
Abstract
The El Niño Southern Oscillation (ENSO) is a semi-periodic fluctuation in sea surface temperature (SST) over the tropical central and eastern Pacific Ocean that influences interannual variability in regional hydrology across the world through long-range dependence or teleconnections. Recent research has demonstrated the value of Deep Learning (DL) methods for improving ENSO prediction as well as Complex Networks (CN) for understanding teleconnections. However, gaps in predictive understanding of ENSO-driven river flows include the black box nature of DL, the use of simple ENSO indices to describe a complex phenomenon and translating DL-based ENSO predictions to river flow predictions. Here we show that eXplainable DL (XDL) methods, based on saliency maps, can extract interpretable predictive information contained in global SST and discover SST information regions and dependence structures relevant for river flows which, in tandem with climate network constructions, enable improved predictive understanding. Our results reveal additional information content in global SST beyond ENSO indices, develop understanding of how SSTs influence river flows, and generate improved river flow prediction, including uncertainty estimation. Observations, reanalysis data, and earth system model simulations are used to demonstrate the value of the XDL-CN based methods for future interannual and decadal scale climate projections.
Similar content being viewed by others


Introduction
The El Niño-Southern Oscillation (ENSO) is a primary mode of interannual weather variability around the globe. ENSO modulates flood timings in Africa1, interannual variability of flow in the Ganges, the Amazon, and the Congo rivers2,3, and has significant influences on regional climate and hydrologic patterns around the globe. A predictive understanding of ENSO is thus of economic and societal importance. However, and our ability to predict ENSO with physics-based numerical simulations or data-driven models at interannual, decadal, and multidecadal time horizons have remained relatively poor4, which has in turn hindered our ability to assess and leverage the predictability of ENSO’s hydrometeorological effects.
Some challenges in ENSO forecasting may be traced back to data limitations, such as the relatively arbitrary rectangular regions that determine ENSO indices. Studies have suggested that ENSO is part of a larger system of interrelated SST oscillations which may co-impact regional hydrometeorology5. Further, our understanding of physical mechanisms6 along with data-driven methods7 suggest that the relationships between ENSO and river flows may be highly nonlinear. The resulting complexity of the earth system calls for methods that can leverage complete information content from global SST data and identify complex geographic dependence structures, which include both proximity-based dependence and long-range teleconnections. Figure 1 shows SST anomalies in year 2008 when there was a cool year (La Nina phenomenon), while Fig. S1a, S1b show SST anomalies in a warm year (El Niño) and a neutral year, respectively. The relationships between river flows and ENSO indices indicate the possibility of significant nonlinear dependency (Table S3 and Figs. S2, S3).

a Regions for calculating El Niño–Southern Oscillation (ENSO) indices (Niño 1 + 2, Niño 3, Niño 3.4 and Niño 4) and Indian Ocean Dipole Mode Index (DMI), and two hydrological regions (Amazon River basin and Congo River basin). The colors shown on the ocean are the annual sea surface temperature (SST) anomaly in 2008, a La Niña year. b Time series of standardized annual river flow in m3/s for Amazon (green) and Congo (lime) and monthly Oceanic Niño Index (ONI) in the Niño 3.4 region at the same time-period. The ONI data are from United States Climate Prediction Center (NOAA 2021). Warm (red) and cold (blue) periods show months that are higher than +0.5 °C or lower than −0.5 °C threshold for a minimum of five consecutive months. A warm/cold year is a year when warm/cold anomaly months dominate, and a neutral year is a year that is neither a warm nor a cold year. For Amazon, the river flow decreases during the warm period and increases during the cold period. However, the relations between Congo River flow and ONI are more complicated and not obvious.
Commonly used methods to identify dependencies among climate variables include visual comparison8, correlation9, mutual information7, coefficient of determination10, and weights in (sparse) linear regression11,12. These methods often require heuristic expertise in selecting features and can be difficult to extend to more complex features such as three-dimensional spatiotemporal features. In the recent years, deep learning methods have seen preliminary success in climate science, meteorology, and hydrology, resulting in improved predictive skills and the development of methods to investigate the spatiotemporal dependencies13,14. Furthermore, methods for interpretation and explanation of deep neural networks, such as saliency maps, can be adapted to climate problems to analyze relevant (SST) regions resulting in understandable predictive information for regional climate and hydrology. Simonyan et al.15 initially proposed the saliency map method as a visualization technique to explain the neural network function mapping, specifically, the extent to which inputs contribute to network output. Due to their effectiveness, explainable deep learning methods have been widely applied to the geosciences and especially to understand climate science and translate to impacts, for example, in spatial drought prediction16, satellite-based PM2.5 (air pollution) measurements17, crop yields18, species distribution models19, analysis of hailstorms20, hydro-climatological process modeling21, precipitation quality control22 and climate drivers for global temperature23, and to localize pest insects in agricultural application24. Ham et al.13 used a saliency map to analyze which regions contributed most in predicting the Niño 3.4 index using their neural network. Similarly, Mahesh et al.25 applied saliency maps to find the important geographic regions for predicting Niño 3.4 index.
Here we address the problem of developing explainable predictive insights relating to the ENSO phenomenon. Our approach is based on an eXplainable Deep Learning (XDL) solution15 that concurrently uses convolutional neural networks (CNN) for the prediction of river flow time series and saliency maps to explain the results by highlighting the relative importance of the spatiotemporal SST data. Our implicit hypothesis is that the XDL approach will lead to advances in predictive skills of river flows by considering the information content in the entire SST map, which should exceed the information content of ENSO indices. Furthermore, the XDL approach may lead to discoveries of robust SST teleconnections with each other and with river flows, which in turn would further explain the gains in predictive skills. We develop correlation-based metrics to quantify SST autocorrelations and teleconnections either owing to known proximity-based spatial correlations or owing to known long-range spatial dependence. The approaches are developed for proxy observations (reanalysis) datasets as well as earth system model (ESM) simulated Coupled Modeling Intercomparison Project phase 5 (CMIP5) data, both for assessments of historical skills as well as for use in future projections of teleconnections and river flows which represent a major gap in current generation earth system models26,27,28.
Results and discussion
We trained a CNN (Fig. S4) to predict monthly Amazon and Congo River flow from monthly SST derived from Earth System Models (ESM) and reanalysis data. We compared the skill to that of an ensemble of ML models, which predicted river flow using only indices calculated from the Niño 3.4 region (5°S–5°N, 170°W–120°W). These indices include mean SST over the Niño 3.4 region as observed and modeled in reanalysis and ESMs, as well as the Niño 3.4 index, an anomaly value. We found that models with access to the larger SST area (41.5°S–37.5°N, 50.5°E–9.5°W), with its full spatial and temporal provenance. outperformed models using the ENSO indices for prediction of three-month rolling mean river flows on both the Amazon on the Congo River (Fig. 2). The CNN ingesting more SST information also outperformed the historical climatological mean as a predictor of the Amazon and Congo River flows. This suggests the larger SST region was useful for capturing the phase and amplitude of annual river flow fluctuations as well as components of interannual variation. Predictive information on the interannual variability of the Amazon River flow was either not fully expressed in the ENSO region, or else was not captured by the ensemble of ML models (linear regression, lasso regression, ridge regression, elastic net regression, random forest regression, and feed forward dense neural network, or DNN, regression).

River flow ground truth observations (black) and predictions using different predictors from January 2003 to December 2005 for Amazon (a) and Congo (b) iver. The predictors are mean Niño 3.4 calculated from 32 Earth System Models (ESM) (ESM Mean Niño 3.4), Niño 3.4 calculated from each of 32 ESMs (ESM Niño 3.4), Niño 3.4 index from NOAA (Niño 3.4), Niño 3.4 calculated from 3 reanalysis (Reanalysis Mean Niño 3.4), Niño 3.4 calculated from each of 3 Reanalysis (Reanalysis Niño 3.4), Niño 3.4 anomaly (Niño 3.4 index calculated by NOAA from HadISST1), sea surface temperature (SST) from 32 ESMs (ESM SST, light purple) and SST from 3 reanalysis (Reanalysis SST, gray). Seasonality was subsequently added to the predictions of river flow anomaly based on Niño 3.4 anomaly to generate absolute river flow. The brown line is the historical average prediction result. For models using El Niño–Southern Oscillation (ENSO) index as predictor, we applied six models [linear regression, ridge regression, elastic net regression, random forest regression and deep neural network regression] and use their ensemble as the final prediction. The shaded areas are 1 standard deviation for ensemble methods and historical averaging.
For SST as a predictor of river flow, seasonality was not removed to avoid potential information loss when delineating between anomaly and climatological states, which may be imprecise due random-frequency climate variability with periods exceeding typical climatological time scales. Thus, the task of the SST models was to predict the temporal climatology of river flow values. With the Niño 3.4 index as a predictor of river flow anomaly, and seasonality was subsequently added back to the river flow value. For the Amazon River, we found that all models using climatological SST in the Niño 3.4 outperformed models using the Niño 3.4 anomaly.
The task of predicting Congo River flow was more challenging, perhaps influenced by the more extensive management of the Congo River basin compared to the Amazon River basin. However, predictions based on reanalysis model SST still resulted in lower RMSE than baseline predictions based on the historical climatological mean for the Congo River. In most cases, Congo River flow predictions based on Niño 3.4 anomaly value (index) outperformed predictions based on the climatological value of SST in the Niño 3.4 region. A full comparison of RMSE for river flow prediction using indices and larger area SST is presented in Table S2.
Prediction of river flow using zero lag (concurrent) SST data is relevant to predicting future river flow in climate projections. Mappings between observations of river flow can also give insight into the predictability of the system; deeper analysis of CNN performance and historical average (presented in Tables S4 and S5) suggests that the methods compare differently when different aspects of performance (linear/nonlinear correlation, seasonal/yearly, extremes, etc.) are examined. For example, the ESM + CNN model achieved a lower mean absolute error and stronger association with Amazon River flow by metrics of linear correlation than the climatological mean, but has a higher RMSE in spring, when Amazon River discharge generally peaks.
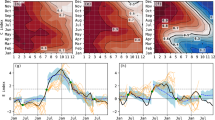
We used a cyclical saliency map method to identify important spatial areas for the network to make predictions of river flows (Fig. 3). From the saliency maps we discover that the predictive power of ESMs comes mainly from the ENSO and the Indian Ocean Dipole (IOD) regions, suggesting a strong link between these two phenomena and a co-impact on regional hydrology. Figure 3a shows that the dominant salient areas for Amazon River flow prediction are in tropical Pacific and Indian Oceans. Figure 3c shows similar patterns but with less strong and smaller salient areas for Congo River flow. When using reanalysis data (Fig. 3b, d), the saliency maps are much more diffused, suggesting that the CNN model does not pick up any strong relationships between the predictor and predictand. However, the presence of linear and nonlinear information content about river flow in global SST is confirmed by the maps in Fig. S6. The yearly cyclical saliency maps and seasonal saliency maps are also presented in Fig. S5–S8. Whereas saliency maps can be used to verify the physically reasonable relationships that are learned, our hypothesis can be confirmed by examining the degree to which known oceanic regions that correspond to the ENSO region, as well as oceanic regions that correlate with the ENSO region, are triggered by the saliency maps as contributors to the information content.

a, b Saliency Map for Amazon River flow prediction using Earth System Models (ESM) (a) and reanalysis (b) sea surface temperature (SST), respectively. c, d Saliency Map for Congo River flow prediction using ESMs (c) and reanalysis (d) SST, respectively. When using ESM SST as predictor, the salient areas mainly lie in the tropical Pacific and Indian Ocean, but they are much more diffused when using reanalysis SST.
Complex network theory provides a complementary tool to investigate the short and long-distance relationships in earth systems, such as teleconnections associated with the ENSO phenomenon that are indicated by our results. We analyzed the correlation structure of global SST data by constructing degree maps for reanalysis and ESM SST (Fig. 4). We quantified temporal correlation by calculating Pearson’s correlation coefficient between every pair of locations in the ocean. The degree of each geographical location is the number of edges connected to this location, where an edge exists if the correlation is larger than a threshold c1. We also set a second correlation threshold c2 and distance threshold d to define a teleconnection. We define that there is a teleconnection between two locations if their distance is larger than d km and the correlation is larger than c2.

a, c Degree map and teleconnections for mean Earth System Model (ESM) sea surface temperature (SST). (a) correlation threshold equal to 0.5 and 0.9 for degree and teleconnection. c correlation threshold equal to 0.9 and 0.9 for degree and teleconnection. b, d Degree map and teleconnections for mean Reanalysis SSTs. b correlation threshold equal to 0.5 and 0.5 for degree and teleconnection. d Correlation threshold equal to 0.9 and 0.9 for degree and teleconnection. We show teleconnections with distance larger than 19,000 km and 15,000 km for ESM and Reanalysis SST, respectively. e.g. the histogram of edges using correlation threshold 0.5 and 0.9 for mean ESM SST. f, h The histogram of edges using correlation threshold 0.5 and 0.9 for mean Reanalysis SST.
We find that ESM SST has high degree values over a large area, indicating that the SST are highly correlated through both proximity-based correlations and teleconnections. There are many teleconnections between tropical Pacific Ocean, Indian Ocean, and even Atlantic Ocean, and they are largely concentrated around the equator (Fig. 4a). The teleconnections remain strong when the correlation threshold is increased (Fig. 4c). This pattern is reflected in the histogram of edges, which shows the degree distribution (Fig. 4e, g). There are many edge counts for long distances, which demonstrate the multicollinearity between SST regions. In contrast, the histograms of edges for reanalysis data (Fig. 4b, d) show fewer long-distance connections for a low correlation threshold, and negligible long-distance connections with a high correlation threshold. These results indicate a weaker correlation structure in reanalysis SST compared to ESM SST, and are consist with recent literature indicating that ESMs tend to exhibit a stronger coupling than reanalysis or observations29,30,31,32. Extending these findings, a hypothesis for future studies by climate science and earth system modeling communities is that the coupling strength of ESM model components are usually stronger than those in observations or reanalysis, and that data-driven sciences may be able to quantify and bridge this gap.
Histograms of connection distance in each of ESMs indicate qualitative differences in the correlation structures of the models (Figs. S9, S10); some exhibit a single peak corresponding to proximity-based correlations (e.g. Fig. S9a), while others also exhibit clusters of long-range connections (e.g. Fig. S9f). Models also vary in the rapidity of decay of proximity-based correlations with increasing distance. These attributes of these plots indicate distinct spatiotemporal correlation structures among the climate models.
ENSO is a complex spatiotemporal process with global impacts on SST and the flows of large rivers globally, especially around the tropics and subtropics. In this work, we combined ML methods and interpretive techniques to obtain gains in predictive power and make discoveries about dependence structures and teleconnections in global SST data. Although researchers often analyze the relationship between ENSO indices and the other climate variables, our results indicate that information outside of the canonical ENSO region can help to predict regional hydrology better than some representations based on hand-selected features. They suggest that additional data and data-driven technologies could lead to a better understanding of mechanisms and the flow of causality in earth systems, as well as to inform climate adaptation through augmented projections of river flow for future climate scenarios.
Methods
Flowcharts detailing the methodology are provided in Fig. S11. The processing, modeling, and evaluation steps are outlined for reanalysis data (Fig. S11a) and ESM data (Fig. S11b). The ensembling approach used to generate probabilistic river flow predictions is shown in Fig. S11c.
Datasets
We obtained monthly sea surface temperature datasets from ESM simulations and reanalysis models. The ESM datasets are downloaded from NASA Earth eXchange (NEX, https://registry.opendata.aws/nasanex/, last access May 2021). From the full set of Coupled Model Intercomparison Project Phase 5 (CMIP5) ESMs by various institutes, we discard those which have some months missing, leaving 32 ESMs. The CMIP5 historical forcing experiment spans from January 1950 to December 2005, or 672 months in total. This ESM dataset covers the whole globe with a spatial resolution of 1° longitude by 1° latitude (approximately 100 km by 100 km) with longitudes range from 0.5°E to 359.5°E, and latitudes from 87.5°N to 87.5°S. The ESM names are shown in Table S1.
In addition to ESM simulation datasets, we also use reanalysis datasets which are combinations of sparse on-site observation with other sources (such as remote sensing and satellite imaging) to produce gridded data. It is common to use reanalysis data as the proxy of true observational data because the site-based observational data are very sparse and not gridded. We use three reanalysis datasets in the experiment as predictors: Hadley-OI SST dataset33, COBE SST dataset34 and ERSSTV5 dataset35.
The merged Hadley-OI SST dataset (https://climatedataguide.ucar.edu/climate-data/merged-hadley-noaaoi-sea-surface-temperature-sea-ice-concentration-hurrell-et-al-2008) is a combination of two reanalysis datasets: HadISST136 and NOAA OI.v237. The HadISST1 dataset is derived gridded, bias-adjusted in situ observations, and the NOAA OI.v2 dataset combines in situ and satellite-derived SST data. The resulting Hadley-NOAA-OI dataset contains monthly mean sea surface temperature from the year 1870 to 2020 with a spatial resolution of 1° longitude by 1° latitude.
The COBE SST dataset (https://climatedataguide.ucar.edu/climate-data/sst-data-cobe-centennial-situ-observation-based-estimates) are centennial in situ observation-based estimation that combines SSTs from International Comprehensive Ocean-Atmosphere Data Set (ICOADS)38 release 2.0, the Japanese Kobe collection and reports from ships and buoys. ICOADS is the most comprehensive archive of global marine surface climate observations available, but the data coverage is sparse and neither gridded nor corrected. These datasets were gridded using optimal interpolation. The resulting COBE dataset contains monthly mean sea surface temperature from 1891 to 2020 with a spatial resolution of 1° longitude by 1° latitude.
The NOAA extended reconstruction SSTs version 5 (ERSSTV5) dataset (https://climatedataguide.ucar.edu/climate-data/sst-data-noaa-extended-reconstruction-ssts-version-5-ersstv5) is based on statistical interpolation of the ICOADS release 3.0 data and Argo (https://argo.ucsd.edu/) float data. The resulting ERSSTV5 dataset contains monthly mean sea surface temperature from the year 1854 to 2019 with a spatial resolution of 2° longitude by 2° latitude.
These datasets have different time spans and spatial resolutions. We performed preprocessing to align the coordinates, interpolate to the same spatial resolution by bilinear interpolation, and select the common time span. A minimal number of missing values were filled with 0, in a similar approach to the zero padding approach in machine learning, where a matrix is surrounded with zeroes to help preserve features at the image edges. After preprocessing, the resulting reanalysis input has 3 channels corresponding to the 3 reanalysis datasets described above with a spatial resolution of 1° longitude by 1° latitude. We extract the region with latitude from 37.5°N to 42.5°S and longitude from 50.5°E to 0.5°W, roughly covering most of low latitude Pacific Ocean and Indian Ocean. The resulting input image size is 80 × 300 height by width.
The Niño 3.4 SST Index time series is anomaly monthly average SST in the region with latitude from 5°S to 5°N and longitude from 170°W to 120°W with the 1981–2010 mean removed. The data is generated by the NOAA Physical Sciences Laboratory using the HadISST1 dataset36.
The river flow dataset was obtained from UCAR (A. Dai 2017) and can be downloaded from UCAR Research Data Archive website (https://rda.ucar.edu/datasets/ds551.0/index.html, last accessed January 2021). The dataset contains monthly runoff (m3/month) for many rivers in the world. The record for Amazon River was observed in the downstream Amazon River at a station in Obidos, Brazil from December 1927 to October 2018, totally 1091 months available. The record for Congo River was measured at a station in Kinshasa, Congo from January 1903 to January 2011, totally 1296 months. We calculated the moving mean river flow using a moving window of length 3 months and used it as the smoothed river flow for the third month. We took the smoothing approach the reduction in noise resulted in more robust predictions across all models.
For both predictor (SST) and predictand (river flow) our monthly data span from January 1950 to December 2005. Of this total 672 months, we use the first 600 months as our training data, the following 36 months as our validation data to select the best parameters for the model, and the last 36 months (January 2003 to December 2005) as the test data. While our dataset is limited in size by the record length, in the future additional data, including discharge data from additional rivers, can be used to bolster the results.
Neural network model
The CNN used in this paper consists of 4 convolutional layers and 3 fully connected layers. The number of output channels for each convolutional layer is 32, 32, 64 and 64, respectively. They all have stride 1. The filter sizes in the first three layers are 3 × 3, and for the fourth layer, it is 1 × 1. All convolutional layers are followed by a ReLU activation and a 2D max pooling layer with size 2 × 2 and stride 2 × 2. For the fully connected layers, the number of output feature for each layer is 128, 64 and 1, respectively. The input image size is 80 × 300 × C with different number of channels C. For all ESMs as input, C = 32. For all reanalysis input, C = 3. For mean ESMs or mean reanalysis as input, C = 1. The network output is a scalar. We set the training batch size as 64 and use Adam optimizer with initial learning rate 5 × 10−5 and weight decay 1 × 10−4.We use squared loss function and the network tries to minimize the loss function: \(\frac{1}{T}{\sum }_{t=1}^{T}{(f\left({X}_{t},w\right)-{y}_{t})}^{2}\), where T is the number of training samples, \({X}_{t}\)∊\({R}^{W\times H\times C}\)is the tth input with width W, height H and number of channels C, yt is the tth ground truth target, w = {w1,…,wL} is the set of weights from all layers. The network output \(f\left({X}_{t},w\right)={f}_{L}({f}_{L-1}(\ldots {f}_{1}({X}_{t},{w}_{1})))\), where \({f}_{l}(.,{w}_{l})\) is the mapping function for the lth layer in the neural network. Predictive uncertainty was estimated as the standard deviation of five repeated CNN predictions with different learning rates.
Saliency map and cyclical saliency map (Cyclic-SM)
The saliency map for a CNN is the derivative of the network output y with respect to the input \(X:S=\frac{\partial y}{\partial X}=\frac{\partial f(X,w)}{\partial X}\) (1), where S is the same size as the input15. The magnitude of elements Sijk in S reflects how important the corresponding input pixel Xijk (where i,j,k is the index of the width, height and channel of X) is to the output prediction. For climate variables viewed as images in different time frames, they usually exhibit some (irregular) periodicity in the time. We can utilize this property to enhance the saliency map by superimposing individual saliency maps to form a conglomerate saliency map. Specifically, we define the Cyclic-SM with a cycle M as: \({S}^{c}=\frac{1}{K+1}{\sum }_{k=0}^{K}{S}_{t+{kM}}=\frac{1}{K+1}{\sum }_{k=0}^{K}\frac{\partial {y}_{t+{kM}}}{\partial {X}_{t+{kM}}}\) (2), where \(K=\left\lfloor \frac{T-t}{M}\right\rfloor\) is the number of individual saliency maps in the cycle.
The averaging nature of the Cyclic-SM makes it more robust to gradient fluctuation and noise compared to an ordinary saliency map. In addition, Cyclic-SMs are meaningful in a climate context. For example, for monthly data, M = 12 corresponds to a natural month cycle (January, February, …, December). And we further define seasonal and yearly Cyclic-SM as the sum of saliency maps of the corresponding months. We can calculate different Cyclic-SMs with different cycles depending on the specific purpose and climate data used. For example, we can get daily, monthly, seasonal, annual or other Cyclic-SMs to analyze the dependencies between climate variables in different time scales.
Data availability
All data used are publicly available. The ESM data used in this study are available from the NASA Earth Exchange (https://registry.opendata.aws/nasanex/). The SST data [Hadley-OI (https://climatedataguide.ucar.edu/climate-data/merged-hadley-noaaoi-sea-surface-temperature-sea-ice-concentration-hurrell-et-al-2008), COBE (https://climatedataguide.ucar.edu/climate-data/sst-data-cobe-centennial-situ-observation-based-estimates), and NOAA ERSSTV5 (https://climatedataguide.ucar.edu/climate-data/sst-data-noaa-extended-reconstruction-ssts-version-5-ersstv5)] used in this study are available from UCAR Climate Data Guide. The river flow dataset was obtained from UCAR and can be downloaded from UCAR Research Data Archive (https://rda.ucar.edu/datasets/ds551.0/index.html).
Code availability
Codes are available online at https://github.com/yuminliu/SaliencyMap39.
References
Ficchì, A. & Stephens, L. Climate variability alters flood timing across Africa. Geophys. Res. Lett. 46, 8809–8819 (2019).
Whitaker, D. W., Wasimi, S. A. & Islam, S. The El Niño southern oscillation and long-range forecasting of flows in the Ganges. Int. J. Climatol. 21, 77–87 (2001).
Amarasekera, K., Lee, R., Williams, E., & Elfitah, Eltahir. ENSO and the natural variability in the flow of tropical rivers. J. Hydrol. 200, 24–39 (1997).
McPhaden, M., Zebiak, S. & Glantz, M. ENSO as an integrating concept in Earth science. Science 314, 1740–1745 (2006).
Cai, W., Rensch, P., van Cowan, T. & Hendon, H. H. Teleconnection pathways of ENSO and the IOD and the mechanisms for impacts on Australian rainfall. J. Clim. 24, 3910–3923 (2011).
Zhang, W., Jiang, F., Stuecker, M. F., Jin, F.-F. & Timmermann, A. Spurious North Tropical Atlantic precursors to El Niño. Nat. Commun. 12, 3096 (2021).
Khan, S. et al. Nonlinear statistics reveals stronger ties between ENSO and the tropical hydrological cycle. Geophys. Res. Lett. 33, (2006).
Abram, N. J. et al. Coupling of Indo-Pacific climate variability over the last millennium. Nature 579, 385–392 (2020).
Déry, S. J. & Wood, E. F. Decreasing river discharge in northern Canada. Geophys. Res. Lett. 32, (2005).
Siam, M. S. & Eltahir, E. A. B. Explaining and forecasting interannual variability in the flow of the Nile River. Hydrol. Earth Syst. Sci. 19, 1181–1192 (2015).
Chatterjee, S., Steinhaeuser, K., Banerjee, A., Chatterjee, S. & Ganguly, A. Sparse Group Lasso: Consistency and Climate Applications. In: Proc. 2012 SIAM International Conference on Data Mining 47–58 https://doi.org/10.1137/1.9781611972825.5 (Society for Industrial and Applied Mathematics, 2012).
Liu, Y., Chen, J., Ganguly, A. & Dy, J. Nonparametric mixture of sparse regressions on spatio-temporal data—an application to climate prediction. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining 2556–2564 https://doi.org/10.1145/3292500.3330692 (2019).
Ham, Y.-G., Kim, J.-H. & Luo, J.-J. Deep learning for multi-year ENSO forecasts. Nature 573, 568–572 (2019).
McGovern, A., Ii, D. J. G., Williams, J. K., Brown, R. A. & Basara, J. B. Enhancing understanding and improving prediction of severe weather through spatiotemporal relational learning. Mach. Learn. 95, 27–50 (2014).
Simonyan, K., Vedaldi, A. & Zisserman, A. Deep inside convolutional networks: visualising image classification models and saliency maps. Preprint at https://arxiv.org/abs/1312.6034 (2014).
Dikshit, A. & Pradhan, B. Interpretable and explainable AI (XAI) model for spatial drought prediction. Sci. Total Environ. 801, 149797 (2021).
Yan, X. et al. A spatial-temporal interpretable deep learning model for improving interpretability and predictive accuracy of satellite-based PM2.5. Environ. Pollut. 273, 116459 (2021).
Wolanin, A. et al. Estimating and understanding crop yields with explainable deep learning in the Indian Wheat Belt. Environ. Res. Lett. 15, 024019 (2020).
Ryo, M. et al. Explainable artificial intelligence enhances the ecological interpretability of black-box species distribution models. Ecography 44, 199–205 (2021).
Gagne, D. J., Haupt, S. E., Nychka, D. W. & Thompson, G. Interpretable deep learning for spatial analysis of severe hailstorms. Monthly Weather Rev. 147, 2827–2845 (2019).
Chakraborty, D., Başağaoğlu, H. & Winterle, J. Interpretable vs. noninterpretable machine learning models for data-driven hydro-climatological process modeling. Expert Syst. Appl. 170, 114498 (2021).
Sha, Y., Ii, D. J. G., West, G. & Stull, R. Deep-learning-based precipitation observation quality control. J. Atmos. Ocean. Technol. 38, 1075–1091 (2021).
Labe, Z. M. & Barnes, E. A. Detecting climate signals using explainable AI with single-forcing large ensembles. J. Adv. Modeling Earth Syst. 13, e2021MS002464 (2021).
Liu, Z., Gao, J., Yang, G., Zhang, H. & He, Y. Localization and Classification of Paddy Field Pests using a Saliency Map and Deep Convolutional Neural Network. Sci. Rep. 6, 20410 (2016).
Mahesh, A. et al. Forecasting El Niño with convolutional and recurrent neural networks. In: Neurips 2019 Workshop—Tackling Climate Change with Machine Learning (2019).
Bellenger, H., Guilyardi, E., Leloup, J., Lengaigne, M. & Vialard, J. ENSO representation in climate models: from CMIP3 to CMIP5. Clim. Dyn. 42, 1999–2018 (2014).
Beobide-Arsuaga, G., Bayr, T., Reintges, A. & Latif, M. Uncertainty of ENSO-amplitude projections in CMIP5 and CMIP6 models. Clim. Dyn. 56, 3875–3888 (2021).
McKenna, S., Santoso, A., Gupta, A. S., Taschetto, A. S. & Cai, W. Indian Ocean Dipole in CMIP5 and CMIP6: characteristics, biases, and links to ENSO. Sci. Rep. 10, 11500 (2020).
Mei, R. & Wang, G. Summer land–atmosphere coupling strength in the united states: comparison among observations, reanalysis data, and numerical models. J. Hydrometeorol. 13, 1010–1022 (2012).
Levine, P. A., Randerson, J. T., Swenson, S. C. & Lawrence, D. M. Evaluating the strength of the land–atmosphere moisture feedback in Earth system models using satellite observations. Hydrol. Earth Syst. Sci. 20, 4837–4856 (2016).
Levine, P. A. et al. Soil moisture variability intensifies and prolongs Eastern Amazon temperature and carbon cycle response to El Niño–Southern Oscillation. J. Clim. 32, 1273–1292 (2019).
Dirmeyer, P. A. The hydrologic feedback pathway for land–climate coupling. J. Hydrometeorol. 7, 857–867 (2006).
Hurrell, J. W., Hack, J. J., Shea, D., Caron, J. M. & Rosinski, J. A new sea surface temperature and sea ice boundary dataset for the community atmosphere model. J. Clim. 21, 5145–5153 (2008).
Ishii, M., Shouji, A., Sugimoto, S. & Matsumoto, T. Objective analyses of sea-surface temperature and marine meteorological variables for the 20th century using ICOADS and the Kobe Collection. Int. J. Climatol. 25, 865–879 (2005).
Huang, B. et al. Extended reconstructed sea surface temperature, Version 5 (ERSSTv5): upgrades, validations, and intercomparisons. J. Clim. 30, 8179–8205 (2017).
Rayner, N. A. et al. Global analyses of sea surface temperature, sea ice, and night marine air temperature since the late nineteenth century. J. Geophys. Res.: Atmos. 108, (2003).
Reynolds, R. W., Rayner, N. A., Smith, T. M., Stokes, D. C. & Wang, W. An improved in situ and satellite SST analysis for climate. J. Clim. 15, 1609–1625 (2002).
Berry, D. I. & Kent, E. C. A new air–sea interaction gridded dataset from ICOADS with uncertainty estimates. Bull. Am. Meteorol. Soc. 90, 645–656 (2009).
Liu, Y. Explainable deep learning for insights in El Niño and river flows. SaliencyMap. https://doi.org/10.5281/zenodo.7472091 (2022).
Acknowledgements
This work was funded by the NSF grants CyberSEES CCF-1442728 (J.G.D., A.R.G.), Big Data IIS-1447587 (A.R.G.), and SES-1735505 (A.R.G). K.D. and A.R.G. acknowledge support from the NASA Ames Research Center.
Author information
Authors and Affiliations
Contributions
Y.L. performed the analysis and wrote the first draft of the paper. K.D. helped define the problem and co-wrote the paper with Y.L. and A.R.G. A.R.G. and J.D. defined the problem. Y.L., K.D., A.R.G., and J.D. interpreted the results and contributed to the writeup.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Carlos Lima and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, Y., Duffy, K., Dy, J.G. et al. Explainable deep learning for insights in El Niño and river flows. Nat Commun 14, 339 (2023). https://doi.org/10.1038/s41467-023-35968-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-023-35968-5
This article is cited by
-
Deep learning for water quality
Nature Water (2024)
-
Deep learning with autoencoders and LSTM for ENSO forecasting
Climate Dynamics (2024)
-
Improved monthly streamflow prediction using integrated multivariate adaptive regression spline with K-means clustering: implementation of reanalyzed remote sensing data
Stochastic Environmental Research and Risk Assessment (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
