Delta of Venus, Mishka’s Café, The Nugget, and Davis Food Co-Op in Davis, California for allowing us to record videos featuring their businesses. Finally, we thank our funding sources for supporting this work: ONR Grant N00014-15-1-0033 to C.R. and NIA T32AG050061 to Z.M.R.
Author information
Authors and Affiliations
Contributions
Z.M.R. and C.R. designed the research and wrote the paper. Z.M.R. conducted the experiments and analyzed the data.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Vishnu Murty and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Reagh, Z.M., Ranganath, C. Flexible reuse of cortico-hippocampal representations during encoding and recall of naturalistic events. Nat Commun 14, 1279 (2023). https://doi.org/10.1038/s41467-023-36805-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-023-36805-5
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
