
Abstract
The analysis of whole-genome sequencing studies is challenging due to the large number of rare variants in noncoding regions and the lack of natural units for testing. We propose a statistical method to detect and localize rare and common risk variants in whole-genome sequencing studies based on a recently developed knockoff framework. It can (1) prioritize causal variants over associations due to linkage disequilibrium thereby improving interpretability; (2) help distinguish the signal due to rare variants from shadow effects of significant common variants nearby; (3) integrate multiple knockoffs for improved power, stability, and reproducibility; and (4) flexibly incorporate state-of-the-art and future association tests to achieve the benefits proposed here. In applications to whole-genome sequencing data from the Alzheimer’s Disease Sequencing Project (ADSP) and COPDGene samples from NHLBI Trans-Omics for Precision Medicine (TOPMed) Program we show that our method compared with conventional association tests can lead to substantially more discoveries.
Similar content being viewed by others


Introduction
The rapid development of whole-genome sequencing technology allows for a comprehensive characterization of the genetic variation in the human genome in both coding and noncoding regions. The noncoding genome covers ~98% of the human genome, and includes regulatory elements that control when, where, and to what degree genes will be expressed. Understanding the role of noncoding variation could provide important insights into the molecular mechanisms underlying different traits.
Despite the increasing availability of whole-genome sequencing datasets including those from moderate to large scale projects such as the Alzheimer’s Disease Sequencing Project (ADSP), the Trans-Omics for Precision Medicine (TOPMed) program etc., our ability to analyze and extract useful information from these datasets remains limited at this point and many studies still focus on the coding regions and regions proximal to genes1,2. The main challenges for analyzing the noncoding regions include the large number of rare variants, the limited knowledge of their functional effects, and the lack of natural units for testing (such as genes in the coding regions). To date, most studies have relied on association testing methods such as single variant tests for common variants, gene-based tests for rare variants in coding regions, or a heuristic sliding window strategy to apply gene-based tests to rare variants in the noncoding genome3,4. Only a few methods have been developed to systematically analyze both common and rare variants across the genome, owing to difficulties such as an increased burden of the multiple testing problem, more complex correlations, and increased computational cost. Moreover, a common feature of the existing association tests is that they often identify proxy variants that are correlated with the causal ones, rather than the causal variants that directly affect the traits of interest. Identification of putative causal variants usually requires a separate fine-mapping step. Fine-mapping methods such as CAVIAR5 and SUSIE6 were developed for single, common variant analysis in GWAS studies, and are not directly applicable to window-based analysis of rare variants in sequencing studies.
Methods that control the family-wise error rate (FWER) have been commonly used to correct for multiple testing in genetic associations studies, e.g., a p-value threshold of 5 × 10−8 based on a Bonferroni correction is commonly used for genome-wide significance in GWAS corresponding to a FWER at 0.05. The number of genetic variants being considered in the analysis of whole-genome sequencing data increases substantially to more than 400 million in TOPMed2, and FWER-controlling methods become highly conservative7. As more individuals are being sequenced, the number of variants increases accordingly. The false discovery rate (FDR), which quantifies the expected proportion of discoveries which are falsely rejected, is an alternative metric to the FWER in multiple testing control, and can have greater power to detect true positives while controlling FDR at a specified level. This metric has been popular in the discovery of eQTLs and Bayesian association tests for rare variation in autism spectrum disorder studies8,9,10,11. Given the limited power of conventional association tests for whole-genome sequencing data and the potential for many true discoveries to be made in studies for highly polygenic traits, controlling FDR can be a more appealing strategy. However, the conventional FDR-controlling methods, such as the Benjamini-Hochberg (BH) procedure12, often do not appropriately account for correlations among tests and therefore cannot guarantee FDR control at the target level, which can limit the widespread application of FDR control to whole-genome sequencing data.
The knockoff framework is a recent breakthrough in statistics to control the FDR under arbitrary correlation structure and to improve power over methods controlling the FWER13,14. The main idea behind it is to first construct synthetic features, i.e., knockoff features, that resemble the true features in terms of the correlation structure but are conditionally independent of the outcome given the true features. The knockoff features serve as negative controls and help us select the truly important features, while controlling the FDR. Compared to the well-known Benjamini-Hochberg procedure12, which controls the FDR under independence or a type of positive-dependence, the knockoff framework appropriately accounts for arbitrary correlations between the original variables while guaranteeing control of the FDR. Moreover, it is not limited to using calibrated p-values, and can be flexibly applied to feature importance scores computed based on a variety of modern machine learning methods, with rigorous finite-sample statistical guarantees. Several knockoff constructions have been proposed in the literature including the second-order knockoff generator proposed by Candès et al.14 and the knockoff generator for Hidden Markov Models (HMMs) proposed by Sesia et al.15,16. The HMM construction has been applied to phased GWAS data in the UK biobank. However, these constructions can fail for rare variants in whole-genome sequencing data whose distribution is highly skewed and zero-inflated, leading to inflated FDR. Romano et al.17 proposed deep generative models for arbitrary and unspecified data distributions, but such an approach is computationally intensive, and therefore not scalable to whole-genome sequencing data.
Our contributions in this paper include a sequential knockoff generator, a powerful genome-wide screening method, and a robust inference procedure integrating multiple knockoffs. The sequential knockoff generator is more than 50 times faster than state-of-the-art knockoff generation methods, and additionally allows for the efficient generation of multiple knockoffs. The genome-wide screening method builds upon our recently proposed scan statistic framework, WGScan18, to localize association signals at genome-wide scale. We adopt the same screening strategy, but incorporate several recent advances for rare-variant analysis in sequencing studies, including the aggregated Cauchy association test to combine single variant tests, burden and dispersion (SKAT) tests, the saddlepoint approximation for unbalanced case-control data, the functional score test that allows incorporation of functional annotations, and a modified variant threshold test that accumulates extremely rare variants such as singletons and doubletons19,20,21,22,23,24,25,26. We compute statistics measuring the importance of the original and knockoff features using an ensemble of these tests. Feature statistics that contrast the original and knockoff statistics are computed for each feature, and can be used by the knockoff filter to select the important features, i.e., those significant at a fixed FDR threshold. The integration of multiple knockoffs further helps improve the power, stability, and reproducibility of the results compared with state-of-the-art alternatives. Using simulations and applications to two whole-genome sequencing studies, we show that the proposed method is powerful in detecting signals across the genome with guaranteed FDR control.
Our knockoff method can be considered a synthetic alternative to knockout functional experiments designed to identify functional variation implicated in a trait of interest. For each individual in the original cohort, the proposed method generates a synthetic sequence where each genetic variant is being randomized, making it silent and not directly affecting the trait of interest while preserving the sequence correlation structure. Then the proposed method compares the original cohort where the variants are potentially functional with the synthetic cohort where the variants are silenced. The randomization utilizes the knockoff framework that ensures that the original sequence and the synthetic sequence are “exchangeable”. That is, if one replaces any part of the original sequence with its synthetic, silenced sequence, the joint distribution of genetic variants (the linkage disequilibrium structure etc.) remains the same. This leads to an important feature of our proposed screening procedure that is similar to real functional experiments, namely the ability to prioritize causal variants over associations due to linkage disequilibrium and other unadjusted confounding effects (e.g., shadow effects of nearby significant variants and unadjusted population stratification) as we show below.
In this paper, we present a statistical approach that addresses the challenges described above, and leads to increased power to detect and localize common and rare risk variants at genome-wide scale. The framework appropriately accounts for arbitrary correlations while guaranteeing FDR control at the desired level, and therefore has higher power than existing association tests that control FWER. Furthermore, the proposed method has additional important advantages over the standard approaches due to some intrinsic properties of the underlying framework. Specifically, it allows for the prioritization of causal variants over associations due to linkage disequilibrium. For analyses specifically focusing on rare variants, the method naturally distinguishes the signal due to rare variants from shadow effects of nearby significant (common or rare) variants. Additionally, it naturally reduces false positives due to unadjusted population stratification.
Results
Overview of the screening procedure with multiple knockoffs (KnockoffScreen)
We describe here the main ideas behind our method, KnockoffScreen. We assume a study population of \(n\) subjects, with \({Y}_{i}\) being the quantitative/dichotomous outcome value; \({{\bf{X}}}_{{\bf{i}}}={\left({X}_{i1},\ldots ,{X}_{{id}}\right)}^{T}\) being the \(d\) covariates which can include age, gender, principal components of genetic variation etc.; \({\left\{{G}_{{ij}}\right\}}_{1\!\le\! j\!\le\! p}\) being the \(p\) genetic variants in the genome. For each target window \({\varPhi }_{{kl}}=\left\{j{{:}}k\le j\le l\right\}\), we are interested in determining whether \({\varPhi }_{{kl}}\) contains any variants associated with the outcome of interest while adjusting for covariates.
The idea of the proposed method is to augment the original cohort with a synthetic cohort with genetic variants, \({\left\{{\widetilde{G}}_{{ij}}\right\}}_{1\!\le\! j\!\le\! p}\), referred to as knockoff features. \({\left\{{\widetilde{G}}_{{ij}}\right\}}_{1\!\le\! j\!\le\! p}\) are generated by a data driven algorithm such that they are exchangeable with \({\left\{{G}_{{ij}}\right\}}_{1\!\le\! j\!\le\! p}\), yet they do not directly affect \({Y}_{i}\) (i.e., are “silenced”, and therefore not causal). More precisely, \({\left\{{\widetilde{G}}_{{ij}}\right\}}_{1\!\le\! j\!\le\! p}\) is independent of \({Y}_{i}\) conditional on \({\left\{{G}_{{ij}}\right\}}_{1\!\le\! j\!\le\! p}\). Note that the knockoff generation procedure is different from the well-known permutation procedure which generates control features by permuting the samples; for such a permutation procedure, the exchangeability property between the original genetic variants and the synthetic ones does not hold and hence the FDR control cannot be guaranteed13,14.
The screening procedure examines every target window \({\varPhi }_{{kl}}\) in the genome and performs hypothesis testing in both the original cohort and the synthetic cohort, to test for association of \({G}_{{\Phi }_{{\rm{kl}}}}\) and \({\widetilde{G}}_{{\Phi }_{{\rm{kl}}}}\) with \(Y\) respectively. As explained below, the knockoff procedure is amenable to any form of association test within the window. Let \({p}_{{\Phi }_{{kl}}}\), \({\widetilde{p}}_{{\Phi }_{{kl}}}\) be the resulting p-values. We define a feature statistic as
where \({T}_{{\Phi }_{{kl}}}=-{{\rm{log }}}_{10}{p}_{{\Phi }_{{\rm{kl}}}}\) and \({\widetilde{T}}_{{\Phi }_{{kl}}}=-{{\rm{log }}}_{10}{\widetilde{p}}_{{\Phi }_{{\rm{kl}}}}\). Essentially, the observed p-value for each window is compared to its control counterpart in the synthetic cohort. A threshold \(\tau\) for \({W}_{{\Phi }_{{kl}}}\) can be determined by the knockoff filter so that the FDR is controlled at the nominal level. We select all windows with \({W}_{{\Phi }_{{kl}}}\ge \tau\). We additionally derived the corresponding Q-value for a window, \({q}_{{\Phi }_{{kl}}}\), that unifies the feature statistic \({W}_{{\Phi }_{{kl}}}\) and the threshold \(\tau\). More details are given in the Methods section.
The knockoff construction ensures exchangeability of features, namely that \(\left\{{G}_{{ij}}\right\}_{1\!\le\! j\!\le\! p}\) and \({\left\{{\widetilde{G}}_{{ij}}\right\}}_{1\!\le\! j\!\le\! p}\) are exchangeable. Hence if one swaps any subset of variants with their synthetic counterpart, the joint distribution remains the same. For instance, suppose that \({G}_{i1}\) and \({G}_{i2}\) are two genetic variants, then the knockoff generator will generate their knockoff counterparts \({\widetilde{G}}_{i1}\) and \({\widetilde{G}}_{i2}\) such that \(\left({G}_{i1},{G}_{i2},{\widetilde{G}}_{i1},{\widetilde{G}}_{i2}\right) \sim \left({G}_{i1},{\widetilde{G}}_{i2},{\widetilde{G}}_{i1},{G}_{i2}\right)\), where “\(\sim\)” denotes equality in distribution. More generally, for any subset \(S\subset \left\{1,\ldots ,p\right\}\),
where \({\left({G}_{i},{\widetilde{G}}_{i}\right)}_{{\rm{swap}}\left(S\right)}\) is obtained from \(\left({G}_{i},{\widetilde{G}}_{i}\right)\) by swapping the variants \({G}_{{ij}}\) and \({\widetilde{G}}_{{ij}}\) for each \(j\in S\). This feature exchangeability implies the exchangeability of the importance scores \({T}_{{\Phi }_{{kl}}}\) and \({\widetilde{T}}_{{\Phi }_{{kl}}}\) under the null hypothesis, i.e., \(\left({T}_{{\Phi }_{{kl}}},{\widetilde{T}}_{{\Phi }_{{kl}}}\right) \sim \left({\widetilde{T}}_{{\Phi }_{{kl}}},{T}_{{\Phi }_{{kl}}}\right)\) if \({\Phi }_{{kl}}\) does not contain any causal variant. Thus \({\widetilde{T}}_{{\Phi }_{{kl}}}\) can be used as the negative control, and we reject the null when \({W}_{{\Phi }_{{kl}}}={T}_{{\Phi }_{{kl}}}-{\widetilde{T}}_{{\Phi }_{{kl}}}\) is sufficiently large. This exchangeability property leads to several interesting properties of our proposed screening procedure relative to conventional association tests as mentioned in the Introduction, and which will be discussed in detail in later sections.
Once the knockoff generation is completed, we apply a genome-wide screening procedure. Our screening procedure considers windows with different sizes (1 bp, 1 kb, 5 kb, 10 kb) across the genome, with half of each window overlapping with adjacent windows of the same size. To calculate the importance score for each window \({\Phi }_{{\rm{kl}}}\), we incorporate several recent advances for association tests for sequencing studies to compute \({p}_{{\Phi }_{{\rm{kl}}}}\).
-
For each 1 bp window (i.e., single variant): we only consider common (minor allele frequency (MAF) > 0.05) and low frequency (0.01 < MAF < 0.05) variants and compute \({p}_{{\Phi }_{{\rm{kl}}}}\) from single variant score test. For binary traits, we implement the saddlepoint approximation for unbalanced case-control data.
-
For each 1 kb/5 kb/10 kb window, we perform:
-
a.
Burden and dispersion tests for common and low frequency variants with Beta (MAF, 1, 25) weights, where Beta (.) is the probability density function of the beta distribution with shape parameters 1 and 2526. These tests aim to detect the combined effects of common and low frequency variants.
-
b.
Burden and dispersion tests for rare variants (MAF < 0.01 & minor allele count (MAC) > = 5) with Beta (MAF, 1, 25) weights. These tests aim to detect the combined effects of rare variants.
-
c.
Burden and dispersion tests for rare variants, weighted by functional annotations23. Current implementation includes CADD27 and tissue/cell type specific GenoNet scores28. These tests aim to utilize functional annotations for improved power.
-
d.
Burden test for aggregation of ultra-rare variants (MAC < 5). These tests aim to aggregate effects from extremely rare variants such as singletons, doubletons etc.
-
e.
Single variant score tests for common, low frequency and rare variants in the window.
-
f.
The aggregated Cauchy association test29 to combine a-e to compute \({p}_{{\Phi }_{{\rm{kl}}}}\).
-
a.
We also extend the single knockoff described above to the setting with multiple knockoffs to improve the power, stability and reproducibility of the findings. Let \(q\) be the FDR threshold. The inference based on a single knockoff is limited by a detection threshold of \(1/q\), defined as the minimum number of independent signals required for making any discovery. It has no power at the target FDR level \(q\) if there are fewer than \(1/q\) discoveries to be made. The multiple knockoffs improve the detection threshold from \(1/q\) to \(1/({Mq})\), where \(M\) is the number of knockoffs30. For example, the detection threshold is 10 when the target FDR = 0.1. In scenarios where the signal is sparse (<10 independent causal variants) in the target region or across the genome, inference based on a single knockoff can have very low power to detect any of the causal variants. In such a setting, KnockoffScreen with \(M\) knockoffs reduces the detection threshold from 10 to \(10/M\), which allows KnockoffScreen to detect sparse signals in a target region or across the genome. Furthermore, integrating multiple knockoffs leads to improvements in the stability and reproducibility of the knockoff procedure. Specifically, the results of the KnockoffScreen procedure depend to some extent on the sampling of knockoff features \({\left\{{\widetilde{G}}_{{ij}}\right\}}_{1\!\le\! j\!\le\! p}\), which is random. Therefore, running the analysis twice on the same dataset may lead to the selection of slightly different subsets of features. In particular, for weak causal effects, there is a chance that the causal variant is selected in only one of the analyses. We demonstrate in the Methods section that our choice of multiple knockoff statistics helps improve the stability of the results compared with state-of-the-art alternatives.
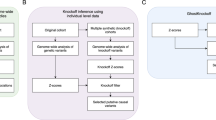
In the Methods section, we describe in detail our computationally efficient method to generate the knockoff features, and our multiple knockoffs method. A flowchart of our approach is shown in Fig. 1.

a Knockoff generation based on the original genotype matrix. Each row in the matrix corresponds to an individual and each column corresponds to a genetic variant. Each cell presents the genotype value/dosage. b Calculation of the importance score for each 1 bp, 1 kb, 5 kb, or 10 kb window. c Example of genome-wide screening results using conventional association testing (top) and KnockoffScreen (bottom).
KnockoffScreen improves power and guarantees FDR control in single-region simulation studies
We performed empirical power and FDR simulations to evaluate the performance of KnockoffScreen in a single region. We compared it with existing alternatives for sequence-based association testing, including the burden and dispersion (SKAT) tests with Beta(MAF;1,25) weights. For a fair and simplified comparison, we did not include additional functional annotations in our method for these simulations. Note that burden and SKAT are also applied within the knockoff framework, and therefore we still aim at controlling the FDR. We also compared state-of-the-art methods for generating knockoff features, including the second-order knockoff generator proposed by Candès et al.14, referred to as SecondOrder, and the knockoff generator for Hidden Markov Models (HMMs) proposed by Sesia et al.15,16 with number of states S = 50. For simulating the sequence data, each replicate consists of 10,000 individuals with genetic data on 1000 genetic variants from a 200 kb region, simulated using the haplotype dataset in the SKAT package. The SKAT haplotype dataset was generated using a coalescent model (COSI), mimicking the linkage disequilibrium structure of European ancestry samples. Simulation details are provided in the Methods section. We compared the methods in different scenarios for common and rare variants, quantitative traits, and dichotomous traits. For each replicate, the empirical power is defined as the proportion of detected windows among all causal windows (windows that contain at least one causal variant); the empirical FDR is defined as the proportion of non-causal windows among all detected windows. We present the average power and FDR over 1000 replicates in Fig. 2. We additionally present the distribution of power and the false discovery proportion (FDP) at target FDR level 0.1 over 1000 replicates in Supplementary Fig. 1.

The four panels show power and FDR base on 500 replicates for different types of traits (quantitative and dichotomous) and different types of variants (rare and common), with different target FDR varying from 0 to 0.2. The different colors indicate different knockoff generators. The different types of lines indicate different tests to define the importance score. Source data are provided as a Source Data file.
The comparisons of the different knockoff generators show that KnockoffScreen has significantly improved power with a better FDR control. For single knockoff generators, SecondOrder and HMMs have inflated FDR for rare variants. We also observed that the HMM-based knockoff has inflated FDR for common variants for the window-based screening procedure considered in this paper. KnockoffScreen has well-controlled FDR, and significantly higher power compared with a single knockoff, especially when the target FDR \(q\) is small. This is due to the high detection threshold (\(1/q\)) needed for the single knockoff. Our multiple knockoff method KnockoffScreen incorporates five knockoffs, and as a consequence the detection threshold is reduced from \(1/q\) to \(1/(5q)\), which helps improve power. We note that the power of methods with single knockoff and multiple knockoffs may be comparable in settings where the detection threshold is not a primary factor that limits the power, such as for higher target FDR values. Furthermore, we observed that the additional tests included in KnockoffScreen improve its power, compared to the burden and SKAT tests with the same number of knockoffs. In summary, the simulation results show that the screening procedure and multiple knockoffs help improve power while controlling FDR at the nominal level.
KnockoffScreen improves genome-wide locus discovery for polygenic traits
We conducted genome-wide empirical FDR and power simulations using ADSP whole-genome sequencing data to evaluate the performance of KnockoffScreen in the presence of multiple causal loci. Specifically, we randomly choose 10 causal loci and 500 noise loci across the whole genome, each of size 200 kb. Each causal locus contains a 10 kb causal window. For each replicate, we randomly set 10% variants in each 10 kb causal window to be causal. In total, there are approximately 335 causal variants on average across the genome. Simulation details are provided in the Methods section. We compared the proposed KnockoffScreen method to conventional p-value based methods including Bonferroni correction for FWER control, and BH procedure for FDR control. For KnockoffScreen we also evaluated the effect of different numbers of knockoffs. We evaluated the empirical power and FDR at target FDR 0.10. For each replicate, the power is defined as proportion of the 200 kb causal loci detected by each method; the empirical FDR is defined as the proportion of significant windows ±100/75/50 kb away from the causal windows. We report the average power and FDR over 100 replicates in Fig. 3.

a, c Empirical power for different types of traits (quantitative and dichotomous), defined as the average proportion of 200 kb causal loci being identified at target FDR 0.1. b, d Empirical FDR for different types of traits (quantitative and dichotomous) at different resolutions, defined as the proportion of significant windows (target FDR 0.1) ± 100/75/50 kb away from the causal windows. The empirical power and FDR have averaged over 100 replicates. Source data are provided as a Source Data file.
The simulation results show that KnockoffScreen exhibits substantially higher power than using Bonferroni correction. Additionally, using the conventional Benjamini-Hochberg FDR control may have higher power than KnockoffScreen, but fails to control FDR at higher resolution (e.g., ±75 kb). Statistically, the knockoff filter is expected to have similar or higher power for independent tests compared with the BH procedure13. For correlated genetic variants/windows, the higher empirical power of the BH procedure in our simulation studies is subject to false-positive inflation. Therefore, we do not recommend directly using the conventional BH procedure in whole genome sequencing studies. In the presence of multiple causal loci and at a moderate target FDR, we observe that the power is similar for different number of knockoffs because the aforementioned detection threshold is no longer an issue. Thus, multiple knockoffs are particularly useful when the number of causal loci is small, and the target FDR is stringent. Regardless of the effect on power, an important advantage of using multiple knockoffs is that it can significantly improve the stability and reproducibility of knockoff-based inference. Since the knockoff sampling is random, each run of the knockoff procedure may lead to different selected sets of features. In practice, strong signals will always be selected but weak signals may be missed at random with a single knockoff. The proposed multiple knockoff procedure has significantly smaller variation in feature statistic in our simulation study based on real data from ADSP. We discuss the details in the Methods section (Fig. 9).
KnockoffScreen prioritizes causal variants/loci over associations due to linkage disequilibrium
The exchangeability properties for the features help the inference based on the feature statistic \({W}_{{\Phi }_{{kl}}}={T}_{{\Phi }_{{kl}}}-{\widetilde{T}}_{{\Phi }_{{kl}}}\) to prioritize causal variants/loci over associations due to linkage disequilibrium (LD). For example, suppose \({G}_{i1}\) is causal and \({G}_{i2}\) is a null variant correlated with \({G}_{i1}\); \(\left({\widetilde{G}}_{i1},{\widetilde{G}}_{i2}\right)\) are exchangeable with \(\left({G}_{i1},{G}_{i2}\right)\), therefore \({\rm{cor}}\left({G}_{i1},{\widetilde{G}}_{i2}\right)\approx {\rm{cor}}\left({G}_{i1},{G}_{i2}\right)\). Thus, the resulting p-values \({p}_{2}\) ~ \({\widetilde{p}}_{2}\), and hence \({W}_{2}=-{\rm{log }}{p}_{2}-\left(-{\rm{log }}{\widetilde{p}}_{2}\right)\) follows a distribution that is symmetric around 0. This way, by comparing the p-value of \({G}_{i2}\) (a null variant) to that of its control counterpart, the method no longer identifies the proxy variant \({G}_{i2}\) as significant. On the other hand, the knockoff generation minimizes the correlation between feature \({G}_{i1}\) and its knockoff counterpart \({\widetilde{G}}_{i1}\), such that \({W}_{1}=-{\rm{log }}{p}_{1}-\left(-{\rm{log }}{\widetilde{p}}_{1}\right)\) takes positive value with higher probability and therefore can identify the causal variant \({G}_{i1}\) as significant.
We compared KnockoffScreen with state-of-the-art methods which perform association tests in each window and apply a hard threshold (e.g., Bonferroni correction) to control for FWER. For a fair comparison, for the conventional association testing we adopted the same combination of tests (i.e., we combined the same single variant and region-based tests) implemented in KnockoffScreen to calculate the p-value. As a proof of concept, we show first the results from an analysis of common and rare variants within a 200 kb region near the apolipoprotein E (APOE) gene for Alzheimer’s Disease (AD), using data on 3,894 individuals from the Alzheimer’s Disease Sequencing Project (ADSP). More details on the data analysis for ADSP are described in a later section. APOE is a major genetic determinant of AD risk, containing AD risk/protective alleles. APOE comes in three forms (APOE \(\varepsilon 2/\varepsilon 3/\varepsilon 4\)). Among them, \(\varepsilon 2\) is the least common and confers reduced risk to AD, \(\varepsilon 4\) is the most common and increases risk to AD, while \(\varepsilon 3\) appears neutral. We found that the conventional association test using a Bonferroni correction identifies a large number of significant associations (\(p\, <\, 0.05\)/number of tested windows), but most of these windows are presumably false positives due to LD since they are no longer significant after adjusting for the APOE alleles (Fig. 4a). In contrast, KnockoffScreen filtered out a considerable number of associations that are likely due to LD, and identified more refined windows that reside in APOE and APOC1 at target FDR = 0.1 (Fig. 4b). A recent study identified AD risk variants and haplotypes in the APOC1 region, and showed that these signals are independent of the APOE-ε4 coding change, consistent with our findings31.

a, b Results of the data analyses of the APOE ± 100 kb region from the ADSP data. Each dot represents a window. Windows selected by KnockoffScreen are highlighted in red. Windows selected by conventional association testing but not by KnockoffScreen are shown in gray. c–e Simulation results based on the APOE ± 100 kb region, comparing the conventional association testing and KnockoffScreen methods in terms of c, frequency of selected variants/windows overlapping with the causal region; d Maximum distance of selected variants/windows to the causal region; e number of false positives due to shadow effect. The target FDR is 0.1. The density plots are based on 500 replicates. Source data are provided as a Source Data file.
We conducted additional simulation studies to further investigate this property. We randomly drew a subset of variants (1000 variants) from the 200 kb region near APOE, set a 5 kb window (similar to the size of APOE) as the causal window, and then simulated disease phenotypes. More details on these simulations are provided in the Methods section. With target FDR = 0.1, we evaluated the proportion of selected windows overlapping the true causal window, and the maximum distance between the selected windows and the causal window. Figure 4c, d shows the results over 500 replicates. We found that windows selected by KnockoffScreen have a significantly better chance to overlap with the causal window relative to the conventional association test. We also found that the maximum distance between the selected windows and the causal window is significantly smaller for KnockoffScreen. Particularly, the distribution of the maximum distance to the causal window is zero-inflated for KnockoffScreen; these are cases where all windows detected by KnockoffScreen overlap/cover the causal window.
Overall, the real data example and these simulation results demonstrate that KnockoffScreen is able to prioritize causal variants over associations due to linkage disequilibrium and produces more accurate results in detecting disease risk variants/loci, thereby improving interpretation of the findings.
KnockoffScreen distinguishes the signal due to rare variants from shadow effects of significant common variants nearby
Conventional sequence-based association tests focused on rare variants (MAF below a certain threshold, e.g., 0.01) can lead to false positive findings by identifying rare variants that are not causal but instead correlated with a known causal common variant at the same locus; this is referred to as the shadow effects32. For illustration, we conducted simulation studies based on the same 200 kb region near the APOE gene as described above. We adopted the same simulation setting but set the causal variants to be common (MAF > 0.01) and apply the methods to rare variants only (MAF < 0.01). More details on these simulations are provided in the Methods section. Since all causal variants are common, all detected windows (focusing on rare variants) are false positives due to the shadow effect. We compared KnockoffScreen with conventional association testing by counting the number of false positives and show the distribution over 500 replicates in Fig. 4e. For a fair comparison, for the conventional association testing we adopted the same ensemble of tests implemented in KnockoffScreen to calculate the p-value. We observed that the conventional tests tend to identify a large number of false positives due to the shadow effect. In contrast, KnockoffScreen has a significantly reduced number of false positives, demonstrating that it is able to distinguish the effect of rare variants from that of common variants nearby. This feature is particularly appealing in detecting novel rare association signals in whole-genome sequencing studies. The same argument also holds if instead rare variants were causal; by construction, KnockoffScreen applied to common variants only can distinguish effects attributable to common causal variants from those due to rare causal variants nearby.
Empirical evaluation of KnockoffScreen in the presence of population stratification
Population structure is an important confounder in genetic association studies. Standard methods to adjust for population stratification, including principal component analysis or mixed effect models, help control for global ancestry in conventional sequencing association tests. We performed an empirical evaluation of KnockoffScreen in the presence of population stratification using sequencing data from the ADSP project. We also evaluated whether, by regressing out the top principal components when computing the association statistics (p-values), KnockoffScreen is able to control FDR. Specifically, we randomly drew a subset of variants (1000 variants) from the 200 kb region near the APOE region in the ADSP study. The ADSP includes three ethnic groups: African American (AA), Non-Hispanic White (NHW), and Others (of which, 98% are Caribbean Hispanic) (see genome-wide PCA results in Fig. 5a). We set the mean/prevalence for the quantitative/dichotomous trait to be a function of the subpopulation, but not directly affected by any genetic variants. More details on these simulations are provided in the Methods section. We compared KnockoffScreen with the conventional association test with no adjustment for population stratification. We also included a modified version of KnockoffScreen that adjusts for the top 10 global PCs when computing the p-values used to compute the window feature statistic, referred to as KnockoffScreen+10PCs. For comparison, we also included the conventional association test based on Bonferroni correction, which defines significant associations by p-value < 0.05/number of tests.

a Principal component analysis of the ADSP data, which contains three ethnic groups: African American (AA), Non-Hispanic White (NHW), and Others (of which, 98% are Caribbean Hispanic). Each dot represents an individual. b, c Simulation results for the FDR control in the presence of population stratification that mimics the ADSP data, comparing KnockoffScreen with conventional association testing. Each panel shows empirical FDR based on 500 replicates. KnockoffScreen 10PCs is a modified version of KnockoffScreen method that includes adjustment for the top principal components while computing the association statistics (p-values). KnockoffScreen controls FDR at 0.10; Association Testing is based on usual Bonferroni correction (0.05/number of tests), controlling FWER at 0.05. Source data are provided as a Source Data file.
Since in these simulations none of the genetic variants are causal, all detected windows are false positives due to the confounding effects of population structure. With a target FDR = 0.1, we calculated the observed FDR, defined as the proportion of replicates where any window is detected, and present the results in Fig. 5b, c. We observed that both PC-adjusted KnockoffScreen and the conventional PC-adjusted association test are able to control FDR at the target level. This is further illustrated by our real data analysis of ADSP where despite the combined analysis of three ethnicities there is no apparent inflation in false positive signals. Interestingly, KnockoffScreen exhibits lower FDR than association test when they are both unadjusted, indicating that the use of knockoffs naturally helps to prioritize causal variants over association due to population stratifications. We additionally performed simulation studies to mimic population stratification driven by rare variants and present the results in Supplementary Table 1. As before, we found that both PC-adjusted KnockoffScreen and association test are able to control FDR in the scenarios considered here, and KnockoffScreen exhibits a lower FDR than the conventional association test for an unadjusted model. Since the reduction of false positives for KnockoffScreen does not require observing/estimating the underlying ancestry, the knockoff procedure can potentially complement existing tools for ancestry adjustment to better reduce false positive findings due to population substructure. However, we clarify that KnockoffScreen itself does not completely eliminate the confounding due to population stratification (Supplementary Table 1) because the current knockoff generator assumes the same LD structure across individuals and it only accounts for local LD structure. Therefore, it does not capture heterogeneous LD structure across populations and strong long-range LD due to population stratification. Development of new knockoff generators that explicitly account for population structure will be of interest33.
KnockoffScreen enables computationally efficient screening of whole-genome sequencing data
One obstacle for the widespread application of knockoffs to genetic data, particularly whole-genome sequencing data, is their computational cost. The knockoff generation can be computationally intensive when the number of genetic variants \(p\) is large; depending on the method, it may require the calculation of the eigen values of a \(p\times p\) covariance matrix, or iteratively fitting a prediction model for every variant. The whole-genome sequencing data from ADSP (~4000 individuals) contains ~85 million variants in total, much larger than the number of variants in GWAS datasets. Similarly, in 53,581 TOPMed samples, more than 400 million single-nucleotide and insertion/deletion variants were detected2. As more individuals are being sequenced, the number of variants will increase accordingly. We demonstrate that the proposed sequential model to simultaneously generate multiple knockoffs is significantly more computationally efficient than existing knockoff generation methods, making it scalable to whole-genome sequencing data. We compared the computing time of our proposed knockoff generator with two existing alternatives: the second-order knockoff generator proposed by Candès et al.14, referred to as SecondOrder; and knockoffs for Hidden Markov Models (HMMs) proposed by Sesia et al.15,16 with varying number of states (S = 12 and S = 50). We estimate the complexity of our proposed method as \(O({np})\), where \(n\) is the sample size and \(p\) is the number of genetic variants. The details of this calculation are described in the Methods section. The complexity of the HMM method is also \(O\left({np}\right)\), as discussed in Sesia et al.16. However, it is significantly less efficient than the proposed method for unphased genotype data as we show below. We note that the computing time of the SecondOrder method is of order \(O\left(n{p}^{2}+{p}^{3}\right)\) because it requires calculating the eigen values of a \(p\times p\) covariance matrix. Therefore, it is not a feasible approach for whole-genome analysis with a large number of variants.
We performed simulations to empirically evaluate the computational time for the different methods. We note that the proposed method focuses on the analysis of whole-genome sequencing data, and thus the computational cost is reported on unphased genotype data, which is the usual format for sequencing data. Since the HMM model assumes the availability of phased data, we report the computing time separately for phasing with fastPhase and sampling with SNPknock as described in Sesia et al.15. We simulated genetic data using the SKAT package, with varying sample sizes and number of genetic variants (Table 1). The computing time was evaluated on a single CPU (Intel(R) Xeon(R) CPU E5-2640 v3 @ 2.60 GHz). For the simulation scenario considered in the previous section with 10,000 individuals and 1,000 genetic variants, we observed that the proposed method takes 6.59 s to generate a single set of knockoff features, which is ~130 times faster than the HMM model with S = 12 states (881.43 s). The application of the HMM model with the recommended S = 50 states to unphased sequencing data (13681.53 s for 10,000 individuals and 1000 genetic variants) is currently not practical at genome-wide scale. As shown, a substantial fraction of the total computing time is taken by the phasing step, and therefore using more computationally efficient phasing algorithms can further improve the computational cost of the HMM-based knockoff generation.
KnockoffScreen detects more independent disease risk loci across the genome in two whole-genome sequencing studies
Here we show results from the application of KnockoffScreen to two whole-genome sequencing datasets from two different studies, namely the Alzheimer’s Disease Sequencing Project (ADSP), and the COPDGene study from the NHLBI Trans-Omics for Precision Medicine (TOPMed) Program. For each study, we considered windows with sizes (1 bp, 1 kb, 5 kb, 10 kb) across the genome as described before. In addition to the different weighting and thresholding strategies, we include several functional scores to improve the power of detecting rare functional variants. The functional scores include non-tissue specific CADD scores and 10 tissue/cell type specific GenoNet scores. The GenoNet scores were trained using epigenetic annotations from the Roadmap Epigenomics Project across 127 tissues/cell types. We partition the tissues/cell types into 10 groups (including Stem Cells, Blood, Connective Tissue, Brain, Internal Organs, Fetal Brain, Muscle, Fetal Tissues, and Gastrointestinal; Supplementary Table 2 has more details on these tissue groupings) and we use the maximum GenoNet score per group.
We show results from conventional association tests (using the same combination of single variant and region-based tests as implemented in KnockoffScreen) and using Bonferroni correction (\(p\, <\, 0.05\)/number of tested windows) to control the family-wise error rate. QQ-plots of all tests (Supplementary Fig. 5) show that the type I error rate is well controlled. We also report results from KnockoffScreen at an FDR threshold of 0.1. We assigned each significant window to its overlapping locus (gene or intergenic region). If the locus is a gene, we report the gene’s name; if the locus is intergenic, we report the upstream and downstream genes (enclosed within parentheses and separated by “-”). To assess the degree of overlap with previously described associations, we additionally searched if the loci have known associations with Alzheimer’s disease and lung related traits in the NHGRI-EBI GWAS Catalog34, acknowledging that some of the studies in the GWAS catalog included ADSP and COPDGene data. The details on gene annotations are described in the Methods section.
Application to ADSP
We first applied KnockoffScreen to the whole-genome sequencing data from the Alzheimer’s Disease Sequencing Project (ADSP) for a genome-wide scan. The data includes 3,085 whole genomes from the ADSP Discovery Extension Study and 809 whole genomes from the Alzheimer’s Disease Neuroimaging Initiative (ADNI), for a total of 3,894 whole genomes. More details on the ADSP data are provided in the Methods section. We adjusted for age, age^2, gender, ethnic group, sequencing center, and the leading 10 principal components of ancestry. We present the results in Fig. 6.

a Manhattan plot of p-values (truncated at \({10}^{-20}\) for clear visualization) from the conventional association testing with Bonferroni adjustment (\(p\, <\, 0.05\)/number of tested windows) for FWER control. b Manhattan plot of KnockoffScreen with target FDR at 0.1. c heatmap that shows stratified p-values (truncated at \({10}^{-10}\) for clear visualization) of all loci passing the FDR = 0.1 threshold, and the corresponding Q-values that already incorporate correction for multiple testing. The loci are shown in descending order of the knockoff statistics. For each locus, the p-values of the top associated single variant and/or window are shown indicating whether the signal comes from a single variant, a combined effect of common variants or a combined effect of rare variants. The names of those genes previously implicated by GWAS studies are shown in bold (names were just used to label the region and may not represent causative gene in the region). Source data are provided as a Source Data file.
The conventional association test with Bonferroni correction identified a region (~50 kb long) at the known APOE locus, containing a large number of significant associations (Fig. 6), but, as discussed before, most of them are presumably due to LD with the known APOE risk variants since they are no longer significant after adjusting for the APOE alleles. Within the APOE region, KnockoffScreen identified fewer windows that overlap with known AD genes, namely APOE, APOC1, APOC1P1, and TOMM40 at FDR < 0.1, while removing a considerable number of associations that are likely due to LD. Beyond the APOE locus, KnockoffScreen identified several other loci that potentially affect AD risk, including KAT8 and an intergenic region on chromosome 18q22 between DSEL and TMX3. KAT8 (lysine acetyltransferase 8) has been recently identified in two large scale GWAS focused on clinically diagnosed AD and AD-by-proxy individuals35,36. It is a promising candidate gene that affects multiple brain regions including the hippocampus and plays a putative role in neurodegeneration in both AD and Parkinson’s disease37. The intergenic region identified by KnockoffScreen resides in a known linkage region for AD and bipolar disorder on chromosome 18q22.138,39. DSEL (dermatan sulfate epimerase-like) is implicated in D-glucuronic acid metabolism and tumor rejection. A recent study has shown that glucuronic acid levels increase with age and predict future healthspan-related outcomes40. Furthermore, DSEL is highly expressed in the brain and has been found associated with AD in an imaging-wide association study41. SNPs upstream of DSEL have also been associated with recurrent early-onset major depressive disorder42. Two other intergenic loci, ANKRD18A-FAM240B and TAFA5-BRD1 were reported in the GWAS catalog to have suggestive associations (\(5\times {10}^{-8}\, <\, p\, <\, 1\times {10}^{-5}\)) with late-onset Alzheimer’s disease43. We additionally present results when applying the Benjamini–Hochberg procedure for FDR control in Supplementary Fig. 6; we observed that the associations identified by KnockoffScreen are largely replicated in the GWAS catalog, while the new discoveries uniquely identified using the conventional BH procedure do not overlap with previous GWAS findings, suggesting they may be false positives.
Application to COPDGene study in TOPMed
The Genetic Epidemiology of COPD (COPDGene) study includes current and former cigarette smokers aged >45. All subjects underwent spirometry to measure lung function. Cases were identified as those with moderate-to-severe chronic obstructive pulmonary disease (COPD), controls were those with normal lung function, and a third set were neither cases nor controls. These individuals have been whole-genome sequenced as part of the larger TOPMed project at an average ~30X coverage depth, with joint-sample variant calling and variant level quality control in TOPMed samples2,44. The COPDGene Freeze 5b dataset used for this analysis includes a total of 8,444 individuals, of which 5,713 are Non Hispanic White and 2,731 are African American. We tested lung function measurements on all individuals: forced expiratory volume in one second (FEV1), forced vital capacity (FVC) and their ratio (FEV1/FVC), as well as for case-control COPD status on a subset (NHW: 2366 cases/2084 controls, AA: 702 cases/1409 controls).
We applied KnockoffScreen separately to the two ethnic groups, and four phenotypes, while adjusting for covariates as follows. In all analyses we adjusted for sequencing center, and the 10 leading principal components of ancestry. Additionally, for FEV1 and FEV1/FVC ratio, we adjusted for age, age2, gender, height, height2, pack-years of smoking, and current smoking. For FVC, we adjusted for age, age2, gender, height, height2, weight, pack-years of smoking, and current smoking. For COPD case/control status, we adjusted for age, gender, and pack-years of smoking. Results for the NHW group for FEV1 are shown in Fig. 7 and those for FEV1/FVC are shown in Supplementary Fig. 4.

a Manhattan plot of p-values from the conventional association testing with Bonferroni adjustment (\(p \,<\, 0.05\)/number of tested windows) for FWER control. b Manhattan plot of KnockoffScreen with target FDR at 0.1. c Heatmap that shows stratified p-values of all loci passing the FDR = 0.1 threshold, and the corresponding Q-values that already incorporate correction for multiple testing. The loci are shown in descending order of the knockoff statistics. For each locus, the p-values of the top associated single variant and/or window are shown indicating whether the signal comes from a single variant, a combined effect of common variants, or a combined effect of rare variants. The names of those genes previously implicated by GWAS studies are shown in bold (names were just used to label the region and may not represent causative gene in the region). Source data are provided as a Source Data file.
Note that for FEV1 and FEV1/FVC, KnockoffScreen has been able to identify many more significant associations compared with the application to Alzheimer’s disease, a reflection of the larger sample size but also the higher degree of polygenicity for lung function phenotypes relative to AD. Compared with the conventional association test with Bonferroni correction, KnockoffScreen detected several known signals for FEV1, including the PSMA4/CHRNA5/CHRNA3 locus on chromosome 15, the INTS12/GSTCD locus on chromosome 4, and the EEFSEC/RUVBL1 locus on chromosome 3. Overall, the majority of the single variant signals that were found significant at FDR 0.1 have been associated with COPD-related phenotypes in the GWAS catalog (81.8% for FEV1 and 69.2% for FEV1/FVC) (Figs. 7 and S4) supporting the ability of KnockoffScreen to identify previously discovered loci in GWAS studies with sample sizes much larger than used here. KnockoffScreen additionally identified new loci by aggregating common/rare variants. Although the new loci identified by KnockoffScreen, particularly those identified by rare variant methods, will need to be validated in larger datasets, and the effector genes are not known, some of the genes in these regions may be of interest. For FVC and COPD, as well as all traits for the African-Americans, we did not identify any significant associations at FDR 0.1, likely a reflection of low power due to the smaller sample size and possibly non-genetic covariates that might be associated with risk in AA and unaccounted for in these analyses.
It is interesting to note that the significant loci identified by KnockoffScreen are markedly enriched for windows (single bp or larger) overlapping protein coding genes despite an unbiased screen of the entire genome. In particular, 40%, 80%, and 56.4% of the loci significant for AD, FEV1, and FEV1/FVC respectively overlap protein coding genes. Given the modest sample size of the datasets analyzed here, this is perhaps expected; KnockoffScreen is able to identify the stronger effects closer to genes (e.g., coding and promoter regions). As sample sizes for whole-genome sequencing studies continue to increase, we can expect additional loci in noncoding regions to be identified.
In summary, these empirical results suggest that KnockoffScreen can identify additional signals that are missed by conventional Bonferroni correction, while filtering out proxy associations that are likely due to LD. Scatter plots comparing genome-wide W statistics vs. −log10(p-values) further illustrate this point (Fig. 8).

Each dot represents one variant/window. The dashed lines show the significance thresholds defined by Bonferroni correction (for p-values) and by false discovery rate (FDR; for W statistic). The p-values are from the conventional association testing described in the main text. Source data are provided as a Source Data file.
Discussion
In summary, we propose a computationally efficient algorithm, KnockoffScreen, for the identification of putative causal loci in whole-genome sequencing studies based on the knockoff framework. This framework guarantees the FDR control at the desired level under general dependence structure, and has appealing properties relative to conventional association tests, including a reduction in LD-contaminated associations and false positive associations due to unadjusted population stratification. Through applications to two whole-genome sequencing studies for Alzheimer’s disease, COPD and lung function phenotypes we demonstrate the ability of the approach to identify more significant associations, many of which have been identified in previous GWAS studies, with sample sizes orders of magnitude larger than the ones considered here. As sample sizes for whole-genome sequencing studies continue to increase, KnockoffScreen can help discover more risk loci with even more stringent FDR thresholds.
In KnockoffScreen, we choose to control FDR at the nominal level. Our analyses of data from ADSP and COPDGene show that our method compared with conventional association tests leads to significantly more discoveries. The majority of the single variant signals that were found significant at FDR 0.1 have been associated with AD or COPD-related phenotypes respectively in the GWAS catalog (87.5% for AD, 81.8% for FEV1 and 69.2% for FEV1/FVC), supporting our claim that the FDR control in KnockoffScreen is able to replicate previously discovered loci in GWAS studies with sample sizes much larger than those used here. Furthermore, KnockoffScreen identified a set of new discoveries driven by the combined effects of multiple common/rare variants. The results demonstrate that controlling FDR is an appealing strategy when there are potentially many discoveries to be made as in genetic association studies for highly polygenic traits, the dependence structure is local, and the investigators are willing to accept a rigorously defined small fraction of false positives in order to substantially increase the total number of true discoveries. We note that the choice of target FDR should be defined rigorously and interpreted appropriately. For example, loci identified at a liberal FDR threshold (e.g., 0.3 as in Iossifoy et al.9) can be useful for enrichment and pathway analyses; our analyses of data from ADSP and COPDGene used FDR = 0.1 for identifying putative causal loci. As large-scale whole-genome sequencing data become increasingly available, one will be able to apply KnockoffScreen with a lower, more stringent FDR threshold (e.g., 0.01 or 0.05).
The model-X knockoff framework underlying KnockoffScreen makes our approach robust to violations of model assumptions. Specifically, by imposing a model on genetic variants (\({G}_{i}\)) instead of on the conditional distribution of the outcome given the variants (distribution of \({Y}_{i}|{G}_{i}\)), the FDR control is guaranteed even when the model for \({Y}_{i}|{G}_{i}\) is mis-specified. We do however need to construct a valid synthetic cohort \({\widetilde{G}}_{i}\)’s such that the exchangeability conditions are satisfied, and define a test statistic with the sign-flip property (i.e., the effect of swapping a variant with its knockoff is only a sign flip of the corresponding test statistic). This robustness feature is particularly useful for genetic studies of complex traits, as the underlying genetic model is unknown, and it is difficult to evaluate whether a model is appropriate for describing the relationship between the trait and the variants.
There is some limited work on controlling the FWER within the knockoff framework using a single knockoff45. One obstacle for its application is that it only allows controlling for \(k\)-FWER at significance level \(\alpha\) (the probability of making at least \(k\) false rejections) where \(k\) or \(\alpha\) has to be relatively large in order to detect any association. Therefore, it cannot be directly applied to control the conventional FWER (\(k=1\), \(\alpha =0.05\)) without further modifications. Although our proposed multiple knockoffs method has the potential to be extended to control the FWER, we estimated that about 20 knockoffs are necessary to achieve the conventional FWER control. This leads to additional computational burden that will need to be overcome in order to become scalable to the large-scale genetic data.
In addition to controlling FDR, our approach contrasts to conventional association testing methods in that it naturally helps prioritize the underlying causal variants, a property that usually requires a second stage conditional analysis or statistical fine mapping46. It also helps separate causal effects from shadow effects of significant variants nearby. This property can help distinguish effects due to common causal variants or rare causal variants at the same locus due to LD, by applying KnockoffScreen to common/rare variants separately. Overall, KnockoffScreen serves as a powerful and efficient method that attempts to unify association testing and statistical fine mapping. However, similar to statistical fine-mapping methods that only leverage LD to fine-map a complex trait, it remains challenging to fully distinguish highly correlated variants. As we discussed in the Methods section, KnockoffScreen currently detects clusters of tightly linked variants, without removing any variants that are potentially causal. In the future, we may consider using functional genomics data to further improve the ability of KnockoffScreen to identify causal variants among highly correlated ones.
Unlike existing knockoff methods for genetic data that define coefficients in a LASSO regression as the importance score15,16, KnockoffScreen directly uses transformed p-values as importance score. This leads to another appealing property of KnockoffScreen, namely it can serve as a wrapper method that can flexibly utilize p-values from any existing or future association testing methods to achieve the benefits proposed here. For example, the current implementation of KnockoffScreen calculates importance score using an ACAT type test to aggregate several recent advances for rare-variant analysis. To extend its application to studies with large unbalanced case-control ratios or sample relatedness, one can apply methods like SAIGE47 to calculate p-values for the original cohort and the synthetic cohort generated by KnockoffScreen, and then apply the same knockoff filter for variable selection. Moreover, recent studies have demonstrated that multivariate models have many advantages over marginal association testing, including improved power by reducing the residual variation and better control of population stratification15. KnockoffScreen is able to integrate tests from multivariate models (e.g., BOLT-LMM and its extension to window-based analysis of sequencing data).
Meta-analyses are important in allowing the integration of results from multiple whole-genome sequencing studies without sharing individual level data. Several methods have been proposed for meta-analysis of single variant tests for common variants or “set” based (e.g., window based) tests for rare variants48,49,50. Those methods integrate summary statistics from each individual cohort, such as p-values or score statistics, and then compute a combined p-value for each genetic variant or each window for a meta-analysis. As we discussed, KnockoffScreen can also directly utilize p-values from existing methods for meta-analysis. We have discussed the detailed procedure in the Methods section.
Variable selection based on knockoff procedure depends on the random sampling of knockoff features \({\left\{{\widetilde{G}}_{{ij}}\right\}}_{1\!\le\! j\!\le\! p}\). Although FDR control is guaranteed, the randomness may lead to slightly different feature statistics and selection of slightly different subsets of variants. We propose a stable inference procedure integrating multiple knockoffs that significantly improves the stability and reproducibility of the results compared with state-of-the-art knockoff methods as discussed in the Method section.
We have demonstrated that the proposed sequential knockoff generator is significantly faster than existing alternatives. Besides the generation of knockoff features, another source of computational burden is the calculation of the importance score (p-value for a window). The total CPU time is 7,616 h for the ADSP data analysis (15.2 h with 500 cores) and 14,274 h for the COPDGene data analysis (28.5 h with 500 cores). The calculation of p-values in the current analysis is time consuming because of the comprehensive inclusion of many different functional annotations. Specifically, for each window, there are in total 29 tests being implemented for the original genetic variants and each of their five knockoffs, leading to a total of 29*6 = 174 p-value calculations per window. If computational resources are limited, using a limited number of functional annotations can substantially reduce the computing time. In addition, several methods have been proposed in recent years to use state-of-the-art optimization strategies for scalable association testing for large scale datasets with thousands of phenotypes in large biobanks.51,52,53 By directly utilizing p-values from those association testing methods, KnockoffScreen can scale up to biobank sized datasets at a comparable computational efficiency.
Despite the aforementioned advantages, KnockoffScreen has some limitations related to underlying modeling assumptions needed to improve the computational efficiency of the multiple knockoff generation and calculation of the feature importance scores. In particular, the implemented feature importance scores rely on computing p-values from a marginal model (e.g., single variant score test, burden test or SKAT) or a partly multivariate model (BOLT-LMM and its extension to window-based analysis of sequencing data). We made this choice of feature importance score due to its flexibility to integrate state-of-the-art tests for sequencing studies, but we recognize that a fully multivariate model as implemented in Sesia et al.15 can be more powerful. In addition, the knockoff generator used in KnockoffScreen assumes a linear approximation model based on unphased genotype dosage data. This model is well motivated based on the sequential model to generate knockoff features, and the approximate multivariate normal model for the genotype data commonly used in the genetic literature. Additionally, it is computationally efficient relative to existing knockoff generation methods. We acknowledge that relative to a generative model like HMM it is less interpretable. More complex models for discrete genotype values that can also account for non-linear effects among genetic variants could be of interest in future work.
Methods
Sequential model to generate model-X knockoff features
We propose a computationally efficient sequential model to generate knockoff features \(\widetilde{{\boldsymbol{G}}}\) that leverages local linkage disequilibrium structure. Our method is an extension of the general sequential conditional independent pairs (SCIP) approach in Candès et al. (2018)14.
Algorithm 1 Sequential Conditional Independent Pairs (Single Knockoff)
\(j=1\)
while \(j\le p\) do
Sample \({\widetilde{G}}_{j}\) independently from \({\mathcal{L}}\left({G}_{j}{\rm{|}}{{\boldsymbol{G}}}_{{\boldsymbol{-}}{\boldsymbol{j}}},{\widetilde{{\boldsymbol{G}}}}_{{\boldsymbol{1}}{\boldsymbol{:}}\left({\boldsymbol{j}}{\boldsymbol{-}}{\boldsymbol{1}}\right)}\right)\)
\(j=j+1\)
end
where \({{\boldsymbol{G}}}_{{\boldsymbol{-}}{\boldsymbol{j}}}\) denotes all genetic variants except for the \(j\)-th variant; \({\mathcal{L}}\left({G}_{j}{\rm{|}}{{\boldsymbol{G}}}_{{\boldsymbol{-}}{\boldsymbol{j}}},{\widetilde{{\boldsymbol{G}}}}_{{\boldsymbol{1}}{\boldsymbol{:}}\left({\boldsymbol{j}}{\boldsymbol{-}}{\boldsymbol{1}}\right)}\right)\) is the conditional distribution of \({G}_{j}\) given \({{\boldsymbol{G}}}_{{\boldsymbol{-}}{\boldsymbol{j}}}\) and \({\widetilde{{\boldsymbol{G}}}}_{{\boldsymbol{1}}{\boldsymbol{:}}\left({\boldsymbol{j}}{\boldsymbol{-}}{\boldsymbol{1}}\right)}\). Candès et al. showed that knockoffs generated by this algorithm satisfy the exchangeability condition, and they lead to a guaranteed FDR control14. Intuitively, the exchangeability condition can be described as follows: if one swaps any subset of variants and their synthetic counterpart, the joint distribution (LD structure etc.) does not change. They also noted that the ordering in which knockoffs are created does not affect the exchangeability property and equally valid constructions may be obtained by looping through an arbitrary ordering of the variants. Although the SCIP method represents a general knockoff generator, the conditional distribution at each iteration depends on all genetic variants in the study, which can be very difficult or impossible to compute in practice. We draw inspiration from Markov models for sequence data to consider the genetic sequence as a Markov chain with memory, such that
where the index set \({B}_{j}\) defines a subset of genetic variants “near” the \(j\)-th variant, which we will define later. Furthermore, by noting that the correlation among genetic variables approximately exhibits a block diagonal structure54, under certain model assumptions which will be specified in the Appendix, we have
To generate knockoff features from \({\mathcal{L}}\left({G}_{j}|{{\boldsymbol{G}}}_{{\boldsymbol{k}}\in {{\boldsymbol{B}}}_{{\boldsymbol{j}}}}{\boldsymbol{,}}\,{\widetilde{{\boldsymbol{G}}}}_{{\boldsymbol{1}}\!\le\! {\boldsymbol{k}}\!\le\! {\boldsymbol{j}}{\boldsymbol{-}}{\boldsymbol{1}}{\boldsymbol{,}}{\boldsymbol{k}}\in {{\boldsymbol{B}}}_{{\boldsymbol{j}}}}\right)\), we assume a semiparametric model
where \({\varepsilon }_{j}\) is a random error term, \(E\left({\varepsilon }_{j}\left|{{\boldsymbol{G}}}_{{\boldsymbol{k}} \in {{\boldsymbol{B}}}_{{\boldsymbol{j}}}}{\boldsymbol{,}}\,{\widetilde{{\boldsymbol{G}}}}_{{\boldsymbol{1}}\!\le\! {\boldsymbol{k}}\!\le {\boldsymbol{j}}{\boldsymbol{-}}{\boldsymbol{1}}{\boldsymbol{,}}{\boldsymbol{k}}\in {{\boldsymbol{B}}}_{{\boldsymbol{j}}}}\right)=0\right.\). We consider \(g\left(\bullet \right)\) to be parametric as follows,
and will explain in detail when such a linear form is an appropriate model in the Appendix. We estimate \(\left(\alpha ,{\boldsymbol{\beta }},{\boldsymbol{\gamma }}\right)\) by minimizing the mean squared loss. Let \({\hat{{\boldsymbol{G}}}}_{{\boldsymbol{j}}}=\hat{\alpha }+{{\sum}}_{k\ne j,k\in {B}_{j}}{\hat{\beta }}_{k}{{\boldsymbol{G}}}_{{\boldsymbol{k}}}+{{\sum}}_{k\!\le\! j-1,k\in {B}_{j}}{\hat{\gamma }}_{k}{\widetilde{{\boldsymbol{G}}}}_{{\boldsymbol{k}}}\). We calculate the residual \({\hat{{\boldsymbol{\varepsilon }}}}_{{\boldsymbol{j}}}={{\boldsymbol{G}}}_{{\boldsymbol{j}}}-{\hat{{\boldsymbol{G}}}}_{{\boldsymbol{j}}}\) and its permutation \({\hat{{\boldsymbol{\varepsilon }}}}_{{\boldsymbol{j}}}^{{\boldsymbol{\ast }}}\), and then define the knockoff feature for \({{\boldsymbol{G}}}_{{\boldsymbol{j}}}\) to be \({\widetilde{{\boldsymbol{G}}}}_{{\boldsymbol{j}}}={\hat{{\boldsymbol{G}}}}_{{\boldsymbol{j}}}+{\hat{{\boldsymbol{\varepsilon }}}}_{{\boldsymbol{j}}}^{{\boldsymbol{\ast }}}\). This permutation-based algorithm is particularly designed to generate knockoff features for rare genetic variants in sequencing studies, whose distribution is highly skewed and zero-inflated. We note that the algorithm does not generate categorical variables in \(\left\{0,1,2\right\}\). Instead, it generates continuous variables to mimic genotype dosage value, making it more robust for rare variants. In addition, we evaluated a multinomial logistic regression model for generating categorical knockoffs. We found that the conditional mean of a rare variant can be extremely small, and it is very likely to generate knockoffs with all 0 values where statistical inference cannot be applied. We show in simulation studies that existing knockoff generators, such as the second-order model-X knockoffs proposed by Candès et al.14 and knockoffs for HMM proposed by Sesia et al.15,16, do not control FDR for rare variant analysis based on the feature score considered in this paper (Fig. 2). In Figs. S7 and S8, we present an additional comparison between the proposed method and HMM-based knockoff generators (S = 12 and S = 50), stratified by allele frequency. As shown, the proposed method generates knockoff versions for rare variants with better exchangeability with the original variants compared with the HMM model. That is, the correlation coefficients are closer to those for the original variants for KnockoffScreen compared to HMM (bottom panel, the dots are mostly above the diagonal line). One plausible explanation is that the application of HMM to whole genome sequencing data requires accurate phased data for rare variants, which itself is a challenging task and also an active research area.
We discuss now in detail how we define \({B}_{j}\) while taking into account the linkage disequilibrium (LD) structure in the neighborhood of \(j\). Let \({r}_{{jk}}\) be the sample correlation coefficient between variants \(j\) and \(k\). We define \({B}_{j}\) to include “\(K\)-nearest” genetic variants within a 200 kb window (±100 kb from the target variant)55 using \(|{r}_{{jk}}|\) as a similarity measure. The choice of the window size aims to balance accurate modeling of local LD structure and computational efficiency. The choice of \(K\) is to ensure that \(P\left({G}_{j}|{{\boldsymbol{G}}}_{{\boldsymbol{k}}\in {{\boldsymbol{B}}}_{{\boldsymbol{j}}}}{\boldsymbol{,}}{\widetilde{{\boldsymbol{G}}}}_{{\boldsymbol{1}}\le {\boldsymbol{k}}\le {\boldsymbol{j}}{\boldsymbol{-}}{\boldsymbol{1}}{\boldsymbol{,}}{\boldsymbol{k}}\in {{\boldsymbol{B}}}_{{\boldsymbol{j}}}}\right)\) accurately mimics the joint distribution \(P\left({G}_{j}|{{\boldsymbol{G}}}_{{\boldsymbol{-}}{\boldsymbol{j}}}{\boldsymbol{,}}{\widetilde{{\boldsymbol{G}}}}_{{\boldsymbol{1}}{\boldsymbol{:j}}{\boldsymbol{-}}{\boldsymbol{1}}}\right)\) and to avoid overfitting. We adopt the theoretical result for regression analysis with diverging number of covariates and choose to include top \(K\) variants with \(|{r}_{{jk}}| \,> \, 0.05\) up to \(K={n}^{1/3}\), which ensures that the coefficient estimations achieve asymptotic normality56.
We note that the sequential model is flexible enough and we could consider other supervised learning techniques like Lasso, support vector regression and artificial neural networks. However, since the auto-regressive model is fitted iteratively for every variant in the genome, these methods require cross-validation at each variant level which is computationally not applicable at genome-wide scale.
Multiple sequential knockoffs to improve power and stability
Inference based on single knockoff is limited by the detection threshold \([\frac{1}{q}]\), which is the minimum number of independent rejections needed in order to detect any association. For example, in scenarios where the signal is sparse (<10 independent true associations) in the target region or across the genome, inference based on a single knockoff has very low power to detect any association with target FDR 0.1. Another limitation of the single knockoff is its instability. Since the knockoff sample is random, running the knockoff procedure multiple times may lead to different selected sets of features. The idea of constructing multiple knockoffs was first discussed by Barber and Candès13 and Candès et al.14, and further studied in detail by Gimenez and Zou30. However, current methods are not applicable to rare variants and not scalable to whole genome sequencing data.
We extend the above SCIP based knockoff generator procedure to multiple knockoffs (\(M\) is the total number of knockoffs), as follows.
Algorithm 2 Sequential Conditional Independent Tuples (Multiple Knockoffs)
\(j=1\)
while \(j\le p\) do
Sample \({\widetilde{G}}_{j}^{1},\cdots ,{\widetilde{G}}_{j}^{M}\)independently from \({\mathcal{L}}\left({G}_{j}{\rm{|}}{{\boldsymbol{G}}}_{{\boldsymbol{-}}{\boldsymbol{j}}}{\boldsymbol{,}}{\widetilde{{\boldsymbol{G}}}}_{{\bf{1}}{\boldsymbol{:}}{\boldsymbol{j}}{\boldsymbol{-}}{\bf{1}}}^{{\boldsymbol{1}}}{\boldsymbol{,}}{{\boldsymbol{\cdots }}{\boldsymbol{,}}\widetilde{{\boldsymbol{G}}}}_{{\bf{1}}{\boldsymbol{:}}{\boldsymbol{j}}{\boldsymbol{-}}{\bf{1}}}^{{\boldsymbol{M}}}\right)\)
\(j=j+1\)
End
Gimenez and Zou30 proposed this general algorithm and proved that the knockoffs generated by this algorithm satisfy the extended exchangeability condition (see Appendix for precise definition and proof). Based on this general algorithm, we extend our previous sequential model to this setting to estimate \({\hat{{\boldsymbol{G}}}}_{{\boldsymbol{j}}}=\hat{\alpha }+{{\sum}}_{k\ne j,k\in {B}_{j}}{\hat{\beta }}_{k}{{\boldsymbol{G}}}_{{\boldsymbol{k}}}+{{\sum }}_{1\le m\le M}\mathop{\sum}\limits_{k\le j-1,k\in {B}_{j}}{\hat{\gamma }}_{k}^{m}{\widetilde{{\boldsymbol{G}}}}_{{\boldsymbol{k}}}^{{\boldsymbol{m}}}\). We calculate the residual \({\hat{{\boldsymbol{\varepsilon }}}}_{{\boldsymbol{j}}}={{\boldsymbol{G}}}_{{\boldsymbol{j}}}-{\hat{{\boldsymbol{G}}}}_{{\boldsymbol{j}}}\) and its \(M\) permutations \({\hat{{\boldsymbol{\varepsilon }}}}_{{\boldsymbol{j}}}^{{\boldsymbol{\ast }}{\boldsymbol{\ast 1}}}{\boldsymbol{,}}{\boldsymbol{\ldots }}{\boldsymbol{,}}{\hat{{\boldsymbol{\varepsilon }}}}_{{\boldsymbol{j}}}^{{\boldsymbol{\ast }}{\boldsymbol{\ast M}}}\), and then define the knockoff feature for \({{\boldsymbol{G}}}_{{\boldsymbol{j}}}\) to be \({\widetilde{{\boldsymbol{G}}}}_{{\boldsymbol{j}}}^{{\boldsymbol{m}}}={\hat{{\boldsymbol{G}}}}_{{\boldsymbol{j}}}{\boldsymbol{+}}{\hat{{\boldsymbol{\varepsilon }}}}_{{\boldsymbol{j}}}^{*{\boldsymbol{m}}}\).
Knockoff filter to define the threshold \({\boldsymbol{\tau }}\) for FDR control
For single knockoff, we follow the result derived by Candès et al.14 to define the feature statistic as \({W}_{{\Phi }_{{kl}}}={T}_{{\Phi }_{{kl}}}-{\widetilde{T}}_{{\Phi }_{{kl}}}\) where \({T}_{{\Phi }_{{kl}}}=-{{\rm{log }}}_{10}{p}_{{\Phi }_{{\rm{kl}}}}\) and \({\widetilde{T}}_{{\Phi }_{{kl}}}=-{{\rm{log }}}_{10}{\widetilde{p}}_{{\Phi }_{{\rm{kl}}}}\) and
where “\(\#\)” denote the number of elements in the set; \(q\) is the target FDR level. We select all windows with \({W}_{{\Phi}_{kl}} \,> \,\tau\). For multiple knockoffs, we modify the result in Gimenez and Zou30 and define
and
where \({T}_{{\Phi }_{{kl}}}^{m}=-{\rm{log }}{p}_{{\varPhi }_{{kl}}}^{m}\); \({I}_{\bullet }\) is an indicator function, \({I}_{{T}_{{\Phi }_{{kl}}}\ge \mathop{{{\max }}}\nolimits_{1\le m\le M}{T}_{{\Phi }_{{kl}}}^{m}}=1\) if \({T}_{{\Phi }_{{kl}}}\ge \mathop{{{\max }}}\nolimits_{1\le m\le M}{T}_{{\Phi }_{{kl}}}^{m}\) and 0 otherwise; \({\kappa }_{{\Phi }_{{kl}}}=\mathop{{\rm{argmax}}}\nolimits_{0\le m\le M}{T}_{{\Phi }_{{kl}}}^{m}\) denote the index of the original (denoted as 0) or knockoff feature that has the largest importance score; \({\tau }_{{\Phi }_{{kl}}}={T}_{{\Phi }_{{kl}}}^{\left(0\right)}-\mathop{{\rm{median}}}\nolimits_{1\le m\le M}{T}_{{\Phi }_{{kl}}}^{(m)}\) denote the difference between the largest importance score and the median of the remaini ng importance scores. It reduces to the knockoff filter for single knockoff when \(M=1\). Essentially, \({W}_{{\Phi }_{{kl}}} > \tau\) selects windows where the original feature has higher importance score than any of the \(M\) knockoffs (i.e., \({\kappa }_{{\Phi }_{{kl}}}=0\)), and the gap with the median of knockoff importance score is above some threshold.
We note that this definition of feature statistic and knockoff filter is a modified version of that proposed by Gimenez and Zou30, where they considered the maximum instead of the median of the knockoff importance scores, i.e., \({\kappa }_{{\Phi }_{{kl}}}=\mathop{{\rm{argmax}}}\nolimits_{0\!\le\! m\!\le\! M}{T}_{{\Phi }_{{kl}}}^{m}\), \({\tau }_{{\Phi }_{{kl}}}={T}_{{\Phi }_{{kl}}}^{\left(0\right)}-\mathop{{{\max }}}\nolimits_{1\le m\le M}{T}_{{\Phi }_{{kl}}}^{(m)}\) and \({W}_{{\Phi }_{{kl}}}=\left({T}_{{\Phi }_{{kl}}}-\mathop{{{\max }}}\nolimits_{1\!\le\! m\!\le\! M}{T}_{{\Phi }_{{kl}}}^{m}\right){I}_{{T}_{{\Phi }_{{kl}}}\ge \mathop{{{\max }}}\nolimits_{1\le m\le M}{T}_{{\Phi }_{{kl}}}^{m}}\). To improve stability and reproducibility of knockoff based inference, we change \({\tau }_{{\Phi }_{{kl}}}\) from \({T}_{{\Phi }_{{kl}}}^{\left(0\right)}-\mathop{{{\max }}}\nolimits_{1\!\le\! m\!\le\! M}{T}_{{\Phi }_{{kl}}}^{(m)}\) to \({T}_{{\Phi }_{{kl}}}^{\left(0\right)}-\mathop{{\rm{median}}}\nolimits_{1\le m\le M}{T}_{{\Phi }_{{kl}}}^{(m)}\). The modified method reduces the randomness coming from sampling knockoff features given the fact that sample median has much smaller variation than each individual sample or the sample maximum.
Knockoff Q-value
The Q-value in statistics is similar to the well-known p-value, except that it measures significance in terms of the FDR57 rather than the FWER and already incorporates correction for multiple testing. For multiple hypothesis testing, a general mathematical definition of the Q-value for a null hypothesis is the minimum FDR that can be attained when all tests showing evidence against the null hypothesis at least as strong as the current one are declared as significant58. For example, the Q-value for usual FDR control based on ordered p-values can be estimated by,
where \(p\) is the p-value of the hypothesis under consideration and \(\widehat{{\rm{FDR}}}\left(t\right)\) is the estimated FDR if we are to reject all tests with p-values less than \(t\). In order to introduce a more informative and interpretable measure of significance for the top signals, we extend the Q-value framework for the usual FDR control to the knockoffs based case. The proposed Q-value combines the information from both feature importance statistics \({W}_{{\Phi }_{{kl}}}\) and the threshold \(\tau\). It also makes results comparable even we choose different feature importance statistics across multiple runs. By definition, we shall see that selecting windows with \({q}_{\Phi }\, <\, q\), where \(q\) is the target FDR, is equivalent to the aforementioned knockoff filter which selects those with \({W}_{\Phi }\, > \, \tau\).
For single knockoff, we define the Q-value for window \(\Phi\) with feature statistic \({W}_{\Phi }\, > \, 0\) as,
where \(\frac{1+{{\#}}\left\{{\Phi }_{{kl}}{{:}}{W}_{{\Phi }_{{kl}}}\le -t\right\}}{{{\#}} \left\{{\Phi }_{{kl}}{{:}}{W}_{{\Phi }_{{kl}}}\ge t \right\}}\) is an estimate of the proportion of false discoveries if we are to select all windows with feature statistic greater than \(t \,> \, 0\), referred to as the knockoff estimate of FDR13. For window \(\Phi\) with feature statistic \({W}_{\Phi }\le 0\), we define \({q}_{\Phi }=1\) and the window will never be selected. For multiple knockoffs, we define the Q-value for window \(\Phi\) with statistics \({\kappa }_{\Phi }=0\) and \({\tau }_{\Phi }\) as
where \(\frac{\frac{1}{M}+\frac{1}{M}{{\#}}\left\{{\Phi }_{{kl}}{{:}}{\kappa }_{{\Phi }_{{kl}}}\ge 1,{\tau }_{{\Phi }_{{kl}}}\ge t\right\}}{{{\#}} \left\{{\Phi }_{{kl}}{{:}}{\kappa }_{{\Phi }_{{kl}}}\,=\,0,{\tau }_{{\Phi }_{{kl}}}\ge t \right\}}\) is an estimate of the proportion of false discoveries if we are to select all windows with feature statistic \({\kappa }_{{\Phi }_{{kl}}}=0,{\tau }_{{\Phi }_{{kl}}}\ge t\), which is our extension of the knockoff estimate of FDR to multiple knockoffs. For window \(\Phi\) with \({\kappa }_{\Phi }\,\ne\, 0\), we again define \({q}_{\Phi }=1\) and the window will never be selected.
Choice of windows for genome-wide screening
KnockoffScreen considers windows with different sizes (1 bp, 1 kb, 5 kb, 10 kb) across the genome, with half of each window overlapping with adjacent windows at the same window size. This choice of windows is similar to the scan statistic framework, WGScan, for whole-genome sequencing data18. It is also similar to that in KnockoffZoom proposed by Sesia et al.15 for GWAS data where they also consider windows of different sizes; for each fixed window size the windows are non-overlapping but smaller windows are fully nested within larger windows. We theoretically prove the FDR control using the proposed statistic in the Appendix for nonoverlapping windows; however, the theoretical justification for the more general setting of overlapping windows remains an open question. For the proposed choice of overlapping windows, we demonstrate via empirical simulation studies that the FDR is well controlled (Fig. 2) as window overlapping is a local phenomenon.
KnockoffScreen improves stability and reproducibility of knockoff-based inference
We conducted simulation studies to compare KnockoffScreen with single knockoff approach, and the multiple knockoffs approach proposed by Gimenez and Zou, referred to as MK-Maximum30.
We designed these simulations to mimic the real data analysis of ADSP. For each replicate, we randomly drew 1,000 variants, including both common and rare variants, from the 200 kb region near gene APOE (chr19: 44905796–44909393). We set 1.25% variants to be causal, all within a 5 kb signal window (similar to the size of APOE) and then simulated a dichotomous trait as follows
where \(g\left(x\right)={\rm{log }}(\frac{x}{1-x})\) and \({\mu }_{i}\) is the conditional mean of \({Y}_{i}\); \({\beta }_{0}\) is chosen such that the prevalence is 10%. We set the effect \({\beta }_{j}=0.7\left|{{\rm{log }}}_{10}{m}_{j}\right|\), where \({m}_{j}\) is the MAF for the \(j\)-th variant. Given the same genotype and phenotype data, we first generated 100 knockoffs. Then we repeatedly drew five knockoffs randomly among them for 100 replicates. For each replicate, we scanned the regions with candidate window sizes (1 bp, 1 kb, 5 kb, 1 kb) using KnockoffScreen, the multiple knockoffs feature statistic based on sample maximum by Gimenez and Zou30, and the single knockoff method. For a fair comparison, we adopted the same tests implemented in KnockoffScreen to calculate the p-value for all comparison methods. We calculated the variation of feature statistic \({W}_{{\Phi }_{{kl}}}\) for each window (stability) and the frequency with which each causal window is selected (reproducibility) over 100 replicates. We present the results in Fig. 9.

Different colors indicate different knockoff procedures: KnockoffScreen, single knockoff and MK – Maximum (the multiple knockoff method based on the maximum statistic proposed by Gimenez and Zou30). All three methods are based on the same knockoff generator proposed in this paper for a fair comparison. The stability (a, c) is quantified as the variation of \({\tau }_{{\Phi }_{{kl}}}\) across 100 replicates due to randomly sampling knockoffs for a given data (left and right panels). The reproducibility (b) is quantified as the frequency of a causal window being selected across 100 replicates. Source data are provided as a Source Data file.
In the left panel, we observed that KnockoffScreen has significantly smaller variation in feature statistic \({W}_{{\Phi }_{{kl}}}\) than the other two comparison methods. We note that the method based on sample maximum, MK-Maximum, exhibits comparable and sometimes even larger variation than the method based on single knockoff. In the mid panel, we observed that KnockoffScreen has a higher chance (~0.94) to replicate findings across different knockoff replicates compared to MK-Maximum (~0.74–0.83) and single knockoff (~0.43). This improvement is further demonstrated in the right panel, where we show that KnockoffScreen exhibits smaller variation in feature statistics for the causal windows, resulting in higher reproducibility. The significantly lower reproducibility rate for single knockoffs relative to MK-Maximum is presumably due to its higher detection threshold because it exhibits similar level of variation as MK-Maximum for the causal windows.
Practical strategy for tightly linked variants
Variants residing in short genetic regions can be in moderate to high LD. Although the knockoff method helps to prioritize causal variants over associations due to low/moderate LD, strong correlations can make it difficult or impossible to distinguish the causal genetic variants from their highly correlated variants (see also Sesia et al.16). In fact, the knockoff method will rank all those highly correlated variants lower, which diminishes the power if causal variants exist (see below for a concrete example). We are primarily interested in the identification of relevant clusters of tightly linked variants, rather than individual variants. To address this issue, we propose a practical solution by slightly modifying \({B}_{j}\). The resulting algorithm improves the power to detect clusters of tightly linked variants, without removing any variants that are potentially causal.
Specifically, we create a hierarchical clustering dendrogram using \(|{r}_{{jk}}|\) as a similarity measure and define clusters by \(|{r}_{{jk}}| \,> \, 0.75\), such that variants from two different clusters do not have a correlation greater than 0.75. To generate the knockoff feature for the \(j\)-th variant, we exclude variants from \({B}_{j}\) that are in the same cluster. For example, let \({G}_{1}\), \({G}_{2}\) and \({G}_{3}\) be three genetic variants; \({G}_{1}\) and \({G}_{2}\) are tightly linked with \(\left|{r}_{12}\right|\, > \, 0.75\). The standard knockoff procedure will generate \({\widetilde{G}}_{1}\) based on \(P\left({G}_{1}|{G}_{2},{G}_{3}\right)\), \({\widetilde{G}}_{2}\) based on \(P({G}_{2}|{G}_{1},{G}_{3},{\widetilde{G}}_{1})\). Since \({G}_{1}\) and \({G}_{2}\) are highly correlated, \({\widetilde{G}}_{1}\approx {G}_{1}\), \({\widetilde{G}}_{2}\approx {G}_{2}\) and there will be no power to detect \({G}_{1}\) or \({G}_{2}\) even if one of them is causal. To improve the power, our modified algorithm simultaneously generates \({\widetilde{G}}_{1}\) and \({\widetilde{G}}_{2}\) based on a joint distribution \(P\left({G}_{1},{G}_{2}{\rm{|}}{G}_{3}\right)\) by first estimating the conditional means and then permuting the residuals jointly. This avoids the situation of \({\widetilde{G}}_{1}\) and \({\widetilde{G}}_{2}\) being identical to \({G}_{1}\) and \({G}_{2}\) because \({G}_{1}({G}_{2})\) is excluded from the generation of \({\widetilde{G}}_{2}({\widetilde{G}}_{1})\). Thus both \({G}_{1}\) and \({G}_{2}\) can be detected as a cluster. The idea is similar to that of group-wise exchangeable knockoffs proposed by Sesia et al.15. We further discuss limitations and some alternative approaches in the Discussion section.
Computational efficiency of the knockoff generator
We estimate the computational complexity of our proposed method for each variant \(j\) as \(O\left({nL}\right)+O\left(L{\log }L\right)+O\left(n{\left(K+{MK}\right)}^{2}+{\left(K+{MK}\right)}^{3}\right)=O\, \left(n\right)\), where \(n\) is the sample size; \(L\) is a predefined constant for the length of the nearby region; \(K\) is the number of variants in the defined set \({B}_{j}\), which is bounded by the predefined constant \(L\); \(M\) is a predetermined constant for the number of knockoffs. \(O\left({nL}\right)\) is for calculating the correlation between variant \(j\) and variants in the nearby region; \(O\left(L{\log }L\right)\) is for the hierarchical clustering; \(O\,\left(n{\left(K+{MK}\right)}^{2}+{\left(K+{MK}\right)}^{3}\right)\) is for fitting the conditional auto-regressive model. Since we iteratively generate the knockoff for every variant, we estimate the complexity of our proposed method for all variants as \(O({np})\), where \(p\) is the number of genetic variants. We note that the genotype matrix \(G\) is sparse for rare variants. Therefore, the cost for calculation of correlation and hierarchical clustering can be drastically reduced. In addition, the approach that we proposed to define \({B}_{j}\) ensures that \(K\) is relatively small and this further reduces the computational cost.
KnockoffScreen allows meta-analysis of multiple cohorts
Meta-analysis is a powerful approach that enables integration of multiple cohorts for a larger sample size without sharing individual level data. Several methods have been proposed for meta-analysis of single variant tests for common variants or set-based (e.g., window based) tests for rare variants48,49,50. Those methods integrate summary statistics from each individual cohort, such as p-values or score statistics, and then compute a combined p-value for each genetic variant or each window for a meta-analysis. Since KnockoffScreen directly uses p-value as importance score, it can flexibly incorporate the aforementioned methods for a meta-analysis. The meta-analysis procedure is described as follows:
-
1.
Generate knockoff features for each individual cohort.
-
2.
Calculate summary statistics within each individual cohort for original data and knockoff data.
-
3.
Apply existing meta-analysis methods to aggregate summary statistics to compute combined p-values \({p}_{{\Phi }_{{\rm{kl}}},{combined}}\) and \({\widetilde{p}}_{{\Phi }_{{\rm{kl}}},{combined}}\), for original data and knockoff data respectively.
-
4.
Define \({W}_{{\Phi }_{{kl}}}={T}_{{\Phi }_{{kl}}}-{\widetilde{T}}_{{\Phi }_{{kl}}}\) where \({T}_{{\Phi }_{{kl}}}=-{{\rm{log }}}_{10}{p}_{{\Phi }_{{\rm{kl}}},{combined}}\) and \({\widetilde{T}}_{{\Phi }_{{kl}}}=-{{\rm{log }}}_{10}{\widetilde{p}}_{{\Phi }_{{\rm{kl}}},{combined}}\), and apply KnockoffScreen to select putative causal variants. It naturally extends to multiple knockoffs as described above.
Single-region empirical power and FDR simulations
We conducted empirical FDR and power simulations. Each replicate consists of 10,000 individuals with genetic data on 1,000 genetic variants from a 200 kb region, simulated using the SKAT package. The SKAT haplotype dataset was generated using a coalescent model (COSI), mimicking the linkage disequilibrium structure of European ancestry samples. The simulations focus on both rare and common variants with minor allele frequency (MAF) <0.01 and >0.01 respectively. It has been discussed in Sesia et al.16 that the false discovery proportion is difficult to define if the method identifies a variant that is tightly linked with the causal variant. The analysis of sequencing data targets different test units (set-based vs. single variant-based), further complicating the FDR comparisons. We note that the simulations here focus on method comparison for locus discovery to identify relevant clusters of tightly linked variants. Therefore, we simplify the simulation design in this particular section to avoid difficulties in defining the FDR in the presence of strong correlations by keeping one representative variant from each tightly linked cluster. Specifically, we applied hierarchical clustering such that no two clusters have cross-correlations above a threshold value of 0.75 and then randomly choose one representative variant from each cluster to be included in the simulation study.
We set 0.5% variants in the 200 kb region to be causal, all within a 10 kb signal window. Then we generated the quantitative/dichotomous trait as follows:
where \({X}_{i1} \sim N\left(0,1\right)\), \({\varepsilon }_{i} \sim N\left(0,3\right)\) and they are all independent; \((\,{g}_{1},\ldots ,{g}_{s})\) are selected risk variants; \(g\left(x\right)={\rm{log }}(\frac{x}{1\,-\,x})\) and \({\mu }_{i}\) is the conditional mean of \({Y}_{i}\); for dichotomous trait, \({\beta }_{0}\) is chosen such that the prevalence is 10%. We set the effect \({\beta }_{j}=\frac{a}{\sqrt{2{m}_{j}(1\,-\,{m}_{j})}}\), where \({m}_{j}\) is the MAF for the \(j\)-th variant. We define \(a\) such that the variance due to the risk variants, \({\beta }_{1}^{2}{var}\left({g}_{1}\right)+\ldots +{\beta }_{s}^{2}{var}\left({g}_{s}\right)\), is 0.05 for the simulations focusing on common variants and 0.1 for the simulations focusing on rare variants. We scan the regions with candidate window sizes (1 bp, 1 kb, 5 kb, 10 kb), and we consider several tests including the burden test, dispersion test, and Cauchy combination test to aggregate burden, dispersion, and individual variant test results (as discussed in the main text). This combined test is the method implemented in the KnockoffScreen method. A window is considered causal if it contains at least one causal variant. For each replicate, the empirical power is defined as the proportion of detected windows among all causal windows; the empirical FDR is defined as the proportion of non-causal windows among all detected windows. We simulated 500 replicates and calculated the average empirical power and FDR.
Genome-wide empirical power and FDR simulations in the presence of multiple causal loci
We conducted empirical FDR and power simulations using ADSP whole genome sequencing data, and compared the proposed method with state-of-the-art tests for sequencing data analysis adjusted by Bonferroni correction and Benjamini–Hochberg procedure for FDR control. We randomly choose 10 causal loci and 500 noise loci across the genome, each spanning 200 kb. Each causal locus contains a 10 kb causal window. For each replicate, we randomly set 10% variants in each 10 kb causal window to be causal. In total, there are approximately 335 causal variants on average across the genome. We generated the quantitative/dichotomous trait as follows:
where \({X}_{i1} \sim N\left(0,1\right)\), \({\varepsilon }_{i} \sim N\left(0,3\right)\) and they are all independent; \((\,{g}_{1},\ldots ,{g}_{s})\) are selected risk variants; \(g\left(x\right)={\rm{log }}(\frac{x}{1\,-\,x})\) and \({\mu }_{i}\) is the conditional mean of \({Y}_{i}\); for dichotomous trait, \({\beta }_{0}\) is chosen such that the prevalence is 10%. We set the effect \({\beta }_{{kj}}=\frac{{a}_{k}}{\sqrt{2{m}_{{kj}}(1\,-\,{m}_{{kj}})}}\), where \({m}_{{kj}}\) is the MAF for the \(j\)-th variant in causal window \(k\). We define \({a}_{k}\) such that the phenotypic variance due to the risk variants for each causal locus, \({\beta }_{k1}{g}_{k1}+\ldots +{\beta }_{k,{k}_{s}}{g}_{k,{k}_{s}}\), is 1. We scan the regions with candidate window sizes (1 bp, 1 kb, 5 kb, 10 kb), and we consider several tests including the burden test, dispersion test, and Cauchy combination test to aggregate burden, dispersion, and individual variant test results (as discussed in the main text). This combined test is the method implemented in the KnockoffScreen method. For each replicate, the empirical power is defined as the proportion of causal loci (the 200 kb regions) being identified; the empirical FDR is defined as the proportion of detected windows not overlapping with the causal window ± 50 kb/75 kb/100 kb, which evaluates FDR at different resolutions. The empirical power and FDR have averaged over 100 replicates.
Simulations for investigating various properties of the KnockoffScreen method (the prioritization of causal variants, the influence of shadow effects from common variants, and robustness to population stratification)
We design these simulations to mimic the real data analysis of ADSP. For each replicate, we randomly drew 1000 variants, including both common and rare variants, from the 200 kb region near gene APOE (chr19: 44905796–44909393). We scanned the regions with candidate window sizes (1 bp, 1 kb, 5 kb, 1 kb) using the conventional association test and KnockoffScreen. For a fair comparison, we adopted the same tests implemented in KnockoffScreen to calculate the p-value for the conventional association testing method.
Prioritization of causal variants
We set 0.25% variants to be causal, all within a 5 kb signal window (similar to the size of APOE), and then simulated a dichotomous trait by
where \(g\left(x\right)={\rm{log }}(\frac{x}{1-x})\) and \({\mu }_{i}\) is the conditional mean of \({Y}_{i}\); for dichotomous trait, \({\beta }_{0}\) is chosen such that the prevalence is 10%. We set the effect \({\beta }_{j}=a\left|{{\rm{log }}}_{10}{m}_{j}\right|\), where \({m}_{j}\) is the MAF for the \(j\)-th variant. We defined \(a=1.4\) such that the risk variant has a similar odds ratio as APOE-\(\varepsilon 4\) (~3.1) given a similar MAF (~0.137)59,60. For each replicate, we compared the two methods in terms of (1) the proportion of selected windows that overlaps with the causal window; and (2) the maximum distance between selected windows and the causal window.
Shadow effect
We adopted the same simulation setting but set the causal variants to be common (MAF > 0.01) and apply the methods to rare variants only (MAF < 0.01). Since all causal variants are common, all detected windows are false positives due to the shadow effect. We counted the number of false positives and show the distribution over 500 replicates.
Population stratification
The ADSP includes three ethnic groups: African American (AA), Non Hispanic White (NHW), and Others (98% of which are Caribbean Hispanic). Let \({Z}_{i}\) denote the ethnic group (\({Z}_{i}=0\): AA; \({Z}_{i}=1\): NHW; \({Z}_{i}=2\): Others). We simulated quantitative and dichotomous traits by
where \({X}_{i1} \sim N\left(0,1\right)\), \({\varepsilon }_{i} \sim N\left(0,3\right)\) and they are all independent; \(g\left(x\right)={\rm{log }}(\frac{x}{1-x})\) and \({\mu }_{i}\) is the conditional mean of \({Y}_{i}\); for dichotomous trait, \({\beta }_{0}\) is chosen such that the prevalence is 10%. This way, the mean/prevalence for the quantitative/dichotomous trait is a function of the subpopulation, but not directly affected by the genetic variants. We counted the number of false positives and show the distribution over 500 replicates. We also calculated an estimate of the FDR, defined as the proportion of replicates where any window is detected.
Population stratification driven by rare variants
We carried out additional simulation studies to simulate population stratification driven by rare variants using the ADSP data. Specifically, we randomly choose 100 regions across the whole genome but outside chromosome 19 with each region of size 200 kb. Each region contains a 10 kb causal window. We randomly set 10% rare variants (MAF < 0.01; MAC > 10) in each causal window to exhibit small effects on the trait of interest, Thus the allele frequency differences across ethnic groups will lead to different disease prevalence, reflecting a population stratification driven by rare variants. Then we evaluate the FDR for the selected 200 kb region near gene APOE (chr19: 44905796–44909393). Since the causal variants are independent of the target region, the confounding effect will be due to population stratification. Specifically, we generated the quantitative/dichotomous trait as follows:
where \({X}_{i1} \sim N\left(0,1\right)\), \({\varepsilon }_{i} \sim N\left(0,3\right)\) and they are all independent; \(({g}_{1},\ldots ,{g}_{s})\) are selected risk variants;\(g\,\left(x\right)={\rm{log }}(\frac{x}{1-x})\) and \({\mu }_{i}\) is the conditional mean of \({Y}_{i}\); for dichotomous trait, \({\beta }_{0}\) is chosen such that the prevalence is 10%. We set the effect \({\beta }_{{kj}}=\frac{{a}_{k}}{\sqrt{2{m}_{{kj}}(1-{m}_{{kj}})}}\), where \({m}_{{kj}}\) is the MAF for the \(j\)-th variant in causal window \(k\). We define \({a}_{k}\) such that the variance due to the risk variants for each causal locus, \({\beta }_{k1}{g}_{k1}+\ldots +{\beta }_{k,{k}_{s}}{g}_{k,{k}_{s}}\), is 0.01; we set \(\gamma =0,0.25,0.5,0.75\) which quantifies the magnitude of population stratification.
The Alzheimer’s disease sequencing project
We first applied KnockoffScreen to whole-genome sequencing (WGS) data from the Alzheimer’s Disease Sequencing Project (ADSP)61. The data include 3,085 whole genomes from the ADSP Discovery Extension Study including 1,096 Non-Hispanic White (NHW), 977 African American (AA) descent and 1,012 Caribbean Hispanic (CH). Sequencing for these samples was conducted through three National Human Genome Research Institute (NHGRI) funded Large Scale Sequencing and Analysis Centers (LSACs): Baylor College of Medicine Human Genome Sequencing Center, the Broad Institute, the McDonnell Genome Institute at Washington University. The samples were sequenced on the Illumina HiSeq X Ten platform with 150 bp paired-end reads. Additionally, the dataset includes 809 whole genomes from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) with 756 NHW, 28 AA, and 25 others. The samples were sequenced on the Illumina HiSeq 2000 platform with 100 bp paired-end reads. Whole-genome sequence data on 809 ADNI subjects (cases, mild cognitive impairment, and controls) have been harmonized using the ADSP pipeline for joint analysis. The ADSP Quality Control Work Group performs QC and concordance checks into an overall ADSP VCF file.
COPDGene from the TOPMed project
Eligible subjects in COPDGene Study (NCT00608764, www.copdgene.org) were of non-Hispanic white (NHW) or African-American (AA) ancestry, aged 45–80 years old, with at least 10 pack-years of smoking and no diagnosed lung disease other than COPD or asthma62. IRB approval was obtained at all study centers, and all study participants provided written informed consent. All subjects underwent a baseline survey, including demographics, smoking history, and symptoms; pre- and post-bronchodilator lung function testing; and chest CT scans. Samples from COPDGene were sequenced at the Broad Institute and at the Northwest Genomics Center at the University of Washington. Variants for all TOPMed samples were jointly called by the Informatics Research Center at the University of Michigan. For details on sequencing and variant calling methods, see https://www.nhlbiwgs.org/topmed-whole-genome-sequencing-project-freeze-5b-phases-1-and-2. QC included comparison of annotated and genetic sex and comparison of genotypes from prior SNP array data with genotypes called from sequencing. Samples with questionable identity from either of these checks were excluded from analysis.
Gene annotation of the identified windows
The windows (single bp or larger) identified as significant at a target FDR threshold are mapped to genes or intergenic regions using the human genome assembly GRCh38.p13 from the Ensembl Release 9963. We assign each significant window to its overlapping locus (gene or intergenic region). If the locus is a gene, we report the gene’s name; if the locus is intergenic, we report the upstream and downstream genes (enclosed within parentheses and separated by “-”). We also check if the assigned locus has known associations with Alzheimer’s disease and lung related traits in the NHGRI-EBI GWAS Catalog34. Specifically, we look up associations with the following seven traits for the ADSP: Alzheimer’s disease, late-onset Alzheimer’s disease, family history of Alzheimer’s disease, t-tau measurement, p-tau measurement, amyloid-beta measurement, and beta-amyloid 1–42 measurement; and associations with the following 20 traits for the COPDGene: FEV1/FEC ratio, FEV1, FVC, PEF (peak expiratory flow), COPD, response to bronchodilator, asthma, chronic bronchitis, lung carcinoma, lung adenocarcinoma, pulmonary artery enlargement, FEV change measurement, pulmonary function measurement, carbon monoxide exhalation measurement, airway responsiveness measurement, serum IgE measurement, smoking behavior measurement, smoking status measurement, smoking behaviour, and smoking initiation. These annotations are shown in Supplemental Tables.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The manuscript used data from existing studies from COPDGene (TopMED, dbGaP phs000951.v4.p4) and the Alzheimer’s Disease Sequencing Project (dbGaP phs000572.v8.p4). Source data are provided with this paper.
Code availability
We have implemented KnockoffScreen in a computationally efficient R package that can be applied generally to the analysis of other whole-genome sequencing studies. The package can be accessed at: https://cran.r-project.org/web/packages/KnockoffScreen/index.html.
References
RK, C. Y. et al. Whole genome sequencing resource identifies 18 new candidate genes for autism spectrum disorder. Nat. Neurosci. 20, 602–611 (2017).
Taliun, D. et al. Sequencing of 53,831 diverse genomes from the NHLBI TOPMed Program. bioRxiv, 563866 (2019).
Morrison, A. C. et al. Practical approaches for whole-genome sequence analysis of heart- and blood-related traits. Am. J. Hum. Genet. 100, 205–215 (2017).
Sazonovs, A. & Barrett, J. C. Rare-variant studies to complement genome-wide association studies. Annu Rev. Genomics Hum. Genet. 19, 97–112 (2018).
Hormozdiari, F., Kostem, E., Kang, E. Y., Pasaniuc, B. & Eskin, E. Identifying causal variants at loci with multiple signals of association. Genetics 198, 497–508 (2014).
Wang, G., Sarkar, A., Carbonetto, P. & Stephens, M. A simple new approach to variable selection in regression, with application to genetic fine mapping. J. R. Stat. Soc.: Ser. B (Stat. Methodol.) 82, 1273–1300 (2020).
Korthauer, K. et al. A practical guide to methods controlling false discoveries in computational biology. Genome Biol. 20, 118 (2019).
He, X. et al. Integrated model of de novo and inherited genetic variants yields greater power to identify risk genes. PLoS Genet. 9 (2013).
Iossifov, I. et al. The contribution of de novo coding mutations to autism spectrum disorder. Nature 515, 216–221 (2014).
Consortium, G. Genetic effects on gene expression across human tissues. Nature 550, 204–213 (2017).
Liu, Y. et al. A statistical framework for mapping risk genes from de novo mutations in whole-genome-sequencing studies. Am. J. Hum. Genet. 102, 1031–1047 (2018).
Benjamini, Y. & Hochberg, Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc.: Ser. B (Methodol.) 57, 289–300 (1995).
Barber, R. F. & Candès, E. J. Controlling the false discovery rate via knockoffs. Ann. Stat. 43, 2055–2085 (2015).
Candes, E., Fan, Y., Janson, L. & Lv, J. Panning for gold:‘model‐X’knockoffs for high dimensional controlled variable selection. J. R. Stat. Soc.: Ser. B (Stat. Methodol.) 80, 551–577 (2018).
Sesia, M., Katsevich, E., Bates, S., Candès, E. & Sabatti, C. Multi-resolution localization of causal variants across the genome. Nat. Commun. 11, 1093 (2020).
Sesia, M., Sabatti, C. & Candès, E. J. Rejoinder: ‘Gene hunting with hidden Markov model knockoffs’. Biometrika 106, 35–45 (2019).
Romano, Y., Sesia, M. & Candès, E. Deep knockoffs. Journal of the American Statistical Association, 1–12 (2019).
He, Z., Xu, B., Buxbaum, J. & Ionita-Laza, I. A genome-wide scan statistic framework for whole-genome sequence data analysis. Nat. Commun. 10, 1–11 (2019).
Liu, Y. & Xie, J. Cauchy combination test: a powerful test with analytic p-value calculation under arbitrary dependency structures. Journal of the American Statistical Association, 1–18 (2019).
Hernandez, R. D. et al. Ultra-rare variants drive substantial cis-heritability of human gene expression. bioRxiv, 219238 (2019).
Zhou, W. et al. Efficiently controlling for case-control imbalance and sample relatedness in large-scale genetic association studies. Nat. Genet. 50, 1335–1341 (2018).
Chen, Z. et al. Threshold for neural tube defect risk by accumulated singleton loss-of-function variants. Cell Res. 28, 1039–1041 (2018).
He, Z., Xu, B., Lee, S. & Ionita-Laza, I. Unified sequence-based association tests allowing for multiple functional annotations and meta-analysis of noncoding variation in metabochip data. Am. J. Hum. Genet. 101, 340–352 (2017).
Li, B. & Leal, S. M. Methods for detecting associations with rare variants for common diseases: application to analysis of sequence data. Am. J. Hum. Genet. 83, 311–321 (2008).
Madsen, B. E. & Browning, S. R. A groupwise association test for rare mutations using a weighted sum statistic. PLoS Genetics 5, e1000384 (2009).
Wu, M. C. et al. Rare-variant association testing for sequencing data with the sequence kernel association test. Am. J. Hum. Genet. 89, 82–93 (2011).
Rentzsch, P., Witten, D., Cooper, G. M., Shendure, J. & Kircher, M. CADD: predicting the deleteriousness of variants throughout the human genome. Nucleic Acids Res. 47, D886–D894 (2019).
He, Z., Liu, L., Wang, K. & Ionita-Laza, I. A semi-supervised approach for predicting cell-type specific functional consequences of non-coding variation using MPRAs. Nat. Commun. 9, 1–12 (2018).
Liu, Y. et al. Acat: A fast and powerful p value combination method for rare-variant analysis in sequencing studies. Am. J. Hum. Genet. 104, 410–421 (2019).
Gimenez, J. R. & Zou, J. Improving the Stability of the Knockoff Procedure: Multiple Simultaneous Knockoffs and Entropy Maximization. arXiv preprint arXiv:1810.11378 (2018).
Zhou, X. et al. Non-coding variability at the APOE locus contributes to the Alzheimer’s risk. Nat. Commun. 10, 1–16 (2019).
Lee, S., Abecasis, G. R., Boehnke, M. & Lin, X. Rare-variant association analysis: study designs and statistical tests. Am. J. Hum. Genet. 95, 5–23 (2014).
Sesia, M., Bates, S., Candès, E., Marchini, J. & Sabatti, C. Controlling the false discovery rate in GWAS with population structure. bioRxiv (2020).
Buniello, A. et al. The NHGRI-EBI GWAS Catalog of published genome-wide association studies, targeted arrays and summary statistics 2019. Nucleic acids Res. 47, D1005–D1012 (2019).
Jansen, I. E. et al. Genome-wide meta-analysis identifies new loci and functional pathways influencing Alzheimer’s disease risk. Nat. Genet. 51, 404–413 (2019).
Marioni, R. E. et al. GWAS on family history of Alzheimer’s disease. Transl. Psychiatry 8, 1–7 (2018).
Dumitriu, A. et al. Integrative analyses of proteomics and RNA transcriptomics implicate mitochondrial processes, protein folding pathways and GWAS loci in Parkinson disease. BMC Med. Genomics 9, 5 (2015).
Lee, J. H. et al. Fine mapping of 10q and 18q for familial Alzheimer’s disease in Caribbean Hispanics. Mol. Psychiatry 9, 1042–1051 (2004).
McInnes, L. A. et al. A complete genome screen for genes predisposing to severe bipolar disorder in two Costa Rican pedigrees. Proc. Natl Acad. Sci. USA 93, 13060–13065 (1996).
Ho, A. et al. Circulating glucuronic acid predicts healthspan and longevity in humans and mice. Aging (Albany NY) 11, 7694 (2019).
Xu, Z., Wu, C. & Pan, W. & Initiative, A.s.D.N. Imaging-wide association study: Integrating imaging endophenotypes in GWAS. Neuroimage 159, 159–169 (2017).
Shi, J. et al. Genome-wide association study of recurrent early-onset major depressive disorder. Mol. Psychiatry 16, 193–201 (2011).
Mez, J. et al. Two novel loci, COBL and SLC10A2, for Alzheimer’s disease in African Americans. Alzheimer’s Dement. 13, 119–129 (2017).
NHLBI Trans-Omics for Precision Medicine. TOPMed Whole Genome Sequencing Project - Freeze 5b, Phases 1 and 2. Vol. 2020 (https://www.nhlbiwgs.org/topmed-whole-genome-sequencing-project-freeze-5b-phases-1-and-2).
Janson, L. & Su, W. Familywise error rate control via knockoffs. Electron. J. Stat. 10, 960–975 (2016).
Schaid, D. J., Chen, W. & Larson, N. B. From genome-wide associations to candidate causal variants by statistical fine-mapping. Nat. Rev. Genet. 19, 491–504 (2018).
Zhou, W. et al. Efficiently controlling for case-control imbalance and sample relatedness in large-scale genetic association studies. Nat. Genet. 50, 1335–1341 (2018).
Liu, D. J. et al. Meta-analysis of gene-level tests for rare variant association. Nat. Genet. 46, 200 (2014).
Feng, S., Liu, D., Zhan, X., Wing, M. K. & Abecasis, G. R. RAREMETAL: fast and powerful meta-analysis for rare variants. Bioinformatics 30, 2828–2829 (2014).
Lee, S., Teslovich, T. M., Boehnke, M. & Lin, X. General framework for meta-analysis of rare variants in sequencing association studies. Am. J. Hum. Genet. 93, 42–53 (2013).
Chen, H. et al. Efficient variant set mixed model association tests for continuous and binary traits in large-scale whole-genome sequencing studies. Am. J. Hum. Genet 104, 260–274 (2019).
Zhou, W. et al. Scalable generalized linear mixed model for region-based association tests in large biobanks and cohorts. (Nature Publishing Group, 2020).
Zhao, Z. et al. UK Biobank whole-exome sequence binary phenome analysis with robust region-based rare-variant test. Am. J. Hum. Genet. 106, 3–12 (2020).
Gabriel, S. B. et al. The structure of haplotype blocks in the human genome. Science 296, 2225–2229 (2002).
Anderson, E. C. & Novembre, J. Finding haplotype block boundaries by using the minimum-description-length principle. Am. J. Hum. Genet. 73, 336–354 (2003).
Wang, L. GEE analysis of clustered binary data with diverging number of covariates. Ann. Stat. 39, 389–417 (2011).
Storey, J. D. The positive false discovery rate: a Bayesian interpretation and the q-value. Ann. Stat. 31, 2013–2035 (2003).
Storey, J. D. & Tibshirani, R. Statistical significance for genomewide studies. Proc. Natl Acad. Sci. USA 100, 9440–9445 (2003).
Liu, C.-C., Kanekiyo, T., Xu, H. & Bu, G. Apolipoprotein E and Alzheimer disease: risk, mechanisms and therapy. Nat. Rev. Neurol. 9, 106 (2013).
Kukull, W. A. et al. Apolipoprotein E in Alzheimer’s disease risk and case detection: a case-control study. J. Clin. Epidemiol. 49, 1143–1148 (1996).
Beecham, G. W. et al. The Alzheimer’s disease sequencing project: study design and sample selection. Neurol. Genet. 3, e194 (2017).
Regan, E. A. et al. Genetic epidemiology of COPD (COPDGene) study design. COPD: J. Chronic Obstr. Pulm. Dis. 7, 32–43 (2011).
Yates, A. D. et al. Ensembl 2020. Nucleic acids Res. 48, D682–D688 (2020).
Acknowledgements
This research is supported by NIH/NIA award AG066206 (Z.H.) and NIH/NIMH awards MH106910 and MH095797 (I.I.-L.). We gratefully acknowledge the studies and participants who provided biological samples and data for ADSP and TOPMed. The full study-specific acknowledgements are detailed in the Supplementary Note.
Author information
Authors and Affiliations
Contributions
Z.H., L.L., and I.I.-L. developed the concepts for the manuscript and proposed the method. Z.H., L.L., S.M., H.T., M.G., and I.I.-L. designed the analyses and applications and discussed results. Z.H., C.W., Y.L., J.L., and F.L. conducted the analyses. E.K.S., S.G., and M.H.C. helped interpret the results of the TOPMed analyses. Z.H., L.L., and I.I.-L. prepared the manuscript and all authors contributed to editing the paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature Communications thanks the anonymous reviewers for their contribution to the peer review of this work. Peer review reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
He, Z., Liu, L., Wang, C. et al. Identification of putative causal loci in whole-genome sequencing data via knockoff statistics. Nat Commun 12, 3152 (2021). https://doi.org/10.1038/s41467-021-22889-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-021-22889-4
This article is cited by
-
BIGKnock: fine-mapping gene-based associations via knockoff analysis of biobank-scale data
Genome Biology (2023)
-
Deep neural networks with controlled variable selection for the identification of putative causal genetic variants
Nature Machine Intelligence (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
