
Abstract
The sudden deterioration of patients with novel coronavirus disease 2019 (COVID-19) into critical illness is of major concern. It is imperative to identify these patients early. We show that a deep learning-based survival model can predict the risk of COVID-19 patients developing critical illness based on clinical characteristics at admission. We develop this model using a cohort of 1590 patients from 575 medical centers, with internal validation performance of concordance index 0.894 We further validate the model on three separate cohorts from Wuhan, Hubei and Guangdong provinces consisting of 1393 patients with concordance indexes of 0.890, 0.852 and 0.967 respectively. This model is used to create an online calculation tool designed for patient triage at admission to identify patients at risk of severe illness, ensuring that patients at greatest risk of severe illness receive appropriate care as early as possible and allow for effective allocation of health resources.
Similar content being viewed by others
Introduction
With coronavirus disease 2019 (COVID-19) now a pandemic, rapid and effective triage is critical for early treatment and effective allocation of hospital resources. COVID-19 disease has shown the worrying trend of sudden progression to critical illness in 6.5% of cases and with a mortality rate of 49% in these patients1,2. The influx of additional health resources in Hubei province, which was the epicenter of the outbreak, greatly improved patient outcomes. Since early intervention is associated with improved prognosis, the ability to identify patients that are most at risk of developing severe disease upon admission will ensure that these patients receive appropriate care as soon as possible.
Clinical researchers have been using survival analysis (also called time-to-event analysis) to estimate the probability of prognostic clinical outcomes such as death and cancer recurrence in the course of disease development and to plan optimal treatment schemes accordingly. The Cox proportional hazards model (CPH)3 is a widely used statistical model that relies on regression analysis to determine the association between a predictor covariate, such as clinical characteristics, with the risk of an event occurring (e.g. “death”). The model assumes that the risk of an event is a linear combination of the patient’s covariates, which may be too simplistic for some complex clinical events such as progression to critical illness.
The increase in computing power and the availability of big data has enabled deep learning to be used successfully in many medical applications4. For instance, convolutional neural networks, a form of deep learning, could detect skin cancers as effectively as dermatologists5. Deep learning could also successfully interpret pathology results to diagnose prostate cancer and basal cell carcinoma6. Deep neural networks have also been used to recommend personal treatment plans7. In this study, we integrate deep learning techniques with the traditional Cox model for survival analysis of the nonlinear effect from clinical covariates to predict clinical outcome of COVID-19 patients. We demonstrate that this Deep Learning Survival Cox model can efficiently triage COVID-19 patients with high accuracy.
Results
Data sources and characteristics
On behalf of the National Clinical Research Center for Respiratory Disease and in collaboration with the National Health Commission (NHC) of the People’s Republic of China, we established a retrospective cohort to study COVID-19 cases throughout China. We obtained medical records and compiled the data from laboratory-confirmed hospitalized cases with COVID-19 reported to the NHC between 21 November 2019 and 31 January 2020. The NHC requested that all of the 1855 designated hospitals for COVID-19 submit clinical records to the database. Hospitals whose clinical records had not been submitted by this deadline were requested again. Our cohort largely represents the overall situation as of 31 January, taking into account the proportion of hospitals (~one-third) and patient number (17.2%, 1590/9252 cases), as well as the broad coverage (covering 31 of 34 provinces/autonomous regions (appendix illustrated the geographic distribution of cases from all hospitals that contributed to the database)), although the non-responsive bias cannot be fully excluded.
Confirmed cases of COVID-19 were defined as patients who tested positive by high-throughput sequencing or real-time reverse-transcription PCR assay on nasal and pharyngeal swab specimens. Only laboratory-confirmed cases were included in our analysis. Critical illness was defined as a composite event of admission to an intensive care unit or requiring invasive ventilation, or death.
Our model training cohort included 1590 patients, of which 131 developed critical illness, from 575 medical centers (Supplementary Tables 1 and 2, and Appendix). To test the generalization of our model, we collected three independent cohorts as external validation sets with wide geographic coverage, one from a hospital in the epicenter Wuhan (940 patients, 94 critically ill), one from multiple centers in ten cities in Hubei province, excluding Wuhan (380 patients, 9 critically ill), and another from a hospital in Guangdong province, representing a province not suffering from the health resource burnout experienced in Wuhan (73 patients, 3 critically ill) (Supplementary Tables 3–5).
Selection of critical illness predictors and model establishment
Seventy-four baseline clinical features with at least 60% data completeness were considered as critical illness predictors and were used for model establishment. Ten features with statistically significant (P < 0.05) hazard ratios were identified through a machine learning variable selection algorithm called least absolute shrinkage and selection operator (LASSO)8. These were X-ray abnormalities, age, dyspnea, COPD (chronic obstructive pulmonary disease), number of comorbidities, cancer history, neutrophil/lymphocytes ratio, lactate dehydrogenase, direct bilirubin, and creatine kinase (Table 1).
Performance of the prediction model
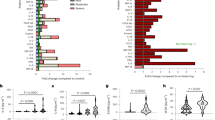
We divided the training cohort into 80% for model training and 20% for internal model validation with balanced data distribution. The concordance index (C-index, a standard performance metric for survival analysis) and area under the receiver-operator characteristic curve (AUC, a performance measurement for classification problem) were evaluated on the model validation cohort to assess discriminative ability. The C-index and AUC of our Deep Learning Survival Cox model were 0.894 (0.95 confidence interval (CI), 0.857–0.930) and 0.911 (0.95 CI, 0.875–0.945), respectively, on the model validation set, whereas those of the classic Cox model were 0.876 (0.95 CI, 0.830–0.921) and 0.889 (0.95 CI, 0.843–0.934), respectively (Fig. 1a). The predictive value of this model was higher than the CURB-6 model9, with a C-index of 0.75 (95% CI, 0.70–0.80). The precision-Recall curves for the internal validation set is shown in Supplementary Fig. 1.

a Comparison of ROC curves for the Deep Learning Survival Cox model and the Cox proportional hazards model on the training-validation set. b The Kaplan–Meier curves for developing critical illness among patients in different risk groups in the training set. Shaded areas indicate 95% confidence interval. c ROC curves for the three external validation cohorts using the entire datasets. d ROC curves for the three independent external validation cohorts, excluding patients that were missing more than three values.
Risk stratification
We further calculated the risk of each individual in the entire training cohort and divided all patients into three groups based on the risk cut-off at 95% sensitivity and 95% specificity. A total of 875, 560, and 155 patients were classified in low-, medium-, and high-risk group, respectively, with the actual risk probability of critical illness events at 0.9%, 7.3%, and 52.9%, respectively. Kaplan–Meier curves of these three patient groups demonstrated statistically significant separation (Fig. 1b).
External validation
To test the generalization of this model, we tested the model performance on three independent cohort from different locations and with different health resource levels. The first cohort was from the epicenter Wuhan, the second from an area outside of Wuhan in Hubei province, and the last was from Guangdong province, a province that was not suffering from health resource burnout. The Wuhan cohort consisted of COVID-19 patients admitted in January and February (without overlap with the training set) to Hankou hospital, the Hubei cohort consisted of cases from multiple centers in ten cities before 31 January (which did not overlap with the training set), and the Guangdong cohort that included cases admitted between January and February to Foshan hospital. Data-processing procedures were identical to those used for the training cohort. Table 2 and Fig. 1c, d show the results of the entire external validation datasets and Ex3 datasets that excluded patients with more than three missing clinical features out of the ten required. The C-index of the entire dataset for the Wuhan, Hubei, and Guangdong cohorts were 0.878, 0.769, and 0.967, respectively. In the Ex3 dataset, the C-index for these cohorts were 0.890, 0.852, and 0.967, respectively.
Risk monitoring
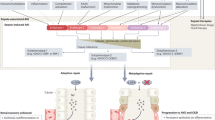
Among the Wuhan cohort of 940 patients with dynamic data, 457 patients had follow-up exams (computed tomography (CT) and blood tests) after hospital admission. In addition to calculating the risk of developing critical illness at hospital admission, we also calculated the risk at follow-up exam times. As shown in Fig. 2, our model not only captures the risk of critical illness at admission but also can be used to monitor the trend of the risk during patients’ hospital stay. The prediction performances of AUC and C-index at the follow-up exam time are 0.960 and 0.935, respectively, which are higher than those at the hospital admission (0.881 and 0.878, respectively). These results indicate that the clinical features better reflect the risk of critical illness as it draws closer to the event.

Red lines with triangle markers are critically ill patients. Green lines with circle markers are other patients. a Visualization of trend of each individual. Each marker indicates a follow-up exam. For better visualization, line color has been slightly disturbed for each patient. b Average trend for different groups of patients. Colored area corresponds to the 25% and 75% of the risk probability.
Online patient triage tool
Nomogram is a pictorial representation for depicting the association between clinical variables and the probabilities of clinical events such as critical illness, which provides an intuitive way to interpret the survival model10. We developed an online tool embedding a nomogram with our Deep Learning Survival Cox model at https://aihealthcare.tencent.com/COVID19-Triage_en.html. After a clinical staff fill in the online form with baseline clinical features, the tool returns a personalized nomogram, together with the probability of critical illness within 5, 10, and 30 days (Fig. 3).

The patient’s total nomogram point is 209, overall critical illness probabilities are 0.58, 0.62, and 0.69 within 5, 10, and 30 days, respectively. The patient is triaged as high-risk.
Discussion
All included variables were independently correlated with disease progression. Age is the most recognized risk factor for prognosis of COVID-19, with the most severe and fatal cases among patients over 60 years old. Respiratory tract symptoms, abnormalities in chest X-rays (compared with CT scans), and low lymphocyte ratios reflect the severity of the disease. Comorbidities, especially COPD and cancer, are strongly linked with the development of critical illness11,12. Similarly, age (over 60 years) and comorbid disease were also risk factors for poor outcome in severe acute respiratory syndrome (SARS) patients in 200313. Compared with SARS-CoV and MERS-CoV, more deaths have been caused by multiple organ dysfunction syndrome rather than respiratory failure during COVID-19, which may be attributed to the widespread distribution of angiotensin-converting enzyme 2, the functional receptor for SARS-CoV-2, in multiple organs14,15. This explains why the blood test, such as lactate dehydrogenase, creatine kinase, will play a role in predicting critical illness.
CPH model is the traditional method for survival analysis and event prediction. However, it is a semiparametric model that assumes that a patient’s risk of failure is a linear combination of the patient’s clinical factors. The deep learning model is able to learn and infer high-order nonlinear associations between clinical covariates and patient outcomes in a fully data-driven manner. Furthermore, data augmentation strategies in deep learning can make the model more resilient to data noise and missing data, which commonly occurs in clinical datasets. The deep learning model can be also extended to incorporate time-dependent covariates such as vital signs and high-dimensional features such a CT or X-ray images.
Our model currently uses ten clinical variables, which are all common demographic and clinical characteristics, as well as laboratory results that are available at most hospitals. Despite this, more than 50% of our patients did not have all required values collected. Missing data can occur particularly with small or poorly equipped hospitals. Our model has a certain tolerance to missing data, as we still achieved high performance on the external validation set for cases missing 30% of the data. However, to take full advantage of this model, we recommend that all clinical features are collected at hospital admission. In real-world practice, missing data on some variables is inevitable. Therefore, missing data on less than three variables is allowed in our online calculation tool and the background can still provide a risk estimation based on deep learning imputation methods.
Our Deep Learning Survival Cox model demonstrated superior discriminating power compared with the classical Cox model, because it unravels the nonlinear relationships among complex clinical covariates and their hazards. To make clinically relevant comparison, we computed partial the area under the receiver operating characteristic curve (p-AUROC), where only the portion of the curve with sensitivity ≥0.8 was counted. The comparison between our deep learning survival Cox model and the classic Cox model is summarized in Supplementary Table 7. From the results, our proposed model is statistically better than (p < 0.05) the classic Cox model in terms of C-index and p-AUROC.
We investigated the false negatives in the external validation sets. Among the 106 critical cases, only 2 cases are classified as low risk. Both cases suffer from data missing and all the observed values land in the range of negative samples. For instance, both cases have no X-ray abnormality findings, no dyspnea, and no comorbidity including COPD and cancer history. Thus, these two cases are all outliers. Based on the observed values, we believe it is reasonable to classify them as low risk.
In our clinical experience, mild COVID-19 cases are generally self-limiting and it is the severe cases that require the most medical attention. Our proposed patient stratification tool has high clinical and economical value for COVID-19 disease management, particularly in light of the unusually rapid disease progression that can occur and the high mortality rate associated with critical illness. By submitting clinical information online, medical staff can triage patients at hospital admission using the predicted risk indicator and arrange patient treatment plans accordingly, ensuring patients receive treatment early and medical resources can be efficiently allocated. Based on the nature of deep leaning, future prospective application and validation can help to further evolve this model.
Methods
Ethical approval
This study was approved by the ethical review committee of the major included hospitals, who also waived the informed consent from patients.
Data extraction and processing
A team of experienced respiratory clinicians reviewed, abstracted, and cross-checked the data. Data were entered into a computerized database and cross-checked. Examination and treatment information was available and collected. The recent exposure history, clinical symptoms and signs, and laboratory findings upon admission were extracted from electronic medical records. Radiologic assessments, including chest X-ray or CT, were performed based on the documentation/description in medical charts or combined with, if imaging films were available, a review by our medical staff. Major disagreement between two reviewers was resolved by consultation with a third reviewer.
Study design
We performed a multivariate imputation by chained equation to fill in the missing data16. We employed a CPH with LASSO penalty to identify baseline clinical features that are associated with the later critical illness status. We then constructed a three-layer feedforward neural network using the selected features for survival modeling7. We designed a nomogram integrating the deep learning output as a patient triage tool at hospital admission8. According to the risk probability returned from the model, the patients are triaged into three groups: low, medium, and high risk of critical illness, at 95% sensitivity and 95% specificity, respectively. The C-index and AUC were evaluated on the validation cohort to assess the discriminative ability. We also compared this model with the CURB-6 model, which has been used in classification of community-acquired pneumonia cases9. All statistical tests were two sided and p-values < 0.05 indicated statistical significant.
Data imputation
We applied multivariate imputation via chained equations to impute the missing data16. The overall features were divided into three groups, numeric features, binary features (with two levels) and factor features (≥2 levels). For each kind of features, we applied different imputation methods. We used predictive mean matching to impute numeric features, logistic regression to impute binary variables and Bayesian polytomous regression to impute factor features. After data imputation, we normalized all features to 0 mean and 1 SD.
Regularized Cox model with LASSO penalty
We performed LASSO algorithm to select and sort the statistically significant clinical features17. We used critical illness as event in the analysis and the training cohort of 1590 patients and 74 clinical features for feature selection. We performed a tenfold cross-validation on the training set to calculate the weight of LASSO penalty (denoted as lambda). The lambda with 1 SE of the minimum partial likelihood deviance was used for feature selection.
Feedforward neural network for survival modeling
We constructed a three-layer feedforward neural network for survival modeling (namely deep survival model)7. The network architecture is illustrated in Supplementary Fig. 2. The ten selected features were fed into the network after data normalization. The network is composed by three fully connected layers including two hidden layers and one output layer. We empirically selected tanh as activation function. Output of the network is a single node, which predicts the risk score of developing critical illness event. If an event i:Ei = 1 happens before event j:Tj > Ti, then its risk score should be higher: Ri > Rj. Given this definition, the loss of the network is defined as following:
where θ is the parameter of the model to be optimized and h(xi|θ) is the risk score predicted by the network given input features xi.
The network was optimized by gradient descending with gradients estimated by Adam optimizer. To avoid overfitting, dropout was applied after each layer during training. Hyperparameters including layer size, learning rate, dropout rate, and training epochs were optimized by Bayesian Hyperparameters Optimization18. The final optimized parameters are listed in Supplementary Table 6. The final model was obtained by training the network with the optimal hyperparameters on the whole training set.
Deep learning survival Cox model
We combined the ten features selected by the LASSO Cox model with the output of our deep survival model and constructed an integrated Cox model (named Deep Learning Survival Cox model). We performed ridge regression with Cox loss on the same training set described above with a tenfold cross-validation.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Data availability
The datasets generated during and/or analyzed during the current study are not publicly available due to the confidential policy of National Health Commission of China, but are available from the corresponding author Jianxing He upon reasonable request. In addition, this database is open for validation of results of other future studies worldwide, through collaboration with the staff of the China Clinical Research Center for Respiratory Disease.
Code availability
The code being used in the current study for developing the algorithm is provided at https://github.com/cojocchen/covid19_critically_ill.
References
Guan, W.-J et al. Clinical characteristics of coronavirus disease 2019 in China. N. Engl. J. Med. 382, 1708–1720 (2020).
Wu, Z. et al. Characteristics of and important lessons from the coronavirus disease 2019 (COVID-19) outbreak in China: Summary of a report of 72314 cases from the Chinese center for disease control and prevention. JAMA. https://doi.org/10.1001/jama.2020.2648 (2020).
Cox, D. R. Regression models and life tables. J. R. Statis. Soc. B 34, 187–220 (1972).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Esteva, A. et al. Dermatologist-level classification of skin cancer with deep neural networks. Nature 542, 115–118 (2017).
Campanella, G. et al. Clinical-grade computational pathology using weakly supervised deep learning on whole slide images. Nat. Med. 25, 1301–1309 (2019).
Katzman, J. et al. DeepSurv: personalized treatment recommender system using a Cox proportional hazards deep neural network. BMC Med. Res. Methodol. 18, (2018).
Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Statis. Soc. B 58, 267–288 (1996).
Neill, A. M. et al. Community acquired pneumonia: aetiology and usefulness of severity criteria on admission. Thorax 51, 179–184 (1996).
Iasonos, A., Schrag, D., Raj, G. V. & Panageas, K. S. How to build and interpret a nomogram for cancer prognosis. J. Clin. Oncol. 26, 1364–1370 (2008).
Guan, W. J. et al. Comorbidity and its impact on 1,590 patients with COVID-19 in China: a nationwide analysis. Eur. Respiratory J. 55, 2000547 (2020).
Liang, W. et al. Cancer patients in SARS-CoV-2 infection: a nationwide analysis in China. Lancet Oncol. S1470-2045, 30096–30096 (2020).
Booth, C. M. et al. Clinical features and short-term outcomes of 144 patients with SARS in the greater Toronto area. JAMA 289, 2801–2809 (2003).
Zhou, P. et al. A pneumonia outbreak associated with a new coronavirus of probable bat origin. Nature 579, 270–273 (2020).
Hamming, I. et al. Tissue distribution of ACE2 protein, the functional receptor for SARS coronavirus: a first step in understanding SARS pathogenesis. J. Pathol. 203, 631–637 (2004).
Buuren, S. & Groothuis-Oudshoorn, K. MICE: multivariate imputation by chained equations in R. J. Stat. Softw. 45, 1–67 (2011).
Simon, N., Friedman, J., Hastie, T. & Tibshirani, R. Regularization paths for Cox’s proportional hazards model via coordinate descent. J. Stat. Softw. 39, 1–13 (2011).
Bergstra, J., Yamins, D. & Cox, D. Making a science of model search: hyperparameter optimization in hundreds of dimensions for vision architectures. In Proc. 30th International Conference on Machine Learning 115–123 (2013).
Acknowledgements
This study is supported by China National Science Foundation (Grant numbers 81871893 and 81903421), Key Project of Guangzhou Scientific Research Project (Grant number 201804020030), High-level university construction project of Guangzhou medical university (Grant numbers 20182737, 201721007, 201715907, and 2017160107), National key R & D Program (Grant numbers 2017YFC0907903 and 2017YFC0112704), and the Guangdong high-level hospital construction “reaching peak” plan. This work was partially supported by the Key Area Research and Development Program of Guangdong Province, China (number 2018B010111001), National Key Research and Development Project (2018YFC2000702), and Science and Technology Program of Shenzhen, China (number ZDSYS201802021814180). We thank the hospital staff (see Supplementary Appendix for a full list of the staff) for their efforts in collecting the information. We are indebted to the coordination of Drs. Zong-jiu Zhang, Ya-hui Jiao, Bin Du, Xin-qiang Gao and Tao Wei (National Health Commission), Yu-fei Duan and Zhi-ling Zhao (Health Commission of Guangdong Province), Yi-min Li, Zi-jing Liang, Nuo-fu Zhang, Shi-yue Li, Qing-hui Huang, Wen-xi Huang, and Ming Li (Guangzhou Institute of Respiratory Health), which greatly facilitate the collection of patient’s data. Special thanks are given to the statistical team members Professor Zheng Chen, Drs. Dong Han, Li Li, Zheng Chen, Zhi-ying Zhan, Jin-jian Chen, Li-jun Xu, and Xiao-han Xu (State Key Laboratory of Organ Failure Research, Department of Biostatistics, Guangdong Provincial Key Laboratory of Tropical Disease Research, School of Public Health, Southern Medical University). We also thank Li-qiang Wang, Wei-peng Cai, Zi-sheng Chen (the sixth affiliated hospital of Guangzhou Medical University), Chang-xing Ou, Xiao-min Peng, Si-ni Cui, Yuan Wang, Mou Zeng, Xin Hao, Qi-hua He, Jing-pei Li, Xu-kai Li, Wei Wang, Li-min Ou, Ya-lei Zhang, Jing-wei Liu, Xin-guo Xiong, Wei-juna Shi, San-mei Yu, Run-dong Qin, Si-yang Yao, Bo-meng Zhang, Xiao-hong Xie, Zhan-hong Xie, Wan-di Wang, Xiao-xian Zhang, Hui-yin Xu, Zi-qing Zhou, Ying Jiang, Ni Liu, Jing-jing Yuan, Zheng Zhu, Jie-xia Zhang, Hong-hao Li, Wei-hua Huang, Lu-lin Wang, Jie-ying Li, Li-fen Gao, Jia-bo Gao, Cai-chen Li, Xue-wei Chen, Jia-bo Gao, Ming-shan Xue, Shou-xie Huang, Jia-man Tang, Wei-li Gu, and Jin-lin Wang (Guangzhou Institute of Respiratory Health) for their dedication to data entry and verification. Finally, we thank all the patients who donate their data for analysis and the medical staffs working in the front line.
Author information
Authors and Affiliations
Contributions
W.L.: write manuscript, design study, data collection, processing, and analysis. J. Yao: write manuscript, design experiment, and data analysis. A.C.: design study, data processing, and collection. Q.L.: data collection and processing. S.W.: write manuscript, design study. M.Z.: write manuscript, design study. Y.L.: administrative support, write manuscript. J. Liu: administrative support, data collection, and processing. J. Lu: data collection and processing. H.L.: data processing and analysis. G.C.: data collection and processing. H.G.: data collection and processing. J.G.: data collection and processing. R.Z.: design study, data collection, and processing. L.O.: write manuscript, data processing, and analysis. N. Zhou: implement model, design experiment, data analysis, and write manuscript. H.C.: implement model, design experiment, data analysis, and write manuscript. F.Y.: implement model, design experiment, data analysis, and write manuscript. X.H.: design experiment and write manuscript. W.T.: design experiment. W.H.: administrative support, design experiment, and write manuscript. W.G.: write manuscript, data processing, and analysis. Z.C.: data processing. Y.Z.: data processing. S. Ling: data collection and processing. Y.X.: data collection and processing. W.W.: data collection and processing. S. Li: administrative support, design study, data collection, and processing. L.L.: data collection and processing. N. Zhang: administrative support. N. Zhong: administrative support, design study, data collection, and write manuscript. J. Huang: modeling problem, design experiment, and write manuscript. J. He: administrative support, design study, data collection, and write manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Peer review information Nature Communications thanks Julian Tang and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liang, W., Yao, J., Chen, A. et al. Early triage of critically ill COVID-19 patients using deep learning. Nat Commun 11, 3543 (2020). https://doi.org/10.1038/s41467-020-17280-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-020-17280-8
This article is cited by
-
COVID-19 outbreaks surveillance through text mining applied to electronic health records
BMC Infectious Diseases (2024)
-
Machine learning techniques for CT imaging diagnosis of novel coronavirus pneumonia: a review
Neural Computing and Applications (2024)
-
Big data analytics on the impact of OMICRON and its influence on unvaccinated community through advanced machine learning concepts
International Journal of System Assurance Engineering and Management (2024)
-
Lung pneumonia severity scoring in chest X-ray images using transformers
Medical & Biological Engineering & Computing (2024)
-
Multi-center study on predicting breast cancer lymph node status from core needle biopsy specimens using multi-modal and multi-instance deep learning
npj Breast Cancer (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
